
hbaes架构2-files
上一篇 / 下一篇 2012-02-08 20:38:00 / 个人分类:分布式技术学习
Hbase在hdfs上有一个可配置的根目录,默认是"/hbase"。
Root-level files:
WAL 的文件:由HLog实例控制,创建在hbase根目录的.logs目录。这个目录为每个HRegionServer创建了一个子目录。在每个子目录下面有HLog的文件。所有的regions共享本台regionserver的HLog文件。
有时候会有这样的现象:hadoop fs -lsr ./hbase/logs 会发现有的log文件是0。当这个文件是最近建立的时候相当的典型,因为hdfs正使用嵌入的附加的支持去往这个文件里面写东西(那段英文不太理解HDFS is using built-in append support towrite to this file),并且只有完整的数据块对读者可用的,包括hadoop fs -ls 这种命令的查看。尽管put操作的数据已经安全的持久化的,但是当前正在写log file的大小还是被轻微的关掉了。
之后等一个小时使得logfile is rolled,这个时候就能看到真是大小,这个时候它被关闭了,hdfs可以加载现在的大小了。下一个新的log file又开始从0开始。
当一个logfile不再被需要,盈威所有包含的编辑都已经被持久化到store files了,logs将被移动到.oldlogs下面。当logfile 基于配置的阀值被 rooled的时候被触发。
old log每10分钟(默认)由master进行删除(hbase.master.logcleaner.ttl这个参数可以配置)。 master会每10分钟检查一次这些文件(默认),这个参数hbase.master.cleaner.interval可以进行配置。
Table-level files:
每个表在hbase上都有一个自己的目录在hbase的根目录下面。
Region-level files:
在每个表目录的下面,每个region有一个独立的目录构成整个表。那些目录的名是MD5哈希值分给每个region的名。
-ROOT-,.META.表的目录名使用的是老的风格,不使用哈希,使用结尾点。
在硬盘上的目录region的名字也是不同的使用的是jenkins 哈希编码。
哈希命名保证了目录名总是有效的,就操作系统的规则而言不包括'/'。从总体上说region文件是这样的:/<hbase-root-dir>/<tablename>/<encoded-regionname>/<column-family>/<filename>.
在每个列族的目录里,可以看到真实的数据的文件HFile。它们的名字是随意的数据,是有java 随机数进行创建的。代码会检查保证名字不发生冲突,如果新的名字已经存在了则循环直到找到一个没用过的名字,用这个来代替。
region的目录也有一个.regioninfo文件,包含了这个region的HRegionInfo的序列化信息。
在split WAL 和region之间有明显的不同。有时从操作系统文件名的角度很难区分文件和目录。因为他们都和split相关。所以操作一定要注意避免误操作。
一旦region需要split,因为它超过了配置的region大小的最大值,一个相称的splits的目录会被创建,它被用来作为两个新子regions的舞台。如果这个进程成功了-通常是几秒钟甚至更短的时间,他们被移动到表的目录里来组成两个新的region,每个相当于原始那个region的一半。
当你看到一个region目录里面没有.tmp目录的时候,说明还没有压缩发生。没有recovered.edits文件说明还没有WAL重做发生。
region slipt进程会创建很多中间文件。
Region splits:
当一个store文件随着一个region的增长超过了配置的hbase.hregion.max.filesize大小或者其他情况在列族等级配置使用HColumnDescriptor时region会被拆分为二。这个起初会完成的非常快,因为系统就是为两个新的region创建两个相关文件,每个承担原始region的一半。
regionserver则通过在父region里创建splits来实现。接着会关闭region使之不提供任何其他的访问。
regionserver之后会通过在splits目录里建立必要的文件结构来为两个新的子regions做准备(使用多线程)。这个包括多个新的region目录和相关文件。如果这个进程成功完成了,它将会这两个新的region 目录移动到table的目录下。然后.META.这个表会被更新父region拆分了,拆分成了哪两个子regions。这样做阻止了它被意外的重新打开。
两个子regions都准备好就将被同一个server平行的打开。这个包括更新.META.表来列出这两个region都是可用的region就像其他的一样。之后regions就可以上线服务了。
打开子region也会为这两个都安排一次压缩。在后台将父region重写store files到两个新的一半里面来替代相关的文件。这个在子region的.tmp目录里面进行。一旦文件已经被搞定,它们将自动替换原来的相关文件。
当父region在没有任何相关的时候就将它彻底清除,从.META.表中移除,硬盘上所有它的文件都将被删除。最后master才被通知split,可以为新的region安排移动到其他的regionserver上以保证负载均衡。
所有的这些步骤包括split都被跟踪记录在zookeeper上。这样做的原因是一旦某个regionserver挂掉了允许其他进程知道region的状态。
Compactions:
store 文件被后台进程管理以保证他们在控制下。flush memstores 慢慢的建立了逐渐增长的硬盘文件数目。当文件数目足够多的时候,compaction 进程就会将他们合并到少但是更大点的文件。这样一直进行知道这些文件的最大值已经超过了配置的streo files大小的最大值,触发region的split。
cmpactions有两种:轻量级的,重量级的。轻量级的compactions 负责重写最近的小文件到一个更大的文件里。文件的数量室友hbase.hstore.compaction.min参数进行设置(之前叫hbase.hstore.compactionThreshold)。默认是被设为3,知道要被设成2或者更多。如果这个数被设置的太大的话compactions将会延迟,但这样也将会需要更多的资源,一旦开始compacions时间也更长。
在轻量级的合并中文件最大数目被设为10默认(hbase.hstore.comaction.max中可以设置)
列表也会被hbase.hstore.compaction.min.size(用来配置region的memstore flush 大小)和hbase.hstore.compaction.max.size(默认Long.MAX_VALUE)参数进一步缩小。任何比最大的合并大小大的文件总是不存在的。合并的最小值工作有轻微的不同:它是一个阀值而不是每个文件的大小限制。它包括在这个值下面的到每个压缩允许的总文件数的所有文件。下图:所有符合在最小值合并阀值下面的文件都包含在合并进程中。

算法使用hbase.hstore.compaction.ratio(默认是1.2或120%)来保证在选中的进程中包括足够多的文件。这个比率也将选择比所有新文件中的store files的总数合并大小大的文件。选举总是先从老的检查到新的,这样可以保证老的文件总是先被压缩。这些合并内容允许你调整有多少文件被包括在轻度合并中。
与轻量级合并相比,重量级的合并所有的文件到一个文件中。这种类型的压缩当压缩检查被执行时是自动运行的。当一个memstore被flush到硬盘,当compact或major_compact的shell命令被执行或者api中进行调用,或者是后台进程要求,压缩的检查都会被触发。这个后台进程被叫做CompactionChecker并且每个regionserver运行一个单独的实例。它是按规则的原则进行检查,有参数hbase.server.thread.wakefrequency(多线程是hbase.server.thread.wakefrequency.multiplier 设成1000会比其他基本线程任务运行的频率更低)参数进行控制。
如果调用majar_compact命令或者majorCompact() API 会强制major compaction 运行。否则,服务会从首次运行先根据hbase.hregion.majorcompacion(默认24小时)参数检查major compaction 是否合理。hbase.hregion.majorcompaction.jitter参数(默认0.2)将会导致这个stores的时间被展开。如果没有他所有stores将会在同一时间没24小时运行一次major compaction。
如果检查发现没有合理的major compaction则将启用轻量级的合并。根据前面提及的配置参数,服务决定对于轻量级的合并是否有足够的文件。当前这包括所有store文件并且比每个合并配置的最大文件数少的时候,轻量级的合并会被提升到重量级的合并。

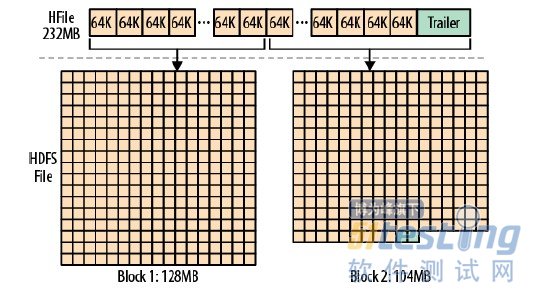
真正的存储文件是由HFile类实现的。是以hadoop TFile类为基础的。这个文件里面包含可变数目的块,只有file info和trailer是固定的块。trailer有指向其他块的指针。当数据被持久化到文件后trailer会被写完成当前数据永恒不变的存储。索引数据块记录data和meta数据块的迁移。data和meta的数据块都是随意存储的。但是鉴于hbase是怎么使用数据文件的,你讲几乎总是可以至少在store文件中找到数据块。数据块的大小可以由参数HColumnDescriptor参数配置,在表被用户创建的时候被指定或默认合理的规格值。Minimum block size:一般用法期待大小是8KB--1MB。如果是连续访问,大的数据块大小是被允许的,然而这也将导致随机访问的低效率,因为有更多的数据需要解压。更小的数据块对随机访问好,但是需要更多的内存来保存数据块的索引,而且创建也会变慢(因为必须我们必须在每个数据块的总结部分flush压缩流,这将导致fs的io的flush)。根据压缩袋的内部的caching,可能的最小数据块大小可以在20KB-30KB左右。
每个数据块包含一个magic头部,和一些序列化了的keyvalue实例。如果不使用压缩算法,每个数据块就和配置的block size一样大。这不是确认无误的科学,作者不得不迎合你要的任何东西,如果你存储的一个keyvalue对比block size大,作者也是不得不接受的。但是就算是小一些的数值,对于block size 的检查是在最后一个值被写完之后检查。所以在实践中,大多数的数据块会稍微大一点。当使用压缩算法的时候会没有多少在block size上的控制。如果可以决定多少数据可以足够获得有效的压缩率那么压缩的编码可以工作的最好。例如,将数据块设为256KB,使用LZO压缩以保证数据块总会被写入少于或等于256KB的数据来配合LZO的内部buffer 大小。
有一件事情需要注意Hdfs文件默认的数据块大小是6MB,是HFile默认数据块大小的1024倍。
有时可以直接访问一个HFile是必要的,通过HBase,例如检查健康,或者dump它的信息。:./bin/hbase org.apache.hadoop.hbase.io.hfile.HFile

keyValue 格式:
在HFiel中的每个KeyValue是一个低位的字节数组,允许零拷贝的访问数据。

这个结构以两个固定长度的用来表示大小的数和key的值开头。有了这些信息,可以以偏移访问数组,例如直接访问数据而忽略key。否则,得的从key中获得需要的信息。一旦数据在keyValue对java实例中解析,就可以使用获得的信息访问详细信息。在先前的例子中,key的平均值比value还大是因为它不得不存储组成key部分的keyValue。key保存rowkey。列族名,列的名,一些信息等等。对于下的负荷,这个就会引起重头。如果你处理的数据很小,也试着使用小的key。选短的row和列key(列族和列都小)以保证检测率。
另一方面,compression也会帮助减轻无法抵抗的key大小问题,这样看起来数据有穷的,并且所有重复数据会被压缩。在store file中,所有keyValue的排序帮助保持简单的key紧密的保存在一起。
TAG:
标题搜索
日历
|
|||||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 | |||
| 1 | 2 | 3 | 4 | ||||||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | |||
| 12 | 13 | 14 | 15 | 16 | 17 | 18 | |||
| 19 | 20 | 21 | 22 | 23 | 24 | 25 | |||
| 26 | 27 | 28 | 29 | 30 | 31 | ||||
我的存档
数据统计
- 访问量: 143728
- 日志数: 50
- 建立时间: 2011-09-28
- 更新时间: 2014-01-10
