
loadrunner_httpіӨБ¬ҪУЙиЦГ
ЙПТ»ЖӘ / ПВТ»ЖӘ 2011-07-22 17:54:50 / ёцИЛ·ЦАаЈәLoadRunner
ЧоҪьРӯЦъН¬КВҪвҫцБЛјёёцОКМвЈ¬ТІ¶ФloadrunnerөДТ»Р©ЙиЦГјУЙоБЛАнҪвЈ¬№ШјьКЗёьјУЦӘЖдЛщТФИ»ЎЈ
1. loadrunner_internetФЛРРКұЙиЦГ ЧЬАА:

2. ЦРОДВТВл_ЙиЦГЧФ¶ҜЧЦ·ыјҜЧӘ»»

3.loadrunner_Б¬ҪУПВФШі¬Кұ_tcpКЗ·сК№УГіӨБ¬ҪУЙиЦГ
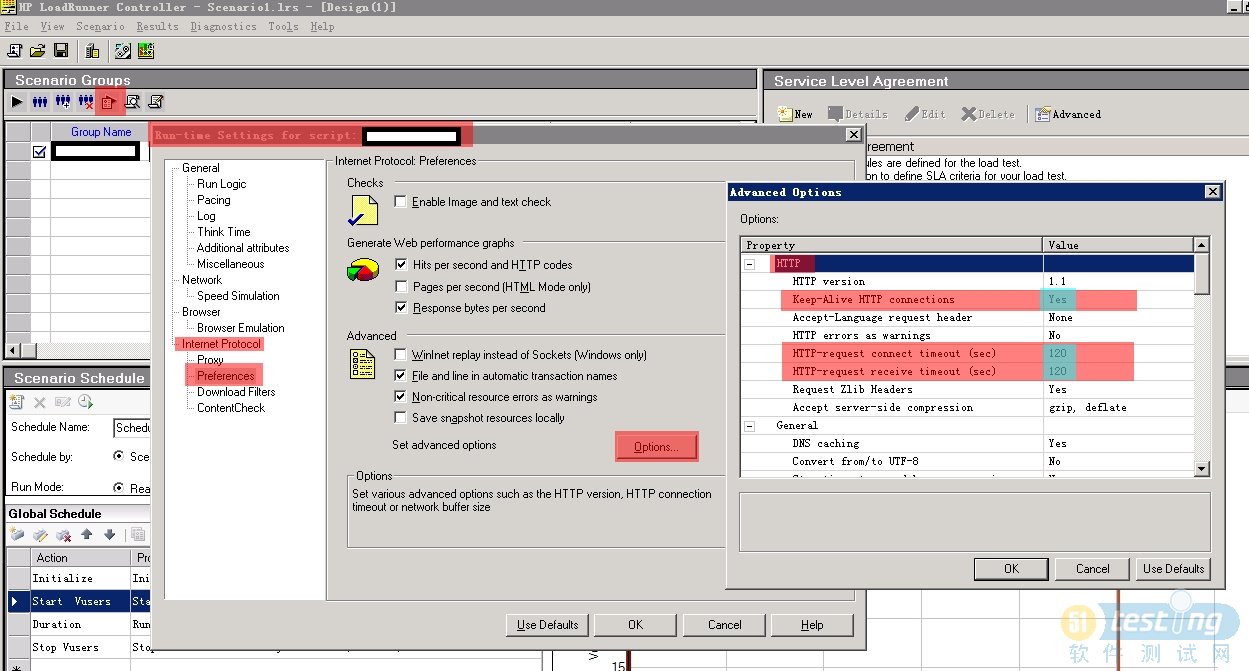
°пЦъОДөөЦРөДЛөГчЈә

ЛжәуФЪҪЕұҫЦРҪшРРБЛІ»Н¬өДЙиЦГЈ¬ҪшРРБЛҪб№ыСйЦӨЈә
3.1 Д¬ИПЦөЈәЙиЦГ Keep-Alive HTTP connections ---> Yes
ФЪҙЛЙиЦГЗйҝцПВ·ГОКbaiduКЧТіЈ¬ЗлЗуН·ИзПВНјЈә

3.2 ЛжәуЈ¬РЮёД ЙиЦГ Keep-Alive HTTP connections ---> No
ФЪҙЛЙиЦГЗйҝцПВ·ГОКbaiduКЧТіЈ¬ЗлЗуН·ИзПВНјЈә

3.3НЁ№э¶ФұИЈ¬ҝЙТФ·ўПЦЈә
ҙЛЙиЦГЙъР§БЛЈ¬¶шЗТКЗНЁ№эЙиЦГHTTPЗлЗуН·ЦРөДІОКэКөПЦөДЈ¬әНПВКцөДОДХВЛщЛөПа·ыЎЈ
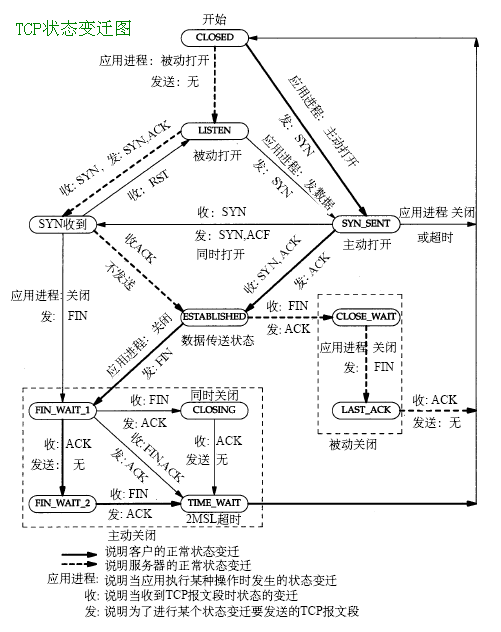
4.ЦБУЪtcpБ¬ҪУҪЁБўБ¬ҪУ3ҙООХКЦЈ¬№ШұХБ¬ҪУ4ҙООХКЦЎЈУРРЛИӨөДҝЙТФСйЦӨПВЎЈ
ёҪTCPЧҙМ¬ұд»ҜНјЈә
ПВГжБРТ»Р©ІОҝјОДХВЈ¬ёРҫх»№КЗВщУРКХ»сөДЎЈ
HTTPіӨБ¬ҪУ¶ЁТеЈә
What is HTTP Persistent Connections?
HTTP persistent connections, also called HTTP keep-alive, or HTTP connection reuse, is the idea of using the same TCP connection to send and receive multiple HTTP requests/responses, as opposed to opening a new one for every single request/response pair. Using persistent connections is very important for improving HTTP performance.
КІГҙКЗHTTPіӨБ¬ҪУЈҝ
HTTPіӨБ¬ҪУЈ¬УлТ»°гГҝҙО·ўЖрhttpЗлЗу»тПмУҰ¶јТӘҪЁБўТ»ёцtcpБ¬ҪУІ»Н¬Ј¬httpіӨБ¬ҪУАыУГН¬Т»ёцtcpБ¬ҪУҙҰАн¶аёцhttpЗлЗуәНПмУҰЈ¬ТІҪРHTTP keep-aliveЈ¬»тХЯhttpБ¬ҪУЦШУГЎЈК№УГhttpіӨБ¬ҪУҝЙТФМбёЯhttpЗлЗу/ПмУҰөДРФДЬЎЈ
5.HTTPОЮЧҙМ¬РӯТйәНConnection:Keep-AliveИЭТЧ·ёөДОуЗш
http://liuzhigong.blog.163.com/blog/static/178272375201141344312315/
6. httpіӨБ¬ҪУУл¶МБ¬ҪУ
http://www.cnblogs.com/Roberts/archive/2010/12/05/1986550.html
ҝЙТФБЛҪвПВіЈјыөДНЁРЕіЎҫ°Јә
Т»ЎўіӨБ¬ҪУУл¶МБ¬ҪУЈә
іӨБ¬ҪУЈәclient·ҪУлserver·ҪПИҪЁБўБ¬ҪУЈ¬Б¬ҪУҪЁБўә󲻶ПҝӘЈ¬И»әуФЩҪшРРұЁОД·ўЛНәНҪУКХЎЈХвЦЦ·ҪКҪПВУЙУЪНЁС¶Б¬ҪУТ»ЦұҙжФЪЎЈҙЛЦЦ·ҪКҪіЈУГУЪP2PНЁРЕЎЈ
¶МБ¬ҪУЈәClient·ҪУлserverГҝҪшРРТ»ҙОұЁОДКХ·ўҪ»ТЧКұІЕҪшРРНЁС¶Б¬ҪУЈ¬Ҫ»ТЧНкұПәуБўјҙ¶ПҝӘБ¬ҪУЎЈҙЛ·ҪКҪіЈУГУЪТ»өг¶Ф¶аөгНЁС¶ЎЈC/SНЁРЕЎЈ¶юЎўіӨБ¬ҪУУл¶МБ¬ҪУөДІЩЧч№эіМЈә
¶МБ¬ҪУөДІЩЧчІҪЦиКЗЈәҪЁБўБ¬ҪУЎӘЎӘКэҫЭҙ«КдЎӘЎӘ№ШұХБ¬ҪУ...ҪЁБўБ¬ҪУЎӘЎӘКэҫЭҙ«КдЎӘЎӘ№ШұХБ¬ҪУіӨБ¬ҪУөДІЩЧчІҪЦиКЗЈәҪЁБўБ¬ҪУЎӘЎӘКэҫЭҙ«Кд...ЈЁұЈіЦБ¬ҪУЈ©...КэҫЭҙ«КдЎӘЎӘ№ШұХБ¬ҪУИэЎўіӨБ¬ҪУУл¶МБ¬ҪУөДК№УГКұ»ъЈә
іӨБ¬ҪУЈә¶МБ¬ҪУ¶аУГУЪІЩЧчЖө·ұЈ¬өг¶ФөгөДНЁС¶Ј¬¶шЗТБ¬ҪУКэІ»ДЬМ«¶аөДЗйҝцЎЈГҝёцTCPБ¬ҪУөДҪЁБў¶јРиТӘИэҙООХКЦЈ¬ГҝёцTCPБ¬ҪУөД¶ПҝӘТӘЛДҙООХКЦЎЈИз№ыГҝҙОІЩЧч¶јТӘҪЁБўБ¬ҪУИ»әуФЩІЩЧчөД»°ҙҰАнЛЩ¶И»бҪөөНЈ¬ЛщТФГҝҙОІЩЧчПВҙОІЩЧчКұЦұҪУ·ўЛНКэҫЭҫНҝЙТФБЛЈ¬І»УГФЩҪЁБўTCPБ¬ҪУЎЈАэИзЈәКэҫЭҝвөДБ¬ҪУУГіӨБ¬ҪУЈ¬Из№ыУГ¶МБ¬ҪУЖө·ұөДНЁРЕ»бФміЙsocketҙнОуЈ¬Жө·ұөДsocketҙҙҪЁТІКЗ¶ФЧКФҙөДАЛ·СЎЈ¶МБ¬ҪУЈәwebНшХҫөДhttp·юОсТ»°г¶јУГ¶МБ¬ҪУЎЈТтОӘіӨБ¬ҪУ¶ФУЪ·юОсЖчАҙЛөТӘәД·СТ»¶ЁөДЧКФҙЎЈПсwebНшХҫХвГҙЖө·ұөДіЙЗ§ЙПНтЙхЦБЙПТЪҝН»§¶ЛөДБ¬ҪУУГ¶МБ¬ҪУёьКЎТ»Р©ЧКФҙЎЈКФПлИз№ы¶јУГіӨБ¬ҪУЈ¬¶шЗТН¬КұУГіЙЗ§ЙПНтөДУГ»§Ј¬ГҝёцУГ»§¶јХјУРТ»ёцБ¬ҪУөД»°Ј¬ҝЙПл¶шЦӘ·юОсЖчөДС№БҰУР¶аҙуЎЈЛщТФІў·ўБҝҙуЈ¬ө«КЗГҝёцУГ»§УЦІ»РиЖө·ұІЩЧчөДЗйҝцПВРиТӘ¶МБ¬ҪУЎЈЧЬЦ®ЈәіӨБ¬ҪУәН¶МБ¬ҪУөДСЎФсТӘКУРиЗу¶ш¶ЁЎЈЛДЎў·ўЛНҪУКХ·ҪКҪЈә
1ЎўТмІҪЈәұЁОД·ўЛНәНҪУКХКЗ·ЦҝӘөДЈ¬Па»Ҙ¶АБўЈ¬»ҘІ»У°ПмөДЎЈХвЦЦ·ҪКҪУЦ·ЦБҪЦЦЗйҝцЈә
ТмІҪЛ«№ӨЈәҪУКХәН·ўЛНФЪН¬Т»ёціМРтЦРЈ¬УРБҪёцІ»Н¬өДЧУҪшіМ·ЦұрёәФр·ўЛНәНҪУЛНЎЈТмІҪөҘ№ӨЈәҪУЛНәН·ўЛНК№УГБҪёцІ»Н¬өДіМРтАҙНкіЙЎЈ2ЎўН¬ІҪЈәұЁОД·ўЛНәНҪУКХКЗН¬ІҪҪшРРЈ¬јҙұЁОД·ўЛНәуөИҙэҪУЛН·ө»ШұЁОДЎЈН¬ІҪ·ҪКҪТ»°гРиТӘҝјВЗі¬КұОКМвЈ¬КФПлОТГЗ·ўЛНұЁОДТФәуТІІ»ДЬОЮПЮөИҙэ°ЎЈ¬ЛщТФОТГЗТӘЙи¶ЁТ»ёцөИҙэКұәтЎЈі¬№эөИҙэКұјд·ўЛН·ҪІ»ФЩөИҙэ¶Б·ө»ШұЁОДЎЈЦұҪУНЁЦӘі¬Кұ·ө»ШЎЈ
ОеЎўұЁОДёсКҪЈә
НЁРЕұЁОДёсКҪ¶аСщРФёь¶аЈ¬ПаУҰөШҫНұШРлЙијЖ¶ФУҰөД¶БРҙұЁОДөДҪУ
КХәН·ўЛНұЁОДәҜКэЎЈЧиИыУл·ЗЧиИы·ҪКҪ
1Ўў·ЗЧиИы·ҪКҪЈә¶БәҜКэІ»НЈөДҪшРР¶Б¶ҜЧчЈ¬Из№ыГ»УРұЁОДҪУКХөҪЈ¬өИҙэТ»¶ОКұјдәуі¬Кұ·ө»ШЈ¬ХвЦЦЗйҝцТ»°гРиТӘЦё¶Ёі¬КұКұјдЎЈ2ЎўЧиИы·ҪКҪЈәИз№ыГ»УРҪУКХөҪұЁОДЈ¬Фт¶БәҜКэТ»ЦұҙҰУЪөИҙэЧҙМ¬Ј¬ЦӘөАұЁОДөҪҙпЎЈСӯ»·¶БРҙ·ҪКҪ
1ЎўТ»ҙОЦұҪУ¶БРҙұЁОДЈәФЪТ»ҙОҪУКХ»т·ўЛНұЁОД¶ҜЧчЦРТ»ҙОРФІ»јУ·ЦұрөШИ«Іҝ¶БИЎ»тИ«Іҝ·ўЛНұЁОДЧЦҪЪЎЈ2ЎўІ»Цё¶ЁіӨ¶ИСӯ»·¶БРҙЈәХвТ»°ж·ўЙъФЪ¶МБ¬ҪУҪшіМЦРЈ¬КЬНшВзВ·УЙөИПЮЦЖЈ¬Т»ҙОҪПіӨөДұЁОДҝЙДЬФЪНшВзҙ«Кд№эіМЦРұ»·ЦҪвіЙәЬ¶аёц°ьЈ¬Т»ҙО¶БИЎҝЙДЬІ»ДЬИ«Іҝ¶БНкТ»ҙОұЁОДЈ¬ХвҫНРиТӘСӯ»·¶БИЎұЁОДЈ¬ЦӘөА¶БНкОӘЦ№ЎЈ3ЎўҙшіӨ¶ИұЁОДН·Сӯ»·¶БРҙЈәХвЦЦЗйҝцТ»°гФЪіӨБ¬ҪУЦРЈ¬УЙУЪФЪіӨБ¬ҪУЦРГ»УРМхјюДЬ№»ЕР¶ПСӯ»·¶БРҙКІГҙКұәтҪбКшЎЈұШРлТӘјУіӨ¶ИұЁОДН·ЎЈ¶БәҜКэПИКЗ¶БИЎұЁОДН·өДіӨ¶ИЈ¬ФЩёщҫЭХвёціӨ¶ИИҘ¶БұЁОДЈ¬КөјКЗйҝцЦРЈ¬ұЁН·ВлЦЖёсКҪ»№ҫӯіЈІ»Т»СщЈ¬Из№ыКЗ·ЗASCIIөДұЁОДН·Ј¬»№ұШРлЧӘ»»іЙASCIIіЈјыөДұЁОДН·ұаЦЖУРЈә1ЎўnёцЧЦҪЪөДASCIIВлЎЈ2ЎўnёцЧЦҪЪөДBCDВлЎЈ3ЎўnёцЧЦҪЪөДНшВзХыРНВлЎЈТФЙПКЗјёЦЦұИҪПөдРНөД¶БРҙұЁОД·ҪКҪЈ¬ҝЙТФУлНЁРЕ·ҪКҪДЈ°еТ»Жр ФӨПИМṩһЩөдРНөДAPI¶БРҙәҜКэЎЈ
өұИ»ФЪКөјКОКМвЦРЈ¬ҝЙДЬ»№ұШРлұаРҙУл¶Ф·ҪұЁОДёсКҪЕдМЧөД¶БРҙAPI.ФЪКөјКЗйҝцЦРЈ¬НщНщРиТӘ
°СОТГЗЧФјәөДПөНіУлұрИЛөДПөНіҪшРРБ¬ҪУЈ¬ УРБЛТФЙПДЈ°еУлAPI,ҝЙТФЛөБ¬ҪУИОәО·ҪКҪөДНЁРЕіМРт
¶јІ»ҙжФЪОКМвЎЈ
7. httpіӨБ¬ҪУјјКхОДХВ·ӯТлЎӘЎӘ№ШУЪhttpіӨБ¬ҪУУРәЬ¶аЦШТӘөДёЕДо
http://www.blogjava.net/xjacker/articles/334709.html
іўКФ·ӯТлЖ¬јјКхОДХВЎЈ
What is HTTP Persistent Connections?
HTTP persistent connections, also called HTTP keep-alive, or HTTP connection reuse, is the idea of using the same TCP connection to send and receive multiple HTTP requests/responses, as opposed to opening a new one for every single request/response pair. Using persistent connections is very important for improving HTTP performance.
КІГҙКЗHTTPіӨБ¬ҪУЈҝ
HTTPіӨБ¬ҪУЈ¬УлТ»°гГҝҙО·ўЖрhttpЗлЗу»тПмУҰ¶јТӘҪЁБўТ»ёцtcpБ¬ҪУІ»Н¬Ј¬httpіӨБ¬ҪУАыУГН¬Т»ёцtcpБ¬ҪУҙҰАн¶аёцhttpЗлЗуәНПмУҰЈ¬ТІҪРHTTP keep-aliveЈ¬»тХЯhttpБ¬ҪУЦШУГЎЈК№УГhttpіӨБ¬ҪУҝЙТФМбёЯhttpЗлЗу/ПмУҰөДРФДЬЎЈ
There are several advantages of using persistent connections, including:
Network friendly. Less network traffic due to fewer setting up and tearing down of TCP connections.
Reduced latency on subsequent request. Due to avoidance of initial TCP handshake
Long lasting connections allowing TCP sufficient time to determine the congestion state of the network, thus to react appropriately.
К№УГhttpіӨБ¬ҪУУРәЬ¶аәГҙҰЈ¬°ьАЁЈә
ёьЙЩөДҪЁБўәН№ШұХtcpБ¬ҪУЈ¬ҝЙТФјхЙЩНшВзБчБҝЎЈ
ТтОӘТСҪЁБўөДtcpОХКЦЈ¬јхЙЩәуРшЗлЗуөДСУКұЎЈ
іӨКұјдөДБ¬ҪУИГtcpУРідЧгөДКұјдЕР¶ПНшВзөДУөИыЗйҝцЈ¬·ҪұгЧціцПВІҪІЩЧчЎЈ
The advantages are even more obvious with HTTPS or HTTP over SSL/TLS. There, persistent connections may reduce the number of costly SSL/TLS handshake to establish security associations, in addition to the initial TCP connection set up.
In HTTP/1.1, persistent connections are the default behavior. of any connection. That is, unless otherwise indicated, the client SHOULD assume that the server will maintain a persistent connection, even after error responses from the server. However, the protocol provides means for a client and a server to signal the closing of a TCP connection.
ХвР©УЕөгФЪК№УГhttpsБ¬ҪУКұёьПФЦшЎЈҝЙТФјхЙЩ¶аҙОҪЁБўёЯПыәДөДSSL/TLSОХКЦЎЈ
ФЪHTTP/1.1ЦРЈ¬Д¬ИПК№УГөДКЗіӨБ¬ҪУ·ҪКҪЎЈҝН»§¶ЛД¬ИП·юОс¶Л»бұЈіЦіӨБ¬ҪУЈ¬јҙұг·ө»ШҙнОуПмУҰЈ»іэ·ЗГчИ·ЦёКҫІ»К№УГіӨБ¬ҪУЎЈН¬КұЈ¬РӯТйЦРТІЦё¶ЁБЛҝН»§¶ЛҝЙТФ·ўЛН№ШұХРЕәЕөҪ·юОс¶ЛАҙ№ШұХTCPБ¬ҪУЎЈ
What makes a connection reusable?
Since TCP by its nature is a stream based protocol, in order to reuse an existing connection, the HTTP protocol has to have a way to indicate the end of the previous response and the beginning of the next one. Thus, it is required that all messages on the connection MUST have a self-defined message length (i.e., one not defined by closure of the connection). Self demarcation is achieved by either setting the Content-Length header, or in the case of chunked transfer encoded entity body, each chunk starts with a size, and the response body ends with a special last chunk.
ФхСщКЗБ¬ҪУҝЙТФЦШУГЈҝ
ТтОӘTCPКЗ»щУЪБчөДРӯТйЈ¬ЛщТФHTTPРӯТйРиТӘУРТ»ЦЦ·ҪКҪАҙЦёКҫЗ°Т»ёцПмУҰөДҪбКшәНәуТ»ёцПмУҰөДҝӘКјАҙЦШУГТСҪЁБўөДБ¬ҪУЎЈЛщТФЈ¬ЛьТӘЗуБ¬ҪУЦРҙ«КдөДРЕПўұШРлУРЧФ¶ЁТеөДПыПўіӨ¶ИЎЈЧФ¶ЁТеПыПўіӨ¶ИҝЙТФНЁ№эЙиЦГ Content-Length ПыПўН·Ј¬Ифҙ«КдұаВлөДКөМеДЪИЭҝйЈ¬ФтГҝёцКэҫЭҝйөДұкГчКэҫЭҝйөДҙуРЎЈ¬¶шЗТПмУҰМеТІКЗТФТ»ёцМШКвөДКэҫЭҝйҪбКшЎЈ
What happens if there are proxy servers in between?
Since persistent connections applies to only one transport link, it is important that proxy servers correctly signal persistent/or-non-persistent connections separately with its clients and the origin servers (or to other proxy servers). From a HTTP client or server's perspective, as far as persistence connection is concerned, the presence or absence of proxy servers is transparent.
ИфЦРјдҙжФЪҙъАн·юОсЖчҪ«»бИзәО?
ТтОӘіӨБ¬ҪУҪцХјУГТ»Мхҙ«КдБҙВ·Ј¬ЛщТФҙъАн·юОсЖчДЬ·сХэИ·өГУлҝН»§¶ЛәН·юОсЖч¶ЛЈЁ»тХЯЖдЛыҙъАн·юОсЖчЈ©·ўЛНіӨБ¬ҪУ»т·ЗіӨБ¬ҪУөДРЕәЕУИОӘЦШТӘЎЈө«КЗHTTPөДҝН»§¶Л»т·юОсЖч¶ЛАҙҝҙЈ¬ҙъАн·юОсЖч¶ФЛыГЗАҙЛөКЗНёГчөДЈ¬јҙұгіӨБ¬ҪУКЗРиТӘ№ШЧўөДЎЈ
What does the current JDK do for Keep-Alive?
The JDK supports both HTTP/1.1 and HTTP/1.0 persistent connections.
When the application finishes reading the response body or when the application calls close() on the InputStream returned by URLConnection.getInputStream(), the JDK's HTTP protocol handler will try to clean up the connection and if successful, put the connection into a connection cache for reuse by future HTTP requests.
The support for HTTP keep-Alive is done transparently. However, it can be controlled by system properties http.keepAlive, and http.maxConnections, as well as by HTTP/1.1 specified request and response headers.
өұЗ°өДJDKИзәОҙҰАнKeep-AliveЈҝ
JDKН¬КұЦ§іЦHTTP/1.1 әН HTTP/1.0ЎЈ
өұУҰУГіМРт¶БИЎНкПмУҰМеДЪИЭәу»тХЯөчУГ close() №ШұХБЛURLConnection.getInputStream()·ө»ШөДБчЈ¬JDKЦРөДHTTPРӯТйҫдұъҪ«№ШұХБ¬ҪУЈ¬ІўҪ«Б¬ҪУ·ЕөҪБ¬ҪУ»әҙжЦРЈ¬ТФұгәуГжөДHTTPЗлЗуК№УГЎЈ
¶ФHTTP keep-Alive өДЦ§іЦКЗНёГчөДЎЈө«КЗЈ¬ДгТІҝЙТФНЁ№эПөНіКфРФhttp.keepAliveәНhttp.maxConnectionsТФј°HTTP/1.1РӯТйЦРөДМШ¶ЁөДЗлЗуПмУҰН·АҙҝШЦЖЎЈ
The system properties that control the behavior. of Keep-Alive are:
http.keepAlive=<boolean>
default: true
Indicates if keep alive (persistent) connections should be supported.
http.maxConnections=<int>
default: 5
Indicates the maximum number of connections per destination to be kept alive at any given time
HTTP header that influences connection persistence is:
Connection: close
If the "Connection" header is specified with the value "close" in either the request or the response header fields, it indicates that the connection should not be considered 'persistent' after the current request/response is complete.
ҝШЦЖKeep-AliveұнПЦөДПөНіКфРФУРЈә
http.keepAlive=<Іј¶ыЦө>
Д¬ИП: true
Цё¶ЁіӨБ¬ҪУКЗ·сЦ§іЦ
http.maxConnections=<ХыКэ>
Д¬ИП: 5
Цё¶Ё¶ФН¬Т»ёц·юОсЖчұЈіЦөДіӨБ¬ҪУөДЧоҙуёцКэЎЈ
У°ПміӨБ¬ҪУөДHTTP headerКЗЈә
Connection: close
Из№ыЗлЗу»тПмУҰЦРөДConnection headerұ»Цё¶ЁОӘcloseЈ¬ұнКҫФЪөұЗ°ЗлЗу»тПмУҰНкіЙәуҪ«№ШұХTCPБ¬ҪУЎЈ
The current implementation doesn't buffer the response body. Which means that the application has to finish reading the response body or call close() to abandon the rest of the response body, in order for that connection to be reused. Furthermore, current implementation will not try block-reading when cleaning up the connection, meaning if the whole response body is not available, the connection will not be reused.
JDKЦРөДөұЗ°КөПЦІ»Ц§іЦ»әҙжПмУҰМеЈ¬ЛщТФУҰУГіМРтұШРл¶БИЎНкПмУҰМеДЪИЭ»тХЯөчУГclose()№ШұХБчІў¶ӘЖъОҙ¶БДЪИЭАҙЦШУГБ¬ҪУЎЈҙЛНвЈ¬өұЗ°КөПЦФЪЗеАнБ¬ҪУКұІўОҙК№УГЧиИы¶БЈ¬ХвҫНТвО¶ХвИз№ыПмУҰМеІ»ҝЙУГЈ¬Б¬ҪУҪ«І»ДЬұ»ЦШУГЎЈ
What's new in Tiger?
When the application encounters a HTTP 400 or 500 response, it may ignore the IOException and then may issue another HTTP request. In this case, the underlying TCP connection won't be Kept-Alive because the response body is still there to be consumed, so the socket connection is not cleared, therefore not available for reuse. What the application needs to do is call HttpURLConnection.getErrorStream() after catching the IOException , read the response body, then close the stream. However, some existing applications are not doing this. As a result, they do not benefit from persistent connections. To address this problem, we have introduced a workaround.
The workaround involves buffering the response body if the response is >=400, up to a certain amount and within a time limit, thus freeing up the underlying socket connection for reuse. The rationale behind this is that when the server responds with a >=400 error (client error or server error. One example is "404: File Not Found" error), the server usually sends a small response body to explain whom to contact and what to do to recover.
JDK1.5ЦРөДРВМШРФ
өұУҰУГҪУКХөҪ400»т500өДHTTPПмУҰКұЈ¬ЛьҪ«әцВФIOException ¶шБн·ўТ»ёцHTTP ЗлЗуЎЈХвЦЦЗйҝцПВЈ¬өЧІгөДTCPБ¬ҪУҪ«І»»бФЩұЈіЦЈ¬ТтОӘПмУҰДЪИЭ»№ФЪөИҙэұ»¶БИЎЈ¬socket Б¬ҪУОҙЗеАнЈ¬І»ДЬұ»ЦШУГЎЈУҰУГҝЙТФФЪІ¶»сIOException ТФәуөчУГHttpURLConnection.getErrorStream() Ј¬¶БИЎПмУҰДЪИЭИ»әу№ШұХБчЎЈө«КЗПЦҙжөДУҰУГГ»УРХвГҙЧцЈ¬І»ДЬМеПЦіціӨБ¬ҪУөДУЕКЖЎЈОӘБЛҪвҫцХвёцОКМвЈ¬ҪйЙЬПВworkaroundЎЈ
өұПмУҰМеөДЧҙМ¬ВлҙуУЪ»төИУЪ400өДКұәтЈ¬workaround Ҫ«ФЪТ»¶ЁКұјдДЪ»әҙжТ»¶ЁКэБҝөДПмУҰДЪИЭЈ¬КН·ЕөЧІгөДsocketБ¬ҪУАҙЦШУГЎЈ»щұҫФӯАнКЗөұПмУҰЧҙМ¬ВлҙуУЪ»төИУЪ400КұЈ¬·юОсЖч¶Л»б·ўЛНТ»ёцјт¶МөДПмУҰМеАҙЦёГчБ¬ҪУЛӯТФј°ИзәО»ЦёҙБ¬ҪУЎЈ
Several new Sun implementation specific properties are introduced to help clean up the connections after error response from the server.
The major one is:
sun.net.http.errorstream.enableBuffering=<boolean>
default: false
With the above system property set to true (default is false), when the response code is >=400, the HTTP handler will try to buffer the response body. Thus freeing up the underlying socket connection for reuse. Thus, even if the application doesn't call getErrorStream(), read the response body, and then call close(), the underlying socket connection may still be kept-alive and reused.
The following two system properties provide further control to the error stream buffering behavior.:
sun.net.http.errorstream.timeout=<int> in millisecond
default: 300 millisecond
sun.net.http.errorstream.bufferSize=<int> in bytes
default: 4096 bytes
ПВГжҪйЙЬТ»Р©SUNКөПЦЦРөДМШ¶ЁКфРФАҙ°пЦъҪУКХөҪҙнОуПмУҰМеәуЗеАнБ¬ҪУЈә
ЦчТӘөДТ»ёцКЗЈә
sun.net.http.errorstream.enableBuffering=<Іј¶ыЦө>
Д¬ИП: false
өұЙПГжКфРФЙиЦГОӘtrueәуЈ¬ФЪҪУКХөҪПмУҰВлҙуУЪ»төИУЪ400КЗЈ¬HTTP ҫдұъҪ«іўКФ»әҙжПмУҰДЪИЭЎЈКН·ЕөЧІгөДsocketБ¬ҪУАҙЦШУГЎЈЛщТФЈ¬јҙұгУҰУГІ»өчУГgetErrorStream()Аҙ¶БИЎПмУҰДЪИЭЈ¬»тХЯөчУГ close()№ШұХБчЈ¬өЧІгөДsocketБ¬ҪУТІҪ«ұЈіЦБ¬ҪУЧҙМ¬ЎЈ
ПВГжөДБҪёцПөНіКфРФКЗОӘБЛёьҪшТ»ІҪҝШЦЖҙнОуБчөД»әҙжРРОӘЈә
sun.net.http.errorstream.timeout=<int> in әБГл
Д¬ИП: 300 әБГл
sun.net.http.errorstream.bufferSize=<int> in bytes
Д¬ИП: 4096 bytes
What can you do to help with Keep-Alive?
Do not abandon a connection by ignoring the response body. Doing so may results in idle TCP connections. That needs to be garbage collected when they are no longer referenced.
If getInputStream() successfully returns, read the entire response body.
When calling getInputStream() from HttpURLConnection, if an IOException occurs, catch the exception and call getErrorStream() to get the response body (if there is any).
Reading the response body cleans up the connection even if you are not interested in the response content itself. But if the response body is long and you are not interested in the rest of it after seeing the beginning, you can close the InputStream. But you need to be aware that more data could be on its way. Thus the connection may not be cleared for reuse.
Here's a code example that complies to the above recommendation:
ДгИзәОЧцҝЙТФұЈіЦБ¬ҪУОӘБ¬ҪУЧҙМ¬ДШЈҝ
І»ТӘәцВФПмУҰМе¶ш¶ӘЖъБ¬ҪУЎЈХвСщ»бКЗTCPБ¬ҪУПРЦГЈ¬өұІ»ФЩұ»ТэУГәуҪ«»бұ»А¬»ш»ШКХЖч»ШКХЎЈ
Из№ыgetInputStream()·ө»ШіЙ№ҰЈ¬¶БИЎИ«ІҝПмУҰДЪИЭЎЈИз№ыЕЧіцIOException Ј¬І¶»сТміЈІўөчУГgetErrorStream() ¶БИЎПмУҰДЪИЭЈЁИз№ыҙжФЪПмУҰДЪИЭЈ©ЎЈ
јҙұгДг¶ФПмУҰДЪИЭІ»ёРРЛИӨЈ¬ТІТӘ¶БИЎЛьЈ¬ТФұгЗеАнБ¬ҪУЎЈө«КЗЈ¬Из№ыПмУҰДЪИЭәЬіӨЈ¬Дг¶БИЎөҪҝӘКјІҝ·ЦәуҫНІ»ёРРЛИӨБЛЈ¬ҝЙТФөчУГclose()Аҙ№ШұХБчЎЈЦөөГЧўТвөДКЗЈ¬ЖдЛыІҝ·ЦөДКэҫЭТСФЪ¶БИЎЦРЈ¬ЛщТФБ¬ҪУҪ«І»ДЬұ»ЗеАнҪш¶шұ»ЦШУГЎЈ
ПВГжКЗТ»ёц»щУЪЙПГжҪЁТйөДҙъВлСщАэЈә

 try
try  {
{2
 URL a = new URL(args[0]);
URL a = new URL(args[0]);3
URLConnection urlc = a.openConnection();4
is = conn.getInputStream();5
int ret = 0;6

 while ((ret = is.read(buf)) > 0) {
while ((ret = is.read(buf)) > 0) {7
processBuf(buf);8
 }
}9
// close the inputstream10
is.close();11
} catch (IOException e) {12
try {13
respCode = ((HttpURLConnection)conn).getResponseCode();14
es = ((HttpURLConnection)conn).getErrorStream();15
int ret = 0;16
// read the response body17
while ((ret = es.read(buf)) > 0) {18
processBuf(buf);19
}20
// close the errorstream21
es.close();22
} catch(IOException ex) {23
// deal with the exception24
}25
 }
}
If you know ahead of time that you won't be interested in the response body, you should issue a HEAD request instead of a GET request. For example when you are only interested in the meta. info of the web resource or when testing for its validity, accessibility and recent modification. Here's a code snippet:
Из№ыДгФӨПИҫН¶ФПмУҰДЪИЭІ»ёРРЛИӨЈ¬ДгҝЙТФК№УГHEAD ЗлЗуАҙҙъМжGET ЗлЗуЎЈАэИзЈ¬»сИЎwebЧКФҙөДmetaРЕПў»тХЯІвКФЛьөДУРР§РФЈ¬ҝЙ·ГОКРФТФј°ЧоҪьөДРЮёДЎЈПВГжКЗҙъВлЖ¬¶ОЈә
 URL a = new URL(args[0]);
URL a = new URL(args[0]);2
URLConnection urlc = a.openConnection();3
HttpURLConnection httpc = (HttpURLConnection)urlc;4
// only interested in the length of the resource5
httpc.setRequestMethod("HEAD");6
int len = httpc.getContentLength();
ёщҫЭЗ°ГжөДНјҝЙТФЦӘөАЈ¬Keep Alive КфРФУР·юОс¶ЛәНҝН»§¶ЛБҪН·¶јҝЙТФЙиЦГЈ¬
ДЗГҙ·юОсЖч¶ЛИзәОЙиЦГІЕҝЙТФ»сөГёьәГөДРФДЬДШЈҝ
8.Apache ЦР Keep Alive ЕдЦГөДәПАнК№УГЎӘЎӘАпГжөД№«КҪәНјЖЛг·Ҫ·ЁЈ¬Г»ҝҙ¶®Ј¬І»ТӘГФРЕ»№КЗТӘКөЦӨ
http://blog.163.com/hai_zone/blog/static/264611372010718103838356/?fromdm&fromSearch&isFromSearchEngine=yes
ФЪ Apache ·юОсЖчЦРЈ¬KeepAlive КЗТ»ёцІј¶ыЦөЈ¬On ҙъұнҙтҝӘЈ¬Off ҙъұн№ШұХЈ¬ХвёцЦёБоФЪЖдЛыЦЪ¶аөД HTTPD ·юОсЖчЦР¶јКЗҙжФЪөДЎЈ
ЎЎЎЎKeepAlive ЕдЦГЦёБоҫц¶ЁөұҙҰАнНкУГ»§·ўЖрөД HTTP ЗлЗуәуКЗ·сБўјҙ№ШұХ TCP Б¬ҪУЈ¬Из№ы KeepAlive ЙиЦГОӘOnЈ¬ДЗГҙУГ»§НкіЙТ»ҙО·ГОКәуЈ¬І»»бБўјҙ¶ПҝӘБ¬ҪУЈ¬Из№ы»№УРЗлЗуЈ¬ДЗГҙ»бјМРшФЪХвТ»ҙО TCP Б¬ҪУЦРНкіЙЈ¬¶шІ»УГЦШёҙҪЁБўРВөД TCP Б¬ҪУәН№ШұХTCP Б¬ҪУЈ¬ҝЙТФМбёЯУГ»§·ГОКЛЩ¶ИЎЈ
ЎЎЎЎДЗГҙОТГЗҝјВЗ3ЦЦЗйҝцЈә
ЎЎЎЎ1ЎЈУГ»§дҜААТ»ёцНшТіКұЈ¬іэБЛНшТіұҫЙнНвЈ¬»№ТэУГБЛ¶аёц javascript. ОДјюЈ¬¶аёц css ОДјюЈ¬¶аёцНјЖ¬ОДјюЈ¬ІўЗТХвР©ОДјю¶јФЪН¬Т»ёц HTTP ·юОсЖчЙПЎЈ
ЎЎЎЎ2ЎЈУГ»§дҜААТ»ёцНшТіКұЈ¬іэБЛНшТіұҫЙнНвЈ¬»№ТэУГТ»ёц javascript. ОДјюЈ¬Т»ёцНјЖ¬ОДјюЎЈ
ЎЎЎЎ3ЎЈУГ»§дҜААөДКЗТ»ёц¶ҜМ¬НшТіЈ¬УЙіМРтјҙКұЙъіЙДЪИЭЈ¬ІўЗТІ»ТэУГЖдЛыДЪИЭЎЈ
ЎЎЎЎ¶ФУЪЙПГж3ЦРЗйҝцЈ¬ОТИПОӘЈә1 ЧоККәПҙтҝӘ KeepAlive Ј¬2 ЛжТвЈ¬3 ЧоККәП№ШұХ KeepAlive
ЎЎЎЎПВГжОТАҙ·ЦОцТ»ПВФӯТтЎЈ
ЎЎЎЎФЪ Apache ЦРЈ¬ҙтҝӘәН№ШұХ KeepAlive №ҰДЬЈ¬·юОсЖч¶Л»бУРКІГҙТмН¬ДШЈҝ
ЎЎЎЎПИҝҙҝҙАнВЫ·ЦОцЎЈ
ЎЎЎЎҙтҝӘ KeepAlive әуЈ¬ТвО¶ЧЕГҝҙОУГ»§НкіЙИ«Іҝ·ГОКә󣬶јТӘұЈіЦТ»¶ЁКұјдәуІЕ№ШұХ»б№ШұХ TCP Б¬ҪУЈ¬ДЗГҙФЪ№ШұХБ¬ҪУЦ®З°Ј¬ұШИ»»бУРТ»ёцApache ҪшіМ¶ФУҰУЪёГУГ»§¶шІ»ДЬҙҰАнЖдЛыУГ»§Ј¬јЩЙи KeepAlive өДі¬КұКұјдОӘ 10 ГлЦЦЈ¬·юОсЖчГҝГлҙҰАн 50ёц¶АБўУГ»§·ГОКЈ¬ДЗГҙПөНіЦР Apache өДЧЬҪшіМКэҫНКЗ 10 * 50 ЈҪ 500 ёцЈ¬Из№ыТ»ёцҪшіМХјУГ 4M ДЪҙжЈ¬ДЗГҙЧЬ№І»бПыәД 2GДЪҙжЈ¬ЛщТФҝЙТФҝҙіцЈ¬ФЪХвЦЦЕдЦГЦРЈ¬ПаөұПыәДДЪҙжЈ¬ө«әГҙҰКЗПөНіЦ»ҙҰАнБЛ 50ҙО TCP өДОХКЦәН№ШұХІЩЧчЎЈ
ЎЎЎЎИз№ы№ШұХ KeepAliveЈ¬Из№ы»№КЗГҝГл50ёцУГ»§·ГОКЈ¬Из№ыУГ»§ГҝҙОБ¬РшөДЗлЗуКэОӘ3ёцЈ¬ДЗГҙ Apache өДЧЬҪшіМКэҫНКЗ 50 * 3= 150 ёцЈ¬Из№ы»№КЗГҝёцҪшіМХјУГ 4M ДЪҙжЈ¬ДЗГҙЧЬөДДЪҙжПыәДОӘ 600MЈ¬ХвЦЦЕдЦГДЬҪЪКЎҙуБҝДЪҙжЈ¬ө«КЗЈ¬ПөНіҙҰАнБЛ 150 ҙО TCPөДОХКЦәН№ШұХөДІЩЧчЈ¬ТтҙЛУЦ»б¶аПыәДТ»Р© CPU ЧКФҙЎЈ
ЎЎЎЎФЪҝҙҝҙКөјщөД№ЫІмЎЈ
ЎЎЎЎОТФЪТ»ЧйҙуБҝҙҰАн¶ҜМ¬НшТіДЪИЭөД·юОсЖчЦРЈ¬ЖріхҙтҝӘ KeepAlive№ҰДЬЈ¬ҫӯіЈ№ЫІмөҪУГ»§·ГОКБҝҙуКұApacheҪшіМКэТІ·ЗіЈ¶аЈ¬ПөНіЖө·ұК№УГҪ»»»ДЪҙжЈ¬ПөНіІ»ОИ¶ЁЈ¬УРКұёәФШ»біцПЦҪПҙуІЁ¶ҜЎЈ№ШұХБЛ KeepAlive№ҰДЬәуЈ¬ҝҙөҪГчПФөДұд»ҜКЗЈә Apache өДҪшіМКэјхЙЩБЛЈ¬ҝХПРДЪҙжФцјУБЛЈ¬УГУЪОДјюПөНіCacheөДДЪҙжТІФцјУБЛЈ¬CPUөДҝӘПъФцјУБЛЈ¬ө«КЗ·юОсёьОИ¶ЁБЛЈ¬ПөНіёәФШТІұИҪПОИ¶ЁЈ¬әЬЙЩУРёәФШҙу·¶О§ІЁ¶ҜөДЗйҝцЈ¬ёәФШУРТ»¶ЁіМ¶ИөДҪөөНЈ»ұд»ҜІ»ГчПФөДКЗЈә·ГОКБҝҪПЙЩөДКұәтЈ¬ПөНіЖҪҫщёәФШГ»УРГчПФұд»ҜЎЈ
ЎЎЎЎЧЬҪбТ»ПВЈә
ЎЎЎЎФЪДЪҙж·ЗіЈідЧгөД·юОсЖчЙПЈ¬І»№ЬКЗ·с№ШұХ KeepAlive №ҰДЬЈ¬·юОсЖчРФДЬІ»»бУРГчПФұд»ҜЈ»
ЎЎЎЎИз№ы·юОсЖчДЪҙжҪПЙЩЈ¬»тХЯ·юОсЖчУР·ЗіЈҙуБҝөДОДјюПөНі·ГОККұЈ¬»тХЯЦчТӘҙҰАн¶ҜМ¬НшТі·юОсЈ¬№ШұХ KeepAlive әуҝЙТФҪЪКЎәЬ¶аДЪҙжЈ¬¶шҪЪКЎіцАҙөДДЪҙжУГУЪОДјюПөНіCacheЈ¬ҝЙТФМбёЯОДјюПөНі·ГОКөДРФДЬЈ¬ІўЗТПөНі»бёьјУОИ¶ЁЎЈ
ЎЎЎЎІ№ід1Јә
ЎЎЎЎ№ШУЪКЗ·сУҰёГ№ШұХ KeepAlive СЎПоЈ¬ОТҫхөГҝЙТФ»щУЪПВГжөДТ»ёц№«КҪАҙЕР¶ПЎЈ
ЎЎЎЎФЪАнПлөДНшВзБ¬ҪУЧҙҝцПВЈ¬ПөНіөД Apache ҪшіМКэәНДЪҙжК№УГҝЙТФУГИзПВ№«КҪұнҙпЈә
HttpdProcessNumber = KeepAliveTimeout * TotalRequestPerSecond / Average(KeepAliveRequests)
HttpdUsedMemory = HttpdProcessNumber * MemoryPerHttpdProcess
ЎЎЎЎ»»іЙЦРОДЈә
ЧЬApacheҪшіМКэ = KeepAliveTimeout * ГҝГлЦЦHTTPЗлЗуКэ / ЖҪҫщKeepAliveЗлЗу
ApacheХјУГДЪҙж = ЧЬApacheҪшіМКэ * ЖҪҫщГҝҪшіМХјУГДЪҙжКэ
ЎЎЎЎРиТӘМШұрЛөГчөДКЗЈә
ЎЎЎЎ[ЖҪҫщKeepAliveЗлЗу] КэЈ¬КЗЦёГҝёцУГ»§Б¬ҪУЙП·юОсЖчәуЈ¬іЦРш·ўіцөД HTTP ЗлЗуКэЎЈөұ KeepAliveTimeout өИ 0»тХЯ KeepAlive №ШұХКұЈ¬KeepAliveTimeout І»ІОУліЛөДФЛЛгҙУЙПГжөД№«КҪҝҙЈ¬Из№ы [ГҝГлУГ»§ЗлЗу]¶аЈ¬[KeepAliveTimeout] өДЦөҙуЈ¬[ЖҪҫщKeepAliveЗлЗу] өДЦөРЎЈ¬¶ј»бФміЙ [ApacheҪшіМКэ] ¶аәН [ДЪҙж]¶аЈ¬ө«КЗөұ [ЖҪҫщKeepAliveЗлЗу] өДЦөФҪҙуКұЈ¬[ApacheҪшіМКэ] әН [ДЪҙж] ¶јКЗЗчПтУЪјхЙЩөДЎЈ
ЎЎЎЎ»щУЪЙПГжөД№«КҪЈ¬ОТГЗҫНҝЙТФНЖЛгіцөұ ЖҪҫщKeepAliveЗлЗу <= KeepAliveTimeout КұЈ¬№ШұХ KeepAlive СЎПоКЗ»®ЛгөДЈ¬·сФтҫНҝЙТФҝјВЗҙтҝӘЎЈ
І№ід2: KeepAlive ёГІОКэҝШЦЖApacheКЗ·сФКРнФЪТ»ёцБ¬ҪУЦРУР¶аёцЗлЗуЈ¬Д¬ИПҙтҝӘЎЈө«¶ФУЪҙу¶аКэВЫМіАаРНХҫөгАҙЛөЈ¬НЁіЈЙиЦГОӘoffТФ№ШұХёГЦ§іЦЎЈ
І№ід3: Из№ы·юОсЖчЗ°ЕЬУРУҰУГsquid·юОсЈ¬»тХЯЖдЛьЖЯІгЙиұё,KeepAlive On Йи¶ЁТӘҝӘЖфіЦРшіӨБ¬ҪУ
КөјКФЪ З°¶ЛУР squid өДЗйҝцПВ, KeepAlive әЬ№ШјьЎЈјЗөГ On
9.І»ҝЙәцВФөДKeepAlive ЎӘЎӘ Apache ЦР Keep Alive ЕдЦГ
http://tomyz0223.iteye.com/blog/603187
ФЪНшТіҝӘ·ў№эіМЦРЈ¬Keep-AliveКЗHTTPРӯТйЦР·ЗіЈЦШТӘөДТ»ёцКфРФЎЈҙујТЦӘөАHTTP№№ҪЁФЪTCPЦ®ЙПЎЈФЪHTTPФзЖЪКөПЦЦРЈ¬ГҝёцHTTPЗлЗу¶јТӘҙтҝӘТ»ёцsocketБ¬ҪУЎЈХвЦЦЧцР§ВКәЬөНЈ¬ТтОӘТ»ёцWeb ТіГжЦРөДәЬ¶аHTTPЗлЗу¶јЦёПтН¬Т»ёц·юОсЖчЎЈАэИзЈ¬әЬ¶аОӘWebТіГжЦРөДНјЖ¬·ўЖрөДЗлЗу¶јЦёПтТ»ёцНЁУГөДНјЖ¬·юОсЖчЎЈіЦҫГБ¬ҪУөДТэИлҪвҫцБЛ¶а¶ФТСЗлЗу·юОсЖчөјЦВөДsocketБ¬ҪУөНР§РФөДОКМвЎЈЛьК№дҜААЖчҝЙТФФЩТ»ёцөҘ¶АөДБ¬ҪУЙПҪшРР¶аёцЗлЗуЎЈдҜААЖчәН·юОсЖчК№УГConnectionН·ilaiЦёіц¶Ф Keep-AliveөДЦ§іЦЎЈ
ұКХЯФЪИҘДкУцөҪТ»ёцёъKeep-AliveөДОКМвЈә
ОКМвПЦПуЈәТ»ёцJSPТіГжЈ¬ҫУИ»ТӘәДКұ40¶аГлЎЈНшТіЦРУРҙуБҝөДНјЖ¬өДCSS
ОКМвҪвҫцЈәФӯТтТІХТБЛ°лМмЈ¬ФӯАҙApacheЕдЦГАпГжЈ¬°СKeep-AliveөДҝӘ№Ш№ШұХБЛЎЈХвёцКЗёцҙуОКМвЈ¬№ӨіМКҰОӘКІГҙТӘ№ШұХЛьЈ¬ФӯАҙЛыҝјВЗөДМ«јтөҘБЛЈ¬ОТГЗЦӘөАApacheККәПҙҰУЪ¶МБ¬ҪУөДЗлЗуЈ¬ҙҰАнКұјдФҪ¶МЈ¬Іў·ўКэІЕДЬЙПИҘЈ¬ФӯАҙЛыКЗХвГҙҝјВЗЈ¬ө«КЗГ»УР°м·ЁЈ¬Ц»ДЬХвСщБЛЈ¬»№КЗҙтҝӘKeep-AliveҝӘ№Ш°ЙЎЈ
өұИ»Ј¬І»КЗЛщУРөДЗйҝц¶јЙиЦГKeepAliveОӘOnЈ¬ПВГжөДОДЧЦЧЬҪбұИҪПәГЈә
ЎҫФЪК№УГapacheөД№эіМЦРЈ¬KeepAliveКфРФОТТ»ЦұұЈіЦОӘД¬ИПЦөOnЈ¬ЖдКөЈ¬ёГКфРФЙиЦГОӘOn»№КЗOff»№КЗТӘҫЯМеОКМвҫЯМе·ЦОцөДЈ¬ФЪЙъІъ»·ҫіЦРөДУ°Пм»№КЗВщҙуөДЎЈ
KeepAliveСЎПоөҪөЧУРКІГҙУГҙҰЈҝИз№ыДгУГ№эMysqlЈ¬УҰёГЦӘөАMysqlөДБ¬ҪУКфРФЦРУРТ»ёцУлKeepAliveАаЛЖөДPersistent ConnectionЈ¬јҙЈәіӨБ¬ҪУ(PConnect)ЎЈёГКфРФҙтҝӘөД»°Ј¬ҝЙТФК№Т»ҙОTCPБ¬ҪУОӘН¬Т»УГ»§өД¶аҙОЗлЗу·юОсЈ¬МбёЯБЛПмУҰЛЩ¶ИЎЈ
ұИИзәЬ¶аНшТіЦРНјЖ¬ЎўCSSЎўJSЎўHtml¶јФЪТ»МЁServerЙПЈ¬өұУГ»§·ГОКЖдЦРөДHtmlНшТіКұЈ¬НшТіЦРөДНјЖ¬ЎўCssЎўJs¶ј№№іЙБЛ·ГОКЗлЗуЈ¬ҙтҝӘKeepAliveКфРФҝЙТФУРР§өШҪөөНTCPОХКЦөДҙОКэ(өұИ»дҜААЖч¶ФН¬Т»УтПВН¬КұЗлЗуөДНјЖ¬КэУРПЮЦЖЈ¬Т»°гКЗ2)Ј¬јхЙЩhttpdҪшіМКэЈ¬ҙУ¶шҪөөНДЪҙжөДК№УГ(јЩ¶ЁpreforkДЈКҪ)ЎЈMaxKeepAliveRequestsәНKeepAliveTimeOutБҪёцКфРФФЪKeepAlive=OnКұЖрЧчУГЈ¬ҝЙТФҝШЦЖіЦҫГБ¬ҪУөДЙъҙжКұјдәНЧоҙу·юОсЗлЗуКэЎЈ
І»№эЈ¬ЙПГжЛөөДЦ»КЗТ»ЦЦЗйРОЈ¬ДЗҫНКЗҫІМ¬НшТіҫУ¶аөДЗйҝцПВЈ¬ІўЗТНшТіЦРөДЖдЛыЗлЗуУлНшТіФЪН¬Т»МЁServerЙПЎЈөұДгөДУҰУГ¶ҜМ¬іМРт(ұИИзЈәphp)ҫУ¶аЈ¬УГ»§·ГОККұУЙ¶ҜМ¬іМРтјҙКұЙъіЙhtmlДЪИЭЈ¬htmlДЪИЭЦРНјЖ¬ЛШІДәНCssЎўJsөИұИҪПЙЩ»тХЯЙўБРФЪЖдЛыServerЙПКұЈ¬KeepAlive=On·ҙ¶ш»бҪөөНApacheөДРФДЬЎЈОӘКІГҙДШЈҝ
З°ГжМбөҪ№эЈ¬KeepAlive=OnКұЈ¬ГҝҙОУГ»§·ГОКЈ¬ҙтҝӘТ»ёцTCPБ¬ҪУЈ¬Apache¶ј»бұЈіЦёГБ¬ҪУТ»¶ОКұјдЈ¬ТФұгёГБ¬ҪУДЬБ¬РшОӘН¬Т»client·юОсЈ¬ФЪKeepAliveTimeOut»№Г»өҪЖЪІўЗТMaxKeepAliveRequests»№Г»өҪгРЦөЦ®З°Ј¬ApacheұШИ»ТӘУРТ»ёцhttpdҪшіМАҙО¬іЦёГБ¬ҪУЈ¬httpdҪшіМІ»КЗБ®јЫөДЈ¬ЛыТӘПыәДДЪҙжәНCPUКұјдЖ¬өДЎЈјЩИзөұЗ°ApacheГҝГлПмУҰ100ёцУГ»§·ГОКЈ¬KeepAliveTimeOut=5Ј¬ҙЛКұhttpdҪшіМКэҫНКЗ100*5=500ёц(preforkДЈКҪ)Ј¬Т»ёцhttpdҪшіМПыәД5MДЪҙжөД»°Ј¬ҫНКЗ500*5M=2500M=2.5GЈ¬ҝдХЕ°ЙЈҝөұИ»Ј¬ApacheУлClientЦ»ҪшРРБЛ100ҙОTCPБ¬ҪУЎЈИз№ыДгөДДЪҙж№»ҙуЈ¬ПөНіёәФШІ»»бМ«ёЯЈ¬Из№ыДгөДДЪҙжРЎУЪ2.5GЈ¬ҫН»бУГөҪSwapЈ¬Жө·ұөДSwapЗР»»»бјУЦШCPUөДLoadЎЈ
ПЦФЪОТГЗ№ШөфKeepAliveЈ¬ApacheИФИ»ГҝГлПмУҰ100ёцУГ»§·ГОКЈ¬ТтОӘОТГЗҪ«НјЖ¬ЎўjsЎўcssөИ·ЦАліцИҘБЛЈ¬ГҝҙО·ГОКЦ»УР1ёцrequestЈ¬ҙЛКұhttpdөДҪшіМКэКЗ100*1=100ёцЈ¬К№УГДЪҙж100*5M=500MЈ¬ҙЛКұApacheУлClientТІКЗҪшРРБЛ100ҙОTCPБ¬ҪУЎЈРФДЬИҙМбЙэБЛМ«¶аЎЈ
ЧЬҪбЈә
1ЎўөұДгөДServerДЪҙжідЧгКұЈ¬KeepAlive=On»№КЗOff¶ФПөНіРФДЬУ°ПмІ»ҙуЎЈ
2ЎўөұДгөДServerЙПҫІМ¬НшТі(HtmlЎўНјЖ¬ЎўCssЎўJs)ҫУ¶аКұЈ¬ҪЁТйҙтҝӘKeepAliveЎЈ
3ЎўөұДгөДServer¶аОӘ¶ҜМ¬ЗлЗу(ТтОӘБ¬ҪУКэҫЭҝвЈ¬¶ФОДјюПөНі·ГОКҪП¶а)Ј¬KeepAlive№ШөфЈ¬»бҪЪКЎТ»¶ЁөДДЪҙжЈ¬ҪЪКЎөДДЪҙжХэәГҝЙТФЧчОӘОДјюПөНіөДCache(vmstatГьБоЦРcacheТ»БР)Ј¬ҪөөНI/OС№БҰЎЈ
PSЈәөұKeepAlive=OnКұЈ¬KeepAliveTimeOutөДЙиЦГЖдКөТІКЗТ»ёцОКМвЈ¬ЙиЦГөД№э¶МЈ¬»бөјЦВApacheЖө·ұҪЁБўБ¬ҪУЈ¬ёшCpuФміЙС№БҰЈ¬ЙиЦГөД№эіӨЈ¬ПөНіЦРҫН»б¶С»эОЮУГөДHttpБ¬ҪУЈ¬ПыәДөфҙуБҝДЪҙжЈ¬ҫЯМеЙиЦГ¶аЙЩЈ¬ҝЙТФҪшРРІ»¶ПөДөчҪЪЈ¬ТтДгөДНшХҫдҜААәН·юОсЖчЕдЦГ¶шТмЎЈ
10. HTTPРӯТйЦРөДіЦҫГБ¬ҪУconnection:keep-aliveЈ¬өДТ»Р©ОКМвәНЛјҝјЈ¬ІОҝјЎЈ
http://www.51sea.com/cache/water/587.html
№ШУЪkeep-aliveХвёц¶«ОчЈ¬КЗ·сТӘҝӘ·ЕЈ¬¶ФРФДЬҫҝҫ№УРәОУ°ПмЈ¬ДҝЗ°ҙујТ№АјЖТІ¶јКЗҙУҫӯСй·ҪГжАҙЙиЦГөДЈ¬Г»УРҙУАнВЫІгГжөДМЦВЫЈ¬ҪсМмОТАҙНЪёцҝУЈ¬ПЈНыҙујТУ»ФҫНщАпМшЎЈ
јтөҘХыАнТ»ПВОКМвТӘөгЈә
1Ј¬keep-aliveөД№ӨЧчФӯАнКЗКІГҙЈ¬ДЬҪвҫцКІГҙОКМвЈҝ
2Ј¬web serverЙиЦГБЛkeep-aliveЈ¬КЗ·сРиТӘПВј¶РӯТйХөөДЦ§іЦІЕЖрЧчУГЈҝАэИзКЗ·сТӘЖфУГtcp/ipөДkeep alive»ъЦЖЈҝ
3Ј¬web serverЙиЦГБЛkeep-aliveЈ¬КЗ·сТӘҝН»§¶ЛдҜААЖчУРПаУҰЦ§іЦЈҝКЗ·сТӘҝН»§¶ЛРӯТйХөөДЦ§іЦЈҝИз№ыТӘөГ»°Ј¬ОТГЗНЁіЈК№УГөДёчЦЦПөНіТФј°ёчЦЦдҜААЖчЦ§іЦөДЗйҝцФхСщЈҝ
4Ј¬keep-alive»бҙшАҙРФДЬМбЙэВрЈҝҫЯМеМеПЦФЪКІГҙ·ҪГжЈҝАэИзҝЙіРФШёЯІў·ў·ГОКЈҝ»тХЯКЗҝЙМбЙэҙ«КдРФДЬЈҝФЩ»тХЯҝЙјхЗб·юОсЖчС№БҰЈҝФЪөН·ГОКБҝәНёЯ·ГОКБҝЗйҝцПВУРәОЗшұрЈҝ
ҫНОТёцИЛөДАнҪвАҙҝҙЈ¬keep-aliveКЗАыУГБЛtcpөДЛ«ПтИ«Л«№ӨБ¬ҪУМШРФЈ¬ФЪweb-server¶ЛҝЙТФІ»¶ПҝӘБ¬ҪУЈ¬АҙҪУКЬҝН»§¶Лёь¶аөДЗлЗуЈ¬УҰёГКЗДЬ№»ёДЙЖБ¬ҪУКұјдЈ¬І»№эЛЖәхФЪБ¬ҪУ·ЗіЈ¶аөДЗйҝцПВ»бҙуҙујУЦШ·юОсЖчёәөЈЈ¬РиТӘtcp/ipРӯТйХөЦ§іЦЈ¬ІўЗТІ»Н¬ҝН»§¶ЛЦ®јдУРІ»Н¬өДЙи¶ЁЈ¬ҫЯМеПёҪЪ»№І»ПкЎЈ
ВҘЙПөДОДХВКЬҪМБЛЈ¬јтөҘЛөҫНКЗҙУhttpРӯТйөДЗйҝцАҙҝҙЈ¬Д¬ИП1.0КЗ№ШұХөДЈ¬РиТӘФЪhttpН·јУИлConnection: Keep-AliveІЕДЬ·ўЖрkeep-aliveөДБ¬ҪУЈ¬¶шhttp1.1РӯТйД¬ИПЖфУГkeep-aliveЈ¬Из№ыјУИлConnection: close ФтҫНЗҝЦЖ№ШұХЎЈ
ДҝЗ°ҙуІҝ·ЦдҜААЖч¶јКЗУГhttp1.1РӯТйЈ¬ТІҫНКЗЛөД¬ИП¶ј»б·ўЖрkeep-aliveөДБ¬ҪУЗлЗуБЛЈ¬ЛщТФКЗ·сДЬНкіЙТ»ёцНкХыөДkeep-aliveБ¬ҪУҫНҝҙ·юОсЖчЙиЦГЗйҝцЎЈ
ОТНЖІв·юОсЖч·ө»ШөДhttpН·УҰёГ°ьә¬№ШУЪkeep-aliveөДРЕПўЈ¬»ШИҘЧҘ°ьХэКЗТ»ПВЎЈ
ВҘЙПөДОДХВЛөОТФЪНшЙПХТөҪөДЈ¬КВКөЙП·юОсЖчИ·Кө»б·ө»Ш№ШУЪkeep-aliveөДПыПўЎЈЧојтөҘөД·Ҫ·ЁЈ¬І»РиТӘИОәО¶оНвөДИнјюЈ¬ДгҝЙТФҙтҝӘСёАЧЈ¬ЛжұгПВФШТ»ёцОДјюЈ¬И»әуІйҝҙИООсПкЗйАпГжЈ¬ЛыҫНУРhttpЗлЗуәН»ШУҰөДheaderРЕПўЈ¬ҙУХвёцАпГжҝЙТФЗеіюөДҝҙөҪҝН»§¶ЛФЪheaderЙиЦГБЛkeep- aliveЈ¬¶ш·юОсЖч·ө»ШКұТІУРХвёцheaderЧЦ¶ОЎЈ
І»№эОТёХҝӘКј»№ФЪөЈРДТ»ёцОКМвЈ¬ЛыКЗФхГҙұЈіЦБ¬ҪУөДДШЈҝјИИ»ЛөөҪhttpКЗОЮЧҙМ¬өДЈ¬ДЗserverёщұҫҫНІ»ЦӘөАХвёцБ¬ҪУҪЁБў¶аҫГБЛЈ¬Из№ыКэҫЭТСҫӯҙ«ЛННкұПЈ¬ДЗҝН»§¶ЛУҰёГІ»»бјМРшПлserverЗлЗуБЛ°ЙЈҝјИИ»Г»УРКэҫЭҪ»»ҘЈ¬ТІГ»УРЧҙМ¬РЕПўЈ¬ДЗФхГҙұЈіЦЙхЦБКЗҪбКшХвёцБ¬ҪУДШЈҝЦБЙЩОТФЪНшЙПҝҙөҪөДҙр°ёКЗХвёцБ¬ҪУКЗІ»ДЬұЈіЦәЬҫГөДЈ¬Т»°гЧо¶аҝХПРБҪ·ЦЦУ¶шТСЎЈХвГҙАҙҝҙ»№КЗҝЙТФҪУКЬөДЎЈ
БнНвТ»ёцОКМвКЗЈ¬НшЙП№ШУЪХв·ҪГжөДЧКБПәГПсәЬЙЩЈ¬ЦБЙЩЦРОДөДКЗХвСщЈ¬°Щ¶ИgooglgeІ»өҪЎЈө«КЗКөјКЙПЎ¶јЖЛг»ъНшВз--ЧФ¶ҘПтПВ·Ҫ·ЁУлinternet МШЙ«Ў·ХвұҫКйКЗҪІөГәЬЗеіюөДЎЈФЪЦРТлұҫP60»тФӯ°жP89ҫНУРК®·ЦПкПёЙъ¶ҜөДҪвКНЈ¬ХвАпГ»УРКұјд°СЛыРҙЙПАҙБЛЎЈөұИ»Ј¬КйЦРөДТ»ёцІ»ЧгКЗГ»УРФЪДЗАпМбөҪХвёціЦҫГБ¬ҪУКЗФЪheaderЦРЙиЦГconnectionЧЦ¶ОАҙКөПЦөДЈ¬өұИ»БЛЈ¬ХвТІКЗТтОӘДЗёцКұәтКйЙП»№Г»УРҪІөҪhttp headerөДҪб№№ЎЈ
11. FireFoxПВөДHTTPЗлЗу№№ФмөчКФ№ӨҫЯTamper
TamperКЗfirefoxПВөДHTTPЗлЗујаМэәНөчКФ№ӨҫЯЈ¬№ҰДЬәНFiddlerІоІ»¶аЈ¬ө«УГЖрАҙұИFiddlerёьјУ·ҪұгЈ¬ұПҫ№КЗfirefoxПВөДА©Х№ЎЈН¬СщөДЈ¬
ҝЙТФ¶ФЗлЗуҪшРРА№ҪШЈ¬РЮёДЗлЗуН·әНЗлЗуІОКэөИРЕПўЈ¬·ҪұгҪшРРіМРтөчКФәНОКМвјаҝШЎЈҝЙТФҙУХвАпПВФШЈәhttps://addons.mozilla.org/zh-CN/firefox/addon/966/
ЦұҪУФЪ"ёҪјУІејю"АпЛСЛчTamper°ЙЈә
ІОҝјОДХВ»гЧЬЈә
1.HTTPОЮЧҙМ¬РӯТйәНConnection:Keep-AliveИЭТЧ·ёөДОуЗш
http://liuzhigong.blog.163.com/blog/static/178272375201141344312315/
2. httpіӨБ¬ҪУУл¶МБ¬ҪУЎӘЎӘҝЙТФБЛҪвПВіЈјыөДНЁРЕіЎҫ°
http://www.cnblogs.com/Roberts/archive/2010/12/05/1986550.html
3. httpіӨБ¬ҪУјјКхОДХВ·ӯТлЎӘЎӘ№ШУЪhttpіӨБ¬ҪУУРәЬ¶аЦШТӘөДёЕДо
http://www.blogjava.net/xjacker/articles/334709.html
4.Apache ЦР Keep Alive ЕдЦГөДәПАнК№УГЎӘЎӘАпГжөД№«КҪәНјЖЛг·Ҫ·ЁЈ¬Г»ҝҙ¶®Ј¬І»ТӘГФРЕ»№КЗТӘКөЦӨ
http://blog.163.com/hai_zone/blog/static/264611372010718103838356/?fromdm&fromSearch&isFromSearchEngine=yes
5.І»ҝЙәцВФөДKeepAlive ЎӘЎӘ Apache ЦР Keep Alive ЕдЦГ
http://tomyz0223.iteye.com/blog/603187
6.HTTPРӯТйЦРөДіЦҫГБ¬ҪУconnection:keep-aliveЈ¬өДТ»Р©ОКМвәНЛјҝјЈ¬ІОҝјЎЈ
http://www.51sea.com/cache/water/587.html
НјЖ¬әНОДХВёҪјюЈә loadrunner_httpіӨБ¬ҪУЙиЦГ.rar(1.39 MB)
loadrunner_httpіӨБ¬ҪУЙиЦГ.rar(1.39 MB)
TAG:
-
ТэУГ Йҫіэ gfbaishikele / 2016-04-11 23:58:03
-
ЖА 5 ·Ц
ОТөДАёДҝ
ұкМвЛСЛч
ИХАъ
|
|||||||||
| ИХ | Т» | ¶ю | Иэ | ЛД | Ое | Бщ | |||
| 1 | 2 | 3 | 4 | 5 | 6 | ||||
| 7 | 8 | 9 | 10 | 11 | 12 | 13 | |||
| 14 | 15 | 16 | 17 | 18 | 19 | 20 | |||
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | |||
| 28 | 29 | 30 | |||||||
ОТөДҙжөө
КэҫЭНіјЖ
- ·ГОКБҝ: 712614
- ИХЦҫКэ: 415
- НјЖ¬Кэ: 1
- ОДјюКэ: 3
- ҪЁБўКұјд: 2008-12-07
- ёьРВКұјд: 2015-07-14
