
浏览器容错 Browsers error tolerance
你从来不会在一个html页面上看到“无效语法”这样的错误,浏览器修复了无效内容并继续工作。
以下面这段html为例:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
这段html违反了很多规则(mytag不是合法的标签,p及div错误的嵌套等等),但是浏览器仍然可以没有任何怨言的继续显示,它在解析的过程中修复了html作者的错误。
浏览器都具有错误处理的能力,但是,另人惊讶的是,这并不是html最新规范的内容,就像书签及前进后退按钮一样,它只是浏览器长期发展的结果。一些比较知名的非法html结构,在许多站点中出现过,浏览器都试着以一种和其他浏览器一致的方式去修复。
Html5规范定义了这方面的需求,webkit在html解析类开始部分的注释中做了很好的总结。
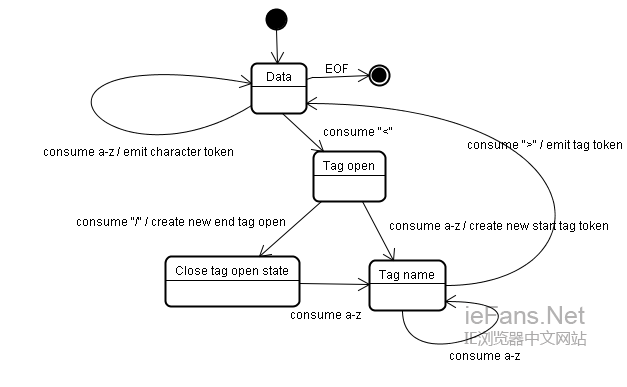
解析器将符号化的输入解析为文档并创建文档,但不幸的是,我们必须处理很多没有很好格式化的html文档,至少要小心下面几种错误情况。
1. 在未闭合的标签中添加明确禁止的元素。这种情况下,应该先将前一标签闭合
2. 不能直接添加元素。有些人在写文档的时候会忘了中间一些标签(或者中间标签是可选的),比如HTML HEAD BODY TR TD LI等
3. 想在一个行内元素中添加块状元素。关闭所有的行内元素,直到下一个更高的块状元素
4. 如果这些都不行,就闭合当前标签直到可以添加该元素。
下面来看一些webkit容错的例子:
</br>替代<br>
一些网站使用</br>替代<br>,为了兼容IE和Firefox,webkit将其看作<br>。
代码:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Note-这里的错误处理在内部进行,用户看不到。
迷路的表格
这指一个表格嵌套在另一个表格中,但不在它的某个单元格内。
比如下面这个例子:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
webkit将会将嵌套的表格变为两个兄弟表格:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
代码:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
webkit使用堆栈存放当前的元素内容,它将从外部表格的堆栈中弹出内部的表格,则它们变为了兄弟表格。
嵌套的表单元素
用户将一个表单嵌套到另一个表单中,则第二个表单将被忽略。
代码:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
太深的标签继承
www.liceo.edu.mx是一个由嵌套层次的站点的例子,最多只允许20个相同类型的标签嵌套,多出来的将被忽略。
代码:
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
放错了地方的html、body闭合标签
又一次不言自明。
支持不完整的html。我们从来不闭合body,因为一些愚蠢的网页总是在还未真正结束时就闭合它。我们依赖调用end方法去执行关闭的处理。
代码:
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
所以,web开发者要小心了,除非你想成为webkit容错代码的范例,否则还是写格式良好的html吧。
CSS解析 CSS parsing
还记得简介中提到的解析的概念吗,不同于html,css属于上下文无关文法,可以用前面所描述的解析器来解析。Css规范定义了css的词法及语法文法。
看一些例子:
每个符号都由正则表达式定义了词法文法(词汇表):
comment ///*[^*]*/*+([^/*][^*]*/*+)*//
num [0-9]+|[0-9]*”.”[0-9]+
nonascii [/200-/377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
“ident”是识别器的缩写,相当于一个class名,“name”是一个元素id(用“#”引用)。
语法用BNF进行描述:
ruleset
: selector [ ',' S* selector ]*
‘{’ S* declaration [ ';' S* declaration ]* ‘}’ S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator selector ] ]
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: ‘.’ IDENT
;
element_name
: IDENT | ‘*’
;
attrib
: ‘[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ‘]’
;
pseudo
: ‘:’ [ IDENT | FUNCTION S* [IDENT S*] ‘)’ ]
;
说明:一个规则集合有这样的结构
div.error , a.error {
color:red;
font-weight:bold;
}
div.error和a.error时选择器,大括号中的内容包含了这条规则集合中的规则,这个结构在下面的定义中正式的定义了:
ruleset
: selector [ ',' S* selector ]*
‘{’ S* declaration [ ';' S* declaration ]* ‘}’ S*
;
这说明,一个规则集合具有一个或是可选个数的多个选择器,这些选择器以逗号和空格(S表示空格)进行分隔。每个规则集合包含大括号及大括号中的一条或多条以分号隔开的声明。声明和选择器在后面进行定义。
Webkit CSS 解析器 Webkit CSS parser
Webkit使用Flex和Bison解析生成器从CSS语法文件中自动生成解析器。回忆一下解析器的介绍,Bison创建一个自底向上的解析器,Firefox使用自顶向下解析器。它们都是将每个css文件解析为样式表对象,每个对象包含css规则,css规则对象包含选择器和声明对象,以及其他一些符合css语法的对象。
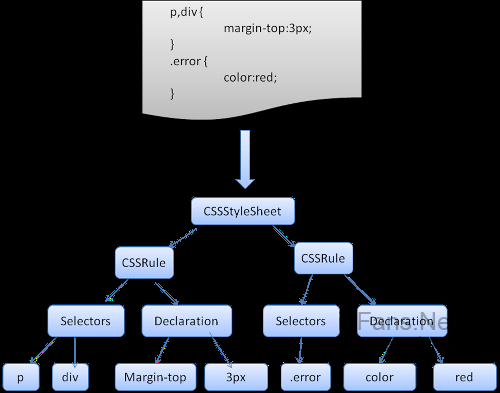
图12:解析css
脚本解析 Parsing scripts
本章将介绍Javascript。
处理脚本及样式表的顺序 The order of processing scripts and style. sheets
脚本
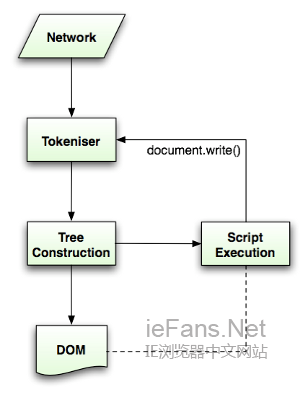
web的模式是同步的,开发者希望解析到一个script标签时立即解析执行脚本,并阻塞文档的解析直到脚本执行完。如果脚本是外引的,则网络必须先请求到这个资源——这个过程也是同步的,会阻塞文档的解析直到资源被请求到。这个模式保持了很多年,并且在html4及html5中都特别指定了。开发者可以将脚本标识为defer,以使其不阻塞文档解析,并在文档解析结束后执行。Html5增加了标记脚本为异步的选项,以使脚本的解析执行使用另一个线程。
预解析 Speculative parsing
Webkit和Firefox都做了这个优化,当执行脚本时,另一个线程解析剩下的文档,并加载后面需要通过网络加载的资源。这种方式可以使资源并行加载从而使整体速度更快。需要注意的是,预解析并不改变Dom树,它将这个工作留给主解析过程,自己只解析外部资源的引用,比如外部脚本、样式表及图片。
样式表 Style. sheets
样式表采用另一种不同的模式。理论上,既然样式表不改变Dom树,也就没有必要停下文档的解析等待它们,然而,存在一个问题,脚本可能在文档的解析过程中请求样式信息,如果样式还没有加载和解析,脚本将得到错误的值,显然这将会导致很多问题,这看起来是个边缘情况,但确实很常见。Firefox在存在样式表还在加载和解析时阻塞所有的脚本,而chrome只在当脚本试图访问某些可能被未加载的样式表所影响的特定的样式属性时才阻塞这些脚本。
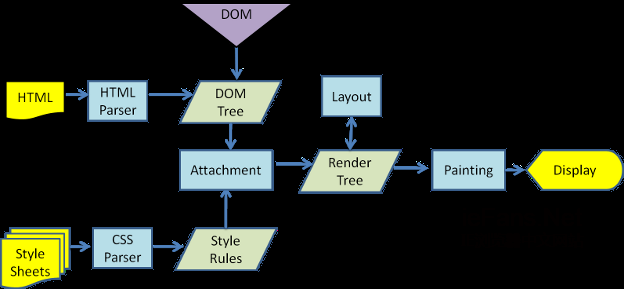
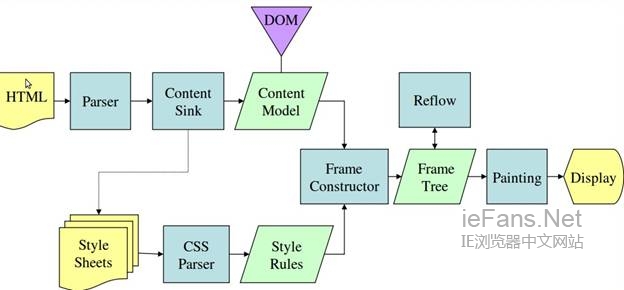
渲染树的构造 Render tree construction
当Dom树构建完成时,浏览器开始构建另一棵树——渲染树。渲染树由元素显示序列中的可见元素组成,它是文档的可视化表示,构建这棵树是为了以正确的顺序绘制文档内容。
Firefox将渲染树中的元素称为frames,webkit则用renderer或渲染对象来描述这些元素。
一个渲染对象直到怎么布局及绘制自己及它的children。
RenderObject是Webkit的渲染对象基类,它的定义如下:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
每个渲染对象用一个和该节点的css盒模型相对应的矩形区域来表示,正如css2所描述的那样,它包含诸如宽、高和位置之类的几何信息。盒模型的类型受该节点相关的display样式属性的影响(参考样式计算章节)。下面的webkit代码说明了如何根据display属性决定某个节点创建何种类型的渲染对象。
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
…
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
…
}
return o;
}
元素的类型也需要考虑,例如,表单控件和表格带有特殊的框架。
在webkit中,如果一个元素想创建一个特殊的渲染对象,它需要复写“createRenderer”方法,使渲染对象指向不包含几何信息的样式对象。
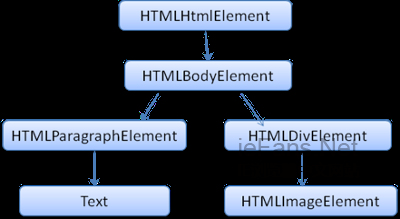
渲染树和Dom树的关系 The render tree relation to the DOM tree
渲染对象和Dom元素相对应,但这种对应关系不是一对一的,不可见的Dom元素不会被插入渲染树,例如head元素。另外,display属性为none的元素也不会在渲染树中出现(visibility属性为hidden的元素将出现在渲染树中)。
还有一些Dom元素对应几个可见对象,它们一般是一些具有复杂结构的元素,无法用一个矩形来描述。例如,select元素有三个渲染对象——一个显示区域、一个下拉列表及一个按钮。同样,当文本因为宽度不够而折行时,新行将作为额外的渲染元素被添加。另一个多个渲染对象的例子是不规范的html,根据css规范,一个行内元素只能仅包含行内元素或仅包含块状元素,在存在混合内容时,将会创建匿名的块状渲染对象包裹住行内元素。
一些渲染对象和所对应的Dom节点不在树上相同的位置,例如,浮动和绝对定位的元素在文本流之外,在两棵树上的位置不同,渲染树上标识出真实的结构,并用一个占位结构标识出它们原来的位置。
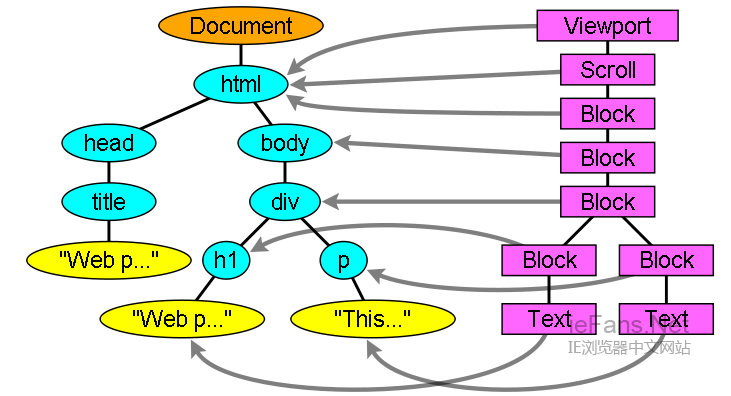
图12:渲染树及对应的Dom树
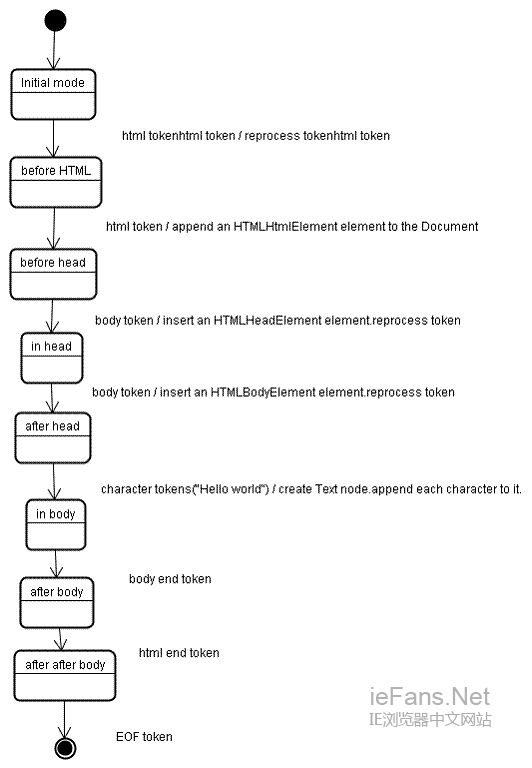
创建树的流程 The flow of constructing the tree
Firefox中,表述为一个监听Dom更新的监听器,将frame的创建委派给Frame. Constructor,这个构建器计算样式(参看样式计算)并创建一个frame。
Webkit中,计算样式并生成渲染对象的过程称为attachment,每个Dom节点有一个attach方法,attachment的过程是同步的,调用新节点的attach方法将节点插入到Dom树中。
处理html和body标签将构建渲染树的根,这个根渲染对象对应被css规范称为containing block的元素——包含了其他所有块元素的顶级块元素。它的大小就是viewport——浏览器窗口的显示区域,Firefox称它为viewPortFrame,webkit称为RenderView,这个就是文档所指向的渲染对象,树中其他的部分都将作为一个插入的Dom节点被创建。
样式计算 Style. Computation
创建渲染树需要计算出每个渲染对象的可视属性,这可以通过计算每个元素的样式属性得到。
样式包括各种来源的样式表,行内样式元素及html中的可视化属性(例如bgcolor),可视化属性转化为css样式属性。
样式表来源于浏览器默认样式表,及页面作者和用户提供的样式表——有些样式是浏览器用户提供的(浏览器允许用户定义喜欢的样式,例如,在Firefox中,可以通过在Firefox Profile目录下放置样式表实现)。
计算样式的一些困难:
1. 样式数据是非常大的结构,保存大量的样式属性会带来内存问题
2. 如果不进行优化,找到每个元素匹配的规则会导致性能问题,为每个元素查找匹配的规则都需要遍历整个规则表,这个过程有很大的工作量。选择符可能有复杂的结构,匹配过程如果沿着一条开始看似正确,后来却被证明是无用的路径,则必须去尝试另一条路径。
例如,下面这个复杂选择符
div div div div{…}
这意味着规则应用到三个div的后代div元素,选择树上一条特定的路径去检查,这可能需要遍历节点树,最后却发现它只是两个div的后代,并不使用该规则,然后则需要沿着另一条路径去尝试
3. 应用规则涉及非常复杂的级联,它们定义了规则的层次
我们来看一下浏览器如何处理这些问题:
共享样式数据
webkit节点引用样式对象(渲染样式),某些情况下,这些对象可以被节点间共享,这些节点需要是兄弟或是表兄弟节点,并且:
- 这些元素必须处于相同的鼠标状态(比如不能一个处于hover,而另一个不是)
- 不能有元素具有id
- 标签名必须匹配
- class属性必须匹配
- 对应的属性必须相同
- 链接状态必须匹配
- 焦点状态必须匹配
- 不能有元素被属性选择器影响
- 元素不能有行内样式属性
- 不能有生效的兄弟选择器,webcore在任何兄弟选择器相遇时只是简单的抛出一个全局转换,并且在它们显示时使整个文档的样式共享失效,这些包括+选择器和类似:first-child和:last-child这样的选择器。
Firefox规则树 Firefox rule tree
Firefox用两个树用来简化样式计算-规则树和样式上下文树,webkit也有样式对象,但它们并没有存储在类似样式上下文树这样的树中,只是由Dom节点指向其相关的样式。
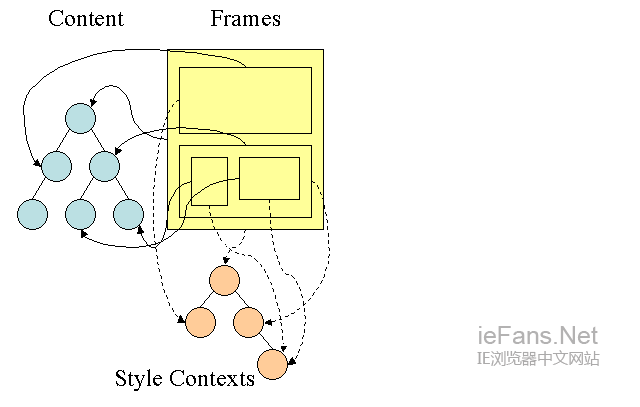
图14:Firefox样式上下文树
样式上下文包含最终值,这些值是通过以正确顺序应用所有匹配的规则,并将它们由逻辑值转换为具体的值,例如,如果逻辑值为屏幕的百分比,则通过计算将其转化为绝对单位。样式树的使用确实很巧妙,它使得在节点中共享的这些值不需要被多次计算,同时也节省了存储空间。
所有匹配的规则都存储在规则树中,一条路径中的底层节点拥有最高的优先级,这棵树包含了所找到的 所有规则匹配的路径(译注:可以取巧理解为每条路径对应一个节点,路径上包含了该节点所匹配的所有规则)。规则树并不是一开始就为所有节点进行计算,而是 在某个节点需要计算样式时,才进行相应的计算并将计算后的路径添加到树中。
我们将树上的路径看成辞典中的单词,假如已经计算出了如下的规则树:
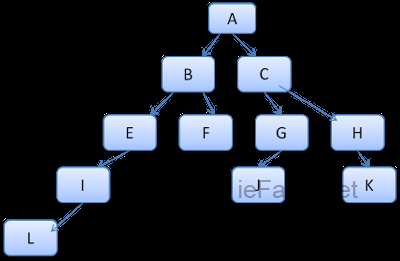
假如需要为内容树中的另一个节点匹配规则,现在知道匹配的规则(以正确的顺序)为B-E-I,因为我们已经计算出了路径A-B-E-I-L,所以树上已经存在了这条路径,剩下的工作就很少了。
现在来看一下树如何保存。
结构化
样式上下文按结构划分,这些结构包括类似border或color这样的特定分类的样式信息。一个结构中的所有特性不是继承的就是非继承的,对继承的特性,除非元素自身有定义,否则就从它的parent继承。非继承的特性(称为reset特性)如果没有定义,则使用默认的值。
样式上下文树缓存完整的结构(包括计算后的值),这样,如果底层节点没有为一个结构提供定义,则使用上层节点缓存的结构。
使用规则树计算样式上下文
当为一个特定的元素计算样式时,首先计算出规则树中的一条路径,或是使用已经存在的一条,然后使 用路径中的规则去填充新的样式上下文,从样式的底层节点开始,它具有最高优先级(通常是最特定的选择器),遍历规则树,直到填满结构。如果在那个规则节点 没有定义所需的结构规则,则沿着路径向上,直到找到该结构规则。
如果最终没有找到该结构的任何规则定义,那么如果这个结构是继承型的,则找到其在内容树中的parent的结构,这种情况下,我们也成功的共享了结构;如果这个结构是reset型的,则使用默认的值。
如果特定的节点添加了值,那么需要做一些额外的计算以将其转换为实际值,然后在树上的节点缓存该值,使它的children可以使用。
当一个元素和它的一个兄弟元素指向同一个树节点时,完整的样式上下文可以被它们共享。
来看一个例子:假设有下面这段html
<html>
<body>
<div class=”err” id=”div1″>
<p>this is a
<span class=”big”> big error </span>
this is also a
<span class=”big”> very big error</span>
error
</p>
</div>
<div class=”err” id=”div2″>another error</div>
</body>
</html>
以及下面这些规则
1. div {margin:5px;color:black}
2. .err {color:red}
3. .big {margin-top:3px}
4. div span {margin-bottom:4px}
5. #div1 {color:blue}
6. #div2 {color:green}
简化下问题,我们只填充两个结构——color和margin,color结构只包含一个成员-颜色,margin结构包含四边。
生成的规则树如下(节点名:指向的规则)
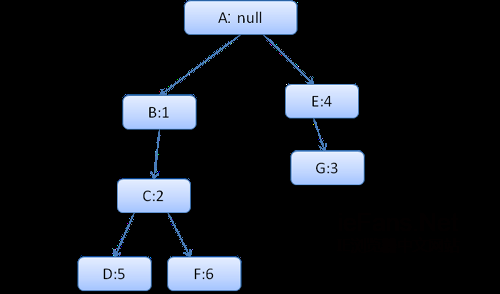
上下文树如下(节点名:指向的规则节点)
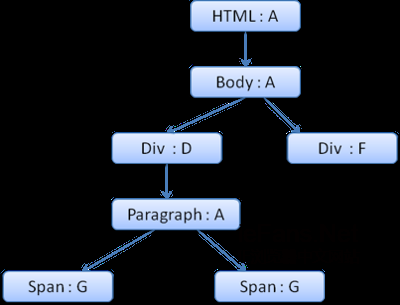
假设我们解析html,遇到第二个div标签,我们需要为这个节点创建样式上下文,并填充它的样式结构。
我们进行规则匹配,找到这个div匹配的规则为1、2、6,我们发现规则树上已经存在了一条我们可以使用的路径1、2,我们只需为规则6新增一个节点添加到下面(就是规则树中的F)。
然后创建一个样式上下文并将其放到上下文树中,新的样式上下文将指向规则树中的节点F。
现在我们需要填充这个样式上下文,先从填充margin结构开始,既然最后一个规则节点没有添加margin结构,沿着路径向上,直到找到缓存的前面插入节点计算出的结构,我们发现B是最近的指定margin值的节点。因为已经有了color结构的定义,所以不能使用缓存的结构,既然color只有一个属性,也就不需要沿着路径向上填充其他属性。计算出最终值(将字符串转换为RGB等),并缓存计算后的结构。
第二个span元素更简单,进行规则匹配后发现它指向规则G,和前一个span一样,既然有兄弟节点指向同一个节点,就可以共享完整的样式上下文,只需指向前一个span的上下文。
因为结构中包含继承自parent的规则,上下文树做了缓存(color特性是继承来的,但Firefox将其视为reset并在规则树中缓存)。
例如,如果我们为一个paragraph的文字添加规则:
p {font-family:Verdana;font size:10px;font-weight:bold}
那么这个p在内容树中的子节点div,会共享和它parent一样的font结构,这种情况发生在没有为这个div指定font规则时。
Webkit中,并没有规则树,匹配的声明会被遍历四次,先是应用非important的高优先级属性(之所以先应用这些属性,是因为其他的依赖于它们-比如display),其次是高优先级important的,接着是一般优先级非important的,最后是一般优先级important的规则。这样,出现多次的属性将被按照正确的级联顺序进行处理,最后一个生效。
总结一下,共享样式对象(结构中完整或部分内容)解决了问题1和3,Firefox的规则树帮助以正确的顺序应用规则。
对规则进行处理以简化匹配过程
----->见下文






 应用服务器Nginx安装及配置.rar(1.5 MB)
应用服务器Nginx安装及配置.rar(1.5 MB)