
-
[转] 如何在Oracle中建表格时就指定主键和外键
2009-02-20 11:56:06
转自:
http://java1573.javaeye.com/blog/144959
创建表的语法
-创建表格语法:
create table 表名(
字段名1 字段类型(长度) 是否为空,
字段名2 字段类型 是否为空
);-增加主键
alter table 表名 add constraint 主键名 primary key (字段名1);-增加外键:
alter table 表名
add constraint 外键名 foreign key (字段名1)
references 关联表 (字段名2);在建立表格时就指定主键和外键
create table T_STU (
STU_ID char(5) not null,
STU_NAME varchar2(8) not null,
constraint PK_T_STU primary key (STU_ID)
);
主键和外键一起建立:
create table T_SCORE (
EXAM_SCORE number(5,2),
EXAM_DATE date,
AUTOID number(10) not null,
STU_ID char(5),
SUB_ID char(3),
constraint PK_T_SCORE primary key (AUTOID),
constraint FK_T_SCORE_REFE foreign key (STU_ID)
references T_STU (STU_ID)
) -
ORACLE中添加删除主键
2009-02-20 11:45:02
转自:
http://www.stronghearted.net/?p=10
1、创建表的同时创建主键约束
(1)无命名
create table student (
studentid int primary key not null,
studentname varchar(8),
age int);
(2)有命名
create table students (
studentid int ,
studentname varchar(8),
age int,
constraint yy primary key(studentid));
2、删除表中已有的主键约束
(1)有命名
alter table students drop constraint yy;
(2)无命名
可用 SELECT * from user_cons_columns;
查找表中主键名称得student表中的主键名为SYS_C002715
alter table student drop constraint SYS_C002715;
3、向表中添加主键约束
alter table student add constraint pk_student primary key(studentid); -
[转]oracle中的SQL语句简介(DQL,DDL,DML,DCL,TCL)
2009-02-19 16:16:52
转自:
1. 数据查询语句(data query language) DQL
这是数据库操作中最常用、最重要的一类。这类语句的作用就是将数据库中数据按自己的需求,有条理的整理出来,包含 select语句
常用的技巧还包括:SQL中在select语句中使用算术运算符
在select语句中使用连接字符串
SQL中为select语句中增加别名(Alias)
在select语句中增加提示型文字
使用like关键字
使用转义字符(换码符)
使用distinct关键字来压缩SQL语句中的select查询结果
使用in关键字来选择SQL语句中的select查询结果2. 数据定义语句(data define language) DDL
这类语句是用来建立数据库基本组件的,例如建立表,建立视图等等。包含create语句、drop语句、alter语句。
3.数据操作语句(data manipulate language)DML
这类语句的作用是根据需要写入、删除、更新数据库中的数据。主要包括Insert 语句,delete语句,update语
4.数据控制语句(data control language)DCL
这类语句主要用来实现用户的权限授予或者取消,保证数据的安全性。主要包括(
如Grant(授权)语句、Revoke(撤消)语句、Deny(拒绝)语句。
5.事物控制语句(Transaction control language)TCL
这类语句主要是用来控制事物的动作。主要包含commit语句,rollback语句,setpoint语句。
-
DML和DDL的区别
2009-02-19 15:55:28
DDL(data definition language)数据定义语言
用于改变数据库的结构,DDL语言可以完成下面的工作:
。创建(Create), 修改(Alter),删除(Drop)模式对象
。权限管理
。对表(Table),索引(Index),聚簇(Cluster)进行分析(Analyze)
。建立审计(Auditing)
。加注释(Comments)到数据字典;DDL包括以下SQL语句:
CREATE TABLE
ALTER TABLE
DROP TABLE
CREATE INDEX
DROP INDEX。。。
DML(data manipulation language)数据操纵语言用于操作数据库中的数据(改变表中的数据),DML语言不隐含COMMIT语句,因此需要用户手动提交对数据库的修改。
DDL不可以rollback,但是DML可以。
INSTER
UPDATE
DELETE
SELECT -
[转] 快速掌握重启Oracle数据库的操作步骤
2009-02-10 10:52:43
转载自:
http://oracle.chinaitlab.com/induction/743186.html
在实际的应用中,有时候工作数据库需要重新启动。本文介绍了一个特别实用的操作步骤,希望对大家有所帮助。
1. 停应用层的各种程序
2. 停Oralce的监听进程
$ lsnrctl stop
3. 在独占的系统用户下,备份控制文件:
$ sqlplus "/as sysdba"
SQL> alter database backup controlfile to trace;
4. 在独占的系统用户下,手工切换重作日志文件,确保当前已修改过的数据存入文件:
SQL> alter system switch logfile;
5. 在独占的系统用户下,运行下面SQL语句,生成杀数据库用户连接的kill_all_session.sql文件:
SQL> set head off;
SQL> set feedback off;
SQL> set newpage none;
SQL> spool ./kill_session.sql
SQL> select 'alter system kill session '''||sid||','||serial#||''';' from v$session where username is not null;
SQL> spool off;
6. 在独占的系统用户下,执行杀数据库用户连接的kill_session.sql文件
SQL> @./kill_session.sql
7. 在独占的系统用户下,用immediate方式关闭数据库:
SQL> shutdown immediate;
或者
SVRMGRL> shutdown immediate;
8. 启动oralce的监听进程
$ lsnrctl start
9. 进入独占的系统用户下,启动Oralce数据库
$ sqlplus /nolog
SQL> connect / as sysdba
SQL> startup;
或者
$ svrmgrl
SVRMGRL> connect internal;
SVRMGRL> startup;
10.启动应用层的各种程序
-
查看ORACLE企业管理器端口号
2009-02-05 17:17:49
查看E:\oracle\product\10.2.0\db_1\install\portlist.ini 文件即可。 -
[转] How to add one or more control files
2009-02-05 15:30:56
转自:
http://blog.csdn.net/dancle/archive/2006/04/07/653783.aspx
When we have one control file, now want to add one or more control files, there is many method to do it,but the better way is:
1. Shut down the database with NORMAL or IMMEDIATE options.
2. Copy the single control file to its new location. Rename it if you want or need to.
3. Modify your INIT.ORA paramter file. Change the CONTROL_FILES parameter to point to both control files.
4. Startup the database.
It is so simplely,but I think the best way is to hava more controle files that is in difficult folder.
Usually I have three control files for every database.
-
[转] Oracle 的参数文件pfile与spfile
2009-02-05 15:26:57
转自:
http://blog.csdn.net/dancle/archive/2006/03/31/645802.aspx
In Oracle Databases through 8i, parameters controling memory, processor usage, control file locations and other key parameters are kept in a pfile (short for parameter file).
The pfile is a static, plain text files which can be altered using a text editor, but it is only read at database startup. Any changes to the pfile will not be read until the database is restarted and any changes to a running database will not be written to the pfile.
Due to these limitations, in 9i Oracle introduced the spfile (server parameter file). The spfile cannot be edited by the DBA; instead it is updated by using ALTER SYSTEM commands from within Oracle. This allows parameter changes to be persistent across database restarts, but can leave you in a pinch if you need to change a parameter to get a database started but you need the database running to change the parameter.
A 9i (or later) database can have either a pfile or an spfile, or even both, but how can you tell which you have? If you have both, which one is being used? How do you go from one to the other? How do you get out of the chicken-and-the-egg quandary of a database that will not start up without you changing a parameter that’s in that file you can’t update unless the database is up?
Note: This information is based on an Oracle 9i installation on Solaris. Your mileage may vary. I have also chosen to ignore issues of RAC installation. In my example I have used ORADB as my SID.
Am I using a pfile or an spfile?
The first thing to check is if you have a pfile or spfile. They can be specified at startup or found in the default location. The default path for the pfile is
$ORACLE_HOME/dbs/init$ORACLE_SID.oraand the default for the spfile is$ORACLE_HOME/dbs/spfile$ORACLE_SID.ora.If both a pfile and an spfile exist in their default location and the database is started without a
pfile='/path/to/init.ora' then the spfile will be used.Assuming your database is running you can also check the
spfileparameter. Either the commandSHOW PARAMETER spfileorSELECT value FROM v$parameter WHERE name='spfile';will return the path to the spfile if you are using one. If the value of spfile is blank you are not using an spfile.The path to the spfile will often be represented in the database by
?/dbs/spfile@.ora. This may seem cryptic, but Oracle translates?to$ORACLE_HOMEand@to$ORACLE_SIDso this string translates to the default location of the spfile for this database.How can I create an spfile from a pfile?
As long as your pfile is in the default locations and you want your spfile in the default location, you can easily create an spfile with the command
CREATE SPFILE FROM PFILE;.If you need to be more specific about the locations you can add paths to the create command like this:
CREATE SPFILE='/u01/app/oracle/product/9.2/dbs/spfileORADB.ora'FROM PFILE=’/u01/app/oracle/product/9.2/dbs/initORADB.ora’;These commands should work even when the database is not running! This is important when you want to change a database to use an spfile before you start it.
How can I create a pfile from an spfile?
The commands for creating a pfile are almost identical to those for creating a spfile except you reverse the order of spfile and pfile:
If your pfile is in the default location and you want your spfile created there as well run
CREATE SPFILE FROM PFILE;.If you have, or want them in custom locations specify the paths like this:
CREATE PFILE='/u01/app/oracle/product/9.2/dbs/initORADB.ora'FROM SPFILE=’/u01/app/oracle/product/9.2/dbs/spfileORADB.ora’;Again, this can be done without the database running. This is useful when the database fails to start due to a parameter set in the spfile. This is also a good step to integrate into your backup procedures.
How can I see what’s in my spfile
To view the settings in the spfile we have two options: First, we can use the command above to create a pfile from the spfile. This is simple, and fairly fast, but unnecessary if the database is running.
The better way, if the database is running, is to select the parameter you want to view from the oracle view v$spparameter with a command like this:
SELECT value FROM v$spparameter WHERE name='processes';If you try to view the spfile with a text editor it may seem like it is plain text, but beware! The spfile will not behave correctly (if it works at all) if it has been edited by a text editor.
How can I update values in my spfile?
The values in spfile are updated with the
ALTER SYSTEMcommand, but to update the spfile we add an additional parameter ofSCOPE.ALTER SYSTEM SET processes=50 SCOPE=spfile;This command would update the parameter
processesin the spfile. Since this parameter can only be set at startup, we saySCOPE=spfileand the change will be reflected when the database is restarted. Other options forSCOPEarememorywhich only changes the parameter until the database is restarted, andbothwhich changes the instance immediately and will remain in effect after the database is restarted.How can I update values in my spfile when my database won’t start?
So your database won’t startup because of a problem in your spfile. You can’t edit it with a text editor and you can’t use
ALTER SYSTEMbecause your database is not running. It sounds like a problem, but really isn’t. Here’s what you do:Connect up to your database as sysdba. You should get the message
Connected to an idle instanceRun the command
CREATE pfile FROM spfile;specifying the location as above if necessary. You should now have a fresh version of the spfile.Edit the pfile to update the parameter you need to update.
Run the command
CREATE spfile FROM pfile;to move the changes you have just made back into the spfile.Startup the database normally. It should read the changed spfile and start up correctly. You can optionally delete the pfile if you are done.
-
oracle spfile和pfile小结
2009-02-05 14:38:34
简单的说:
1、pfile 文本文件 client端参数文件;不能动态修改,可以用普通的编辑器修改,修改之后需要重启。pfile可能会导致服务器启动不一致,因为可以在客户端启动。
2、spfile 二进制文件 服务器端参数文件,有了spfile,oracle可以实现动态参数在线修改,部分参数修改之后无需重启。但是,因为是二进制文件,所以不能用普通的编辑器修改,要用alter命令从sql里面来修改。spfile保证服务器每次的启动都是一致的。只有spfile而没有pfile文件时,可以通过:create pfile='位置+名字' from spfile;
如:
create pfile='E:\ORACLE\PRODUCT\10.2.0\DB_1\DBS\spfileorcl_bak.ora' from spfile;进行创建pfile文件。
同理,只有pfile而没有spfile时,可以通过:
create spfile='位置+名字' from pfile;
进行创建spfile文件。pfile和spfile二者可以互相备份。
3、通过spfile或pfile启动数据库:
(1)startup nomount启动方式,查找文件的顺序是 spfileSID.ora-〉spfile.ora-〉initSID.ora-〉init.ora(spfile优先于pfile)。
(2)startup pfile='文件目录'----通过pfile文件启动;
(3)startup spfile='文件目录'----通过spfile文件启动。以下转自:
http://www.cnblogs.com/jacktu/archive/2008/02/27/1083232.html
查看系统是以pfile还是spfile启动
Select isspecified,count(*) from v$spparameter group by isspecified;
如果isspecified里有true,表明用spfile进行了指定配置
如果全为false,则表明用pfile启动
使用SPfile的好处
Spfile改正了pfile管理混乱的问题,在多结点的环境里,pfile会有多个image
启动时候需要跟踪最新的image。这是个烦琐的过程。
用spfile以后,所有参数改变都写到spfile里面(只要定义scope=spfile或both),参数配置有个权威的来源。查看spfile location
show parameter spfile从spfile获取pfile
Create pfile='d:pfileSID.ora' from spfile;
Create pfile='d:pfileSID.ora' from spfile='spfile_location';从pfile获取spfile
Create spfile from pfile='Your_pfile_location'
Create spfile='spfile_location' from pfile='Your_pfile_location'
动态修改参数
alter system set parameter=Value scope=spfile|both|memory
Startup nomount的时候需要读去spfile或pfile,两者共存,spfile优先强制用pfile启动
SQL>startup pfile='Your_Pfile.ora'
startup spfile='/data/oracle/product/10.2.0/db_1/dbs/dbs/spfile_mqq.ora' force通过pfile连接到spfile启动
修改pfile文件
-
[转] Oracle全局数据库名、环境变量和sid的区别
2009-02-05 11:23:58
转自:
http://haoxiai.net/shujuku/Oracle/111145.html
一、数据库名
什么是数据库名
数据库名就是一个数据库的标识,就像人的身份证号一样。他用参数DB_NAME表示,如果一台机器上装了多全数据库,那么每一个数据库都有一个数据库名。在数据库安装或创建完成之后,参数DB_NAME被写入参数文件之中。格式如下:
DB_NAME=myorcl
...
在创建数据库时就应考虑好数据库名,并且在创建完数据库之后,数据库名不宜修改,即使要修改也会很麻烦。因为,数据库名还被写入控制文件中,控制文件是以二进制型式存储的,用户无法修改控制文件的内容。假设用户修改了参数文件中的数据库名,即修改DB_NAME的值。但是在Oracle启动时,由于参数文件中的DB_NAME与控制文件中的数据库名不一致,导致数据库启动失败,将返回ORA-01103错误。数据库名的作用
数据库名是在安装数据库、创建新的数据库、创建数据库控制文件、修改数据结构、备份与恢复数据库时都需要使用到的。
有很多Oracle安装文件目录是与数据库名相关的,如:
winnt: d:\oracle\product\10.1.0\oradata\DB_NAME\...
Unix: /home/app/oracle/product/10.1.0/oradata/DB_NAME/...
pfile:
winnt: d:\oracle\product\10.1.0\admin\DB_NAME\pfile\ini.ora
Unix: /home/app/oracle/product/10.1.0/admin/DB_NAME/pfile/init$ORACLE_SID.ora
跟踪文件目录:
winnt: /home/app/oracle/product/10.1.0/admin/DB_NAME/bdump/...
另外,在创建数据时,careate database命令中的数据库名也要与参数文件中DB_NAME参数的值一致,否则将产生错误。
同样,修改数据库结构的语句alter database,当然也要指出要修改的数据库的名称。
如果控制文件损坏或丢失,数据库将不能加载,这时要重新创建控制文件,方法是以nomount方式启动实例,然后以create controlfile命令创建控制文件,当然这个命令中也是指指DB_NAME。
还有在备份或恢复数据库时,都需要用到数据库名。
总之,数据库名很重要,要准确理解它的作用。查询当前数据名
方法一:select name from v$database;
方法二:show parameter db
方法三:查看参数文件。修改数据库名
前面建议:应在创建数据库时就确定好数据库名,数据库名不应作修改,因为修改数据库名是一件比较复杂的事情。那么现在就来说明一下,如何在已创建数据之后,修改数据库名。步骤如下:
1.关闭数据库。
2.修改数据库参数文件中的DB_NAME参数的值为新的数据库名。
3.以NOMOUNT方式启动实例,修建控制文件(有关创建控制文件的命令语法,请参考oracle文档)二、数据库实例名
二、数据库实例名
什么是数据库实例名?
数据库实例名是用于和操作系统进行联系的标识,就是说数据库和操作系统之间的交互用的是数据库实例名。实例名也被写入参数文件中,该参数为instance_name,在winnt平台中,实例名同时也被写入注册表。
数据库名和实例名可以相同也可以不同。
在一般情况下,数据库名和实例名是一对一的关系,但如果在oracle并行服务器架构(即oracle实时应用集群)中,数据库名和实例名是一对多的关系。这一点在第一篇中已有图例说明。查询当前数据库实例名
方法一:select instance_name from v$instance;
方法二:show parameter instance
方法三:在参数文件中查询。数据库实例名与ORACLE_SID
虽然两者都表是oracle实例,但两者是有区别的。instance_name是oracle数据库参数。而ORACLE_SID是操作系统的环境变量。ORACLD_SID用于与操作系统交互,也就是说,从操作系统的角度访问实例名,必须通过ORACLE_SID。在winnt不台,ORACLE_SID还需存在于注册表中。
且ORACLE_SID必须与instance_name的值一致,否则,你将会收到一个错误,在unix平台,是“ORACLE not available”,在winnt平台,是“TNS:协议适配器错误”。数据库实例名与网络连接
数据库实例名除了与操作系统交互外,还用于网络连接的oracle服务器标识。当你配置oracle主机连接串的时候,就需要指定实例名。当然8i以后版本的网络组件要求使用的是服务名SERVICE_NAME。这个概念接下来说明。
三、数据库域名
什么是数据库域名?
在分布工数据库系统中,不同版本的数据库服务器之间,不论运行的操作系统是unix或是windows,各服务器之间都可以通过数据库链路进行远程复制,数据库域名主要用于oracle分布式环境中的复制。举例说明如:
全国交通运政系统的分布式数据库,其中:
福建节点: fj.jtyz
福建厦门节点: xm.fj.jtyz
江西: jx.jtyz
江西上饶:sr.jx.jtyz
这就是数据库域名。
数据库域名在存在于参数文件中,他的参数是db_domain.查询数据库域名
方法一:select value from v$parameter where name = 'db_domain';
方法二:show parameter domain;
方法三:在参数文件中查询。全局数据库名
全局数据库名=数据库名+数据库域名,如前述福建节点的全局数据库名是:oradb.fj.jtyz四、数据库服务名
什么是数据库服务名?
从oracle9i版本开始,引入了一个新的参数,即数据库服务名。参数名是SERVICE_NAME。
如果数据库有域名,则数据库服务名就是全局数据库名;否则,数据库服务名与数据库名相同。查询数据库服务名
方法一:select value from v$parameter where name = 'service_name';
方法二:show parameter service_name;
方法三:在参数文件中查询。数据库服务名与网络连接
从oracle8i开始的oracle网络组件,数据库与客户端的连接主机串使用数据库服务名。之前用的是ORACLE_SID,即数据库实例名。
-
[转] Oracle9i归档日志配置指南
2009-02-04 17:12:40
转自:
http://blog.oracle.com.cn/html/62/t-58262.html
1.归档日志模式和非归档日志模式的区别
2.配置数据库的归档模式
3.启用自动归档
4.手动归档
5.归档模式和非归档模式的转换
6.配置多个归档进程
7.配置归档目标,多归档目标,远程归档目标
1.归档日志模式和非归档日志模式的区别
非归档模式只能做冷备份,并且恢复时只能做完全备份.最近一次完全备份到系统出错期间的数据不能恢复.
归档模式可以做热备份,并且可以做增量备份,可以做部分恢复.
用ARCHIVE LOG LIST 可以查看期模式状态时归档模式还是非归档模式.
2.配置数据库的归档模式
改变非归档模式到归档模式:
1)SQL>SHUTDOWN NORMAL/IMMEDIATE;
2)SQL>STARTUP MOUNT;
3)SQL>ALTER DATABASE ARCHIVELOG;
4)SQL>ALTER DATABASE OPEN;
5)SQL>做一次完全备份,因为非归档日志模式下产生的备份日志对于归档模式已经不可用了.这一步非非常重要!
改变归档模式到非归档模式:
1)SQL>SHUTDOWN NORMAL/IMMEDIATE;
2)SQL>STARTUP MOUNT;
3)SQL>ALTER DATABASE NOARCHIVELOG;
4)SQL>ALTER DATABASE OPEN;
3.启用自动归档: LOG_ARCHIVE_START=TRUE
归档模式下,日志文件组不允许被覆盖(重写),当日志文件写满之后,如果没有进行手动归档,那么系统将挂起,知道归档完成为止.
这时只能读而不能写.
运行过程中关闭和重启归档日志进程
SQL>ARCHIVE LOG STOP
SQL>ARCHIVE LOG START
4.手动归档: LOG_ARCHIVE_START=FALSE
归档当前日志文件
SQL>ALTER SYSTEM ARCHIVE LOG CURRENT;
归档序号为052的日志文件
SQL>ALTER SYSTEM ARCHIVE LOG SEQUENCE 052;
归档所有日志文件
SQL>ALTER SYSTEM ARCHIVE LOG ALL;
改变归档日志目标
SQL>ALTER SYSTEM ARCHIVE LOG CURRENT TO '& ATH';
ATH';
5.归档模式和非归档模式的转换
转换到归档日志模式
SQL>SHUTDOWN
SQL>STARTUP MOUNT
SQL>ALTER DATABASE ARCHIVELOG;
SQL>ALTER DATABASE OPEN;
转换到非归档日志模式
SQL>SHUTDOWN
SQL>STARTUP MOUNT
SQL>ALTER DATABASE NOARCHIVELOG;
SQL>ALTER DATABASE OPEN;
6.配置多个归档进程
Q:什么时候需要使用多个归档进程?
A:如果归档过程会消耗大量的时间,那么可以启动多个归档进程,这是个动态参数,可以用ALTER SYSTEM动态修改.
SQL>ALTER SYSTEM SET LOG_ARCHIVE_MAX_PROCESSES=10;
Oracle9i中最多可以指定10个归档进程
与归档进程有关的动态性能视图
v$bgprocess,v$archive_processes
7.配置归档目标,多归档目标,远程归档目标,归档日志格式
归档目标 LOG_ARCHIVE_DEST_n
本地归档目标:
SQL>LOG_ARCHIVE_DEST_1 = "LOCATION=D:\ORACLE\ARCHIVEDLOG";
远程归档目标:
SQL>LOG_ARCHIVE_DEST_2 = "SERVICE=STANDBY_DB1";
强制的归档目标,如果出错,600秒后重试:
SQL>ALTER SYSTEM SET LOG_ARCHIVE_DEST_4 = "LOCATION=E:\ORACLE\ARCHIVEDLOG MANDATORY REOPEN=600";
可选的归档目标,如果出错,放弃归档:
SQL>ALTER SYSTEM SET LOG_ARCHIVE_DEST_3 = "LOCATION=E:\ORACLE\ARCHIVEDLOG OPTIONAL";
归档目标状态:关闭归档目标和打开归档目标
关闭归档目标1
SQL>ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_1 = DEFER
打开归档目标2
SQL>ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2 = ENABLE
归档日志格式
LOG_ARCHIVE_FORMAT
8.获取归档日志信息
V$ARCHVIED_LOG
V$ARCHVIE_DEST
V$LOG_HISTORY
V$DATABASE
V$ARCHIVE_PROCESSES
ARCHIVE LOG LIST; -
[转] 初识ORACLE的审计功能
2009-02-01 16:52:13
转自:
http://rake.itpub.net/post/4038/24963
顺着这样的思路去学习。
1、审计可以达到怎样的效果?我用来做什么?
2、任何概念都该有分类的吧,审计也不例外?
3、如何启用审计?数据库一级。
4、如何设定我所需要的审计?针对某个特定的监视目标了。
5、如何看审计的结果?
6、论坛上一些常见的问题,自己认为比较难理解的问题。
初识ORACLE的审计功能
顺着这样的思路去学习。
1、审计可以达到怎样的效果?我要来做什么?
2、有分类吗?
3、如何启用审计?数据库一级。
4、如何设定我所需要的审计?针对某个特定的监视目标了。
5、如何看审计的结果?
6、论坛上一些常见的问题,自己认为比较难理解的问题。一、审计可以达到怎样的效果?
可以记录对数据库对象的所有操作。什么时候,什么用户对什么对象进行了什么类型的操作。
但是无法得知操作的细节,比如到底数据更新成了1还是2?
不过现在新出现的精细审计(Fine grained Auditing),好像也可以记录DML语句了。二、审计可以分为3类。或者说,可以从3种角度去启用审计。
1、语句审计(Statement Auditing)。
对预先指定的某些SQL语句进行审计。这里从SQL语句的角度出发,进行指定。审计只关心执行的语句。
例如,audit CREATE TABLE;命令,就表明对"create table"语句的执行进行记录。
不管这语句是否是针对某个对象的操作2、权限审计(Privilege Auditing)
对涉及某些权限的操作进行审计。这里强调“涉及权限”
例如,audit CREATE TABLE;命令,又可以表明对涉及“CREATE TABLE”权限的操作进行审计。
所以说,在这种命令的情况下,既产生一个语句审计,又产生了一个权限审计。
有时候“语句审计”和“权限审计”的相互重复的。这一点可以后面证明。3、对象审计(Object Auditing)。
记录作用在指定对象上的操作。
三、如何启用审计。
通过数据库初始化参数文件中的AUDIT_TRAIL 初始化参数启用和禁用数据库审计。
DB 启用数据库审计并引导所有审计记录到数据库的审计跟踪
OS 启用数据库审计并引导所有审计记录到操作系统的审计跟踪。可以用AUDIT_FILE_DEST 初始化参数来指定审计文件存储的目录。
NONE 禁用审计这个值是默认值四、如何设定所需的审计
AUDIT语句。
例如:审计属于用户jward 的dept 表上的所有的SELECT INSERT 和DELETE 语句
AUDIT SELECT, INSERT, DELETE
ON jward.dept;五、控制何时触发审计动作。
1)By session / By Access
by session对每个session中发生的重复操作只记录一次
by access对每个session中发生的每次操作都记录,而不管是否重复。2)Whenever successful/ Whenever not successful
Whenever successful表示操作成功以后才记录下来。
Whenever not successful表示操作失败后才记录下来。六、审计实施
1、语句审计
Audit session; Audit session By;
与instance连接的每个会话生成一条审计记录。
审计记录将在连接时期插入并且在断开连接时期进行更新。
保留有关会话的信息比如连接时期断开连接时期处理的逻辑和物理I/O,
以及更多信息将存储在单独一条审计记录中
该审计记录与会话相对应
2、audit delete table
2) 权限审计
Audit DELETE ANY TABLE
by access
whenever not successful;
所有不成功的,使用DELETE ANY TABLE权限进行的操作。3) 对象审计
AUDIT SELECT, INSERT, DELETE
ON jward.dept
BY ACCESS
WHENEVER SUCCESSFUL;
七、审计结果
1)数据库初始化参数文件中AUDIT_TRAIL=OS时,审计记录存在操作系统的文件中。
UNIX系统的话,默认存在“$oracle_home/rdbms/audit/” 目录下。
If you have set AUDIT_TRAIL = OS, modify the "init.ora" file to specify
the destination for the audited records using the AUDIT_FILE_DEST parameter.
If your operating system supports AUDIT_TRAIL = OS auditing, files are
automatically created in the AUDIT_FILE_DEST for certain actions, and the
generated name contains the OS PID of the shadow process audited:
Example:
AUDIT_FILE_DEST = $ORACLE_HOME/rdbms/audit
b)windows系统的审计信息存储在事件管理器中。
你可以通过控制面板——管理工具——事件查看器——应用程序日志中找到相应的审计记录2)数据库初始化参数文件中AUDIT_TRAIL=DB时,审计记录存在数据库中。
相关表和视图:
SYS.AUD$ 是唯一保留审计结果的表。其它的都是视图。STMT_AUDIT_OPTION_MAP 包含有关审计选项类型代码的信息由SQL.BSQ 脚本在CREATEDATABASE 的时候创建
AUDIT_ACTIONS 包含对审计跟踪动作类型代码的说明
ALL_DEF_AUDIT_OPTS 包含默认对象审计选项。当创建对象时将应用这些选项DBA_STMT_AUDIT_OPTS 描述由用户设置的跨系统的当前系统审计选项
DBA_PRIV_AUDIT_OPTS 描述由用户正在审计的跨系统的当前系统权限
DBA_OBJ_AUDIT_OPTS 描述在所有对象上的审计选项
USER_OBJ_AUDIT_OPTS USER 视图描述当前用户拥有的所有对象上的审计选项以下是审计记录
DBA_AUDIT_TRAIL 列出所有审计跟踪条目
USER_AUDIT_TRAIL USER视图显示与当前用户有关的审计跟踪条目DBA_AUDIT_OBJECT 包含系统中所有对象的审计跟踪记录
USER_AUDIT_ OBJECT USER 视图列出一些审计跟踪记录而这些记录涉及当前用户可以访问的对象的语句DBA_AUDIT_SESSION 列出涉及CONNECT 和DISCONNECT 的所有审计跟踪记录
USER_AUDIT_ SESSION USER视图列出涉及当前用户的CONNECT 和DISCONNECT 的所有审计跟踪记录DBA_AUDIT_STATEMENT 列出涉及数据库全部的GRANT REVOKE AUDIT NOAUDIT 和ALTER SYSTEM 语句的审计跟踪记录
USER_ AUDIT_ STATEMENT 对于USER 视图来说这些语句应是用户发布的DBA_AUDIT_EXISTS 列出BY AUDIT NOT EXISTS 产生的审计跟踪条目
下面的视图用于细粒度审计
DBA_AUDIT_POLICIES 显示系统上的所有审计策略
DBA_FGA_AUDIT_TRAIL 列出基于值的审计的审计跟踪记录
八、一些特殊问题
1、有时候“语句审计”和“权限审计”是相互重复的。并不需要明确的区分这2种类型。
主要是考虑你对审计的需求是什么?考虑出发的角度是什么?
例如:
SQL> audit CREATE TABLE;Audit succeeded
SQL> SELECT * FROM DBA_STMT_AUDIT_OPTS;
AUDIT_OPTION SUCCESS FAILURE
---------------------------------------- ---------- ----------
CREATE TABLE BY ACCESS BY ACCESSSQL> SELECT * FROM DBA_PRIV_AUDIT_OPTS;
PRIVILEGE SUCCESS FAILURE
---------------------------------------- ---------- ----------
CREATE TABLE BY ACCESS BY ACCESS以上的一条审计设定命令,生成了两条审计规则。其实最后的结果都是一样。
就是当CREATE TABLE语句执行后,存下审计记录。2、开启某个用户下所有表的审计
audit table by user_name。据说可以。
九、参考
http://blog.itpub.net/post/468/6806http://download-west.oracle.com/docs/cd/B10501_01/server.920/a96521/audit.htm#1108
获得应用程序所执行的SQL语句
http://www.softhouse.com.cn/html/200412/2004121608315200002957.html细粒度审计(FGA)
http://www.itpub.net/showthread.php?s=&threadid=239693&highlight=%C9%F3%BC%C6 -
[转] ORACLE概要文件管理
2009-02-01 16:32:13
转自:
http://3492zhang.itpub.net/post/8531/457529
profile相关参数的单位以及参数说明。(中文)
Oracle系统为了合理分配和使用系统的资源提出了概要文件的概念。所谓概要文件,就是一份描述如何使用系统的资源(主要是CPU资源)的配置文件。将概要文件赋予某个数据库用户,在用户连接并访问数据库服务器时,系统就按照概要文件给他分配资源。在有的书中将其翻译为配置文件,其作用包括。
1、管理数据库系统资源。
利用Profile来分配资源限额,必须把初始化参数resource_limit设置为true
ALTER SYSTEM SET resource_limit=TRUE SCOPE=BOTH;
2、管理数据库口令及验证方式。
默认给用户分配的是DEFAULT概要文件,将该文件赋予了每个创建的用户。但该文件对资源没有任何限制,因此管理员常常需要根据自己数
据库系统的环境自行建立概要文件,下面介绍如何创建及管理概要文件。示例:
CREATE PROFILE pro_test
LIMIT CPU_PER_SESSION 1000
--cpu每秒会话数
任意一个会话所消耗的CPU时间量(时间量为1/100秒)
CPU_PER_CALL 1000
--cpu每秒调用数
任意一个会话中的任意一个单独数据库调用所消耗的CPU时间量(时间量为1/100秒)
CONNECT_TIME 30
--允许连接时间
任意一个会话连接时间限定在指定的分钟数内
IDLE_TIME DEFAULT
--允许空闲时间
SESSIONS_PER_USER 10
--用户最大并行会话数(指定用户的会话数量)
LOGICAL_READS_PER_SESSION 1000 --读取数/会话(单位:块)
LOGICAL_READS_PER_CALL 1000 --读取数/调用(单位:块)
PRIVATE_SGA 16K --专用sga
COMPOSITE_LIMIT 1000000 --组合限制(单位:单元)
FAILED_LOGIN_ATTEMPTS 10 --登录几次后
PASSWORD_LOCK_TIME 10 --锁定时间(单位:天)
PASSWORD_GRACE_TIME 120 --多少天后锁定
PASSWORD_LIFE_TIME 60 --口令有效期(单位:天)
PASSWORD_REUSE_MAX UNLIMITED --保留口令历史记录:保留次数(单位:次)
PASSWORD_REUSE_TIME 120 --保留口令历史记录:保留时间(单位:天)
PASSWORD_VERIFY_FUNCTION DEFAULT --启用口令复杂性函数(null或者default)
更改参数实例:alter profile pro_test LIMIT CPU_PER_SESSION 5000
删除概要文件:drop profile pro_test
为一个具体用户分配 概要文件alter user test profile pro_test;
将用户的概要文件改为默认
alter user test profile default;
查看概要文件的信息
select * from SYS.DBA_PROFILES;
select * from SYS.USER_RESOURCE_LIMITS;
-
数据库基础知识实践(七)-----创建索引、视图和序列
2009-02-01 15:35:00
oracle创建索引
适当的使用索引可以提高数据检索速度,可以给经常需要进行查询的字段创建索引
oracle的索引分为5种:唯一索引,组合索引,反向键索引,位图索引,基于函数的索引
创建索引的标准语法:
CREATE INDEX 索引名 ON 表名(列名)
TABLESPACE 表空间名;
(1)创建唯一索引:
CREATE unique INDEX 索引名 ON 表名(列名)
TABLESPACE 表空间名;
(2)创建组合索引:
CREATE INDEX 索引名 ON 表名(列名1,列名2)
TABLESPACE 表空间名;
(3)创建反向键索引:
CREATE INDEX 索引名 ON 表名(列名) reverse
TABLESPACE 表空间名;
ORACLE创建视图
create or replace view 视图名 as select * from 表 where 条件 with check option;
eg:
create or replace view view_student as
select id,name
from student with read only;
在单表视图下可以通过视图向数据表中插入数据,但前提是插入的数据要满足约束,视图查询的列不能使用系统函数,在多表视图下不能通过视图插入数据,视图实际上就是一张虚拟的表,但它不是存在于物理文件中,而是在内存中,这样的好处就是可以提高读取效率,在复杂的多表查询时可以降低开发难度。
ORACLE创建序列
create sequence 序列名称
start with 1
increment by 1
minvalue 1
maxvalue 100
nocycle;
序列创建后用
序列名.nextval得到下一个序列编号
序列名.currval得到当前序列编号
如果一个数据表的主键需要自动增长就需要创建一个序列
然后在像表中插入数据时
insert into 表名(id,name) values(序列名.nextval,'aaa');就可以了
-
数据库基础知识实践(六)-----SQL删除和更新数据
2009-01-21 14:38:54
1.用SQL删除数据
(1) 删除记录
delete from 数据表 where 条件;
(2) 整表数据删除
truncate table 数据表;
注意:truncate table 命令将快速删除数据表中的所有记录,但保留数据表结构,这种快速删除与delete from 数据表的删除全部数据表记录不一样,delete命令删除的数据将存储在系统回滚段中,需要的时候,数据可以回滚恢复,而truncate 命令删除的数据是不可以恢复的。
2.用SQL更新数据
(1) 直接赋值更新
语法:
update 数据表
set 字段名1=新的赋值,字段名2=新的赋值,......
where 条件
eg:update emp
set empno=8888,ename='TOM',hiredate='03-9月-2002'
where empno=7566;
(2) 嵌套更新
语法:
update 数据表
set 字段名1=(select 字段列表 from 数据表 where 条件),字段名2=(select 字段列表 from 数据表 where 条件),......
eg:update emp
set sal=
(
select sal+300 from emp
where empno=7599
)
where empno=7599;
-
数据库基础知识实践(五)-----SQL函数查询
2009-01-21 13:39:57
1.[ceil] 函数
用法:ceil(n),取大于等于数值n的最小整数。
eg:select mgr,mgr/100,ceil(mgr/100) from emp;
2.[floor]函数
用法:floor(n),取笑于等于数值n的最大整数。
eg:select mgr,mgr/100,floor(mgr/100) from emp;
3.[mod] 函数
用法:mod(m,n),取m整除n后的余数。
eg:select mgr,mod(mgr,1000),mod(mgr,100),mod(mgr,10) from emp;
4.[power] 函数
用法:power(m,n),取m的n次方。
eg:select mgr,power(mgr,2),power(mgr,3) from emp;
5.[round] 函数
用法:round(m,n),四舍五入,保留n位。
eg:select mgr,round(mgr/100,2),round(mgr/1000,2) from emp;
6.[sign] 函数
用法:sign(n),n>0,取1;n=0,取0;n<0,取-1。
eg:select mgr,mgr-7800,sign(mgr-7800) from emp;
7.[avg] 函数
用法:avg(字段名),求平均值。要求字段为数值型。
eg:select avg(mgr) 平均薪水 from emp;
8.[count] 函数
用法:count(字段名)或count(*),统计总数。
eg:select count(distinct job) 工作类别总数 from emp;
9.[min] 函数
用法:min(字段名),计算数值型字段最小数。
eg:select min(sal) 最少薪水 from emp;
10.[max] 函数
用法:max(字段名),计算数值型字段最大数。
eg:select max(sal) 最高薪水 from emp;
11.[sum] 函数
用法:sum(字段名),计算数值型字段总和。
eg:select sum(sal) 薪水总和 from emp;
-
数据库基础知识实践(四)-----SQL嵌套查询
2009-01-20 15:06:49
在select查询语句里可以嵌入select查询语句,称为嵌套查询。
注意:子查询可以嵌套多层,自查询操作的数据表可以是父查询不操作的数据表。子查询中不能有order by 分组语句。
1.简单嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal>=(select sal from emp where ename='小白');
2.带[in] 的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal in (select sal from emp where ename='小白') ;
3.带[any] 的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal>any(select sal from emp where job='MANAGER');
4.带[some]的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal=some(select sal from emp where job='MANAGER');
5.带[all]的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal>all(select sal from emp where job='MANAGER');
6.带exists的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp,dept
where exists
(select * from emp where emp.deptno=dept.deptno);
7.并操作的嵌套查询
(select deptno from dept)
union
(select deptno from emp);
8.交操作的嵌套查询
(select deptno from dept)
intersect
(select deptno from emp);
9.差操作的嵌套查询
(select deptno from dept)
minus
(select deptno from emp);
-
数据库基础知识实践(三)-----SQL单表查询
2009-01-19 14:04:22
用SQL进行单表查询
-
查询所有记录: select * from 数据表
-
查询所有记录的某些字段:select 字段名1,字段名2,.... from 数据表 (将显示某些特定的字段,注意这里的字段名之间的逗号是英文状态下的逗号)。
-
查询某些字段不同记录:select distinct 字段名 from 数据表
-
单条件的查询:where可以指定查询条件

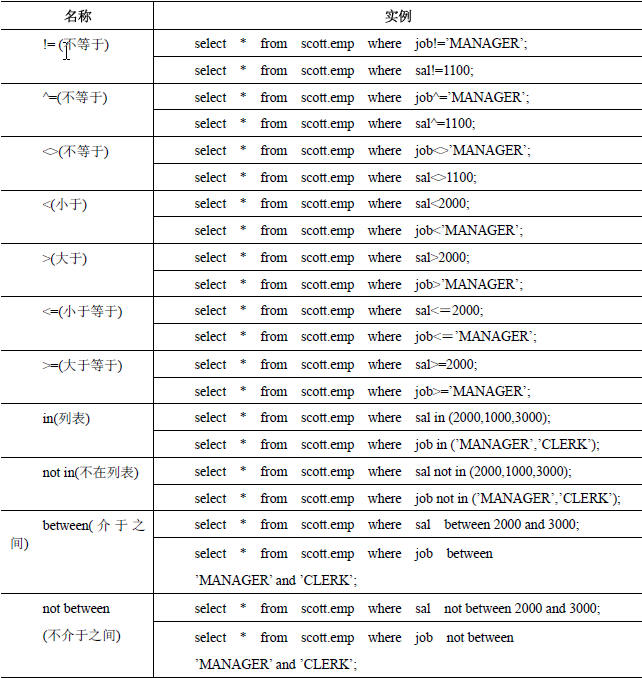

like和not like 适合字符字段的查询,%代表任意长度的字符串,_下划线代表一个任意的字符,like 'm%' 代表m开头的任意长度的字符串,like 'm__'代表m开头的长度为3的字符串。
5.组合条件查询
例如: select empno,ename,job from scott.emp where not job='CLERK'
说明:not job='CLERK' 等价于 job <> 'CLERK'。
组合条件中使用的逻辑比较符如下表所示:
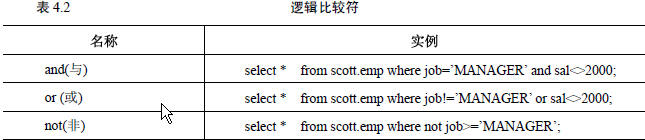
6.排序查询(order by)
例如:select empno,ename,job from scott.emp where job<='CLERK' order by job asc,sal desc;
order by 可以指定查询结果如何排序,形式为“order by 字段名 排序关键字”;asc代表升序排列,desc代表降序排列,多个排序字段通过逗号分割,若有where查询条件,order by 放在where语句之后。
7.分组查询(group by)
注意:group by 后要加所查询的所有的非聚合字段
(1)使用having字句的分组查询
select empno,ename,job,sal from scott.emp group by job,empno,ename,sal having sal<=2000;
(2)使用where字句的分组查询
select empno,ename,job,sal from scott.emp where sal<=2000 group by job,empno,ename,sal;
select job,sum(sal) from scott.emp where sal<=2000 group by job;
注意:where检查每条记录是否符合条件,having是检查分组后的各组是否满足条件。having语句只能配合group by语句使用,没有group by 时不能使用having,但可以使用where。
8.字段运算查询
可以利用集中基本的算术运算符来查询数据。常见的+,-,*,/都可以用来查询数据。
select empno,ename,sal,mgr+sal from scott.emp
注意:算术运算符仅仅适合多个数值型字段或字段与数字之间的运算。
9.变换查询显示
select empno 编号,ename 姓名,job 工作,sal 薪水 from scott.emp;
-
-
数据库基础知识实践(二)
2009-01-19 12:18:14
转自:
http://blog.chinaunix.net/u/25952/showart_207048.html
修改表
改类型、长度、是否为空:
alter table mytable modify (mycol varchar2(20) not null);
要修改类型,字段必须是空的;
要修改长度,如果字段是空的,完全可以改,如果字段不空,则只能增加长度,不能减小;
要修改是否为空,字段必须符合constraint的要求
修改列名:关于列名,没有直接的方法改变。但是可以通过其他方法达到改变列名的目的。
例如:
表A结构如下:
ID(NUMBER) NAME(VARCHAR2(20)
------------------------------------
1 TOM
2 MIKE
3 JHON
将列名NAME改变为NAME1
方法1.列复制法
1.增加一个与NAME相同结构的字段NAME1
Alter table A add(NAME1 varchar2(20));
2.将NAME中的数据复制到NAME1中
Update A Set NAME1=NAME;
3.删除NAME列
Alter table A drop column NAME;
4.修改完成
方法2.表复制法
1.将表A改名
Alter table A rename to A1
2.创建新表并复制数据
Create table A(ID,NAME1) as Select * from A1
3.删除表A1
4.修改完成
通过上面两种方法,
重新检索表A结果如下:
ID(NUMBER) NAME1(VARCHAR2(20)
------------------------------------
1 TOM
2 MIKE
3 JHON -
[转] 修改oracle 10g的字符集
2009-01-16 18:04:17
转自:
修改数据库字符集为:ZHS16GBK
查看服务器端字符集
SQL > select * from V$NLS_PARAMETERS
修改:
$sqlplus /nolog
SQL>conn / as sysdba;
若此时数据库服务器已启动,则先执行 SHUTDOWN IMMEDIATE 命
令关闭数据库服务器,然后执行以下命令:
SQL>shutdown immediate;
SQL>STARTUP MOUNT;
SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION;
SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
SQL>ALTER SYSTEM SET AQ_TM_PROCESSES=0;
SQL>ALTER DATABASE OPEN;
SQL>ALTER DATABASE CHARACTER SET ZHS16GBK;
*
ERROR at line 1:
ORA-12721: operation cannot execute when other sessions are active
若出现上面的错误,使用下面的办法进行修改,使用INTERNAL_USE可以跳过超集的检查:
SQL>ALTER DATABASE CHARACTER SET INTERNAL_USE ZHS16GBK;
SQL>SHUTDOWN IMMEDIATE;
SQL>STARTUP
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 147617
- 日志数: 249
- 书签数: 41
- 建立时间: 2007-08-11
- 更新时间: 2013-03-28
