
-
详细记录一下JAVA应用程序服务出现内存溢出的利用MAT分析过程
2018-03-05 18:24:13
说明:本次以系统在并发情况下后台出现java.lang.OutOfMemoryError:GC overhead limit exceeded错误来分析整个性能测试分析的一个过程。中间用到的工具包括了:loadrunner 、AWR 报告、jstack、MAT等
1、使用LoadRunner进行50用户的并发测试,先进行2分钟的预热测试,为了系统能用到缓存的地方都先进行缓存,然后进行5分钟的施压测试。
2、在施压5分钟的后半段时间,应用后台开始出现了“java.lang.OutOfMemoryError”的错误信息;
具体错误信息如下:
3、既然出现了OutOfMemoryError的错误信息,一般出现该错误信息都是堆内存的溢出,所以我们需要考虑捕捉一下堆内存的信息,捕捉堆内存的信息有2种方式:
3.1 通过在应用中间件(weblogic、tomcat 等)上加入相应的JVM参数,具体参数如下(加入参数后,系统在出现OutOfMemoryError错误的时候便会自动生成类似java_pid9388.hprof的这样一个文件):
-Xloggc:D:\heapdump\managed1_gc.log
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=D:\heapdump
3.2 使用JDK自带的JMAP工具,具体使用方法如下:
第一步:先使用jps.exe命令找到相应的java进程ID,一般找Server PID的;
第二步:jmap.exe-dump:format=b,file=d:\dump\java_pid(第一步查询到的PID号).hprof PID(该地方一定要空格后跟着相应的PID号)
如果只dump heap中的存活对象,则加上选项-live,如下:
jmap.exe -dump:live,format=b,file=/path/heap_pid. hprof 进程ID(PID)
4.使用MAT工具来分析生成的hprof文件内容
4.1打开需要分析的hprof文件:
4.2 在Overview(概述)界面利用饼图的摘要信息来分析哪些对象比较占内存
4.3分析Action部分内容:
4.3.1点击“Leak Suspects”后的结果如下:
4.3.2 在怀疑问题的第点Details
4.3.3查看有问题的的类所引用的所有对象。此时使用鼠标左键点击,然后弹出菜单中进行如下选择:List Objects->with outgoing references
(说明:
图中的Shallow Heap(浅堆):指对象自身占用内存的大小,不包括它引用的对象。
图中的 Retained Heap(深堆):指当前对象大小+当前对象可直接或间接引用到对象的大小总和
)
此时可以点击鼠标左键,将sql语句的内容进行拷贝.
此时就找到了问题。
-
【JAVA 工具】jstack简单使用,定位死循环、线程阻塞、死锁等问题
2018-03-05 17:24:48
转载地址:http://www.cnblogs.com/chenpi/p/5377445.html
当我们运行java程序时,发现程序不动,但又不知道是哪里出问题时,可以使用JDK自带的jstack工具去定位;
废话不说,直接上例子吧,在window平台上的;
死循环
写个死循环的程序如下:

package concurrency; public class Test { public static void main(String[] args) throws InterruptedException { while (true) { } } }
先运行以上程序,程序进入死循环;
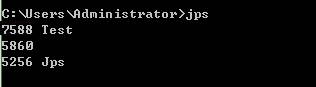
打开cmd,输入jps命令,jps很简单可以直接显示java进程的pid,如下为7588:
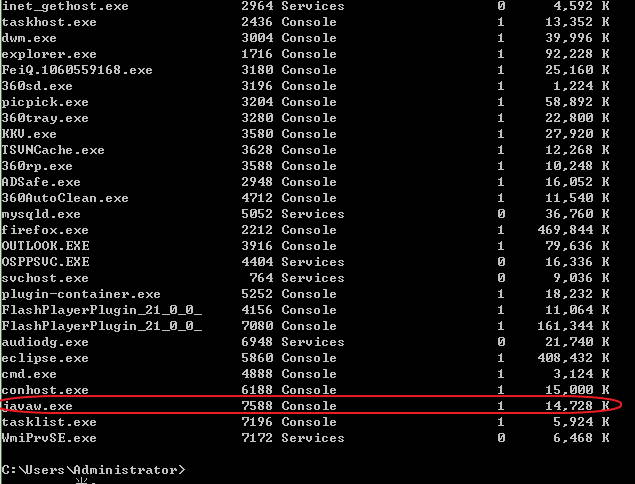
或者输入tasklist,找到javaw.exe的PID,如下为7588:
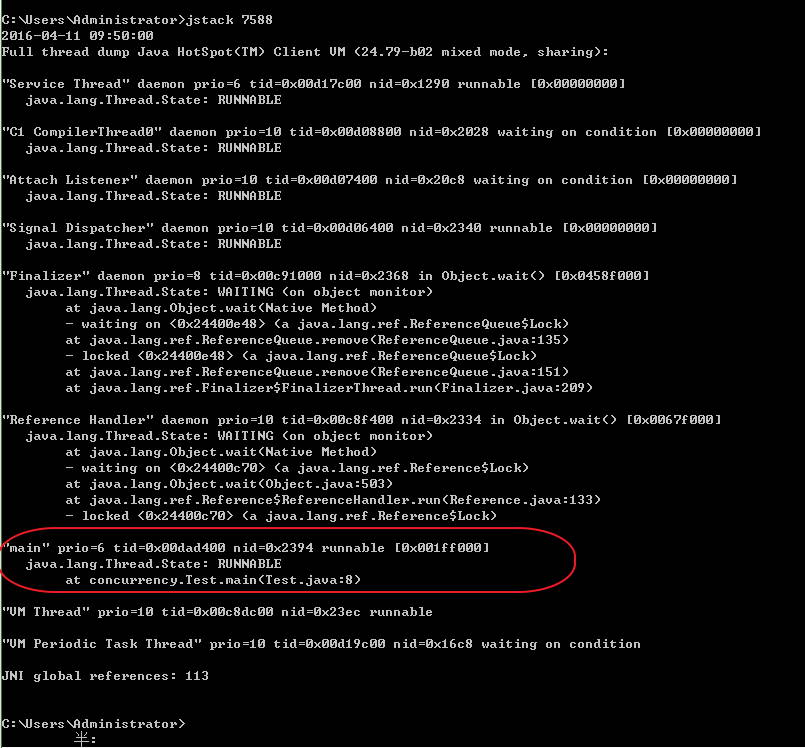
输入jstack 7588命令,找到跟我们自己代码相关的线程,如下为main线程,处于runnable状态,在main方法的第八行,也就是我们死循环的位置:
Object.wait()情况
写个小程序,调用wait使其中一线程等待,如下:
package concurrency; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; class TestTask implements Runnable { @Override public void run() { synchronized (this) { try { //等待被唤醒 wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class Test { public static void main(String[] args) throws InterruptedException { ExecutorService ex = Executors.newFixedThreadPool(1); ex.execute(new TestTask()); } }
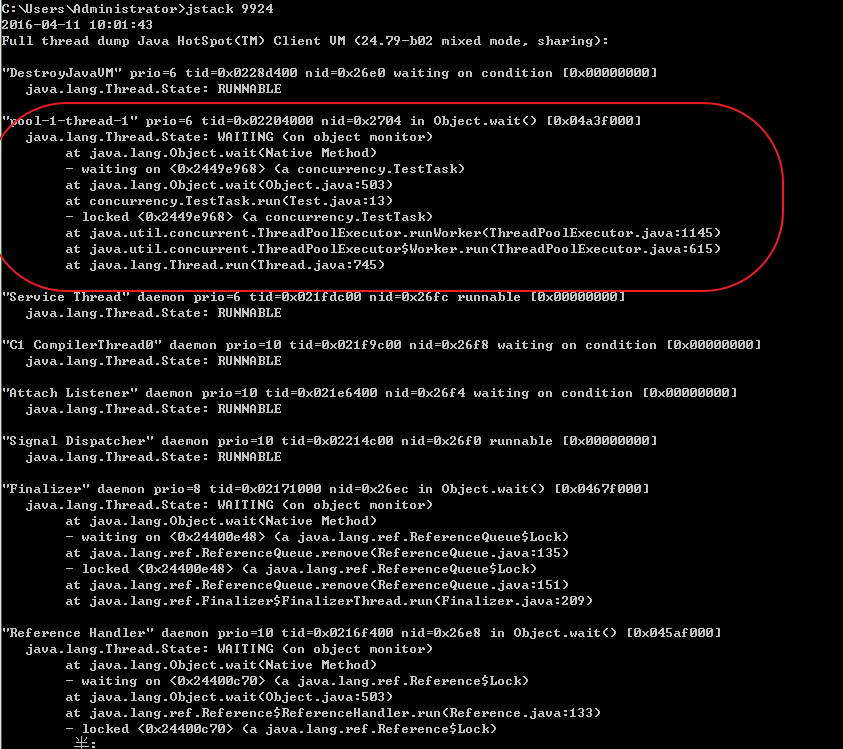
同样我们先找到javaw.exe的PID,再利用jstack分析该PID,很快我们就找到了一个线程处于WAITING状态,在Test.java文件13行处,正是我们调用wait方法的地方,说明该线程目前还没等到notify,如下:
死锁
写个简单的死锁例子,如下:
package concurrency; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; class TestTask implements Runnable { private Object obj1; private Object obj2; private int order; public TestTask(int order, Object obj1, Object obj2) { this.order = order; this.obj1 = obj1; this.obj2 = obj2; } public void test1() throws InterruptedException { synchronized (obj1) { //建议线程调取器切换到其它线程运行 Thread.yield(); synchronized (obj2) { System.out.println("test。。。"); } } } public void test2() throws InterruptedException { synchronized (obj2) { Thread.yield(); synchronized (obj1) { System.out.println("test。。。"); } } } @Override public void run() { while (true) { try { if(this.order == 1){ this.test1(); }else{ this.test2(); } } catch (InterruptedException e) { e.printStackTrace(); } } } } public class Test { public static void main(String[] args) throws InterruptedException { Object obj1 = new Object(); Object obj2 = new Object(); ExecutorService ex = Executors.newFixedThreadPool(10); // 起10个线程 for (int i = 0; i < 10; i++) { int rder = i%2==0 ? 1 : 0; ex.execute(new TestTask(order, obj1, obj2)); } } }
同样我们先找到javaw.exe的PID,再利用jstack分析该PID,很快jstack就帮我们找到了死锁的位置,如下所示:
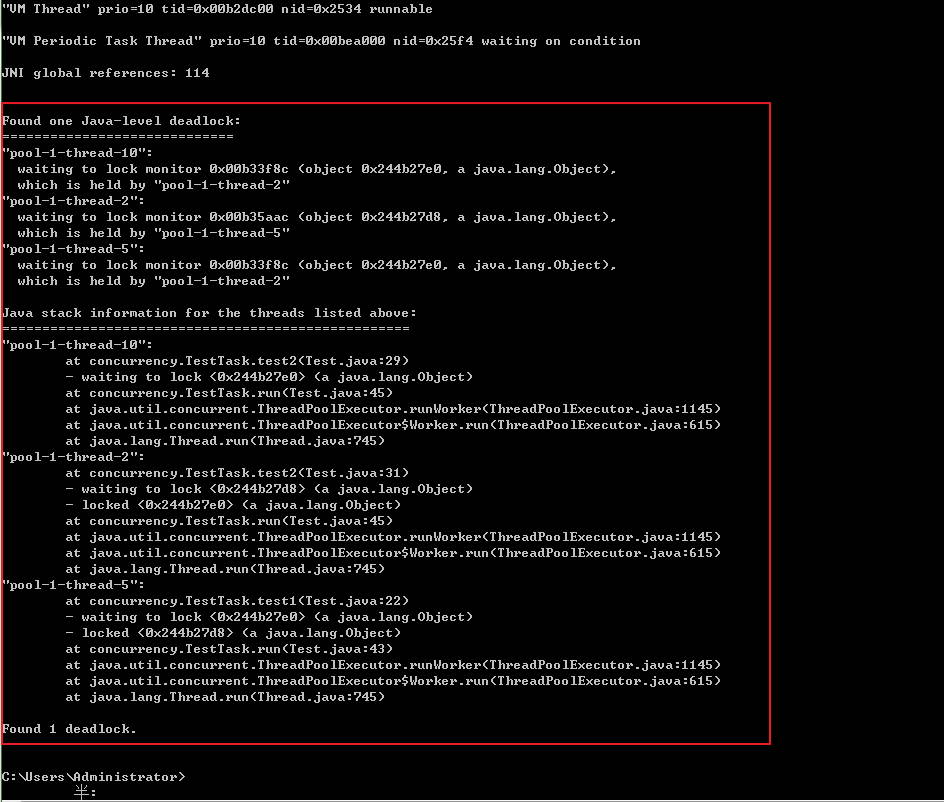
等待IO
写个简单的等待用户输入例子:
package concurrency; import java.io.IOException; import java.io.InputStream; public class Test { public static void main(String[] args) throws InterruptedException, IOException { InputStream is = System.in; int i = is.read(); System.out.println("exit。"); } }
同样我们先找到javaw.exe的PID,再利用jstack分析该PID,很快jstack就帮我们找到了位置,Test.java文件12行,如下所示:
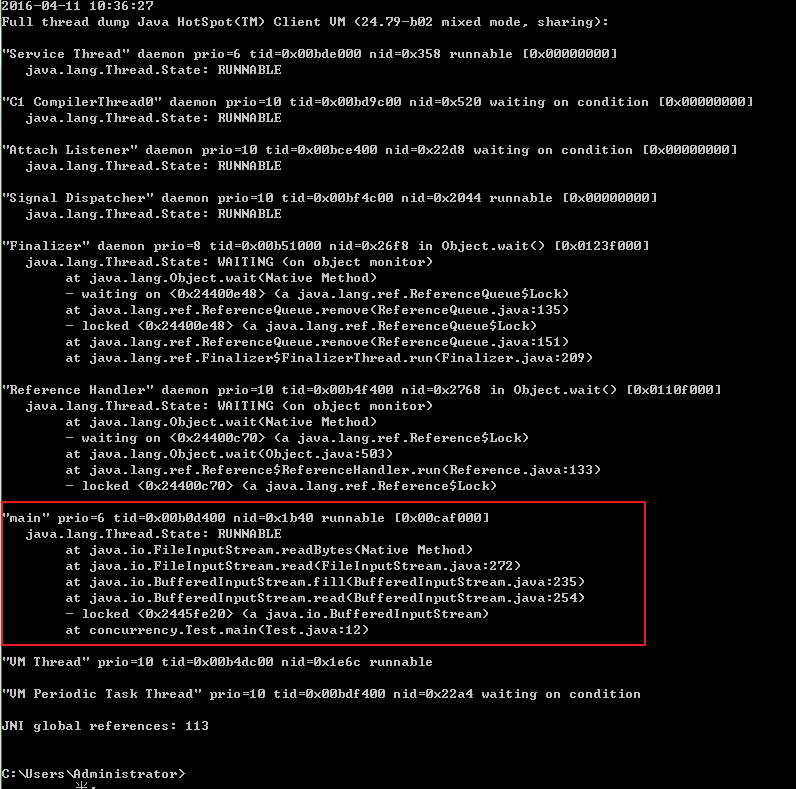
其它
像调用sleep使线程进入睡眠,suspend()暂停线程等就不举例了,都是类似的;
-
Java中的String,StringBuilder,StringBuffer三者的区别
2018-02-26 18:33:53
这三个类之间的区别主要是在两个方面,即运行速度和线程安全这两方面。
- 首先说运行速度,或者说是执行速度,在这方面运行速度快慢为:StringBuilder > StringBuffer > String
String最慢的原因:
String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但后两者的对象是变量,是可以更改的。以下面一段代码为例:
public class StringTest { public static void main(String args[]){ String str="abc"; System.out.println(str); str=str+"de"; System.out.println(str);// } }
如果运行这段代码会发现先输出“abc”,然后又输出“abcde”,好像是str这个对象被更改了,其实,这只是一种假象罢了,JVM对于这几行代码是这样处理的,首先创建一个String对象str,并把“abc”赋值给str,然后在第三行中,其实JVM又创建了一个新的对象也名为str,然后再把原来的str的值和“de”加起来再赋值给新的str,而原来的str就会被JVM的垃圾回收机制(GC)给回收掉了,所以,str实际上并没有被更改,也就是前面说的String对象一旦创建之后就不可更改了。所以,Java中对String对象进行的操作实际上是一个不断创建新的对象并且将旧的对象回收的一个过程,所以执行速度很慢。
而StringBuilder和StringBuffer的对象是变量,对变量进行操作就是直接对该对象进行更改,而不进行创建和回收的操作,所以速度要比String快很多。
另外,有时候我们会这样对字符串进行赋值:
1 String str="abc"+"de"; 2 StringBuilder stringBuilder=new StringBuilder().append("abc").append("de"); 3 System.out.println(str); 4 System.out.println(stringBuilder.toString());
这样输出结果也是“abcde”和“abcde”,但是String的速度却比StringBuilder的反应速度要快很多,这是因为第1行中的操作和
String str="abcde";
是完全一样的,所以会很快,而如果写成下面这种形式
1 String str1="abc"; 2 String str2="de"; 3 String str=str1+str2;
那么JVM就会像上面说的那样,不断的创建、回收对象来进行这个操作了。速度就会很慢。
2. 再来说线程安全
在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的
如果一个StringBuffer对象在字符串缓冲区被多个线程使用时,StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但StringBuilder的方法则没有该关键字,所以不能保证线程安全,有可能会出现一些错误的操作。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,但是在单线程的情况下,还是建议使用速度比较快的StringBuilder。
3. 总结一下
String:适用于少量的字符串操作的情况StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
-
Java基础之int和Integer有什么区别
2018-02-26 17:46:38
一、int 是基本类型,直接存数值,进行初始化时int类的变量初始为0。
integer是对象,用一个引用指向这个对象,Integer的变量则初始化为null。从Java 5开始引入了自动装箱/拆箱机制,使得二者可以相互转换。二、自动装箱:将基本数据类型重新转化为对象public class Test { public static void main(String[] args) { //声明一个Integer对象 Integer num = 9; //以上的声明就是用到了自动的装箱:解析为:Integer num = new Integer(9); } }三、自动拆箱:将对象重新转化为基本数据类型public class Test { public static void main(String[] args) { //声明一个Integer对象 Integer num = 9; //进行计算时隐含的有自动拆箱 System.out.print(num--); } } -
jmeter测试接口--解决参数化取唯一值的问题(用UUID)
2018-02-23 16:18:45
一、用时间函数:
jmeter参数化,而且要取唯一值,可以考虑用时间函数加上其他函数一起:
1{"merchant_id":"615051940310129","biz_code":"1001","order_id":"${__time(,)}${__counter(,)}","order_amt":"100","bg_url":"www.baidu.com","sign":"22A356FF1010B22670417E2107DB4229"}但是如果接口的处理能力很快,这个参数还是会存在重复的id;
二、用UUID:
解决上面的问题,还可以用UUID来作为参数,UUID通常以36字节的字符串表示,示例如下:
13F2504E0-4F89-11D3-9A0C-0305E82C3301订单ID多数是数字的,如果不需要“-”,可以去掉。
如下是分析在jmeter中如何使用:
1.新建一个事务;
2.新建一个BeanShell Sampler;
3.新建一个http请求;
如下图:
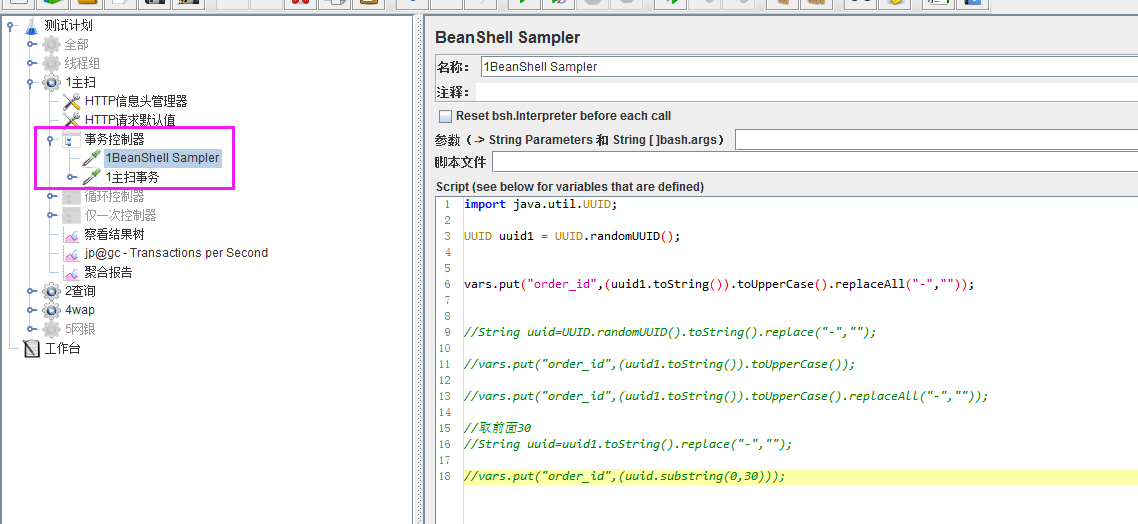
4.在BeanShell Sampler编写UUID的代码:
12345678910importjava.util.UUID;UUID uuid1 = UUID.randomUUID();//获取UID的值vars.put("order_id",(uuid1.toString()).toUpperCase().replaceAll("-",""));//去掉UUID的“-”,再赋值给order_id 运行获取的参数就是:3F2504E04F8911D39A0C0305E82C3301//vars.put("order_id",(uuid1.toString()).toUpperCase());查看(3566) 评论(0) 收藏 分享 管理瓶颈分析
2018-02-23 10:51:54
CMS GC知识
CMS,全称Concurrent Mark and Sweep,用于对年老代进行回收,目标是尽量减少应用的暂停时间,减少full gc发生的机率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代。
一次CMS至少会给Full GC的次数 + 2,因为Full GC的次数是按照老年代GC时stop the world的次数而定的。
我们可以认为Major GC == Full GC,他们是一个概念,就是针对老年代/永久代进行GC。
- 应用系统负载分析:
服务器负载瓶颈经常表现为,服务器受到的并发压力比较低的情况下,服务器的资源使用率比预期要高,甚至高很多。导致服务器处理能力严重下降,最终有可能导致服务器宕机。实际性能测试工作中,经常会用以下三类资源指标判定是否存在服务器负载瓶颈:
- CPU使用率
- 内存使用率
- Load
一般cup的使用率应低于50%,如果过高有可能程序的算法耗费太多cpu,或者某些代码块进行不合理的占用。Load值尽量保持在cpuS+2 或者cpuS*2,其中cpu和load一般与并发数成正比。
- 内存可以通过2种方式来查看:
1) 当vmstat命令输出的si和so值显示为非0值,则表示剩余可支配的物理内存已经严重不足,需要通过与磁盘交换内容来保持系统的稳定;由于磁盘处理的速度远远小于内存,此时就会出现严重的性能下降;si和so的值越大,表示性能瓶颈越严重。
2) 用工具监控内存的使用情况,如果出现下图的增长趋势(used曲线呈线性增长),有可能系统内存占满的情况:

如果出现内存占用一直上升的趋势,有可能系统一直在创建新的线程,旧的线程没有销毁;或者应用申请了堆外内存,一直没有回收导致内存一直增长。
3)内存分页监控sar -B 5 10
输出项说明:pgpgin/s:表示每秒从磁盘或swap置换到内存的字节数(KB)pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和。majflt/s:每秒钟产生的主缺页数。pgfree/s:每秒被放入空闲队列中的页个数。是已经扫描到了的空闲页,扫描的空闲page越大,代表内存空余越大pgscank/s:每秒被kswapd扫描的页个数。pgscand/s:每秒直接被扫描的页个数。pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数。%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比。pgsteal/s 除以( pgscank/s + pgscand/s ),pgsteal/s表示每秒释放的cache((pagecache and swapcache)),这个其实就是cache可以释放的页,当CPU需要的page不在cache中时,需要释放cache中的原来的page,从内存和swap中加载需要的page,pgscank/s表示每秒扫描swap的page , pgscand/s表示每秒扫描内存的page,实际上pgscank/s+pgscand/s就是RAM+SWAP 。当vmeff的值变大时,表示从RAM和Swap中置换到cache的page变多,这就意味着用到swap的机会变多。这个参数用来衡量页面置换效率, 超30% 证明物理内存已经处理不过来。这个值越大,则请求越多,越代表内存有问题。4.2 Jvm瓶颈分析对于java应用来说,过高的GC频率也会在很大程度上降低应用的性能。即使采用了并发收集的策略,GC产生的停顿时间积累起来也是不可忽略的,特别是出现cmsgc失败,导致fullgc时的场景。下面举几个例子进行说明:
- Cmsgc频率过高,当在一段较短的时间区间内,cmsGC值超出预料的大,那么说明该JAVA应用在处理对象的策略上存在着一些问题,即过多过快地创建了长寿命周期的对象,是需要改进的。或者old区大小分配或者回收比例设置得不合理,导致cms频繁触发,下面看一张gc监控图(蓝色线代表cmsgc)

由图看出:cmsGC非常频繁,后经分析是因为jvm参数-XX:CMSInitiatingOccupancyFraction设置为15,比例太小导致cms比较频繁,这样可以扩大cmsgc占old区的比例,降低cms频率注。
调优后的图如下:

- fullgc频繁触发
当采用cms并发回收算法,当cmsgc回收失败时会导致fullgc:

由上图可以看出fullgc的耗时非常长,在6~7s左右,这样会严重影响应用的响应时间。经分析是因为cms比例过大,回收频率较慢导致,调优方式:调小cms的回比例,尽早触发cmsgc,避免触发fullgc。调优后回收情况如下

可以看出cmsgc时间缩短了很多,优化后可以大大提高。从上面2个例子看出cms比例不是绝对的,需要根据应用的具体情况来看,比如应用创建的对象存活周期长,且对象较大,可以适当提高cms的回收比例。
- 疑似内存泄露,先看下图

分析:每次cmsgc没有回收干净,old区呈上升趋势,疑似内存泄露
最终有可能导致OOM,这种情况就需要dump内存进行分析:
- 找到oom内存dump文件,具体的文件配置在jvm参数里:
- -XX:HeapDumpPath=/home/admin/logs
-XX:ErrorFile=/home/admin/logs/hs_err_pid%p.log
- 借助工具:MAT,分析内存最大的对象。
结论
- 在单接口压测时,我们用“请求总数/总时长”得到吞吐量;然后再用“吞吐量/平均响应时间”得到实际并发,此举可用来观察系统实际承受的并发;
- 在多接口压测时,由于短板效应,同一个流程中的所有接口获得的请求总数和总时长都一样,显然“请求总数/总时长”计算各个子接口的吞吐量不合适,所以改用“并发/平均响应时间”,其中的并发数应在压测工具中埋点统计,不可简单使用工具线程数。
JMeter-Java Sampler遇到的问题
2018-02-22 16:59:12
当运行main方法进行调试时报错,报错如下:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/jorphan/logging/LoggingManager
at org.apache.jmeter.protocol.java.sampler.AbstractJavaSamplerClient.<clinit>(AbstractJavaSamplerClient.java:55)
Caused by: java.lang.ClassNotFoundException: org.apache.jorphan.logging.LoggingManager
at java.net.URLClassLoader$1.run(Unknown Source)
at java.net.URLClassLoader$1.run(Unknown Source)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at sun.misc.Launcher$AppClassLoader.loadClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
... 1 more问题在于少加载了依赖包,可以把jmeterhome/ lib下所有jar加载到eclipse环境变量中试试。HashMap数据结构及其一些方法
2018-01-16 10:26:07
1、hashmap的数据结构
要知道hashmap是什么,首先要搞清楚它的数据结构,在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,hashmap也不例外。Hashmap实际上是一个数组和链表的结合体(在数据结构中,一般称之为“链表散列“),请看下图(横排表示数组,纵排表示数组元素【实际上是一个链表】)。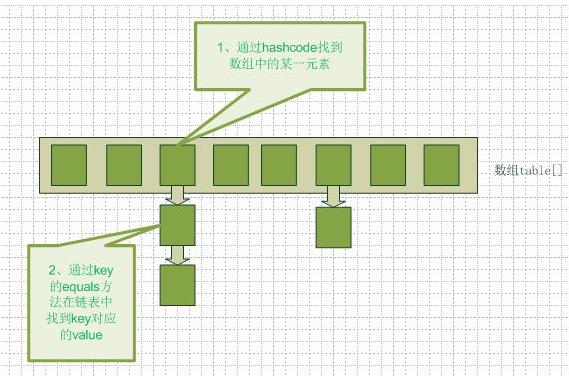
性能测试问题排查一例——网络带宽瓶颈
2017-09-27 19:52:34
近期在做一个项目的性能测试时,在打压时发现压力达到100hps后就一直打不上去,同时还会报读redis服务器超时的错误。查看了下打压服务器的cpu和内存占用,没有发现什么异常。近期在做一个项目的性能测试时,在打压时发现压力达到100hps后就一直打不上去,同时还会报读redis服务器超时的错误。查看了下打压服务器的cpu和内存占用,没有发现什么异常。
Cpu占用:
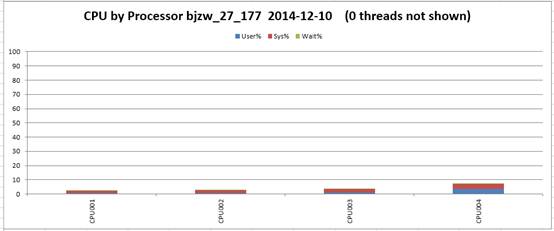
内存占用:
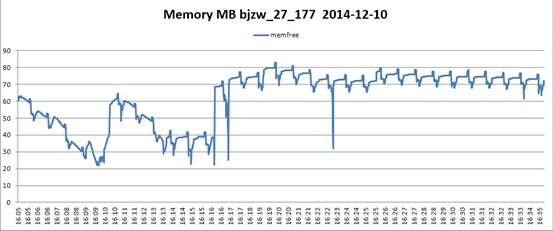
1、由于会报redis链接超时错误,首先定位到的是redis服务器挂了,找到开发将log中添加具体连接超时的redis服务器ip信息后,重新跑了一遍。
依然会报连接redis服务器超时错误,开发立即查看了下对应ip的redis服务器。发现运行情况没有出现任何问题,各项指标均正常。
2、于是查看压力服务器的各项指标来定位问题。
用sar命令看了下磁盘性能,发现每秒写扇区的次数达到300以上,怀疑是写入次数过多导致的,于是查了下开发的脚本,发现开发每一步判断逻辑中都加了写errorlog操作。于是怀疑是写log导致的。
将开发的写log操作大部分都关闭(除了读redis服务器错误)后,重新跑了一下,发现写扇区的次数降到100左右,但是hps依然打不上去。排出了磁盘写入的问题。
3、接下来安装了nmon工具后,重新跑了一遍,看了下网络传输,发现hps达到100左右时,网络出口占用为120M/s!这是千兆网卡的满载速率了。于是定位到网络成为主要的瓶颈。
网络I/O传输表:可以发现eth0-write的速率达到120千KB,也就是120M(注意这里的单位是“千”)
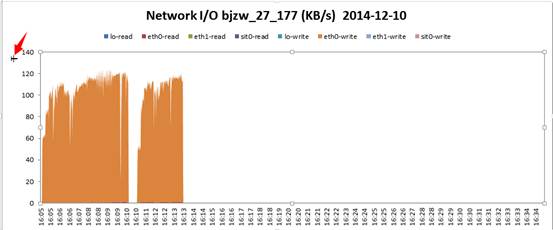
4、查了下自己的打压脚本,发现部分请求的返回数据大小为4M。果断将请求的返回改为200K后重新打压后,压力可以成功达到2000hps以上。同时也没有再出现读redis超时的错误。
至此,此次问题排查圆满结束。同时向大家着力推荐一下nmon工具。里面记录的参数很全,基本上定位性能的指标(比如cpu、内存、每个cpu、每个磁盘分区的读写、磁盘busy情况、网络吞吐、网络包数据等)都能够统计到。
性能测试瓶颈定位——磁盘IO和线程切换过多
2017-09-27 19:39:01
近期在一个性能测试项目中遇到了一个调优的过程。分享一下给大家。
1、 第一次打压时,发现A请求压力80tps后,cpu占用就非常高了(24核的机器,每个cpu占用率全面飙到80%以上),且设置的检查点没有任何报错。
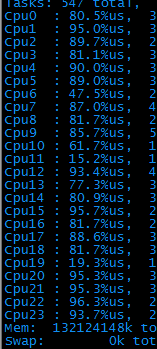
2、 了解了一下后台实现逻辑:大体是这样的:服务器接到请求后,会再到另一台kv服务器请求数据,拿回来数据后,根据用户的机器码做个性化运算,最后将结果返回给客户端,期间会输出一些调试log。
查了下,kv服务器正常,说明是本机服务服务器的问题。具体用vmstat命令看一下异常的地方。
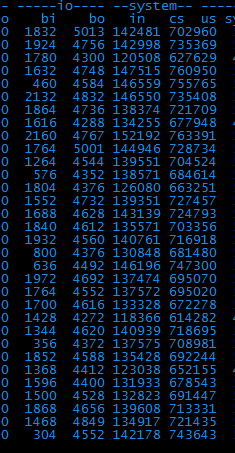
3、 从图中可以直观的看出,bi、bo、in、cs这四项的值都很高,根据经验,bi和bo代表磁盘io相关、in和cs代表系统进程相关。一个一个解决吧,先看io。
4、 用iostat –x命令看了下磁盘读写,果然,磁盘慢慢给堵死了。

5、 看了下过程,只有写log操作才能导致频繁读写磁盘。果断关闭log。重新打压试下。
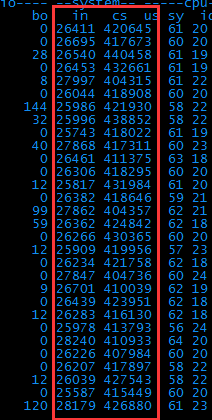
6、 Bi和bo降到正常值了,说明磁盘的问题解决了。但是上下文切换数竟然达到了每秒40万次!好可怕~
7、 只知道上下文切换数很大,怎么知道是在哪些进程间切换呢?
到网上搜了一个脚本,这个脚本用来统计特定时间内进程切换的top20并打印出来。
#! /usr/bin/env stap
#
#
global csw_count
global idle_count
probe scheduler.cpu_off {
csw_count[task_prev, task_next]++
idle_count+=idle
}
function fmt_task(task_prev, task_next)
{
return sprintf("%s(%d)->%s(%d)",
task_execname(task_prev),
task_pid(task_prev),
task_execname(task_next),
task_pid(task_next))
}
function print_cswtop () {
printf ("%45s %10s\n", "Context switch", "COUNT")
foreach ([task_prev, task_next] in csw_count- limit 20) {
printf("%45s %10d\n", fmt_task(task_prev, task_next), csw_count[task_prev, task_next])
}
printf("%45s %10d\n", "idle", idle_count)
delete csw_count
delete idle_count
}
probe timer.s($1) {
print_cswtop ()
printf("--------------------------------------------------------------\n")
}
保存成cs.stp后,用stap cswmon.stp 5命令执行下。
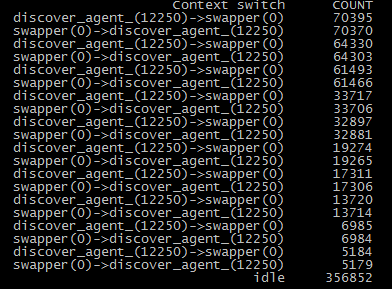
8、发现是discover进程在反复和系统进程进行切换。从此消耗了大量资源。
9、从网上查了下减少切换进程的一些方法:

开发随后改了下:将线程数开大了一倍,控制在一个进程中。
重新打压了一下。发现上下文切换数降低到25万次左右。
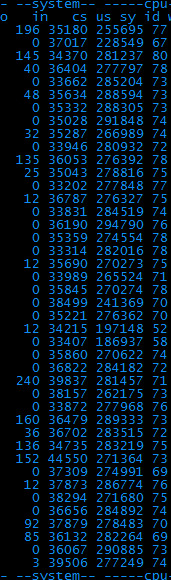
此时的性能数据可以达到每秒260次左右,远远高于之前的80次。已经达到可以上线的需求。
但是由于页面中断书和上下文切换数还是很高,后续还是需要优化~
利用intellij idea创建maven 多模块项目
2017-06-01 19:00:30
我的selenium自动化测试最终环境(Java篇)
2017-06-01 18:21:58
我的selenium自动化测试最终环境(Java篇)
我的最终环境为:Java+maven+selenium+testng+jenkins
1. Java环境
安装好Java jdk,如图所示:
配置好Java环境,在环境变量中添加Java所需要的环境:
首先添加JAVA_HOME,把jdk的安装目录填入变量中。其次再添加CLASSPATH变量。
变量值为:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar; (前面还有一个点也要复制哦)
最后还需在Path环境中添加Java的bin目录。
变量值为:%JAVA_HOME%\bin;
配置完成后如需测试Java是否成功,则可以在cmd命令行中输入JAVAC,出现该页面即可:2. maven环境
直接下载maven压缩包解压至本地目录:
配置maven环境变量,添加M2_HOME变量。
更新系统Path 变量, 添加;%M2_HOME%\bin;到尾部
测试maven配置是否成功打开命令行窗口,输入mvn -v,如果有maven 版本信息输出则证明配置成功。
配置maven本地仓库,我们需要打开maven的配置文件,在文件中添加本地仓库路径。不修改则默认为C盘用户目录下的m2文件。以下为我的本地库:
<localRepository>C:\maven\mvnRespo</localRepository>
配置一个镜像仓库,加快下载jar包,由于maven自带的仓库访问量过大下载jar包显得太慢,我们需要选择其他的仓库加快我们的下载。
<mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror>
<profile> <id>jdk-1.4</id> <activation> <jdk>1.4</jdk> </activation> <repositories> <repository> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </pluginRepository> </pluginRepositories> </profile>
3. selenium环境




pom.xml设置:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.9.10</version>
</dependency>
<dependency>
<groupId>org.uncommons</groupId>
<artifactId>reportng</artifactId>
<version>1.1.4</version>
<exclusions>
<exclusion>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.inject</groupId>
<artifactId>guice</artifactId>
<version>4.0-beta5</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>2.44.0</version>
</dependency>
</dependencies>
public class SeleniumDemo {
public static void main(String[] args) {
//声明一个火狐浏览器driver对象,启动浏览器
WebDriver driver = new FirefoxDriver();
//输入要访问的网页地址
driver.get("http://www.haosou.com/");
//通过查看元素,查找到search输入框元素name属性
WebElement searchinput = driver.findElement(By.name("q"));
//输入“selenium”
searchinput.sendKeys("selenium");
//通过查看元素,查找到search按钮 元素id属性
WebElement searchButton = driver.findElement(By.id("search-button"));
//点击按钮
searchButton.click();
//加载网页
try {
Thread.sleep(2000);
} catch(InterruptedException e) {
e.printStackTrace();
}
//跳转之后的页面关键字输入框元素
WebElement keywordinput = driver.findElement(By.id("keyword"));
//验证输入框中是否输入selenium字段
Assert.assertEquals(keywordinput.getAttribute("value"), "selenium");
//关闭浏览器
driver.quit();
}
}90% Line
2017-03-15 20:32:30
90% Line -- 如果把响应时间从小到大顺序排序,那么90%的请求的响应时间在这个范围之内假如:
有10个数:
1、2、3、4、5、6、7、8、9、10 按由大到小将其排列。
求它的第90%百分位,也就是第9个数刚好是9 ,那么他的90%Line 就是9 。
另一组数:
2、2.1、2.5、3、3.4、3.4、4、4、4、4、5、5、5、5.9、5.91、6.8、8、12、24、24.1 按由大到小将其排列。
求它的第90%百分位,第18个数是12 么,他的90%Line 就是12。
再来解释90%Line
一组数由小到大进行排列,找到他的第90%个数(假如是12),那么这个数组中有90%的数将小于等于12 。
用在性能测试的响应时间也将非常有意义,也就是90%用户响应时间不会超过12 秒。
不能在finally块中return
2017-03-15 20:30:39
【现象描述】
try-catch块中永远返回finally中return的值
【错误代码】
static boolean f() {
try {
return true;
} finally {
return false;
}
}
错误分析
在这个应用场景中,不要用return来退出finally语句块,因为finally语句块都会被执行到,这样try程序块中执行正常也会在finally中退出,不会再回到try程序块中。
Try-catch的流程说明:
try {
…
…
return true;
}catch(异常){
…
} finally {
…
}
}
1,try-catch-finally,
如果try语句块遇到异常,try下面的代码就不执行了,转而执行catch语句块,执行完再执行finally语句块,最后结束。
2,try-finally,
如果在try语句块中执行到return语句前一条,未遇到异常,转而执行finally语句块,执行完再执行try中的return语句。
不要用return、break、continue或throw来退出finally语句块
正确用法
//该方法返回false
static boolean f() {
try {
return true;
} finally {
//不做return操作
}
}虚拟机下64位win7+jdk1.8+jmeter3.0启动报错解决方法
2016-11-03 15:04:52
1、虚拟机下64位win7+jdk1.8+jmeter3.0启动时,
发现GUI界面总是有warning提示:
WARNING: Could not open/create prefs root node Software\JavaSoft\Prefs at root 0x80000002. Windows RegCreateKeyEx(...) returned error code 5.
在网上搜了搜,发现是Jmeter需要写注册表。
解决方法:The work around is to login as the administrator and create the key HKEY_LOCAL_MACHINE\Software\JavaSoft\Prefs.
以管理员身份登录,regedit,创建HKEY_LOCAL_MACHINE\Software\JavaSoft\Prefs项
2、启动时报错:OpenGL Warning: No pincher,please call crStateSetCurrentPointers() in your SPU
解决方法:前面的勾去掉。如下图。
charles使用教程指南
2016-05-26 14:04:02
Charles各版本下载:
Charles for Windows 32 bit
Charles for Windows 64 bit
Charles for linux
Charles for Mac OS X
Charles for Mac OS X (uses Apple Java 6)
0x01 前言:
Charles是一款抓包修改工具,相比起burp,charles具有界面简单直观,易于上手,数据请求控制容易,修改简单,抓取数据的开始暂停方便等等优势!下面来详细介绍下这款强大好用的抓包工具。
0x02 下载与安装
首先是工具下载和安装 首先需要下载java的运行环境支持(一般用burp的人肯定也都有装java环境)。装好java环境后,可以直接去百度搜索并下载charles的破解版,下载到破解版之后,里面一般会有注册的jar文件,然后注册后就可以永久使用了(ps:不注册的话,每次使用30分钟,工具就会自动关闭)。
0x03 PC端抓包
下面是pc端的抓包使用情况 Charles支持抓去http、https协议的请求,不支持socket。
然后charles会自动配置IE浏览器和工具的代理设置,所以说打开工具直接就已经是抓包状态了。 这里打开百度抓包下,工具界面和相关基础功能如下图所示:

上图中的7个位置是最常用的几个功能。
1 那个垃圾桶图标,功能是clear,清理掉所有请求显示信息。
2 那个望远镜图标,功能是搜索关键字,也可以使用ctrl+f实现,可以设置搜索的范围。

3 圆圈中间红点的图标,功能是领抓去的数据显示或者不显示的设置。 这个本人认为是charles工具很方便的一个两点,一般都使其为不显示抓去状态,只有当自己测试的时候的前后,在令其为抓取并显示状态。这样可以快准狠的获取到相关自己想要的信息,而不必在一堆数据请求中去寻找。
4 编辑修改功能,可以编辑修改任意请求信息,修改完毕后点击Execute就可以发送一个修改后的请求数据包。

5 抓取的数据包的请求地址的url信息显示。
6 抓取的数据包的请求内容的信息显示。

post请求可以显示form形式,直观明了。

7 返回数据内容信息的显示。

其中5、6、7中都有各种形式的数据显示形式,其中raw是原始数据包的状态。
0x04 显示模式
charles抓包的显示,支持两种模式,Structure和Sequence,其优点分别如下。
Structure形式如下图 优点:可以很清晰的看到请求的数据结构,而且是以域名划分请求信息的,可以很清晰的去分析和处理数据。

Sequence形式如下图 优点:可以很清晰的看到全部请求,不用一层一层的去点开,这里是以数据请求的顺序去执行的,也就是说那个请求快就在前面显示。

具体要说两种形式哪个更好,这个就是见仁见智了。本人比较喜欢第二种,粗矿豪放!
0x05 移动APP抓包
这里相比其他抓包软件来说要简单的多了,具体步骤如下:
1 使手机和电脑在一个局域网内,不一定非要是一个ip段,只要是同一个漏油器下就可以了,比如电脑连接的有线网ip为192.168.16.12,然后手机链接的wifi ip为192.168.1.103,但是这个有线网和无线网的最终都是来自于一个外部ip,这样的话也是可以的。
2 下面说说具体配置,这里电脑端是不用做任何配置的,但是需要把防火墙关掉(这点很重要)!
然后charles设置需要设置下允许接收的ip地址的范围。 设置首先要进入这个位置 Proxy - Access Control Settings 然后如果接收的ip范围是192.168.1.xxx的话,那么就添加并设置成192.168.1.0/24 如果全部范围都接收的话,那么就直接设置成0.0.0.0/0

然后如果勾选了Proxy - Windows Proxy 的话,那么就会将电脑上的抓包请求也抓取到,如果只抓手机的话,可以将这个设置为不勾选。
3 接下来下面是手机端的配置
首先利用cmd - ipconfig命令查看自己电脑的ip地址

然后在手机端的wifi代理设置那里去进行相关的配置设置。
这里的代理服务器地址填写为电脑的ip地址,然后端口这里写8888(这个是charles的默认设置),如果自己修改了就写成自己所修改的端口就可以了。

4 好了,这样就配置完成就大功告成了!下面打开UC浏览器或者其他东西,随便访问个网页看有没有抓取到数据就可以了(我这里是直接访问的新浪新闻首页)。

0x06 其他常用功能
相信上面介绍的那些你已经学会了吧,下面再说说charles的一些其他常用的功能
选择请求后,右键可以看到一些常用的功能,这里说说Repeat 就是重复发包一次。 然后Advanced Repeat就是重复发包多次,这个功能用来测试短信轰炸漏洞很方便。

还有比如说修改referer测试CSRF漏洞,修改form内容测试XSS,修改关键的参数测试越权,修改url、form、cookie等信息测试注入等,都非常方便。
好了,这款工具的介绍就到这里了,相信这款方便好用的工具,以后肯定会被更多的人使用到的。
0x07 charles使用问题汇总
Charles是一款很好用的抓包修改工具,但是如果你不是很熟悉这个工具的话,肯定会遇到各种感觉很莫名其妙的状况,这里就来帮你一一解答。
1 为什么下载了不能用啊?打不开啊。
因为charles是需要java环境才能运行的,需要先安装java环境才可以。
2 为什么我用着用着就自动关闭了?大概30分钟就会关闭一次。
因为charles如果没有注册的话,每次打开后就只能哟个30分钟,然后就会自动关闭,所以最好在使用前先按照说明去进行工具的注册操作。
3 为什么我在操作的时候有时候就直接工具就界面卡住死了,关都关不掉,只能用任务管理器才可以关掉?
这个的确是charles这个工具的一个bug,开始用的时候,我也很恶心,而且经常悲剧,但是现在也有相应的解决办法了,下面那样操作就可以了。
首先随便抓些包,要求有图片的请求。

然后选中一个图片的请求,然后分别点击 Response - Raw 然后那里会加载其中的内容,然后加载完毕后,再去随便操作就可以了,就不会在悲剧的直接工具卡死掉了。。。

4 为什么用了charles后,我就上不了网页了,但是qq可以。
因为如果charles是非正常状态下关闭的话,那么IE的代理就不会被自动取消,所以会导致这种情况。
解决办法:
第一种:直接打开charles,然后再正常关闭即可。 第二种:去将IE浏览器代理位置的勾选去掉。

5 为什么我用charles不能抓到socket和https的数据呢?
首先,charles是不支持抓去socket数据的。 然后,如果抓不到https的数据的话,请查看你是不是没有勾选ssl功能。 Proxy - Proxy Settings - SSL 设置
6 为什么我用charles抓取手机APP,什么都是配置正确的,但是却抓不到数据。
首先,请确保电脑的防火墙是关闭状态,这个很重要。

如果,防火墙关了还是不行,那么请把手机wifi断掉后重新连接,这样一般就可以解决问题了。 如果以上方法还是不行的话,那么请将手机wifi位置的ip地址设置成静态ip,然后重启charles工具。
7 抓包后发现form中有些数据显示是乱码怎么办?
请在Raw模式下查看,Raw模式显示的是原始数据包,一般不会因为编码问题导致显示为乱码。
8 我用charles抓手机app的数据,但是同时也会抓去到电脑端的数据,可以设置吗?
可以,设置位置在Proxy - Windows Proxy ,勾选表示接收电脑的数据抓包,如果只想抓去APP的数据请求,可以不勾选此功能。
9 为什么我用IE可以抓到数据,但是用360或者谷歌浏览器就不行?
请确保360或者谷歌的代码设置中是不是勾选设置的是 使用IE代理。

10 想要复制粘贴某些数据的话,怎么办,右键没有相应功能啊?
请直接使用Ctrl +C 和 Ctrl+V 即可。
以上就是charles在使用过程中常见的10中问题和相应的解决情况,有了这个文章,大家就不用在遇到问题的时候懊恼了,嘿嘿
如何在Chrome下使用Postman进行rest请求测试
2016-04-20 18:48:33
在web和移动端开发时,常常会调用服务器端的restful接口进行数据请求,为了调试,一般会先用工具进行测试,通过测试后才开始在开发中使用。这里介绍一下如何在chrome浏览器利用postman应用进行restful api接口请求测试。
1、安装Postman
- 1
下载postman,这里提供两种方式。
1、通过postman官方网站直接点击百度搜索“postman”
就可以找到。
点击“get it now it's free!”进入chrome商店下载
注意:chrome商店需要到“墙外”在才能下载。

- 2
2、离线安装:
文件已经放在百度云上:
链接: http://pan.baidu.com/s/1bni9Dzp 密码: kkgb
解压下载的文件“Postman-REST-Client_v0.8.1”,内容文件结构如下:

- 3
打开Chrome,依次选择“选项”>>"更多工具">>“扩展程序”,
也可以在地址栏里直接输入:“chrome://extensions/”
打开后如下图
勾选“开发者模式”
然后点击“加载已解压的扩展程序”,选择刚才我们下载并解压出来的文件夹。


- 4
安装好后如图:
 END
END
2、进行Restful请求测试
- 1
打开chrome的“应用”,或者直接在地址栏里输入“chrome://apps/”也可以打开应用页面
打开postman

- 2
Get请求:
在地址栏里输入请求url:http://localhost:9998/api/user
选择“GET”方式,
点击"Url params",添加url params key:id , value:1
点击“send”得到json数据如下:

- 3
如果想要Post请求:
在地址栏里输入请求url:http://localhost:9998/api/user/1
选择“POST”方式,
点击"application/x-www-form-urlencoded",
添加key:name , value:baidu-lulee007
添加key:sex , value:man

- 4
注意:请求支不支持post请求是由服务端决定。
如果服务端需要请求类型为json,需要在“headers”添加
key:Content-Type , value:application/json
选择“raw”,并添加:
{
"id": 1,
"data": {
"name": "baidu-lulee007",
"sex": "man"
}
}

Oracle诊断--Spotlight On Oracle
2016-04-16 23:31:18
http://blog.csdn.net/jim110/article/details/6947989
Spotlight on Oracle 能让你迅速发现任何性能瓶颈,无论是实时还是历史查询。Spotlight 能鉴别和诊断几千种性能问题,无论是特定用户问题、集中资源SQL事务、 I/O瓶颈、锁定等待或者其它源码问题。Spotlight for Oracle 能自动为每个实例建立正常活动的底线,当检测到性能瓶颈时自动发出警告.
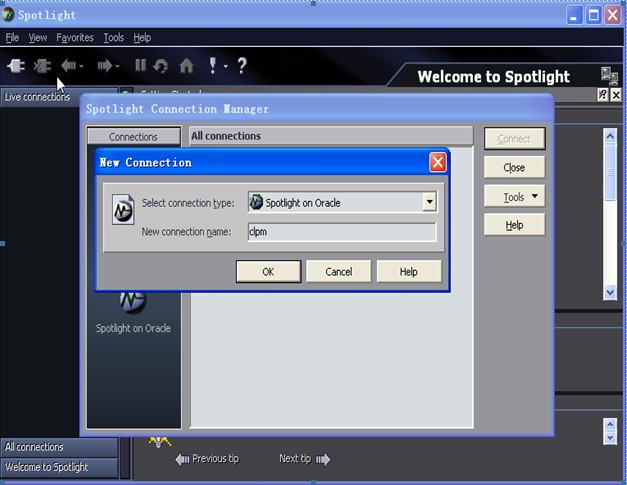
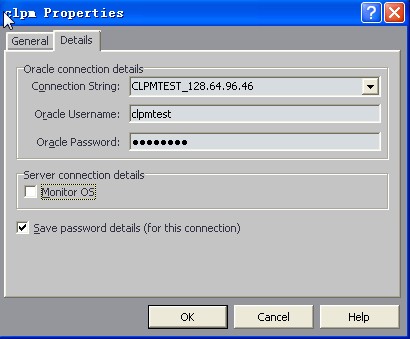
一、首先建立Oracle的连接
第一步要新建connection,这样能够使用spotlight连接到要监测的数据库。
一、系统主界面
系统主界面反映了系统的整体运行情况,如果系统哪方面出现问题,会报相应的警告,不同级别显示不同的颜色,最严重为红色警告。然后据此警告可下钻到相应的子窗口,查看相应情况。下面介绍各子窗口。
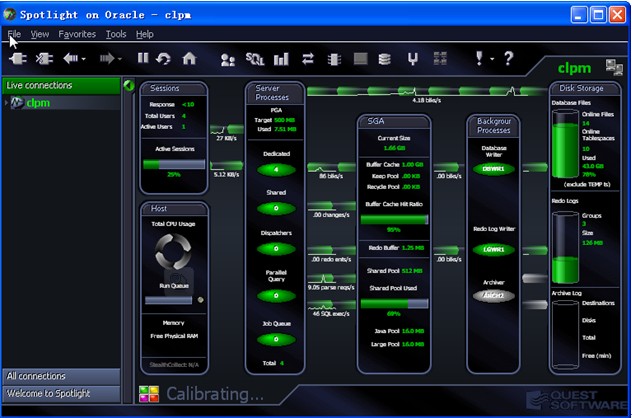
1.Session面板:
(1)Response<10,系统的响应时间
(2)Total Users:总用户SESSION数
(3)Active Users:当前正在执行的用户SESSION数
2.Host面板:
(1)CPU利用率
(2)内存的使用情况
3. Server Processes面板:显示服务器进程的信息
(1)PGA Target/Used显示PGA目标总数及当前使用数
(2)dedicated显示专用服务器进程的个数
(3)Shared显示共享服务器进程的个数。
(4)Dispatchers显示dispathers的个数.
(5)JobQueue显示作业进程的个数
4. SGA面板:显示SGA中各组件的内存使用情况
(1)CurrentSize显示当前sga使用M数
(2)BufferCache,KeepPool,RecyclePool显示数据缓冲区的内存情况
(3)SharedPool:共享池的使用情况
(4)RedoLog:重作日志的使用情况
(5)LargePool:大池的使用情况
(6)JavaPool:java池的使用情况
5.Background process面板-后台进程面板:显示与磁盘I/O相关的后台进程。
(1)DBWR 数据写入进程
(2)LGWR 日志进程
(3)ARCH 规档进程式
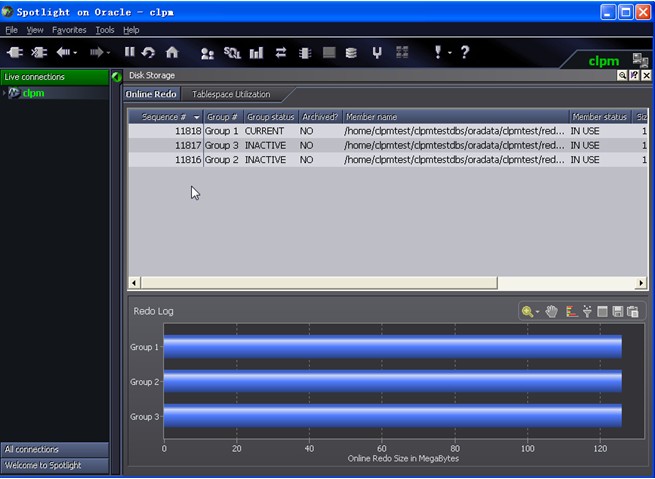
6. 磁盘存储面板:显示主要数据库文件的情况(控制文件除外)
(1)DatabaseFiles:显示数据文件使用情况。
(2)联机日志文件情况。包括组数及大小。
(3)归档日志情况。
三、TopSessions
通过topSession面板可以查看当前哪个session当前占用了大量的资源,以此定位数据库问题。单击上部列表,会在session Information中显示该会话的所有详细信息。
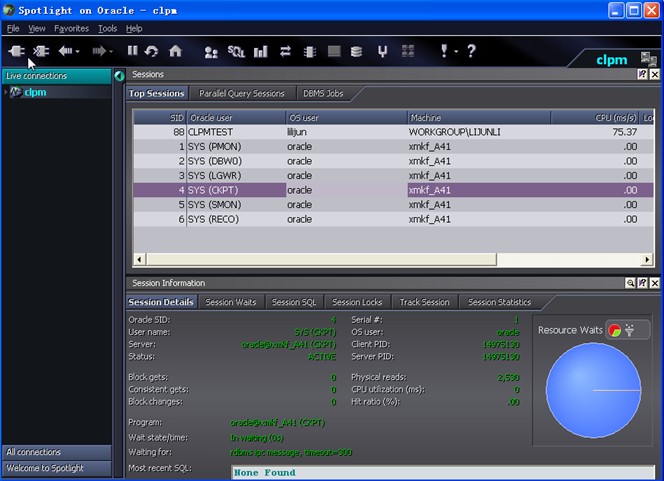
下面是几个应注意的地方:
most recent sql:可以用来确定当前占用资源最大的sql语句
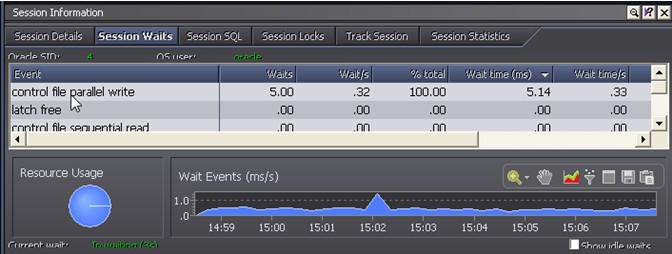
Session waits:可以找出与该session相关的等待事件。
Session locks:显示相关的锁信息。

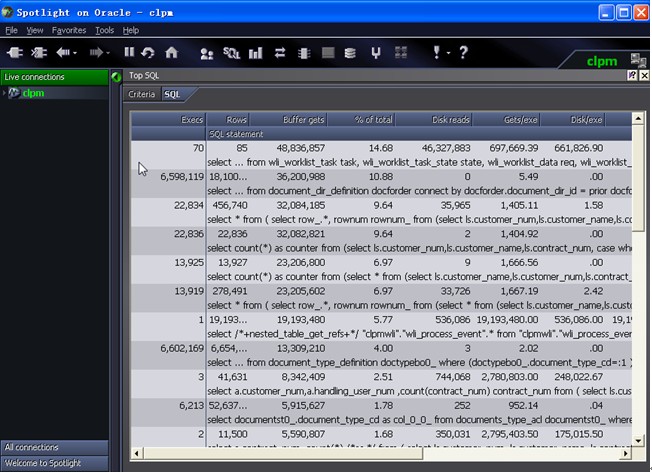
四、top sql:根据条件来查看libraryCache中相应的sql.
主要的选项为sorting
可以据此来找出影响大的sql

点击Fetch SQL按钮,可以查看到相应的SQL语句
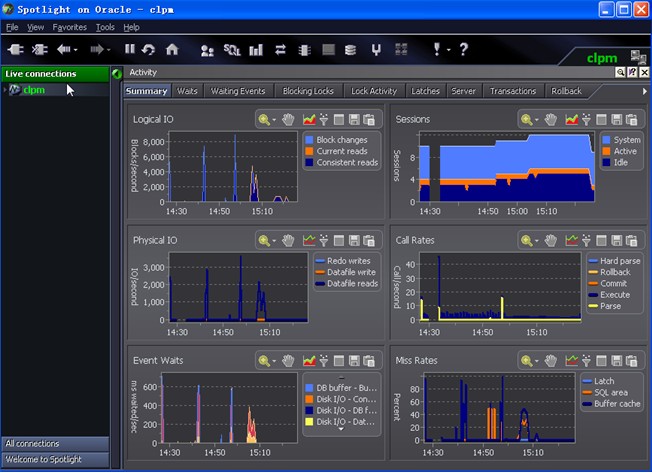
五、Activity:这个窗口,主要提供了等待事件,锁等待,闫锁等待,当前事务等。
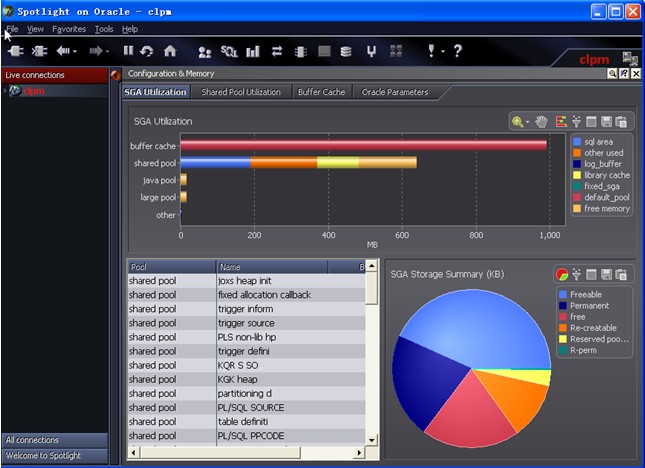
六、配置和内存:主要显示SGA的使用情况及参数配置情况
七、磁盘存储情况:显示表空间利用率和在线日志的使用情况。
AWR报告详解(二)
2016-04-16 23:05:52
SQL Statistics v$sqlarea
- SQL ordered by Elapsed Time
- SQL ordered by CPU Time
- SQL ordered by Gets
- SQL ordered by Reads
- SQL ordered by Executions
- SQL ordered by Parse Calls
- SQL ordered by Sharable Memory
- SQL ordered by Version Count
- SQL ordered by Cluster Wait Time
- Complete List of SQL Text
本节按各种资源分别列出对资源消耗最严重的SQL语句,并显示它们所占统计期内全部资源的比例,这给出我们调优指南。例如在一个系统中,CPU资源是系统性能瓶颈所在,那么优化buffer gets最多的SQL语句将获得最大效果。在一个I/O等待是最严重事件的系统中,调优的目标应该是physical IOs最多的SQL语句。
在STATSPACK报告中,没有完整的SQL语句,可使用报告中的Hash Value通过下面语句从数据库中查到:
SELECT sql_text
FROM stats$sqltext
WHERE hash_value = &hash_value
ORDER BY piece;
SQL ordered by Elapsed Time
- Resources reported for PL/SQL code includes the resources used by all SQL statements called by the code.
- % Total DB Time is the Elapsed Time of the SQL statement divided into the Total Database Time multiplied by 100
SQL ordered by CPU Time
- Resources reported for PL/SQL code includes the resources used by all SQL statements called by the code.
- % Total DB Time is the Elapsed Time of the SQL statement divided into the Total Database Time multiplied by 100
SQL ordered by Gets
- Resources reported for PL/SQL code includes the resources used by all SQL statements called by the code.
- Total Buffer Gets: 16,648,792
- Captured SQL account for 97.9% of Total
这一部分,通过Buffer Gets对SQL语句进行排序,即通过它执行了多少个逻辑I/O来排序。顶端的注释表明一个PL/SQL单元的缓存获得(Buffer Gets)包括被这个代码块执行的所有SQL语句的Buffer Gets。因此将经常在这个列表的顶端看到PL/SQL过程,因为存储过程执行的单独的语句的数目被总计出来。在这里的Buffer Gets是一个累积值,所以这个值大并不一定意味着这条语句的性能存在问题。通常我们可以通过对比该条语句的Buffer Gets和physical reads值,如果这两个比较接近,肯定这条语句是存在问题的,我们可以通过执行计划来分析,为什么physical reads的值如此之高。另外,我们在这里也可以关注gets per exec的值,这个值如果太大,表明这条语句可能使用了一个比较差的索引或者使用了不当的表连接。
另外说明一点:大量的逻辑读往往伴随着较高的CPU消耗。所以很多时候我们看到的系统CPU将近100%的时候,很多时候就是SQL语句造成的,这时候我们可以分析一下这里逻辑读大的SQL。
SELECT *
FROM ( SELECT SUBSTR (sql_text, 1, 40) sql,
buffer_gets,
executions,
buffer_gets / executions "Gets/Exec",
hash_value,
address
FROM v$sqlarea
WHERE buffer_gets > 0 AND executions > 0
ORDER BY buffer_gets DESC)
WHERE ROWNUM <= 10;
AWR 是 Oracle 10g 版本 推出的新特性, 全称叫Automatic Workload Repository-自动负载信息库, AWR 是通过对比两次快照(snapshot)收集到的统计信息,来生成报表数据,生成的报表包括多个部分
WORKLOAD REPOSITORY report for
DB Name
DB Id
Instance
Inst num
Release
RAC
Host
ICCI
1314098396
ICCI1
1
10.2.0.3.0
YES
HPGICCI1
Snap Id
Snap Time
Sessions
Cursors/Session
Begin Snap:
2678
25-Dec-08 14:04:50
24
1.5
End Snap:
2680
25-Dec-08 15:23:37
26
1.5
Elapsed:
78.79 (mins)
DB Time:
11.05 (mins)
DB Time不包括Oracle后台进程消耗的时间。如果DB Time远远小于Elapsed时间,说明数据库比较空闲。
db time= cpu time + wait time(不包含空闲等待) (非后台进程)说白了就是db time就是记录的服务器花在数据库运算(非后台进程)和等待(非空闲等待)上的时间DB time = cpu time + all of nonidle wait event time
在79分钟里(其间收集了3次快照数据),数据库耗时11分钟,RDA数据中显示系统有8个逻辑CPU(4个物理CPU),平均每个CPU耗时1.4分钟,CPU利用率只有大约2%(1.4/79)。说明系统压力非常小。
列出下面这两个来做解释:
Report A:
Snap Id Snap Time Sessions Curs/Sess
--------- ------------------- -------- ---------
Begin Snap: 4610 24-Jul-08 22:00:54 68 19.1
End Snap: 4612 24-Jul-08 23:00:25 17 1.7
Elapsed: 59.51 (mins)
DB Time: 466.37 (mins)
Report B:
Snap Id Snap Time Sessions Curs/Sess
--------- ------------------- -------- ---------
Begin Snap: 3098 13-Nov-07 21:00:37 39 13.6
End Snap: 3102 13-Nov-07 22:00:15 40 16.4
Elapsed: 59.63 (mins)
DB Time: 19.49 (mins)
服务器是AIX的系统,4个双核cpu,共8个核:/sbin> bindprocessor -q
The available processors are: 0 1 2 3 4 5 6 7先说Report A,在snapshot间隔中,总共约60分钟,cpu就共有60*8=480分钟,DB time为466.37分钟,则:
cpu花费了466.37分钟在处理Oralce非空闲等待和运算上(比方逻辑读)
也就是说cpu有 466.37/480*100% 花费在处理Oracle的操作上,这还不包括后台进程
看Report B,总共约60分钟,cpu有 19.49/480*100% 花费在处理Oracle的操作上
很显然,2中服务器的平均负载很低。
从awr report的Elapsed time和DB Time就能大概了解db的负载。
可是对于批量系统,数据库的工作负载总是集中在一段时间内。如果快照周期不在这一段时间内,或者快照周期跨度太长而包含了大量的数据库空闲时间,所得出的分析结果是没有意义的。这也说明选择分析时间段很关键,要选择能够代表性能问题的时间段。
Report Summary
Cache Sizes
Begin
End
Buffer Cache:
3,344M
3,344M
Std Block Size:
8K
Shared Pool Size:
704M
704M
Log Buffer:
14,352K
显示SGA中每个区域的大小(在AMM改变它们之后),可用来与初始参数值比较。
shared pool主要包括library cache和dictionary cache。library cache用来存储最近解析(或编译)后SQL、PL/SQL和Java classes等。library cache用来存储最近引用的数据字典。发生在library cache或dictionary cache的cache miss代价要比发生在buffer cache的代价高得多。因此shared pool的设置要确保最近使用的数据都能被cache。
Load Profile
Per Second
Per Transaction
Redo size:
918,805.72
775,912.72
Logical reads:
3,521.77
2,974.06
Block changes:
1,817.95
1,535.22
Physical reads:
68.26
57.64
Physical writes:
362.59
306.20
User calls:
326.69
275.88
Parses:
38.66
32.65
Hard parses:
0.03
0.03
Sorts:
0.61
0.51
Logons:
0.01
0.01
查看(2219) 评论(0) 收藏 分享 管理 标题搜索
我的存档
数据统计
- 访问量: 147520
- 日志数: 83
- 文件数: 1
- 建立时间: 2008-08-20
- 更新时间: 2018-03-05
RSS订阅
清空Cookie - 联系我们 - 51Testing软件测试网 - 交流论坛 - 空间列表 - 站点存档 - 升级自己的空间
Powered by 51Testing © 2003-2021
沪ICP备05003035号





















