用TortoiseSVN用同一个https网址访问版本库始终出现server sent unexpected return value(403 forbidden)in response to options…… ,察看了下apache的ssl错误记录,发现原来是指定了DocumentRoot的缘故。在ssl.conf中注释掉DocumentRoot这一行就可以了。http也是一样的,如果你配置了虚拟主机,就不能指定该ServerName的DocumentRoot。

-
Test Bach Runner运行后QTP菜单栏下拉菜单消失解决方法
2010-11-29 21:43:20
QTP10.0使用Test Batch Runner运行后,会造成QTP的菜单栏的下拉菜单为空,这是QTP的一个BUG,在Test Batch Runner调用QTP运行完成后,没有将菜单栏还原。解决方法为:在菜单栏点击右键,选择“Customize”,在Customize窗口的ToolBarTab页,点击“Restore All”后即可。 -
Daily Build Using CC and MSBuild
2010-05-25 15:14:27
在上一篇项目管理实践教程二、源代码控制【Source Control Using VisualSVN Server and TortoiseSVN】中我们已经讲解了如何使用TortoiseSVN和VisualSVN Server来做简单的版本控制,这一篇我们将会讲解使用CruiseControl.NET和MSBuild来搭建每日构建系统。
在第一篇项目管理实践教程一、工欲善其事,必先利其器【Basic Tools】 中我们已经安装了CruiseControl.NET 1.4,因为我们还要用到MSBuild,所以如果你的系统没有安装Visual Studio,那么你需要首先安装Visual Studio 2005/2008,我们在这里使用的是Visual Studio 2008,准备好这些了吗?OK,我们正式开始今天的课程!
首先,我们要配置CruiseControl.NET【下面简写为CCNET】,配置完成后,我们每次提交源代码到SVN服务器后,CCNET就可以自动从SVN服务器上签出源代码,并调用MSBuild自动进行编译。我们以昨天的教程中创建的StartKit项目为实例,先看看下面的配置文件:

 CCNET配置文件代码
CCNET配置文件代码
1 <cruisecontrol xmlns:cb="urn:ccnet.config.builder">
2 <!--项目名称-->
3 <name>StartKit</name>
4 <!--标示类型,有多种类型。下面为默认标示,作为每次编译时生成的日志文件的名称-->
5 <labeller type="defaultlabeller">
6 <!--前缀-->
7 <prefix>StartKit-1-</prefix>
8 <!--编译失败时是否增加-->
9 <incrementOnFailure>false</incrementOnFailure>
10 <!--格式-->
11 <labelFormat>00000</labelFormat>
12 </labeller>
13 <!--项目的WebDashboard地址,CruiseControl.NET包括二部分,一是Server用来配置项目和监视文件修改,二是WebDashboard,是一个显示项目信息及编译信息的Website-->
14 <webURL>http://202.196.96.55:8080/server/local/project/StartKit/ViewProjectReport.aspx</webURL>
15 <!--触发器,包含多种,有兴趣可以查看官方文档-->
16 <triggers>
17 <!--时间间隔触发器,下面是60秒触发一次-->
18 <intervalTrigger seconds="60" />
19 </triggers>
20 <!--如果发现修改,延迟多久开始编译,下面是2秒-->
21 <modificationDelaySeconds>2</modificationDelaySeconds>
22 <!--源代码控制系统,支持多种,有兴趣可以查看官方文档,下面采用svn-->
23 <sourcecontrol type="svn">
24 <!--源代码在SVN服务器上的路径-->
25 <trunkUrl>http://zt.net.henu.edu.cn/svn/StartKit/StartKit/</trunkUrl>
26 <!--svn服务器所在路径,在这里就是VisualSVN Server安装目录中的bin目录下的svn.exe -->
27 <executable>C:/Program Files/VisualSVN Server/bin/svn.exe</executable>
28 <!--用来迁出源代码的用户名,svn服务器进行验证-->
29 <username>starter</username>
30 <!--用来迁出源代码的用户名对应的密码-->
31 <password>123456</password>
32 <!--web获取源代码的地址,类似于开源网站上浏览代码的那部分功能,这里的类型是trac-->
33 <!--<webUrlBuilder type="trac">
34 <!--trac中对应项目的地址¬-->
35 <tracProjectUrl>http://svn.net.henu.edu.cn/pojects/StartKit/</tracProjectUrl>
36 <!--trac中对应项目的源代码库地址,相对于上面的路径-->
37 <tracRepositoryRoot>/StartKit</tracRepositoryRoot>
38 </webUrlBuilder>-->
39 </sourcecontrol>
40 <!--该节点用来配置具体执行那些任务-->
41 <tasks>
42 <!--msbuild任务配置,用来编译项目-->
43 <msbuild>
44 <!--MSBuild.exe的路径-->
45 <executable>C:\WINDOWS\Microsoft.NET\Framework\v3.5\MSBuild.exe</executable>
46 <!--从SVN迁出的源代码的存放位置,可以不配置,下面的即为默认值 -->
47 <!--我这里的CruiseControl.NET 安装在D盘,你们使用时候,改成自己的安装路径即可-->
48 <workingDirectory>D:\Program Files\CruiseControl.NET\server\StartKit\WorkingDirectory</workingDirectory>
49 <!--对这个项目的监控过程的日志记录目录,可以不配置,下面的即为默认值-->
50 <!--我这里的CruiseControl.NET 安装在D盘,你们使用时候,改成自己的安装路径即可-->
51 <artifactDirectory> D:\Program Files\CruiseControl.NET\server\StartKit\ Artifacts</artifactDirectory>
52 <!--要编译的项目名称 -->
53 <projectFile>StartKit.sln</projectFile>
54 <!-- MSBuild编译时的参数,具体参数信息可以查看MSDN上的说明-->
55 <buildArgs>/p:configuration=debug</buildArgs>
56 <!--指定日志记录模块-->
57 <!--我这里的CruiseControl.NET 安装在D盘,你们使用时候,改成自己的安装路径即可-->
58 <logger>ThoughtWorks.CruiseControl.MsBuild.XmlLogger,D:\Program Files\CruiseControl.NET\server\ThoughtWorks.CruiseControl.MsBuild.dll</logger>
59 <!--编译目标-->
60 <targets />
61 </msbuild>
62 <!--在这里还可以添加其他的程序,比如运行测试、部署项目等等-->
63 </tasks>
64 <!--项目编译状态信息的保存位置-->
65 <!--我这里的CruiseControl.NET 安装在D盘,你们使用时候,改成自己的安装路径即可-->
66 <state type="state" directory="D:\Program Files\CruiseControl.NET\server\CCState" />
67 <!--发布和部署配置-->
68 <publishers>
69 <!--如果编译成功,那么下面的配置,会将源代码复制到指定目录HistoryVersion下,名称为版本标识(自动增长,labeller配置)的子目录下-->
70 <buildpublisher>
71 <!--源代码路径-->
72 <!--我这里的CruiseControl.NET 安装在D盘,你们使用时候,改成自己的安装路径即可-->
73 <sourceDir> D:\Program Files\CruiseControl.NET\server\StartKit\WorkingDirectory </sourceDir>
74 <!--编译成功后保存源代码到该目录下名称为版本标示labeller的目录中-->
75 <!--我这里的CruiseControl.NET 安装在D盘,你们使用时候,改成自己的安装路径即可-->
76 <publishDir> D:\Program Files\CruiseControl.NET\server\StartKit\HistoryVersion </publishDir>
77 </buildpublisher>
78 <!--该节点用来配置合并多个文件,当时有外部插件时,要把他们分别产生的输出文件合并-->
79 <merge>
80 <!--要合并的文件,合并后的信息可以显示在Web Dashboard和邮件通知里-->
81 <files>
82 <!--我这里的CruiseControl.NET 安装在D盘,你们使用时候,改成自己的安装路径即可-->
83 <file>D:\Program Files\CruiseControl.NET\server\StartKit\WorkingDirectory\results.xml</file>
84 </files>
85 </merge>
86 <!--源代码路径-->
87 <xmllogger />
88 <!--显示历史修改记录列表, 在Web Dashboard中可以查看-->
89 <modificationHistory />
90 <!--所有编译信息的统计, 在Web Dashboard中可以查看-->
91 <statistics />
92 <!--邮件通知配置,每次编译后,都会邮件通知下面配置中添加的用户-->
93 <!-- mailhost是发送邮件的主机,mailport是邮件发送端口,mailhostUsername发送邮件的邮箱用户名,mailhostPassword发送邮件的邮箱密码,from希望显示在发件人中的邮箱地址, includeDetails邮件内容是否包含详细的编译信息 -->
94 <email mailhost="smtp.qq.com" mailport="25"
95 mailhostUsername="******" mailhostPassword="******" from="******@qq.com" includeDetails="true">
96 <!--接收邮件通知的用户 -->
97 <users>
98 <!--name是SVN服务器上存在的用户名,group是SVN服务器上存在的组,address是该用户的邮箱地址 -->
99 <user name="zt" group="StartKit" address="******1@qq.com" />
100 <user name="***" group="StartKit" address="******2@qq.com" />
101 <user name="***" group="StartKit" address="******3@qq.com" />
102 </users>
103 <!--接收邮件通知的组-->
104 <groups>
105 <!--name必须是SVN服务器上存在的组,notification是什么时候发送通知,可选有Always/Success/Change/Fixed/Failed --> 106 <group name="StartKit " notification="always" /> 107 </groups>
108 </email>
109 </publishers>
110 </project>
111 <!--可以同时添加多个项目
112 <project >
113 <name>test</name>
114 ……
115 </project>
116 -->
117 </cruisecontrol
好了,我们已经对CCNET的配置文件有了大致的了解,接下来,你打开CCNET的安装路径,找到子目录server下的ccnet.config文件,把上面的配置信息Copy到ccnet.config文件中,记得把配置文件中的一些路径修改为自己的实际路径啊,修改好后,保存。这时候,检查Windows服务CruiseControl.NET Server是否启动,如果没有则启动它,启动该服务后,打开浏览在地址栏输入上面配置文件中的webUrl地址:http://202.196.96.55:8080/server/local/project/StartKit/ViewProjectReport.aspx 也可以直接输入http://202.196.96.55:8080/server/ ,这里是演示地址,要根据自己的实际情况修改为正确的地址,OK,看到类似下图的效果,好了,搞定!如果你遇到了什么麻烦,请在下面留言,我一定会及时回复!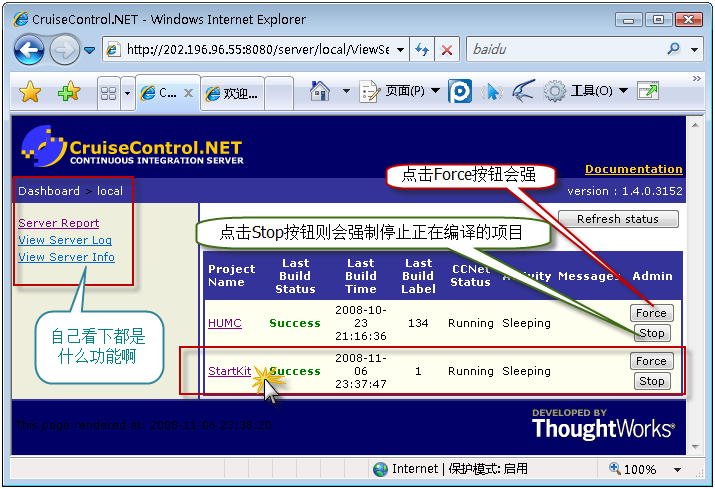 点击StartKit,转入下图所示的页面:
点击StartKit,转入下图所示的页面: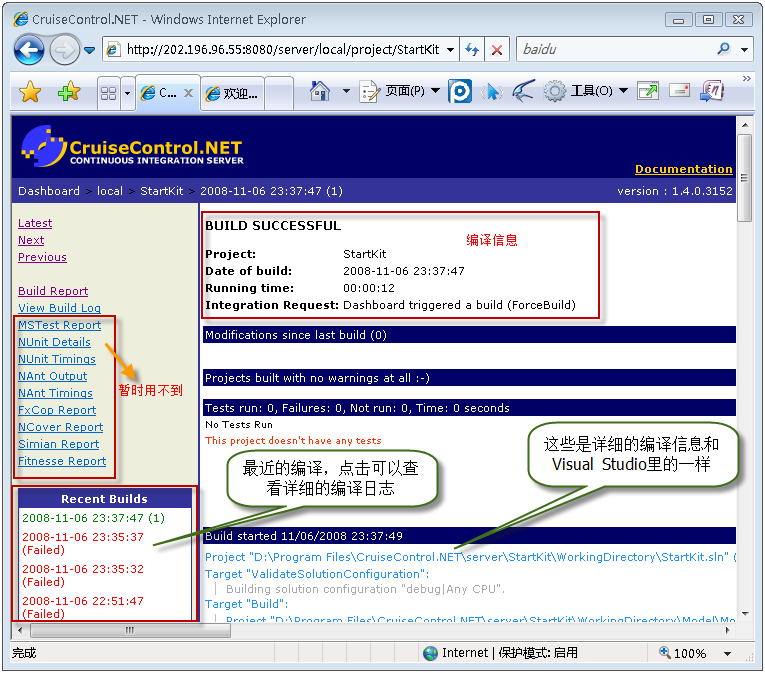 OK,到这里,我们提交更新到SVN服务器后,CCNET就会根据我们配置自动编译项目,而且我们也可以通过Web Dashboard来查看具体的编译信息了,提示如果配置了邮件发送,那么我们还可以通过邮件收到详细的编译信息,怎么样?够方便吧!
OK,到这里,我们提交更新到SVN服务器后,CCNET就会根据我们配置自动编译项目,而且我们也可以通过Web Dashboard来查看具体的编译信息了,提示如果配置了邮件发送,那么我们还可以通过邮件收到详细的编译信息,怎么样?够方便吧!
其实,CCNET的功能是相当强大的,上面只是最常用的配置,其他还有很多非常好的功能。你想知道吗?那你可以在这里查看CCNET官方文档 ,实际上,你安装CCNET后,文档也已经安装到你的电脑了,在CCNET的安装目录下的webdashboard的子目录doc中就是。
好了,我们今天的教程就到这里,本来我应该把如何使用CruiseControl.NET Tray来监视每次更新后的编译状态,但是今天真的太晚了,明天还要做项目,所以我明天补上,请大家见谅!
补充部分:
下面我简单讲一下,如何使用CruiseControl.NET Tray【以下简称CCTray】来监视每次提交后的编译状态。
安装好打开CCTray后,运行CCTray程序,点击左上角的菜单File下的Settings…,如下图:
点击Settings…会弹出下面的窗体: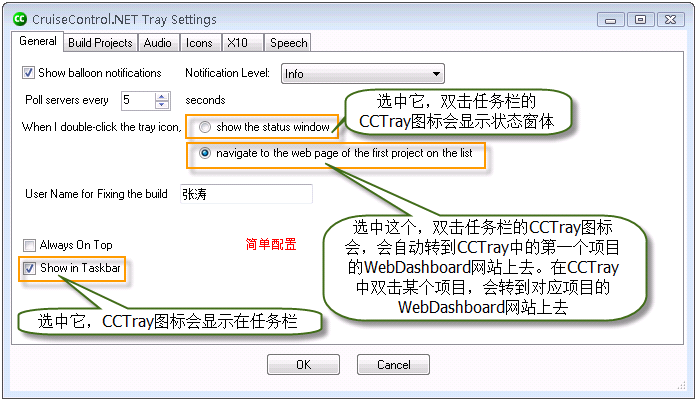
切换到Build Projects选项卡,如下图: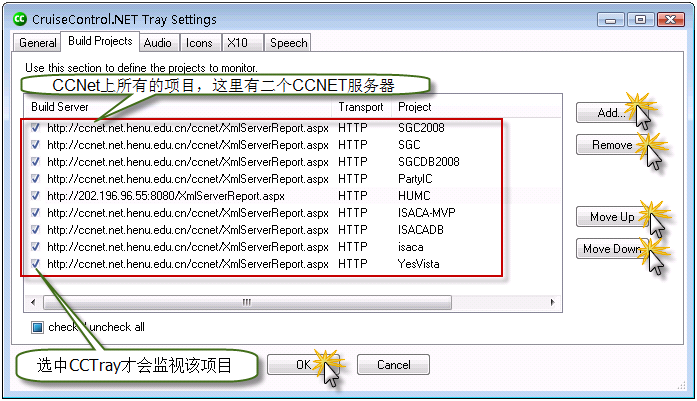
点击Add…按钮,添加我们的CCNET服务器,如下图: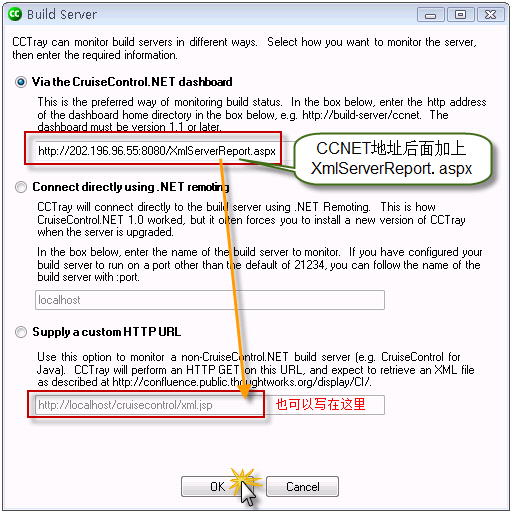
输入我们的CCNET服务器后,CCNET服务器上的项目就会在右侧显示出来,如下图: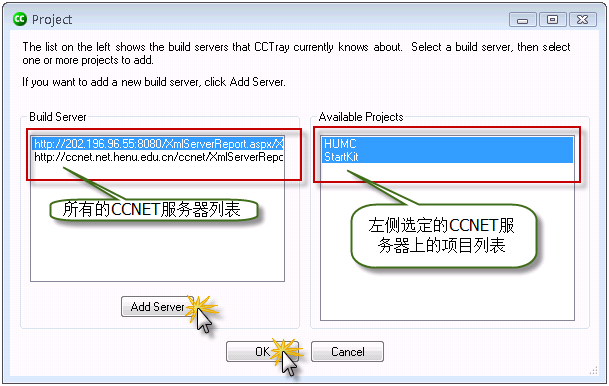
选中右侧的项目后,点击OK按钮,返回CCTray打开时的界面,我们的二个项目已经添加进来了,如下图: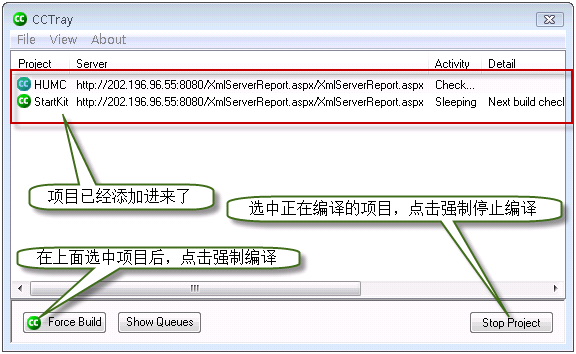
我们在桌面的右下角的任务栏,可以看到如下图所示的图标:
绿色的那个标示就是CCTray的标示,绿色表示所有的项目都通过了编译,紫红色表示至少有一个项目没有通过编译,橘黄色表示有项目正在编译,橘红色表示有项目被强制编译,显示为灰色则说明和CCNET服务器失去了链接。
OK,大家可以使用CCTray实时监视提交更新后项目的编译状态了。 -
cruisecontrol下载地址
2010-05-25 12:06:56
http://cruisecontrol.sourceforge.net/download.html
-
FxCop 设计规则
2010-05-25 12:05:14
一、 Design(设计)
1. Abstract types should not have constructors
抽象类不应该声明构造方法2. Assemblies should have valid strong names
程序集应该具有强名称3. Avoid empty interfaces
避免使用空的接口4. Avoid excessive parameters on generic types
避免在泛型类中使用过多的类型参数5. Avoid namespaces with few types
避免让名字空间含有过少的类型6. Avoid out parameters
避免使用 out类型的参数7. Collections should implement generic interface
集合类应该实现泛型接口8. Consider passing base types as parameters
尽量使用基本类型作为参数9. Declare event handlers correctly
正确的声明事件处理器,事件处理器不应该具有返回值10. Declare types in namespaces
应该在名字空间里面定义类型,而不是外面11. Default parameters should not be used
不应该使用参数默认值(C#没有参数默认值)12. Define accessors for attribute arguments
应该为特性(特性)的构造方法参数定义访问器,其名字跟构造方法参数仅首字母大小写不一样13. Do not catch general exception types
不要捕捉普通的异常(即System.Exception)14. Do not declare protected members in sealed types
不要在封闭类型中定义受保护的成员15. Do not declare static members on generic types
不要在泛型类型中使用静态成员16. Do not declare virtual members in sealed types
不要在封闭类型中定义虚成员17. Do not declare visible instance fields
不要定义可见的(public/internal)实例域变量18. Do not expose generic lists
不要直接暴露范型表19. Do not hide base class methods
不要隐藏(使用或者不使用new)基类的方法20. Do not nest generic types in member signatures
不要在成员的签名(参数或者返回值)中嵌套泛型类21. Do not override operator equals on reference types
不要在引用类型中重载==操作符22. Do not pass types by reference
不要使用引用(ref or out)传递类型23. Enum Storage should be Int32
枚举应该是 Int32 类型的24. Enumerators should be strongly typed
枚举器应该是强类型的25. Enums should have zero value
枚举应该具有0值26. Generic methods should provide type parameter
泛型类的方法应该提供类型参数27. ICollection implementations have strongly typed members
集合接口的实现中应该使用强类型的成员28. Implement standard exception constructors
自定义的异常应该实现异常类的四个标准构造方法29. Indexers should not be multidimensional
索引不应该是多维的30. Interface methods should be callable by child types
接口方法应该可以被子类调用31. Lists are strongly typed
表应该是强类型的32. Mark assemblies with assembly version
用程序集版本标示程序集33. Mark assemblies with CLSCompliant
使用CLSCompliant特性标示程序集34. Mark assemblies with ComVisible
使用 System.Runtime.InteropServices.ComVisibleAttribute 特性标示程序集35. Mark attributes with AttributeUsageAttribute
使用 AttributeUsageAttribute 特性标示特性类36. Mark enums with FlagsAttribute
含有组合的枚举应该使用FlagsAttribute特性标示,相反则不应该37. Members should not expose certain concrete types
成员(返回值或者参数)不应该暴露具体类型,尽量使用接口38. Move pinvokes to native methods class
将调用移到本地方法类(不是很理解)39. Nested types should not be visible
嵌套类型不应该是可见的40. Override methods on comparable types
可比较类型应该重写 equals 等方法41. Override operator equals on overriding add and subtract
在重写+和-运算的时候应该同时重写==操作符42. Properties should not be write only
属性不应该是只写的43. Provide ObsoleteAttribute message
过时的成员应该使用ObsoleteAttribute特性标示,并提供相应的Message提示使用者44. Replace repetitive arguments with params array
使用参数数组代替重复的参数45. Static holder types should be sealed
仅含有静态成员的类型应该声明为封闭的46. Static holder types should not have constructors
仅含有静态成员的类型应该具有构造方法47. String uri overloads call system uri overloads
使用string类型的uri参数的重载应调用系统的使用URI类型参数的重载48. Types should not extend certain base types
类型不应该从具体的类(已经过派生的类)继承,比如异常类不应该从ApplicationException继承,而应该从System.Exception继承49. Types that own disposable fields should be disposable
含有可释放成员的类型应该是可以释放的(实现IDisposable接口)50. Types that own native resources should be disposable
使用了非托管资源的类型应该是可以释放的(实现IDisposable接口)51. Uri parameters should not be strings
Uri 参数不应该是string类型的52. Uri properties should not be strings
Uri 属性不应该是string类型的53. Uri return values should not be strings
Uri 类型的返回值不应该是string类型的54. Use events where appropriate
在适当的时候使用事件55. Use generic event handler instances
使用泛型的事件处理器实例56. Use generics where appropriate
在适当的时候使用范型57. Use integral or string argument for indexers
索引器应该使用整数或者字符串类型的参数58. Use properties where appropriate
在适当的时候使用属性(而不是以Get或者Set开头的方法)59. Validate arguments of public methods
对public的方法的参数应该在方法开头处进行检验(比如是否为null的检验)二、 Globalization(全球化)
1. Avoid duplicate accelerators
避免在顶层控件中使用重复的快捷键(加速键)
2. Do not hardcode locale specific strings
不要对本地的特殊字符串(比如特殊的系统路径)进行硬编码3. Do not pass literals as localized parameters
不要把文本作为需要本地化的参数直接传递(尽量使用资源文件)4. Set locale for data types
<P class=MsoNormal style="MARGIN: 9pt 0cm
为某些数据类型设定区域和语言属性(DataSet和DataTable的locale属性) -
如何用CruiseControl.Net来进行持续化集成
2010-05-25 12:02:47
本文总结了过去一年中使用CruiseControl.Net来对工作流程进行持续化集成的经验教训,详细地讲述安装,配置,使用CruiseControl.Net的具体步骤,希望通过阅读本文,能理解和掌握使用CruiseControl.Net的基本使用技巧,用工具来改善工作流程和提高工作效率。
什么是持续化集成
首先,我们先搞清楚什么是持续化集成?它对我们的日常工作有什么样的帮助?在过去几年中,敏捷已经是一个非常热门的话题,它高效的工作方式和快速的需求应对能力,赢得了很多中小软件厂商的关注。那么敏捷除了一些经常谈论到编程思维和迭代的开发模式等,其实还部分依赖于好的改善工作流程的工具。持续化集成工具便是服务于敏捷软件开发的一个系列。它主要将原本分散,无序的工作流程,通过工具软件有机的组织起来,并且在组织的过程中,参与开发设计测试的各个部门的人员都能从中获取到自动化方面的优惠。使得团队的工作效率大大提升。
CruiseControl.Net是什么?
上面讲解了什么是持续化集成,那CruiseControl.Net就是一款由ThoughtWorks公司提供给我们的轻量级的持续化集成工具。它能够将代码版本控制,单元测试,代码规范检查,项目的发布部署等工作步骤有机的组织起来,并且利用其调度性可作自动化处理,它还有强大的日志记录功能,能将集成结果及时地反馈给项目管理人员和项目开发人员。在下文中凡是用到CruiseControl.Net均用CC.Net来代替。下面是CC.Net的工作流程图
附件: 030308_1005_CruiseContr1.png
如何安装CC.Net
CC.Net是一款开源软件,它的官方主页是: http://confluence.public.thoughtworks.org/display/CCNET/Welcome+to+CruiseControl.NET
打开它的主页,便能看出他的官方采用另外一款非常出色的团队协作平台:Confluence,用它结合jira Bug管理系统,也能极大限度的提高团队协作能力,有关他们的介绍请访问:http://www.jira.com/ 。好了,返回来继续介绍CC.Net,当前官方已经发布了最新的CruiseControl.NET-1.3.0.2918,在首页的release栏中,便可以找到下载最新版CC.Net的连接,它是一款开源软件,你也可以在http://www.sf.net中找到它的源码和安装文件。如果你就是想使用CC.Net直接下载exe文件即可。下载后,在本地的安装过程如下:- 双击CruiseControl.NET-1.3-Setup.exe程序,打开软件安装界面,如下:
附件: 030308_1005_CruiseContr2.png
- 一直点击Next,选择软件安装路径,等待软件安装完成,界面如下:
附件: 030308_1005_CruiseContr3.png
- 软件安装完成之后,在系统windows服务中将增加名为CruiseControl.Net Server的系统服务,如下:
附件: 030308_1005_CruiseContr4.png
注意,默认情况该服务是出于未启动状态的。
- 代码版本管理工具如VSS
- 代码构建工具,如果您是vs.net的用户,强烈建议不要使用NAnt,配置起来比较麻烦,建议使用MsBuild来做构建工具。MsBuild是随.Net FrameWork 2.0一起安装的,所您需要在CC.Net服务器上安装.Net FrameWork 2.0或者以上版本。
- 代码规范检查工具,.Net用户推荐使用FxCop.exe,下载地址:http://www.microsoft.com/downloads/details.aspx?FamilyID=3389f7e4-0e55-4a4d-bc74-4aeabb17997b&displaylang=en,很不幸的是,它原来的官方主页 http://code.msdn.microsoft.com/GotDotNet.aspx 关闭了,在新的站点中,我没有搜索到它。
- 单元测试工具:Nunit,官方主页:http://sourceforge.net/projects/nunit
- 发布部署工具,如果是asp.net网站,可以使用ASP.NET 编译工具 (Aspnet_compiler.exe),但我感觉它不好用,于是我自己实现了一系列的代码发布,FTP上传,XCopy安装等组件,在后面会提到。
如何配置和部署
假定上述的几个工具已经成功安装,下面就用一个项目来演示一下如何实现自动化构建,单元测试,代码规范检测,自动发布部署。并且可以演示项目管理和开发人员通过什么样的手段能及时了解持续集成化的结果。
在演示制作之前,我们先来看一下当前的持续集成环境。
工具 地址和路径 Visual Studio SouceSafe 本局域网下一台服务器,IP地址192.168.1.200,共享目录:VSS,所以其根路径为: [url=file://192.168.1.200//VSS]\\192.168.1.200\\VSS[/url] ,用户名user,密码pwd CC.Net CC.Net安装在IP地址为:192.168.1.10的服务器上。 单元测试工具NUnit 和CC.Net安装在同一主机 代码规范工具FxCop 和CC.Net安装在同一主机 发布服务器 位于公网的一台服务器,IP假设为200.100.11.15
首先,我们创建用于演示的解决方案Jillzhang.DailyBuild,其中包括四个项目:
项目 项目描述 Jillzhang.DailyBuild.Core 这个是一个公共类库项目,目的是测试类似这样的项目也在构建范围之内。 Jillzhang.DailyBuild.Test 单元测试项目 Jillzhang.DailyBuild.Web 网站项目一 Jillzhang.DailyBuild.Web2 网站项目二
建立好解决方案之后,将其添加到VSS项目管理器中。层次结构如下:
附件: 030308_1005_CruiseContr5.png
下面我让我们看一下,如何配置CC.Net使其工作起来。- 在CC.Net服务器上,点击开始菜单,在所有程序中选择CruiseControl.Net,打开CruiseControl.NET Config配置文件。
- CC.Net支持同时监控和集成多个解决方案,每个解决方案在CC.Net中被称为1个Project.,在CruiseControl.NET Config中1个Project被一个<project>元素来描述。当然我们还要为每个Project指定名称和工作目录和日志存放目录。阅读CC.Net的文档,你可以了解<project>元素的一些属性和子元素。这里我只讲述一些我用到的。
- name ,如<project name="Project1">表示1个名称为Project1的新工程,这个名称在日后会作为项目的标识显示给查看报告的用户。比如显示在cctray上或者在网站doashboard上进行显示。还有一个比较重要的子元素<workingDirectory>这个元素非常类似于WCF配置中的<baseAddress>,用它来指示工程的工作目录,也就是从版本管理器上下载文件的根目录。除了这些我们还需要设定子元素<artifactDirectory >它用来指示日志记录的保存位置。CC.Net为我们提供了几种版本管理方式,可以用<labeler> 来指定使用哪种类型的版本标签,如Date Labeller,Default Labeller等,具体也可以查阅文档。我们这里使用Date Laberller,所以设置为<labeler type="dateLabeller"/>。下面可以设置源代码管理器,CC.Net支持目前绝大多数主流的版本控制工具,如CVS,VSS,Rational ClearCase,VSTS, Alienbrain等十几种。我们这里使用VSS,根据上文VSS和解决方案的配置,我们这里设置为:
复制代码- <sourcecontrol type="vss" autoGetSource="true" applyLabel="true">
- <project>$/Jillzhang.DailyBuild.root/Jillzhang.DailyBuild</project>
- <username>user</username>
- <password>pwd</password>
- <ssdir>\\192.168.1.200\vss\</ssdir>
- <cleanCopy>false</cleanCopy>
- </sourcecontrol>

将autoGetSource设置为true,CC.Net会通过监视VSS中代码的版本变化,自动从版本管理器中获取源代码。Project是要使用的解决方案在vss中的路径,值为如下:
附件: 030308_1005_CruiseContr6.png
Username为访问vss的用户名,password为访问vss的密码。ssdir是 vss代码库的共享路径,我这里为\\192.168.1.200\vss\ 。如果将cleanCopy设置为true,那么CC.Net每次获取最新文件的时候是否完全覆盖更新文件。
当前,我们的配置文件为:
设置好VSS后,我们可以启动CC.Net了,方法如下,打开Services.Msc,找到CruismControl.Net Server服务,在启动之前,需要先解决一下可能最影响情绪的问题:我们知道windows services默认情况下是用本地系统账户运行的,可一般情况下我们会在当前操作用户下设置对vss共享目录的访问权限,比如当前windows运行账户为administrator,那么我们在administrator中通过net use设置对[url=file://192.168.1.200/vss/]\\192.168.1.200\vss\[/url]的访问,也可以通过Source Safe Client打开该代码库,可这往往是一个烟雾弹,当我们在CC.Net中试图用服务来访问[url=file://192.168.1.200/vss/]\\192.168.1.200\vss\[/url] 的时候,系统服务账户并没有与该共享目录建立会话,所以会拒绝访问[url=file://192.168.1.200/vss/]\\192.168.1.200\vss\[/url],连访问权限都没有,更不用说获取代码了。所以首先要注意的是启动前,先设置服务的运行账户:复制代码- <cruisecontrol>
- <project name="TestProject" webURL="http://127.0.0.1/ccnet/">
- <workingDirectory >E:\DailyBuild</workingDirectory>
- <artifactDirectory>E:\DailyBuild\Log</artifactDirectory>
- <labeller type="dateLabeller"></labeller>
- <sourcecontrol type="vss" autoGetSource="true" applyLabel="true">
- <project>$/Jillzhang.DailyBuild.root/Jillzhang.DailyBuild</project>
- <username>user</username>
- <password>pwd</password>
- <ssdir>\\192.168.1.200\vss\</ssdir>
- <cleanCopy>false</cleanCopy>
- </sourcecontrol>
- </project>
- </cruisecontrol>
附件: 030308_1005_CruiseContr7.png
只有这样,我们才能进行下面的工作:
启动CruismControl.Net Server服务,重新签出,嵌入一下解决方案,稍等一段时间,我们便会在工作目录E:\DailyBuild中看到自动获取过来的文件。还要值得注意的一点是在log目录中最好事先创建好buildlogs,如果您在启动CrusimControl.Net Server服务的时候有错误出现,比如在启动的时候总是出现:
附件: 030308_1005_CruiseContr8.png
很可能得情况就是上面的配置有错误,您可以通过下面两种方式来确定服务到底出现了什么样的问题:
- 按照提示,在事件查看器中查看错误,如:
附件: 030308_1005_CruiseContr9.png
- 您还可以到CrusimControl.Net Server的应用程序目录查找名为ccnet.log的文件,里面有CC.Net详细的操作步骤。
附件: 030308_1005_CruiseContr10.png
当Last Build Status为Success的时候表示项目集成成功,此时点击项目名,可以查看具体的集成结果:
附件: 030308_1005_CruiseContr11.png
如果调用MsBuild来对代码进行生成,调用FxCop进行代码规范检查,和调用NUnit进行单元测试集成,还需要对CC.Net进行下一步的配置。
代码规范检侧工具FxCop不能被CC.Net直接使用,它必须附加到MsBuild.Exe的命令行中,有关如何使用MSBuild,可以参考msdn,不做具体介绍。为此我们创建一个用于生成并检查代码规范的任务,CC.Net支持自定义任务,方法是:使用Task中的Executable Task。
首先在工作目录,创建一个用于msbuild参数的DailyBuild.msbuild文件,文件内容如下:
这个MsBuild选项会使得msbuild.exe在生成完成之后调用工作目录中的exeu.bat文件,exeu.bat中是关于使用FxCop方法的,内容如下:复制代码- <Project DefaultTargets="Build" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
- <Target Name="Build">
- <!-- Clean, then rebuild entire solution -->
- <MSBuild Projects="Jillzhang.DailyBuild.sln" Targets="Clean;Rebuild"/>
- <!-- Run FxCop analysis -->
- <Exec Command="exeu.bat"
- />
- </Target>
- </Project>
目的就是通过调用FxCop安装目录下的FxCopCmd命令行工具,对指定的程序集进行规范性检查,上述代码中,E:\DailyBuild\Jillzhang.DailyBuild.FxCop是事先生成好的FxCop项目文件,生成办法是打开FxCop 可视化界面,添加target,并保存到此为位置即可,如图:cd D:\Program Files\Microsoft FxCop 1.36 d: FxCopCmd /project:E:\DailyBuild\Jillzhang.DailyBuild.FxCop /out:E:\DailyBuild\log\DailyBuild.FxCop.xml
附件: 030308_1005_CruiseContr12.png
并保存到E:\DailyBuild\Jillzhang.DailyBuild.FxCop
添加能生成代码并且检测代码规范性的配置如下:
注意,buildTimeoutSeconds是生成操作的超时时间,还有最好设置/p:Configuration=Release,因为这样有利于以后发布。而Merge是将上面各个任务中生成的日志进行合并。复制代码- <tasks>
- <exec>
- <executable>D:\WINDOWS\Microsoft.NET\Framework\v2.0.50727\MSBuild.exe</executable>
- <baseDirectory>E:\DailyBuild</baseDirectory>
- <buildArgs>DailyBuild.msbuild /p:Configuration=Release</buildArgs>
- <buildTimeoutSeconds>1200</buildTimeoutSeconds>
- </exec >
- <merge>
- <files>
- <file>E:\DailyBuild\log\Build.FxCop.xml</file>
- </files>
- </merge>
- </tasks>
下面重新签出嵌入,观察集成结果:
附件: 030308_1005_CruiseContr13.png可以看到,已经release成功。
下面就看一下生成的DailyBuild.FxCop.xml,
附件: 030308_1005_CruiseContr14.png
打开看里面的内容便可以发现代码检测结果。 - 双击CruiseControl.NET-1.3-Setup.exe程序,打开软件安装界面,如下:
-
CruiseControl 配置
2010-05-25 12:00:17
CruiseControl 的概念和好处,我就不在复诉,下面是我的配置环境与配置文件。
配置环境:
CruiseControl : cruisecontrol-bin-2.7.zip
Apache-Ant : 1.7.0
Junit : 4.0
JRE : 5.0_12
Eclipse :
在此环境中,要保持Ant与Junit的版本协调,最初使用Cruisecontrol-2.7随包发布的apache-ant-1.6.5进行单元测试时,会报 No tests found in .... ,Ant1.7是支持JUnit4的,所以将Ant升级为1.7.0的版本,问题解决。
1、设置环境变量
由于使用ZIP的版本,所以需要设置 JAVA_HOME 的路径。注意由ANT的版本已升级为1.7.0,所以在config.xm中应该指定ant_home的路径。2、CruiseControl 的config.xml
1 <?xml version='1.0' encoding='gb2312'?>
<?xml version='1.0' encoding='gb2312'?>
2<cruisecontrol>
3 <project name="projectName">
4
5 <!-- 用于处理一些项目有关的事件 -->
6 <listeners>
7 <!-- 用来访问项目当前创建的状态 file: 指定了状态文件的位置 -->
8 <currentbuildstatuslistener file="logs/${project.name}/status.txt"/>
9 </listeners>
10
11 <!-- 在 CC 进行创建之前运行,是创建前的准备工作 -->
12 <bootstrappers>
13 <!-- 从源码控制系统更新本地文件: cvsbootstrappers、vssbootstrappers、svnbootstrapper -->
14 <svnbootstrapper localWorkingCopy="projects/${project.name}" />
15 </bootstrappers>
16
17 <!-- 检查各个源码控制系统中是否发生变化;quietperiod: 单位为秒 设定等待的时间 -->
18 <!-- 第一次的取出工作为手动执行 -->
19 <modificationset quietperiod="600">
20 <svn localWorkingCopy="projects/${project.name}"/>
21 </modificationset>
22
23 <!-- 指定了构建的时间间隔 单位为秒-->
24 <schedule interval="60">
25 <ant anthome="apache-ant-1.7.0" buildfile="projects/${project.name}/build.xml"/>
26 </schedule>
27
28 <!-- 指定项目日志保存的地点 -->
29 <log>
30 <!-- 通常是指定 CC 的合并日志的目录 -->
31 <merge dir="projects/${project.name}/test-reports"/>
32 </log>
33
34 <!-- 在 build loop 结束之后运行,发布 build 的结果 -->
35 <publishers>
36 <!--onsuccess-->
37 <!--用于对创建过程中产生的人工制品进行发布-->
38 <!--artifactspublisher dest="artifacts/${project.name}" file="projects/${project.name}/target/${project.name}.jar"/>
39 </onsuccess-->
40
41 <!--
42 mailhost=邮件主机
43 returnname=发件人
44 returnaddress=发件地址
defaultsuffix=默认邮件后缀
45 -->
46 <htmlemail
47 charset="UTF-8"
48 mailhost="smtp.163.com"
49 defaultsuffix="@xxx.com"
50 username="xxx@163.com"
51 password="xxx"
52 returnname="CruiseControl"
53 returnaddress="xxx@163.com"
54 subjectprefix="构建日志"
55 xsldir="webapps/cruisecontrol/xsl"
56 css="webapps/cruisecontrol/css/cruisecontrol.css">
57 <always address="xxx@xxx.com.cn"/>
58 <failure address="xxx@xxx,yyy@yyy.com.cn"/>
59
60 </htmlemail>
61
62 </publishers>
63
64 </project>
65</cruisecontrol>
2、build.xml的特性文件1
2projcet.path=xxx
3
4projcet.name=xxx
5
6catalina.home=xxx
7
8catalina.port=xxx
9
10catalina.username=xxx
11
12catalina.password=xxx
3、工程的build.xml1<?xml version="1.0" encoding="UTF-8" ?>
2
3<!-- Continuous Integration 工程名称 Gms 默认任务 CI -->
4<project default="CI" name="xxx" basedir=".">
5
6
7 <!-- 特性文件 在特性文件中 注意路径的正反斜杠问题 -->
8 <property file="build.properties"/>
9
10 <!-- ================================ 工程参数 ================================ -->
11
12 <!-- 工程中文名称 -->
13 <property name="projectName_CN" value="xxx"/>
14 <!-- 工程目录 -->
15 <property name="projectFolder" value="${projcet.path}/${projcet.name}"/>
16
17 <!-- 源程序目录 -->
18 <property name="sourceFolder" value="${projectFolder}/src/main/java"/>
19 <!-- 配置文件目录 -->
20 <property name="configFolder" value="${projectFolder}/src/main/config"/>
21 <!-- 测试程序目录 -->
22 <property name="testFolder" value="${projectFolder}/src/test/java"/>
23 <!-- lib目录 -->
24 <property name="libFolder" value="${projectFolder}/WebRoot/WEB-INF/lib"/>
25 <!-- 编译程序目录 -->
26 <property name="classFolder" value="${projectFolder}/WebRoot/WEB-INF/classes"/>
27
28 <!-- 单元测试报告目录 -->
29 <property name="reportFolder" value="${projectFolder}/test-reports"/>
30 <!-- 单元测试报告文件名 -->
31 <property name="reportFileName" value="junit-noframes.html"/>
32
33 <!-- ================================ 发布设置 ================================ -->
34
35 <!-- 生成war文件 -->
36 <property name="warFile" value="${projectFolder}/${projcet.name}.war"/>
37 <!-- web.xml文件 -->
38 <property name="webFile" value="${projectFolder}/WebRoot/WEB-INF/web.xml"/>
39 <!-- 生成war文件的基础路径 -->
40 <property name="warSource" value="${projectFolder}/target/classes"/>
41
42 <!-- ================================ 路径设置 ================================ -->
43
44 <!-- 编译过程中用到的路径 -->
45 <path id="compilePath">
46 <!-- 编译程序目录 -->
47 <pathelement path="${classFolder}" />
48 <!-- 编译时lib路径 -->
49 <path refid="libPath" />
50 </path>
51
52 <!-- 单元测试时用到的路径 -->
53 <path id="jUnitPath">
54 <!-- 编译程序目录 -->
55 <pathelement path="${classFolder}" />
56 <!-- 编译时lib路径 -->
57 <path refid="libPath" />
58 </path>
59
60 <!-- 编译时lib路径 -->
61 <path id="libPath">
62 <!-- lib目录 -->
63 <fileset dir="${libFolder}">
64 <include name="**/*.jar" />
65 </fileset>
66 </path>
67
68 <!-- ================================ 持续集成 ================================ -->
69
70 <!-- 集成流程 暂时没有加入 Test -->
71 <target name="CI" depends="init,compile,test,makewar,deploy-catalina" description="持续集成"/>
72
73 <!-- 1.初始化目标目录, class ; report -->
74 <target name="init" description="初始化">
75
76 <echo>正在删除编译程序目录 </echo>
</echo>
77 <delete dir="${classFolder}" />
78 <echo>正在创建编译程序目录</echo>
79 <mkdir dir="${classFolder}" />
80
81 <echo>正在删除单元测试报告目录</echo>
82 <delete dir="${reportFolder}" />
83 <echo>正在创建单元测试报告目录</echo>
84 <mkdir dir="${reportFolder}" />
85 </target>
86
87 <!-- 2.编译程序生成目标类 -->
88 <target name="compile" depends="init" description="编译">
89 <echo>编译源程序</echo>
90 <!-- classpathref="编译路径" destdir="${编译程序目录}" -->
91 <javac classpathref="compilePath" fork="true" memorymaximumsize="128m"
92 destdir="${classFolder}" debug="true" deprecation="false"
93 failonerror="false" verbose -
适用于 .NET 的静态分析工具
2010-05-25 11:55:52
http://msdn.microsoft.com/zh-cn/magazine/dd263071.aspx
使用静态代码分析工具提高软件质量许多软件团队使用代码评审来确保开发人员编写的代码正确、安全且符合公司的设计原则。这些原则可能规定了访问数据或其他外部资源所使用的命名约定、模式等内容。代码评审过程的很多方面都很机械,因此可以自动执行。静态代码分析工具扫描源代码或中间代码,并搜索违反定义的设计原则规则的代码。FxCop (1.36 版)就是这样一个针对 Microsoft .NET Framework 中的应用程序的静态分析工具,由 Microsoft 创建,免费提供。FxCop 分析编译的 .NET 程序集的中间代码,并提供相关的建议来改进设计、安全性和性能。默认情况下,FxCop 根据开发类库的设计原则设定的规则分析程序集。设计原则规则可划分为九个类别,其中包括设计、全球化、性能和安全性等内容。例如,其中一个命名规则是“事件不能使用‘before’或‘after’前缀”。如果 FxCop 识别出某事件的名称为 BeforeUpdate,它便会建议您将 BeforeUpdate 替换为事件名称的现在时形式,即 Update。您也可以插入自定义规则类来反映您公司的内部设计原则。要分析程序集,先启动 FxCop,创建新的项目,然后将程序集添加到该项目。FxCop 会显示分析该程序集时使用的 200 多个规则;您可以关闭现有的规则或添加您自己的规则。单击“分析”按钮开始分析。在枚举出该程序集的类型、类、方法和成员后,FxCop 会显示分析结果,其中将列出违反规则的代码和其所违反的规则。选择一项结果可以查看更加详细的描述和解决方案。FxCop 作为独立的应用程序提供,还包含命令行实现功能,用户可轻松将其插入到自动执行的构建过程中。(代码分析是一项与 FxCop 非常相似的工具,附带 Visual Studio Team System,并已集成到 Visual Studio Shell 中。)有关如何使用 FxCop 的详细信息,请参阅 John Robbins 撰写的 Bugslayer 专栏:“遇到糟糕代码?FxCop 相助”和“三个重要的 FXCop 规则。”.gif) FxCop 根据 .NET 设计原则设定的规则分析程序集(单击图像可查看大图)Microsoft 还提供了一个静态代码分析工具,即 StyleCop (4.3 版)。FxCop 评估中间代码是否符合设计原则,而 StyleCop 评估的对象是 C# 源代码的样式。样式原则是指定应该如何对源代码进行格式化的规则,规定是否应该在 for 循环、if 语句和其他结构的缩进和格式中使用空格和制表符。StyleCop 示例规则包括:for 语句的主体应括在一对大括号中;= 和 != 运算符两边应有空格;对类内部成员变量的调用必须以“this”开头。StyleCop 没有集成到 Visual Studio Team System 中,您必须亲自安装。在 Visual Studio 中执行 StyleCop 会分析当前打开的解决方案中的源代码,并在错误列表窗口中以警告的形式显示结果。StyleCop 也可以与 MSBuild 集成。当 FxCop 和 StyleCop 查明违反规则的代码时,开发人员仍负责实现这些工具的建议。SubMain 的 CodeIt.Right(1.1 版)通过使违反规则的代码自动重构为一致的代码,将静态代码分析提升到了一个更高的级别。与 FxCop 类似,CodeIt.Right 也附带一组丰富的预定义规则(如前面提到的设计原则文档所述),能够添加自定义规则,但 CodeIt.Right 使创建和使用自定义规则更加轻松。使用 FxCop 中的自定义规则需要构建和编译规则类并将其插入 FxCop。使用 CodeIt.Right,会从图形用户界面生成自定义规则;定义新规则需要采用基本行为模式,然后自定义一些属性。CodeIt.Right 集成了 Visual Studio .NET 2003、Visual Studio 2005 和 Visual Studio 2008 的解释器,还提供了命令行实现功能。
FxCop 根据 .NET 设计原则设定的规则分析程序集(单击图像可查看大图)Microsoft 还提供了一个静态代码分析工具,即 StyleCop (4.3 版)。FxCop 评估中间代码是否符合设计原则,而 StyleCop 评估的对象是 C# 源代码的样式。样式原则是指定应该如何对源代码进行格式化的规则,规定是否应该在 for 循环、if 语句和其他结构的缩进和格式中使用空格和制表符。StyleCop 示例规则包括:for 语句的主体应括在一对大括号中;= 和 != 运算符两边应有空格;对类内部成员变量的调用必须以“this”开头。StyleCop 没有集成到 Visual Studio Team System 中,您必须亲自安装。在 Visual Studio 中执行 StyleCop 会分析当前打开的解决方案中的源代码,并在错误列表窗口中以警告的形式显示结果。StyleCop 也可以与 MSBuild 集成。当 FxCop 和 StyleCop 查明违反规则的代码时,开发人员仍负责实现这些工具的建议。SubMain 的 CodeIt.Right(1.1 版)通过使违反规则的代码自动重构为一致的代码,将静态代码分析提升到了一个更高的级别。与 FxCop 类似,CodeIt.Right 也附带一组丰富的预定义规则(如前面提到的设计原则文档所述),能够添加自定义规则,但 CodeIt.Right 使创建和使用自定义规则更加轻松。使用 FxCop 中的自定义规则需要构建和编译规则类并将其插入 FxCop。使用 CodeIt.Right,会从图形用户界面生成自定义规则;定义新规则需要采用基本行为模式,然后自定义一些属性。CodeIt.Right 集成了 Visual Studio .NET 2003、Visual Studio 2005 和 Visual Studio 2008 的解释器,还提供了命令行实现功能。.gif) CodeIt.Right 更新所选的违反规则的代码,使之符合规则(单击图像可查看大图)要在 Visual Studio 中使用 CodeIt.Right,请在 CodeIt.Right 菜单中选择“开始分析”选项。分析完解决方案后,CodeIt.Right 在 Visual Studio IDE 的窗口中显示结果,其中将列出每个违反规则的代码。此报表可以导出为 XML 文件,也可以导出为 Microsoft Office Excel 文件。CodeIt.Right 最大的优点是自动代码重构功能。您可以通过结果屏幕查看需要修复哪些违反规则的代码,然后单击“修复选中项”(Correct Checked) 按钮。CodeIt.Right 所做的所有更改都会在 Visual Studio 中突出显示,单击一个按钮即可将自动进行的更改恢复到原来状态。静态代码分析工具提供了一种快速、自动化的方法,来确保您的源代码符合预定义的设计和样式原则。遵循这些原则有助于生成更统一的代码,还可以查出潜在的安全性、性能、互操作性和全球化方面的缺陷。静态代码分析工具不能代替人为代码评审,但是,它们可以先检查一遍代码库,并突出显示需要高级开发人员特别注意的地方。价格:FxCop(免费);StyleCop(免费);CodeIt.Right(每个用户许可证 250 美元)。
CodeIt.Right 更新所选的违反规则的代码,使之符合规则(单击图像可查看大图)要在 Visual Studio 中使用 CodeIt.Right,请在 CodeIt.Right 菜单中选择“开始分析”选项。分析完解决方案后,CodeIt.Right 在 Visual Studio IDE 的窗口中显示结果,其中将列出每个违反规则的代码。此报表可以导出为 XML 文件,也可以导出为 Microsoft Office Excel 文件。CodeIt.Right 最大的优点是自动代码重构功能。您可以通过结果屏幕查看需要修复哪些违反规则的代码,然后单击“修复选中项”(Correct Checked) 按钮。CodeIt.Right 所做的所有更改都会在 Visual Studio 中突出显示,单击一个按钮即可将自动进行的更改恢复到原来状态。静态代码分析工具提供了一种快速、自动化的方法,来确保您的源代码符合预定义的设计和样式原则。遵循这些原则有助于生成更统一的代码,还可以查出潜在的安全性、性能、互操作性和全球化方面的缺陷。静态代码分析工具不能代替人为代码评审,但是,它们可以先检查一遍代码库,并突出显示需要高级开发人员特别注意的地方。价格:FxCop(免费);StyleCop(免费);CodeIt.Right(每个用户许可证 250 美元)。 -
FXCOP 下载地址
2010-05-25 11:54:04
http://www.microsoft.com/downloads/en/confirmation.aspx?familyId=9aeaa970-f281-4fb0-aba1-d59d7ed09772&displayLang=en
http://msdn.microsoft.com/library/bb429476
-
性能测试指标的基本概念
2010-05-25 11:45:56
性能测试指标的基本概念
吞吐量/处理能力
处理能力又叫吞吐量,指的是单位时间内处理的客户端请求数量。通常情况下,吞吐量用请求数/秒Or页面数/秒来衡量。从业务角度看,吞吐量也可以用访问人数/天Or页面访问量/天来衡量。负载
负载分为客户端负载和服务器端负载客户端负载的通俗解释就是有多少个用户在同时使用软件服务器端负载的通俗解释就是有多少个请求同时到达了服务器端,要求服务器进行处理。例如,某个网站当前有10000个人在线访问,从他们的客户端层面看过去,这个负载就是客户端负载,为10000。若某个网站当前有10000个人在线访问,某一时刻,从他们的客户端同时发出了1000个页面的请求到服务器,从服务器端层面看过去,这个负载就是服务器端负载,为1000。响应时间
响应时间是可以判断一个被测应用系统是否存在性能瓶颈的最直观的要素。例如,在执行完性能测试后,发现某个交易的“平均响应时间”为8秒,超过了预先确定下来的性能指标“该交易的性能指标为平均响应时间要小于等于3秒”。此时,就可以认为被测应用系统存在性能瓶颈了,要利用一定的手段去探查被测应用系统中哪个地方引起了系统的处理效率低以及低的原因了。响应时间一般包括最大响应时间和平均响应时间,响应时间包括网络上的传输时间,WEB服务器上处理时间、APP服务器上的处理时间、DB服务器上的处理时间,响应时间不包括浏览器上的内容显示时间。同时在线用户
对于一个网站来讲,当一个用户登录到该网站的首页后,开始在该网站上进行各种操作,包括浏览网页、检索内容、提交表单等,这个过程中的用户称为在线用户。若同一时间点或同一个时间段内,有很多这样的用户在访问该网站,这些用户统称为该网站的同时在线用户。同时在线用户的另一层理解是,将应用系统整体看作是一个黑盒子,从用户的客户端层面看向系统,总共有多少个人在使用它。当进行性能测试时,如果你使用的是同时在线用户,则可以称之为同时在线负载。超级并发用户
对于一个网站来讲,可能存在WEB服务器、应用服务器、数据库服务器三个层次,而用户所使用的浏览器是在最外面的客户端层面。如果某个时间点或时间段内,共有1000个用户同时在线,他们进行着各种各样的操作,而某个时间点上可能存在10个左右的用户同时进行了一个或多个操作,导致WEB服务器同时接收到了10个左右的交易请求,我们称这个10个左右的用户为超级并发用户。当进行性能测试时,如果你使用的是超级并发用户,则可以称之为超级并发负载。性能测试脚本
脚本是用负载模拟工具开发出来的。脚本是一些代码的组合体,它用代码来实现用户对应用系统的操作。例如,你在一个网站上访问首页、输入用户名和密码后点击登录按钮进行登录,这是用户对应用系统的两步操作内容,在脚本中则包含了实现这两个操作步骤的代码。如果你要模拟10000个用户的负载,这10000个用户中50%进行首页的访问、20%进行注册、20%进行查询、10%进行某个页面的浏览,则你需要制作5个脚本,分别是首页访问脚本、注册脚本、查询脚本、页面浏览脚本。事务
事务是脚本的一个特性,每个事务都包含开始事务和结束事务。事务用来衡量脚本中一行代码或多行代码的执行所耗费的时间。你可以将开始事务放置在脚本中某行代码的前面,将结束事务放置在该行代码的后面,在该脚本的虚拟用户运行时,这个事务将衡量该行代码的执行花费了多长时间。交易
交易分为业务层面和技术层面两种定义。业务层面交易是指完成一次完整的业务操作,例如进行一次取款、查询操作。技术层面的交易是指进行一次应用程序至应用程序、或者应用程序至数据库的系统操作。一般的一笔业务交易由多笔技术交易组成,根据业务交易的复杂度和系统应用架构的不同,其比例大致为1:2-1:10。TPS与HPS
TPS (Transactions Per Second)是估算应用系统性能的重要依据。其意义是应用系统每秒钟处理完成的交易数量,尤其是交易类系统。一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。依据经验,应用系统的处理能力一般要求在10-100左右。不同应用系统的TPS有着十分大的差别,一般需要通过性能测试进行准确估算。当系统没有达到性能瓶颈时,TPS随着负载的增加呈近似线性增长,当接近性能瓶颈时出现拐点;如果系统健壮性较好,在到达性能瓶颈后,TPS基本保持水平,不会再随着负载的增加而有显著增长;而如果系统存在比较严重的性能问题,当到达性能瓶颈后,TPS会出现明显的下降趋势。HPS:(Hits per Second)每秒点击次数,是指在一秒钟的时间内用户对Web页面的链接、提交按钮等点击总和它一般和TPS成正比关系,是B/S系统中非常重要的性能指标之一。
TPS可以有多种衡量单位,在进行性能测试的业务模型分析时使用,例如:
(1)在税务系统中,可以用“系统每个月要处理10万用户的业务操作”,这里的TPS用企业数/月来衡量;(2)在税务系统中,也可以用“系统在第七天的8个小时内要处理4万用户的业务操作”,这里的TPS用企业数/天来衡量;(3)在税务系统中,也可以用“系统在第七天的10点到11点之间要处理1.2万用户的3种缴税交易操作,即3.6万次缴税交易操作”,这里的TPS用交易数/小时来衡量;(4)在税务系统中,也可以用“系统在第七天的10点到11点之间要处理1.2万用户的3种缴税交易操作,即3.6万次缴税交易操作,每次缴税交易要从客户端向服务器发送平均10次HTTP请求,即36万次HTTP请求操作”,这里的TPS用请求数/小时来衡量。
HPS是用来衡量很多用户使用客户端进行操作,向服务器发送请求的效率。我们认为HPS表现的是最终用户的整体行为,是衡量在线负载程度的一个指标。而TPS表现的是服务器端的程序行为,是衡量服务器处理能力高低的一个主要指标。
例如:HPS=“点击次数/秒”;TPS=“处理事务数/秒”,HPS与TPS没有绝对的关系。性能测试实现的准确性
在进行了正确的性能测试分析后,获得了正确的性能测试需求,从而使用性能测试工具开发相应的性能测试脚本、开发相应的性能测试场景、在性能测试脚本中利用性能测试数据、在性能测试脚本中设置相应的思考时间、在性能测试场景中设置运行的参数等,以期能利用自动化的性能测试工具模拟现实中大量用户同时访问被测系统的情形。即,如果性能测试工具操作不当,将会导致无法准确的实现“模拟实际情况”的目标。例如,某些性能测试工程师在使用性能测试工具时不懂得利用“检查点”这个功能,从而无法发现在性能测试执行过程中大量虚拟用户甚至没有登陆到系统中的严重问题,仍然认为性能测试执行效果良好,被测系统性能没有问题。Web服务器和APP服务器
通俗的讲,Web服务器传送(serves)页面使浏览器可以浏览,然而应用程序服务器提供的是客户端应用程序可以调用(call)的方法(methods)。确切一点,你可以说:Web服务器专门处理HTTP请求(request),但是应用程序服务器是通过很多协议来为应用程序提供(serves)商业逻辑(business logic)。Web服务器(Web Server)Web服务器可以解析(handles)HTTP协议。当Web服务器接收到一个HTTP请求(request),会返回一个HTTP响应(response),例如送回一个HTML页面。为了处理一个请求(request),Web服务器可以响应(response)一个静态页面或图片,进行页面跳转(redirect),或者把动态响应(dynamic response)的产生委托(delegate)给一些其它的程序例如CGI脚本,JSP(JavaServer Pages)脚本,servlets,ASP(Active Server Pages)脚本,服务器端(server-side)Javascrīpt,或者一些其它的服务器端(server-side)技术。无论它们(译者注:脚本)的目的如何,这些服务器端(server-side)的程序通常产生一个HTML的响应(response)来让浏览器可以浏览。要知道,Web服务器的代理模型(delegation model)非常简单。当一个请求(request)被送到Web服务器里来时,它只单纯的把请求(request)传递给可以很好的处理请求(request)的程序(译者注:服务器端脚本)。Web服务器仅仅提供一个可以执行服务器端(server-side)程序和返回(程序所产生的)响应(response)的环境,而不会超出职能范围。服务器端(server-side)程序通常具有事务处理(transaction processing),数据库连接(database connectivity)和消息(messaging)等功能。虽然Web服务器不支持事务处理或数据库连接池,但它可以配置(employ)各种策略(strategies)来实现容错性(fault tolerance)和可扩展性(scalability),例如负载平衡(load balancing),缓冲(caching)。集群特征(clustering—features)经常被误认为仅仅是应用程序服务器专有的特征。
应用程序服务器(The Application Server)根据我们的定义,作为应用程序服务器,它通过各种协议,可以包括HTTP,把商业逻辑暴露给(expose)客户端应用程序。Web服务器主要是处理向浏览器发送HTML以供浏览,而应用程序服务器提供访问商业逻辑的途径以供客户端应用程序使用。应用程序使用此商业逻辑就象你调用对象的一个方法(或过程语言中的一个函数)一样。应用程序服务器的客户端(包含有图形用户界面(GUI)的)可能会运行在一台PC、一个Web服务器或者甚至是其它的应用程序服务器上。在应用程序服务器与其客户端之间来回穿梭(traveling)的信息不仅仅局限于简单的显示标记。相反,这种信息就是程序逻辑(program logic)。 正是由于这种逻辑取得了(takes)数据和方法调用(calls)的形式而不是静态HTML,所以客户端才可以随心所欲的使用这种被暴露的商业逻辑。在大多数情形下,应用程序服务器是通过组件(component)的应用程序接口(API)把商业逻辑暴露(expose)(给客户端应用程序)的,例如基于J2EE(Java 2 Platform, Enterprise Edition)应用程序服务器的EJB(Enterprise JavaBean)组件模型。此外,应用程序服务器可以管理自己的资源,例如看大门的工作(gate-keeping duties)包括安全(security),事务处理(transaction processing),资源池(resource pooling), 和消息(messaging)。就象Web服务器一样,应用程序服务器配置了多种可扩展(scalability)和容错(fault tolerance)技术。 例如,设想一个在线商店(网站)提供实时定价(real-time pricing)和有效性(availability)信息。这个站点(site)很可能会提供一个表单(form)让你来选择产品。当你提交查询(query)后,网站会进行查找(lookup)并把结果内嵌在HTML页面中返回。网站可以有很多种方式来实现这种功能。我要介绍一个不使用应用程序服务器的情景和一个使用应用程序服务器的情景。观察一下这两中情景的不同会有助于你了解应用程序服务器的功能。
情景1:不带应用程序服务器的Web服务器在此种情景下,一个Web服务器独立提供在线商店的功能。Web服务器获得你的请求(request),然后发送给服务器端(server-side)可以处理请求(request)的程序。此程序从数据库或文本文件(flat file,译者注:flat file是指没有特殊格式的非二进制的文件,如properties和XML文件等)中查找定价信息。一旦找到,服务器端(server-side)程序把结果信息表示成(formulate)HTML形式,最后Web服务器把会它发送到你的Web浏览器。简而言之,Web服务器只是简单的通过响应(response)HTML页面来处理HTTP请求(request)。
情景2:带应用程序服务器的Web服务器情景2和情景1相同的是Web服务器还是把响应(response)的产生委托(delegates)给脚本(译者注:服务器端(server-side)程序)。然而,你可以把查找定价的商业逻辑(business logic)放到应用程序服务器上。由于这种变化,此脚本只是简单的调用应用程序服务器的查找服务(lookup service),而不是已经知道如何查找数据然后表示为(formulate)一个响应(response)。 这时当该脚本程序产生HTML响应(response)时就可以使用该服务的返回结果了。在此情景中,应用程序服务器提供(serves)了用于查询产品的定价信息的商业逻辑。(服务器的)这种功能(functionality)没有指出有关显示和客户端如何使用此信息的细节,相反客户端和应用程序服务器只是来回传送数据。当有客户端调用应用程序服务器的查找服务(lookup service)时,此服务只是简单的查找并返回结果给客户端。通过从响应产生(response-generating)HTML的代码中分离出来,在应用程序之中该定价(查找)逻辑的可重用性更强了。其他的客户端,例如收款机,也可以调用同样的服务(service)来作为一个店员给客户结帐。相反,在情景1中的定价查找服务是不可重用的因为信息内嵌在HTML页中了。总而言之,在情景2的模型中,在Web服务器通过回应HTML页面来处理HTTP请求(request),而应用程序服务器则是通过处理定价和有效性(availability)请求(request)来提供应用程序逻辑的。
警告(Caveats)现在,XML Web Services已经使应用程序服务器和Web服务器的界线混淆了。通过传送一个XML有效载荷(payload)给服务器,Web服务器现在可以处理数据和响应(response)的能力与以前的应用程序服务器同样多了。另外,现在大多数应用程序服务器也包含了Web服务器,这就意味着可以把Web服务器当作是应用程序服务器的一个子集(subset)。虽然应用程序服务器包含了Web服务器的功能,但是开发者很少把应用程序服务器部署(deploy)成这种功能(capacity)(译者注:这种功能是指既有应用程序服务器的功能又有Web服务器的功能)。相反,如果需要,他们通常会把Web服务器独立配置,和应用程序服务器一前一后。这种功能的分离有助于提高性能(简单的Web请求(request)就不会影响应用程序服务器了),分开配置(专门的Web服务器,集群(clustering)等等),而且给最佳产品的选取留有余地。性能瓶颈
性能瓶颈实际上就是一个软件的性能缺陷,最通俗的理解“性能瓶颈”。
(1)硬件上的性能瓶颈主要指的是CPU、RAM方面的问题。例如,在进行软件需求分析、概要设计时,确定了在数据库服务器上需要6个CPU、12G内存,但是在测试时,发现CPU的持续利用率超过95%,这时可以认为在硬件上出现了性能瓶颈。
(2)应用软件上的性能瓶颈一般指的是应用服务器、WEB服务器等应用软件,还包括数据库系统。例如,在WEBLogic平台上配置了JDBC连接池的参数,最大连接数为50,最小连接数为5,增加量为10。在测试时发现,当负载增加时,现有的连接数不足,系统会动态生成10个新的连接数,这样导致了交易处理的响应时间大大的增加。这时可以认为在应用软件上出现了性能瓶颈。
(3)应用程序上的性能瓶颈,一般指的是开发人员新开发出来的应用程序。例如,用Java或者C开发出来的部署在应用服务器上用于用户交易请求处理的应用程序。例如,某个开发员开发了一个缴费处理程序,在测试时发现,这个缴费处理程序在处理用户发过来的并发缴费请求时,只能串行处理,无法并行处理,导致缴费交易的处理响应时间非常长,这时可以认为在应用程序上出现了性能瓶颈。
(4)操作系统上的性能瓶颈,一般指的是Windows、Unix、Linux这些操作系统。例如,在windows系统中,虚拟内存设置的不合理,都指定为C驱提供虚拟内存,在测试时发现当出现物理内存不足时,虚拟内存的交换效果非常不理想,导致交易的响应时间大大增加。这时可以认为在操作系统上出现了性能瓶颈。
(5)网络设备上的性能瓶颈,一般指的是防火墙、动态负载均衡器、交换机等设备。例如,在动态负载均衡器上设置了动态分发负载的机制,当发现某个应用服务器上的硬件资源已经到达极限时,动态负载均衡器将后续的交易请求发送到其它负载较轻的应用服务器上。在测试时发现,动态负载均衡机制没有起到相应的作用,这时可以认为在网络设备上出现了性能瓶颈。 -
性能测试指标的计算
2010-05-25 11:41:16
.介绍软件性能:是一种指标,是参考一定标准的表现,表明软件系统或构件对于其及时性要求的符合程度,即在相应的硬件和软件环境下,该软件系统应该达到的一个水平。另外,性能是一种特性,可以用时间和空间来进行度量。
3种角度看性能:(1)用户角度:直观印象,主要是从响应时间来看;(2)管理员角度:建立在响应时间基础上,要考虑系统状态如系统资源的利用率,系统的扩展性和系统的稳定性;(3)开发人员:主要从系统架构,数据库设计,代码的优化来看待。
2.主要关键词
响应时间:对请求作出响应所需要的时间。web的普遍标准是2/5/10秒,即2秒以内的客户响应被认为是“非常好非常吸引人”的,5秒内是“比较不错”的,10秒是能接受的上限。但是响应时间具有相对性,如:一个月才进行一次的操作,20分钟是一个可以接受的等待时间。即:具体环境具体判断。
用户并发数:主要取决于服务端和客户端的性能。对服务端来说,每个用户和服务断都是离散的,用比较形象的话来说,就是一群小孩对着一堵墙踢球,每个小孩都有一个球,具体多少个小孩,每个小孩每次对着墙踢球的时间是不确定的或有一定规律的。而墙能承受多少小孩踢球而不跨掉,便是一个用户并发数的问题。而对客户端来说,每个小孩踢球的时间都是根据自己的实际情况来决定的,即根据用户实际的业务场景来决定的。所以,系统的服务端能承受的最大并发访问数主要取决于并发用户数和业务场景,一般可以通过对服务器日志的分析可以得到。 并发数确定的理论公式:C=nL/T (C是平均的并发用户数,n是login session“用户从登陆系统到退出系统的时间段”,T是考察的时间段即用户可能使用系统的总时间段)C^=C+3根号C。
例如:一OA系统,该系统有200用户,每天大约100人访问系统,一天内用户从登陆系统到退出系统的平均时间是4小时,一天内,用户最多使用8小时。
那么可以得到C=200*4/8=100 (并发用户数)
C^=100+3*根号100 (最大用户数)
吞吐量:单位时间内系统处理的客户请求的数量,主要体现软件系统的性能承载能力。
吞吐量的单位不定,可以是:请求数/秒,人数/天,业务数/小时……对于web系统来说,常用的是请求数(点击数)/秒或字节数/秒来体现
计算公式:F=N*R/T
F代表吞吐量,N代表Virtuae User的个数,R代表每个用户的请求数,T代表性能测试的时间
可以看到上列公式在图表里显示理论上是一根平滑的斜线,理论上随着用户数的请求数增加,时间也跟着增加,如果实际测试中。系统的性能出问题时,即用户数增加到一定数量,系统不能及时处理,此时,图表表现出来就会发生变化。
一般来说,2个不同的系统可能具有不同的用户数和用户使用模式,但如果具有基本一致的吞吐量,则可以说,他们具有基本相同的平均处理能力。
性能计数器(Counter)是描述服务器或操作系统性能的一些数据指标。例如,对windows操作系统来说,使用内存数,进程时间等都是常见的计数器。
思考时间:指用户在进行操作时,每个请求之间的间隔时间。
-
svn 中tag branch trunk 的用法
2010-05-25 11:37:02
在SVN中Branch/tag在一个功能选项中,在使用中也往往产生混淆。
在实现上,branch和tag,对于svn都是使用copy实现的,所以他们在默认的权限上和一般的目录没有区别。至于何时用tag,何时用branch,完全由人主观的根据规范和需要来选择,而不是强制的(比如cvs)。
一般情况下,
tag,是用来做一个milestone的,不管是不是release,都是一个可用的版本。这里,应该是只读的。更多的是一个显示用的,给人一个可读(readable)的标记。
branch,是用来做并行开发的,这里的并行是指和trunk进行比较。
比如,3.0开发完成,这个时候要做一个tag,tag_release_3_0,然后基于这个tag做release,比如安装程序等。trunk进入 3.1的开发,但是3.0发现了bug,那么就需要基于tag_release_3_0做一个branch,branch_bugfix_3_0,基于这 个branch进行bugfix,等到bugfix结束,做一个tag,tag_release_3_0_1,然后,根据需要决定 branch_bugfix_3_0是否并入trunk。
对于svn还要注意的一点,就是它是全局版本号,其实这个就是一个tag的标记,所以我们经常可以看到,什么什么release,基于xxx项目的 2xxxx版本。就是这个意思了。但是,它还明确的给出一个tag的概念,就是因为这个更加的可读,毕竟记住tag_release_1_0要比记住一个 很大的版本号容易的多。
branches:分枝
当多个人合作,可能有这样的情况出现:John突然有个想法,跟原先的设计不太一致,可能是功能的添加或者日志格式的改进等等,总而言之,这个想法可能需 要花一段时间来完成,而这个过程中,John的一些操作可能会影响Sally的工作,John从现有的状态单独出一个project的话,又不能及时得到 Sally对已有代码做的修正,而且独立出来的话,John的尝试成功时,跟原来的合并也存在困难。这时最好的实践方法是使用branches。 John建立一个自己的branch,然后在里面实验,必要的时候从Sally的trunk里取得更新,或者将自己的阶段成果汇集到trunk中。
(svn copy SourceURL/trunk DestinationURL/branchName -m "Creating a private branch of xxxx/trunk." )
trunk:主干
主干,一般来说就是开发的主要呆的地方,
tag:
在经过了一段时间的开发后,项目到达了一个里程碑阶段,你可能想记录这一阶段的代码的状态,那么你就需要给代码打上标签。
(svn cp file:///svnroot/mojavescripts/trunk file:///svnroot/mojavescripts/tags/mirrorutils_rel_0_0_1
-m "taged mirrorutils_rel_0_0_1")
另有一说,无所谓谁对谁错。
trunk:表示开发时版本存放的目录,即在开发阶段的代码都提交到该目录上。
branches:表示发布的版本存放的目录,即项目上线时发布的稳定版本存放在该目录中。
tags:表示标签存放的目录。
在这需要说明下分三个目录的原因,如果项目分为一期、二期、三期等,那么一期上线时的稳定版本就应该在一期完成时将代码copy到branches上,这 样二期开发的代码就对一期的代码没有影响,如新增的模块就不会部署到生产环境上。而branches上的稳定的版本就是发布到生产环境上的代码,如果用户 使用的过程中发现有bug,则只要在branches上修改该bug,修改完bug后再编译branches上最新的代码发布到生产环境即可。tags的 作用是将在branches上修改的bug的代码合并到trunk上时创建个版本标识,以后branches上修改的bug代码再合并到trunk上时就 从tags的version到branches最新的version合并到trunk,以保证前期修改的bug代码不会再合并。
-------------------------------------------------------------------------------------------
一直以来用svn只是当作cvs,也从来没有仔细看过文档,直到今天用到,才去翻看svn book文档,惭愧
需求一:
有一个客户想对产品做定制,但是我们并不想修改原有的svn中trunk的代码。
方法:
用svn建立一个新的branches,从这个branche做为一个新的起点来开发
svn copy svn://server/trunk svn://server/branches/ep -m "init ep"
Tip:
如果你的svn中以前没有branches这个的目录,只有trunk这个,你可以用
svn mkdir branches
新建个目录
需求二:
产品开发已经基本完成,并且通过很严格的测试,这时候我们就想发布给客户使用,发布我们的1.0版本
svn copy svn://server/trunk svn://server/tags/release-1.0 -m "1.0 released"
咦,这个和branches有什么区别,好像啥区别也没有?
是的,branches和tags是一样的,都是目录,只是我们不会对这个release-1.0的tag做修改了,不再提交了,如果提交那么就是branches
需求三:
有一天,突然在trunk下的core中发现一个致命的bug,那么所有的branches一定也一样了,该怎么办?
svn -r 148:149 merge svn://server/trunk branches/ep
其中148和149是两次修改的版本号。 -
svn 版本管理详解
2010-05-10 10:27:55
1. 导入一个未进行版本管理的本地项目到svn中
命令:
svn import [svn_path] [local folder]
注意:
本命令仅仅是将一个本地目录加入到svn responsitory 中。本地路径中的文件未进行管理,
必须重新 svn checkout 一个本地拷贝进行操作。
2. svn 常用命令
2.1 更新命令
svn update
2.2 做出修改
svn add
svn delete
svn copy
svn move
2.3 检验修改
svn status
svn diff
2.4 取消修改
svn revert
一般在本地修改了文件,尚未提交修改之前,可以使用该命令,取消你所做的本地修改。
或者:
你在本地使用了 svn add/delete等修改操作, 但是尚未进行svn commint,也可以
通过该命令取消之前的操作。
例:
你在本地创建了一个新的目录foo
$svn status
? foo //说明foo目录尚未加入到svn版本控制中
$svn add foo
$svn status
A foo
$svn revert
$svn status
? foo
2.5 解决冲突(合并别人的修改)
svn update
在进行svn update命令后,一般我们会看到每个更新文件的状态,具体状态字有如下几种:
A: 表示添加
D: 表示删除
U: 表示更新
G: 表示合并,并且合并过程中没有冲突
C: 表示与本地文件发生冲突
例:
$svn update
U intall
G readme
c bar.cpp
update to revision 46.
一旦发生冲突,svn会在你的更新目录下产生3个临时文件,等待你将冲突解决,
冲突解决前不允许提交,即svn commit命令处理失败。
例:
$svn update
C sandwich.txt
update to revision 2;
$ls -l
sandwich.txt
sandwich.txt.mine
sandwich.txt.r1
sandwich.txt.r2
背景说明:
张三和李四,同时在 revision 1的时候,checkout 到了本地;
张三做为修改,并提交, 版本到 revision 2;
李四此时未更新新版本,仍然在 revision 1 下修改sandwich.txt, 并且修改的地方与张三的修改冲突;
李四修改后, 提交自己的修给, 发现提交失败, 报告版本太老;
李四更新svn新版本,结果出现现在的冲突情况;
sandwich.txt
sandwich.txt.mine //! 当前李四修改的未提交的新版本本文件
sandwich.txt.r1 //! 当前李四更新冲突前的svn版本文件
sandwich.txt.r2 //! 当前李四更新冲突前的svn版本文件
而sandwich.txt 则是冲突版本文件, 该文件中,svn系统会自动添加很多冲突标记
<<<<<<<.mine //!冲突标记
[李四修给内容]
======= //!冲突标记
[张三修给内容]
>>>>>>>.r2 //!冲突标记
解决冲突的方法有3种:
1. 手动修给冲突文件,将冲突标记删除
2. 使用一个临时文件(.mine, .r1, .r2)覆盖当前版本
3. 放弃本地修给 svn revert <filename>
svn resolved
一旦冲突解决,就可以使用 svn resolved命令 , 该命令会自动删除3个临时文件。
例:
$svn resolved
Resolved conflicted state of "sandwich.txt".
2.6 提交修改
svn commit
提交命令很简单,但是很多人在提交的时候,忘了写提交备注,或者备注写得不规范,给以后查询修给内容带来不便。
备注例子:(使用序号说明每个修改)
1. add xxx function
2. fixed xxxx bug
3. remove xxxx
3. svn 版本控制:分支、合并、标签
3.1 规划版本库
svn 目录:
/
|
|——project_name
| |
| |-- trunk (主干)
| |
| |-- branches (分支)
| |
| |-- tags (标签)
主干: 是整个项目开发的主线;
分支: 可以是开发者自己独立出来的一个分支,
也可以是一个新的项目,与主干项目有一些功能上的差异,需要单独分开出来;
标签: 项目开发过程中,各阶段发布的版本快照;
svn revision 编号说明:
+(r4) +(r7)
----------------->braches/tom_branch
| +r(5) +r(10) +r(20)
0--------------------------trunk---------------------->n
|
----------------------------->branches/sally_brach
+(r6) |(r12)
----------按时间递增---------------------------------------->
svn merge
svn merge 是个比较复杂的命令,下面做一个简单例子说明:
背景:
tom在自己的分支下走到了revision 7状态,
此时主干开发,发现了一个bug, 该bug在tom的分支下也存在,
主干开发修复该bug,主干版本到revision 10
此时,tom决定将主干中该bug的修复,提交到自己的分支中:
$svn merge -r 5:10 <svn目录>/trunk <svn目录>>/branches/tom_branch
U aa.c
C bb.c
发现此时 bb.c 文件在tom的分支下出现冲突,于是我们参照冲突的处理办法,解决冲突。
$svn commit
提交此次合并的操作。
svn copy
该命令主要于用户开新的分支与打标签。
例子:
tom从当前的trunk版本下,开一个独立的分支
$svn copy <svn目录>/trunk <svn目录>>/branches/tom_branch
$svn commit
tom将自己的开发分支,发布一个新的版本,此时就打一个标签
$svn copy <svn目录>>/branches/tom_branch <svn目录>/tags/project_tom.1.0.0
$svn commit
svn export
发布项目时,不能将一些.svn信息也发布到安装包中,此时就需用 svn export命令
例子:
$svn export <svn目录>/tags/project_tom.1.0.0 ./project_tom.release.1.0.0
$tar -cvzf project_tom.release.1.0.0.tar.gz ./project_tom.release.1.0.0
-
Server sent unexpected return value (403 Forbidden) in response to OPTIONS
2010-04-07 19:12:49
TortoiseSVN 的 403 Forbidden错误
Server sent unexpected return value (403 Forbidden) in response to OPTIONS
-
ORA-01031: insufficient privileges的解决方法
2010-04-01 18:28:45
首先查看文件:sqlnet.ora
发现里面是SQLNET.AUTHENTICATION_SERVICES = (NONE)
把此文件修改为:
SQLNET.AUTHENTICATION_SERVICES = (NTS)
NAMES.DIRECTORY_PATH= (TNSNAMES, EZCONNECT)
这个时候再启动就没有问题了,顺利解决这个问题!
-
附加SQL Server数据库时为只读的解决办法(转载)
2010-03-31 11:52:35
现象:
运行.Net的程序时,提示数据库是只读的。” - 运行 SQL Server Management Studio(开始,运行:Sqlwb):
从配置文件,看不出有什么问题,已经具有最高权限了,应该不影响读写。但是从数据库列表中我们却发现附件的数据库是“只读”状态。这应该是导致不能修改数据的原因。
原因:- 附加数据库时,数据库文件的属性是只读。
- 运行SQL Server实例的帐户对附加的数据库文件不具备相应的修改权限。
解决办法:- 取消文件的只读属性。
在取消文件的“只读”属性后,查看数据库属性可能仍然是“只读”的,可能还需要进行下面的操作。 - 查看运行SQL Server实例的帐户。
在服务(Services.msc)管理控制台中或者SQL Server配置管理器(Configuration Manager)中查看: - 如上图所示,如果启动SQL Server实例的帐户是Network Service,那么将其修改为Local Service,然后重新启动SQL Server实例。如果是指定的帐号用于启动SQL Server实例,那么进行下面操作。
- 修改文件安全属性。
如图所示,将本例中运行SQL Server实例的帐户SqlBoot添加到对物理文件Contacts.mdf的访问权限列表中。如果存在日志文件,相应地,日志文件属性也应添加。其实,这里我们发现,在上面也可以不修改启动SQL Server实例的帐户,直接将启动SQL Server实例的帐户Network Service或者Local Service添加到对数据库物理文件的访问权限列表中即可。
附:-
附件数据库的T-SQL语句:
CREATE DATABASE Contacts
ON (filename='C:\Program Files\Microsoft ASP.NET\ASP.NET AJAX Sample Applications\v1.0.61025\Contacts\App_Data\Contacts.mdf')
FOR ATTACH - 关于之前使用“sp_attach_db”附加数据库,微软建议不要继续使用。”重要事项:后续版本的 Microsoft SQL Server 将删除该功能。请避免在新的开发工作中使用该功能,并应着手修改当前还在使用该功能的应用程序。我们建议您改用 CREATE DATABASE database_name FOR ATTACH。“
-
ArcGIS中自动连接线
2010-03-19 17:46:21
ArcGIS中自动连接线
背景:首位相接的线段根据用户自定义属性进行自动连接。
方法:可以使用FME来实现。
Spatial ETL Tool/LineJoiner,如下图
-
修改注册表相关键值来显示隐藏文件
2010-03-18 15:07:21
你可以通过修改注册表相关键值来显示隐藏文件,方法如下:点“开始”-“运行”―输入regedit打开注册表,定位到HKEY_LOCAL_MACHINE\Software\Microsoft\windows\CurrentVersion\explorer\Advanced\Folder\Hidden\SHOWALL,将CheckedValue键值修改为1(0为隐藏,1为显示)。
在查找文件或文件夹时,能不能搜索到隐藏的文件和文件夹?
解决方法如下:
开始——搜索——文件或文件夹,在窗口左侧,展开“更多高级选项”,勾上“搜索隐藏的文件和文件夹”即可。 -
ArcGIS中的北京54和西安80投影坐标系【转载】
2010-03-18 12:08:21
ArcGIS中的北京54和西安80投影坐标系
1、首先理解地理坐标系(Geographic coordinate system),Geographic coordinate system直译为
地理坐标系统,是以经纬度为地图的存储单位的。很明显,Geographic coordinate syst
em是球面坐标系统。我们要将地球上的数字化信息存放到球面坐标系统上,如何进行操作
呢?地球是一个不规则的椭球,如何将数据信息以科学的方法存放到椭球上?这必然要求
我们找到这样的一个椭球体。这样的椭球体具有特点:可以量化计算的。具有长半轴,短
半轴,偏心率。以下几行便是Krasovsky_1940椭球及其相应参数。
Spheroid: Krasovsky_1940
Semimajor Axis: 6378245.000000000000000000
Semiminor Axis: 6356863.018773047300000000
Inverse Flattening(扁率): 298.300000000000010000
然而有了这个椭球体以后还不够,还需要一个大地基准面将这个椭球定位。在坐标系统描
述中,可以看到有这么一行:
Datum: D_Beijing_1954
表示,大地基准面是D_Beijing_1954。
--------------------------------------------------------------------------------
有了Spheroid和Datum两个基本条件,地理坐标系统便可以使用。
完整参数:
Alias:
Abbreviation:
Remarks:
Angular Unit: Degree (0.017453292519943299)
Prime Meridian(起始经度): Greenwich (0.000000000000000000)
Datum(大地基准面): D_Beijing_1954
Spheroid(参考椭球体): Krasovsky_1940
Semimajor Axis: 6378245.000000000000000000
Semiminor Axis: 6356863.018773047300000000
Inverse Flattening: 298.3000000000000100002、接下来便是Projection coordinate system(投影坐标系统),首先看看投影坐
标系统中的一些参数。
Projection: Gauss_Kruger
Parameters:
False_Easting: 500000.000000
False_Northing: 0.000000
Central_Meridian: 117.000000
Scale_Factor: 1.000000
Latitude_Of_Origin: 0.000000
Linear Unit: Meter (1.000000)
Geographic Coordinate System:
Name: GCS_Beijing_1954
Alias:
Abbreviation:
Remarks:
Angular Unit: Degree (0.017453292519943299)
Prime Meridian: Greenwich (0.000000000000000000)
Datum: D_Beijing_1954
Spheroid: Krasovsky_1940
Semimajor Axis: 6378245.000000000000000000
Semiminor Axis: 6356863.018773047300000000
Inverse Flattening: 298.300000000000010000
从参数中可以看出,每一个投影坐标系统都必定会有Geographic Coordinate System。
投影坐标系统,实质上便是平面坐标系统,其地图单位通常为米。
那么为什么投影坐标系统中要存在坐标系统的参数呢?
这时候,又要说明一下投影的意义:将球面坐标转化为平面坐标的过程便称为投影。
好了,投影的条件就出来了:
a、球面坐标
b、转化过程(也就是算法)
也就是说,要得到投影坐标就必须得有一个“拿来”投影的球面坐标,然后才能使用算法
去投影!
即每一个投影坐标系统都必须要求有Geographic Coordinate System参数。3、关于北京54和西安80是我们使用最多的坐标系
先简单介绍高斯-克吕格投影的基本知识,了解就直接跳过,我国大中比例尺地图均采用高斯-克吕格投影,其通常是按6度和3度分带投影,1:2.5万-1:50万比例尺地形图采用经差6度分带,1:1万比例尺的地形图采用经差3度分带。具体分带法是:6度分带从本初子午线开始,按经差6度为一个投影带自西向东划分,全球共分60个投影带,带号分别为1-60;3度投影带是从东经1度30秒经线开始,按经差3度为一个投影带自西向东划分,全球共分120个投影带。为了便于地形图的测量作业,在高斯-克吕格投影带内布置了平面直角坐标系统,具体方法是,规定中央经线为X轴,赤道为Y轴,中央经线与赤道交点为坐标原点,x值在北半球为正,南半球为负,y值在中央经线以东为正,中央经线以西为负。由于我国疆域均在北半球,x值均为正值,为了避免y值出现负值,规定各投影带的坐标纵轴均西移500km,中央经线上原横坐标值由0变为500km。为了方便带间点位的区分,可以在每个点位横坐标y值的百千米位数前加上所在带号,如20带内A点的坐标可以表示为YA=20 745 921.8m。在Coordinate Systems\Projected Coordinate Systems\Gauss Kruger\Beijing 1954目录中,我们可以看到四种不同的命名方式: Beijing 1954 3 Degree GK CM 75E.prj
Beijing 1954 3 Degree GK Zone 25.prj
Beijing 1954 GK Zone 13.prj
Beijing 1954 GK Zone 13N.prj 对它们的说明分别如下: 三度分带法的北京54坐标系,中央经线在东75度的分带坐标,横坐标前不加带号
三度分带法的北京54坐标系,中央经线在东75度的分带坐标,横坐标前加带号
六度分带法的北京54坐标系,分带号为13,横坐标前加带号
六度分带法的北京54坐标系,分带号为13,横坐标前不加带号 在Coordinate Systems\Projected Coordinate Systems\Gauss Kruger\Xian 1980目录中,文件命名方式又有所变化: Xian 1980 3 Degree GK CM 75E.prj
Xian 1980 3 Degree GK Zone 25.prj
Xian 1980 GK CM 75E.prj
Xian 1980 GK Zone 13.prj 西安80坐标文件的命名方式、含义和北京54前两个坐标相同,但没有出现“带号+N”这种形式,为什么没有采用统一的命名方式?让人看了有些费解 -
3度,6度带,中央经线的算法
2010-03-18 10:41:27
我国采用6度分带和3度分带:
1∶2.5万及1∶5万的地形图采用6度分带投影,即经差为6度,从零度子午线开始,自西向东每个经差6度为一投影带,全球共分60个带,用1,2,3,4,5,……表示.即东经0~6度为第一带,其中央经线的经度为东经3度,东经6~12度为第二带,其中央经线的经度为9度。我省位于东经113度-东经120度之间,跨第19带和20带,其中东经114度以西(包括阜平县的下庄乡以西、平山的温塘、苏家庄以西,井陉的矿区以西,邢台县的浆水镇以西,武安的活水乡以西,涉县全境)位于第19带,其中央经线为东经111度;114度以东到山海关均在第20带,其中央经线为117度。
1∶1万的地形图采用3度分带,从东经1.5度的经线开始,每隔3度为一带,用1,2,3,……表示,全球共划分120个投影带,即东经1.5~4.5度为第1带,其中央经线的经度为东经3度,东经4.5~7.5度为第2带,其中央经线的经度为东经6度.我省位于东经113度-东经120度之间,跨第38、39、40共计3个带,其中东经115.5度以西为第38带,其中央经线为东经114度;东经115.5~118.5度为39带,其中央经线为东经117度;东经118.5度以东到山海关为40带,其中央经线为东经120度。
地形图上公里网横坐标前2位就是带号,例如:我省1:5万地形图上的横坐标为20345486,其中20即为带号,345486为横坐标值。
当地中央经线经度的计算
六度带中央经线经度的计算:当地中央经线经度=6°×当地带号-3°,例如:地形图上的横坐标为20345,其所处的六度带的中央经线经度为:6°×20-3°=117°(适用于1∶2.5万和1∶5万地形图)。
三度带中央经线经度的计算:中央经线经度=3°×当地带号(适用于1∶1万地形图)。 -
并行开发版本管理之路(转载)
2010-03-18 10:31:30
版本管理危机
起始阶段:
项目的开始,项目组只有从第三方获取的类库、具备编程知识的程序员和PM(项目经理)。由于成员数量不少,使用简单共享方式的版本管理往往难以胜任,某些人往往会因为新功能的需要或者无意将一些代码改得面目全非,无从追踪。我们需要一个简单的版本管理工具,比如Visual Source Safe,每个人在修改代码之前要求先将代码文件标记为“检出”状态,每一次“检入”代码都在服务器上生成一个新的版本。好了,所有的代码都有了版本记录,我们可以查看代码的演进过程,对任何两个版本进行比较,也可以轻松的获取到早先的版本。开始迭代:
由于客户的要求,项目开始进行简单的迭代。PM要求所有人员检入可以工作的代码。然后开始执行构建。第一次全部构建的过程可能并不顺利,因为有人修改了A组件导致了依赖A组件的B组件不能正常工作了。当然这个不难解决,我们需要对成员进行培训,要求每个人在检入代码前保证所有的构建都是成功的。这很凑效,虽然每次构建要耗费不少时间。编译的错误很容易发现,但是逻辑的错误却没有那么简单了。不过,到现在为止,这个并不太重要,毕竟项目刚刚开始迭代,在给客户演示的时候偶尔崩溃也是可以忍受的。版本建立:
随着项目第一次交付期的临近,PM决定停止新特性的开发,确定1.0版本。并且将这个版本发布SIT(系统集成测试)。刚刚SIT测试的时候,大家都忙于修改自己的代码中的BUG,忙得不亦乐乎。慢慢的,BUG数量曲线开始趋于平滑。很多人开始觉的可以将当前版本发布,从而可以投入精力进行新特性的开发了。PM也这么认为,因为从需求跟踪矩阵的情况看,还有许多的工作量,客户会要求在第二次交付(2.0.x版本)的时候看到剩下的需求都已经实现。为了不影响1.0.x版本的构建,PM下令所有人可以在本地编辑代码以添加新特性,但是不得检入版本机,唯一允许被检入版本机的是修改BUG的代码。这在一段时间里看起来工作得不错,知道有一天,小王发现他在 a.java 文件中添加和编辑了许多的新特性相关的代码,但是 现在要命的是发现了一个跟 a.java 相关的BUG。冥思苦想,小王决定将a.java先备份起来,然后撤销检出,ok,回到1.0.x的代码了,在a.java中修改了一通,检入了,很幸运,居然没有引起问题。小王开始将原先备份的 a.java和修改过BUG的a.java中的更改进行合并,合并的结果将产生一个新的a.java文件,这个文件没有了已经发现的BUG,而且包含了新特性的代码。由于小王是高手,所编写的代码遵从了SRP(单一职责原则),所以小王的合并并没有耗费缩少时间。但是接下来的时间里,小王又发现b.java,c.java,d.java…x.java需要进行这种手工的合并,每一次合并,他都要将文件预先备份起来。而且,因为在1.0.x稳定运行之前,小王不得检入自己的代码,因此小王担心,如果自己的硬盘崩溃,小王也为不能够使用其它人编写的新特性代码而感到无比郁闷。PM也意识到这种情况,在一个晚上的权衡之后,PM决定在版本服务器上建立了2.0.x的目录,将1.0.x的代码拷贝到这里来。Ok,所有的新特性的开发在2.0.x中进行,所有的BUG修改在1.0.x和2.0.x中同时进行。这真是一个不错的主意。但是,过不了多久,项目组就被频繁的拷贝粘贴折腾的死去活来,代码的修改没有办法被有效跟踪则更是让人伤透了脑筋。典型的版本管理难题
看完了上篇,我们对于多分支开发容易产生的问题应该有了一些基本的了解吧。事实上,通常,并行开发的版本管理面临以下几个典型的难题:
如何保证新版本开发与BugFix同时进行?也就是要求修改过的BUG不能存在于新版本中。
如何保证两个新版本并行开发?可能的情况是两个完全不同的版本,或者一个是另外一个基础。
如何保证版本的发布不受开发人员无意的代码检入影响?
不再拐弯抹角了,解决这三个难题的答案是使用分支(这里涉及到一个著名的版本管理工具ClearCase,分支正是其中的重要工具和概念)。要理解分支必须同时理解其他的术语,比如标签、视图。本文不打算详细地描述基础的概念,相关的概念可以参考ClearCase的文档。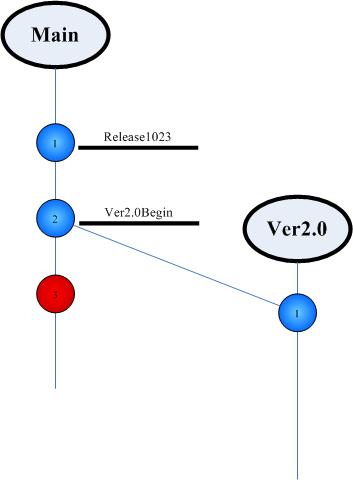
图1
上面是一棵版本树,形象地记载了一个文件的版本变化情况。
其中,1、2、3是不同的版本;Main、Ver2.0就是分支;Release1023和Ver2.0Begin则是标签,标签就像是打在代码版本上的标记;视图就是由分支类型、标签名称、获取规则动态的决定的代码横截面。可以建立Main分支的视图,在这个视图中我们就看不到Ver2.0分支中的任何代码修改;也可以建立Ver2.0分支的视图,在这个视图中我们可以看到Ver2.0分支的最新代码和未在Ver2.0分支中产生修改的Main分支中位于Ver2.0Begin标签处的代码。
开发人员总是习惯工作于一个视图上。那看看解决第一个问题的办法。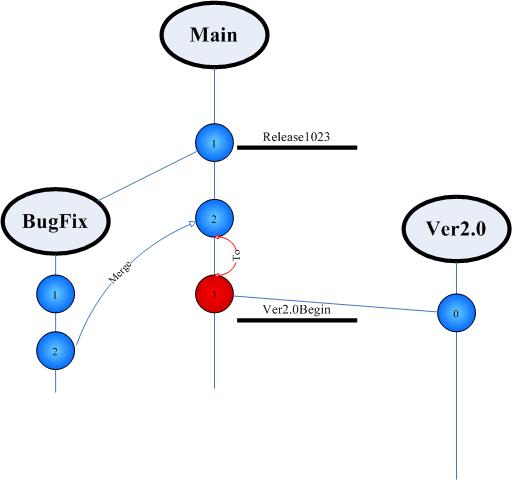
图2
1. 建立用于修改Bug的分支视图,在此视图上进行修改。
2. 将在BugFix上修改的代码合并到主分支中,合并产生新的版本3,移动Ver2.0Begin标签到版本3,Ver2.0分支自动获取到修复Bug以后的代码,同时,主分支上的Bug也得到了修正。
3. 如果此时代码已经在Ver2.0上发生了变化,则需要执行另外一个合并,将更改合并到Ver2.0中。但幸运的是,大多数时候不会在BugFix之前修改Ver2.0的代码。
这样做我们至少收获了几个附加的好处:
我们获得了从Main分支发布稳定版本的能力;
我们获得了从Ver2.0分支发布最新预览版的能力;
开发人员的检入检出不影响版本发布;
版本管理员可以对Main分支进行锁定等控制,防止其他人员越权或者意外的修改Main分支的代码。版本的强制控制和版本合并
版本需要强制控制的几种常见场景:
1. 要转产或者上市了,不希望开发者随意的代码检入影响到产品的质量和稳定性。
2. 已经转产了,希望控制Bug的修改,不希望开发者随意的代码检入影响到补丁(包)的发布。
版本强制控制的手段包括:
1. 将需要保护的分支锁定(仅允许版本管理员修改),打上Release标签。
2. 让开发者在以Release标签为基线的分支上进行开发。
3. 登记开发者在以Release标签为基线的分支上的代码修改动作。
4. 在以Release标签为基线的分支上发布版本进行集成测试。
5. 对于集成测试通过的代码修改,通过版本合并手段合并到被保护的分支上。
上面提到了版本合并。事实上,版本合并也有如下的几种常见情景:
1. 修改了Bug ,需要合并到基线版本中,以便可以发布稳定版本。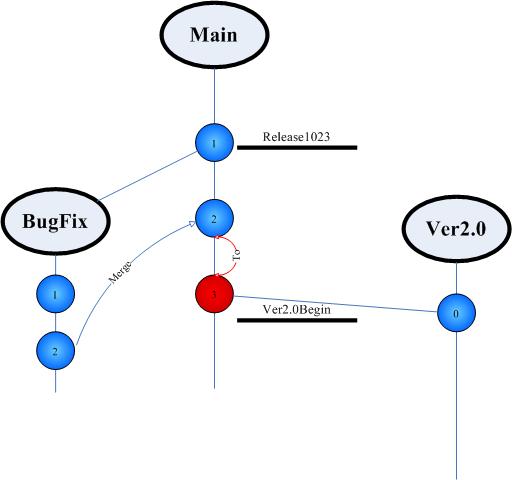
图3
2. 修改了Bug,需要合并到其他正在开发新功能的代码中。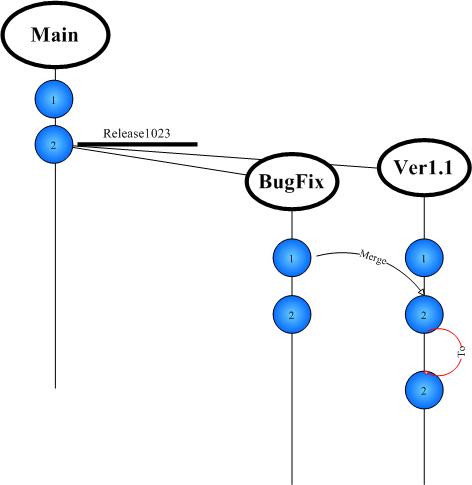
图4
3. 修改了Bug,导致基线发生改变,希望将改变体现到已经发生了改变的2.0版本中。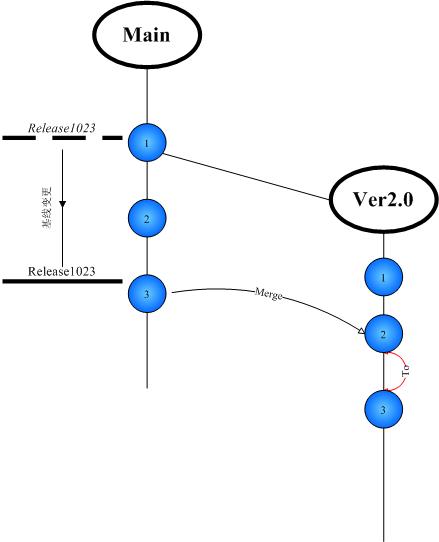
图5
4. 1.1版本开发完成,1.0版不再维护,希望将1.1版本合并到基线版本中,作为以后开发新版本的基础.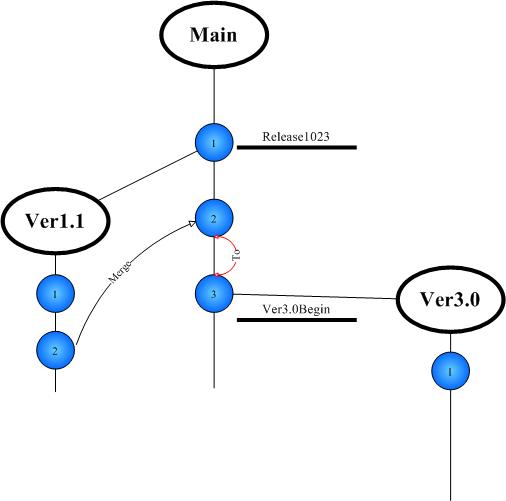
图6
流动的基线基线——所有代码起始版本的集合。如果没有并行开发,基线也许就是版本机上的一个简单文件夹。如果进行并行开发,那么基线就是具有了指定标签的版本的集合。
在进行并行开发的时候,我们希望基线是流动的,会随着我们的期望变化。比如,我们在1.1版本捉虫的时候开始了2.0版本的开发,我们希望2.0的起始版本保持与1.1的最终版本一致。这里基于一点假设,假设2.0版本不回全面改写1.1版本的代码,而是小部分的改动。这种假设依赖于良好的设计。在扩展功能的时候,对原有代码的改动尽量少。假设我们有A1-A10共10个文件,在2.0版本中,为了增加新的功能,我们改动了A9,A10两个文件,在1.1版Preview以后,1.1版本中因为修改Bug,又改动了A8,A9两个文件。我们要使2.0版本的初始代码包含1.1版本的最总代码,我们需要做的事情就是将A8按照上篇所介绍的第一种合并场景进行合并,即合并到基线中(简单的移动基线标签),而A9文件,则除了要合并到基线中意外,还要进行上篇所介绍的的第三种场景的合并,即将基线的变化合并到已经发生改变的2.0版本中(移动基线标签并进行合并)。通常,基线变更涉及的文件数应该尽量少。
这就是流动的基线。因基线的变更需要许多人工判断的介入,所以基线应该是稳定经受考验的版本。我们要保证基线的稳定性,不是所有的人都可以随意改变基线,基线也不是每时每刻不断的变化(上篇已经介绍了版本的强制控制)。事实上,基线的变化越少越好。通常基线发生变化也存在常见的场景。
1. 1.1版本Preview。如果1.1版本是在分支上进行开发的,那么VM希望将分支上的代码完全合并到主分支上,以避免开发者的代码检入影响版本的稳定性和分支的长期存在对于版本服务器性能的影响。这种合并的工作量比较大,必须借助于一些自动合并的工具进行。
2. 版本交替期,即1.1版本已经开始Preview但是并没有RTM,2.0已经开始Coding。这个时候1.1版本的任何将要发布的修改都应该反映到2.0版本的初始代码中,即使是设计的改动(最好不要有)。
3. 补丁(包)发布前,Bug的修改明显将导致基线的移动。
跟版本强制控制一样,基线的变更也是并行开发的基础。






标题搜索
我的存档
数据统计
- 访问量: 56917
- 日志数: 55
- 建立时间: 2009-02-11
- 更新时间: 2010-12-01
