前段时间开发了http消息监控工具filterLogTool,同时也
为此写了篇实践的论文。应用的结果由于涉及实际项目具体内容就不介绍了。该工具已经在现场作为监控使用。
在这里介绍论文的理论部分。
摘要
WEB系统的日常工作是处理每个HTTP请求,同时也会对每个请求作出响应。我们对每个请求的消息内容和响应时间等重要信息进行记录,并对这些数据进行分析,可以帮助我们从各个不同的方面去了解现在系统的性能和用户行为等方面的信息。本文描述了一个HTTP服务端消息监控分析方案的实现原理,以及在XX系统中该方案的实践情况。
关键词
HTTP、实时监控、数据挖掘、过滤器
1 引言
WEB系统的日常工作是处理每个HTTP请求,同时也会对每个请求作出响应。如果我们在服务端对每个请求的消息内容和响应时间等重要信息进行记录,那么这些数据是第一手的、真实的、精确的、服务端现状的数据。对于这些有巨大价值的数据,我们可以根据我们的需要进行挖掘,从而精确的分析,可以帮助我们从各个不同的方面去了解软件性能和用户行为等方面的信息。这个就是实时监控和数据挖掘的思想。
实时监控,可以监控实验室或者现场的系统,随时的自动收集数据,也可以有选择的监控数据。该数据的特点是,第一手的、真实的、精确的。蕴含巨大的价值。
数据挖掘,就是要挖掘出我们监控数据的价值。可以在性能方面分析,分析请求的处理能力。可以对请求频率进行分析统计,分析用户的行为。也可以对某些请求进行分析,判断异常的请求,预警系统。
2 设计实现
HTTP服务器有许多类型,而且不同的服务器还支持不同的语言。但是每种服务器都是基于“请求—响应“模式实现的。所以要实现获取“请求—响应“的重要信息在不同的服务器和语言有可能不一样,但是原理是一样的。当然,有些服务器也提供了请求数据的日志记录,但是里面包含的信息不一定存在我们需要的。所以我们采用自行开发的方式来取得“请求—响应“的重要信息。
下面介绍的这个实现方案是基于JAVA的WEB服务器的实现,采用过滤器作为获取“请求—响应“信息的切入点。
2.1 系统分析
2.1.1 典型web计算模式

由上图1我们可以知道,一个请求到达以后是会经过一层一层调用传递过去的。Servlert层是与http协议相关的,包装了有关协议的信息。其他层次,一般的软件架构会设计成与http协议无关。红色框起来的就是整个web的计算组件。最右边的一般就是数据库或者其他第三方应用了。2.2 监控实现方案
2.2.1 收集数据的切入点

图2
在JAVA WEB中有个可以自定义的组件叫做过滤器,它可以插入到处理请求逻辑的最前端。所有的请求必须经过过滤器,执行完了以后又返回过滤器。这个点正是我们实现记录“请求—响应“的重要信息的非常好的切入点。在该点切入有如下优点:
1)最前端拦截
2)跟应用代码无耦合
3)拔插方便
4)真正的服务端耗时
2.2.2 收集日志的流程
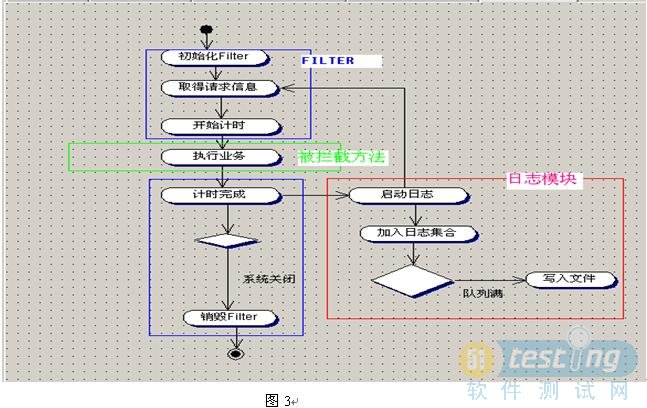
图3
在切入点,我们可以进行收集我们需要的数据。收集数据的流程如图3所示。每当有请求过来,就启动计时器,然后执行业务方法。业务方法执行完之后,计时完成。然后把收集的请求信息,计时信息等传入到日志模块中,日志模块根据策略把信息写入到文件中。实际上是有两个模块组成。
1)过滤器
负责启停计时器和执行业务方法,收集信息,启动日志模块。
2)日志模块
负责收集和整理信息,并按照策略写入日志文件。牺牲一点性能
2.3 数据挖掘方案
当系统把需要的数据记录以后,下一步我们需要的是对这些数据进行挖掘,从各个不同的角度进行分析。
2.3.1 分析过程
分析过程可以多种多样,我们推荐采用“导入数据库---sql分析”的方法进行。借助数据库的sql来进行分析我们的数据。
2.3.1.1 日志各个字段含义
各个字段之间逗号隔开
日志文件各个字段含义:
appName, 应用名称,该名称是配置过滤器的时候配置的
serverIP, 服务器IP,配置过滤器的时候配置的
serverName, 服务器名,配置过滤器的时候配置的
sessionid, 会话ID,
clentIP, 客户端IP
clientHostName, 客户端机器名
URL, 请求的URL
startDate, 开始执行的时间
durationTime, 执行URL耗费的时间
parameterList URL的参数
2.3.1.2 分析的步骤
分析方式有许多中,下面为推荐的一些分析方法
l 分析步骤
1.把数据log文件拷贝出来。修改后缀为csv
2.把数据导入导分析的临时表中
可以用sql dev的imprt txt功能
整理临时表的数据,比如去掉空格
3.把数据导入导正式表
2.3.1.3 分析过程用到的表
可以创建保存日志的表
cclLog_tmp 用于临时导入数据,导入的日志数据,往往还需要进行整理
cclLog_ok 用于保存已经整理后正确的数据
l 创建用于分析的表
正式表
create table cclLog_ok
(
filename varchar2(100),
appName varchar2(100),
serverIP varchar2(100),
serverName varchar2(100),
sessionid varchar2(200),
clentIP varchar2(100),
clientHostName varchar2(100),
URL varchar2(1024),
startDate date,
durationTime number,
parameterList varchar2(2000)
)
;
临时表
create table cclLog_tmp
(
appName varchar2(100),
serverIP varchar2(100),
serverName varchar2(100),
sessionid varchar2(200),
clentIP varchar2(100),
clientHostName varchar2(100),
URL varchar2(1024),
startDate date,
durationTime number,
parameterList varchar2(2000)
)
;
l 整理临时表数据
去掉多的字符
update cclLog_tmp tt set tt.appName=ltrim(rtrim(tt.appName)) ,
tt.serverIP=ltrim(rtrim(tt.serverIP)),
tt.serverName=ltrim(rtrim(tt.serverName)),
tt.sessionid=ltrim(rtrim(tt.sessionid)),
tt.clentIP=ltrim(rtrim(tt.clentIP)),
tt.clientHostName=ltrim(rtrim(tt.clientHostName)),
tt.URL=ltrim(rtrim(tt.URL)),
tt.parameterList=ltrim(rtrim(tt.parameterList));
l 转入正式库
注意修改文件名,正式表比临时表多了filename字段
insert into cclLog_ok
(filename,appName ,serverIP,serverName,sessionid,clentIP,clientHostName ,URL ,startDate,durationTime ,parameterList
)
(
select '2009-03-25~09#24#20_1.log',//这里要修改文件名
appName ,serverIP,serverName,sessionid,clentIP,clientHostName ,URL ,startDate,durationTime ,parameterList
from ccllog_tmp
)
2.3.1.4 分析用到的sql
分析可以从不同的角度进行,主要是根据我们的需要进行。
可以分析临时表或者正式表,灵活处理
下面列举几个常见的分析sql
l 分析平均时间
select t.url, count(*), max(t.durationtime),min(t.durationtime),round(avg(t.durationtime),0) avgt from cclLog_ok t
group by t.url
order by avgt
l 取平均时间超过4S
select t.url url , count(*) total, max(t.durationtime) maxt,min(t.durationtime) mint,round(avg(t.durationtime),0) avgt from cclLog_ok t
group by t.url having round(avg(t.durationtime),0)>4000
order by avgt
2.3.2 性能收集工具对系统的影响
在XX系统中,我们对A1在部署了和没有部署性能收集工具的情况下,进行测试。以了解性能收集工具对系统性能的影响。
测试场景:每秒增加2个用户,最大用户为100,达到最大用户后持续运行5分钟
从用户数量上来看,都能平稳达到。
从平均事务响应时间上来看,部署了是1.856秒,没有部署是1.8秒。也就是说加上了性能收集工具占3%左右的性能消耗时间。
从每秒点击率上看,部署了是137.786,没有部署是141.388.
2.3.2.1 部署了性能收集工具
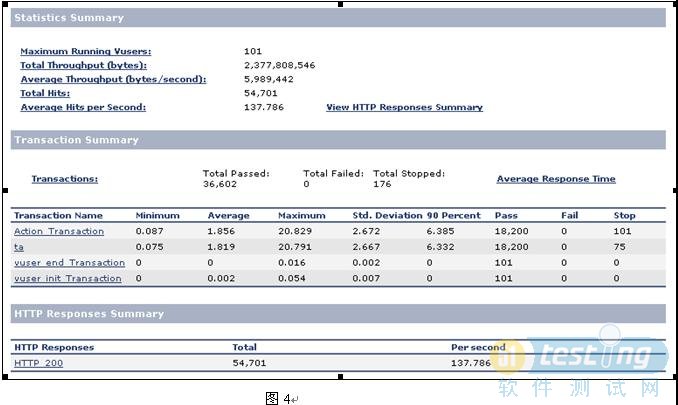
图4
2.3.2.2 没有部署性能收集工具

图5

引用 删除 xiaohanjiang / 2010-04-07 17:03:22
引用 删除 fengxueren / 2010-04-07 11:10:18
