
国际化(本地化)收集
上一篇 / 下一篇 2010-08-27 14:57:42 / 个人分类:国际化
第一级:保证英文版本的产品可以在本地化系统上正常运行
第二级:保证软件在何区域性或区域设置中都能正常运行,并且能够支持本地化的字符输入,输出和显示。
第三级:保证测试软件可以被方便的本地化而不需要重新设计或修改代码。
第四级:支持双向识别能力。
8.1.1 软件国际化的基本要求
在介绍软件国际化之前,先举和日常生活密切相关的几个简单的例子。
示例
(1)姓名。英文中一个人的名字为3部分--First Name(名)、Middle Name(字)和 Last Name(姓),在软件中显示时可以省去中间部分,即First Name+空格+Last Name。英文名和中文名在软件中的显示至少有两点不同:
姓和名次序正好相反。
英文名在名和姓之间必须有一个空格。
在雅虎日历中文版上,用户登录后显示的只有名而没有姓,这不合乎中文的习惯,如下图所示,"欢迎光临 琪"是一个缺陷(如图8-2所示)。
 |
| 图8-2 |
(2)日期。美国表示日期的习惯是"月/日/年",而英国人喜欢用"日/月/年",如2007年1月31日,美语中表示为"1/31/2007",而英语中表示为"31/1/2007"。
(3)
时区,我国处在东8区,即北京时间比格林威治时间早8个小时,而美国西海岸的时间比格林威治时间迟8个小时,也就是比北京时间迟16个小时。在北京用户使
用的软件上显示2007年1月31日上午9点,则在美国用户的计算机上应显示当地时间为"5:00pm 1/30/2007"。
通过这几个例子可以理解软件国际化可能要碰到的各种问题,而且这些问题需要解决掉。例如,在数据库中,不能用一个字段去存储人名,必须将"姓"和" 名"分开存储;在取得"姓"和"名"后,也不能直接将"姓"和"名"两字符串直接相加,而必须用单独的函数处理,即先判断这个用户处在什么地区,然后采用 对应的字符串处理方法。对于时间,绝不能直接在数据库中存储各种不同时区的时间,而应该转化为格林威治标准时间(Greenwich Mean Time,GMT)后存储到数据库中,即在数据库中的所有时间都是零时区GMT时间,当客户端要显示时间时先把它转化为当地的时间,这样就不会把时间搞乱 了。
从上面几个例子可以看出来,国际化软件需要从设计、编程等多个方面来实现。从程序角度看,国际化软件的编程不能像一次性软件项目那样随意,许多东西 都不能简单处理,也不能写死(hard code)。例如,对于姓名处理、日期处理,不能仅仅通过一个简单的程序语句来处理,而需要通过一个函数处理,根据用户所处的时区、所用的语言和所在的国 家,分别进行相应的处理。其次,软件处理和输出的文字、图片等数据,都应该从程序中分离出来,存储在单独的资源文件中,为以后软件本地化创造良好的条件。
国际化的软件,其用户的分布很广,用户的喜好和宗教等相差甚远。从设计角度看,系统首先要支持多字节字符的处理,支持UniCode字符集,然后设 计出灵活的组件结构,使之能根据要求进行剪裁、定制等;客户端的时区和语言设置被抽象出来,融入到系统的整体设计中。如果是提供软件服务,则设计的系统架 构和数据应具有很强的分布性,不仅可以在全球范围内构造分布式的网络传输系统,而且应很好地满足数据的异地备份,系统异地故障转移和用户就近访问系统的网 络节点等一系列设计要求。
在软件国际化(I18N)测试中,设计部分的审查纳入到第3章中,而本章主要讨论软件国际化的实现部分,即着重讨论如何测试或验证下列特殊需求。
支持Unicode字符集。如建立用于本地字符编码(ANSI或OEM)和Unicode之间变换的字符映射表,既可以处理类似于英文的单字节语言,又能处理类似于中文、日文等双字节或多字节语言。
支持不同时区的设定、显示和切换。
分离程序代码和显示内容(文本、图片、对话框、信息框和按钮等)。如建立资源文件(*.rc)来存储这些内容。
消除硬代码(Hard code。指程序代码中所包含的一些特定的数据),而尽量使用变量处理,将数据存储在数据库或初始化文件中。
使用Header files定义经常被调用的代码段。
弹出的窗口、按钮、菜单等的尺寸具有自动伸缩性或可灵活地调整,以适应不同语言显示文本的长度变化。
支持各个国家的键盘设置,但要统一热键。
支持文字排序和大小写转换;
支持各国家的度量衡、时间、货币单位等不同格式的显示方式;
支持颜色字体等自定义,
拥有国际化用户界面设计。
概念
字符集是操作系统中所使用的字符映射表。最早的字符集,可以认为是UNIX系统使用的,包含128个字符的7- bit ASCII 字符集(包括tabs、空格、标点、符号、大小写字母、数字和回车键等)。随后,就是标准8- bit ASCII,包含256个字符,早期的Windows 操作系统使用8- bit ASCII字符集。由于扩展后的ASCII字符集还是无法满足所有语言的需求,如汉语、日语和韩语这些语言的字符都高达几万个字符。所以产生了16- bit字符集(双字节、多字节或变数字节)--统一的字符编码标准为Unicode。
Unicode是一个国际标准,采用双字节字符进行编码,提供了在世界主要语言中通用的字符,所以也称为基本多文种平面。Unicode以明确的方 式表述文本数据,简化了混合平台环境中的数据共享。目前,很多操作系统都支持Unicode,包括Windows系统、Linux系统和Mac OS、Solaris、IBM-AIX、HP-UX等。Unicode简称为UCS,现在用的是UCS-2,即2个字节编码,与国际标准字符集ISO 10646-1相对应。UCS的最新版本是2005年的Unicode 4.1.0,而ISO的最新标准是ISO 10646-3:2003。
Codepage是各国的文字编码和Unicode之间的映射表。例如,简体中文和Unicode的映射表就是CP936,其他的映射关系有:
codepage=950 繁体中文BIG5 |
UTF-8/ UTF-16/ UTF-32。UCS只是规定如何编码,并没有规定如何传输、保存编码。所以有了UniCode实用的编码体系,如UTF-8、UTF-7、UTF- 16。UTF-8(UCS Transformation Format)和ISO-8859-1完全兼容,解决了UniCode编码在不同的计算机之间的传输、保存的问题,使得双字节的Unicode能够在现存 的单字节的系统上正确传输。UTF-8使用可变长度的字节来储存 Unicode字符,这能解决敏感字符引起的问题。前面有几个1,就表示整个UTF-8串是由几个字节构成的。以下是Unicode和UTF-8之间的转 换关系表:
U-00000000 - U-0000007F: 0xxxxxxx |
示例
<meta. http-equiv="Content-Type" content="text/html; charset=UTF-8"> |
软件国际化的测试就是验证软件产品是否支持上述特性,包括多字节字符集的支持、区域设置、时区设置、界面定制性、内嵌字符串编码和字符串扩展等。软 件国际化的测试通常在本地化开始前进行,以识别潜在的不支持软件国际化特性的问题。理想的情况是,国际化测试在英文版本完成时就已结束。
实际上,设计评审和代码审查是国际化测试中最有效的方法,首先在设计上,要验证其是否遵守软件国际化的软件开发标准,是否具有国际化特性的一些基本 功能--用户的时区、语言和地区等设置,然后审查程序代码和资源文件,确认源代码和显示内容是否被分离、是否使用各类正确的数据格式处理函数等。代码审 查,可以采用走查的方法。先列出一个简单的检查列表(Checklist),依据这个列表,从头到尾快速地浏览所有代码,确保在代码上对I18N的充分支 持。通过代码审查,可以发现大部分有关I18N的问题。
除了设计评审和代码审查之外,I18N测试有两种基本方法:
一种是针对源语言的功能测试。在源语言版本中,直接检查某些功能特性是否符合要求,如不同的区域设置、不同的时区显示等。
另一种是针对伪翻译(pseudocode,pseudo-translation)版本的测试。即文字、图片信息中的源语言被混合式的多种语言(如英文、中文、日文和德文等)替代,然后进行全面的I18N测试,包括相关的功能测试、界面测试,但不包括翻译验证等。
概念
伪翻译(Pseudo Translation)是软件国际化测试的重要手段之一,它可以选择一种以上的本地化语言模拟本地化处理的结果。可以在进行实际本地化处理之前预览和查 看本地化的问题。通过伪本地化翻译,可以发现源语言软件的国际化设计中的错误,方便后续本地化时处理,提高软件的可本地化能力。在某些本地化工具中,可以 设置在进行了本地化翻译后字符长度的扩展比例,替换字符,前缀和后缀字符。
1.针对源语言的功能测试
I18N的测试不同于本地化的测试,其中部分测试工作可以在源语言中进行。假定源语言是英文,我们可以在英文版本中进行下列测试:
时区的设置及其相应的时间显示。
地区的设置及其相应的日期、货币显示。
可以选择不同的语言。
输入多字节字符串。
图8-3、图8-4就是两个例子,用户可以设置时区、地区和语言的界面。
 |
| 图8-3 时区、地区和语言的设置界面 |
 |
| 图8-4 以GMT为中心的时区划分 |
2. 针对伪翻译版本的测试
源语言的测试具有局限性,不能完全验证软件产品是否能很好地支持多字节字符集,例如弹出的窗口是否可以根据显示内容的长度进行自我调整,窗口中显示 的内容是否会出现会乱码现象等?这时,可采用伪翻译(pseudo-translation或pseudocode)的版本,进一步完成I18N的测试。 采用伪翻译版本,可以完成下列测试任务:
测试多字节字符集和脚本。
测试多字节字符串的输入显示是否正确。
测试多字节字符文件、文件名、文件夹及其处理。
测试索引和排序。
测试本地化的操作系统、键盘支持等。
如果采用正式翻译的版本,也可以进行相关的I18N测试,例如当源语言是英文,可以采用繁体中文、日文和阿拉伯文等作为几种典型的语言版本来对 I18N进行更充分的测试。I18N测试的重点在功能上,但将2~3种语言的本地化测试和I18N测试结合起来也没有坏处。采用伪翻译版本的好处是:
可更早地进行I18N测试,能够比较快也更容易在源语言版本之上构造伪翻译版本,因为不需要准确翻译,甚至不需要翻译,仅仅是替换成不同语言的文字。
可以一举两得,即同时验证多种语言的不同特性,如中文的多字节文字又精炼简短,德文的长度,以及中英文混合等。
给测试者一个清晰的信号,让他知道这是I18N测试,不是L10N测试。
小技巧
Windows是支持Unicode的多语言操作系统,所以在进行I18N测试时,可以充分利用它支持多语言的特性,安装多种语言的字库,通过改变Windows控制面板中"区域和语言"选项的"Unicode支持和系统显示语言",使测试机可以测试多种语言的安装包。
8.1.3 I18N测试实例
如果软件支持Unicode,即使同时显示不同的语言,也不会出现乱码。据此可分别对雅虎日历和Google Talk进行Unicode支持方面的测试。
在雅虎日历中,输入简体中文的活动名称,然后把这个用户的语言切换到繁体中文上,看其是否存在乱码。结果,活动名称的显示出现了乱码,这表明雅虎日历不支持Unicode和UTF-8/UTF-16,如图8-5所示。
 |
| (点击查看大图)图8-5 不支持Unicode而出现乱码 |
Google Talk的"Unicode支持"的测试结果又是怎样呢?为了验证这个问题,可先安装简体中文和日文的Google Talk,然后在他们之间相互发送本语言文字的聊天内容。测试结果表明Google Talk支持Unicode,中文和日文都可以正确地显示在对方的聊天对话框里面,没有任何乱码,如图8-6所示。
 |
| (点击查看大图)图8-6 在客户端同时显示中文和日文 |
图8-7更能说明Google Talk完全支持Unicode,在发送的一条信息中,同时显示了土耳其文、繁体中文、法文、日文、简体中文、葡萄牙文、俄文、意大利文、德文、荷兰文、韩文、英文等。
 |
| (点击查看大图)图8-7 同时显示多种文字的界面 |
L10N的功能测试
任何一件软件产品,人们最关心的还是它所能提供的服务,所以功能的实现总是很重要的。如果软件得到了充分的I18N测试,在软件本地化的实施过程中 一般不会产生功能方面的缺陷,功能方面的风险很小。但是,在实际工作中,I18N测试的覆盖率只在80%左右,还有20%的I18N特性需要在本地化测试 阶段被验证,因此,软件本地化(L10N)的功能测试还是必要的。
本地化测试,不仅要查看用户界面,而且要对文件保存、打印等类似的功能进行测试,特别要注意语言环境特定的组件,比如对时间、日期格式以及文字处理 等相关方面的功能进行测试。对软件进行L10N测试,关键一点是要在相对真实的本地用户环境上运行测试,如在本地化的操作系统、浏览器和特定的字符集(如 中文GB2312、日文SHIFT_JIS、韩文EUC-KR等)、网络设置和硬件等上进行测试。比如,在日本有一种 NEC9800 系列计算机的特定版本,这些系统与在美国使用的系统截然不同。那么就需要在客户实际使用的设备上进行测试。在环境的验证测试中,安装测试是必要的一个环 节,能比较全面地验证环境的适应性和兼容性。在安装完之后,进一步验证功能有没有受到本地化工作的影响。
下面通过一些例子来说明如何进行L10N各个方面的功能测试。
1.集成测试
集成测试的一个重点是测试在客户端和服务器端之间的相互作用,客户端的本地化往往考虑得比较充分,而服务器端有时会被忽视。如果源语言是单字节字符
集的欧美语系(如英文、法文等),在转换为多字节字符集的目标语言(如中文、日文等)后,容易引起问题,如客户端发出的请求,服务器端不能识别,甚至会出
现崩溃。
2.默认值
当从源语言转化到目标语言时,软件功能特性中许多设置的缺省值(时区、城市、数字等)是不同的,需要进行全面验证。例如,在中文里,时间缺省值从0 点开始;而在英语里,没有0点,是从12点开始的,即12:00am, 1:00am, …, 11:00am后仍为12:00pm, 1:00pm, …, 11:00pm。12:00am相对于我国的0:00am, 而12:00pm不是半夜,是中午。
3. 索引和排序
英文的排序和索引习惯上按照字母的顺序来编排,但是对于一些非字母文字的国家(亚洲、阿拉伯国家等)来说,这种方法就不适用了。如中文就有拼音、部 首和笔画等不同的索引方法。即使是使用字母文字的国家,其排序方法和英文也有较大不同。比如瑞典语,它的字母比英文字母多3个,在索引排序时也应加以考 虑。所以,在本地化软件时,应该根据不同国家和地区的语言习惯分别加以考虑,在进行本地化测试的时候更应该仔细核对这些问题,如把英文软件本地化的瑞典语 软件版本中,用来排序的有29个字母,在字母A, B, C, …, X, Y, Z 后会增加几个特殊的字母--瑞典语中的3个字母,即?、?、?。
4. 联机文档的功能测试
不论是HTML格式的,还是PDF、Flash等格式的联机文档,都需要得到测试。因为在这些文档中包含有菜单、链接、按钮等操作,测试可确保这些 操作达到预期的结果,如链接能正常跳转,能打开正确的页面,包括页面中的图片可以正确地显示出来。测试人员需要关注页面上的超级链接,以发现其"提示未被 本地化或链接到非本地化的页面上"等一系列问题。即使暂时不能完成所有页面的本地化,不得不引用部分源语言(英文)的页面,也需要用目标语言在这些链接旁 给出提示,指出这些站点是英文的。
5. DST的处理
一般情况下夏令时(DST)在程序中的处理比较简单。相当于多了一个时区,如美国西海岸采用太平洋时区(GMT-8:00),比格林威治标准时间迟 8个小时,如果在夏令时(从每年3月最后一周的星期日到11月第一周的星期日)时区就相当于变成了GMT-7:00,比格林威治标准时间迟7个小时。
但是,如果某些软件功能特性是跨时间段的,如MS OutLook、Lotus Notes、雅虎日历等功能,这时夏令时的处理会变为一个很复杂的问题。例如,当安排一个年内的每周会议时,规定在每周星期四9:00am开,不管是不是 在DST,会议总应该在9:00am开,不能出现下列情况:
在非DST期间安排的会议,在DST期间会议则变为8:00am开。
在DST期间安排的会议,在非DST期间会议则变为10:00am开。
示例
如果某个会议被邀请的人员有的来自于美国旧金山,有的来自于中国北京,有的来自于澳大利亚悉尼。这其中中国不实行DST,美国、澳大利亚实行 DST,但DST起始和结束的日期又是不一样的,因为澳大利亚悉尼的DST起始时间是10月的第3周星期日,结束时间是第二年3月的第3周星期日。要保证 来自于不同国家的用户都能准时、同步加入会议,客户端显示的时间绝对不能出错。
假如会议开始时间是北京时间的星期四9:00am,这时至少要完成下列一些测试用例,如表8-2所示。
表8-2
用例时间 | 北京用户客户端显示时间 | 旧金山用户客户端显示时间 | 悉尼用户客户端显示时间 | 说 明 |
3月第3周的星期四 | 星期四 9:00am | 星期三 5:00pm | 星期四 11:00am | 旧金山和悉尼都不在DST期间 |
3月第1周的星期四 | 星期四 9:00am | 星期三 5:00pm | 星期四 11:00am(DST) | 旧金山不在DST期间 悉尼在DST期间 |
10月第2周的星期四 | 星期四 9:00am | 星期三 5:00pm | 星期四 11:00am(DST) | 旧金山在DST期间 悉尼不在DST期间 |
10月第3周的星期四 | 星期四 9:00am | 星期三 5:00pm | 星期四 11:00am(DST) | 旧金山和悉尼都在DST期间 |
如果会议在中国的星期一早上开,则美国为周日,这时要考虑DST切换的那个周日,即增加对边界条件的测试,问题更复杂一些。极端情况下,在北京时间周日下午4点的活动,会碰到美国周日凌晨12:00am,即在DST切换的那一个时刻,需要进行更多的测试。
L10N的数据格式验证
在本章开始时曾介绍过姓名、日期等格式的例子,除此之外,数字、货币和度量衡等的表达方法或格式在不同的国家也是不相同的,所以在把软件本地化的测 试中,数据格式的验证也是重要的工作之一。如果是Windows编程,可以使用其标准应用接口(API)来处理这类转换的问题,问题会简单得多。但在一些 Web开发和一些特殊的客户端开发,还要依赖于程序本身的处理,通过定义相关变量和函数,来对这些本地化的数据格式进行处理。但从测试的角度来看,不管是 哪种方式,都需要对这些数据格式的输入和输出进行充分的测试。
在Java 2 SDK中,已能很好地支持国际化的编程,已建立了支持国际化和本地化的类(如Calendar、TimeZone、DateFormat、 SimpleDateFormat等)和方法。如果所使用的编程语言没有特定的类或函数支持,就不得不自己构造一些特殊的函数来处理不同语言的数据格式 了。例如使用自定义函数LocLongdate()、LocShortdate()等替换原来的date()函数,来处理日期的完整格式或简单格式的显 示。
1. 数字
很多欧洲语言使用逗号而不是小数点来表示千位,有的则使用句号或空格代替逗号。所以,本地化的软件也必须注意这个问题。否则,有可能一个顾客存入了5000欧元,却只能取出5美元。例如,同一个数字(5700),在美国、意大利和瑞士有3种不同的表达方式:
美国:5,700 |
2. 货币
除了数字转换外,几乎每一个国家都有标志本国货币的特殊符号,这些符号应该出现在金额的前面或后面也各不相同。例如,我国人民币符号"¥"出现在数量前,而美元符号出现在数量后面。
美国 Dollar,$ 或US$ |
3. 时间
各国时间的习惯表达方式也总是不一样的,美国习惯上使用12小时来表达时间,而欧洲国家使用24小时模式来表达时间。如晚上10点45分,其表达方式有:
美国:10:45 PM, |
4. 日期格式
不同国家的日期显示格式也不是一致的。美国的标准是用MM/DD/YY来显示月、日、年,也有很多不同的分割符号(如"/"和"-");欧洲(除少数例外)的标准是日、月、年(DD/MM/YY);中国的标准则是年、月、日。下面以2003年2月14日为例来说明:
美国:2/14/2003 |
即使是一个星期的起始天各国也不相同,如在美国,一个星期的第一天是星期天,而法国的日历每周第一天是星期一。
5. 度量衡的单位
虽然许多国家开始使用国际公制度量系统,如米、公里、克、千克(公斤)、升等,但美国、英国等一些国家仍旧使用英式度量单位,如英尺、英里、盎司、 英磅等。因此,软件本地化必须解决公制和英式度量单位的问题,对于不同的国家可以显示其适用的度量衡体系。在比较理想情况下,软件应提供度量衡的用户设置 功能和不同度量单位之间的转换功能。
6. 复数问题
生成复数的规则会因语言的不同而有差异。即使在英语中,复数的规则也并不是始终如一的,如"bed"的复数是"beds",而"leaf"的复数却不是"leafs",以下例子说明了复数的问题。如搜索结果显示可以表示为:
"%d program%s searched" 和 "%d file%s searched"。 |
如果%d大于1,%s将把"s"插入到该单词中去从而组成其复数形式,则该信息显示格式如下:
"1 program searched" and "1 file searched" |
或者
"3 programs searched" and "3 files searched" |
在英语中,这样编码是没有问题的,但是对于德语和多数其他欧洲语言,它们的复数规则却不是这样的,如:
program = programma 而其复数 programs = programma's |
在做本地化测试的时候,一定要注意这些地方是否被充分地考虑并做了适当的修改。
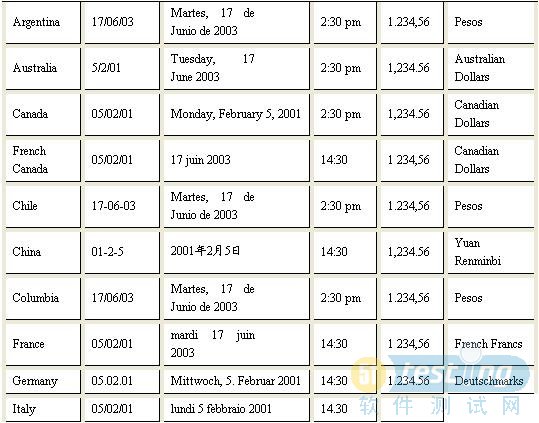
表8-3 一些国家和地区的日期、时间和货币格式
TAG:
-
引用 删除 iseedeadpeople / 2012-12-09 22:01:04
- 也就是说,本地,国际两个完全不同概念的东西,可以流程,但是针对的是简体中文版的国际化
-
- 本地化---本地化能力--国际化能力---国际化
我的栏目
标题搜索
日历
|
|||||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 | |||
| 1 | 2 | 3 | 4 | 5 | 6 | ||||
| 7 | 8 | 9 | 10 | 11 | 12 | 13 | |||
| 14 | 15 | 16 | 17 | 18 | 19 | 20 | |||
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | |||
| 28 | 29 | 30 | |||||||
我的存档
数据统计
- 访问量: 329992
- 日志数: 369
- 建立时间: 2009-09-23
- 更新时间: 2015-03-12
