
-
[转]最好用的免费ARP绑定工具
2009-11-08 16:34:42
经过测试,下面的脚本完全能够替代网上一般的ARP绑定工具,我已验证通过:
主要代码如下:cls
@echo offrem 自动绑定192.168.1.x 这个网段的ARP
rem 本脚本在xp下测试通过rem local_net_ip 是你所在的网络,可以根据你的实际情况做相应的更改
set local_net_ip=192.168.1
rem 保存配置的文件
set arp_ini=c:\arp.inititle ARP自动绑定脚本 v1.0
echo ===============================================
echo ARP自动绑定脚本 v1.0
echo ===============================================
echo 本程序将扫描%local_net_ip%.255这个网段
echo 如果你的PC不是这个网段的IP,请终止本程序
echo 并修改set local_net_ip=192.168.1语句为你实际的IP网段
echo ===============================================
pauserem 如果文件存在,就执行绑定
rem 如果要重新扫描,请删除%arp_ini%文件,或者改变%arp_ini%文件
if exist %arp_ini% goto ARPBIND
for /l %%a in (1,1,254) do (
cls
echo 正在搜索ARP对应关系 %%a/255,请稍后 当前正在处理%local_net_ip%.%%a
arp -d
ping -w 50 -n 1 %local_net_ip%.%%a > 1.tmp
arp -a |find "dynamic">>%arp_ini%
)echo ARP搜索完毕
:ARPBIND
echo 正在进行ARP绑定
for /F "tokens=1-2" %%a in (%arp_ini%) do (
echo %%a %%b
arp -s %%a %%b
)echo ARP绑定完成
echo 请执行arp -a 检查是否正确
echo 如果要在其它PC上执行ARP绑定,请把本脚本和%arp_ini%,拷贝到其他PC上,运行即可
echo ============================================================================:Select
echo 是否要每次开机自动绑定
echo yes 谢谢,请帮我自动绑定
echo no 不用了,谢谢
set /p a="yes|no:"
if /i %a% EQU yes (
echo @echo off >staticarp.bat
echo echo 正在进行ARP绑定 >>staticarp.bat
for /F "tokens=1-2" %%a in (%arp_ini%) do echo arp -s %%a %%b >>staticarp.bat
echo echo ARP 绑定完毕,请执行命令arp -a 检查 >>staticarp.bat
echo pause >>staticarp.bat
copy staticarp.bat "C:\Documents and Settings\cygang\「开始」菜单\程序\启动\staticarp.bat" /y
echo 以后每次开启PC,都会自动执行ARP绑定脚本goto MEND
)if /i %a% EQU no goto MEND
cls
goto Select:MEND
----
-
(整理)SSH简介及配置应用
2009-11-08 16:18:28
1.什么是SSH
传统的网络服务程序,如:ftp、POP和telnet在本质上都是不安全的,因为它们在网络上用明文传送口令和数据,别有用心的人非常容易就可以截获这些口令和数据。而且,这些服务程序的安全验证方式也是有其弱点的,就是很容易受到“中间人”(man-in-the-middle)这种方式的攻击。所谓“中间人”的攻击方式,就是“中间人”冒充真正的服务器接收你传给服务器的数据,然后再冒充你把数据传给真正的服务器。服务器和你之间的数据传送被“中间人”一转手做了手脚之后,就会出现很严重的问题。
从前,一个名为Tatu Ylnen的芬兰程序员开发了一种网络协议和服务软件,称为SSH(Secure SHell的缩写)。 通过使用SSH,你可以把所有传输的数据进行加密,这样“中间人”这种攻击方式就不可能实现了,而且也能够防止DNS和IP欺骗。还有一个额外的好处就是传输的数据是经过压缩的,所以可以加快传输的速度。SSH有很多功能,虽然许多人把Secure Shell仅当作Telnet的替代物,但你可以使用它来保护你的网络连接的安全。你可以通过本地或远程系统上的Secure Shell转发其他网络通信,如POP、X、PPP和FTP。你还可以转发其他类型的网络通信,包括CVS和任意其他的TCP通信。另外,你可以使用带TCP包装的Secure Shell,以加强连接的安全性。除此之外,Secure Shell还有一些其他的方便的功能,可用于诸如Oracle之类的应用,也可以将它用于远程备份和像SecurID卡一样的附加认证。
2.SSH的工作机制
SSH分为两部分:客户端部分和服务端部分。
服务端是一个守护进程(demon),他在后台运行并响应来自客户端的连接请求。服务端一般是sshd进程,提供了对远程连接的处理,一般包括公共密钥认证、密钥交换、对称密钥加密和非安全连接。
客户端包含ssh程序以及像scp(远程拷贝)、slogin(远程登陆)、sftp(安全文件传输)等其他的应用程序。
他们的工作机制大致是本地的客户端发送一个连接请求到远程的服务端,服务端检查申请的包和IP地址再发送密钥给SSH的客户端,本地再将密钥发回给服务端,自此连接建立。刚才所讲的只是SSH连接的大致过程,SSH 1.x和SSH 2.x在连接协议上还有着一些差异。
SSH被设计成为工作于自己的基础之上而不利用超级服务器(inetd),虽然可以通过inetd上的tcpd来运行SSH进程,但是这完全没有必要。启动SSH服务器后,sshd运行起来并在默认的22端口进行监听(你可以用 # ps -waux | grep sshd 来查看sshd是否已经被正确的运行了)如果不是通过inetd启动的SSH,那么SSH就将一直等待连接请求。当请求到来的时候SSH守护进程会产生一个子进程,该子进程进行这次的连接处理。
但是因为受版权和加密算法的限制,现在很多人都转而使用OpenSSH。OpenSSH是SSH的替代软件,而且是免费的,
SSH是由客户端和服务端的软件组成的,有两个不兼容的版本分别是:1.x和2.x。用SSH 2.x的客户程序是不能连接到SSH 1.x的服务程序上去的。OpenSSH 2.x同时支持SSH 1.x和2.x。
3.安装使用OpenSSH
这里主要讲的是基于FreeBSD的OpenSSH的配置,其它Unix及派生系统使用OpenSSH的方法大致相同FreeBSD中集成了OpenSSH,在很多Linux的发行版中都没有包括OpenSSH。但是,可以从网络上下载并安装OpenSSH,他是完全免费的。(可以访问OpenSSH的主页 http://www.openssh.org)
生成密钥对
使用ssh-keygen来生成密钥对,比如要用DSA加密算法生成一个4096Bit的密钥对可以输入如下命令(具体参数请参阅man ssh-keygen):
#ssh-keygen -b 4096 -t dsa
%ssh-keygen -b 4096 -t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/fdy84/.ssh/id_dsa):(密钥对将要存的路径,括号内为默认)
Created directory '/home/fdy84/.ssh'.
Enter passphrase (empty for no passphrase):
(输入口令)
Enter same passphrase again:
(再次输入口令,千万不要忘记否则就只有从新生成密钥了)
Your identification has been saved in /home/fdy84/.ssh/id_dsa.
(你的私钥)
Your public key has been saved in /home/fdy84/.ssh/id_dsa.pub.
(你的公钥)
The key fingerprint is:
bb:1b:f5:1c:77:62:90:21:59:7e:c6:65:e5:24:c6:e5 fdy84@freebsd密钥分发
刚才生成了一对密钥,把私钥放在自己的机器上的~/.ssh/目录下并保证访问权限是“-rw-------”(即600)。再把生成的公钥放在要连接的远程主机的~/.ssh/目录下并改名为authorized_keys,并且保证文件除了属主外没有被人修改的权限。
4.配置使用SSH
配置服务端
启动SSH服务端很简单只需要运行
# sshd
就可以了。或者在/etc/rc.conf中加入
sshd_enable="YES"
就可以在每次启动时自动运行SSH服务端了。
SSH服务端的配置使用的配置文件是“/etc/ssh/sshd_config”,并且OpenSSH1.x和2.x的服务器配置文件均为此文件。
配置客户端
客户端想连接远程服务器只需要输入
比如想以fdy84用户连接IP地址为192.168.0.6的一台远程服务器 需要键入
#ssh 域名(或ip)
就可以了
只要配置正确就可以连上远端的服务器了# ssh 192.168.0.6 -l fdy84 5.使用Windows下的SecureCRT进行SSH连接
如果在Windows下想要通过SSH远程管理服务器怎么办?其实Windows有很多远程管理软件,我们在这主要介绍一下SecureCRT中SSH连接的使用。(以Version 4.1.1为准介绍)
Create Public Key...
SecureCRT也可以生成密钥对,不过SecureCRT最大只支持2048Bit的密钥,点选Tools->Create Public Key...,选择密钥算法和密钥长度,输入完口令后再使劲晃鼠标以给它生成密钥的足够的随机量之后就等待计算机生成密钥对,如图
点选左上角的Connect按钮
 ,开启Connect对话框
,开启Connect对话框
再点击红圈所示的New Session按钮进入Session Options对话框

在这里我们选择SSH连接,并填入要连接的主机名称(或者ip地址),用户名,再选择基于公钥方式的认证,点击Properties...进入密钥配置对话框

在红色圈所示的位置填入你的私钥文件。
现在点击刚才建立的那个连接进行SSH连接,根据提示点击几个对话框之后就连接上远程的服务器了,如图

特别要注意的是由SecureCRT生成的密钥对和用OpenSSH生成的密钥对在格式上不一样,而且二者都只能认识自己的密钥的格式,所以在用SecureCRT同OpenSSH连接时分别都要用它们自己的密钥格式,可以用任何一个方法生成然后使用ssh-keygen -i 把SecureCRT生成的的密钥转换成OpenSSH的密钥格式,或者用ssh-keygen -e把OpenSSH的密钥格式转换成SecureCRT能够识别的IETF SECSH格式。
虽然SSH提供基于密码的登陆,不过基于安全考虑笔者并不推荐使用这种登陆,鉴于现在机器的速度普遍已经很快,推荐使用4096位的密钥以加强安全性。
目前远程登录工具非常多,建议大家还是用开源的ssh工具。
-
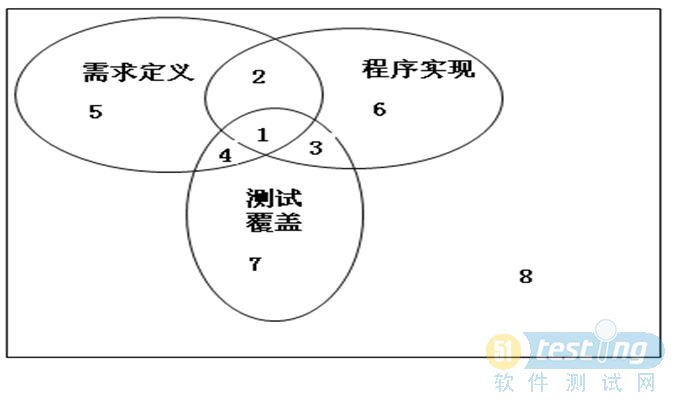
【原创】需求定义、程序实现与测试用例的关系
2009-11-08 15:52:15
要想得知三者的关系,细细观看上面的图既能得出答案,下面也给出一个非常详细的我的解答,可以很形象的描述三者的关系。
1:正确定义,正确实现,测试覆盖 tc status =pass
2:正确定义,正确实现,测试未覆盖 (比较幸运),
3:会引起故障,程序实现了多余的部分,这部分内容也应是bug,一是成本的额外支出,二,多余实现的部分可能会对现有系统造成影响
4:实现与需求不符,报bug,实现遗漏。
5:为漏测,会引起故障。实现遗漏。
6 :为测试遗漏,会引起故障。
7:应在测例评审阶段被发现。
8:用户需求确认遗漏,测试遗漏,会一起故障,或是返工或重构。
-
理解Linux 的处理器负载均值(翻译)
2009-11-04 19:32:42
Linux 负载均值到底是什么意思? 这个数值究竟如何说明服务器是忙是闲?依据这个数值来决定是否需要添加服务器,靠谱么?在网上google了一篇文章描述的非常形象,当然也通俗易懂喔。可以收藏喔
你可能对于 Linux 的负载均值(load averages)已有了充分的了解。负载均值在 uptime 或者 top 命令中可以看到,它们可能会显示成这个样子:
load average: 0.09, 0.05, 0.01很多人会这样理解负载均值:三个数分别代表不同时间段的系统平均负载(一分钟、五 分钟、以及十五分钟),它们的数字当然是越小越好。数字越高,说明服务器的负载越 大,这也可能是服务器出现某种问题的信号。
而事实不完全如此,是什么因素构成了负载均值的大小,以及如何区分它们目前的状况是 “好”还是“糟糕”?什么时候应该注意哪些不正常的数值?
回答这些问题之前,首先需要了解下这些数值背后的些知识。我们先用最简单的例子说明, 一台只配备一块单核处理器的服务器。
行车过桥
一只单核的处理器可以形象得比喻成一条单车道。设想下,你现在需要收取这条道路的过桥 费 -- 忙于处理那些将要过桥的车辆。你首先当然需要了解些信息,例如车辆的载重、以及 还有多少车辆正在等待过桥。如果前面没有车辆在等待,那么你可以告诉后面的司机通过。 如果车辆众多,那么需要告知他们可能需要稍等一会。
因此,需要些特定的代号表示目前的车流情况,例如:
- 0.00 表示目前桥面上没有任何的车流。 实际上这种情况与 0.00 和 1.00 之间是相同的,总而言之很通畅,过往的车辆可以丝毫不用等待的通过。
- 1.00 表示刚好是在这座桥的承受范围内。 这种情况不算糟糕,只是车流会有些堵,不过这种情况可能会造成交通越来越慢。超过 1.00,那么说明这座桥已经超出负荷,交通严重的拥堵。 那么情况有多糟糕? 例如 2.00 的情况说明车流已经超出了桥所能承受的一倍,那么将有多余过桥一倍的车辆正在焦急的等待。3.00 的话情况就更不妙了,说明这座桥基本上已经快承受不了,还有超出桥负载两倍多的车辆正在等待。
上面的情况和处理器的负载情况非常相似。一辆汽车的过桥时间就好比是处理器处理某线程 的实际时间。Unix 系统定义的进程运行时长为所有处理器内核的处理时间加上线程 在队列中等待的时间。
和收过桥费的管理员一样,你当然希望你的汽车(操作)不会被焦急的等待。所以,理想状态 下,都希望负载平均值小于 1.00 。当然不排除部分峰值会超过 1.00,但长此以往保持这 个状态,就说明会有问题,这时候你应该会很焦急。
“所以你说的理想负荷为 1.00 ?”
嗯,这种情况其实并不完全正确。负荷 1.00 说明系统已经没有剩余的资源了。在实际情况中 ,有经验的系统管理员都会将这条线划在 0.70:
- “需要进行调查法则”: 如果长期你的系统负载在 0.70 上下,那么你需要在事情变得更糟糕之前,花些时间了解其原因。
- “现在就要修复法则”:1.00 。 如果你的服务器系统负载长期徘徊于 1.00,那么就应该马上解决这个问题。否则,你将半夜接到你上司的电话,这可不是件令人愉快的事情。
- “凌晨三点半锻炼身体法则”:5.00。 如果你的服务器负载超过了 5.00 这个数字,那么你将失去你的睡眠,还得在会议中说明这情况发生的原因,总之千万不要让它发生。
那么多个处理器呢?我的均值是 3.00,但是系统运行正常!
哇喔,你有四个处理器的主机?那么它的负载均值在 3.00 是很正常的。
在多处理器系统中,负载均值是基于内核的数量决定的。以 100% 负载计算,1.00 表示单个处理器,而 2.00 则说明有两个双处理器,那么 4.00 就说明主机具有四个处理器。
回到我们上面有关车辆过桥的比喻。1.00 我说过是“一条单车道的道路”。那么在单车道 1.00 情况中,说明这桥梁已经被车塞满了。而在双处理器系统中,这意味着多出了一倍的 负载,也就是说还有 50% 的剩余系统资源 -- 因为还有另外条车道可以通行。
所以,单处理器已经在负载的情况下,双处理器的负载满额的情况是 2.00,它还有一倍的资源可以利用。
多核与多处理器
先脱离下主题,我们来讨论下多核心处理器与多处理器的区别。从性能的角度上理解,一台主 机拥有多核心的处理器与另台拥有同样数目的处理性能基本上可以认为是相差无几。当然实际 情况会复杂得多,不同数量的缓存、处理器的频率等因素都可能造成性能的差异。
但即便这些因素造成的实际性能稍有不同,其实系统还是以处理器的核心数量计算负载均值 。这使我们有了两个新的法则:
- “有多少核心即为有多少负荷”法则: 在多核处理中,你的系统均值不应该高于处理器核心的总数量。
- “核心的核心”法则: 核心分布在分别几个单个物理处理中并不重要,其实两颗四核的处理器 等于 四个双核处理器 等于 八个单处理器。所以,它应该有八个处理器内核。
审视我们自己
让我们再来看看 uptime 的输出
~ $ uptime23:05 up 14 days, 6:08, 7 users, load averages: 0.65 0.42 0.36这是个双核处理器,从结果也说明有很多的空闲资源。实际情况是即便它的峰值会到 1.7,我也从来没有考虑过它的负载问题。
那么,怎么会有三个数字的确让人困扰。我们知道,0.65、0.42、0.36 分别说明上一分钟、最后五分钟以及最后十五分钟的系统负载均值。那么这又带来了一个问题:
我们以哪个数字为准?一分钟?五分钟?还是十五分钟?
其实对于这些数字我们已经谈论了很多,我认为你应该着眼于五分钟或者十五分钟的平均数 值。坦白讲,如果前一分钟的负载情况是 1.00,那么仍可以说明认定服务器情况还是正常的。 但是如果十五分钟的数值仍然保持在 1.00,那么就值得注意了(根据我的经验,这时候你应 该增加的处理器数量了)。
那么我如何得知我的系统装备了多少核心的处理器?
在 Linux 下,可以使用
cat /proc/cpuinfo获取你系统上的每个处理器的信息。如果你只想得到数字,那么就使用下面的命令:
grep 'model name' /proc/cpuinfo | wc -l - 0.00 表示目前桥面上没有任何的车流。 实际上这种情况与 0.00 和 1.00 之间是相同的,总而言之很通畅,过往的车辆可以丝毫不用等待的通过。
-
【整理】软件自动化测试的意义与定位何在
2009-11-03 19:29:09
通常情况下,软件测试的工作量都很大。而测试中的许多操作是重复性的、非智力性的和非创造性的,并要求工程师做准确细致的工作,这样,计算机就比人更适合完成任务。另一方面,手工测试存在如下的局限性:1. 通过手工测试无法做到覆盖所有代码路径。
2. 简单的功能性测试用例在每一轮测试中都不能少,而且具有一定的机械性、重复性,工作量往往较大。
3. 许多死锁、资源冲突、多线程等有关的错误,通过手工测试很难捕捉到。
4. 进行系统压力、性能测试时,需要模拟大量数据或大量并发用户等各种应用场合时,很难通过于工测试来进行。
5. 进行系统可靠性测试时,需要模拟系统长时间运行,以验证系统能否稳定运行,这也是手工测试无法模拟的。
6. 如果有大量(几千)的测试用例,需要在短时间内(1天)完成,手工测试几乎不可能做到。
于是,就诞生了软件自动化测试这个领域。软件自动化测试是相对手工测试而存在的,主要是通过所开发的软件测试工具、脚本等来实现,具有良好的可操作性、可重复性和高效率等特点。其主要好处有:
1. 缩短软件开发测试周期,可以让产品更快投放市场。
2. 测试效率高,充分利用硬件资源。
3. 节省人力资源,降低测试成本。
4. 增强测试的稳定性和可靠性。
5. 提高软件测试的准确度和精确度,增加软件信任度。
6. 软件测试工具使测试工作相对比较容易,但能产生更高质量的测试结果。
7. 手工不能做的事情,自动化测试能做,如压力、性能测试。
如上所述,软件自动化测试有很多优点,可以带来非常明显的收益,但是,目前情况下,软件自动化测试还不能解决所有的测试问题,也有以下限制:
1. 不能取代手工测试
2. 手工测试比自动测试发现的缺陷更多
3. 对测试质量的依赖性极大
4. 测试自动化不能提高有效性
5. 测试自动化可能会制约软件开发。
6. 工具本身并无想象力,不能主动发现缺陷
另外,人工测试比测试工具更优越的另一个方面是可以处理意外事件。虽然工具也能处理部分异常事件,但是对真正的突发事件和不能由软件解决的问题就无能为力。
因此,在引入自动化测试前,我们需要建立正确的自动化测试目标。
1. 一种测试工具不完全适用于所有测试
2. 自动测试不一定减轻工作量
3. 测试进度可能不一定缩短
4. 测试工具不一定易于使用
5. 自动化测试的普遍应用存在局限
6. 测试覆盖率不会达到百分之百
所以,软件自动化测试能提高测试效率、覆盖率和可靠性等,同时,自动化测试虽然具有很多优点,但它只是测试工作的一部分,是对手工测试的一种补充,我们要综合评估和运用两者的互补关系,手工和自动化测试结合进行测试,最大限度提高测试效率,减低资源利用率,从而提高软件质量。
-
安全测试见解
2009-11-03 18:40:34
安全测试和传统软件测试的对比:
(1)传统软件测试关注的主要是验证功能,是否满足需求文档
(2)安全测试关注系统对危险防止和危险处理是否有效,能够尽可能的找出系统所存在的漏洞
像一些数据类型,如字符串、实数、浮点数、整数等等
罗拉:XSS恶意数据测试
URL拼接数据测试(恶意攻击者往跳转的URL加入不合法的域名,使之欺骗用户点击跳转到钓鱼网站)
CSRF:跨站点请求伪造
SQL INJECTION:SQL注入
自动化安全测试工具推荐工具像AppScan,可以下载使用使用
-
【共享】 web-performance and scalability
2009-11-03 18:30:28
web-performance and scalability 非常好的纯英文版,有兴趣的可以down下看看 -
常见的java内存泄露
2009-11-03 18:16:40
如果JVM里运行的程序, 它的heap space和perm gen都full,这时候程序还企图创建新的对象实例的话,jvm gc就会启动,试图释放足够的内存来创建这个对象。这时候如果gc无法释放出足够的内存,它就会抛出OutOfMemoryError内存溢出错误
常见的内存泄露:
(1) OutOfMemoryError: Java heap space
(2) OutOfMemoryError: PermGen space
-
【整理】典型应用对系统资源使用的特点
2009-10-15 17:55:06
1.动态内容为主的Web应用1)频繁执行程序,如 Perl, PHP, Java 等,消耗CPU严重。
2)提供并发用户访问,因此系统进程数多,消耗内存多,当内存不足时,使用交换内存也会增加CPU的开销。
3)磁盘的写IO比较频繁(主要为随机写),比如生成cache文件,更新session文件等。
4)内存充足时读取的内容可以被cache住,cache的命中率和文件更新的频繁程度成反比,磁盘的读IO相对较小 。
2. 静态内容为主的Web应用 (如Squid Cache)
1)网络带宽瓶颈。
2)小文件的随机读取频繁,内存充足时可以缓解磁盘随机读的压力。
3) 系统内存不足时磁盘IO量会比较大(读、写、交换内存),因此增加CPU的开销。
3. 数据库应用
1)数据库查询语句复杂,大量的 where 子句,order by, group by 排序等,CPU容易出现瓶颈。
2)表太大时,查询遍历全表造成磁盘读的IO量大,容易出现读IO等待的情况。
3)数据更新量大或者更新频繁时,造成磁盘写的IO量大。
4)内存不足时频繁使用交换内存。
4. 软件下载
1)网络带宽瓶颈
2)存储系统带宽瓶颈(读)
5. 流媒体服务
1)网络带宽瓶颈
2)存储系统带宽瓶颈(读)
-
Siege工具使用
2009-07-07 16:46:27
Siege
一款开源的压力测试工具,可以根据配置对一个WEB站点进行多用户的并发访问,记录每个用户所有请求过程的相应时间,并在一定数量的并发访问下重复进行。
官方:http://www.joedog.org/
Siege下载:http://soft.vpser.net/test/siege/siege-2.67.tar.gz
解压:
# tar -zxf siege-2.67.tar.gz
进入解压目录:
# cd siege-2.67/
安装:
#./configure #make
#make install使用
siege -c 100 -r 10 -f test.url
-c是并发量,-r是重复次数。 url文件就是一个文本,每行都是一个url,它会从里面随机访问的。test.url内容:
结果说明
Lifting the server siege… done.Transactions: 994 hits//完成994次处理
Availability: 99.40 %//99.40成功率
Elapsed time: 36.22 secs//总共用时36.22s
Data transferred: 0.88 MB//共计传输数据大小
Response time: 0.08 secs//响应时间多少
Transaction rate: 27.44 trans/sec//完成多少次处理
Throughput: 0.02 MB/sec//平均每秒传输数据
Concurrency: 2.25//最高并发数
Successful transactions: 994//成功处理次数
Failed transactions: 6//失败数
Longest transaction: 0.47//每次传输所花最长时间
Shortest transaction: 0.00//每次传输所花最短时间
FILE: /usr/local/var/siege.log
You can disable this annoying message by editing
the .siegerc file in your home directory; change
the directive 'show-logfile' to false. -
TPS与HPS
2009-03-30 23:29:52
TPS 是估算应用系统性能的重要依据。其意义是应用系统每秒钟处理完成的交易数量。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。 系统整体处理能力取决于处理能力最低模块的TPS 值。依据经验,应用系统的处理能力一般要求在10-100左右。不同应用系统的TPS有着十分大的差别,一般需要通过性能测试进行准确估算。
HPS:Hits per Second 每秒点击次数
是指在一秒钟的时间内用户对Web页面的链接、提交按钮等点击总和。 它一般和TPS成正比关系,是B/S系统中非常重要的性能指标之一 -
并发用户数的计算方法
2009-03-30 23:12:35
系统用户数:系统额定的用户数量,如一个OA系统,可能使用该系统的用户总数是2000个,那么这个数量,就是系统用户数
同时在线用户数:在一定的时间范围内,最大的同时在线用户数量
平均并发用户数的计算:
C=nL /T
其中C是平均的并发用户数,n是平均每天访问用户数,L是一天内用户从登录到退出的平均时间(操作平均时间),T是考察时间长度(一天内多长时间有用户使用系统)
并发用户数峰值计算:
C^约等于C + 3*根号C
其中C^是并发用户峰值,C是平均并发用户数,该公式遵循泊松分布理论
-
对apache中并发控制参数prefork理解和调优
2009-03-30 22:59:48
一个apache有linux下的并发不是很高的,大约到3K的样子(其实处理的http的请求可能只有300/s),普通的服务器都会不同程度的出现问题.apache有关并发控制主要是 prefork和worker二个其中一个来控制.我们可以使用httpd -l来确定当前使用的MPM是prefork.c,还是Worker.c.下面是apache中有关prefork的配置.下面是我优化过的参数.
<IfModule prefork.c>
#有这个参数就不必像apache1一样修改源码才能修改256客户数的限制,听讲要放到最前面才会生效,2000是这个参数的最大值
ServerLimit 2000
#指定服务器启动时建立的子进程数量,prefork默认为5。
StartServers 25#指定空闲子进程的最小数量,默认为5。如果当前空闲子进程数少于MinSpareServers ,那么Apache将以最大每秒一个的速度产生新的子进程。此参数不要设的太大。
MinSpareServers 25#设置空闲子进程的最大数量,默认为10。如果当前有超过MaxSpareServers数量的空闲子进程,那么父进程将杀死多余的子进程。此参数 不要设的太大。如果你将该指令的值设置为比MinSpareServers小,Apache将会自动将其修改成"MinSpareServers+1"。
MaxSpareServers 50#限定同一时间客户端最大接入请求的数量(单个进程并发线程数),默认为256。任何超过MaxClients限制的请求都将进入等候队列,一旦一个链接被释放,队列中的请求将得到服务。要增大这个值,你必须同时增大ServerLimit 。
MaxClients 2000#每个子进程在其生存期内允许伺服的最大请求数量,默认为10000.到达MaxRequestsPerChild的限制后,子进程将会结束。如果MaxRequestsPerChild为"0",子进程将永远不会结束。
MaxRequestsPerChild 10000</IfModule>
将MaxRequestsPerChild设置成非零值有两个好处:
1.可以防止(偶然的)内存泄漏无限进行,从而耗尽内存。
2.给进程一个有限寿命,从而有助于当服务器负载减轻的时候减少活动进程的数量。工作方式:
一个单独的控制进程(父进程)负责产生子进程,这些子进程用于监听请求并作出应答。Apache总是试图保持一些备用的 (spare)或者是空闲的子进程用于迎接即将到来的请求。这样客户端就不需要在得到服务前等候子进程的产生。在Unix系统中,父进程通常以root身 份运行以便邦定80端口,而 Apache产生的子进程通常以一个低特权的用户运行。User和Group指令用于设置子进程的低特权用户。运行子进程的用户必须要对它所服务的内容有 读取的权限,但是对服务内容之外的其他资源必须拥有尽可能少的权限。对上面的有些值,一定要记的不是越大越好.这个需要经过几次尝试和出错之后才能选好要使用的值(不同的硬件处理水平不一样)。最重要的值是maxclient允许足够多的 工作进程,同时又不会导致服务器进行过度的交换(死机)。如果传入的请求超出处理能力而让服务器当掉的话,那么至少满足此值的那些请求会得到服务,其他请求被阻塞这样会更加好。
我们调优常常要查看httpd进程数(即prefork模式下Apache能够处理的并发请求数):
#ps -ef | grep httpd | wc -l
出现的结果,就是当前Apache能够处理的多少个并发请求,这个值Apache根据负载情况自动调.
查看Apache的并发请求数及其TCP连接状态:
#netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
上面这句来自己我一个新浪的朋友张宴.
返回结果示例:
LAST_ACK 5
SYN_RECV 30
ESTABLISHED 1597
FIN_WAIT1 51
FIN_WAIT2 504
TIME_WAIT 1057
其中的SYN_RECV表示正在等待处理的请求数;ESTABLISHED表示正常数据传输状态;TIME_WAIT表示处理完毕,等待超时结束的请求数。状态:描述
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT:另一边已初始化一个释放
LAST_ACK:等待所有分组死掉可以使用Linux下的webbench来作压力测试.
-
JVM参数调优[整理收藏]
2009-03-30 22:50:39
JVM参数调优是一个很头痛的问题,可能和应用有关系,别人说可以的对自己不一定管用。下面是本人一些调优的实践经验,希望对读者能有帮助,环境LinuxAS4,resin2.1.17,JDK6.0,2CPU,4G内存,dell2950服务器,网站是舍得网,http://shedewang.com
一:串行垃圾回收,也就是默认配置,完成10万request用时153秒,JVM参数配置如下
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps ";
这种配置一般在resin启动24小时内似乎没有大问题,网站可以正常访问,但查看日志发现,在接近24小时时,Full GC执行越来越频繁,大约每隔3分钟就有一次Full GC,每次Full GC系统会停顿6秒左右,作为一个网站来说,用户等待6秒恐怕太长了,所以这种方式有待改善。MaxTenuringThreshold=7表示一个对象如果在救助空间移动7次还没有被回收就放入年老代,GCTimeRatio=19表示java可以用5%的时间来做垃圾回收,1/(1+19)=1/20=5%。
二:并行回收,完成10万request用时117秒,配置如下:
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xmx2048M -Xms2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=500 -XX:+UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 ";
并行回收我尝试过多种组合配置,似乎都没什么用,resin启动3小时左右就会停顿,时间超过10秒。也有可能是参数设置不够好的原因,MaxGCPauseMillis表示GC最大停顿时间,在resin刚启动还没有执行Full GC时系统是正常的,但一旦执行Full GC,MaxGCPauseMillis根本没有用,停顿时间可能超过20秒,之后会发生什么我也不再关心了,赶紧重启resin,尝试其他回收策略。
三:并发回收,完成10万request用时60秒,比并行回收差不多快一倍,是默认回收策略性能的2.5倍,配置如下:
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 ";
这个配置虽然不会出现10秒连不上的情况,但系统重启3个小时左右,每隔几分钟就会有5秒连不上的情况,查看gc.log,发现在执行ParNewGC时有个promotion failed错误,从而转向执行Full GC,造成系统停顿,而且会很频繁,每隔几分钟就有一次,所以还得改善。UseCMSCompactAtFullCollection是表是执行Full GC后对内存进行整理压缩,免得产生内存碎片,CMSFullGCsBeforeCompaction=N表示执行N次Full GC后执行内存压缩。
四:增量回收,完成10万request用时171秒,太慢了,配置如下
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xincgc ";
似乎回收得也不太干净,而且也对性能有较大影响,不值得试。
五:并发回收的I-CMS模式,和增量回收差不多,完成10万request用时170秒。
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode -XX:+CMSIncrementalPacing -XX:CMSIncrementalDutyCycleMin=0 -XX:CMSIncrementalDutyCycle=10 -XX:-TraceClassUnloading ";
采用了sun推荐的参数,回收效果不好,照样有停顿,数小时之内就会频繁出现停顿,什么sun推荐的参数,照样不好使。
六:递增式低暂停收集器,还叫什么火车式回收,不知道属于哪个系,完成10万request用时153秒
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseTrainGC ";
该配置效果也不好,影响性能,所以没试。
七:相比之下,还是并发回收比较好,性能比较高,只要能解决ParNewGC(并行回收年轻代)时的promotion failed错误就一切好办了,查了很多文章,发现引起promotion failed错误的原因是CMS来不及回收(CMS默认在年老代占到90%左右才会执行),年老代又没有足够的空间供GC把一些活的对象从年轻代移到年老代,所以执行Full GC。CMSInitiatingOccupancyFraction=70表示年老代占到约70%时就开始执行CMS,这样就不会出现Full GC了。SoftRefLRUPolicyMSPerMB这个参数也是我认为比较有用的,官方解释是softly reachable objects will remain alive for some amount of time after the last time they were referenced. The default value is one second of lifetime per free megabyte in the heap,我觉得没必要等1秒,所以设置成0。配置如下
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -XX:+DisableExplicitGC -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSPermGenSweepingEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime -Xloggc:log/gc.log ";
上面这个配置内存上升的很慢,24小时之内几乎没有停顿现象,最长的只停滞了0.8s,ParNew GC每30秒左右才执行一次,每次回收约0.2秒,看来问题应该暂时解决了。
参数不明白的可以上网查,本人认为比较重要的几个参数是:-Xms -Xmx -Xmn MaxTenuringThreshold GCTimeRatio UseConcMarkSweepGC CMSInitiatingOccupancyFraction SoftRefLRUPolicyMSPerMB -
LR中输出当前系统时间的脚本
2009-03-30 22:36:01
LR提供了char *ctime(const time_t *time)函数,调用参数为一个long型的整数指针,用于存放返回时间的数值。调用的脚本和返回的代码如下: typedef long time_t; Action() { time_t t; lr_message("Time in seconds since 1/1/70: %ld\n",time(& t)); lr_message("System time and date: %s",ctime(&t)); } 输出结果为: Time in seconds since 1/1/70:1185329968 System time and date:Mon MAR 30 22:35:30 2009 -
LR录制脚本时出现乱码的处理办法
2009-03-30 22:25:46
我们在用LR录制web页面http请求脚本时,会生成脚本中存在乱码,一般是LR的参数没有设置正确,下面分享下设置步骤。
录制脚本前,打开录制选项配置对话框Record-Options,进入到Advanced高级标签,先勾选‘Support charse’,然后再选中支持UTF-8。再次录制脚本时,就不会出现中文乱码问题了。你不妨试试看,^_^
-
LR关于ODBC测试的一点知识
2009-02-12 12:47:33
关于开发数据库Vuser脚本
1、录制与服务器进行通信得数据库应用程序时,Vugen将生成数据库Vuser脚本。VuGen支持下列数据库类型:CtLib/DbLib/Informix/Oracle/ODBC和DB2-CLI;录制出来得脚本中包含描述数据库活动得LRD函数,每个LRD函数均以lrd为前缀;
2、数据库Vuser能够:
连接到数据库服务器
提交SQL查询
检索并处理信息
断开与服务器得连接
3、自动事务:可以指示VuGen把每个lrd_exec和lrd_fetch函数标记为事务;
脚本选项:指示VuGen在录制得脚本中自动生成注释;
思考时间:Vugen自动录制操作者得思考时间。
4、函数顺序:(以Oracle数据库会话过程为例)
lrd_init 初始化环境
lrd_open_connection 连接到数据库服务器
lrd_open_curosr 打开数据库光标
lrd_stmt 将SQL语句与光标关联
lrd_bind_col 将主机变量绑定到列
lrd_exec 执行SQL语句
lrd_fetch 提取结果集中得下一条记录
lrd_commit 提交数据库事务
lrd_close_cursor 关闭光标
lrd_close_connection 断开与数据库服务器得连接
lrd_end 清理环境
5、关联函数:
lrd_save_value 将表单元格得值保存到参数中;该函数置于提取数据之前,将后续lrd_fetch检索到得值分配给指定参数
lrd_save_col 将占位符描述符值保存到参数中;该函数与设置输出占位符得数据库函数(例如Oracle得某些存储过程) 配合使用
lrd_sav_ret_param 将返回参数得值保存到参数中(仅适用于CtLib),该函数主要与存储在DbLib中的、生成返回值的数据库过程配合使用。
注意:如果保存的值无效或为NULL(不返回行),则Vugen将不应用关联。
lrd_ora8_save_col 将上一个行ID保存到参数中(Oracle)
注意:如果要关联Lrd_stmt函数中的值,则不支持下列数据类型:日期、时间、和二进制(RAW/VARRAW) -
新年好!!
2009-01-28 13:37:06
给大家拜年了!!
牛年牛气冲天!!
-
[论坛] bug分析建模工具及度量方法
2009-01-08 13:46:39
软件缺陷管理过程中,我们会发现很多bug,处理掉很多bug,但有没有想过去收集bug,去分析,并建立一个bug趋势的图。分析过程中我们如何去度量,有哪些指标去度量,
譬如bug发现阶段、bug发现原因、bug类型、bug等级...有很多,然后使用什么样的工具可以把想度量的指标给图形化,可以用饼图、曲线图、柱状图等。
有经验或有兴趣的同学可以讨论下,在这里! -
Bug分析可为bug预防奠定基础
2008-12-31 11:42:17
1.引言:生产软件的企业安排很多人来测试它们的软件产品。测试的目的就是发现bug(缺陷,defect)以便修正它们。正常情况是尽快处理可能的bug,从而减少修正bug的成本。因为,众所周知,bug越早被发现并修正,所消耗的资源越少。问题是在很多情况下,由于修正已发现的bug,测试过程不得不停顿下来。
那么,以目前正忙于软件产品测试的同样资源来促进组织长期的质量目标不是更好?为了做到这一点,我们应该尽快地提前发现可能的bug。就像克劳士比(Philip Crosby)几年前所说的那样,我们应该努力预防bug,而不仅仅是修正它们。这就是真正的质量。
2.目标:预防bug
预防的重要性
正如我们所知,bug应该尽早地在开发过程中被发现。修正处于开发阶段的产品的bug的成本远远低于修正处于QC(Quality Control,质量控制)阶段的产品的bug,而相对与修正已经发布给客户的产品的bug的成本更是可以忽略不计。原因就是当你修正一个bug的时候,相当于把你之前做的事情重做一次。因此,越晚修正bug,你所重做的事情就越多。如果bug修正是在产品测试之前,那么重做的工作只有代码实现。如果bug修是在测试阶段,那么重做的工作就包括代码实现和测试。另一个导致成本增加的因素是依赖的组件和流程(process),随着项目的进行,产品依赖的组件和流程也会随之增加。
接下来,从另一个层面来讨论这个问题。如果bug发现和修正越早,开发成本越少,那么在第一时间就避免bug引入是不是成本消耗得更少?如果bug可以被完全预防,那么在开发过程中就不会出现重复工作的情况。这个被克劳士比极力推荐的观点非常有意义,而且在很多情况下已得到严密的证实。然而,并不是所有的生产软件产品的组织都试着去避免bug。它们花费了大部分的精力在产品发布给客户之前发现和修正其中的bug。在某些情况下,软件企业并不试着去达到这样的目标。在产品发布之后,企业通过迅速修正产品中的bug来处理客户的抱怨。这是因为,这样的企业始终处于“问题解决模式”,它们并不试图发现问题的根本原因,而只是把局部的大火扑灭。
这种模式并不仅仅导致重复工作直接带来成本的增加,而且会带来一个长期效应,而这将影响企业的业务。首先,发布带有bug的产品将给企业的声誉造成影响,并可能造成对潜在客户的影响——他们在是否建立合作关系上拿不定主意。另外,由于企业需要资源来不断解决现有产品中的问题,那么开发新产品的资源势必减少。
对很多人来说,零缺陷的软件产品似乎是不切实际的。我们总是听到软件开发者说:“软件永远有bug”。产品进入QC阶段时含有bug并不奇怪,因为我们“期望”开发人员制造bug。不幸的是,发布一个包含很多bug的产品给客户仍然不令人感到惊讶。甚至连客户本身也不再感到惊讶。
事实上,每个软件企业都可以通过一些简单的方法,在不增加任何额外资源的情况下预防bug。bug预防在于一个简单的道理:最好的方法是适当借鉴我们自己的经验。
今天的发现就是明天的预防
为了能够预防bug,我们必须首先了解bug的来源。软件bug可以分为几个类别(可能相互之间有所重叠)。第一类bug可能是随机的,它们通常是因为一时的疏忽造成的。尽管这些bug可能由于其随机性很难预防,但是,适当的分析将有助于避免这些bug。
另一类的bug来自于需求的误解、开发环境的错误或者纯粹由于缺乏解决问题的相关技术。这类bug共同的特点是都来自于开发人员。除非被发现,否则这些bug将一直存在。例如,一个还不完全理解需求的开发工程师在单元测试阶段可能无法发现这些问题,只有当产品被其他组织(如QC组)测试时才会发现产品实现与需求不一致。这使得在前期避免类似问题的出现更加重要。
一个好消息是,软件中的bug往往倾向于重复出现,即使是一个随机出现的bug。软件bug的不断出现不仅表现在同一个开发人员的工作上,而且表现在一个项目甚至是企业的层面上。这当然不是说公司中的每一个开发人员都会犯同样的错误。但是,至少其中一些的错误足以成为经常性出现的问题。所以,为什么我们认为重复的错误是一个好消息?因为可以预见的bug更容易预防。事实是我们可以找到一些常见的问题,并采取相应的措施去预防它(或至少减少类似错误出现的次数)。
人为bug的子集?那么这些bug被预防的可能性更大。域bug?域bug和产品的问题域或解决方案域紧密相关。这样的bug有更大的机会重现,因为开发人员、项目组甚至企业不断地在这个域上工作。
现在的问题是如何预防各种bug的产生。基于这次讨论的目的,我建议我们设定一个更加实际的目标。让我不要考虑完全预防某个bug,而是将目标设为——预防我们已经知道有一定可能性产生的Bug。这意味着我们可以通过我们各种发现bug的活动来促进将来的bug预防。当某个bug被发现时,我们就有了一个很好的机会来阻止类似问题的发生。
前提:记录bug
前提条件是持续跟踪发现的bug并正确地记录它们,离开了这个前提条件将不能将bug发现作为一个工具来预防bug。不论你使用bug跟踪系统,还是只手写了一个报告总结测试的结果,重要的是保存这些数据以便用于后来的分析。
在分析bug时,bug记录的问题值得注意。bug的定义越广泛,bug分析的数据越有用。报告bug的测试人员应该明白这一点,并不限于狭义上的bug。可能的话,测试人员应该运用他们的经验对bug产生的原因做最初的假设。我们将稍后在阐述分析过程时讨论这个问题。
和记录bug同样重要的是bug分析的第一步。仅仅跟踪过去的bug不能预防bug的发生,因为许多不同的bug可能来源于同一个核心问题。不同于信息收集,适当地分析bug的原因对bug预防非常有用。
3.缺陷分析
目标
在上一节,我们说明了bug分析的理由。如上所述,最终目标是预防bug而不是修正它们。然而,我们可以定义一个重要的子目标,这就使不断提高整个开发团队(包括QC组)的技能和实践经验。当然,这两个目标是息息相关的。离开了不断的知识累积,也不能实现bug预防。不过,我觉得有必要提及这个子目标以强调持续性的过程。bug预防并不是一个不切实际的目标。但是,你不能期望它在一夜之间发生。你应该为开发小组提供教育和知识,以使他们逐渐改善他们的工作。
策略
本次讨论的焦点——bug预防策略非常简单和容易实现。秘诀就是使用在大多数开发环境中已经存在的过程元素。我们不会介绍任何新的花费昂贵的活动,也不会引入一些新的角色到开发过程中。
我们的策略是发现bug,找出bug的根源,然后寻找一个方法来预防类似的bug在将来出现。因为QC过程已经用于在目前的产品中发现bug,因此该策略的大部分工作实际上已经执行,大多数开发过程缺少的正是分析在QC过程中发现的bug。正如你将看到,尽管策略的这一部分并不需要昂贵的花费,但是却带来了极大的额外价值。
分析过程(1) Bug发现和初步分析
如前所述,bug分析的第一步是发现bug。然而,发现bug的QC工程师(注:测试工程师)不应该满足于记录bug的表面症状。QC工程师的一个重要职责就是试图发现bug的根本原因。QC小组在检验产品质量时,不应该将产品看作一个黑盒,而应该像开发人员那样了解产品的内在,包括深入源代码,理解产品的设计和实现。这些能力都是QC小组开始bug分析的基本要求。熟悉了产品的代码,QC工程师就可能推测出bug的根本原因。
我要强调是下面这个短语的本质:bug的根本原因?bug的根本原因并不是产生这bug的源代码所在,尽管这些信息可能和分析过程关系密切。但是,发现bug的根本原因意味着找到造成这些错误的原因。通过一些实例来说明这个问题可能更清楚一些。
让我们看一个普遍存在的关于线程同步的问题。假设一个多线程的应用程序需要同步地访问某个数据结构。被指派测试这个产品的QC工程师发现在某种情景下,应用程序尽管没有Crash,但是会停止响应。正常的QC过程是,这个bug被记录在bug跟踪系统中,并描述了测试情景和停止响应的实际结果。然而,如果这个QA工程师熟悉源代码,就可以进行bug产生原因的初步分析。例如,这个QC工程师可能断定这个bug产生的原因是之前的线程没有释放mutex,从而造成了冲突。这些分析可以记录在bug的详细说明中,作为bug分析的一个基础。
(2) Bug修订和进一步分析
一如既往,发现一个bug之后,开发人员应该负责处理它。但是,如果bug的发现过程包含了bug根本原因的初步分析,那么关于如何解决这个bug,开发人员可能拥有了更多的信息。虽然这不是QC工程师bug初步分析的目的,但是它可能为开发人员提供了更多的观点。除了修正缺陷以及记录实现的具体步骤,开发人员还应该对bug进行进一步的分析。这次分析应该着眼于导致bug产生的开发情景。
在线程同步的例子中,开发人员不应该仅仅记录增加了一个调用来释放mutex(注:Mutal Exclusion = 互斥锁,保证了共享数据不会同时被多个线程访问,只向一个线程授予对共享资源的独占访问权)。反之,开发人员应该找出没有释放mutex的原因。假设分析的原因是:因为需要同步的方法超过一个的返回点,因此开发人员在某些控制路径上忘记清理代码。
这一类简单的分析实际带来了非常大的价值。不同于记录具体问题的具体解决办法,我们现在有了可以解决许多情况的经验,有些情况甚至并不涉及到线程同步和释放mutex。但是,分析过程并没有结束,我们需要进一步的分析来将收集的所有数据转换为实践,从而帮助在将来避免类似bug的发生。
(3) bug预防分析
分析的最后一步就是寻找一个预防类似错误的方法。这一方法不仅涉及到开发、QC工程师,还涉及到不直接负责代码编写的资深开发人员。
这一阶段的成果是一些有用的实践经验,开发人员可以通过这些实践预防bug而不是修正bug。这些实践不应该是某个具体问题的解决方案。在我们线程同步的例子中,可能得到这样一个实践:是否有审计范围机制来获取和释放资源?这种实践 (不一定适合所有编程语言)可以指导开发人员用一个类(class)封装资源, 这样构造(constructor)函数容易分配和而与析构(destructor) 函数释放资源。如果遵守这样的约定, 当程序结束这方法时,不管控制路径是怎样的,资源(上述例子中获得的mutex)总能被释放。
Bug预防分析是整个bug分析过程的核心。这一阶段总结出的实践可以在更广泛的范围内预防潜在的缺陷。由于分析结果的广泛应用性,分析某个具体问题的投入将很容易被收回。
非常重要的是我们前面所举的例子是一个随机性的bug。开发人员由于疏忽而忘记了释放资源。在代码实现时,这样的bug是随机产生的,但是类似bug产生的几率却非常高。所以,尽管这一类bug是随机的,但仍然可以被预见并防止发生。
(4) 发布经验
分析得出的实践经验应该被记录并发布,这样其他的开发人员就可以通过学习这些经验避免类似的错误。一个发布经验最好的办法就是知识库。这将使得新的知识在组织内流动并被相关的开发人员所学习。
如果不将分析结果传达给组织内相关的其他人员,那么分析的目的就没有达到。避免下一个bug出现的唯一办法就是让开发人员知道如何避免它,并鼓励他们这么做。
Bug分析实例
让我们研究另外一个例子,以便更好地理解bug分析的益处。在这个事例中,QC工程师进行了如下的操作:当输入一个长字符串到应用程序时造成其崩溃(crash)。这一结论本身就需要一定程度的分析,但这个QC工程师并不满足于这样的分析,进一步研究了相关的代码,发现crash的原因是输入字符串时的处理有问题。其中一个步骤是将输入的字符缓存在一个固定大小的数组中,而这个数组有时候显得太小了。
和线程同步的例子一样,QC工程师的初步分析带来了很大的价值,开发可以更容易的发现和修正这个bug。此外,记录缺陷的真正原因而不是表象,将帮助其他人避免类似的bug。
接着,开发人员开始修正这个bug。当修正的时候,她不仅记录了解决措施,并说明了导致缺陷产生的原因。在这个例子中,造成bug的原因是在操作未经处理的C/C++缓冲区时,没有经常检验缓冲区的大小是否不够。然而,这个结论甚至可以被进一步总结为更广泛应用的经验以便帮助开发人员在以后避免类似的缺陷发生。所以,在分析的最后阶段,开发人员在组内更资深的开发人员的帮助下,得到了下面的实践经验:避免使用未经处理的C/C++缓冲区,尽量使用安全的collections和strings,如标准模版数据库中提供的可用collections和strings。这样就完全可以避免前面发现的这个bug。
益处
Bug分析带来了很多的好处。第一个好处就是帮助产生错误的开发人员总结经验,并使他在将来避免类似的错误。有时,只修正一个具体的bug而不去分析它产生的原因并不会帮助在日后得到提高。在这种情况下,只有深入分析和资深开发人员的指导才能使开发人员成长和提高能力。
更广泛的好处是使得其他开发人员从同事的错误中吸取教训。分析总结的实践经验可以预防bug的产生,这样的知识在组织内的成员间共享。某个开发人员产生的bug可以帮助组织内的其他人避免类似的bug出现。
从更一般的角度来看,发布最佳实践(如bug分析总结的实践)促进了组织内成员的学习和自我提高。这样看来,Bug分析的价值还不仅仅是缺陷的预防。
另一个好处是通过从更广的角度上记录bug,组织内的其他QC工程师将知道如何发现类似的错误。除了分享组织内的测试知识和经验,bug分析过程可以促进开发更好的测试技术和工具,从而帮助发现类似的bug。所以,就算缺陷没有被完全预防,也能更容易被发现。
作为上面所有好处的结果,QC在一轮测试中将有更多的时间来测试更复杂的情景并发现更“狡猾的”bug。如果类似的bug都已经被预防而不容易产生,而且QC都有更好的技术来发现类似的bug,就有了更充裕的时间来进行更高级的测试。当然,组织所生产的产品的质量也将得到提高。
最后,我想强调的是bug分析不仅收集了执行中的问题,而且从这些问题中总结了实践经验。举例来说,导致一个bug产生的原因可能是需求不够清楚。这样,通过bug分析得到的经验提供了一种方法来预防需求不清楚。这个经验可能不会对组织中的开发人员产生效果。所以尽管QC工程师开始验证开发人员的实现结果,但是还需要改善开发流程,如需求收集、设计流程等。
4.总结
真正的质量是生产没有bug的产品。任何其他目标都使组织内的成员从思想上接受软件缺陷是正常工作流的一部分。所以,第一步就是防止相同的bug再次发生。我们可以很轻易地执行这个目标。我们可以通过某个开发人员产生的一个bug提高整个组织的实践经验。
通过深入产品分析一个bug,我们可以明白这个bug的机制:为什么会产生?如何去预防它?下一次我们如何更容易地发现它?只要花一点时间去理解我们的bug,而不是仅仅是尽快修正它,我们就可以从中得到经验。这样,因为一个缺陷所浪费的时间也可以转化为投入:确保类似的错误永远不会再发生。
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 106594
- 日志数: 144
- 图片数: 1
- 建立时间: 2008-11-02
- 更新时间: 2010-03-25
