题记:笔者做了近6年的性能专项,从电信行业的华为项目,到OTA行业携程的支付,再到社交类的网易云音乐,最后到吉利汽车的信息工程中心内部系统,涉及业务、架构、环境等等也算广泛,下面来汇总下周围人经常问到的一些问题和注意事项,有些东西看似很初级,但我面试过程中,很多有三年性能经验的人还捋不清。
(个人经验无保留呈现,纯干货。未经允许,请勿转载!)

1、关于TPS、QPS区别
我日常都会使用TPS,每秒事务数,之所以是事务这个概念,是因为我们在请求过程中会增加检查点,检查点成功就是事务成功,检查点失败就意味着失败,所以我们的请求就是一次事务,故TPS=QPS(每秒请求说),所以大部分条件下,这两个概念不用纠结的!
那么什么时候不相等呢?
举个例子,我需要进行一次查询,但这个查询需要调用A服务和B服务,而调用B服务需要2次调用,那么这种情况,以我查询这个场景成功作为一次事务的话,我一秒请求一笔就是1tps,当然对于A系统是1tps=1qps的,但对于B系统而言,就是2qps,因为调用了两次(如果只看B服务的话,把每次请求当做一次事务的话2qps=2tps,还是可以等同的)
所以仅仅是关注维度的不同,绝大多数时候我们不用去刻意区分的,毕竟我可以说我流程是1tps,B系统受到的双倍额压力是2tps的量(压测过程中也务必关注这样的流量放大服务,因为很有可能前面的服务抗的住,后面扛不住),这样也是完全没有问题的。
2、关于压测机的忠告
选择和被测目标服务同网段的机器作为压测机,很多人都是直接在办公环境的自己机器上压测,我可以很负责的告诉你,这种压测很不稳定,时好时坏,如果你们没有做流量隔离,说不定你会把你们的办公环境压垮!
我之前由于没有压测机资源,凑合在本机压测,当时同一个网口还接了IP电话,再到电脑上,我发现压测过程出现丢包和不稳定的问题,排查了半天才知道是IP电话的网卡有瓶颈的(因为之前没接电话时,那个并发数压测时没问题的。)
此外,还容易出现socket连接数问题(linux to many open files),还有tcpd端口的问题(Address already in use),当然压测机如果这这些参数没有调优,也要记得修改哦~
3、关于JMeter UI和non-UI 的方式
有人说JMeter UI容易消耗资源,而官方也是建议使用nonUI的方式,在此我想说明的是,其实还好,nonUI的方式对报表的呈现不够实时,这点我很不喜欢(报表后面我会说),所以我日常更喜欢UI实时压测的方式。
关于性能损耗我想说的的是,有没有损耗,肯定有,这点是无疑的;
但是损耗在我们可以接受范围内的,我验证过1000tps下,UI和non-UI的差距,其实耗时不大的,也就是二三十毫秒,这点损失我们完全可以接受的,对压测真心没有任何影响(因为被测性能真出拐点时或瓶颈时,耗时会成倍的增加,十分明显,和UI方式并没太大关系的。)
所以追求简单、直观,且并发1000以下的情况下,建议使用UI方式。
4、关于JMeter分布式
接着上面的说,日常情况,大部分公司的性能需求,单台压测机就可以抗住的。
我4C8G的window server机器,使用UI方式,最高压测过2000并发(RT 20ms以内),单机没什么问题(当然如果IO很高的话,注意压测机网卡可能会先出现瓶颈。)
5、关于断言或者检查点配置技巧
A、断言越少越好,但要能保证事务的绝对正确性;
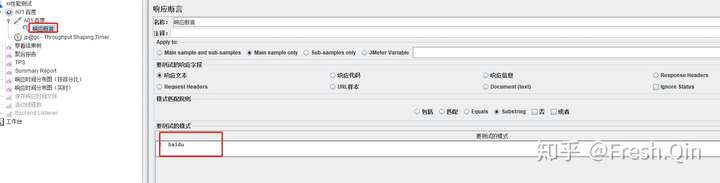
B、注意情况1,如果返回报文是如下情况
{resultcode:200,message:XXXXX123456,}
很多人习惯配置检查点resultcode:200,事实上这中策略是不科学的,如果返回报文如下时
{resultcode:200,message:null,}
你的检查点是成功的,但事务却是失败的(比如后端调用哪个服务超时或者失败了,通讯层面是成功的,但消息并没有成功返回)
所以,可以找返回体的某个关键字段作为检查点。
断言设置,一定要真正的保证事务的正确性!
C、注意情况2,大报文返回场景,如下:
{resultcode:200,list:[…………12345………………………………………………],}
如果按照传统的断言配置,我设置断言为12345作为内容检查就会出现问题,比如我list返回存在10条,甚至100条内容,我请求每次返回固定的10条,事实上如果就返回了1条,检查点通过,但实则事务失败。
所以建议使用Size Assertion
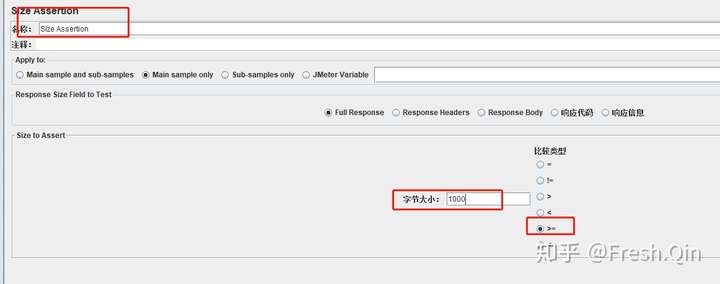
返回报文复制到本地文本,查看下字体大小,如果是1100字节,配置为>=1000字节,保证list返回报文量足够;
此外resultcode:200检查点要留,避免出现exception返回,字节很大,其实是失败的场景。
6、关于线上指标的估算
性能测试过程中,我们调研时需要确认指标要求,以下是我总结的几种估算场景
A、监控观察法--准确度高:
针对线上现有接口,存在监控数据(请求量和RT),可以直接查看该接口的某一段时间的调用峰值,将统计粒度换算为每秒请求量(qps)。
例:某服务1天36万笔(粗粒度统计),平均RT在100ms,指标计算如下
指标=(日量36万/10小时高峰期/3600秒)x5倍保险系数=50qps、rt100ms
例:某服务近期监控请求峰值为1小时36万笔(粗粒度统计),平均RT在100ms,,指标计算如下
指标=(时量36万/3600秒)x5倍保险系数=500qps、rt100ms
(监控粒度粗细和线上监控工具有关,分钟级的类似,除以60s即可)
B、类比法--准确度中:
针对新接口或者线上无监控的接口,但存在类似接口的监控,可以类比计算。
例:A接口线上指标为50qps、rt100ms,新接口B的使用场景和A相似度很高,那可以将B接口的性能也指标定位50qps、rt100ms
C、估算法--准确度低:
针对新接口或者线上无监控的接口,也没有类似的接口可以参考,仅从产品或者市场调研估算出某一天的量或者某一段时间的量,接下来估算方法和A方法类似。关于RT,如没特别说明,将会采用默认性能要求值(单服务单表类rt<100ms;较复杂接口rt<300ms;大list类或调用链较长接口rt<1s)
例:通过运营数据得知接口A在1天内要完成36万笔交易,指标计算如下
指标=(日量36万/10小时高峰期/3600秒)x8倍保险系数=80qps、rt100ms
D、其他情况:
除以上场景外,针对新接口无任何数据,无法给出指标值情况,性能压测不再关注指标压测,仅执行阶梯性的负载测试,压测出该接口的最优处理能力。(此情况存在较大风险,上线后需要时刻关注,请避免此情形。)
综上可知,你提供的请求总量和时间段越精确,估算出来的指标将会越准确。(另外,估算指标一般都会大于实际线上流量的,因为业务给数据的时候会上浮请求量,而我们本身又乘以了几倍的峰值系数)
7、关于指标折算
99%的情况不会在线上环境进行性能压测,
10%的公司会有独立的性能压测环境,而一般都是单机环境,由于机器数量的差异,我们需要对线上指标折算为测试环境压测指标。

8、关于压测策略
我们日常性能压测分为三类:指标压测、负载测试、混合场景稳定性测试,我也建议如果在时间计划允许的前提下,将这三项全部做到!
结合上面说到的指标,多说一点:比如我们某个接口线上指标为200tps,测试环境指标50tps,经过我负载测试,该接口单机都能压测到200tps(可能cpu会占用较高,),那么这类接口的性能风险可以说几乎没有(即便在指标上我们估算稍微有点低了,也一点都不用担心。)。
9、关于压测脚本对TPS的控制
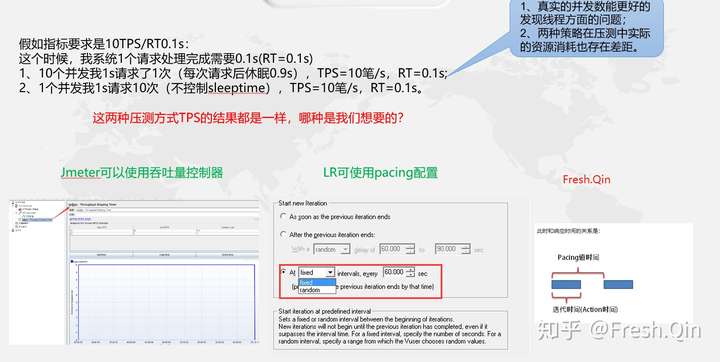
所以,我们在压测时,都要对TPS进行控制,做到100并发线程,压测出100tps的目的,这样的统计数据会更合理一点!
那么,什么时候不做控制呢?
只有一种场景,那就是逼不得已的时候--大并发压测,而压测机资产不足以支撑那么多并发时!
以我实际做过的项目来说,之前做过一次线上压测,我们的压测指标高达20万qps+,如果要控制并发达到这个压力的话,也就意味着我得使用20万个线程。
当时我们的压测机只有100台,由于都是云机器,单台最多支持500并发,这样算下来才5万并发……所以这个时候,就不要控制tps了,让线程尽情自由循环吧~
这种情况是可以接受的,因为对后端服务而言,你只要达到20万qps的请求压力就行了,至于是压测机端是1万,还是5万,或者还是20万并发造出来的压力并没太大区别。
10、JMeter必备必看图表
jp@gc - Throughput Shaping Timer 吞吐量控制器:控制10并发打出10tps的效果,控制压测时间
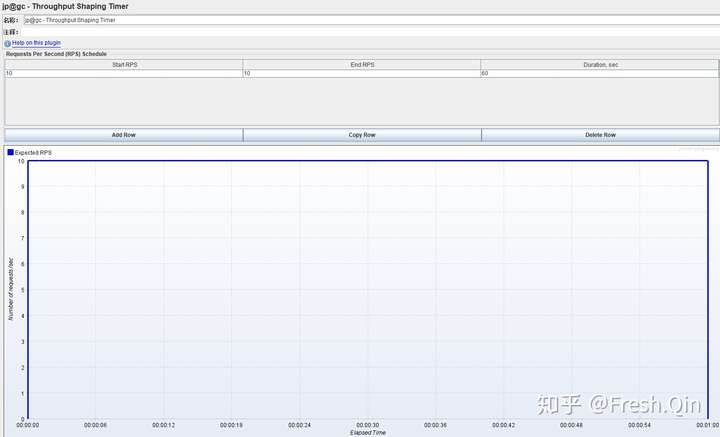
察看结果树:调试必备,不多说,压测执行时千万要勾选“仅错误日志”!

聚合报告和Summary Report:这两个表基本上相同,一般一个聚合报告就够了,但Summary Report有个std.dev(标准方差),可以稍微关注下~


jp@gc - Transactions per Second TPS实时图:必看图,压测过程tps的波动情况

jp@gc - Response Times Over Time RT实时图:必看图,压测过程响应时间的波动情况,同TPS(RT增大时,TPS会下降)
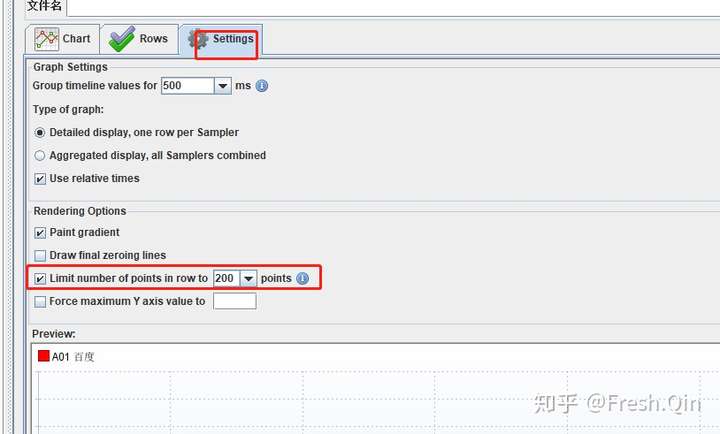
BTW:以上这些报表注意在实际使用过程中,设置展示点数量,10分钟压测还行,如果是稳定性,图表上的点过多一方面会影响本地JMeter的性能,另外一方面展示的图基本上不能看!
11、性能过程关注
我们性能压测时关注过程和细节的一项活动,所以要把握过程,注意监控工具的介入!
A、硬件资源层:
应用和DB的服务器的基础资源监控,包括cpu、内存、IO等,
监控工具可以使用JMeter自带监控agent、ZABBIX监控平台或者手动Linux命令(定向定位时使用)
B、应用级监控:
分两点,服务监控和DB监控,
如Java服务需要监控JVM信息(关注堆内存gc频率、线程状态等),.Net服务需要监控.NetCLR内存等信息;DB层主要就是慢查询和死锁。
C、全链路级监控:
针对压测过程中的链路请求监控,对于长链路,方便快速定位到哪个服务导致整个链路慢,从而方便定向的定位原因。

