
PHP学习笔记之 HTTP协议
上一篇 / 下一篇 2015-04-12 22:25:17 / 个人分类:软件开发
一、什么是HTTP协议
1. 超文本传输协议(HyperText Transfer Protocol),是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。
2. 工作在Tcp/Ip协议基础上。
3. 最初目的,为了提供一种发布和接收HTML页面的方法。
4. WEB开发数据的传输都是依赖于HTTP协议。
5. http1.0:短连接(数据发过去马上断掉)
http1.1长连接(keep-alive),一般30s左右,和浏览器有关系。
问题1:访问以下页面(test.html),浏览器共发出几次http请求?
----------test.html--------------
<h1>abc</h1>
<img src="test1.jpg"/>
<img src="test2.jpg"/>
解析:
浏览器发出了3次请求:
第一次:请求整个页面;
第二次:浏览器发请求test1.jpg;
第三次:浏览器发请求test2.jpg;
二、HTTP请求
1.客户端连上服务器后,向服务器请求某个web资源,称之为客户端想服务器发送了一个HTTP请求。
2.一个完整的HTTP请求包括以下内容:一个请求行、若干消息头、以及实体内容三部分组成。
3.请求行:用于描述客户端的请求类型,请求的资源名称以及使用的HTTP协议版本号。
4.在HTTP中,请求方式有POST、HEAD、OPTIONS、DELETE、TRACE、PUT,常用的有GET请求和POST请求。
5. GET与POST的区别:
(1)POST的安全性要比GET的安全性高,GET请求的数据会显示在地址栏上,POST请求放在HTTP协议消息体中。
(2)传输数据大小:
A.HTTP协议本身并没有限制数据大小,HTTP协议规范也没有对URL长度进行限制。
B.浏览器对get和post请求做限制:GET方式提交的数据最多只能是1024字节,因为GET是通过URL提交数据。IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。Post没有限制。
(3)get请求可以更好的添加到我的收藏夹
6.消息头(请求头):用于描述客户端请求以及一些环境信息等。
7.最常见的请求头:
Accept:用于指定客户端接受哪些类型的信息。eg:Accept:image/gif,表明客户端希望接受GIF图象格式的资源;Accept:text/html,表明客户端希望接受html文本。
Accept - Charset:用于指定客户端接受的字符集。eg:Accept-Charset:iso-8859-1,gb2312.如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。
Accept - Encoding:用于指定客户端接受什么样的数据压缩格式。eg:Accept - Encoding:gzip,deflate
Accept - Language:浏览器所希望的语言种类。
Connection:表示是否需要持久连接。
Content - Length:表示请求消息正文的长度。
Cookie:这是最重要的请求头信息之一,格式Cookie:NAME1=VALUE1;NAME2=VALUE2;.....;NAMEn=VALUEn。
Host:用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的,默认端口号是80.
If - Modified - Since:只有当所请求的内容在指定的日期之后又经过修改才返回它,否则返回304“Not Modified”应答。
Pragma:指定“no - cache”值表示服务器必须返回一个刷新后的文档,在HTTP/1.1协议中,它的含义和Cache-Control:no-cache相同。。
Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
User - Agent:浏览器类型。
实例1:查看客户端究竟给服务器端发送了哪些消息?
********http.php*********
<?php
foreach($_SERVER as $key=>$val){
echo "$key=$val <br/>";
}
?>
注:在服务器端,我们可以通过$_SERVER来获取我们需要的信息,$_SERVER是一个包含了诸如头信息(header)、路径(path)、以及脚本位置(script. locations)等等信息的数组。
重要的元素有
$_SERVER [‘HTTP_HOST’] 获取主机名
$_SERVER [‘REMOTE_ADDR’]访问该页面的ip
$_SERVER [‘ DOCUMENT_ROOT’] 可以获取apache的主目录
$_SERVER [‘ REQUEST_URI’]可以获取请求的资源名
实例2:使用一些HTTP请求,完成一个防盗链。
***********a.html*****************
<a href="information.php">查看账号信息</a>
***********information.php*******************
<?php
//获取REFERER
if(isset($_SERVER['HTTP_REFERER'])){
//判断$_SERVER['HTTP_REFERER']是不是以http://localhost/http开始的
if(strpos($_SERVER['HTTP_REFERER'],"http://localhost/http")==0){
echo "账号信息。。。。";
}else{
//跳转到警告页面
header("Location:warning.php");
}
}else{
//跳转到警告页面
header("Location:warning.php");
}
?>
************warning.php***************
<h1>您是非法盗链者</h1>
结果:
1) 如果直接通过URL(http://localhost/php/http/information.php)访问账号信息页面,会跳转到warning页面。
2) 如果从a.html页面点击【查看账号信息】,能正常跳转到账号信息页面。
三、HTTP响应
1. 一个HTTP响应代表服务器向客户端回送的数据,它包括:一个状态行、若干消息头以及实体内容,其中的一些消息头和实体内容都是可选的,消息头和实体内容直接要用空行隔开。
2.状态行:用于描述服务器请求的处理结果。
基本结构
格式:HTTP版本号、状态码、原因叙述<CRLF>
举例:HTTP/1.1 200 OK
状态码用户表示服务器对请求的处理结果,它是一个三位的十进制数。响应状态码分为5类,以下所示:
状态码 含义
100~199 表示成功接收请求,要求客户端继续提交下一次请求才能完成整个处理过程
200~299 表示成功接收请求并已完成整个处理过程,常用200
300~399 为完成请求,客户需进一步细化请求,例如,请求的资源已经移动到一个新地址, 常用302、304
400~499 客户端的请求有错误,常用404
500~599 服务器端出现错误,常用500
实例3:HTTP响应的实际应用。
(1)302状态码:告诉浏览器去别的URL(转向)。
302状态码的使用:访问a.php页面,自动重定向到b.php页面。
***********a.php********************
<?php
// 向客户端发送一个302状态码,告诉浏览器重新访问b.php页面
//header可以向http响应头写入信息
header("location:b.php");
?>
*****************b.php*******************
<?php
echo "b.php";
?>
(2)404状态码:一般指该页面不存在。
(3)304状态码:告诉浏览器资源没有修改,无需再获取。
3.消息头:用于描述服务器基本信息,以及数据描述,服务器通过这数据的描述信息,可以知道客户端如果处理
Ø 下面是比较详细的一个HTTP响应
Location:http://www.baidu.com.org/index.php
Server:apache
Content-Encoding:gzip 【内容编码支持gzip压缩算法】
Content-Length:80 【返回数据大小】
Content-Type:text/html;charset=GB2312
Last-Modified:Tue,11 Jul 2000 18:23:51 GMT【表示浏览器请求资源,最新时间】
Refresh: 1; url=http://www.baidu.com【告诉浏览器,间隔1s重定向baidu.com】
Content-Disposition:attachment;filename=aaa.zip
Transfer-Encoding:chunked
Set-Cookie:SS=Q0=5Lb_nQ;path=/search
Expires:-1
Cache-Control:no cache
Pragma:no-cache
实例4:HTTP应答头Refresh的应用,通过HTTP响应,控制浏览器间隔一定时间去跳转。
**********refresh.php************
<?php
header(“Refresh:3;url=http://www.souhu.com”);
?>
实例5:通过HTTP响应控制页面缓存(在默认情况下,浏览器会缓存页面).
**************cache.php*********
<?php
//通过header来禁用缓存
header("Expires:-1");
header("Cache-Control:no cache");
header("Progma:no cache");
echo "Hello,cache!";
?>
实例6:HTTP实际应用--文件下载
Ø 文件下载原理
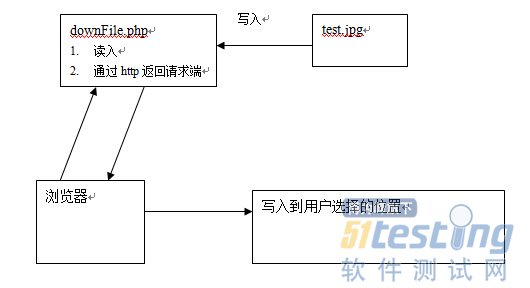
Ø 代码实现:
**************fileDown.php***********************
<?php
//对函数的说明:
//参数说明:$file_name文件名
//$file_sub_dir:下载文件的子路径 '"/XXX/XXX/"'
function down_file($file_name,$file_sub_dir){
//如果文件是中文名,因为php文件函数比较古老,需要对中文转码gb2312
$file_name=iconv("utf-8","gb2312","$file_name");
//绝对路径
$file_path=$_SERVER['DOCUMENT_ROOT'].$file_sub_dir.$file_name;
//打开文件
if(!file_exists($file_path)){
echo "文件不存在";
return;
}
$fp=fopen($file_path,"r");
//获取下载文件大小
$file_size=filesize($file_path);
//返回的文件
header("Content-type:application/octet-stream");
//按照字节大小返回
header("Accept-Ranges:bytes");
//返回文件大小
header("Accept-Length:$file_size");
//客户端的弹出对话框,对应的文件名
header("Content-Disposition:attachment;filename=".$file_name);
//向客户端回送数据
$buffer=1024;
//为了下载的安全,做一个文件字节读取计数器
$file_count=0;
//判断文件是否结束
while(!feof($fp) && ($file_size-$file_count>0)){
$file_data=fread($fp,$buffer);
//统计读了多少个字节
$file_count+=$buffer;
//把部分数据回送给浏览器
echo $file_data;
}
//关闭文件
fclose($fp);
}
//测试函数是否可用
down_file("test.jpg","/php/http/down/")
?>
TAG:
标题搜索
日历
|
|||||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 | |||
| 1 | 2 | 3 | 4 | 5 | 6 | ||||
| 7 | 8 | 9 | 10 | 11 | 12 | 13 | |||
| 14 | 15 | 16 | 17 | 18 | 19 | 20 | |||
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | |||
| 28 | 29 | 30 | |||||||
我的存档
数据统计
- 访问量: 310007
- 日志数: 243
- 建立时间: 2011-07-13
- 更新时间: 2018-07-15
