
-
Linux 定时关机设置-sybase和web
2011-06-01 16:59:45
sybase
1.在/usr/local/目录下创建shutdown_sybase.sh文件,内容为:
#!/bin/bash##shutdown_sybase##先关闭sybase服务,等10分钟后关机。su - sybase -c'isql -Szdsoft -Usa -P123456'<<EOFshutdown SYB_BACKUPgoshutdown with nowaitgoexitEOF/sbin/shutdown -h10注意赋权。
2.执行命令:crontab -u root -e,编辑以下内容后保存退出。
0023* *0,4/bin/sh /usr/local/shutdown_sybase.shweb
只需执行命令:crontab -u root -e,编辑以下内容后保存退出。
0023* *0,4/sbin/shutdown -h now -
Linux 定时关机和自启动设置-oracle服务器
2011-05-31 14:09:41
-
[转]LR录制Oracle协议
2011-04-11 16:17:39
参考:http://www.51testing.com/?uid-14711-action-viewspace-itemid-111678
在用Loadrunner进行oracle数据库压力测试的时候,可以选择oracle 2tier协议进行录制。
(一)如果选择录制脚本的话
1、vugen会生成以下这些跟其他协议不同的文件
vdf.h
作用:定义各种变量
print.inl
作用:打印表格使用的函数。录制脚本时才有用,写脚本的话没有用
pre_cci.c
作用:整个录制脚本的程序全部写在这里,可以在这里查看完整的函数过程
2、录制脚本的好处需要的东西什么都有了。只要找到要执行的sql。然后将其中的sqltext部分参数化掉就可以了。
select时生成的几个表格不错。可以在上面完成参数的保存和将搜索的结果保存成dat文件。用起来还是比较直观的
3、录制脚本不好的地方
使用plsql或者toad这样的工具录制出来的脚本有很多的操作就是测试中不需要的。对于不了解lr脚本的用户来说这些东西会造成一些麻烦。了解的话把这些不需要的语句都去掉就行了。
(二)如果选择自己写脚本的话
需要用到以下这些语句
#include "lrd.h"
//定义各种变量。录制生成的脚本中,这些变量的定义在vdf.h中。
static LRD_INIT_INFO InitInfo = {LRD_INIT_INFO_EYECAT};
static LRD_DEFAULT_DB_VERSION DBTypeVersion[] =
{
{LRD_DBTYPE_NONE, LRD_DBVERSION_NONE}
};Action()
{
//变量定义
static void FAR * OraEnv1;
static void FAR * OraSvc1;
static void FAR * OraSes1;static void * OraDef12;
static void * OraDef13;
static void * OraDef14;static unsigned long uliRowsProcessed;
static unsigned long uliFetchedRows;
//LRD_VAR_DESC数据结构声明是很重要的,他是用来存储sql结果数据集的结构体
//第一个参数,头文件中就是这么写的
//第二个参数,设置结果集中最大行数,在lrd_ora8_fetch中的第二个参数如果大于该值,则会报错。
//第三个参数,设置结果集中每一行的最大长度,如果获得的查询结果比定义的长,运行时就会报错,提示列被截断
//最后一个参数是查询结果的类型,可以再帮助中的索引输入data types, database,列出的表格中是各种变量类型的名称
//常用的数据类型有DT_VARCHAR, DT_DECIMAL, DT_DATETIME, DT_SF, DT_SZ, DT_NUMERIC
static LRD_VAR_DESC NAME_D13 =
{"LVD", 15, 25, 0, {1, 1, 0}, DT_VARCHAR};
static LRD_VAR_DESC VAL2_D1 =
{"LVD", 15, 25, 0, {1, 1, 0}, DT_NUMERIC};
static LRD_VAR_DESC VAL1_D1 =
{"LVD", 15, 25, 0, {1, 1, 0}, DT_VARCHAR};//初始化数据库部分
lrd_init(&InitInfo, DBTypeVersion);
lrd_initialize_db(LRD_DBTYPE_ORACLE, 2, 0);
lrd_env_init(LRD_DBTYPE_ORACLE, &OraEnv1, 0, 0);
lrd_ora8_handle_alloc(OraEnv1, SERVER, &OraSrv1, 0);
lrd_ora8_handle_alloc(OraEnv1, SVCCTX, &OraSvc1, 0);
lrd_ora8_handle_alloc(OraEnv1, SESSION, &OraSes1, 0);//连接数据库
lrd_server_attach(OraSrv1, "1.155", 5, 0, 0);
lrd_ora8_attr_set_from_handle(OraSvc1, SERVER, OraSrv1, 0, 0);
//设定数据库密码
lrd_ora8_attr_set(OraSes1, USERNAME, "im", -1, 0);
lrd_ora8_attr_set(OraSes1, PASSWORD, lr_decrypt("4a90de5201be6597554e"), -1, 0);
//初始化连接session
lrd_ora8_attr_set_from_handle(OraSvc1, SESSION, OraSes1, 0, 0);
//开始执行事务
lrd_session_begin(OraSvc1, OraSes1, 1, 0, 0);
lrd_ora8_handle_alloc(OraEnv1, STMT, &OraStm7, 0);
//提交sql
lrd_ora8_stmt(OraStm7, "select userid, username, gender, name from userinfo where userid = 1", 1, 0, 0);
//执行sql
//第三个参数,执行次数
//第四个参数,跳过记录数
//第五个参数,返回执行影响的行数
//第九个参数,设置执行模式,0是默认值执行(不提交),16不执行,32代表执行且自动提交
//第十个参数,设置警告级别,0是默认值,代表错误,1代表警告
lrd_ora8_exec(OraSvc1, OraStm7, 1, 0, &uliRowsProcessed, 0, 0, 0, 32, 1);//列绑定,如果不进行列绑定,lrd_ord8_fetch 将不能用。
lrd_ora8_bind_col(OraStm7, &OraDef9, 1, &USERID_D10, 0, 0);
lrd_ora8_bind_col(OraStm7, &OraDef10, 2, &USERNAME_D11, 0, 0);
lrd_ora8_bind_col(OraStm7, &OraDef11, 3, &GENDER_D12, 0, 0);
lrd_ora8_bind_col(OraStm7, &OraDef12, 4, &NAME_D13, 0, 0);
//设置列属性
lrd_ora8_attr_set(OraDef10, CHARSET_FORM, "1", -1, 0);
lrd_ora8_attr_set(OraDef12, CHARSET_FORM, "1", -1, 0);//获取结果集
//第二参数,如果是0返回最后一行,如果是负数则返回全部结果集,如果是整数则返回该数目的结果集行数(该整数小于结果集中定义的行数)
//第三个参数,是控制RrintRow返回的结果集数。
//第四个参数,返回查询结果集行数
//第五个参数,是回调函数,用于打印返回的结果集
lrd_ora8_fetch(OraStm7, 0, 15, &uliFetchedRows, PrintRow8, 0, 0, 0);//释放连接
lrd_handle_free(&OraStm7, 0);//关闭连接session
lrd_session_end(OraSvc1, OraSes1, 0, 0);
//释放数据库资源
lrd_server_detach(OraSrv1, 0, 0);
//释放环境资源
lrd_handle_free(&OraEnv1, 0);
return 0;
}(三)Oracle中常用函数的用法
lrd_ora8_exec(OraSvc1, OraStm7, 3, 0, &uliRowsProcessed, 0, 0, 0, 32, 1);
//将返回结果中的某个单元格中的传入参数供使用,它的使用方式类似注册函数,需要在fetch前调用,fetch后才能看到结果,行和列都从1开始。这里返回第4列、第一行的值
lrd_ora8_save_col(OraStm7, 4, 1, 0, "value");
lrd_ora8_fetch(OraStm7, 0, 15, &uliFetchedRows, PrintRow8, 0, 0, 0);
lr_output_message("value is %s", lr_eval_string("{value}"));
-------------------------------------------------------//这里的倒数第二个参数如果设置为0,代表光执行不提交事务,那么我们可以配合使用lrd_ora8_commit提交事务
lrd_ora8_exec(OraSvc1, OraStm7, 3, 0, &uliRowsProcessed, 0, 0, 0, 0, 1);lrd_ora8_commit(OraSvc1, 0, 0);
-------------------------------------------------------
//要查看返回的结果集,必须设置log属性为extended log 且勾选data returened by server时,才能看到结果
lrd_ora8_print(OraStm7, PrintRow8);-------------------------------------------------------
//rowid这个函数不是随便用的,只有在进行了insert、update后才可以用,普通使用select查询后使用lrd_ora8_save_last_rowid是无效的
lrd_ora8_save_last_rowid(OraStm7, "rowid");
lr_output_message("rowid is %s", lr_eval_string("{rowid}"));-------------------------------------------------------
//变量绑定操作,如果绑定了多个变量,那么在调用exec的时候也需要指定执行多次,据说采用这种方式进行参数化的效率比直接sql进行参数化的效率高
lrd_ora8_stmt(OraStm7, "insert into testtable values(:V2, :V1)", 1, 0, 0);//变量绑定
lrd_assign(&VAL1_D1, "abc", "", 0, 0);
lrd_assign(&VAL1_D1, "def", "", 1, 0);
lrd_assign(&VAL1_D1, "ghi", "", 2, 0);
lrd_assign(&VAL2_D1, "123", "", 0, 0);
lrd_assign(&VAL2_D1, "456", "", 1, 0);
lrd_assign(&VAL2_D1, "789", "", 2, 0);
//绑定变量操作符
lrd_ora8_bind_placeholder(OraStm7, &OraDef13, "V1", &VAL1_D1, 0, 0, 0);
lrd_ora8_bind_placeholder(OraStm7, &OraDef14, "V2", &VAL2_D1, 0, 0, 0);
//由于变量绑定了3条记录,那么在执行的时候也需要执行三次
lrd_ora8_exec(OraSvc1, OraStm7, 3, 0, &uliRowsProcessed, 0, 0, 0, 32, 1); -
sar/iostat/vmstat
2011-01-13 14:50:52
安装过程见http://www.51testing.com/?uid-188107-action-viewspace-itemid-225762
sar:既能收集系统CPU、硬盘网络设备等动态数据,更能查看二进制数据文件等。
用法:
sar [参数选项] t [n] [-o file] (t为采样间隔秒,必须有,n为采样次数,可选,默认值1)
参数说明:
-A 显示所有历史数据,通过读取/var/log/sar 目录下的所有文件,并把它们分门别类的显示出来;
-b 通过设备的I/O中断读取设置的吞吐率;
-B 报告内存或虚拟内存交换统计;
-c 报告每秒创建的进程数;
-d 报告物理块设备(存储设备)的写入、读取之类的信息,如果直观一点,可以和p参数共同使用,-dp
-f 从一个二进制的数据文件中读取内容,比如 sar -f filename;
-n 分析网络设备状态的统计,后面可以接的参数有DEV、EDEV、NFS、NFSD、SOCK等。比如-n DEV
-o 把统计信息以二进制格式写入一个文件,比如 -o filename;
-u 报告CPU利用率的参数;
-P 报告每个处理器应用统计,用于多处理器机器,并且启用SMP内核才有效;
-p 显示友好设备名字,以方便查看,也可以和-d 和-n 参数结合使用;-r 内存和交换区占用统计;
-t 这个选项对从文件读取数据有用,如果没有这个参数,会以本地时间为标准读出;
-v 报告inode, 文件或其它内核表的资源占用信息;
-w 报告系统交换活动的信息; 每少交换数据的个数;
-W 报告系统交换活动吞吐信息;
-x 用于监视进程的,在其后要指定进程的PID值;
-X 用于监视进程的,但指定的应该是一个子进程ID;CPU利用率:
[root@B1943 ~]# sar -u 1 5
Linux 2.6.18-53.el5 (B1943) 2011年01月13日14时58分08秒 CPU %user %nice %system %iowait %steal %idle
14时58分09秒 all 0.00 0.00 0.00 0.00 0.00 100.00
14时58分10秒 all 0.50 0.00 0.00 0.00 0.00 99.50
14时58分11秒 all 0.00 0.00 0.00 0.00 0.00 100.00
14时58分12秒 all 0.00 0.00 0.00 0.00 0.00 100.00
14时58分13秒 all 0.00 0.00 0.00 0.00 0.00 100.00
Average: all 0.10 0.00 0.00 0.00 0.00 99.90%usr cpu用户模式下时间(百分比)
%sys cpu系统模式下时间(百分比)%nice 表示CPU在用户层优先级的百分比,0表示正常;
%iowait cpu等待输入/输出完成(时间百分比)
%idle cpu空闲时间(百分比)将动态信息写入文件中:
[root@localhost ~]# sar -u 1 5 > sar000.txt
[root@localhost ~]# cat sar000.txt也可以输出到一个二进制的文件中,然后通过sar来查看;
[root@localhost ~]# sar -u 1 5 -o sar002
[root@localhost ~]# sar -f sar002网络设备的吞吐情况:
[root@B1943 ~]# sar -n DEV 2 5 |grep eth0
15时04分12秒 eth0 6.97 1.00 0.54 0.07 0.00 0.00 0.00
15时04分14秒 eth0 7.50 1.50 0.71 0.16 0.00 0.00 0.00
15时04分16秒 eth0 6.00 1.50 0.43 0.16 0.00 0.00 0.00
15时04分18秒 eth0 7.50 1.50 0.58 0.16 0.00 0.00 0.00
15时04分20秒 eth0 7.50 1.50 0.50 0.16 0.00 0.00 0.00
Average: eth0 7.09 1.40 0.55 0.14 0.00 0.00 0.00IFACE:设备名;
rxpck/s:每秒收到的包;
rxbyt/s:每秒收到的所有包的体积;
txbyt/s:每秒传输的所有包的体积;
rxcmp/s:每秒收到数据切割压缩的包总数;
txcmp/s:每秒传输的数据切割压缩的包的总数;
rxmcst/s:每秒收到的多点传送的包。
iostat:用法:
iostat [ -c | -d ] [ -k ] [ -t ] [ -V ] [ -x [ device ] ] [ interval [ count ] ] > outputfile
其中,-c为汇报CPU的使用情况;-d为汇报磁盘的使用情况;-k表示每秒按kilobytes字节显示数据;-x可获得更多信息;interval指每次统计间隔的时间;count指按照这个时间间隔统计的次数。
[root@B1943 ~]# iostat -d -k -x
Linux 2.6.18-53.el5 (B1943) 2011年01月13日Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.02 4.10 0.11 1.77 2.11 23.45 27.24 0.00 1.15 0.63 0.12rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);
wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
rsec/s:每秒读取的扇区数;
wsec/:每秒写入的扇区数。
r/s:The number of read requests that were issued to the device per second;
w/s:The number of write requests that were issued to the device per second;
await:每一个IO请求的处理的平均时间(单位是微秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
%util:在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,
所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满
负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁
盘使用未必就到了瓶颈)。
[root@B1943 ~]# iostat -d -k
Linux 2.6.18-53.el5 (B1943) 2011年01月13日Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 1.88 2.11 23.45 1122861 12458568tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;
kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
iostat -cdx 1 >outfile
cat outfile
vmstat: 也可以输出到文件vmstat > outputfile
[root@B1943 ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 4812568 199472 2125952 0 0 1 12 18 10 0 0 100 0 0
r: The number of processes waiting for run time.
b: The number of processes in uninterruptable sleep.
w: The number of processes swapped out but otherwise runnable.Memory
swpd: the amount of virtual memory used (kB).
free: the amount of idle memory (kB).
buff: the amount of memory used as buffers (kB).Swap
si: Amount of memory swapped in from disk (kB/s).
so: Amount of memory swapped to disk (kB/s).IO
bi: Blocks sent to a block device (blocks/s).
bo: Blocks received from a block device (blocks/s).System
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.CPU
These are percentages of total CPU time.
us: user time
sy: system time
id: idle time -
文件句柄数Too many open files
2011-01-07 16:32:35
问题描述:java.io.IOException: Too many open files
[root@B1943 ~]# ulimit -a(查看文件句柄数)
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
max nice (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 71680
max locked memory (kbytes, -l) 32
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
max rt priority (-r) 0
stack size (kbytes, -s) 10240
cpu time (seconds, -t) unlimited
max user processes (-u) 71680
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited[root@B1943 ~]# ulimit -n
1024ulimit应该是用户的限制,如果太小则修改大小:ulimit -n 2048
如果要重启后仍生效,则可修改/etc/security/limits.conf,后面加上:* - nofile 2048
(此时type用“-”,表示hard和soft同时设定。domain设置为星号代表全局,也可以针对不同的用户做出不同的限制)/proc/sys/fs/file-max应该是系统级的限制
[root@B1943 ~]# cat /proc/sys/fs/file-max(查看)
8192
[root@B1943 ~]# echo 65536 > /proc/sys/fs/file-max(修改)如果要重启后仍生效,则可修改/etc/sysctl.conf,加上:fs.file-max = 65536
另外还有一个,/proc/sys/fs/file-nr
只读,可以看到整个系统目前使用的文件句柄数量
-
oracle中删除归档日志
2010-12-31 15:31:03
查看数据库是否是归档模式
SELECT log_mode FROM v$database
查看归档日志信息
select * from v$archived_log
status:D已删除,A正常查看归档日志使用大小
select sum(a.BLOCK_SIZE*a.BLOCKS)/1024/1024 from v$archived_log a where a.DELETED='NO'
正常来说,归档日志文件大小差不多数多少个归档,乘以每个的大小也行。删除归档日志并回收空间方法
controlfile中记录着每个archivelog的相关信息,我们在OS下把这些物理文件删掉后,controlfile中仍然记录着这些archivelog的信息,也就是oracle并不知道这些文件已经不存在了!删除归档日志时,操作如下:
1.进入rman
[root@linux150 ~]# su - oracle
[oracle@linux150 ~]$ rman target/2.DELETE ARCHIVELOG ALL COMPLETED BEFORE 'SYSDATE-7';
说明:SYSDATA-7,表明当前系统时间7天前,before关键字表示在7天前的归档日志。3.list archivelog all;(查看归档日志,检验下就发现已删除了)
或者
1.先在linux下删除物理日志文件
find /u02/oradata/center/archive -mtime +7 -name '*.dbf' -exec rm {} \;
2.再进入rman后,执行:
crosscheck archivelog all;
delete expired archivelog all;(确认时键入"yes")
目的:校验归档日志,然后删除已不存在的归档日志。3.list archivelog all;(查看归档日志,检验下就发现已删除了)
4.退出rman:exit
-
JDK自带工具jps,jstat,jmap,jconsole
2010-12-29 11:21:30
jps
与ps命令类似,用来显示本地的java进程,查看本地运行着几个java应用,并显示进程号。
[root@B1943 ~]# jps(只显示进程号)
23813 Jps
710 Bootstrap
792 Bootstrap[root@B1943 ~]# jps -v(显示jvm参数)
23852 Jps -Denv.class.path=.:/usr/jdk1.6.0_21/lib/dt.jar:/usr/jdk1.6.0_21/lib/tools.jar -Dapplication.home=/usr/jdk1.6.0_21 -Xms8m
710 Bootstrap -Xms2048m -Xmx2048m -XX:NewRatio=2 -XX:PermSize=256M -XX:MaxPermSize=512M -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.util.logging.config.file=/root/zhusj/apache-tomcat-6.0.18_1/conf/logging.properties -Dcom.sun.management.jmxremote.port=8799 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.endorsed.dirs=/root/zhusj/apache-tomcat-6.0.18_1/endorsed -Dcatalina.base=/root/zhusj/apache-tomcat-6.0.18_1 -Dcatalina.home=/root/zhusj/apache-tomcat-6.0.18_1 -Djava.io.tmpdir=/root/zhusj/apache-tomcat-6.0.18_1/tempjstat
很强大的监视jvm内存工具,可用来查看堆内各个部分的使用量,以及加载类的数量。使用时,需指定java进程号。一般使用 -gcutil 查看gc情况。
[root@B1943 ~]# jstat -class 710(显示加载class的数量,及所占空间等信息)
Loaded Bytes Unloaded Bytes Time
11242 24450.0 41 65.8 30.25jstat -compiler pid:显示VM实时编译的数量等信息。
jstat -gc pid:可以显示gc的信息,查看gc的次数及时间。其中最后五项,分别是young gc的次数,young gc的时间,full gc的次数,full gc的时间,gc的总时间。
jstat -gccapacity pid:可以显示VM内存中三代(young,old,perm)对象的使用和占用大小,如:PGCMN显示的是最小perm的内存使用量,PGCMX显示的是perm的内存最大使用量,PGC是当前新生成的perm内存占用量,PC是但前perm内存占用量。S0 — Heap上的 Survivor space 0 区已使用空间的百分比
S1 — Heap上的 Survivor space 1 区已使用空间的百分比
E — Heap上的 Eden space 区已使用空间的百分比
O — Heap上的 Old space 区已使用空间的百分比
P — Perm space 区已使用空间的百分比
YGC — 从应用程序启动到采样时发生 Young GC 的次数
YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒)
FGC — 从应用程序启动到采样时发生 Full GC 的次数
FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒)
GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒)[root@B1943 ~]# jstat -gcutil 710(gc的统计信息)
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 15.69 80.03 38.70 33.30 123 21.421 1 0.817 22.238
[root@B1943 ~]# jstat -gcutil 710 1000 5(每1000毫秒打印一次,共5次)jmap
可以输出某个java进程内存内对象的情况,甚至可以将VM 中的heap,以二进制输出成文本。
[root@B1943 ~]# jmap -histo 710 >mem.txt(可使用文本对比工具对比出GC回收了哪些对象)
该文件中内容如:
num #instances #bytes class name
----------------------------------------------
4: 1202692 67350752 java.io.ObjectStreamClass$WeakClassKey[root@B1943 ~]# jmap -dump:format=b,file=mem.bin 710(将该进程heap输出到mem.bin文件中,使用二进制形式。该文件可供其他分析工具使用,如eclipse memory analyser)
注:jmap使用的时候jvm是处在假死状态的,只能在服务瘫痪的时候为了解决问题来使用,否则会造成服务中断jconsole
一个java GUI监视工具,可以以图表化的形式显示各种数据。并可通过远程连接监视远程的服务器VM,略。
-
【转】Eclipse Memory Analyzer tool(MAT)分析内存泄露2
2010-12-24 11:16:13
出处:http://www.blogjava.net/rosen/archive/2010/06/13/323522.html
前言
在使用Memory Analyzer tool(MAT)分析内存泄漏(一)中,我介绍了内存泄漏的前因后果。在本文中,将介绍MAT如何根据heap dump分析泄漏根源。由于测试范例可能过于简单,很容易找出问题,但我期待借此举一反三。
一开始不得不说说ClassLoader,本质上,它的工作就是把磁盘上的类文件读入内存,然后调用java.lang.ClassLoader.defineClass方法告诉系统把内存镜像处理成合法的字节码。Java提供了抽象类ClassLoader,所有用户自定义类装载器都实例化自ClassLoader的子类。system class loader在没有指定装载器的情况下默认装载用户类,在Sun Java 1.5中既sun.misc.Launcher$AppClassLoader。更详细的内容请参看下面的资料。
准备heap dump
请看下面的Pilot类,没啥特殊的。/**
* Pilot class
* @author rosen jiang
*/
package org.rosenjiang.bo;
public class Pilot{
String name;
int age;
public Pilot(String a, int b){
name = a;
age = b;
}
}
然后再看OOMHeapTest类,它是如何撑破heap dump的。/**
* OOMHeapTest class
* @author rosen jiang
*/
package org.rosenjiang.test;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import org.rosenjiang.bo.Pilot;
public class OOMHeapTest {
public static void main(String[] args){
oom();
}
private static void oom(){
Map<String, Pilot> map = new HashMap<String, Pilot>();
Object[] array = new Object[1000000];
for(int i=0; i<1000000; i++){
String d = new Date().toString();
Pilot p = new Pilot(d, i);
map.put(i+"rosen jiang", p);
array[i]=p;
}
}
}
是的,上面构造了很多的Pilot类实例,向数组和map中放。由于是Strong Ref,GC自然不会回收这些对象,一直放在heap中直到溢出。当然在运行前,先要在Eclipse中配置VM参数-XX:+HeapDumpOnOutOfMemoryError。好了,一会儿功夫内存溢出,控制台打出如下信息。java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid3600.hprof
Heap dump file created [78233961 bytes in 1.995 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
java_pid3600.hprof既是heap dump,可以在OOMHeapTest类所在的工程根目录下找到。
MAT安装
话分两头说,有了heap dump还得安装MAT。可以在http://www.eclipse.org/mat/downloads.php选择合适的方式安装。安装完成后切换到Memory Analyzer视图。在Eclipse的左上角有Open Heap Dump按钮,按照刚才说的路径找到java_pid3600.hprof文件并打开。解析hprof文件会花些时间,然后会弹出向导,直接Finish即可。稍后会看到下图所示的界面。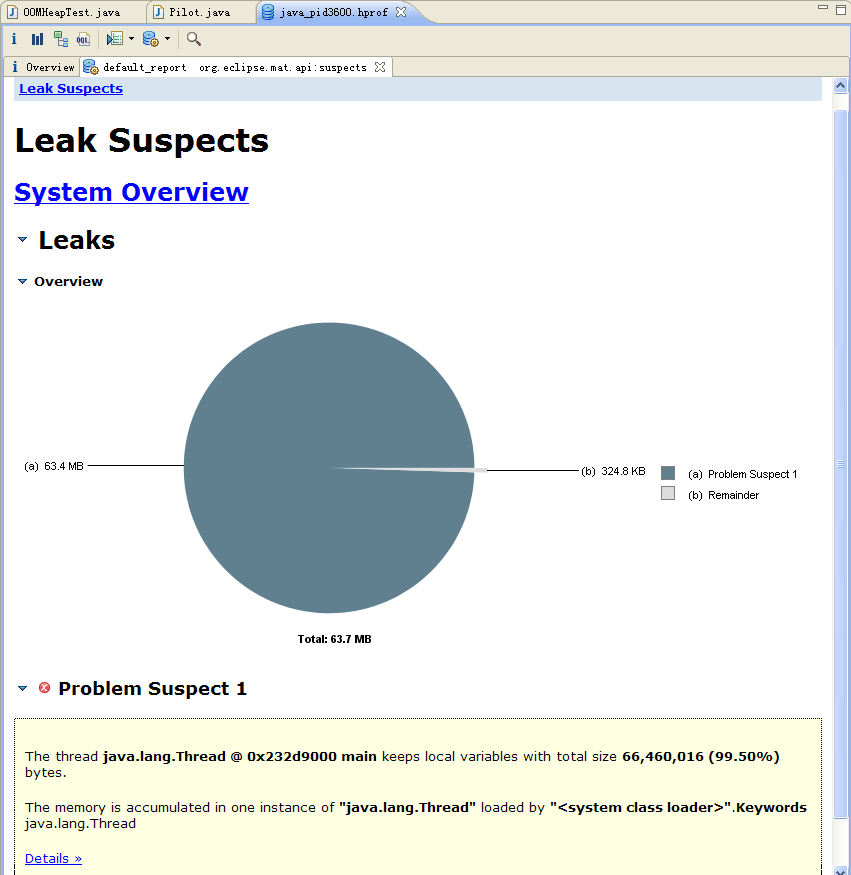
MAT工具分析了heap dump后在界面上非常直观的展示了一个饼图,该图深色区域被怀疑有内存泄漏,可以发现整个heap才64M内存,深色区域就占了99.5%。接下来是一个简短的描述,告诉我们main线程占用了大量内存,并且明确指出system class loader加载的"java.lang.Thread"实例有内存聚集,并建议用关键字"java.lang.Thread"进行检查。所以,MAT通过简单的两句话就说明了问题所在,就算使用者没什么处理内存问题的经验。在下面还有一个"Details"链接,在点开之前不妨考虑一个问题:为何对象实例会聚集在内存中,为何存活(而未被GC)?是的——Strong Ref,那么再走近一些吧。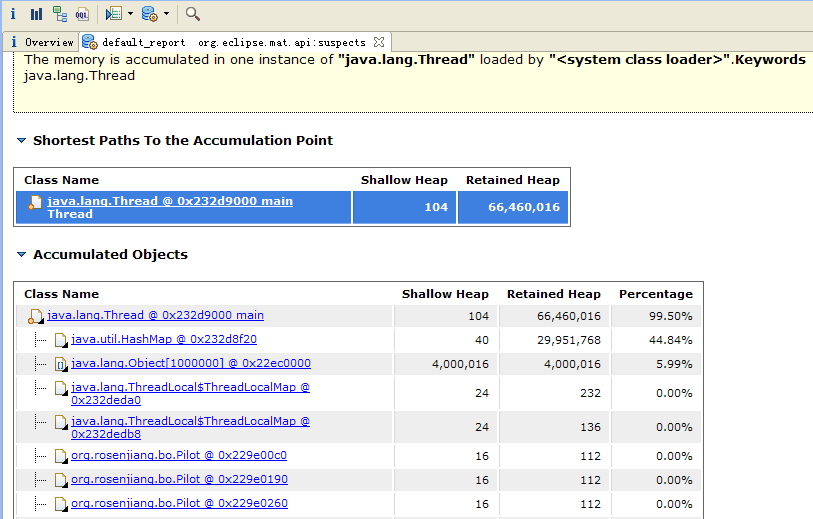
点击了"Details"链接之后,除了在上一页看到的描述外,还有Shortest Paths To the Accumulation Point和Accumulated Objects部分,这里说明了从GC root到聚集点的最短路径,以及完整的reference chain。观察Accumulated Objects部分,java.util.HashMap和java.lang.Object[1000000]实例的retained heap(size)最大,在上一篇文章中我们知道retained heap代表从该类实例沿着reference chain往下所能收集到的其他类实例的shallow heap(size)总和,所以明显类实例都聚集在HashMap和Object数组中了。这里我们发现一个有趣的现象,既Object数组的shallow heap和retained heap竟然一样,通过Shallow and retained sizes一文可知,数组的shallow heap和一般对象(非数组)不同,依赖于数组的长度和里面的元素的类型,对数组求shallow heap,也就是求数组集合内所有对象的shallow heap之和。好,再来看org.rosenjiang.bo.Pilot对象实例的shallow heap为何是16,因为对象头是8字节,成员变量int是4字节、String引用是4字节,故总共16字节。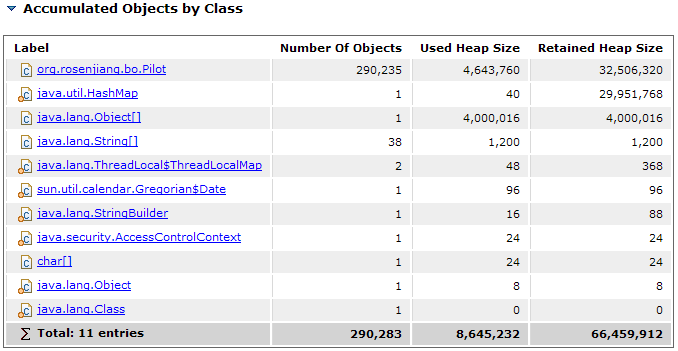
接着往下看,来到了Accumulated Objects by Class区域,顾名思义,这里能找到被聚集的对象实例的类名。org.rosenjiang.bo.Pilot类上头条了,被实例化了290,325次,再返回去看程序,我承认是故意这么干的。还有很多有用的报告可用来协助分析问题,只是本文中的例子太简单,也用不上。以后如有用到,一定撰文详细叙述。
又是perm gen
我们在上一篇文章中知道,perm gen是个异类,里面存储了类和方法数据(与class loader有关)以及interned strings(字符串驻留)。在heap dump中没有包含太多的perm gen信息。那么我们就用这些少量的信息来解决问题吧。
看下面的代码,利用interned strings把perm gen撑破了。/**
* OOMPermTest class
* @author rosen jiang
*/
package org.rosenjiang.test;
public class OOMPermTest {
public static void main(String[] args){
oom();
}
private static void oom(){
Object[] array = new Object[10000000];
for(int i=0; i<10000000; i++){
String d = String.valueOf(i).intern();
array[i]=d;
}
}
}
控制台打印如下的信息,然后把java_pid1824.hprof文件导入到MAT。其实在MAT里,看到的状况应该和“OutOfMemoryError: Java heap space”差不多(用了数组),因为heap dump并没有包含interned strings方面的任何信息。只是在这里需要强调,使用intern()方法的时候应该多加注意。java.lang.OutOfMemoryError: PermGen space
Dumping heap to java_pid1824.hprof
Heap dump file created [121273334 bytes in 2.845 secs]
Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
倒是在思考如何把class loader撑破废了些心思。经过尝试,发现使用ASM来动态生成类才能达到目的。ASM(http://asm.objectweb.org)的主要作用是处理已编译类(compiled class),能对已编译类进行生成、转换、分析(功能之一是实现动态代理),而且它运行起来足够的快和小巧,文档也全面,实属居家必备之良品。ASM提供了core API和tree API,前者是基于事件的方式,后者是基于对象的方式,类似于XML的SAX、DOM解析,但是使用tree API性能会有损失。既然下面要用到ASM,这里不得不啰嗦下已编译类的结构,包括:
1、修饰符(例如public、private)、类名、父类名、接口和annotation部分。
2、类成员变量声明,包括每个成员的修饰符、名字、类型和annotation。
3、方法和构造函数描述,包括修饰符、名字、返回和传入参数类型,以及annotation。当然还包括这些方法或构造函数的具体Java字节码。
4、常量池(constant pool)部分,constant pool是一个包含类中出现的数字、字符串、类型常量的数组。
已编译类和原来的类源码区别在于,已编译类只包含类本身,内部类不会在已编译类中出现,而是生成另外一个已编译类文件;其二,已编译类中没有注释;其三,已编译类没有package和import部分。
这里还得说说已编译类对Java类型的描述,对于原始类型由单个大写字母表示,Z代表boolean、C代表char、B代表byte、S代表short、I代表int、F代表float、J代表long、D代表double;而对类类型的描述使用内部名(internal name)外加前缀L和后面的分号共同表示来表示,所谓内部名就是带全包路径的表示法,例如String的内部名是java/lang/String;对于数组类型,使用单方括号加上数据元素类型的方式描述。最后对于方法的描述,用圆括号来表示,如果返回是void用V表示,具体参考下图。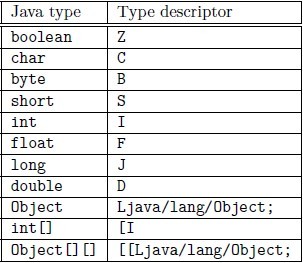
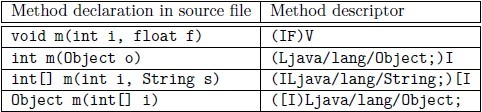
下面的代码中会使用ASM core API,注意接口ClassVisitor是核心,FieldVisitor、MethodVisitor都是辅助接口。ClassVisitor应该按照这样的方式来调用:visit visitSource? visitOuterClass? ( visitAnnotation | visitAttribute )*( visitInnerClass | visitField | visitMethod )* visitEnd。就是说visit方法必须首先调用,再调用最多一次的visitSource,再调用最多一次的visitOuterClass方法,接下来再多次调用visitAnnotation和visitAttribute方法,最后是多次调用visitInnerClass、visitField和visitMethod方法。调用完后再调用visitEnd方法作为结尾。
注意ClassWriter类,该类实现了ClassVisitor接口,通过toByteArray方法可以把已编译类直接构建成二进制形式。由于我们要动态生成子类,所以这里只对ClassWriter感兴趣。首先是抽象类原型:/**
* @author rosen jiang
* MyAbsClass class
*/
package org.rosenjiang.test;
public abstract class MyAbsClass {
int LESS = -1;
int EQUAL = 0;
int GREATER = 1;
abstract int absTo(Object o);
}
其次是自定义类加载器,实在没法,ClassLoader的defineClass方法都是protected的,要加载字节数组形式(因为toByteArray了)的类只有继承一下自己再实现。/**
* @author rosen jiang
* MyClassLoader class
*/
package org.rosenjiang.test;
public class MyClassLoader extends ClassLoader {
public Class defineClass(String name, byte[] b) {
return defineClass(name, b, 0, b.length);
}
}
最后是测试类。/**
* @author rosen jiang
* OOMPermTest class
*/
package org.rosenjiang.test;
import java.util.ArrayList;
import java.util.List;
import org.objectweb.asm.ClassWriter;
import org.objectweb.asm.Opcodes;
public class OOMPermTest {
public static void main(String[] args) {
OOMPermTest o = new OOMPermTest();
o.oom();
}
private void oom() {
try {
ClassWriter cw = new ClassWriter(0);
cw.visit(Opcodes.V1_5, Opcodes.ACC_PUBLIC + Opcodes.ACC_ABSTRACT,
"org/rosenjiang/test/MyAbsClass", null, "java/lang/Object",
new String[] {});
cw.visitField(Opcodes.ACC_PUBLIC + Opcodes.ACC_FINAL + Opcodes.ACC_STATIC, "LESS", "I",
null, new Integer(-1)).visitEnd();
cw.visitField(Opcodes.ACC_PUBLIC + Opcodes.ACC_FINAL + Opcodes.ACC_STATIC, "EQUAL", "I",
null, new Integer(0)).visitEnd();
cw.visitField(Opcodes.ACC_PUBLIC + Opcodes.ACC_FINAL + Opcodes.ACC_STATIC, "GREATER", "I",
null, new Integer(1)).visitEnd();
cw.visitMethod(Opcodes.ACC_PUBLIC + Opcodes.ACC_ABSTRACT, "absTo",
"(Ljava/lang/Object;)I", null, null).visitEnd();
cw.visitEnd();
byte[] b = cw.toByteArray();
List<ClassLoader> classLoaders = new ArrayList<ClassLoader>();
while (true) {
MyClassLoader classLoader = new MyClassLoader();
classLoader.defineClass("org.rosenjiang.test.MyAbsClass", b);
classLoaders.add(classLoader);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
不一会儿,控制台就报错了。java.lang.OutOfMemoryError: PermGen space
Dumping heap to java_pid3023.hprof
Heap dump file created [92593641 bytes in 2.405 secs]
Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
打开java_pid3023.hprof文件,注意看下图的Classes: 88.1k和Class Loader: 87.7k部分,从这点可看出class loader加载了大量的类。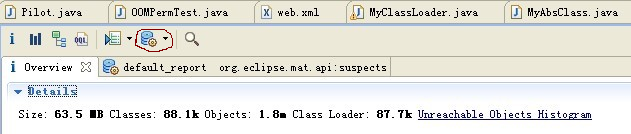
更进一步分析,点击上图中红框线圈起来的按钮,选择Java Basics——Class Loader Explorer功能。打开后能看到下图所示的界面,第一列是class loader名字;第二列是class loader已定义类(defined classes)的个数,这里要说一下已定义类和已加载类(loaded classes)了,当需要加载类的时候,相应的class loader会首先把请求委派给父class loader,只有当父class loader加载失败后,该class loader才会自己定义并加载类,这就是Java自己的“双亲委派加载链”结构;第三列是class loader所加载的类的实例数目。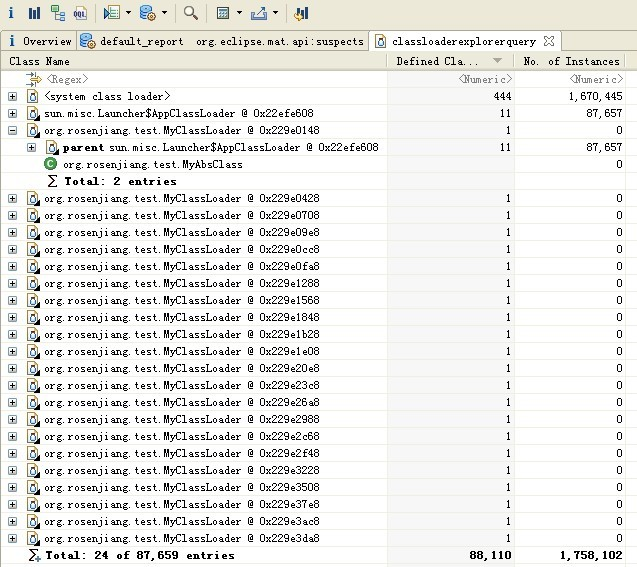
在Class Loader Explorer这里,能发现class loader是否加载了过多的类。另外,还有Duplicate Classes功能,也能协助分析重复加载的类,在此就不再截图了,可以肯定的是MyAbsClass被重复加载了N多次。
最后
其实MAT工具非常的强大,上面故弄玄虚的范例代码根本用不上MAT的其他分析功能,所以就不再描述了。其实对于OOM不只我列举的两种溢出错误,还有多种其他错误,但我想说的是,对于perm gen,如果实在找不出问题所在,建议使用JVM的-verbose参数,该参数会在后台打印出日志,可以用来查看哪个class loader加载了什么类,例:“[Loaded org.rosenjiang.test.MyAbsClass from org.rosenjiang.test.MyClassLoader]”。
全文完。
参考资料
memoryanalyzer Blog
java类加载器体系结构
ClassLoader
请注意!引用、转贴本文应注明原作者:Rosen Jiang 以及出处: http://www.blogjava.net/rosen -
【转】Eclipse Memory Analyzer tool(MAT)分析内存泄露1
2010-12-24 10:58:24
出处
http://www.blogjava.net/rosen/archive/2010/05/21/321575.html
前言
在平时工作过程中,有时会遇到OutOfMemoryError,我们知道遇到Error一般表明程序存在着严重问题,可能是灾难性的。所以找出是什么原因造成OutOfMemoryError非常重要。现在向大家引荐Eclipse Memory Analyzer tool(MAT),来化解我们遇到的难题。如未说明,本文均使用Java 5.0 on Windows XP SP3环境。
为什么用MAT
之前的观点,我认为使用实时profiling/monitoring之类的工具,用一种非常实时的方式来分析哪里存在内存泄漏是很正确的。年初使用了某profiler工具测试消息中间件中存在的内存泄漏,发现在吞吐量很高的时候profiler工具自己也无法响应,这让人很头痛。后来了解到这样的工具本身就要消耗性能,且在某些条件下还发现不了泄漏。所以,分析离线数据就非常重要了,MAT正是这样一款工具。
为何会内存溢出
我们知道JVM根据generation(代)来进行GC,根据下图所示,一共被分为young generation(年轻代)、tenured generation(老年代)、permanent generation(永久代, perm gen),perm gen(或称Non-Heap 非堆)是个异类,稍后会讲到。注意,heap空间不包括perm gen。
 绝大多数的对象都在young generation被分配,也在young generation被收回,当young generation的空间被填满,GC会进行minor collection(次回收),这次回收不涉及到heap中的其他generation,minor collection根据weak generational hypothesis(弱年代假设)来假设young generation中大量的对象都是垃圾需要回收,minor collection的过程会非常快。young generation中未被回收的对象被转移到tenured generation,然而tenured generation也会被填满,最终触发major collection(主回收),这次回收针对整个heap,由于涉及到大量对象,所以比minor collection慢得多。
绝大多数的对象都在young generation被分配,也在young generation被收回,当young generation的空间被填满,GC会进行minor collection(次回收),这次回收不涉及到heap中的其他generation,minor collection根据weak generational hypothesis(弱年代假设)来假设young generation中大量的对象都是垃圾需要回收,minor collection的过程会非常快。young generation中未被回收的对象被转移到tenured generation,然而tenured generation也会被填满,最终触发major collection(主回收),这次回收针对整个heap,由于涉及到大量对象,所以比minor collection慢得多。JVM有三种垃圾回收器,分别是throughput collector,用来做并行young generation回收,由参数-XX:+UseParallelGC启动;concurrent low pause collector,用来做tenured generation并发回收,由参数-XX:+UseConcMarkSweepGC启动;incremental low pause collector,可以认为是默认的垃圾回收器。不建议直接使用某种垃圾回收器,最好让JVM自己决断,除非自己有足够的把握。
Heap中各generation空间是如何划分的?通过JVM的-Xmx=n参数可指定最大heap空间,而
-Xms=n则是指定最小heap空间。在JVM初始化的时候,如果最小heap空间小于最大heap空间的话,如上图所示JVM会把未用到的空间标注为Virtual。除了这两个参数还有-XX:MinHeapFreeRatio=n和 -XX:MaxHeapFreeRatio=n来分别控制最大、最小的剩余空间与活动对象之比例。在32位Solaris SPARC操作系统下,默认值如下,在32位windows xp下,默认值也差不多。参数
默认值
MinHeapFreeRatio
40
MaxHeapFreeRatio
70
-Xms
3670k
-Xmx
64m
由于tenured generation的major collection较慢,所以tenured generation空间小于young generation的话,会造成频繁的major collection,影响效率。Server JVM默认的young generation和tenured generation空间比例为1:2,也就是说young generation的eden和survivor空间之和是整个heap(当然不包括perm gen)的三分之一,该比例可以通过-XX:NewRatio=n参数来控制,而Client JVM默认的-XX:NewRatio是8。至于调整young generation空间大小的NewSize=n和MaxNewSize=n参数就不讲了,请参考后面的资料。
young generation中幸存的对象被转移到tenured generation,但不幸的是concurrent collector线程在这里进行major collection,而在回收任务结束前空间被耗尽了,这时将会发生Full Collections(Full GC),整个应用程序都会停止下来直到回收完成。Full GC是高负载生产环境的噩梦……
现在来说说异类perm gen,它是JVM用来存储无法在Java语言级描述的对象,这些对象分别是类和方法数据(与class loader有关)以及interned strings(字符串驻留)。一般32位OS下perm gen默认64m,可通过参数-XX:MaxPermSize=n指定,JVM Memory Structure一文说,对于这块区域,没有更详细的文献了,神秘。
回到问题“为何会内存溢出?”。
要回答这个问题又要引出另外一个话题,既什么样的对象GC才会回收?当然是GC发现通过任何reference chain(引用链)无法访问某个对象的时候,该对象即被回收。名词GC Roots正是分析这一过程的起点,例如JVM自己确保了对象的可到达性(那么JVM就是GC Roots),所以GC Roots就是这样在内存中保持对象可到达性的,一旦不可到达,即被回收。通常GC Roots是一个在current thread(当前线程)的call stack(调用栈)上的对象(例如方法参数和局部变量),或者是线程自身或者是system class loader(系统类加载器)加载的类以及native code(本地代码)保留的活动对象。所以GC Roots是分析对象为何还存活于内存中的利器。知道了什么样的对象GC才会回收后,再来学习下对象引用都包含哪些吧。
从最强到最弱,不同的引用(可到达性)级别反映了对象的生命周期。
<!--[if !supportLists]-->l <!--[endif]-->Strong Ref(强引用):通常我们编写的代码都是Strong Ref,于此对应的是强可达性,只有去掉强可达,对象才被回收。
<!--[if !supportLists]-->l <!--[endif]-->Soft Ref(软引用):对应软可达性,只要有足够的内存,就一直保持对象,直到发现内存吃紧且没有Strong Ref时才回收对象。一般可用来实现缓存,通过java.lang.ref.SoftReference类实现。
<!--[if !supportLists]-->l <!--[endif]-->Weak Ref(弱引用):比Soft Ref更弱,当发现不存在Strong Ref时,立刻回收对象而不必等到内存吃紧的时候。通过java.lang.ref.WeakReference和java.util.WeakHashMap类实现。
<!--[if !supportLists]-->l <!--[endif]-->Phantom Ref(虚引用):根本不会在内存中保持任何对象,你只能使用Phantom Ref本身。一般用于在进入finalize()方法后进行特殊的清理过程,通过 java.lang.ref.PhantomReference实现。
有了上面的种种我相信很容易就能把heap和perm gen撑破了吧,是的利用Strong Ref,存储大量数据,直到heap撑破;利用interned strings(或者class loader加载大量的类)把perm gen撑破。
关于shallow size、retained size
Shallow size就是对象本身占用内存的大小,不包含对其他对象的引用,也就是对象头加成员变量(不是成员变量的值)的总和。在32位系统上,对象头占用8字节,int占用4字节,不管成员变量(对象或数组)是否引用了其他对象(实例)或者赋值为null它始终占用4字节。故此,对于String对象实例来说,它有三个int成员(3*4=12字节)、一个char[]成员(1*4=4字节)以及一个对象头(8字节),总共3*4 +1*4+8=24字节。根据这一原则,对String a=”rosen jiang”来说,实例a的shallow size也是24字节(很多人对此有争议,请看官甄别并留言给我)。
Retained size是该对象自己的shallow size,加上从该对象能直接或间接访问到对象的shallow size之和。换句话说,retained size是该对象被GC之后所能回收到内存的总和。为了更好的理解retained size,不妨看个例子。
把内存中的对象看成下图中的节点,并且对象和对象之间互相引用。这里有一个特殊的节点GC Roots,正解!这就是reference chain的起点。


从obj1入手,上图中蓝色节点代表仅仅只有通过obj1才能直接或间接访问的对象。因为可以通过GC Roots访问,所以左图的obj3不是蓝色节点;而在右图却是蓝色,因为它已经被包含在retained集合内。
所以对于左图,obj1的retained size是obj1、obj2、obj4的shallow size总和;右图的retained size是obj1、obj2、obj3、obj4的shallow size总和。obj2的retained size可以通过相同的方式计算。
Heap Dump
heap dump是特定时间点,java进程的内存快照。有不同的格式来存储这些数据,总的来说包含了快照被触发时java对象和类在heap中的情况。由于快照只是一瞬间的事情,所以heap dump中无法包含一个对象在何时、何地(哪个方法中)被分配这样的信息。
在不同平台和不同java版本有不同的方式获取heap dump,而MAT需要的是HPROF格式的heap dump二进制文件。想无需人工干预的话,要这样配置JVM参数:-XX:-HeapDumpOnOutOfMemoryError,当错误发生时,会自动生成heap dump,在生产环境中,只有用这种方式。如果你想自己控制什么时候生成heap dump,在Windows+JDK6环境中可利用JConsole工具,而在Linux或者Mac OS X环境下均可使用JDK5、6自带的jmap工具。当然,还可以配置JVM参数:-XX:+HeapDumpOnCtrlBreak,也就是在控制台使用Ctrl+Break键来生成heap dump。由于我是windows+JDK5,所以选择了-XX:-HeapDumpOnOutOfMemoryError这种方式,更多配置请参考MAT Wiki。
参考资料
Strong,Soft,Weak,Phantom Reference
Tuning Garbage Collection with the 5.0 Java[tm] Virtual Machine
-
Jsonsole监视tomcat
2010-12-23 14:03:25
配置
1.修改bin/catalina.sh文件
确认端口8799没被占用:netstat -a | grep -i 8799 查看端口占有情况
CATALINA_OPTS="-Dcom.sun.management.jmxremote.port=8799
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false"
2.重启tomcat后就能用jconsole监视了
可能问题:jconsole无法连接
解决:
1.Linux服务器执行hostname -i,一定要是该机器的ip地址,否则修改/etc/hosts文件;
2.修改hosts文件前确认该机器的hostname
cat /etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME=B1943(这个就是hostname)也可执行hostname(或uname -n)命令查看主机名
3.然后修改hosts文件,加上
192.168.1.62 B1943 //真实ip和主机名(有时候要放在最前面)
-
(备忘)集群部署注意点
2010-12-17 16:13:44
-
监控工具sysstat安装
2010-12-17 16:05:50
sysstat:
linux系统自带的功能全面的性能分析工具。RedHat Enterprise Linux Server 自身的发行版就带了这个工具安装包的。可以从发行光盘中的找到rpm安装包,或者从http://pagespersoorange.fr/sebastien.godard/download.html
 页面下载tar包安装。安装步骤:检查是否安装了sysstat:[root@a1_145 ~]#which iostat/usr/bin/which: no iostat in (/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/opt/sybdump/mongodb-linux-x86_64-1.6.2/bin:/root/bin)说明没有安装。/usr/bin/iostat说明已安装。安装的时候需要开发工具包,如gcc make等。
页面下载tar包安装。安装步骤:检查是否安装了sysstat:[root@a1_145 ~]#which iostat/usr/bin/which: no iostat in (/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/opt/sybdump/mongodb-linux-x86_64-1.6.2/bin:/root/bin)说明没有安装。/usr/bin/iostat说明已安装。安装的时候需要开发工具包,如gcc make等。[root@a1_145 ~]# wget http://pagesperso-orange.fr/sebastien.godard/sysstat-9.1.6.tar.gz直接tar有问题,就先解压了:gzip -d sysstat-9.1.6.tar.gz
[root@a1_145 ~]# tar -zxvf sysstat-9.1.6.tar
[root@a1_145 ~]# cd sysstat-9.1.6
[root@a1_145 sysstat-9.1.6]# ./configure
[root@a1_145 sysstat-9.1.6]# make && make install完毕!每两秒监控输出磁盘使用情况:
# iostat -d -k 2
Linux 2.6.18-194.el5 (ora208) 07/16/2010 _x86_64_ (1 CPU)Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 8.58 142.06 122.23 31504830 27107903
hdc 0.00 0.00 0.00 76 0 -
(备忘)linux解压缩-tar
2010-12-17 15:35:32
-
loadrunner中调用sha1算法
2010-08-04 19:03:29
http://ptfrontline.wordpress.com/2010/03/02/sha-1-hash-for-loadrunner/
示例:
#include "lr_sha1.c"
Action()
{
sha1_hash("passpord","_sha1");
lr_output_message( "SHA1 Hash: %s",lr_eval_string("{_sha1}"));return 0;
}执行后,加密成功!
附件是lr_sha1.c,放到脚本目录中。
-
监控网络延迟出错
2010-06-13 17:30:32
监控网络延迟
出错信息如下:
Error: Network Delay Monitor (Webtrace): Request from source machine MICROSOF-chenhm to destination 192.168.1.62 failed. (Internal error code: -40958).
Error: : Cannot get data for Network path '192.168.1.68 -> 192.168.1.62 (Network delay)'.See documentation for information about Network Delay Monitor limitations. [MsgId: MERR0]
主机192.168.1.68是control机器,loadrunner agent是打开的。
目标机192.168.1.62是linux系统,我用control中的unix resources监控这台机器是成功的。
不知道为什么监控网络延迟不成功
-
LR监控windows
2010-06-13 16:43:42
LR监控windows
总结:
1.确保被监视的windows机子开启这二个服务:Remote Procedure Call(RPC)和Remote Registry
2.在lr机器上运行,输入\\被监视机器IP\C$,然后输入管理员帐号和密码,要能成功看到被监视机器的C盘。这样就说明你得到了被监视机器的管理员权限,可以使用LR去连接了。
关于第2点说明:
1.若被监视的机器没有C$这个共享文件夹,恢复的方法如下:
确保将AutoShareServer和AutoShareWks注册表值,设置为1。
依次点击“开始→运行”,输入regedit,然后按回车键进入注册表编辑器。
HKEY_LOCAL_MACHINE-System-CurrentControlSet-Services-LanmanServer—Parameters。
然后重新启动计算机,会在启动过程中自动创建。
2.输入\\被监视机器IP\C$前,确保没有启用guest,防止是用GUEST连过去的。
在本地安全策略->网络访问:本地帐户的共享和安全模式->经典-本地用户以自己的身份登录,然后再访问共享文件夹,如果要求输入管理员密码应该就应该可以了。
成功!!
说明: LR要连接WINDOWS机器进行监视貌似要有管理员帐号和密码才行。
-
rstatd的安装
2010-06-12 12:45:46
步骤如下:
[root@etoh2 ~]# tar -xzvf rpc.rstatd-
[root@etoh2 ~]# cd rpc.rstatd-
[root@etoh2 rpc.rstatd-
[root@etoh2 rpc.rstatd-
[root@etoh2 rpc.rstatd-
[root@etoh2 rpc.rstatd-
[root@etoh2 rpc.rstatd-
程序 版本 协议 端口
100000 2 tcp 111 portmapper
100000 2 udp 111 portmapper
100024 1 udp 775 status
100024 1 tcp 778 status
100001 5 udp 786 rstatd
100001 3 udp 786 rstatd
100001 2 udp 786 rstatd
100001 1 udp 786 rstatd
-
LR监控linux
2010-06-12 12:00:11
只要保证Linux机器上的进程里有rstatd和xinetd这二个服务就可以用LR去监视。
rstatd 守护程序是一个返回从内核获取的性能统计信息的服务程序。
1.检查机器是否配置了rstatd进程
可使用find命令:
[root@etoh2_sc2 ~]# find / -name rpc.rstatd
/root/rpc.rstatd-4.0.1/rpc.rstatd
/usr/local/sbin/rpc.rstatd
说明已配置,若没有,就安装。
2.检查是否已启用rstatd进程
方法一:rup命令,用于报告机器的统计信息。
[root@etoh2_sc2 rpc.rstatd-4.0.1]# rup 192.168.1.62
localhost up 30 days, 17:07, 2 users, load average: 0.00 0.00 0.00
表示已开启rstatd守护进程。
方法二:rpcinfo -p命令
[root@B1943 ~]# rpcinfo -p
程序 版本 协议 端口
100000 2 tcp 111 portmapper
100000 2 udp 111 portmapper
100024 1 udp 796 status
100024 1 tcp 799 status
100001 5 udp 896 rstatd
100001 3 udp 896 rstatd
100001 2 udp 896 rstatd
100001 1 udp 896 rstatd
表示已开启rstatd守护进程。
3.若没有开启,用命令rpc.rstatd (启动rstatd进程)
可能会提示:Cannot register service: RPC: Unable to receive; errno = Connection refused
这是因为你的服务器没有开启端口映射的功能。[root@etoh2_sc2 rpc.rstatd-4.0.1]# setup
这时会弹出一个类似图形化的界面,光标移动到System services(用方向键),回车。在新界面中找到portmap项,选中(用空格)。然后选择OK(用tab键选),再选择quit。
[root@etoh2_sc2 rpc.rstatd-4.0.1]# /etc/rc.d/init.d/portmap start //启动portmap
再试下rpc.rstatd4.确认守护进程xinetd的配置
a.主配置文件是/etc/xinetd.conf
b.还有/etc/xinetd.d/下的三个配置文件:rlogin, rsh, rexec,把disable = yes都改成 disable = no,意思就是在xinetd启动的时候默认都启动上面的三个服务!
5.检查是否启动xinetd守护进程
rsh服务监听的TCP 是514。
[root@mg04 root]# netstat -an |grep 514
tcp 0 0 0.0.0.0:514 0.0.0.0:* LISTEN
如果能看到514在监听就说明rsh服务器已经启动。 -
QTP识别和操作对象的原理 【转】
2008-09-26 14:35:04
QTP识别和操作对象的原理(http://www.yabest.net)
一、QTP识别对象的原理(by yabest, http://www.yabest.net)
QTP里的对象有两个概念,一个是Test Object(简称TO),一个是Runtime Object(简称RO)。
这两个概念从字面上不大好理解,也容易混淆。
但从实际作用上来看,应该说TO就是是仓库文件里定义的仓库对象,RO是被测试软件的实际对象。
QTP识别对象,一般是要求先在对象仓库文件里定义仓库对象,里面存有实际对象的特征属性的值。
然后在运行的时候,QTP会根据脚本里的对象名字,在对象仓库里找到对应的仓库对象,
接着根据仓库对象的特征属性描述,在被测试软件里搜索找到相匹配的实际对象,最后就可以对实际对象进行操作了。
仓库对象TO一般在录制/编写脚本时加入仓库文件,它不仅可以在录制编写时进行修改,
也可以在运行过程中进行动态修改,以匹配实际对象。
和TO、RO相关的几个函数有:
GetTOProperty():取得仓库对象的某个属性的值
GetTOProperties():取得仓库对象的所有属性的值
SetTOProperty():设置仓库对象的某个属性的值
GetROProperty():取得实际对象的某个属性的值
(注:这几个函数访问的都是对象的封装属性,不是对象的自身属性,封装属性和自身属性的区别详见后面第二章QTP操作对象的原理)
理解了TO的含义,你就可以自由的用SetTOProperty()定义TO,以灵活的操作RO
比如有个测试任务,窗口上有很多待检查的记录,每条记录右边都有一个Check按钮,用来检查各条记录。
记录个数不定,所以Check按钮个数也就不定,只有一个Edit显示记录个数。
我们要对每条记录进行检查,也就是要点击每个Check按钮。
但是Check按钮个数不定,不好录制,而且个数可能也很多(上百个),即使能一一录制,那也很麻烦。
那我有一个好办法,只录制一个按钮对象,它设有两个特征属性 label=OK, index=0
然后用下面的脚本,就可以完成测试
buttonNum = CInt(JavaWindow("Test").JavaEdit("Record Num").GetROProperty("value"))
For buttonIndex = 0 to buttonNum - 1
JavaWindow("Test").JavaButton("Check").SetTOProperty("index", buttonIndex)
JavaWindow("Test").JavaButton("Check").Click
Next
或者窗口上有New、Modify、Delete、Check等好几个按钮,要把这几个按钮一一按过去
我在对象仓库里只设置一个按钮对象AnyButton,label特征属性值填任意值,然后用下面脚本执行测试
JavaWindow("Test").JavaButton("AnyButton").SetTOProperty("label", "New")
JavaWindow("Test").JavaButton("AnyButton").Click
JavaWindow("Test").JavaButton("AnyButton").SetTOProperty("label", "Modify")
JavaWindow("Test").JavaButton("AnyButton").Click
JavaWindow("Test").JavaButton("AnyButton").SetTOProperty("label", "Delete")
JavaWindow("Test").JavaButton("AnyButton").Click
JavaWindow("Test").JavaButton("AnyButton").SetTOProperty("label", "Check")
JavaWindow("Test").JavaButton("AnyButton").Click
另外,QTP还支持脚本描述的方法来定义和访问对象,即不需要在仓库里定义,也能访问和操作实际对象
( Written by yabest,http://www.yabest.net )
如上面两个任务,可以如下实现
1. 不需要在仓库里定义Check按钮对象,直接用下面脚本来实现测试
buttonNum = CInt(JavaWindow("Test").JavaEdit("Record Num").GetROProperty("value"))
For buttonIndex = 0 to buttonNum - 1
JavaWindow("Test").JavaButton("label:=Check", "index:="+CStr(buttonIndex)).Click
Next
2. 不需要在仓库里定义New、Modify、Delete、Check按钮对象,直接用下面脚本来实现测试
JavaWindow("Test").JavaButton("label:=New").Click
JavaWindow("Test").JavaButton("label:=Modify").Click
JavaWindow("Test").JavaButton("label:=Delete").Click
JavaWindow("Test").JavaButton("label:=Check").Click
二、QTP操作对象的原理(by yabest, http://www.yabest.net)
QTP为用户提供了两种操作对象的接口,一种就是对象的封装接口,另一种是对象的自身接口。
对象的自身接口是对象控件本身的接口,只要做过软件开发,使用过控件的人应该很清楚。
对象的封装接口是QTP为对象封装的另一层接口,它是QTP通过调用对象的自身接口来实现的。
两种接口的脚本书写格式的差别在于:
自身接口需要在对象名后面加object再加属性名或方法名,
封装接口就不用在对象名后面加object。
具体格式如下:
对实际对象的操作:
对象.object.自身属性
对象.object.自身方法()
对象.GetROProperty("封装属性")
对象.封装方法()
对仓库对象的操作:
对象.GetTOProperty("封装属性")
对象.GetTOProperties() ’获取所有封装属性的值
对象.SetTOProperty("封装属性", "封装属性值")
比如操作JavaEdit对象,通过QTP封装的封装接口,脚本如下:
设置JavaEdit的内容:
JavaDialog("Add NE").JavaEdit("NE Name").Set "NE1"
读取JavaEdit的内容:
msgbox JavaDialog("Add NE").JavaEdit("NE Name").GetROProperty("value")
如果通过JavaEdit的自身接口,脚本如下:
设置JavaEdit的内容:
JavaDialog("Add NE").JavaEdit("NE Name").object.setText("NE1")
读取JavaEdit的内容:
Msgbox JavaDialog("Add NE").JavaEdit("NE Name").object.getText()
QTP执行JavaEdit().Set语句时,是通过执行JavaEdit().object.setText()来实现的。
QTP执行JavaEdit().GetROProperty("value"),是通过执行JavaEdit().object.getText()来实现的。
JavaEdit对象的封装接口Set()和GetROProperty("value"),是QTP封装JavaEdit对象的自身接口setText()和getText()而得来的。
对象的封装接口是QTP使用的缺省接口,我们录制出来的脚本都是使用封装接口,大家用的也都是封装接口。
但是封装接口不如自身接口丰富,因为QTP只是封装了部分常用的自身接口嘛。
所以我们在需要时,可以绕过封装接口,直接调用对象的自身接口。
不过有些自身接口不够稳定,在实践中偶尔会出现问题,但是概率很少。
封装接口有相应功能的话,就尽量用封装接口吧!
( Written by yabest,http://www.yabest.net )
理解了封装接口和自身接口的原理,我们就可以更加灵活的操作对象了。
但是我们怎么知道对象都有哪些封装接口和自身接口呢?
其实很简单,用对象查看器(Object Spy)查看对象,在查看窗口里有列出这些接口,包括属性和方法。
窗口中间有选择栏让你选择Run-time Object或者Test Object,
当你选择Runtime Object时,它显示的就是对象的自身接口(自身的属性和方法)
当你选择Test Object时,它显示的就是对象的封装接口(封装的属性和方法)
(注意:GetROProperty访问的是实际对象的封装接口,GetTOProperty访问的是仓库对象的封装接口,
两者访问的都是对象的封装接口,即Object Spy窗口里选Test Object时显示的属性。
不要以为GetROProperty访问的是自身接口,即Object Spy窗口里选Run-time Object时显示的属性。
QTP里的Test Object/Run-time Object的概念太容易让人混淆了!
它既用来区分仓库对象和实际对象,又用来区分对象的封装接口和自身接口。
) -
全面介绍单元测试 -转贴
2008-09-08 13:24:28
全面介绍单元测试 -转贴
这是一篇全面介绍单元测试的经典之作,对理解单元测试和Visual Unit很有帮助,作者老纳,收录时作了少量修改]
一 单元测试概述
工厂在组装一台电视机之前,会对每个元件都进行测试,这,就是单元测试。
其实我们每天都在做单元测试。你写了一个函数,除了极简单的外,总是要执行一下,看看功能是否正常,有时还要想办法输出些数据,如弹出信息窗口什么 的,这,也是单元测试,老纳把这种单元测试称为临时单元测试。只进行了临时单元测试的软件,针对代码的测试很不完整,代码覆盖率要超过70%都很困难,未 覆盖的代码可能遗留大量的细小的错误,这些错误还会互相影响,当BUG暴露出来的时候难于调试,大幅度提高后期测试和维护成本,也降低了开发商的竞争力。 可以说,进行充分的单元测试,是提高软件质量,降低开发成本的必由之路。
对于程序员来说,如果养成了对自己写的代码进行单元测试的习惯,不但可以写出高质量的代码,而且还能提高编程水平。
要进行充分的单元测试,应专门编写测试代码,并与产品代码隔离。老纳认为,比较简单的办法是为产品工程建立对应的测试工程,为每个类建立对应的测试类,为每个函数(很简单的除外)建立测试函数。首先就几个概念谈谈老纳的看法。
一般认为,在结构化程序时代,单元测试所说的单元是指函数,在当今的面向对象时代,单元测试所说的单元是指类。以老纳的实践来看,以类作为测试单位, 复杂度高,可操作性较差,因此仍然主张以函数作为单元测试的测试单位,但可以用一个测试类来组织某个类的所有测试函数。单元测试不应过分强调面向对象,因 为局部代码依然是结构化的。单元测试的工作量较大,简单实用高效才是硬道理。
有一种看法是,只测试类的接口(公有函数),不测试其他函数,从面向对象角度来看,确实有其道理,但是,测试的目的是找错并最终排错,因此,只要是包 含错误的可能性较大的函数都要测试,跟函数是否私有没有关系。对于C++来说,可以用一种简单的方法区隔需测试的函数:简单的函数如数据读写函数的实现在 头文件中编写(inline函数),所有在源文件编写实现的函数都要进行测试(构造函数和析构函数除外)。
什么时候测试?单元测试越早越好,早到什么程度?XP开发理论讲究TDD,即测试驱动开发,先编写测试代码,再进行开发。在实际的工作中,可以不必过 分强调先什么后什么,重要的是高效和感觉舒适。从老纳的经验来看,先编写产品函数的框架,然后编写测试函数,针对产品函数的功能编写测试用例,然后编写产 品函数的代码,每写一个功能点都运行测试,随时补充测试用例。所谓先编写产品函数的框架,是指先编写函数空的实现,有返回值的随便返回一个值,编译通过后 再编写测试代码,这时,函数名、参数表、返回类型都应该确定下来了,所编写的测试代码以后需修改的可能性比较小。
由谁测试?单元测试与其他测试不同,单元测试可看作是编码工作的一部分,应该由程序员完成,也就是说,经过了单元测试的代码才是已完成的代码,提交产品代码时也要同时提交测试代码。测试部门可以作一定程度的审核。
关于桩代码,老纳认为,单元测试应避免编写桩代码。桩代码就是用来代替某些代码的代码,例如,产品函数或测试函数调用了一个未编写的函数,可以编写桩 函数来代替该被调用的函数,桩代码也用于实现测试隔离。采用由底向上的方式进行开发,底层的代码先开发并先测试,可以避免编写桩代码,这样做的好处有:减 少了工作量;测试上层函数时,也是对下层函数的间接测试;当下层函数修改时,通过回归测试可以确认修改是否导致上层函数产生错误。
二 测试代码编写
多数讲述单元测试的文章都是以Java为例,本文以C++为例,后半部分所介绍的单元测试工具也只介绍C++单元测试工具。下面的示例代码的开发环境是VC6.0。
产品类:
class CMyClass
{
public:
int Add(int i, int j);
CMyClass();
virtual ~CMyClass();
private:
int mAge; //年龄
CString mPhase; //年龄阶段,如"少年","青年"
};
建立对应的测试类CMyClassTester,为了节约编幅,只列出源文件的代码:
void CMyClassTester::CaseBegin()
{
//pObj是CMyClassTester类的成员变量,是被测试类的对象的指针,
//为求简单,所有的测试类都可以用pObj命名被测试对象的指针。
pObj = new CMyClass();
}
void CMyClassTester::CaseEnd()
{
delete pObj;
}
测试类的函数CaseBegin()和CaseEnd()建立和销毁被测试对象,每个测试用例的开头都要调用CaseBegin(),结尾都要调用CaseEnd()。
接下来,我们建立示例的产品函数:
int CMyClass::Add(int i, int j)
{
return i+j;
}
和对应的测试函数:
void CMyClassTester::Add_int_int()
{
}
把参数表作为函数名的一部分,这样当出现重载的被测试函数时,测试函数不会产生命名冲突。下面添加测试用例:
void CMyClassTester::Add_int_int()
{
//第一个测试用例
CaseBegin();{ //1
int i = 0; //2
int j = 0; //3
int ret = pObj->Add(i, j); //4
ASSERT(ret == 0); //5
}CaseEnd(); //6
}
第1和第6行建立和销毁被测试对象,所加的{}是为了让每个测试用例的代码有一个独立的域,以便多个测试用例使用相同的变量名。
第2和第3行是定义输入数据,第4行是调用被测试函数,这些容易理解,不作进一步解释。第5行是预期输出,它的特点是当实际输出与预期输出不同时自动报 错,ASSERT是VC的断言宏,也可以使用其他类似功能的宏,使用测试工具进行单元测试时,可以使用该工具定义的断言宏。
示例中的格式显得很不简洁,2、3、4、5行可以合写为一行:ASSERT(pObj->Add(0, 0) == 0);但这种不简洁的格式却是老纳极力推荐的,因为它一目了然,易于建立多个测试用例,并且具有很好的适应性,同时,也是极佳的代码文档,总之,老纳建 议:输入数据和预期输出要自成一块。
建立了第一个测试用例后,应编译并运行测试,以排除语法错误,然后,使用拷贝/修改的办法建立其他测试用例。由于各个测试用例之间的差别往往很小,通常只需修改一两个数据,拷贝/修改是建立多个测试用例的最快捷办法。
三 测试用例
下面说说测试用例、输入数据及预期输出。输入数据是测试用例的核心,老纳对输入数据的定义是:被测试函数所读取的外部数据及这些数据的初始值。外部数 据是对于被测试函数来说的,实际上就是除了局部变量以外的其他数据,老纳把这些数据分为几类:参数、成员变量、全局变量、IO媒体。IO媒体是指文件、数 据库或其他储存或传输数据的媒体,例如,被测试函数要从文件或数据库读取数据,那么,文件或数据库中的原始数据也属于输入数据。一个函数无论多复杂,都无 非是对这几类数据的读取、计算和写入。预期输出是指:返回值及被测试函数所写入的外部数据的结果值。返回值就不用说了,被测试函数进行了写操作的参数(输 出参数)、成员变量、全局变量、IO媒体,它们的预期的结果值都是预期输出。一个测试用例,就是设定输入数据,运行被测试函数,然后判断实际输出是否符合 预期。下面举一个与成员变量有关的例子:
产品函数:
void CMyClass::Grow(int years)
{
mAge += years;
if(mAge < 10)
mPhase = "儿童";
else if(mAge <20)
mPhase = "少年";
else if(mAge <45)
mPhase = "青年";
else if(mAge <60)
mPhase = "中年";
else
mPhase = "老年";
}
测试函数中的一个测试用例:
CaseBegin();{
int years = 1;
pObj->mAge = 8;
pObj->Grow(years);
ASSERT( pObj->mAge == 9 );
ASSERT( pObj->mPhase == "儿童" );
}CaseEnd();
在输入数据中对被测试类的成员变量mAge进行赋值,在预期输出中断言成员变量的值。现在可以看到老纳所推荐的格式的好处了吧,这种格式可以适应很复杂的 测试。在输入数据部分还可以调用其他成员函数,例如:执行被测试函数前可能需要读取文件中的数据保存到成员变量,或需要连接数据库,老纳把这些操作称为初 始化操作。例如,上例中 ASSERT( ...)之前可以加pObj->OpenFile();。为了访问私有成员,可以将测试类定义为产品类的友元类。例如,定义一个宏:
#define UNIT_TEST(cls) friend class cls##Tester;
然后在产品类声明中加一行代码:UNIT_TEST(ClassName)。
下面谈谈测试用例设计。前面已经说了,测试用例的核心是输入数据。预期输出是依据输入数据和程序功能来确定的,也就是说,对于某一程序,输入数据确定 了,预期输出也就可以确定了,至于生成/销毁被测试对象和运行测试的语句,是所有测试用例都大同小异的,因此,我们讨论测试用例时,只讨论输入数据。
前面说过,输入数据包括四类:参数、成员变量、全局变量、IO媒体,这四类数据中,只要所测试的程序需要执行读操作的,就要设定其初始值,其中,前两 类比较常用,后两类较少用。显然,把输入数据的所有可能取值都进行测试,是不可能也是无意义的,我们应该用一定的规则选择有代表性的数据作为输入数据,主 要有三种:正常输入,边界输入,非法输入,每种输入还可以分类,也就是平常说的等价类法,每类取一个数据作为输入数据,如果测试通过,可以肯定同类的其他 输入也是可以通过的。下面举例说明:
正常输入
例如字符串的Trim函数,功能是将字符串前后的空格去除,那么正常的输入可以有四类:前面有空格;后面有空格;前后均有空格;前后均无空格。
边界输入
上例中空字符串可以看作是边界输入。
再如一个表示年龄的参数,它的有效范围是0-100,那么边界输入有两个:0和100。
非法输入
非法输入是正常取值范围以外的数据,或使代码不能完成正常功能的输入,如上例中表示年龄的参数,小于0或大于100都是非法输入,再如一个进行文件操作的函数,非法输入有这么几类:文件不存在;目录不存在;文件正在被其他程序打开;权限错误。
如果函数使用了外部数据,则正常输入是肯定会有的,而边界输入和非法输入不是所有函数都有。一般情况下,即使没有设计文档,考虑以上三种输入也可以找 出函数的基本功能点。实际上,单元测试与代码编写是“一体两面”的关系,编码时对上述三种输入都是必须考虑的,否则代码的健壮性就会成问题。
四 白盒覆盖
上面所说的测试数据都是针对程序的功能来设计的,就是所谓的黑盒测试。单元测试还需要从另一个角度来设计测试数据,即针对程序的逻辑结构来设计测试用 例,就是所谓的白盒测试。在老纳看来,如果黑盒测试是足够充分的,那么白盒测试就没有必要,可惜“足够充分”只是一种理想状态,例如:真的是所有功能点都 测试了吗?程序的功能点是人为的定义,常常是不全面的;各个输入数据之间,有些组合可能会产生问题,怎样保证这些组合都经过了测试?难于衡量测试的完整性 是黑盒测试的主要缺陷,而白盒测试恰恰具有易于衡量测试完整性的优点,两者之间具有极好的互补性,例如:完成功能测试后统计语句覆盖率,如果语句覆盖未完 成,很可能是未覆盖的语句所对应的功能点未测试。
白盒测试针对程序的逻辑结构设计测试用例,用逻辑覆盖率来衡量测试的完整性。逻辑单位主要有:语句、分支、条件、条件值、条件值组合,路径。语句覆盖 就是覆盖所有的语句,其他类推。另外还有一种判定条件覆盖,其实是分支覆盖与条件覆盖的组合,在此不作讨论。跟条件有关的覆盖就有三种,解释一下:条件覆 盖是指覆盖所有的条件表达式,即所有的条件表达式都至少计算一次,不考虑计算结果;条件值覆盖是指覆盖条件的所有可能取值,即每个条件的取真值和取假值都 要至少计算一次;条件值组合覆盖是指覆盖所有条件取值的所有可能组合。老纳做过一些粗浅的研究,发现与条件直接有关的错误主要是逻辑操作符错误,例如: ||写成&&,漏了写!什么的,采用分支覆盖与条件覆盖的组合,基本上可以发现这些错误,另一方面,条件值覆盖与条件值组合覆盖往往需要 大量的测试用例,因此,在老纳看来,条件值覆盖和条件值组合覆盖的效费比偏低。老纳认为效费比较高且完整性也足够的测试要求是这样的:完成功能测试,完成 语句覆盖、条件覆盖、分支覆盖、路径覆盖。做过单元测试的朋友恐怕会对老纳提出的测试要求给予一个字的评价:晕!或者两个字的评价:狂晕!因为这似乎是不 可能的要求,要达到这种测试完整性,其测试成本是不可想象的,不过,出家人不打逛语,老纳之所以提出这种测试要求,是因为利用一些工具,可以在较低的成本 下达到这种测试要求,后面将会作进一步介绍。
关于白盒测试用例的设计,程序测试领域的书籍一般都有讲述,普通方法是画出程序的逻辑结构图如程序流程图或控制流图,根据逻辑结构图设计测试用例,这 些是纯粹的白盒测试,不是老纳想推荐的方式。老纳所推荐的方法是:先完成黑盒测试,然后统计白盒覆盖率,针对未覆盖的逻辑单位设计测试用例覆盖它,例如, 先检查是否有语句未覆盖,有的话设计测试用例覆盖它,然后用同样方法完成条件覆盖、分支覆盖和路径覆盖,这样的话,既检验了黑盒测试的完整性,又避免了重 复的工作,用较少的时间成本达到非常高的测试完整性。不过,这些工作可不是手工能完成的,必须借助于工具,后面会介绍可以完成这些工作的测试工具。
五 单元测试工具
现在开始介绍单元测试工具,老纳只介绍三种,都是用于C++语言的。
首先是CppUnit,这是C++单元测试工具的鼻祖,免费的开源的单元测试框架。由于已有一众高人写了不少关于CppUnit的很好的文章,老纳就不现丑了,想了解CppUnit的朋友,建议读一下Cpluser 所作的《CppUnit测试框架入门》,网址是:http://blog.csdn.net/cpluser/archive/2004/09/21/111522.aspx。该文也提供了CppUnit的下载地址。
然后介绍C++Test,这是Parasoft公司的产品。[C++Test是一个功能强大的自动化C/C++单元级测试工具,可以自动测试任何 C/C++函数、类,自动生成测试用例、测试驱动函数或桩函数,在自动化的环境下极其容易快速的将单元级的测试覆盖率达到100%]。[]内的文字引自http://www.superst.com.cn/softwares_testing_c_cpptest.htm, 这是华唐公司的网页。老纳想写些介绍C++Test的文字,但发现无法超越华唐公司的网页上的介绍,所以也就省点事了,想了解C++Test的朋友,建议 访问该公司的网站。华唐公司代理C++Test,想要购买或索取报价、试用版都可以找他们。老纳帮华唐公司做广告,不知道会不会得点什么好处?
最后介绍Visual Unit,简称VU,这是国产的单元测试工具,据说申请了多项专利,拥有一批创新的技术,不过老纳只关心是不是有用和好用。[自动生成测试代码 快速建立功能测试用例 程序行为一目了然 极高的测试完整性 高效完成白盒覆盖 快速排错 高效调试 详尽的测试报告]。[]内的文字是VU开发商的网页上摘录的,网址是:http://www.unitware.cn。 前面所述测试要求:完成功能测试,完成语句覆盖、条件覆盖、分支覆盖、路径覆盖,用VU可以轻松实现,还有一点值得一提:使用VU还能提高编码的效率,总 体来说,在完成单元测试的同时,编码调试的时间还能大幅度缩短。算了,不想再讲了,老纳显摆理论、介绍经验还是有兴趣的,因为可以满足老纳好为人师的虚荣 心,但介绍工具就觉得索然无味了,毕竟工具好不好用,合不合用,要试过才知道,还是自己去开发商的网站看吧,可以下载演示版,还有演示课件。
这是一篇全面介绍单元测试的经典之作,对理解单元测试和Visual Unit很有帮助,作者老纳,收录时作了少量修改]
一 单元测试概述
工厂在组装一台电视机之前,会对每个元件都进行测试,这,就是单元测试。
其实我们每天都在做单元测试。你写了一个函数,除了极简单的外,总是要执行一下,看看功能是否正常,有时还要想办法输出些数据,如弹出信息窗口什么 的,这,也是单元测试,老纳把这种单元测试称为临时单元测试。只进行了临时单元测试的软件,针对代码的测试很不完整,代码覆盖率要超过70%都很困难,未 覆盖的代码可能遗留大量的细小的错误,这些错误还会互相影响,当BUG暴露出来的时候难于调试,大幅度提高后期测试和维护成本,也降低了开发商的竞争力。 可以说,进行充分的单元测试,是提高软件质量,降低开发成本的必由之路。
对于程序员来说,如果养成了对自己写的代码进行单元测试的习惯,不但可以写出高质量的代码,而且还能提高编程水平。
要进行充分的单元测试,应专门编写测试代码,并与产品代码隔离。老纳认为,比较简单的办法是为产品工程建立对应的测试工程,为每个类建立对应的测试类,为每个函数(很简单的除外)建立测试函数。首先就几个概念谈谈老纳的看法。
一般认为,在结构化程序时代,单元测试所说的单元是指函数,在当今的面向对象时代,单元测试所说的单元是指类。以老纳的实践来看,以类作为测试单位, 复杂度高,可操作性较差,因此仍然主张以函数作为单元测试的测试单位,但可以用一个测试类来组织某个类的所有测试函数。单元测试不应过分强调面向对象,因 为局部代码依然是结构化的。单元测试的工作量较大,简单实用高效才是硬道理。
有一种看法是,只测试类的接口(公有函数),不测试其他函数,从面向对象角度来看,确实有其道理,但是,测试的目的是找错并最终排错,因此,只要是包 含错误的可能性较大的函数都要测试,跟函数是否私有没有关系。对于C++来说,可以用一种简单的方法区隔需测试的函数:简单的函数如数据读写函数的实现在 头文件中编写(inline函数),所有在源文件编写实现的函数都要进行测试(构造函数和析构函数除外)。
什么时候测试?单元测试越早越好,早到什么程度?XP开发理论讲究TDD,即测试驱动开发,先编写测试代码,再进行开发。在实际的工作中,可以不必过 分强调先什么后什么,重要的是高效和感觉舒适。从老纳的经验来看,先编写产品函数的框架,然后编写测试函数,针对产品函数的功能编写测试用例,然后编写产 品函数的代码,每写一个功能点都运行测试,随时补充测试用例。所谓先编写产品函数的框架,是指先编写函数空的实现,有返回值的随便返回一个值,编译通过后 再编写测试代码,这时,函数名、参数表、返回类型都应该确定下来了,所编写的测试代码以后需修改的可能性比较小。
由谁测试?单元测试与其他测试不同,单元测试可看作是编码工作的一部分,应该由程序员完成,也就是说,经过了单元测试的代码才是已完成的代码,提交产品代码时也要同时提交测试代码。测试部门可以作一定程度的审核。
关于桩代码,老纳认为,单元测试应避免编写桩代码。桩代码就是用来代替某些代码的代码,例如,产品函数或测试函数调用了一个未编写的函数,可以编写桩 函数来代替该被调用的函数,桩代码也用于实现测试隔离。采用由底向上的方式进行开发,底层的代码先开发并先测试,可以避免编写桩代码,这样做的好处有:减 少了工作量;测试上层函数时,也是对下层函数的间接测试;当下层函数修改时,通过回归测试可以确认修改是否导致上层函数产生错误。
二 测试代码编写
多数讲述单元测试的文章都是以Java为例,本文以C++为例,后半部分所介绍的单元测试工具也只介绍C++单元测试工具。下面的示例代码的开发环境是VC6.0。
产品类:
class CMyClass
{
public:
int Add(int i, int j);
CMyClass();
virtual ~CMyClass();
private:
int mAge; //年龄
CString mPhase; //年龄阶段,如"少年","青年"
};
建立对应的测试类CMyClassTester,为了节约编幅,只列出源文件的代码:
void CMyClassTester::CaseBegin()
{
//pObj是CMyClassTester类的成员变量,是被测试类的对象的指针,
//为求简单,所有的测试类都可以用pObj命名被测试对象的指针。
pObj = new CMyClass();
}
void CMyClassTester::CaseEnd()
{
delete pObj;
}
测试类的函数CaseBegin()和CaseEnd()建立和销毁被测试对象,每个测试用例的开头都要调用CaseBegin(),结尾都要调用CaseEnd()。
接下来,我们建立示例的产品函数:
int CMyClass::Add(int i, int j)
{
return i+j;
}
和对应的测试函数:
void CMyClassTester::Add_int_int()
{
}
把参数表作为函数名的一部分,这样当出现重载的被测试函数时,测试函数不会产生命名冲突。下面添加测试用例:
void CMyClassTester::Add_int_int()
{
//第一个测试用例
CaseBegin();{ //1
int i = 0; //2
int j = 0; //3
int ret = pObj->Add(i, j); //4
ASSERT(ret == 0); //5
}CaseEnd(); //6
}
第1和第6行建立和销毁被测试对象,所加的{}是为了让每个测试用例的代码有一个独立的域,以便多个测试用例使用相同的变量名。
第2和第3行是定义输入数据,第4行是调用被测试函数,这些容易理解,不作进一步解释。第5行是预期输出,它的特点是当实际输出与预期输出不同时自动报 错,ASSERT是VC的断言宏,也可以使用其他类似功能的宏,使用测试工具进行单元测试时,可以使用该工具定义的断言宏。
示例中的格式显得很不简洁,2、3、4、5行可以合写为一行:ASSERT(pObj->Add(0, 0) == 0);但这种不简洁的格式却是老纳极力推荐的,因为它一目了然,易于建立多个测试用例,并且具有很好的适应性,同时,也是极佳的代码文档,总之,老纳建 议:输入数据和预期输出要自成一块。
建立了第一个测试用例后,应编译并运行测试,以排除语法错误,然后,使用拷贝/修改的办法建立其他测试用例。由于各个测试用例之间的差别往往很小,通常只需修改一两个数据,拷贝/修改是建立多个测试用例的最快捷办法。
三 测试用例
下面说说测试用例、输入数据及预期输出。输入数据是测试用例的核心,老纳对输入数据的定义是:被测试函数所读取的外部数据及这些数据的初始值。外部数 据是对于被测试函数来说的,实际上就是除了局部变量以外的其他数据,老纳把这些数据分为几类:参数、成员变量、全局变量、IO媒体。IO媒体是指文件、数 据库或其他储存或传输数据的媒体,例如,被测试函数要从文件或数据库读取数据,那么,文件或数据库中的原始数据也属于输入数据。一个函数无论多复杂,都无 非是对这几类数据的读取、计算和写入。预期输出是指:返回值及被测试函数所写入的外部数据的结果值。返回值就不用说了,被测试函数进行了写操作的参数(输 出参数)、成员变量、全局变量、IO媒体,它们的预期的结果值都是预期输出。一个测试用例,就是设定输入数据,运行被测试函数,然后判断实际输出是否符合 预期。下面举一个与成员变量有关的例子:
产品函数:
void CMyClass::Grow(int years)
{
mAge += years;
if(mAge < 10)
mPhase = "儿童";
else if(mAge <20)
mPhase = "少年";
else if(mAge <45)
mPhase = "青年";
else if(mAge <60)
mPhase = "中年";
else
mPhase = "老年";
}
测试函数中的一个测试用例:
CaseBegin();{
int years = 1;
pObj->mAge = 8;
pObj->Grow(years);
ASSERT( pObj->mAge == 9 );
ASSERT( pObj->mPhase == "儿童" );
}CaseEnd();
在输入数据中对被测试类的成员变量mAge进行赋值,在预期输出中断言成员变量的值。现在可以看到老纳所推荐的格式的好处了吧,这种格式可以适应很复杂的 测试。在输入数据部分还可以调用其他成员函数,例如:执行被测试函数前可能需要读取文件中的数据保存到成员变量,或需要连接数据库,老纳把这些操作称为初 始化操作。例如,上例中 ASSERT( ...)之前可以加pObj->OpenFile();。为了访问私有成员,可以将测试类定义为产品类的友元类。例如,定义一个宏:
#define UNIT_TEST(cls) friend class cls##Tester;
然后在产品类声明中加一行代码:UNIT_TEST(ClassName)。
下面谈谈测试用例设计。前面已经说了,测试用例的核心是输入数据。预期输出是依据输入数据和程序功能来确定的,也就是说,对于某一程序,输入数据确定 了,预期输出也就可以确定了,至于生成/销毁被测试对象和运行测试的语句,是所有测试用例都大同小异的,因此,我们讨论测试用例时,只讨论输入数据。
前面说过,输入数据包括四类:参数、成员变量、全局变量、IO媒体,这四类数据中,只要所测试的程序需要执行读操作的,就要设定其初始值,其中,前两 类比较常用,后两类较少用。显然,把输入数据的所有可能取值都进行测试,是不可能也是无意义的,我们应该用一定的规则选择有代表性的数据作为输入数据,主 要有三种:正常输入,边界输入,非法输入,每种输入还可以分类,也就是平常说的等价类法,每类取一个数据作为输入数据,如果测试通过,可以肯定同类的其他 输入也是可以通过的。下面举例说明:
正常输入
例如字符串的Trim函数,功能是将字符串前后的空格去除,那么正常的输入可以有四类:前面有空格;后面有空格;前后均有空格;前后均无空格。
边界输入
上例中空字符串可以看作是边界输入。
再如一个表示年龄的参数,它的有效范围是0-100,那么边界输入有两个:0和100。
非法输入
非法输入是正常取值范围以外的数据,或使代码不能完成正常功能的输入,如上例中表示年龄的参数,小于0或大于100都是非法输入,再如一个进行文件操作的函数,非法输入有这么几类:文件不存在;目录不存在;文件正在被其他程序打开;权限错误。
如果函数使用了外部数据,则正常输入是肯定会有的,而边界输入和非法输入不是所有函数都有。一般情况下,即使没有设计文档,考虑以上三种输入也可以找 出函数的基本功能点。实际上,单元测试与代码编写是“一体两面”的关系,编码时对上述三种输入都是必须考虑的,否则代码的健壮性就会成问题。
四 白盒覆盖
上面所说的测试数据都是针对程序的功能来设计的,就是所谓的黑盒测试。单元测试还需要从另一个角度来设计测试数据,即针对程序的逻辑结构来设计测试用 例,就是所谓的白盒测试。在老纳看来,如果黑盒测试是足够充分的,那么白盒测试就没有必要,可惜“足够充分”只是一种理想状态,例如:真的是所有功能点都 测试了吗?程序的功能点是人为的定义,常常是不全面的;各个输入数据之间,有些组合可能会产生问题,怎样保证这些组合都经过了测试?难于衡量测试的完整性 是黑盒测试的主要缺陷,而白盒测试恰恰具有易于衡量测试完整性的优点,两者之间具有极好的互补性,例如:完成功能测试后统计语句覆盖率,如果语句覆盖未完 成,很可能是未覆盖的语句所对应的功能点未测试。
白盒测试针对程序的逻辑结构设计测试用例,用逻辑覆盖率来衡量测试的完整性。逻辑单位主要有:语句、分支、条件、条件值、条件值组合,路径。语句覆盖 就是覆盖所有的语句,其他类推。另外还有一种判定条件覆盖,其实是分支覆盖与条件覆盖的组合,在此不作讨论。跟条件有关的覆盖就有三种,解释一下:条件覆 盖是指覆盖所有的条件表达式,即所有的条件表达式都至少计算一次,不考虑计算结果;条件值覆盖是指覆盖条件的所有可能取值,即每个条件的取真值和取假值都 要至少计算一次;条件值组合覆盖是指覆盖所有条件取值的所有可能组合。老纳做过一些粗浅的研究,发现与条件直接有关的错误主要是逻辑操作符错误,例如: ||写成&&,漏了写!什么的,采用分支覆盖与条件覆盖的组合,基本上可以发现这些错误,另一方面,条件值覆盖与条件值组合覆盖往往需要 大量的测试用例,因此,在老纳看来,条件值覆盖和条件值组合覆盖的效费比偏低。老纳认为效费比较高且完整性也足够的测试要求是这样的:完成功能测试,完成 语句覆盖、条件覆盖、分支覆盖、路径覆盖。做过单元测试的朋友恐怕会对老纳提出的测试要求给予一个字的评价:晕!或者两个字的评价:狂晕!因为这似乎是不 可能的要求,要达到这种测试完整性,其测试成本是不可想象的,不过,出家人不打逛语,老纳之所以提出这种测试要求,是因为利用一些工具,可以在较低的成本 下达到这种测试要求,后面将会作进一步介绍。
关于白盒测试用例的设计,程序测试领域的书籍一般都有讲述,普通方法是画出程序的逻辑结构图如程序流程图或控制流图,根据逻辑结构图设计测试用例,这 些是纯粹的白盒测试,不是老纳想推荐的方式。老纳所推荐的方法是:先完成黑盒测试,然后统计白盒覆盖率,针对未覆盖的逻辑单位设计测试用例覆盖它,例如, 先检查是否有语句未覆盖,有的话设计测试用例覆盖它,然后用同样方法完成条件覆盖、分支覆盖和路径覆盖,这样的话,既检验了黑盒测试的完整性,又避免了重 复的工作,用较少的时间成本达到非常高的测试完整性。不过,这些工作可不是手工能完成的,必须借助于工具,后面会介绍可以完成这些工作的测试工具。
五 单元测试工具
现在开始介绍单元测试工具,老纳只介绍三种,都是用于C++语言的。
首先是CppUnit,这是C++单元测试工具的鼻祖,免费的开源的单元测试框架。由于已有一众高人写了不少关于CppUnit的很好的文章,老纳就不现丑了,想了解CppUnit的朋友,建议读一下Cpluser 所作的《CppUnit测试框架入门》,网址是:http://blog.csdn.net/cpluser/archive/2004/09/21/111522.aspx。该文也提供了CppUnit的下载地址。
然后介绍C++Test,这是Parasoft公司的产品。[C++Test是一个功能强大的自动化C/C++单元级测试工具,可以自动测试任何 C/C++函数、类,自动生成测试用例、测试驱动函数或桩函数,在自动化的环境下极其容易快速的将单元级的测试覆盖率达到100%]。[]内的文字引自http://www.superst.com.cn/softwares_testing_c_cpptest.htm, 这是华唐公司的网页。老纳想写些介绍C++Test的文字,但发现无法超越华唐公司的网页上的介绍,所以也就省点事了,想了解C++Test的朋友,建议 访问该公司的网站。华唐公司代理C++Test,想要购买或索取报价、试用版都可以找他们。老纳帮华唐公司做广告,不知道会不会得点什么好处?
最后介绍Visual Unit,简称VU,这是国产的单元测试工具,据说申请了多项专利,拥有一批创新的技术,不过老纳只关心是不是有用和好用。[自动生成测试代码 快速建立功能测试用例 程序行为一目了然 极高的测试完整性 高效完成白盒覆盖 快速排错 高效调试 详尽的测试报告]。[]内的文字是VU开发商的网页上摘录的,网址是:http://www.unitware.cn。 前面所述测试要求:完成功能测试,完成语句覆盖、条件覆盖、分支覆盖、路径覆盖,用VU可以轻松实现,还有一点值得一提:使用VU还能提高编码的效率,总 体来说,在完成单元测试的同时,编码调试的时间还能大幅度缩短。算了,不想再讲了,老纳显摆理论、介绍经验还是有兴趣的,因为可以满足老纳好为人师的虚荣 心,但介绍工具就觉得索然无味了,毕竟工具好不好用,合不合用,要试过才知道,还是自己去开发商的网站看吧,可以下载演示版,还有演示课件。
标题搜索
我的存档
数据统计
- 访问量: 17875
- 日志数: 21
- 图片数: 1
- 建立时间: 2008-09-07
- 更新时间: 2011-06-01
