

读:魅族UIP(用户洞察平台)通过对三方受众数据的汇聚、清洗、智能运算,构建了庞大的精准人群数据中心,提供丰富的用户画像数据以及实时场景识别能力。本文介绍了魅族用户洞察平台的功能和架构,还原建设过程中遇到的技术难点和解决方式。
以用户洞察平台的目标定位为出发点,综合技术与业务需求的考量进行架构设计,用户洞察平台的功能包括人群管理、人群洞察分析、自定义标签、人群扩展、画像查询服务等。文章还介绍了画像标签的生成、底层存储以及平台功能。
一、总体介绍
1.1. 用户洞察平台的定位
魅族 UIP(用户洞察平台),通过对三方受众数据的汇聚、清洗、智能运算,构建了庞大的精准人群数据中心,提供丰富的用户画像数据以及实时的场景识别力。
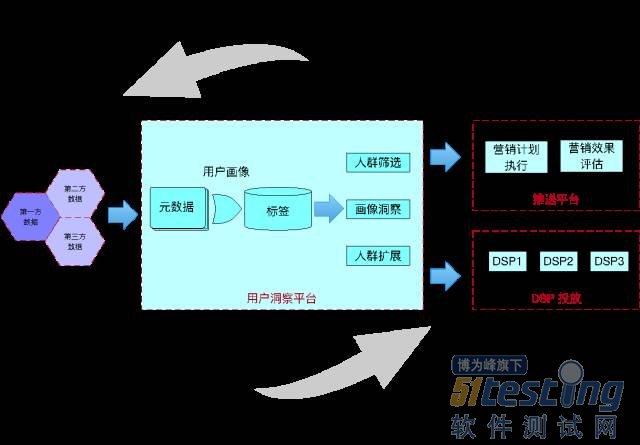
对内:无缝对接各类业务平台的数据应用,如广告平台、PUSH推送、个性化推荐之间建立了数据通道,支持公司级的精准营销,消息及时送达服务等场景。营销效果评估,反馈数据可进一步加工,用于提升画像标签质量。
对外:完善对数据的管理及输出流程,以开放接口形式为全行业从业者提供标准的精准人群标签,帮助优化投放和提升营销效果。达到对受众的精准投放,释放数据真正价值!
1.2. 用户洞察平台的核心需求
用户洞察平台的核心需求包括几个部分:
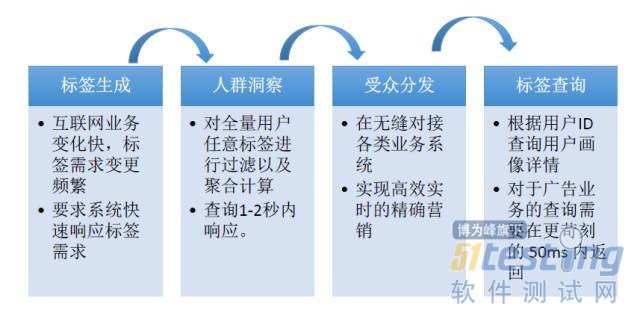
标签生成
用户洞察的核心是用户画像,必须有完善的机制和流程来生成用户标签。
人群洞察
指定标签条件选项选出用户群体,指定要分析的标签,通过聚合运算,分析用户该用户群的特征。
受众分发
采取一定的技术手段,把指定人群推至下游的营销渠道(广告平台、推送平台、OTA等)
标签查询
对下游系统提供查询接口,调用方指定用户标识(imei)查询该用户的画像标签。例如当用户在访问某个页面的时候,广告平台会查询用户的画像信息以确定广告位应该展示什么内容。
1.3. 数据流视图
从数据流的角度看,用户洞察系统可划分为几个阶段:标签生成、标签存储、平台功能、对外服务,如下图:

标签生成
从时效性角度,标签分为两类:离线计算与实时计算。
离线标签
这些标签为用户的静态属性,比如用户性别、年龄、职业、地理位置等, 这些标签通过离线计算生成,每天计算一次即可。标签生成的相关计算任务是由大数据平台提供计算能力,任务调度系统(集成开发平台)对相关作业进行调度和管理。
实时标签
这些标签为用户的动态属性,如地理位置,搜索行为等,需要通过流平台进行实时计算生成(更新),例如户现在搜索了一个热门关键词或一款产品,我们就会根据这些行为进行精准推荐,在之后的一段时间内他会看到相应产品的广告。
从计算生成方式,标签也可分为两类:统计类标签和算法类标签。
统计类标签
根据用户行为直接进行聚合运算生成的标签,中用户的消费等级,设备属性等。
算法类标签
使用机器学习算法进行属性预测生成的标签,如用户的性别,职业,兴趣爱好等。
标签存储
计算生成的标签会同时存储在ElasticSearch、HBase和Redis里。其中 ElasticSearch 主要用于实现平台功能,如人群筛选、画像洞察等。而 Hbase 与 Redis 用于实现画像查询。
平台功能
在用户画像的基础上构建丰富的人群筛选、洞察分析与受众分发功能。
对外服务
通过开放平台(OpenAPI)对下游系统(如 push 平台, OTA 平台, 广告平台等)提供服务。
1.4. 总体架构
用户洞察平台的总体架构图如下 :

集成开发平台作业调度,配置和运行离线计算任务(Hive&MR)
流平台(AnyStream)负责实时标签计算
管理模块生成的相关规则,存储在MySQL,供标签生成任务(Hive/MR/流平台)使用
用户画像(标签)宽表保存在ES上
Hbase和Redis提供kv查询
使用开发平台(OpenAPI)提供对外接口
二、标签生成过程
2.1 统计类标签
顾名思义,统计类标签可由用户行为通过直接的统计计算而生成。例如我们需要计算名为“消费等级”的标签(分为低、中、高三个等级)
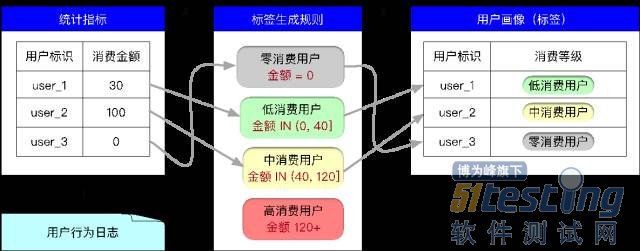
这个标签的生成过程分为 3 步:
指标统计,通过 Hive 计算生成;
标签生成规则,通过指标管理/标签管理模块维护;
基于统计指标 + 标签生成规则,用 MR 生成;
总结:统计指标与画像生成分离。
把指标和规则分开的目的是获取更高的灵活性,比如业务发展之后,需要把标签的三个等级变成 Lv1, Lv2, …, Lv10等 10 个等级,我们只需要更改规则而不需要修改指标统计逻辑,实现标签生成规则的配置化。
2.2 算法类标签
一些标签,比如人口属性,是没有办法直接统计出来的,我们需要借助机器学习算法来进行预测。
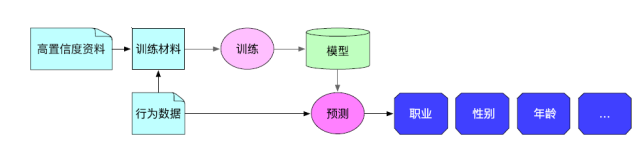
模型训练
选取高置信度资料(例如用户注册信息)+用户行为数据作输入进行模型训练。例如性别标签,我们使用用户行为进行模型训练,可用户注册 Flyme 帐号所填写的性别信息作为高置信度的资料进行监督训练。
属性预测
根据用户的行为数据,使用训练好的模型进行预测,输出相应的标签。
2.3. 单值标签与多值标签
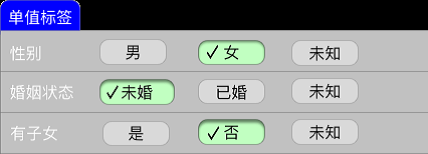
单值标签
单值标签是指用户在该标签下只能取一个值,不能多选。例如性别要么是男,要么是女,要么是未知。
多值标签
多值标签是指用户可以取该标签下的多个取值组合。比如用户可以有多个兴趣爱好

多值标签的存在,会影响存储查询引擎的选型和存储结构设计。
2.4 标签生成过程总述
离线标签计算过程:
多个统计与算法完成后,使用一个 MR 作业对生成的指标集与算法标签集进行合并。
所有的统计指标与算法标签合并到一张总表之后,由一个通用的 MR 根据配置好的规则生成标签宽表。

好处
配置化管理,提供 Web UI 管理标签的生命周期
基于配置生成标签,标签宽表数据与元数据100%一致
存在的不足:
目前配置化管理只涵盖到最终的标签宽表生成。与上游的指标统计和算法预有脱节。
上游计算过程是单独开发,指标定义只是另外配置的数据描述(可能存在不一致)
一些标签下线(废除)后,相应的上游任务的依赖需要另外废除,否则会遗留无用的作业浪费计算资源。
改进方向
扩大标签管理的功能范围,与调度平台打通,把指标生成与算法预测等任务管理起来。
指标计算也配置化,增加标签无需手写 Hive 或 MR 程序,全部在配置平台上完成。
自动管理作业依赖,一些标签下线后,自动识别并删除无用依赖,优化标签生成过程。
2.5. 实时标签
实时计算依赖于流平台,流平台根据用户行为做实时标签的计算并存储到 ElasticSearch、HBase 与 Redis。
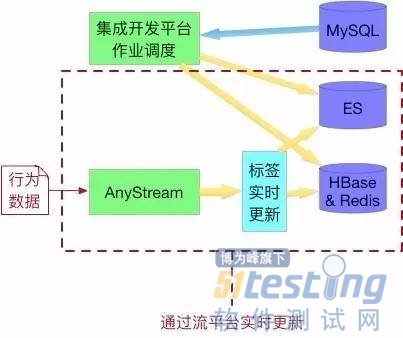
实时标签举例:
比如实时位置标签可以根据用户的地理位置识别用户的所处场景,还可以产生其他的一些比如搜索、支付的实时标签。













