
-
JavaScript的Table表格对象
2009-07-06 22:10:45
JavaScript的Table表格对象收藏
Table表格对象 Table对象:表示HTML文档中的表,对于文档中每个标记,浏览器都创建一个Table对象.
Table对象集合
集合
描述
cells[] 获取包含表格中所有单元格的数组
rows[] 获取包含表格中所有行的数组
tBodies[] 获取包含表格中所有tbody的数组
Table对象属性
border 设置或获取表格边框
caption 设置或获取表格标题
cellPadding 设置或获取每个单元格边框与内容的宽度
cellSpacing 设置或获取表格中单元格的间距
frame. 设置或获取表格具有哪些边框
rules 设置或获取表格中的内部边框
summary 设置或获取表格的描述
tFoot 获取表格的tFoot对象
tHead 获取表格的tHead对象
width 设置或获取表格宽度
Table对象方法
createCaption() 为表格创建一个空的标题元素
createTFoot() 为表格创建一个空的tFoot元素
createTHead() 为表格创建一个空的tHead元素
deleteCaption() 删除表格的标题元素
deleteRow() 删除指定的表格行
deleteTFoot() 删除表格的tFoot元素
deleteTHead() 删除表格的tHead元素 insertRow() 向表格中插入新行
TableCell对象:表示HTML文档中表的单元格,对于文档中每个标记,浏览器都创建一个TableCell对象.
TableCell对象属性
属性
描述
abbr 设置或获取单元格的摘要
align 设置或获取单元格中文字的水平对齐方向
axis 设置或获取以逗号分隔的相关单元格组成的列表
cellIndex 获取行单元格集合中某单元格的位置
ch 设置或获取单元格的对齐特征
chOff 设置或获取单元格的对齐偏移特征
colSpan 设置或获取单元格跨越的表格列数
headers 设置或获取以空格分表头单元格的id列表
height 设置或获取单元格的高度
innerHTML 设置或获取单元格标记间的HTML文本
noWrap 设置或获取单元格是否自动换行
rowSpan 设置或获取单元格跨越的表格行数
scope 设置或获取与标题相关联的数据列
vAlign 设置或获取单元格文字的垂直对齐方向
width 设置或获取单元格的宽度
TableRow对象:表示HTML文档中表的行,对于文档中每个标记,浏览器都创建一个TableRow对象.
描述
cells[] 获取表格行中所有列组成的数组
Table对象属性
accessKey 设置或获取该对象的快捷键
align 设置或获取表格行中单元格中文字的水平对齐方向
chOff 设置或获取单元格的对齐偏移特征
colSpan 设置或获取单元格跨越的表格列数
height 设置或获取表格行的高度
innerHTML 设置或获取表格行标记间的HTML文本
innerText 设置或获取表格行标记间的文本
rowIndex 获取表格行对象在表格行集合中的位置
sectionRowIndex 获取tBody,tHead或tFoot中,表格行对象在行集合中的位置
tabIndex 设置或获取表格行的Tab顺序索引
vAlign 设置或获取表格行中文字的垂直对齐方向
width 设置或获取表格行的宽度
Table对象方法
blur() 取消该对象的激活状态
click() 模拟鼠标单击该对象
deleteCell([i]) 删除表格行中的指定的单元格
focus() 将焦点移至表格行
insertCell() 在表格行中插入新单元格 -
JAVA/JSP/HTML 命名规范
2009-07-06 22:08:51
基础教程:JAVA代码编写程序的基本规范[转贴]
1.Java命名规范
1.1 Package 的命名
Package 的名字应该都是由一个小写单词组成,例如:net.ebseries.modules。
1.2 Class 的命名
Class 的名字必须由大写字母开头而其他字母都小写的单词组成,例如:DataFile或InfoParser。
1.3 Class 变量的命名
变量的名字可大小写混用,但首字符应小写。词由大写字母分隔,限制用下划线,限制使用美元符号($),因为这个字符对内部类有特殊的含义。如: inputFileSize。
类中的属性不能定义为public变量直接存取,而是定义成protect变量来防止继承类使用他们并编写get/set方法。
1.4 Class 属性(成员变量)使用
Class 属性(成员变量)使用一定要加前缀this或super标识对应的成员变量,以增加程序的可读性。
1.5 Static Final 变量的命名
Static Final 变量的名字应该都大写,并且指出完整含义,例如:final MAXUPLOADFILESIZE=1024。
1.6 方法的命名
方法名应该是动词,大小写可混用,但首字母应小写。在每个方法名内,大写字母将词分隔并限制使用下划线。参数的名字必须和变量的命名规范一致,问题参数名是否采用以下划线开始作为统一标识,如setCounter(int _size),以标识成员变量size和传入参数_size区别。使用有意义的参数命名,如果可能的话,使用和要赋值的字段一样的名字:
setCounter(int size){
this.size = size;
}
1.7 数组的命名
数组应该总是用下面的方式来命名:byte[] buffer;而不是:byte buffer[];
2.代码格式
2.1 代码样式
代码应该用 unix 的格式,而不是 windows 的(比如:回车变成回车+换行)
2.2 文档化
必须用 javadoc 来为类生成文档。不仅因为它是标准,这也是被各种 java 编译器都认可的方法。
2.3 缩进
缩进应该是每行4个空格. 不要在源文件中保存Tab字符. 在使用不同的源代码管理工具时Tab字符将因为用户设置的不同而扩展为不同的宽度.
2.4 大括号{}
{} 中的语句应该单独作为一行. 例如, 下面的第1行是错误的, 第2行是正确的:
if (i>0) { i ++ }; // 错误, { 和 } 在同一行
if (i>0) {
i ++
}; // 正确, { 单独作为一行
2.5 括号()
左括号和后一个字符之间不应该出现空格, 同样, 右括号和前一个字符之间也不应该出现空格. 下面的例子说明括号和空格的错误及正确使用:
CallProc( AParameter ); // 错误
CallProc(AParameter); // 正确
不要在语句中使用无意义的括号. 括号只应该为达到某种目的而出现在源代码中。下面的例子说明错误和正确的用法:
if ((I) = 42) { // 错误 - 括号毫无意义
if (I == 42) or (J == 42) then // 正确 - 的确需要括号
2.6 注释
// 注释一行
/* ...... */ 注释若干行
文档注释:
/** ...... */ 注释若干行,并写入 javadoc 文档
在每个源文件的头部要有必要的注释信息,包括:文件名;版本号;作者;生成日期;模块功能描述(如功能、主要算法、内部各部分之间的关系、该文件与其它文件关系等。
在每个函数或过程的前面要有必要的注释信息,包括:函数或过程名称;功能描述;输入、输出及返回值说明;调用关系及被调用关系说明等。
3. 方法
l 方法的规模尽量限制在200行以内。
l 一个方法最好仅完成一件功能。
l 为简单功能编写方法。
l 方法的功能应该是可以预测的,也就是只要输入数据相同就应产生同样的输出。
l 尽量不要编写依赖于其他方法内部实现的方法。
l 避免设计多参数方法,不使用的参数从接口中去掉。
l 用注释详细说明每个参数的作用、取值范围及参数间的关系。
l 检查方法所有参数输入的有效性。
l 检查方法所有非参数输入的有效性,如数据文件、公共变量等。
l 方法名应准确描述方法的功能。
l 避免使用无意义或含义不清的动词为方法命名
l 方法的返回值要清楚、明了,让使用者不容易忽视错误情况。
l 明确方法功能,精确(而不是近似)地实现方法设计。
l 减少方法本身或方法间的递归调用。
l 编写可重入方法时,若使用全局变量,则应通过关中断、信号量(即P、V操作)等手段对其加以保护。
4. jsp规范
4.1 jsp目录命名规范
参照Package命名规则,用小写单个单词作为目录名
4.2 jsp文件名规范
参照class命名规则,采用首子母大写,多单词间采用大写字母分割
4.3 jsp传递参数命名规则
参照class变量命名规划
4.4 文件命名其它常见规范
l jsp主页面(游览功能) XxxxIndex.jsp (一般记录的删除在此页面做连接)
l jsp添加功能页面 XxxxAdd.jsp,相关的处理页面XxxxAddAction.jsp
l jsp修改功能页面 XxxxModify.jsp, 相关的处理页面XxxxModifyAction.jsp
l jsp删除功能页面 XxxxDel.jsp, 相关的处理页面XxxxDelAction.jsp -
html 控件命名规范
2009-07-06 22:07:26
WebControls
ADO.NETType Prefix Example AdRotator adrt adrtTopAd Button btn btnSubmit Calendar cal calMettingDates CheckBox chk chkBlue CheckBoxList chkl chklFavColors CompareValidator valc valcValidAge CustomValidator valx valxDBCheck DataGrid dgrd dgrdTitles DataList dlst dlstTitles DropDownList drop dropCountries HyperLink lnk lnkDetails Image img imgAuntBetty ImageButton ibtn ibtnSubmit Label lbl lblResults LinkButton lbtn lbtnSubmit ListBox lst lstCountries Panel pnl pnlForm2 PlaceHolder plh plhFormContents RadioButton rad radFemale RadioButtonList radl radlGender RangeValidator valg valgAge RegularExpression vale valeEmail_Validator Repeater rpt rptQueryResults RequiredFieldValidator valr valrFirstName Table tbl tblCountryCodes TableCell tblc tblcGermany TableRow tblr tblrCountry TextBox txt txtFirstName ValidationSummary vals valsFormErrors XML xmlc xmlcTransformResults -
TCL catch 详解
2009-07-06 22:05:57
catch - 执行脚本并捕获错误
语法
catch script. ?resultVarName? ?optionsVarName?
描述
catch命令用来防止出现错误而导致脚本执行终止,catch命令可以调用Tcl解释器去执行脚本,并且能够正常返回。
如果脚本产生一个错误,catch将返回一个非0的整数,如果没有捕获到错误就返回0或TCL_OK,Tcl还定义了四种异常代码:1(TCL_ERROR)、2(TCL_RETURN)、3(TCL_BREAK)和4(TCL_CONTINUE)。当执行脚本产生错误时就返回TCL_ERROR,其它的异常由return、break和continue命令产生。
如果给出了resultVarName变元,当返回1时,存储在resultVarName中的为错误信息,如果返回0,存储在resultVarName中的为脚本运行结果。
如果给出了optionsVarName变元,变量里面包含有-code和-level两个条目,如果返回代码不是TCL_RETURN时,-level为0,-code为返回的异常代码,当返回代码为TCL_RETURN时,-level和-code为其它的值,详细解释见return命令。
当返回TCL_ERROR时,三个额外的条目将会添加到optionsVarName中:-errorinfo、-errorcode和-errorline,-errorinfo条目是产生错误的信息,-errorcode条目是关于错误的一些额外信息,存储为列表方式,-errorline指出了错误发生的位置。-errorinfo和-errorcode条目都是最近发生的错误并且可以使用::errorInfo和::errorCode。
示例
catch命令可以在if命令中使用。if { [catch {open $someFile w} fid] } {puts stderr "Could not open $someFile for writing\n$fid"
exit 1
}
在return命令中有更多的关于catch的示例。 -
FreeWrap:TCL/TK的脚本和二进制文件打包成应用程序
2009-07-06 22:03:54
FreeWrap可以把TCL/TK的脚本和二进制文件打包成应用程序,FreeWrap将所有的文件组合成一个单独的可执行文件。
FreeWrap的原理是把脚本和tcl/tk解释器和库文件都打包在一个文件当中,做成一个可执行程序。生成的可执行文件实际上是一个压缩包,里面包含有需要使用的所有内容。不同的版本对应不同的tcl/tk版本,由于原始的tcl/tk版本只包括一些基本的库,所以如果需要使用更多的库,需要额外添加到文件中,还需要注意添加的方法和调用的顺序,如果是二进制的库就更麻烦了,需要额外的添加一段脚本。
FreeWrap的可执行程序本身就是一个shell,如果修改了可执行程序的名字,在windows下把freeWrap修改为shell,再运行则是一个tcl/tk的shell。
FreeWrap使用非常方便,就是一条命令,语法参考如下。
语法:freewrap dir/test.tcl [-debug] [-f FileLoadList] [-forcewrap] [-i ICOfile] [-o OutFile][-p] [-w WrapStub] File1 ... FileN
参数:
dir/test.tcl TCL/TK脚本主文件目录
File1 ... FileN 需要打包在可执行程序里面的文件,用空格间隔
-debug 在打包的时候打开一个可以查看调试信息的窗口
-f 需要打包的在命令后面的文件名详单
-forcewrap 当freeWrap应用程序名被修改后,强制freeWrap程序以打包程序来运行
-i 指定生成的可执行应用程序的图标
-o 指定生成的可执行应用程序的名称
-p 创建一个freeWrap格式的程序包而不是创建一个可执行程序
-w 生成跨平台的可执行文件
参数详解:
dir/test.tcl
TCL/TK脚本主文件目录,命令紧接着的默认为主脚本,其它的文件都为额外添加的文件。
File1 ... FileN
可以是任意的文件,但是要注意在生成的可执行程序包中的访问方式。比如你在命令中添加的file路径为C:\myfile\lib.tcl,那么在在打包程序中的目录结构是如下:
\myfile\lib.tcl
test.tcl
所以在添加库文件时要十分小心,要保证在脚本中调用的文件为source \myfile\lib.tcl而不是source lib.tcl。
-f
可以罗列需要打包的文件路径名到一个txt文件当中,运行命令后自动添加,避免命令过长。比如有3个文件C:\lib1.tcl、C:\lib2.tcl和D:\lib3.tcl,那么就可以在一个txt文件中写入上面的全路径,注意一个文件路径名占用一行。在调用的时候就可以正常添加所需的文件了。
-forcewrap
简单点说就是默认的应用程序为freewrap,如果由于需要程序名称修改成了shell,那么就可以使用 freewrap dir/test.tcl -forcewrap来打包一个程序,如果没有-forcewrap则是调用一个shell。
-i
使用-i选项去指定生成的可执行程序使用的图标。比如freewrap test.tcl -i test.ico,ico文件需要满足一下三种条件之一:1、16*16 16位色 2、32*32 16位色 3、32*32 2位色,如果是其他ico文件格式,在生成可执行文件时还是会采用默认的图标。
-o
指定生成的可执行应用程序的名称,比如freewrap test.tcl -o my.exe,生成的可执行程序就是my.exe而不是test.exe。
-w
生成跨平台的可执行文件,生成的时候需要有目标平台的freewarp,举例如下:
在windows下生成可以在linux下运行的打包应用程序:freewrap test.tcl -w freewrap
在linux下生成可以在windows下运行的打包应用程序:freewrap test.tcl -w freewrap.exe
如果需要freewrap,可以在http://sourceforge.net/中找到,目前的最新版本为6.4,支持tcl/tk8.5.0
-
a Python package for Tcl
2009-07-06 22:02:37
This package allows the execution of Python code from a Tcl interpreter, as in:
which outputs:package require tclpython 4 set interpreter [python::interp new] $interpreter exec {print("Hello World")} puts [$interpreter eval 3/2.0] python::interp delete $interpreterHello World 1.5
and, starting with version 4.0, execution of Tcl code from Python interpreters, as in:
package require tclpython 4 set interpreter [python::interp new] puts [$interpreter eval {tcl.eval('clock format [clock seconds]')}] python::interp delete $interpreterIt works by creating one or more embedded Python interpreters and sending them strings to evaluate or execute. Modules can be loaded in the Python interpreter as if it were the real Python program.
The commands created by the package are very simple:
- python::interp new
- python::interp delete interpreter
- interpreter eval script.
- interpreter exec script.
As expected, eval returns the Python interpreter result or reports an error at the Tcl level when the Python interpreter itself fails in executing the code string, while exec simply lets the Python interpreter execute the code and returns nothing or eventually report an error.
You can create several Python interpreters, if the tclpython package was linked against a Python library compiled with threads support, otherwise only 1 Python interpreter can exist at a time.
Notes:
- for Python 2.2 and above, the automatic import site on a new thread is suppressed because it otherwise makes the program hang (you can still use import site in your code, as described at the top of the Lib/site.py file).
- on a Redhat system, use the tclpython rpm on my homepage.
- tclpython is used by the moodss system monitoring software (information on my homepage) to allow its modules to be written in Python as well as Tcl and Perl.
Upgrading from tclpython version 2
In tclpython version 2, only the eval command was available to an interpreter. Some such invocations, generally that return nothing, need to be converted to the exec command, as the following examples show:
-
$interpreter eval {print("Hello World")} ;# version 2 $interpreter exec {print("Hello World")} ;# version 3 or 4 -
$interpreter eval {def initialize(): pass} ;# version 2 $interpreter exec {def initialize(): pass} ;# version 3 or 4 -
# version 2: set exists [$interpreter eval "try: type(initialize) == FunctionType\nexcept: 0"] # version 3 or 4: $interpreter exec "try: result = (type(initialize) == FunctionType)\nexcept: result = 0" set exists [$interpreter eval result]
Send your comments, complaints, ... to jfontain@free.fr.
My homepage is at http://jfontain.free.fr/. -
TCL eval 使用详解
2009-07-06 22:01:17
eval命令本身使用非常简单,但是用处非常大,如果需要动态的构造命令,那么必须使用eval命令。
eval命令参考:http://blog.csdn.net/dulixin/archive/2008/03/27/2223978.aspx
命令格式:eval arg ?arg ...?
如果是一个参数,那么相当于把这个参数当作命令来执行,如果有多个参数,eval命令会把多个参数以concat命令风格连接起来然后再执行命令。
举一个最简单的例子:
% set cmd "puts \"This is a tcltk example\""
puts "This is a tcltk example"
% eval $cmd
This is a tcltk example
一般在动态脚本中,主要是由脚本片断组成,脚本片断一般是一个变量,根据实际情况进行变量修改来达到执行不同脚本的目的。
% set a puts
puts
% set b stdout
stdout
% set c "haha"
haha
% eval $a $b $c
haha
-
TCL 实例: 让一个命令运行一定的时间
2009-07-06 21:59:31
[root@ntp tcl]# vi timed-run.tcl
exec tclsh "$0" ${1+"$@"}
#
# run a program for a given amount of time,
# aborting after the number of seconds
#
# Usage:
# tclsh timed-run.tcl 20 long_running_program program_args
#
# Author: Jeff Hobbs, based off shorter example by Don Libes
#
# This is required to declare that we will use Expect
package require Expect
proc usage {} {
puts stderr "usage: $::argv0 <timeInSecs> <program> <program args> "
exit 1
}
if {$argc < 2} { usage }
# timeout value is first to be passed in
set timeout [lindex $argv 0]
if {![string is integer -strict $timeout]} { usage }
# program and args are the rest
set cmd [lrange $argv 1 end]
# invoke the cmd with spawn
eval spawn $cmd
# just call expect and wait for it to timeout or eof to occur
expect
运行结果:
[root@ntp tcl]# ./timed-run.tcl
usage: ./timed-run.tcl <timeInSecs> <program> <program args>
以下调用 vmstat 运行时间长1秒,自然退出
[root@ntp tcl]# ./timed-run.tcl 9 vmstat
spawn vmstat
procs memory swap io system cpu
r b w swpd free buff cache si so bi bo in cs us sy id
0 0 0 0 835304 43340 90120 0 0 0 4 83 40 0 0 100
以下调用 vmstat 运行时间长9秒,超时退出
[root@ntp tcl]# ./timed-run.tcl 9 vmstat 1
spawn vmstat 1
procs memory swap io system cpu
r b w swpd free buff cache si so bi bo in cs us sy id
1 0 0 0 835304 43340 90120 0 0 0 4 83 40 0 0 100
0 0 0 0 835304 43340 90120 0 0 0 0 1019 33 0 0 100
1 0 0 0 835300 43340 90120 0 0 0 0 1024 48 0 0 100
0 0 0 0 835980 43340 90108 0 0 0 272 1046 88 0 0 100
0 0 0 0 835980 43340 90108 0 0 0 0 1029 57 0 0 100
0 0 0 0 835980 43340 90108 0 0 0 0 1035 59 0 0 100
0 0 0 0 835980 43340 90108 0 0 0 0 1048 91 1 1 98
0 0 0 0 835980 43340 90108 0 0 0 0 1031 51 0 0 100
0 0 0 0 835980 43340 90108 0 0 0 12 1023 54 0 0 100
1 0 0 0 835980 43340 90108 0 0 0 0 1016 38 0 0 100
[root@ntp tcl]#
[root@ntp tcl]# cat timed-run.tcl
#!/bin/sh
# \
exec tclsh "$0" ${1+"$@"}
优点:
1,二进制文件的位置不需要填入,它可以在你的 shell 查找路径中的任何地方。
2,突破了#!只有30个字符的限制
3,再shell中, 第2行是注释,第3行不是.但是在tcl中, \是连接符号,下一行依旧是注释.所以只有shell有机会执行第3行.exec 语句导致 shell 停止处理而启动 tclsh 来重新处理整个脚本。当 tclsh启动时,因为第二行的反斜线导致第三行被作为第二行注释的一部分,它把所有三行都作为注释对待。
exec tclsh "$0" ${1+"$@"}
很多地方是这样表达:exec wish "$0" "$@"
[root@ntp tcl]# vi test
#!/bin/sh
# \
echo hello
echo $0
echo ${1+"$@"}
echo "$@"
[root@ntp tcl]# ./test 1 2 3
hello
./test
1 2 3
1 2 3
可见两者没有太大的区别.
$::argv0 应该是TCL在双引号中调用系统参数的方法? -
如何在Tcl中加载包
2009-07-06 21:57:10
先说一下 ActiveTcl,一般来说,安装完ActiveTcl,会有一个lib的文件夹,在这个文件夹下面会有很多很常用到的一些Tcl或者Tk的包,例如:bwidget, treectrl 等等。 一般来说,要用这些包,只需要运行 package require Bwidget 就可以,但是很多情况下,也许我们对于这些包,有些特定的目录来放置,那么如何来Load这些包呢?在Tcl,Tk中,有一个变量来控制查找包,就是auto_path, 默认情况下,如果在ActiveTcl环境下,初始值是C:/Tcl/lib/tcl8.4 C:/Tcl/lib C:/Tcl/lib/tcllib1.8 C:/Tcl/lib/tklib0.4 C:/Tcl/lib/tk8.4这里我是在Wish中运行:set auto_path
如果现在我们有一个blt的包放置在D:/lib下面,那么我们需要运行:lappend auto_path D:/lib把需要加入的包所属的文件夹加入到变量auto_path中,这样我们就可以正确运行 package require blt. -
Tcl 内建命令
2009-07-05 23:26:33
Tcl 内建命令
Tcl 内建命令
Built-in commands 内建的命令
Tcl提供了下面描述的内建函数。
... 表示参数不定
append varName value
append varName value value value ...
将那一大堆value附加到varName后面。如果变量不存在,会新
建一个。
例子:
set i "aaa"
append i "bbb" "ccc"
//i = aaabbbccc
array subcommand arrayName
array subcommand arrayName arg ...
这是一组用于向量操作的命令。第二个参数是子命令名。
假设:
set a(1) 1111
set a(2) 2222
set a(three) 3333
一下均以它为例子(tclsh在中运行)。
array names arrayName
返回一个数组元素名字的列表。
tclsh>array names a
1 2 three
array size arrayName
返回数组的元素个数。
tclsh>array size a
3
下面是用于遍历的命令
arrry startsearch arrayName
初始化一次遍历,返回一个遍历标示(searchId)在下面的命令
是中使用。
array nextelement arrayName searchId
返回下一个数组中的元素。如果没有返回一个空串。
array anymore arrayName searchId
返回 1 表示还有更多的元素。0 表示没有了。
array donesearch arrayName searchId
结束该次遍历。
array nextelement arrayName searchId
返回下一个元素。
tclsh>array startsearch a
s-1-a
tclsh>array nextelement a s-1-a
1111
tclsh>array nextelement a s-1-a
2222
tclsh>array anymore a s-1-a
1
tclsh?array nextelement a s-1-a
3333
tclsh>array donesearch a s-1-a
注意可以同时并发多个遍历。
break
跳出最近的循环。
case string in patList body ...
case string patList body ...
case string in {patList body ...}
case string {patList body ...}
分支跳转。
例如:
case abc in {a b} {puts 1} default {puts 2} a* {puts 3}
return 3.
case a in {
{a b} {format 1}
default {format 2}
a* {format 3}
}
returns 1.
case xyz {
{a b}
{format 1}
default
{format 2}
a*
{format 3}
}
returns 2.
注意default不可以放在第一位。支持shell文件名风格的匹配
符。
catch command
catch command varName
用于阻止由于错误而导致中断执行。执行command, 每次都返
回TCL_OK, 无论是否有错误发生。如有错误发生返回1 ,反之返回0
。如果给了varName这被置为错误信息。注意varName是已经存在的
变量。
cd
cd dirName
转换当前工作目录。如dirName未给出则转入home目录。
close fileId
关闭文件描述符。
concat arg ...
将参数连接产生一个表。
concat a b {c d e} {f {g h}}
return `a b c d e f {g h}'
continue
结束该次循环并继续循环。
eof fileId
如fileId以结束 返回1,反之返回 0。
error message
error message info
error message info code
返回一个错误,引起解释器停止运行。info用于初始化全局变
量errorInfo。code被付给errorCode。
eval arg ...
将所有的参数连起来作为命令语句来执行。
exec arg ...
仿佛是在shell下执行一条命令。
exec ls --color
exec cat /etc/passwd > /tmp/a
exit
exit returnCode
中断执行。
expr arg
处理表达式。
set a [expr 1+1]
//a=2
file subcommand name
一组用于文件处理的命令。
file subcommand name arg ...
file atime name
返回文件的最近存取时间。
file dirname name
返回name所描述的文件名的目录部分。
file executable name
返回文件是否可被执行。
file exists name
返回1 表示文件存在,0 表示文件不存在。
file extension name
返回文件的扩展名。
file isdirectory name
判断是否为目录。
file isfile name
判断是否为文件。
file lstat name varName
以数组形式返回。执行lstat系统函数。存储在varName。
file mtime name
文件的最近修改时间。
file owned name
判断文件是否属于你。
file readable name
判断文件是否可读。
file readlink name
都出符号连接的真正的文件名。
file rootname name
返回不包括最后一个点的字符串。
file size name
返回文件的大小。
file stat name varName
调用stat内和调用,以数组形式存在varName中。
file tail name
返回最后一个斜线以后的部分。
file type name
返回文件类型file, directory, characterSpecial,
blockSpecial, fifo, link, 或
socket。
file writable name
判断文件是否可写。
flush fileId
立即处理由fileId描述的文件缓冲区。
for start test next body
for循环。同C总的一样。
for {set i 1} {$i < 10} {incr i} {puts $i}
foreach varname list body
类似于C Shell总的foreach或bash中的for..in...
format formatString
format formatString arg ...
格式化输出,类似于C中的sprintf。
set a [format "%s %d" hello 100]
//a="hello 100"
gets fileId
gets fileId varName
从文件中读出一行。
set f [open /etc/passwd r]
gets $f
glob filename ...
glob -nocomplain filename ...
使用C Shell风格的文件名通配规则,对filename进行扩展。
ls /tmp
a b c
tclsh>glob /tmp/*
a b c
当加上参数 -nocomplain 时,如文件列表为空则发生一个错
误。
global varname ...
定义全局变量。
if test trueBody
if test trueBody falseBody
if test then trueBody
if test then trueBody else falseBody
条件判断,是在没什么说的。
incr varName
incr varName increment
如果没有incremnet,将varName加一,反之将varName加
上increment。
set i 10
incr i
//i=11
incr i 10
//i=21
info subcommand
info subcommand arg ...
取得当前的Tcl解释器的状态信息。
info args procname
返回由procname指定的命令(你自己创建的)的参数列表。
如:
proc ff { a b c } {puts haha}
info args ff
//return "a b c"
info body procname
返回由procname指定的命令(你自己创建的)的函数体。
如:
proc ff { a b c } {puts haha}
info body ff
//return "puts haha"
info cmdcount
返回当前的解释器已经执行的命令的个数。
info commands
info commands pattern
如果不给出模式,返回所有的命令的列表,内建和自建的。
模式是用C Shell匹配风格写成的。
info complete command
检查名是否完全,有无错误。
info default procname arg varname
procname的参数arg,是否有缺省值。
info exists varName
判断是否存在该变量。
info globals
info globals pattern
返回全局变量的列表,模式同样是用C Shell风格写成的。
info hostname
返回主机名。
info level
info level number
如果不给参数number则返回当前的在栈中的绝对位置,参
见uplevel中的描述。如加了参数number,则返回一个列表包
含了在该level上的命令名和参数。
info library
返回标准的Tcl脚本的可的路径。实际上是存在变量
tcl_library中。
info locals
info locals pattern
返回locale列表。
info procs
info procs pattern
返回所有的过程的列表。
info script.
返回最里面的脚本(用 source 来执行)的文件名。
info tclversion
返回Tcl的版本号。
info vars
info vars pattern
返回当前可见的变量名的列表。
下面是一些用于列表的命令,范围可以是end。
join list
join list joinString
将列表的内容连成一个字符串。
lappend varName value ...
将value加入列表varName中。
lindex list index
将list视为一个列表,返回其中第index个。列表中的第一个
元素下标是0。
lindex "000 111 222" 1
111
linsert list index element ...
在列表中的index前插入element。
list arg ...
将所有的参数发在一起产生一个列表。
list friday [exec ls] [exec cat /etc/passwd]
llength list
返回列表中元素的个数。
set l [list sdfj sdfjhsdf sdkfj]
llength $l
//return 3
lrange list first last
返回列表中从frist到last之间的所有元素。
set l [list 000 111 222 333 444 555]
lrange $l 3 end
//return 333 444 555
lreplace list first last
lreplace list first last element ...
替换列表中的从first到last的元素,用element。
set l [list 000 111 222 333 444 555]
lreplace $l 1 2 dklfj sdfsdf dsfjh jdsf
000 dklfj sdfsdf dsfjh jdsf 333 444 555
lsearch -mode list pattern
在列表中搜索pattern,成功返回序号,找不到返回-1。
-mode : -exact 精确
-glob shell的通配符
-regexp 正则表达式
lsearch "111 222 333 444" 111
//return 0
lsearch "111 222 333 444" uwe
//return 1
lsort -mode list
排列列表。
-mode : -ascii
-dictionary 与acsii类似,只是不区分大小写
-integer 转化为整数再比较
-real 转化为浮点数再比较
-command command 执行command来做比较
open fileName
open fileName access
打开文件,返回一个文件描述符。
access
r w a r+ w+ a+
定义与C中相同。如文件名的第一个字符为|表示一管道的形式
来打开。
set f [open |more w]
set f [open /etc/pass r]
proc name args body
创建一个新的过程,可以替代任何存在的过程或命令。
proc wf {file str} {
puts -nonewline $file str
flush $file
}
set f [open /tmp/a w]
wf $f "first line\n"
wf $f "second line\n"
在函数末尾可用 return 来返回值。
puts -nonewline fileId string
向fileId中写入string,如果不加上 -nonewline 则自动产
生一个换行符。
pwd
返回当前目录。
read fileId
read fileId numBytes
从fileId中读取numBytes个字节。
regexp ?switches? exp string ?matchVar? ?subMatchVar
subMatchVar ...?
执行正则表达式的匹配。
?switches? -nocase 不区分大小写
-indices 返回匹配区间
如:
regexp ^abc abcjsdfh
//return 1
regexp ^abc abcjsdfh a
//return 1
puts $a
//return abc
regexp -indices ^abc abcsdfjkhsdf a
//return 1
puts $a
//return "0 2"
regsub ?switchs? exp string subSpec varName
执行正则表达式的替换,用subSpec的内容替换string中匹配exp
的部分。
?switchs? -all 将所有匹配的部分替换,缺省子替换第一
个,返回值为替换的个数。
-nocase 不区分大小写。
如:
regsub abc abcabcbac eee b
//return 1
puts $b
//return "eeeabcabc"
regsub -all abc abcabcabc eee b
//return 3
puts $b
//return "eeeeeeeee"
return
立即从当前命令中返回。
proc ff {} {
return friday
}
set a [ff]
//a = "friday"
scan string `format' varname ...
从string中安format来读取值到varname。
seek fileId offset ?origin?
移动文件指针。
origin: start current end
offset从哪里开始算起。
set varname ?value?
设置varname用value,或返回varname的值。如果不是在一
个proc命令中则生成一个全局变量。
source fileName
从filename中读出内容传给Tcl解释起来执行。
split string ?splitChars?
将string分裂成列表。缺省以空白为分隔符,也可通
过splitChars来设定分隔符
string subcommand arg ...
用于字符串的命令。
string compare string1 string2
执行字符串的比较,按 C strcmp 的方式。返回 -1, 0, or 1。
string first string1 string2
在string1种查找string2的定义次出现的位置。未找到返回-1。
string length string
返回字符串string的长度。
string match pattern string
判断string是否能匹配pattern。pattern是以shell文件名的
统配格式来给出。
string range string first last
返回字符串string中从first到last之间的内容。
string tolower string
将string转换为小写。
string toupper string
将string转换为大写。
string trim string
将string的左右空白去掉。
string trimleft string
将string的左空白去掉。
string trimright string
将string的右空白去掉。
tell fileId
返回fileId的文件指针位置。
time command
执行命令,并计算所消耗的时间。
time "ls --color"
some file name
503 microseconds per iteration
trace subcommand
trace subcommand arg ...
监视变量的存储。子命令定义了不少,但目前只实现了
virable。
trace variable name ops command
name 为变量的名字。
ops 为要监视的操作。
r 读
w 写
u unset
command 条件满足时执行的命令。
以三个参数来执行 name1 name2 ops
name1时变量的名字。当name1为矢量时,name2为下标,ops
为执行的操作。
例如:
proc ff {name1 name2 op} {
puts [format "%s %s %s" name1 name2 op]
}
set a hhh
trace variable a r {ff}
puts $a
//return "a r\nhhh"
unknown cmdName
unknown 并不是 Tcl 的一部分,当 Tcl 发现一条不认识的命
令时会看看是否存在 unknown命令,如果有,则调用它,没有则出
错。
如:
#!/usr/bin/tclsh
proc unknown {cwd args} {
puts $cwd
puts $args
}
//下面是一条错误命令
sdfdf sdf sdkhf sdjkfhkasdf jksdhfk
//return "sdfdf sdf sdkhf sdjkfhkasdf jksdhfk"
unset name ...
删除一个或多个变量(标量或矢量)。
uplevel command ...
将起参数连接起来(象是在concat中)。最后在由level所指
定的上下文中来执行。如果level是一个整数,给出了在栈中的距
离(是跳到其它的命令环境中来执行)。
缺省为1(即上一层)。
如:
#!/usr/bin/tcl
proc ff {} {
set a "ff" //设置了局部的a
-------------------------
}
set a "global"
ff
puts $a
//return "global"
再看下一个:
#!/usr/bin/tcl
proc ff {} {
uplevel set a "ff" //改变上一级栈中的a
-------------------------------------
}
set a global
ff
puts $a
//return "ff"
如果level是以#开头后接一个整数,则level指出了在栈中的
绝对位置。如#0表示了顶层(top-level)。
a b c 分别为三个命令,下面是它们之间的调用关系,
top-level -> a -> b -> c -> uplevel level
绝对位置: 0 1 2 3
当level为 1 或 #2 都是在 b 的环境中来执行。
3 或 #0 都是在 top-level 的环境中来执行。
upvar ?level? otherVar myVar ?otherVar myVar ...?
在不同的栈中为变量建立连接。这里的level与uplevel中
的level是同样风格的。
例如:
#!/usr/bin/tcl
proc ff {name } {
upvar $name x
set x "ff"
}
set a "global"
ff a
puts $a
//return "ff"
while test body
举个例子吧:
set x 0
while {$x<10} {
puts "x is $x"
incr x
}
Built-in variables 内建的变量
下名的全局变量是由 Tcl library 自动来管理的。一般是只
读的。
env
环境变量数组。
如:
puts $env(PATH)
// return /bin:/usr/bin:/usr/X11R6/bin
errorCode
当错误发生时保存了一些错误信息。用下列格式来存储:
CHILDKILLED pid sigName msg
当由于一个信号而被终止时的信息。
CHILDSTATUS pid code
当一个子程序以非0值退出时的格式。
CHILDSUSP pid sigName msg
当一个子程序由于一个信号而被终止时的格式。
NONE
错误没有附加信息。
UNIX errName msg
当一个内核调用发生错误时使用的格式。
errorInfo
包含了一行或多行的信息,描述了错误发生处的程序和信息。
原文的作者也是Tcl的缔造者 John Ousterhout
(`ouster@sprite.berkeley.edu')写于伯克利分校。
Tcl 名字空间
namespace
创建和操纵命令和变量的上下文(content)。
简介:
一个名字空间是一个命令和变量的集合,通过名字空间的封装来
保证他们不会影响其它名字空间的变量和命令。 Tcl 总是维护了一
个全局名字空间 global namespace 包含了所有的全局变量和命令。
namespace eval允许你创建一个新的namespace。
例如:
namespace eval Counter {
namespace export Bump
variable num 0
proc Bump {} {
variable num//声明局部变量
incr num
}
}
名字空间是动态的,可变的。
例如:
namespace eval Counter {
variable num 0//初始化
proc Bump {} {
variable num
return [incr num]
}
}
//添加了一个过程
namespace eval Counter {
proc test {args} {
return $args
}
}
//删除test
namespace eval Counter {
rename test ""
}
引用:
set Counter::num
//return 0
也可以用下面的方式添加:
proc Foo::Test {args} {return $args}
或在名字空间中移动:
rename Foo::Test Bar::Test -
UT ROBOT 解决方案介绍
2009-02-23 18:40:42
有一段时间没有更新了,在这里给大家继续汇报一下UT ROBOT的进度,希望与有兴趣的朋友继续交流
灵活支持不同类型的应用程序:
1.接口类型测试
2.面向过程应用测试
3.Web Service测试
4.Web GUI测试
5.回归测试
特点:
1.无需编写脚本
2.轻易支持新应用
3.关系型数据驱动
4.自动产生CASE脚本
5.CASE版本管理
6.灵活的结果检查点管理
7.支持多用户
8.动态日志跟踪
9.运用于多个项目测试
“五年磨一剑,鼠标一点,轻轻松松完成新功能测试及自动化测试”
截图1:增加新应用
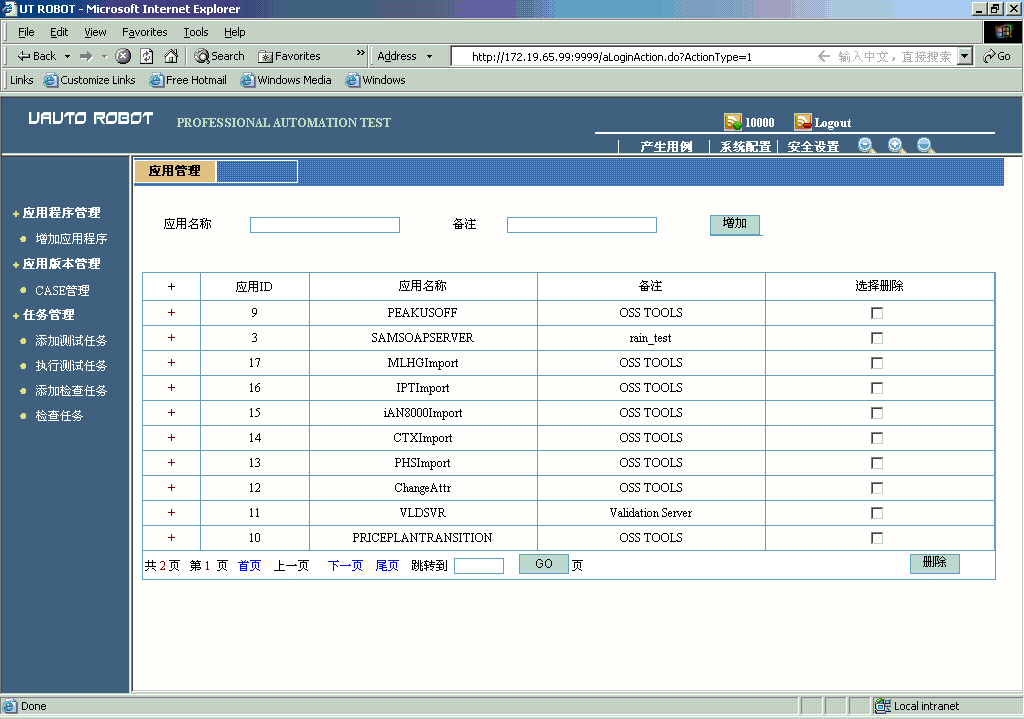
截图2:灵活版本管理,支持主线开发及分支开发 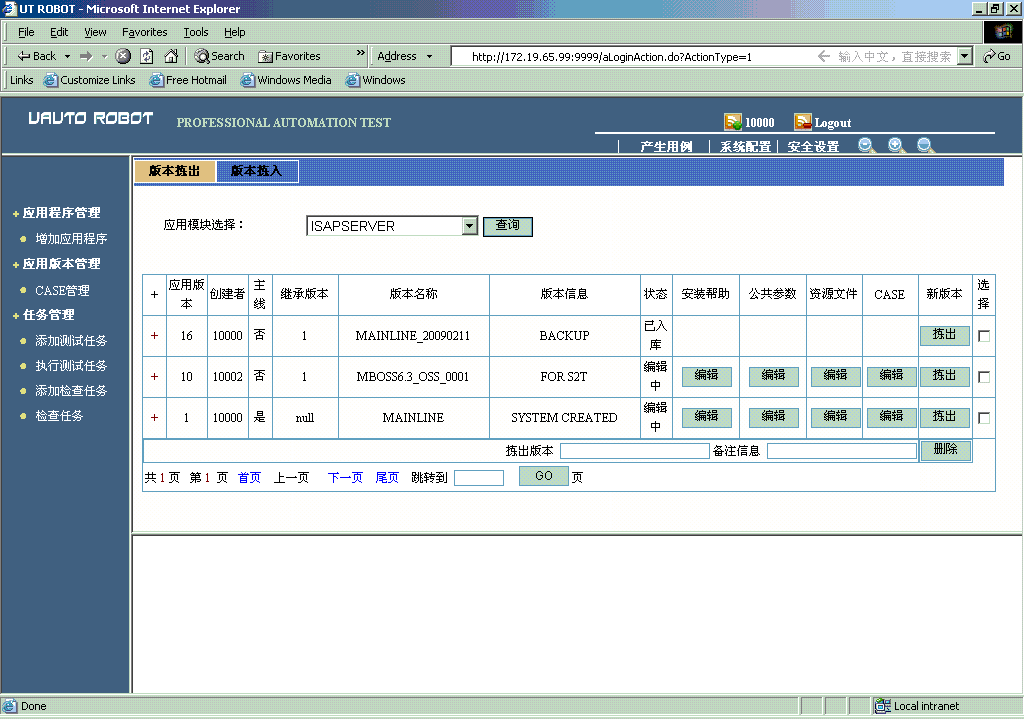
截图3:灵活的测试任务管理 
截图4:轻松的CASE执行方式 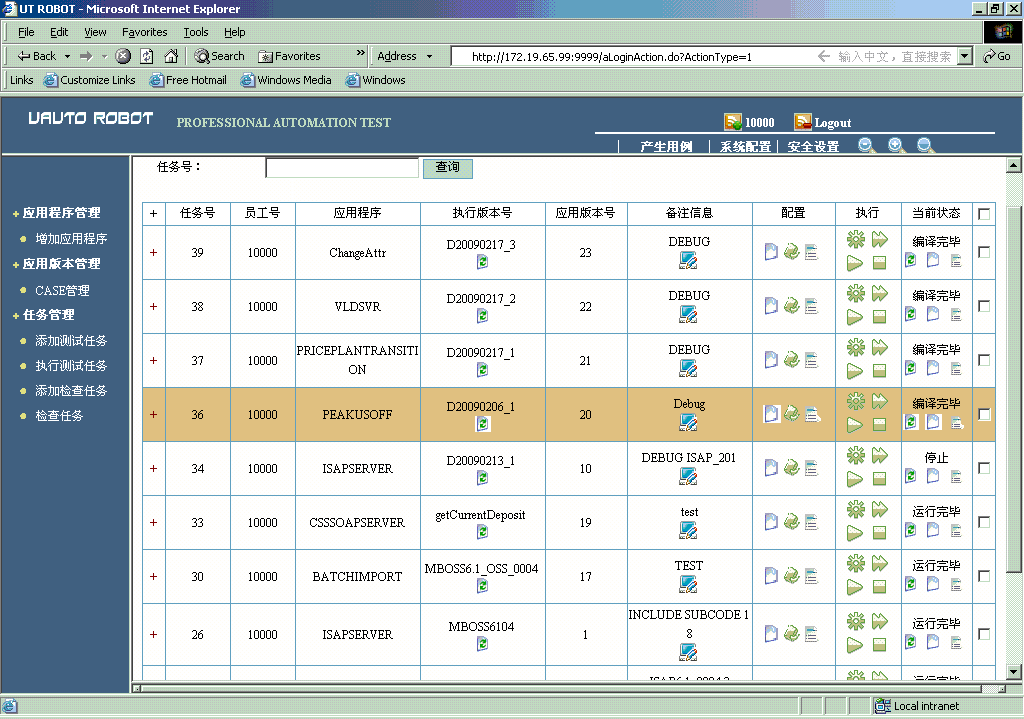
截图5:CASE脚本的动态编译及实时查看 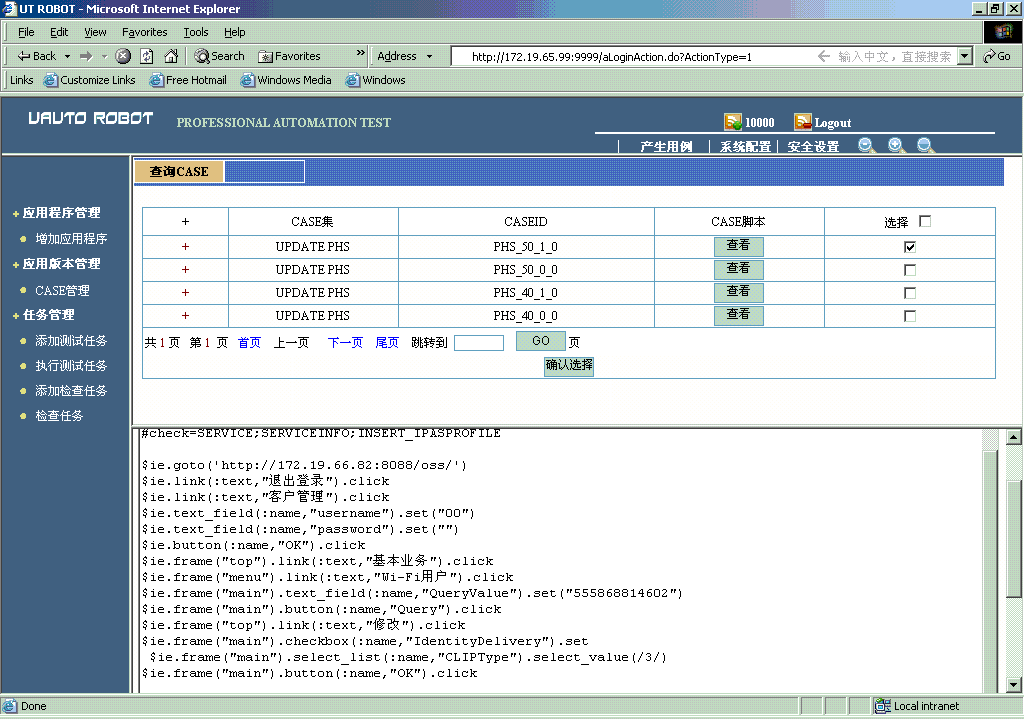
截图6:灵活的CASE选择 
截图7:动态日志跟踪 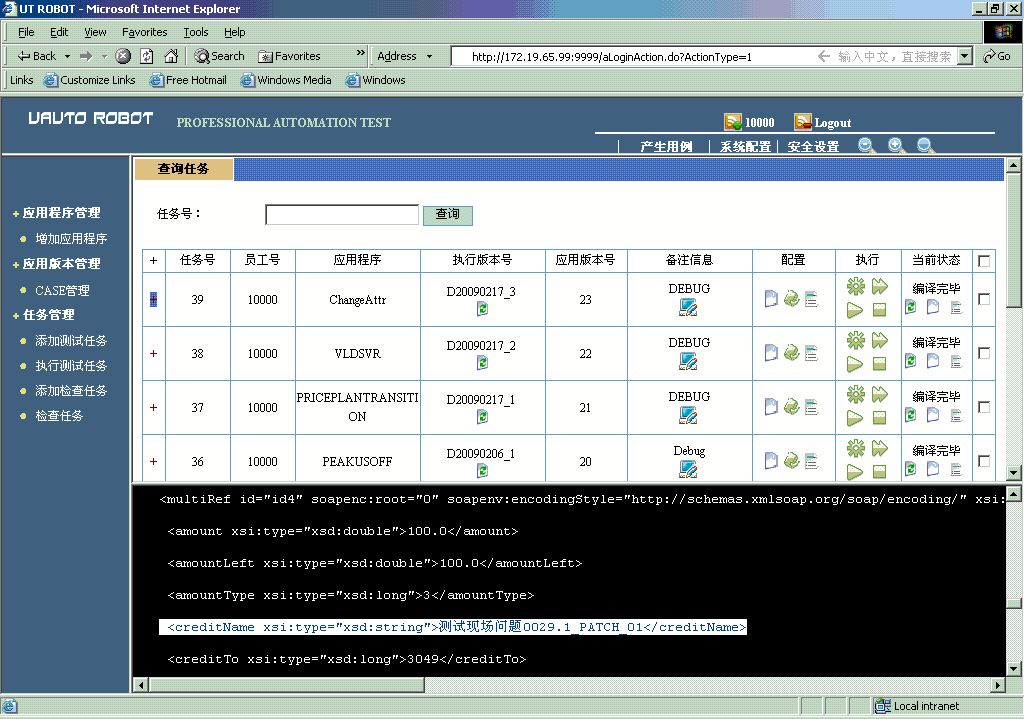
截图8:轻松的结果检查点配置 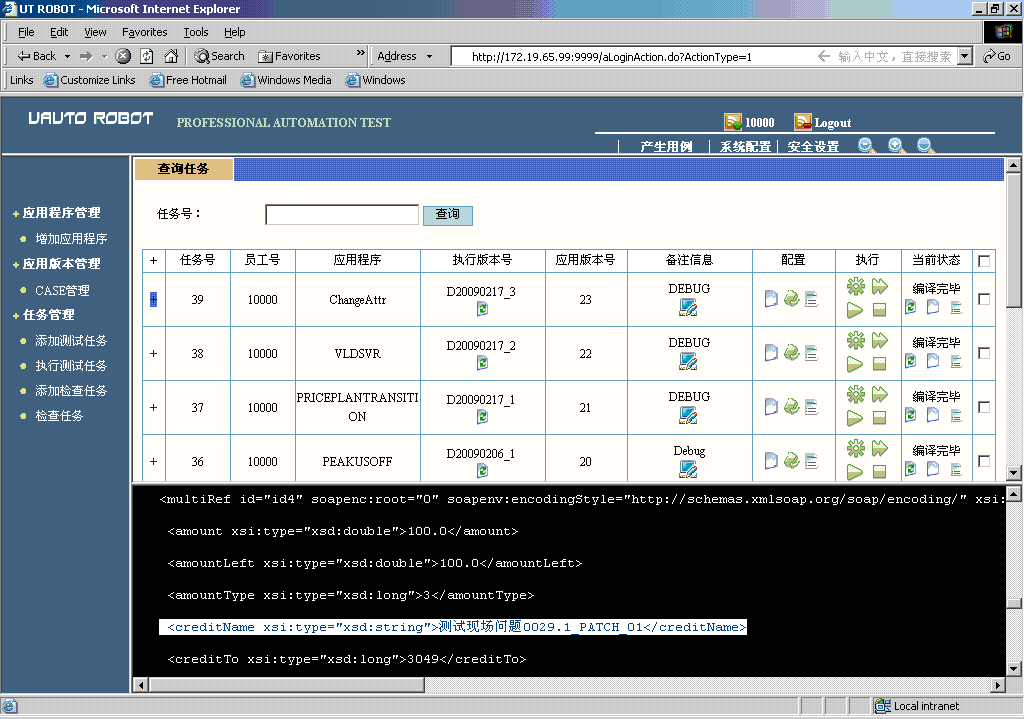
-
开放性敏捷自动化测试架构介绍(6)
2008-09-17 23:55:10
有一段时间没有上来了,前段时间去杭州参加了公司组织的持续创新比赛,UT ROBOT项目作为唯一一个软件测试项目,从初赛的300多个项目中脱颖而出进入16强,最终获得了铜牌成绩,我们的软件测试架构获得公司上下的肯定,也为团队赢得了外出旅游的奖金。
在这里回答帖子中同行所提出的问题:1.你提到此框架已经应用于若干项目中,想问一下这些项目是完全不同的项目么?还是框架的实现本身已经包含了对这些项目中共同点的一些假设?
UT ROBOT强调的是框架,并不是仅为某个应用设计,应用的项目有相似的,也有不尽相同的。当然,对于软件产品,不管怎样都是有相通之处的,对于框架的设计,就是要对不同的软件产品进行高度的抽象,以尽量满足大部分软件产品测试的需要。同时我们也要承认,没有任何一个工具或者框架是放之四海而皆准的,所以,这也是我所提倡的架构要为产品服务,只有根据不同公司的产品特点来进行开发才能提高测试框架的适用性,否则就很容易出现水土不服的情况。测试框架必须来源于对测试深刻理解,象我们即使从事多年软件的测试,每天都会不断的涌现出新的想法,每天看着做出来的框架还是有很多可以改进的地方,试想如果只是简单使用了商用的架构,要把新的想法融合进去是非常困难的。
2.关于CASE的自动生成,是不是主要是测试数据的不同组合,也就是场景相同,测试数据不同的情况?
Test Case的主要有几个元素:预设场景,数据集合,数据处理,收集结果,环境清理,结果检查点;这些都是UT ROBOT考虑的重要因素,当然还有一点非常非常重要的也是容易被忽视的就是Case的版本控制,这点我将在后面专门阐述。通过实现以上的要点,可以灵活的跟据具体的情况,针对不同的数据组合结合部同的测试场景来自动生成CASE。3. 对于GUI测试这个架构能否一样适用?
简单的说,可以;大家都知道GUI的测试是要有专门的GUI模拟技术来支持,UT ROBOT的核心在于数据,所以通过UT ROBOT+RUBY+WATIR的结合,利用WATIR+RUBY进行封装,通过UT ROBOT进行关键字驱动,从而实现对GUI测试的支持,这个工作正在进行当中。
这里我想重点说说Test Case的版本控制问题,这也是UT ROBOT最新支持的重要特性。在我们的软件产品中,Test Case的版本涉及到以下几方面的版本变更:
1.被测试软件本身的版本变更;
2.不同语言版本的变更
3.不同国家版本的变更
4.不同业务的版本变更
5.不同应用模式的版本变更
6.不可预期的版本变更
对于以往的一些测试工具或者架构,以上任何一方面的版本变更都会带来极大的Case维护代价,大家常见的是被测试软件本身的版本变更,这里就不多说;就举不同国家版本的变更来说,我们的产品应用到不同的国家地区,如台湾、巴西、菲律宾、智利等等10几个国家,每个国家的应用模式都不一样,同样的测试参数在不同国家的应用方式都不一样。如果为每个国家都去维护一套CASE的话,不难想象,这种维护量是致命的,更加致命的是还有很多是不可预期的版本变更,这样会带来极大的维护工作,对于传统的通过业务脚本去实现测试业务逻辑的方法而言,版本变更就愈加显得力不从心了,试想,一个业务逻辑的变更要导致10几个国家版本的CASE的变更和其它因素的变更,这种变更CASE的代价就很有可能抵消自动所带来的好处。UT ROBOT考虑到以上的变更因素,尤其是不可预期的版本变更,通过扩展框架数据结构,实现了非常灵活的版本变更管理,只需要维护一套CASE就可以轻松应付以上的种种变更因素,其实现的原理是通过引入变量和条件表达式的方式来处理各种变更情况,从而达到只需要维护一套CASE就可以适用于不同的语言、不同的国家、不同的业务、不同的应用模式的情况。
总结一下,一套健壮的框架需要对测试知识进行高度的抽象,考虑的因素越多,框架就越容易扩展,当然,实现的难度和代价也就越大。和不同的人交流,有助于我们在设计及实现框架的时候少走一些弯路,正所谓:三人行,必有我师焉。 -
开放性敏捷自动化测试架构介绍(5)
2008-08-02 00:39:14
多谢大家的捧场!刚过去的一周事情比较多,除了培训,日程项目安排管理,为下周的客户来公司参观准备DEMO环境之外,也刚刚参加完公司的一个比赛。
这个比赛的目的是提升公司各个环节的持续改进能力,最终达到提高质量,降低成本,缩短周期的目标。ROBOT作为参赛项目之一,一共有18只队伍参加,参赛队伍覆盖了从生产线、质量部、客服部、技术支持部、研发部等各个环节的部门;大部分的队伍都是与生产线有关,因为生产线是最好量化及体现成本节约成果的。我们的队伍是两只与软件测试相关的队伍之一。比赛在杭州与深圳通过视频会议两地同步进行,总体感觉演讲的效果还不错,赢得了不少的掌声。有幸的ROBOT项目进入了8强,下周要参加在杭州的总决赛。
言归正传,我们还是来讨论自动化技术方案。上周末参加了IBM举办的技术加油站,主要是以介绍工具为主,感觉IBM的测试工具就是进行界面的自动化录制等等,与行业的LR,QTP没有太本质的区别,对于接口测试,举了SOA应用的例子,感觉也就是简单的手工接口测试,要想实现大规模的接口回归测试还有很大的差距,如果要想支持不同特点的应用的测试就更加不可能。
我一直提倡用有效性来衡量一项创新的用途,包括自动化测试也一样,如果自动化测试单纯停留在宣传上说又多么多么的重要,多么多么的节省人力,另外一方面却发现不了问题,没有数据的支撑的话,是经不起时间考验的,更不能说服别人心甘情愿的学习和推行自动化。另外一方面,如果自动化很有效果,但要花很多时间去写自动化脚本的话,其维护量是惊人的,这条路走起来代价非常大,测试人员根本享受不到自动化带来的便捷,因为我们以前是走过弯路的,所以感受特别深;试想,当你开发了一万个CASE,但是一旦系统修改了设计,要去修改一半的CASE,即使你再有耐心,也会被这种修改脚本的无意义劳动所打倒。
如果想当然的认为一个软件版本到一定程度就能稳定,那是理想的状况,一般情况下除非小软件或者软件被废弃了才会有这种情况,实际情况下,对于有一定规模的软件公司,其软件版本的代码超过千万行是很普遍的,而且系统会随着不同客户的需求不断的增加修改和删除,这就是软件缺陷的来源。UT ROBOT就是在这种背景下产生的,把ROBOT比喻为一条生产线的话,解析引擎是核心,抽象的模板的机器运转的传输带,数据就是原料,数据整合部分一个过滤器,分离的结果检查点则是自动质检系统,每一部分看似都是独立的部分,因为独立也就意味着低耦合,这也就是ROBOT能实现不同类型的软件自动化测试的原因。
有很多人发邮件问我ROBOT怎么可能不需要编写脚本,其实大家有所误解,ROBOT与业务无关,但是对于数据模板的解析还是要根据不同的应用进行模块化扩充的,实际的扩充代价是比较少,因为我把模板中的标签进行了自动解析识别,增加模板中的元素只需要配置解析的规则就可以轻易支持新的模板。另外如果有新的传输协议,还是要增加底层支持的。一旦新的模板加入,测试人员就只需要根据接口文档进行业务数据接口配置,再通过ROBOT的编译引擎产生大量的自动化可执行CASE,一定业务逻辑发生了变化,只需要在数据配置文档进行数据的修改,重新编译数据文档就可以重新生成自动化CASE,维护代价是非常低的。
我认为如果要推行自动化测试,就不要盲目的使用商业测试工具,从长远来讲,要根据各行业各公司的特点去开发符合自己需求的的自动化框架。测试无止境,需要我们在平时的工作中敢于发现问题、多从不同的角度去思考,才能真正开发出有效的自动化测试软件,技术不是自动化最重要的因素,好的想法才是王道。
时间不早了,有空再和大家探讨。 -
开放性敏捷自动化测试架构介绍(4)
2008-07-21 22:32:15
这几天有点忙,我们的BOSS系统已经比较稳定,但是最近根据某个运营商提的需求对系统的框架进行了比较大的改动,安排了几个同事进行新接口的测试,从上星期开始,一切似乎比较正常,没有发现一些大的问题。但是,做测试的人一般都会有这种直觉,没有发现问题才是最大的问题!而且与开发沟通知道改动量并不少,所以有抱着比较怀疑的态度,本来想着在测试的后期再安排回归的,在这种状况下就要把回归提前了。
因为改动的主要是业务受理接口,主要是对这块的CASE进行回归,CASE大概是2000个,结果检查点有200000。于是运用了UT ROBOT框架做了一次回归测试,运行到差不多第100个CASE的时候,以前正常的一个CASE报错,于是查了一下错误的代码,将测试结果交给开发分析,发现对某个表的status字段处理上,对于status=00001与status=000001出了问题,再一细查所有的代码,发现竟然有30多处的判断处理中存在这个问题;而同时进行的手工测试没有发现这个重大问题,与开发沟通知道,这次的改动主要就包括出错的地方。ROBOT再次立功!除此以外,ROBOT也还发现了其它几个重要问题。
回归迭代测试不可少,有效的框架是解决回归迭代测试的最有效途径!
另外,这几天也在忙于IPTV业务的Web Service的自动化支持模板改造,可能要几天之后才能完成,到时再给大家报告新动向。
-
开放性敏捷自动化测试架构介绍(3)
2008-07-13 16:19:29
这段时间正在为这个架构申请公司的一个创新大奖,也就准备了一下PPT介绍,我把其中的几页摘下来供大家参考。有同事推荐这个创新大奖完了之后,我将有可能会去申请一下专利。
下面是对该架构技术的一些重点: 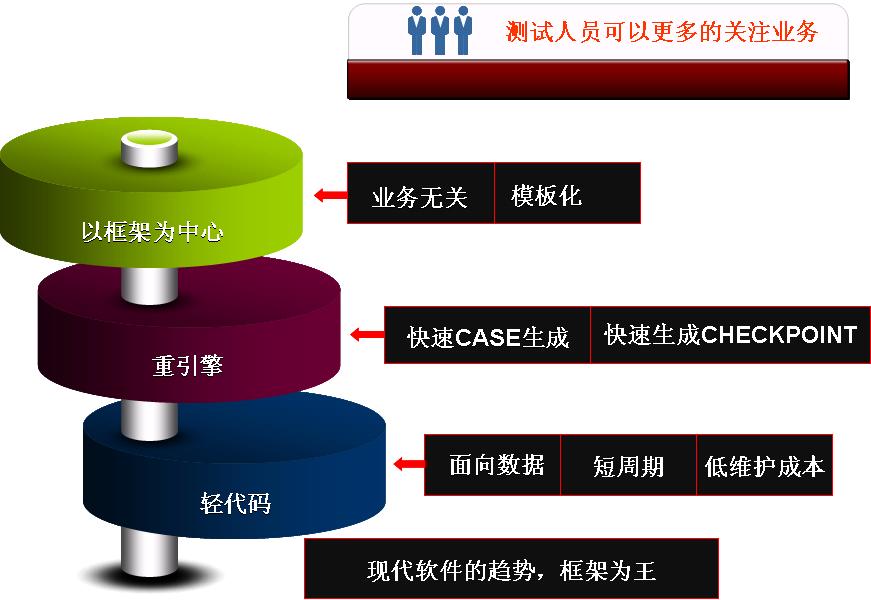
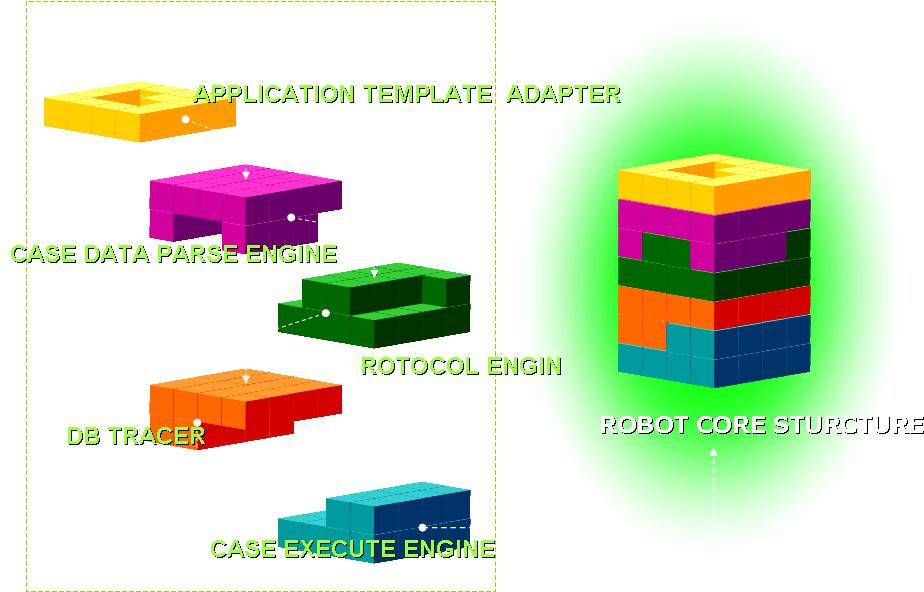

我还想谈一下测试与开发的关系,因为这个架构在测试公司的新项目(Web service类的BOSS业务)中发现了大量的问题,这个新项目设计到的SOAP接口也就是20几个新接口,但是通过ROBOT架构自动产生了超过5000个CASE(其中包括了枚举值,边界值,异常数据,各类自定制的参数组合),自动产生200000的数据库检查点,完全通过自动化回归的方式进行CASE执行和结果点检查,结果短短几个星期内发现了超过一百个问题,而且很多是严重问题。在刚支持的IPTV业务上,也只是花了几天时间就支持了其中一个应用的自动化测试,结果也发现了几个严重问题,这种成果是以前任何一种架构的自动化所无法比拟的。开发部门也对这个架构刮目相看,专门组织了几次培训来学习这个架构,因此我这段时间也在帮开发建立他们内部的单元测试体系,开发也认真的投入到了测试当中,和我们一起为提高测试质量而共同探讨测试技术,我们也向开发提出了各种要求来配合我们自动化CASE的产生,从这点来看,开发与测试的关系并不一定是对立的,当我们的创新给开发带来了软件质量水平的提高,他们反过来会更加尊敬测试团队。 -
开放性敏捷自动化测试架构介绍(2)
2008-07-13 16:17:23
BOSS是指为电信运营商提供的营帐支撑系统,因为移动电信的业务的特点是业务非常复杂,有成千上万的价格计划套餐,计费也比较复杂,后台的支持网元有上百个,我们现在整套BOSS系统能支撑软交换,GSM,IPTV等等多业务,现在的BOSS相关网元已经超过300个,所以接口是非常多的,因为这种特点,所以接口协议和后台数据的测试就是主要方面
UT ROBOT的主要成绩体现在我们通过ROBOT回归的部分网元,在现场实施之后几乎没有再报回归方面的遗漏问题。BUG下降了85%,因为有了这个数据说话,所以坚定了我们在这个架构上的信心
UT Robot强调的是框架,也就是可以适用在多个应用,多业务的测试中,即使不是我们公司的产品也可以应用
自动化测试需要考虑以下方面:
1.CASE执行前的环境准备:这是为了保证批量测试的时候不影响其它CASE的执行
2.CASE执行后的环境清理:这也是为了保证批量测试的时候不影响其它CASE的执行
3.结果检查点:非常重要,这是测试准确性的根本
4.参数的组合关系:只有可以自由组合CASE,才能覆盖各种场景
5.核心思想:CASE的生成,执行,结果记录,以及回归要分离
6.协议无关:具体完成协议发送的功能与框架想分离
7.业务无关
现在Robot已经应用到我们BOSS的部分网元的测试中,并且做到了与协议和业务无关,我们现在的效率是,一周之内就可以支持新的简单网元的自动化测试。
举例:对于WebService的SOAP接口测试,通过CASE的生成,执行,结果记录,以及回归要分离,可以实现数据库基本的所有字段的测试。可以在短时间内完成40个接口,超过5000个CASE的生成,生成的CASE中包括:枚举值、边界值、异常值、各种自定义组合的CASE,这个测试效果非常好,不仅发现了大量的功能问题,同时也发现了大量的版本变更过程中回归业务的问题。因为ROBOT在实现功能测试的同时也要支持自动化回归测试,当然,这是要求测试人员按照规范来写的。
因为采用的是模板定制测试数据的方式,测试人员不需要编写任何代码,只需要关注业务层面,即使webservice发生了变化,也只需要进行数据的变更就可以了,同时数据的版本管理可以很好的适应不同版本的变化情况。
为了更好的说明,我把测试环境中的数据拿出来说明一下,下面是SOAPSERVER几个CASE的返回结果,如第1个case,caseid=InsertAddress_2 从WEBSERVICE返回的值是1,可能有些人认为这个CASE就算PASS了,实际,这还远远不够,我们需要关注的是数据级别的变化,因此,我们需要另外的手段去记录所有数据库变化的情况,一个CASE,所涉及到的结果检查点就达到几十甚至上百个。
说到这里,大家应该明白了,UT ROBOT的特点是将结果检查点与CASE的回归执行时相分离的,否则在一个CASE中同时包含了上百个结果检查点的检查,得写多少脚本才能完成,维护代价得多大?
在这里,还得提到我们的数据库变化追踪技术(就是一次接口的请求带来的后台数据库的所有表所有字段的变化情况),这个技术保障了所有结果检查点的完整性。
CASESET CASEID CASETYPE VERSIONID TYPE PARATYPE RESULT
1 SAMSOAPSERVER InsertAddress_1.1_0_0 IMPORT 1 -1600
2 SAMSOAPSERVER InsertAddress_2.1_0_0 IMPORT 1 1
3 SAMSOAPSERVER InsertAddress_2.1_1_0 IMPORT 1 1
4 SAMSOAPSERVER InsertAddress_1 IMPORT 1 1
5 SAMSOAPSERVER InsertAddress_2 IMPORT 1 1 -1 -1555
6 SAMSOAPSERVER UpdateAddress_1.1_0_0 IMPORT 1 1
下面是对CASEID=InsertAccount_1的具体表的具体数据的结果,只有到了字段级别的检查才是有效的结果检查
CASESET CASEID CASETYPE VERSIONID TABLE_NAME FIELD_NAME VALUETYPE UNITE_KEY_VAL LAST_VALUE LAST_VALUE2
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT CONTACTPERSON 2 ACCOUNTNUM=114 sdf
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT CANCELDATE 3 ACCOUNTNUM=114
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT BILLINGMONTH 2 ACCOUNTNUM=114
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT CREATEDATE 3 ACCOUNTNUM=114 2008-05-29 00:00:00
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT CREDITLIMIT 1 ACCOUNTNUM=114 30
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT CREDITEXPIREDATE 2 ACCOUNTNUM=114 2008-05-29
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT CREDITCARDNUMBER 2 ACCOUNTNUM=114 2323
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT ACCOUNTNAME 2 ACCOUNTNUM=114 UTStar_SST_Rain
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT AVERAGEUSAGE 1 ACCOUNTNUM=114 20
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT ACTIVATEDATE 3 ACCOUNTNUM=114 2008-06-20 06:53:55
SAMSOAPSERVER InsertAccount_1 1 ACCOUNT BILLINGADDRESSID 1 ACCOUNTNUM=114 654
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT CREDITCARDNUMBER 2 ACCOUNTNUM=109 2323
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT CREDITLIMIT 1 ACCOUNTNUM=109 30
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT CREDITEXPIREDATE 2 ACCOUNTNUM=109 2008-05-29
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT ACCOUNTNAME 2 ACCOUNTNUM=109 UTStar_SST_Rain
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT CREATEDATE 3 ACCOUNTNUM=109 2008-05-29 00:00:00
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT AVERAGEUSAGE 1 ACCOUNTNUM=109 20
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT BILLINGMONTH 2 ACCOUNTNUM=109
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT BILLINGADDRESSID 1 ACCOUNTNUM=109 642
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT ACTIVATEDATE 3 ACCOUNTNUM=109 2008-06-20 04:58:19
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT CONTACTPERSON 2 ACCOUNTNUM=109 sdf
SAMSOAPSERVER InsertAccount_1 2 ACCOUNT CANCELDATE 3 ACCOUNTNUM=109

