

我们讨论过定性变量,也就是表示类别的变量,比如性别、省份等。对于这类变量,不能在模型里直接使用它们,因为定性变量之间的数学计算是毫无意义的。另一方面,定性变量是一类很常见的变量,通常带着很有价值的信息。因此,这篇文章就将讨论如何正确地在模型里使用定性变量。

数据科学中的陷阱:定性变量的处理
对于定性变量,常见的处理方法有两种:一种是将定性变量转换为多个虚拟变量,另一种对将有序的定性变量转换为定量变量。
一、虚拟变量
正如前文中讨论的,直接对定性变量数字编码,得到的变量将无法进行有意义的数学运算。那么,相应的解决方法就是使得变换之后的变量不能直接做数学运算。
为了便于理解,我们先来看一个简单的例子:使用身高和性别对体重构建线性回归模型。性别是一个二元定性变量,可能的取值为男或女。用两个新生成的变量来取代性别,记为(x1, x2)。其中,x1 = 1表示性别为男, x1 = 0表示性别不为男; x2类似,表示性别是否为女。在学术上,新生成的变量被称为虚拟变量(dummy variable)。虚拟变量是一种特殊的离散型变量,可能的值只有两个:0或1,因此也被称为0/1变量。
用y表示体重, z表示身高,于是有:
注意到,也就是变量和变量成线性关系。这会导致另外一个问题:多重共线性(多重共线性源自线性模型,它是指由于自变量之间存在高度相关关系而使模型参数估计不准确,我们会在后面的文章里详细讨论)这个由虚拟变量引起的多重共线性问题在学术上被称为虚拟变量陷阱(dummy variable trap)。为了规避这个问题,我们对公式(1)做如下的数学变换,得到:
上面的数学转换可翻译为:首先选择性别男为基准类别,生成一维虚拟变量,变量的含义与之前相同。这个变量前面的系数b - a表示性别女相对于性别男(基准类别)的体重差异。需要注意的是,针对二元定性变量,从表面上来看,直接对变量数字编码同虚拟变量效果一样。但这只是一个巧合而已,两种方法有本质的区别。
将上面的方法推广到n元定性变量(可能取值为n个的定性变量)。选择一个类别作为基准类别,并生成n - 1个虚拟变量,分别表示剩下的n - 1个类别。在搭建模型时,用这n - 1个新生成的虚拟变量代替原来的定性变量。具体过程如图1所示。
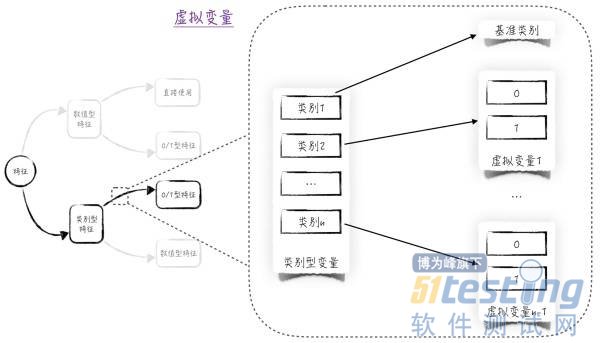
图1
二、从定性变量到定量变量
前面讨论的虚拟变量的方法是比较通用的处理方法。但这种方法有一个很明显的缺点:每个虚拟变量都是0或1,无法提供更多的信息。特别是对于多个有序的定性变量,这会损失掉每个定性变量本身的顺序信息和定性变量间的关联信息。为了解决这个问题,常常根据类别的顺序,将定性变量转换为定量变量。具体的转换方法有很多,但限于篇幅,这里只讨论其中的一种:针对二元分类问题的Ridit scoring(此方法在保险业中应用很广),如图2所示。
假设有序的定性变量x有t个可能的取值,记为。而且对于被预测值,排在后面的类别,y = 1发生的可能性越小。也就是说,对于y = 1这件事,其他变量相同时,类别1的概率最大,类别t的概率最小。用分别表示各个类别所占比例,于是类别的Ridit scoring为:
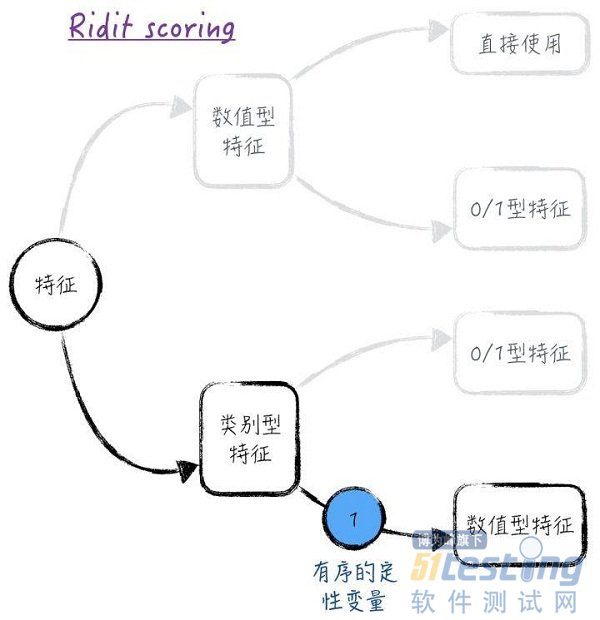
图2
对于一般的定性变量,我们也可以使用所谓的WOE(weight of evidence)方法来将其转换为定量变量,这种方法在信贷风控领域十分广泛。具体来说,假设二元分类问题里有两个类别,用B和G表示(这样标记源自金融领域,B表示bad,G表示good)。同样假设,定性变量x有t个可能的取值,记为。那么对于取值i,它的WOE值为:
其中表示x等于i时,B类别的数量,表示B类别的总数量;和表示的意思类似。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












