
-
ORACLE SQL性能优化(四)
2007-06-19 11:50:37
13. 计算记录条数
和一般的观点相反, count(*) 比count(1)稍快 , 当然如果可以通过索引检索,对索引列的计数仍旧是最快的. 例如 COUNT(EMPNO)
(译者按: 在CSDN论坛中,曾经对此有过相当热烈的讨论, 作者的观点并不十分准确,通过实际的测试,上述三种方法并没有显著的性能差别)
14. 用Where子句替换HAVING子句
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作. 如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销.
例如:
低效:
SELECT REGION,AVG(LOG_SIZE) FROM LOCATION GROUP BY REGION HAVING REGION REGION != ‘SYDNEY’ AND REGION != ‘PERTH’
高效
SELECT REGION,AVG(LOG_SIZE) FROM LOCATION WHERE REGION REGION != ‘SYDNEY’ AND REGION != ‘PERTH’GROUP BY REGION
(译者按: HAVING 中的条件一般用于对一些集合函数的比较,如COUNT() 等等. 除此而外,一般的条件应该写在WHERE子句中)
15. 减少对表的查询
在含有子查询的SQL语句中,要特别注意减少对表的查询.
例如:
低效
SELECT TAB_NAME FROM TABLES WHERE TAB_NAME = ( SELECT TAB_NAME FROM TAB_COLUMNS
WHERE VERSION = 604) AND DB_VER= ( SELECT DB_VER FROM TAB_COLUMNS WHERE VERSION = 604)
高效
SELECT TAB_NAME FROM TABLES WHERE (TAB_NAME,DB_VER) = ( SELECT TAB_NAME,DB_VER)
FROM TAB_COLUMNS WHERE VERSION = 604)
Update 多个Column 例子:
低效:
UPDATE EMP SET EMP_CAT = (SELECT MAX(CATEGORY) FROM EMP_CATEGORIES), SAL_RANGE = (SELECT MAX(SAL_RANGE) FROM EMP_CATEGORIES) WHERE EMP_DEPT = 0020;
高效:
UPDATE EMP SET (EMP_CAT, SAL_RANGE) = (SELECT MAX(CATEGORY) , MAX(SAL_RANGE)
FROM EMP_CATEGORIES) WHERE EMP_DEPT = 0020;
16. 通过内部函数提高SQL效率.
SELECT H.EMPNO,E.ENAME,H.HIST_TYPE,T.TYPE_DESC,COUNT(*) FROM HISTORY_TYPE T,EMP E,EMP_HISTORY H WHERE H.EMPNO = E.EMPNO AND H.HIST_TYPE = T.HIST_TYPE GROUP BY H.EMPNO,E.ENAME,H.HIST_TYPE,T.TYPE_DESC;
通过调用下面的函数可以提高效率.
FUNCTION LOOKUP_HIST_TYPE(TYP IN NUMBER) RETURN VARCHAR2
AS
TDESC VARCHAR2(30);
CURSOR C1 IS
SELECT TYPE_DESC FROM HISTORY_TYPE WHERE HIST_TYPE = TYP;
BEGIN OPEN C1;
FETCH C1 INTO TDESC;
CLOSE C1;
RETURN (NVL(TDESC,’?’));
END;
FUNCTION LOOKUP_EMP(EMP IN NUMBER) RETURN VARCHAR2
AS
ENAME VARCHAR2(30);
CURSOR C1 IS
SELECT ENAME FROM EMP WHERE EMPNO=EMP;
BEGIN
OPEN C1;
FETCH C1 INTO ENAME;
CLOSE C1;
RETURN (NVL(ENAME,’?’));
END;
SELECT H.EMPNO,LOOKUP_EMP(H.EMPNO),H.HIST_TYPE,LOOKUP_HIST_TYPE(H.HIST_TYPE),COUNT(*) FROM EMP_HISTORY H GROUP BY H.EMPNO , H.HIST_TYPE;
(译者按: 经常在论坛中看到如 ’能不能用一个SQL写出….’ 的贴子, 殊不知复杂的SQL往往牺牲了执行效率. 能够掌握上面的运用函数解决问题的方法在实际工作中是非常有意义的) -
ORACLE SQL性能优化(三)
2007-06-19 11:43:58
8.使用DECODE函数来减少处理时间
使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表.
例如:
SELECT COUNT(*),SUM(SAL) FROM EMP WHERE DEPT_NO = 0020 AND ENAME LIKE ‘SMITH%’;
SELECT COUNT(*),SUM(SAL) FROM EMP WHERE DEPT_NO = 0030 AND ENAME LIKE ‘SMITH%’;
你可以用DECODE函数高效地得到相同结果
SELECT COUNT(DECODE(DEPT_NO,0020,’X’,NULL)) D0020_COUNT, COUNT(DECODE(DEPT_NO,0030,’X’,NULL)) D0030_COUNT,SUM(DECODE(DEPT_NO,0020,SAL,NULL)) D0020_SAL,
SUM(DECODE(DEPT_NO,0030,SAL,NULL)) D0030_SAL FROM EMP WHERE ENAME LIKE ‘SMITH%’;
类似的,DECODE函数也可以运用于GROUP BY 和ORDER BY子句中.
9. 整合简单,无关联的数据库访问
如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)
例如:
SELECT NAME FROM EMP WHERE EMP_NO = 1234;
SELECT NAME FROM DPT WHERE DPT_NO = 10 ;
SELECT NAME FROM CAT WHERE CAT_TYPE = ‘RD’;
上面的3个查询可以被合并成一个:
SELECT E.NAME , D.NAME , C.NAME FROM CAT C , DPT D , EMP E,DUAL X WHERE NVL(‘X’,X.DUMMY) = NVL(‘X’,E.ROWID(+)) AND NVL(‘X’,X.DUMMY) = NVL(‘X’,D.ROWID(+))
AND NVL(‘X’,X.DUMMY) = NVL(‘X’,C.ROWID(+)) AND E.EMP_NO(+) = 1234 AND D.DEPT_NO(+) = 10 AND C.CAT_TYPE(+) = ‘RD’;
(译者按: 虽然采取这种方法,效率得到提高,但是程序的可读性大大降低,所以读者 还是要权衡之间的利弊)
10. 删除重复记录
最高效的删除重复记录方法 ( 因为使用了ROWID)
DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID) FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
11. 用TRUNCATE替代DELETE
当删除表中的记录时,在通常情况下, 回滚段(rollback segments ) 用来存放可以被恢复的信息. 如果你没有COMMIT事务,ORACLE会将数据恢复到删除之前的状态(准确地说是恢复到执行删除命令之前的状况)而当运用TRUNCATE时, 回滚段不再存放任何可被恢复的信息.当命令运行后,数据不能被恢复.因此很少的资源被调用,执行时间也会很短.
(译者按: TRUNCATE只在删除全表适用,TRUNCATE是DDL不是DML)
12. 尽量多使用COMMIT
只要有可能,在程序中尽量多使用COMMIT, 这样程序的性能得到提高,需求也会因为COMMIT所释放的资源而减少:
COMMIT所释放的资源:
a. 回滚段上用于恢复数据的信息.
b. 被程序语句获得的锁
c. redo log buffer 中的空间
d. ORACLE为管理上述3种资源中的内部花费
(译者按: 在使用COMMIT时必须要注意到事务的完整性,现实中效率和事务完整性往往是鱼和熊掌不可得兼) -
ORACLE SQL性能优化(二)
2007-06-19 11:36:05
4. 选择最有效率的表名顺序(只在基于规则的优化器中有效)
ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表 driving table)将被最先处理. 在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表.当ORACLE处理多个表时, 会运用排序及合并的方式连接它们.首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出的记录与第一个表中合适记录进行合并.
例如:
表 TAB1 16,384 条记录
表 TAB2 1 条记录
选择TAB2作为基础表 (最好的方法)
select count(*) from tab1,tab2 执行时间0.96秒
选择TAB2作为基础表 (不佳的方法)
select count(*) from tab2,tab1 执行时间26.09秒
如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表.
例如:
EMP表描述了LOCATION表和CATEGORY表的交集.
SELECT * FROM LOCATION L , CATEGORY C, EMP E
WHERE E.EMP_NO BETWEEN 1000 AND 2000 AND E.CAT_NO = C.CAT_NO AND E.LOCN = L.LOCN
将比下列SQL更有效率
SELECT * FROM EMP E,LOCATION L,CATEGORY C
WHERE E.CAT_NO = C.CAT_NO AND E.LOCN = L.LOCN AND E.EMP_NO BETWEEN 1000 AND 2000
5. WHERE子句中的连接顺序.
ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾.
例如:(低效,执行时间156.3秒)
SELECT … FROM EMP E WHERE SAL > 50000 AND JOB = ‘MANAGER’AND 25 < (SELECT COUNT(*) FROM EMP WHERE MGR=E.EMPNO);
(高效,执行时间10.6秒)
SELECT … FROM EMP E WHERE 25 < (SELECT COUNT(*) FROM EMP WHERE MGR=E.EMPNO) AND SAL > 50000 AND JOB = ‘MANAGER’;
6. SELECT子句中避免使用 ‘ * ‘
当你想在SELECT子句中列出所有的COLUMN时,使用动态SQL列引用 ‘*’ 是一个方便的方法.不幸的是,这是一个非常低效的方法. 实际上,ORACLE在解析的过程中, 会将’*’ 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间.
7. 减少访问数据库的次数
当执行每条SQL语句时, ORACLE在内部执行了许多工作: 解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等等. 由此可见, 减少访问数据库的次数 , 就能实际上减少ORACLE的工作量.
例如,以下有三种方法可以检索出雇员号等于0342或0291的职员.
方法1 (最低效)
SELECT EMP_NAME,SALARY,GRADE FROM EMP WHERE EMP_NO = 342;
SELECT EMP_NAME,SALARY,GRADE FROM EMP WHERE EMP_NO = 291;
方法2 (次低效)
DECLARE
CURSOR C1 (E_NO NUMBER) IS
SELECT EMP_NAME,SALARY,GRADE FROM EMP WHERE EMP_NO = E_NO;
BEGIN
OPEN C1(342);
FETCH C1 INTO …,..,.. ;
…..
OPEN C1(291);
FETCH C1 INTO …,..,.. ;
CLOSE C1;
END;
方法3 (高效)
SELECT A.EMP_NAME , A.SALARY , A.GRADE,B.EMP_NAME , B.SALARY , B.GRADE
FROM EMP A,EMP B WHERE A.EMP_NO = 342 AND B.EMP_NO = 291;
注意:
在SQL*Plus , SQL*Forms和Pro*C中重新设置ARRAYSIZE参数, 可以增加每次数据库访问的检索数据量 ,建议值为200 -
ORACLE SQL性能优化(一)
2007-06-19 10:53:45
1.选用适合的ORACLE优化器
ORACLE的优化器共有3种:
a. RULE (基于规则) b. COST (基于成本) c. CHOOSE (选择性)
设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS . 你当然也在SQL句级或是会话(session)级对其进行覆盖.
为了使用基于成本的优化器(CBO, Cost-Based Optimizer) , 你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性.
如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关. 如果table已经被analyze过, 优化器模式将自动成为CBO , 反之,数据库将采用RULE形式的优化器.
在缺省情况下,ORACLE采用CHOOSE优化器, 为了避免那些不必要的全表扫描(full table scan) , 你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器.
2.访问Table的方式
ORACLE 采用两种访问表中记录的方式:
a.全表扫描
全表扫描就是顺序地访问表中每条记录. ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描.
b.通过ROWID访问表
你可以采用基于ROWID的访问方式情况,提高访问表的效率, , ROWID包含了表中记录的物理位置信息..ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系. 通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高.
3.共享SQL语句
为了不重复解析相同的SQL语句,在第一次解析之后, ORACLE将SQL语句存放在内存中.这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的内存可以被所有的数据库用户共享. 因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同, ORACLE就能很快获得已经被解析的语句以及最好的执行路径. ORACLE的这个功能大大地提高了SQL的执行性能并节省了内存的使用.可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering) ,这个功能并不适用于多表连接查询.
数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了.当你向ORACLE 提交一个SQL语句,ORACLE会首先在这块内存中查找相同的语句. 这里需要注明的是,ORACLE对两者采取的是一种严格匹配,要达成共享,SQL语句必须完全相同(包括空格,换行等).
共享的语句必须满足三个条件:
A.字符级的比较:当前被执行的语句和共享池中的语句必须完全相同.
例如:
SELECT * FROM EMP;
和下列每一个都不同
SELECT * from EMP;
Select * From Emp;
SELECT * FROM EMP;
B.两个语句所指的对象必须完全相同:
例如:
考虑一下下列SQL语句能否在这两个用户之间共享.
C.两个SQL语句中必须使用相同的名字的绑定变量(bind variables)
例如:
第一组的两个SQL语句是相同的(可以共享),而第二组中的两个语句是不同的(即使在运行时,赋于不同的绑定变量相同的值)
a.select pin , name from people where pin = :blk1.pin;
select pin , name from people where pin = :blk1.pin;
b.select pin , name from people where pin = :blk1.ot_ind;
select pin , name from people where pin = :blk1.ov_ind; -
软件系统架购
2007-06-15 17:03:10
软件系统架构
软件架构(software architecture)是一系列相关的抽象模式,用于指导大型软件系统各个方面的设计。 软件架构是一个系统的草图。软件架构描述的对象是直接构成系统的抽象组件。各个组件之间的连接则明确和相对细致地描述组件之间的通讯。在实现阶段,这些抽象组件被细化为实际的组件,比如具体某个类或者对象。在面向对象领域中,组件之间的连接通常用接口_(计算机科学)来实现。
软件体系结构是构建计算机软件实践的基础。与建筑师设定建筑项目的设计原则和目标,作为绘图员画图的基础一样,一个软件架构师或者系统架构师陈述软件构架以作为满足不同客户需求的实际系统设计方案的基础。
软件构架是一个容易理解的概念,多数工程师(尤其是经验不多的工程师)会从直觉上来认识它,但要给出精确的定义很困难。特别是,很难明确地区分设计和构架:构架属于设计的一方面,它集中于某些具体的特征。
在“软件构架简介”中,David GArlan 和 Mary Shaw 认为软件构架是有关如下问题的设计层次:“在计算的算法和数据结构之外,设计并确定系统整体结构成为了新的问题。结构问题包括总体组织结构和全局控制结构;通信、同步和数据访问的协议;设计元素的功能分配;物理分布;设计元素的组成;定标与性能;备选设计的选择。”[GS93]
但构架不仅是结构;IEEE Working Group on Architecture 把其定义为“系统在其环境中的最高层概念”[IEEE98]。构架还包括“符合”系统完整性、经济约束条件、审美需求和样式。它并不仅注重对内部的考虑,而且还在系统的用户环境和开发环境中对系统进行整体考虑,即同时注重对外部的考虑。
在 Rational Unified ProcESs 中,软件系统的构架(在某一给定点)是指系统重要构件的组织或结构,这些重要构件通过接口与不断减小的构件与接口所组成的构件进行交互。
从和目的、主题、材料和结构的联系上来说,软件架构可以和建筑物的架构相比拟。一个软件架构师需要有广泛的软件理论知识和相应的经验来事实和管理软件产品的高级设计。软件架构师定义和设计软件的模块化,模块之间的交互,用户界面风格,对外接口方法,创新的设计特性,以及高层事物的对象操作、逻辑和流程。
是一般而言,软件系统的架构(ArchitECture)有两个要素:
·它是一个软件系统从整体到部分的最高层次的划分。
一个系统通常是由元件组成的,而这些元件如何形成、相互之间如何发生作用,则是关于这个系统本身结构的重要信息。
详细地说,就是要包括架构元件(Architecture Component)、联结器(Connector)、任务流(TASk-flow)。所谓架构元素,也就是组成系统的核心"砖瓦",而联结器则描述这些元件之间通讯的路径、通讯的机制、通讯的预期结果,任务流则描述系统如何使用这些元件和联结器完成某一项需求。
·建造一个系统所作出的最高层次的、以后难以更改的,商业的和技术的决定。
在建造一个系统之前会有很多的重要决定需要事先作出,而一旦系统开始进行详细设计甚至建造,这些决定就很难更改甚至无法更改。显然,这样的决定必定是有关系统设计成败的最重要决定,必须经过非常慎重的研究和考察。历史
早在1960年代,诸如E·W·戴克斯特拉就已经涉及软件架构这个概念了。自1990年代以来,部分由于在 Rational Software Corporation 和MiCROSoft内部的相关活动,软件架构这个概念开始越来越流行起来。卡内基梅隆大学和加州大学埃尔文分校在这个领域作了很多研究。卡内基·梅隆大学的Mary Shaw和David Garlan于1996年写了一本叫做 Software Architecture perspective on an emerging DIscipline的书,提出了软件架构中的很多概念,例如软件组件、连接器、风格等等。 加州大学埃尔文分校的软件研究院所做的工作则主要集中于架构风格、架构描述语言以及动态架构。
计算机软件的历史开始于五十年代,历史非常短暂,而相比之下建筑工程则从石器时代就开始了,人类在几千年的建筑设计实践中积累了大量的经验和教训。建筑设计基本上包含两点,一是建筑风格,二是建筑模式。独特的建筑风格和恰当选择的建筑模式,可以使一个独一无二。
下面的照片显示了中美洲古代玛雅建筑,Chichen-Itza大金字塔,九个巨大的石级堆垒而上,九十一级台阶(象征着四季的天数)夺路而出,塔顶的神殿耸入云天。所有的数字都如日历般严谨,风格雄浑。难以想象这是石器时代的建筑物。
图1、位于墨西哥Chichen-Itza(在玛雅语中chi意为嘴chen意为井)的古玛雅建筑。(摄影:作者)软件与人类的关系是架构师必须面对的核心问题,也是自从软件进入历史舞台之后就出现的问题。与此类似地,自从有了建筑以来,建筑与人类的关系就一直是建筑设计师必须面对的核心问题。英国首相丘吉尔说,我们构造建筑物,然后建筑物构造我们(We shape our buildings, and afterwaRDS our buildings shape us)。英国下议院的会议厅较狭窄,无法使所有的下议院议员面向同一个方向入座,而必须分成两侧入座。丘吉尔认为,议员们入座的时候自然会选择与自己政见相同的人同时入座,而这就是英国政党制的起源。Party这个词的原意就是"方"、"面"。政党起源的关键就是建筑物对人的影响。
在软件设计界曾经有很多人认为功能是最为重要的,形式必须服从功能。与此类似地,在建筑学界,现代主义建筑流派的开创人之一Louis Sullivan也认为形式应当服从于功能(FORMs follows function)。
几乎所有的软件设计理念都可以在浩如烟海的建筑学历史中找到更为遥远的历史回响。最为著名的,当然就是模式理论和XP理论。
架构的目标是什么
正如同软件本身有其要达到的目标一样,架构设计要达到的目标是什么呢?一般而言,软件架构设计要达到如下的目标:
·可靠性(Reliable)。软件系统对于用户的商业经营和管理来说极为重要,因此软件系统必须非常可靠。
·安全行(Secure)。软件系统所承担的交易的商业价值极高,系统的安全性非常重要。
·可扩展性(SCAlable)。软件必须能够在用户的使用率、用户的数目增加很快的情况下,保持合理的性能。只有这样,才能适应用户的市场扩展得可能性。
·可定制化(CuSTomizable)。同样的一套软件,可以根据客户群的不同和市场需求的变化进行调整。
·可扩展性(Extensible)。在新技术出现的时候,一个软件系统应当允许导入新技术,从而对现有系统进行功能和性能的扩展
·可维护性(MAIntainable)。软件系统的维护包括两方面,一是排除现有的错误,二是将新的软件需求反映到现有系统中去。一个易于维护的系统可以有效地降低技术支持的花费
·客户体验(Customer Experience)。软件系统必须易于使用。
·市场时机(Time to Market)。软件用户要面临同业竞争,软件提供商也要面临同业竞争。以最快的速度争夺市场先机非常重要。
架构的种类
根据我们关注的角度不同,可以将架构分成三种:
·逻辑架构、软件系统中元件之间的关系,比如用户界面,数据库,外部系统接口,商业逻辑元件,等等。
比如下面就是笔者亲身经历过的一个软件系统的逻辑架构图
图2、一个逻辑架构的例子从上面这张图中可以看出,此系统被划分成三个逻辑层次,即表象层次,商业层次和数据持久层次。每一个层次都含有多个逻辑元件。比如WEB服务器层次中有HTML服务元件、Session服务元件、安全服务元件、系统管理元件等。
·物理架构、软件元件是怎样放到硬件上的。
比如下面这张物理架构图描述了一个分布于北京和上海的分布式系统的物理架构,图中所有的元件都是物理设备,包括网络分流器、代理服务器、WEB服务器、应用服务器、报表服务器、整合服务器、存储服务器、主机等等。
图3、一个物理架构的例子·系统架构、系统的非功能性特征,如可扩展性、可靠性、强壮性、灵活性、性能等。
系统架构的设计要求架构师具备软件和硬件的功能和性能的过硬知识,这一工作无疑是架构设计工作中最为困难的工作。
此外,从每一个角度上看,都可以看到架构的两要素:元件划分和设计决定。
首先,一个软件系统中的元件首先是逻辑元件。这些逻辑元件如何放到硬件上,以及这些元件如何为整个系统的可扩展性、可靠性、强壮性、灵活性、性能等做出贡献,是非常重要的信息。
其次,进行软件设计需要做出的决定中,必然会包括逻辑结构、物理结构,以及它们如何影响到系统的所有非功能性特征。这些决定中会有很多是一旦作出,就很难更改的。
根据作者的经验,一个基于数据库的系统架构,有多少个数据表,就会有多少页的架构设计文档。比如一个中等的数据库应用系统通常含有一百个左右的数据表,这样的一个系统设计通常需要有一百页左右的架构设计文档。构架描述
为了讨论和分析软件构架,必须首先定义构架表示方式,即描述构架重要方面的方式。在 Rational Unified Process 中,软件构架文档记录有这种描述。
构架视图
我们决定以多种构架视图来表示软件构架。每种构架视图针对于开发流程中的涉众(例如最终用户、设计人员、管理人员、系统工程师、维护人员等)所关注的特定方面。
构架视图显示了软件构架如何分解为构件,以及构件如何由连接器连接来产生有用的形式 [PW92],由此记录主要的结构设计决策。这些设计决策必须基于需求以及功能、补充和其他方面的约束。而这些决策又会在较低层次上为需求和将来的设计决策施加进一步的约束。
典型的构架视图集
构架由许多不同的构架视图来表示,这些视图本质上是以图形方式来摘要说明“在构架方面具有重要意义”的模型元素。在 Rational Unified Process 中,您将从一个典型的视图集开始,该视图集称为“4+1 视图模型”[KRU95]。它包括:
用例视图:包括用例和场景,这些用例和场景包括在构架方面具有重要意义的行为、类或技术风险。它是用例模型的子集。
逻辑视图:包括最重要的设计类、从这些设计类到包和子系统的组织形式,以及从这些包和子系统到层的组织形式。它还包括一些用例实现。它是设计模型的子集。
实施视图:包括实施模型及其从模块到包和层的组织形式的概览。 同时还描述了将逻辑视图中的包和类向实施视图中的包和模块分配的情况。它是实施模型的子集。
进程视图:包括所涉及任务(进程和线程)的描述,它们的交互和配置,以及将设计对象和类向任务的分配情况。只有在系统具有很高程度的并行时,才需要该视图。在 Rational Unified Process 中,它是设计模型的子集。
配置视图:包括对最典型的平台配置的各种物理节点的描述以及将任务(来自进程视图)向物理节点分配的情况。只有在分布式系统中才需要该视图。它是部署模型的一个子集。
构架视图记录在软件构架文档中。您可以构建其他视图来表达需要特别关注的不同方面:用户界面视图、安全视图、数据视图等等。对于简单系统,可以省略 4+1 视图模型中的一些视图。构架重点
虽然以上视图可以表示系统的整体设计,但构架只同以下几个具体方面相关:
模型的结构,即组织模式,例如分层。
基本元素,即关键用例、主类、常用机制等,它们与模型中的各元素相对。
几个关键场景,它们表示了整个系统的主要控制流程。
记录模块度、可选特征、产品线状况的服务。构架视图在本质上是整体设计的抽象或简化,它们通过舍弃具体细节来突出重要的特征。在考虑以下方面时,这些特征非常重要:
系统演进,即进入下一个开发周期。
在产品线环境下复用构架或构架的一部分。
评估补充质量,例如性能、可用性、可移植性和安全性。
向团队或分包商分配开发工作。
决定是否包括市售构件。
插入范围更广的系统。构架模式
构架模式是解决复发构架问题的现成形式。构架框架或构架基础设施(中间件)是可以在其上构建某种构架的构件集。许多主要的构架困难应在框架或基础设施中进行解决,而且通常针对于特定的领域:命令和控制、MIS、控制系统等等。
构架模式示例
[BUS96] 根据构架模式最适用的系统的特征将其分类,其中一个类别处理更普遍的结构问题。下表显示了 [BUS96] 中所提供的类别和这些类别所包含的模式。
类别 模式 结构 层 管道和过滤器 黑板 分布式系统 代理 交互系统 模型-视图-控制器 表示-抽象-控制 自适应系统 反射 微核 软件构架是一个容易理解的概念,多数工程师(尤其是经验不多的工程师)会从直觉上来认识它,但要给出精确的定义很困难。特别是,很难明确地区分设计和构架:构架属于设计的一方面,它集中于某些具体的特征。
在“软件构架简介”中,David Garlan 和 Mary Shaw 认为软件构架是有关如下问题的设计层次:“在计算的算法和数据结构之外,设计并确定系统整体结构成为了新的问题。结构问题包括总体组织结构和全局控制结构;通信、同步和数据访问的协议;设计元素的功能分配;物理分布;设计元素的组成;定标与性能;备选设计的选择。”[GS93]
但构架不仅是结构;IEEE Working Group on Architecture 把其定义为“系统在其环境中的最高层概念”[IEEE98]。构架还包括“符合”系统完整性、经济约束条件、审美需求和样式。它并不仅注重对内部的考虑,而且还在系统的用户环境和开发环境中对系统进行整体考虑,即同时注重对外部的考虑。
在 Rational Unified Process 中,软件系统的构架(在某一给定点)是指系统重要构件的组织或结构,这些重要构件通过接口与不断减小的构件与接口所组成的构件进行交互。
为阐明其含义,下面将详述其中的两个;完整说明请参见 [BUS96]。模式以下列广泛使用的形式来表示:
模式名
环境
问题
影响,描述应考虑的不同问题方面
解决方案
基本原理
结果环境
示例
模式名
层环境
需要进行结构分解的大系统。问题
必须处理不同抽象层次的问题的系统。例如:硬件控制问题、常见服务问题和针对于不同领域的问题。最好不要编写垂直构件来处理所有抽象层次的问题。否则要在不同的构件中多次处理相同的问题(可能会不一致)。影响
系统的某些部分应当是可替换的
构件中的变化不应波动
相似的责任应归为一组
构件大小 -- 复杂构件可能要进行分解
解决办法
将系统分成构件组,并使构件组形成层叠结构。使上层只使用下层(决不使用上层)提供的服务。尽量不使用非紧邻下层提供的服务(不跳层使用服务,除非中间层只添加通过构件)。示例:
1. 通用层
严格的分层构架规定设计元素(类、构件、包、子系统)只能使用下层提供的服务, 服务可以包括事件处理、错误处理、数据库访问等等。 相对于记录在底层的原始操作系统级调用,它包括更明显的机制。
2. 业务系统层
上图显示了另一个分层示例,其中有垂直特定应用层、水平层和基础设施层。注意:此处的目标是采用非常短的业务“烟囱”并实现各种应用程序间的通用性。 否则,就可能有多个人解决同一问题,从而导致潜在的分歧。
有关该模式的深入讨论,请参见指南:分层。
模式名
黑板环境
没有解决问题的确定方法(算法)或方法不可行的领域。例如 AI 系统、语音识别和监视系统。问题
多个问题解决顾问(知识顾问)必须通过协作来解决他们无法单独解决的问题。各顾问的工作结果必须可以供所有其他顾问访问,使他们可以评估自己是否可以参与解决方案的查找并发布其工作结果。影响
知识顾问参与解决问题的顺序不是确定的,这可能取决于问题解决策略
不同顾问的输入(结果或部分解决方案)可能有不同的表示方式
各顾问并不直接知道对方的存在,但可以评估对方发布的工作
解决办法
多名知识顾问都可访问一个称为“黑板”的共享数据库。黑板提供监测和更新其内容的接口。控制模块/对象激活遵循某种策略的顾问。激活后,顾问查看黑板,以确定它是否能参与解决问题。如果顾问决定它可以参与,控制对象就可以允许顾问将其部分(或最终)解决方案放置于黑板上。示例:
以上显示了使用 UML 建模的结构或静态视图。 它将成为参数化协作的一部分,然后会绑定到实参上对模式进行实例化。
构架风格
软件构架(或仅是构架视图)可以具有名为构架风格的属性,该属性减少了可选的形式,并使构架具有一定程度的一致性。样式可以通过一组模式或通过选择特定构件或连接器作为基本构件来定义。对给定系统,某些样式可作为构架描述的一部分记录在构架风格指南(Rational Unified Process 中设计指南文档的一部分)中。样式在构架的可理解性与完整性方面起着主要的作用。构架设计图
构架视图的图形描述称为构架设计图。对于以上描述的各种视图,设计图由以下统一建模语言图组成 [UML99]:逻辑视图:类图、状态机和对象图。
进程视图:类图与对象图(包括任务 - 进程与线程)。
实施视图:构件图。
部署视图:配置图。
用例视图:用例图描述用例、主角和普通设计类;顺序图描述设计对象及其协作关系。
构架设计流程
在 Rational Unified Process 中,构架主要是分析设计工作流程的结果。当项目再次进行此工作流程时,构架将在一次又一次迭代中不断演化、改进、精炼。由于每次迭代都包括集成和测试,所以在交付产品时,构架就相当强壮了。构架是精化阶段各次迭代的重点,构架的基线通常会在此阶段结束时确定。架构师
软体设计师中有一些技术水平较高、经验较为丰富的人,他们需要承担软件系统的架构设计,也就是需要设计系统的元件如何划分、元件之间如何发生相互作用,以及系统中逻辑的、物理的、系统的重要决定的作出。
这样的人就是所谓的架构师(Architect)。在很多公司中,架构师不是一个专门的和正式的职务。通常在一个开发小组中,最有经验的程序员会负责一些架构方面的工作。在一个部门中,最有经验的项目经理会负责一些架构方面的工作。
但是,越来越多的公司体认到架构工作的重要性,并且在不同的组织层次上设置专门的架构师位置,由他们负责不同层次上的逻辑架构、物理架构、系统架构的设计、配置、维护等工作。 -
需求分析的20条法则
2007-04-16 10:26:01
对商业用户来说,他们后面是成百上千个供应商,前面是成千上万个消费顾客。怎样利用软件管理错综复杂的供应商和消费顾客,如何做好精细到一个小小调料包的进、销、调、存的商品流通工作,这些都是商业企业需要信息管理系统的理由。软件开发的意义也就在于此。而弄清商业用户如此复杂需求的真面目,正是软件开发成功的关键所在。
经理:“我们要建立一套完整的商业管理软件系统,包括商品的进、销、调、存管理,是总部-门店的连锁经营模式。通过通信手段门店自动订货,供应商自动结算,卖场通过扫条码实现销售,管理人员能够随时查询门店商品销售和库存情况。另外,我们也得为政府部门提供关于商品营运的报告。”
分析员:“我已经明白这个项目的大体结构框架,这非常重要,但在制定计划之前,我们必须收集一些需求。”
经理觉得奇怪:“我不是刚告诉你我的需求了吗?”
分析员:“实际上,您只说明了整个项目的概念和目标。这些高层次的业务需求不足以提供开发的内容和时间。我需要与实际将要使用系统的业务人员进行讨论,然后才能真正明白达到业务目标所需功能和用户要求,了解清楚后,才可以发现哪些是现有组件即可实现的,哪些是需要开发的,这样可节省很多时间。”
经理:“业务人员都在招商。他们非常忙,没有时间与你们详细讨论各种细节。你能不能说明一下你们现有的系统?”
分析员尽量解释从用户处收集需求的合理性:“如果我们只是凭空猜想用户的要求,结果不会令人满意。我们只是软件开发人员,而不是采购专家、营运专家或是财务专家,我们并不真正明白您这个企业内部运营需要做些什么。我曾经尝试过,未真正明白这些问题就开始编码,结果没有人对产品满意。”
经理坚持道:“行了,行了,我们没有那么多的时间。让我来告诉您我们的需求。实际上我也很忙。请马上开始开发,并随时将你们的进展情况告诉我。”
风险躲在需求的迷雾之后
以上我们看到的是某客户项目经理与系统开发小组的分析人员讨论业务需求。在项目开发中,所有的项目风险承担者都对需求分析阶段备感兴趣。这里所指的风险承担者包括客户方面的项目负责人和用户,开发方面的需求分析人员和项目管理者。这部分工作做得到位,能开发出很优秀的软件产品,同时也会令客户满意。若处理不好,则会导致误解、挫折、障碍以及潜在的质量和业务价值上的威胁。因此可见——需求分析奠定了软件工程和项目管理的基础。
拨开需求分析的迷雾
像这样的对话经常出现在软件开发的过程中。客户项目经理的需求对分析人员来讲,像“雾里看花”般模糊并令开发者感到困惑。那么,我们就拨开雾影,分析一下需求的具体内容:
·业务需求——反映了组织机构或客户对系统、产品高层次的目标要求,通常在项目定义与范围文档中予以说明。
·用户需求——描述了用户使用产品必须要完成的任务,这在使用实例或方案脚本中予以说明。
·功能需求——定义了开发人员必须实现的软件功能,使用户利用系统能够完成他们的任务,从而满足了业务需求。
·非功能性的需求——描述了系统展现给用户的行为和执行的操作等,它包括产品必须遵从的标准、规范和约束,操作界面的具体细节和构造上的限制。
·需求分析报告——报告所说明的功能需求充分描述了软件系统所应具有的外部行为。“需求分析报告”在开发、测试、质量保证、项目管理以及相关项目功能中起着重要作用。
前面提到的客户项目经理通常阐明产品的高层次概念和主要业务内容,为后继工作建立了一个指导性的框架。其他任何说明都应遵循“业务需求”的规定,然而“业务需求”并不能为开发人员提供开发所需的许多细节说明。
下一层次需求——用户需求,必须从使用产品的用户处收集。因此,这些用户构成了另一种软件客户,他们清楚要使用该产品完成什么任务和一些非功能性的特性需求。例如:程序的易用性、健壮性和可靠性,而这些特性将会使用户很好地接受具有该特点的软件产品。
经理层有时试图代替实际用户说话,但通常他们无法准确说明“用户需求”。用户需求来自产品的真正使用者,必须让实际用户参与到收集需求的过程中。如果不这样做,产品很可能会因缺乏足够的信息而遗留不少隐患。
在实际需求分析过程中,以上两种客户可能都觉得没有时间与需求分析人员讨论,有时客户还希望分析人员无须讨论和编写需求说明就能说出用户的需求。除非遇到的需求极为简单;否则不能这样做。如果您的组织希望软件成功,那么必须要花上数天时间来消除需求中模糊不清的地方和一些使开发者感到困惑的方面。
优秀的软件产品建立在优秀的需求基础之上,而优秀的需求源于客户与开发人员之间有效的交流和合作。只有双方参与者都明白自己需要什么、成功的合作需要什么时,才能建立起一种良好的合作关系。
由于项目的压力与日俱增,所有项目风险承担者有着一个共同目标,那就是大家都想开发出一个既能实现商业价值又能满足用户要求,还能使开发者感到满足的优秀软件产品。
客户的需求观
客户与开发人员交流需要好的方法。下面建议20条法则,客户和开发人员可以通过评审以下内容并达成共识。如果遇到分歧,将通过协商达成对各自义务的相互理解,以便减少以后的磨擦(如一方要求而另一方不愿意或不能够满足要求)。
1、 分析人员要使用符合客户语言习惯的表达
需求讨论集中于业务需求和任务,因此要使用术语。客户应将有关术语(例如:采价、印花商品等采购术语)教给分析人员,而客户不一定要懂得计算机行业的术语。
2、分析人员要了解客户的业务及目标
只有分析人员更好地了解客户的业务,才能使产品更好地满足需要。这将有助于开发人员设计出真正满足客户需要并达到期望的优秀软件。为帮助开发和分析人员,客户可以考虑邀请他们观察自己的工作流程。如果是切换新系统,那么开发和分析人员应使用一下目前的旧系统,有利于他们明白目前系统是怎样工作的,其流程情况以及可供改进之处。3、 分析人员必须编写软件需求报告
分析人员应将从客户那里获得的所有信息进行整理,以区分业务需求及规范、功能需求、质量目标、解决方法和其他信息。通过这些分析,客户就能得到一份“需求分析报告”,此份报告使开发人员和客户之间针对要开发的产品内容达成协议。报告应以一种客户认为易于翻阅和理解的方式组织编写。客户要评审此报告,以确保报告内容准确完整地表达其需求。一份高质量的“需求分析报告”有助于开发人员开发出真正需要的产品。
4、 要求得到需求工作结果的解释说明
分析人员可能采用了多种图表作为文字性“需求分析报告”的补充说明,因为工作图表能很清晰地描述出系统行为的某些方面,所以报告中各种图表有着极高的价值;虽然它们不太难于理解,但是客户可能对此并不熟悉,因此客户可以要求分析人员解释说明每个图表的作用、符号的意义和需求开发工作的结果,以及怎样检查图表有无错误及不一致等。
5、 开发人员要尊重客户的意见
如果用户与开发人员之间不能相互理解,那关于需求的讨论将会有障碍。共同合作能使大家“兼听则明”。参与需求开发过程的客户有权要求开发人员尊重他们并珍惜他们为项目成功所付出的时间,同样,客户也应对开发人员为项目成功这一共同目标所做出的努力表示尊重。
6、 开发人员要对需求及产品实施提出建议和解决方案
通常客户所说的“需求”已经是一种实际可行的实施方案,分析人员应尽力从这些解决方法中了解真正的业务需求,同时还应找出已有系统与当前业务不符之处,以确保产品不会无效或低效;在彻底弄清业务领域内的事情后,分析人员就能提出相当好的改进方法,有经验且有创造力的分析人员还能提出增加一些用户没有发现的很有价值的系统特性。
7、 描述产品使用特性
客户可以要求分析人员在实现功能需求的同时还注意软件的易用性,因为这些易用特性或质量属性能使客户更准确、高效地完成任务。例如:客户有时要求产品要“界面友好”或“健壮”或“高效率”,但对于开发人员来讲,太主观了并无实用价值。正确的做法是,分析人员通过询问和调查了解客户所要的“友好、健壮、高效所包含的具体特性,具体分析哪些特性对哪些特性有负面影响,在性能代价和所提出解决方案的预期利益之间做出权衡,以确保做出合理的取舍。
8、 允许重用已有的软件组件
需求通常有一定灵活性,分析人员可能发现已有的某个软件组件与客户描述的需求很相符,在这种情况下,分析人员应提供一些修改需求的选择以便开发人员能够降低新系统的开发成本和节省时间,而不必严格按原有的需求说明开发。所以说,如果想在产品中使用一些已有的商业常用组件,而它们并不完全适合您所需的特性,这时一定程度上的需求灵活性就显得极为重要了。
9、 要求对变更的代价提供真实可靠的评估
有时,人们面临更好、也更昂贵的方案时,会做出不同的选择。而这时,对需求变更的影响进行评估从而对业务决策提供帮助,是十分必要的。所以,客户有权利要求开发人员通过分析给出一个真实可信的评估,包括影响、成本和得失等。开发人员不能由于不想实施变更而随意夸大评估成本。
10、 获得满足客户功能和质量要求的系统
每个人都希望项目成功,但这不仅要求客户要清晰地告知开发人员关于系统“做什么”所需的所有信息,而且还要求开发人员能通过交流了解清楚取舍与限制,一定要明确说明您的假设和潜在的期望,否则,开发人员开发出的产品很可能无法让您满意。
11、 给分析人员讲解您的业务
分析人员要依靠客户讲解业务概念及术语,但客户不能指望分析人员会成为该领域的专家,而只能让他们明白您的问题和目标;不要期望分析人员能把握客户业务的细微潜在之处,他们可能不知道那些对于客户来说理所当然的“常识”。
12、 抽出时间清楚地说明并完善需求
客户很忙,但无论如何客户有必要抽出时间参与“头脑高峰会议”的讨论,接受采访或其他获取需求的活动。有些分析人员可能先明白了您的观点,而过后发现还需要您的讲解,这时请耐心对待一些需求和需求的精化工作过程中的反复,因为它是人们交流中很自然的现象,何况这对软件产品的成功极为重要。
13、 准确而详细地说明需求
编写一份清晰、准确的需求文档是很困难的。由于处理细节问题不但烦人而且耗时,因此很容易留下模糊不清的需求。但是在开发过程中,必须解决这种模糊性和不准确性,而客户恰恰是为解决这些问题作出决定的最佳人选,否则,就只好靠开发人员去正确猜测了。
在需求分析中暂时加上“待定”标志是个方法。用该标志可指明哪些是需要进一步讨论、分析或增加信息的地方,有时也可能因为某个特殊需求难以解决或没有人愿意处理它而标注上“待定”。客户要尽量将每项需求的内容都阐述清楚,以便分析人员能准确地将它们写进“软件需求报告”中去。如果客户一时不能准确表达,通常就要求用原型技术,通过原型开发,客户可以同开发人员一起反复修改,不断完善需求定义。
14、 及时作出决定
分析人员会要求客户作出一些选择和决定,这些决定包括来自多个用户提出的处理方法或在质量特性冲突和信息准确度中选择折衷方案等。有权作出决定的客户必须积极地对待这一切,尽快做处理,做决定,因为开发人员通常只有等客户做出决定才能行动,而这种等待会延误项目的进展。
15、 尊重开发人员的需求可行性及成本评估
所有的软件功能都有其成本。客户所希望的某些产品特性可能在技术上行不通,或者实现它要付出极高的代价,而某些需求试图达到在操作环境中不可能达到的性能,或试图得到一些根本得不到的数据。开发人员会对此作出负面的评价,客户应该尊重他们的意见。
16、 划分需求的优先级
绝大多数项目没有足够的时间或资源实现功能性的每个细节。决定哪些特性是必要的,哪些是重要的,是需求开发的主要部分,这只能由客户负责设定需求优先级,因为开发者不可能按照客户的观点决定需求优先级;开发人员将为您确定优先级提供有关每个需求的花费和风险的信息。
在时间和资源限制下,关于所需特性能否完成或完成多少应尊重开发人员的意见。尽管没有人愿意看到自己所希望的需求在项目中未被实现,但毕竟是要面对现实,业务决策有时不得不依据优先级来缩小项目范围或延长工期,或增加资源,或在质量上寻找折衷。
17、 评审需求文档和原型
客户评审需求文档,是给分析人员带来反馈信息的一个机会。如果客户认为编写的“需求分析报告”不够准确,就有必要尽早告知分析人员并为改进提供建议。
更好的办法是先为产品开发一个原型。这样客户就能提供更有价值的反馈信息给开发人员,使他们更好地理解您的需求;原型并非是一个实际应用产品,但开发人员能将其转化、扩充成功能齐全的系统。
18、 需求变更要立即联系
不断的需求变更,会给在预定计划内完成的质量产品带来严重的不利影响。变更是不可避免的,但在开发周期中,变更越在晚期出现,其影响越大;变更不仅会导致代价极高的返工,而且工期将被延误,特别是在大体结构已完成后又需要增加新特性时。所以,一旦客户发现需要变更需求时,请立即通知分析人员。
19、 遵照开发小组处理需求变更的过程
为将变更带来的负面影响减少到最低限度,所有参与者必须遵照项目变更控制过程。这要求不放弃所有提出的变更,对每项要求的变更进行分析、综合考虑,最后做出合适的决策,以确定应将哪些变更引入项目中。
20、 尊重开发人员采用的需求分析过程
软件开发中最具挑战性的莫过于收集需求并确定其正确性,分析人员采用的方法有其合理性。也许客户认为收集需求的过程不太划算,但请相信花在需求开发上的时间是非常有价值的;如果您理解并支持分析人员为收集、编写需求文档和确保其质量所采用的技术,那么整个过程将会更为顺利。
“需求确认”意味着什么
在“需求分析报告”上签字确认,通常被认为是客户同意需求分析的标志行为,然而实际操作中,客户往往把“签字”看作是毫无意义的事情。“他们要我在需求文档的最后一行下面签名,于是我就签了,否则这些开发人员不开始编码。”
这种态度将带来麻烦,譬如客户想更改需求或对产品不满时就会说:“不错,我是在需求分析报告上签了字,但我并没有时间去读完所有的内容,我是相信你们的,是你们非让我签字的。”
同样问题也会发生在仅把“签字确认”看作是完成任务的分析人员身上,一旦有需求变更出现,他便指着“需求分析报告”说:“您已经在需求上签字了,所以这些就是我们所开发的,如果您想要别的什么,您应早些告诉我们。”
这两种态度都是不对的。因为不可能在项目的早期就了解所有的需求,而且毫无疑问地需求将会出现变更,在“需求分析报告”上签字确认是终止需求分析过程的正确方法,所以我们必须明白签字意味着什么。
对“需求分析报告”的签名是建立在一个需求协议的基线上,因此我们对签名应该这样理解:“我同意这份需求文档表述了我们对项目软件需求的了解,进一步的变更可在此基线上通过项目定义的变更过程来进行。我知道变更可能会使我们重新协商成本、资源和项目阶段任务等事宜。”对需求分析达成一定的共识会使双方易于忍受将来的摩擦,这些摩擦来源于项目的改进和需求的误差或市场和业务的新要求等。
需求确认将迷雾拨散,显现需求的真面目,给初步的需求开发工作画上了双方都明确的句号,并有助于形成一个持续良好的客户与开发人员的关系,为项目的成功奠定了坚实的基础。 -
SQL Server 2005性能测试实践 - CPU篇(1) 编译与重编译
2007-03-08 17:59:02
如果在没有额外复杂条件下突然出现CPU瓶颈,有可能是因为没有优化查询,错误的数据库配置,或者是数据库设计上的原因和硬件资源不足引起。在决定采用增加CPU数量或者使用更快速的CPU之前,应该先检查消耗CPU资源最多的操作是否能够被优化
如果发现性能计数器Processor: % Processor Time的值很高,每一个CPU的% Processor Time都超过80%时,可视为出现CPU瓶颈。也可以通过视图sys.dm_os_schedulers监视SQL Server的进程调度(schedulers)来确认可执行的任务是否为非零值。非零值表示任务被迫等待时间片来运行,如果这个数值非常高,说明存在CPU瓶颈。
Select scheduler_id,current_task_count,runnable_task_count from sys.dm_os_schedulers where scheduler_id<255
下面的查询将给出一个较高层的视图来说明当前被缓存的消耗CPU资源最多的批处理或者过程。查询通过相同查询句柄的所有语句合计CPU的消耗情况。
Select top 50 sum (qs_total_worker_time) as total_cpu_time,sum(qs.execution_count) as total_execution_count, count(*) as number_of_statements,qs.plan_handle from sys.dm_exec_query_stats qs group by qs.plan_handle order by sum(qs.total_worker_time) desc
过多的compilation和recompilation
在批处理或者远程过程调用(RPC)提交到服务器执行之前,系统会检查查询计划的有效性和正确性。如果在检查过程中出现了失败的情况,这些批处理可能会被再次编译来产生新的查询计划。这样的编译被称为重编译(recompilations)。这些重编译一般必须确定正确性且通常在服务器认定在潜在数据发生变化后存在可能被优厚的查询计划时执行。编译的特性是CPU敏感的操作,因此过分的重编译可以导致CPU性能问题。
在SQL Server 2000中,当SQL Server重新编译一个存储过程时,整个存储过程都会被重编译,而不只是触发重编译的语句。SQL Server 2005引入了一种语句级别重编的存储过程。当SQL Server 2005重新编译存储过程时,只有引起重编译的语句才会被编译而不是整个过程。这就减少了CPU带宽并且减少了资源锁出现的可能,例如:COMPLIE locks. 重编译可以由于很多不同的原因造成,如:
l 架构变化
l 统计变化
l 延期编译
l SET选项变化
l 临时表变化
l 存储过程以RECOMPLIE选项建立。
检测
使用System Monitor 或者 SQL Server Profiler来检测过多的编译和重编译。
System Monitor
SQL Statistics对象提供计数器来监视编译和发送到SQL Server实例的请求类型。必须通过监视查询编译和重编译的数量结合接收到的批处理数量来找出高CPU消耗是否是由编译引起。理想情况下,SQL Recompilations/sec和Batch Requests/sec的比率应该应该非常低,除非用户提交的是即席查询。
以下是关键数据计数器:
l SQL Server: SQL Statistics: Batch Requests/sec
l SQL Server: SQL Statistics: SQL Compilations/sec
l SQL Server: SQL Statistics: SQL Recompilations/sec
SQL Trace
如果性能计数器显示非常大的重编译数量,重编译可能正在造成高CPU消耗。接下来需要需要利用SQL Profiler纪录的trace来找出当时被重新编译的存储过程。SQL Server Profiler trace可以给出这些信息连同重编译的原因。可以使用事件来获取这些信息。
SP: Recompile / SQL: StmtRecompile. The SP:Recompile and the SQL:StmtRecompile事件类显示哪些存储过程和语句曾经被重新编译过。当编译一个存储过程时,为存储过程和每一个被编译的语句生成事件。然而,当一个存储过程被重新编译时,只有引起重新编译的语句才会被生成一个事件(不同于SQL Server 2000中的整体存储过程编译)。
SP:Recompile事件类中的重要的数据列如下所示:
l Event Class
l EventSubClass
l ObjectID(表示包含这个语句的存储过程)
l SPID
l Start Time
l SqlHandle
l TextData
EventSubClass数据列对于确定重编译原因来说非常重要。一旦过程或者触发器被重新编译,SP:Recompile就会被触发,但是有可能被重编译的即席批处理不会引发这个事件。 在SQL Server 2005中,监视SQL:StmtRecompiles时非常有用的,任何类型的批处理,即席查询,存储过程或者触发器被重编译时,这个事件类都会被触发。
保存trace文件,使用下面的查询来查看所有的重编译事件。
Select spid,starttime,textdata,eventsubclass,objected,databaseid,sqlhandle from fn_trace_gettable (‘filepath.trc’,1) where EventClass in(37,75,166)
EventClass 37是SP:Recompile, 75是CursorRecompile, 166是SQL:StmtRecompile.
也可以进一步对这些查询结果根据Sqlhandle和ObjectID列进行分组来查看是否有某个存储过程存在大量的重编译或者由于其他原因导致的重编译(如Set选项变化)。
Showplan XML For Query Compile. 这个事件类在Microsoft SQL Server编译或者重新编译SQL语句时发生。这个事件中有关于被编译或者重编译的语句的信息。这些信息包括查询计划和存在问题的过程的Object ID。如果发现SQL Compilations/sec计数器数值很高,应该监视这个事件类。通过这些信息可以发现哪些语句被频繁的重编译。可以使用这些信息改变那些语句的参数。这应该会降低重新编译的次数。
DMVs
当使用sys.dn_exec_query_optimizer_info DMV时,可以得到SQL Server花费在优化上的时间。
Select * from sys.dn_exec_query_optimizer_info
Counter occurrence value
Optimizations XX XX
Elaspsed time XX XX
Elaspsed time是消耗在优化上的时间。这个事件一般接近于消耗在优化上的CPU时间。
另外一个用来捕获这些信息的DMV是 sys.dm_exec_query_stats
下列是需要查询的数据列:
l Sql_handle
l Total worker time
l Plan generation number
l Statement Start Offset
Plan_generation_num表示查询被编译的次数。下列语句给出前25个被编译的存储过程。
Select top 25 sql_text.test,sqlhandle,plan_geration_num,execution_count,dbid,objectid from sys.dm_exec_query_stats across apply sys.dm_exec_sql_text(sql_handle) as sql_text where plan_generation_num>1 order by plan_generation_num desc
解决方法
如果检测到过多的编译/重编译,考虑以下解决方法:
l 如果重编译是因为SET选项引起,使用SQL Profiler确定是哪一个SET发生了变化。尽量避免在存储过程内部修改SET选项。可以选择在连接级别上设置,并确保SET选项在连接的生命周期中不会发生变化。
l 临时表的重编译极值比一般表要低。如果由于统计信息变化导致重新编译临时表时,可以考虑把临时表替换为一个table变量,同样的变化不会影响table变量。这种方法的缺点是查询优化器不能跟踪table变量的信息,因为系统不会为table变量建立和维护统计信息。这可能导致不能优化对于表变量的查询。
另外一个选择是使用KEEP PLAN查询提示。它设置临时表的极限值与永久表一致。EventSubClass列将显示临时表上发生了”Statistics Changed” 操作。
l 避免由于统计信息发生变化而导致的重编译(例如,当查询计划因为改变统计信息而不能被达到最优时),指定KEEPFIXED PLAN查询提示。通过这个选项的作用,重编译仅当出现正确性相关的变化时才会发生(例如,当底层表结构发生变化时才会重新编译查询)而不是由于统计数据。如果一个表的架构发生变化,或者表被sp_recompile存储过程标记,重编译将会发生。
l 关闭被定义在一个表上的或者被索引的视图上的index & statistics的statistics自动更新防止由于在对象上的statistics的改变引起的重编译。注意,无论如何,关闭”auto-stats” 功能不是很好的选择。这是因为查询优化器不在对数据变化产生作,可能会导致非最优查询计划被执行。
l 批处理中应该使用具属对象名(如:dbo.table1)来避免重编译和对象之间的二义性。
l 避免由于延迟编译导致的重编译,不要使用条件结构(如IF)来插入DML和DDL或者建立DDL。
l 运行DTA查看是否有可以改善编译时间和查询执行时间。
l 检查是否存储过程使用WITH RECOMPILE选项建立或者查询是否使用了RECOMPILE。如果存储过程使用WITH RECOMPILE选项建立,在SQL Server 2005中,考虑利用语句级别的RECOMPILE如果存储过程中的某个语句需要被重新编译。这可以避免每次执行存储过程时的强制编译,同时允许单独的语句重编译。
性能测试应用
从性能测试的角度出发,可以在负载测试过程中收集有关的性能计数器,同时利用SQL Profiler收集负载测试期间有关重编译的事件类。一般情况下负载测试都会产生较高的CPU利用率,特别是压力测试。在测试结束后收集性能计数器确定是否存在过多的编译和重编译情况。
在确定系统出现过多的编译和重编译后,对trace和DMV结果进行分析找出产生大量编译和重编译的存储过程或者语句。根据不同的原因提出相应的解决方案。 -
怎么查询表中某一字段最大值所在行的数据
2007-03-01 16:29:47
自己想的:
SQL> select * from aaa;
ID SEQ_ID NAME
---------- ---------- --------------------
1 1 A
1 2 A
1 3 A
2 1 B
2 2 B
3 1 C
3 2 C
3 3 C
3 4 C9 rows selected
SQL>
SQL> SELECT *
2 FROM AAA A
3 WHERE A.SEQ_ID = (SELECT MAX(B.SEQ_ID) FROM AAA B WHERE B.ID = A.ID)
4 /ID SEQ_ID NAME
---------- ---------- --------------------
1 3 A
2 2 B
3 4 Cwww.cnoug.org 论坛 yesl
TOP N中的TOP1,(依需要选用rank,dense_rank,row_number)
SELECT ID, SEQ_ID, NAME
FROM (SELECT ID,
SEQ_ID,
NAME,
RANK() OVER(PARTITION BY ID ORDER BY SEQ_ID DESC NULLS LAST) DRN
FROM TA)
WHERE DRN = 1SQL> SELECT ID, SEQ_ID, NAME
2 FROM (SELECT ID,
3 SEQ_ID,
4 NAME,
5 RANK() OVER(PARTITION BY ID ORDER BY SEQ_ID DESC NULLS LAST) DRN
6 FROM AAA)
7 WHERE DRN =1
8 /ID SEQ_ID NAME
---------- ---------- --------------------
1 3 A
2 2 B
3 4 C -
SQL查询语句精华使用简要
2007-01-29 10:11:52
一、 简单查询
简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。它们分别说明所查询列、查询的表或视图、以及搜索条件等。
例如,下面的语句查询testtable表中姓名为"张三"的nickname字段和email字段。SELECT nickname,email
FROM testtable
WHERE name='张三'(一) 选择列表
选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。
1、选择所有列
例如,下面语句显示testtable表中所有列的数据:
SELECT *
FROM testtable2、选择部分列并指定它们的显示次序
查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。
例如:SELECT nickname,email
FROM testtable3、更改列标题
在选择列表中,可重新指定列标题。定义格式为:
列标题=列名
列名 列标题
如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列标题:SELECT 昵称=nickname,电子邮件=email
FROM testtable4、删除重复行
SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。
5、限制返回的行数
使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT时,说明n是表示一百分数,指定返回的行数等于总行数的百分之几。
例如:SELECT TOP 2 *
FROM testtable
SELECT TOP 20 PERCENT *
FROM testtable(二)FROM子句
FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。
在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列所属的表或视图。例如在usertable和citytable表中同时存在cityid列,在查询两个表中的cityid时应使用下面语句格式加以限定:SELECT username,citytable.cityid
FROM usertable,citytable
WHERE usertable.cityid=citytable.cityid在FROM子句中可用以下两种格式为表或视图指定别名:
表名 as 别名
表名 别名(二) FROM子句
FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。
在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列所属的表或视图。例如在usertable和citytable表中同时存在cityid列,在查询两个表中的cityid时应使用下面语句格式加以限定:SELECT username,citytable.cityid
FROM usertable,citytable
WHERE usertable.cityid=citytable.cityid在FROM子句中可用以下两种格式为表或视图指定别名:
表名 as 别名
表名 别名
例如上面语句可用表的别名格式表示为:SELECT username,b.cityid
FROM usertable a,citytable b
WHERE a.cityid=b.cityidSELECT不仅能从表或视图中检索数据,它还能够从其它查询语句所返回的结果集合中查询数据。
例如:
SELECT a.au_fname+a.au_lname
FROM authors a,titleauthor ta
(SELECT title_id,title
FROM titles
WHERE ytd_sales>10000
) AS t
WHERE a.au_id=ta.au_id
AND ta.title_id=t.title_id此例中,将SELECT返回的结果集合给予一别名t,然后再从中检索数据。
(三) 使用WHERE子句设置查询条件
WHERE子句设置查询条件,过滤掉不需要的数据行。例如下面语句查询年龄大于20的数据:
SELECT *
FROM usertable
WHERE age>20WHERE子句可包括各种条件运算符:
比较运算符(大小比较):>、>=、=、<、<=、<>、!>、!<
范围运算符(表达式值是否在指定的范围):BETWEEN...AND...
NOT BETWEEN...AND...
列表运算符(判断表达式是否为列表中的指定项):IN (项1,项2......)
NOT IN (项1,项2......)
模式匹配符(判断值是否与指定的字符通配格式相符):LIKE、NOT LIKE
空值判断符(判断表达式是否为空):IS NULL、NOT IS NULL
逻辑运算符(用于多条件的逻辑连接):NOT、AND、OR1、范围运算符例:age BETWEEN 10 AND 30相当于age>=10 AND age<=30
2、列表运算符例:country IN ('Germany','China')
3、模式匹配符例:常用于模糊查找,它判断列值是否与指定的字符串格式相匹配。可用于char、varchar、text、ntext、datetime和smalldatetime等类型查询。
可使用以下通配字符:
百分号%:可匹配任意类型和长度的字符,如果是中文,请使用两个百分号即%%。
下划线_:匹配单个任意字符,它常用来限制表达式的字符长度。
方括号[]:指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。[^]:其取值也[] 相同,但它要求所匹配对象为指定字符以外的任一个字符。
例如:
限制以Publishing结尾,使用LIKE '%Publishing'
限制以A开头:LIKE '[A]%'
限制以A开头外:LIKE '[^A]%'4、空值判断符例WHERE age IS NULL
5、逻辑运算符:优先级为NOT、AND、OR
(四)查询结果排序
使用ORDER BY子句对查询返回的结果按一列或多列排序。ORDER BY子句的语法格式为:
ORDER BY {column_name [ASC|DESC]} [,...n]
其中ASC表示升序,为默认值,DESC为降序。ORDER BY不能按ntext、text和image数据类型进行排
序。
例如:SELECT *
FROM usertable
ORDER BY age desc,userid ASC另外,可以根据表达式进行排序。
二、 联合查询
UNION运算符可以将两个或两个以上上SELECT语句的查询结果集合合并成一个结果集合显示,即执行联合查询。UNION的语法格式为:
select_statement
UNION [ALL] selectstatement
[UNION [ALL] selectstatement][...n]其中selectstatement为待联合的SELECT查询语句。
ALL选项表示将所有行合并到结果集合中。不指定该项时,被联合查询结果集合中的重复行将只保留一行。
联合查询时,查询结果的列标题为第一个查询语句的列标题。因此,要定义列标题必须在第一个查询语句中定义。要对联合查询结果排序时,也必须使用第一查询语句中的列名、列标题或者列序号。
在使用UNION 运算符时,应保证每个联合查询语句的选择列表中有相同数量的表达式,并且每个查询选择表达式应具有相同的数据类型,或是可以自动将它们转换为相同的数据类型。在自动转换时,对于数值类型,系统将低精度的数据类型转换为高精度的数据类型。
在包括多个查询的UNION语句中,其执行顺序是自左至右,使用括号可以改变这一执行顺序。例如:
查询1 UNION (查询2 UNION 查询3)
三、连接查询
通过连接运算符可以实现多个表查询。连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志。
在关系数据库管理系统中,表建立时各数据之间的关系不必确定,常把一个实体的所有信息存放在一个表中。当检索数据时,通过连接操作查询出存放在多个表中的不同实体的信息。连接操作给用户带来很大的灵活性,他们可以在任何时候增加新的数据类型。为不同实体创建新的表,尔后通过连接进行查询。
连接可以在SELECT 语句的FROM子句或WHERE子句中建立,似是而非在FROM子句中指出连接时有助于将连接操作与WHERE子句中的搜索条件区分开来。所以,在Transact-SQL中推荐使用这种方法。
SQL-92标准所定义的FROM子句的连接语法格式为:
FROM join_table join_type join_table
[ON (join_condition)]其中join_table指出参与连接操作的表名,连接可以对同一个表操作,也可以对多表操作,对同一个表操作的连接又称做自连接。
join_type 指出连接类型,可分为三种:内连接、外连接和交叉连接。内连接(INNER JOIN)使用比较运算符进行表间某(些)列数据的比较操作,并列出这些表中与连接条件相匹配的数据行。根据所使用的比较方式不同,内连接又分为等值连接、自然连接和不等连接三种。外连接分为左外连接(LEFT OUTER JOIN或LEFT JOIN)、右外连接(RIGHT OUTER JOIN或RIGHT JOIN)和全外连接(FULL OUTER JOIN或FULL JOIN)三种。与内连接不同的是,外连接不只列出与连接条件相匹配的行,而是列出左表(左外连接时)、右表(右外连接时)或两个表(全外连接时)中所有符合搜索条件的数据行。
交叉连接(CROSS JOIN)没有WHERE 子句,它返回连接表中所有数据行的笛卡尔积,其结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。
连接操作中的ON (join_condition) 子句指出连接条件,它由被连接表中的列和比较运算符、逻辑运算符等构成。
无论哪种连接都不能对text、ntext和image数据类型列进行直接连接,但可以对这三种列进行间接连接。例如:
SELECT p1.pub_id,p2.pub_id,p1.pr_info
FROM pub_info AS p1 INNER JOIN pub_info AS p2
ON DATALENGTH(p1.pr_info)=DATALENGTH(p2.pr_info)(一)内连接
内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值。内连接分三种:
1、等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。
2、不等连接: 在连接条件使用除等于运算符以外的其它比较运算符比较被连接的列的列值。这些运算符包括>、>=、<=、<、!>、!<和<>。
3、自然连接:在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。
例,下面使用等值连接列出authors和publishers表中位于同一城市的作者和出版社:SELECT *
FROM authors AS a INNER JOIN publishers AS p
ON a.city=p.city
又如使用自然连接,在选择列表中删除authors 和publishers 表中重复列(city和state):
SELECT a.*,p.pub_id,p.pub_name,p.country
FROM authors AS a INNER JOIN publishers AS p
ON a.city=p.city(二)外连接
内连接时,返回查询结果集合中的仅是符合查询条件( WHERE 搜索条件或 HAVING 条件)和连接条件的行。而采用外连接时,它返回到查询结果集合中的不仅包含符合连接条件的行,而且还包括左表(左外连接时)、右表(右外连接时)或两个边接表(全外连接)中的所有数据行。如下面使用左外连接将论坛内容和作者信息连接起来:SELECT a.*,b.* FROM luntan LEFT JOIN usertable as b
ON a.username=b.username下面使用全外连接将city表中的所有作者以及user表中的所有作者,以及他们所在的城市:
SELECT a.*,b.*
FROM city as a FULL OUTER JOIN user as b
ON a.username=b.username(三)交叉连接
交叉连接不带WHERE 子句,它返回被连接的两个表所有数据行的笛卡尔积,返回到结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。例,titles表中有6类图书,而publishers表中有8家出版社,则下列交叉连接检索到的记录数将等于6*8=48行。
SELECT type,pub_name
FROM titles CROSS JOIN publishers
ORDER BY type -
LR参数设置
2007-01-16 15:40:21
1、虚拟用户使用不同的参数
只要将parameter properties中select next row 设为unique,update value on 设为once就可以了,这样设置必须满足一个条件:虚拟用户<=参数的个数。
下面是51testing论坛上lavender2004 关于参数设置的一个子,URL:http://bbs.51testing.com/thread-59787-1-1.html
文件/表参数的数据分配和更新方法
用LR作测试时,往往要设置参数,参数设置的不同直接影响到测试结果,所以是测试中至关重要的一环。曾经在论坛和其他网站上搜寻过类似的问题,想从中找出实际的操作过程,但很遗憾,找到的大都比较零散,或是看了也不明白如何作,实在没办法,才想到了手册,一看之下,才发现用手册上归纳的来作为初步的指导已经绰绰有余。以下是从LR自带的帮助文件里摘出的。
警戒:以后碰到问题,边在网上搜索,边查手册,不必急着发问,因为你问的别人不一定遇到过,或者根本不理解你的意思,更惨的,放N天也无人问津。
对于文件和表类型参数,所选的数据分配方法和更新方法会共同影响在场景或会话步骤运行期间 Vuser 用来替换参数的值。
下表总结了根据所选的数据分配和更新属性的不同,Vuser 所使用的值:
示例更新方法
数据分配方法顺序
随机
唯一每次迭代 对于每次迭代,Vuser 会从数据表中提取下一个值。 对于每次迭代,Vuser 会从数据表中提取新的随机值。 对于每次迭代,Vuser 会从数据表中提取下一个唯一值。 每次出现
(仅数据文件)参数每次出现时,Vuser 将从数据表中提取下一个值,即使在同一迭代中。 参数每次出现时,Vuser 将从数据表中提取新的随机值,即使在同一迭代中。 参数每次出现时,Vuser 将从数据表中提取新的唯一值,即使在同一迭代中。 一次 对于每一个 Vuser,第一次迭代中分配的值将用于所有的后续迭代。 第一次迭代中分配的随机值将用于该 Vuser 的所有迭代。 第一次迭代中分配的唯一值将用于该 Vuser 的所有后续迭代。
假设表/文件包括以下所示的值:
Kim;David;Michael;Jane;Ron;Alice;Ken;Julie;Fred
- 如果选择使用“顺序”方法分配数据,则:
- 如果选择在“每次迭代”进行更新,则所有 Vuser 就会在第一次迭代使用 Kim,第二次迭代使用 David,第三次迭代使用 Michael,等等。
- 如果选择在“每次出现”进行更新,则所有 Vuser 就会在第一次出现时使用 Kim,第二次出现使用 David,第三次出现使用 Michael,等等。
- 如果选择更新“一次”,则所有 Vuser 就会在所有的迭代中使用 Kim。
如果数据表中没有足够的值,则 VuGen 返回到表中的第一个值,循环继续直到测试结束。
- 如果选择在“每次迭代”进行更新,则所有 Vuser 就会在第一次迭代使用 Kim,第二次迭代使用 David,第三次迭代使用 Michael,等等。
- 如果选择使用“随机”方法分配数据,则:
- 如果选择在“每次迭代”进行更新,则 Vuser 在每次迭代时使用表中的随机值。
- 如果选择在“每次出现”进行更新,则 Vuser 就会在参数每次出现时使用随机值。
- 如果选择更新“一次”,则所有 Vuser 就会在所有的迭代中使用第一次随机分配的值。
- 如果选择在“每次迭代”进行更新,则 Vuser 在每次迭代时使用表中的随机值。
- 如果选择使用“唯一”方法分配数据,则:
- 如果选择在“每次迭代”进行更新,则对于一个有 3 次迭代的测试运行,第一个 Vuser 将在第一次迭代时提取 Kim,第二次迭代提取 David,第三次迭代提取 Michael。第二个 Vuser 提取 Jane、Ron 和 Alice。第三个 Vuser 提取 Ken、Julie 和 Fred。
- 如果选择在“每次出现”进行更新,则 Vuser 就会在参数每次出现时使用列表的唯一值。
- 如果选择更新“一次” ,则第一个 Vuser 就会在所有迭代时都提取 Kim,第二个 Vuser 就会在所有迭代时提取 David,等等。
- 如果选择在“每次迭代”进行更新,则对于一个有 3 次迭代的测试运行,第一个 Vuser 将在第一次迭代时提取 Kim,第二次迭代提取 David,第三次迭代提取 Michael。第二个 Vuser 提取 Jane、Ron 和 Alice。第三个 Vuser 提取 Ken、Julie 和 Fred。
- 如果选择使用“顺序”方法分配数据,则:
-
找回SYS密码
2006-12-11 14:06:32
1、
SQL> select username,password from dba_users;
USERNAME PASSWORD
------------------------------ ------------------------------
SYS 8A8F025737A9097A
SYSTEM 2D594E86F93B17A1
DBSNMP E066D214D5421CCC
TOAD A1BA01CF0DD82695
OUTLN 4A3BA55E08595C81
WMSYS 7C9BA362F8314299
已选择6行。
SQL> connect system/oracle
已连接。
SQL> connect sys/oracle as sysdba
已连接。
修改用户system密码为manager
SQL> alter user system identified by manager;
用户已更改。
SQL> select username,password from dba_users;
USERNAME PASSWORD
------------------------------ ------------------------------
SYS 8A8F025737A9097A
SYSTEM D4DF7931AB130E37
DBSNMP E066D214D5421CCC
TOAD A1BA01CF0DD82695
OUTLN 4A3BA55E08595C81
WMSYS 7C9BA362F8314299
已选择6行。
SQL> connect system/manager
已连接。
然后此时可以做想要做的任何操作了
SQL> connect sys/oracle as sysdba
已连接。
修改用户system密码为以前的值
SQL> alter user system identified by values '2D594E86F93B17A1';
用户已更改。
SQL> connect system/oracle
已连接。
SQL> connect sys/oracle as sysdba
已连接。
SQL> connect system/manager
ERROR:
ORA-01017: invalid username/password; logon denied
警告: 您不再连接到 ORACLE。
2、用system登陆 然后用
alter user sys identified by 密码 -
Oracle9i初始化参数中文说明
2006-12-08 15:37:40
说明: 如果值为TRUE, 即使源长度比目标长度 (SQL92 兼容) 更长, 也允许分配数据。
值范围: TRUE | FALSE
默认值: FALSE
serializable:
说明: 确定查询是否获取表级的读取锁, 以防止在包含该查询的事务处理被提交之前更新任何对象读取。这种操作模式提供可重复的读取,
并确保在同一事务处理种对相同数据的两次查询看到的是相同的值。
值范围: TRUE | FALSE
默认值: FALSE
row_locking:
说明: 指定在表已更新或正在更新时是否获取行锁。如果设置为 ALWAYS, 只有在表被更新后才获取行锁。如果设置为 INTENT,
只有行锁将用于
SELECT
FOR
UPDATE, 但在更新时将获取表锁。
值范围: ALWAYS | DEFAULT | INTENT
默认值: ALWAYS
shared_servers
说明 : 指定在启动例程后, 要为共享服务器环境创建的服务器进程的数量。
值范围: 根据操作系统而定。
默认值 : 1
circuits:
说明 : 指定可用于入站和出站网络会话的虚拟电路总数。 该参数是构成某个例程的总 SGA 要求的若干参数之一。
默认值 : 派生: SESSIONS 参数的值 (如果正在使用共享服务器体系结构); 否则为 0。
Mts_multiple_listeners:
说明: 指定多个监听程序的地址是分别指定的, 还是用一个 ADDRESS_LIST 字符串指定。如果该值为 TRUE,
MTS_LISTENER_ADDRESS 参数可被指定为:
(ADDRESS_LIST=(ADDRESS=(PROTOCOL=tcp)(PORT=5000)(HOST=zeus))
(ADDRESS=(PROTOCOL=decnet)(OBJECT=outa)(NODE=zeus))
此参数在 8.1.3 版中已废弃。
值范围: TRUE | FALSE
默认值: FALSE
mts_servers:
说明 : 指定在启动例程后, 要为共享服务器环境创建的服务器进程的数量。
值范围: 根据操作系统而定。
默认值 : 1
mts_service:
说明 : 一个共享服务器参数, 用于指定已在调度程序上注册,
用来建立数据库连接的唯一服务名。如果要在没有调度程序的情况下仍能连接到数据库, 请将该值设置为与例程名相同。此参数自
8.1.3 版起已废弃。
值范围: 根据操作系统而定。
默认值 :0
mts_sessions:说明 : 指定允许的共享服务器体系结构用户会话的总数。设置此参数可为专用服务器保留一些用户会话。
值范围: 0 到 SESSIONS - 5
默认值 : 派生: MTS_CIRCUITS 和 SESSIONS - 5 两者中的较小值
shared_server_sessions:
说明 : 指定允许的共享服务器体系结构用户会话的总数。设置此参数可为专用服务器保留一些用户会话。
值范围: 0 到 SESSIONS - 5
默认值 : 派生: MTS_CIRCUITS 和 SESSIONS - 5 两者中的较小值
mts_max_dispatchers
说明 : 指定在一个共享服务器环境中可同时运行的调度程序进程的最大数量。
值范围: 根据操作系统而定。
默认值 : 如果已配置了调度程序, 则默认值为大于 5 的任何数目或配置的调度程序的数目
mts_max_servers:
说明 : 指定在一个共享服务器环境中可同时运行的共享服务器进程的最大数量。
值范围: 根据操作系统而定。
默认值 : 20
dispatchers:
说明 : 为设置使用共享服务器的共享环境而设置调度程序的数量和类型。可以为该参数指定几个选项。有关详细信息,
请参阅“Oracle8i 管理员指南”和“Oracle Net Administrator's
Guide”。这是字符串值的一个示例: '(PROTOCOL=TCP)(DISPATCHERS=3)'。
值范围: 参数的有效指定值。
默认值 : NULL
max_shared_servers:
说明 : 指定在一个共享服务器环境中可同时运行的共享服务器进程的最大数量。
值范围: 根据操作系统而定。
默认值 : 20
mts_circuits:
说明 : 指定可用于入站和出站网络会话的虚拟电路总数。 该参数是构成某个例程的总 SGA 要求的若干参数之一。
默认值 : 派生: SESSIONS 参数的值 (如果正在使用共享服务器体系结构); 否则为 0。
Mts_listener_address:
说明 : 指定共享服务器的监听程序配置。监听程序进程需要一个监听地址, 以便处理系统所用的各个网络协议的连接请求。 除非
MTS_MULTIPLE_LISTENERS=TRUE, 否则每个条目都必须有一个独立的相邻值。此参数自 8.1.3
版起已废弃
语法 : (ADDRESS=(PROTOCOL=tcp)(HOST=myhost)(PORT=7002))
默认值 : NULL
mts_dispatchers:
说明 : 为设置使用共享服务器的共享环境而设置调度程序的数量和类型。可以为该参数指定几个选项。有关详细信息,
请参阅“Oracle8i 管理员指南”和“Oracle Net Administrator's
Guide”。这是字符串值的一个示例: '(PROTOCOL=TCP)(DISPATCHERS=3)'。
值范围: 参数的有效指定值。
默认值 : NULL
max_dispatchers:说明 : 指定在一个共享服务器环境中可同时运行的调度程序进程的最大数量。
值范围: 根据操作系统而定。
默认值 : 如果已配置了调度程序, 则默认值为大于 5 的任何数目或配置的调度程序的数目
nls_nchar_conv_excp:
说明: (如果值为 TRUE) 当在隐式转换中丢失数据时返回错误的参数。
值范围: FALSE | TRUE
默认值: TRUE
nls_numeric_characters:
说明: 指定将用作组分隔符和小数位的字符。组分隔符就是用来分隔整数位组 (如千, 百万等等)
的字符。小数分隔符用来将一个数字的整数部分与小数部分分隔开。其格式是
<decimal_character><group_separator>。
值范围: 任何单字节字符, '+', '-', '<', '>' 除外。
默认值: 从 NLS_TERRITORY 中获得
nls_sort:
说明: 指定 ORDER BY 查询的比较顺序。对于二进制排序, ORDER BY 查询的比较顺序是以数值为基础的。对于语言排序,
则需要进行全表扫描, 以便将数据按照所定义的语言排序进行整理。
值范围: BINARY 或有效的语言定义名。
默认值: 从 NLS_LANGUAGE 中获得
nls_territory:
说明: 为以下各项指定命名约定, 包括日期和星期的编号, 默认日期格式, 默认小数点字符和组分隔符, 以及默认的 ISO
和本地货币符号。可支持的区域包括美国, 法国和日本。有关所有区域的信息, 请参阅 Oracle8i National
Language Support Guide。
值范围: 任何有效的地区名。
默认值: 根据操作系统而定
nls_timestamp_format:
说明: 与 NLS_TIME_FORMAT 相似, 只不过它设置的是 TIMESTAMP 数据类型的默认值, 该数据类型既存储
YEAR, MONTH 和 DAY 这几个日期值, 也存储 HOUR, MINUTE 和 SECOND 这几个时间值。
语法: TIMESTAMP '1997-01-31 09:26:50.10' (将值存储为 11 个字节)。
默认值: 从 NLS_TERRITORY 中获得
nls_time_format:
说明: 指定一个字符串值, 设置 TIME 数据类型的默认值, 该数据类型包含 HOUR, MINUTE 和 SECOND
这几个日期时间字段。
语法: TIME '09:26:50' (将值存储为 7 个字节)。
默认值: 从 NLS_TERRITORY 中获得
nls_time_tz_format:
说明: 指定一对值 (UTC,TZD), 设置 TIME WITH TIME ZONE 数据类型的默认值, 该数据类型包含
HOUR, MINUTE, SECOND, TIMEZONE_HOUR 和 TIMEZONE_MINUTE
这几个日期时间字段。UTC 是世界时而 TZD 是当地时区。
语法: TIME '09:26:50.20+ 02:00' (将值存储为 9 个字节)。
默认值: 从 NLS_TERRITORY 中获得
nls_length_semantics:说明: 使用字节或码点语义来指定新列的创建, 如 char, varchar2, clob, nchar, nvarchar2,
nclob 列。各种字符集对字符都有各自的定义。在客户机和服务器上使用同一字符集时,
应以该字符集所定义的字符来衡量字符串。现有的列将不受影响。
值范围: BYTE 或 CHAR。
默认值: nls_length_semantics 的数据库字符集的字符所使用的度量单位。BYTE。
nls_date_format:
说明: 指定与 TO_CHAR 和 TO_DATE 函数一同使用的默认日期格式。该参数的默认值由 NLS_TERRITORY
确定。该参数的值可以是包含在双引号内的任何有效的日期格式掩码。例如: ''MMM/DD/YYYY''。
值范围: 任何有效的日期格式掩码, 但不得超过一个固定长度。
默认值: 派生
nls_timestamp_tz_format:
说明: 与 NLS_TIME_TZ_FORMAT 相似, 其中的一对值指定 TIMESTAMP 数据类型的默认值, 该类型除存储
YEAR, MONTH 和 DAY 日期值, HOUR, MINUTE 和 SECOND 时间值, 还存储
TIMEZONE_HOUR 和 TIMEZONE_MINUTE。
语法: TIMESTAMP '1997- 01- 31 09:26:50+ 02:00' (将值存储为 13 个字节)。
默认值: 从 NLS_TERRITORY 中获得
nls_language:
说明: 指定数据库的默认语言, 该语言将用于消息, 日期和月份名, AD, BC, AM 和 PM 的符号,
以及默认的排序机制。可支持的语言包括英语, 法语和日语等等。
值范围: 任何有效的语言名。
默认值: 根据操作系统而定
nls_comp:
说明: 在 SQL 语句中, 应避免使用繁琐的 NLS_SORT 进程。正常情况下,
WHERE 子句中进行的比较是二进制的, 但语言比较则需要 NLSSORT 函数。可以使用 NLS_COMP 指定必须根据
NLS_SORT 会话参数进行语言比较。
值范围: Oracle8i National Language Support Guide 中指定的任何有效的10 字节字符串。
默认值: BINARY
nls_currency:
说明: 为 L 数字格式元素指定用作本地货币符号的字符串。该参数的默认值由 NLS_TERRITORY 确定。
值范围: Oracle8i National Language Support Guide 中指定的任何有效的10 字节字符串。
默认值: 从 NLS_TERRITORY 中获得
nls_date_language:
说明: 指定拼写日期名, 月名和日期缩写词 (AM, PM, AD, BC) 的语言。该参数的默认值是由 NLS_LANGUAGE
指定的语言。
值范围: 任何有效的 NLS_LANGUAGE 值。
默认值: NLS_LANGUAGE 的值
nls_dual_currency:
说明: 用于覆盖 NLS_TERRITORY 中定义的默认双重货币符号。如果不设置该参数, 就会使用默认的双重货币符号;
否则就会启动一个值为双重货币符号的新会话。
值范围: 任何有效的格式名。。
默认值: 双重货币符号
nls_iso_currency:说明: 为 C 数字格式元素指定用作国际货币符号的字符串。该参数的默认值由 NLS_TERRITORY 确定。
值范围: 任何有效的 NLS_TERRITORY 值。
默认值: 从 NLS_TERRITORY 中获得
nls_calendar:
说明: 指定 Oracle 使用哪种日历系统作为日期格式。例如, 如果 NLS_CALENDAR 设置为 'Japanese
Imperial', 那么日期格式为 'E YY-MM-DD'。即: 如果日期是 1997 年 5 月 15 日, 那么
SYSDATE 显示为 'H 09-05-15'。
值范围: Arabic Hijrah, English Hijrah, Gregorian, Japanese Imperial, Persian, ROC Official (Republic of China) 和 Thai Buddha。
默认值: Gregorian
plsql_native_c_compiler:
说明: 指定用于将生成的 C 文件编译为目标文件的 C 编译程序的完整路径名。此参数是可选的。随每个平台附带的特有的 make
文件中包含此参数的默认值。如果为此参数指定了一个值, 则该值将覆盖 make 文件中的默认值。
值范围: C 编译程序的完整路径。
默认值: 无
-
Oracle中优化SQL的原则
2006-12-08 15:36:56
1。已经检验的语句和已在共享池中的语句之间要完全一样
2。变量名称尽量一致
3。合理使用外联接
4。少用多层嵌套
5。多用并发
语句的优化步骤一般有:
1。调整sga区,使得sga区的是用最优。
2。sql语句本身的优化,工具有explain,sql trace等
3。数据库结构调整
4。项目结构调整
写语句的经验:
1。对于大表的查询使用索引
2、少用in,exist等
3、使用集合运算
1.对于大表查询中的列应尽量避免进行诸如To_char,to_date,to_number 等转换
2.有索引的尽量用索引,有用到索引的条件写在前面如有可能和有必要就建立一些索引
3.尽量避免进行全表扫描,限制条件尽可能多,以便更快搜索到要查询的数据
如何让你的SQL运行得更快
交通银行长春分行电脑部
任亮
---- 人们在使用SQL时往往会陷入一个误区,即太关注于所得的结果是否正确,而忽略了不同的实现方法之间可能存在的性能差异,这种性能差异在大型的或是复杂的数据库环境中(如联机事务处理OLTP或决策支持系统DSS)中表现得尤为明显。笔者在工作实践中发现,不良的SQL往往来自于不恰当的索引设计、不充份的连接条件和不可优化的where子句。在对它们进行适当的优化后,其运行速度有了明显地提高!下面我将从这三个方面分别进行总结:
---- 为了更直观地说明问题,所有实例中的SQL运行时间均经过测试,不超过1秒的均表示为(< 1秒)。
---- 测试环境--
---- 主机:HP LH II
---- 主频:330MHZ
---- 内存:128兆
---- 操作系统:Operserver5.0.4
----数据库:Sybase11.0.3一、不合理的索引设计
----例:表record有620000行,试看在不同的索引下,下面几个 SQL的运行情况:
---- 1.在date上建有一非个群集索引select count(*) from record where date >
'19991201' and date < '19991214'and amount >
2000 (25秒)
select date,sum(amount) from record group by date
(55秒)
select count(*) from record where date >
'19990901' and place in ('BJ','SH') (27秒)
---- 2.在date上的一个群集索引
---- 分析:
----date上有大量的重复值,在非群集索引下,数据在物理上随机存放在数据页上,在范围查找时,必须执行一次表扫描才能找到这一范围内的全部行select count(*) from record where date >
'19991201' and date < '19991214' and amount >
2000 (14秒)
select date,sum(amount) from record group by date
(28秒)
select count(*) from record where date >
'19990901' and place in ('BJ','SH')(14秒)
---- 分析:
---- 在群集索引下,数据在物理上按顺序在数据页上,重复值也排列在一起,因而在范围查找时,可以先找到这个范围的起末点,且只在这个范围内扫描数据页,避免了大范围扫描,提高了查询速度。
---- 3.在place,date,amount上的组合索引select count(*) from record where date >
'19991201' and date < '19991214' and amount >
2000 (26秒)
select date,sum(amount) from record group by date
(27秒)
select count(*) from record where date >
'19990901' and place in ('BJ, 'SH')(< 1秒)
---- 4.在date,place,amount上的组合索引
---- 分析:
---- 这是一个不很合理的组合索引,因为它的前导列是place,第一和第二条SQL没有引用place,因此也没有利用上索引;第三个SQL使用了place,且引用的所有列都包含在组合索引中,形成了索引覆盖,所以它的速度是非常快的。select count(*) from record where date >
'19991201' and date < '19991214' and amount >
2000(< 1秒)
select date,sum(amount) from record group by date
(11秒)
select count(*) from record where date >
'19990901' and place in ('BJ','SH')(< 1秒)
---- 5.总结:
---- 分析:
---- 这是一个合理的组合索引。它将date作为前导列,使每个SQL都可以利用索引,并且在第一和第三个SQL中形成了索引覆盖,因而性能达到了最优。---- 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的;合理的索引设计要建立在对各种查询的分析和预测上。一般来说:
---- ①.有大量重复值、且经常有范围查询(between, >,< ,>=,< =)和order by group by发生的列,可考虑建立群集索引;
---- ②.经常同时存取多列,且每列都含有重复值可考虑建立组合索引; ---- ③.组合索引要尽量使关键查询形成索引覆盖,其前导列一定是使用最频繁的列。二、不充份的连接条件:
---- 例:表card有7896行,在card_no上有一个非聚集索引,表account有191122行,在 account_no上有一个非聚集索引,试看在不同的表连接条件下,两个SQL的执行情况:select sum(a.amount) from account a,
card b where a.card_no = b.card_no(20秒)
---- 将SQL改为:
select sum(a.amount) from account a,
card b where a.card_no = b.card_no and a.
account_no=b.account_no(< 1秒)
---- 外层表account上的22541页+(外层表account的191122行*内层表card上对应外层表第一行所要查找的3页)=595907次I/O
---- 分析:
---- 在第一个连接条件下,最佳查询方案是将account作外层表,card作内层表,利用card上的索引,其I/O次数可由以下公式估算为:
---- 在第二个连接条件下,最佳查询方案是将card作外层表,account作内层表,利用account上的索引,其I/O次数可由以下公式估算为:
---- 外层表card上的1944页+(外层表card的7896行*内层表account上对应外层表每一行所要查找的4页)= 33528次I/O
---- 可见,只有充份的连接条件,真正的最佳方案才会被执行。
---- 总结:
---- 1.多表操作在被实际执行前,查询优化器会根据连接条件,列出几组可能的连接方案并从中找出系统开销最小的最佳方案。连接条件要充份考虑带有索引的表、行数多的表;内外表的选择可由公式:外层表中的匹配行数*内层表中每一次查找的次数确定,乘积最小为最佳方案。
---- 2.查看执行方案的方法-- 用set showplanon,打开showplan选项,就可以看到连接顺序、使用何种索引的信息;想看更详细的信息,需用sa角色执行dbcc(3604,310,302)。三、不可优化的where子句
---- 1.例:下列SQL条件语句中的列都建有恰当的索引,但执行速度却非常慢:select * from record where
substring(card_no,1,4)='5378'(13秒)
select * from record where
amount/30< 1000(11秒)
select * from record where
convert(char(10),date,112)='19991201'(10秒)
---- 分析:
---- where子句中对列的任何操作结果都是在SQL运行时逐列计算得到的,因此它不得不进行表搜索,而没有使用该列上面的索引;如果这些结果在查询编译时就能得到,那么就可以被SQL优化器优化,使用索引,避免表搜索,因此将SQL重写成下面这样:select * from record where card_no like'5378%'(< 1秒)
select * from record where amount
< 1000*30(< 1秒)
select * from record where date= '1999/12/01'
(< 1秒)
---- 你会发现SQL明显快起来!
---- 2.例:表stuff有200000行,id_no上有非群集索引,请看下面这个SQL:select count(*) from stuff where id_no in('0','1')
(23秒)
---- 实践证明,表的行数越多,工作表的性能就越差,当stuff有620000行时,执行时间竟达到220秒!还不如将or子句分开:
---- 分析:
---- where条件中的'in'在逻辑上相当于'or',所以语法分析器会将in ('0','1')转化为id_no ='0' or id_no='1'来执行。我们期望它会根据每个or子句分别查找,再将结果相加,这样可以利用id_no上的索引;但实际上(根据showplan),它却采用了"OR策略",即先取出满足每个or子句的行,存入临时数据库的工作表中,再建立唯一索引以去掉重复行,最后从这个临时表中计算结果。因此,实际过程没有利用id_no上索引,并且完成时间还要受tempdb数据库性能的影响。select count(*) from stuff where id_no='0'
select count(*) from stuff where id_no='1'
---- 得到两个结果,再作一次加法合算。因为每句都使用了索引,执行时间只有3秒,在620000行下,时间也只有4秒。或者,用更好的方法,写一个简单的存储过程:create proc count_stuff as
declare @a int
declare @b int
declare @c int
declare @d char(10)
begin
select @a=count(*) from stuff where id_no='0'
select @b=count(*) from stuff where id_no='1'
end
select @c=@a+@b
select @d=convert(char(10),@c)
print @d
---- 可见,所谓优化即where子句利用了索引,不可优化即发生了表扫描或额外开销。
---- 直接算出结果,执行时间同上面一样快!
---- 总结:
---- 1.任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
---- 2.in、or子句常会使用工作表,使索引失效;如果不产生大量重复值,可以考虑把子句拆开;拆开的子句中应该包含索引。
---- 3.要善于使用存储过程,它使SQL变得更加灵活和高效。 ---- 从以上这些例子可以看出,SQL优化的实质就是在结果正确的前提下,用优化器可以识别的语句,充份利用索引,减少表扫描的I/O次数,尽量避免表搜索的发生。其实SQL的性能优化是一个复杂的过程,上述这些只是在应用层次的一种体现,深入研究还会涉及数据库层的资源配置、网络层的流量控制以及操作系统层的总体设计。 -
简明oracle8i培训手册
2006-12-08 15:32:43
ORACLE公司自86年推出版本5开始,系统具有分布数据库处理功能.88年推出版本6,ORACLE RDBMS(V6.0)可带事务处理选项(TPO),提高了事务处理的速度.1992年推出了版本7,在ORACLE RDBMS中可带过程数据库选项(procedural database option)和并行服务器选项(parallel server option),称为ORACLE7数据库管理系统,它释放了开放的关系型系统的真正潜力。ORACLE7的协同开发环境提供了新一代集成的软件生命周期开发环境,可用以实现高生产率、大型事务处理及客户/服务器结构的应用系统。协同开发环境具有可移植性,支持多种数据来源、多种图形用户界面及多媒体、多民族语言、CASE等协同应用系统。
一. ORACLE系统1. ORACLE产品结构及组成
ORACLE系统是由以RDBMS为核心的一批软件产品构成,其产品结构轮廓下图所示: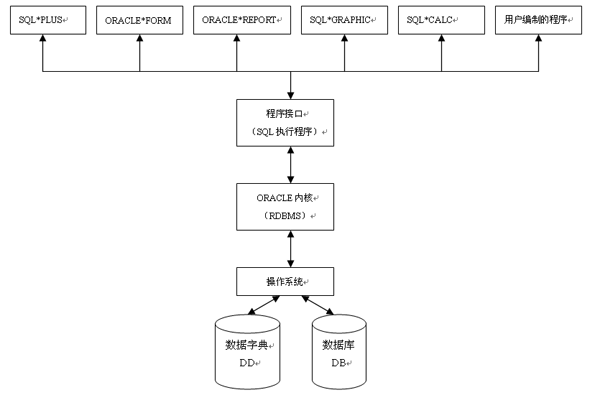
2. ORACLE系统特点
二. ORACLE数据库系统的体系结构
ORACLE公司于1979年,首先推出基于SQL标准的关系数据库产品,可在100多种硬件平台上运行(所括微机、工作站、小型机、中型机和大型机),支持很多种操作系统。用户的ORACLE应用可方便地从一种计算机配置移至另一种计算机配置上。ORACLE的分布式结构可将数据和应用驻留在多台计算机上,而相互间的通信是透明的。1992年6月ORACLE公司推出的ORACLE7协同服务器数据库,使关系数据库技术迈上了新台阶。根据IDG(国际数据集团)1992年全球UNIX数据库市场报告,ORACLE占市场销售量50%。它之所以倍受用户喜爱是因为它有以下突出的特点:
● 支持大数据库、多用户的高性能的事务处理。ORACLE支持最大数据库,其大小可到几百千兆,可充分利用硬件设备。支持大量用户同时在同一数据上执行各种数据应用,并使数据争用最小,保证数据一致性。系统维护具有高的性能,ORACLE每天可连续24小时工作,正常的系统操作(后备或个别计算机系统故障)不会中断数据库的使用。可控制数据库数据的可用性,可在数据库级或在子数据库级上控制。
● ORACLE遵守数据存取语言、操作系统、用户接口和网络通信协议的工业标准。所以它是一个开放系统,保护了用户的投资。美国标准化和技术研究所(NIST)对ORACLE7 SERVER进行检验,100%地与ANSI/ISO SQL89标准的二级相兼容。
● 实施安全性控制和完整性控制。ORACLE为限制各监控数据存取提供系统可靠的安全性。ORACLE实施数据完整性,为可接受的数据指定标准。
● 支持分布式数据库和分布处理。ORACLE为了充分利用计算机系统和网络,允许将处理分为数据库服务器和客户应用程序,所有共享的数据管理由数据库管理系统的计算机处理,而运行数据库应用的工作站集中于解释和显示数据。通过网络连接的计算机环境,ORACLE将存放在多台计算机上的数据组合成一个逻辑数据库,可被全部网络用户存取。分布式系统像集中式数据库一样具有透明性和数据一致性。
● 具有可移植性、可兼容性和可连接性。由于ORACLE软件可在许多不同的操作系统上运行,以致ORACLE上所开发的应用可移植到任何操作系统,只需很少修改或不需修改。ORACLE软件同工业标准相兼容,包括许多工业标准的操作系统,所开发应用系统可在任何操作系统上运行。可连接性是指ORALCE允许不同类型的计算机和操作系统通过网络可共享信息。ORACLE数据库系统为具有管理ORACLE数据库功能的计算机系统。每一个运行的ORACLE数据库与一个ORACLE实例(INSTANCE)相联系。一个ORACLE实例为存取和控制一数据库的软件机制。每一次在数据库服务器上启动一数据库时,称为系统全局区(SYSTEM GLOBAL AREA)的一内存区(简称SGA)被分配,有一个或多个ORACLE进程被启动。该SGA 和 ORACLE进程的结合称为一个ORACLE数据库实例。一个实例的SGA和进程为管理数据库数据、为该数据库一个或多个用户服务而工作。
在ORACLE系统中,首先是实例启动,然后由实例装配(MOUNT)一数据库。在松耦合系统中,在具有ORACLE PARALLEL SERVER 选项时,单个数据库可被多个实例装配,即多个实例共享同一物理数据库。1. ORACLE实例的进程结构和内存结构
1) 进程结构
进程是操作系统中的一种机制,它可执行一系列的操作步。在有些操作系统中使用作业(JOB)或任务(TASK)的术语。一个进程通常有它自己的专用存储区。ORACLE进程的体系结构设计使性能最大。
ORACLE实例有两种类型:单进程实例和多进程实例。
单进程ORACLE(又称单用户ORACLE)是一种数据库系统,一个进程执行全部ORACLE代码。由于ORACLE部分和客户应用程序不能分别以进程执行,所以ORACLE的代码和用户的数据库应用是单个进程执行。
在单进程环境下的ORACLE 实例,仅允许一个用户可存取。例如在MS-DOS上运行ORACLE 。
多进程ORACLE实例(又称多用户ORACLE)使用多个进程来执行ORACLE的不同部分,对于每一个连接的用户都有一个进程。
在多进程系统中,进程分为两类:用户进程和ORACLE进程。当一用户运行一应用程序,如PRO*C程序或一个ORACLE工具(如SQL*PLUS),为用户运行的应用建立一个用户进程。ORACLE进程又分为两类:服务器进程和后台进程服务器进程用于处理连接到该实例的用户进程的请求。当应用和ORACELE是在同一台机器上运行,而不再通过网络,一般将用户进程和它相应的服务器进程组合成单个的进程,可降低系统开销。然而,当应用和ORACLE运行在不同的机器上时,用户进程经过一个分离服务器进程与ORACLE通信。它可执行下列任务:
●对应用所发出的SQL语句进行语法分析和执行。
●从磁盘(数据文件)中读入必要的数据块到SGA的共享数据库缓冲区(该块不在缓冲区时)。
●将结果返回给应用程序处理。
系统为了使性能最好和协调多个用户,在多进程系统中使用一些附加进程,称为后台进程。在许多操作系统中,后台进程是在实例启动时自动地建立。一个ORACLE实例可以有许多后台进程,但它们不是一直存在。后台进程的名字为:
DBWR 数据库写入程序
LGWR 日志写入程序
CKPT 检查点
SMON 系统监控
PMON 进程监控
ARCH 归档
RECO 恢复
LCKn 封锁
Dnnn 调度进程
Snnn 服务器
每个后台进程与ORACLE数据库的不同部分交互。
下面对后台进程的功能作简单介绍:
DBWR进程:该进程执行将缓冲区写入数据文件,是负责缓冲存储区管理的一个ORACLE后台进程。当缓冲区中的一缓冲区被修改,它被标志为“弄脏”,DBWR的主要任务是将“弄脏”的缓冲区写入磁盘,使缓冲区保持“干净”。由于缓冲存储区的缓冲区填入数据库或被用户进程弄脏,未用的缓冲区的数目减少。当未用的缓冲区下降到很少,以致用户进程要从磁盘读入块到内存存储区时无法找到未用的缓冲区时,DBWR将管理缓冲存储区,使用户进程总可得到未用的缓冲区。
ORACLE采用LRU(LEAST RECENTLY USED)算法(最近最少使用算法)保持内存中的数据块是最近使用的,使I/O最小。在下列情况预示DBWR 要将弄脏的缓冲区写入磁盘:
● 当一个服务器进程将一缓冲区移入“弄脏”表,该弄脏表达到临界长度时,该服务进程将通知DBWR进行写。该临界长度是为参数DB-BLOCK-WRITE-BATCH的值的一半。
● 当一个服务器进程在LRU表中查找DB-BLOCK-MAX-SCAN-CNT缓冲区时,没有查到未用的缓冲区,它停止查找并通知DBWR进行写。
● 出现超时(每次3秒),DBWR 将通知本身。
● 当出现检查点时,LGWR将通知DBWR
在前两种情况下,DBWR将弄脏表中的块写入磁盘,每次可写的块数由初始化参数DB-BLOCK-WRITE-BATCH所指定。如果弄脏表中没有该参数指定块数的缓冲区,DBWR从LUR表中查找另外一个弄脏缓冲区。
如果DBWR在三秒内未活动,则出现超时。在这种情况下DBWR对LRU表查找指定数目的缓冲区,将所找到任何弄脏缓冲区写入磁盘。每当出现超时,DBWR查找一个新的缓冲区组。每次由DBWR查找的缓冲区的数目是为寝化参数DB-BLOCK-WRITE-BATCH的值的二倍。如果数据库空运转,DBWR最终将全部缓冲区存储区写入磁盘。
在出现检查点时,LGWR指定一修改缓冲区表必须写入到磁盘。DBWR将指定的缓冲区写入磁盘。
在有些平台上,一个实例可有多个DBWR。在这样的实例中,一些块可写入一磁盘,另一些块可写入其它磁盘。参数DB-WRITERS控制DBWR进程个数。
LGWR进程:该进程将日志缓冲区写入磁盘上的一个日志文件,它是负责管理日志缓冲区的一个ORACLE后台进程。LGWR进程将自上次写入磁盘以来的全部日志项输出,LGWR输出:
●当用户进程提交一事务时写入一个提交记录。
● 每三秒将日志缓冲区输出。
● 当日志缓冲区的1/3已满时将日志缓冲区输出。
●当DBWR将修改缓冲区写入磁盘时则将日志缓冲区输出。
LGWR进程同步地写入到活动的镜象在线日志文件组。如果组中一个文件被删除或不可用,LGWR 可继续地写入该组的其它文件。
日志缓冲区是一个循环缓冲区。当LGWR将日志缓冲区的日志项写入日志文件后,服务器进程可将新的日志项写入到该日志缓冲区。LGWR 通常写得很快,可确保日志缓冲区总有空间可写入新的日志项。
注意:有时候当需要更多的日志缓冲区时,LWGR在一个事务提交前就将日志项写出,而这些日志项仅当在以后事务提交后才永久化。
ORACLE使用快速提交机制,当用户发出COMMIT语句时,一个COMMIT记录立即放入日志缓冲区,但相应的数据缓冲区改变是被延迟,直到在更有效时才将它们写入数据文件。当一事务提交时,被赋给一个系统修改号(SCN),它同事务日志项一起记录在日志中。由于SCN记录在日志中,以致在并行服务器选项配置情况下,恢复操作可以同步。CKPT进程:该进程在检查点出现时,对全部数据文件的标题进行修改,指示该检查点。在通常的情况下,该任务由LGWR执行。然而,如果检查点明显地降低系统性能时,可使CKPT进程运行,将原来由LGWR进程执行的检查点的工作分离出来,由CKPT进程实现。对于许多应用情况,CKPT进程是不必要的。只有当数据库有许多数据文件,LGWR在检查点时明显地降低性能才使CKPT运行。CKPT进程不将块写入磁盘,该工作是由DBWR完成的。
初始化参数CHECKPOINT-PROCESS控制CKPT进程的使能或使不能。缺省时为FALSE,即为使不能。SMON进程:该进程实例启动时执行实例恢复,还负责清理不再使用的临时段。在具有并行服务器选项的环境下,SMON对有故障CPU或实例进行实例恢复。SMON进程有规律地被呼醒,检查是否需要,或者其它进程发现需要时可以被调用。
PMON进程:该进程在用户进程出现故障时执行进程恢复,负责清理内存储区和释放该进程所使用的资源。例:它要重置活动事务表的状态,释放封锁,将该故障的进程的ID从活动进程表中移去。PMON还周期地检查调度进程(DISPATCHER)和服务器进程的状态,如果已死,则重新启动(不包括有意删除的进程)。
PMON有规律地被呼醒,检查是否需要,或者其它进程发现需要时可以被调用。RECO进程:该进程是在具有分布式选项时所使用的一个进程,自动地解决在分布式事务中的故障。一个结点RECO后台进程自动地连接到包含有悬而未决的分布式事务的其它数据库中,RECO自动地解决所有的悬而不决的事务。任何相应于已处理的悬而不决的事务的行将从每一个数据库的悬挂事务表中删去。
当一数据库服务器的RECO后台进程试图建立同一远程服务器的通信,如果远程服务器是不可用或者网络连接不能建立时,RECO自动地在一个时间间隔之后再次连接。
RECO后台进程仅当在允许分布式事务的系统中出现,而且DISTRIBUTED – TRANSACTIONS参数是大于0。ARCH进程:该进程将已填满的在线日志文件拷贝到指定的存储设备。当日志是为ARCHIVELOG使用方式、并可自动地归档时ARCH进程才存在。
LCKn进程:是在具有并行服务器选件环境下使用,可多至10个进程(LCK0,LCK1……,LCK9),用于实例间的封锁
Dnnn进程(调度进程):该进程允许用户进程共享有限的服务器进程(SERVER PROCESS)。没有调度进程时,每个用户进程需要一个专用服务进程(DEDICATEDSERVER PROCESS)。对于多线索服务器(MULTI-THREADED SERVER)可支持多个用户进程。如果在系统中具有大量用户,多线索服务器可支持大量用户,尤其在客户_服务器环境中。
在一个数据库实例中可建立多个调度进程。对每种网络协议至少建立一个调度进程。数据库管理员根据操作系统中每个进程可连接数目的限制决定启动的调度程序的最优数,在实例运行时可增加或删除调度进程。多线索服务器需要SQL*NET版本2或更后的版本。在多线索服务器的配置下,一个网络接收器进程等待客户应用连接请求,并将每一个发送到一个调度进程。如果不能将客户应用连接到一调度进程时,网络接收器进程将启动一个专用服务器进程。该网络接收器进程不是ORACLE实例的组成部分,它是处理与ORACLE有关的网络进程的组成部分。在实例启动时,该网络接收器被打开,为用户连接到ORACLE建立一通信路径,然后每一个调度进程把连接请求的调度进程的地址给予于它的接收器。当一个用户进程作连接请求时,网络接收器进程分析请求并决定该用户是否可使用一调度进程。如果是,该网络接收器进程返回该调度进程的地址,之后用户进程直接连接到该调度进程。有些用户进程不能调度进程通信(如果使用SQL*NET以前的版本的用户),网络接收器进程不能将如此用户连接到一调度进程。在这种情况下,网络接收器建立一个专用服务器进程,建立一种合适的连接。2)、ORACLE内存结构
ORACLE在内存存储下列信息:
●执行的程序代码。
●连接的会话信息
●程序执行期间所需数据和共享的信息
●存储在外存储上的缓冲信息。
ORACLE具有下列基本的内存结构:
●软件代码区
●系统全局区,包括数据库缓冲存储区、日志缓冲区和共享池.
●程序全局区,包括栈区和数据区.
● 排序区软件代码区
用于存储正在执行的或可以执行的程序代码。
软件区是只读,可安装成共享或非共享。ORACLE系统程序是可共享的,以致多个ORACLE用户可存取它,而不需要在内存有多个副本。用户程序可以共享也可以不共享。系统全局区
为一组由ORACLE分配的共享的内存结构,可包含一个数据库实例的数据或控制信息。如果多个用户同时连接到同一实例时,在实例的SGA中数据可为多个用户所共享,所以又称为共享全局区。当实例起动时,SGA的存储自动地被分配;当实例关闭时,该存储被回收。所有连接到多进程数据库实例的全部用户可自动地被分配;当实例关闭时,该存储被回收。所有连接到多进程数据库实例的全部用户可使用其SGA中的信息,但仅仅有几个进程可写入信息。在SGA中存储信息将内存划分成几个区:数据库缓冲存储区、日志缓冲区、共享池、请求和响应队列、数据字典存储区和其它各种信息。程序全局区
PGA是一个内存区,包含单个进程的数据和控制信息,所以又称为进程全局区(PROCESS GLOBAL AREA)。排序区
排序需要内存空间,ORACLE利用该内存排序数据,这部分空间称为排序区。排序区存在于请求排序的用户进程的内存中,该空间的大小为适就排序数据量的大小,可增长,但受初始化参数SORT-AREA-SIZER所限制。2. ORACLE的配置方案
所有连接到ORACLE的用户必须执行两个代码模块可存取一个ORACLE数据库实例:
● 应用或ORACLE工具:一数据库用户执行一数据库应用或一个ORACLE工具,可向ORACLE数据库发出SQL语句。
●ORACLE服务器程序:负责解释和处理应用中的SQL语句。
在多进程实例中,连接用户的代码可按下列三种方案之一配置:
● 对于每一个用户,其数据库应用程序和服务器程序组合成单个用户进程
● 对于每一个用户,其数据库应用是由用户进程所运行,并有一个专用服务器进程。执行ORACLE服务器的代码。这样的配置称为专用服务器体系结构
●执行数据库应用的进程不同于执行ORACLE服务器代码的进程,而且每一个服务器进程(执行ORACLE服务器代码)可服务于多个用户进程,这样的配置称为多线索服务器体系结构。1) USER/SERVER进程相结合的结构
在这种配置下,数据库应用和ORACLE服务器程序是在同一个进程中运行,该进程称为用户进程。
这种ORACLE配置有时称为单任务ORACLE(single_task ORACLE),该配置适用于这样的操作系统,它可在同一进程中的数据库应用和ORACLE代码之间维护一个隔离,该隔离是为数据安全性和完整性所需。其中程序接口(program interface)是负责ORACLE服务器代码的隔离和保护,在数据库应用和ORACLE用户程序之间传送数据。2) 使用专用服务器进程的系统结构
使用专用服务器进程的ORACLE系统在两台计算机上运行。在这种系统中,在一计算机上用户进程执行数据库应用,而在另一台计算机上的服务器进程执行相应的ORACLE服务器代码,这两个进程是分离的。为每个用户进程建立的不同的服务器进程称为专用服务器进程,因为该服务器进程仅对相连的用户进程起作用。这种配置又称为两任务ORACLE。每一个连接到ORACLE的用户进程有一个相应的专用服务进程。这种系统结构允许客户应用是有工作站上执行,通过网络与运行ORACLE的计算机通信。当客户应用和ORACLE服务器代码是在同一台计算机上执行时,这种结构也可用。3) 多线索服务器的系统结构
多线索服务器配置允许许多用户进程共享很少服务器进程。在没有多线索服务器的配置中,每一个用户进程需要自己的专用服务器进程。在具有多线索服务器的配置中,许多用户进程连接到调度进程,由调度进程将客户请求发送到一个共享服务器进程。多线索服务器配置的优点是降低系统开销,增加用户个数。该系统中需要下列类型的进程:
● 网络接收器进程,将用户进程连接到调度进程和专用服务器进程。
●一个或多个调度进程
●一个或多个共享服务器进程
其中网络接收器进程等待新来的连接请求,决定每一用户进程能否用共享服务器进程。如果可以使用,接收器进程将一调度进程的地址返回给用户进程。如果用户进程请求一专用服务器,该接收器进程将建立一个专用服务器进程,将用户进程连接到该专用服务器进程。对于数据库客户机所使用的每种网络协议至少配置一个调度进程,并启动它。
当用户作一次调用时,调度进程将请求放置在SGA的请求队列中,由可用的共享服务器进程获取。共享服务器进程为完成每一个用户进程的请求作所有必要的数据库调用。当服务器完成请求时,将结果返回到调度进程的队列,然后由调度进程将完成的请求返回给用户进程。
共享服务器进程:除共享服务器进程不是连接指定的用户进程外,共享服务器进程和专用服务器进程提供相同的功能,一个共享服务器进程在多线索服务器的配置中可为任何客户请求服务。一个共享服务器进程的SGA不包含有与用户相关的数据,其信息可为所有共享服务器进程存取,它仅包含栈空间、进程指定变量。所有与会话有关的信息是包含有SGA中。每一个共享服务器进程可存取全部会话的数据空间,以致任何服务进程可处理任何会话的请求。对于每一个会话的数据空间是在SGA中分配空间。
ORACLE根据请求队列的长度可动态地调整共享服务器进程。可建立的共享服务器进程将请求放到请求队列。一个用户请求是对数据库的一次程序接口调用,为SQL语句。在SGA中请求队列对实例的全部调度进程是公用的。服务器进程为新请求检查公用请求队列,按先进先出的原则从队列检出一个请求,然后为完成该请求对数据库作必要的调用。共享服务器进程将响应放在调度进程的响应队列。每一个调度进程在SGA中有自己的响应队列,每个调度进程负责将完成的请求回送给相应的用户进程。3.ORACLE运行
1) 使用专用服务进程的ORACLE的运行
在这种配置下,ORACLE运行过程如下:
(1) 数据库服务器计算机当前正在运行ORACLE(后台进程)。
(2) 在一客户工作站运行一个数据库应用(为用户进程),如SQL*PLUS。客户应用使用SQL*NET DRIVER建立对服务器的连接。
(3) 数据库服务器计算机当前正运行合适的SQL*NET DRIVER,该机上接收器进程检出客户数据库应用的连接请求,并在该机上为用户进程建立专用服务器进程。
(4) 用户发出单个SQL语句。
(5) 专用服务器进程接收该语句,在此处有两种方法处理SQL语句:
●如果在共享池一共享SQL区中包含有相同SQL语句时,该服务器进程可利用已存在的共享SQL区执行客户的SQL语句。
●如果在共享池中没有一个SQL区包含有相同的SQL语句时,在共享池中为该语句分配一新的共享SQL区。
在每一种情况,在会话的PGA中建立一个专用SQL区,专用服务器进程检查用户对查询数据的存取权限。
(6) 如果需要,服务器进程从数据文件中检索数据块,或者可使用已存储在实例SGA中的缓冲存储区的数据块。
(7) 服务器进程执行存储在共享SQL区中的SQL语句。数据首先在SGA中修改,由DBWR进程在最有效时将它写入磁盘。LGWR进程在在线日志文件中记录用户提交请求的事务。
(8)如果请求成功,服务器将通过网络发送一信息。如果请求不成功,将发送相应的错误信息。
(9)在整个过程中,其它的后台进程是运行的,同时注意需要干预的条件。另外,ORACLE管理其它事务,防止不同事务之间请求同一数据的竞争。
2) 使用多线索服务器的ORACLE的运行
在这种配置下,ORACLE运行过程如下:
(1) 一数据库服务器计算机运行使用多线索服务器配置的ORACLE。
(2) 在一客户工作站运行一数据库应用(在一用户进程中)。客户应用合适的SQL*NET驱动器试图建立到数据库服务器计算机的连接。
(3) 数据库服务器计算机当前运行合适的SQL*NET驱动器,它的网络接收器进程检出用户进程的连接请求,并决定用户进程如何连接。如果用户是使用SQL*NET版本2,该网络接收器通知用户进程使用一个可用的调度进程的地址重新连接。
(4) 用户发出单个SQL语句
(5) 调度进程将用户进程的请求放入请求队列,该队列位于SGA中,可为所有调度进程共享。
(6) 一个可用共享服务器检验公用调度进程请求队列,并从队列中检出下一个SQL语句。然后处理该SQL语句,同前一(5),(6)和(7)。注意:会话的专用SQL区是建立在SGA中。
(7) 一当共享服务器进程完成SQL处理,该进程将结果放置发入该请求的调度进程的响应队列。
(8) 调度进程检查它的响应队列,并将完成的请求送回请求的用户进程。4.数据库结构和空间管理
一个ORACLE数据库是数据的集合,被处理成一个单位。一个ORACLE数据库有一个物理结构和一个逻辑结构。
物理数据库结构(physical database structure)是由构成数据库的操作系统文件所决定。每一个ORACLE数据库是由三种类型的文件组成:数据文件、日志文件和控制文件。数据库的文件为数据库信息提供真正的物理存储。
逻辑数据库结构是用户所涉及的数据库结构。一个ORACLE数据库的逻辑结构由下列因素决定:
● 一个或多个表空间
●数据库模式对象(即表、视图、索引、聚集、序列、存储过程)
逻辑存储结构如表空间(dataspace)、段(segment)和范围将支配一个数据库的物理空间如何使用。模式对象(schema object)用它们之间的联系组成了一个数据库的关系设计。1) 物理结构
(1) 数据文件
每一个ORACLE数据库有一个或多个物理的数据文件(data file)。一个数据库的数据文件包含全部数据库数据。逻辑数据库结构(如表、索引)的数据物理地存储在数据库的数据文件中。数据文件有下列特征:
●一个数据文件仅与一个数据库联系。
●一旦建立,数据文件不能改变大小
● 一个表空间(数据库存储的逻辑单位)由一个或多个数据文件组成。
数据文件中的数据在需要时可以读取并存储在ORACLE内存储区中。例如:用户要存取数据库一表的某些数据,如果请求信息不在数据库的内存存储区内,则从相应的数据文件中读取并存储在内存。当修改和插入新数据时,不必立刻写入数据文件。为了减少磁盘输出的总数,提高性能,数据存储在内存,然后由ORACLE后台进程DBWR决定如何将其写入到相应的数据文件。(2) 日志文件
每一个数据库有两个或多个日志文件(redo log file)的组,每一个日志文件组用于收集数据库日志。日志的主要功能是记录对数据所作的修改,所以对数据库作的全部修改是记录在日志中。在出现故障时,如果不能将修改数据永久地写入数据文件,则可利用日志得到该修改,所以从不会丢失已有操作成果。
日志文件主要是保护数据库以防止故障。为了防止日志文件本身的故障,ORACLE允许镜象日志(mirrored redo log),以致可在不同磁盘上维护两个或多个日志副本。
日志文件中的信息仅在系统故障或介质故障恢复数据库时使用,这些故障阻止将数据库数据写入到数据库的数据文件。然而任何丢失的数据在下一次数据库打开时,ORACLE自动地应用日志文件中的信息来恢复数据库数据文件。(3) 控制文件
每一ORACLE数据库有一个控制文件(control file),它记录数据库的物理结构,包含下列信息类型:
● 数据库名;
● 数据库数据文件和日志文件的名字和位置;
● 数据库建立日期。
为了安全起见,允许控制文件被镜象。
每一次ORACLE数据库的实例启动时,它的控制文件用于标识数据库和日志文件,当着手数据库操作时它们必须被打开。当数据库的物理组成更改时,ORACLE自动更改该数据库的控制文件。数据恢复时,也要使用控制文件。2) 逻辑结构
数据库逻辑结构包含表空间、段、范围(extent)、数据块和模式对象。
(1) 表空间
一个数据库划分为一个或多个逻辑单位,该逻辑单位称为表空间(TABLESPACE)。一个表空间可将相关的逻辑结构组合在一起。DBA可利用表空间作下列工作:
●控制数据库数据的磁盘分配。
● 将确定的空间份额分配给数据库用户。
●通过使单个表空间在线或离线,控制数据的可用性。
●执行部分数据库后备或恢复操作。
●为提高性能,跨越设备分配数据存储。
数据库、表空间和数据文件之间的关系如下图所示: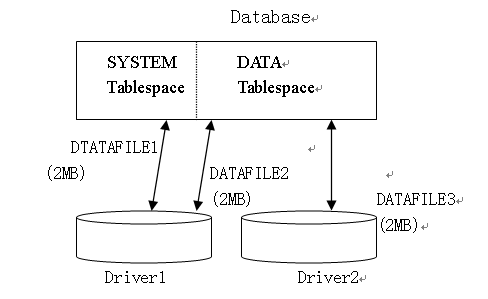
每个数据库可逻辑划分为一个或多个表空间。
每一个表空间是由一个或多个数据文件组成,该表空间物理地存储表空间中全部逻辑结构的数据。DBA可以建立新的表空间,可为表空间增加数据文件或可删除数据文件,设置或更改缺省的段存储位置。每一个ORACLE数据库包含有一个名为SYSTEM的表空间,在数据库建立是自动建立。在该表空间中总包含有整个数据库的数据字典表。最小的数据库可只需要SYSTEM表空间。该表空间必须总是在线。表和存储的PL/SQL程序单元(过程函数、包和触发器)的全部存储数据是存储在SYSTEM表空间中。如果这些PL/SQL对象是为数据库建的,DBA在SYSTEM表空间中需要规划这些对象所需要的空间。
表空间利用增加数据文件扩大表空间,表空间的大小为组成该表空间的数据文件大小的和。
DBA可以使ORACLE数据库中任何表空间(除SYSTEM表空间外)在线(ONLINE)或离线(OFFLINE)。表空间通常是在线以致它所包含的数据对数据库用户是可用的。当表空间为离线时,其数据不可使用。在下列情况下,DBA可以使其离线。
使部分数据不可用,而剩余的部分允许正常存取
执行离线的表空间后备
。为了修改或维护一应用,使它和它的一组表临时不可用。
包含有正在活动的回滚段的表空间不能被离线,仅当回滚段不正在使用时,该表空间才可离线。
在数据字典中记录表空间的状态,在线还是离线。如果在数据库关闭时一表空间为离线,那么在下次数据库装配和重新打开后,它仍然保持离线。
当出现某些错误时,一个表空间可自动地由在线改变为离线。通过使用多个表空间,将不同类型的数据分开,更方便DBA来管理数据库。
ORACLE数据库中一表空间是由一个或多个物理数据文件组成,一个数据文件只可与一个表空间想联系。当为一表空间建立一数据文件时,ORACLE建立该文件,分配指定的磁盘空间容量。在数据文件初时建立后,所分配的磁盘不包含任何数据。表空间可以在线或离线。在ORACLE中还允许单独数据文件在线或离线。(2) 段、范围和数据块
ORACLE通过段、范围和数据块逻辑数据结构可更细地控制磁盘空间的使用。段
段(SEGMENT)包含表空间中一种指定类型的逻辑存储结构,是由一组范围组成。在ORACLE数据库中有几种类型的段:数据段、牵引段、回滚段和临时段。
数据段:对于每一个非聚集的表有一数据段,表的所有数据存放在该段。每一聚集有一个数据段,聚集中每一个表的数据存储在该段中。
索引段:每一个索引有一索引段,存储索引数据。
回滚段:是由DBA建立,用于临时存储要撤消的信息,这些信息用于生成读一致性数据库信息、在数据库恢复时使用、回滚未提交的事务。
临时段:当一个SQL语句需要临时工作区时,由ORACLE建立。当语句执行完毕,临时段的范围退回给系统。
ORACLE对所有段的空间分配,以范围为单位。范围
一个范围(EXTENT)是数据库存储空间分配的一个逻辑单位,它由连续数据块所组成。每一个段是由一个或多个范围组成。当一段中间所有空间已完全使用时,ORACLE为该段分配一个新的范围。
为了维护的目的,在数据库的每一段含有段标题块(segment header block)说明段的特征以及该段中的范围目录。数据块
数据块(data block)是ORACLE管理数据文件中存储空间的单位,为数据库使用的I/O的最小单位,其大小可不同于操作系统的标准I/O块大小。
数据块的格式:公用的变长标题表目录行目录未用空间行数据(3) 模式和模式对象
一个模式(schema)为模式对象(scehma object)的一个集合,每一个数据库用户对应一个模式。模式对象为直接引用数据库数据的逻辑结构,模式对象包含如表、视图、索引、聚集、序列、同义词、数据库链、过程和包等结构。模式对象是逻辑数据存储结构,每一种模式对象在磁盘上没有一个相应文件存储其信息。一个模式对象逻辑地存储在数据库的一个表空间中,每一个对象的数据物理地包含在表空间的一个或多个数据文件中。表
表(table)为数据库中数据存储的基本单位,其数据按行、列存储。每个表具有一表名和列的集合。每一列有一个列名、数据类型、宽度或精度、比例。一行是对应单个记录的列信息的集合。视图
一个视图(view)是由一个或多个表(或其他视图)中的数据的一种定制的表示,是用一个查询定义,所以可认为是一个存储的查询(stored query)或是一个虚表(virtual table)。视图可在使用表的许多地方使用。
由于视图是由表导出的,视图和表存在许多类似,视图象表最多可定义254列。视图可以被查询,而在修改、插入或删除时具有一定的限制,在视图上执行的全部操作真正地影响视图的基本表中的数据,受到基本表的完整性约束和触发器的限制。
视图与表不同,一个视图不分配任何存储空间,视图不真正地包含数据。由查询定义的视图相应于视图引用表中的数据。视图只在数据字典中存储其定义。
引入视图有下列好处:
。通过限制对表的行预定义集合的存取,为表提供附加的安全性
。隐藏数据复杂性。
。为用户简化命令
。为基本表的数据提供另一种观点。
。可将应用隔离基本表定义的修改
。用于不用视图无法表示的查询。
。可用于保存复杂查询。聚集
聚集(cluster)是存储表数据的可选择的方法。一个聚集是一组表,将具有同一公共列值的行存储在一起,并且它们经常一起使用。这些公共列构成聚集码。例如:EMP表各DEPT表共享DEPTNO列,所以EMP表和DEPT表可聚集在一起,聚集码的列为DEPTNO列,该聚集将每个部门的全部职工行各该部门的行物理地存储在同一数据块中。索引
索引(index)是与表和聚集相关的一种选择结构。索引是为提高数据检索的性能而建立,利用它可快速地确定指定的信息。ORACLE索引为表数据提供快速存取路径。索引适用于一范围的行查询或指定行的查询。
索引可建立在一表的一列或多列上,一旦建立,由ORACLE自动维护和使用,对用户是完全透明的。索引是逻辑地和物理地独立于数据,它们的建立或删除对表没有影响,应用可继续处理。索引数据的检索性能几乎保持常数,而当一表上存在许多索引时,修改、删除和插入操作的性能会下降。
索引有唯一索引各非唯一索引。唯一索引保证表中没有两行在定义索引的列上具有重复值。ORACLE在唯一码上自动地定义唯一索引实施UNIQUE完整性约束。
组合索引是在表的某个列上所建立的一索引。组全索引可加快SELECT语句的检索速度,在其WHERE子句中可引用组合索引的全部或主要部分 。所以在定义中给出列的次序,将经常存取的或选择最多的列放在首位。
在建立索引时,将在表空间自动地建立一索引段,索引段空间分配和保留空间的使用受下列方式控制:
索引段范围的分配常驻该索引段的存储参数控制。
其数据块中未用空间可受该段的PCTFREE参数设置所控制。序列生成器
序列生成器(sequence generator)产生序列号。在多用户环境下该序列生成器特别有用,可生成各返回序列号而不需要磁盘I/O或事务封锁。
序列号为ORACLE整数,最多可有38个数字。一个序列定义指出一般信息:序列的名字、上升或下降、序列号之间间距和其它信息。对所有序列的确的定义以行存储在SYSTEM表空间中的数据字典表中,所以所有序列定义总是可用。由引用序列号的SQL语句使用序列号,可生成一个新的序列号或使用当前序列号。一旦在用户会话中的SQL语句生成一序列号,该序列号仅为该会话可用。序列号生成是独立于表,所以同一序列生成器可用于一个和多个表。所生成序列号可用于生成唯一的主码。同义词
一个同义词(synonym)为任何表、视图、快照、序列、过程、函数或包的别名,其定义存储在数据字典中。同义词因安全性和方便原因而经常使用,可用于:
●可屏蔽对象的名字及其持有者。
●为分布式数据库的远程对象提供位置透明性。
●为用户简化SQL语句。
有两种同义词:公用和专用。一个公用同义词为命名为PUBLIC特殊用户组所持有,可为数据库中每一个用户所存取。一个专用同义词是包含在指定用户的模式中,仅为该用户和授权的用户所使用。杂凑
杂凑(hashing)是存储表数据一种可选择的方法,用以改进数据检索的性能。要使用杂凑,就要建立杂凑聚集,将表装入到该聚集。在骠凑聚集中的表行根据杂凑函数的结果进行物理学存储和检索。杂凑函数用于生成一个数值的分布,该数值称为杂凑值,它是基于指定的聚集码值。程序单元
程序单元(program unit)是指存储过程、函数和包(PACKAGE)。一个过程和函数,是由SQL语句和PL/SQL语句组合在一起,为执行某一个任务的一个可执行单位。一个过程或函数可被建立,在数据库中存储其编译形式,可由用户或数据库应用所执行。过程和函数差别在函数总返回单个值给调用者,而过程没有值返回给调用者。
包提供相关的过程、函数、变量和其它包结构封装起来并存贮在一起的一种方法,允许管理者和应用开发者利用该方法组织如此的程序(routine),来提供更多的功能和提高性能。数据库链
数据库链是一个命名的对象,说明从一数据库到另一数据库的一路径(PATH)。在分布式数据库中,对全局对象名引用时,数据库链隐式地使用。三. 数据库和实例的启动和关闭
一个ORACLE数据库没有必要对所有用户总是可用,数据库管理员可启动数据库,以致它被打开。在数据库打开情况下,用户可存取数据库中的信息。当数据库不使用时,DBA可关闭它,关闭后的数据库,用户不能存取其信息。
数据库的启动和关闭是非常重要的管理功能,通过以INTERNAL连接到ORACLE的能力来保护。以INTERNAL 连接到ORACLE需要有下列先决条件:
该用户的操作系统账号具有使用INTERNAL连接的操作系统特权。
对INTERNAL数据库有一口令,该用户知道其口令。
另外:当用户以INTERNAL连接时,可连接到专用服务器,而且是安全连接。1. 数据库启动
启动数据库并使它可用有三步操作:
●启动一个实例;
●装配数据库
●打开数据库1) 启动一个实例
启动一实例的处理包含分配一个SGA(数据库信息使用的内存共享区)和后台进程的建立。实例起动的执行先于该实例装配一数据库。如果仅启动实例,则没有数据库与内存储结构和进程相联系2) 装配一数据库
装配数据库是将一数据库与已启动的实例相联。当实例安装一数据库之后,该数据库保持关闭,仅DBA可存取。3) 打开一数据库
打开一数据库是使数据库可以进行正常数据库操作的处理。当一数据库打开所有用户可连接到该数据库用存取其信息。在数据库打开时,在线数据文件和在线日志文件也被打开。如果一表空间在上一次数据库关闭时为离线,在数据库再次打开时,该表空间与它所相联的数据文件还是离线的。2. 数据库和实例的关闭
关闭一实例以及它所连接的数据库也有三步操作:
1) 关闭数据库
数据库停止的第一步是关闭数据库。当数据库关闭后,所有在SGA中的数据库数据和恢复数据相应地写入到数据文和日志文件。在这操作之后,所有联机数据文件和联机的日志文件也被关闭,任何离线表空间中数据文件夹是已关闭的。在数据库关闭后但还安装时,控制文件仍保持打开。2) 卸下数据库
停止数据库的第二步是从实例卸下数据库。在数据库卸下后,在计算机内存中仅保留实例。在数据库卸下后,数据库的控制文件也被关闭。3) 停止实例
停止数据库的最后一步是停止实例。当实例停止后,SAG是从内存中撤消,后台进程被中止。3. 初始化参数文件
在启动一个实例时,ORACLE必须读入一初始化参数文件(initialization parameter file),该参数文件是一个文本文件,包含有实例配置参数。这些参数置成特殊值,用于初始ORACLE实例的许多内存和进程设置,该参数文件包:
●一个实例所启动的数据库名字
● 在SGA中存储结构使用多少内存;
● 在填满在线日志文件后作什么;
● 数据库控制文件的名字和位置;
●在数据库中专用回滚段的名字。
四. 数据字典的使用
数据字典是ORACLE数据库的最重要的部分之一,是由一组只读的表及其视图所组成。它提供有关该数据库的信息,可提供的信息如下:
● ORACLE用户的名字;
● 每一个用户所授的特权和角色;
●模式对象的名字(表、视图、快照、索引、聚集、同义词、序列、过程、函数、包及触发器等);
● 关于完整性约束的信息;
● 列的缺省值;
● 有关数据库中对象的空间分布及当前使用情况;
● 审计信息(如谁存取或修改各种对象);
●其它一般的数据库信息。
可用SQL存取数据字典,由于数据字典为只读,允许查询。1. 数据字典的结构
数据库数据字典是由基本表和用户可存取的视图组成。
基本表:数据字典的基础是一组基本表组成,存储相关的数据库的信息。这些信息仅由ORACLE读和写,它们很少被ORACLE用户直接存取。
用户可存取视图:数据字典包含用户可存取视图,可概括地方便地显示数据字典的基本表的信息。视图将基本表中信息解码成可用信息。2. 数据字典的使用
当数据库打开时,数据字典总是可用,它驻留在SYSTEM表空间中。数据字典包含视图集,在许多情况下,每一视图集有三种视图包含有类似信息,彼此以 前缀 相区别,前缀 USER、ALL和DBA。
● 前缀为USER的视图,为用 视图,是在用户的模式内。
●前缀为ALL的视图,为扩展的用户视图(为用户可存取的视图)。
●前缀为DBA的视图为DBA的视图(为全部用户可存取的视图)。
在数据库中ORACLE还维护了一组虚表记录当前数据库的活动,这些表称为动态性能表。动态性能表不是真正的表,许多用户不能存取,DBA可查询这些表,可以建立视图,给其它用户授予存取视图权。五. 事务管理
1. 事务
一个事务为工作的一个逻辑单位,由一个或多个SQL语句组成。一个事务是一个原子单位,构成事务的全部SQL语句的结果可被全部提交或者全部回滚。一个事务由第一个可执行SQL语句开始,以提交或回滚结束,可以是显式的,也可是隐式的(执行DDL语句)。
在执行一个SQL语句出现错误时,该语句所有影响被回滚,好像该语句没有被执行一样,但它不会引起当前事务先前的工作的丢失。2. ORACLE的事务管理
在ORACLE中一个事务是由一个可执行的SQL语句开始,一个可执行SQL语句产生对实例的调用。在事务开始时,被赋给一个可用回滚段,记录该事务的回滚项。一个事务以下列任何一个出现而结束。
●当COMMIT或ROLLBACK(没有SAVEPOINT子句)语句发出。
●一个DDL语句被执行。在DDL语句执行前、后都隐式地提交。
● 用户撤消对ORACLE的连接(当前事务提交)。
●用户进程异常中止(当前事务回滚)。1) 提交事务
提交一事务,即将在事务中由SQL语句所执行的改变永久化。在提交前,ORACLE已有下列情况:
●在SGA的回滚段缓冲区已生成回滚段记录,回滚信息包含有所修改值的老值。
●在SGA的日志缓冲区已生成日志项。这些改变在事务提交前可进入磁盘。
●对SGA的数据库缓冲区已作修改,这些修改在事务真正提交之前可进入磁盘。
在事务提交之后,有下列情况:
●对于与回滚段相关的内部事务表记录提交事务,并赋给一个相应的唯一系统修改号(SCN),记录在表中。
● 在SGA的日志缓冲区中日志项由LGWR进程写入到在线日志文件, 这是构成提交事务的原子事务。
●在行上和表上的封锁被释放。
●该事务标志为完成 。
注意:对于提交事务的数据修改不必由DBWR后台进程立即写入数据文件,可继续存储在SGA的数据库缓冲区中,在最有效时将其写入数据文件。2) 回滚事务
回滚事务的含义是撤消未提交事务中的SQL语句所作的对数据修改。ORALCE允许撤消未提交的整个事务,也允许撤消部分。
在回滚整个事务(没有引用保留点)时,有下列情况:
●在事务中所有SQL语句作的全部修改,利用相应的回滚段被撤消。
● 所有数据的事务封锁被释放。
●事务结束。
当事务回滚到一保留点(具有SAVEPOINT)时,有下列情况:
● 仅在该保留点之后执行的语句被撤消。
● 该指定的保留点仍然被保留,该保留点之后所建立的保留点被删除。
●自该保留点之后所获取的全部表封锁和行封锁被释放,但指定的保留点以前所获取的全部数据封锁继续保持。
●该事务仍可继续。3) 保留点
保留点(savepoint)是在一事务范围内的中间标志,经常用于将一个长的事务划分为小的部分。保留点可标志长事务中的任何点,允许可回滚该点之后的工作。在应用程序中经常使用保留点;例如一过程包含几个函数,在每个函数前可建立一个保留点,如果函数失败,很容易返回到每一个函数开始的情况。在回滚到一个保留点之后,该保持点之后所获得的数据封锁被释放。六. 数据库触发器
1. 触发器介绍
数据库触发器(database trigger)是存储在数据库中的过程,当表被修改时它隐式地被激发(执行)。在ORACLE中允许在对表发出INSERT、UPDATE或DELETE语句时隐式地执行所定义的过程,这些过程称为数据库触发器。触发器存储在数据库中,并与所相关表分别存储。触发器仅可在表上定义。在许多情况中触发器用于提供很高级的专用数据库管理系统,来补充ORACLE的标准功能。触发器一般用于:
● 自动地生成导出的列值;
● 防止无效的事务;
●实施更复杂的安全性检查
●在分布式数据库中实施跨越结点的引用完整性;
●实施复杂的事务规则;
● 提供透明事件日志;
●提供高级的审计;
●维护同步表复制;
●收集关于存取表的统计。
注意:数据库触发器与SQL*FORMS触发器之间的差别。数据库触发器是定义在表上,存储在数据库中,当对表执行INSERT、UPDATE或DELETE语句时被激发,不管是谁或哪一应用发出。而SQL*FORMS触发器是SQL*FORM应用的部分,仅当在指定SQL*FORMS应用中执行一个指定触发器点时才被激发。
触发器和说明性完整性约束都可用于约束数据的输入,但它们之间有一定区别:
说明性完整性约束是关于数据库总是为“真”的语句。一个完整性约束应用于表中已有数据和操纵表的任何语句。
而触发器约束事务不可应用于在定义触发器前已装入的数据,所以它不能保证表中全部数据服从该触发器的规则。触发器实施瞬时约束,即在数据改变时实施一约束。2. 触发器的组成:
一个触发器有三个基本部件:触发事件或语句、触发器的限制、触发器动作。
触发事件或语句:为引起触发器激发的SQL语句,是对指定表INSERT、UPDATE或DELETE语句。触发器限制:为一布尔表达式,当触发器激发时该条件必须为TRUE。触发器的限制是用WHEN子句来指定。
触发器的动作:为一个PL/SQL块(过程),由SQL语句和PL/SQL语句组成。当触发语句发出,触发器的限制计算得TRUE时,它被执行。在触发器动作的语句中,可使用触发器的处理的当前行的列值(新值、老值),使用形式为:
NEW.列名 引用新值
OLE.列名 引用老值
在定义触发器时可指定触发器动作执行次数:受触发语句影响每一行执行一次或是对触发语句执行一次。
对每一触发语句可有四种类型触发器:
行触发器:对受触发语句所影响的每一行,行触发器激发一次。
语句触发器:该类型触发器对触发语句执行一次,不管其受影响行数。
定义触发器可以指定触发时间,指定激发器动作的执行相对于触发语句执行之后或之前。
BEFORE触发器:该触发器执行触发器动作是在触发语句执行之前。
AFTER触发器:该触发器执行触发器动作是在触发语句执行之后。
一个触发器可处于两种不同的方式:使能触发器和使不能触发器。
使能触发器:只要当触发语句发出,触发器限制计算为TRUE,这种类型的触发器执行其触发动作。
使不能触发器:这种触发器即使其触发语句被发出,触发器限制计算为TRUE,也不执行触发器动作。
触发器的源代码存储在数据库中,在第一次执行时,触发器的源代码被编译,存储在共享池中。如果触发器从共享池中挤了,再使用时必须再重新编译。七. 分布处理和分布式数据库
1. 简介
一个分布式数据库在用户面前为单个逻辑数据库,但实际上是由存储在多台计算机上的一组数据库组成。在几台计算机 上的数据库通过网络可同时修改和存取,每一数据库受它的局部的DBMS控制。分布式数据库中每一个数据库服务器合作地维护全局数据库的一致性。
在系统中的每一台计算机称为结点。如果一结点具有管理数据库 软件,该结点称为数据库服务器。如果一个结点为请求服务器的信息的一应用,该结点称为客户。在ORACLE客户,执行数据库应用,可存取数据信息和与用户交互。在服务器,执行ORACLE软件,处理对ORACLE数据库并发、共享数据存取。ORACLE允许上述两部分在同一台计算机上,但当客户部分和服务器部分是由网连接的不同计算机上时,更有效。
分布处理是由多台处理机分担单个任务的处理。在ORACLE数据库系统中分布处理的例子如:
客户和服务器是位于网络连接的不同计算机上。
单台计算机上有多个处理器,不同处理器分别执行客户应用。
SQL*NET是ORACLE网络接口,允许运行在网络工作站的ORACLE工具和服务器上,可存取、修改、共享和存储在其它服务器上的数据。SAQL*NET可被认为是网络通信的程序接口。SQL*NET利用通信协议和应用程序接口(API)为OARCLE提供一个分布式数据库和分布处理。
SQL*NET驱动器为在数据库服务器上运行的ORACLE进程与ORACLE工具的用户进程之间提供一个接口。
参与分布式数据库的每一服务器是分别地独立地管理数据库,好 像每一数据库不是网络化的数据库。每一个数据库独立地被管理,称为场地自治性。场地自治性有下列好处:
●系统的结点可反映公司的逻辑组织。
● 由局部数据库管理员控制局部数据,这样每一个数据库管理员责任域要小一些,可更
好管理。
●只要一个数据库和网络是可用,那么全局数据库可部分可用。不会因一个数据库的故
障而停止全部操作或引起性能瓶颈。
● 故障恢复通常在单个结点上进行。
●每个局部数据库存在一个数据字典。
●结点可独立地升级软件。
可从分布式数据库的所有结点存取模式对象,因此正像非分布的局部的DBMS,必须提供一种机制,可在局部数据库中引用一个对象。分布式DBMS必须提供一种命名模式,以致分布式数据库中一个对象可在应用中唯一标识和引用。一般彩在层次结构的每一层实施唯一性。分布式DVMS简单地扩充层次命名模型,实施在网络上唯一数据库命名。因此一个对象的全局对象名保证在分布式数据库内是唯一。
ORACLE允许在SQL语句中使用佤对象名引用分布式数据库中的模式对象(表、视图和过程)。在ORACLE中,一个模式对象的全局名由三部分组成:包含对象的模式名、对象名、数据库名、其形式如:
SCOTT.EMP@SALES.DIVISION3.ACME.COM
其中SCOTT为模式名,EMP为表名,@符号之后为数据库名.
一个远程查询为一查询,是从一个或多个远程表中选择信息,这些表驻留在同一个远程结点.
一个分布式查询可从两个或多个结点检索数据.一个分布式更新可修改两个或两个以上结点的数据.
一个远程事务为一个事务,包含一人或多个远程语句,它所引用的全部是在同一个远程结点上.一个分布式事务中一个事务,包含一个或多个语句修改分布式数据库的两个或多个不同结点的数据.
在分布式数据库中,事务控制必须在网络上直辖市,保证数据一致性.两阶段提交机制保证参与分布式事务的全部数据库服务器是全部提交或全部回滚事务中的语句.
ORACLE分布式数据库系统结构可由ORACLE数据库管理员为终端用户和应用提供位置透明性,利用视图、同义词、过程可提供ORACLE分布式数据库系统中的位置透明性.
ORACLE允许在SELECT(查询)、INSERT、UPDATE、DELETE、SELECT…FOR UPDATE和LOCK TABLE语句中引用远程数据。对于查询,包含有连接、聚合、子查询和SELECT …FOR UPDATE,可引用本地的、远程的表和视图。对于UPDATE、INSERT、DELETE和LOCK TABLE语句可引用本地的和远程的表。注意在引用LONG和LONG RAW列、序列、修改表和封锁表时,必须位于同一个结点。ORACLE不允许作远程DDL语句。
在单场地或分布式数据库中,所有事务都是用COMMIT或ROLLBACK语句中止。ORACLE提供两种机制实现分布式数据库中表重复的透明性:表快照提供异步的表重复;触发器实现同步的表的重复。在两种情况下,都实现了对表重复的透明性。2. 分布式数据库全局名与数据库链
1) 分布式数据库全局名:每一个数据库有一个唯一的全局名,由两部分组成:数据库名(小于等于8字符)和网络域。全局数据库名的网络域成分必须服从标准互联网规范。域名中的层次 由符号“.”分开,域名的次序由叶至根,从左至右。
2) 数据库链:为对过程数据库定义的一路径。数据库链对分布式数据库的用户是透明的,数据库链的名字与链所指向的数据库的全局名相同。其由二部分组成:远程账号和数据库串。例建立数据库链的形式:
CREAT PUBLIC DATEBASE LINK sale。Division3。acme。com
CONNECT TO guest IDENTIFIED BY password
USING‘DB串’;
其中:sales。Divisin3。acme。com为定义的链名;guest/password 为远程数据库的用户账号和口令;DB串用于远程连接。由账号和DB串构成完全路径。如果只有一个则为部分路径。
有三种数据库链可用于决定用户对全部对象名的引用:
专用数据库链:为一指定用户建立。专用数据库链仅链的主人可使用。在SQL语句中用于指定一全局对象名或者在持有者的视图过程定义中使用。
公用数据库链:为特殊的用户组PUBLIC建立。公用数据库链可为任何用户使用,在SQL语句中用于指定一个全局对象名或对象定义。
网络数据链:由网络域服务器建立和管理,可为网络中的任何数据库的任何用户使用,可在SQL语句中指定全局对象名或对象定义中使用。注意:当前网络域服务器对ORACLE不能用,所以网络数据库链不可用。3. 表快照
ORACLE的表快照特征允许一个主表在分布式数据库的其它结点进行复制。只允许修改主表,而复制只可读。主表达式每一个复制称为一个快照。快照异步的刷新,反映主表的一个最近事务一致状态。
一个快照可为表的完全拷贝或者为表的一个子集,由引用一个或多个主表、视图或其它快照的分布式查询所定义。包含主表的数据库称为主数据库。
快照有简单快照和复杂快照。简单快照的每行是基于单个远程表中的一行。所以定义简单快照的查询中不能有GROUB BY或CONNECT BY子句,或子查询、连接或集合操作。如果在快照定义的查询中包含有上述子句或操作,这种快照称为复杂快照。
在快照建立时,ORACLE在快照的模式中建立几种内部对象:
在快照结点,ORACLE建立一基表用于存储由快照定义的查询所检索的行,然后为该表建立一个只读的视图,并为远程主表建立一视图,该视图用于新快照。
一个快照周期地被刷新,反映它的主表的当前情况。为了刷新一快照,快照定义查询是被发出,其查询结果想在存储在快照中,代替以前的快照数据。
当快照为简单快照时,可以由快照日志来刷新,这样可加快刷新处理。快照日志是在主表数据库中的一表,与主表相关。ORACLE使用快照日志跟踪主表中已修改的行。当基于主表的简单快照刷新时,仅需要快照日志的相应行来刷新快照,这种刷新称为快速刷新。
数据库的安全性、完整性、并发控制和恢复为了保证数据库数据的安全可靠性和正确有效,DBMS必须提供统一的数据保护功能。数据保护也为数据控制,主要包括数据库的安全性、完整性、并发控制和恢复。
一. 数据库的安全性
数据库的安全性是指保护数据库以防止不合法的使用所造成的数据泄露、更改或破坏。计算机系统都有这个问题,在数据库系统中大量数据集中存放,为许多用户共享,使安全问题更为突出。
在一般的计算机系统中,安全措施是一级一级设置的。
在DB存储这一级可采用密码技术,当物理存储设备失窃后,它起到保密作用。在数据库系统这一级中提供两种控制:用户标识和鉴定,数据存取控制。
在ORACLE多用户数据库系统中,安全机制作下列工作:
● 防止非授权的数据库存取;
● 防止非授权的对模式对象的存取;
● 控制磁盘使用;
●控制系统资源使用;
● 审计用户动作。数据库安全可分为二类:系统安全性和数据安全性。
系统安全性是指在系统级控制数据库的存取和使用的机制,包含:
● 有效的用户名/口令的组合;
● 一个用户是否授权可连接数据库;
● 用户对象可用的磁盘空间的数量;
● 用户的资源限制;
● 数据库审计是否是有效的;
● 用户可执行哪些系统操作。数据安全性是指在对象级控制数据库的存取和使用的机制,包含:
●哪些用户可存取一指定的模式对象及在对象上允许作哪些操作类型。
在ORACLE服务器上提供了一种任意存取控制,是一种基于特权限制信息存取的方法。用户要存取一对象必须有相应的特权授给该用户。已授权的用户可任意地可将它授权给其它用户,由于这个原因,这种安全性类型叫做任意型。ORACLE利用下列机制管理数据库安全性:
● 数据库用户和模式;
● 特权;
●角色;
●存储设置和空间份额;
●资源限制;
●审计。1. 数据库的存取控制
ORACLE保护信息的方法采用任意存取控制来控制全部用户对命名对象的存取。用户对对象的存取受特权控制。一种特权是存取一命名对象的许可,为一种规定格式。
ORACLE使用多种不同的机制管理数据库安全性,其中有两种机制:模式和用户。模式为模式对象的集合,模式对象如表、视图、过程和包等。第一数据库有一组模式。
每一ORACLE数据库有一组合法的用户,可存取一数据库,可运行一数据库应用和使用该用户各连接到定义该用户的数据库。当建立一数据库用户时,对该用户建立一个相应的模式,模式名与用户名相同。一旦用户连接一数据库,该用户就可存取相应模式中的全部对象,一个用户仅与同名的模式相联系,所以用户和模式是类似的。用户的存取权利受用户安全域的设置所控制,在建立一个数据库的新用户或更改一已有用户时,安全管理员对用户安全域有下列决策:
●是由数据库系统还是由操作系统维护用户授权信息。
●设置用户的缺省表空间和临时表空间。
●列出用户可存的表空间和在表空间中可使用空间份额。
●设置用户资源限制的环境文件,该限制规定了用户可用的系统资源的总量。
●规定用户具有的特权和角色,可存取相应的对象。每一个用户有一个安全域,它是一组特性,可决定下列内容:
●用户可用的特权和角色;
●用户可用的表空间的份额;
●用户的系统资源限制。1) 用户鉴别:
为了防止非授权的数据库用户的使用,ORACLE提供二种确认方法
操作系统确认和相应的ORACLE数据库确认。
如果操作系统允许,ORACLE可使用操作系统所维护的信息来鉴定用户。由操作系统鉴定用户的优点是:
●用户可更方便地连接到ORACLE,不需要指定用户名和口令。
●对用户授权的控制集中在操作系统,ORACLE不需要存储和管理用户口令。然而用户名在数据库中仍然要维护。
●在数据库中的用户名项和操作系统审计跟踪相对应。ORACLE数据库方式的用户确认:ORACLE利用存储在数据库中的信息可鉴定试图接到数据库的一用户,这种鉴别方法仅当操作系统不能用于数据库用户鉴别时才使用。当用户使用一ORACLE数据库时执行用户鉴别。每个用户在建立时有一个口令,用户口令在建立对数据库连接时使用,以防止对数据库非授权的使用。用户的口令以密码的格式存储在数据库数据字典中,用户可随时修改其口令。
2) 用户的表空间设置和定额
关于表空间的使用有几种设置选择:
●用户的缺省表空间;
●用户的临时表空间;
●数据库表空间的空间使用定额。3) 用户资源限制和环境文件
用户可用的各种系统资源总量的限制是用户安全域的部分。利用显式地设置资源限制;安全管理员可防止用户无控制地消耗宝贵的系统资源。资源限制是由环境文件管理。一个环境文件是命名的一组赋给用户的资源限制。另外ORACLE为安全管理员在数据库级提供使能或使不能实施环境文件资源限制的选择。
ORACLE可限制几种类型的系统资源的使用,每种资源可在会话级、调用级或两者上控制。在会话级:每一次用户连接到一数据库,建立一会话。每一个会话在执行SQL语句的计算机上耗费CPU时间和内存量进行限制。对ORACLE的几种资源限制可在会话级上设置。如果会话级资源限制被超过,当前语句被中止(回滚),并返回指明会话限制已达到的信息。此时,当前事务中所有之前执行的语句不受影响,此时仅可作COMMIT、ROLLBACK或删除对数据库的连接等操作,进行其它操作都将出错。
在调用级:在SQL语句执行时,处理该语句有好几步,为了防止过多地调用系统,ORACLE在调用级可设置几种资源限制。如果调用级的资源限制被超过,语句处理被停止,该 语句被回滚,并返回一错误。然而当前事务的已执行所用语句不受影响,用户会话继续连接。有下列资源限制:
●为了防止无控制地使用CPU时间,ORACLE可限制每次ORACLE调用的CPU时间和在一次会话期间ORACLE调用所使用的CPU的时间,以0.01秒为单位。
●为了防止过多的I/O,ORACLE可限制每次调用和每次会话的逻辑数据块读的数目。
●ORACLE在会话级还提供其它几种资源限制。每个用户的并行会话数的限制;
会话空闲时间的限制,如果一次会话的ORACLE调用之间时间达到该空闲时间,当前事务被回滚,会话被中止,会话资源返回给系统;
每次会话可消逝时间的限制,如果一次会话期间超过可消逝时间的限制,当前事务被回滚,会话被删除,该会话的资源被释放;
每次会话的专用SGA空间量的限制。
用户环境文件:
用户环境文件是指定资源限制的命名集,可赋给ORACLE数据库的有效的用户。利用用户环境文件可容易地管理资源限制。要使用用户环境文件,首先应将数据库中的用户分类,决定在数据库中全部用户类型需要多少种用户环境文件。在建立环境文件之前,要决定每一种资源限制的值。例如一类用户通常不执行大量逻辑数据块读,那就可将LOGICAL-READS-PER-SESSION和LOGICAL-READS-PER-CALL设置相应的值。在许多情况中决定一用户的环境文件的合适资源限制的最好的方法是收集每种资源使用的历史信息。2. 特权和角色
1) 特权:特权是执行一种特殊类型的SQL语句或存取另一用户的对象的权力。有两类特权:系统特权和对象特权。
系统特权:是执行一处特殊动作或者在对象类型上执行一种特殊动作的权利。ORACLE有60多种不同系统特权,每一种系统允许用户执行一种特殊的数据库操作或一类数据库操作.
系统特权可授权给用户或角色,一般,系统特权全管理人员和应用开发人员,终端用户不需要这些相关功能.授权给一用户的系统特权并具有该 系统特权授权给其他用户或角色.反之,可从那些被授权的用户或角色回收系统特权.
对象特权:在指定的表、视图、序列、过程、函数或包上执行特殊动作的权利。对于不同类型的对象,有不同类型的对象特权。对于有些模式对象,如聚集、索引、触发器、数据库链没有相关的对象特权,它们由系统特权控制。
对于包含在某用户名的模式中的对象,该用户对这些对象自动地具有全部对象特权,即模式的持有者对模式中的对象具有全部对象特权。这些对象的持有者可将这些对象上的任何对象特权可授权给其他用户。如果被授者包含有GRANT OPTION 授权,那么该被授者也可将其权利再授权给其他用户。2) 角色:为相关特权的命名组,可授权给用户和角色。ORACEL利用角色更容易地进行特权管理。有下列优点:
●减少特权管理,不要显式地将同一特权组授权给几个用户,只需将这特权组授给角色,然后将角色授权给每一用户。
● 动态特权管理,如果一组特权需要改变,只需修改角色的特权,所有授给该角色的全部用户的安全域将自动地反映对角色所作的修改。
● 特权的选择可用性,授权给用户的角色可选择地使其使能(可用)或使不能(不可用)。
● 应用可知性,当一用户经一用户名执行应用时,该数据库应用可查询字典,将自动地选择使角色使能或不能。
●专门的应用安全性,角色使用可由口令保护,应用可提供正确的口令使用权角色使能,达到专用的应用安全性。因用户不知其口令,不能使角色使能。
一般,建立角色服务于两个目的:为数据库应用管理特权和为用户组管理特权。相应的角色称为应用角色和用户角色。
应用角色是授予的运行一数据库应用所需的全部特权。一个应用角色可授给其它角色或指定用户。一个应用可有几种不同角色,具有不同特权组的每一个角色在使用应用时可进行不同的数据存取。
用户角色是为具有公开特权需求的一组数据库用户而建立的。用户特权管理是受应用角色或特权授权给用户角色所控制,然后将用户角色授权给相应的用户。
数据库角色包含下列功能:
● 一个角色可授予系统特权或对象特权。
●一个角色可授权给其它角色,但不能循环授权。
● 任何角色可授权给任何数据库用户。
●授权给一用户的每一角色可以是使能的或者使不能的。一个用户的安全域仅包含当前对该用户使能的全部角色的特权。
● 一个间接授权角色(授权给另一角色的角色)对一用户可显式地使其能或使不能。
在一个数据库中,每一个角色名必须唯一。角色名与用户不同,角色不包含在任何模式中,所以建立一角色的用户被删除时不影响该角色。
ORACLE为了提供与以前版本的兼容性,预定义下列角色:CONNENT、RESOURCE、DBA、EXP-FULL-DATABASE和IMP-FULL-DATABASE。3. 审计
审计是对选定的用户动作的监控和记录,通常用于:
●审查可疑的活动。例如:数据被非授权用户所删除,此时安全管理员可决定对该 数据库的所有连接进行审计,以及对数据库的所有表的成功地或不成功地删除进行审计。
● 监视和收集关于指定数据库活动的数据。例如:DBA可收集哪些被修改、执行了多少次逻辑的I/O等统计数据。
ORACLE支持三种审计类型:
●语句审计,对某种类型的SQL语句审计,不指定结构或对象。
● 特权审计,对执行相应动作的系统特权的使用审计。
●对象审计,对一特殊模式对象上的指定语句的审计。
ORACLE所允许的审计选择限于下列方面:
● 审计语句的成功执行、不成功执行,或者其两者。
● 对每一用户会话审计语句执行一次或者对语句每次执行审计一次。
●对全部用户或指定用户的活动的审计。
当数据库的审计是使能的,在语句执行阶段产生审计记录。审计记录包含有审计的操作、用户执行的操作、操作的日期和时间等信息。审计记录可存在数据字典表(称为审计记录)或操作系统审计记录中。数据库审计记录是在SYS模式的AUD$表中。
二. 数据完整性
它是指数据的正确性和相容性。数据的完整性是为了防止数据库存在不符合主义的数据,防止错误信息输入和输出,即数据要遵守由DBA或应用开发者所决定的一组预定义的规则。ORACLE应用于关系数据库的表的数据完整性有下列类型:
● 在插入或修改表的行时允许不允许包含有空值的列,称为空与非空规则。
● 唯一列值规则,允许插入或修改的表行在该列上的值唯一。
●引用完整性规则,同关系模型定义
● 用户对定义的规则,为复杂性完整性检查。
ORACLE允许定义和实施上述每一种类型的数据完整性规则,这些规则可用完整性约束和数据库触发器定义。
完整性约束,是对表的列定义一规则的说明性方法。
数据库触发器,是使用非说明方法实施完整性规则,利用数据库触发器(存储的数据库过程)可定义和实施任何类型的完整性规则。1. 完整性约束
ORACLE利用完整性约束机制防止无效的数据进入数据库的基表,如果任何DML执行结果破坏完整性约束,该语句被回滚并返回一上个错误。ORACLE实现的完整性约束完全遵守ANSI X3。135-1989和ISO9075-1989标准。
利用完整性约束实施数据完整性规则有下列优点:
●定义或更改表时,不需要程序设计,便很容易地编写程序并可消除程序性错误,其功能是由ORACLE控制。所以说明性完整性约束优于应用代码和数据库触发器。
● 对表所定义的完整性约束是存储在数据字典中,所以由任何应用进入的数据都必须遵守与表相关联的完整性约束。
●具有最大的开发能力。当由完整性约束所实施的事务规则改变时,管理员只需改变完整性约束的定义,所有应用自动地遵守所修改的约束。
●由于完整性约束存储在数据字典中,数据库应用可利用这些信息,在SQL语句执行之前或由ORACLE检查之前,就可立即反馈信息。
●由于完整性约束说明的语义是清楚地定义,对于每一指定说明规则可实现性能优化。
●由于完整性约束可临时地使不能,以致在装入大量数据时可避免约束检索的开销。当数据库装入完成时,完整性约束可容易地使其能,任何破坏完整性约束的任何新行在例外表中列出。
ORACLE的DBA和应用开始者对列的值输入可使用的完整性约束有下列类型:
● NOT NULL约束:如果在表的一列的值不允许为空,则需在该列指定NOT NULL约束。
●UNIQUE码约束:在表指定的列或组列上不允许两行是具有重复值时,则需要该列或组列上指定UNIQUE码完整性约束。在UNIQUE码约束定义中的列或组列称为唯一码。所有唯一完整性约束是用索引方法实施。
●PRIMARY KEY约束:在数据库中每一个表可有一个PRIMARY KEY约束。包含在PRIMARY KEY完整性约束的列或组列称为主码,每个表可有一个主码。ORACLE使用索引实施PRIMARY KEY约束。
● FOREIGN KEY约束(可称引用约束):在关系数据库中表可通过公共列相关联,该 规则控制必须维护的列之间的关系。包含在引用完整性约束定义的列或组列称为外来码。由外来码所引用的表中的唯一码或方码,称为引用码。包含有外来码的表称为子表或从属表。由子表的外来码所引用的表称为双亲表或引用表。如果对表的每一行,其外来码的值必须与主码中一值相匹配,则需指定引用完整性约束。
● CHECK约束:表的每行对一指定的条件必须是TRUE或未知,则需在一列或列组上指定CHECK完整性约束。如果在发出一个DML语句时,CHECK约束的条件计算得FALSE时,该语句被回滚。2. 数据库触发器
ORACLE允许定义过程,当对相关的表作INSERT、UPDATE或DELETE语句时,这些过程被隐式地执行。这些过程称为数据库触发器。触发器类似于存储的过程,可包含SQL语句和PL/SQL语句,可调用其它的存储过程。过程与触发器差别在于调用方法:过程由用户或应用显式执行;而触发器是为一激发语句 (INSERT、UPDATE、DELETE)发出进由ORACLE隐式地触发。一个数据库应用可隐式地触发存储在数据库中多个触发器。
在许多情况中触发器补充ORACLE的标准功能,提供高度专用的数据库管理系统。一般触发器用于:
●自动地生成导出列值。
●防止无效事务。
● 实施复杂的安全审核。
●在分布式数据库中实施跨结点的引用完整性。
● 实施复杂的事务规则。
●提供透明的事件记录。
● 提供高级的审计。
●维护同步的表副本。
● 收集表存取的统计信息。
注意:在ORACLE环境中利用ORACLE工具SQL*FORMS也可定义、存储和执行触发器,它作为由SQL*FORMS所开发有应用的一部分,它与在表上定义的数据库触发器有差别。数据库触发器在表上定义,存储在相关的数据库中,在对该表发出IMSERT、UPDATE、DELETE语句时将引起数据库触发器的执行,不管是哪些用户或应用发出这些语句。而SQL*FORMS的触发器是SQL*FORMS应用的组成,仅当在指定SQL*FORMS应用中执行指定触发器点时才激发该触发器。
一个触发器由三部分组成:触发事件或语句、触发限制和触发器动作。触发事件或语句是指引起激发触发器的SQL语句,可为对一指定表的INSERT、UNPDATE或DELETE语句。触发限制是指定一个布尔表达式,当触发器激以时该布尔表达式是必须为真。触发器作为过程,是PL/SQL块,当触发语句发出、触发限制计算为真时该过程被执行。3. 并发控制
数据库是一个共享资源,可为多个应用程序所共享。这些程序可串行运行,但在许多情况下,由于应用程序涉及的数据量可能很大,常常会涉及输入/输出的交换。为了有效地利用数据库资源,可能多个程序或一个程序的多个进程并行地运行,这就是数据库的并行操作。在多用户数据库环境中,多个用户程序可并行地存取数据库,如果不对并发操作进行控制,会存取不正确的数据,或破坏数据库数据的一致性。
例:在飞机票售票中,有两个订票员(T1,T2)对某航线(A)的机动性票作事务处理,操作过程如图所示:
数据库中的A 1 1 1 1 0 0
T1 READ A A:=A-1 WRITE A
T2 READ A A:=A-1 WRITE A
T1工作区中的A 1 1 0 0 0 0
T2工作区中的A 1 1 0 0 0
首先T1读A,接着T2也读A。然后T1将其工作区中的A减1,T2也采取同样动作,它们都得0值,最后分别将0值写回数据库。在这过程中没有任何非法操作,但实际上多出一张机票。这种情况称为数据库的不一致性,这种不一致性是由于并行操作而产生的。所谓不一致,实际上是由于处理程序工作区中的数据与数据库中的数据不一致所造成的。如果处理程序不对数据库中的数据进行修改,则决不会造成任何不一致。另一方面,如果没有并行操作发生,则这种临时的不一致也不会造成什么问题。数据不一致总是是由两个因素造成:一是对数据的修改,二是并行操作的发生。因此为了保持数据库的一致性,必须对并行操作进行控制。最常用的措施是对数据进行封锁。1) 数据库不一致的类型
●不一致性
在一事务期间,其它提交的或未提交事务的修改是显然的,以致由查询所返回的数据集不与任何点相一致。
●不可重复读
在一个事务范围内,两个相同查询将返回不同数据,由于查询注意到其它提交事务的修改而引起。
● 读脏数据
如果事务T1将一值(A)修改,然后事务T2读该值,在这之后T1由于某种原因撤销对该值的修改,这样造成T2读取的值是脏的。
● 丢失更改
在一事务中一修改重写另一事务的修改,如上述飞机票售票例子。
● 破坏性的DDL操作
在一用户修改一表的数据时,另一用户同时更改或删除该表。2) 封锁
在多用户数据库中一般采用某些数据封锁来解决并发操作中的数据一致性和完整性问题。封锁是防止存取同一资源的用户之间破坏性的干扰的机制,该干扰是指不正确地修改数据或不正确地更改数据结构。
在多用户数据库中使用两种封锁:排它(专用)封锁和共享封锁。排它封锁禁止相关资源的共享,如果一事务以排它方式封锁一资源,仅仅该事务可更改该资源,直至释放排它封锁。共享封锁允许相关资源可以共享,几个用户可同时读同一数据,几个事务可在同一资源上获取共享封锁。共享封锁比排它封锁具有更高的数据并行性。
在多用户系统中使用封锁后会出现死锁,引起一些事务不能继续工作。当两个或多个用户彼此等待所封锁数据时可发生死锁。3) ORACLE多种一致性模型。
ORACLE利用事务和封锁机制提供数据并发存取和数据完整性。在一事务内由语句获取的全部封锁在事务期间被保持,防止其它并行事务的破坏性干扰。一个事务的SQL语句所作的修改在它提交之后所启动的事务中才是可见的。在一事务中由语句所获取的全部封锁在该事务提交或回滚时被释放。
ORACLE在两个不同级上提供读一致性:语句级读一致性和事务级一致性。ORCLE总是实施语句级读一致性,保证单个查询所返回的数据与该查询开始时刻相一致。所以一个查询从不会看到在查询执行过程中提交的其它事务所作的任何修改。为了实现语句级读一致性,在查询进入执行阶段时,在注视SCN的时候为止所提交的数据是有效的,而在语句执行开始之后其它事务提交的任何修改,查询将是看不到的。
ORACLE允许选择实施事务级读一致性,它保证在同一事务内所有查询的数据4) 封锁机制
ORACLE自动地使用不同封锁类型来控制数据的并行存取,防止用户之间的破坏性干扰。ORACLE为一事务自动地封锁一资源以防止其它事务对同一资源的排它封锁。在某种事件出现或事务不再需要该资源时自动地释放。
ORACLE将封锁分为下列类:
●数据封锁:数据封锁保护表数据,在多个用户并行存取数据时保证数据的完整性。数据封锁防止相冲突的DML和DDL操作的破坏性干扰。DML操作可在两个级获取数据封锁:指定行封锁和整个表封锁,在防止冲突的DDL操作时也需表封锁。当行要被修改时,事务在该行获取排它数据封锁。表封锁可以有下列方式:行共享、行排它、共享封锁、共享行排它和排它封锁。
●DDL封锁(字典封锁)
DDL封锁保护模式对象(如表)的定义,DDL操作将影响对象,一个DDL语句隐式地提交一个事务。当任何DDL事务需要时由ORACLE自动获取字典封锁,用户不能显式地请求DDL封锁。在DDL操作期间,被修改或引用的模式对象被封锁。
● 内部封锁:保护内部数据库和内存结构,这些结构对用户是不可见的。5) 手工的数据封锁
下列情况允许使用选择代替ORACLE缺省的封锁机制:
● 应用需要事务级读一致或可重复读。
●应用需要一事务对一资源可排它存取,为了继续它的语句,具有对资源排它存取的事务不必等待其它事务完成。
ORACLE自动封锁可在二级被替代:事务级各系统级。
●事务级:包含下列SQL语句的事务替代ORACLE缺省封锁:LOCK TABLE命令、SELECT…FOR UPDATE命令、具有READ ONLY选项的SET TRANSACTIN命令。由这些语句所获得的封锁在事务提交或回滚后所释放。
●系统级:通过调整初始化参数SERIALIZABLE和REO-LOCKING,实例可用非缺省封锁启动。该两参数据的缺省值为:
SERIALIZABLE=FALSE
ORW-LOCKING=ALWAYS4. 数据库后备和恢复
当我们使用一个数据库时,总希望数据库的内容是可靠的、正确的,但由于计算机系统的故障(硬件故障、软件故障、网络故障、进程故障和系统故障)影响数据库系统的操作,影响数据库中数据的正确性,甚至破坏数据库,使数据库中全部或部分数据丢失。因此当发生上述故障后,希望能重新建立一个完整的数据库,该处理称为数据库恢复。恢复子系统是数据库管理系统的一个重要组成部分。恢复处理随所发生的故障类型所影响的结构而变化。1) 恢复数据库所使用的结构
ORACLE数据库使用几种结构对可能故障来保护数据:数据库后备、日志、回滚段和控制文件。
数据库后备是由构成ORACLE数据库的物理文件的操作系统后备所组成。当介质故障时进行数据库恢复,利用后备文件恢复毁坏的数据文件或控制文件。
日志,每一个ORACLE数据库实例都提供,记录数据库中所作的全部修改。一个实例的日志至少由两个日志文件组成,当实例故障或介质故障时进行数据库部分恢复,利用数据库日志中的改变应用于数据文件,修改数据库数据到故障出现的时刻。数据库日志由两部分组成:在线日志和归档日志。
每一个运行的ORACLE数据库实例相应地有一个在线日志,它与ORACLE后台进程LGWR一起工作 -
存储过程编写经验和优化措施
2006-12-08 15:31:00
一、适合读者对象:数据库开发程序员,数据库的数据量很多,涉及到对SP(存储过程)的优化的项目开发人员,对数据库有浓厚兴趣的人。
二、介绍:在数据库的开发过程中,经常会遇到复杂的业务逻辑和对数据库的操作,这个时候就会用SP来封装数据库操作。如果项目的SP较多,书写又没有一定的规范,将会影响以后的系统维护困难和大SP逻辑的难以理解,另外如果数据库的数据量大或者项目对SP的性能要求很,就会遇到优化的问题,否则速度有可能很慢,经过亲身经验,一个经过优化过的SP要比一个性能差的SP的效率甚至高几百倍。
三、内容:
1、开发人员如果用到其他库的Table或View,务必在当前库中建立View来实现跨库操作,最好不要直接使用“databse.dbo.table_name”,因为sp_depends不能显示出该SP所使用的跨库table或view,不方便校验。
2、开发人员在提交SP前,必须已经使用set showplan on分析过查询计划,做过自身的查询优化检查。
3、高程序运行效率,优化应用程序,在SP编写过程中应该注意以下几点:
a)SQL的使用规范:
i. 尽量避免大事务操作,慎用holdlock子句,提高系统并发能力。
ii. 尽量避免反复访问同一张或几张表,尤其是数据量较大的表,可以考虑先根据条件提取数据到临时表中,然后再做连接。
iii. 尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该改写;如果使用了游标,就要尽量避免在游标循环中再进行表连接的操作。
iv. 注意where字句写法,必须考虑语句顺序,应该根据索引顺序、范围大小来确定条件子句的前后顺序,尽可能的让字段顺序与索引顺序相一致,范围从大到小。
v. 不要在where子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
vi. 尽量使用exists代替select count(1)来判断是否存在记录,count函数只有在统计表中所有行数时使用,而且count(1)比count(*)更有效率。
vii. 尽量使用“>=”,不要使用“>”。
viii. 注意一些or子句和union子句之间的替换
ix. 注意表之间连接的数据类型,避免不同类型数据之间的连接。
x. 注意存储过程中参数和数据类型的关系。
xi. 注意insert、update操作的数据量,防止与其他应用冲突。如果数据量超过200个数据页面(400k),那么系统将会进行锁升级,页级锁会升级成表级锁。
b)索引的使用规范:
i. 索引的创建要与应用结合考虑,建议大的OLTP表不要超过6个索引。
ii. 尽可能的使用索引字段作为查询条件,尤其是聚簇索引,必要时可以通过index index_name来强制指定索引
iii. 避免对大表查询时进行table scan,必要时考虑新建索引。
iv. 在使用索引字段作为条件时,如果该索引是联合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用。
v. 要注意索引的维护,周期性重建索引,重新编译存储过程。
c)tempdb的使用规范:
i. 尽量避免使用distinct、order by、group by、having、join、cumpute,因为这些语句会加重tempdb的负担。
ii. 避免频繁创建和删除临时表,减少系统表资源的消耗。
iii. 在新建临时表时,如果一次性插入数据量很大,那么可以使用select into代替create table,避免log,提高速度;如果数据量不大,为了缓和系统表的资源,建议先create table,然后insert。
iv. 如果临时表的数据量较大,需要建立索引,那么应该将创建临时表和建立索引的过程放在单独一个子存储过程中,这样才能保证系统能够很好的使用到该临时表的索引。
v. 如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先truncate table,然后drop table,这样可以避免系统表的较长时间锁定。
vi. 慎用大的临时表与其他大表的连接查询和修改,减低系统表负担,因为这种操作会在一条语句中多次使用tempdb的系统表。
d)合理的算法使用:
根据上面已提到的SQL优化技术和ASE Tuning手册中的SQL优化内容,结合实际应用,采用多种算法进行比较,以获得消耗资源最少、效率最高的方法。具体可用ASE调优命令:set statistics io on, set statistics time on , set showplan on 等。
出处:CSDN
-
庆贺空间开通
2006-12-07 12:35:03
终于有自己的空间了,记录留念
