дкЖрИіСаЩЯУцНЈСЂЫїв§ЕФЪБКђЃЌЮвУЧГЃГЃЛсгіЕНетбљЕФвЛИіЮЪЬтЁАашвЊАбФФИіСаЗХдкЧАУцЁБЃЌвђЮЊЫїв§жаСаЫГађЕФВЛЭЌЃЌЛсЖдЫїв§ЕФЪЙгУЃЌвджСадФмВњЩњКмДѓЕФгАЯьЁЃЮвУЧБОЦЊОЭРДЗжЮіетИіЮЪЬтЁЃ
�M8~ q-C
x
y&r8?0ЁЁЁЁЖдгкЩЯУцЕФЮЪЬтЃЌвЛИіГЃМћЕФЛиД№ОЭЪЧЁААббЁдёадзюДѓСаЗХдкЧАУцЁБЃЌетРяЮЊСЫЪЙЕУКѓУцЕФНВЪіЫГађНјааЃЌЮвУЧЯШРДНтЪЭвЛЯТбЁдёадЕФКЌвхЁЃбЁдёадЪЧгУРДУшЪіЪ§ОнЕФВювьЧщПіЕФЃЌР§ШчЃЌШчЙћвЛИіБэжага1000ЬѕЪ§ОнЃЌЦфжаЕФФГИізжЖЮЃЌШчIDЃЌШчЙћУПвЛЬѕЪ§ОнЕФIDжЕЖМВЛвЛбљЃЌФЧУДIDЕФбЁдёадОЭЪЧ1ЃЛШчЙћЦфжага 300АйИіIDЪЧвЛбљЕФЃЌФЧУДОЭЪЧЫЕЃЌга700ИіIDВЛЭЌЃЌФЧУДбЁдёадОЭЪЧ70%ЁЃКмЯдШЛЃЌЪ§ОнЕФбЁдёаддНИпЃЌФЧУДдкЩЯУцНЈСЂЫїв§аЇЙћОЭдНКУЁЃ
U"|&]#n;f1G0.u�\�M"h&`
G0u:Y0ЁЁЁЁЯТУцЃЌЮвУЧОЭРДНтЪЭвЛЯТЮЊЪВУДдкЖрИіСаЩЯУцНЈСЂЫїв§ЕФЪБКђашвЊАббЁдёадИпЕФСаЗХдкзюЧАУцЁЃ51TestingШэМўВтЪдЭј/r,Z�I�J+Y)o
�j�f P�B7p:Y�l B7\�r0ЁЁЁЁвВаэгаХѓгбЬ§ЕНЩЯУцЕФНЈвщжЎКѓЃЌдкНЈСЂШЮКЮЛљгкЖрИіСаЕФЫїв§ЕФЪБКђЃЌЖМЛсАбБэЕФОлМЏЫїв§ЫљдкЕФСазїЮЊетИіЖрСаЫїв§ЕФЕквЛИізжЖЮЁЃР§ШчЃЌМйЩшЯждкБэжага4 ИізжЖЮЃЌIDЃЌNameЃЌAgeЃЌBirthDateЃЌЦфжаIDЪЧжїМќЃЌвВЪЧОлМЏЫїв§ЃЌЯждкЮвУЧашвЊдкNameЃЌBirthDateЩЯУцНЈСЂЫїв§ЃЌетИіЪБКђЃЌгаХѓгбЗЂЯжЃКIDЕФбЁдёадзюИпЃЌФЧУДАбIDЗХдкаТЕФЫїв§жаЃЌЪЦБиЛсИќКУЃЌгкЪЧвЛИіУћзжЮЊIX_IndexЕФЫїв§ОЭАќКЌСЫШ§ИіСаЃКIDЃЌNameЃЌBirthDateЁЃЕНКѓРДЃЌПЩФмОЭЗЂЯжЃЌШчЙћУАУАШЛЕФетбљзіЃЌЪЙЕУетИіаТНЈЕФЫїв§УЛгаЗЂЛгзїгУЃЌЗДЖјЕМжТадФмЮЪЬтЁЃ
-b�_�J�[#{�W�i051TestingШэМўВтЪдЭј M�]�@3f�v)j7^ЁЁЁЁЖдгкЪ§ОнПтжаЕФУПвЛИіЫїв§ЃЌЖМЛсгаЯргІЕФЭГМЦЪ§ОнаХЯЂЃЌетИіЭГМЦЪ§ОнЯдЪОСЫЪ§ОнЕФЗжВМЧщПіЃЌЭГМЦаХЯЂвдвЛИіРрЫЦжљаЮЕФаЮЪНБэЯжСЫЪ§ОнЕФЗжВМЁЃЪ§ОнПтжЛАбЫїв§жаЕФЕквЛИіСаЕФЪ§ОнЗжВМЧщПіЗХдкжљаЮЭМжаЃЌЛЛОфЛАЫЕЃЌетИіЭГМЦаХЯЂЯдЪОЕФОЭЪЧЫїв§жаЕФЕквЛИіЪ§ОнСаЕФЪ§ОнЗжВМЧщПіЃЈетРяУцЩцМАЕНЕФФкШнгаЕуЩюЃЌДѓМвПЩвдЙизЂБОеОЕуЕФ ЁАВщбЏгХЛЏЦїФкКЫЯЕСаЁБЃЌРяУцЛсНВЪіЕНЃЉЁЃ
�r�J�s&}#T!e051TestingШэМўВтЪдЭј�E5U+n�I:X!lЁЁЁЁЮвИјДѓМвПДИіР§згАЩЃЌМйЩшдкSalesOrderDetailБэЩЯУцгавЛИіЫїв§ЃКX_SalesOrderDetail_ProductIDЃЌдЫааЯТУцЕФгяОфЃК51TestingШэМўВтЪдЭј�V1p�M(U(n�f7x j�m

�R�H q-B;f;Y0ЁЁЁЁетИіЫїв§АќКЌЕФСагаЃКProductIDЃЌSalesOrderIDКЭSalesOrderDetailIDЁЃЮвУЧВщПДЫќЕФЪ§ОнЕФжљаЮЗжВМЭМЃЌШчЯТЃК51TestingШэМўВтЪдЭј�z�j%}0^�i
 51TestingШэМўВтЪдЭј G�L�~�o�@�u�h0F�E
51TestingШэМўВтЪдЭј G�L�~�o�@�u�h0F�E
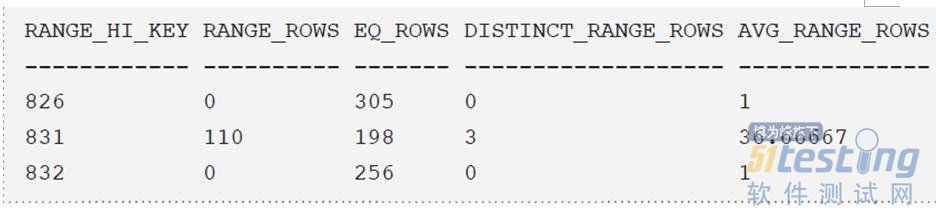
ЁЁЁЁЮвУЧЗЂЯжЃЌЦфжаЕФRANGE_HI_KEYСаГіЕФОЭЪЧProductIDЕФжЕЃЌЭЈЙ§ЭМжаЃЌЮвУЧПЩвджЊЕРЃКProductIDжЕЮЊ826ЕФЪ§Онга305 ЬѕЃЌжЕЮЊ831ЕФЪ§Онга198ЬѕЁЃProductIDЕФжЕдк826ЕН831жЎМфЕФЪ§Онга110ЬѕЁЃВщбЏгХЛЏЦїОЭЪЧИљОнетИіРДЙРЫуЪ§ОнЕФЬѕЪ§ЕФЁЃ
,B |�]'e�b�W4I�j0ЁЁЁЁЭЈЙ§ЩЯУцПЩвджЊЕРЃКАбЫїв§жаЕФФФИіСаЗХдкЧАУцжСЙиживЊЃЌШчЙћАбвЛИібЁдёадКмЕЭЕФСаЗХдкЧАУцЃЌФЧУДОЭЕМжТЫїв§ЕФЭГМЦЪ§ОнЯдЪОЕФЪ§ОнЗжВМЭъШЋИФБфЃЌПЩФмЕМжТВщбЏгХЛЏЦїбЁдёБШНЯЕЭаЇЕФжДааМЦЛЎЁЃ51TestingШэМўВтЪдЭј+d7|)v�|�m�g
ЁЁЁЁЯТУцЃЌЮвУЧОЭЭЈЙ§вЛИіР§згРДНјвЛВНЕФПДПДетИіЮЪЬтЁЃ51TestingШэМўВтЪдЭј�F"T3N�n1|�Y�E�m
ЁЁЁЁЪзЯШЃЌНЈСЂвЛИіВтЪдЕФБэЃЌШчЯТЃК
?�v�G"i0P)Q)W:A0
6b
L�e-E6u�`
|�R0ЁЁЁЁетИіБэжага10000ЬѕЪ§ОнЃЌВЂЧветИіБэЪЧвЛИіЖбБэЃЌМДУЛгаОлМЏЫїв§ЕФБэЁЃВЂЧвдкетИіБэжага100ИіВЛЭЌЕФSomeStringжЕЃЌга5000ИіВЛЭЌЕФSomeDateжЕЃЌЖјIDЪЧЮЈвЛЕФЃЌШЋВПЖМВЛЭЌЁЃ51TestingШэМўВтЪдЭј�S�s2G n�w3I
ЁЁЁЁФЧУДЃЌЩЯУцЕФжЕЕФбЁдёадШчЯТЃК
�x�S!x�X�g�u�K�T7F�E.d!X0зжЖЮУћ
N
Q�D(@
j2X({�{�S0 | бЁдёад �G�F%{�l C!M�z0 |
�N�w�m)q+f%E�R0ID51TestingШэМўВтЪдЭј�e�d�V)R0Z | 51TestingШэМўВтЪдЭј(B�g�v6?�Y�c-m%N�U 100%51TestingШэМўВтЪдЭј+j�f�z:o�C |
/E#q0y�{/K:n�K�Q(i0SomeString51TestingШэМўВтЪдЭј5N!| H"S G/z�C/r | 51TestingШэМўВтЪдЭј�T�^�u%|�^/H�u0K 100/10000*100%=1%51TestingШэМўВтЪдЭј�|�T�s7{3v�R#N |
| 51TestingШэМўВтЪдЭј9{)F�x�j�n SomeDate �X�B�y�[�t
B.d�H-x0 | 51TestingШэМўВтЪдЭј,B�Q�h/t"E 5000/10000*100%=50%51TestingШэМўВтЪдЭј R�K8L5t3~�k6F)d |
дкБэжаЃЌгавЛИіЗЧОлМЏЫїв§ЃЌМйЩшУћзжЮЊIdx_testЃЌАќКЌСЫБэжаЕФШ§ИіжЕЃЌШ§ИіСадкЫїв§жаЕФЫГађЮЊЃКID,SomeDateЃЌSomeStringЃЌАДеебЁдёадХХађЃЌШЗЪЕВЛДэЃЁ�[-R*l'O�\-n051TestingШэМўВтЪдЭј�i$O�U�L8[�D�s
- Ё WHERE ID = @ID AND SomeDate = @dt AND SomeString = @str
- Ё WHERE ID = @ID AND SomeDate = @dt
- Ё WHERE ID = @ID
|
51TestingШэМўВтЪдЭј�x#Z4P0X0S�E1K�X6{ЁЁЁЁЛЛОфЛАЫЕЃЌОЭЪЧетИіЫїв§жЛдкВщбЏжаЕФWhere/JoinЕФСаАДееЫїв§жаЕФСаЕФЫГађЪЙгУЕФЪБКђВХгааЇЁЃШчЙћВщбЏЪЧетбљЕФЃЌШчЯТЃК51TestingШэМўВтЪдЭј-R%y.J;{*Z T6{�}
51TestingШэМўВтЪдЭј�n�` F5l�q!M2eЁЁЁЁЖдгкЩЯУцЕФЫїв§ЃЌжЛгадкРрЫЦЯТУцЕФВщбЏНсЙЙжаЗЂЛгзїгУЃЌШчЯТЃК
(L:@�c X�{ q051TestingШэМўВтЪдЭј�B8K c�t"@'n�R�b| Ё WHERE SomeDate = @dtЛђепЁ SomeDate = @dt AND SomeString = @str |
51TestingШэМўВтЪдЭј'F�i4_
j
Z�E0Z!d�K
R�W�t�J4K%| X�k0ЁЁЁЁФЧУДЃЌетИіЫїв§ОЭВЛЛсЩЯУцЕФВщбЏжаЪЙгУСЫЃЌФЧУДВщбЏдкжДааЕФЪБКђОЭЛсЩЈУшећБэСЫЁЃ51TestingШэМўВтЪдЭј!m(e�~"m�?�n3t�`
�Z)|�]4k*j�})Z#j)j0ЁЁЁЁЮвУЧЭЈЙ§жДааМЦЛЎРДПДПДЪЧВЛЪЧетбљЕФЁЃ51TestingШэМўВтЪдЭј0C�m(m�u-s�]�`2z;B�V0f
4[7v*\
@�x*G�j0ЁЁЁЁЖдгкЃЌWHERE ID = @IDЕФВщбЏЃЌжДааМЦЛЎШчЯТЃК
D-^�K+T�A�P
i v M�n�l0 51TestingШэМўВтЪдЭј�o8{�v.W%l-~�s�@
51TestingШэМўВтЪдЭј�o8{�v.W%l-~�s�@
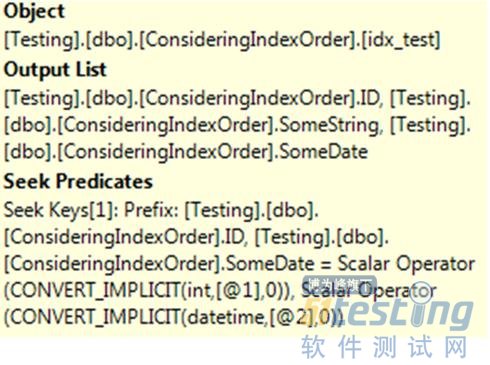
ЁЁЁЁКмЯдШЛЃЌжДааСЫSeekВйзїЃЌЪЧКмПьЕФЁЃ51TestingШэМўВтЪдЭј�W8r#z�s"m�q2r�n-K ~
ЁЁЁЁЖдгкWHERE ID = @ID AND SomeDate = @dtЕФВщбЏЃЌжДааМЦЛЎШчЯТЃК51TestingШэМўВтЪдЭј�x�U
I+}/J#]4e
 51TestingШэМўВтЪдЭј�A�L�U)] ~�D
y
51TestingШэМўВтЪдЭј�A�L�U)] ~�D
y
ЁЁЁЁЛЙЪЧНјааСЫSeekВйзїЁЃ51TestingШэМўВтЪдЭј/v+g�Z-n&s3g�n�z
ЁЁЁЁФЧУДЖдгкЁ SomeDate = @dt AND SomeString = @strЕФВщбЏЃЌШчЯТЃК
�_;B
d1u9I J0 51TestingШэМўВтЪдЭј�Y'z�p2k/M�H5b3c
51TestingШэМўВтЪдЭј�Y'z�p2k/M�H5b3c
ЁЁЁЁДѓМвПЩвдПДЕНЃЌетИіЪБКђвбОПЊЪМНјааШЋБэЩЈУшСЫЁЃ
�{1T�W�f�v0ЁЁЁЁЮвУЧБОЦЊНВЪіСЫдкЫїв§ЕФНјааСаЕФЯрЕШВйзїЪБКђЃЌСаЕФЫГађЮЪЬтЃЌЮвУЧЯТвЛЦЊОЭНВЪіШчЙћЪЧдкСаЩЯНјааВЛЕШВйзїЃЌР§ШчID>1ЃЌФЧУДЫїв§жаЕФСаЕФЫГађЛЙЪЧетбљНјааТ№ЃП
-j�X8?)P�I*g�s�P�h0

