
-
详细记录一下JAVA应用程序服务出现内存溢出的利用MAT分析过程
2018-03-05 18:24:13
说明:本次以系统在并发情况下后台出现java.lang.OutOfMemoryError:GC overhead limit exceeded错误来分析整个性能测试分析的一个过程。中间用到的工具包括了:loadrunner 、AWR 报告、jstack、MAT等
1、使用LoadRunner进行50用户的并发测试,先进行2分钟的预热测试,为了系统能用到缓存的地方都先进行缓存,然后进行5分钟的施压测试。
2、在施压5分钟的后半段时间,应用后台开始出现了“java.lang.OutOfMemoryError”的错误信息;
具体错误信息如下:
3、既然出现了OutOfMemoryError的错误信息,一般出现该错误信息都是堆内存的溢出,所以我们需要考虑捕捉一下堆内存的信息,捕捉堆内存的信息有2种方式:
3.1 通过在应用中间件(weblogic、tomcat 等)上加入相应的JVM参数,具体参数如下(加入参数后,系统在出现OutOfMemoryError错误的时候便会自动生成类似java_pid9388.hprof的这样一个文件):
-Xloggc:D:\heapdump\managed1_gc.log
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=D:\heapdump
3.2 使用JDK自带的JMAP工具,具体使用方法如下:
第一步:先使用jps.exe命令找到相应的java进程ID,一般找Server PID的;
第二步:jmap.exe-dump:format=b,file=d:\dump\java_pid(第一步查询到的PID号).hprof PID(该地方一定要空格后跟着相应的PID号)
如果只dump heap中的存活对象,则加上选项-live,如下:
jmap.exe -dump:live,format=b,file=/path/heap_pid. hprof 进程ID(PID)
4.使用MAT工具来分析生成的hprof文件内容
4.1打开需要分析的hprof文件:
4.2 在Overview(概述)界面利用饼图的摘要信息来分析哪些对象比较占内存
4.3分析Action部分内容:
4.3.1点击“Leak Suspects”后的结果如下:
4.3.2 在怀疑问题的第点Details
4.3.3查看有问题的的类所引用的所有对象。此时使用鼠标左键点击,然后弹出菜单中进行如下选择:List Objects->with outgoing references
(说明:
图中的Shallow Heap(浅堆):指对象自身占用内存的大小,不包括它引用的对象。
图中的 Retained Heap(深堆):指当前对象大小+当前对象可直接或间接引用到对象的大小总和
)
此时可以点击鼠标左键,将sql语句的内容进行拷贝.
此时就找到了问题。
-
【JAVA 工具】jstack简单使用,定位死循环、线程阻塞、死锁等问题
2018-03-05 17:24:48
转载地址:http://www.cnblogs.com/chenpi/p/5377445.html
当我们运行java程序时,发现程序不动,但又不知道是哪里出问题时,可以使用JDK自带的jstack工具去定位;
废话不说,直接上例子吧,在window平台上的;
死循环
写个死循环的程序如下:

package concurrency; public class Test { public static void main(String[] args) throws InterruptedException { while (true) { } } }
先运行以上程序,程序进入死循环;
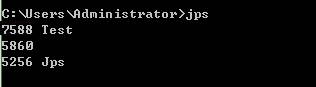
打开cmd,输入jps命令,jps很简单可以直接显示java进程的pid,如下为7588:
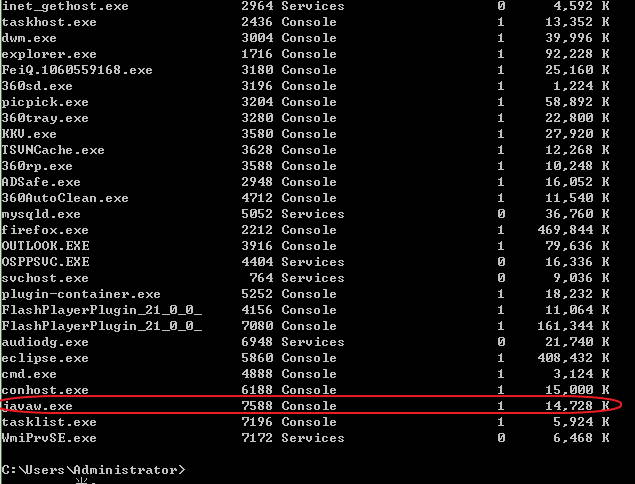
或者输入tasklist,找到javaw.exe的PID,如下为7588:
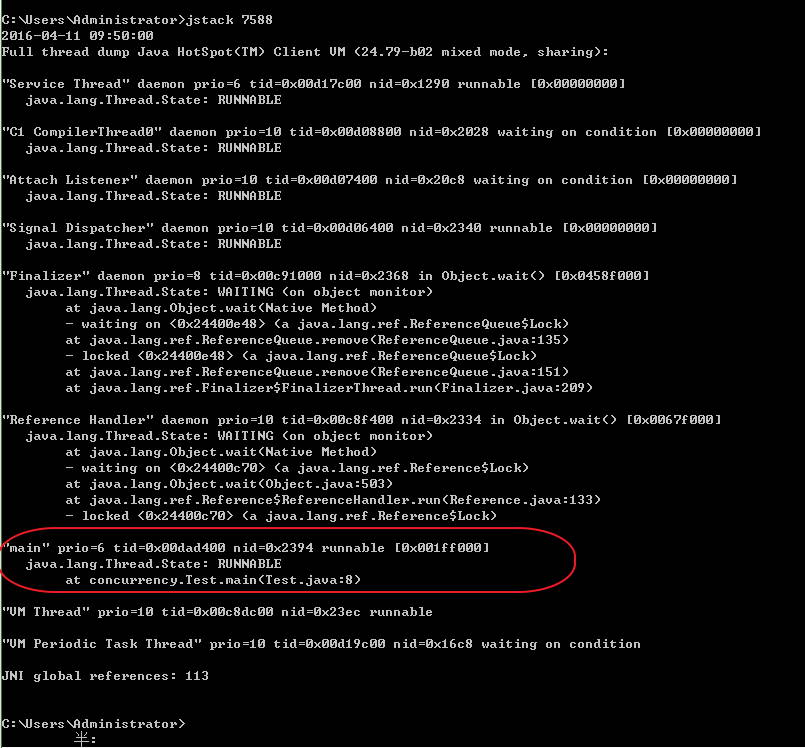
输入jstack 7588命令,找到跟我们自己代码相关的线程,如下为main线程,处于runnable状态,在main方法的第八行,也就是我们死循环的位置:
Object.wait()情况
写个小程序,调用wait使其中一线程等待,如下:
package concurrency; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; class TestTask implements Runnable { @Override public void run() { synchronized (this) { try { //等待被唤醒 wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class Test { public static void main(String[] args) throws InterruptedException { ExecutorService ex = Executors.newFixedThreadPool(1); ex.execute(new TestTask()); } }
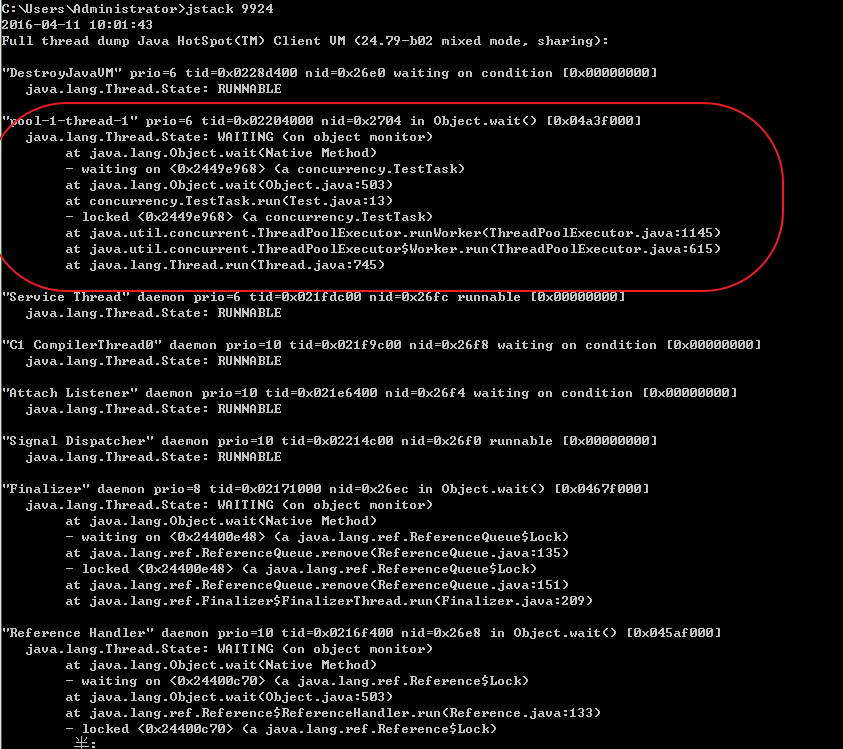
同样我们先找到javaw.exe的PID,再利用jstack分析该PID,很快我们就找到了一个线程处于WAITING状态,在Test.java文件13行处,正是我们调用wait方法的地方,说明该线程目前还没等到notify,如下:
死锁
写个简单的死锁例子,如下:
package concurrency; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; class TestTask implements Runnable { private Object obj1; private Object obj2; private int order; public TestTask(int order, Object obj1, Object obj2) { this.order = order; this.obj1 = obj1; this.obj2 = obj2; } public void test1() throws InterruptedException { synchronized (obj1) { //建议线程调取器切换到其它线程运行 Thread.yield(); synchronized (obj2) { System.out.println("test。。。"); } } } public void test2() throws InterruptedException { synchronized (obj2) { Thread.yield(); synchronized (obj1) { System.out.println("test。。。"); } } } @Override public void run() { while (true) { try { if(this.order == 1){ this.test1(); }else{ this.test2(); } } catch (InterruptedException e) { e.printStackTrace(); } } } } public class Test { public static void main(String[] args) throws InterruptedException { Object obj1 = new Object(); Object obj2 = new Object(); ExecutorService ex = Executors.newFixedThreadPool(10); // 起10个线程 for (int i = 0; i < 10; i++) { int rder = i%2==0 ? 1 : 0; ex.execute(new TestTask(order, obj1, obj2)); } } }
同样我们先找到javaw.exe的PID,再利用jstack分析该PID,很快jstack就帮我们找到了死锁的位置,如下所示:
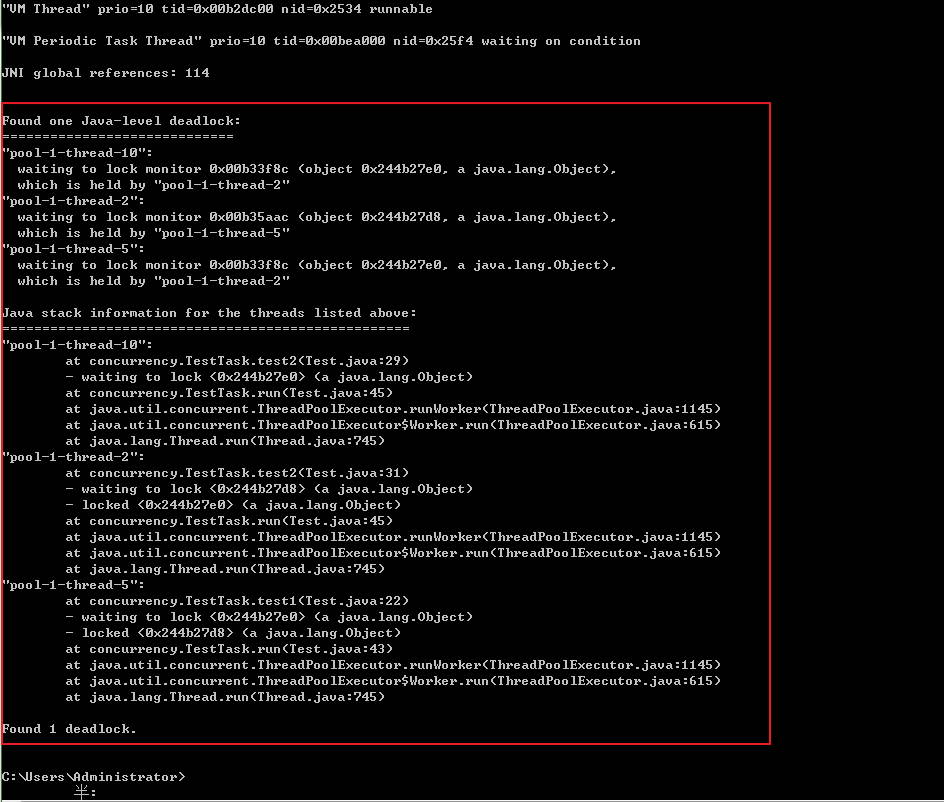
等待IO
写个简单的等待用户输入例子:
package concurrency; import java.io.IOException; import java.io.InputStream; public class Test { public static void main(String[] args) throws InterruptedException, IOException { InputStream is = System.in; int i = is.read(); System.out.println("exit。"); } }
同样我们先找到javaw.exe的PID,再利用jstack分析该PID,很快jstack就帮我们找到了位置,Test.java文件12行,如下所示:
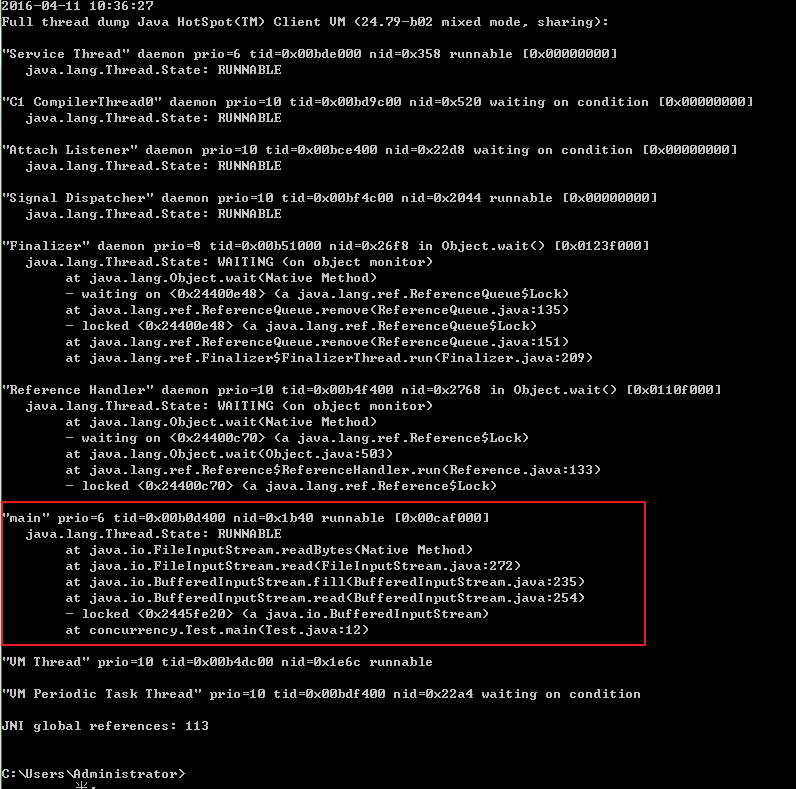
其它
像调用sleep使线程进入睡眠,suspend()暂停线程等就不举例了,都是类似的;
-
瓶颈分析
2018-02-23 10:51:54
CMS GC知识
CMS,全称Concurrent Mark and Sweep,用于对年老代进行回收,目标是尽量减少应用的暂停时间,减少full gc发生的机率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代。
一次CMS至少会给Full GC的次数 + 2,因为Full GC的次数是按照老年代GC时stop the world的次数而定的。
我们可以认为Major GC == Full GC,他们是一个概念,就是针对老年代/永久代进行GC。
- 应用系统负载分析:
服务器负载瓶颈经常表现为,服务器受到的并发压力比较低的情况下,服务器的资源使用率比预期要高,甚至高很多。导致服务器处理能力严重下降,最终有可能导致服务器宕机。实际性能测试工作中,经常会用以下三类资源指标判定是否存在服务器负载瓶颈:
- CPU使用率
- 内存使用率
- Load
一般cup的使用率应低于50%,如果过高有可能程序的算法耗费太多cpu,或者某些代码块进行不合理的占用。Load值尽量保持在cpuS+2 或者cpuS*2,其中cpu和load一般与并发数成正比。
- 内存可以通过2种方式来查看:
1) 当vmstat命令输出的si和so值显示为非0值,则表示剩余可支配的物理内存已经严重不足,需要通过与磁盘交换内容来保持系统的稳定;由于磁盘处理的速度远远小于内存,此时就会出现严重的性能下降;si和so的值越大,表示性能瓶颈越严重。
2) 用工具监控内存的使用情况,如果出现下图的增长趋势(used曲线呈线性增长),有可能系统内存占满的情况:

如果出现内存占用一直上升的趋势,有可能系统一直在创建新的线程,旧的线程没有销毁;或者应用申请了堆外内存,一直没有回收导致内存一直增长。
3)内存分页监控sar -B 5 10
输出项说明:pgpgin/s:表示每秒从磁盘或swap置换到内存的字节数(KB)pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和。majflt/s:每秒钟产生的主缺页数。pgfree/s:每秒被放入空闲队列中的页个数。是已经扫描到了的空闲页,扫描的空闲page越大,代表内存空余越大pgscank/s:每秒被kswapd扫描的页个数。pgscand/s:每秒直接被扫描的页个数。pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数。%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比。pgsteal/s 除以( pgscank/s + pgscand/s ),pgsteal/s表示每秒释放的cache((pagecache and swapcache)),这个其实就是cache可以释放的页,当CPU需要的page不在cache中时,需要释放cache中的原来的page,从内存和swap中加载需要的page,pgscank/s表示每秒扫描swap的page , pgscand/s表示每秒扫描内存的page,实际上pgscank/s+pgscand/s就是RAM+SWAP 。当vmeff的值变大时,表示从RAM和Swap中置换到cache的page变多,这就意味着用到swap的机会变多。这个参数用来衡量页面置换效率, 超30% 证明物理内存已经处理不过来。这个值越大,则请求越多,越代表内存有问题。4.2 Jvm瓶颈分析对于java应用来说,过高的GC频率也会在很大程度上降低应用的性能。即使采用了并发收集的策略,GC产生的停顿时间积累起来也是不可忽略的,特别是出现cmsgc失败,导致fullgc时的场景。下面举几个例子进行说明:
- Cmsgc频率过高,当在一段较短的时间区间内,cmsGC值超出预料的大,那么说明该JAVA应用在处理对象的策略上存在着一些问题,即过多过快地创建了长寿命周期的对象,是需要改进的。或者old区大小分配或者回收比例设置得不合理,导致cms频繁触发,下面看一张gc监控图(蓝色线代表cmsgc)

由图看出:cmsGC非常频繁,后经分析是因为jvm参数-XX:CMSInitiatingOccupancyFraction设置为15,比例太小导致cms比较频繁,这样可以扩大cmsgc占old区的比例,降低cms频率注。
调优后的图如下:

- fullgc频繁触发
当采用cms并发回收算法,当cmsgc回收失败时会导致fullgc:

由上图可以看出fullgc的耗时非常长,在6~7s左右,这样会严重影响应用的响应时间。经分析是因为cms比例过大,回收频率较慢导致,调优方式:调小cms的回比例,尽早触发cmsgc,避免触发fullgc。调优后回收情况如下

可以看出cmsgc时间缩短了很多,优化后可以大大提高。从上面2个例子看出cms比例不是绝对的,需要根据应用的具体情况来看,比如应用创建的对象存活周期长,且对象较大,可以适当提高cms的回收比例。
- 疑似内存泄露,先看下图

分析:每次cmsgc没有回收干净,old区呈上升趋势,疑似内存泄露
最终有可能导致OOM,这种情况就需要dump内存进行分析:
- 找到oom内存dump文件,具体的文件配置在jvm参数里:
- -XX:HeapDumpPath=/home/admin/logs
-XX:ErrorFile=/home/admin/logs/hs_err_pid%p.log
- 借助工具:MAT,分析内存最大的对象。
结论
- 在单接口压测时,我们用“请求总数/总时长”得到吞吐量;然后再用“吞吐量/平均响应时间”得到实际并发,此举可用来观察系统实际承受的并发;
- 在多接口压测时,由于短板效应,同一个流程中的所有接口获得的请求总数和总时长都一样,显然“请求总数/总时长”计算各个子接口的吞吐量不合适,所以改用“并发/平均响应时间”,其中的并发数应在压测工具中埋点统计,不可简单使用工具线程数。
-
性能测试问题排查一例——网络带宽瓶颈
2017-09-27 19:52:34
近期在做一个项目的性能测试时,在打压时发现压力达到100hps后就一直打不上去,同时还会报读redis服务器超时的错误。查看了下打压服务器的cpu和内存占用,没有发现什么异常。近期在做一个项目的性能测试时,在打压时发现压力达到100hps后就一直打不上去,同时还会报读redis服务器超时的错误。查看了下打压服务器的cpu和内存占用,没有发现什么异常。
Cpu占用:
内存占用:
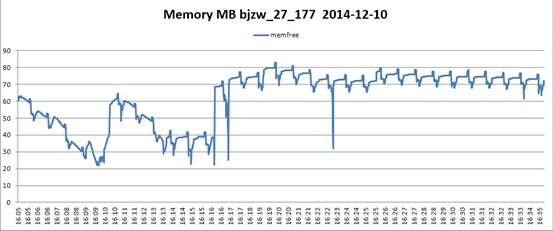
1、由于会报redis链接超时错误,首先定位到的是redis服务器挂了,找到开发将log中添加具体连接超时的redis服务器ip信息后,重新跑了一遍。
依然会报连接redis服务器超时错误,开发立即查看了下对应ip的redis服务器。发现运行情况没有出现任何问题,各项指标均正常。
2、于是查看压力服务器的各项指标来定位问题。
用sar命令看了下磁盘性能,发现每秒写扇区的次数达到300以上,怀疑是写入次数过多导致的,于是查了下开发的脚本,发现开发每一步判断逻辑中都加了写errorlog操作。于是怀疑是写log导致的。
将开发的写log操作大部分都关闭(除了读redis服务器错误)后,重新跑了一下,发现写扇区的次数降到100左右,但是hps依然打不上去。排出了磁盘写入的问题。
3、接下来安装了nmon工具后,重新跑了一遍,看了下网络传输,发现hps达到100左右时,网络出口占用为120M/s!这是千兆网卡的满载速率了。于是定位到网络成为主要的瓶颈。
网络I/O传输表:可以发现eth0-write的速率达到120千KB,也就是120M(注意这里的单位是“千”)
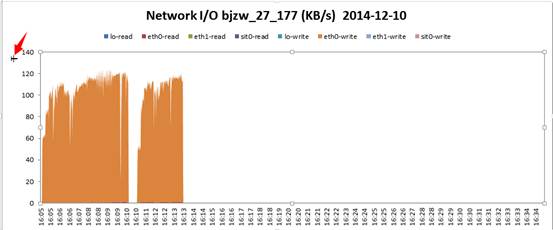
4、查了下自己的打压脚本,发现部分请求的返回数据大小为4M。果断将请求的返回改为200K后重新打压后,压力可以成功达到2000hps以上。同时也没有再出现读redis超时的错误。
至此,此次问题排查圆满结束。同时向大家着力推荐一下nmon工具。里面记录的参数很全,基本上定位性能的指标(比如cpu、内存、每个cpu、每个磁盘分区的读写、磁盘busy情况、网络吞吐、网络包数据等)都能够统计到。
-
性能测试瓶颈定位——磁盘IO和线程切换过多
2017-09-27 19:39:01
近期在一个性能测试项目中遇到了一个调优的过程。分享一下给大家。
1、 第一次打压时,发现A请求压力80tps后,cpu占用就非常高了(24核的机器,每个cpu占用率全面飙到80%以上),且设置的检查点没有任何报错。
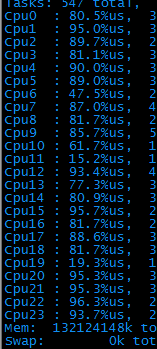
2、 了解了一下后台实现逻辑:大体是这样的:服务器接到请求后,会再到另一台kv服务器请求数据,拿回来数据后,根据用户的机器码做个性化运算,最后将结果返回给客户端,期间会输出一些调试log。
查了下,kv服务器正常,说明是本机服务服务器的问题。具体用vmstat命令看一下异常的地方。
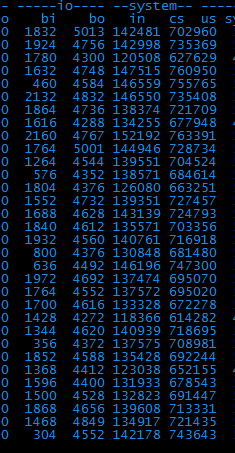
3、 从图中可以直观的看出,bi、bo、in、cs这四项的值都很高,根据经验,bi和bo代表磁盘io相关、in和cs代表系统进程相关。一个一个解决吧,先看io。
4、 用iostat –x命令看了下磁盘读写,果然,磁盘慢慢给堵死了。

5、 看了下过程,只有写log操作才能导致频繁读写磁盘。果断关闭log。重新打压试下。
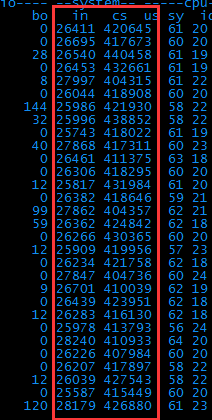
6、 Bi和bo降到正常值了,说明磁盘的问题解决了。但是上下文切换数竟然达到了每秒40万次!好可怕~
7、 只知道上下文切换数很大,怎么知道是在哪些进程间切换呢?
到网上搜了一个脚本,这个脚本用来统计特定时间内进程切换的top20并打印出来。
#! /usr/bin/env stap
#
#
global csw_count
global idle_count
probe scheduler.cpu_off {
csw_count[task_prev, task_next]++
idle_count+=idle
}
function fmt_task(task_prev, task_next)
{
return sprintf("%s(%d)->%s(%d)",
task_execname(task_prev),
task_pid(task_prev),
task_execname(task_next),
task_pid(task_next))
}
function print_cswtop () {
printf ("%45s %10s\n", "Context switch", "COUNT")
foreach ([task_prev, task_next] in csw_count- limit 20) {
printf("%45s %10d\n", fmt_task(task_prev, task_next), csw_count[task_prev, task_next])
}
printf("%45s %10d\n", "idle", idle_count)
delete csw_count
delete idle_count
}
probe timer.s($1) {
print_cswtop ()
printf("--------------------------------------------------------------\n")
}
保存成cs.stp后,用stap cswmon.stp 5命令执行下。
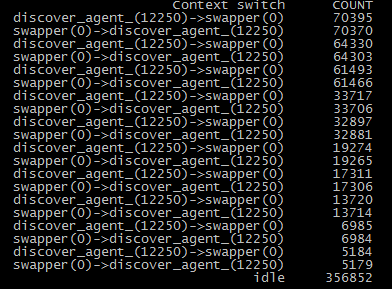
8、发现是discover进程在反复和系统进程进行切换。从此消耗了大量资源。
9、从网上查了下减少切换进程的一些方法:

开发随后改了下:将线程数开大了一倍,控制在一个进程中。
重新打压了一下。发现上下文切换数降低到25万次左右。
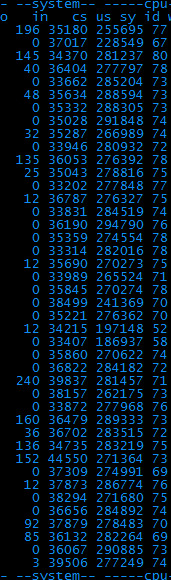
此时的性能数据可以达到每秒260次左右,远远高于之前的80次。已经达到可以上线的需求。
但是由于页面中断书和上下文切换数还是很高,后续还是需要优化~











标题搜索
我的存档
数据统计
- 访问量: 147529
- 日志数: 83
- 文件数: 1
- 建立时间: 2008-08-20
- 更新时间: 2018-03-05
