
-
需求不足或很少时的测试
2009-07-03 14:14:59
需求不足或很少时的测试
项目没有明确定义的(或任何)需求规格说明书就开始实施,这很常见,特别是在小公司里面。即使是在大型企业,在他们认为不需要规范领域,也可能存在项目缺少需求规格说明书的情况。在这种情况下如何进行测试是一个常见的问题。
在项目缺少需求规格说明书的情况,并不存在一个做好测试简单快捷的方法,因为需求规格说明书对功能性测试的效力有很大的推动作用。其中关键的一点是要注意保持对需求来源进行追踪,和从这些需求源头上可衍生出哪些需求。这将大大简化对需求合法性的验证。以下是在以往测试成功过的几种策略:
把用户手册当作需求规格说明书使用,这种方法是有效的和符合要求的。如果用户手册提供了足够的细节信息并且被信息组织编排得很有条理,使用它和使用需求规格说明书的效果几乎是一样的。关键是学会在用户手册上系统化地查找需求,确认和追踪这些需求。另外,经常需要从其它的来源获取需求信息来对用户手册进行补充,因为用户手册很少会包含压力和响应时间方面等精确数目信息。
把设计文档当作需求规格说明书使用,大部分的开发人员至少会在某处的文件上记录或保存系统的一些相关信息。查找出这些设计文档后,它可作为需求的一个源头,特别是对于那些在用户手册上无法找到的硬性指标需求。关键是要小心选择可用作需求的信息,要注意避免把设计信息当作需求。销售文档同样也可以这样用。
与人交谈。小项目的一个常见问题是“两只腿的需求”,这是指长驻客户公司的应用软件技术支持人员,他们围绕描述软件的用途与客户反复沟通。通常这些技术支持人员都会写下一些信息,这些信息可用作需求,但多半时候这些信息用处不大,这需要和他们坐下来谈论一下这个系统要实现哪些功能。另外,走出去和开发人员,系统的实际用户,甚至购买产品的客户等交谈。在每次会谈中,及时作笔记,然后把这些笔记作为进行测试的基础资料。使用常识。使用常识这个方法应该是所有其它方法都失败后的最后选择。虽然使用常识可能会发现问题,但使用这种方法会引发所发现故障的重要性和关联性的争论,甚至这个缺陷实际上是不是缺陷也可能需要论证。测试准备不足情况下的测试
一个关键的考虑因素可能是根本上这个软件是否可测,如果没有
足够的时间去为一个全新的产品作测试做准备,唯一可行的办法是向项目管理人
员报告这个软件达不到测试的条件,让其决定如何处理这个问题。如何项目管理
人员做出的决定是宣布这个产品达不到测试的条件,测试人员需提供详细的信息
以解释为什么这个软件达不到测试的条件和需要作哪些改进使它达到测试的条
件。时间不足的测试
-
故障分析
2009-07-03 12:21:20
进行故障分析的第一步相对比较简单,只是简单地往BUG 追踪过程添加一些信息,以允许分析问题的根源。这些信息应包括那部分代码出现了失效和这些代码存在什么问题等信息。还需包括出错代码的编写者名字,和其它一些关于故障如何发生和为何发生的信息。当经过几个软件版本的数据积累后,搜索其中有着共同主题或故障发生原因的数据。通常,软件的那些经过多次修改的代码会被检索出来,重新设计这些代码可以显著提升软件的质量,同时可加快项目开发进度。可能有些界面接口缺少相关的说明文档,或是难以理解的,从而引发不少问题,这时需要重写这些接口,使它们得以简化以利于将来的使用。错误的出现也可能和代码没有直接的关系,例如,可能因为软件运行环境存在过多的干扰,或对于特殊代码,开发人员缺乏相关的培训。当这些错误被逐渐消除后,继续收集数据和评估这些错误移除后产生的作用,以及确认更多错误的来源。这种处理软件故障和故障的源头错误的方法被称为故障避免。这种方法的基本原理是,在故障首次出现之前消除它比等它成为麻烦后再发现和修改它所花费的成本会少很多。随着越来越多的错误被确认和阻止出现,更多的错误将会出现,并且可得到修正。这种方法的净作用是将会极大地节省项目时间和成本。
-
软件测试的目标
2009-07-03 10:45:27
也许,对于公司产品的长期质量保证来说,测试团队的最重要的贡献并不来自测试本身。如果我们重点关注那些不同软件项目都出现的故障,可能无需测试,就可避免一些故障或错误的出现。这里的目标并不是直接提高测试的质量,而是提高待测软件的质量,这样无需测试,就可直接影响项目的质量。 -
软件测试工作规范【转载】
2009-07-03 10:36:51
刚开始工作,以下方面可以注意,虽然公司不一定要求你这么规范的做,但你可以有意识去规范的做事情:
1、 进行测试用例设计时思路清晰,用例文档写作规范,描述详细清楚;
2、缺陷描述详细规范,有隔离等措施;
3、能对工作中的心得、经验等总结成案例,交给测试经理共享;
4、在测试执行期间能每天规范地提交测试日志;
5、在测试结束后能规范的进行总结,写作测试报告,进行各种测试度量数据的分析。 -
细说LoadRunner参数化【转载】
2009-07-03 09:42:52
首先:为什么要对脚本进行参数化
a) 为了减少脚本的大小和脚本数量,借助参数化我们可以减少脚本的数量,
如果不进行参数化,我们为了达到目标可能要拷贝并修改很多个脚本。
b) 使业务更接近真实的客户的业务,每个虚拟用户使用不同参数值来模拟
这样才接近客户的实际情况。第二:怎么进行参数化
a) 编辑脚本,使用参数代替常量;
b) 设置参数的属性和数据源;
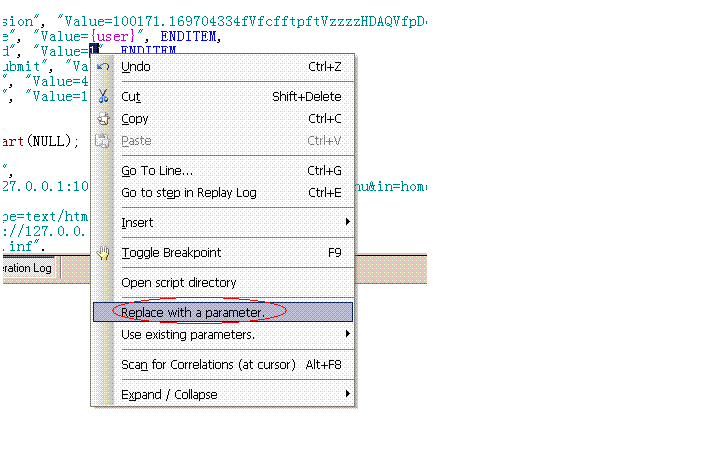
那么如何进行参数化呢?选中要参数化的内容点右键->Replace with a parameter(如下图)。输入参数化的名称,假设为password。
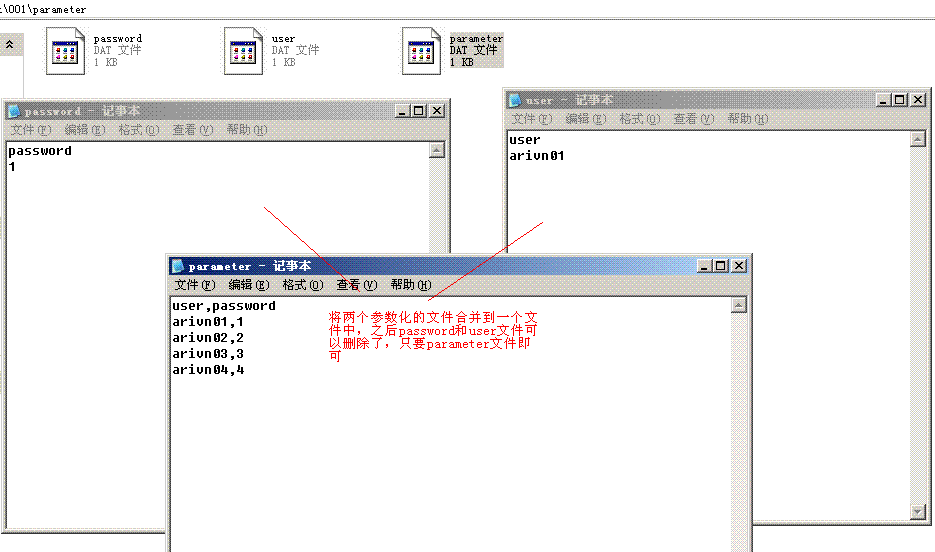
这时要我们要注意的一个问题是,当参数化结束后,脚本保存的根目录下会
多出两个参数化的文件,就是刚才对两个数进行参数化后的文本文件,当然一般的情况下我们不要将这个参数化的文件放到脚本的目录下,而应该是放到一个专门的文件下,这样可以保证参数化文件与脚本分离,如我们新建一个文件夹parameter,将所有参数化的文本文件都放到这个文件夹下。那么当有很多参数化文件怎么办呢,因为当一个项目很大时,其录制的业务很多时,参数化文件会很多,甚至上几百MB 时,这时为了方便管理参数化文件和节约空间我们会对参数化文件进行合并到一个文件夹中,如上面两个参数化文件就可以合并,参数化之间用逗号隔开即可,如下图合并好后的参数化文件。
再看一下参数化的属性:
a) 参数类型属性:
1. "Date/Time"(日期/时间)参数类型:
"Date/Time"类型用当前的日期和/或时间替换参数。要指定日期/时间的格式,可以从菜单列表中选择,或者指定实际需要的格式。该格式应该
与脚本中录制的日期/时间格式相对应。还可以单击该对话框中相应的按
钮对格式进行添加、删除、还原等操作、2. "Group Name"(组名)参数类型:
用Vuser 组的名称替换参数。创建方案时,要指定Vuser 组的名称,否
则运行VuGen 的脚本时,组名始终为"无"。但在VuGen 中运行时,Group
Name 将会是None。3. "Iteration Number"(迭代编号)参数类型:用当前的迭代编号替换参数。
4. "Load Generator Name"(负载生成器名)参数类型:用Vuser 脚本的负
载生成器名替换参数。负载生成器是运行Vuser 的计算机。
5. "Random Number"(随机编号)参数类型:用一个随机生成的整数替换
参数,可以通过指定最小和最大值,设置随机编号的范围。
6. "Unique Number"(唯一编号)参数类型:用一个唯一编号替换参数。"Block
size"(块大小)指明分配给每个Vuser 的编号块的大小。每个Vuser 都
从其范围的下限(start)开始,在每次迭代时递增该参数值。7. "Vuser ID"参数类型:LoadRunner 使用该虚拟用户的ID 来代替参数值,
该ID 是由Controller 来控制。在VuGen 中运行脚本时,VuGen 将会是-1。
8. File 参数类型:可以在参数属性中编辑参数文件,也可以直接编辑好参
数文件通过路径来选择,还有从现成的数据库中提取。这是参数化最常的一种参数类型。
b) Browse 属性:
这里是用来选择参数文件的路径,这里要注意的一个问题是,一般我们在做
参数化的时候没有单独把参数文件放到一个文件夹下,所以一般我们都没有更改
过这块,但我们上面已经讲过,一般都会将参数化文件合并到一个文件下并放到
一个专门管理参数的文件夹下,保证参数化文件与脚本分离,这样我们就要选择
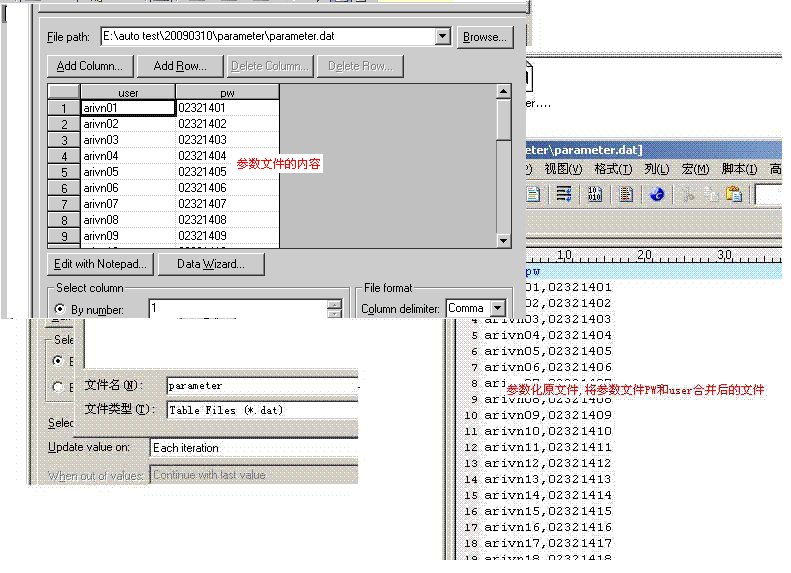
参数的路径,否则无法读到参数文件中的参数,具体的如下图。
选择好之后,会列出参数化文件中所有的项,如下图:
注意:读者可能会发现,这样如果我们把这个脚本拷贝到另外一台机器上去,
这个路径不就出错了吗?也就是我们的脚本可移植性不好,对是的,会出错,因
为这里写的是绝对路径,如果换到其它的一个盘或机器,运行就报错了,那么怎
么解决这个问题?这里我们采用相对路径来解决这个问题,这是我们Browse 设
置为相对路径,将脚本的根目录使用“.”来代替。c) 导入数据方法:
LoadRunner 允许使用Microsoft Query 或者指定数据库连接字符串与SQL 语
句,利用参数化从已存在的数据库中导入数据。在这里这两种导入数据的方法的
区别在于使用Microsoft Query 时,不要新建数据源,在导入向导过程中直接连
接数据库,而手动指定数据库字符器,需要先做好数据源,现在一般都使用这种
方法。d) Select next now 属性:
注意:这里要注意的是所有的Select next now 属性选择是针对虚拟用户来说
的,也就是这里的策略是针对Controller 设置的,在调试脚本的过程中是看不出
来的,其决定虚拟用户如何选择参数的过程。
Sequential:虚拟用户Vuser 按照行顺序的进行读取参数文件中的数据,
如果参数文件中没有足够的数据,则返回到第一个值,并一直循环到结束。
Random:每个Vuser 从表中随机的读起参数数据。
Unique:唯一的数,即每个Vuser 取到的参数均不一致,这里强调了用户的差异性。
Same link as ***:如果一个脚本中定义了多个参数,而有一些参数应
该是对应的关系,如上图中的用户名和密码就是对应关系,即密码应该始终和用
户名对应,这时就要用到这个选项。
e) Update value on 属性:
注意:这里设置的策略是针对脚本的迭代来讲的,也就是说这里的一切策略
其仅仅在脚本迭代次数发挥作用,而对Vuser 选择参数没有影响。
Each iteration:脚本每迭代一次都访问数据表中的下一个值。
注意:如果在一次迭代过程中,某个参数使用到多次,如下图这个例子中,
在一次迭代中使用到两次用户名和密码,这两次使用的同一个数据,而并不是两
个数据。
Each occurrence:参数在每次迭代的过程中,参数的值都的更新。注意:如果一个参数在一次迭代过程中出现多次,即使在同一次迭代过程中
也得更新 Once:在同一个Vuser 中一直取同一个参数,表中的数据不参于迭代的
过程。
到这里参数化的过程已经全部讲完,这里总结一下,参数化过程中要注意的
问题:
1) 参数化文件尽可能少,因为参数是放在内存中的,占用了内存的资源;2) 参数化文件与脚本分离;
3) 参数文件的路径应该以相对路径来取;
4) 一些时候为了使参数更具有真实性,参数应该从数据库中来获得;
5) 参数类型的选择;
6) 参数的数据一般要由业务决定 -
基于WebService的性能测试方法
2009-07-02 18:07:21
我们需要测试的webserivce 分两种情况:带有soapheader,需要进行并发性能测试;不带有soapheader,需要进行单线程的大数据量测试,一个请求接着一个请求的发送。
现在的公司是做电信增值业务的。通过在客户端构建的用户对象,对所需的业务进行soapheader 的验证后,再由webserivce 传递到服务器端,服务器接收到数据后,在电信的后台服务器中进行业务处理,再将处理后的结果通过webserivce 返回给客户端。
测试环境:
测试PC(一台LoadRunner测试主控台+N台负载生成器)、WebService服务器、业务管理服务器、数据库服务器
录制脚本:
1.打开“Virtual User Generator”。
2.New一个virtual user,选择“Web Services”,点击“ok”。3。在弹出的脚本页面,选择“ ScanWSDL”,在URL 中输入要测试的webseri
vce URL,点击“下一步”。4.点击“Open Validation Report”来验证URL的有效性,点击“下一步”
5.选择你要测试Methods,点击“下一步”
6.输入Specify argument values,点击“下一步”。
7.勾选“Run script. after generation”
8.设置“ run-time-settingwebserivceClient Emulation.Net”点击“完成”,
loadrunner 将会自动产生脚本。9.soapheader 的添加
在script. View 模式中可以看到在刚才录制完后,脚本回放成功,但是这并不
代表你的webserivce 的功能正确,你需要查看所保存脚本文件夹目录下\result1\Iteration1\t1.xml 中的response 来判断request 是否成功。如果提示无效的验证错误,这是因为你未输入soapheader 造成的,那么我们需要自己编写一段脚本来添加soapheader:即:SOAPHeader=<soap:Header xmlns=\"http://bell.ca/vas/getServiceStatus\"><
AuthenticationHeader><Username>user</Username><Password>pass</Password></
AuthenticationHeader></soap:Header>并保持在一行再次回放,查看\result1\Iteration1\t1.xml 中的response 是否返回success。
(另外介绍一下不带有soapheader的在录制时需要注意的地方:
需要在run-time-settingwebserivceClient EmulationMS soap 进行设置。)
脚本的加强
在脚本中添加事务与集合点,参数化部分参数,并且屏蔽掉lr_think_time(3),因为这会影响性能测试结果
(不带soapheader的不需要要设置事务和集合点,因为模拟的是单线程测试情况,只需要屏蔽掉lr_think_time(3)。)
运行场景
在run-time-settings 中
持续发送情况下:选择pacing As soon as the previous iteration ends
间隔相同时间发送情况下:选择pacing After the previous iteration endsFi
xed输入设置时间间隔不同时间发送情况下:选择pacing AtRandom输入设置时间
-
软件测试面试题[转载]
2009-06-29 17:55:00
软通动力面试
1.白箱测试和黑箱测试是什么?什么是回归测试?
白箱测试要了解软件内部的结构,测试代码是否正确实现了功能。黑盒测试是不需要了解软件内部节后,依据软件的需求规格说明书,检查程序的功能是否符合需求说明
回归测试一是检查所作的修改是否达到了预定目的,如错误得到改正,能够适应新的运行环境等等;二是不影响软件的其他功能的正确性。
2.单元测试、集成测试、系统测试的侧重点是什么?
单元测试是一种白盒测试,一般有程序员来完成,单元测试重点:深入到系统内部,有效的验证代码是否与设计相符,尽早发现设计和需求中存在的错误,以及在编码阶段引入的错误;
在效率方面,单元测试往往是集成测试的2倍,系统测试的3倍;
集成测试的重点:将主要测试模块之间的接口和接口数据传递关系,以及模块组合后的整体功能。
系统测试的侧重点:对已经集成好的软件系统进行彻底的测试,以验证软件系统的正确性和性能等满足其规约所指定的要求,检查软件的行为和输出是否正确
3.设计用例的方法、依据有那些?
黑盒测试法中的等价类划分,边界值分析,因果图法,错误推测法,场景设计法;
4.一个测试工程师应具备那些素质和技能?
5.集成测试通常都有那些策略?
6.你用过的测试工具的主要功能、性能及其他?
7.一个缺陷测试报告的组成
8.基于WEB信息管理系统测试时应考虑的因素有哪些?
9.软件本地化测试比功能测试都有哪些方面需要注意?
10.软件测试项目从什么时候开始,?为什么?
11.需求测试注意事项有哪些?
12.简述一下缺陷的生命周期
13.测试分析测试用例注意(事项)?
瑞星笔试题
1.一台计算机的IP是192.168.10.71子网掩码255.255.255.64与192.168.10.201是同一局域网吗?是的
2.internet中e-mail协仪,IE的协仪,NAT是什么,有什么好处,能带来什么问题?DNS是什么,它是如何工作的?
3.PROXY是如何工作的?
4.win2k系统内AT命令完成什么功能,Messenger服务是做什么,怎么使用?
5进程,线程的定义及区别
6,32位操作系统内,1进程地址空间多大,进程空间与物理内存有什么关系?
7网络攻击常用的手段,防火墙如何保证安全.
8如何配静态IP,如何测网络内2台计算机通不通,PING一次返几个数据包?
9WIN9X与WINNT以上操作系统有"服务"吗,服务是什么,如何停止服务?
10AD在WIN2KSERVER上建需什么文件格式,AD是什么?XP多用户下"注销"与"切换"的区别.
11UDP可以跨网段发送吗?
12最简单的确认远程计算机(win2K以上)某个监听端口是正常建立的?
13软件测试的定义,测试工作是枯燥反复的,你是如何理解的?黑盒,白盒,回归,压力测试的定义.
14winrunner,loadrunner是什么,区别
15磁盘分区如何分类,请举例说明安装操作系统的注意事项.
(1小时答题)
中软的面试题
一. 简答题.
1. 避免死锁的方法有哪些?
2. 在Sybase数据库中注册用户与数据库用户有什么区别?
3. 在MS SQL_Server 数据库中通过什么约束保证数据库的实体完整性
4. 内存有哪几种存储组织结构.请分别加以说明 软件开发网 www.mscto.com
5. JAVA中的Wait() 和notify()方法使用时应注意些什么?
6. 用户输入一个整数.系统判断,并输出是负数还是非负数,请设计测试用例.
7. 操作系统中的同步和互诉解决了什么问题
8. UNIX 中init
二. 编写类String 的构造函数,析构函数和赋值函数
已知类String 的原型为
class string
{
public:
string(const char *str=null);//普通构造函数
string(const string &other);//拷贝构造函数
---string(void);
string &operate=(const string &other);//赋值函数
private:
char * m-data;//用于保存字符串
};
请编写string 的上述4个函数
三. 有关内存的思考题
1. void getmemory(char *p)
{ p=(char*)mallol(100);
}
void test(void)
{
char * str =null;
getmemory(str);
strcpy(str,”hello,world”);
printf(str);
}
请问运行Test函数会有什么样的结果
2. char*getmemory(void)
{ char p[]=”hello world”;
return p;
}
void test(void)
{
char *str=null;
str=Getmemory();
printf(str);
} 请问运行Test 函数会有什么样的结果.
奇虎面试题
前三道程序题
(下面的题不排序,有笔试题,也有面试题)
4、怎么划分缺陷的等级?
5、怎么评价软件工程师?
6、软件工程师的素质是什么?
7、怎么看待软件测试?
8、软件测试是一个什么样的行业?
9、图书(图书号,图书名,作者编号,出版社,出版日期)
作者(作者姓名,作者编号,年龄,性别)
用SQL语句查询年龄小于平均年龄的作者姓名、图书名,出版社。
10、你的职业生涯规划
11、测一个三角形是普通三角形、等腰三角形、等边三角形的流程图,测试用例。
12、写出你常用的测试工具。
13、lordrunner分哪三部分?
14、希望以后的软件测试是怎么样的一个行业?
15、.软件测试项目从什么时候开始?
我答:从软件项目的需要分析开始。
问:为什么从需求分析开始?有什么作用?
北京博彦科技笔试+面试
笔试题
1.文件格式系统有哪几种类型?分别说说win95、win98、winMe、w2k、winNT、winXP分别支持那些文件系统。
2.分别填入一个语句,完成下面的函数,通过递归计算数组a[100]的前n个数之和。
Int sum ( int a[],int n )
{
if (n>0) return___________________________;
else return________________________;
}
3.写出你所知道的3种常用的排序方法,并用其中一种方法设计出程序为数组a[100]排序。
4.什么是兼容性测试?兼容性测试侧重哪些方面,请按照优先级用矩阵图表列出。
(这题的第二问我不会答,所以原题目记得不是很清楚,大家能看明白问什么就好)
5.我现在有个程序,发现在WIN98上运行得很慢,怎么判别是程序存在问题还是软硬件系统存在问题?
6.翻译,中——英,有关P2P点对点文件传输的原理。
7.翻译,英——中,有关互联网的发展对商务、学习、交流的影响。
笔试完了是初步的面试
先问了个问题:FAT16/FAT32/NTFS 哪个的安全性最好,为什么?(不会答)
又做了两道题,
一题是关于C++类的继承,看程序写出输出结果,A是虚类,B继承A,跟一般C++的书上的习题差不多。
一题是写出在32位机器下,计算几个变量的size,
最后用英文介绍一下自己 -
[转载]基于实际测试的功能测试点总结
2009-06-26 17:42:45
1. 页面链接检查:每一个链接是否都有对应的页面,并且页面之间切换正确。可以使用一些工具,如LinkBotPro、File-AIDCS、HTML Link Validater、Xenu等工具。LinkBotPro不支持中文,中文字符显示为乱码;HTML Link Validater只能测试以Html或者htm结尾的网页链接;Xenu无需安装,支持asp、do、jsp等结尾的网页,xenu测试链接包括内部链接和外部链接,在使用的时候应该注意,同时能够生成html格式的测试报告。如果系统用QTP进行自动化测试,也可以使用QTP的页面检查点检查链接。2. 相关性检查:
Ø 功能相关性:删除/增加一项会不会对其他项产生影响,如果产生影响,这些影响是否都正确,常见的情况是,增加某个数据记录以后,如果该数据记录某个字段内容较长,可能会在查询的时候让数据列表变形。
Ø 数据相关性:下来列表默认值检查,下来列表值检查,如果某个列表的数据项依赖于其他模块中的数据,同样需要检查,比如,某个数据如果被禁用了,可能在引用该数据项的列表中不可见。
3. 检查按钮的功能是否正确:如新建、编辑、删除、关闭、返回、保存、导入,上一页,下一页,页面跳转,重置等功能是否正确。常见的错误会出现在重置按钮上,表现为功能失效。
4. 字符串长度检查: 输入超出需求所说明的字符串长度的内容, 看系统是否检查字符串长度。还要检查需求规定的字符串长度是否是正确的,有时候会出现,需求规定的字符串长度太短而无法输入业务数据。
5. 字符类型检查: 在应该输入指定类型的内容的地方输入其他类型的内容(如在应该输入整型的地方输入其他字符类型),看系统是否检查字符类型。
6. 标点符号检查: 输入内容包括各种标点符号,特别是空格,各种引号,回车键。看系统处理是否正确。常见的错误是系统对空格的处理,可能添加的时候,将空格当作一个字符,而在查询的时候空格被屏蔽,导致无法查询到添加的内容。
7.特殊字符检查:输入特殊符号,如@、#、$、%、!等,看系统处理是否正确。常见的错误是出现在% ‘ \ 这几个特殊字符
8. 中文字符处理: 在可以输入中、英文的系统输入中文,看会否出现乱码或出错。
9. 检查信息的完整性: 在查看信息和更新信息时,查看所填写的信息是不是全部更新,更新信息和添加信息是否一致。要注意检查的时候每个字段都应该检查,有时候,会出现部分字段更新了而个别字段没有更新的情况。
10. 信息重复: 在一些需要命名,且名字应该唯一的信息输入重复的名字或ID,看系统有没有处理,会否报错,重名包括是否区分大小写,以及在输入内容的前后输入空格,系统是否作出正确处理。
11. 检查删除功能:在一些可以一次删除多个信息的地方,不选择任何信息,按“delete”,看系统如何处理,会否出错;然后选择一个和多个信息,进行删除,看是否正确处理。如果有多页,翻页选,看系统是否都正确删除,并且要注意,删除的时候是否有提示,让用户能够更正错误,不误删除。
12. 检查添加和修改是否一致: 检查添加和修改信息的要求是否一致,例如添加要求必填的项,修改也应该必填;添加规定为整型的项,修改也必须为整型.
13. 检查修改重名:修改时把不能重名的项改为已存在的内容,看会否处理,报错.同时,也要注意,会不会报和自己重名的错.
14. 重复提交表单:一条已经成功提交的纪录,返回后再提交,看看系统是否做了处理。对于Web系统来说,可以通过浏览器返回键或者系统提供的返回功能。
15. 检查多次使用返回键的情况: 在有返回键的地方,返回到原来页面,重复多次,看会否出错。
16. 搜索检查: 有搜索功能的地方输入系统存在和不存在的内容,看搜索结果是否正确.如果可以输入多个搜索条件,可以同时添加合理和不合理的条件,看系统处理是否正确,搜索的时候同样要注意特殊字符,某些系统会在输入特殊字符的时候,将系统中所有的信息都搜索到。
17. 输入信息位置: 注意在光标停留的地方输入信息时,光标和所输入的信息会否跳到别的地方。
18. 上传下载文件检查:上传下载文件的功能是否实现,上传文件是否能打开。对上传文件的格式有何规定,系统是否有解释信息,并检查系统是否能够做到。下载文件能否打开或者保存,下载的文件是否有格式要求,如需要特殊工具才可以打开等。上传文件测试同时应该测试,如果将不能上传的文件后缀名修改为可以上传文件的后缀名,看是否能够上传成功,并且,上传文件后,重新修改,看上传的文件是否存在。
19. 必填项检查:应该填写的项没有填写时系统是否都做了处理,对必填项是否有提示信息,如在必填项前加“*”;对必填项提示返回后,焦点是否会自动定位到必填项。
20. 快捷键检查:是否支持常用快捷键,如Ctrl+C、 Ctrl+V、 Backspace等,对一些不允许输入信息的字段,如选人,选日期对快捷方式是否也做了限制。
21. 回车键检查: 在输入结束后直接按回车键,看系统处理如何,会否报错。这个地方很有可能会出现错误。
22.刷新键检查:在Web系统中,使用浏览器的刷新键,看系统处理如何,会否报错。
23.回退键检查:在Web系统中,使用浏览器的回退键,看系统处理如何,会否报错。对于需要用户验证的系统,在退出登录后,使用回退键,看系统处理如何;多次使用回退键,多次使用前进键,看系统如何处理。
24.直接URL链接检查:在Web系统中,直接输入各功能页面的URL地址,看系统如何处理,对于需要用户验证的系统更为重要。如果系统安全性设计的不好,直接输入各功能页面的URL地址,很有可能会正常打开页面。
25.空格检查:在输入信息项中,输入一个或连串空格,查看系统如何处理。如对于要求输入整型、符点型变量的项中,输入空格,既不是空值,又不是标准输入。
26.输入法半角全角检查:在输入信息项中,输入半角或全角的信息,查看系统如何处理。如对于要求输入符点型数据的项中,输入全角的小数点(“。”或“.”,如4.5);输入全角的空格等。
27.密码检查:一些系统的加密方法采用对字符Ascii码移位的方式,处理密码加密相对较为简单,且安全性较高,对于局域网系统来说,此种方式完全可以起到加密的作用,但同时,会造成一些问题,即大于128的Ascii对应的字符在解密时无法解析,尝试使用“uvwxyz”等一些码值较大的字符作为密码,同时,密码尽可能的长,如17位密码等,造成加密后的密码出现无法解析的字符。
28.用户检查:任何一个系统,都有各类不同的用户,同样具有一个或多个管理员用户,检查各个管理员之间是否可以相互管理,编辑、删除管理员用户。同时,对于一般用户,尝试删除,并重建同名的用户,检查该用户其它信息是否重现。同样,提供注销功能的系统,此用户再次注册时,是否作为一个新的用户。而且还要检查该用户的有效日期,过了有效日期的用户是不能登录系统的。容易出现错误的情况是,可能有用户管理权限的非超级管理员,能够修改超级管理员的权限。
29.系统数据检查:这是功能测试最重要的,如果系统数据计算不正确,那么功能测试肯定是通不过的。数据检查根据不同的系统,方法不同。对于业务管理平台,数据随业务过程、状态的变化保持正确,不能因为某个过程出现垃圾数据,也不能因为某个过程而丢失数据。
30.系统可恢复性检查:以各种方式把系统搞瘫,测试系统是否可正常迅速恢复。
31.确认提示检查:系统中的更新、删除操作,是否提示用户确认更新或删除,操作是否可以回退(即是否可以选择取消操作),提示信息是否准确。事前或事后提示,对于Update或Delete操作,要求进行事前提示。
32.数据注入检查:数据注入主要是对数据库的注入,通过输入一些特殊的字符,如“’”,“/”,“-”等或字符组合,完成对SQL语句的破坏,造成系统查询、插入、删除操作的SQL因为这些字符而改变原来的意图。如select * from table where id = ‘ ’ and name = ‘ ’,通过在id输入框中输入“
33.刷新检查:web系统中的WebForm控件实时刷新功能,在系统应用中有利有弊,给系统的性能带来较大的影响。测试过程中检测刷新功能对系统或应用造成的影响(白屏),检查控件是否回归默认初始值,检查是否对系统的性能产生较大影响(如每次刷新都连接数据库查询等)。
34.事务检查:对于事务性操作,断开网络或关闭程序来中断操作,事务是否回滚。
35.时间日期检查:时间、日期验证是每个系统都必须的,如2006-2-29、2006-6-31等错误日期,同时,对于管理、财务类系统,每年的1月与前一年的12月(同理,每年的第1季度与前一年的第4季度)。另外,对于日期、时间格式的验证,如
36.多浏览器验证:越来越多的各类浏览器的出现,用户访问Web程序不再单单依赖于Microsoft Internet Explorer,而是有了更多的选择:Maxthon、Firefox、Tencent Traveler等,考虑使用多种浏览器访问系统,验证效果。
37.安装测试:对于C/S架构的系统,安装程序的测试是一个重要方面,安装程序自动化程度、安装选项和设置(验证各种方案是否都能正常安装)、安装过程中断测试、安装顺序测试(分布式系统)、修复安装及卸载测试。
38.文档测试:主要是对用户使用手册、产品手册进行测试,校验是否描述正确、完整,是否与当前系统版本对照,是否易理解,是否二义性等。
39.测试数据检查:事实告诉我们,测试数据比代码更有可能是错的,因此,当测试结果显示有错误发生的时候,怀疑代码错误前要先对测试数据检查一遍。
40.请让我的机器来运行:在某些项目中,出现一个病态的问题:系统没有问题呀,它在我的机器上是能够通过的。这就说明了其中存在着和环境相关的BUG。“是否所有的一切都受到了版本控制工具的管理?”、“本机的开发环境和服务器的环境是否一样?”、“这里是否存在一个真正的BUG,只不过是在其他的机器里偶然出现?”。所有的测试必须在所有系统要求的机器上运行通过,否则的话,代码就可能存在问题。
41.Ajax技术的应用:Ajax有很多优点,但也有很多缺点,如果利用优点、避免缺点,是我们对新的Web2.0应用的一个挑战。而Ajax的应用最直接的问题就是用户体验,用户体验的效果直接关系到是否使用Ajax技术。“会做,并不意味着应该做、必须做”,这就是对Ajax技术的很重要的注解。
42.Ajax技术的应用:Ajax采用异步调用的机制实现页面的部分刷新功能,异步调用存在异常中断的可能,尝试各种方法异常中断异步的数据调用,查看是否出现问题。在这里遇到的一个问题就是对日期控件的操作,已经如果页面数据较多的时候的刷新。
43.脚本错误:随着Ajax、IFrame等异步调用技术的发展,Javascrīpt技术也越来越受到开发人员的重视,但Javascrīpt存在调试困难、各浏览器存在可能不兼容等问题,因此在Web系统中,可能会出现脚本错误。同时,脚本错误造成的后果可大、可小,不能忽视。
-
养成好的工作习惯
2009-06-15 10:52:36
-
安全性测试常见的十个问题【转载】
2009-06-11 14:41:18
1、问题:没有被验证的输入测试方法:
数据类型(字符串,整型,实数,等)
允许的字符集
最小和最大的长度
是否允许空输入
参数是否是必须的
重复是否允许
数值范围
特定的值(枚举型)
特定的模式(正则表达式)
2、问题:有问题的访问控制
测试方法:
主要用于需要验证用户身份以及权限的页面,复制该页面的url地址,关闭该页面以后,查看是否可以直接进入该复制好的地址
例:从一个页面链到另一个页面的间隙可以看到URL地址
直接输入该地址,可以看到自己没有权限的页面信息
3、错误的认证和会话管理
分析:帐号列表:系统不应该允许用户浏览到网站所有的帐号,如果必须要一个用户列表,推荐使用某种形式的假名(屏幕名)来指向实际的帐号。
浏览器缓存:认证和会话数据不应该作为GET的一部分来发送,应该使用POST。
4、问题:跨站脚本(XSS)
分析:攻击者使用跨站脚本来发送恶意代码给没有发觉的用户,窃取他机器上的任意资料
测试方法:
HTML标签:<…>…
转义字符:&(&);<(<);>(>); (空格) ;
脚本语言:
特殊字符:‘ ’ < > /
最小和最大的长度
是否允许空输入
例:对Grid、Label、Tree view类的输入框未作验证,输入的内容会按照html语法解析出来
5、缓冲区溢出
分析:用户使用缓冲区溢出来破坏web应用程序的栈,通过发送特别编写的代码到web程序中,攻击者可以让web应用程序来执行任意代码。
6、注入式漏洞
例:一个验证用户登陆的页面, 如果使用的sql语句为:
Select * from table A where username=’’ + username+’’ and pass word …..
Sql 输入 ‘ or 1=1 ―― 就可以不输入任何password进行攻击
7、不恰当的异常处理
分析:程序在抛出异常的时候给出了比较详细的内部错误信息,暴露了不应该显示的执行细节,网站存在潜在漏洞,
8、不安全的存储
没有加密关键数据
例:view-source:http地址可以查看源代码
在页面输入密码,页面显示的是 *****, 右键,查看源文件就可以看见刚才输入的密码,
9、拒绝服务
分析:攻击者可以从一个主机产生足够多的流量来耗尽狠多应用程序,最终使程序陷入瘫痪。需要做负载均衡来对付。
10、不安全的配置管理
分析:Config中的链接字符串以及用户信息,邮件,数据存储信息都需要加以保护
程序员应该作的: 配置所有的安全机制,关掉所有不使用的服务,设置角色权限帐号,使用日志和警报。
-
针对现公司状况的的测试工作方式【转载加个人修改】
2009-06-11 14:27:58
1.了解需求攥写用例
拿到一个成品,首先熟悉需求,要想更细的了解最好参照开发编写的需求说明书。如果这些文档并不齐全,那就参照已经成形的系统。首先要用心分析需求文档,每个业务流程,每个细节。对于不懂的或者与现有系统不符的地方,及时张开自己的金嘴去问熟悉这个系统的相关人员。
需求分析后,最好是能画出一个功能流程图。对于每个子功能,尽可能把各种可能的路径都显示在这张图上面。
对于如何画好这张图,这个时候最好的方式采用数据驱动的方式。每个模块之所以能关联在一起,归根到底都是因为它们有数据传递。分析出数据流的流向,一般都能把握住功能与子功能的各个分支,尽量做到无遗漏。
2.测试执行
1)BVT测试,确保基本功能都跑通。
2)接口测试,将整个业务流程从创建数据,到处理数据,然后到处理结束,整个过程走一边,确保流程能走得通。【全程跟踪一条数据,从它创建,修改,查询到删除】
3)各个子功能深度测试。这个过程谁经验丰富谁占优势,但是也是有些技巧的。怎么确保此功能不会出现严重的问题了,首先研究数据。这个功能涉及到哪些数据,然后从界面上提交关键数据,确保数据信息成功保存在数据库中。
4)关联测试。这个阶段,首先要搞清楚数据的关联。搞清楚这个关联可以采用两种方式结合:一个是从界面上了解数据之间的关联,另外一个更准确的方式是分析数据库。分析数据库中各个表中的数据,把每个外键找出来,然后找出外键相关的表。然后弄清楚这些表中的数据界面上哪里调用上。
-
功能测试的经验总结[转载]
2009-06-11 13:47:10
测试准备:1、实际测试总比你预想的要花更多的时间,遇到更多的麻烦,所以要尽量争取足够的测试时间,不要不加思索的说这个东西我一星期肯定可以测完。还要尽可能考虑到测试过程中的风险,比如测试环境的问题、部署失败的问题、开发延期的问题、人员变动的问题等等。
2、实际上从来都没有过完善的需求,可惜的是教科书从来也没讲过如何应对不完善的需求。我曾不止一次的想如果让做需求的和编程人员都来做两个月的测试,他们的工作能力肯定会有质的飞跃,可惜这只是我的梦想。需求说明书中总会遗漏很多细节,通常需求人员认为那些地方都是理所当然无需赘言的,但开发人员却会有不同的理解,所以测试人员要尽可能的在开始编程之前找出需求中所有不明确、有遗漏的地方。如果能在讨论需求的时候就提出问题那比从已经写好的需求说明书中挑错要好的多。问题越早发现越容易解决。
3、测试人员最好能在开发开始之前,总结出一个列表,列表中列出需要开发人员统一处理的一些细节,比如表单中表头和表内容用什么字体字号;是左对齐还是居中;翻页控件是放在表单左下角还是右下角还是居中;标点符号是用中文半角还是全角;选择框和下拉菜单中的内容按什么排序;搜索结果是否需要排序;错误提示是弹出窗口还是显示在原界面;错误提示语也应尽量统一风格;查询后是否要保存查询条件;浏览器的前进后退是否需要限制等等。项目经理最好统一给开发人员讲一下这些规矩,这样会在测试时省很多事。
测试用例:
1、测试用例要因人而异,如果自己已经很熟练了,测试用例可以只是简单的提示,不需写出详细的执行步骤和测试数据,以免因为无谓的文档浪费太多时间。如果很可能别人还要复用你的测试用例而且有充足的时间,这时就可以把测试用例写详细点。
2、至于测试数据需不需要在设计测试用例时就写出需要根据实际项目情况来定,我一般认为最好把测试用例都写完之后,再准备测试数据,一条数据可以覆盖多个测试用例,这样很可能四五条数据就可以覆盖十几个测试用例,这样可以提高效率。教科书通常认为一条测试数据最好对应一个测试用例,这样测试执行失败时就容易定位问题出在哪里。但实际情况是只有极少数的测试会执行失败并因此发现bug,但如果因为这极少数的失败的情况来降低整个测试执行的效率就显得缺乏实践性了,况且并不是说一条测试数据覆盖了多个用例时就不容易定位错误的根源。所以测试要根据实际情况灵活进行。
3、如果要写详细的测试用例,就一定要写的非常的清楚明了,最好让一个不懂项目情况的人也能根据用例执行测试。而且测试用例和测试数据中的关键值一定要用颜色标出。最好还能写出每条用例的测试目的,这样方便日后别人补充你的测试用例。
测试执行:
1、如果时间允许,测试一个页面时,要把这个页面的所有功能点的正常异常情况都测完之后再去测下一个页面,这样不容易遗漏。大多时候时间都不很充足,这时要先测主要流程和主要的功能点,这些完成之后再去测细节和异常情况,因为并不是有bug就不能上线的。 [Page]
2、如果发现了很多界面性的小问题,不要连续提出,最好先提一两个功能性的问题,再提一两个界面性的问题,这样间隔着提bug有利于开发人员接收,免得他把你提的连续的四五个界面性的bug都拒绝了。另外,一个bug里最好不要既包括功能性问题又包括界面性问题,这样有可能开发人员只解决了功能性问题就把bug 关了。
3、可以一条测试数据覆盖多个测试用例,这样可以提高效率,前提是程序的质量还可以或者可以根据测试结果(结果数据和log)定位是哪个功能点的问题。
4、如果时间充足的话,测试要在安静的环境中不慌不忙地进行,这样容易联想到更多的测试功能点,也可能因此发现更多的bug。如果测试太匆忙,通常测试人员只是想尽快地执行完所有测试用例。
5、如果测试还要进行多个版本,则需要不断完善测试用例,并总结为什么一开始会遗漏这些测试点。
6、测试的目的是发现bug,不是执行完所有用例或者覆盖尽可能多的路径。所以如果全面的测试已无益于发现新的bug时,要让测试人员充分发挥自己的主观能动性,随机地对可疑的地方进行测试。
7、发现bug时要确定自己操作和理解没有问题再向开发人员提出,而且要注意表达方式。
8、平日最好能和开发人员保持不错的关系,这样有利于测试的进行。
9、不要迷信功能测试的自动化,我认为只有在版本稳定后还需要进行多个版本的测试时才需要测试自动化,而且要求测试人员都可以熟练使用测试自动化工具。自动化测试的最大困难可能是需求和界面的频繁变化。
-
09年06、07月工作计划
2009-06-09 11:50:51
在完成公司计划安排的工作的同时,完成以下任务
一,提升设计测试用例的技术
1,了解测试系统基本的测试点【web系统测试方法】
2,结合公司具体的业务情况
3,根据自己的经验结合其他方面的知识
4,每想到新的测试点,或是学到新的设计用例的方法 都做总结
二,为找工作做准备
1,完善简历【加入进两月对功能测试、性能测试的理解】
2,发简历
3,熟悉软件测试面试题目
注:在目前的公司只能在测试技能方面有提升,软件生命周期的深入理解,与其他部门的沟通协调能力等都得不到锻炼
-
流媒体的技术
2009-06-04 16:33:43
一、流式传输的基础
在网络上传输音/视频等多媒体信息,目前主要有下载和流式传输两种方案。A/V文件一般都较大,所以需要的存储容量也较大;同时由于网络带宽的限制,下载常常要花数分钟甚至数小时,所以这种处理方法延迟也很大。流式传输时,声音、影像或动画等时基媒体由音视频服务器向用户计算机的连续、实时传送,用户不必等到整个文件全部下载完毕,而只需经过几秒或十数秒的启动延时即可进行观看。当声音等时基媒体在客户机上播放时,文件的剩余部分将在后台从服务器内继续下载。流式不仅使启动延时成十倍、百倍地缩短,而且不需要太大的缓存容量。流式传输避免了用户必须等待整个文件全部从Internet上下载才能观看的缺点。
流媒体指在Internet/Intranet中使用流式传输技术的连续时基媒体,如:音频、视频或多媒体文件。流式媒体在播放前并不下载整个文件,只将开始部分内容存入内存,流式媒体的数据流随时传送随时播放,只是在开始时有一些延迟。流媒体实现的关键技术就是流式传输。
流式传输定义很广泛,现在主要指通过网络传送媒体(如视频、音频)的技术总称。其特定含义为通过Internet 将影视节目传送到PC机。实现流式传输有两种方法:实时流式传输(Realtime streaming)和顺序流式传输(progressive streaming)。一般说来,如视频为实时广播,或使用流式传输媒体服务器,或应用如RTSP的实时协议,即为实时流式传输。如使用HTTP服务器,文件即通过顺序流发送。采用那种传输方法依赖你的需求。当然,流式文件也支持在播放前完全下载到硬盘。
顺序流式传输
顺序流式传输是顺序下载,在下载文件的同时用户可观看在线媒体,在给定时刻,用户只能观看已下载的那部分,而不能跳到还未下载的前头部分,顺序流式传输不象实时流式传输在传输期间根据用户连接的速度做调整。顺序流式传输经常被称作HTTP流式传输。顺序流式传输比较适合高质量的短片段,对通过调制解调器发布短片段,顺序流式传输显得很实用,顺序流式文件是放在标准HTTP 或 FTP服务器上,易于管理,基本上与防火墙无关。顺序流式传输不适合长片段和有随机访问要求的视频,如:讲座、演说与演示。它也不支持现场广播,严格说来,它是一种点播技术。
实时流式传输
实时流式传输指保证媒体信号带宽与网络连接配匹,使媒体可被实时观看到。实时流与HTTP流式传输不同,他需要专用的流媒体服务器与传输协议。实时流式传输总是实时传送,特别适合现场事件,也支持随机访问,用户可快进或后退以观看前面或后面的内容。理论上,实时流一经播放就可不停止,但实际上,可能发生周期暂停。实时流式传输必须配匹连接带宽,这意味着在以调制解调器速度连接时图象质量较差。而且,由于出错丢失的信息被忽略掉,网络拥挤或出现问题时,视频质量很差。如欲保证视频质量,顺序流式传输也许更好。实时流式传输需要特定服务器,如:QuickTime Streaming Server、RealServer与Windows Media Server。这些服务器允许你对媒体发送进行更多级别的控制,因而系统设置、管理比标准HTTP服务器更复杂。实时流式传输还需要特殊网络协议,如:RTSP (Realtime Streaming Protocol)或MMS (Microsoft Media Server)。这些协议在有防火墙时有时会出现问题,导致用户不能看到一些地点的实时内容。
二、 流媒体技术原理
流式传输的实现需要缓存。因为Internet以包传输为基础进行断续的异步传输,对一个实时A/V源或存储的A/V文件,在传输中它们要被分解为许多包,由于网络是动态变化的,各个包选择的路由可能不尽相同,故到达客户端的时间延迟也就不等,甚至先发的数据包还有可能后到。为此,使用缓存系统来弥补延迟和抖动的影响,并保证数据包的顺序正确,从而使媒体数据能连续输出,而不会因为网络暂时拥塞使播放出现停顿。通常高速缓存所需容量并不大,因为高速缓存使用环形链表结构来存储数据:通过丢弃已经播放的内容,流可以重新利用空出的高速缓存空间来缓存后续尚未播放的内容。——流式传输的实现需要合适的传输协议。由于TCP需要较多的开销,故不太适合传输实时数据。在流式传输的实现方案中,一般采用HTTP/TCP来传输控制信息,而用RTP/UDP来传输实时声音数据。流式传输的过程一般是这样的:用户选择某一流媒体服务后,Web浏览器与Web服务器之间使用HTTP/TCP交换控制信息,以便把需要传输的实时数据从原始信息中检索出来;然后客户机上的Web浏览器启动A/VHelper程序,使用HTTP从Web服务器检索相关参数对Helper程序初始化。这些参数可能包括目录信息、A/V数据的编码类型或与A/V检索相关的服务器地址。
A/VHelper程序及A/V服务器运行实时流控制协议(RTSP),以交换A/V传输所需的控制信息。与CD播放机或VCRs所提供的功能相似,RTSP提供了操纵播放、快进、快倒、暂停及录制等命令的方法。A/V服务器使用RTP/UDP协议将A/V数据传输给A/V客户程序(一般可认为客户程序等同于Helper程序),一旦A/V数据抵达客户端,A/V客户程序即可播放输出。
需要说明的是,在流式传输中,使用RTP/UDP和RTSP/TCP两种不同的通信协议与A/V服务器建立联系,是为了能够把服务器的输出重定向到一个不同于运行A/VHelper程序所在客户机的目的地址。实现流式传输一般都需要专用服务器和播放器,其基本原理如图所示。
流媒体播放方式1.单播
在客户端与媒体服务器之间需要建立一个单独的数据通道,从一台服务器送出的每个数据包只能传送给一个客户机,这种传送方式称为单播。每个用户必须分别对媒体服务器发送单独的查询,而媒体服务器必须向每个用户发送所申请的数据包拷贝。这种巨大冗余首先造成服务器沉重的负担,响应需要很长时间,甚至停止播放;管理人员也被迫购买硬件和带宽来保证一定的服务质量。
2.组播
IP组播技术构建一种具有组播能力的网络,允许路由器一次将数据包复制到多个通道上。采用组播方式,单台服务器能够对几十万台客户机同时发送连续数据流而无延时。媒体服务器只需要发送一个信息包,而不是多个;所有发出请求的客户端共享同一信息包。信息可以发送到任意地址的客户机,减少网络上传输的信息包的总量。网络利用效率大大提高,成本大为下降。
3.点播与广播
点播连接是客户端与服务器之间的主动的连接。在点播连接中,用户通过选择内容项目来初始化客户端连接。用户可以开始、停止、后退、快进或暂停流。点播连接提供了对流的最大控制,但这种方式由于每个客户端各自连接服务器,却会迅速用完网络带宽。
流媒体技术应用互联网的迅猛发展和普及为流媒体业务发展提供了强大的市场动力,流媒体业务正变得日益流行。 流媒体技术广泛用于多媒体新闻发布、在线直播、网络广告、电子商务、视频点播、远程教育、远程医疗、网络电台、 实时视频会议等互联网信息服务的方方面面。流媒体技术的应用将为网络信息交流带来革命性的变化,对人们的工作和生活将产生深远的影响。
一个完整的流媒体解决方案应是相关软硬件的完美集成,它大致包括下面几个方面的内容: 内容采集、 视音频捕获和压缩编码、内容编辑、内容存储和播放、应用服务器内容管理发布及用户管理等。
-
工作日志-20090603
2009-06-03 14:33:24
发发牢骚:
近三天要做后台管理系统的第一轮测试,可是公司的网络老是出状况。
仔细回想以下,从进公司到现在的两个月里,公司的网络(内网+外网)也就是最开始的半个月正常过,之后就一直出状况。好像我还未顺利的完成过一轮测试,每次中间都要出状况。为了不影响后面的工作,我又开始写另一个管理系统的测试用例。等到第二天,服务器可以用了,可是才测了2小时,网络又出问题了。
难道公司的网络管理就那么困难,再说公司也就才20多人,都折腾一个多月了,还不能正常的工作。都快崩溃了。
个人总结:
公司网络频频出问题,我的工作热情也被折腾的所剩无几了。
做测试工作差不多也有一年半了,大多数还是做的Web应用程序的测试。有.net,也有Java,关于.net的我不是很了解其内部结构以及外部结构,但对于Java项目,还是比较清楚的,毕竟之前也做过一年多的Java开发工作。
我接触过的web项目,也就两种类型。一种是工作流形式的,还有一种是管理系统形式的。
关于工作流形式的项目,主要就是测试发起的任务经过反复的颠沛流离,是否仍然按照定制的流程,走向终点。
关于管理系统形式的,主要就是数据的增删改差以及用户权限的管理。除了基本的增删改差外,还应该考虑对有主外键关系的主键数据进行删除时,程序的处理情况,数据库的情况。还要注意大数据量的操作速度,如果速度较慢,再进行其他相关数据操作时,是否引发数据库死锁
-
数据库死锁及解决死锁问题
2009-06-03 10:39:31
deadlocks(死锁)
所谓死锁<DeadLock>: 是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程. 由于资源占用是互斥的,当某个进程提出申请资源后,使得有关进程在无外力协助下,永远分配不到必需的资源而无法继续运行,这就产生了一种特殊现象死锁。 一种情形,此时执行程序中两个或多个线程发生永久堵塞(等待),每个线程都在等待被其他线程占用并堵塞了的资源。例如,如果线程A锁住了记录1并等待记录2,而线程B锁住了记录2并等待记录1,这样两个线程就发生了死锁现象。 计算机系统中,如果系统的资源分配策略不当,更常见的可能是程序员写的程序有错误等,则会导致进程因竞争资源不当而产生死锁的现象。锁有多种实现方式,比如意向锁,共享-排他锁,锁表,树形协议,时间戳协议等等。锁还有多种粒度,比如可以在表上加锁,也可以在记录上加锁。
产生死锁的原因主要是: (1) 因为系统资源不足。 (2) 进程运行推进的顺序不合适。 (3) 资源分配不当等。
如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则就会因争夺有限的资源而陷入死锁。其次,进程运行推进顺序与速度不同,也可能产生死锁。 产生死锁的四个必要条件: (1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。 这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。 死锁的解除与预防:
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和
解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确 定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态 的情况下占用资源,在系统运行过程中,对进程发出的每一个系统能够满足的资源申请进行动态检查,并根据检查结果决定是否分配资源,若分配后系统可能发生死锁,则不予分配,否则予以分配 。因此,对资源的分配要给予合理的规划。
如何将死锁减至最少虽然不能完全避免死锁,但可以使死锁的数量减至最少。将死锁减至最少可以增加事务的吞吐量并减少系统开销,因为只有很少的事务:
◆回滚,而回滚会取消事务执行的所有工作。
◆由于死锁时回滚而由应用程序重新提交。
下列方法有助于最大限度地降低死锁:
◆按同一顺序访问对象。
◆避免事务中的用户交互。
◆保持事务简短并在一个批处理中。
◆使用低隔离级别。
◆使用绑定连接。
按同一顺序访问对象
如果所有并发事务按同一顺序访问对象,则发生死锁的可能性会降低。例如,如果两个并发事务获得 Supplier 表上的锁,然后获得 Part 表上的锁,则在其中一个事务完成之前,另一个事务被阻塞在 Supplier 表上。第一个事务提交或回滚后,第二个事务继续进行。不发生死锁。将存储过程用于所有的数据修改可以标准化访问对象的顺序。
避免事务中的用户交互
避免编写包含用户交互的事务,因为运行没有用户交互的批处理的速度要远远快于用户手动响应查询的速度,例如答复应用程序请求参数的提示。例如,如果事务正在等待用户输入,而用户去吃午餐了或者甚至回家过周末了,则用户将此事务挂起使之不能完成。这样将降低系统的吞吐量,因为事务持有的任何锁只有在事务提交或回滚时才会释放。即使不出现死锁的情况,访问同一资源的其它事务也会被阻塞,等待该事务完成。
保持事务简短并在一个批处理中
在同一数据库中并发执行多个需要长时间运行的事务时通常发生死锁。事务运行时间越长,其持有排它锁或更新锁的时间也就越长,从而堵塞了其它活动并可能导致死锁。
保持事务在一个批处理中,可以最小化事务的网络通信往返量,减少完成事务可能的延迟并释放锁。
使用低隔离级别
确定事务是否能在更低的隔离级别上运行。执行提交读允许事务读取另一个事务已读取(未修改)的数据,而不必等待第一个事务完成。使用较低的隔离级别(例如提交读)而不使用较高的隔离级别(例如可串行读)可以缩短持有共享锁的时间,从而降低了锁定争夺。
使用绑定连接
使用绑定连接使同一应用程序所打开的两个或多个连接可以相互合作。次级连接所获得的任何锁可以象由主连接获得的锁那样持有,反之亦然,因此不会相互阻塞。
用存储过程查出引起死锁的进程和SQL语句
假如发生了死锁,我们怎么去检测具体发生死锁的是哪条SQL语句或存储过程?此时我们可以使用以下存储过程来检测,就可以查出引起死锁的进程和SQL语句。
use master go create procedure sp_who_lock as begin declare @spid int,@bl int, @intTransactionCountOnEntry int, @intRowcount int, @intCountProperties int, @intCounter int create table #tmp_lock_who ( id int identity(1,1), spid smallint, bl smallint) IF @@ERROR<>0 RETURN @@ERROR insert into #tmp_lock_who(spid,bl) select 0 ,blocked from (select * from sysprocesses where blocked>0 ) a where not exists(select * from (select * from sysprocesses where blocked>0 ) b where a.blocked=spid) union select spid,blocked from sysprocesses where blocked>0 IF @@ERROR<>0 RETURN @@ERROR -- 找到临时表的记录数 select @intCountProperties = Count(*),@intCounter = 1 from #tmp_lock_who IF @@ERROR<>0 RETURN @@ERROR if @intCountProperties=0 select '现在没有阻塞和死锁信息' as message -- 循环开始 while @intCounter <= @intCountProperties begin -- 取第一条记录 select @spid = spid,@bl = bl from #tmp_lock_who where Id = @intCounter begin if @spid =0 select '引起数据库死锁的是: '+ CAST(@bl AS VARCHAR(10)) + '进程号,其执行的SQL语法如下' else select '进程号SPID:'+ CAST(@spid AS VARCHAR(10))+ '被' + '进程号SPID:'+ CAST(@bl AS VARCHAR(10)) +'阻塞,其当 前进程执行的SQL语法如下'DBCC INPUTBUFFER 与锁定有关的两个问题--死锁和阻塞
死锁
死锁是一种条件,不仅仅是在关系数据库管理系统 (RDBMS) 中发生,在任何多用户系统中都可以发生的。当两个用户(或会话)具有不同对象的锁,并且每个用户需要另一个对象的锁时,就会出现死锁。每个用户都等待另一个用户释放他的锁。当两个连接陷入死锁时,Microsoft® SQL Server™ 会进行检测。其中一个连接被选作死锁牺牲品。该连接的事务回滚,同时应用程序收到错误。
如果死锁变成单个公用事件,而且它们的回滚造成过多的性能降级,那么就需要再次进行深入彻底的调查。使用跟踪标记 1204。例如,下面的命令从命令提示符启动 SQL Server,并启用跟踪标记 1204:
c:\mssql\binn\sqlservr -T1204
现在所有消息都会显示在启动 SQL Server 的控制台屏幕上和错误日志中。
使用分布式事务时,也可能发生死锁。
阻塞
任何基于锁的并发系统都不可避免地具有可能在某些情况下发生阻塞的特征。当一个连接控制了一个锁,而另一个连接需要冲突的锁类型时,将发生阻塞。其结果是强制第二个连接等待,或在第一个连接上阻塞。
在本主题中,术语"连接"是指数据库的单个登录会话。每个连接都作为系统进程 ID (SPID) 出现。尽管每一个 SPID 一般都不是单独的进程上下文,但这里常常用来指一个进程。更确切的说,每个 SPID 都是由服务器资源和数据结构(为给定客户单个连接的请求提供服务)组成。单个客户应用程序可能有一个或多个连接。就 SQL Server 而言,从单个客户机上的单个客户应用程序来的多个连接和从多个客户应用程序或多个客户机来的多个连接是没有区别的。不管是来自同一应用程序还是来自两台不同客户机上单独的应用程序,一个连接都可以阻塞另一个连接。
-
工作日志-20090601
2009-06-02 11:27:46
今天是执行Web后台管理系统的第一轮测试的第一天,基本功能的测试都没问题,但是在删除多条数据时,竟然出现了进度条,过了近一分钟,操作仍未结束,程序估计出问题了,赶紧取消了操作。
一开始我以为是因为删除的数据中有主外键关系,导致动作执行缓慢,我取消了操作,数据中的相关操作也就回滚了。事情没这么简单,接下来的测试中,我只要执行跟数据库有关的操作,都迟迟不见结果。
赶紧跟开发反映,经过他的查证,数据库出现死锁了。。
具体原因我不清楚,不过确实是因为我删除的多条数据跟其他模块的数据有主外键关系,。。。。。。最终导致了数据库死锁。。
-
治疗近视
2009-06-02 11:23:45
做手术治疗近视:
从手术的安全性、稳定性、有效性、预测性综合考虑,同时还要考虑医疗设备的先进性。目前主要有下列四类方法可供选择:
1、 放射状角膜切开手术(RK)
其原理是在角膜非瞳孔区做4-12条放射状切口,切口的深度达到角膜厚度的90%以上,从而改变角膜曲率,减少屈光度。该手术效果较好,矫正近视范围在600度以下,对医师的要求高,治疗效果依赖手术者的技巧和经验。该手术的缺陷为近视部分回退,炫光感,角膜瘢痕。
2、 眼内屈光手术(IOL)
该手术适合老年人及超高度近视眼的治疗,通过摘除透明或不透明晶体,植入不同的前房或后房型人工晶体来改变原有的屈光度。优点是治疗后屈光稳定、无回退、术后恢复快。
3、 准分子激光手术(PRK)
准分子激光手术是利用193nm波长的紫外激光准确切削角膜的光学区,重塑角膜表面屈率。用于治疗近视,矫治近视的范围以600以下效果最好。存在的缺点是些术破坏了角膜的前弹力层,易造成角膜雾状混浊,视力回退及类固醇性高眼压,少数病人术后一段时间视力回退。
4、 准分子激光是角膜原位磨镶术(LASIK读"来塞克")
该术的治疗原理同PRK,但它在不破坏角膜及前弹力层的基础上,用准分子激光在角膜基质层进行高精度的切削与原位磨镶相结合,使手术的预测性、稳定性、及安全性大大提高。该术矫治的范围广,可矫治3000度以下的任何近视(术前全面检查和各项指标都符合的情况下)治疗后,几乎无眼
部不适,无需遮眼,第二天即可上班、上学及参加体检。
5、准分子激光上皮瓣下角膜磨镶术(LASEK),此法用于角膜薄、近视度数高等特殊病例。中药治疗:
此方的提供者是一名执业中的中医师兼教授,他的爸爸也是中医师。有一天一起泡茶聊天时,聊到了这一道药方。
他的外甥曾经近视一千度,他就叫他煮用以上这道药方, 每天喝。八个月后外甥的近视降到只有两百度。
所以这是一有经亲身体验而成功过的药方。
药方:龙眼肉+龙眼核(即带核的龙眼)、枸杞
煮法:以上三味适量,加水煮成茶,龙眼核不必打碎。
服法:就当一般茶来喝就好,每天喝,至少连喝两个月。 (没效可放弃不再喝,有效而还不满意,则应续喝。)
疗效:一切跟眼睛的水晶体不正常有关的眼睛问题,包括近视,远视,散光等等。
重点:一定要用龙眼核,只用龙眼肉,则效果折半。
建议:请饭后喝,效果最佳。(因为病在头部,而饭后喝会使药性发挥在头部较多,也就是此方的目的
任何滋补品都不要过量食用,枸杞子也不例外。一般来说,健康的成年人每天吃20克 约120--160粒 注:一克=8粒枸杞
粒左右的枸杞子比较合适;如果想起到治疗的效果,每天最好吃30克左右。现在,很多关于枸杞子毒性的动物实验证明,枸杞子是非常安全的食物,
里面不含任何毒素,可以长期食用。
十二颗带核的龙眼干+龙眼肉+一小把枸杞(25克,大概200粒)+加菊花
-
LoadRunner常见测试结果分析【转载】
2009-05-13 10:50:23
LoadRunner常见测试结果分析
分析原则:
<1> 具体问题具体分析(这是由于不同的应用系统,不同的测试目的,不同的性能关注点)
<2> 查找瓶颈时按以下顺序,由易到难。
服务器硬件瓶颈-〉网络瓶颈(对局域网,可以不考虑)-〉服务器操作系统瓶颈(参数配置)-〉中间件瓶颈(参数配置,数据库,web服务器等)-〉应用瓶颈(SQL语句、数据库设计、业务逻辑、算法等)
注:以上过程并不是每个分析中都需要的,要根据测试目的和要求来确定分析的深度。对一些要求低的,我们分析到应用系统在将来大的负载压力(并发用户数、数据量)下,系统的硬件瓶颈在哪儿就够了。
<3>分段排除法 很有效。
<4>分析的信息来源:
1 根据场景运行过程中的错误提示信息
2 根据测试结果收集到的监控指标数据
一.错误提示分析
分析实例:
1 •Error: Failed to connect to server "10.10.10.30:8080": [10060] Connection
•Error: timed out Error: Server "10.10.10.30" has shut down the connection prematurely
分析:
•A、应用服务死掉。
(小用户时:程序上的问题。程序上处理数据库的问题)
•B、应用服务没有死
(应用服务参数设置问题)
例:在许多客户端连接Weblogic应用服务器被拒绝,而在服务器端没有错误显示,则有可能是Weblogic中的server元素的AcceptBacklog属性值设得过低。如果连接时收到connection refused消息,说明应提高该值,每次增加25%
•C、数据库的连接
(1、在应用服务的性能参数可能太小了 2、数据库启动的最大连接数(跟硬件的内存有关))
2 Error: Page download timeout (120 seconds) has expired
分析:
可能是以下原因造成
•A、应用服务参数设置太大导致服务器的瓶颈
•B、页面中图片太多
•C、在程序处理表的时候检查字段太大多
二.监控指标数据分析
1.最大并发用户数:
应用系统在当前环境(硬件环境、网络环境、软件环境(参数配置))下能承受的最大并发用户数。
在方案运行中,如果出现了大于3个用户的业务操作失败,或出现了服务器shutdown的情况,则说明在当前环境下,系统承受不了当前并发用户的负载压力,那么最大并发用户数就是前一个没有出现这种现象的并发用户数。
如果测得的最大并发用户数到达了性能要求,且各服务器资源情况良好,业务操作响应时间也达到了用户要求,那么OK。否则,再根据各服务器的资源情况和业务操作响应时间进一步分析原因所在。
2.业务操作响应时间:
• 分析方案运行情况应从平均事务响应时间图和事务性能摘要图开始。使用“事务性能摘要”图,可以确定在方案执行期间响应时间过长的事务。
• 细分事务并分析每个页面组件的性能。查看过长的事务响应时间是由哪些页面组件引起的?问题是否与网络或服务器有关?
• 如果服务器耗时过长,请使用相应的服务器图确定有问题的服务器度量并查明服务器性能下降的原因。如果网络耗时过长,请使用“网络监视器”图确定导致性能瓶颈的网络问题
3.服务器资源监控指标:
内存:
1 UNIX资源监控中指标内存页交换速率(Paging rate),如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。也可能是内存访问命中率低。
2 Windows资源监控中,如果Process\Private Bytes计数器和Process\Working Set计数器的值在长时间内持续升高,同时Memory\Available bytes计数器的值持续降低,则很可能存在内存泄漏。
内存资源成为系统性能的瓶颈的征兆:
很高的换页率(high pageout rate);
进程进入不活动状态;
交换区所有磁盘的活动次数可高;
可高的全局系统CPU利用率;
内存不够出错(out of memory errors)
处理器:
1 UNIX资源监控(Windows操作系统同理)中指标CPU占用率(CPU utilization),如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。如果服务器专用于SQL Server,可接受的最大上限是80-85%
合理使用的范围在60%至70%。
2 Windows资源监控中,如果System\Processor Queue Length大于2,而处理器利用率(Processor Time)一直很低,则存在着处理器阻塞。
CPU资源成为系统性能的瓶颈的征兆:
很慢的响应时间(slow response time)
CPU空闲时间为零(zero percent idle CPU)
过高的用户占用CPU时间(high percent user CPU)
过高的系统占用CPU时间(high percent system CPU)
长时间的有很长的运行进程队列(large run queue size sustained over time)
磁盘I/O:
1 UNIX资源监控(Windows操作系统同理)中指标磁盘交换率(Disk rate),如果该参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统。
2 Windows资源监控中,如果 Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec页面读取操作速率很低,则可能存在磁盘瓶径。
I/O资源成为系统性能的瓶颈的征兆 :
过高的磁盘利用率(high disk utilization)
太长的磁盘等待队列(large disk queue length)
等待磁盘I/O的时间所占的百分率太高(large percentage of time waiting for disk I/O)
太高的物理I/O速率:large physical I/O rate(not sufficient in itself)
过低的缓存命中率(low buffer cache hit ratio(not sufficient in itself))
太长的运行进程队列,但CPU却空闲(large run queue with idle CPU)
4.数据库服务器:
SQL Server数据库:
1 SQLServer资源监控中指标缓存点击率(Cache Hit Ratio),该值越高越好。如果持续低于80%,应考虑增加内存。
2 如果Full Scans/sec(全表扫描/秒)计数器显示的值比1或2高,则应分析你的查询以确定是否确实需要全表扫描,以及SQL查询是否可以被优化。
3 Number of Deadlocks/sec(死锁的数量/秒):死锁对应用程序的可伸缩性非常有害,并且会导致恶劣的用户体验。该计数器的值必须为0。
4 Lock Requests/sec(锁请求/秒),通过优化查询来减少读取次数,可以减少该计数器的值。
Oracle数据库:
1 如果自由内存接近于0而且库快存或数据字典快存的命中率小于0.90,那么需要增加SHARED_POOL_SIZE的大小。
快存(共享SQL区)和数据字典快存的命中率:
select(sum(pins-reloads))/sum(pins) from v$librarycache;
select(sum(gets-getmisses))/sum(gets) from v$rowcache;
自由内存: select * from v$sgastat where name=’free memory’;
2 如果数据的缓存命中率小于0.90,那么需要加大DB_BLOCK_BUFFERS参数的值(单位:块)。
缓冲区高速缓存命中率:
select name,value from v$sysstat where name in ('db block gets’,
'consistent gets','physical reads') ;
Hit Ratio = 1-(physical reads / ( db block gets + consistent gets))
3 如果日志缓冲区申请的值较大,则应加大LOG_BUFFER参数的值。
日志缓冲区的申请情况 :
select name,value from v$sysstat where name = 'redo log space requests' ;
4 如果内存排序命中率小于0.95,则应加大SORT_AREA_SIZE以避免磁盘排序 。
内存排序命中率 :
select round((100*b.value)/decode((a.value+b.value), 0, 1, (a.value+b.value)), 2)from v$sysstat a, v$sysstat b where a.name='sorts (disk)' and b.name='sorts (memory)'在测试过程中,可能会出现以下常见的几种测试情况:
一、当事务响应时间的曲线开始由缓慢上升,然后处于平衡,最后慢慢下降这种情形表明:
* 从事务响应时间曲线图持续上升表明系统的处理能力在下降,事务的响应时间变长;
* 持续平衡表明并发用户数达到一定数量,在多也可能接受不了,再有请求数,就等待;
* 当事务的响应时间在下降,表明并发用户的数量在慢慢减少,事务的请求数也在减少。
如果系统没有这种下降机制,响应时间越来越长,直到系统瘫痪。
从以上的结果分析可发现是由以下的原因引起:
1. 程序中用户数连接未做限制,导致请求数不断上升,响应时间不断变长;
2. 内存泄露;
二、CPU的使用率不断上升,内存的使用率也是不断上升,其他一切都很正常;
表明系统中可能产生资源争用情况;
引起原因:
开发人员注意资源调配问题。
三、 所有的事务响应时间、cpu等都很正常,业务出现失败情况;
引起原因:
数据库可能被锁,就是说,你在操作一张表或一条记录,别人就不能使用,即数据存在互斥性;
当数据量大时,就会出现数据错乱情况。
四.磁盘队列值上升的同时,页面读取并未下降,则可能是内存不足,并不是内存泄漏
-
LoadRunner安装在虚拟机上要注意的
2009-05-13 10:05:13
1、 虚拟机首选用vmware,稳定好用
2、在vmware上装lr时,网络类型在选择Host-only、NAT和Bridge中任选一个就可以了。主要看你自己的需要
三种网络类型的区别在于
host-only :支持虚拟机之间的互联和本机的互联,不能访问外网。
NAT:共享本机的真实网卡和IP地址访问外网。
Bridge:可以模拟出一块虚拟的网卡,让他有独立的IP和mark地址可以访问外网。
一般常用Host-only
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 244557
- 日志数: 139
- 图片数: 1
- 建立时间: 2009-01-06
- 更新时间: 2017-06-09
