以下均转自:http://hi.baidu.com/higkoo/home
http://hi.baidu.com/higkoo/blog/category/Loadrunner/index/0
1. LoadRunner/C语言 实现:Base64加解码
之前分享过一个LoadRunner执行Base64编码的函数,由于当时没有提供解码。如今又在网上重新收集了一套编解码的函数。
在LoadRunner脚本里包含头文件即可使用,示例如下:
Action(){
int res;
// ENCODE
lr_save_string("
testddd_001@dddd.cn:ttttt","plain");
b64_encode_string( lr_eval_string("{plain}"), "b64str" );
lr_output_message("Encoded: %s", lr_eval_string("{b64str}") );
// DECODE
b64_decode_string( lr_eval_string("{b64str}"), "plain2" );
lr_output_message("Decoded: %s", lr_eval_string("{plain2}") );
// Verify decoded matches original plain text
res = strcmp( lr_eval_string("{plain}"), lr_eval_string("{plain2}") );
if (res==0) lr_output_message("Decoded matches original plain text");
return 0 ;
}
文件base64.h源码如下:
//为LoadRunner提供Base64的编码和解码函数,
//有直接编码和解决的函数和输出LoadRunner参数的函数。
/*
Base 64 Encode and Decode functions for LoadRunner
==================================================
This include file provides functions to Encode and Decode
LoadRunner variables. It's based on source codes found on the
internet and has been modified to work in LoadRunner.
Created by Kim Sandell / Celarius -
www.celarius.com*/
// Encoding lookup table
char base64encode_lut[] = {
'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q',
'R','S','T','U','V','W','X','Y','Z','a','b','c','d','e','f','g','h',
'i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y',
'z','0','1','2','3','4','5','6','7','8','9','+','/','='};
// Decode lookup table
char base64decode_lut[] = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0,62, 0, 0, 0,63,52,53,54,55,56,57,58,59,60,61, 0, 0,
0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,
15,16,17,18,19,20,21,22,23,24,25, 0, 0, 0, 0, 0, 0,26,27,28,
29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,
49,50,51, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, };
void base64encode(char *src, char *dest, int len)
// Encodes a buffer to base64
{
int i=0, slen=strlen(src);
for(i=0;i<slen && i<len;i+=3,src+=3)
{ // Enc next 4 characters
*(dest++)=base64encode_lut[(*src&0xFC)>>0x2];
*(dest++)=base64encode_lut[(*src&0x3)<<0x4|(*(src+1)&0xF0)>>0x4];
*(dest++)=((i+1)<slen)?base64encode_lut[(*(src+1)&0xF)<<0x2|(*(src+2)&0xC0)>>0x6]:'=';
*(dest++)=((i+2)<slen)?base64encode_lut[*(src+2)&0x3F]:'=';
}
*dest='\0'; // Append terminator
}
void base64decode(char *src, char *dest, int len)
// Encodes a buffer to base64
{
int i=0, slen=strlen(src);
for(i=0;i<slen&&i<len;i+=4,src+=4)
{ // Store next 4 chars in vars for faster access
char c1=base64decode_lut[*src], c2=base64decode_lut[*(src+1)], c3=base64decode_lut[*(src+2)], c4=base64decode_lut[*(src+3)];
// Decode to 3 chars
*(dest++)=(c1&0x3F)<<0x2|(c2&0x30)>>0x4;
*(dest++)=(c3!=64)?((c2&0xF)<<0x4|(c3&0x3C)>>0x2):'\0';
*(dest++)=(c4!=64)?((c3&0x3)<<0x6|c4&0x3F):'\0';
}
*dest='\0'; // Append terminator
}
int b64_encode_string( char *source, char *lrvar )
// ----------------------------------------------------------------------------
// Encodes a string to base64 format ----- Method 1
//
// Parameters:
// source Pointer to source string to encode
// lrvar LR variable where base64 encoded string is stored
//
// Example:
//
// b64_encode_string( "Encode Me!", "b64" )
// ----------------------------------------------------------------------------
{
int dest_size;
int res;
char *dest;
// Allocate dest buffer
dest_size = 1 + ((strlen(source)+2)/3*4);
dest = (char *)malloc(dest_size);
memset(dest,0,dest_size);
// Encode & Save
base64encode(source, dest, dest_size);
lr_save_string( dest, lrvar );
// Free dest buffer
res = strlen(dest);
free(dest);
// Return length of dest string
return res;
}
int b64_decode_string( char *source, char *lrvar )
// ----------------------------------------------------------------------------
// Decodes a base64 string to plaintext ----- Method 2
//
// Parameters:
// source Pointer to source base64 encoded string
// lrvar LR variable where decoded string is stored
//
// Example:
//
// b64_decode_string( lr_eval_string("{b64}"), "Plain" )
// ----------------------------------------------------------------------------
{
int dest_size;
int res;
char *dest;
// Allocate dest buffer
dest_size = strlen(source);
dest = (char *)malloc(dest_size);
memset(dest,0,dest_size);
// Encode & Save
base64decode(source, dest, dest_size);
lr_save_string( dest, lrvar );
// Free dest buffer
res = strlen(dest);
free(dest);
// Return length of dest string
return res;
}
2.LoadRunner实现:计算字符串Md5
尝试在LR里实现字符串的MD5计算。
在LR里添加头文件md5.h,在globals.h里添加引用#include "md5.h";md5.h代码如下:
#ifndef MD5_H
#define MD5_H
#ifdef __alpha
typedef unsigned int uint32;
#else
typedef unsigned long uint32;
#endif
struct MD5Context {
uint32 buf[4];
uint32 bits[2];
unsigned char in[64];
};
extern void MD5Init();
extern void MD5Update();
extern void MD5Final();
extern void MD5Transform();
typedef struct MD5Context MD5_CTX;
#endif
#ifdef sgi
#define HIGHFIRST
#endif
#ifdef sun
#define HIGHFIRST
#endif
#ifndef HIGHFIRST
#define byteReverse(buf, len) /* Nothing */
#else
void byteReverse(buf, longs)unsigned char *buf; unsigned longs;
{
uint32 t;
do {
t = (uint32) ((unsigned) buf[3] << 8 | buf[2]) << 16 |((unsigned) buf[1] << 8 | buf[0]);
*(uint32 *) buf = t;
buf += 4;
} while (--longs);
}
#endif
void MD5Init(ctx)struct MD5Context *ctx;
{
ctx->buf[0] = 0x67452301;
ctx->buf[1] = 0xefcdab89;
ctx->buf[2] = 0x98badcfe;
ctx->buf[3] = 0x10325476;
ctx->bits[0] = 0;
ctx->bits[1] = 0;
}
void MD5Update(ctx, buf, len) struct MD5Context *ctx; unsigned char *buf; unsigned len;
{
uint32 t;
t = ctx->bits[0];
if ((ctx->bits[0] = t + ((uint32) len << 3)) < t)
ctx->bits[1]++;
ctx->bits[1] += len >> 29;
t = (t >> 3) & 0x3f;
if (t) {
unsigned char *p = (unsigned char *) ctx->in + t;
t = 64 - t;
if (len < t) {
memcpy(p, buf, len);
return;
}
memcpy(p, buf, t);
byteReverse(ctx->in, 16);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
buf += t;
len -= t;
}
while (len >= 64) {
memcpy(ctx->in, buf, 64);
byteReverse(ctx->in, 16);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
buf += 64;
len -= 64;
}
memcpy(ctx->in, buf, len);
}
void MD5Final(digest, ctx)
unsigned char digest[16]; struct MD5Context *ctx;
{
unsigned count;
unsigned char *p;
count = (ctx->bits[0] >> 3) & 0x3F;
p = ctx->in + count;
*p++ = 0x80;
count = 64 - 1 - count;
if (count < 8) {
memset(p, 0, count);
byteReverse(ctx->in, 16);
MD5Transform(ctx->buf, (uint32 *) ctx->in);
memset(ctx->in, 0, 56);
} else {
memset(p, 0, count - 8);
}
byteReverse(ctx->in, 14);
((uint32 *) ctx->in)[14] = ctx->bits[0];
((uint32 *) ctx->in)[15] = ctx->bits[1];
MD5Transform(ctx->buf, (uint32 *) ctx->in);
byteReverse((unsigned char *) ctx->buf, 4);
memcpy(digest, ctx->buf, 16);
memset(ctx, 0, sizeof(ctx));
}
#define F1(x, y, z) (z ^ (x & (y ^ z)))
#define F2(x, y, z) F1(z, x, y)
#define F3(x, y, z) (x ^ y ^ z)
#define F4(x, y, z) (y ^ (x | ~z))
#define MD5STEP(f, w, x, y, z, data, s) ( w += f(x, y, z) + data, w = w<<s | w>>(32-s), w += x )
void MD5Transform(buf, in)
uint32 buf[4]; uint32 in[16];
{
register uint32 a, b, c, d;
a = buf[0];
b = buf[1];
c = buf[2];
d = buf[3];
MD5STEP(F1, a, b, c, d, in[0] + 0xd76aa478, 7);
MD5STEP(F1, d, a, b, c, in[1] + 0xe8c7b756, 12);
MD5STEP(F1, c, d, a, b, in[2] + 0x242070db, 17);
MD5STEP(F1, b, c, d, a, in[3] + 0xc1bdceee, 22);
MD5STEP(F1, a, b, c, d, in[4] + 0xf57c0faf, 7);
MD5STEP(F1, d, a, b, c, in[5] + 0x4787c62a, 12);
MD5STEP(F1, c, d, a, b, in[6] + 0xa8304613, 17);
MD5STEP(F1, b, c, d, a, in[7] + 0xfd469501, 22);
MD5STEP(F1, a, b, c, d, in[8] + 0x698098d8, 7);
MD5STEP(F1, d, a, b, c, in[9] + 0x8b44f7af, 12);
MD5STEP(F1, c, d, a, b, in[10] + 0xffff5bb1, 17);
MD5STEP(F1, b, c, d, a, in[11] + 0x895cd7be, 22);
MD5STEP(F1, a, b, c, d, in[12] + 0x6b901122, 7);
MD5STEP(F1, d, a, b, c, in[13] + 0xfd987193, 12);
MD5STEP(F1, c, d, a, b, in[14] + 0xa679438e, 17);
MD5STEP(F1, b, c, d, a, in[15] + 0x49b40821, 22);
MD5STEP(F2, a, b, c, d, in[1] + 0xf61e2562, 5);
MD5STEP(F2, d, a, b, c, in[6] + 0xc040b340, 9);
MD5STEP(F2, c, d, a, b, in[11] + 0x265e5a51, 14);
MD5STEP(F2, b, c, d, a, in[0] + 0xe9b6c7aa, 20);
MD5STEP(F2, a, b, c, d, in[5] + 0xd62f105d, 5);
MD5STEP(F2, d, a, b, c, in[10] + 0x02441453, 9);
MD5STEP(F2, c, d, a, b, in[15] + 0xd8a1e681, 14);
MD5STEP(F2, b, c, d, a, in[4] + 0xe7d3fbc8, 20);
MD5STEP(F2, a, b, c, d, in[9] + 0x21e1cde6, 5);
MD5STEP(F2, d, a, b, c, in[14] + 0xc33707d6, 9);
MD5STEP(F2, c, d, a, b, in[3] + 0xf4d50d87, 14);
MD5STEP(F2, b, c, d, a, in[8] + 0x455a14ed, 20);
MD5STEP(F2, a, b, c, d, in[13] + 0xa9e3e905, 5);
MD5STEP(F2, d, a, b, c, in[2] + 0xfcefa3f8, 9);
MD5STEP(F2, c, d, a, b, in[7] + 0x676f02d9, 14);
MD5STEP(F2, b, c, d, a, in[12] + 0x8d2a4c8a, 20);
MD5STEP(F3, a, b, c, d, in[5] + 0xfffa3942, 4);
MD5STEP(F3, d, a, b, c, in[8] + 0x8771f681, 11);
MD5STEP(F3, c, d, a, b, in[11] + 0x6d9d6122, 16);
MD5STEP(F3, b, c, d, a, in[14] + 0xfde5380c, 23);
MD5STEP(F3, a, b, c, d, in[1] + 0xa4beea44, 4);
MD5STEP(F3, d, a, b, c, in[4] + 0x4bdecfa9, 11);
MD5STEP(F3, c, d, a, b, in[7] + 0xf6bb4b60, 16);
MD5STEP(F3, b, c, d, a, in[10] + 0xbebfbc70, 23);
MD5STEP(F3, a, b, c, d, in[13] + 0x289b7ec6, 4);
MD5STEP(F3, d, a, b, c, in[0] + 0xeaa127fa, 11);
MD5STEP(F3, c, d, a, b, in[3] + 0xd4ef3085, 16);
MD5STEP(F3, b, c, d, a, in[6] + 0x04881d05, 23);
MD5STEP(F3, a, b, c, d, in[9] + 0xd9d4d039, 4);
MD5STEP(F3, d, a, b, c, in[12] + 0xe6db99e5, 11);
MD5STEP(F3, c, d, a, b, in[15] + 0x1fa27cf8, 16);
MD5STEP(F3, b, c, d, a, in[2] + 0xc4ac5665, 23);
MD5STEP(F4, a, b, c, d, in[0] + 0xf4292244, 6);
MD5STEP(F4, d, a, b, c, in[7] + 0x432aff97, 10);
MD5STEP(F4, c, d, a, b, in[14] + 0xab9423a7, 15);
MD5STEP(F4, b, c, d, a, in[5] + 0xfc93a039, 21);
MD5STEP(F4, a, b, c, d, in[12] + 0x655b59c3, 6);
MD5STEP(F4, d, a, b, c, in[3] + 0x8f0ccc92, 10);
MD5STEP(F4, c, d, a, b, in[10] + 0xffeff47d, 15);
MD5STEP(F4, b, c, d, a, in[1] + 0x85845dd1, 21);
MD5STEP(F4, a, b, c, d, in[8] + 0x6fa87e4f, 6);
MD5STEP(F4, d, a, b, c, in[15] + 0xfe2ce6e0, 10);
MD5STEP(F4, c, d, a, b, in[6] + 0xa3014314, 15);
MD5STEP(F4, b, c, d, a, in[13] + 0x4e0811a1, 21);
MD5STEP(F4, a, b, c, d, in[4] + 0xf7537e82, 6);
MD5STEP(F4, d, a, b, c, in[11] + 0xbd3af235, 10);
MD5STEP(F4, c, d, a, b, in[2] + 0x2ad7d2bb, 15);
MD5STEP(F4, b, c, d, a, in[9] + 0xeb86d391, 21);
buf[0] += a;
buf[1] += b;
buf[2] += c;
buf[3] += d;
}
void GetMd5FromString(const char* s,char* resStr)
{
struct MD5Context md5c;
unsigned char ss[16];
char subStr[3];
int i;
MD5Init( &md5c );
MD5Update( &md5c, s, strlen(s) );
MD5Final( ss, &md5c );
strcpy(resStr,"");
for( i=0; i<16; i++ )
{
sprintf(subStr, "%02x", ss[i] );
itoa(ss[i],subStr,16);
if (strlen(subStr)==1) {
strcat(resStr,"0");
}
strcat(resStr,subStr);
}
strcat(resStr,"\0");
}
源码都是网上共享的,仅CMd5()函数稍作了改动,要验证可以上http://www.cmd5.com/。在LR里调用就非常简单:void main()
{
char Md5[33];
GetMd5FromString("a",Md5);
lr_output_message(Md5);
}
输出结果:
Running Vuser...
Starting iteration 1.
Starting action main.
main.c(5): 0cc175b9c0f1b6a831c399e269772661
Ending action main.
3. C语言实现:替换字符串中指定字符
不用多介绍了,可以在LoadRunner里直接使用,挺好的!
int ReplaceStr(char* sSrc, char* sMatchStr, char* sReplaceStr)
{
int StringLen;
char caNewString[64];
char* FindPos;
FindPos =(char *)strstr(sSrc, sMatchStr);
if( (!FindPos) || (!sMatchStr) )
return -1;
while( FindPos )
{
memset(caNewString, 0, sizeof(caNewString));
StringLen = FindPos - sSrc;
strncpy(caNewString, sSrc, StringLen);
strcat(caNewString, sReplaceStr);
strcat(caNewString, FindPos + strlen(sMatchStr));
strcpy(sSrc, caNewString);
FindPos =(char *)strstr(sSrc, sMatchStr);
}
free(FindPos);
return 0;
}
譬如:ReplaceStr("abcd-efgh-ijklm-nopq","-","");//把字符串中的“-”删除掉!
4. LoadRunner生成唯一数
void Main()
{
int i;
char uStr[64];
srand( (unsigned)time( NULL ) );// 最好放在vuser_init里
for (i=0;i<10;i++) {
GetUniqueString(i,uStr);
lr_output_message(uStr);
}
}
void GetUniqueString(int inValue,char *outStr)
{
int id, scid;
char *vuser_group;
lr_whoami(&id, &vuser_group, &scid);
web_save_timestamp_param("tStamp", LAST);
sprintf(outStr,"%s%05d%010d%04d",lr_eval_string("{tStamp}"),id,rand(),inValue);
free(vuser_group);
}
建议把随机种子(srand( (unsigned)time( NULL ) );)放在脚本初始化函数里,只需要初始化一次。若放在子函数里,每次调用都初始化一下的话,产生的随机数可能是一样的。是不安全的代码!
这个唯一数,有四关:毫秒级的时间+虚拟用户ID+随机数+传入的参数;基本上在同一个Controller里不会出现重复了!再稍微处理一下就可以得到想法的东西了,譬如:LoadRunner实现:计算字符串Md5 加密成md5串,再改装一下就成GUID了!
这里有一个安全问题值得说明,随机种子最好只初始化一次,随机数的算法是和时间有一定关系的。若把随机种子放在子函数里,你会发现生成出来的随机数都是一样的。
不要惊讶,为什么说是个安全问题,说严重一点,随机数是一种算法,有可能被别人劫获并计算出下一个随机值,故不安全!
 base64.rar(1.28 KB)
base64.rar(1.28 KB)
md5.rar(1.91 KB)

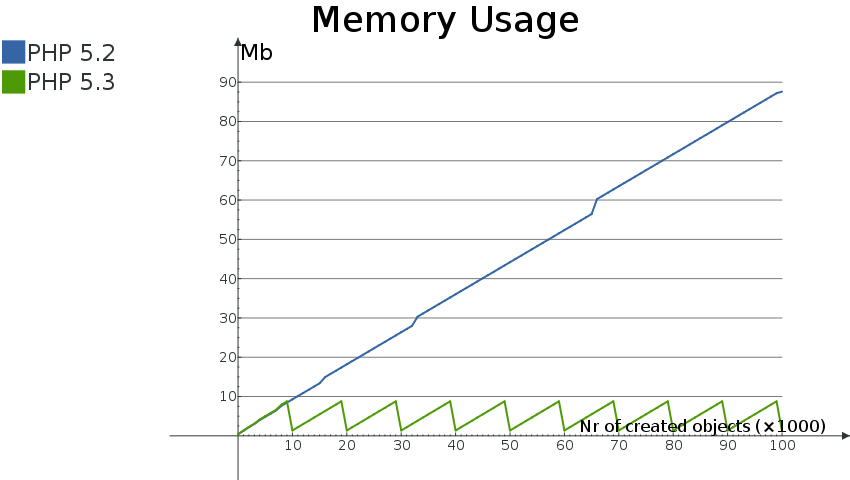
 图1
图1 图2
图2 图3
图3