性能测试新手误区(一):找不到测试点,不知为何而测-n8Y*@�p�E0 测试环境的重要性无需多说,大家都知道测试环境要尽量的模拟生产环境,当然也包括数据。这样测试的结果才会更加准确的反应真实的性能。就连开发过程,都已经开始在大数据量下加压开发了。那么,关于测试数据,你了解多少呢?51Testing软件测试网�z�u�Y�}�t$e-e
51Testing软件测试网�L�k7a*r/x*E�a#@�U;D 通常说的测试数据可以分为两类:51Testing软件测试网({ @*E4R�O7S)?
51Testing软件测试网�V-t�P�J5Z�Q�C 一是为了测试性能而准备的数据,这是用来模拟“压力”的数据。也就是常说的数据量、历史数据等。一般都会根据需求或者经验很容易估算出来,比如案件年增长量为5%,去年数据量为100W,测试需要保证3年后系统仍可正常运行,那么就需要计算并模拟出3年后的总数据量,在这个基础上进行测试。
�[�n8B�O�V0�v2g�C8l%A%R2E9j�\0 二是用来辅助测试使用的数据。比
如有一个对案件进行打分的功能,只有符合一定条件的案件才会出现在打分列表中。那么我们要测这个打分的操作,首先就要保证有可用的案件,这就需要去生成测
试数据,该数据可能一经使用就失效了(已经打过分就不能再打了)。这样,每次测试这个功能,就需要准备这样一批数据。这里的测试数据,更多的是和测试流程
有关,是为了能够正常的进行测试,而不是涉及到性能的。
(s�T�z�X/t0&s�Q�V6r�E�g!R0 我们这里要说的是第一类,对性能测试结果产生直接影响的数据。
j�M4}7c.}�t!c0,R
j
q8Q�E�Y0 先看两个小案例,涉及到了案件表(T_AJ)和法院编号列(N_FY)、立案日期列(D_LARQ)。案件表中模拟了一百万测试数据,测试简单的查询操作,根据经验,预期响应时间在2秒之内。
�`!D�@�M�Q�@�i*d
[;p0�k�a�A1B B6O�v0~0 案例1.查询本院案件列表,相应的SQL如下:
�R-W�j�P3Z P�f0select*fromT_AJ51Testing软件测试网)N�q�h�h/A:b�b�o�H"_
whereN_FY=1051Testing软件测试网�d-p%`"o�\/]�r
orderbyD_LARQdesc |
�S ~�X
@�U0 执行这个操作耗时近10s,显然达不到正常预期。
�}8l�D*L�N051Testing软件测试网8Q.J"u�B�{
经排查,生成的100W测试数据中,所有的N_FY列值都为10。这样,最明显的问题就是,查询的结果集数量完全偏离了正常范围。如果实际有100家法
院,正常分布下,每家法院只有1W的案件,但测试数据的FY只有一个值,通过这个查询,查出了原来100家法院的数据。无论是在数据库处理中(如本例的排序),还是在程序的处理中(如展现或者是对数据做进一步处理),两者的性能差异都是很显著的。所以这个测试结果是无效的。
�D#b7Q�g�J�V�~051Testing软件测试网4T
Y�@:H�s7a�@ p 有人说,这个例子太弱了,结果集差了100倍,性能当然不一样了。那是不是数据总量和结果集大小都一致,测试结果就是有效了呢?51Testing软件测试网�_$Q�U�C�g�G
�g�B Y5U�I)f�c0 案例2.查询本院一个月内收的案件,相应SQL如下:51Testing软件测试网 j6@�[-I�u9j
select*fromT_AJ
!] E�m'g�u�@0whereN_FY=10andD_LARQbetween'20110101'and'20110201' |
�A1?*|�t�_2z+T e*b9d1A0 这个操作,查出来的结果只有一千条数据,属于正常范围。但查询的时间还是超过5秒,依然超出了我们的预期。
�@!o�X�q�m�I0�V�l6K's�F�`�x�X'V0 查看数据发现,N_FY=10的数据有近50万,占了总数据量的一半,D_LARQ在一月份的数据也占了差不多一半。但是同时符合两个条件的数据还是一千条左右。那么这里的问题就不在于结果集了,而是是否能利用索引进行查询,看如下两个图就能很好理解了。51Testing软件测试网,?�s�H9_�w�Y�i
�P$W�v(U({�X�m&`0
在正常数据中,每家法院的数据可能占总数据量的1%,一个月时间段内的数据可能占总数据量更少,假设是0.5%。那么这时我们通过N_FY和
D_LARQ两个条件进行查询,数据库会进行估算:符合D_LARQ查询条件的数据大概有5000条,符合N_FY查询条件的数据大概有1万条,那么用
D_LARQ上的索引进行查询是最快的,可以迅速的将查询范围缩小到5000条,然后在这5000条中去检查N_FY是否也符合条件。
8T(C6w�Y
o051Testing软件测试网2{�C�U,P�~ 过程如图一所示(手绘草图^_^)。51Testing软件测试网%W/^�t�i9s D3Q�S
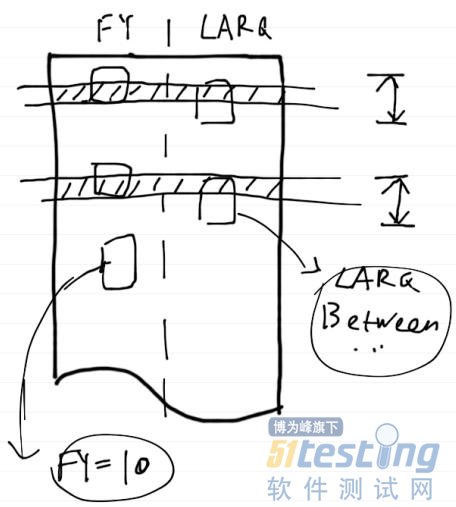
�G6h+V�}�@+Q�M�o0图一
x�g;~0p:L�e�r,l0 注:数据按行存储,小方块表示符合该列查询条件的数据,阴影表示符合所有查询条件,也就是最终的结果集。箭头线段表示为了完成查询,需要扫描的数据量,本图中即符合LARQ查询条件的数据。下同。
s�f#I�F�U9b2j0但在本例中不正常的数据条件下,数据库会知道:符合N_FY查询条件的数据有50万条,符合D_LARQ的也有近50万条,如果使用其中一列的索引
将一百万的范围缩减到50万,比从头到尾扫描整个表做的工作还要多(为什么呢?需要了解索引的结构和原理),那还是不要用索引了吧。于是数据库会依次检查
每一条数据,判断N_FY和D_LARQ是否符合条件。�C�x�t.k:W�Z7E�z�K0 如图二所示。51Testing软件测试网�I�W�C�n�e�~�q;G ^�c�r
 51Testing软件测试网 A�M�a�m�I;f
51Testing软件测试网 A�M�a�m�I;f
图二51Testing软件测试网.v�y�{�m:]$Y�E
注:本图中实际扫描的数据量就是整张表的数据,但结果集和图一是一样大的。51Testing软件测试网�e�M�Z9U9J#Q/_�I�U
这样,就可以知道,总数据量一样,结果集大小一样,为什么性能差了很多了。就是因为数据分布不合理,导致数据库无法
正常使用索引,从而进行了全表扫描。当然,这个数据分布,我们依然可以归类到结果集中去,那就是要保证每一个查询条件“单独的结果集”都要符合真实情况,
而不仅仅是整个查询最终的“总结果集”。51Testing软件测试网!f�P#r `*a�g8A�~�J�v�i
看个这两个简单的小例子,我们再来总结一下关于测试数据,需要注意的内容:51Testing软件测试网2p�c�e�w�g�t3V
1、最根本、也是大家都知道的就是数据量,性能测试必须保证能在预期的数据量下进行测试。在一万条记录中查询,和在一百万数据中查询,显然是大大不同的,可以把数据量看做一种“压力”,这个就不用再解释了。
�Q*F�]3~.Z0 但是在比较大型的系统中,这一点可能也不是很容易做好,因为这类系统往往有着复杂的数据库,上百张的数据表。对每张
表都进行数据模拟显然是不现实的,也是没有意义的,因为不是每张表都涉及到大数据量。那么如何选取不容易遗漏呢?通常通过两种方式:从设计和业务角度分析
表间关系、从现有实际数据量进行分析推测。51Testing软件测试网�h�u%y�T�j�j�S/T
2、确保结果集在正常范围内。结果集的大小直接影响后续很多工作的性能,如数据排序分组、分页、程序中的逻辑校验或者是展现。51Testing软件测试网�l/]�@�i)q-l0]�S"q
3、数据分布必须合理,尽量接近真实。数据的分布,其实也就是数据的真实性,它直接决定了数据库是否使用索引、选用哪个索引,也就是常说的查询计划。不同的查询计划也就是不同的数据访问路径,性能差别可能会很大。51Testing软件测试网,u
^�i�b;u�I
这里主要涉及到的是索引的问题,需要大家对索引的原理有一定的了解,索引如何工作、数据库如何选择索引、和索引有关的一写重要概念如区分度(selectivity)等等。51Testing软件测试网.^2i�c�n&C!j9a3x�?
4、最好的数据来自生产环境。这是显而易见的,使用真实的数据测出来的结果才是最准确的。但是绝大多数情况下,
我们没有这样的好运,可能是客户禁止、也可能是生产环境数据量比较小。那就只好自己想办法来模拟了,需要注意的也就是上面说到的几点。这里再推荐一种方
法,数据翻倍。比如已经有了真实的数据十万条,但我们需要一百万条,那就可以通过写一些SQL或者存储过程,将现有的数据不断翻倍(简单的说,复制到临时
表,根据需要修改一些列,再插回到原表),这样的数据真实性还是比较高的。
5D�t�k2K4?,k;\051Testing软件测试网3^�n:Z"r�H-D#n4_8| 关于测试数据,我想说的就是以上几点了。另外再补充上一些相关内容,也是性能测试人员需要关注的。51Testing软件测试网
n�i�|"I o�[$X
)}�H0j#i%e,x5S�i�?$F.B1N0 ● 重点了解IO的概念,更准确的说应该是物理IO。一般来讲,数据库的瓶颈或者查询的主要耗时就是IO。所以,数据库优化的一个重要方向就是尽量减小IO。51Testing软件测试网�U�v:v�k�~�z8U�s
4`�J�]
m:f5d(U4]0 IO是不是只和数据量(行数)有关呢?举一个例子:
7B�e2W,l7G0�U!I�Y:W#R0Q {0
�T:m5Q�L�_�|4c0selectco1, col2, col3, col4, col5fromT_AJ51Testing软件测试网9U�C(d A�U5x!v7m�v�T3}�J
wherecondition... |
51Testing软件测试网+N�h
F&u&\�n�E5y
@2q�\ T_AJ数据量有100万,表中有近200列,此查询耗时大于10秒。而另一种实现方式,首先将col1-col5以及查询条件中的几个列的数据抽取到一张临时表(#T_AJ)中。然后,51Testing软件测试网7c�i�|�H�@�^
51Testing软件测试网�j�y�U:g*C�`8]*B"l e�F�[;h�o6?0selectco1, col2, col3, col4, col5
�]�]0C�i�w�N�A0from#T_AJwherecondition... |
2z�~3N)z6I"?0 临时表#T_AJ和原数据表有同样的数据量(行数),但是此查询却只需要1秒(暂不考虑抽取到临时表的耗时),这就是不同IO引起的差异。通常
我们使用的数据库都是行式存储的,可以简单的理解为,一行数据从头读到尾,才能进入到下一行。这样,不管一行中的200列,你只读取其中的一列还是几列,
其余的190多列仍然需要一定的IO。在大数据量下,这个性能差异就很明显了。所以上面的这个例子就是一种典型的优化手段,索引覆盖也是处理类似问题的典
型方法,各位自行了解吧。列式存储数据库(如Sybase IQ)之所以性能这么高,也是同样的道理。
8V'H,S
L-L�I,S�G�n ?�J-y051Testing软件测试网2y6F�s3_*~(V2f"} ● 尽量深入了解这些概念,如执行计划,基于开销的估算,统计信息等等。我用一句话来简单描述:数据库通过统计信息来估计查询开销,统计信息不准时,开销估计就可能不准确,从而导致选择了错误的执行计划。
�C�Y�x&O9O�z�a4E0�A*B�M�n�c�s�c0 ● 测试过程中数据的清理。性能测试过程中可能又会生成大量的数据,积累到一定程度又会对性能结果造成影响,所以每一轮测试时都应该清理掉之前测试过程中产生的数据,保证每次测试是在相同的条件下进行的。
!~*f+S/a�u;V0�P'}�M%r1r�Z�@0 ● 性能测试过程中,如果定位到了某一个查询或SQL有问题,首先要确认的是数据是否合理。通过查询计划来判断是否按预期进行了查询,如果不是,查看数据的分布是否真实。一般数据库会提供很多种手段来进行验证。
#R�{:A�x�G-y8Y.T0�{�G8X�z�?�x,U"?0 最后,本文所写内容都是针对传统的行式存储数据库的,还请大家注意。51Testing软件测试网�p4b)}%G9l)y/h
51Testing软件测试网4H�i*w&X2m�s相关链接:
�O�Y8y�z�b�p%t1P#A�v0,M�]6v�u�p%E(e�L0性能测试新手误区(一):找不到测试点,不知为何而测
�f�K�m�c�u0y8C0

