
-
关于Regression TestCase设计的思考之四: 对于testcase表现形式的思考
2013-12-15 12:37:32
对于testcase表现形式的思考
Regression testcase的描述本身是为了人类的阅读。 但是因为其最终会被自动化实现,所以引入一些形式化的表述手段可以增强描述的精确性, 更容易实现出自动化的testcase。
我目前想到了两点可以用“形式化的描述手段”。一个是对于资源的描述, 另外一个是对检查点的描述。
l 资源描述的格式:
ResourceType[ResourceName]{resourcePropertyName=resourcePropertyValue}
比如一个创建资源的语句可以写成下面的样子
Create BizRule[bizrule002003001]{
type=Assign;
AssignGroup=Abc;
Assignee=admin
}
l Checkpoint的描述格式:
Checkpoint[checktarget]{ name operation value}
比如一个检查点语句可以写成下面的样子
Checkpoint[ticket attribute]{
assigneeGroup=WincorBank Helpdesk;
assignee=adim;
createTime in latestFiveMinute;
}
需要注意的是, 这些形式化的手段只是为了增强描述的准确性,而不是为了被一个自动化引擎解释执行。所以没有必要设计“复杂的”描述语言(像一些UAT框架一样)。
-
关于Regression TestCase设计的思考之三: 设计用于自动化的Regression Testcase
2013-12-15 12:36:37
设计用于自动化的Regression Testcase
一种更高效率的方式是,在功能验证testcase里挑选一些。 比如把一些主要的testcase标记为regression, 而把细枝末节的, 和一些异常情况testcase排除在外。在我经历过的一个测试组织中, 他们使用了一种类似的方法, 那就是在功能验证测试之外,重新定义一个regression testcase库, 这些testcase的组织方式是按照产品的功能逐渐细化, 每一个testcase代表了一个足够细化的功能点, 整个testcase库看上去像产品功能树。
但是, 这还不是最高效率的regression testcase设计,至少对于大多数的企业应用程序来说是如此。 企业应用程序一般属于自动化数据处理系统(Automatic Data Processing System), ERP系统是比较典型的自动化数据处理系统。 这种程序的特点是,1)系统具有很高的可配置型, 可以按照企业的不同需求配置。2)系统具有多个接口, 和其它系统交换数据。
在我看来, regression testcase应该和产品所支持的业务模型联系起来。 这是什么意思呢?
1) 在设计regression testcase的时候, 面对系统不是一个“光秃秃“ 系统, 而是已经有一些静态资源配置在里面, 而且这些静态资源的配置最好来源于真实的用户。
2) 同时,这个系统也不是一个静态的系统, 它的输入输出接口,还有相关的第三方系统是活动的。 也就是说, 在测试的时候,系统的各个接口已经在实时的处理数据。 数据的类型和数量还是来源于真实的用户。
Regression testcase的特点和功能验证的testcase也很不一样。 简单来说 regression testcase更注重描述一个过程,这个过程涉及到多个功能, 而不是一个功能点。 一般来说这样的过程来源于use story,但我觉得也不一定要拘泥于如此, 毕竟测试系统和真实用户使用系统还是不一样的,特别是仅仅使用use story,覆盖率会不够。 所以如果需要,用一个“假的use story“把一些功能点串在一起也是可以的。
从testcase的执行效率来说, 这样的regression testcase有更高的效率。 因为
1. 很多静态资源不需要在testcase里准备, 而是在系统运行起来的时候已经准备好了
2. 因为系统已经在自动化的处理各种数据,也就是很多重要的功能已经在运行了, 所以很多checkpoint可以直接开始执行,而不需要额外的准备步骤。
3. 面向过程的testcase比面向功能点的testcase天然具有更高的执行效率。
从覆盖率来说。 主要功能和真实用户对这些功能的使用方式已经能cover。
Regression Testcase设计挑战
设计专门的regression testcase的最大挑战是,如何设计出“足够好的testcase“。 对于testcase的设计者来说, 其面对的复杂性比设计功能验证testcase要高很多。
1. 首先,从知识储备来说, 设计者需要更了解产品在客户环境的使用情况。
2. 在设计之初就要考虑到,基础资源, 输入输出接口的数据, 第三方接口的数据交换,这些整体构成一个基础的用户业务模型。
3. 在设计testcase架构时, 要有足够的全局观。 这体现在如何对testcase分类和如何组织testcase。不像功能验证的testcase, 天然的可以按照功能分类, regression testcase涉及到多个功能,其如何分类需要深入的了解产品的功能后才能做好。
4. 在设计testcase架构和具体设计testcase过程中,都要对全局资源进行明确的定义和管理。需要协调好只读的资源和可以修改的资源。
5. 在设计具体的一个testcase的时候, 需要灵活运用已有的资源和创建新的资源,需要在use story和testcoverage中保持平衡。
设计Regression testcase库就像设计一个复杂的软件产品, 只是产品恰好是一个testcase库。
-
关于Regression TestCase设计的思考之二: 自动化的Regression Test的问题
2013-12-15 12:35:08
自动化的Regression Test的问题
第一个调查是对QA工程师的, 让他们给出对现有自动化的testcase的感觉, 他们提到“即使跑过了所有的自动化的testcase, 但对于产品的质量还是没有足够的信心“。
另外一个是面向这个项目的开发人员的反馈调查。 值得一提的是, 这次项目里的开发人员并不是专职的QTP测试开发, 他们本来是产品的开发人员, 对于Java开发有相当的经验, 这是他们第一次开发QTP的testcase。 他们的反馈非常有意思, 因为这些反馈触及到了我初次接触QTP就在心里产生的问题。
这些开发人员反馈 “testcase的覆盖效率不高”,表现在
1. testcase中很多步骤都是在准备测试, 反而真正的验证点不多
2. 很多testcase有重复的步骤
所以, 综合起来就是, “我们实现了一些testcase, 但这些testcase的覆盖效率和执行效率都不高, 即使自动化执行了所有的testcase, 我们并没有感到足够的信心“。说实话, 对于自动化项目的一个主要实现者来说, 这挺让人沮丧的。
但是, 仔细想来, 这样的反馈并不奇怪。 我先描述一下我们自动化开发使用的testcase的base。 我们采用的testcase base是QA为功能测试而开发的。这种testcase的特点是, 多个testcase围绕一个功能点做多方位的覆盖, 以尽可能的发现bug。比如针对一个创建用户的功能, 用各种输入组合来测试。 所以这种testcase base的testcase量是很大的。
Testcase的这种设计思路本身是没有问题的, 它非常适合对新功能验证的测试需求。 但问题是, 这样的testcase适合以regression test为目的的自动化测试吗?
一个事实是, QTP开发的自动化的testcase,主要是应用在Regression test中。 而regression test的目的是: 保证产品的已有的功能没有因为新的代码更改而产生质量问题。 Regression test的目的不是穷尽各种方法去发现这些已有功能的bug, 因为这些功能并不是新功能, 而是已有的功能, 这些功能的全面测试已经在一起的功能验证测试中执行过了。
所以, 对于Regression test来说, 把所有的功能验证testcase都执行一遍是不经济的,因为执行了十几个testcase, 却仅仅测试了一个“功能点”。 但不幸的是, 大多数我经历的测试组织都是简单把功能验证的testcase作为regression testcase。 其原因是值得思考的。
-
关于Regression TestCase设计的思考之一: 忽视全局资源管理造成大问题
2013-12-15 12:32:39
关于Regression TestCase设计的思考
忽视全局资源管理造成大问题
前段时间做了一个QTP自动化测试项目。 这是一个比较小的项目(或许这是唯一比较幸运的地方), 实现的testcase数只有80个, 时间也不长4个人做了一个月(非full time), 但是它却让我得到了做QTP以来最大的一个教训。
这个项目在开发阶段没有什么问题, 但是在开发完成后的批量执行中出现了问题, 那就是还不到一半的testcase能成功运行。 也就是一个testcase,即使他们在开发阶段都能顺利执行, 但把他们放在一起批量执行, 却是问题多多。
为什么会出现这样的后果, 我后来分析, 有下面一些原因
1. 全局资源管理不善
在多人进行开发的时候, 并不完全清楚系统里哪些资源是可以使用的, 哪些资源是不能修改的。 导致的后果是, 有一些在testcase里引用的资源在批量运行时却不存在,有一些资源的属性的值被一些testcase引用, 但却被另外一些testcase修改。
2. 底层函数库不完善。
在底层函数不完善的情况下开始大规模testcase开发, 后果是有一些功能被重复实现, 另外的情况是顾不上代码重用, 先把testcase自动化起来, 至于代码是否高质量, 就管不上了。
3. 开发人员并没有完全掌握QTP和Framework
部分开发人员本来是做Java开发的, 而这些开发人员没有足够时间的学习和培训就开始实行testcase, 其结果是testcase的代码质量不高。
在这些问题中, 问题2和问题3, 实际上项目开始之前我就意识到有问题,并上报了可能的风险, 最后出问题并不奇怪。 但是, 全局资源管理不够清晰这个问题我开始却没有意识到,因为在以前的开发项目中, 全局资源管理并没有真正成为一个问题。
因为以前的项目首先只面对一个产品, 但是, 这个项目面对的是一个比以前所有项目都要复杂得多的情况, 因为它涉及到两个产品的集成。 所以在testcase里引用到很多全局资源,但在项目开始之前, 所有开发人员并没有对全局资源管理特别留心。 这样出现的后果是, 全局资源的使用上出现了冲突。 比如一个testcase修改了另外一个testcase引用的全局资源, 所以也就出现了单个testcase能通过, 放在一起运行就fail的情况。
其次以前的项目都是我完成了大部分底层函数库,然后是有经验的开发工程师加入进来, 一起大规模的实现testcase, 所以也没有问题2)和问题3)。
我们还是回到问题1), 为什么这些testcase 由人来执行没有问题, 由QTP实现出来, 执行却有这么大问题呢? 毕竟这些自动化的testcase的基础是功能testcase库, 里面的testcase已经有tester执行多次。
因为人具有很大的灵活性。 相对于程序, 人特别善于处理并不精确的描述。 在这个case里, 就是testcase所依赖的资源描述不精确。
举个例子, 如果一个testcase的检查点是关于一个没有“modify rule”权限的用户去modify rule, 那么这个testcase就有一个潜在的precondition “系统已经存在用户AAA,没有modify rule的权限“。但是对于自动化脚本来说,有两选择
1) 在testcase里创建AAA
2) 在全局创建AAA,
第一个方法的好处是,没有全局依赖, 从testsuite角度来说设计简单,但是可能会存在浪费, 因为别的testcase可能也需要这样一个用户, 出现重复创建同样性质用户的情况。 第二个方法正好相反, 它引入了全局依赖, 从testsuite角度来说设计更复杂, 要全盘考虑, 但是整体执行效率更高。
在QTP测试项目开发过程中, 全局资源管理是一个值得注意的问题. 这就是我从这个失败的项目中获得的教训。 这是一个很有意义的教训,但是还没有到此为止。 因为后面的两个调查反馈的结果, 触及到了我刚开始做QTP时就有的一个疑问: 用于自动化testcase的 testcase库是否需要专门设计?还是使用已有的为手工测试设计的testcase库?
-
JMeter插件开发
2013-06-12 12:26:09
前言:JMeter,不仅仅是性能测试
JMeter是用Java开发的开源性能测试工具。其官网在此, jmeter.apache.org。 经过多年的发展, JMeter已经成为支持较多协议, 功能比较完善的性能测试工具。当然和主流的商业性能测试工具比较, 它的功能和使用界面都略显粗糙, 但因为其开源且免费的特性, JMeter在性能测试领已经是相当流行的工具, 特别是对于中小型的项目, 它完全能够胜任的。
JMeter最大的优点之一是其开放的插件(Plugin)体系。 它允许你针对非常见的, 或者非标准的协议开发性能测试模拟器,而通用的封闭的商业性能测试工具对此是无能为力的(除非购买针对性的商业工具)。比如有一个Client-Server项目, 前端是Java Swing开发的, 通讯协议类似于RPC, 基于HTTP协议, 但是传输数据是序列化后的Java对象,是二进制的。我使用了XStream+Java Sampler, 甚至不用写一行GUI代码, 就在JMeter上实现了模拟器。
JMeter另外一个优点是它具有比较完善的TestCase的管理功能,测试运行的管理功能, 测试报告的生成功能。 这就使得JMeter不但是一个性能测试工具, 而且还能成为一个自动化测试 工具的开发平台。曾经有一个失败的自动化项目,该项目测试的产品是C-S架构,客户端 通过XML-RPC调用服务器端的服务。因为当时不了解JMeter, 所以我用了JUnit来作为测试框架,ant作为测试执行管理。 这种设计在功能上没有问题, 但是使用起来却是问题, 因为它需要code, 需要配置xml文件, 这一点即使对于普通的QA工程师来说学习曲线也比较陡峭, 所以项目最终没能成功。 如果是现在, 我肯定会使用JMeter, 用户通过GUI就能完成所有testcase设计,执行工作。
所以, 我觉得,至少在目前, JMeter是一个非常值得学习的工具平台。 特别你测试的产品是CS架构,而且能够基于协议来测试功能,JMeter是首选的 性能测试/自动化测试 平台。
请注意, 这些文章的内容更多是我的经验的总结, 而不是对JMeter插件开发的完整的介绍。 而且, 你需要一些Java经验,因为有很多地方都有JMeter源代码的片段。
-
性能测试模型分析:总结
2013-06-02 00:25:34
从前面的描述,我们可以看到, 性能测试的参数, 输入场景, 关键性能指标都是和性能测试的目的密切相关。 比如, 为了验证是否满足一个重要客户的性能要求, 性能测试可以很复杂, 测试环境包括应用服务器Cluster, DB Cluster, 专用的存储服务器,测试耗时一个月; 为了验证是否在版本之间有性能下降, 性能测试也可以很简单, 所有软件都部署在同一个机器上, 且测试集成在DailyBuild里面。
不同的性能测试目的决定了不同的性能测试方法。 好的性能测试不是求大求全, 而是用最小的成本, 满足测试的要求。
下面是对性能测试目的的总结。
性能参数
输入场景
目的
执行成本
执行者
性能基准
在一个给定的性能影响参数集合上,,
运行一个给定的输入场景
获得一个性能基准。 这个基准可以作为性能比较的基准, 或者参考的数值。
中
QA
性能验证/性能规划
通常是在一个贴近客户的软硬件平台上,
运行贴近客户系统的输入场景
验证客户系统能否满足客户的要求。
高
QA/Support
性能调优
通常对基础软件硬件无特别的要求。 对某个系统本身的参数,或者应用服务或者数据库参数进行变化。
输入场景可以灵活变化, 根据调优的关注点不同。
发现瓶颈, 优化性能
低
QA/Dev
使用性能测试模型分析方法的性能测试流程如下。
Task
输出文档
计划
确定软件性能模型
确定性能测试目的
确定性能测试参数
确定输入场景
确定关键性能指标和选择性能计数器
测试计划
测试案例
准备
开发测试脚本
部署测试环境
脚本
测试环境清单
实施
执行TestCase
性能计数器原始数据
报告
分析测试结果
制作测试报告
测试报告
======================================================后记:
真实世界的性能测试项目是复杂的。 这是我半年性能测试的体会, 其中最令人纠结的是如何能让性能测试让各方满意。 当性能测试项目刚开始的时候, 每个人都在提出自己的意见, 那时我入道尚浅, 所以分不清轻重缓急, 识别不出重点, 因为自己对性能测试理解不深, 所以工作中总是被外界牵引得团团转, 每天很忙的工作, 想让每一个人都满意, 结果却是大家都不满意。
慢慢的, 在失败和挫折中吸取教训, 不断的梳理思路, 总结出来了这样的性能测试模型分析方法。 我希望能通过这样的分析方法在性能测试中能够抓住主线, 能够知道要做什么和不要做什么,能够设计出有效率的性能测试案例。
因为自己的性能测试经验范围其实还是相当窄的, 所以文章的内容是相当粗糙; 而且这样的分析方法可能在其他的项目并不一定适用。无论怎样, 希望能对阅读过这些文字的你有所启发, 并欢迎任何指正和交流。
-
性能测试模型分析:压力输入场景
2013-06-02 00:23:54
压力输入场景描述了系统输入压力的构成情况。 和性能参数类似, 压力输入场景也是多种多样的。 那么到底选用什么样的压力输入场景呢?
对于大多数性能测试, 压力场景一般从客户真实环境获得, 然后经过合理的简化,应用在性能测试中。
要注意, 压力输入场景并不是说越真实越好。 因为如果要构造非常真实环境的压力输入场景, 会需要更多的开发成本和执行成本。 合理的简化能够在不偏离测试目标的情况下,提高测试的效率。 我之所以提到这点是因为, 有时候,有来自客户或者高层的这方面的压力, 因为他们不太了解系统的原理和怀有对性能不良造成后果的恐惧。 作为性能测试工程师, 应该要深入理解系统, 甄别出有意义的压力输入场景。
也有一些性能测试对压力输入的真实性要求不高, 比如对于获取性能Benchmark的测试,对于压力输入场景要求是简单和易于执行。 常见的对于CPU, Disk的Benchmark测试, 测试压力都是简单直接的, 并不是模拟真实使用场景。 但这不会影响这些Benchmark数值的可信度。
因为压力输入的千差万别, 所以并没有统一的获取压力输入场景的方法。 对于一般的OLTP类型软来说, 在分析压力输入场景时, 要考虑下面一些方面。
Description
输入的量
单位时间有多少request进入系统
输入类型
这里指Request的类型. 比如一个在线购物网站, 每一次交易涉及到3次查询, 或者5次查询, 会对性能造成影响.
用户数目
还是以在线购物为例, 10个用户10分钟产生100个交易, 和100个用户10分钟100个交易, 其Response Time可能会不一样.
Think Time
上一个Response和下一个Request之间的等待时间。
高峰时段
高峰时段的输入场景需要单独考虑
-
性能测试模型分析:性能参数(Performance Factor)
2013-06-02 00:22:25
性能参数是包括所有会对性能产生影响的因素. 比如软件参数设置, 硬件的能力, 输入的类型等等。 性能测试的结果只有在给定性能参数的条件下, 才有意义。在性能测试中, 性能参数类似于功能测试中的”输入组合“, 所以,设计时都会面对同一个问题, 不可能穷举的可能。 即使对于一个小的软件, 性能参数的组合也可能是一个非常庞大的数字。 这一点对于 企业应用软件产品 尤其是一个问题。 因为客户的部署环境是千差万别的。在性能测试分析中,1) 首先要识别出所有性能参数, 重要的和不重要的。 需要注意的是, 性能参数的重要性并不是绝对的, 而是取决于性能测试的目的。 比如对于验证客户环境的性能, 硬件配置是很重要的参数;对于性能调优为目的的测试, 硬件配置并不重要, 软件的参数设置时很重要的参数。2) 然后对性能参数打包。既然不能覆盖所有组合, 当然只能选择典型的组合来测试。分类影响性能参数是包括所有会对性能产生影响的因素. 这其实会包括非常多的因素. 他们可以分为下面一些类型.
Factor
Samples
服务应用程序配置 服务应用程序的一些参数配置会对性能造成影响.
l 比如某种工作线程的数量,
l 比对于流水线类型的性能模型. 一个Data配置了几个模块进行处理显然会影响Processing Time.
l 比如后台运行的报表程序
同步调用的第三方应用程序 比如银行交易处理时, 会同步调用Core Banking System, 那么CBS的性能也会直接影响交易处理的Response Time)
基础软件 比如应用程序服务器, 操作系统, Database服务器
硬件配置 CPU, Memory, Storage
百兆网络还是千兆网络.
其他 其他一些系统特定的因素.
总之, 有非常多的因素会对系统的性能造成影响. 测试中不可能把每一个因素都涉及到, 更别说他们的组合了. 为了能进行有效的测试, 需要对性能参数打包。
打包影响性能参数如何确定性能测试中的影响性能参数的具体的取值. 这是性能测试准备中最关键的步骤. 这就和功能测试设计testcase一样, 如何能设计出最有效率的testcase.
这个时候, 需要把相关的因素打包, 这样在性能测试的时候就不用考虑每一个因素, 而是考虑有限的一些”因素的组合”.
对”影响性能参数”打包的目的是, 在设计性能测试Case时, 不用处理如此庞大的因素所有组合, 而是挑选一些合理的预想定义好的组合.
比如说, 对 基础软件, 硬件配置, 网络配置 进行打包, 归纳出三种组合: 小型系统, 中型系统, 大型系统.
CPU/Mem/Storage
OS/AppServer/DB
Network
小型系统
2Cores/4G/7200RPM(SATA)
Linux/JBoss/MySQL
100M
中型系统
4Cores/8G/15000RPM(SAS)
Windows2008/WAS/SQLServer
1G
大型系统
4Node cluster, Each Node
2Cores/4G/SAN
Aix/WAS Cluster/Oracle
APP-DB: 10G Ethernet
Storage Network: 4G光纤
对于输入类型和应用程序相关的配置, 参考典型用户的使用场景. 有下面的组合, 以一个监控系统为例
使用场景
监控
命令
监控为主型
每个Device每天1000条数据
每个Device每天接受2个命令
发送命令为主型
每个Device每天100条数据
每个Device每天接受200条命令
平衡型
每个Device每天500条数据
每个Device每天接受100条命令
对于静态压力模型的性能因素, 例子如下
Device
Hierarchy Levels
小型网络
100
查看(1019) 评论(0) 收藏 分享 管理 性能测试模型分析:关键性能指标 和 性能计数器
2013-06-02 00:17:49
关键性能指标(Key Performance Indicator, KPI)
关键性能指标是最能描述系统性能的一种数据。 关键性能指标的类型如下表所示。
其中服务能力指标是最核心的指标。 也是用户最关心的指标。对于最常见的Web网站, 服务能力指标最常用的是“相应时间”和“吞吐量”
分类
举例
服务能力指标*
l 响应时间: 表示从发出request到收到response的时间
l 吞吐量:表示单位时间系统处理的request的数量
对于吞吐量,不仅仅限于单位时间Request的数量,比如对于一个文件服务器,单位时间读写的字节数也是“吞吐量
资源利用率指标
主要是CPU和Mem利用率
稳定性指标
长时间运行, 系统服务能力是否下降, 资源利用率是否非正常上升。
可扩展性指标
增加更高级的硬件(Scale up), 或者增加更多的节点(Scale out), 对于服务能力的提升程度。
对于 流水线模型的软件, 其服务能力的获得相对OLTP模型的软件会比较困难。 对于Response Time, 需要收集信息入口和出口的时间;对于Throughput, 需要收集各个关键module的吞吐量。
性能计数器
性能计数器是在性能测试执行时收集的数据。 关键性能指标其实就是从性能计数器中直接或者间接产生出来。 但是性能计数器不仅仅包括关键性能指标, 性能计数器的范围会宽广很多。
从性能计数器的来说, 通常分为以下几类。
l 压力模拟器的计数器
单位时间比如Request的数量, 及其响应时间。
l 被测试产品本身的计数器
比如内部Queue的长度, 单位时间Queue的输入的量和消费的量。
l 应用服务器和数据库的计数器
参见相应文档。
l 操作系统提供的计数器
参见相应文档。
性能计数器除了用来标示系统性能, 还可以用来分析性能瓶颈, 指导性能优化。比如说, 磁盘读写Queue的长度是衡量磁盘是否是瓶颈的关键信息。
无论是OS还是商业性能测试软件, 都提供了海量的性能计数器。 通常来说性能计数器的问题是, 如何选择最有价值的性能计数器。这需要对被测试软件, Application服务器, DB服务器, 和操作系统有深入的了解。
性能测试模型分析: 模型分类
2013-06-02 00:16:24
一提到性能模型, 可能大多数人马上就想到网站。 网站的性能模型属于“在线交易处理“模型(On-Line Transaction Processing Model),这是最常见的性能模型。
此外我还总结出另外两种。 流水线模型(Pipe Line Model)和静态数据模型(Static Data Model)。不同的性能测试模型类型,其测试方法, 性能指标都会很不一样。 比如对于OLTP模型, Response Time是一个关键性能指标, 但对于 流水线模型, Response time就并不是一个关键性能指标。
在开始性能测试项目的第一步就应该识别出其性能测试模型的类型。这样你的测试才可以有的放矢。
在线交易处理型(OLTP)
这是最常见的类型. 所有的Web网站都是这种类型. 银行, 股票等的交易系统也是这种类型. 这种类型的特点是客户发起一个Request, 然后等待Request被处理完成, 如下所示。 这种模型的特点是1)对于Client来说, Request是阻塞执行的, 也就是在发起下一个Request之前, 必须得到上一个Request的Response。
2)信息的流动式封闭的, 也就是信息从Client发出, 回归于Client
+-------------+
request | Server |
+-----+ +------->| |
|Client | |
| | response | |
+-----+<---------+ |
| |
+-------------+
流水线型(Pipe Line)
流水线模型最常见的就是监控服务器. Agent采集数据然后发往服务器. 服务器在收到数据后, 马上告诉Agent数据已经收到. 但是这个时候该数据的处理才刚刚开始, 比如数据会被存到数据库, 数据可能会trigger一封Email, 等. 这种模型的特点是
1) 对于Source端来说, request的执行是异步的。也就是说无论上一次的Request是否已经完全处理,Source端都可以发起第二次request。
2) 信息的流动式开放的。也就是信息的起点和终点不是同一个。
3) 一般来说这种系统内部的信息处理模块有多个,而且模块间都是异步的, 通过Queue来串联. 就像流水线一样. 如果某一个模块处理能力慢了, 它的前端并不会受到直接影响.
+----------------+
|Server |
+-------+ | +---+ +--+ +--+| +-------+
|Source |+--->| |M1 | |M2| |M3||+-->|Target |
| | | +---+ +--+ +--+| | |
+-------+ | | +-------+
| |
+----------------+现实生活, 快递物流系统就是典型的流水线模型的体现. 当你把物品交到快递公司的工作人员手里时, 你马上就能就能收到一张回执, 但是物品并没有到达目的地. 物品会先存放在本地仓库, 然后运输到目的地的仓库, 然后由目的地所在的快递人员吧物品派送到对方手中.
+----------------------------------+
|Express Company |
| |
| |
| +-------+ |
+---------+ | |Local | +---------+ |
|Customer||+->|Branch | |Warehource |
| | | | | +---------+ |
+---------+ | +-------+ |
| +--------+ |
| |Logistics |
| |Company | |
| | | |
| +--------+ |
| +---------+|
| +----------+ |Remote || +------+
| |Warehource| |Branch +->|Target|
| +----------+ | || | |
| +---------+| +------+
| |
| |
+----------------------------------+
静态数据压力型(Static Data Load Model)静态数据压力型和前两种不一样. 它并没有一个所谓的输入端. 下面是两个例子
l 在Console展现一个包含非常多元素的页面.
l 提交一个非常耗时的产生Report的Request.
这种类型的性能模型看上去并不像我们通常理解的性能模型, 它也不能被前面两种模型所覆盖. 所以单独定义为静态数据压力模型.
值得指出的是, 这种压力模型往往被软件开发或者测试人员所忽略, 但是它却是客户非常关心的, 因为客户会去真正使用这些功能.
性能测试模型分析: 为什么需要性能测试模型
2013-05-31 06:39:54
前言:
做了很长时间功能测试,自动化测试, 但性能测试一直都是蜻蜓点水的样子。 这半年终于, 能够对性能测试有了比较深入的了解,并积累了一些经验。 所以准备在这里记录下来。
首先, 我想先指出的是, 我所测试的产品不是通常的网站, 而是 企业内部使用的监控类型的 软件产品。和网站相比, 其性能测试有自己的一些特点。
总的来说, 性能测试的经验包括三个方面。- 性能测试模型分析方法
- 性能测试工具开发(VBS)
- Jmeter的应用和Plugin开发
第一篇, 我想说说 “为什么需要对性能测试模型”
====================================================================
模型的意义在于它化复杂为简单, 同时不丢失最关键的属性。 建立模型是为了帮助我们更好的理解一个复杂的事物。 那么问题是“性能测试很复杂吗?”, 接下来的问题是“如果说性能测试很复杂, 那么复杂性体现在什么地方?”
性能测试复杂吗? 一句很废话但是也是真话就是, 初看简单, 深入复杂。
我认为性能测试的复杂性体现在三个地方。 第一个是性能参数, 第二个是输入场景, 第三个是性能测试的目的。
性能测试的参数, 就是任何对系统性能有影响的参数。 比如不同硬件配置, 不同的应用服务器或者数据库服务器, 不同的系统的配置参数, 这些参数的变化都会影响最终系统的性能, 那么在搭建性能测试环境是, 到底如何对他们进行选择呢?选i5还是志强, 工作线程选5还是10?
输入场景是对于性能测试时输入的描述。 比如对一个电子商务网站的性能测试, 每一次成功的购物应该包含几个request, 分别是什么类型? 如果是大型打折活动, 用户的购物流程有什么变化?
性能测试的目的更是令人头疼。 在开始一次性能测试之前,对软件产品的相关角色做一个调查, 会发现你收集到的结果是五花八门。
- l 客户: 我觉得某个页面反应很慢.
- l 客户: 某一个通知邮件本来应该在5分钟内收到, 但是半个小时都没有收到
- l 技术支持: 客户问该系统到底能支持多少用户?
- l 技术支持: 客户问如果交易量提高50%, 需要购买什么样的硬件?
- l Dev: 我希望性能测试能帮助我们找到系统的瓶颈.
- l Dev: 我想优化性能, 但是我需要得到不同参数下系统的性能, 你能提供吗?
- l 产品经理: 客户对我们的系统性能抱怨很大, 你能不能告诉我系统的性能到底如何?
- l 产品经理: 新版本性能提高了多少?
作为性能测试项目的Owner, 你要考虑, 应该如何设计性能测试, 使得最少的测试能满足最多的要求?
建立性能测试模型可以帮助我们处理上面所涉及到的复杂性。帮助我们生成最有效率的性能测试案例。
Different QTP: 后记
2012-09-08 22:39:24
后记
QTP软件测试开发应该是什么样的?怎样才是高效的开发方式?QTP软件测试只需要三个月的培训就能做好吗?
在开始进入QTP自动化测试开发之前和之中, 我有这样一些疑问。 慢慢的, 我体会到自动化测试开发和其他通用的软件开发并无根本之不同。 也就是说软件开发中你能看到的一些概念,比如: 模块化, 低耦合, 面向对象, 敏捷, 设计模式, 可维护性, 接口设计。。。在QTP自动化测试开发中同样适用。 没有软件开发的基本素养, 同样也不能开发好一个QTP自动化测试项目(我承认,或许能够开发出来, 但可维护性会很糟糕)。
但是, 因为从事QTP自动化测试开发的人员很多都是QA而不是Developer, 所以QTP提供了很多方便的智能的工具来降低上手的难度, 并且打出了”不会程序设计也可以做QTP自动化测试”的口号(这种现象其实在别的开发领域也有, 比如“三十天掌握J2EE”等等)但是, 这些工具虽说是捷径但却牺牲了软件开发中一些基本的要素。简单来说, 这些工具像积木, 可以搭房子,但不能建立大厦。所以, 我慢慢的抛弃了这些工具, 而转向了我所熟悉的, 通常的软件开发方式来开发QTP自动化测试项目。
实践也证明了, 通常的软件开发方式也完全可以开发QTP自动化测试项目, 而且开发效率和可维护性还更高(至少对我而言)。
到此为止, 我对于QTP自动化测试开发的绝大部分想法和经验都和你分享了。希望能对你有所启发和帮助。(DFL,
Different QTP: QTP使用中的陷阱
2012-09-08 22:35:31
QTP使用中的陷阱
不要使用Reuable Action
用Function, 不要用Reusable Action。 没有一种通用的语言里有Reusable Action这个概念。 而且通过Function等一些标准的程序设计语言的元素, 你能够实现任何Reusable Action可以实现的功能, 而且更好, 更快, 更易于维护。
以前我还不能肯定这一点。 现在我能肯定的告诉你, 因为有好几个QTP项目, 上千个Testcases在支持我的观点。
不要用Smart Identification
有一天, 我发现一个奇怪的现象, 一个testcase里某一个点击logout button的步骤运行非常慢, 大概要20秒,但是最终它还能成功点击。 不巧的是每一个testcase几乎都会点击这个button, 所有我还必须把这个问题找出来。 最后发现这是因为button的name有了变化, 但是因为Smart Identification是被enable, 所以QTP会试图去适应这个变化, 但是这个“适应”的效果非常不理想。
我认为测试开发者应该完全控制对象的识别。把选择权交给对被测程序业务一无所知的工具是毫无道理的。我想不到任何使用SmartIdentification的原因。 所以,从那之后, 任何Testcase的Smart Identification我都禁止了。
不要在base目录里添加两个或以上目录
Base目录是用来只能识别相对路径的目录。其配置在Menu: Tools->Options->Folders。我的建议是这里只放项目根目录。其他目录都不要放进去。
曾经, 我接手了一个QTP项目。 开始的时候我根本就不能把哪怕一个testcase成功跑起来。于是我去问起开发者, 他告诉我需要把某一个特定的Reusable Action添加到"folders"里面。 这种坑是在是让人哭笑不得。
QTP作为一种工具, 或许需要提供这种灵活性。但我们除非有必要, 不要去用它。 如果必须要用, 也要很好的document这点。
不要用keyword view, 而是提供业务逻辑封装层
如果你要让你的testcase简单, 直接,那么你应该通过合理的抽象提供完善的业务逻辑封装层, 它会使得你的testcase script读起来像testcase descript一样。 这个时候, 你根本不需要keyword view。
不用Reporter.ReportEvent 而用Assert
当执行一个Testcase时候, 如果遇到错误, QTP支持两种操作。"stop run" 和"proceed to next step"。(注意, 其实还有另外两个选项。 "pop up message box"是针对开发时使用。 "proceed to next action iteration"不常用。 所以不讨论。)
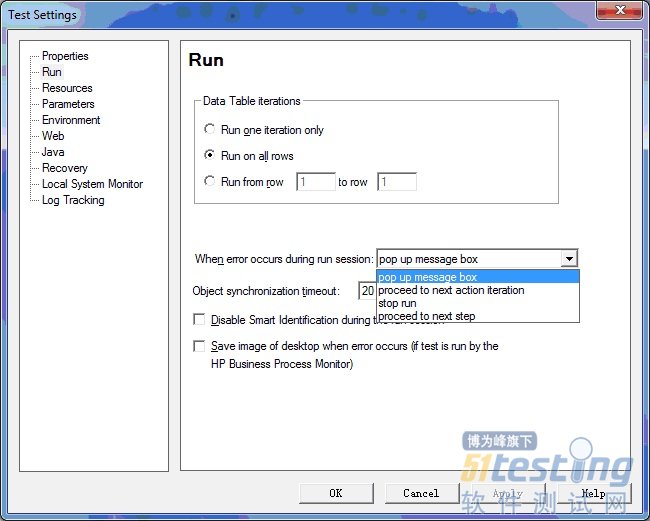
基本上, QTP鼓励"proceed to next step"这种方式:如果出现了错误, 那么记录错误, 但testcase仍旧会执行下去。
对于QTP检查到的错误是这样, 对于测试脚本自己检查到的错误也是如此。 QTP提供了一个错误报告机制。
Reporter.ReportEvent micFail, stepName, errorMsg
这种处理方式违背了一个程序设计的基本原理:如果出现不能处理的错误, 那么就抛出错误。通常来说如果出现了错误, 执行下去是没有意义的。 我猜想QTP之所以会支持这种方式是因为, 如果出现错误马上退出, 那么testcase里的负责cleanup的代码就无法执行。 想想看JUnit里的Setup和Teardown机制, 在VBS里是无法实现的。
即使考虑到这点, 这样做还有一个问题,导致我不采用它的原因。 那就是不能在batch run的结果报告里显示错误。 如果采用"stop run"的方式, 那么batch run脚本能够获得导致testcase退出的错误信息。 然后在产生report的时候, 能够呈现出来。 再结合错误时刻的screenshot, 实践表明, 大多数错误都能在阅读report的时候确定原因。 下面是一个Report里一个失败Testcase的呈现情况。

如果使用Reporter.ReportEvent的方式, 那么在Report里你看不到任何错误消息,只能在Result View里面打开result xml。这是一个耗时的操作,因为Result View很慢。 大多数时候,你是在等待Result View把测试结果渲染出来。
为了更好的支持checkpoint, 我在framwork里定义了一套Assert函数, 可以对大多数情况下的断言语义提供直接的支持, 比如“相等”, “不等”, “包含”, “匹配”, 等。在Assert函数里面, 会抛出一个Error。 下面是一个从popup窗口读取信息, 然后验证信息是否正确的例子。
AssertMatch GUI_MsgBox_Msg("Information"),_
".*is invalid or you don't have the permission.", _
"Error message not displayed or correct"
如果该Checkpoint失败, 那么在HTML report里看到的信息像下面的样子。
AssertMatch: Error message not displayed or correct. Expected<,".*is invalid or you don't have the permission.>, Actual<>
总结一下。在错误处理上,采用"stop run"的方式, 这也是所有程序设计里采用的方式。 在写checkpoint的时候,用Assert而不要用Reporter.ReportEvent, 因为前者会帮助你更快的分析错误。
Different QTP: Project目录架构
2012-09-08 22:27:10
Project目录架构
在安排QTP test Project的目录树的时候,需要考虑到下面的问题
· 如何组织Function Library, 如何引用function library文件?
· 如何组织Testcase, 如何在testcas间共享数据/代码?
· 如何配置静态参数, 运行时环境和全局测试数据?
如何组织Function Library?
按照前面的设计方法搭建的Function Library会包含大量的函数, 最终代码量也会比较庞大(基本上取决于业务逻辑封装函数的多少)。比如最大的一个项目, 其 Function Library总共代码量达到11000多行, 假设1/4是注释, 那么实际代码行数 大约是8000多行, 按照一个函数20行代码, 总共大约400多个函数。
为了维护这么多函数, 肯定要分成多个文件, 按照Module组织起来。 但是QTP对于外部文件引用支持很差。 基本上10个以上的外部文件引用就让人抓狂了。
所以我采用了一种折中的方法。 首先, 一个Module对应一个vbs文件, 这样代码维护最方便。 然后有一个脚本能把所有的Module文件合并为一个大的qfl文件, 方便QTP引用。
下面是一个真实项目的Library目录。

· BIZ
业务逻辑封装函数文件所在目录。
· FRM
VBS 运行时扩展库文件所在目录。因为VBS的运行时库实在是太简陋(当然, 这个也是情有可原, 毕竟是70年代的语言), 所以必须要写一些基本的扩展例程。 比如断言机制, Log机制, 动态数组, 动态字符串, 文件处理, 时间格式化, 等等。 接口基本上参照JVM做可以了 :)。
把这些基本功能作为VBS扩展库, 和项目的Function Library分开有助于你维护一个跨项目的VBS function Library, 更有效的利用代码。
所以, 我的项目里, 自testcase script向下有下面的层次
+----------------------------------------+
| |
| TestCase Script |
| |
+---------------------------------------->
| |
| Function Library (BIZ, GUI, UTI) |
| |
+---------------------------------------->
| |
| VBS Extension Library |
| |
+----------------------------------------+
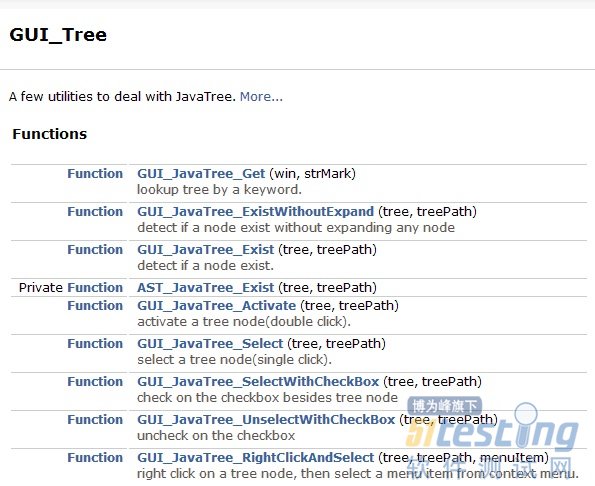
· GUI
GUI封装库所在目录。除了前面介绍的GUI元素库用来定位一个GUI元素, 还有对常用的GUI元素操作封装的函数。 比如下面是一个对Java Tree的封装。
· Screen
是所有Screen定义文件所在的目录。
· UTI
其他功能函数所在的目录。
· AllInOne_Lib.bat AllInOne_Lib.qfl
AllInOne_Lib.bat把所有上面目录里的vbs文件合并到AllInOne_Lib.qf里, 方便QTP引用。
· INIT.qfl
初始化函数库里Module的函数所在文件。因为某些Module的初始化可能有依赖关系, 所以提供一个专门用来初始化函数库的地方。
· Library.cfg
配置函数库里Module的配置文件. 这个文件内容必须满足VBS的语法.因为他也会合并到AllInOne_Lib.qfl里。在实践中我发现, 绝大多数Module其实都不需要外部配置, 因为毕竟这只是一个测试项目的Library,对灵活性的要求远没有开发产品的library那么高。
如何组织TestCase?
TestCase被组织在一个四层树状结构列. 如下所示.
+-------------+
| TestRepo +-----> Test.qfl
+-+-----------+
|
| +---------------+
+---->| TestModule +-----> TestModule.qfl
+--+------------+
|
| +----------------+
+->| TestSuite +------> TestSuite.qfl
+--+-------------+
|
| +-----------------+
+->| TestCase |
+-----------------+
最顶层是TestRepo(TestCase Repository Root)。下面是TestModule, 是针对产品的一个功能模块的所有testcase的集合。再下面是TestSuite,一般是针对一个特定的测试点的所有testcase的集合。最下面是TestCase。
对于Testcase组织来说, 有两个重要的问题,
1) 如何在TestCase之间共享数据和函数
对于第一个问题,每一个TestRepo, TestModule和TestSuite都有一个公共库文件。 这个文件会被它所包含的所有Testcase引用。 所以在这个文件里, 一般配置特定范围的, 公共数据和公用方法。 举个例子: 如果某一个Testsuite里的 部分/全部TestCase都依赖于一个特定的对象。 那么可以把这个对象的数据, 比如名字, 配置在TestSuite.qfl里。因为此TestSuite里所有TestCase都引用此文件, 所以数据得以共享。
对于任意一个Testcase, 它的Resource引用都像下面的样子。
· Library\AllInOne_Lib.qfl
· ..\..\..\Test.qfl
· ..\..\TestModule.qfl
· ..\TestSuite.qfl
· Library\INIT.qfl
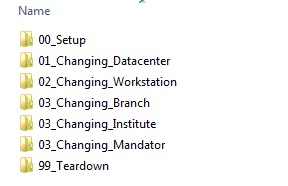
2) 如何实现Setup和Cleanup
对于这个问题, 通过增加两个特殊的TestCase, 00_Setup和99_Teardown来解决。一个TestSuite里如果有这两个TestCase, 那么00_Seup会被最先执行, 99_Teardown会被最后执行。 下面是一个实例。
如何配置运行时环境
对于一个QTP Test Project, 环境数据必须是可配置的,而不是绑定到代码里。
我使用了QTP风格的Environment配置文件, 方便在运行时被Load进来。 QTP的Environment配置文件是XML格式,位置在 Conf/Environment.xml, 示例 如下
<Environment>
<Variable>
<Name>ServerIP</Name>
<Value>172.17.68.40</Value>
</Variable>
</Environment>
在运行时, 通过Framwork加载此文件, 然后就可以用Environment.Value("ServerIP")的形式在代码里直接获取相应变量的值。
如何把测试数据和测试逻辑分离?
测试数据和测试逻辑分离是一句在自动化测试领域流程甚广的一句话。 但有时候它被过于强调, 成了QA对外宣传的口号, 于是它就成了政治人物. 比如对于QTP Project, 有一种做法是定义一个外部的,集中式的的Testdata文件(Excel文件)。但是因为各个TestCase对数据种类的要求是不一样的, 把所有这些数据强行统一在一张sheet里的结果就是导致大量的column。 我见过在Excel里面用到“T”这个column,也就是用20个Column,简直是维护的灾难。
基本上, 最适合”测试数据和逻辑分离”的是这样一个场景。 某一批testcase具有类似的逻辑, 于是把这个逻辑实现为代码, 而用testdata来表达其每一个testcase的不同点。但是事实是, 对于QTP Project, 这样的情况并不多。 特别有些testcase看上去好像测试逻辑差不多, 但是从实现上来看, 差别很大。 如果强行统一, 那么测试数据会比较复杂, 增加开发和维护的负担。
但是对于QTP Project, “测试数据和测试逻辑分开”其实也是被遵守的。那就是在编写一个具体的testcase的时候,
Different QTP: 测试执行流程与Mngt Tools
2012-09-08 22:16:10
测试执行流程与Mngt Tools
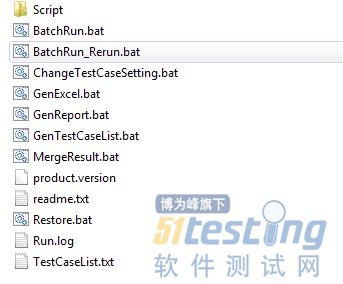
一套测试套件设计出来之后, 它的价值在一遍一遍的执行中体现出来。如何能最大化的优化执行的流程, 是Mngt tools 的任务。 在我的项目中, Mngt Tools是由一些VBS脚本和BAT脚本构成。
下图是Mngt Tools所包含的脚本。用户直接调用的脚本都是BAT脚本, 实际实现在VBS脚本里。VBS脚本放在Script文件夹里面, 如下图所示。
测试项目的执行流程定义如下。
+-----------------+
| Prepare Test |
+-------+---------+
|
|
+-------v---------+
| Execute Test |
+-------+---------+
|
|
+-------v----------+
| Generate Report |
+-------+----------+
|
|
+-------v----------+
| Analyze Result |
+------------------+
Prepare Test
在准备Test阶段, 最重要的是产生一份所有要执行的testcase的清单,在这里是TestCaseList.txt。显然, 可以通过扫描Test Case Repository目录来达成。 这是通过脚本 GenTestCaseList.bat来完成的。
另外, 被测试产品的版本号是一个非常重要的信息, 必须在product.version文件里指定。
Execute Test
通过调用Batchrun.bat,所有定义在TestCaseList.txt里的testcase都会被顺序执行。执行过程中的所有log会记录到Run.log文件里。
执行结果所有信息会在一个目录里保存, 如下图所示。
其中,Batchrun.bat会把每一个Testcase的执行结果和错误信息(如果有的话)保存在TestResult.txt。这个文件会在"Generate Report"阶段被转换成TestResult.html。
Execute Test Twice
因为GUI测试天然的不稳定性, 有时候, 你会希望执行两次,并且取两次运行合并后的结果作为最终结果。合并的算法是, 一个testcase,只要有一次通过, 就认为是通过的。 这钟方式能够有效的消除 不稳定性导致的testcase失败的机会。
对于这种方式, 执行过程是下面这样.
1. Batch run all test cases in TestCaseList.txt)
2. Restore test environment
3. Batch run only failed test cass
4. Merge test results
BatchRun_Rerun.bat能自动的完成上述的流程。测试结果目录是下面的样子。
注意这里有三个TestResult文件。 TestResult.txt, TestResult_Rerun.txt 和 TestResult_Merged.txt,分别是“第一次”,“第二次”,“合并后”的结果。
Generate Report
在所有testcase执行完之后, 调用GenReport.bat, 会为该次执行产生一个HTML report,如下所示。这个动作已经集成在BatchRun.bat和BatchRun_Rerun.bat脚本里面。 不过也可以在测试执行完成后的任何时候调用GenReport.bat。
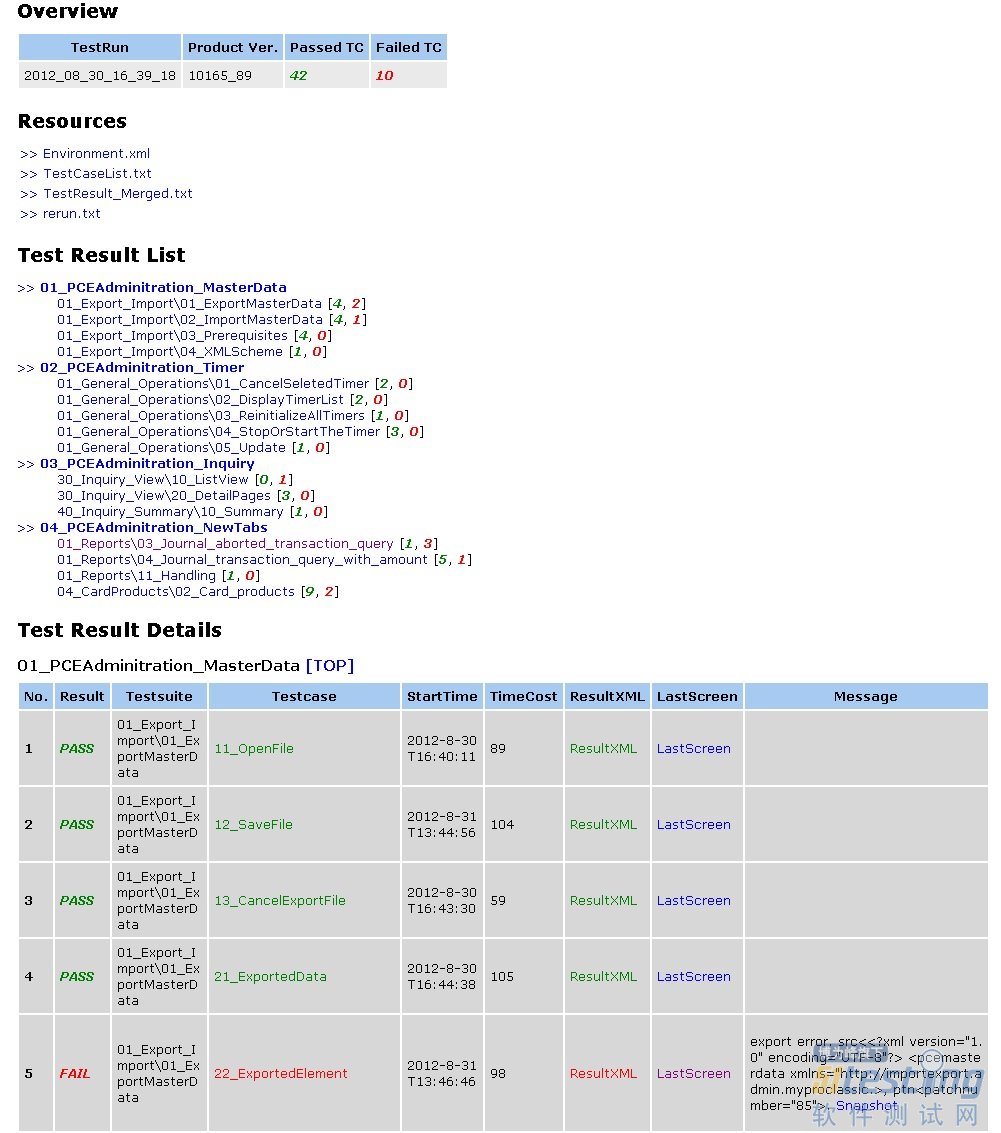
这个Report由总到分, 逐级展示测试结果。最上面是整个testrun的结果, 下面是TestModule和TestSuite的结果, 最下面是每一个testcase的测试结果。
在查看每一条Testcase结果记录的地方, 你可以立即获得错误信息和当时的Screenshot, 他们都是对于结果分析非常有用的信息。 实践表明, 这种便利性可以大大加快结果分析的效率。 如果你需要在Result Viewer里面查看更详细的信息, 那么可以打开ResultXML,这个文件正是Result Viewer需要的文件。
Analyze Result
为了方便结果分析, 需要用到GenExcel.bat这个脚本。 它可以根据测试结果文件(TestResult.txt)文件, 产生一个TestResult.xls文件。 利用Excel的能力, 你可以方便的根据测试结果过滤所有testcase, 并且可以随时记录下分析结果。

如果需要汇报测试执行结果, 那么可以在邮件正文给出汇总的信息,并附上TestResult.html和TestResult.xls两个文件。 这样你的邮件基本上包含了各种stakeholder(team leader, manager, developer...)可能感兴趣的信息, 而且还不会显得凌乱。
Different QTP: 总结2:适应变化和可测试性
2012-09-08 22:14:53
总结2:适应变化和可测试性
适应变化而不是控制变化
相对于单元测试, 接口测试等自动化测试, 对基于GUI的测试面对一个很大的问题是GUI是容易改变的。
对于这种情况, QTP给出了SmartIdentification, 试图让工具更智能, 实践表明大多数时候它只是在帮倒忙。
有些公司出台了一些Policy, 限制Developer对GUI元素识别标识符(比如ID)的修改。比如我现在的公司就提出过修改GUI的一些policy, 结果是不了了之。因为很多Developer根本就记不住那些约束, 或者不愿意被约束。另外, 有些时候, 一些GUI元素是由工具生成的, 其ID变化不在Developer的控制之中。
所以, 在设计GUI元素库的时候, 如何应对GUI的变化是需要重点考虑的。 我的答案是, 不去试图控制变化, 而是提高自己适应变化的能力。这就是“所见即所得”识别方式背后的动因。相对于“对象库”方式, “所见即所得”不仅仅带来了快速定位GUI元素的能力, 它还让修改变得很简单。当GUI元素修改了, 如果你只需要花几分钟就能修改好的你的代码, 那么你也不会太在意这种修改。
可测试性与代码重用率
可测试性与代码重用率看似两个不相干的东西, 但我发现代码重用率高的软件相对有更好的可测试性。 简单来说高质量的软件相对具有更好的可测试性, 及时developer在开发的时候并没有专门去思考“可测试性”这回事。
有一本叫“重构”(refactory)的书说, “重复的代码”是代码臭味的一种。当代码具有臭味时, 你就需要去重构它。通过重构去掉“重复的代码”其实就是在提高代码的重用率。 代码的重用率一定程度上也能反映出代码的整体质量。 简单来说, 通过copy-paste构建的程序肯定比通过抽象构建的程序代码质量差, 因为它导致大量的重复代码。
为什么 代码重用率高的程序一定程度上也是可测试性高的程序? GUI元素库对于元素定位的每一种基本方法(包括组合元素定位)是针对某一类型的GUI元素的抽象。一个程序, 如果它的GUI部分的代码重用率高,那么就有更多的GUI元素其定位标识是有规律的。 那么同样数量的定位方法就能覆盖更多的GUI元素。 一个程序如果是通过copy-paste建立起来的, 因为paste之后, 程序员是可以任意修改代码的, 这种修改可能破坏了原有的GUI元素定位规律。所以结果就是, 不得不写更多GUI元素定位基本方法(或者组合元素)来覆盖所有的情况。
所以, 我发现, 使用这个GUI元素库, 越是高质量的软件,其测试套件开发起来越轻松。
Different QTP: 总入口
2012-08-28 14:59:24
Different QTP系列文章入口Different QTP: 前言
Different QTP: 两个抽象之一:产品业务逻辑抽象Different QTP:两个抽象之二:GUI元素操作抽象层
Different QTP: GUI元素库:架构
Different QTP: GUI元素库:查找函数
Different QTP: GUI元素库:标识符匹配的规则
Different QTP: GUI元素库:智能查找与批量输入
Different QTP: GUI元素库:复杂对象描述机制
Different QTP: GUI元素库:组合元素
Different QTP: GUI元素库:快捷方式
Different QTP: GUI元素库:用Screen-Field解决复杂组合元素
Different QTP: 总结Different QTP: 测试执行流程与Mngt Tools
Different QTP: 业务逻辑封装接口设计
2012-08-28 14:56:26
业务逻辑封装接口设计
为了达到“testcase script和testcase的描述有简单而直接的对应”这样一个目标, 需要对产品功能有一个全面而系统的封装, 然后提供一套API供testcase script调用。 显然, 这会导致大量的API单元产生出来。
QTP提供了resuable action作为业务逻辑封装的工具, 但是resuable action过于重型, 而且并没有提供与其重量级相对应的强大功能。 function相比于reusable action提供了同样的封装能力, 但体积只有1/10,而且使用方式更自然。 这也是不用reuable action的若干重要原因之一。
另外一个必须要考虑的问题就是如何降低这套API使用的难度。 这里有一些技巧。
命名规则
VBS没有Module的概念, 但显然数量众多业务逻辑封装函数必须组织在模块里。 所以我们在命名规则上来模块化。一个业务封装函数的命名如下
BIZ_ModuleName_DoWhat(paramters)
首先BIZ前缀把它与framework里的其他函数分离出来。 ModuleName是第二个前缀, 指出了模块名。 第三个参数才描述了函数所封装的业务。
文档化
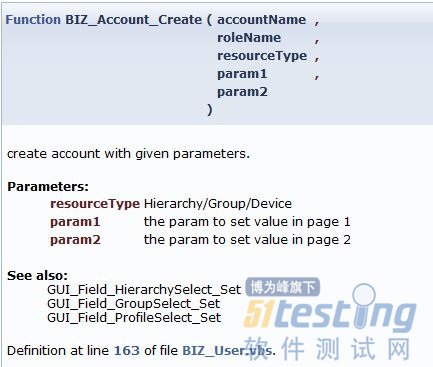
VBS没有专门的文档化定义(类似JavaDoc的东东)。当然你不能对它责怪太多, 毕竟这是上个世纪70年代的语言。 我使用Doxygen加上一个定制的filter来生成framwork里所有函数的文档。
比如下面这段的代码
' create account with given parameters.
'
' @param resourceType Hierarchy/Group/Device
' @param param1 the param to set value in page 1
' @param param2 the param to set value in page 2
'
' @see GUI_Field_HierarchySelect_Set
' @see GUI_Field_GroupSelect_Set
' @see GUI_Field_ProfileSelect_Set
Function BIZ_Account_Create(accountName, roleName, resourceType, param1, param2)通过Doxygen生成的文档像下面的样子
去除页面依赖这里的“页面依赖“是一种函数前置条件。 它特指业务逻辑封装函数对进入此函数时的当前页面的要求。比如一个BIZ_User_Create函数, 它的前置条件可以是“当前页面在User Management页面”。 不满足前置条件时, 调用一个函数通常会导致object not found错误。
但是如果BIZ_User_Create函数针真的对前置条件如此要求, 那么成百上千的类似的业务封装函数会让Testcase script的设计者“步步惊心”。 为了消除这种不必要的心理负担。 我对业务逻辑封装函数的要求就是:只要有可能, 所有业务逻辑函数都要去除页面依赖。也就是说无论当前应用程序处于那一个页面, 函数都能正常工作。对于大部分应用程序来说,前置条件的要求其实是“用户已经登陆进入系统, 但可以处于任意页面”。
显然, 这会导致更多的执行时间。在函数内部, 首先做的就是导航(通过菜单或别的方式)到实际开始业务逻辑的页面。 但是相对于其带来的接口的简化, 和后续的维护简化。 这点成本简直就是微不足道。
这是一个很小的规则, 但它在提高API的可用性方面效果非常大。Different QTP: 业务逻辑封装原则
2012-08-28 14:53:30
业务逻辑封装原则
业务逻辑封装原则就是 严格分离测试逻辑和业务逻辑
这里的测试逻辑就是指Testcase里面的逻辑, 业务逻辑就是产品功能相关的逻辑。
这个原则看上去很简单明了, 但是实践时非常容易把二者混淆。
为了“严格分离测试逻辑和业务逻辑”, 我对开发人员的角色进行了划分, 分为“framwork开发人员”和“testcase script开发人员”。 framework开发人员在开发封装业务逻辑的API的时候, 心里要忘掉任何具体的某个testcase的测试逻辑, 而只关心如何能从产品业务逻辑的角度提供最合适的API。
其次, 我还对函数所在的位置进行了隔离。 所有业务逻辑封装的代码放在函数库目录里, 而与测试逻辑相关的一些共享函数放在TestCase repository目录里。
即便如此, 开发人员也会遇到“不能确定一个function是属于业务逻辑还是测试逻辑的问题”。 我举了两个个例子。
· 验证用户存在
验证用户存在是一个经常会用到的功能, 所以对于开发人员有极大的诱惑把它封装为一个函数, 放在framework里。 但实际上这是错误的, 因为“验证”这个动作本身就与业务逻辑无关, 而属于测试逻辑。
· 创建一组特定的 “角色,用户, 用户组”
在某件些testcase的前置条件里, 要求一组特定的“角色,用户,用户组”存在。 写一个函数封装这一系列操作是一个好主意, 但这个函数仍然属于测试逻辑。 因为对于产品来说, 并没有一组“角色,用户, 用户组”这个概念。
Different QTP: 总结
2012-08-26 22:22:30
总结:关于framwork设计的一些思考
到这里, 我已经把这个framework里最重要的部分, 开发testcase的基石, Function Library介绍完了。
在设计这个Function Library的时候, 有两个最重要的抽象层, 一个是对产品业务逻辑的封装, 一个是对GUI元素访问的封装。 对于业务逻辑封装, 最重要的原则是”把业务逻辑和测试逻辑严格分离“, 另外就是不要使用QTP提供的Reusable Action。 对于GUI元素的封装, 我舍弃了QTP本身提供的对象库, 而完全用描述性编程的方式建立了一套”所见即所得“的GUI对象查询库。
为什么是这样子抽象?是两层抽象, 而不是一层(仅仅提供一些GUI元素操作的封装), 或者三层(提供data-driven/keywork-driven类似的用户接口)? 我的经验告诉我, QTP软件测试项目最大的挑战其实是可维护性。无论你是用record还是层层封装, 基本上你都能实现一个testcase。 但是真正的问题在于当testcase的总数上升到成百上千的数量级,代码库是否还能保持清晰? Testcase是否能够适应今后产品的变化?维护人员是否能快速定位错误?当前的抽象模型是我认为对我目前项目最合适的。
我始终认为,好的framwork设计者应该尽可能取悦framwork的用户。 一个QTP test framwork的用户其实有三类,
· 业务逻辑封装函数的开发人员
· testcase script开发人员
· testsuite 维护人员
一个framwork的设计者,最好同时也从事上面提到的三种类型的开发 ,这样才能”叫好又叫座“
最后, 是没有最好的framework, 而只有最合适的framework。 如前言说讲, 这是一种“非 常规”的开发模式,特别是 舍弃了很多QTP提供的智能工具。QTP提供这些工具的目的是为了支持它的”keyword driven”这样一种开发模式。客观的说, 这是一种易用,快速的开发模式,但个人之见是仅仅适合小型,且短期的项目, 而且和普通的编程语言开发模式非常不一样(java/c#/c++)。基本上, 我是把QTP测试的开发模式, 转变成了普通语言开发的模式。
我曾经一位在HP工作过的同事告诉我, 在HP内部也是用QTP推荐的模式, 而且其项目也是不小。 所以我有时候怀疑这是不是因为我使用Java太长以至于形成了思维定势, 也许QTP本身的模式并不是那么脆弱, 低效。 但是无论怎么样, 我现在使用 的模式也有成功案例的支持, 所以我想可能这个也是一个因人而异的事情吧。 只是希望一些新的想法, 方法的出现能够激发更多人的灵感, 把QTP测试项目开发模式更加完善, 进一步提高QTP测试开发人员的生产效率。
标题搜索
我的存档
数据统计
- 访问量: 118543
- 日志数: 110
- 建立时间: 2007-05-28
- 更新时间: 2013-12-15
RSS订阅
清空Cookie - 联系我们 - 51Testing软件测试网 - 交流论坛 - 空间列表 - 站点存档 - 升级自己的空间
Powered by 51Testing © 2003-2021
沪ICP备05003035号
 Different QTP.zip(635 KB)
Different QTP.zip(635 KB)