
-
精妙的SQL语句
peag 发布于 2010-05-08 10:53:32
说明:复制表(只复制结构,源表名:a 新表名:b)
select * into b from a where 1<>1
说明:拷贝表(拷贝数据,源表名:a 目标表名:b)
insert into b(a, b, c) select d,e,f from b;
说明:显示文章、提交人和最后回复时间
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
说明:外连接查询(表名1:a 表名2:b)
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
说明:日程安排提前五分钟提醒
select * from 日程安排 where datediff(''minute'',f开始时间,getdate())>5
说明:两张关联表,删除主表中已经在副表中没有的信息
delete from info where not exists ( select * from infobz where info.infid=infobz.infid )
说明:--
SQL:
Select A.NUM, A.NAME, B.UPD_DATE, B.PREV_UPD_DATE
FROM TABLE1,
(Select X.NUM, X.UPD_DATE, Y.UPD_DATE PREV_UPD_DATE
FROM (Select NUM, UPD_DATE, INBOUND_QTY, STOCK_ONHAND
FROM TABLE2
Where TO_CHAR(UPD_DATE,''YYYY/MM'') = TO_CHAR(SYSDATE, ''YYYY/MM'')) X,
(Select NUM, UPD_DATE, STOCK_ONHAND
FROM TABLE2
Where TO_CHAR(UPD_DATE,''YYYY/MM'') =
TO_CHAR(TO_DATE(TO_CHAR(SYSDATE, ''YYYY/MM'') || ''/01'',''YYYY/MM/DD'') - 1, ''YYYY/MM'') ) Y,
Where X.NUM = Y.NUM (+)
AND X.INBOUND_QTY + NVL(Y.STOCK_ONHAND,0) <> X.STOCK_ONHAND ) B
Where A.NUM = B.NUM
说明:--
select * from studentinfo where not exists(select * from student where studentinfo.id=student.id) and 系名称=''"&strdepartmentname&"'' and 专业名称=''"&strprofessionname&"'' order by 性别,生源地,高考总成绩
从数据库中去一年的各单位电话费统计(电话费定额贺电化肥清单两个表来源)
Select a.userper, a.tel, a.standfee, TO_CHAR(a.telfeedate, ''yyyy'') AS telyear,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''01'', a.factration)) AS JAN,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''02'', a.factration)) AS FRI,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''03'', a.factration)) AS MAR,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''04'', a.factration)) AS APR,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''05'', a.factration)) AS MAY,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''06'', a.factration)) AS JUE,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''07'', a.factration)) AS JUL,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''08'', a.factration)) AS AGU,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''09'', a.factration)) AS SEP,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''10'', a.factration)) AS OCT,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''11'', a.factration)) AS NOV,
SUM(decode(TO_CHAR(a.telfeedate, ''mm''), ''12'', a.factration)) AS DEC
FROM (Select a.userper, a.tel, a.standfee, b.telfeedate, b.factration
FROM TELFEESTAND a, TELFEE b
Where a.tel = b.telfax) a
GROUP BY a.userper, a.tel, a.standfee, TO_CHAR(a.telfeedate, ''yyyy'')
说明:四表联查问题
select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....
说明:得到表中最小的未使用的ID号
Select (CASE WHEN EXISTS(Select * FROM Handle b Where b.HandleID = 1) THEN MIN(HandleID) + 1 ELSE 1 END) as HandleID FROM Handle Where NOT HandleID IN (Select a.HandleID - 1 FROM Handle a)
一个SQL语句的问题:行列转换
select * from v_temp
上面的视图结果如下:
user_name role_name
-------------------------
系统管理员 管理员
feng 管理员
feng 一般用户
test 一般用户
想把结果变成这样:
user_name role_name
---------------------------
系统管理员 管理员
feng 管理员,一般用户
test 一般用户
===================
create table a_test(name varchar(20),role2 varchar(20))
insert into a_test values(''李'',''管理员'')
insert into a_test values(''张'',''管理员'')
insert into a_test values(''张'',''一般用户'')
insert into a_test values(''常'',''一般用户'')
create function join_str(@content varchar(100))
returns varchar(2000)
as
begin
declare @str varchar(2000)
set @str=''''
select @str=@str+'',''+rtrim(role2) from a_test where [name]=@content
select @str=right(@str,len(@str)-1)
return @str
end
go
--调用:
select [name],dbo.join_str([name]) role2 from a_test group by [name]
--select distinct name,dbo.uf_test(name) from a_test
快速比较结构相同的两表
结构相同的两表,一表有记录3万条左右,一表有记录2万条左右,我怎样快速查找两表的不同记录?
============================
给你一个测试方法,从northwind中的orders表取数据。
select * into n1 from orders
select * into n2 from orders
select * from n1
select * from n2
-'
END
GO
BEGIN
declare @ptr_a_remark binary(16)
select @ptr_a_remark = TEXTPTR(a_remark) from [dbo].[db_article] where [a_id] = 1199
updatetext [dbo].[db_article].a_remark @ptr_a_remark NULL 0 N'-添加主键,然后修改n1中若干字段的若干条
alter table n1 add constraint pk_n1_id primary key (OrderID)
alter table n2 add constraint pk_n2_id primary key (OrderID)
select orderID from (select * from n1 union select * from n2) a group by orderID having count(*) > 1
应该可以,而且将不同的记录的ID显示出来。
下面的适用于双方记录一样的情况,
select * from n1 where orderid in (select orderID from (select * from n1 union select * from n2) a group by orderID having count(*) > 1)
至于双方互不存在的记录是比较好处理的
--删除n1,n2中若干条记录
delete from n1 where orderID in (''10728'',''10730'')
delete from n2 where orderID in (''11000'',''11001'')
--*************************************************************
-- 双方都有该记录却不完全相同
select * from n1 where orderid in(select orderID from (select * from n1 union select * from n2) a group by orderID having count(*) > 1)
union
--n2中存在但在n1中不存的在10728,10730
select * from n1 where orderID not in (select orderID from n2)
union
--n1中存在但在n2中不存的在11000,11001
select * from n2 where orderID not in (select orderID from n1)
四种方法取表里n到m条纪录:
1.
select top m * into 临时表(或表变量) from tablename order by columnname -- 将top m笔插入
set rowcount n
select * from 表变量 order by columnname desc
2.
select top n * from (select top m * from tablename order by columnname) a order by columnname desc
3.如果tablename里没有其他identity列,那么:
select identity(int) id0,* into #temp from tablename
取n到m条的语句为:
select * from #temp where id0 >=n and id0 <= m
如果你在执行select identity(int) id0,* into #temp from tablename这条语句的时候报错,那是因为你的DB中间的select into/bulkcopy属性没有打开要先执行:
exec sp_dboption 你的DB名字,''select into/bulkcopy'',true
4.如果表里有identity属性,那么简单:
select * from tablename where identitycol between n and m
如何删除一个表中重复的记录?
create table a_dist(id int,name varchar(20))
insert into a_dist values(1,''abc'')
insert into a_dist values(1,''abc'')
insert into a_dist values(1,''abc'')
insert into a_dist values(1,''abc'')
exec up_distinct ''a_dist'',''id''
select * from a_dist
create procedure up_distinct(@t_name varchar(30),@f_key varchar(30))
--f_key表示是分组字段﹐即主键字段
as
begin
declare @max integer,@id varchar(30) ,@sql varchar(7999) ,@type integer
select @sql = ''declare cur_rows cursor for select ''+@f_key+'' ,count(*) from '' +@t_name +'' group by '' +@f_key +'' having count(*) > 1''
exec(@sql)
open cur_rows
fetch cur_rows into @id,@max
while @@fetch_status=0
begin
select @max = @max -1
set rowcount @max
select @type = xtype from syscolumns where id=object_id(@t_name) and name=@f_key
if @type=56
select @sql = ''delete from ''+@t_name+'' where '' + @f_key+'' = ''+ @id
if @type=167
select @sql = ''delete from ''+@t_name+'' where '' + @f_key+'' = ''+''''''''+ @id +''''''''
exec(@sql)
fetch cur_rows into @id,@max
end
close cur_rows
deallocate cur_rows
set rowcount 0
end
select * from systypes
select * from syscolumns where id = object_id(''a_dist'')
查询数据的最大排序问题(只能用一条语句写)
Create TABLE hard (qu char (11) ,co char (11) ,je numeric(3, 0))
insert into hard values (''A'',''1'',3)
insert into hard values (''A'',''2'',4)
insert into hard values (''A'',''4'',2)
insert into hard values (''A'',''6'',9)
insert into hard values (''B'',''1'',4)
insert into hard values (''B'',''2'',5)
insert into hard values (''B'',''3'',6)
insert into hard values (''C'',''3'',4)
insert into hard values (''C'',''6'',7)
insert into hard values (''C'',''2'',3)
要求查询出来的结果如下:
qu co je
----------- ----------- -----
A 6 9
A 2 4
B 3 6
B 2 5
C 6 7
C 3 4
就是要按qu分组,每组中取je最大的前2位!!
而且只能用一句sql语句!!!
select * from hard a where je in (select top 2 je from hard b where a.qu=b.qu order by je)
求删除重复记录的sql语句?
怎样把具有相同字段的纪录删除,只留下一条。
例如,表test里有id,name字段
如果有name相同的记录 只留下一条,其余的删除。
name的内容不定,相同的记录数不定。
有没有这样的sql语句?
==============================
A:一个完整的解决方案:
将重复的记录记入temp1表:
select [标志字段id],count(*) into temp1 from [表名]
group by [标志字段id]
having count(*)>1
2、将不重复的记录记入temp1表:
insert temp1 select [标志字段id],count(*) from [表名] group by [标志字段id] having count(*)=1
3、作一个包含所有不重复记录的表:
select * into temp2 from [表名] where 标志字段id in(select 标志字段id from temp1)
4、删除'
END
GO
BEGIN
declare @ptr_a_remark binary(16)
select @ptr_a_remark = TEXTPTR(a_remark) from [dbo].[db_article] where [a_id] = 1199
updatetext [dbo].[db_article].a_remark @ptr_a_remark NULL 0 N'重复表:
delete [表名]
5、恢复表:
insert [表名] select * from temp2
6、删除临时表:
drop table temp1
drop table temp2
================================
B:
create table a_dist(id int,name varchar(20))
insert into a_dist values(1,''abc'')
insert into a_dist values(1,''abc'')
insert into a_dist values(1,''abc'')
insert into a_dist values(1,''abc'')
exec up_distinct ''a_dist'',''id''
select * from a_dist
create procedure up_distinct(@t_name varchar(30),@f_key varchar(30))
--f_key表示是分组字段﹐即主键字段
as
begin
declare @max integer,@id varchar(30) ,@sql varchar(7999) ,@type integer
select @sql = ''declare cur_rows cursor for select ''+@f_key+'' ,count(*) from '' +@t_name +'' group by '' +@f_key +'' having count(*) > 1''
exec(@sql)
open cur_rows
fetch cur_rows into @id,@max
while @@fetch_status=0
begin
select @max = @max -1
set rowcount @max
select @type = xtype from syscolumns where id=object_id(@t_name) and name=@f_key
if @type=56
select @sql = ''delete from ''+@t_name+'' where '' + @f_key+'' = ''+ @id
if @type=167
select @sql = ''delete from ''+@t_name+'' where '' + @f_key+'' = ''+''''''''+ @id +''''''''
exec(@sql)
fetch cur_rows into @id,@max
end
close cur_rows
deallocate cur_rows
set rowcount 0
end
select * from systypes
select * from syscolumns where id = object_id(''a_dist'')
行列转换--普通
假设有张学生成绩表(CJ)如下
Name Subject Result
张三 语文 80
张三 数学 90
张三 物理 85
李四 语文 85
李四 数学 92
李四 物理 82
想变成
姓名 语文 数学 物理
张三 80 90 85
李四 85 92 82
declare @sql varchar(4000)
set @sql = ''select Name''
select @sql = @sql + '',sum(case Subject when ''''''+Subject+'''''' then Result end) [''+Subject+'']''
from (select distinct Subject from CJ) as a
select @sql = @sql+'' from test group by name''
exec(@sql)
行列转换--合并
有表A,
id pid
1 1
1 2
1 3
2 1
2 2
3 1
如何化成表B:
id pid
1 1,2,3
2 1,2
3 1
创建一个合并的函数
create function fmerg(@id int)
returns varchar(8000)
as
begin
declare @str varchar(8000)
set @str=''''
select @str=@str+'',''+cast(pid as varchar) from 表A where id=@id
set @str=right(@str,len(@str)-1)
return(@str)
End
go
--调用自定义函数得到结果
select distinct id,dbo.fmerg(id) from 表A
如何取得一个数据表的所有列名
方法如下:先从SYSTEMOBJECT系统表中取得数据表的SYSTEMID,然后再SYSCOLUMN表中取得该数据表的所有列名。
SQL语句如下:
declare @objid int,@objname char(40)
set @objname = ''tablename''
select @objid = id from sysobjects where id = object_id(@objname)
select ''Column_name'' = name from syscolumns where id = @objid order by colid
或
Select * FROM INFORMATION_SCHEMA.COLUMNS Where TABLE_NAME =''users''
通过SQL语句来更改用户的密码
修改别人的,需要sysadmin role
EXEC sp_password NULL, ''newpassword'', ''User''
如果帐号为SA执行EXEC sp_password NULL, ''newpassword'', sa
怎么判断出一个表的哪些字段不允许为空?
select COLUMN_NAME from INFORMATION_SCHEMA.COLUMNS where IS_NULLABLE=''NO'' and TABLE_NAME=tablename
如何在数据库里找到含有相同字段的表?
a. 查已知列名的情况
Select b.name as TableName,a.name as columnname
From syscolumns a INNER JOIN sysobjects b
ON a.id=b.id
AND b.type=''U''
AND a.name=''你的字段名字''
未知列名查所有在不同表出现过的列名
Select o.name As tablename,s1.name As columnname
From syscolumns s1, sysobjects o
Where s1.id = o.id
And o.type = ''U''
And Exists (
Select 1 From syscolumns s2
Where s1.name = s2.name
And s1.id <> s2.id
)
查询第xxx行数据
假设id是主键:
select * from (select top xxx * from yourtable) aa where not exists(select 1 from (select top xxx-1 * from yourtable) bb where aa.id=bb.id)
如果使用游标也是可以的
fetch absolute [number] from [cursor_name]
行数为绝对行数
SQL Server日期计算
a. 一个月的第一天
Select DATEADD(mm, DATEDIFF(mm,0,getdate()), 0)
b. 本周的星期一
Select DATEADD(wk, DATEDIFF(wk,0,getdate()), 0)
c. 一年的第一天
Select DATEADD(yy, DATEDIFF(yy,0,getdate()), 0)
d. 季度的第一天
Select DATEADD(qq, DATEDIFF(qq,0,getdate()), 0)
e. 上个月的最后一天
Select dateadd(ms,-3,DATEADD(mm, DATEDIFF(mm,0,getdate()), 0))
f. 去年的最后一天
Select dateadd(ms,-3,DATEADD(yy, DATEDIFF(yy,0,getdate()), 0))
g. 本月的最后一天
Select dateadd(ms,-3,DATEADD(mm, DATEDIFF(m,0,getdate())+1, 0))
h. 本月的第一个星期一
select DATEADD(wk, DATED'
END
GO
BEGIN
declare @ptr_a_remark binary(16)
select @ptr_a_remark = TEXTPTR(a_remark) from [dbo].[db_article] where [a_id] = 1199
updatetext [dbo].[db_article].a_remark @ptr_a_remark NULL 0 N'IFF(wk,0,
dateadd(dd,6-datepart(day,getdate()),getdate())
), 0)
i. 本年的最后一天
Select dateadd(ms,-3,DATEADD(yy, DATEDIFF(yy,0,getdate())+1, 0))。
获取表结构[把 ''sysobjects'' 替换 成 ''tablename'' 即可]
Select CASE IsNull(I.name, '''')
When '''' Then ''''
Else ''*''
End as IsPK,
Object_Name(A.id) as t_name,
A.name as c_name,
IsNull(SubString(M.text, 1, 254), '''') as pbc_init,
T.name as F_DataType,
CASE IsNull(TYPEPROPERTY(T.name, ''Scale''), '''')
WHEN '''' Then Cast(A.prec as varchar)
ELSE Cast(A.prec as varchar) + '','' + Cast(A.scale as varchar)
END as F_Scale,
A.isnullable as F_isNullAble
FROM Syscolumns as A
JOIN Systypes as T
ON (A.xType = T.xUserType AND A.Id = Object_id(''sysobjects'') )
LEFT JOIN ( SysIndexes as I
JOIN Syscolumns as A1
ON ( I.id = A1.id and A1.id = object_id(''sysobjects'') and (I.status & 0x800) = 0x800 AND A1.colid <= I.keycnt) )
ON ( A.id = I.id AND A.name = index_col(''sysobjects'', I.indid, A1.colid) )
LEFT JOIN SysComments as M
ON ( M.id = A.cdefault and ObjectProperty(A.cdefault, ''IsConstraint'') = 1 )
orDER BY A.Colid ASC
提取数据库内所有表的字段详细说明的SQL语句
Select
(case when a.colorder=1 then d.name else '''' end) N''表名'',
a.colorder N''字段序号'',
a.name N''字段名'',
(case when COLUMNPROPERTY( a.id,a.name,''IsIdentity'')=1 then ''√''else ''''
end) N''标识'',
(case when (Select count(*)
FROM sysobjects
Where (name in
(Select name
FROM sysindexes
Where (id = a.id) AND (indid in
(Select indid
FROM sysindexkeys
Where (id = a.id) AND (colid in
(Select colid
FROM syscolumns
Where (id = a.id) AND (name = a.name))))))) AND
(xtype = ''PK''))>0 then ''√'' else '''' end) N''主键'',
b.name N''类型'',
a.length N''占用字节数'',
COLUMNPROPERTY(a.id,a.name,''PRECISION'') as N''长度'',
isnull(COLUMNPROPERTY(a.id,a.name,''Scale''),0) as N''小数位数'',
(case when a.isnullable=1 then ''√''else '''' end) N''允许空'',
isnull(e.text,'''') N''默认值'',
isnull(g.[value],'''') AS N''字段说明''
FROM syscolumns a
left join systypes b
on a.xtype=b.xusertype
inner join sysobjects d
on a.id=d.id and d.xtype=''U'' and d.name<>''dtproperties''
left join syscomments e
on a.cdefault=e.id
left join sysproperties g
on a.id=g.id AND a.colid = g.smallid
order by object_name(a.id),a.colorder
快速获取表test的记录总数[对大容量表非常有效]
快速获取表test的记录总数:
select rows from sysindexes where id = object_id(''test'') and indid in (0,1)
update 2 set KHXH=(ID+1)\2 2行递增编号
update [23] set id1 = ''No.''+right(''00000000''+id,6) where id not like ''No%'' //递增
update [23] set id1= ''No.''+right(''00000000''+replace(id1,''No.'',''''),6) //补位递增
delete from [1] where (id%2)=1
奇数
替换表名字段
update [1] set domurl = replace(domurl,''Upload/Imgswf/'',''Upload/Photo/'') where domurl like ''%Upload/Imgswf/%''
截位
Select LEFT(表名, 5) -
WEB界面测试小结
peag 发布于 2010-05-14 19:04:46
我是从事web测试的,现在大部分客户对界面的要求非常高,所以对于测试人员来讲,也必须特别注意界面的一些东西。从前几个项目来看,个人认为界面测试的测试点以及应该注意的问题:
1:界面的线条是否一致,每个界面中线条是否对齐,是否一致。(静态页面没有确认的情况下)2:整个系统的界面是否保持一致
3:界面中是否存在错别字
4:界面所有的按钮样式是否一致
5:每个界面是否同原静态页面设计一致(静态页面确认的情况下)
6:操作是否友好
7:界面所有的按钮、下拉框是否有响应
8:界面所有的链接是否正常
9:界面所有的输入框是否都进行校验(例如:搜索框、字段输入框)
10:界面所有的列表页标题字是否会折行,标题字是否统一居中等,当然也可以居左,这需要同客户沟通(折行的话影响美观)
11:界面所有的展示图片是否样式一致
12:浏览器的兼容性问题,检查页面在不同浏览器下是否会发生异常
13:每个页面的提示字体的颜色、格式是否统一准确
14:界面中所有字段后面是否都存在冒号,有冒号,查看是否冒号为统一的中文冒号还是英文冒号。
15:界面中的提示说明叙述是否太啰嗦,有时候需要能简化尽量简化,并且字体显示格式一致,颜色统一。
16:在web网站,一般经常是后台控制前台的显示,因此在对后台进行数据添加时,查看前台是否有变化,并且查看界面的数据是否溢出框外。
当然,我们在进行界面测试时,必须明确UI测试的目的,它是确保用户界面通过测试对象的功能来为用户提供相应的访问或浏览功能。
确保用户界面符合公司和行业的标准。
通过用户界面测试来核实用户与软件的交互,UI测试的目标在于确保用户界面向用户提供了适当的访问和浏览对象功能的操作,除此之外,UI测试还却表UI功能内部的对象符号预期的要求,并遵循公司和行业的标准。
接下来,具体的分析一下界面测试的依据从哪些方面着手。
测试目标:
1:窗口与窗口之间、字段与字段之间的浏览,以及各种访问方法(tab键、鼠标移动和快捷键)的使用
2:窗口的对象和特征(例如:菜单、大小、位置、状态和中心)都符号标准
测试方法:为每个窗口创建或修改测试,以核实各个应用程序窗口和对象都可正确的进行浏览,并处于正常的对象状态。
我们在实际工作当中,针对web应用程序,也就是经常所说的B/S系统,可以从如下方面来进行用户界面测试:
1:导航测试
导航描述了用户在一个页面内操作的方式,在不同的用户接口控制之间,例如按钮、对话框、列表和窗口等;
不同的链接页面之间,通过考虑下列问题,可以决定一个web应用系统是否易于导航;导航是否直观?web系统的主要部分是否可通过主页存取?web系统是否需要站点地图、搜索引擎或其他的导航帮助
当然,这些同美工以及客户需求有关。我们是根据已经确认的页面进行测试即可。
2:图形测试
图形包括图片、动画、边框、颜色、字体、背景、按钮等。
(1) 要确保图形有明确的用途,图片或动画不要胡乱的堆在一起,以免浪费传输时间,web应用系统的图片尺寸要尽量地小,并且要能清楚的说明某件事情。一般都链接到某个具体的页面
(2)验证所有页面字体的风格是否一致
(3)背景颜色与字体颜色和背景色相搭配
(4)图片的大小和质量,一般采用jpg或gif压缩,最好能使用图片的大小减小到30k以下
(5)演示文字回绕是否正确,如果说明文字指向右边的图片,应该确保该图片出现在右边,不要因为使用图片而使窗口和段落排列古怪或者出现骨性。
3:内容测试
内容测试用来检验Web应用系统提供信息的正确性、准确性和相关性。信息的正确性是指信息是可靠的还是误传的。信息的相关性是指是否在当前页面可以找到与当前浏览信息相关的信息列表或入口,也就是一般Web站点中的所谓“相关文章列表”
4:表格测试
需要验证表格是否设置正确,用户是否需要向右滚动页面才能看见产品的价格?
把价格放在左边,产品细节放在右边是否更有效?
每一栏的宽度是否足够宽,表格里的文字是否都有折行?
是否因为某一格的内容太多,而将整行的内容拉长?
5:整体界面测试
整体界面是指整个Web应用系统的页面结构设计,是给用户的一个整体感。例如:当用户浏览Web应用系统时是否感到舒适,是否凭直觉就知道要找的信息在什么地方?整个Web应用系统的设计风格是否一致?
对整体界面的测试过程,其实是一个对最终用户进行调查的过程。一般Web应用系统采取在主页上做一个调查问卷的形式,来得到最终用户的反馈信息。
对所有的用户界面测试来说,都需要有外部人员(与Web应用系统开发没有联系或联系很少的人员)的参与,最好是最终用户的参与。
-
[论坛] 做个专业的软件测试工程师
peag 发布于 2010-05-21 21:14:42
同样是测试人员,做着可能相同的工作,作出的结果也可能大致相同。那么以什么作为你工作更加专业的区分呢?测试的工作用例编写,测试执行,bug上报,以及功能点测试完成度控制。这些方面都可以体现我们的劳动价值。
测试用例的编写——当别人不愿意编写测试用例,甚至觉得编写用例是浪费时间时,倘若你体会到了用例编写在测试过程中带来的功能点覆盖的全面性。那么你就站在了比他人更高的高度。细到用例的每条,当别人只是简单的划分出这是某个测试点,而你已经清晰的知道这个测试点是使用什么方法划分出来的测试点-例如边界值,等价类,因果图。那么你的确要比那些简单罗列测试点的人技能上要更高一些。当别人还因为测试功能点未全面,而在赶工期忙碌时,倘若你能够很坦然的根据自己的测试用例通过率确定已测试功能的质量时,你就会知道你站在了更高的台阶上。这些都是理论,测试用例要写的好,要覆盖面全,那是需要思考的,是绝对全心投入的思考。是一种创作,不是你拷贝策划案里的条目就能够理清的。而是通过把策划案中的功能点不断的划分,直至精确到某个输入和输出结果。这是一个急需要脑力劳动的过程,一方面要肯定策划案中的正确的内容,另外一方面要考虑这些正常的内容是否存在何种异常的操作,而任何一个异常的内容都是不允许没有输出结果的。
测试的执行——不是所有的用例都会精确到点击鼠标左右键。所以测试执行的速度反应着一个测试人员基本功的扎实程度。同样是一个功能我们会发现,熟悉系统的测试人员在执行测试过程中往往比不熟悉系统的测试人员快。但是不熟悉系统本身就是测试人员自身的素质问题。没有任何借口,既然你是做这个的,那么允许你开始的懵懂,却不允许你一而再,再而三的愚蠢。想要比别人突出,那么好好熟悉你得系统,最好做到别人知道的你清楚,别人不知道的你知道。
bug的上报——其实就是把bug的出现方法和具体出现导致的问题说清楚的过程。语言要简洁,但是不能简洁到别人看不懂。要步骤分明,要在执行测试过程中不断尝试,直至把bug的重现过程缩短到最短。可能会浪费你很多时间,但是你要看到这个的另外一个好处。当别的测试员跟程序人员重现bug,总是找不到重点步骤时,你已经深刻理解到要获得程序人员的重视,bug的步骤越短,越是能够得到程序人员的赞许。这个赞许积蓄到一定时间就成了你自负的资本。测试结果的汇报也很重要,清晰而明了的告诉程序人员或者测试主管,用例的执行情况,需要解决的问题-最好指出你问题在用例内的出处。这样有便于程序人员养成查看你用例的习惯。一般用例生成和程序实现是同步进行的,在这个过程中,如果程序人员发现你用例内有的测试点而自己没有实现,那么可以节省很多时间。当他多次出现你用例有的内容,他没有实现到时这种深刻的记忆将驱使他检查你的用例。
测试时间点的把控——根据测试用例中测试点的执行难易程序,以及测试用例中测试点的条数可以初步判定功能点的测试完成时间。最初这个是需要积累的,当用例达到某个数量,当用例难度与其它用例执行难度可进行比较时就很容易把控时间点。最好的时间把控不是预期3天而实际只测试1天半,也不是预期3天实际测试了5天。最好的时间点应该控制在半个工作日内。测试点的时间把控对于测试人员来说也很重要。有时如果为了进度需要宁可多几个人一起来完成测试,也不可以因为时间点的问题导致版本发布延迟。 -
特殊的用法忘记,我特此整理了一下SQL语句操作。(转)
peag 发布于 2010-06-09 23:57:26
一、基础1、说明:创建数据库
CREATE DATABASE database-name
2、说明:删除数据库
drop database dbname
3、说明:备份sql server
--- 创建 备份数据的 device
USE master
EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'
--- 开始 备份
BACKUP DATABASE pubs TO testBack
4、说明:创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
根据已有的表创建新表:
A:create table tab_new like tab_old (使用旧表创建新表)
B:create table tab_new as select col1,col2… from tab_old definition only
5、说明:删除新表
drop table tabname
6、说明:增加一个列
Alter table tabname add column col type
注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
7、说明:添加主键: Alter table tabname add primary key(col)
说明:删除主键: Alter table tabname drop primary key(col)
8、说明:创建索引:create [unique] index idxname on tabname(col….)
删除索引:drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
9、说明:创建视图:create view viewname as select statement
删除视图:drop view viewname
10、说明:几个简单的基本的sql语句
选择:select * from table1 where 范围
插入:insert into table1(field1,field2) values(value1,value2)
删除:delete from table1 where 范围
更新:update table1 set field1=value1 where 范围
查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料!
排序:select * from table1 order by field1,field2 [desc]
总数:select count as totalcount from table1
求和:select sum(field1) as sumvalue from table1
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
11、说明:几个高级查询运算词
A: UNION 运算符
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。
B: EXCEPT 运算符
EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。
C: INTERSECT 运算符
INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。
注:使用运算词的几个查询结果行必须是一致的。
12、说明:使用外连接
A、left outer join:
左外连接(左连接):结果集几包括连接表的匹配行,也包括左连接表的所有行。
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
B:right outer join:
右外连接(右连接):结果集既包括连接表的匹配连接行,也包括右连接表的所有行。
C:full outer join:
全外连接:不仅包括符号连接表的匹配行,还包括两个连接表中的所有记录。二、提升
1、说明:复制表(只复制结构,源表名:a 新表名:b) (Access可用)
法一:select * into b from a where 1<>1
法二:select top 0 * into b from a2、说明:拷贝表(拷贝数据,源表名:a 目标表名:b) (Access可用)
insert into b(a, b, c) select d,e,f from b;3、说明:跨数据库之间表的拷贝(具体数据使用绝对路径) (Access可用)
insert into b(a, b, c) select d,e,f from b in ‘具体数据库’ where 条件
例子:..from b in '"&Server.MapPath(".")&"\data.mdb" &"' where..4、说明:子查询(表名1:a 表名2:b)
select a,b,c from a where a IN (select d from b ) 或者: select a,b,c from a where a IN (1,2,3)5、说明:显示文章、提交人和最后回复时间
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b6、说明:外连接查询(表名1:a 表名2:b)
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c7、说明:在线视图查询(表名1:a )
select * from (SELECT a,b,c FROM a) T where t.a > 1;8、说明:between的用法,between限制查询数据范围时包括了边界值,not between不包括
select * from table1 where time between time1 and time2
select a,b,c, from table1 where a not between 数值1 and 数值29、说明:in 的使用方法
select * from table1 where a [not] in (‘值1’,’值2’,’值4’,’值6’)10、说明:两张关联表,删除主表中已经在副表中没有的信息
delete from table1 where not exists ( select * from table2 where table1.field1=table2.field1 )11、说明:四表联查问题:
select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....12、说明:日程安排提前五分钟提醒
SQL: select * from 日程安排 where datediff('minute',f开始时间,getdate())>513、说明:一条sql 语句搞定数据库分页
select top 10 b.* from (select top 20 主键字段,排序字段 from 表名 order by 排序字段 desc) a,表名 b where b.主键字段 = a.主键字段 order by a.排序字段14、说明:前10条记录
select top 10 * form. table1 where 范围15、说明:选择在每一组b值相同的数据中对应的a最大的记录的所有信息(类似这样的用法可以用于论坛每月排行榜,每月热销产品分析,按科目成绩排名,等等.)
select a,b,c from tablename ta where a=(select max(a) from tablename tb where tb.b=ta.b)16、说明:包括所有在 TableA 中但不在 TableB和TableC 中的行并消除所有重复行而派生出一个结果表
(select a from tableA ) except (select a from tableB) except (select a from tableC)17、说明:随机取出10条数据
select top 10 * from tablename order by newid()18、说明:随机选择记录
select newid()19、说明:删除重复记录
Delete from tablename where id not in (select max(id) from tablename group by col1,col2,...)20、说明:列出数据库里所有的表名
select name from sysobjects where type='U'21、说明:列出表里的所有的
select name from syscolumns where id=object_id('TableName')22、说明:列示type、vender、pcs字段,以type字段排列,case可以方便地实现多重选择,类似select 中的case。
select type,sum(case vender when 'A' then pcs else 0 end),sum(case vender when 'C' then pcs else 0 end),sum(case vender when 'B' then pcs else 0 end) FROM tablename group by type
显示结果:
type vender pcs
电脑 A 1
电脑 A 1
光盘 B 2
光盘 A 2
手机 B 3
手机 C 323、说明:初始化表table1
TRUNCATE TABLE table1
24、说明:选择从10到15的记录
select top 5 * from (select top 15 * from table order by id asc) table_别名 order by id desc三、技巧
1、1=1,1=2的使用,在SQL语句组合时用的较多
“where 1=1” 是表示选择全部 “where 1=2”全部不选,
如:
if @strWhere !=''
begin
set @strSQL = 'select count(*) as Total from [' + @tblName + '] where ' + @strWhere
end
else
begin
set @strSQL = 'select count(*) as Total from [' + @tblName + ']'
end我们可以直接写成
set @strSQL = 'select count(*) as Total from [' + @tblName + '] where 1=1 安定 '+ @strWhere2、收缩数据库
--重建索引
DBCC REINDEX
DBCC INDEXDEFRAG
--收缩数据和日志
DBCC SHRINKDB
DBCC SHRINKFILE3、压缩数据库
dbcc shrinkdatabase(dbname)4、转移数据库给新用户以已存在用户权限
exec sp_change_users_login 'update_one','newname','oldname'
go5、检查备份集
RESTORE VERIFYONLY from disk='E:\dvbbs.bak'6、修复数据库
ALTER DATABASE [dvbbs] SET SINGLE_USER
GO
DBCC CHECKDB('dvbbs',repair_allow_data_loss) WITH TABLOCK
GO
ALTER DATABASE [dvbbs] SET MULTI_USER
GO7、日志清除
SET NOCOUNT ON
DECLARE @LogicalFileName sysname,
@MaxMinutes INT,
@NewSize INTUSE tablename -- 要操作的数据库名
SELECT @LogicalFileName = 'tablename_log', -- 日志文件名
@MaxMinutes = 10, -- Limit on time allowed to wrap log.
@NewSize = 1 -- 你想设定的日志文件的大小(M)-- Setup / initialize
DECLARE @OriginalSize int
SELECT @OriginalSize = size
FROM sysfiles
WHERE name = @LogicalFileName
SELECT 'Original Size of ' + db_name() + ' LOG is ' +
CONVERT(VARCHAR(30),@OriginalSize) + ' 8K pages or ' +
CONVERT(VARCHAR(30),(@OriginalSize*8/1024)) + 'MB'
FROM sysfiles
WHERE name = @LogicalFileName
CREATE TABLE DummyTrans
(DummyColumn char (8000) not null)DECLARE @Counter INT,
@StartTime DATETIME,
@TruncLog VARCHAR(255)
SELECT @StartTime = GETDATE(),
@TruncLog = 'BACKUP LOG ' + db_name() + ' WITH TRUNCATE_ONLY'DBCC SHRINKFILE (@LogicalFileName, @NewSize)
EXEC (@TruncLog)
-- Wrap the log if necessary.
WHILE @MaxMinutes > DATEDIFF (mi, @StartTime, GETDATE()) -- time has not expired
AND @OriginalSize = (SELECT size FROM sysfiles WHERE name = @LogicalFileName)
AND (@OriginalSize * 8 /1024) > @NewSize
BEGIN -- Outer loop.
SELECT @Counter = 0
WHILE ((@Counter < @OriginalSize / 16) AND (@Counter < 50000))
BEGIN -- update
INSERT DummyTrans VALUES ('Fill Log')
DELETE DummyTrans
SELECT @Counter = @Counter + 1
END
EXEC (@TruncLog)
END
SELECT 'Final Size of ' + db_name() + ' LOG is ' +
CONVERT(VARCHAR(30),size) + ' 8K pages or ' +
CONVERT(VARCHAR(30),(size*8/1024)) + 'MB'
FROM sysfiles
WHERE name = @LogicalFileName
DROP TABLE DummyTrans
SET NOCOUNT OFF8、说明:更改某个表
exec sp_changeobjectowner 'tablename','dbo'9、存储更改全部表
CREATE PROCEDURE dbo.User_ChangeObjectOwnerBatch
@OldOwner as NVARCHAR(128),
@NewOwner as NVARCHAR(128)
ASDECLARE @Name as NVARCHAR(128)
DECLARE @Owner as NVARCHAR(128)
DECLARE @OwnerName as NVARCHAR(128)DECLARE curObject CURSOR FOR
select 'Name' = name,
'Owner' = user_name(uid)
from sysobjects
where user_name(uid)=@OldOwner
order by nameOPEN curObject
FETCH NEXT FROM curObject INTO @Name, @Owner
WHILE(@@FETCH_STATUS=0)
BEGIN
if @Owner=@OldOwner
begin
set @OwnerName = @OldOwner + '.' + rtrim(@Name)
exec sp_changeobjectowner @OwnerName, @NewOwner
end
-- select @name,@NewOwner,@OldOwnerFETCH NEXT FROM curObject INTO @Name, @Owner
ENDclose curObject
deallocate curObject
GO10、SQL SERVER中直接循环写入数据
declare @i int
set @i=1
while @i<30
begin
insert into test (userid) values(@i)
set @i=@i+1
end小记存储过程中经常用到的本周,本月,本年函数
Dateadd(wk,datediff(wk,0,getdate()),-1)
Dateadd(wk,datediff(wk,0,getdate()),6)Dateadd(mm,datediff(mm,0,getdate()),0)
Dateadd(ms,-3,dateadd(mm,datediff(m,0,getdate())+1,0))Dateadd(yy,datediff(yy,0,getdate()),0)
Dateadd(ms,-3,DATEADD(yy, DATEDIFF(yy,0,getdate())+1, 0))上面的SQL代码只是一个时间段
Dateadd(wk,datediff(wk,0,getdate()),-1)
Dateadd(wk,datediff(wk,0,getdate()),6)
就是表示本周时间段.
下面的SQL的条件部分,就是查询时间段在本周范围内的:
Where Time BETWEEN Dateadd(wk,datediff(wk,0,getdate()),-1) AND Dateadd(wk,datediff(wk,0,getdate()),6)
而在存储过程中
select @begintime = Dateadd(wk,datediff(wk,0,getdate()),-1)
select @endtime = Dateadd(wk,datediff(wk,0,getdate()),6) -
如何生成比较像样的假数据
peag 发布于 2010-09-01 17:23:27
在做项目的时候经常会遇到这样的问题:
- 根据数据模型建立了数据库,但是数据库中却没有数据,在给客户做Demo的时候必须要一条一条的添加假数据,而且这些假数据还得像模像样 的,不能乱输入,尽是看不出任何意义的“aaaaa”、“ttttttttttttt”、“123123”、“是打发斯蒂芬”这样的数据。
- 已经做好了一个系统,并且上线给部分客户使用了,现在要将该系统推广到所有的客户,所以需要做一个虚拟客户的系统,系统中需要有许多像样 的数据,但是由于保密方面的原因,原有客户的数据必须经过处理,不能出现真实的信息。
- 系统开发完成了,需要制造大量的假数据,以进行压力测试,看在有几百万上千万数据量的情况下的系统性能。
方案
其中要生成大量的没有意义的测试数据,以便进行压力测试,这个数据是最好生成的,只需要写几条SQL语句,多运行几次即可。如果不想写SQL语句, 也可以使用数据生成工具:VisualStudio、PowerDesigner、DataFactory等都可以使用。我推荐使用 DataFactory,有较强的定制性。
下面主要说一下另外一种假数据,那就是前面2种情况,具有一定业务规则和可读性的假数据。要生成比较像样的假数据主要是基于已有的系统,在真实数据 的基础上进行随机的混淆和交叉,从而产生大量看起来比较真实但是实际上却全是假的数据。对于第一种情况,可以将其他系统中的对应实体表的数据导入到 Demo环境中,然后再进行混淆交叉。
我们可以将系统中的数据分为:数字、日期和字符串3种类型分别进行混淆。
- 数字类型的数据混淆最简单,使用随机函数RAND()即可,如果是整数则可以再乘以一个系数后取整,也可以用原来的数据加上生成的随机 数,从而使得数据的范围保持在原真实数据相同的分布。比如有Revenue字段,是从客户处的收入,大客户和小客户参数的收入数不能完全随机,可以在原有 Revenue的基础上随机增加10000以内的数即可:Revenue+RAND()*10000
- 日期类型的数据混淆可以在原日期或者当前日期的基础上加减一个随机的天数形成,使用DATEADD()函数和RAND()函数即可。比如 生成随机的最近100天内的日期:DATEADD("day",0-RAND()*100,GETDATE())
- 字符串类型的数据混淆最为复杂,因为字符串具有很明确的意义,比如名字字段、公司名字段等,如果随机的生成字符将没有任何意义。这时可以 考虑将字符串拆分成两部分然后进行交叉组合,用随机的交叉组合来代替真是的数据。比如原来的姓名是:李宇春、曾轶可、刘著,经过交叉组合就会形成:李著、 曾宇春、刘轶可之类的组合。
姓名的拆分是分为姓和名,而公司的拆分可以拆分成前2个字和后面的字。如果是英文姓名或者英文公司名则可以按照第一个空格将英文字符串拆分成第一个 单词和后面的单词。然后将产生的两个字段存入临时表,用两个临时表进行交叉联接,得到两个字段的所有组合,然后再随机选出一定条数的数据,用选出的随机数 据将原有数据替换即可。
示例
以一个HR系统为例。假设其中有一个Employee表,该表记录了员工的工号、姓名等信息,现在要对姓名进行处理,具体操作如下:
1.区分出中文名和英文名,分别进行拆分。中文姓名以第一个字为A列,剩下的字尾B列,英文名以第一个单词为A列,剩下的单词为B列,将拆分的数据 存入临时表,具体SQL语句如下:
select SUBSTRING(Name,1,1) A,SUBSTRING(Name,2,10) B into #CName
from Employee
where UNICODE( Name)>255 --中文
select Name,SUBSTRING(Name,1,CHARINDEX(' ',Name,1)) A,SUBSTRING(Name,CHARINDEX(' ',Name,1),50) B into #EName
from Employee
where UNICODE( Name)<255 --英文2.让A列和B列进行交叉联接,得到姓名组合的全集,然后随机选出与源数据相同数据量的姓名存入临时表(临时表中有ID流水号字段)。假设员工表里 有5000员工数据,则可以选取5000个随机姓名,代码如下:
create table #newCName(ID int identity primary key,Name nvarchar(50))
insert into #newCName(Name)
select top 5000 n1.A+n2.B
from #CName n1
cross join #CName n2
order by NEWID() --随机选取行3.由于Employee中没有自增的ID字段,只有字符串形式的员工号作为主键,所以需要给每个员工号编一个流水号,用于和随机姓名中的流水号对 应,以便接下来的UPDATE操作:
create table #newEmployeeID(ID int identity primary key,EmployeeID varchar(10))
insert into #newEmployeeID
select EmployeeId
from Employee
where UNICODE( Name)>255 --中文4.更新Employee表中的姓名字段为随机生成的姓名:
update Employee
set Name=n.Name
from Employee e
inner join #newEmployeeID i
on e.EmployeeId=i.EmployeeID
inner join #newCName n
on i.ID=n.ID
where UNICODE(e.Name)>255 --只更新中文姓名5.用同样的方法,可以对英文姓名进行混淆交叉替换。
优化
这里需要注意的是第2步,使用了CROSS JOIN操作,也就是求两个表的笛卡尔积,如果一个表中有10W条数据,那么将会产生100亿行结果,然后再进行排序,那将是近乎不可能完成的任务,所以 必须减少进行笛卡尔积的表的数据量,比如每个表只取500条不重复的数据,那么修改后的SQL语句是:
select top 5000 n1.A+n2.B
from
(select distinct top 500 A from #CName )n1 --取不重复的500个姓
cross join
(select distinct top 500 B from #CName ) n2--取不重复的500个名
order by NEWID() --随机选取行这样最多只是500*500条记录,进行排序选取随机行将会很快完成。
select SUBSTRING(Name,1,1) A,SUBSTRING(Name,2,10) B into #CName from emp_Employee where UNICODE( Name)>255
drop table #newCName
create table #newCName(ID int identity primary key,Name nvarchar(50))
insert into #newCName(Name)
select top 10000 n1.A+n2.B
from
(select distinct top 100 A from #CName )n1
cross join
(select distinct top 100 B from #CName ) n2select * from #newCName
drop table #Cname
drop table #newCnamecreate table #NewNO(emp_no nvarchar(50),name nvarchar(50) )
drop table #NewNO
insert into #NewNO(emp_no,name)
select 'A020'+cast(n.ID as varchar(10)) ,n.name
from #newCName n -
js操作cookie
紫忧 发布于 2007-06-04 11:54:13
一篇写的比较好的js cookie的文章
Cookies,有些人喜欢它们,有些人憎恨它们。但是,很少有人真正知道如何使用它们。现在你可以成为少数人中的成员-可以自傲的Cookie 大师。-->
如果你象作者一样记性不好,那么你可能根本记不住人们的名字。我遇到人时,多半只是点点头,问句“吃了嘛!”,而且期望问候到此为止。如果还需要表示些什么,那么我就得求助于一些狡猾的技巧,好让我能想对方是谁。比如胡扯起一些和对方有关的人,不管他们之间关系多远,只要能避免不记得对方名字的尴尬就好: “你隔壁邻居的侄子的可爱小狗迈菲斯特怎么样?”通过这个方法,我希望能让对方感到,我确实很重视他(她),甚至还记得这些琐事,虽然实际上连名字都忘记了。但是,不是我不重视,而是我的记忆力实在是糟糕,而且要记住的名字又实在太多。如果我能给每个人设置cookies,那么我就不会再犯这种记忆力问题了。
在这篇文章里,我们要学习:
1. 什么是 Cookies?
2. Cookie 的构成
3. 操纵 Cookies
4. Cookie 怪兽
什么是Cookies?
你会问,什么是cookies呢? cookie 是浏览器保存在用户计算机上的少量数据。它与特定的WEB页或WEB站点关联起来,自动地在WEB浏览器和WEB服务器之间传递。
比如,如果你运行的是Windows操作系统,使用Internet Explorer上网,那么你会发现在你的“Windows”目录下面有一个子目录,叫做“Temporary Internet Files”。如果你有空看看这个目录,就会发现里面有一些文件,文件名称看起来就象电子邮件地址。比如在我机器上的这个目录里,就有 “jim@support.microsoft.com”这样的文件。这是一个cookie 文件,这个文件从哪来呢?猜一猜,它来自微软的支持站点。顺便说一句,这不是我的电子邮件地址,特此澄清。
对于管理细小的、不重要的、不想保存在中央数据库里的细节信息,Cookies 是个很不错的方案。(这不是说大家的名字不重要。)比如,目前网站上不断增长的自定义服务,可以为每个用户定制他们要看的内容。如果你设计的就是这样一个站点,那么你怎么来管理这样的信息:一个用户喜欢绿色的菜单条,而另一个喜欢红色的。确实是个累人的问题。不过,这样的信息,可以很安全地记录到cookie,并保存在用户的计算机上,而你自己的数据库空间可以留给更长久更有意义的数据。
FYI: Cookies 对于安全用途,通常很有用。我不想在此就这一问题过于深入,只是提供一个示例,可以看到如何使用在一段时间之后过期的cookies来保证站点安全:
1. 使用用户名和口令,通过 SSL 登录。
2. 在服务器的数据库里检查用户名和口令。如果登录成功,建立一个当前时间标签的消息摘要 (比如 MD5) ,并把它保存在cookie和服务器数据库里。把用户的登录时间保存在服务器数据库里面的用户记录里。
3. 在进行每个安全事务时(用户处于登录状态的任何事务),把cookie的消息摘要和保存在服务器数据库里的摘要进行比较,如果比较失败,就把用户引导到登录界面。
4. 如果第3步检查通过,那么检查当前时间和登录时间之音经过的时间是否超过允许的时间长度。如果用户已经超时,那么就把用户引到登录界面。
5. 如果第3步和第4步都通过了,那么把登录时间重新设置成当前时间,允许事务发生。那些需要你登录的安全站点,可能多数使用的都是和这里介绍的类似的方法。
Cookie的构成
Cookies最初设计时,是为了CGI编程。但是,我们也可以使用Javascrīpt脚本来操纵cookies。在本文里,我们将演示如何使用Javascrīpt脚本来操纵cookies。(如果有需求,我可能会在以后的文章里介绍如何使用Perl进行cookie管理。但是如果实在等不得,那么我现在就教你一手:仔细看看CGI.pm。在这个CGI包里有一个cookie()函数,可以用它建立cookie。但是,还是让我们先来介绍cookies的本质。
在Javascrīpt脚本里,一个cookie 实际就是一个字符串属性。当你读取cookie的值时,就得到一个字符串,里面当前WEB页使用的所有cookies的名称和值。每个cookie除了name名称和value值这两个属性以外,还有四个属性。这些属性是: expires过期时间、 path路径、 domain域、以及 secure安全。
Expires – 过期时间。指定cookie的生命期。具体是值是过期日期。如果想让cookie的存在期限超过当前浏览器会话时间,就必须使用这个属性。当过了到期日期时,浏览器就可以删除cookie文件,没有任何影响。
Path – 路径。指定与cookie关联的WEB页。值可以是一个目录,或者是一个路径。如果http://www.zdnet.com/devhead/index.html 建立了一个cookie,那么在http://www.zdnet.com/devhead/目录里的所有页面,以及该目录下面任何子目录里的页面都可以访问这个cookie。这就是说,在http://www.zdnet.com/devhead/stories/articles 里的任何页面都可以访问http://www.zdnet.com/devhead/index.html建立的cookie。但是,如果http://www.zdnet.com/zdnn/ 需要访问http://www.zdnet.com/devhead/index.html设置的cookes,该怎么办?这时,我们要把cookies 的path属性设置成“/”。在指定路径的时候,凡是来自同一服务器,URL里有相同路径的所有WEB页面都可以共享cookies。现在看另一个例子:如果想让 http://www.zdnet.com/devhead/filters/ 和http://www.zdnet.com/devhead/stories/共享cookies,就要把path设成“/devhead”。
Domain – 域。指定关联的WEB服务器或域。值是域名,比如zdnet.com。这是对path路径属性的一个延伸。如果我们想让 catalog.mycompany.com 能够访问shoppingcart.mycompany.com设置的cookies,该怎么办? 我们可以把domain属性设置成“mycompany.com”,并把path属性设置成“/”。FYI:不能把cookies域属性设置成与设置它的服务器的所在域不同的值。
Secure – 安全。指定cookie的值通过网络如何在用户和WEB服务器之间传递。这个属性的值或者是“secure”,或者为空。缺省情况下,该属性为空,也就是使用不安全的HTTP连接传递数据。如果一个 cookie 标记为secure,那么,它与WEB服务器之间就通过HTTPS或者其它安全协议传递数据。不过,设置了secure属性不代表其他人不能看到你机器本地保存的cookie。换句话说,把cookie设置为secure,只保证cookie与WEB服务器之间的数据传输过程加密,而保存在本地的cookie文件并不加密。如果想让本地cookie也加密,得自己加密数据。
操纵Cookies
请记住,cookie就是文档的一个字符串属性。要保存cookie,只要建立一个字符串,格式是name=<value>(名称=值),然后把文档的 document.cookie 设置成与它相等即可。比如,假设想保存表单接收到的用户名,那么代码看起来就象这样:
document.cookie = "username" + escape(form.username.value);
在这里,使用 escape() 函数非常重要,因为cookie值里可能包含分号、逗号或者空格。这就是说,在读取cookie值时,必须使用对应的unescape()函数给值解码。
我们当然还得介绍cookie的四个属性。这些属性用下面的格式加到字符串值后面:
name=<value>[; expires=<date>][; domain=<domain>][; path=<path>][; secure]
名称=<值>[; expires=<日期>][; domain=<域>][; path=<路径>][; 安全]
<value>, <date>, <domain> 和 <path> 应当用对应的值替换。<date> 应当使用GMT格式,可以使用Javascrīpt脚本语言的日期类Date的.toGMTString() 方法得到这一GMT格式的日期值。方括号代表这项是可选的。比如在 [; secure]两边的方括号代表要想把cookie设置成安全的,就需要把"; secure" 加到cookie字符串值的后面。如果"; secure" 没有加到cookie字符串后面,那么这个cookie就是不安全的。不要把尖括号<> 和方括号[] 加到cookie里(除非它们是某些值的内容)。设置属性时,不限属性,可以用任何顺序设置。
下面是一个例子,在这个例子里,cookie "username" 被设置成在15分钟之后过期,可以被服务器上的所有目录访问,可以被"mydomain.com"域里的所有服务器访问,安全状态为安全。
// Date() 的构造器设置以毫秒为单位
// .getTime() 方法返回时间,单位为毫秒
// 所以要设置15分钟到期,要用60000毫秒乘15分钟
var expiration = new Date((new Date()).getTime() + 15 * 60000);
document.cookie = "username=" + escape(form.username.value)+ "; expires ="
+ expiration.toGMTString() + "; path=" + "/" + "; _
domain=" + "mydomain.com" + "; secure";
读取cookies值有点象个小把戏,因为你一次就得到了属于当前文档的所有cookies。
// 下面这个语句读取了属于当前文档的所有cookies
var allcookies = document.cookie;
现在,我们得解析allcookies变量里的不同cookies,找到感兴趣的指定cookie。这个工作很简单,因为我们可以利用Javascrīpt语言提供的扩展字符串支持。
如果我们对前面分配的cookie "username" 感兴趣,可以用下面的脚本来读取它的值。
// 我们定义一个函数,用来读取特定的cookie值。
function getCookie(cookie_name)
{
var allcookies = document.cookie;
var cookie_pos = allcookies.indexOf(cookie_name);
// 如果找到了索引,就代表cookie存在,
// 反之,就说明不存在。
if (cookie_pos != -1)
{
// 把cookie_pos放在值的开始,只要给值加1即可。
cookie_pos += cookie_name.length + 1;
var cookie_end = allcookies.indexOf(";", cookie_pos);
if (cookie_end == -1)
{
cookie_end = allcookies.length;
}
var value = unescape(allcookies.substring(cookie_pos, cookie_end));
}
return value;
}
// 调用函数
var cookie_val = getCookie("username");
上面例程里的 cookie_val 变量可以用来生成动态内容,或者发送给服务器端CGI脚本进行处理。现在你知道了使用Javascrīpt脚本操纵cookies的基本方法。但是,如果你跟我一样,那么我们要做的第一件事,就是建立一些接口函数,把cookies处理上的麻烦隐藏起来。不过,在你开始编程之前,稍候片刻。这些工作,早就有人替你做好了。你要做的,只是到哪去找这些接口函数而已。
比如,在David Flangan的Javascrīpt: The Definitive Guide 3rd Ed.这本书里,可以找到很好的cookie应用类。你也可以在Oreilly的WEB站点上找到这本书里的例子。本文最后的链接列表里,有一些访问这些cookie示例的直接链接。
Cookies 怪兽
因为某些原因Cookies 的名声很不好。许多人利用cookies做一些卑鄙的事情,比如流量分析、点击跟踪。Cookies 也不是非常安全,特别是没有secure属性的cookies。不过,即使你用了安全的cookies,如果你和别人共用计算机,比如在网吧,那么别人就可以窥探计算机硬盘上未加密保存的cookie文件,也就有可能窃取你的敏感信息。所以,如果你是一个WEB开发人员,那么你要认真考虑这些问题。不要滥用cookies。不要把用户可能认为是敏感的数据保存在cookies里。如果把用户的社会保险号、信用卡号等保存在cookie里,等于把这些敏感信息放在窗户纸下,无异于把用户投到极大危险之中。一个好的原则是,如果你不想陌生人了解你的这些信息,那就不要把它们保存在cookies里。
另外,cookies还有一些实际的限制。Cookies保留在计算机上,不跟着用户走。如果用户想换计算机,那么新计算机无法得到原来的cookie。甚至用户在同一台计算机上使用不同浏览器,也得不到原来的cookie:Netscape 不能读取Internet Explorer 的cookies。
还有,用户也不愿意接受cookies。所以不要以为所有的浏览器都能接受你发出的cookies。如果浏览器不接受cookies,你要保证自己的WEB站点不致因此而崩溃或中断。
另外WEB 浏览器能保留的cookies不一定能超过300个。也没有标准规定浏览器什么时候、怎么样作废cookies。所以达到限制时,浏览器能够有效地随机删除cookies。浏览器保留的来自一个WEB服务器上的cookies,不超过20个,每个cookie的数据(包括名称和值),不超过4K字节。(不过,本文里的cookie尺寸没问题,它只占了12 K字节,保存在3个3 cookies里。)
简而言之,注意保持cookie简单。不要依赖cookies的存在,不要在每个cookie里保存太多信息。不要保存太多的cookes。但是,抛除这些限制,在技巧高超的WEB管理员手里,cookie的概念是一个有用的工具。
外部链接
每个 Javascrīpt 程序员都应当有一份Javascrīpt: David Flanagan 的The Definitive Guide。 这本书里找到cookie 类例程可以帮助你把不止一个变量编码到单一的cookie,克服掉“每个WEB服务器20 个cookies的限制”。 -
(转)在QTP中如何运用XML管理参数
shuishixingyu 发布于 2009-03-05 10:48:51
我们现阶段是运用XML文件,存放页面输入操作数据
优点:树型结构,可读性较好;操作简便
缺点:如数据庞大,不便维护;以文件形式管理数据,效率太低另外也可以运用EXCLE维护数据
优点:操作简便
缺点:可读性差;维护效率低或者连接数据库,以数据库形式管理(这点LR支持的比较好,提供了连接功能接口,操作简便,而我用的QTP8.2支持不大好),总的来说,以数据库形式管理参数数据,其优势是其他两种数据管理方式无法取代的
优点:对于参数数据量很大的情况下,便于管理
缺点:平时要维护数据库,增加工作量2)实现方法与规范:
QTP的“Test settings”->"Environment"中,提供了环境变量设置的功能。我们可以运用此接口,在外部文件的形式存储与管理对象库和参数,其中我们把对象集中放在名为Object Repository的文件夹中,对象文件的后缀名均为TSR。参数文件均放在名为XML的文件夹中,参数文件的后缀名均为XML。实现步骤:a、设置环境变量:
“Test settings”->"Environment"
b、Variable type:User-defined
c、Click “New”
d、input “name”、“Value”
(such as->name:XMLPath_1)
e、save
f、QTP脚本中写语句读取环境变量:
( Such as->XMLPath=Environment.Value("XMLPath_1") )
g、用VB写函数,用于检索XML中的关键字,提取参数值
(见如下代码),VB函数可以写在后缀名为VBS的文件中
h、在QTP中加载VB函数:
“Test settings”->"Resources"
在"Associated library files"中加载VBS函数文件
点击“Set as Default”注:1)这里的Value我们可以输入XML的存放地址,用于把文件地址传到QTP脚本中
-
XML 语法简介
hades 发布于 2006-12-11 13:48:07
一个 XML 文档的例子XML 文档使用了自描述的和简单的语法。
<?xml version="1.0" encoding="ISO-8859-1"?><NOTE>
<TO>Lin</TO><FROM>Ordm</FROM>
<HEADING>Reminder</HEADING>Don't forget me this weekend!</NOTE>
文档的第 1 行:XML 声明——定义此文档所遵循的 XML 标准的版本,在这个例子里是 1.0 版本的标准,使用的是 ISO-8859-1 (Latin-1/West European)字符集。
文档的第 2 行是根元素(就象是说“这篇文档是一个便条”):
</NOTE>
文档的第 3--6 行描述了根元素的四个子节点(to, from, heading,和 body):
<TO>Lin</TO><FROM>Ordm</FROM><HEADING>Reminder</HEADING>Don't forget me this weekend!
文档的最后一行是根元素的结束:
<NOTE>
你能从这个文档中看出这是 Ordm 给 Lin 留的便条么?难道能不承认 XML 是一种美丽的自描述语言么?
所有的 XML 文档必须有一个结束标记
在 XML 文档中, 忽略结束标记是不符合规定的。
在 HTML 文档中,一些元素可以是没有结束标记的。下面的代码在 HTML 中是完全合法的:
This is a paragraph
This is another paragraph但是在 XML 文档中必须要有结束标记,象下面的例子一样:
This is a paragraph
This is another paragraph注意:你可能已经注意到了,上面例子中的第一行并没有结束标记。这不是一个错误。因为 XML 声明并不 是 XML 文档的一部分,他不是 XML 元素,也就不应该有结束标记。
XML 标记都是大小写敏感的
这与 HTML 不一样,XML 标记是大小写敏感的。
在 XML 中,标记与标记是两个不同的标记。
因此在 XML 文档中开始标记和结束标记的大小写必须保持一致。
<Message>This is incorrectmessage> //错误的
This is correct //正确的所有的 XML 元素必须合理包含
在 XML 中不允许不正确的嵌套包含。
在 HTML 中,允许有一些不正确的包含,例如下面的代码可以被浏览器解析:
This text is bold and italic
在 XML 中所有元素必须正确的嵌套包含,上面的代码应该这样写:
This text is bold and italic
所有的 XML 文档必须有一个根元素
XML 文档中的第一个元素就是根元素。
所有 XML 文档都必须包含一个单独的标记来定义,所有其他元素的都必须成对的在根元素中嵌套。XML 文档有且只能有一个根元素。
所有的元素都可以有子元素,子元素必须正确的嵌套在父元素中,下面的代码可以形象的说明:
<ROOT><CHILD><SUBCHILD>.....</SUBCHILD></CHILD></ROOT>
属性值必须使用引号""
在 XML 中,元素的属性值没有引号引着是不符合规定的。
如同 HTML 一样,XML 元素同样也可以拥有属性。XML 元素的属性以名字/值成对的出现。XML 语法规范要求 XML 元素属性值必须用引号引着。请看下面的两个例子,第一个是错误的,第二个是正确的。
date=12/11/99>
Lin
Ordm
Reminder
Don't forget me this weekend!<?xml version="1.0" encoding="ISO-8859-1"?>
<NOTE date="12/11/99"><TO>Tove</TO><FROM>Jani</FROM>
<HEADING>Reminder</HEADING>Don't forget me this weekend!</NOTE>
第一个文档的错误之处是属性值没有用引号引着。正确的写法是:date="12/11/99"。
不正确的写法: date=12/11/99。
使用 XML,空白将被保留
在 XML 文档中,空白部分不会被解析器自动删除。
这一点与 HTML 是不同的。在 HTML 中,这样的一句话:
"Hello my name is Ordm"将会被显示成:“Hello my name is Ordm”,
因为 HTML 解析器会自动把句子中的空白部分去掉。
使用 XML,CR / LF 被转换为 LF
使用 XML,新行总是被标识为 LF(Line Feed,换行)。
你知道打字机是什么么?呵呵,打字机是在上个世纪里使用的一种专门打字的机器。
当你用打字机敲完一行字后,你通常不得不再把打字头移动到纸的左端。
在 Windows 应用程序中,文本中的新行通常标识为 CR LF (carriage return, line feed,回车,换行)。在 Unix 应用程序中,新行通常标识为 LF。还有一些应用程序只使用 CR 来表示一个新行。
XML 中的注释
在 XML 中注释的语法基本上和HTML中的一样。
XML 确实没有什么特别的地方。他只是一些用尖括号扩在一起的普通的纯文本。
编辑普通文本的软件也可以编辑 XML 文档。
然而在一个支持 XML 的应用程序中,XML 标记往往对应着特殊的操作,有些标记可能是可见的,而有些标记则可能不会显示出来,而不会有什么特殊的操作。
-
测试web报错info总结
xiaoningln 发布于 2010-03-15 09:09:48
今天总结一下所有web信息错误和访问web一些报错信息总结。HTTP 400 - 请求无效
HTTP 401.1 - 未授权:登录失败
HTTP 401.2 - 未授权:服务器配置问题导致登录失败
HTTP 401.3 - ACL 禁止访问资源
HTTP 401.4 - 未授权:授权被筛选器拒绝
HTTP 401.5 - 未授权:ISAPI 或 CGI 授权失败HTTP 403 - 禁止访问
HTTP 403 - 对 Internet 服务管理器 的访问仅限于 Localhost
HTTP 403.1 禁止访问:禁止可执行访问
HTTP 403.2 - 禁止访问:禁止读访问
HTTP 403.3 - 禁止访问:禁止写访问
HTTP 403.4 - 禁止访问:要求 SSL
HTTP 403.5 - 禁止访问:要求 SSL 128
HTTP 403.6 - 禁止访问:IP 地址被拒绝
HTTP 403.7 - 禁止访问:要求客户证书
HTTP 403.8 - 禁止访问:禁止站点访问
HTTP 403.9 - 禁止访问:连接的用户过多
HTTP 403.10 - 禁止访问:配置无效
HTTP 403.11 - 禁止访问:密码更改
HTTP 403.12 - 禁止访问:映射器拒绝访问
HTTP 403.13 - 禁止访问:客户证书已被吊销
HTTP 403.15 - 禁止访问:客户访问许可过多
HTTP 403.16 - 禁止访问:客户证书不可信或者无效
HTTP 403.17 - 禁止访问:客户证书已经到期或者尚未生效 HTTP 404.1 -无法找到 Web 站点
HTTP 404- 无法找到文件
HTTP 405 - 资源被禁止
HTTP 406 - 无法接受
HTTP 407 - 要求代理身份验证
HTTP 410 - 永远不可用
HTTP 412 - 先决条件失败
HTTP 414 - 请求 - URI 太长
HTTP 500 - 内部服务器错误
HTTP 500.100 - 内部服务器错误 - ASP 错误
HTTP 500-11 服务器关闭
HTTP 500-12 应用程序重新启动
HTTP 500-13 - 服务器太忙
HTTP 500-14 - 应用程序无效
HTTP 500-15 - 不允许请求 global.asa
Error 501 - 未实现
HTTP 502 - 网关错误用户试图通过 HTTP 或文件传输协议 (FTP) 访问一台正在运行 Internet 信息服务 (IIS) 的服务器上的内容时,IIS 返回一个表示该请求的状态的数字代码。该状态代码记录在 IIS 日志中,同时也可能在 Web 浏览器或 FTP 客户端显示。状态代码可以指明具体请求是否已成功,还可以揭示请求失败的确切原因。
日志文件的位置
在默认状态 下,IIS 把它的日志文件放在 %WINDIRSystem32Logfiles 文件夹中。每个万维网 (WWW) 站点和 FTP 站点在该目录下都有一个单独的目录。在默认状态下,每天都会在这些目录下创建日志文件,并用日期给日志文件命名(例如,exYYMMDD.log)。
HTTP
1xx - 信息提示这些状态代码表示临时的响应。客户端在收到常规响应之前,应准备接收一个或多个 1xx 响应。 • 100 - 继续。
• 101 - 切换协议。
2xx - 成功这类状态代码表明服务器成功地接受了客户端请求。 • 200 - 确定。客户端请求已成功。
• 201 - 已创建。
• 202 - 已接受。
• 203 - 非权威性信息。
• 204 - 无内容。
• 205 - 重置内容。
• 206 - 部分内容。
3xx - 重定向客户端浏览器必须采取更多操作来实现请求。例如,浏览器可能不得不请求服务器上的不同的页面,或通过代理服务器重复该请求。 • 302 - 对象已移动。
• 304 - 未修改。
• 307 - 临时重定向。
4xx - 客户端错误发生错误,客户端似乎有问题。例如,客户端请求不存在的页面,客户端未提供有效的身份验证信息。 • 400 - 错误的请求。
• 401 - 访问被拒绝。IIS 定义了许多不同的 401 错误,它们指明更为具体的错误原因。这些具体的错误代码在浏览器中显示,但不在 IIS 日志中显示: • 401.1 - 登录失败。
• 401.2 - 服务器配置导致登录失败。
• 401.3 - 由于 ACL 对资源的限制而未获得授权。
• 401.4 - 筛选器授权失败。
• 401.5 - ISAPI/CGI 应用程序授权失败。
• 401.7 – 访问被 Web 服务器上的 URL 授权策略拒绝。这个错误代码为 IIS 6.0 所专用。• 403 - 禁止访问:IIS 定义了许多不同的 403 错误,它们指明更为具体的错误原因: • 403.1 - 执行访问被禁止。
• 403.2 - 读访问被禁止。
• 403.3 - 写访问被禁止。
• 403.4 - 要求 SSL。
• 403.5 - 要求 SSL 128。
• 403.6 - IP 地址被拒绝。
• 403.7 - 要求客户端证书。
• 403.8 - 站点访问被拒绝。
• 403.9 - 用户数过多。
• 403.10 - 配置无效。
• 403.11 - 密码更改。
• 403.12 - 拒绝访问映射表。
• 403.13 - 客户端证书被吊销。
• 403.14 - 拒绝目录列表。
• 403.15 - 超出客户端访问许可。
• 403.16 - 客户端证书不受信任或无效。
• 403.17 - 客户端证书已过期或尚未生效。
• 403.18 - 在当前的应用程序池中不能执行所请求的 URL。这个错误代码为 IIS 6.0 所专用。
• 403.19 - 不能为这个应用程序池中的客户端执行 CGI。这个错误代码为 IIS 6.0 所专用。
• 403.20 - Passport 登录失败。这个错误代码为 IIS 6.0 所专用。• 404 - 未找到。 • 404.0 -(无) – 没有找到文件或目录。
• 404.1 - 无法在所请求的端口上访问 Web 站点。
• 404.2 - Web 服务扩展锁定策略阻止本请求。
• 404.3 - MIME 映射策略阻止本请求。• 405 - 用来访问本页面的 HTTP 谓词不被允许(方法不被允许)
• 406 - 客户端浏览器不接受所请求页面的 MIME 类型。
• 407 - 要求进行代理身份验证。
• 412 - 前提条件失败。
• 413 – 请求实体太大。
• 414 - 请求 URI 太长。
• 415 – 不支持的媒体类型。
• 416 – 所请求的范围无法满足。
• 417 – 执行失败。
• 423 – 锁定的错误。
5xx - 服务器错误服务器由于遇到错误而不能完成该请求。 • 500 - 内部服务器错误。 • 500.12 - 应用程序正忙于在 Web 服务器上重新启动。
• 500.13 - Web 服务器太忙。
• 500.15 - 不允许直接请求 Global.asa。
• 500.16 – UNC 授权凭据不正确。这个错误代码为 IIS 6.0 所专用。
• 500.18 – URL 授权存储不能打开。这个错误代码为 IIS 6.0 所专用。
• 500.100 - 内部 ASP 错误。• 501 - 页眉值指定了未实现的配置。
• 502 - Web 服务器用作网关或代理服务器时收到了无效响应。 • 502.1 - CGI 应用程序超时。
• 502.2 - CGI 应用程序出错。application.• 503 - 服务不可用。这个错误代码为 IIS 6.0 所专用。
• 504 - 网关超时。
• 505 - HTTP 版本不受支持。常见的 HTTP 状态代码及其原因
• 200 - 成功。 此状态代码表示 IIS 已成功处理请求。
• 304 - 未修改。客户端请求的文档已在其缓存中,文档自缓存以来尚未被修改过。客户端使用文档的缓存副本,而不从服务器下载文档。
• 401.1 - 登录失败。 登录尝试不成功,可能因为用户名或密码无效。
• 401.3 - 由于 ACL 对资源的限制而未获得授权。 这表示存在 NTFS 权限问题。即使您对试图访问的文件具备相应的权限,也可能发生此错误。例如,如果 IUSR 帐户无权访问 C:WinntSystem32Inetsrv 目录,您会看到这个错误。 有关如何解决此问题的其他信息,请单击下面的文章编号,查看 Microsoft 知识库中相应的文章:
187506 INFO: IIS 4.0 的基础 NTFS 权限
• 403.1 - 执行访问被禁止。 下面是导致此错误信息的两个常见原因: • 您没有足够的执行许可。例如,如果试图访问的 ASP 页所在的目录权限设为“无”,或者,试图执行的 CGI 脚本所在的目录权限为“只允许脚本”,将出现此错误信息。若要修改执行权限,请在 Microsoft 管理控制台 (MMC) 中右击目录,然后依次单击属性和目录选项卡,确保为试图访问的内容设置适当的执行权限。
• 您没有将试图执行的文件类型的脚本映射设置为识别所使用的谓词(例如,GET 或 POST)。若要验证这一点,请在 MMC 中右击目录,依次单击属性、目录选项卡和配置,然后验证相应文件类型的脚本映射是否设置为允许所使用的谓词。• 403.2 - 读访问被禁止。验证是否已将 IIS 设置为允许对目录进行读访问。另外,如果您正在使用默认文件,请验证该文件是否存在。有关如何解决此问题的其他信息,请单击下面的文章编号,查看 Microsoft 知识库中相应的文章:
247677 错误信息:403.2 Forbidden:Read Access Forbidden(403.2 禁止访问:读访问被禁止)
• 403.3 - 写访问被禁止。 验证 IIS 权限和 NTFS 权限是否已设置以便向该目录授予写访问权。有关如何解决此问题的其他信息,请单击下面的文章编号,查看 Microsoft 知识库中相应的文章:
248072 错误信息:403.3 Forbidden:Write Access Forbidden(403.3 禁止访问:写访问被禁止)
• 403.4 - 要求 SSL。禁用要求安全通道选项,或使用 HTTPS 代替 HTTP 来访问该页面。如果没有安装证书的 Web 站点出现此错误,请单击下面的文章编号,查看 Microsoft 知识库中相应的文章:
224389 错误信息:HTTP 错误 403、403.4、403.5 禁止访问:要求 SSL
• 403.5 - 要求 SSL 128。禁用要求 128 位加密选项,或使用支持 128 位加密的浏览器以查看该页面。如果没有安装证书的 Web 站点出现此错误,请单击下面的文章编号,查看 Microsoft 知识库中相应的文章:
224389 错误信息:HTTP 错误 403、403.4、403.5 禁止访问:要求 SSL
• 403.6 - IP 地址被拒绝。您已把您的服务器配置为拒绝访问您目前的 IP 地址。有关如何解决此问题的其他信息,请单击下面的文章编号,查看 Microsoft 知识库中相应的文章:
248043 错误信息:403.6 - Forbidden:IP Address Rejected(403.6 - 不可用:IP 地址被拒绝)
• 403.7 - 要求客户端证书。您已把您的服务器配置为要求客户端身份验证证书,但您未安装有效的客户端证书。有关其他信息,请单击下面的文章编号,查看 Microsoft 知识库中相应的文章:
190004 错误 403.7 或“Connection to Server Could Not Be Established”(无法建立与服务器的连接)
186812 PRB:错误信息:403.7 Forbidden:Client Certificate Required(403.7 禁止访问:要求客户端证书)
• 403.8 - 站点访问被拒绝。您已为您用来访问服务器的域设置了域名限制。有关如何解决此问题的其他信息,请单击下面的文章编号,查看 Microsoft 知识库中相应的文章:
248032 错误信息:Forbidden:Site Access Denied 403.8(禁止访问:站点访问被拒绝 403.8)
• 403.9 - 用户数过多。与该服务器连接的用户数量超过了您设置的连接限制。有关如何更改此限制的其他信息,请单击下面的文章编号,以查看 Microsoft 知识库中相应的文章:
248074 错误信息:Access Forbidden:Too Many Users Are Connected 403.9(禁止访问:连接的用户太多 403.9)
注意:Microsoft Windows 2000 Professional 和 Microsoft Windows XP Professional 自动设置了在 IIS 上最多 10 个连接的限制。您无法更改此限制。
• 403.12 - 拒绝访问映射表。 您要访问的页面要求提供客户端证书,但映射到您的客户端证书的用户 ID 已被拒绝访问该文件。有关其他信息,请单击下面的文章编号,以查看 Microsoft 知识库中相应的文章:
248075 错误信息:HTTP 403.12 - Access Forbidden:Mapper Denied Access(HTTP 403.12 - 禁止访问:映射表拒绝访问)
• 404 - 未找到。 发生此错误的原因是您试图访问的文件已被移走或删除。如果在安装 URLScan 工具之后,试图访问带有有限扩展名的文件,也会发生此错误。这种情况下,该请求的日志文件项中将出现“Rejected by URLScan”的字样。
• 500 - 内部服务器错误。 很多服务器端的错误都可能导致该错误信息。事件查看器日志包含更详细的错误原因。此外,您可以禁用友好 HTTP 错误信息以便收到详细的错误说明。 有关如何禁用友好 HTTP 错误信息的其他信息,请单击下面的文章编号,以查看 Microsoft 知识库中相应的文章:
294807 如何在服务器端禁用 Internet Explorer 5 的“显示友好 HTTP 错误信息”功能
• 500.12 - 应用程序正在重新启动。 这表示您在 IIS 重新启动应用程序的过程中试图加载 ASP 页。刷新页面后,此信息即会消失。如果刷新页面后,此信息再次出现,可能是防病毒软件正在扫描 Global.asa 文件。有关其他信息,请单击下面的文章编号,以查看 Microsoft 知识库中相应的文章:
248013 错误信息:HTTP Error 500-12 Application Restarting(HTTP 错误 500-12 应用程序正在重新启动)
• 500-100.ASP - ASP 错误。 如果试图加载的 ASP 页中含有错误代码,将出现此错误信息。若要获得更确切的错误信息,请禁用友好 HTTP 错误信息。默认情况下,只会在默认 Web 站点上启用此错误信息。有关如何在非默认的 Web 站点上看到此错误信息的其他信息,请单击下面的文章编号,以查看 Microsoft 知识库中相应的文章:
261200 显示 HTTP 500 错误信息,而不显示 500-100.asp 的 ASP 错误信息
• 502 - 网关错误。 如果试图运行的 CGI 脚本不返回有效的 HTTP 标头集,将出现此错误信息。FTP
1xx - 肯定的初步答复这些状态代码指示一项操作已经成功开始,但客户端希望在继续操作新命令前得到另一个答复。 • 110 重新启动标记答复。
• 120 服务已就绪,在 nnn 分钟后开始。
• 125 数据连接已打开,正在开始传输。
• 150 文件状态正常,准备打开数据连接。
2xx - 肯定的完成答复一项操作已经成功完成。客户端可以执行新命令。 • 200 命令确定。
•MySQL查询优化技术之使用索引
xiaoningln 发布于 2007-02-07 14:50:06
MySQL查询优化技术系列讲座之使用索引索引是提高查询速度的最重要的工具。当然还有其它的一些技术可供使用,但是一般来说引起最大性能差异的都是索引的正确使用。在MySQL邮件列表中,人们经常询问那些让查询运行得更快的方法。在大多数情况下,我们应该怀疑数据表上有没有索引,并且通常在添加索引之后立即解决了问题。当然,并不总是这样简单就可以解决问题的,因为优化技术本来就并非总是简单的。然而,如果没有使用索引,在很多情况下,你试图使用其它的方法来提高性能都是在浪费时间。首先使用索引来获取最大的性能提高,接着再看其它的技术是否有用。
这一部分讲述了索引是什么以及索引是怎么样提高查询性能的。它还讨论了在某些环境中索引可能降低性能,并为你明智地选择数据表的索引提供了一些指导方针。在下一部分中我们将讨论MySQL查询优化器,它试图找到执行查询的效率最高的方法。了解一些优化器的知识,作为对如何建立索引的补充,对我们是有好处的,因为这样你才能更好地利用自己所建立的索引。某些编写查询的方法实际上让索引不起作用,在一般情况下你应该避免这种情形的发生。
索引的优点
让我们开始了解索引是如何工作的,首先有一个不带索引的数据表。不带索引的表仅仅是一个无序的数据行集合。例如,图1显示的ad表就是不带索引的表,因此如果需要查找某个特定的公司,就必须检查表中的每个数据行看它是否与目标值相匹配。这会导致一次完全的数据表扫描,这个过程会很慢,如果这个表很大,但是只包含少量的符合条件的记录,那么效率会非常低。
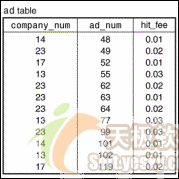
图1:无索引的ad表
图2是同样的一张数据表,但是增加了对ad表的company_num数据列的索引。这个索引包含了ad表中的每个数据行的条目,但是索引的条目是按照company_num值排序的。现在,我们不是逐行查看以搜寻匹配的数据项,而是使用索引。假设我们查找公司13的所有数据行。我们开始扫描索引并找到了该公司的三个值。接着我们碰到了公司14的索引值,它比我们正在搜寻的值大。索引值是排过序的,因此当我们读取了包含14的索引记录的时候,我们就知道再也不会有更多的匹配记录,可以结束查询操作了。因此使用索引获得的功效是:我们找到了匹配的数据行在哪儿终止,并能够忽略其它的数据行。另一个功效来自使用定位算法查找第一条匹配的条目,而不需要从索引头开始执行线性扫描(例如,二分搜索就比线性扫描要快一些)。通过使用这种方法,我们可以快速地定位第一个匹配的值,节省了大量的搜索时间。数据库使用了多种技术来快速地定位索引值,但是在本文中我们不关心这些技术。重点是它们能够实现,并且索引是个好东西。
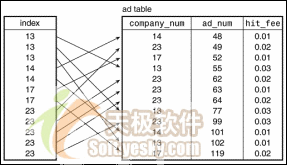
图2:索引后的ad表
你可能要问,我们为什么不对数据行进行排序从而省掉索引?这样不是也能实现同样的搜索速度的改善吗?是的,如果表只有一个索引,这样做也可能达到相同的效果。但是你可能添加第二个索引,那么就无法一次使用两种不同方法对数据行进行排序了(例如,你可能希望在顾客名称上建立一个索引,在顾客ID号或电话号码上建立另外一个索引)。把与数据行相分离的条目作为索引解决了这个问题,允许我们创建多个索引。此外,索引中的行一般也比数据行短一些。当你插入或删除新的值的时候,移动较短的索引值比移动较长数据行的排序次序更加容易。
不同的MySQL存储引擎的索引实现的具体细节信息是不同的。例如,对于MyISAM数据表,该表的数据行保存在一个数据文件中,索引值保存在索引文件中。一个数据表上可能有多个索引,但是它们都被存储在同一个索引文件中。索引文件中的每个索引都包含一个排序的键记录(它用于快速地访问数据文件)数组。
与此形成对照的是,BDB和InnoDB存储引擎没有使用这种方法来分离数据行和索引值,尽管它们也把索引作为排序后的值集合进行操作。在默认情况下,BDB引擎使用单个文件存储数据和索引值。InnoDB使用单个数据表空间(tablespace),在表空间中管理所有InnoDB表的数据和索引存储。我们可以把InnoDB配置为每个表都在自己的表空间中创建,但是即使是这样,数据表的数据和索引也存储在同一个表空间文件中。
前面的讨论描述了单个表查询环境下的索引的优点,在这种情况下,通过减少对整个表的扫描,使用索引明显地提高了搜索的速度。当你运行涉及多表联结(jion)查询的时候,索引的价值就更高了。在单表查询中,你需要在每个数据列上检查的值的数量是表中数据行的数量。在多表查询中,这个数量可能大幅度上升,因为这个数量是这些表中数据行的数量所产生的。
假设你拥有三个未索引的表t1、t2和t3,每个表都分别包含数据列i1、i2和i3,并且每个表都包含了1000条数据行,其序号从1到1000。查找某些值匹配的数据行组合的查询可能如下所示:
SELECT t1.i1, t2.i2, t3.i3
FROM t1, t2, t3
WHERE t1.i1 = t2.i2 AND t2.i1 = t3.i3;
这个查询的结果应该是1000行,每个数据行包含三个相等的值。如果在没有索引的情况下处理这个查询,那么如果我们不对这些表进行全部地扫描,我们是没有办法知道哪些数据行含有哪些值的。因此你必须尝试所有的组合来查找符合WHERE条件的记录。可能的组合的数量是1000 x 1000 x 1000(10亿!),它是匹配记录的数量的一百万倍。这就浪费了大量的工作。这个例子显示,如果没有使用索引,随着表的记录不断增长,处理这些表的联结所花费的时间增长得更快,导致性能很差。我们可以通过索引这些数据表来显著地提高速度,因为索引让查询采用如下所示的方式来处理:
1.选择表t1中的第一行并查看该数据行的值。
2.使用表t2上的索引,直接定位到与t1的值匹配的数据行。类似地,使用表t3上的索引,直接定位到与表t2的值匹配的数据行。
3.处理表t1的下一行并重复前面的过程。执行这样的操作直到t1中的所有数据行都被检查过。
在这种情况下,我们仍然对表t1执行了完整的扫描,但是我们可以在t2和t3上执行索引查找,从这些表中直接地获取数据行。理论上采用这种方式运行上面的查询会快一百万倍。当然这个例子是为了得出结论来人为建立的。然而,它解决的问题却是现实的,给没有索引的表添加索引通常会获得惊人的性能提高。
MySQL有几种使用索引的方式:
· 如上所述,索引被用于提高WHERE条件的数据行匹配或者执行联结操作时匹配其它表的数据行的搜索速度。
· 对于使用了MIN()或MAX()函数的查询,索引数据列中最小或最大值可以很快地找到,不用检查每个数据行。
· MySQL利用索引来快速地执行ORDER BY和GROUP BY语句的排序和分组操作。
· 有时候MySQL会利用索引来读取查询得到的所有信息。假设你选择了MyISAM表中的被索引的数值列,那么就不需要从该数据表中选择其它的数据列。在这种情况下,MySQL从索引文件中读取索引值,它所得到的值与读取数据文件得到的值是相同的。没有必要两次读取相同的值,因此没有必要考虑数据文件。索引的代价
一般来说,如果MySQL能够找到方法,利用索引来更快地处理查询,它就会这样做。这意味着,对于大多数情况,如果你没有对表进行索引,就会使性能受到损害。这就是我所描绘的索引优点的美景。但是它有缺点吗?有的,它在时间和空间上都有开销。在实践中,索引的优点的价值一般会超过这些缺点,但是你也应该知道到底有一些什么缺点。
首先,索引加快了检索的速度,但是减慢了插入和删除的速度,同时还减慢了更新被索引的数据列中的值的速度。也就是说,索引减慢了大多数涉及写操作的速度。发生这种现象的原因在于写入一条记录的时候不但需要写入数据行,还需要改变所有的索引。数据表带有的索引越多,需要做出的修改就越多,平均性能的降低程度也就越大。在本文的"高效率载入数据"部分中,我们将更细致地了解这些现象并找出处理方法。
其次,索引会花费磁盘空间,多个索引相应地花费更多的磁盘空间。这可能导致更快地到达数据表的大小限制:
· 对于MyISAM表,频繁地索引可能引起索引文件比数据文件更快地达到最大限制。
· 对于BDB表,它把数据和索引值一起存储在同一个文件中,添加索引引起这种表更快地达到最大文件限制。
· 在InnoDB的共享表空间中分配的所有表都竞争使用相同的公共空间池,因此添加索引会更快地耗尽表空间中的存储。但是,与MyISAM和BDB表使用的文件不同,InnoDB共享表空间并不受操作系统的文件大小限制,因为我们可以把它配置成使用多个文件。只要有额外的磁盘空间,你就可以通过添加新组件来扩展表空间。
使用单独表空间的InnoDB表与BDB表受到的约束是一样的,因为它的数据和索引值都存储在单个文件中。
这些要素的实际含义是:如果你不需要使用特殊的索引帮助查询执行得更快,就不要建立索引。
选择索引
假设你已经知道了建立索引的语法,但是语法不会告诉你数据表应该如何索引。这要求我们考虑数据表的使用方式。这一部分指导你如何识别出用于索引的备选数据列,以及如何最好地建立索引:
用于搜索、排序和分组的索引数据列并不仅仅是用于输出显示的。换句话说,用于索引的最好的备选数据列是那些出现在WHERE子句、join子句、ORDER BY或GROUP BY子句中的列。仅仅出现在SELECT关键字后面的输出数据列列表中的数据列不是很好的备选列:SELECT
col_a <- 不是备选列
FROM
tbl1 LEFT JOIN tbl2
ON tbl1.col_b = tbl2.col_c <- 备选列
WHERE
col_d = expr; <- 备选列
当然,显示的数据列与WHERE子句中使用的数据列也可能相同。我们的观点是输出列表中的数据列本质上不是用于索引的很好的备选列。
Join子句或WHERE子句中类似col1 = col2形式的表达式中的数据列都是特别好的索引备选列。前面显示的查询中的col_b和col_c就是这样的例子。如果MySQL能够利用联结列来优化查询,它一定会通过减少整表扫描来大幅度减少潜在的表-行组合。
考虑数据列的基数(cardinality)。基数是数据列所包含的不同值的数量。例如,某个数据列包含值1、3、7、4、7、3,那么它的基数就是4。索引的基数相对于数据表行数较高(也就是说,列中包含很多不同的值,重复的值很少)的时候,它的工作效果最好。如果某数据列含有很多不同的年龄,索引会很快地分辨数据行。如果某个数据列用于记录性别(只有"M"和"F"两种值),那么索引的用处就不大。如果值出现的几率几乎相等,那么无论搜索哪个值都可能得到一半的数据行。在这些情况下,最好根本不要使用索引,因为查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。惯用的百分比界线是"30%"。现在查询优化器更加复杂,把其它一些因素也考虑进去了,因此这个百分比并不是MySQL决定选择使用扫描还是索引的唯一因素。
索引较短的值。尽可能地使用较小的数据类型。例如,如果MEDIUMINT足够保存你需要存储的值,就不要使用BIGINT数据列。如果你的值不会长于25个字符,就不要使用CHAR(100)。较小的值通过几个方面改善了索引的处理速度:
· 较短的值可以更快地进行比较,因此索引的查找速度更快了。
· 较小的值导致较小的索引,需要更少的磁盘I/O。
· 使用较短的键值的时候,键缓存中的索引块(block)可以保存更多的键值。MySQL可以在内存中一次保持更多的键,在不需要从磁盘读取额外的索引块的情况下,提高键值定位的可能性。
对于InnoDB和BDB等使用聚簇索引(clustered index)的存储引擎来说,保持主键(primary key)短小的优势更突出。聚簇索引中数据行和主键值存储在一起(聚簇在一起)。其它的索引都是次级索引;它们存储主键值和次级索引值。次级索引屈从主键值,它们被用于定位数据行。这暗示主键值都被复制到每个次级索引中,因此如果主键值很长,每个次级索引就需要更多的额外空间。
索引字符串值的前缀(prefixe)。如果你需要索引一个字符串数据列,那么最好在任何适当的情况下都应该指定前缀长度。例如,如果有CHAR(200)数据列,如果前面10个或20个字符都不同,就不要索引整个数据列。索引前面10个或20个字符会节省大量的空间,并且可能使你的查询速度更快。通过索引较短的值,你可以获得那些与比较速度和磁盘I/O节省相关的好处。当然你也需要利用常识。仅仅索引某个数据列的第一个字符串可能用处不大,因为如果这样操作,那么在索引中不会有太多的唯一值。
你可以索引CHAR、VARCHAR、BINARY、VARBINARY、BLOB和TEXT数据列的前缀。
使用最左(leftmost)前缀。建立多列复合索引的时候,你实际上建立了MySQL可以使用的多个索引。复合索引可以作为多个索引使用,因为索引中最左边的列集合都可以用于匹配数据行。这种列集合被称为"最左前缀"(它与索引某个列的前缀不同,那种索引把某个列的前面几个字符作为索引值)。
假设你在表的state、city和zip数据列上建立了复合索引。索引中的数据行按照state/city/zip次序排列,因此它们也会自动地按照state/city和state次序排列。这意味着,即使你在查询中只指定了state值,或者指定state和city值,MySQL也可以使用这个索引。因此,这个索引可以被用于搜索如下所示的数据列组合:
state, city, zip
state, city
state
MySQL不能利用这个索引来搜索没有包含在最左前缀的内容。例如,如果你按照city或zip来搜索,就不会使用到这个索引。如果你搜索给定的state和具体的ZIP代码(索引的1和3列),该索引也是不能用于这种组合值的,尽管MySQL可以利用索引来查找匹配的state从而缩小搜索的范围。
不要过多地索引。不要认为"索引越多,性能越高",不要对每个数据列都进行索引。我们在前面提到过,每个额外的索引都会花费更多的磁盘空间,并降低写操作的性能。当你修改表的内容的时候,索引就必须被更新,甚至可能重新整理。如果你的索引很少使用或永不使用,你就没有必要减小表的修改操作的速度。此外,为检索操作生成执行计划的时候,MySQL会考虑索引。建立额外的索引会给查询优化器增加更多的工作量。如果索引太多,有可能(未必)出现MySQL选择最优索引失败的情况。维护自己必须的索引可以帮助查询优化器来避免这类错误。
如果你考虑给已经索引过的表添加索引,那么就要考虑你将增加的索引是否是已有的多列索引的最左前缀。如果是这样的,不用增加索引,因为已经有了(例如,如果你在state、city和zip上建立了索引,那么没有必要再增加state的索引)。
让索引类型与你所执行的比较的类型相匹配。在你建立索引的时候,大多数存储引擎会选择它们将使用的索引实现。例如,InnoDB通常使用B树索引。MySQL也使用B树索引,它只在三维数据类型上使用R树索引。但是,MEMORY存储引擎支持散列索引和B树索引,并允许你选择使用哪种索引。为了选择索引类型,需要考虑在索引数据列上将执行的比较操作类型:
· 对于散列(hash)索引,会在每个数据列值上应用散列函数。生成的结果散列值存储在索引中,并用于执行查询。散列函数实现的算法类似于为不同的输入值生成不同的散列值。使用散列值的好处是散列值比原始值的比较效率更高。散列索引用于执行=或<=>操作等精确匹配的时候速度非常快。但是对于查询一个值的范围效果就非常差了:
id < 30
weight BETWEEN 100 AND 150
· B树索引可以用于高效率地执行精确的或者基于范围(使用操作<、<=、=、>=、>、<>、!=和BETWEEN)的比较。B树索引也可以用于LIKE模式匹配,前提是该模式以文字串而不是通配符开头。
如果你使用的MEMORY数据表只进行精确值查询,散列索引是很好的选择。这是MEMORY表使用的默认的索引类型,因此你不需要特意指定。如果你希望在MEMORY表上执行基于范围的比较,应该使用B树索引。为了指定这种索引类型,需要给索引定义添加USING BTREE。例如:
CREATE TABLE lookup
(
id INT NOT NULL,
name CHAR(20),
PRIMARY KEY USING BTREE (id)
) ENGINE = MEMORY;
如果你希望执行的语句的类型允许,单个MEMORY表可以同时拥有散列索引和B树索引,即使在同一个数据列上。
有些类型的比较不能使用索引。如果你只是通过把值传递到函数(例如STRCMP())中来执行比较操作,那么对它进行索引就没有价值。服务器必须计算出每个数据行的函数值,它会排除数据列上索引的使用。
使用慢查询(slow-query)日志来识别执行情况较差的查询。这个日志可以帮助你找出从索引中受益的查询。你可以直接查看日志(它是文本文件),或者使用mysqldumpslow工具来统计它的内容。如果某个给定的查询多次出现在"慢查询"日志中,这就是一个线索,某个查询可能没有优化编写。你可以重新编写它,使它运行得更快。你要记住,在评估"慢查询"日志的时候,"慢"是根据实际时间测定的,在负载较大的服务器上"慢查询"日志中出现的查询会多一些。MySQL数据库索引经验之浅见
xiaoningln 发布于 2007-08-07 18:09:00
在数据库表中,使用索引可以大大提高查询速度。
假如我们创建了一个testIndex表:
CREATE TABLE testIndex(i_testID INT NOT NULL,vc_Name VARCHAR(16) NOT NULL);
我们随机向里面插入了1000条记录,其中有一条
i_testIDvc_Name
555erquan
在查找vc_Name="erquan"的记录
SELECT * FROM testIndex WHERE vc_Name='erquan';
时,如果在vc_Name上已经建立了索引,MySql无须任何扫描,即准确可找到该记录!相反,MySql会扫描所有记录,即要查询1000次啊~~可以索引将查询速度提高100倍。
一、索引分单列索引和组合索引
单列索引:即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。
组合索引:即一个索包含多个列。
二、介绍一下索引的类型
1.普通索引。
这是最基本的索引,它没有任何限制。它有以下几种创建方式:
(1)创建索引:CREATE INDEX indexName ON tableName(tableColumns(length));如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB 和 TEXT 类型,必须指定length,下同。
(2)修改表结构:ALTER tableName ADD INDEX [indexName] ON (tableColumns(length))
(3)创建表的时候直接指定:CREATE TABLE tableName ( [...], INDEX [indexName] (tableColumns(length)) ;
2.唯一索引。
它与前面的"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
(1)创建索引:CREATE UNIQUE INDEX indexName ON tableName(tableColumns(length))
(2)修改表结构:ALTER tableName ADD UNIQUE [indexName] ON (tableColumns(length))
(3)创建表的时候直接指定:CREATE TABLE tableName ( [...], UNIQUE [indexName] (tableColumns(length));
3.主键索引
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引:CREATE TABLE testIndex(i_testID INT NOT NULL AUTO_INCREMENT,vc_Name VARCHAR(16) NOT NULL,PRIMARY KEY(i_testID)); 当然也可以用ALTER命令。
记住:一个表只能有一个主键。
4.全文索引
MySQL从3.23.23版开始支持全文索引和全文检索。这里不作讨论,呵呵~~
删除索引的语法:DROP INDEX index_name ON tableName
三、单列索引和组合索引
为了形象地对比两者,再建一个表:
CREATE TABLE myIndex ( i_testID INT NOT NULL AUTO_INCREMENT, vc_Name VARCHAR(50) NOT NULL, vc_City VARCHAR(50) NOT NULL, i_Age INT NOT NULL, i_SchoolID INT NOT NULL, PRIMARY KEY (i_testID) );
在这10000条记录里面7上8下地分布了5条vc_Name="erquan"的记录,只不过city,age,school的组合各不相同。
来看这条T-SQL:
SELECT i_testID FROM myIndex WHERE vc_Name='erquan' AND vc_City='郑州' AND i_Age=25;
首先考虑建单列索引:
在vc_Name列上建立了索引。执行T-SQL时,MYSQL很快将目标锁定在了vc_Name=erquan的5条记录上,取出来放到一中间结果集。在这个结果集里,先排除掉vc_City不等于"郑州"的记录,再排除i_Age不等于25的记录,最后筛选出唯一的符合条件的记录。
虽然在vc_Name上建立了索引,查询时MYSQL不用扫描整张表,效率有所提高,但离我们的要求还有一定的距离。同样的,在vc_City和i_Age分别建立的单列索引的效率相似。
为了进一步榨取MySQL的效率,就要考虑建立组合索引。就是将vc_Name,vc_City,i_Age建到一个索引里:
ALTER TABLE myIndex ADD INDEX name_city_age (vc_Name(10),vc_City,i_Age);--注意了,建表时,vc_Name长度为50,这里为什么用10呢?因为一般情况下名字的长度不会超过10,这样会加速索引查询速度,还会减少索引文件的大小,提高INSERT的更新速度。
执行T-SQL时,MySQL无须扫描任何记录就到找到唯一的记录!!
肯定有人要问了,如果分别在vc_Name,vc_City,i_Age上建立单列索引,让该表有3个单列索引,查询时和上述的组合索引效率一样吧?嘿嘿,大不一样,远远低于我们的组合索引~~虽然此时有了三个索引,但MySQL只能用到其中的那个它认为似乎是最有效率的单列索引。
建立这样的组合索引,其实是相当于分别建立了
vc_Name,vc_City,i_Age
vc_Name,vc_City
vc_Name
这样的三个组合索引!为什么没有vc_City,i_Age等这样的组合索引呢?这是因为mysql组合索引"最左前缀"的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这三列的查询都会用到该组合索引,下面的几个T-SQL会用到:
SELECT * FROM myIndex WHREE vc_Name="erquan" AND vc_City="郑州"
SELECT * FROM myIndex WHREE vc_Name="erquan"
而下面几个则不会用到:
SELECT * FROM myIndex WHREE i_Age=20 AND vc_City="郑州"
SELECT * FROM myIndex WHREE vc_City="郑州"
四、使用索引
到此你应该会建立、使用索引了吧?但什么情况下需要建立索引呢?一般来说,在WHERE和JOIN中出现的列需要建立索引,但也不完全如此,因为MySQL只对 <,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE(后面有说明)才会使用索引。
SELECT t.vc_Name FROM testIndex t LEFT JOIN myIndex m ON t.vc_Name=m.vc_Name WHERE m.i_Age=20 AND m.vc_City='郑州' 时,有对myIndex表的vc_City和i_Age建立索引的需要,由于testIndex表的vc_Name开出现在了JOIN子句中,也有对它建立索引的必要。
刚才提到了,只有某些时候的LIKE才需建立索引?是的。因为在以通配符 % 和 _ 开头作查询时,MySQL不会使用索引,如
SELECT * FROM myIndex WHERE vc_Name like'erquan%'
会使用索引,而
SELECT * FROM myIndex WHEREt vc_Name like'%erquan'
就不会使用索引了。
五、索引的不足之处
上面说了那么多索引的好话,它真的有像传说中那么优秀么?当然会有缺点了。
1.虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
2.建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
篇尾:
讲了这么多,无非是想利用索引提高数据库的执行效率。不过索引只是提高效率的一个因素。如果你的MySQL有大数据的表,就需要花时间研究建立最优秀的索引或优化查询语句。xml 编程 -DOM技术
xiaoningln 发布于 2007-08-07 18:15:16
DOM 对象
<?xml version="1.0" encoding="gb2312" ?>
<书籍>
<书名>Red Hat Linux系统管理大全</书名>
<作者 email="Thomas@newyork.net">Thomas Schenk</作者>
<出版社>机械工业出版社</出版社>
</书籍>
------------------------------------------------------------------------------------
<HTML>
<HEAD>
<TITLE>访问XML文档根节点</TITLE>
<scrīpt LANGUAGE="Javascrīpt" FOR="window" EVENT="ONLOAD"> //设置当浏览器第一次在窗口中打开该页时执行脚本元素scrīpt中的代码
var xmlDoc =xmldso.XMLDocument; //表示XML文档的根节点
xmlDoc.load("test5-2.xml"); //加载XML文件
url.innerText=xmlDoc.url; //使用HTML元素中的id元素的innerText来显示XML文件到HTML中
root.innerText=xmlDoc.nodeName;
rootElement.innerText=xmlDoc.documentElement.nodeName;
content.innerText=xmlDoc.documentElement.xml;
</scrīpt>
</HEAD>
<BODY>
<OBJECT width=0 height=0
classid="clsid:550dda30-0541-11d2-9ca9-0060b0ec3d39"
id="xmldso">
</OBJECT> //通过OBJECT元素在文档中插入一个DSO对象
<h2>XML文档信息</h2>
<span><b>XML文档URL:</b></span>
<span id="url"></span>
<br>
<span><b>根节点名称:</b></span>
<span id="root"></span>
<br>
<span><b>根元素名称:</b></span>
<span id="rootElement"></span>
<br>
<span><b>根元素内容:</b></span>
<br>
<span id="content"></span>
<br>
<html>
</BODY>
</HTML>
访问XML文档中元素的内容
1。使用childNodes()方法访问元素
<HTML>
<HEAD>
<TITLE>访问XML文档元素</TITLE>
<scrīpt LANGUAGE="Javascrīpt" FOR="window" EVENT="ONLOAD">
var xmlDoc =xmldso.XMLDocument;
xmlDoc.load("test5-2.xml");
var rootElement=xmlDoc.documentElement;
title.innerText=rootElement.childNodes(0).text;
writer.innerText=rootElement.childNodes(1).text;
publish.innerText=rootElement.childNodes(2).text;
</scrīpt>
</HEAD>
<BODY>
<OBJECT width=0 height=0
classid="clsid:550dda30-0541-11d2-9ca9-0060b0ec3d39"
id="xmldso">
</OBJECT>
<h3>书籍元素内容</h3>
<span><b>书名:</b></span>
<span id="title"></span>
<br>
<span><b>作者:</b></span>
<span id="writer"></span>
<br>
<span><b>出版社:</b></span>
<span id="publish"></span>
</BODY>
</HTML>
2。使用getElementsByTagName()方法访问元素
<HTML>
<HEAD>
<TITLE>访问XML文档元素</TITLE>
<scrīpt LANGUAGE="Javascrīpt" FOR="window" EVENT="ONLOAD">
var xmlDoc =xmldso.XMLDocument;
xmlDoc.load("test5-2.xml");
var rootElement=xmlDoc.documentElement;
var el1=rootElement.getElementsByTagName("书名");
var el2=rootElement.getElementsByTagName("作者");
var el3=rootElement.getElementsByTagName("出版社");
title.innerText=el1(0).text;
writer.innerText=el2(0).text;
publish.innerText=el3(0).text;
</scrīpt>
</HEAD>
<BODY>
<OBJECT width=0 height=0
classid="clsid:550dda30-0541-11d2-9ca9-0060b0ec3d39"
id="xmldso">
</OBJECT>
<h3>书籍元素内容</h3>
<span><b>书名:</b></span>
<span id="title"></span>
<br>
<span><b>作者:</b></span>
<span id="writer"></span>
<br>
<span><b>出版社:</b></span>
<span id="publish"></span>
</BODY>
</HTML>
3。使用document.write方法输出HTML文档内容
<HTML>
<HEAD>
<TITLE>访问XML文档元素</TITLE>
</HEAD>
<BODY>
<OBJECT width=0 height=0
classid="clsid:550dda30-0541-11d2-9ca9-0060b0ec3d39"
id="xmldso">
</OBJECT>
<scrīpt LANGUAGE="Javascrīpt" FOR="window" EVENT="ONLOAD">
var xmlDoc =xmldso.XMLDocument;
xmlDoc.load("test5-2.xml");
var rootElement=xmlDoc.documentElement;
document.write("<h3>书籍元素内容</h3>");
var str="";
str=rootElement.childNodes(0).text;
document.write("<b>书名:</b>"+str+"<br>");
str=rootElement.childNodes(1).text;
document.write("<b>作者:</b>"+str+"<br>");
str=rootElement.childNodes(2).text;
document.write("<b>出版社:</b>"+str+"<br>");
</scrīpt>
</BODY>
</HTML>
4。使用HTML元素的innerHTML属性显示XML文档数据
<HTML>
<HEAD>
<TITLE>访问XML文档元素</TITLE>
<scrīpt LANGUAGE="Javascrīpt" FOR="window" EVENT="ONLOAD">
var xmlDoc =xmldso.XMLDocument;
xmlDoc.load("test5-2.xml");
var rootElement=xmlDoc.documentElement;
outhtml.innerHTML=
"<b>书名:</b>"+
rootElement.childNodes(0).text+
"<br><b>作者:</b>"+
rootElement.childNodes(1).text+
"<br><b>出版社:</b>"+
rootElement.childNodes(2).text;
</scrīpt>
</HEAD>
<BODY>
<OBJECT width=0 height=0
classid="clsid:550dda30-0541-11d2-9ca9-0060b0ec3d39"
id="xmldso">
</OBJECT>
<h3>书籍元素内容</h3>
<span id="outhtml"></span>
</BODY>
</HTML>
访问元素属性
元素的attributes属性用于获得元素的属性节点集合
<HTML>
<HEAD>
<TITLE>访问XML文档元素属性</TITLE>
<scrīpt LANGUAGE="Javascrīpt" FOR="window" EVENT="ONLOAD">
var xmlDoc =xmldso.XMLDocument;
xmlDoc.load("test5-2.xml");
var rootElement=xmlDoc.documentElement;
var element=rootElement.getElementsByTagName("作者");
var attribute=element(0).attributes;
outhtml.innerHTML=
"<b>属性名称:</b>"+
attribute(0).nodeName+ //获得属性名
"<br><b>属性值:</b>"+
attribute(0).nodeValue; //获得属性值
</scrīpt>
</HEAD>
<BODY>
<OBJECT width=0 height=0
classid="clsid:550dda30-0541-11d2-9ca9-0060b0ec3d39"
id="xmldso">
</OBJECT>
<h3>“作者”元素属性</h3>
<span id="outhtml"></span>
</BODY>
</HTML>测试需要考虑什么呢。。。。。ing
xiaoningln 发布于 2007-10-18 18:15:25
黑盒测试:不基于内部设计和代码的任何知识,而是基于需求和功能性。
白盒测试:基于一个应用代码的内部逻辑知识,测试是基于覆盖全部代码、分支、路径、条件。
单元测试:最微小规模的测试;以测试某个功能或代码块。典型地由程序员而非测试员来做,因为它需要知道内部程序设计和编码的细节知识。这个工作不容易作好,除非应用系统有一个设计很好的体系结构; 还可能需要开发测试驱动器模块或测试套具。
累积综合测试:当一个新功能增加后,对应用系统所做的连续测试。它要求应用系统的不同形态的功能能够足够独立以可以在全部系统完成前能分别工作,或当需要时那些测试驱动器已被开发出来; 这种测试可由程序员或测试员来做。
集成测试:一个应用系统的各个部件的联合测试,以决定他们能否在一起共同工作。部件可以是代码块、独立的应用、网络上的客户端或服务器端程序。这种类型的测试尤其与客户服务器和分布式系统有关。
功能测试:用于测试应用系统的功能需求的黑盒测试方法。这类测试应由测试员做,这并不意味着程序员在发布前不必检查他们的代码能否工作(自然他能用于测试的各个阶段)。
系统测试:基于系统整体需求说明书的黑盒类测试;应覆盖系统所有联合的部件。
端到端测试:类似于系统测试;测试级的“宏大”的端点;涉及整个应用系统环境在一个现实世界使用时的模拟情形的所有测试。例如与数据库对话,用网络通讯,或与外部硬件、应用系统或适当的系统对话。
健全测试:典型地是指一个初始化的测试工作,以决定一个新的软件版本测试是否足以执行下一步大的测试努力。例如,如果一个新版软件每5分钟与系统冲突,使系统陷于泥潭,说明该软件不够“健全”,目前不具备进一步测试的条件。
衰竭测试:软件或环境的修复或更正后的“再测试”。可能很难确定需要多少遍再次测试。尤其在接近开发周期结束时。自动测试工具对这类测试尤其有用。
接受测试:基于客户或最终用户的规格书的最终测试,或基于用户一段时间的使用后,看软件是否满足客户要求。
负载测试:测试一个应用在重负荷下的表现,例如测试一个 Web 站点在大量的负荷下,何时系统的响应会退化或失败。
强迫测试:在交替进行负荷和性能测试时常用的术语。也用于描述象在异乎寻常的重载下的系统功能测试之类的测试,如某个动作或输入大量的重复,大量数据的输入,对一个数据库系统大量的复杂查询等。
性能测试:在交替进行负荷和强迫测试时常用的术语。理想的“性能测试”(和其他类型的测试)应在需求文档或质量保证、测试计划中定义。
可用性测试:对“用户友好性”的测试。显然这是主观的,且将取决于目标最终用户或客户。用户面谈、调查、用户对话的录象和其他一些技术都可使用。程序员和测试员通常都不宜作可用性测试员。
安装/卸载测试:对软件的全部、部分或升级安装/卸载处理过程的测试。
恢复测试:测试一个系统从如下灾难中能否很好地恢复,如遇到系统崩溃、硬件损坏或其他灾难性问题。
安全测试:测试系统在防止非授权的内部或外部用户的访问或故意破坏等情况时怎么样。这可能需要复杂的测试技术。
兼容测试:测试软件在一个特定的硬件/软件/操作系统/网络等环境下的性能如何。
比较测试:与竞争伙伴的产品的比较测试,如软件的弱点、优点或实力。
Alpha 测试:在系统开发接近完成时对应用系统的测试;测试后,仍然会有少量的设计变更。这种测试一般由最终用户或其他人员员完成,不能由程序员或测试员完成。
Beta 测试:当开发和测试根本完成时所做的测试,而最终的错误和问题需要在最终发行前找到。这种测试一般由最终用户或其他人员员完成,不能由程序员或测试员完成。Linux 基初到深入介绍(学习好东西,会继续总结的)
xiaoningln 发布于 2008-01-11 16:08:14
用 umask 命令,在 /etc/init.dev 文件中进行系统范围内的、或在 .profile 文件中进行的本地的文件权限默认设置。这个命令指示用 777 减去这个数字来获取默认的权限:
# umask 022
这将为用户创建的所有新文件生成一个默认的文件权限 755。umask
1.作用
umask设置用户文件和目录的文件创建缺省屏蔽值,若将此命令放入profile文件,就可控制该用户后续所建文件的存取许可。它告诉系统在创建文件时不给谁存取许可。使用权限是所有用户。
2.格式
umask [-p] [-S] [mode]
3.参数
-S:确定当前的umask设置。
-p:修改umask 设置。
[mode]:修改数值。
4.说明
传统Unix的umask值是022,这样就可以防止同属于该组的其它用户及别的组的用户修改该用户的文件。既然每个用户都拥有并属于一个自己的私有组,那么这种“组保护模式”就不在需要了。严密的权限设定构成了Linux安全的基础,在权限上犯错误是致命的。需要注意的是,umask命令用来设置进程所创建的文件的读写权限,最保险的值是0077,即关闭创建文件的进程以外的所有进程的读写权限,表示为-rw-------。在~/.bash_profile中,加上一行命令umask 0077可以保证每次启动Shell后, 进程的umask权限都可以被正确设定。
5.应用实例
umask -S
u=rwx,g=rx,o=rx
umask -p 177
umask -S
u=rw,g=,o=
上述5行命令,首先显示当前状态,然后把umask值改为177,结果只有文件所有者具有读写文件的权限,其它用户不能访问该文件。这显然是一种非常安全的设置。Linux的系统安全命令
虽然Linux和Windows NT/2000系统一样是一个多用户的系统,但是它们之间有不少重要的差别。对于很多习惯了Windows系统的管理员来讲,如何保证Linux操作系统安全、可靠将会面临许多新的挑战。本文将重点介绍Linux系统安全的命令。
passwd
1.作用
passwd命令原来修改账户的登陆密码,使用权限是所有用户。
2.格式
passwd [选项] 账户名称
3.主要参数
-l:锁定已经命名的账户名称,只有具备超级用户权限的使用者方可使用。
-u:解开账户锁定状态,只有具备超级用户权限的使用者方可使用。
-x, --maximum=DAYS:最大密码使用时间(天),只有具备超级用户权限的使用者方可使用。
-n, --minimum=DAYS:最小密码使用时间(天),只有具备超级用户权限的使用者方可使用。
-d:删除使用者的密码, 只有具备超级用户权限的使用者方可使用。
-S:检查指定使用者的密码认证种类, 只有具备超级用户权限的使用者方可使用。
4.应用实例
$ passwd
Changing password for user cao.
Changing password for cao
(current) UNIX password:
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
从上面可以看到,使用passwd命令需要输入旧的密码,然后再输入两次新密码。
su
1.作用
su的作用是变更为其它使用者的身份,超级用户除外,需要键入该使用者的密码。
2.格式
su [选项]... [-] [USER [ARG]...]
3.主要参数
-f , --fast:不必读启动文件(如 csh.cshrc 等),仅用于csh或tcsh两种Shell。
-l , --login:加了这个参数之后,就好像是重新登陆为该使用者一样,大部分环境变量(例如HOME、SHELL和USER等)都是以该使用者(USER)为主,并且工作目录也会改变。如果没有指定USER,缺省情况是root。
-m, -p ,--preserve-environment:执行su时不改变环境变数。
-c command:变更账号为USER的使用者,并执行指令(command)后再变回原来使用者。
USER:欲变更的使用者账号,ARG传入新的Shell参数。
4.应用实例
变更账号为超级用户,并在执行df命令后还原使用者。 su -c df root
umask
1.作用
umask设置用户文件和目录的文件创建缺省屏蔽值,若将此命令放入profile文件,就可控制该用户后续所建文件的存取许可。它告诉系统在创建文件时不给谁存取许可。使用权限是所有用户。
2.格式
umask [-p] [-S] [mode]
3.参数
-S:确定当前的umask设置。
-p:修改umask 设置。
[mode]:修改数值。
4.说明
传统Unix的umask值是022,这样就可以防止同属于该组的其它用户及别的组的用户修改该用户的文件。既然每个用户都拥有并属于一个自己的私有组,那么这种“组保护模式”就不在需要了。严密的权限设定构成了Linux安全的基础,在权限上犯错误是致命的。需要注意的是,umask命令用来设置进程所创建的文件的读写权限,最保险的值是0077,即关闭创建文件的进程以外的所有进程的读写权限,表示为-rw-------。在~/.bash_profile中,加上一行命令umask 0077可以保证每次启动Shell后, 进程的umask权限都可以被正确设定。
5.应用实例
umask -S
u=rwx,g=rx,o=rx
umask -p 177
umask -S
u=rw,g=,o=
上述5行命令,首先显示当前状态,然后把umask值改为177,结果只有文件所有者具有读写文件的权限,其它用户不能访问该文件。这显然是一种非常安全的设置。
chgrp
1.作用
chgrp表示修改一个或多个文件或目录所属的组。使用权限是超级用户。
2.格式
chgrp [选项]... 组 文件...
或
chgrp [选项]... --reference=参考文件 文件...
将每个<文件>的所属组设定为<组>。
3.参数
-c, --changes :像 --verbose,但只在有更改时才显示结果。
--dereference:会影响符号链接所指示的对象,而非符号链接本身。
-h, --no-dereference:会影响符号链接本身,而非符号链接所指示的目的地(当系统支持更改符号链接的所有者,此选项才有效)。
-f, --silent, --quiet:去除大部分的错误信息。
--reference=参考文件:使用<参考文件>的所属组,而非指定的<组>。
-R, --recursive:递归处理所有的文件及子目录。
-v, --verbose:处理任何文件都会显示信息。
4.应用说明
该命令改变指定指定文件所属的用户组。其中group可以是用户组ID,也可以是/etc/group文件中用户组的组名。文件名是以空格分开的要改变属组的文件列表,支持通配符。如果用户不是该文件的属主或超级用户,则不能改变该文件的组。
5.应用实例
改变/opt/local /book/及其子目录下的所有文件的属组为book,命令如下:
$ chgrp - R book /opt/local /book
chmodChmod使用格式:
Chmod [参数][模式]<文件或目录>
参数:-R:改变目录及其所有子目录的文件权限。
举例:
#chmod u+x inittab
#chmod ug+wx,o-x inittab
#chmod 0644 inittab
#chmod 0755 inittab
#chmod –R 700 ~
目录权限的补充说明:
1、目录的只读访问不允许使用cd进入目录,必须要有执行的权限才能进入。
2、只有执行权限只能进入目录,不能看到目录下的内容,要想看到目录下的文件名和目录名,需要可读权限。
3、一个文件能不能被删除,主要看该文件所在的目录对用户是否具有写权限,如果目录对用户没有写权限,则该目录下的所有文件都不能被删除,文件所有者除外
对特殊位的举例说明: 操作这些特殊位与操作文件权限的命令是一样的, 都是 chmod. 有两种方法来操作, 1) chmod u+s temp : 为temp文件加上setuid标志. (setuid 只对文件有效) chmod g+s tempdir :为tempdir目录加上setgid标志 (setgid 只对目录有效) chmod o+t tempdir : 为temp文件加上sticky标志 (sticky只对目录有效)
2) 采用八进制方式. 对一般文件通过三组八进制数字来置标志, 如 666, 777, 644等. 如果设置这些特殊标志, 则在这组数字之外外加一组八进制数字. 如 4666, 2777等.
设置完这些标志后, 可以用 ls -l 来查看. 如果有这些标志, 则会在原来的执行标志位置上显示. 如 rwsrw-r-- 表示有setuid标志 rwxrwsrw- 表示有setgid标志 rwxrw-rwt 表示有sticky标志 那么原来的执行标志x到哪里去了呢? 系统是这样规定的, 如果本来在该位上有x, 则这些特殊标志显示为小写字母 (s, s, t). 否则, 显示为大写字母 (S, S, T)
1.作用
chmod命令是非常重要的,用于改变文件或目录的访问权限,用户可以用它控制文件或目录的访问权限,使用权限是超级用户。
2.格式
chmod命令有两种用法。一种是包含字母和操作符表达式的字符设定法(相对权限设定);另一种是包含数字的数字设定法(绝对权限设定)。
(1)字符设定法
chmod [who] [+ | - | =] [mode] 文件名
◆操作对象who可以是下述字母中的任一个或它们的组合
u:表示用户,即文件或目录的所有者。
g:表示同组用户,即与文件属主有相同组ID的所有用户。
o:表示其它用户。
a:表示所有用户,它是系统默认值。
◆操作符号
+:添加某个权限。
-:取消某个权限。
=:赋予给定权限,并取消其它所有权限(如果有的话)。
◆设置mode的权限可用下述字母的任意组合
r:可读。
w:可写。
x:可执行。
X:只有目标文件对某些用户是可执行的或该目标文件是目录时才追加x属性。
s:文件执行时把进程的属主或组ID置为该文件的文件属主。方式“u+s”设置文件的用户ID位,“g+s”设置组ID位。
t:保存程序的文本到交换设备上。
u:与文件属主拥有一样的权限。
g:与和文件属主同组的用户拥有一样的权限。
o:与其它用户拥有一样的权限。
文件名:以空格分开的要改变权限的文件列表,支持通配符。
一个命令行中可以给出多个权限方式,其间用逗号隔开。
(2) 数字设定法
数字设定法的一般形式为: chmod [mode] 文件名
数字属性的格式应为3个0到7的八进制数,其顺序是(u)(g)(o)文件名,以空格分开的要改变权限的文件列表,支持通配符。
数字表示的权限的含义如下:0001为所有者的执行权限;0002为所有者的写权限;0004为所有者的读权限;0010为组的执行权限;0020为组的写权限;0040为组的读权限;0100为其他人的执行权限;0200为其他人的写权限;0400为其他人的读权限;1000为粘贴位置位;2000表示假如这个文件是可执行文件,则为组ID为位置位,否则其中文件锁定位置位;4000表示假如这个文件是可执行文件,则为用户ID为位置位。
3.实例
如果一个系统管理员写了一个表格(tem)让所有用户填写,那么必须授权用户对这个文件有读写权限,可以使用命令:#chmod 666 tem
上面代码中,这个666数字是如何计算出来的呢?0002为所有者的写权限,0004为所有者的读权限,0020为组的写权限,0040为组的读权限,0200为其他人的写权限,0400为其他人的读权限,这6个数字相加就是666(注以上数字都是八进制数),结果见图1所示。
图1 用chmod数字方法设定文件权限
从图1可以看出,tem文件的权限是-rw-rw-rw-,即用户对这个文件有读写权限。
如果用字符权限设定使用下面命令:
#chmod a =wx tem
chown
1.作用
更改一个或多个文件或目录的属主和属组。使用权限是超级用户。
2.格式
chown [选项] 用户或组 文件
3.主要参数
--dereference:受影响的是符号链接所指示的对象,而非符号链接本身。
-h, --no-dereference:会影响符号链接本身,而非符号链接所指示的目的地(当系统支持更改符号链接的所有者,此选项才有效)。
--from=目前所有者:目前组只当每个文件的所有者和组符合选项所指定的,才会更改所有者和组。其中一个可以省略,这已省略的属性就不需要符合原有的属性。
-f, --silent, --quiet:去除大部分的错误信息。
-R, --recursive:递归处理所有的文件及子目录。
-v, --verbose:处理任何文件都会显示信息。
4.说明
chown将指定文件的拥有者改为指定的用户或组,用户可以是用户名或用户ID;组可以是组名或组ID;文件是以空格分开的要改变权限的文件列表,支持通配符。系统管理员经常使用chown命令,在将文件拷贝到另一个用户的目录下以后,让用户拥有使用该文件的权限。
5.应用实例
1.把文件shiyan.c的所有者改为wan
$ chown wan shiyan.c
2.把目录/hi及其下的所有文件和子目录的属主改成wan,属组改成users。
$ chown - R wan.users /hi
chattr
1.作用
修改ext2和ext3文件系统属性(attribute),使用权限超级用户。
2.格式
chattr [-RV] [-+=AacDdijsSu] [-v version] 文件或目录
3.主要参数
-R:递归处理所有的文件及子目录。
-V:详细显示修改内容,并打印输出。
-:失效属性。
+:激活属性。
= :指定属性。
A:Atime,告诉系统不要修改对这个文件的最后访问时间。
S:Sync,一旦应用程序对这个文件执行了写操作,使系统立刻把修改的结果写到磁盘。
a:Append Only,系统只允许在这个文件之后追加数据,不允许任何进程覆盖或截断这个文件。如果目录具有这个属性,系统将只允许在这个目录下建立和修改文件,而不允许删除任何文件。
i:Immutable,系统不允许对这个文件进行任何的修改。如果目录具有这个属性,那么任何的进程只能修改目录之下的文件,不允许建立和删除文件。
D:检查压缩文件中的错误。
d:No dump,在进行文件系统备份时,dump程序将忽略这个文件。
C:Compress,系统以透明的方式压缩这个文件。从这个文件读取时,返回的是解压之后的数据;而向这个文件中写入数据时,数据首先被压缩之后才写入磁盘。
s:Secure Delete,让系统在删除这个文件时,使用0填充文件所在的区域。
u:Undelete,当一个应用程序请求删除这个文件,系统会保留其数据块以便以后能够恢复删除这个文件。
4.说明
chattr命令的作用很大,其中一些功能是由Linux内核版本来支持的,如果Linux内核版本低于2.2,那么许多功能不能实现。同样-D检查压缩文件中的错误的功能,需要2.5.19以上内核才能支持。另外,通过chattr命令修改属性能够提高系统的安全性,但是它并不适合所有的目录。chattr命令不能保护/、/dev、/tmp、/var目录。
5.应用实例
1.恢复/root目录,即子目录的所有文件
# chattr -R +u/root
2.用chattr命令防止系统中某个关键文件被修改
在Linux下,有些配置文件(passwd ,fatab)是不允许任何人修改的,为了防止被误删除或修改,可以设定该文件的“不可修改位(immutable)”,命令如下:
# chattr +i /etc/fstab
sudo
1.作用
sudo是一种以限制配置文件中的命令为基础,在有限时间内给用户使用,并且记录到日志中的命令,权限是所有用户。
2.格式
sudo [-bhHpV] [-s <shell>] [-u <用户>] [指令]
sudo [-klv]
3.主要参数
-b:在后台执行命令。
-h:显示帮助。
-H:将HOME环境变量设为新身份的HOME环境变量。
-k:结束密码的有效期,即下次将需要输入密码。
-l:列出当前用户可以使用的命令。
-p:改变询问密码的提示符号。
-s <shell>:执行指定的Shell。
-u <用户>:以指定的用户为新身份,不使用时默认为root。
-v:延长密码有效期5分钟。
4.说明
sudo命令的配置在/etc/sudoers文件中。当用户使用sudo时,需要输入口令以验证使用者身份。随后的一段时间内可以使用定义好的命令,当使用配置文件中没有的命令时,将会有报警的记录。sudo是系统管理员用来允许某些用户以root身份运行部分/全部系统命令的程序。一个明显的用途是增强了站点的安全性,如果需要每天以超级用户的身份做一些日常工作,经常执行一些固定的几个只有超级用户身份才能执行的命令,那么用sudo是非常适合的。
ps
1.作用
ps显示瞬间进程 (process) 的动态,使用权限是所有使用者。
2.格式
ps [options] [--help]
3.主要参数
ps的参数非常多, 此出仅列出几个常用的参数。
-A:列出所有的进程。
-l:显示长列表。
-m:显示内存信息。
-w:显示加宽可以显示较多的信息。
-e:显示所有进程。
a:显示终端上的所有进程,包括其它用户的进程。
-au:显示较详细的信息。
-aux:显示所有包含其它使用者的进程。
4.说明
要对进程进行监测和控制,首先要了解当前进程的情况,也就是需要查看当前进程。ps命令就是最基本、也是非常强大的进程查看命令。使用该命令可以确定有哪些进程正在运行、运行的状态、进程是否结束、进程有没有僵尸、哪些进程占用了过多的资源等。图2给出了ps-aux命令详解。大部分信息都可以通过执行该命令得到。最常用的三个参数是u、a、x。下面就结合这三个参数详细说明ps命令的作用:ps aux
图2 ps-aux命令详解
图2第2行代码中,USER表示进程拥有者;PID表示进程标示符;%CPU表示占用的CPU使用率;%MEM占用的物理内存使用率;VSZ表示占用的虚拟内存大小;RSS为进程占用的物理内存值;TTY为终端的次要装置号码。
STAT表示进程的状态,其中D为不可中断的静止(I/O动作);R正在执行中;S静止状态;T暂停执行;Z不存在,但暂时无法消除;W没有足够的内存分页可分配;高优先序的进程;N低优先序的进程;L有内存分页分配并锁在内存体内 (实时系统或 I/O)。START为进程开始时间。TIME为执行的时间。COMMAND是所执行的指令。
4.应用实例
在进行系统维护时,经常会出现内存使用量惊人,而又不知道是哪一个进程占用了大量进程的情况。除了可以使用top命令查看内存使用情况之外,还可以使用下面的命令:
ps aux | sort +5n
who
1.作用
who显示系统中有哪些用户登陆系统,显示的资料包含了使用者ID、使用的登陆终端、上线时间、呆滞时间、CPU占用,以及做了些什么。 使用权限为所有用户。
2.格式
who - [husfV] [user]
3.主要参数
-h:不要显示标题列。
-u:不要显示使用者的动作/工作。
-s:使用简短的格式来显示。
-f:不要显示使用者的上线位置。
-V:显示程序版本。
4.说明
该命令主要用于查看当前在线上的用户情况。如果用户想和其它用户建立即时通信,比如使用talk命令,那么首先要确定的就是该用户确实在线上,不然talk进程就无法建立起来。又如,系统管理员希望监视每个登录的用户此时此刻的所作所为,也要使用who命令。who命令应用起来非常简单,可以比较准确地掌握用户的情况,所以使用非常广泛。
动手练习
1.使用Linux命令检测系统入侵者
安装过Mandrake Linux和Red Hat Linux的用户都会知道,Linux系统会内置三种不同级别(标准、高、更高)的防火墙,当进行了Linux服务器的安装和一些基本的设置后,服务器应该说是比较安全的,但是也会有黑客通过各种方法利用系统管理员的疏忽侵入系统。如何快速查找黑客非常重要。一般来说,可以使用命令查询黑客是否入侵,见表1。
表1 查询黑客入侵现象的命令对应表
举例说明,如果黑客嗅探网络,那么它必须使网卡接口处于混杂模式,使用下面命令进行查询:
#ifconfig -a
eth0 Link encap:Ethernet HWaddr 00:00:E8:A0:25:86
inet addr:192.168.1.7 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING PROMISCUOUS MTU:1500 Metric:1
......
从这个命令的输出中,可以看到上面讲到的这些概念。第一行的00:00:E8:A0:25:86是mac地址,第二行的192.168.1.7是IP地址,第四行讲的是接收数据状态,这时正在被黑客嗅探。一般而言,网卡有几种接收数据帧的状态,如Broadcast、Multicast、Promiscuous等。Broadcast是指接收所有类型为广播报文的数据帧;Multicast是指接收特定的组播报文;Promiscuous则是通常说的混杂模式,是指对报文中的目的硬件地址不加任何检查、全部接收的工作模式。
2.限制su命令的滥用
我们知道,超级用户在Linux中有最大的权利,几乎所有黑客都想得到这个目标。Linux可以增加对切换到超级用户的限制。使用PAM(Pluggable Authentication Modules)可以禁止除在wheel组以外的任何人su成root,修改/etc/pam.d/su文件,除去屏蔽标识#。使用/usr/sbin/usermod G10 bjecadm将bjecadm这个账号加入gid为10的组,就是wheel组。命令如下:
/etc/pam.d/su # 使用密码验证#
auth sufficient /lib/security/pam_wheel.so debug
# 限制只有wheel组用户才可以切换到root#
auth required /lib/security/pam_wheel.so use_uid
chmod -G10 bjecadm
另外,每当用户试图使用su命令进入系统用户时,命令将在/usr/adm/sulog文件中写一条信息,若该文件记录了大量试图用su进入root的无效操作信息,则表明了可能有人企图破译root口令。
Linux命令有着强大的功能。对于Linux系统管理员来说,往往只需要通过各种安全命令技巧,组合构成安全防线。从计算机安全的角度看,世界上没有绝对安全的计算机系统,Linux系统也不例外。其他信息列述
1.1 Linux操作系统概述
开放性的系统
多用户多任务的系统
具有出色的稳定性和速度性能
具有可靠的系统安全性
提供了丰富的网络功能
标准兼容性和可移植性
提供了良好的用户界面
Linux系统的组成
Kernel(内核)和版本
Linux 发行套件
Linux Shell
Linux 文件系统
Linux 文件系统标准结构
1.2 红旗Linux的安装
1.2.1 安装前的准备
1.2.2 使用安装光盘从CD-ROM安装
1.2.3 使用Linux启动盘从硬盘安装
1.2.1 安装前的准备
收集计算机硬件信息
规划硬盘空间
选取工作站类型:至少需要1.2G左右空间;最多需要1.5G左右空间。
选取服务器类型:至少需要650M左右空间,最多需要1.2G左右空间。
选取便携式类型:与工作站类型所需空间相当。
选取自定义类型:至少需要350M左右空间,最多需要2.4G左右空间。
规划网络配置信息
1.2.2 使用安装光盘从CD-ROM安装
设置CMOS
安装
安装红旗linux
Server和Workstation模式:自动分割硬盘
Custom:手工分割 ? Mount Point
/ ? root根分区(建议:256MB)
SWAP ?交换分区(建议:略小于实际内存2倍)
/usr:? 安装软件存放位置(建议:2.5GB)
/home:? 视用户多少而定
/var:? 存放临时文件(建议:256MB)
/boot: ? 存放启动文件(建议:32MB)
1.2.3 Linux的其他安装方式
本地安装
远程网络安装
使用Linux启动盘从硬盘安装
制作启动软盘
1、在DOS下创建:
进入dosutils子目录,运行rawrite程序 。
输入../images/boothd.img 。
2、在linux下创建:
#dd if=/images/boothd.img ōf=/dev/fd0 bs=1440
修改CMOS设置中的引导顺序
明确系统文件在硬盘中的存放位置
使用Linux安装启动盘从远程FTP服务器安装
远程网络安装Linux系统的方法和本地硬盘安装类似,也需要制作启动软盘。制作启动软盘的步骤和前面相同,唯一不同的是制作启动软盘时使用的软盘镜像文件是bootnet.img。
1.3、linux安装须具备的知识
磁盘的标识:
IDE硬盘:/dev/hdxx:其中第一个X表示第几块硬盘,采用a、b、c、d分别对应四块硬盘,第二个X表示分区,1-4表示主分区或扩展分区,逻辑分区从5开始。
SCSI硬盘:/dev/sdxx
光盘:/dev/cdrom
软盘:/dev/fd0
1.4 Linux运行级别和系统的启动和关闭
21.4.1 Linux的运行级别和切换
21.4.2 Linux的启动过程
1.4.1 Linux的运行级别和切换
Linux的运行级别
Linux运行级别的切换
Linux的启动、关闭和重新启动
Linux的运行级别
Linux运行级别的切换
在inittab文件中,操作initdefault将在系统初始化之后启动预设的运行级别,用户可以通过更改此项设置来改变系统的预设运行级别。
用户也可以在系统运行过程当中来改变系统的运行级别,方法是用init命令,后面加上要切换到的运行级别。
Linux的启动、关闭和重新启动
linux启动
红旗linux在启动过程中首先加载Linux内核,在内存中执行内核操作,检查硬件,挂载根文件系统,然后启动init进程。init进程就会根据inittab文件中的设置来使系统进入预设的运行级别,读取相关的配置文件和脚本程序,最后启用相关服务,完成整个系统的启动。Linux的重启方法
Reboot
Init 6
Ctrl+alt+delete
Shutdown –r time [warning-message]
如:#shutdown –r +3 “system will be down in 3 minites,please save you work”
#shutdown –r now
#shutdown –r 03:15
Linux关机的方法
Halt
Init 0
Shutdown –h time [warning-message]
如:#shutdown –h now
1.5 Linux的初步使用
1.5.1 Linux的字符运行方式
1.5.2 linux的图形界面
1.5.3 常见问题
1.5.1 Linux的字符运行方式
登录和注销 :
超级用户登录后的操作提示符是“#”;普通用户登录后的操作提示符是“$”
若要注销登录,用户可以在当前的登录终端上输入logout命令或使用Ctrl+d热键进行。
终端之间的切换采用:alt+f1—f7
1.5.2 linux的图形界面
图形界面下运行终端命令:rxvt
图形界面切换到字符界面:ctrl+alt +f1—f6
图形界面下的注销:ctrl+alt+delete
图形界面下的锁定:ctrl+alt+L1.5.3 常见问题
最基本的安全问题
root口令丢失的解决方法
删除Linux操作系统
最基本的安全问题
如果机箱有锁,应该上锁,并保证钥匙与机箱分离放置;
若机箱没有锁,如果必要,当正常运行后断开电源按钮和复位按钮的连接线;
禁止三键热启功能,修改/etc/inittab,将此行注释掉;
禁止BIOS中的软驱启动功能,并设置BIOS开机密码;
禁止公开root密码,若有多个系统管理员则应该避免root密码的扩散;
必须准备引导软盘以防硬盘无法启动时使用。
root口令丢失的解决方法
使用单用户模式 ,重设root密码
在红旗linux4桌面版中,在开始菜单中选3按e,再选2按e,把3改成1,回车再按b。删除Linux操作系统
首先要修改MBR,删除LILO。
在DOS或Windows下用fdisk命令加上/mbr参数来完成 。
重新格式化ext3分区为FAT32分区或NTFS分区。
hls
查看公开信息
发送悄悄话给hls
给hls发送Email
查找hls发表的更多帖子
添加 hls 到好友列表第2章:linux shell和常用命令
2.1 linux常用命令
2.2 shell
2.3 vi的使用
2.1 linux的常用命令
第一节:文件目录类命令
1、 查看联机帮助信息
man 命令 如:#man ls
info 命令 如:#info cd
2、列出当前目录或指定目录的文件名和目录名
ls [选项] 文件或目录
常用[选项]如下:
-a:显示所有的文件,包括以“.”开头的隐含文件。
-l:长格式输出
-m:宽行输出
-F:以各种符号表示不同的文件类型
--color:彩色输出
-R:递归输出
3、touch
功能:修改文件的创建日期或以当前系统日期创建一个空文件。
-d:修改文件的日期。
#touch –d 20030123 test.txt
4、cp
功能:复制文件
用法:cp [选项] 源文件或目录 目标文件或目录
选项:
a: 该选项通常在拷贝目录时使用。它保留链接、文件属性,并递归地拷贝目录,其作用等于dpR选项的组合。
- d 拷贝时保留链接。
- f 删除已经存在的目标文件而不提示。
- i 和f选项相反,在覆盖目标文件之前将给出提示要求用户确认。回答y时目标文件将被覆盖,是交互式拷贝。
- p 此时cp除复制源文件的内容外,还将把其修改时间和访问权限也复制到新文件中。
- r 若给出的源文件是一目录文件,此时cp将递归复制该目录下所有的子目录和文件。此时目标文件必须为一个目录名。5、mv
功能:给文件或目录改名或将一个文件或目录移到另一个目录
用法:mv [选项] 源文件或目录 目标文件或目录
-i 交互方式操作。如果mv操作将导致对已存在的目标文件的覆盖,此时系统询问是否重写,要求用户回答y或n,这样可以避免误覆盖文件。
- f 禁止交互操作。在mv操作要覆盖某已有的目标文件时不给任何指示,指定此选项后,i选项将不再起作用。6、rm
功能:删除文件或目录
用法:rm [选项] 文件…
- f 强制删除
- r 指示rm将参数中列出的全部目录和子目录均递归地删除。
- i 进行交互式删除7、cd
功能:改变工作目录。
语法:cd [directory]
用法:
#cd ..返回上一层目录
#cd ~进入自家目录
8、pwd
功能:显示当前工作目录
用法:#pwd9、mkdir
功能:创建一个目录(类似MSDOS下的md命令)。
语法:mkdir [选项] dir-name
- m 对新建目录设置存取权限。也可以用chmod命令设置。
- p 可以是一个路径名称。此时若路径中的某些目录尚不存在, 加上此选项后, 系统将自动建立好那些尚不存在的目录,即一次可以建立多个目录。
#mkdir –m a=rwx test
#mkdir –m u=rwx,g=rx,o=rx test1
#mkdir –m 755 test2
#mkdir –p test3/test4(test3和test4均为新目录)10、rmdir
功能:删除空目录。
语法:rmdir [选项] dir-name
- p 递归删除目录dirname,当子目录删除后其父目录为空时,也一同被删除。
11、file
功能:查看文件类型
语法:file 文件名12、cat
功能:查看文本文件的内容
语法:cat 文件名
13、more
功能:分屏显示文本文件的内容。
14、less
功能:显示文本文件的内容,可使用pageup和pagedown上翻页下翻页。15、head
功能:查看文件的开头部分内容
语法:head [行数] 文件名
用法:#head test.txt:显示前10行内容
#head -20 test.txt 显示前20行内容。
16、tail
功能:查看文件的结尾部分内容。
语法:tail [行数] 文件名
默认的行数为10行。17、sort
功能:对文本文件中的各行进行排序
用法:sort 文件名
例:#sort 123.txt >456.txt 将123.txt排序后重定向到456.txt文件中。
18、uniq
功能:将重复行从输出文件中删除,只留下每条记录的唯一样本
语法: uniq 文件名
#uniq 456.txt文件中的重复行删除后输出19、pr
功能:处理文件以便打印,输出到标准输出
语法:pr [参数] 文件名列表
[参数]
-d:将输出的每一行后加一新的空白行
-n:输出行号
如:#pr –n 123.txt
20、ln
功能:建立链接文件
语法:ls [-s] 源文件名 目标文件名
说明:链接文件分为硬连接和软连接,硬连接相当于一个数据源有两个文件名,删除一个文件另一个文件不变,修改一个文件的内容另一个文件的内容也跟着改变。硬连接不能和另一个目录链接,也不能和其他文件系统的文件进行链接。软链接相当于快捷方式,没有上面的限制,加-s参数创建软链接。21、wc
功能:统计文件的行数、字符数和单词数。
语法:wc [-lwc] 文件名
-l: 只显示行数,-w:只显示单词数,-c:只显示字符总数。
22、whatis
功能:可以用一行内容显示对命令行后输入的关键词的说明。
语法:whatis 关键词
用法:#whatis find whereis23、Whereis
功能:确定指定文件的源程序/二进制程序和手册部分的位置。
用法:#whereis ls
24、which
功能:显示可执行命令的路径和它的别名。
用法:#which ls
25、locate
功能:可以查找具体文件或命令的路径,可以查找具体的字符串或子串
用法:locate 文件名或关键字26、du
功能:统计文件和目录所占用的磁盘空间
语法:du [-ask] 文件名或目录名
-a:显示对涉及到的所有文件的统计,而不仅仅统计目录
-s:只打印出合计数
-k:以kB字节数显示Find使用范例
find . -name ls.txt
find . -name ls.txt –print
find / -name ‘c??’ –print
find / -name ‘f*’ –print
find . -name ‘f*’ –exec ls –l {} \;
find . -name f\* –ok rm {} \; (交互式提问)
find . -perm 644 –mtime 4
find . -name ‘c??’ –o -name ‘d??’
28、grep
功能:在文件中搜寻匹配的行并进行输出
语法:grep [参数]<要找的字串><原文件>
-num:输出匹配行前后各num行的内容
-A num:输出匹配行后num行的内容
-B num:输出匹配行前num行的内容
-i:忽略大小写的区别
-v:只显示出那些不包括某字串的行和文件,和默认的相反二、文件压缩和归档类命令
1、gzip
功能:是一种压缩程序,特点是可以得到最佳的压缩率,但速度较慢。
语法:gzip [-vd9] 文件名
-v:冗长型选项,可以显示每个文件的大小等
-d:解压
-9:产生最佳压缩效果,但速度较慢。2、gunzip
功能:可以把压缩的文件解压成原始文件状态,可以解压扩展名为.gz,.z,.Z和.tgz等类型的压缩文件
语法:gunzip [-v] 文件名
-v:显示解压缩文件的冗长结果3、tar
功能:可以归档多个文件和目录到一个.tar文件下,还可以从一个归档文件中抽取一个文件和目录。
语法:tar [-c][-r][-t][-x][-v][-z][f 文件名] 文件和目录名
-c:创建归档文件
-r:增加文件到归档文件中
-t:查看归档文件中的文件
-x:解开归档文件
-v:显示冗长信息
-z:进行压缩和解压
如: #tar –cvf back.tar 文件1 目录1 文件2
#tar –rvf back.tar 文件3
#tar –tf back.tar
#tar –xvf back.tar
#tar –czvf back.tar.gz 文件1 目录1 文件2
#tar –xzvf back.tar.gz4、安装以rpm方式提供的软件
Rpm(the red hat package manager)是一个开放的软件包管理系统。
功能:可以安装和卸载RPM包的软件
#rpm –ivh *.rpm 安装RPM包;
#rpm –ivh –force *.rpm 在原先安装的基础上再强行安装一次;
#rpm –Uvh *.rpm 升级rpm包
#rpm –qa 查找列出系统中所有安装的rpm包
#rpm –q sendmail:查看sendmail包的情况
#rpm –ql sendmail:查看sendmail安装的位置
#rpm –e *.rpm 卸载rpm包
#rpm - qlp name.rpm 查看name.rpm有哪些文件
#rpm - qf name.rpm 查看已经装好的文件属于哪个rpm包
#rpm2cpio filename.rpm 使用“rpm2cpio”来从RPM文档中提取文件5、安装以源代码方式提供的软件
(1)、解包解压:
#tar –xzvf *.tar.gz 解包解压后会在当前目录下建立一个子目录,如xxxx
(2)、#cd xxxx
(3)、#./configure
(4)、#make
(5)、#make install三、系统状态类命令
1、dmesg
功能:显示引导时内核显示的状态信息
#dmesg |grep -4 “eth0”显示状态信息中与eth0相关的前后4行内容
2、uname
功能:显示当前的系统信息
#uname -a
3、uptime
功能:显示当前时间,自从上次重新引导之后系统运行的时间,服务器和多少用户链接以及系统前1、5、15分钟的负载信息。
4、who
功能:显示当前登录在系统上的用户信息。
-r:查看系统运行等级
-w,在登录帐号后面显示一个字符来表示用户的信息状态:
+:允许写信息; -:不允许写信息; ?:不能找到终端设备5、w
功能:查看其他登录的用户(who增强版)
第一行输出内容:当前时间,系统启动到现在的时间,登录用户的数目,系统在最近1秒、5秒和15秒的平均负载
第二行输出内容:登录帐号、终端名称、远程主机名、登录时间、空闲时间、JCPU、PCPU、当前正在运行进程的命令行。
*JCPU时间指的是和该终端(tty)连接的所有进程占用的时间
*PCPU时间则是指当前进程(即在WHAT项中显示的进程)所占用的时间6、whoami
功能:显示当前用户名
7、hostname
功能:显示系统的主机名
8、cal [月份] [年份]
功能:显示日历
9、bc
功能:计算器,使用quit退出
10、date
功能:显示或修改日期时间。
11、df
功能:报告文件系统磁盘空间的使用情况
语法:df[参数]
[参数]
-h:用常见的格式显示出大小(例如:1K,23M,2G等)
-t:只显示指定类型的文件系统
12、free
功能:查看当前内存和交换空间的使用情况
四、网络类命令
1、write
功能:向另外一个用户发信息,以Ctrl+D作为结束,普通用户发信息受到mesg状态影响。
语法:write <用户名>
2、wall
功能:向所有用户广播信息,普通用户受到mesg状态影响。
语法:wall [message]3、mesg
功能:显示或设置是否接受其他用户发来的信息。
语法:mesg [参数]
[参数]
y:接受从其他用户发来的信息
n:不接受从其他用户发来的信息
#mesg
显示当前是否接受其他用户发来的信息4、ping
功能:通过检查网络中其他主机的应答信息,来确认网络的连通性。
语法:ping [参数] 主机名(或ip地址)
参数:
-c count:共发出count次信息。
-R:显示路由表的详细信息5、telnet
功能:远程登录
语法:telnet [<主机名>][:端口号]
6、ifconfig
功能:配置网络接口
语法:
ifconfig [interface] [up][down][netmask mask]
#ifconfig
#ifconfig eth0 192.168.0.3 netmask 255.255.255.0 up7、netstat
功能:显示本地系统的网络连接状态
语法:netstat [-a][-r][-c][-i]
-a:显示所有本地系统中的网络连接
-r:显示路由表
-c:显示连续的网络连接状态
-i:显示全部网络接口信息。8、ftp
功能:文件传输
语法:ftp [<主机名>]
子命令:
?:列出所有的FTP命令;
pwd:显示远程主机的当前目录
lcd:切换和显示本机主机的当前目录
ls:列出远程主机当前目录下的内容
!dir:列出本机主机的当前目录下的内容
cd:切换远程主机的目录get:下载一个文件
mget:成批下载文件
put:上传一个文件
mput:成批上传文件
prompt:使用mget和mput时是否采用交互式询问
bye:中止一个FTP连接
open:打开一个FTP连接
close:关闭一个FTP连接
binary:采用二进制模式传输
ascii:采用ascii模式传输
type:查看传输模式2.2 shell
一、shell简介
二、shell功能一、shell简介
(一)、定义:shell是用户与操作系统内核之间的接口,具有命令解释器和编程语言的双重功能。
(二)、shell中的命令分为内部命令和外部命令,内部命令包含在shell自身之中的,如cd,exit等,查看内部命令的方法可用help命令;而外部命令是存在于文件系统某个目录下的具体的可执行程序,如cp等,查看外部命令的路径可用which。(三)、命令解释过程
二、shell功能
(一)、命令行解释
1、交互模式
2、后台运行:如#fsck / &
(二)、通配符
*:表示任一串字符
?:表示任一个字符
[…]:匹配方括号内的任意字符
[!...]或[^…]:匹配除方括号内的任意字符
[a-zA-Z]:匹配首字符是字母的所有文件
(三)、重定向
1、>:输出重定向 如:#ls >1.txt
2、>>:追加重定向
如:#cat /etc/inittab >>1.txt
3、<:输入重定向 如#wc </etc/passwd
4、<<!...!:输入重定向特例
如#wc <<!
hello
it is a nice day
!
5、2>:错误重定向
6、&>:同时实现输出重定向和错误重定向(四)、管道操作符 |
功能:把一个命令的输出内容作为另外一个命令的输入内容。
#ls |more:分屏显示
#dmesg |grep eth0
(五)、命令替换符` `
功能:把一个命令的输出内容作为另外一个命令的参数。
#cd `pwd`
#tar –cvf zsan.tar `find / -user “zsan”`
#tar –cvf conf.tar `ls /etc *.conf`(六)、命令执行顺序
1、;按顺序执行命令 如#date;cal
2、&&逻辑与的关系,只有前面的命令执行成功后面的命令才会被执行。
如:#mail zsan@sje.cn <123.txt &&rm –fr 123.txt
3、||逻辑或的关系,只有前面的命令执行失败后面的命令才会被执行。
如:#write zsan <123.txt ||mail zsan@sje.cn <123.txt
4、( )组合命令行中的命令,改变执行顺序
如:#date;cal|wc与#(date;cal)|wc(七)、自动补全:在bash下输入命令时不必把命令输全,bash就能判断出用户所要输入的命令,可通过tab键完成自动补全功能。
(八)、命令别名
功能:可以使工作变得轻松的工具
语法:alias [<别名>=“<原文件名>”]
#alias 显示所有的别名
#alias md=“mkdir” 建立别名
#unalias md 取消别名(九)、命令历史
功能:可以记录一定数目的以前在shell中输入的命令以避免重复劳动
1、查看所有的历史命令:#history
2、查看某条历史命令:#history n
3、引用历史命令:#!<命令编号>2.3 vi的使用
一、编辑模式下的常用命令
1、0:移光标到当前行的行首
2、$:移光标到当前行的行尾
3、H:移光标到当前屏第一行的行首
4、M:移光标到当前屏中间行的行首
5、L:移光标到当前屏最后一行的行首
6、pageup、pagedown:上翻页,下翻页
7、ctrl+g:显示状态信息
8、X:删除一个字符
9、dd:删除或剪切光标所在的行
10、d0:删除光标处到行首的内容
11、d$:删除光标处到行尾的内容
12、u:取消上次命令
13、. :重复操作
14、YY:复制当前行
15、p:粘贴二、命令状态下操作:
1、:n 跳行
2、:w 保存
3、:q 退出(须先保存)
4、:w filename 另存为
5、:wq 保存退出
6、:q! 不保存强制退出
7、:a,b w filename 将a行到b行的内容另存为
8、:.,$ w filename 将当前行到行尾的内容另存为
9、:1,. W filename 将第一行到当前行的内容另存为
10、:/string 在全文中查找string字符串
11、:a,b s/string1/string2/g 将a行到b行之间的所有string1替换成string2
12、:% s/string1/string2/g 将全文中的string1替换成string2
13、:e filename 新建文件
14、: r filename 打开一个文件
15、:f filename 重命名当前文件16、:n1,n2 co n3 将n1和n2行的内容复制到n3行位置上
17、:n1,n2 m n3 将n1和n2行的内容移到n3行的位置上
18、:n1,n2 d 将n1到n2行的内容删除掉
19、:set number 设置行号
20、:set autoindent 设置自动缩进
21、:!Cmd 执行shell命令
22、:r ! Cmd 将shell命令的执行结果作为文件的内容
23、:sh 暂时退出vi到系统下,按ctrl+d结束
24、:X 文件保存退出前加密。
hls
查看公开信息
发送悄悄话给hls
给hls发送Email
查找hls发表的更多帖子
添加 hls 到好友列表第三章:文件系统管理
3.1 文件系统概述
一、文件管理
(一)、文件的类型
1、普通文件:包括文本文件和二进制文件
2、目录文件
3、链接文件:包括硬链接和软链接。
4、特殊文件:
设备文件:包括字符类设备(如打印机)和块设备(如硬盘)以及空设备(null)
管道文件:是一个先进先出(FIFO)的缓冲区。文件类型及其代表字符
(二)、文件权限
1、chmod
功能:改变文件(目录)的访问权限
权限的表示法有两种:
一是采用符号标记模式进行更改
二是采用八进制数指定新的访问权限
符号表示法的格式:[ugoa][+-=][rwx]
u:表示文件的所有者;
g:表示文件所有者同组的用户;
o:其他用户
a:所有用户
+:添加权限
-:撤消权限
=:指定权限
r:读权限
w:写权限
x:执行权(或对目录的访问权)八进制数字表示法:
用1—4个八进制数来表示,其中:
第一位:
用4表示setuid:设置使文件在执行阶段具有文件所有者的权限,如/usr/bin/passwd的权限设置 ;
用2表示setgid:该权限只对目录有效. 目录被设置该位后, 任何用户在此目录下创建的文件都具有和该目录所属的组相同的组;
用1表示sticky bit :该位可以理解为防删除位,一个文件是否可以被某用户删除, 主要取决于该文件所在的目录是否对该用户具有写权限. 如果没有写权限, 则这个目录下的所有文件都不能被删除, 同时也不能添加新的文件. 如果希望用户能够添加文件但同时不能删除别的文件, 则可以对目录使用sticky bit位. 用户对目录设置该位后, 就算对目录具有写权限, 也不能删除不属于该用户的文件。第二位:用来设置文件所有者的权限,用4表示可读,用2表示可写,用1表示可执行
第三位:用来设置文件所在组用户的权限,用4表示可读,用2表示可写,用1表示可执行
第四位:用来设置其他用户的权限,用4表示可读,用2表示可写,用1表示可执行。
Chmod使用格式:
Chmod [参数][模式]<文件或目录>
参数:-R:改变目录及其所有子目录的文件权限。
举例:
#chmod u+x inittab
#chmod ug+wx,o-x inittab
#chmod 0644 inittab
#chmod 0755 inittab
#chmod –R 700 ~目录权限的补充说明:
1、目录的只读访问不允许使用cd进入目录,必须要有执行的权限才能进入。
2、只有执行权限只能进入目录,不能看到目录下的内容,要想看到目录下的文件名和目录名,需要可读权限。
3、一个文件能不能被删除,主要看该文件所在的目录对用户是否具有写权限,如果目录对用户没有写权限,则该目录下的所有文件都不能被删除,文件所有者除外
对特殊位的举例说明: 操作这些特殊位与操作文件权限的命令是一样的, 都是 chmod. 有两种方法来操作, 1) chmod u+s temp : 为temp文件加上setuid标志. (setuid 只对文件有效) chmod g+s tempdir :为tempdir目录加上setgid标志 (setgid 只对目录有效) chmod o+t tempdir : 为temp文件加上sticky标志 (sticky只对目录有效)2) 采用八进制方式. 对一般文件通过三组八进制数字来置标志, 如 666, 777, 644等. 如果设置这些特殊标志, 则在这组数字之外外加一组八进制数字. 如 4666, 2777等.
设置完这些标志后, 可以用 ls -l 来查看. 如果有这些标志, 则会在原来的执行标志位置上显示. 如 rwsrw-r-- 表示有setuid标志 rwxrwsrw- 表示有setgid标志 rwxrw-rwt 表示有sticky标志 那么原来的执行标志x到哪里去了呢? 系统是这样规定的, 如果本来在该位上有x, 则这些特殊标志显示为小写字母 (s, s, t). 否则, 显示为大写字母 (S, S, T)
2、chown
功能:修改文件(目录)所有者和组别
语法:
chown [参数]<用户名[.组名]><文件或目录>
参数:-R:递归地修改目录及其下面内容的所有权。
#chown zsan history.doc
#chown –R zsan.sales /home/zsan3、chgrp
功能:改变文件的组所有权
格式:chgrp [参数]<组><文件或目录>
[参数]:-R:递归地将指定目录下的所有文件和子目录的组名修改为指定的组。
#chgrp –R student /home/st01
4、umask
功能:用于设置文件的默认生成掩码,告诉系统当创建一个文件或目录时不应该赋予其哪些权限。(三)ext2(ext3)文件系统安全选项
A:Atime。告诉系统不要修改对这个文件的最后访问时间
S:Sync。一旦应用程序对这个文件执行了写操作,使系统立刻把修改的结果写到磁盘。 a:Append Only。系统只允许在这个文件之后追加数据,不允许任何进程覆盖或者截断这个文件。如果目录具有这个属性,系统将只允许在这个目录下建立和修改文件,而不允许删除任何文件。 i:Immutable。系统不允许对这个文件进行任何的修改。如果目录具有这个属性,那么任何的进程只能修改目录之下的文件,不允许建立和删除文件。
ext2(ext3)文件系统安全选项
d:No dump。在进行文件系统备份时,dump程序将忽略这个文件。 C:Compress。系统以透明的方式压缩这个文件。从这个文件读取时,返回的是解压之后的数据;而向这个文件中写入数据时,数据首先被压缩之后,才写入磁盘。 s:Secure Delete。让系统在删除这个文件时,使用0填充文件所在的区域。 u:Undelete。当一个应用程序请求删除这个文件,系统会保留其数据块以便以后能够恢复删除这个文件。
chattr修改文件属性
chattr +i filename 设置i属性
chattr –i filename 取消i属性
lsattr 查看设置的属性
二、linux支持的文件系统:
Ext2或ext3文件系统
FAT(适用各种版本的DOS)
NTFS(适用Windows NT -- Windows 2000)
VFAT和FAT32(适用Windows 9x)
HFS(适用MacOS)
HPFS(适用OS/2)
Swap(交换分区)3.2 fdisk分区工具
#fdisk –l /dev/hda
#fdisk /dev/hda
:m 列出所有的分区命令
:p 显示分区情况
:d 删除原有的分区
:n 增加新分区
:t 改变分区类型
:l 查看分区类型
:a 设置活动分区
: w 保存退出
: q 不保存退出
3.3 使用mkfs创建文件系统
mkfs命令的格式是:mkfs 选项 设备名
例如:
mkfs –t ext2 –c /dev/hda2
-t:指定文件系统类型
-c:建立文件系统前先检测有无坏块#mke2fs –c /dev/hda2
3.4 挂载和卸载文件系统
挂载文件系统
卸载文件系统
挂载文件系统
mount /dev/sdb1 /tmp/test1
mount /mnt/floppy
mount
注意
挂载目录必须存在
Linux专门提供了挂载目录/mnt
不要在挂载目录下进行挂载操作
将软盘或光盘放入驱动器后在实施挂载操作
卸载前不要取出软盘或光盘
不能在同一个目录下挂载两个文件系统
卸载文件系统
umount /mnt/cdrom
umount /dev/sdb1
umount /tmp/test1
mount –a:卸载所有挂载设备注意:不能在挂载目录下进行卸载操作
3.5 软盘、光盘、USB硬盘的使用
1、软盘格式化:fdformat –n /dev/fd0H1440
2、建立文件系统
mkfs –t ext2 –c /dev/fd0H1440
3、挂载文件系统
mount –t ext2 /dev/fd0H1440 /mnt/floppy
4、使用
cp /etc/lilo.conf /mnt/floppy
mkdir /mnt/floppy/mydir1
5、卸载
umount /mount/floppy
1、挂载文件系统
mount –t iso9660 /dev/cdrom /mnt/cdrom
或
mount /mnt/cdrom
2、卸载
umount /mnt/cdrom
eject(弹出光盘)
USB硬盘的使用
USB硬盘在Linux系统下是被模拟成SCSI设备来使用的,因此对应的设备文件是/dev/sda,如果有多块USB硬盘,则设备文件依次是/dev/sdb、/dev/sdc等。
用mount命令加-o loop选项挂载光盘镜像文件
1、#mkdir /mnt/iso
2、#mount –o loop rfdesktop4.iso /mnt/iso
3.6在系统启动时自动挂装文件系统
要系统自动挂载文件系统必须修改系统配置文件/etc/fstab。系统启动所要挂载的文件系统、挂载点、文件系统类型等都记录在/etc/fstab文件里。
3.7 文件系统管理的常用命令
df:显示文件系统的统计数据
du:显示硬盘使用的统计信息
ln:创建链接文件
tar:文件打包
fsck:文件系统检查命令
dd:文件拷贝命令
fsck
功能:检查文件系统
语法:fsck [选项]<设备名>
选项:
-t fstype:检查的文件系统类型
-A 检查所有在/etc/fstab中列出的文件系统
-p:整理文件系统,自动修正所有问题
注意:
1、当检查一个文件系统时,应该确保处于未挂装状态
2、当要检查根文件系统时,应该使用急救软盘或安装光盘重新引导机器后时行fsck命令输入的错误代码
Linux引导盘的制作
#cd /lib/modules
#mkbootdisk --device /dev/fd0 2.4.20-8
制作引导盘的好处:
1、替代LILO
2、紧急情况下使用引导盘和急救盘恢复系统
3、当其他系统覆盖了LILO
dd:文件拷贝命令
制作Linux安装启动盘
dd if=boot.img ōf=/dev/fd0 bs=1440k
制作redhat linux急救盘
#dd if=rescue.img ōf=/dev/fd0
rescue.img存放在redhat linux安装光盘的images目录中。
备份和恢复软盘数据
dd if= /dev/fd0 ōf=backup
dd if=backup ōf= /dev/fd0
第四章:用户管理
本章主要内容
4.1 用户和组管理概述
4.2 用户帐号的管理
4.3 组的管理
4.4 磁盘限额4.1 用户和组管理概述
一、帐号管理包括用户的管理、组的管理和口令的管理
二、linux下的用户分为三类:
1、超级用户:超级用户的uid和gid均为0
2、普通用户:普通用户的uid和gid是在500-60000范围内的一个值
3、伪用户:uid的值是在1-499之间,不能登录,只是满足系统管理的要求,如bin,sys,lp 等。三、linux下的组分为标准组和私有组:
1、当在创建一个新用户时,若没有指定他所属于的组,系统就会建立一个和该用户同名的私有组;
2、标准组可以容纳多个用户,若使用标准组,在创建一个新的用户时就可以指定他所属于的组。
四、帐号系统文件
1、linux下的帐号系统文件主要有/etc/passwd,/etc/group,/etc/shadow ,这些文件只有超级用户才可以修改
2、其他文件或目录
(1)、默认设置文件
/etc/login.defs,/etc/default/useradd
(2)、默认设置目录
/etc/skel
2.1 用户帐号管理
一、创建新的用户帐号系统将会
1、在/etc/passwd中添加一笔记录
2、创建用户的自家目录
3、在用户自家目录中设置默认的配置文件
4、设置用户初始口令
二、创建帐号
Useradd [<选项>]<用户名>[<选项>]
-u uid:指定新用户的uid,默认为使用当前最大的uid加1
-g group:指定新用户所在的组,该组必须已经存在
-G group:指定新用户的附加组
-d dir :指定新用户的自家目录
-s shell:指定新用户使用的shell,默认为bash,也可以使用chsh命令修改,/etc/shells
-c comment:说明新用户的附加信息,如全名等
-e expire:指定用户的登录失交效时间,格式yyyy-mm-dd
-m 建立新用户的自家目录
-M 不建立新用户的自家目录
-R 建立一个系统用户举例:
#useradd –g ll –e 12/31/2001 lei
#passwd lei
三、删除已存在的用户帐号
Userdel –r lei
-r :表示连同自家目录一起删除
四、修改用户属性
Usermod [<选项>]<用户名>
其中[<选项>]和useradd中的选项基本相同,但增加
-l:更改用户的帐号名
-L:锁定用户
-U:取消帐号锁定
#usermod –l xjlei –d /home/xjlei –G girl lei
五、成为超级用户
修改用户的uid和gid为0即可。
命令:usermod –u 0 –o zsan
-o:强迫修改uid
六、禁用和恢复用户帐户
命令:passwd [<选项>]<用户名>
[选项]
-l:锁定用户
-u:对被锁定的用户解锁
-d:删除用户密码
-S:查看用户帐号的状态,如是否被锁定等七、切换到其他用户
命令:su [-] [username]
说明:如果目录用户是普通用户,则可以切换到超级用户或其他普通用户,但需要口令,如果目录用户是超级用户,则可以直接切换到普通用户,不需要密码。
[-] :连同工作环境一起切换。
八、sudo
sudo是可以让普通用户执行某个超级用户执行的程序,如:sudo vi /etc/shadow
所有这些配置项要保存在/etc/sudoers文件中
sudo文件中语法如下:
1、用Host_Alias关键字定义主机列表
如:Host_Alias RED=www,ftp
2、用User_Alias关键字定义用户别名列表
如:User_Alias US=wdn,zsan
3、用Cmnd_Alias关键字定义命令别名列表
如:Cmnd_Alias CMDS=/bin/rm,/bin/chown一个实例:/etc/sudoers
User_Alias US=wdn
User_Alias US1=lsi,wemz
User_Alias US2=zsan
US ALL=ALL
US1 ALL=/sbin/shutdown
US2 ALL=ALL,!/bin/su4.3 组的管理
一、添加组
命令:groupadd [<选项>]<组名>
[选项]
-g gid:指定新组的gid,默认为使用当前最大的gid加1
-r:建立一个系统用户组,不指定-g选项,则分配一个1-499之间的值
#groupadd –g 888 ll二、删除组
命令:groupdel <组名>
三、修改组的属性
命令:groupmod [<选项>]<组名>
其中选项与groupadd选项基本相同,但增加一个-n选项,用于修改新的组名。
#groupmod –n girl ll
四、为标准组添加用户
命令:gpasswd [选项][用户][组]
-a:把用户加入组
-d:把用户从组中删除
#gpasswd –a zsan sales五、查看当前用户属于哪些组
groups [username]
六、切换到某组运行(必须已属此组)
newgrp [group]七、其他命令
1、id命令
功能:可以查看一个用户的uid和gid
格式:id 用户名
2、finger
功能:查看用户的相关信息
格式:finger 用户名
3、chfn
功能:修改用户信息
格式:chfn 用户名
4.4 磁盘限额
一、安装磁盘限额
在安装光盘中找到quota的rpm软件包。如:
#rpm –ivh quota-version.i386.rpm
可用rpm –q quota查看是否安装
二、启用系统的quota功能
编辑etc/fstab,在要启用磁盘限额的分区
(如/home)行中的添加相应参数如
/dev/hda6 /home ext3 rw defaults,usrquota,grpquota 0 2三、创建quota文件
在/home分区中添加aquota.user和aquota.group文件
#touch aquota.user
#touch aquota.group
系统重启,运行quotacheck –avug命令在配额文件中创建磁盘信息。
四、设置用和组的quota
对一个用户的磁盘使用限制有两种,一种是软限制(soft limit),一种是硬限制(hard limit),硬限制是分配给用户的最大磁盘空间,使用完了就立即拒绝用户再存放文件,而当用户的磁盘使用空间超过了软限制时,在一定期限内仍可继续存储文件,但系统会有警告。而这个期限可用edquota –t 来设置1、为用户设置quota
#edquota –u zsan
2、为组设置quota
#edquota –g sales
3、若为多个用户重复设置quota
#edquota –p 参考用户 待设置用户
#edquota –p zsan lsi wdn
四、启动quota
#quotaon -avug五、查看磁盘限额的情况
#quota zsan
#quota –a
六、显示有关quota的摘要信息
# repquota /home
hls
查看公开信息
发送悄悄话给hls
给hls发送Email
查找hls发表的更多帖子
添加 hls 到好友列表第五章 进程管理
本章主要内容
5.1 进程的基本概念
5.2 进程的管理和监控
5.3 进程的自动执行
5.1 进程的基本概念
一、程序、进程和作业的概念
1、程序是机器指令的集合,一般以文件的形式存储在磁盘上,是静态的。
2、进程是一个程序在地址空间中的一次执行活动,是动态的。
3、作业是指用户提交给计算机进行加工的一项任务,是由用户程序、数据以及某种形式的控制信息组成。二、进程的类型
1、交互进程:由一个shell启动的进程,既可以在前台运行,也可以在后台运行。
2、批处理进程:不与特定的终端相关联,提交到等待队列中顺序执行进程。
3、守护进程:在linux启动是初始化,需要时运行于后台的一些服务进程。三、进程的启动方式:
1、手工启动,分为前台启动和后台启动,通常情况下,我们执行一个命令就会启动一个进程。
#ls / –R >test 前台启动
#ls / -R >test & 后台启动
2、调度启动:事先设置好,根据用户要求让系统自动启动。
2.2 进程的管理和监控
一、查看系统中的进程
1、ps [选项]
[选项]
-a 显示所有用户的进程,但不包括没有控制终端的进程
-u 显示用户名和启动时间
-x 显示没有控制终端的进程
PS命令输出的重要信息的含义
PID:进程号
PPID:父进程的进程号
TTY:进程启动的终端
STAT:进程当前的状态,S代表休眠,R代表运行,T代表追踪或停止,Z代表僵尸进程,W代表进程没有固定的pages,<表示高优先级的进程,N代表低优先级的进程。
TIME:进程自从启动以来占用CPU的总时间
COMMAND/CMD:进程的命令名
USER:用户名
%CPU:占用CPU的时间与总时间的百分比
%mem:占用内存与系统总内存的百分比
SIZE:进程代码大小二、控制系统中的进程
1、kill
功能:杀死一个进程
格式:kill -9 进程号
2、renice
功能:改变一个正在运行进程的优先级
格式:renice –n pid
-n:进程的优先级,大于0是降低优先级,小于0是提高优先级,优先级的范围是从19到-203、 nohup
功能:当用户退出登录后,进程仍然能够在后台继续运行.
语法:nohup myprogram &
4、top
功能:以动态的方式显示进程状态
Top命令的显示栏说明:
PID:进程号
User:进程的所有者
Pri:进程运行的优先级
Ni:nice值,表示进程的优先级
VIRT:进程占用的虚拟内存的总量
RES:进程占用的非swap内存的总量
SHR:和其他进程共享内存的总量。
S:进程的状态
TIME+:进程的累积运行时间Top中的子命令
l,t,m:调整显示的摘要信息,l是平均负载,t是cpu状态,m是内存信息
f:用来添加、删除显示栏位
u:列出某个用户的进程
n:设置显示总进程数的最大值
k,r:k用来杀死某个进程,r是renice
q:退出TOP5、进程的挂起和恢复
按ctrl+z可以暂停正在运行的进程,
执行jobs可以显示当前终端下有哪些程序在后台运行以及哪些进程被挂起了。
执行fg可以在前台恢复一个被挂起的进程。
执行bg可以在后台恢复一个被挂成的进程。
5.3 进程的自动运行
1、at
功能:指定在某一时刻执行命令
格式:at [选项] 时间
选项:
-l:列出已经排定的任务
-d n 删除序号为n的任务
-v:显示命令将被执行的时间
时间表示法:
HH:MM 当天中的某小时、某分钟,如果此时刻已经过去了,linux 文件结构是什么样的分析
xiaoningln 发布于 2008-01-11 16:09:30
一 、linux文件结构
文件结构是文件存放在磁盘等存贮设备上的组织方法。主要体现在对文件和目录的组织上。
目录提供了管理文件的一个方便而有效的途径。
linux使用标准的目录结构,在安装的时候,安装程序就已经为用户创建了文件系统和完整而固定的目录组成形式,并指定了每个目录的作用和其中的文件类型。
/根目录
┃
┏━━━┳━━━━┳━━━━┳━━━━╋━━━━┳━━━━┳━━━━┳━━━━┓
┃ ┃ ┃ ┃ ┃ ┃ ┃ ┃ ┃
bin home dev etc lib sbin tmp usr var
┃ ┃
┏━┻━┓ ┏━━━━┳━━━┳━┻━┳━━━┳━━━┓
┃ ┃ ┃ ┃ ┃ ┃ ┃ ┃
rc.d cron.d X11R6 src lib local man bin
┃ ┃ ┃
┏━━━┳━━━┳━┻━┳━━━━┓ ┃ ┏━━━╋━━━┓
┃ ┃ ┃ ┃ ┃ ┃ ┃ ┃ ┃
init.d rc0.d rc1.d rc2.d …… linux bin lib src
linux 采用的是树型结构。最上层是根目录,其他的所有目录都是从根目录出发而生成的。微软的DOS和windows也是采用树型结构,但是在DOS和 windows中这样的树型结构的根是磁盘分区的盘符,有几个分区就有几个树型结构,他们之间的关系是并列的。但是在linux中,无论操作系统管理几个磁盘分区,这样的目录树只有一个。从结构上讲,各个磁盘分区上的树型目录不一定是并列的。
如果这样讲不好理解的话,我来举个例子:
有一块硬盘,分成了4个分区,分别是/;/boot;/usr和windows下的fat
对于/和/boot或者/和/usr,它们是从属关系;对于/boot和/usr,它们是并列关系。
如果我把windows下的fat分区挂载到/mnt/winc下,(挂载??哦,别急,呵呵,一会就讲,一会就讲。)那么对于/mnt/winc和/usr或/mnt/winc和/boot来说,它们是从属于目录树上没有任何关系的两个分支。
因为linux是一个多用户系统,制定一个固定的目录规划有助于对系统文件和不同的用户文件进行统一管理。但就是这一点让很多从windows转到linux的初学者感到头疼。下面列出了linux下一些主要目录的功用。
/bin 二进制可执行命令
/dev 设备特殊文件
/etc 系统管理和配置文件
/etc/rc.d 启动的配置文件和脚本
/home 用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示
/lib 标准程序设计库,又叫动态链接共享库,作用类似windows里的.dll文件
/sbin 系统管理命令,这里存放的是系统管理员使用的管理程序
/tmp 公用的临时文件存储点
/root 系统管理员的主目录(呵呵,特权阶级)
/mnt 系统提供这个目录是让用户临时挂载其他的文件系统。
/lost+found 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里
/proc 虚拟的目录,是系统内存的映射。可直接访问这个目录来获取系统信息。
/var 某些大文件的溢出区,比方说各种服务的日志文件
/usr 最庞大的目录,要用到的应用程序和文件几乎都在这个目录。其中包含:
/usr/X11R6 存放X window的目录
/usr/bin 众多的应用程序
/usr/sbin 超级用户的一些管理程序
/usr/doc linux文档
/usr/include linux下开发和编译应用程序所需要的头文件
/usr/lib 常用的动态链接库和软件包的配置文件
/usr/man 帮助文档
/usr/src 源代码,linux内核的源代码就放在/usr/src/linux里
/usr/local/bin 本地增加的命令
/usr/local/lib 本地增加的库
二 、linux文件系统
文件系统指文件存在的物理空间,linux系统中每个分区都是一个文件系统,都有自己的目录层次结构。linux会将这些分属不同分区的、单独的文件系统按一定的方式形成一个系统的总的目录层次结构。一个操作系统的运行离不开对文件的操作,因此必然要拥有并维护自己的文件系统。
linux文件系统使用索引节点来记录文件信息,作用像windows的文件分配表。
索引节点是一个结构,它包含了一个文件的长度、创建及修改时间、权限、所属关系、磁盘中的位置等信息。一个文件系统维护了一个索引节点的数组,每个文件或目录都与索引节点数组中的唯一一个元素对应。系统给每个索引节点分配了一个号码,也就是该节点在数组中的索引号,称为索引节点号。
linux文件系统将文件索引节点号和文件名同时保存在目录中。所以,目录只是将文件的名称和它的索引节点号结合在一起的一张表,目录中每一对文件名称和索引节点号称为一个连接。
对于一个文件来说有唯一的索引节点号与之对应,对于一个索引节点号,却可以有多个文件名与之对应。因此,在磁盘上的同一个文件可以通过不同的路径去访问它。
可以用ln命令对一个已经存在的文件再建立一个新的连接,而不复制文件的内容。
连接有软连接和硬连接之分,软连接又叫符号连接。它们各自的特点是:
硬连接:原文件名和连接文件名都指向相同的物理地址。
目录不能有硬连接;硬连接不能跨越文件系统(不能跨越不同的分区)
文件在磁盘中只有一个拷贝,节省硬盘空间;
由于删除文件要在同一个索引节点属于唯一的连接时才能成功,因此可以防止不必要的误删除。
符号连接:用ln -s命令建立文件的符号连接
符号连接是linux特殊文件的一种,作为一个文件,它的数据是它所连接的文件的路径名。类似windows下的快捷方式。
可以删除原有的文件而保存连接文件,没有防止误删除功能。
这一段的的内容过于抽象,又是节点又是数组的,我已经尽量通俗再通俗了,又不好加例子作演示。大家如果还是云里雾里的话,我也没有什么办法了,只有先记住,日后在实际应用中慢慢体会、理解了。这也是我学习的一个方法吧。
三 、挂载文件系统
由上一节知道,linux系统中每个分区都是一个文件系统,都有自己的目录层次结构。linux会将这些分属不同分区的、单独的文件系统按一定的方式形成一个系统的总的目录层次结构。这里所说的“按一定方式”就是指的挂载。
将一个文件系统的顶层目录挂到另一个文件系统的子目录上,使它们成为一个整体,称为挂载。把该子目录称为挂载点。
举个例子吧:
根分区:
/根目录
┃
┏━━━━┳━━━━┳━━━━┳━━━━╋━━━━┳━━━━┳━━━━┳━━━━┓
┃ ┃ ┃ ┃ ┃ ┃ ┃ ┃ ┃
bin home dev etc lib sbin tmp usr var
┃
┏━┻━┓
┃ ┃
rc.d cron.d
┃
┏━━━┳━━━┳━┻━┳━━━━┓
┃ ┃ ┃ ┃ ┃
init.d rc0.d rc1.d rc2.d ……
/usr分区 :
usr
┃
┏━━━━┳━━━╋━━━┳━━━┳━━━┓
┃ ┃ ┃ ┃ ┃ ┃
X11R6 src lib local man bin
┃ ┃
┃ ┏━━━╋━━━┓
┃ ┃ ┃ ┃
linux bin lib src
挂载之后就形成了文章开始时的那个图。像不像挂上去的?
注意:1、挂载点必须是一个目录。
2、一个分区挂载在一个已存在的目录上,这个目录可以不为空,但挂载后这个目录下以前的内容将不可用。
对于其他操作系统建立的文件系统的挂载也是这样。但是需要理解的是:光盘、软盘、其他操作系统使用的文件系统的格式与linux使用的文件系统格式是不一样的。光盘是ISO9660;软盘是fat16或ext2;windows NT是fat16、NTFS;windows98是fat16、fat32;windows2000和windowsXP是fat16、fat32、 NTFS。挂载前要了解linux是否支持所要挂载的文件系统格式。
挂载时使用mount命令:
格式:mount [-参数] [设备名称] [挂载点]
其中常用的参数有
-t<文件系统类型> 指定设备的文件系统类型,常见的有:
minix linux最早使用的文件系统
ext2 linux目前常用的文件系统
msdos MS-DOS的fat,就是fat16
vfat windows98常用的fat32
nfs 网络文件系统
iso9660 CD-ROM光盘标准文件系统
ntfs windows NT 2000的文件系统
hpfs OS/2文件系统
auto 自动检测文件系统
-o<选项> 指定挂载文件系统时的选项。有些也可用在/etc/fstab中。常用的有
codepage=XXX 代码页
iocharset=XXX 字符集
ro 以只读方式挂载
rw 以读写方式挂载
nouser 使一般用户无法挂载
user 可以让一般用户挂载设备
提醒一下,mount命令没有建立挂载点的功能,因此你应该确保执行mount命令时,挂载点已经存在。(不懂?说白了点就是你要把文件系统挂载到哪,首先要先建上个目录。这样OK?)
例子:windows98装在hda1分区,同时计算机上还有软盘和光盘需要挂载。
# mk /mnt/winc
# mk /mnt/floppy
# mk /mnt/cdrom
# mount -t vfat /dev/hda1 /mnt/winc
# mount -t msdos /dev/fd0 /mnt/floppy
# mount -t iso9660 /dev/cdrom /mnt/cdrom
现在就可以进入/mnt/winc等目录读写这些文件系统了。
要保证最后两行的命令不出错,要确保软驱和光驱里有盘。(要是硬盘的磁盘片也可以经常随时更换的话,我想就不会犯这样的错误了:-> )
如果你的windows98目录里有中文文件名,使用上面的命令挂载后,显示的是一堆乱码。这就要用到 -o 参数里的codepage iocharset选项。codepage指定文件系统的代码页,简体中文中文代码是936;iocharset指定字符集,简体中文一般用cp936或 gb2312。
当挂载的文件系统linux不支持时,mount一定报错,如windows2000的ntfs文件系统。可以重新编译linux内核以获得对该文件系统的支持。关于重新编译linux内核,就不在这里说了。
四 、自动挂载
每次开机访问windows分区都要运行mount命令显然太烦琐,为什么访问其他的linux分区不用使用mount命令呢?
其实,每次开机时,linux自动将需要挂载的linux分区挂载上了。那么我们是不是可以设定让linux在启动的时候也挂载我们希望挂载的分区,如windows分区,以实现文件系统的自动挂载呢?
这是完全可以的。在/etc目录下有个fstab文件,它里面列出了linux开机时自动挂载的文件系统的列表。我的/etc/fstab文件如下:
/dev/hda2 / ext3 defaults 1 1
/dev/hda1 /boot ext3 defaults 1 2
none /dev/pts devpts gid=5,mode=620 0 0
none /proc proc defaults 0 0
none /dev/shm tmpfs defaults 0 0
/dev/hda3 swap swap defaults 0 0
/dev/cdrom /mnt/cdrom iso9660 noauto,codepage=936,iocharset=gb2312 0 0
/dev/fd0 /mnt/floppy auto noauto,owner,kudzu 0 0
/dev/hdb1 /mnt/winc vfat defaults,codepage=936,iocharset=cp936 0 0
/dev/hda5 /mnt/wind vfat defaults,codepage=936,iocharset=cp936 0 0
在/etc/fstab文件里,第一列是挂载的文件系统的设备名,第二列是挂载点,第三列是挂载的文件系统类型,第四列是挂载的选项,选项间用逗号分隔。第五六列不知道是什么意思,还望高手指点。
在最后两行是我手工添加的windows下的C;D盘,加了codepage=936和ocharset=cp936参数以支持中文文件名。参数defaults实际上包含了一组默认参数:
rw 以可读写模式挂载
suid 开启用户ID和群组ID设置位
dev 可解读文件系统上的字符或区块设备
exec 可执行二进制文件
auto 自动挂载
nouser 使一般用户无法挂载
async 以非同步方式执行文件系统的输入输出操作
大家可以看到在这个列表里,光驱和软驱是不自动挂载的,参数设置为noauto。(如果你非要设成自动挂载,你要确保每次开机时你的光驱和软驱里都要有盘,呵呵。) GCC参数详解
GCC参数详解 [介绍]
gcc and g++分别是gnu的c & c++编译器
gcc/g++在执行编译工作的时候,总共需要4步
1.预处理,生成.i的文件
2.将预处理后的文件不转换成汇编语言,生成文件.s
3.有汇编变为目标代码(机器代码)生成.o的文件
4.连接目标代码,生成可执行程序[参数详解]
-c
只激活预处理,编译,和汇编,也就是他只把程序做成obj文件
例子用法:
gcc -c hello.c
他将生成.o的obj文件
-S
只激活预处理和编译,就是指把文件编译成为汇编代码。
例子用法
gcc -S hello.c
他将生成.s的汇编代码,你可以用文本编辑器察看
-E
只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里
面.
例子用法:
gcc -E hello.c > pianoapan.txt
gcc -E hello.c | more
慢慢看吧,一个hello word 也要与处理成800行的代码
-o
制定目标名称,缺省的时候,gcc 编译出来的文件是a.out,很难听,如果
你和我有同感,改掉它,哈哈
例子用法
gcc -o hello.exe hello.c (哦,windows用习惯了)
gcc -o hello.asm -S hello.c
-ansi
关闭gnu c中与ansi c不兼容的特性,激活ansi c的专有特性(包括禁止一
些asm inline typeof关键字,以及UNIX,vax等预处理宏,-wall
显示警告信息
-fno-asm
此选项实现ansi选项的功能的一部分,它禁止将asm,inline和typeof用作
关键字。
-fno-strict-prototype
只对g++起作用,使用这个选项,g++将对不带参数的函数,都认为是没有显式
的对参数的个数和类型说明,而不是没有参数.
而gcc无论是否使用这个参数,都将对没有带参数的函数,认为城没有显式说
明的类型
-fthis-is-varialble
就是向传统c++看齐,可以使用this当一般变量使用.
-fcond-mismatch
允许条件表达式的第二和第三参数类型不匹配,表达式的值将为void类型
-funsigned-char
-fno-signed-char
-fsigned-char
-fno-unsigned-char
这四个参数是对char类型进行设置,决定将char类型设置成unsigned char(前
两个参数)或者 signed char(后两个参数)-include file
包含某个代码,简单来说,就是便以某个文件,需要另一个文件的时候,就可以
用它设定,功能就相当于在代码中使用#include
例子用法:
gcc hello.c -include /root/pianopan.h
-imacros file
将file文件的宏,扩展到gcc/g++的输入文件,宏定义本身并不出现在输入文件
中
-Dmacro
相当于C语言中的#define macro
-Dmacro=defn
相当于C语言中的#define macro=defn
-Umacro
相当于C语言中的#undef macro
-undef
取消对任何非标准宏的定义
-Idir
在你是用#include"file"的时候,gcc/g++会先在当前目录查找你所制定的头
文件,如果没有找到,他回到缺省的头文件目录找,如果使用-I制定了目录,他
回先在你所制定的目录查找,然后再按常规的顺序去找.
对于#include,gcc/g++会到-I制定的目录查找,查找不到,然后将到系
统的缺省的头文件目录查找
-I-
就是取消前一个参数的功能,所以一般在-Idir之后使用
-idirafter dir
在-I的目录里面查找失败,讲到这个目录里面查找.
-iprefix prefix
-iwithprefix dir
一般一起使用,当-I的目录查找失败,会到prefix+dir下查找
-nostdinc
使编译器不再系统缺省的头文件目录里面找头文件,一般和-I联合使用,明确
限定头文件的位置
-nostdin C++
规定不在g++指定的标准路经中搜索,但仍在其他路径中搜索,.此选项在创建
libg++库使用
-C
在预处理的时候,不删除注释信息,一般和-E使用,有时候分析程序,用这个很
方便的
-M
生成文件关联的信息。包含目标文件所依赖的所有源代码
你可以用gcc -M hello.c来测试一下,很简单。
-MM
和上面的那个一样,但是它将忽略由#include造成的依赖关系。
-MD
和-M相同,但是输出将导入到.d的文件里面
-MMD
和-MM相同,但是输出将导入到.d的文件里面
-Wa,option
此选项传递option给汇编程序;如果option中间有逗号,就将option分成多个选
项,然后传递给会汇编程序
-Wl.option
此选项传递option给连接程序;如果option中间有逗号,就将option分成多个选
项,然后传递给会连接程序.
-llibrary
制定编译的时候使用的库
例子用法
gcc -lcurses hello.c
使用ncurses库编译程序
-Ldir
制定编译的时候,搜索库的路径。比如你自己的库,可以用它制定目录,不然
编译器将只在标准库的目录找。这个dir就是目录的名称。
-O0
-O1
-O2
-O3
编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最
高
-g
只是编译器,在编译的时候,产生条是信息。
-gstabs
此选项以stabs格式声称调试信息,但是不包括gdb调试信息.
-gstabs+
此选项以stabs格式声称调试信息,并且包含仅供gdb使用的额外调试信息.
-ggdb
此选项将尽可能的生成gdb的可以使用的调试信息.CVS使用手册-珍藏版
xiaoningln 发布于 2008-05-14 12:29:35
CVS是一个C/S系统,多个开发人员通过一个中心版本控制系统来记录文件版本,从而达到保证文件同步的目的。CVS的管理员则更需要懂的更多一些,最后还简单介绍了一些Windows下的cvs客户端使用,CVS远程用户认证的选择及与BUG跟踪系统等开发环境的集成问题。CVS环境初始化:CVS环境的搭建 管理员
CVS的日常使用:日常开发中最常用的CVS命令, 开发人员 管理员
CVS的分支开发:项目按照不同进度和目标并发进行 管理员
CVS的用户认证:通过SSH的远程用户认证,安全,简单 管理员
CVSWEB:CVS的WEB访问界面大大提高代码版本比较的效率 管理员
CVS TAG:将$Id$ 加入代码注释中,方便开发过程的跟踪开发人员
CVS vs VSS: CVS和Virsual SourceSafe的比较 开发人员 管理员
WinCVS: 通过SSH认证的WinCVS认证设置
基于CVSTrac的小组开发环境搭建:通过CVSTrac实现web界面的CVS用户管理,集成的BUG跟踪和WIKI交流
CVS中的用户权限管理:基于系统用户的CVS权限管理和基于CVSROOT/passwd的虚拟用户管理
一个系统20%的功能往往能够满足80%的需求,CVS也不例外,以下是CVS最常用的功能,可能还不到它全部命令选项的20%,作为一般开发人员平时会用cvs update和cvs commit就够了,更多的需求在实际应用过程中自然会出现,不时回头看看相关文档经常有意外的收获。CVS环境初始化
环境设置:指定CVS库的路径CVSROOT
tcsh
setenv CVSROOT /path/to/cvsroot
bash
CVSROOT=/path/to/cvsroot ; export CVSROOT后面还提到远程CVS服务器的设置:
CVSROOT=:ext:$USER@test.server.address#port:/path/to/cvsroot CVS_RSH=ssh; export CVSROOT CVS_RSH初始化:CVS版本库的初始化。
cvs init一个项目的首次导入
cvs import -m "write some comments here" project_name vendor_tag release_tag
执行后:会将所有源文件及目录导入到/path/to/cvsroot/project_name目录下
vender_tag: 开发商标记
release_tag: 版本发布标记项目导出:将代码从CVS库里导出
cvs checkout project_name
cvs 将创建project_name目录,并将最新版本的源代码导出到相应目录中。这个checkout和Virvual SourceSafe中的check out不是一个概念,相对于Virvual SourceSafe的check out是cvs update, check in是cvs commit。CVS的日常使用
注意:第一次导出以后,就不是通过cvs checkout来同步文件了,而是要进入刚才cvs checkout project_name导出的project_name目录下进行具体文件的版本同步(添加,修改,删除)操作。
将文件同步到最新的版本
cvs update
不制定文件名,cvs将同步所有子目录下的文件,也可以制定某个文件名/目录进行同步
cvs update file_name
最好每天开始工作前或将自己的工作导入到CVS库里前都要做一次,并养成“先同步 后修改”的习惯,和Virvual SourceSafe不同,CVS里没有文件锁定的概念,所有的冲突是在commit之前解决,如果你修改过程中,有其他人修改并commit到了CVS 库中,CVS会通知你文件冲突,并自动将冲突部分用
>>>>>>
content on cvs server
<<<<<<
content in your file
>>>>>>
标记出来,由你确认冲突内容的取舍。
版本冲突一般是在多个人修改一个文件造成的,但这种项目管理上的问题不应该指望由CVS来解决。确认修改写入到CVS库里
cvs commit -m "write some comments here" file_name注意:CVS的很多动作都是通过cvs commit进行最后确认并修改的,最好每次只修改一个文件。在确认的前,还需要用户填写修改注释,以帮助其他开发人员了解修改的原因。如果不用写-m "comments"而直接确认`cvs commit file_name` 的话,cvs会自动调用系统缺省的文字编辑器(一般是vi)要求你写入注释。
注释的质量很重要:所以不仅必须要写,而且必须写一些比较有意义的内容:以方便其他开发人员能够很好的理解
不好的注释,很难让其他的开发人员快速的理解:比如: -m "bug fixed" 甚至 -m ""
好的注释,甚至可以用中文: -m "在用户注册过程中加入了Email地址校验"修改某个版本注释:每次只确认一个文件到CVS库里是一个很好的习惯,但难免有时候忘了指定文件名,把多个文件以同样注释commit到CVS库里了,以下命令可以允许你修改某个文件某个版本的注释:
cvs admin -m 1.3:"write some comments here" file_name添加文件
创建好新文件后,比如:touch new_file
cvs add new_file
注意:对于图片,Word文档等非纯文本的项目,需要使用cvs add -kb选项按2进制文件方式导入(k表示扩展选项,b表示binary),否则有可能出现文件被破坏的情况
比如:
cvs add -kb new_file.gif
cvs add -kb readme.doc如果关键词替换属性在首次导入时设置错了怎么办?
cvs admin -kkv new_file.css然后确认修改并注释
cvs ci -m "write some comments here"删除文件
将某个源文件物理删除后,比如:rm file_name
cvs rm file_name
然后确认修改并注释
cvs ci -m "write some comments here"
以上面前2步合并的方法为:
cvs rm -f file_name
cvs ci -m "why delete file"
注意:很多cvs命令都有缩写形式:commit=>ci; update=>up; checkout=>co/get; remove=>rm;添加目录
cvs add dir_name查看修改历史
cvs log file_name
cvs history file_name查看当前文件不同版本的区别
cvs diff -r1.3 -r1.5 file_name
查看当前文件(可能已经修改了)和库中相应文件的区别
cvs diff file_name
cvs的web界面提供了更方便的定位文件修改和比较版本区别的方法,具体安装设置请看后面的cvsweb使用正确的通过CVS恢复旧版本的方法:
如果用cvs update -r1.2 file.name
这个命令是给file.name加一个STICK TAG: "1.2" ,虽然你的本意只是想将它恢复到1.2版本
正确的恢复版本的方法是:cvs update -p -r1.2 file_name >file_name
如果不小心已经加成STICK TAG的话:用cvs update -A 解决移动文件/文件重命名
cvs里没有cvs move或cvs rename,因为这两个操作是可以由先cvs remove old_file_name,然后cvs add new_file_name实现的。删除/移动目录
最方便的方法是让管理员直接移动,删除CVSROOT里相应目录(因为CVS一个项目下的子目录都是独立的,移动到$CVSROOT目录下都可以作为新的独立项目:好比一颗树,其实砍下任意一枝都能独立存活),对目录进行了修改后,要求其开发人员重新导出项目cvs checkout project_name 或者用cvs update -dP同步。项目发布导出不带CVS目录的源文件
做开发的时候你可能注意到了,每个开发目录下,CVS都创建了一个CVS/目录。里面有文件用于记录当前目录和CVS库之间的对应信息。但项目发布的时候你一般不希望把文件目录还带着含有CVS信息的CVS目录吧,这个一次性的导出过程使用cvs export命令,不过export只能针对一个TAG或者日期导出,比如:
cvs export -r release1 project_name
cvs export -D 20021023 project_name
cvs export -D now project_nameCVS Branch:项目多分支同步开发
确认版本里程碑:多个文件各自版本号不一样,项目到一定阶段,可以给所有文件统一指定一个阶段里程碑版本号,方便以后按照这个阶段里程碑版本号导出项目,同时也是项目的多个分支开发的基础。cvs tag release_1_0
开始一个新的里程碑:
cvs commit -r 2 标记所有文件开始进入2.x的开发注意:CVS里的revsion和软件包的发布版本可以没有直接的关系。但所有文件使用和发布版本一致的版本号比较有助于维护。
版本分支的建立
在开发项目的2.x版本的时候发现1.x有问题,但2.x又不敢用,则从先前标记的里程碑:release_1_0导出一个分支 release_1_0_patch
cvs rtag -b -r release_1_0 release_1_0_patch proj_dir一些人先在另外一个目录下导出release_1_0_patch这个分支:解决1.0中的紧急问题,
cvs checkout -r release_1_0_patch
而其他人员仍旧在项目的主干分支2.x上开发在release_1_0_patch上修正错误后,标记一个1.0的错误修正版本号
cvs tag release_1_0_patch_1如果2.0认为这些错误修改在2.0里也需要,也可以在2.0的开发目录下合并release_1_0_patch_1中的修改到当前代码中:
cvs update -j release_1_0_patch_1CVS的远程认证通过SSH远程访问CVS
使用cvs本身基于pserver的远程认证很麻烦,需要定义服务器和用户组,用户名,设置密码等,常见的登陆格式如下:
cvs -d :pserver:cvs_user_name@cvs.server.address:/path/to/cvsroot login
例子:
cvs -d :pserver:cvs@samba.org:/cvsroot login不是很安全,因此一般是作为匿名只读CVS访问的方式。从安全考虑,通过系统本地帐号认证并通过SSH传输是比较好的办法,通过在客户机的 /etc/profile里设置一下内容:
CVSROOT=:ext:$USER@cvs.server.address#port:/path/to/cvsroot CVS_RSH=ssh; export CVSROOT CVS_RSH
所有客户机所有本地用户都可以映射到CVS服务器相应同名帐号了。比如:
CVS服务器是192.168.0.3,上面CVSROOT路径是/home/cvsroot,另外一台开发客户机是192.168.0.4,如果 tom在2台机器上都有同名的帐号,那么从192.168.0.4上设置了:
export CVSROOT=:ext:tom@192.168.0.3:/home/cvsroot
export CVS_RSH=ssh
tom就可以直接在192.168.0.4上对192.168.0.3的cvsroot进行访问了(如果有权限的话)
cvs checkout project_name
cd project_name
cvs update
...
cvs commit
如果CVS所在服务器的SSH端口不在缺省的22,或者和客户端与CVS服务器端SSH缺省端口不一致,有时候设置了:
:ext:$USER@test.server.address#port:/path/to/cvsroot仍然不行,比如有以下错误信息:
ssh: test.server.address#port: Name or service not known
cvs [checkout aborted]: end of file from server (consult above messages if any)解决的方法是做一个脚本指定端口转向(不能使用alias,会出找不到文件错误):
创建一个/usr/bin/ssh_cvs文件,假设远程服务器的SSH端口是非缺省端口:34567
#!/bin/sh
/usr/bin/ssh -p 34567 "$@"
然后:chmod +x /usr/bin/ssh_cvs
并CVS_RSH=ssh_cvs; export CVS_RSH注意:port是指相应服务器SSH的端口,不是指cvs专用的pserver的端口
CVSWEB:提高文件浏览效率
CVSWEB就是CVS的WEB界面,可以大大提高程序员定位修改的效率:使用的样例可以看:http://www.freebsd.org/cgi/cvsweb.cgi
CVSWEB的下载:CVSWEB从最初的版本已经演化出很多功能界面更丰富的版本,这个是我个人感觉安装设置比较方便的:
原先在:http://www.spaghetti-code.de/software/linux/cvsweb/,但目前已经删除,目前仍可以在本站下载CVSWEB,其实最近2年FreeBSD的CVSWeb项目已经有了更好的发展吧,而当初没有用FreeBSD那个版本主要就是因为没有彩色的文件Diff功能。
下载解包:
tar zxf cvsweb.tgz
把配置文件cvsweb.conf放到安全的地方(比如和apache的配置放在同一个目录下),
修改:cvsweb.cgi让CGI找到配置文件:
$config = $ENV{'CVSWEB_CONFIG'} || '/path/to/apache/conf/cvsweb.conf';转到/path/to/apache/conf下并修改cvsweb.conf:
修改CVSROOT路径设置:
%CVSROOT = (
'Development' => '/path/to/cvsroot', #<==修改指向本地的CVSROOT
);
缺省不显示已经删除的文档:
"hideattic" => "1",#<==缺省不显示已经删除的文档
在配置文件cvsweb.conf中还可以定制页头的描述信息,你可以修改$long_intro成你需要的文字
CVSWEB可不能随便开放给所有用户,因此需要使用WEB用户认证:
先生成 passwd:
/path/to/apache/bin/htpasswd -c cvsweb.passwd user修改httpd.conf: 增加
<Directory "/path/to/apache/cgi-bin/cvsweb/">
AuthName "CVS Authorization"
AuthType Basic
AuthUserFile /path/to/cvsweb.passwd
require valid-user
</Directory>CVS TAGS: $Id: cvs_card.html,v 1.5 2003/03/09 08:41:46 chedong Exp $
将$Id: cvs_card.html,v 1.9 2003/11/09 07:57:11 chedong Exp $ 加在程序文件开头的注释里是一个很好的习惯,cvs能够自动解释更新其中的内容成:file_name version time user_name 的格式,比如:cvs_card.txt,v 1.1 2002/04/05 04:24:12 chedong Exp,可以这些信息了解文件的最后修改人和修改时间
几个常用的缺省文件:default.php<?php/* * Copyright (c) 2002 Company Name. * $Header: /home/cvsroot/tech/cvs_card.html,v 1.9 2003/11/09 07:57:11 chedong Exp $ */?>====================================Default.java: 注意文件头一般注释用 /* 开始 JAVADOC注释用 /** 开始的区别/* * Copyright (c) 2002 MyCompany Name. * $Header: /home/cvsroot/tech/cvs_card.html,v 1.9 2003/11/09 07:57:11 chedong Exp $ */package com.mycompany;import java.;/** * comments here */public class Default { /** * Comments here * @param * @return */ public toString() { }}====================================default.pl:#!/usr/bin/perl -w# Copyright (c) 2002 Company Name.# $Header: /home/cvsroot/tech/cvs_card.html,v 1.9 2003/11/09 07:57:11 chedong Exp $# file comments hereuse strict;CVS vs VSS
CVS没有文件锁定模式,VSS在check out同时,同时记录了文件被导出者锁定。CVS的update和commit, VSS是get_lastest_version和check in
对应VSS的check out/undo check out的CVS里是edit和unedit
在CVS中,标记自动更新功能缺省是打开的,这样也带来一个潜在的问题,就是不用-kb方式添加binary文件的话在cvs自动更新时可能会导致文件失效。
$Header: /home/cvsroot/tech/cvs_card.html,v 1.5 2003/03/09 08:41:46 chedong Exp $ $Date: 2003/11/09 07:57:11 $这样的标记在Virsual SourceSafe中称之为Keyword Explaination,缺省是关闭的,需要通过OPITION打开,并指定需要进行源文件关键词扫描的文件类型:*.txt,*.java, *.html...
对于Virsual SourceSafe和CVS都通用的TAG有:
$Header: /home/cvsroot/tech/cvs_card.html,v 1.5 2003/03/09 08:41:46 chedong Exp $
$Author: chedong $
$Date: 2003/11/09 07:57:11 $
$Revision: 1.9 $我建议尽量使用通用的关键词保证代码在CVS和VSS都能方便的跟踪。
WinCVS
下载:cvs Windows客户端:目前稳定版本为1.2
http://cvsgui.sourceforge.net
ssh Windows客户端
http://www.networksimplicity.com/openssh/安装好以上2个软件以后:
WinCVS客户端的admin==>preference设置
1 在general选单里
设置CVSROOT: username@192.168.0.123:/home/cvsroot
设置Authorization: 选择SSH server2 Port选单里
钩上:check for alternate rsh name
并设置ssh.exe的路径,缺省是装在 C:\Program Files\NetworkSimplicity\ssh\ssh.exe然后就可以使用WinCVS进行cvs操作了,所有操作都会跳出命令行窗口要求你输入服务器端的认证密码。
当然,如果你觉得这样很烦的话,还有一个办法就是生成一个没有密码的公钥/私钥对,并设置CVS使用基于公钥/私钥的SSH认证(在general 选单里)。
可以选择的diff工具:examdiff
下载:
http://www.prestosoft.com/examdiff/examdiff.htm
还是在WinCVS菜单admin==>preference的WinCVS选单里
选上:Externel diff program
并设置diff工具的路径,比如:C:\Program Files\ed16i\ExamDiff.exe
在对文件进行版本diff时,第一次需要将窗口右下角的use externel diff选上。基于CVSTrac的小组开发环境搭建
作为一个小组级的开发环境,版本控制系统和BUG跟踪系统等都涉及到用户认证部分。如何方便的将这些系统集成起来是一个非常困难的事情,毕竟我们不能指望 Linux下有像Source Offsite那样集成度很高的版本控制/BUG跟踪集成系统。我个人是很反对使用pserver模式的远程用户认证的,但如果大部分组员使用WINDOWS客户端进行开发的话,总体来说使用 CVSROOT/passwd认证还是很难避免的,但CVS本身用户的管理比较麻烦。本来我打算自己用perl写一个管理界面的,直到我发现了 CVSTrac:一个基于WEB界面的BUG跟踪系统,它外挂在CVS系统上的BUG跟踪系统,其中就包括了WEB界面的CVSROOT/passwd文件的管理,甚至还集成了WIKIWIKI讨论组功能。
这里首先说一下CVS的pserver模式下的用户认证,CVS的用户认证服务是基于inetd中的:
cvspserver stream tcp nowait apache /usr/bin/cvs cvs --allow-root=/home/cvsroot pserver
一般在2401端口(这个端口号很好记:49的平方)CVS用户数据库是基于CVSROOT/passwd文件,文件格式:
[username]:[crypt_password]:[mapping_system_user]
由于密码都用的是UNIX标准的CRYPT加密,这个passwd文件的格式基本上是apache的htpasswd格式的扩展(比APACHE的 PASSWD文件多一个系统用户映射字段),所以这个文件最简单的方法可以用
apache/bin/htpasswd -b myname mypassword
创建。注意:通过htpasswd创建出来的文件会没有映射系统用户的字段
例如:
new:geBvosup/zKl2
setup:aISQuNAAoY3qw
test:hwEpz/BX.rEDU映射系统用户的目的在于:你可以创建一个专门的CVS服务帐号,比如用apache的运行用户apache,并将/home/cvsroot目录下的所有权限赋予这个用户,然后在passwd文件里创建不同的开发用户帐号,但开发用户帐号最后的文件读写权限都映射为apache用户,在SSH模式下多个系统开发用户需要在同一个组中才可以相互读写CVS库中的文件。
进一步的,你可以将用户分别映射到apache这个系统用户上。
new:geBvosup/zKl2:apache
setup:aISQuNAAoY3qw:apache
test:hwEpz/BX.rEDU:apacheCVSTrac很好的解决了CVSROOT/passwd的管理问题,而且包含了BUG跟踪报告系统和集成WIKIWIKI交流功能等,使用的 CGI方式的安装,并且基于GNU Public License:
在inetd里加入cvspserver服务:
cvspserver stream tcp nowait apache /usr/bin/cvs cvs --allow-root=/home/cvsroot pserverxietd的配置文件:%cat cvspserver
service cvspserver
{
disable = no
socket_type = stream
wait = no
user = apache
server = /usr/bin/cvs
server_args = -f --allow-root=/home/cvsroot pserver
log_on_failure += USERID
}注意:这里的用户设置成apache目的是和/home/cvsroot的所有用户一致,并且必须让这个这个用户对/home/cvsroot/下的 CVSROOT/passwd和cvstrac初始化生成的myproj.db有读取权限。
安装过程下载:可以从http://www.cvstrac.org 下载
我用的是已经在Linux上编译好的应用程序包:cvstrac-1.1.2.bin.gz,
%gzip -d cvstrac-1.1.2.bin.gz
%chmod +x cvstrac-1.1.2.bin
#mv cvstarc-1.1.1.bin /usr/bin/cvstrac
如果是从源代码编译:
从 http://www.sqlite.org/download.html 下载SQLITE的rpm包:
rpm -i sqlite-devel-2.8.6-1.i386.rpm
从 ftp://ftp.cvstrac.org/cvstrac/ 下载软件包
解包,假设解包到/home/chedong/cvstrac-1.1.2下,并规划将cvstrac安装到/usr/local/bin目录下, cd /home/chedong/cvstrac-1.1.2 编辑linux-gcc.mk:
修改:
SRCDIR = /home/chedong/cvstrac-1.1.2
INSTALLDIR = /usr/local/bin
然后
mv linux-gcc.mk Makefile
make
#make install
初始化cvstrac数据库:假设数据库名是 myproj
在已经装好的CVS服务器上(CVS库这时候应该已经是初始化好了,比如:cvs init初始化在/home/cvsroot里),运行一下
%cvstrac init /home/cvsroot myproj
运行后,/home/cvsroot里会有一个的myproj.db库,使用CVSTRAC服务,/home/cvsroot/myproj.db /home/cvsroot/CVSROOT/readers /home/cvsroot/CVSROOT/writers /home/cvsroot/CVSROOT/passwd这几个文件对于web服务的运行用户应该是可写的,在RedHat8上,缺省就有一个叫 apache用户和一个apache组,所以在httpd.conf文件中设置了用apache用户运行web服务:
User apache
Group apache,
然后设置属于apache用户和apache组
#chown -R apache:apache /home/cvsroot
-rw-r--r-- 1 apache apache 55296 Jan 5 19:40 myproj.db
drwxrwxr-x 3 apache apache 4096 Oct 24 13:04 CVSROOT/
drwxrwxr-x 2 apache apache 4096 Aug 30 19:47 some_proj/
此外还在/home/cvsroot/CVSROOT中设置了:
chmod 664 readers writers passwd在apche/cgi-bin目录中创建脚本cvstrac:
#!/bin/sh
/usr/bin/cvstrac cgi /home/cvsroot
设置脚本可执行:
chmod +x /home/apache/cgi-bin/cvstrac从 http://cvs.server.address/cgi-bin/cvstrac/myproj 进入管理界面
缺省登录名:setup 密码 setup
对于一般用户可以从:
http://cvs.server.address/cgi-bin/cvstrac/myproj
在setup中重新设置了CVSROOT的路径后,/home/cvsroot
如果是初次使用需要在/home/cvsroot/CVSROOT下创建passwd, readers, writers文件
touch passwd readers writers
然后设置属于apache用户,
chown apache.apache passwd readers writers
这样使用setup用户创建新用户后会同步更新CVSROOT/passwd下的帐号修改登录密码,进行BUG报告等,
更多使用细节可以在使用中慢慢了解。
对于前面提到的WinCVS在perference里设置:
CVSROOT栏输入:username@ip.address.of.cvs:/home/cvsroot
Authenitication选择:use passwd file on server side
就可以了从服务器上进行CVS操作了。
CVS的用户权限管理
CVS的权限管理分2种策略:
基于系统文件权限的系统用户管理:适合多个在Linux上使用系统帐号的开发人员进行开发。
基于CVSROOT/passwd的虚拟用户管理:适合多个在Windows平台上的开发人员将帐号映射成系统帐号使用。
为什么使用apache/apache用户?首先RedHat8中缺省就有了,而且使用这个用户可以方便通过cvstrac进行WEB管理。
chown -R apache.apache /home/cvsroot
chmod 775 /home/cvsrootLinux上通过ssh连接CVS服务器的多个开发人员:通过都属于apache组实现文件的共享读写
开发人员有开发服务器上的系统帐号:sysuser1 sysuser2,设置让他们都属于apache组,因为通过cvs新导入的项目都是对组开放的:664权限的,这样无论那个系统用户导入的项目文件,只要文件的组宿主是apache,所有其他同组系统开发用户就都可以读写;基于ssh远程认证的也是一样。
apache(system group)
/ | \
sysuser1 sysuser2 sysuser3
Windows上通过cvspserver连接CVS服务器的多个开发人员:通过在passwd文件种映射成 apache用户实现文件的共享读写
他们的帐号通过CVSROOT/passwd和readers writers这几个文件管理;通过cvstrac设置所有虚拟用户都映射到apache用户上即可。
apache(system user)
/ | \
windev1 windev2 windev3利用CVS WinCVS/CVSWeb/CVSTrac 构成了一个相对完善的跨平台工作组开发版本控制环境。
相关资源:
CVS HOME:
http://www.cvshome.orgCVS FAQ:
http://www.loria.fr/~molli/cvs-index.html
CVS--并行版本系统
http://www.soforge.com/cvsdoc/zh_CN/book1.htmlCVS 免费书:
http://cvsbook.red-bean.com/CVS命令的速查卡片 refcards.com/refcards/cvs/
WinCVS:
http://cvsgui.sourceforge.net/CVSTrac: A Web-Based Bug And Patch-Set Tracking System For CVS
http://www.cvstrac.orgStatCVS:基于CVS的代码统计工具:按代码量,按开发者的统计表等
http://sourceforge.net/projects/statcvs
如何在WEB开发中规划CVS上:在Google上查 "cvs web development"
http://ccm.redhat.com/bboard-archive/cvs_for_web_development/index.html一些集成了CVS的IDE环境:
Eclipse
Magic C++再编辑
引用通告
TrackBack URL for this entry:
如果您想引用这篇文章到您的Blog,
请复制下面的链接,并放置到您发表文章的相应界面中。
http://www.chedong.com/cgi-bin/mt/trackback.cgi/1003.1413112852mysql数据库优化
xiaoningln 发布于 2008-06-30 18:23:55
第一:
1:磁盘寻道能力,以高速硬盘(7200转/秒),理论上每秒寻道7200次.这是没有办法改变的,优化的方法是----用多个硬盘,或者把数据分散存储.
2:硬盘的读写速度,这个速度非常的快,这个更容易解决--可以从多个硬盘上并行读写.
3:cpu.cpu处理内存中的数据,当有相对内存较小的表时,这是最常见的限制因素.
4:内存的限制.当cpu需要超出适合cpu缓存的数据时,缓存的带宽就成了内存的一个瓶颈---不过现在内存大的惊人,一般不会出现这个问题.
第二:
1:调节服务器参数
用shell>mysqld-help这个命令声厂一张所有mysql选项和可配置变量的表.输出以下信息:
possible variables for option--set-variable(-o) are:
back_log current value:5 //要求mysql能有的连接数量.back_log指出在mysql暂停接受连接的时间内有多少个连接请求可以被存在堆栈中
connect_timeout current value:5 //mysql服务器在用bad handshake(不好翻译)应答前等待一个连接的时间
delayed_insert_timeout current value:200 //一个insert delayed在终止前等待insert的时间
delayed_insert_limit current value:50 //insert delayed处理器将检查是否有任何select语句未执行,如果有,继续前执行这些语句
delayed_queue_size current value:1000 //为insert delayed分配多大的队
flush_time current value:0 //如果被设置为非0,那么每个flush_time 时间,所有表都被关闭
interactive_timeout current value:28800 //服务器在关上它之前在洋交互连接上等待的时间
join_buffer_size current value:131072 //用与全部连接的缓冲区大小
key_buffer_size current value:1048540 //用语索引块的缓冲区的大小,增加它可以更好的处理索引
lower_case_table_names current value:0 //
long_query_time current value:10 //如果一个查询所用时间大于此时间,slow_queried计数将增加
max_allowed_packet current value:1048576 //一个包的大小
max_connections current value:300 //允许同时连接的数量
max_connect_errors current value:10 //如果有多于该数量的中断连接,将阻止进一步的连接,可以用flush hosts来解决
max_delayed_threads current value:15 //可以启动的处理insert delayed的数量
max_heap_table_size current value:16777216 //
max_join_size current value:4294967295 //允许读取的连接的数量
max_sort_length current value:1024 //在排序blob或者text时使用的字节数量
max_tmp_tables current value:32 //一个连接同时打开的临时表的数量
max_write_lock_count current value:4294967295 //指定一个值(通常很小)来启动mysqld,使得在一定数量的write锁定之后出现read锁定
net_buffer_length current value:16384 //通信缓冲区的大小--在查询时被重置为该大小
query_buffer_size current value:0 //查询时缓冲区大小
record_buffer current value:131072 //每个顺序扫描的连接为其扫描的每张表分配的缓冲区的大小
sort_buffer current value:2097116 //每个进行排序的连接分配的缓冲区的大小
table_cache current value:64 //为所有连接打开的表的数量
thread_concurrency current value:10 //
tmp_table_size current value:1048576 //临时表的大小
thread_stack current value:131072 //每个线程的大小
wait_timeout current value:28800 //服务器在关闭它3之前的一个连接上等待的时间
根据自己的需要配置以上信息会对你帮助.
第三:
1:如果你在一个数据库中创建大量的表,那么执行打开,关闭,创建(表)的操作就会很慢. 2:mysql使用内存
a: 关键字缓存区(key_buffer_size)由所有线程共享
b: 每个连接使用一些特定的线程空间.一个栈(默认为64k,变量thread_stack),一个连接缓冲区(变量net_buffer_length)和 一个结果缓冲区(net_buffer_length).特定情况下,连接缓冲区和结果缓冲区被动态扩大到max_allowed_packet.
c:所有线程共享一个基存储器
d:没有内存影射
e:每个做顺序扫描的请求分配一个读缓冲区(record_buffer)
f:所有联结均有一遍完成并且大多数联结甚至可以不用一个临时表完成.最临时的表是基于内存的(heap)表
g:排序请求分配一个排序缓冲区和2个临时表
h:所有语法分析和计算都在一个本地存储器完成
i:每个索引文件只被打开一次,并且数据文件为每个并发运行的线程打开一次
j:对每个blob列的表,一个缓冲区动态的被扩大以便读入blob值
k:所有正在使用的表的表处理器被保存在一个缓冲器中并且作为一个fifo管理.
l:一个mysqladmin flush-tables命令关闭所有不在使用的表并且在当前执行的线程结束时标记所有在使用的表准备关闭
3:mysql锁定表
mysql中所有锁定不会成为死锁. wirte锁定: mysql的锁定原理:a:如果表没有锁定,那么锁定;b否则,把锁定请求放入写锁定队列中
read锁定: mysql的锁定原理:a:如果表没有锁定,那么锁定;b否则,把锁定请求放入读锁定队列中
有时候会在一个表中进行很多的select,insert操作,可以在一个临时表中插入行并且偶尔用临时表的记录更新真正的表
a:用low_priority属性给一个特定的insert,update或者delete较低的优先级
b:max_write_lock_count指定一个值(通常很小)来启动mysqld,使得在一定数量的write锁定之后出现read锁定
c:通过使用set sql_low_priority_updates=1可以从一个特定的线程指定所有的更改应该由较低的优先级完成
d:用high_priority指定一个select
e:如果使用insert....select....出现问题,使用myisam表------因为它支持因为它支持并发的select和insert
4:最基本的优化是使数据在硬盘上占据的空间最小.如果索引做在最小的列上,那么索引也最小.实现方法:
a:使用尽可能小的数据类型
b:如果可能,声明表列为NOT NULL.
c:如果有可能使用变成的数据类型,如varchar(但是速度会受一定的影响)
d:每个表应该有尽可能短的主索引 e:创建确实需要的索引
f:如果一个索引在头几个字符上有唯一的前缀,那么仅仅索引这个前缀----mysql支持在一个字符列的一部分上的索引
g:如果一个表经常被扫描,那么试图拆分它为更多的表
四步:
1:索引的使用,索引的重要性就不说了,功能也不说了,只说怎么做. 首先要明确所有的mysql索引(primary,unique,index)在b树中有存储.索引主要用语:
a:快速找到where指定条件的记录 b:执行联结时,从其他表检索行 c:对特定的索引列找出max()和min()值
d:如果排序或者分组在一个可用键的最前面加前缀,排序或分组一个表
e:一个查询可能被用来优化检索值,而不用访问数据文件.如果某些表的列是数字型并且正好是某个列的前缀,为了更快,值可以从索引树中取出
2:存储或者更新数据的查询速度 grant的执行会稍稍的减低效率.
mysql的函数应该被高度的优化.可以用benchmark(loop_count,expression)来找出是否查询有问题
select的查询速度:如果想要让一个select...where...更快,我能想到的只有建立索引.可以在一个表上运行myisamchk- -analyze来更好的优化查询.可以用myisamchk--sort-index--sort-records=1来设置用一个索引排序一个索引和 数据.
3:mysql优化where子句
3.1:删除不必要的括号:
((a AND b) AND c OR (((a AND b) AND (a AND d))))>(a AND b AND c) OR (a AND b AND c AND d)
3.2:使用常数
(ab>5 AND b=c AND a=5
3.3:删除常数条件
(b>=5 AND b=5) OR (b=6 AND 5=5) OR (b=100 AND 2=3) >b=5 OR b=6
3.4:索引使用的常数表达式仅计算一次
3.5:在一个表中,没有一个where的count(*)直接从表中检索信息
3.6:所有常数的表在查询中在任何其他表之前读出
3.7:对外联结表最好联结组合是尝试了所有可能性找到的
3.8:如果有一个order by字句和一个不同的group by子句或者order by或者group by包含不是来自联结的第一个表的列,那么创建一个临时表
3.9:如果使用了sql_small_result,那么msyql使用在内存中的一个表
3.10:每个表的索引给查询并且使用跨越少于30%的行的索引.
3.11在每个记录输出前,跳过不匹配having子句的行
4:优化left join
在mysql中 a left join b按以下方式实现
a:表b依赖于表a
b:表a依赖于所有用在left join条件的表(除了b)
c:所有left join条件被移到where子句中
d:进行所有的联结优化,除了一个表总是在所有他依赖的表后读取.如果有一个循环依赖,那么将发生错误
e:进行所有的标准的where优化 f:如果在a中有一行匹配where子句,但是在b中没有任何匹配left join条件,那么,在b中生成的所有设置为NULL的一行
g:如果使用left join来找出某些表中不存在的行并且在where部分有column_name IS NULL测试(column_name为NOT NULL列).那么,mysql在它已经找到了匹配left join条件的一行后,将停止在更多的行后寻找
5:优化limit
a:如果用limit只选择一行,当mysql需要扫描整个表时,它的作用相当于索引
b:如果使用limit#与order by,mysql如果找到了第#行,将结束排序,而不会排序正个表
c:当结合limit#和distinct时,mysql如果找到了第#行,将停止
d:只要mysql已经发送了第一个#行到客户,mysql将放弃查询
e:limit 0一直会很快的返回一个空集合.
f:临时表的大小使用limit#计算需要多少空间来解决查询
6:优化insert
插入一条记录的是由以下构成:
a:连接(3)
b:发送查询给服务器(2)
c:分析查询(2)
d:插入记录(1*记录大小)
e:插入索引(1*索引)
f:关闭(1)
以上数字可以看成和总时间成比例
改善插入速度的一些方法:
6.1:如果同时从一个连接插入许多行,使用多个值的insert,这比用多个语句要快
6.2:如果从不同连接插入很多行,使用insert delayed语句速度更快
6.3: 用myisam,如果在表中没有删除的行,能在select:s正在运行的同时插入行
6.4: 当从一个文本文件装载一个表时,用load data infile.这个通常比insert快20 倍
6.5:可以锁定表然后插入--主要的速度差别是在所有insert语句完成后,索引缓冲区仅被存入到硬盘一次.一般与有不同的insert语句那样 多次存入要快.如果能用一个单个语句插入所有的行,锁定就不需要.锁定也降低连接的整体时间.但是对某些线程最大等待时间将上升.例如:
thread 1 does 1000 inserts
thread 2,3 and 4 does 1 insert
thread 5 does 1000 inserts
如果不使用锁定,2,3,4将在1和5之前完成.如果使用锁定,2,3,4,将可能在1和5之后完成.但是整体时间应该快40%.因为insert, update,delete操作在mysql中是很快的,通过为多于大约5次连续不断的插入或更新一行的东西加锁,将获得更好的整体性能.如果做很多一行 的插入,可以做一个lock tables,偶尔随后做一个unlock tables(大约每1000行)以允许另外的线程存取表.这仍然将导致获得好 的性能.load data infile对装载数据仍然是很快的.
为了对load data infile和insert得到一些更快的速度,扩大关键字缓冲区.
7优化update的速度
它的速度依赖于被更新数据的大小和被更新索引的数量
使update更快的另一个方法是推迟修改,然后一行一行的做很多修改.如果锁定表,做一行一行的很多修改比一次做一个快
8优化delete速度
删除一个记录的时间与索引数量成正比.为了更快的删除记录,可以增加索引缓存的大小 从一个表删除所有行比删除这个表的大部分要快的多
第五:
1:选择一种表类型 1.1静态myisam
这种格式是最简单且最安全的格式,它是磁盘格式中最快的.速度来自于数据能在磁盘上被找到的难易程度.当锁定有一个索引和静态格式的东西是,它很简 单,只是行长度乘以数量.而且在扫描一张表时,每次用磁盘读取来读入常数个记录是很容易的.安全性来源于如果当写入一个静态myisam文件时导致计算机 down掉,myisamchk很容易指出每行在哪里开始和结束,因此,它通常能收回所有记录,除了部分被写入的记录.在mysql中所有索引总能被重建
1.2动态myisam
这种格式每一行必须有一个头说明它有多长.当一个记录在更改期间变长时,它可以在多于一个位置上结束.能使用optimize tablename或 myisamchk整理一张表.如果在同一个表中有像某些varchar或者blob列那样存取/改变的静态数据,将动态列移入另外一个表以避免碎片.
1.2.1压缩myisam,用可选的myisampack工具生成
1.2.2内存
这种格式对小型/中型表很有用.对拷贝/创建一个常用的查找表到洋heap表有可能加快多个表联结,用同样数据可能要快好几倍时间.
select tablename.a,tablename2.a from tablename,tablanem2,tablename3 where
tablaneme.a=tablename2.a and tablename2.a=tablename3.a and tablename2.c!=0;
为了加速它,可以用tablename2和tablename3的联结创建一个临时表,因为用相同列(tablename1.a)查找.
CREATE TEMPORARY TABLE test TYPE=HEAP
SELECT
tablename2.a as a2,tablename3.a as a3
FROM
tablenam2,tablename3
WHERE
tablename2.a=tablename3.a and c=0;
SELECT tablename.a,test.a3 from tablename,test where tablename.a=test.a1;
SELECT tablename.a,test,a3,from tablename,test where tablename.a=test.a1 and ....;
1.3静态表的特点
1.3.1默认格式.用在表不包含varchar,blob,text列的时候
1.3.2所有的char,numeric和decimal列填充到列宽度
1.3.3非常快
1.3.4容易缓冲
1.3.5容易在down后重建,因为记录位于固定的位置
1.3.6不必被重新组织(用myisamchk),除非是一个巨量的记录被删除并且优化存储大小
1.3.7通常比动态表需要更多的存储空间
1.4动态表的特点
1.4.1如果表包含任何varchar,blob,text列,使用该格式
1.4.2所有字符串列是动态的
1.4.3每个记录前置一个位.
1.4.4通常比定长表需要更多的磁盘空间
1.4.5每个记录仅仅使用所需要的空间,如果一个记录变的很大,它按需要被分成很多段,这导致了记录碎片
1.4.6如果用超过行长度的信息更新行,行被分段.
1.4.7在系统down掉以后不好重建表,因为一个记录可以是多段
1.4.8对动态尺寸记录的期望行长度是3+(number of columns+7)/8+(number of char columns)+packed size of numeric columns+length of strings +(number of NULL columns+7)/8
对每个连接有6个字节的惩罚.无论何时更改引起记录的变大,都有一个动态记录被连接.每个新连接至少有20个字节,因此下一个变大将可能在同一个连接 中.如果不是,将有另外一个连接.可以用myisamchk -恶毒检查有多少连接.所有连接可以用myisamchk -r删除.
1.5压缩表的特点
1.5.1一张用myisampack实用程序制作的只读表.
1.5.2解压缩代码存在于所有mysql分发中,以便使没有myisampack的连接也能读取用myisampack压缩的表
1.5.3占据很小的磁盘空间
1.5.4每个记录被单独压缩.一个记录的头是一个定长的(1~~3个字节)这取决于表的最大记录.每列以不同的方式被压缩.一些常用的压缩类型是:
a:通常对每列有一张不同的哈夫曼表 b:后缀空白压缩 c:前缀空白压缩 d:用值0的数字使用1位存储
e:如果整数列的值有一个小范围,列使用最小的可能类型来存储.例如:如果所有的值在0到255之间,一个bigint可以作为一个tinyint存储
g:如果列仅有可能值的一个小集合,列类型被转换到enum h:列可以使用上面的压缩方法的组合
1.5.5能处理定长或动态长度的记录,去不能处理blob或者text列 1.5.6能用myisamchk解压缩
mysql能支持不同的索引类型,但一般的类型是isam,这是一个B树索引并且能粗略的为索引文件计算大小为(key_length+4)*0.67,在所有的键上的总和.
字符串索引是空白压缩的。如果第一个索引是一个字符串,它可将压缩前缀如果字符串列有很多尾部空白或是一个总部能甬道全长的varchar列,空白压缩使索引文件更小.如果很多字符串有相同的前缀.
1.6内存表的特点
mysql内部的heap表使用每偶溢出去的100%动态哈希并且没有与删除有关的问题.只能通过使用在堆表中的一个索引来用等式存取东西(通常用'='操作符)
堆表的缺点是:
1.6.1想要同时使用的所有堆表需要足够的额外内存
1.6.2不能在索引的一个部分搜索
1.6.3不能按顺序搜索下一个条目(即,使用这个索引做一个order by)
1.6.4mysql不能算出在2个值之间大概有多少行.这被优化器使用是用来决定使用哪个索引的,但是在另一个方面甚至不需要磁盘寻道
xml全收集|XML|XSL|W3C Schema|DTD |DOM|SAX|XPath|名称空间|RDBMS |Xlinks|
xiaoningln 发布于 2009-03-31 12:46:34
XML 技术资料列表
文章部分:
1. XML FAQ
一份关于 XML 的非常重要的文档。
2. XML Message 教程
http://www.javaworld.com/javaworld/jw-03-2001/jw-0302-xmlmessaging.html
http://www.javaworld.com/javaworld/jw-06-2001/jw-0622-xmlmessaging2.html
JavaWorld 上两篇关于 XML Message 的教程。
3. 为什么 XML 意味着 Java
http://www.xml.com/pub/a/1999/06/fuchs/fuchs.html
介绍 XML 与 Java 的关系。
4. Perl XML 快速起步
http://www.xml.com/pub/a/2001/04/18/perlxmlqstart1.html
http://www.xml.com/pub/a/2001/05/16/perlxml.html
http://www.xml.com/pub/a/2001/06/13/perlxml.html
介绍如何使用 Perl 做 XML 开发。
5. Perl 和 XML 犯了什么错?
http://www.xml.com/pub/a/2000/10/11/perlxml/index.html
讨论了 Perl 目前在做 XML 开发中还存在哪些不足。
6. 使用 Python 处理 XML
http://www.xml.com/pub/a/1999/12/xml99/python.html
介绍如何使用 Python 做 XML 开发。
7. 使用 C++ 做 XML 编程
http://www.xml.com/pub/a/1999/11/cplus/index.html
介绍如何使用 C++ 做 XML 开发。
8. LXXXII. XML 解析器的功能
http://www.php.net/manual/en/ref.xml.php
介绍如何使用 PHP 做 XML 开发
9. W3C XML Schema 使事情变得简单
http://www.xml.com/pub/a/2001/06/06/schemasimple.html
介绍如何避免设计 XML Schema 时的一些常见缺陷。
10. 便宜的 XML
http://www.xml.com/pub/a/2001/06/27/cheapxml.html
介绍在 Web 上大量可以免费使用的 XML 软件资源。
11. 实用国际化 (i18n)
http://www.xml.com/pub/a/2001/04/18/i18n.html
关于在 XML 开发中的国际化问题对 Tim Bray 的访谈。
12. 一个 XSLT 样式单和一个用来实现国际化 (i18n) 的 XML 词典
http://www-106.ibm.com/developerworks/web/library/wa-xslt/?dwzone=web
演示了一个实现站点 Web 页面国际化的策略。
13. JAXP -- 用词不当和修正
http://www.zdnet.com/enterprise/stories/main/0,10228,2766317,00.html
对 JAXP 规范的介绍和其今后发展的预测。
14. 实体与 XSLT
http://www.xml.com/pub/a/2001/03/14/trxml10.html
介绍在 XSLT 中如何使用实体 (Entities)
15. 处理指令与 XSLT
http://www.xml.com/pub/a/2000/08/09/xslt/xslt.html
介绍在 XSLT 中如何使用处理指令 (PI)。
16. HTML 和 XSLT
http://www.xml.com/pub/a/2000/08/30/xsltandhtml/index.html
介绍如何使用 HTML 作为 XSLT 的输入和输出。
17. XSLT 外科手术
http://www.xml.com/pub/a/2001/04/25/styleqanda.html
关于 XSLT 的一些问答。
18. XT 的未来
http://www.xml.com/pub/a/2000/06/07/deviant/index.html
介绍目前最快的 XSLT 引擎 -- XT 的发展状况。
19. XSLT 测试结果
http://www.xml.com/pub/a/2001/03/28/xsltmark/index.html
http://www.xml.com/pub/a/2001/03/28/xsltmark/results.html
最近一次 XSLT 测试的结果和评论。
20. XML 技术:一个成功的故事
http://www.xml.com/pub/a/2001/05/16/wrestle.html
做 XML 开发的一个实例。
21. 几部分的集成 -- XSLT,XLink 和 SVG
http://www.xml.com/pub/a/2000/03/22/style/index.html
介绍如何集成这几种 XML 应用。
22. OpenOffice 和 XML 的冒险
http://www.xml.com/pub/a/2001/02/07/openoffice.html
介绍了在 OpenOffice 中应用 XML 技术所做的大胆实践。
23. Jetspeed 中的 XML
http://www.xml.com/pub/a/2000/05/15/jetspeed/index.html
介绍了在 Jetspeed 项目中的 XML 应用。
24. Internet 脚本:Zope 和 XML-RPC
http://www.xml.com/pub/a/2000/01/xmlrpc/index.html
介绍如何在 Zope 中做 XML-RPC 开发。
25. Semantic Web
http://www.scientificamerican.com/2001/0501issue/0501berners-lee.html
Tim Berners-Lee 关于 Semantic Web 的定义。
26. Tim Berners-Lee 关于 W3C 的 Semantic Web 活动的访谈
http://www.xml.com/pub/a/2001/03/21/timbl.html
Tim Berners-Lee 关于 W3C 的 Semantic Web 活动的访谈。
27. 创建一个 Semantic Web
http://www.xml.com/pub/a/2001/03/07/buildingsw.html
介绍如何创建一个 Semantic Web (机器可读的 Web)。
28. 荒野中的 Dublin Core
http://www.xml.com/pub/a/2000/10/25/dublincore/dc8.html
对 Dublin Core 的介绍。
29. RSS:轻量的 Web 企业联合 (Syndication)
http://www.xml.com/pub/a/2000/07/17/syndication/rss.html
介绍了 RSS 的概念。
30. 学习 RELAX
http://www.xml.com/pub/a/2000/10/16/relax/index.html
一篇介绍 RELAX 的文章。
31. XQuery 是否是在重新发明轮子?
http://www.xml.com/pub/a/2001/02/28/deviant.html
关于 XQuery 的网上大讨论。
32. 直觉和二进制的 XML
http://www.xml.com/pub/a/2001/04/18/binaryXML.html
将 XML 编码为二进制格式以加快应用程序执行效率的讨论。
33. 一篇介绍 SOAP 历史的短文
http://www.xml.com/pub/a/2001/04/04/soap.html
一篇介绍 SOAP 历史的短文。
34. 理解 ebXML,UDDI 和 XML/EDI
http://www.xml.org/feature_articles/2000_1107_dutton.shtml
介绍用于电子商务的这三种技术的体系结构。
35. ebXML:到结束时仍然没有结束
http://www.xml.com/pub/a/2001/05/16/ebxml.html
关于 ebXML 的讨论。
36. 为什么 UDDI 将会成功
http://www.stencilgroup.com/ideas_scope_200104uddi.html
关于 UDDI 的 whitepaper。
37. 数据坩埚:使用 XML 创建 B2B 应用程序
http://www-106.ibm.com/developerworks/library/xml-b2b/index.html
介绍如何使用 XML 创建 B2B 应用程序。
38. 第 10 届国际 WWW 大会的报告
http://www.xml.com/pub/a/2001/05/09/www10/index.html
第 10 届国际 WWW 大会的报告
39. XML Schema 成为 W3C 的建议
http://www-106.ibm.com/developerworks/xml/library/x-schrec.html
关于 W3C 通过 XML Schema 建议的评述。
40. XML 已经不再是旧日模样
http://www.xml.com/pub/a/2001/02/28/eightytwenty.html
介绍了 XML 在 W3C 的最新发展动态。
41. 将混乱变为有序:管理 Web 项目
http://www.webtechniques.com/archives/2000/01/desi/
介绍如何管理一个 Web 项目。
42. 建立你的 Web 团队
http://www.webtechniques.com/archives/2001/01/berry/
介绍如何建立一个 Web 团队。
43. Jabber 中的 XML 消息传递
http://www.openp2p.com/pub/a/p2p/2000/10/06/jabber_xml.html?page=1
介绍在 Jabber 中如何使用 XML 做消息传递。
44. P3P 部署指南
http://www.w3.org/TR/2001/NOTE-p3pdeployment-20010510
W3C 的 P3P 部署指南。
45. 设计 JSP 定制标记库
http://www.onjava.com/pub/a/onjava/2000/12/15/jsp_custom_tags.html
介绍如何设计 JSP 定制标记库。
46. 创建一个 Semantic Web 站点
http://www.xml.com/pub/a/2001/05/02/semanticwebsite.html
介绍如何使用 RSS 创建一个 Semantic Web 站点。
47. XML 的状态:为什么个人同样重要
http://www.xml.com/pub/a/2001/05/30/stateofxml.html
介绍过去一年中 XML 的发展,强调除了大公司以外,个人的贡献依旧关键。
48. Web Services 体系结构概述
http://www-106.ibm.com/developerworks/library/w-ovr/?dwzone=components
IBM 的 Web Services 的体系结构概述。
49. XML 和脚本语言
http://www-106.ibm.com/developerworks/library/xml-perl/
使用 Perl 和其它脚本语言处理 XML 文档的教程。
50. W3C 与 XML 有关的活动
http://www.xml.com/pub/a/2001/01/03/w3c.html
介绍在 W3C 与 XML 有关的活动。
51. 一篇 SVG 的介绍
http://www.xml.com/pub/a/2001/03/21/svg.html
一篇介绍 SVG 的文章。
52. 使用 JSP 技术开发 XML 解决方案
http://java.sun.com/products/jsp/pdf/JSPXML.pdf
Sun 的使用 JSP 做 XML 开发的 whitepaper。
53. ebXML 包围了 SOAP
http://www.xml.com/pub/a/2001/04/04/ebXML.html
介绍了 ebXML 与 SOAP 的关系。
54. 分布式的 XML
http://www.xml.com/pub/a/2000/09/06/distributed.html
介绍 XML 在下一代 Web 中所扮演的角色。
55. Infoset 调查
http://www.xml.com/pub/a/2000/08/02/deviant/infoset.html
介绍什么是 XML Infoset 和它的作用。
56. TREX 基础
http://www.xml.com/pub/a/2001/04/11/trex.html
一篇介绍 TREX 的文章。
57. 菜单上的 XML 和 Java
http://www.java-pro.com/upload/free/features/javapro/2001/04apr01/dw0104/dw0104-1.asp
介绍如何使用 Xerces 和 Java 创建 XML 分级菜单。
58. 使 SOAP 离开 Java
http://www.java-pro.com/upload/free/features/javapro/2001/04apr01/prs0104/prs0104-1.asp
一篇介绍 Apache SOAP 的 HOWTO。
59. 选择你的 Java XML 解析器
http://www.xml-zone.com/articles/pm020101/pm020101-1.asp
对 Apache,Oracle 和 Sun 的 XML 解析器的比较分析。
60. 在 Open Source 运动的中心
http://www.xmlmag.com/upload/free/features/xml/2001/01jan01/sj0101xml/sj0101xml-1.asp
详细介绍了 XML 与 Open Source 运动密不可分的关系。
61. 做 Web 开发的一种更好的方式
http://www.xmlmag.com/upload/free/features/xml/2000/04fal00/kj0004/kj0004.asp
一篇介绍 Cocoon 的 HOWTO。
62. 使用 JSP 为 XML 服务
http://www.xmlmag.com/upload/free/features/xml/2000/04fal00/ww0004/ww0004.asp
介绍如何使用 JSP 做 XML 开发。
63. XLink 可以为你的应用程序做什么
http://www.xmlmag.com/upload/free/features/xml/2000/02spr00/bdspr00/bdspr00.asp
介绍 XLink 对于开发应用程序将起到的作用。
64. 推开 Web 的樊篱
http://www.xmlmag.com/upload/free/features/xml/2001/01jan01/kc0101xml/kc0101xml.asp
介绍如何使用 XSLT 扩展 XHTML 来创建复杂的界面。
65. SOAP FAQ
http://www.develop.com/soap/soapfaq.htm
关于 SOAP 的 FAQ。
66. 使用 W3C XSLT 规范
http://www.xml.com/pub/a/2001/06/06/xsltspec.html
介绍如何阅读 W3C 的 XSLT 规范,澄清一些容易搞混的术语。
67. 从 JSP 中与 XML 交互
http://www.xml-zone.com/articles/pm050401/pm050401-1.asp
介绍使用 JSP 做 XML 开发。
68. 在关系数据库中存储 XML
http://www.xml.com/pub/a/2001/06/20/databases.html?page=1
介绍了在几种主流关系数据库 Oracle,DB2,SQL Server,Sybase 中存储和检索 XML 数据的方法。
69. 经理的 XML
http://www.arbortext.com/Think_Tank/XML_Resources/XML_for_Managers/xml_for_managers.html
为软件经理们介绍采用 XML 的众多优点。
70. 使 SOAP 和 ebXML 开始工作
http://www.advisor.com/Articles.nsf/aid/DRUMR12
一篇介绍 SOAP 和 ebXML 的文章。
71. 实现 ebXML
http://www.gca.org/papers/xmleurope2001/papers/html/s18-2a.html
关于 ebXML 如何适应 OMG 工作组的座谈。
教程部分:
1. XSLT 教程,含有大量实例
http://www.xfront.com/xsl.html
2. XML Schema 教程,含有大量实例
http://www.xfront.com/xml-schema.html
3. XML Schema 最佳实践
http://www.xfront.com/BestPracticesHomepage.html
4. XML 教程
http://www.troubleshooters.com/tpromag/200103/200103.htm
5. DOM 教程
http://developerlife.com
6. SAX 教程
http://developerlife.com
7. 使用 XML 建立 B2B 和 B2C 应用程序
http://www.redbooks.ibm.com/redbooks/SG246104.html
IBM 关于 XML 在电子商务中应用的红皮书。
8. DocBook 权威指南
http://www.docbook.org/tdg/en/html/docbook.html
一本关于 DocBook 的经典著作。JAVA开发者最常去的20个英文网站
xiaoningln 发布于 2010-01-24 13:22:04
JAVA开发者最常去的20个英文网站
1.[http://www.javaalmanac.com] – Java开发者年鉴一书的在线版本. 要想快速查到某种Java技巧的用法及示例代码, 这是一个不错的去处.
2.[http://www.onjava.com] – O’Reilly的Java网站. 每周都有新文章.
3.[http://java.sun.com] – 官方的Java开发者网站 – 每周都有新文章发表.
4.[http://www.developer.com/java] – 由Gamelan.com 维护的Java技术文章网站. 5.[http://www.java.net] – Sun公司维护的一个Java社区网站.
6.[http://www.builder.com] – Cnet的Builder.com网站 – 所有的技术文章, 以Java为主. 7.[http://www.ibm.com/developerworks/java] – IBM的Developerworks技术网站; 这是其中的Java技术主页.
8.[http://www.javaworld.com] – 最早的一个Java站点. 每周更新Java技术文章. 9.[http://www.devx.com/java] – DevX维护的一个Java技术文章网站.
10.[http://www.fawcette.com/javapro] – JavaPro在线杂志网站.
11.[http://www.sys-con.com/java] – Java Developers Journal的在线杂志网站. 12.[http://www.javadesktop.org] – 位于Java.net的一个Java桌面技术社区网站. 13.[http://www.theserverside.com] – 这是一个讨论所有Java服务器端技术的网站. 14.[http://www.jars.com] – 提供Java评论服务. 包括各种framework和应用程序. 15.[http://www.jguru.com] – 一个非常棒的采用Q&A形式的Java技术资源社区. 16.[http://www.javaranch.com] – 一个论坛,得到Java问题答案的地方,初学者的好去处。 17.[http://www.ibiblio.org/javafaq/javafaq.html] – comp.lang.java的FAQ站点 – 收集了来自comp.lang.java新闻组的问题和答案的分类目录.
18.[http://java.sun.com/docs/books/tutorial/] – 来自SUN公司的官方Java指南 – 对于了解几乎所有的java技术特性非常有帮助.
19.[http://www.javablogs.com] – 互联网上最活跃的一个Java Blog网站. 20.[http://java.about.com/] – 来自About.com的Java新闻和技术文章网站.注册表下的HKEY_CURRENT_USER和HKEY_LOCAL_MACHINE区别
takiro 发布于 2010-06-02 23:32:47
由于工作内容的原因,要写注册表,所以就立马恶补下注册表的知识
1、HKEY_CURRENT_USER
包含当前登录用户的配置信息的根目录。用户文件夹、屏幕颜色和“控制面板”设置均存储在此处。该信息被称为用户配置文件。
2、HKEY_LOCAL_MACHINE
包含针对该计算机(对于任何用户)的配置信息。主要由HARDWARE、SAM、SECURITY、SOFTWARE、SYSTEM等项组成:
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 11648
- 日志数: 23
- 图片数: 1
- 文件数: 2
- 书签数: 1
- 建立时间: 2008-12-24
- 更新时间: 2016-05-02
