
-
HttpUnit
2010-02-01 14:47:28
HttpUnit是一个集成测试工具,主要关注Web应用的测试,提供的帮助类让测试者可以通过Java类和服务器进行交互,并且将服务器端的响应当作文本或者DOM对象进行处理。HttpUnit还提供了一个模拟Servlet容器,让你可以不需要发布Servlet,就可以对Servlet的内部代码进行测试。本文中作者将详细的介绍如何使用HttpUnit提供的类完成集成测试。
1. 如何使用httpunit处理页面的内容
- WebConversation类是HttpUnit框架中最重要的类,它用于模拟浏览器的行为
- WebRequest类,模仿客户请求,通过它可以向服务器发送信息
- WebResponse类,模拟浏览器获取服务器端的响应信息
1.1 获取指定页面的内容
1.1.1 直接获取页面内容java 代码- System.out.println("直接获取网页内容:");
- //建立一个WebConversation实例
- WebConversation wc = new WebConversation();
- //向指定的URL发出请求,获取响应
- WebResponse wr = wc.getResponse( "http://localhost:6888/HelloWorld.html" );
- //用getText方法获取相应的全部内容
- //用System.out.println将获取的内容打印在控制台上
- System.out.println( wr.getText() );
1.1.2 通过Get方法访问页面并且加入参数
java 代码- System.out.println("向服务器发送数据,然后获取网页内容:");
- //建立一个WebConversation实例
- WebConversation wc = new WebConversation();
- //向指定的URL发出请求
- WebRequest req = new GetMethodWebRequest( "http://localhost:6888/HelloWorld.jsp" );
- //给请求加上参数
- req.setParameter("username","姓名");
- //获取响应对象
- WebResponse resp = wc.getResponse( req );
- //用getText方法获取相应的全部内容
- //用System.out.println将获取的内容打印在控制台上
- System.out.println( resp.getText() );
1.1.3 通过Post方法访问页面并且加入参数
java 代码- System.out.println("使用Post方式向服务器发送数据,然后获取网页内容:");
- //建立一个WebConversation实例
- WebConversation wc = new WebConversation();
- //向指定的URL发出请求
- WebRequest req = new PostMethodWebRequest( "http://localhost:6888/HelloWorld.jsp" );
- //给请求加上参数
- req.setParameter("username","姓名");
- //获取响应对象
- WebResponse resp = wc.getResponse( req );
- //用getText方法获取相应的全部内容
- //用System.out.println将获取的内容打印在控制台上
- System.out.println( resp.getText() );
大家关注一下上面代码中打了下划线的两处内容,应该可以看到,使用Get、Post方法访问页面的区别就是使用的请求对象不同。
1.2 处理页面中的链接
这里的演示是找到页面中的某一个链接,然后模拟用户的单机行为,获得它指向文件的内容。比如在我的页面HelloWorld.html中有一个链接,它显示的内容是TestLink,它指向我另一个页面TestLink.htm. TestLink.htm里面只显示TestLink.html几个字符。
下面是处理代码:java 代码- System.out.println("获取页面中链接指向页面的内容:");
- //建立一个WebConversation实例
- WebConversation wc = new WebConversation();
- //获取响应对象
- WebResponse resp = wc.getResponse( "http://localhost:6888/HelloWorld.html" );
- //获得页面链接对象
- WebLink link = resp.getLinkWith( "TestLink" );
- //模拟用户单击事件
- link.click();
- //获得当前的响应对象
- WebResponse nextLink = wc.getCurrentPage();
- //用getText方法获取相应的全部内容
- //用System.out.println将获取的内容打印在控制台上
- System.out.println( nextLink.getText() );
1.3 处理页面中的表格
表格是用来控制页面显示的常规对象,在HttpUnit中使用数组来处理页面中的多个表格,你可以用resp.getTables()方法获取页面所有的表格对象。他们依照出现在页面中的顺序保存在一个数组里面。[注意] Java中数组下标是从0开始的,所以取第一个表格应该是resp.getTables()[0],其他以此类推。
下面的例子演示如何从页面中取出第一个表格的内容并且将他们循环显示出来:
java 代码- System.out.println("获取页面中表格的内容;");
- //建立一个WebConversation实例
- WebConversation wc = new WebConversation();
- //获取响应对象
- WebResponse resp = wc.getResponse( "http://localhost:6888/HelloWorld.html" );
- //获得对应的表格对象
- WebTable webTable = resp.getTables()[0];
- //将表格对象的内容传递给字符串数组
- String[][] datas = webTable.asText();
- //循环显示表格内容
- int i = 0 ,j = 0;
- int m = datas[0].length;
- int n = datas.length;
- while (i
- j=0;
- while(j
- System.out.println("表格中第"+(i+1)+"行第"+
- (j+1)+"列的内容是:"+datas[i][j]);
- ++j;
- }
- ++i;
- }
1.4 处理页面中的表单
表单是用来接受用户输入,也可以向用户显示用户已输入信息(如需要用户修改数据时,通常会显示他以前输入过的信息),在HttpUnit中使用数组来处理页面中的多个表单,你可以用resp.getForms()方法获取页面所有的表单对象。他们依照出现在页面中的顺序保存在一个数组里面。[注意] Java中数组下标是从0开始的,所以取第一个表单应该是resp.getForms()[0],其他以此类推。
下面的例子演示如何从页面中取出第一个表单的内容并且将他们循环显示出来:
java 代码- System.out.println("获取页面中表单的内容:");
- //建立一个WebConversation实例
- WebConversation wc = new WebConversation();
- //获取响应对象
- WebResponse resp = wc.getResponse( "http://localhost:6888/HelloWorld.html" );
- //获得对应的表单对象
- WebForm webForm = resp.getForms()[0];
- //获得表单中所有控件的名字
- String[] pNames = webForm.getParameterNames();
- int i = 0;
- int m = pNames.length;
- //循环显示表单中所有控件的内容
- while(i
- System.out.println("第"+(i+1)+"个控件的名字是"+pNames[i]+
- ",里面的内容是"+webForm.getParameterValue(pNames[i]));
- ++i;
- }
2. 如何使用httpunit进行测试
2.1 对页面内容进行测试
httpunit中的这部分测试完全采用了JUnit的测试方法,即直接将你期望的结果和页面中的输出内容进行比较。不过这里的测试就简单多了,只是字符串和字符串的比较。比如你期望中的页面显示是中有一个表格,它是页面中的第一个表格,而且他的第一行第一列的数据应该是显示username,那么你可以使用下面的代码进行自动化测试:
java 代码- System.out.println("获取页面中表格的内容并且进行测试:");
- //建立一个WebConversation实例
- WebConversation wc = new WebConversation();
- //获取响应对象
- WebResponse resp = wc.getResponse( "http://localhost:6888/TableTest.html" );
- //获得对应的表格对象
- WebTable webTable = resp.getTables()[0];
- //将表格对象的内容传递给字符串数组
- String[][] datas = webTable.asText();
- //对表格内容进行测试
- String expect = "中文";
- Assert.assertEquals(expect,datas[0][0]);
2.2 对Servlet进行测试
除了对页面内容进行测试外,有时候(比如开发复杂的Servlets的时候),你需要对Servlet本身的代码块进行测试,这时候你可以选择HttpUnit,它可以提供一个模拟的Servlet容器,让你的Servlet代码不需要发布到Servlet容器(如tomcat)就可以直接测试。2.2.1 原理简介
使用httpunit测试Servlet时,请创建一个ServletRunner的实例,他负责模拟Servlet容器环境。如果你只是测试一个Servlet,你可以直接使用registerServlet方法注册这个Servlet,如果需要配置多个Servlet,你可以编写自己的web.xml,然后在初始化ServletRunner的时候将它的位置作为参数传给ServletRunner的构造器。在测试Servlet时,应该记得使用ServletUnitClient类作为客户端,他和前面用过的WebConversation差不多,都继承自WebClient,所以他们的调用方式基本一致。要注意的差别是,在使用ServletUnitClient时,他会忽略URL中的主机地址信息,而是直接指向他的ServletRunner实现的模拟环境。
2.2.2 简单测试
本实例只是演示如何简单的访问Servlet并且获取他的输出信息,例子中的Servlet在接到用户请求的时候只是返回一串简单的字符串:Hello World!.1. Servlet的代码如下:
java 代码- package janier.servlet;
- import java.io.IOException;
- import java.io.PrintWriter;
- import javax.servlet.http.HttpServlet;
- import javax.servlet.http.HttpServletRequest;
- import javax.servlet.http.HttpServletResponse;
- /**
- * @author Janier
- *
- */
- public class HelloWorld extends HttpServlet {
- /**
- *
- */
- private static final long serialVersionUID = 7242188527423883719L;
- public void service(HttpServletRequest req, HttpServletResponse resp)
- throws IOException
- {
- PrintWriter out = resp.getWriter();
- //向浏览器中写一个字符串Hello World!
- out.println("Hello World!");
- out.close();
- }
- }
- import java.io.PrintWriter;
2. 测试的调用代码如下:
java 代码- package test.servlet;
- import janier.servlet.HelloWorld;
- import com.meterware.httpunit.GetMethodWebRequest;
- import com.meterware.httpunit.WebRequest;
- import com.meterware.httpunit.WebResponse;
- import com.meterware.servletunit.ServletRunner;
- import com.meterware.servletunit.ServletUnitClient;
- import junit.framework.TestCase;
- /**
- * @author Janier
- *
- */
- public class HttpUnitTestHelloWorld extends TestCase{
- protected void setUp() throws Exception {
- super.setUp();
- }
- protected void tearDown() throws Exception {
- super.tearDown();
- }
- public void testHelloWorld() {
- try {
- //创建Servlet的运行环境
- ServletRunner sr = new ServletRunner();
- //向环境中注册Servlet
- sr.registerServlet( "HelloWorld", HelloWorld.class.getName() );
- //创建访问Servlet的客户端
- ServletUnitClient sc = sr.newClient();
- //发送请求
- WebRequest request = new GetMethodWebRequest( "http://localhost/HelloWorld" );
- //获得模拟服务器的信息
- WebResponse response = sc.getResponse( request );
- //将获得的结果打印到控制台上
- System.out.println(response.getText());
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
2.2 测试Servlet的内部行为
下面的代码演示了如何使用HttpUnit模拟Servlet容器,并且通过InvocationContext对象,测试Servlet内部行为的大部分工作,比如控制request、session、response等。1.测试代码
java 代码- package test.servlet;
- import janier.servlet.HelloWorld;
- import com.meterware.httpunit.GetMethodWebRequest;
- import com.meterware.httpunit.WebRequest;
- import com.meterware.httpunit.WebResponse;
- import com.meterware.servletunit.InvocationContext;
- import com.meterware.servletunit.ServletRunner;
- import com.meterware.servletunit.ServletUnitClient;
- import junit.framework.Assert;
- import junit.framework.TestCase;
- /**
- * @author Janier
- *
- */
- public class HttpUnitTestHelloWorld extends TestCase{
- protected void setUp() throws Exception {
- super.setUp();
- }
- protected void tearDown() throws Exception {
- super.tearDown();
- }
- public void testHelloWorld() {
- try {
- // 创建Servlet的运行环境
- ServletRunner sr = new ServletRunner();
- //向环境中注册Servlet
- sr.registerServlet( "HelloWorld", HelloWorld.class.getName() );
- //创建访问Servlet的客户端
- ServletUnitClient sc = sr.newClient();
- //发送请求
- WebRequest request = new GetMethodWebRequest( "http://localhost/HelloWorld" );
- request.setParameter("username","testuser");
- //获得该请求的上下文环境
- InvocationContext ic = sc.newInvocation( request );
- //调用Servlet的非服务方法
- HelloWorld is = (HelloWorld)ic.getServlet();
- //测试servlet的某个方法
- Assert.assertTrue(is.authenticate());
- //直接通过上下文获得request对象
- System.out.println("request中获取的内容:"+ic.getRequest().getParameter("username"));
- //直接通过上下文获得response对象,并且向客户端输出信息
- ic.getResponse().getWriter().write("haha");
- //直接通过上下文获得session对象,控制session对象,给session赋值
- ic.getRequest().getSession().setAttribute("username","timeson");
- //获取session的值
- System.out.println("session中的值:"+ic.getRequest().getSession().getAttribute("username"));
- //使用客户端获取返回信息,并且打印出来
- WebResponse response = ic.getServletResponse();
- System.out.println(response.getText());
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
2.调用代码
java 代码- package janier.servlet;
- import java.io.IOException;
- import javax.servlet.http.HttpServlet;
- import javax.servlet.http.HttpServletRequest;
- import javax.servlet.http.HttpServletResponse;
- /**
- * @author Janier
- *
- */
- public class HelloWorld extends HttpServlet {
- public void saveToSession(HttpServletRequest request) {
- request.getSession().setAttribute("testAttribute",request.getParameter("testparam"));
- }
- public void doGet(HttpServletRequest request,
- HttpServletResponse response) throws IOException{
- String username=request.getParameter("username");
- response.getWriter().write(username+":Hello World!");
- }
- public boolean authenticate(){
- return true;
- }
- }
对于开发者来说,仅仅测试请求和返回信息是不够的,所以HttpUnit提供的ServletRunner模拟器可以让你对被调用Servlet内部的行为进行测试。和简单测试中不同,这里使用了InvocationContext获得该Servlet的环境,然后你可以通过InvocationContext对象针对request、response等对象或者是该Servlet的内部行为(非服务方法)进行操作。
上述例子其实是junit的一个测试例子,在其中使用了httpunit模拟的servlet环境,使用上述方法测试servlet可以脱离容器,容易把该测试写入ant或maven脚本,让测试进行。httpunit网址:http://httpunit.sourceforge.net/
使用该种方法测试的弱点就是:如果要使用request(response)的setCharercterEncoding方法时,测试会出现一些问题,而且httpunit在测试servlet行为时,采用的是完全模拟浏览器,有时测试比较难写。[注意]在测试Servlet的之前,你必须通过InvocationContext完成Servlet中的service方法中完成的工作,因为通过newInvocation方法获取InvocationContext实例的时候该方法并没有被调用。
3. Httpunit测试小总结
- 模拟用户行为向服务器发送请求,传递参数
- 模拟用户接受服务器的响应信息,并且通过辅助类分析这些响应信息,结合JUnit框架进行测试
- 使用HttpUnit提供的模拟Servler容器,测试开发中的Servlet的内部行为
Mock objects方法的最大优点就是,执行测试时不需要运行的容器。可以很快就建立起测试,而且测试运行速度也很快用mock objects来对J2EE组件进行单元测试的缺点是:
- 它们没有测试容器和组件的交互;
- 它们没有测试组件的部署部分;
- 需要熟悉被调用的API,这样才能模拟它,而这个要求可能太高了(尤其对于外部库而言);
- 无法让你确信代码会在目标容器中正常运行
-
读书笔记一
2010-02-01 10:12:48
http://www.uml.org.cn/Test/test.asp
测试计划中有关计划的相关主题:
- 测试结束标准
- 一些相关约定,部分模板中添加入“术语”一栏
- 测试工作中产生的文档及定义(测试用例文档,缺陷报告文档等)
- 测试工作个团队之前的协调工作,主要包括开发组需要对测试组提供的相关帮助
- 测试的范围
- 测试的时间安排(时间进度表)
- 测试的策略
- 测试过程中的资源要求
- 测试人员的任务分派
- 测试中可能遇到的风险等问题
- 测试工作的度量和统计
- 测试工具相关的计划
等等。
以上这些主题都是常见且有助于我们做好计划工作的内容,至于测试费用等的计划,笔者认为适当估计但不要过分追求,因为在实际的操作过程中,测试工作延期、测试工具购置、人员流动造成的培训费用等会打乱这个计划,并且在测试计划中列出的费用是不会跟财务直接挂钩的,具体费用还得依照公司专用流程,因此“测试费用”这类主题在笔者计划测试的过程中不会考虑太多。
也就是5W1H定义:
> WHY:为什么要写测试计划;
> WHAT:测试什么;
> WHEN:测试不同阶段的起止时间;
> WHERE:文档放哪;
> WHO:哪些人去做;
> HOW:怎么测试;中国有句老话“养兵千日,用在一时”。这句话往往是在临战的时候将军(测试负责人)对战士(普通测试人员)说的。中国古代还有一个方法叫做“战时兵闲时农”的策略,即我们广大的劳动人民在没有战争的时候安心种我们的地,一旦战争爆发或者国家需要的时候我们就披上盔甲去作战。这两句话给我们一个提示:我们应该培养我们的测试人员或者说我们的测试队伍。
者 先拿“养兵千日用在一时”来讲,正如我上面提到的,往往在临战的时候大家才想起这句话,可是我们不妨倒过来想一想,一时的用是需要千日的积累的。这也是在提示我们,一支优秀的测试队伍的每个人都应该是优秀的并且我们需要在“用一时”之前好好“养千日”。这种积累不是一天两天可以形成的,正所谓冰冻三尺非一日之寒。为什么要在谈论计划测试的时候谈论这个问题呢?原因在于“巧妇难为无米之炊”,我们在做计划的时候如果发现没有一个可用之才,那我们的计划怕是做不下去了,或者我们只有准备另外招新人到行伍中间来,亦或者只能外包测试给专业队伍,这无疑又增加了项目的风险,因为新人或者其他队伍使我们不了解的,他们会做成什么样子只有老天知道,当我们把命运交给老天的时候,这相当于在玩火。我们需要把“养千日兵”拉到我们的计划中来,从更加长远的角度来计划一下我们的测试工作,测试方向等等。对于人才的培养,一般使用的是人尽其才的分工制度,即某一个或者一些人熟练掌握某一些测试技能,并对其他技能有所了解,最理想的情况下,我们在测试的方向(或者说是本公司主要的开发方向相关联的各个测试技术方面)都有“专家”,这样才可以保证一个测试队伍可以应付不可预知的测试任务。
我们的学习方向,笔者大概归纳一下:
> 测试理论(包括测试基本概念,流程,管理等等内容。对于测试来讲,这才是基本)
> 测试文档 (虽然网络上的文档中的内容对于目前的你来说不可能完全有用,但是知道一份专业或者说完整的文档是怎么写的也是必要的)
> 测试工具(对于刚起步的测试人员,如果你不是开发大牛,建议你还是先使用别人已经写好的工具)
> 开发知识 (有则加之,无则添之,总是是要学,因为这一点是为将来打算,这些知识有助于我们更好地测试)
对于一般外包项目来讲,对于测试要求相对较低,而时间是固定的。对于这种项目的测试工作来讲,一般是标准的段段式的,即计划测试,测试用例设计,测试用例执行及bug管理,测试报告提交等等阶段。这就好弄多了,根据经验(如果一点经验都没有,那还有直觉)我们把这几个阶段换算成比例,然后把测试总时间瓜分了,需要提醒大家的就是记得在瓜分之后留点“缓冲时间”来,否则到时候出了点意外就麻烦了,记住是在每段时间之后加上一个缓冲期,而不是最后加上一次。
对于产品来讲,测试要求会比较高,时间当然也是需要考虑的,套用IT界最常被引用的一句话,“在这个瞬息万变的时代”,把握时机对于一个产品来讲无疑是很重要的。这个时候我们还是先将测试分段,对于这种项目,我们首先站在测试质量的角度,实事求是按照功能点数目、难度,测试经验等来估计测试时间,然后将总时间加起来,如果时间充裕,我们考虑加入更多测试面,如果时间紧迫,我们考虑是否删除部分非核心功能,以降低开发和测试的时间成本,从而为测试质量保驾护航
测试标准应该包含的内容:
》有效测试用例(功能)执行率达到X%?
》单元测试代码行覆盖率达到X%?
》单元测试用例通过率X%?
》单元测试用例设计通过评审
》核心模块(A,;B,D等模块)测试覆盖
》所发现缺陷均纳入缺陷管理系统
》优先级最高的bug全部修复
》其他bug全部被处理(修复,延迟并报告等处理方式)
》功能测试用例模块,功能点覆盖率达到?
按照测试类型来的测试停止标准:
比如单元测试活动在满足以下所有条件之后可停止:
》核心模块代码100% 经过Code Review
》单元测试用例设计通过评审
》测试用例执行率100%
》最新版本的单元测试通过率为100%
》单元测试全局代码行覆盖率不低于80%
》单元测试单个模块代码行覆盖率不低于70%
》单元测试中被测单元发现的bug产生率不低于3个/千行代码
》所有发现缺陷都纳入缺陷追踪系统
》优先级1类bug全部被修复
》优先级2,3类bug全部被处理(修复或者不处理并明确在测试报告指出且获得通过)
》完成了单元测试报告并通过评审
……
实际工作中会出现的停止“标准”
测试活动在满足下列条件之一时需要暂停或者终止:
》新的需求变更过大,测试活动应暂停,待需求定义稳定后继续;
》测试超过了预定时间,且测试时间不可能继续增加的情况下应停止测试;
》测试成本增高(Bug发现率低于1个/周,此时所发现缺陷低于预定义的上限);
》若开发暂停,则相应测试也应暂停,并备份暂停点数据;
》软件系统通过验收测试;
》软件项目在其开发生命周期内出现重大估算和进度偏差,需暂停或终止时,测试应随之暂停或终止,并备份暂停或终止点数据;
》项目负责人申明停止项目;
》团队集体(开发,管理,测试,市场,销售人员)同意停止项目(因市场及利益等原因);
…… -
初学UML之-------用例图
2010-01-22 10:50:43
转自网络
一.UML简介
UML(统一建模语言,Unified Modeling Language)是一种定义良好、易于表达、功能强大且普遍适用的可视化建模语言。它融入了软件工程领域的新思想、新方法和新技术。它的作用域不限于支持面向对象的分析与设计,还支持从需求分析开始的软件开发的全过程。在系统分析阶段,我们一般用UML来画很多图,主要包括用例图、状态图、类图、活动图、序列图、协作图、构建图、配置图等等,要画哪些图要根据具体情况而定。其实简单的理解,也是个人的理解,UML的作用就是用很多图从静态和动态方面来全面描述我们将要开发的系统。
二.用例建模简介
用例建模是UML建模的一部分,它也是UML里最基础的部分。用例建模的最主要功能就是用来表达系统的功能性需求或行为。依我的理解用例建模可分为用例图和用例描述。用例图由参与者(Actor)、用例(Use Case)、系统边界、箭头组成,用画图的方法来完成。用例描述用来详细描述用例图中每个用例,用文本文档来完成。
1. 用例图
参与者不是特指人,是指系统以外的,在使用系统或与系统交互中所扮演的角色。因此参与者可以是人,可以是事物,也可以是时间或其他系统等等。还有一点要注意的是,参与者不是指人或事物本身,而是表示人或事物当时所扮演的角色。比如小明是图书馆的管理员,他参与图书馆管理系统的交互,这时他既可以作为管理员这个角色参与管理,也可以作为借书者向图书馆借书,在这里小明扮演了两个角色,是两个不同的参与者。参与者在画图中用简笔人物画来表示,人物下面附上参与者的名称。
用例是对包括变量在内的一组动作序列的描述,系统执行这些动作,并产生传递特定参与者的价值的可观察结果。这是 UML对用例的正式定义,对我们初学者可能有点难懂。我们可以这样去理解,用例是参与者想要系统做的事情。对于对用例的命名,我们可以给用例取一个简单、描述性的名称,一般为带有动作性的词。用例在画图中用椭圆来表示,椭圆下面附上用例的名称。
系统边界是用来表示正在建模系统的边界。边界内表示系统的组成部分,边界外表示系统外部。系统边界在画图中方框来表示,同时附上系统的名称,参与者画在边界的外面,用例画在边界里面。因为系统边界的作用有时候不是很明显,所以我个人理解,在画图时可省略。
箭头用来表示参与者和系统通过相互发送信号或消息进行交互的关联关系。箭头尾部用来表示启动交互的一方,箭头头部用来表示被启动的一方,其中用例总是要由参与者来启动。
2. 用例描述
用例图只是简单地用图描述了一下系统,但对于每个用例,我们还需要有详细的说明,这样就可以让别人对这个系统有一个更加详细的了解,这时我们就需要写用例描述。
对于用例描述的内容,一般没有硬性规定的格式,但一些必须或者重要的内容还是必须要写进用例描述里面的。用例描述一般包括:简要描述(说明)、前置(前提)条件、基本事件流、其他事件流、异常事件流、后置(事后)条件等等。下面说说各个部分的意思:
简要描述:对用例的角色、目的的简要描述;
前置条件:执行用例之前系统必须要处于的状态,或者要满足的条件;
基本事件流:描述该用例的基本流程,指每个流程都“正常”运作时所发生的事情,没有任何备选流和异常流,而只有最有可能发生的事件流;
其他事件流:表示这个行为或流程是可选的或备选的,并不是总要总要执行它们;
异常事件流:表示发生了某些非正常的事情所要执行的流程;
后置条件:用例一旦执行后系统所处的状态;三. 用例图和用例描述设计实例
这里用我开发的一个家教网站来简单的分析用例图的画法和用例描述的写法。这个网站我用UML完整的分析一下,以下我提取了用例图和用例描述的部分。这个家教网站分为前台客户系统和后台管理系统。
前台客户系统的用例图如下:

后台管理系统用例图如下:

感谢:http://www.51cto.com 2006-01-13 10:10 出处:51CTO.com整理
补充:
用例之间也可以存在包含、扩展和泛化等关系:
(1)包含关系:用例可以简单地包含其他用例具有的行为,并把它所包含的用例行为做为自身行为的一部分,这被称作包含关系。
(2)扩展关系:扩展关系是从扩展用例到基本用例的关系,它说明为扩展用例定义的行为如何插入到为基本用例定义的行为中。它是以隐含形式插入的,也就是说,扩展用例并不在基本用例中显示。在以下几种情况下,可使用扩展用例:
a.表明用例的某一部分是可选的系统行为(这样,您就可以将模型中的可选行为和必选行为分开);
b.表明只在特定条件(如例外条件)下才执行的分支流;
c.表明可能有一组行为段,其中的一个或多个段可以在基本用例中的扩展点处插入。所插入的行为段和插入的顺序取决于在执行基本用例时与主角进行的交互。
图2.3给出了一个扩展关系的例子,在还书的过程中,只有在例外条件(读者遗失书籍)的情况下,才会执行赔偿遗失书籍的分支流。

(3)泛化关系:用例可以被特别列举为一个或多个子用例,这被称做用例泛化。当父用例能够被使用时,任何子用例也可以被使用。如在图2.4中,订票是电话订票和网上订票的抽象。

------------------------------------------------------------
泛化、包含和扩展
泛化(Generalization)在面向对象的技术中无处不在,它的另一个名字也许更为著名,就是“继承”。下图给出了一个使用泛化的用例图:
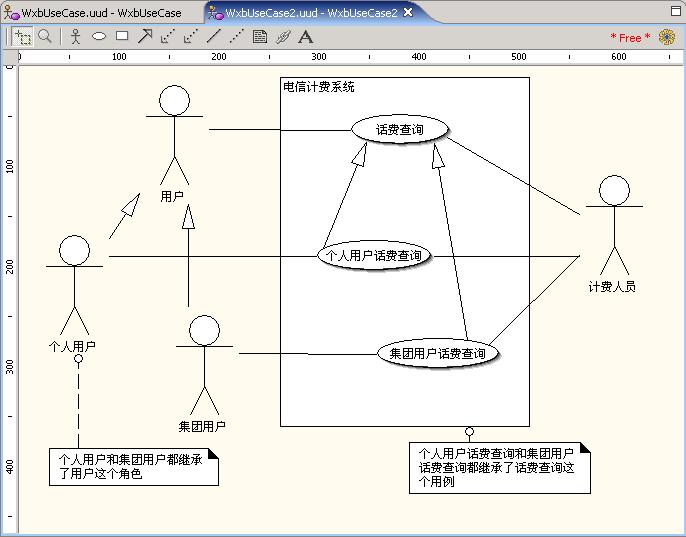
可知,在用例图中,角色和用例都能够泛化。角色的泛化/继承很容易理解,因为角色本来就是类(Class),它是一种版型(stereotype)为Actor的类,所以角色的继承直观而自然。但是用例的继承实际上分为两种情况,并不是简单的使用泛化,而是使用扩展(extended)和包含(include)两种泛化的特例。扩展用于子用例的动作步骤基本上和父用例的动作步骤相同,只是增加了另外的一些步骤的情况下。包含用于子用例包含了所有父用例的动作,它将父用例作为了自己的一个大步骤,子用例常常包含一个以上的父用例。如下图:

对于用例描述,篇幅有限,我在这里只列了后台管理系统中的网站公告发布这个用例的描述。如下:
四. 总结
其实用例建模并不是这么简单,它涉及到的知识还有很多,这里只是简单的介绍一下。 -
UML用例图
2010-01-22 10:41:18
转自网络:http://www.cnblogs.com/panjun-Donet/archive/2008/10/20/1315030.html
用例图主要用来图示化系统的主事件流程,它主要用来描述客户的需求,即用户希望系统具备的完成一定功能的动作,通俗地理解用例就是软件的功能模块,所以是设计系统分析阶段的起点,设计人员根据客户的需求来创建和解释用例图,用来描述软件应具备哪些功能模块以及这些模块之间的调用关系,用例图包含了用例和参与者,用例之间用关联来连接以求把系统的整个结构和功能反映给非技术人员(通常是软件的用户),对应的是软件的结构和功能分解。
用例是从系统外部可见的行为,是系统为某一个或几个参与者(Actor)提供的一段完整的服务。从原则上来讲,用例之间都是独立、并列的,它们之间并不存在着包含从属关系。但是为了体现一些用例之间的业务关系,提高可维护性和一致性,用例之间可以抽象出包含(include)、扩展(extend)和泛(generalization)几种关系。
共性:都是从现有的用例中抽取出公共的那部分信息,作为一个单独的用例,然后通后过不同的方法来重用这个公共的用例,以减少模型维护的工作量。
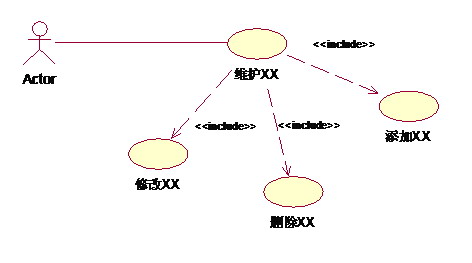
1、包含(include)包含关系:使用包含(Inclusion)用例来封装一组跨越多个用例的相似动作(行为片断),以便多个基(Base)用例复用。基用例控制与包含用例的关系,以及被包含用例的事件流是否会插入到基用例的事件流中。基用例可以依赖包含用例执行的结果,但是双方都不能访问对方的属性。
包含关系对典型的应用就是复用,也就是定义中说的情景。但是有时当某用例的事件流过于复杂时,为了简化用例的描述,我们也可以把某一段事件流抽象成为一个被包含的用例;相反,用例划分太细时,也可以抽象出一个基用例,来包含这些细颗粒的用例。这种情况类似于在过程设计语言中,将程序的某一段算法封装成一个子过程,然后再从主程序中调用这一子过程。例如:业务中,总是存在着维护某某信息的功能,如果将它作为一个用例,那新建、编辑以及修改都要在用例详述中描述,过于复杂;如果分成新建用例、编辑用例和删除用例,则划分太细。这时包含关系可以用来理清关系。
2、扩展(extend)
扩展关系:将基用例中一段相对独立并且可选的动作,用扩展(Extension)用例加以封装,再让它从基用例中声明的扩展点(Extension Point)上进行扩展,从而使基用例行为更简练和目标更集中。扩展用例为基用例添加新的行为。扩展用例可以访问基用例的属性,因此它能根据基用例中扩展点的当前状态来判断是否执行自己。但是扩展用例对基用例不可见。
对于一个扩展用例,可以在基用例上有几个扩展点。
例如,系统中允许用户对查询的结果进行导出、打印。对于查询而言,能不能导出、打印查询都是一样的,导出、打印是不可见的。导入、打印和查询相对独立,而且为查询添加了新行为。因此可以采用扩展关系来描述: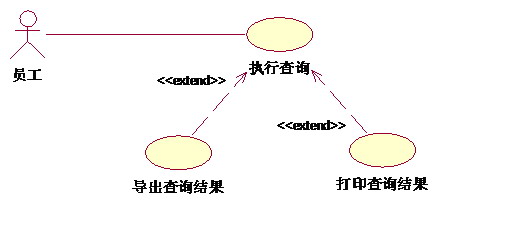
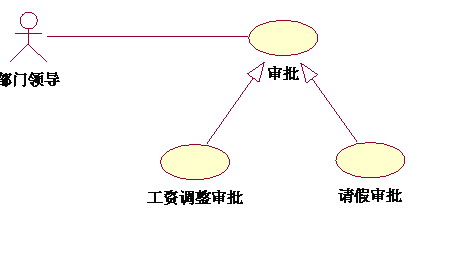
4、泛化(generalization)泛化关系:子用例和父用例相似,但表现出更特别的行为;子用例将继承父用例的所有结构、行为和关系。子用例可以使用父用例的一段行为,也可以重载它。父用例通常是抽象的。在实际应用中很少使用泛化关系,子用例中的特殊行为都可以作为父用例中的备选流存在。
例如,业务中可能存在许多需要部门领导审批的事情,但是领导审批的流程是很相似的,这时可以做成泛化关系表示:
上面是我参考的一篇文章,觉得将三种关系的区别讲得很清晰,在此基础上结合自己的系统,对项目(在线购物系统)的用例做了整体的描绘。
*****************************************************************
(1)系统整体用例图
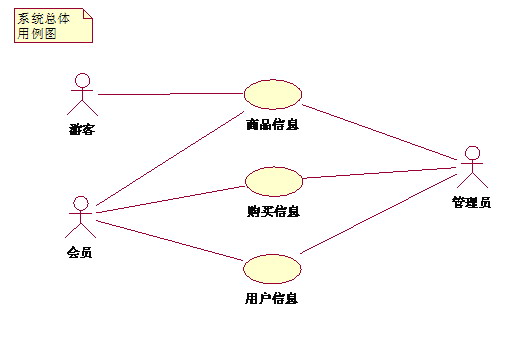
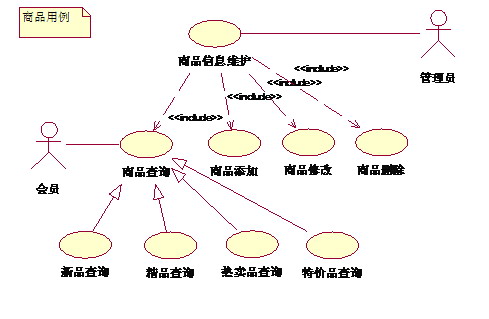
(商品用例图)
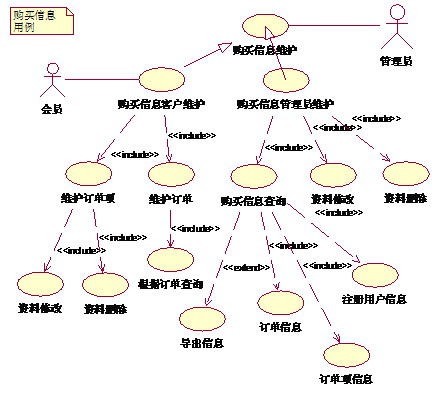
(购买信息用例)
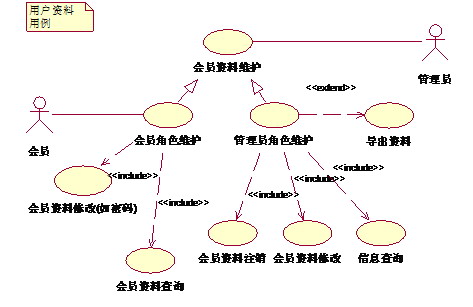
(用户资料用例)
按照先整体用例,后子系统用例来进行描绘的,欢迎大家提出好的建议!
转:UML中扩展和泛化的区别
泛化表示类似于OO术语“继承”或“多态”。UML中的Use Case泛化过程是将不同Use Case之间的可合并部分抽象成独立的父Use Case,并将不可合并部分单独成各自的子Use Case;包含以及扩展过程与泛化过程类似,但三者对用例关系的优化侧重点是不同的。如下:
●泛化侧重表示子用例间的互斥性;
●包含侧重表示被包含用例对Actor提供服务的间接性;
●扩展侧重表示扩展用例的触发不定性;详述如下:
既然用例是系统提供服务的UML表述,那么服务这个过程在所有用例场景中是必然发生的,但发生按照发生条件可分为如下两种情况:
⒈无条件发生:肯定发生的;
⒉有条件发生:未必发生,发生与否取决于系统状态;因此,针对用例的三种关系结合系统状态考虑,泛化与包含用例属于无条件发生的用例,而扩展属于有条件发生的用例。进一步,用例的存在是为Actor提供服务,但用例提供服务的方式可分为间接和直接两种,依据于此,泛化中的子用例提供的是直接服务,而包含中的被包含用例提供的是间接服务。同样,扩展用例提供的也是直接服务,但扩展用例的发生是有条件的。
另外一点需要提及的是:泛化中的子用例和扩展中的扩展用例均可以作为基本用例事件的备选择流而存在。
-
理解业务用例与系统用例的相似和不同之处
2010-01-21 15:26:26
学习有关业务用例与系统用例相似和不同之处的知识,包括应该使用什么样的 UML 图,通过建模工具来建模这些用例。绝大多数构架师都认为业务建模是开发软件解决方案中到一个非常重要的活动。成功的解决方案会支持这个业务,它们能够解决业务问题并确保业务目标的实现。
当开发一个合理的业务模型以后,业务流程分析员能够探究不同业务改进的选项,比如取消多余的任务,使重复且平凡的任务或者容易出现的错误实现自动化操作。 IBM® Rational Unified Process®,或者 RUP®,以及 Unisys 3D Visual Enterprise,或者 3D-VE, 或者 3D-VE,提供了一个系统化的方法,利用统一建模语言(UML)可以直观地表现业务模型,同时还可以派生出一个一致的且能够追溯到这个业务模型的起点系统用例模型。
这篇文章提供了 RUP 业务建模的概述,并解决了以下的问题:
业务用例模型与系统用例模型有怎样的相似之处?
业务用例模型与系统用例模型有什么不同之处?
构建业务模型应该使用哪个 UML 图?
业务用例模型与系统用例模型之间有什么关系?
背景
在谈论这个问题之前,我想解释一下为什么要挑选这个特殊的话题来写。自从1990年我就作为一名软件构架师从事系统用例的工作。当我是一名由 Unisys Global Public Sector 开发的 Integrated Justice Information Sharing (IJIS) 框架解决方案的总构架师时,还没有接触到业务用例,直到2002年。IJIS 现在已经发展成为 Unisys Information Sharing Management Framework (ISM)。
ISM 是一套支持信息共享的总体业务过程的可重用的组件。ISM Framework 利用 Service Oriented Architecture (SOA) 技术整合了不同类型的司法与公共安全系统,从而在关键决定点时分配关键的数据,文档以及图片。ISM 解决方案将为司法与公共安全 团体提供了一个业务框架、技术框架、基础应用软件以及方法,使政府机构能够继续使用他们的遗留系统。
ISM 是使用 RUP 进行设计的,ISM 业务模型是为 ISM 项目开发的首批工件之一。开发 ISM 业务模型对我来说是一个有意义的学习经历:我认识到的一个问题是,对于如何开发一个业务模型有很多含混不清的地方,为开发 UML 业务模型提供指导的文献相对比较少,而且有些不一致。
自从我离开 Unisys Global Public Sector 加入到 Unisys University 作为一名培训和开发顾问后,就一直负责开发和交付软件构架和 IBM Rational 工具培训。我的职责之一就是 IBM Rational 课程 "Mastering Requirements Management with Use Cases" (MRMUC) 的教学。这门课程主要阐述的是开发系统用例,但是这门课程仅仅提供了什么是业务模型以及它如何与这个系统用例模型相联系的一个很有限的讨论。因此这篇文章的目的之一就是为 MRMUC 课程补充材料。
这篇文章假定您已经有了系统用例建模和 RUP 需求规程的基本知识。如果您对系统用例建模并不熟悉,我建议您学习 RUP 需求规程的知识。
正如前面提到的,这篇文献关于业务建模的内容比较少,但是我们发现了一些非常有用的参考资料,远远多于您在 RUP 中找到的信息:
Writing Effective Use Cases, 由 Alistair Cockburn 编著。这是我最喜欢的关于业务和系统用例说明的著作。Alistair 强调一个业务或者系统用例模型最重要的部分是用例说明。这本书强调的就是用例说明,而不是 UML。
UML for the IT Business Analyst, 由 Howard Podeswa 编写。本书主要强调的是利用 UML 来开发一个业务模型,以及对 Alistair 的书进行补充。 UML for the IT Business Analyst 帮助我完成了关于如何开发一个有效的业务用例模型的课程培训。
Rational Edge 中的文章“Effective Business Modeling with UML: Describing Business Use Cases and Realizations”,由 Pan-Wei Ng 编写。那篇文章与这篇文章有些类似。那篇文章是从 UML 1.x 的角度来编写的。而这篇文章是从一个 UML 2.0 的角度来编写的,并且阐述了业务用例模型,业务分析模型,以及系统用例模型之间更深刻的关系。既然我已经完成了预备工作,就让我们开始提一些问题。
业务用例模型与系统用例模型有什么相似之处?
业务用例模型与系统用例模型有很多相似之处。两个模型都有用例说明。如果您对业务用例模型以及系统用例模型的 RUP 模版进行检查,您会发现它们的格式十分相似。两者都包含先决条件、后置条件、扩展点 以及特殊需求。业务用例说明有基本的工作流和可选择的工作流,从而取代了基本的事件流和可选流。
业务用例说明与系统用例说明的格式十分相似,但是在设计范围上有些分歧。业务用例的设计范围是业务操作。它是这个组织外部的业务参与者,实现与业务组织相关的业务目标。让我们查看这个业务用例的 RUP 定义:
业务用例从一个外部的,增加值的角度来描述一个业务过程。为了给这个业务的涉众创造价值,业务用例是超越组织边界的业务过程,很可能包括合作伙伴和供应商。"
简单地说,这个定义标识了一些重要点,比如:
一个业务用例描述的是业务过程——而不是软件系统过程。
一个业务用例为涉众创造价值。这些涉众要么是业务参与者要么是业务工作者。
一个业务用例可以超越组织的边界。有些构架师对于这一点有非常严密的态度。许多业务用例确实超越来组织的边界,但是有些业务用例仅仅关注于一个组织。我稍后将在这篇中给出一些例子。
让我们也看看 Podeswa 的书 UML for the IT Business Analyst 中对业务用例的定义:
"业务用例:业务过程是描述这个业务的具体工作流的;一次涉众与实现业务目标的业务之间的交互。它可能包含手工和自动化的过程,也可能发生在一个长期的时间段中。"
这个定义表明了通过实现业务目标创造价值的观点。它通过把一个业务过程描述成一个可能包含手工和自动化过程的具体工作流来详述 RUP 的定义。这个定义还指出,工作流可能发生在一个长期时间段中。所有的这些都十分的重要。
那么系统用例又是怎样的呢?系统用例的设计范围就是这个计算机系统设计的范围。它是一个系统参与者,与计算机系统一起实现一个目标。系统用例就是参与者如何与计算机技术相联系,而不是业务过程。理解业务用例与系统用例的相似和不同之处(二)
Cockburn 的 Writing Effective Use Cases 给业务和系统用例使用了相同的用例说明模版。业务用例与系统用例说明使用这个模版的区别是设计范围,而不是模版。Cockburn 想通过目标层次对用例进行分类,如表格1所示。
图1: Alistair Cockburn 对业务和系统用例的分类 高层概要 高层概要
高层概要 概要
概要 用户目标
用户目标 子功能
子功能 最低层
最低层
Cockburn 编写 Writing Effective Use Cases 的最初目标是系统用例,但他在业务用例上也花了很多精力。他利用目标层次来区分业务与系统用例,而不是使用不同的模版类型。那么这些图标和目标层次又意味着什么呢?
这些图标本身代表着一个简单的系统,它是根据用例与“海平面”(用户的实际层次)的相对高低来确定的。系统用例的最佳点是用户目标,通过海平面图标来表明。有时候需要将复杂的系统用例分解成其它有子功能目标、通过鱼图标表明的用例。但是您应该尽量避免将海平面系统用例分解成蛤或者最低层系统用例。
也许您会猜测到,概要或者蛤用例应该是业务用例。云或者高层概要也可能是业务用例。
Cockburn 的方法是将这些用例看作是一个光谱,从一个组织的最高层次业务目标,到为实现这些业务目标而执行的软件解决方案的需求详细资料。这种方法将系统用例看作是一个业务用例的分解。这个用例分解方法可以用来帮助您从这个业务模型驱动系统用例模型,我稍后会对这个问题进行讨论。
那么业务用例模型与系统用例模型图有什么其他相似之处呢?
两者都有参与者。在业务用例图中,您将一个参与者原型化为 <<BusinessActor>>。
两者都有用例。在业务用例模型中,您将一个用例原型化为 <<BusinessUseCase>>。
在参与者与用例之间两者都有一个通信关联。
业务用例和系统用例都能够包含、扩展,以及一般化关联。
用例图中的通信关联对于学习用例建模的人们来说,通常是一个容易混淆的地方。我应该使用箭头吗?这个箭头应该指向什么方向呢?通信关联已经被描绘出来,因为 1.4 UML 规范是一条实线。这条线可以配上一个箭头。这条线和箭头代表角色与系统之间的双方对话。如果呈现出一个箭头,那么说明只有这个关联末尾的“这个事物”能够发起通信。没有箭头的表明任何一方都可以发起通信(而不是两端都发起通信)。
UML 2.0 规范使它更简单。UML 2.0 不允许角色与用例之间或者业务角色与业务用例之间存在这种可灵活操作的关联。我个人比较喜欢箭头,但是如果您把 IBM Rational Software Architect (RSA) 当作您的 UML 建模工具,您就不能在角色和用例之间描绘出一个箭头。此时的 RSA 是完全没有错的。 UML 2.0 是通信关联不可灵活操作的原因。
既然我们已经讨论了业务用例模型和系统用例模型之间的相似之处,下面我们就看看它们的不同点。
业务用例模型与系统用例模型之间究竟有怎样的差别呢?
业务用例模型与系统用例模型之间主要有三点重大不同之处:设计范围、白盒测试与黑盒测试,以及业务操作者。
范围
在前面的部分中,我借助 Alistair Cockburn 的处于“水平线”上面、下面,或正好处于“水平线”的规定对设计范围进行了讨论。
业务用例着重于业务操作。它们表示实现业务目标的业务中的具体工作流。业务过程可能涉及手工和自动过程,并且在一段长期的时间内进行。
系统用例着重于要设计的软件系统。参与者如何与软件系统进行交互?我们在系统用例说明中书写的事件流应该足够详细,从而用作编写系统测试脚本的出发点。
白盒与黑盒
业务用例常常是以白盒形式编写的。它们描述了被建模的组织中的人和部门之间的交互。我们使用业务用例来说明在“现有”业务模型中组织如何工作。然后我们重构“现有”的业务用例模型,让其面向将要建模的组织的未来设计。我们需要创建什么新角色和部门来提供更多价值,或者消除业务问题?什么角色和部门需要消失?
系统用例几乎总是以黑盒形式编写的。它们描述了软件系统之外的参与者如何与将被设计的系统进行交互。系统用例详细阐明了系统需求。系统用例模型的目的是从涉众的角度说明需求,而不是设计如何满足需求。
业务角色
那么业务角色是什么?在系统用例图中,您只让参与者与用例进行交互。但在业务用例图中,您可以让业务参与者和业务角色与业务用例进行交互。
业务参与者是业务之外的人。它可以是一个角色或其他组织实体。例如,在刑事审判系统中,业务参与者可以是证人、嫌疑犯、外部的政府机构,例如健康服务,或业务实体,例如,业务资信咨询机构。
业务角色是业务内部的某个人或某个部门。在刑事审判系统中,业务角色可以是治安人员、法官、检察官,或假释官。当您实现了一个业务用例,并且创建了时序图和/或 通信图来显示业务参与者、业务角色,和业务实体如何协作执行业务用例时,您将会把业务角色从业务用例模型转入业务分析模型,并且加入所需的额外业务角色来提供业务用例功能。图 1 显示了基于 ISM 项目的示例业务用例图。
理解业务用例与系统用例的相似和不同之处(三)作为最佳实践,我推荐断开业务用例和业务角色之间的导航,从而保持业务角色与业务参与者的一致。业务角色及其用例关联应该按照业务参与者与业务用例通信的同样方式来绘制。
您必须在您的工程的 Properties 标签页中选择 Profiles 选项卡,然后单击 Add Profile 按钮,来向您的工程中添加业务建模和健壮性分析原型。在 IBM Rational Rose 中,这是自动包含的。在 UML 2.0 中,概要文件用于包装原型和标记值 UML 扩展。UML 2.0 规范要求您向 UML 建模工程中添加概要文件来使用业务建模原型。
UML 业务模型包括两个模型:用例视图(Use-Case View)中的业务用例模型和逻辑视图(Logical View)中的业务分析模型。 1 业务用例模型中的主图是业务用例图。您还可以随意加入表示单个业务用例的 UML 活动图,来图形化地显示工作流过程,如图 2 所示,逮捕被告业务用例的活动图。
图 2:ISM 逮捕被告业务用例活动图
业务分析模型描述了通过业务角色和业务实体的交互来实现业务用例。它用作业务角色和业务实体需要如何相关联,以及它们需要如何协作,来执行业务用例的抽象。业务分析模型中有三种类型的 UML 图,如图 3 所示:类(Class)、时序(Sequence)和通信(Communication)图。
图 3:业务分析模型图
业务分析模型中的主要的图是时序图。您手工地创建显示出业务参与者、业务角色,和业务实体如何交互执行业务用例的时序图。时序图显示出以时间时序安排的对象交互。特别是,它显示出参与交互的对象,以及消息交换的顺序。
通信图是以前在 UML 1.x 中所称的协作图(Collaboration diagram),它描述了对象之间交互的模式,通过对象间的链接和发送给对方的消息来展示参与交互的对象。通信图和时序图都显示出交互,但它们强调了不同的方面。时序图清楚地显示出时间顺序,但没有明确地显示出对象关系。通信图清楚地显示出对象关系,但必须从顺序号那儿获得时间顺序。
两个图都显示出同样的行为,但方式不同。我个人喜欢时序图,因为它通常比较容易读懂。您还可以使用参与类的视图(View of Participating Classes,VOPC)来显示协作执行业务用例的业务参与者、业务角色和业务实体的静态视图。
图 4 显示出 ISM 逮捕被告业务用例实现的时序图。图 5 显示出 ISM 逮捕被告业务用例实现的 VOPC。图 6 显示出 ISM 逮捕被告业务用例实现的通信图。
图 4:ISM 逮捕被告业务用例实现的时序图
在 ISM 逮捕被告业务时序图这部分中,如图 4 所示,有三个从业务用例模型转入的业务角色:执法人、签署者(Subscriber)和刑事审判系统。刑事审判系统是执法人、法院、检察官,等等的一般化。为了让时序图简单化,我们使用该泛化来表示 ISM 可以使用的任意刑事审判系统。
图 4 还显示出引入到业务分析模型中的两个新的业务角色:档案管理系统(Records Management System,RMS)和 ISM Broker。RMS 通常是商业化成品(commercial off-the-shelf,COTS)解决方案,它将地方的执法用作刑事案件管理系统。ISM Broker 是 Unisys 计划开发的软件解决方案的自动化候选者或代理。
Unisys ISM 解决方案利用中心辐射型 SOA 技术整合了多个各种各样的司法系统,从而在重要决策点处,分享关键任务的数据、文档、图像和事务。ISM 可以在 Microsoft BizTalk Server 或 IBM WebSphere Business Integration 上实现。ISM Broker 作为在审判团之中数据共享的导管,并且利用当前的技术来推、拉、发布和订阅信息,从而支持日常的审判操作。
图 5:ISM 逮捕被告业务用例实现的 VOPC 图理解业务用例与系统用例的相似和不同之处(四)
图 5 中的 VOPC 图显示了参与逮捕被告业务用例的业务参与者、业务角色和业务实体的静态视图。注意为每个业务角色显示的操作。这些操作被称为业务职责。VOPC 图的更精确的名称是参与的业务参与者、业务角色和业务实体的视图(View of Participating Business Actors,、Business Workers 和 Business Entities)。在本实例中,只有业务角色协作执行业务用例。
图 6:ISM 逮捕被告业务用例实现的通信图
如前面所提到的,通信图(如图 6 所示)是观察时序图中所示行为的另一种方法。RSA 提供了从时序图创建通信图的自动能力,反之亦然。
还有一个要回答的问题。
业务用例模型和系统用例模型之间的关系是什么?
图 7,业务用例到系统用例的向下流动(Business to System Use-Case Flow Down),出自我所教授的 IBM Rational 课程“Mastering Requirements Management with Use Cases”。
图 7,业务用例到系统用例的向下流动
图 7 例举了课程中最难教授的主题之一,因为您要理解该图所需的大部分基础不在标准课程材料之内。本文的其中一个目的是提供额外的基础。
图 7 显示了业务模型中所找到的东西和系统用例模型中的东西之间的清晰映射。在此特殊的实例中,可以看出,系统能够将业务角色的职责自动化。它还显示出关键的业务角色是自动化的候选者。
记住,业务模型包含业务用例模型和业务分析模型。业务分析模型是业务用例模型的实现,并且拥有紧密的集成化和可追溯性。系统用例模型可以追溯到业务分析模型。业务分析模型可以追溯到业务用例模型。
使用该方法,您可以构建从业务分析模型演化来的系统用例模型。这向您的整个 UML 模型提供了一致性和可追溯性。
那么系统参与者和系统用例从那里来的呢?系统参与者是根据业务分析模型中的业务参与者和业务角色而生成的。与业务角色自动化候选者交互的业务参与者总是成为系统参与者。不是自动化候选者的,与业务角色自动化候选者交互的业务角色成为系统参与者。例如,ISM 业务分析模型中的执法人和法院成为了系统参与者。ISM Broker 是“纯”自动化候选者。它不会成为系统参与者。
我所谓的纯是什么意思呢?简单的说,自动化候选者的唯一目的就是成为我们正在开发的软件解决方案的代理。注意到图 7 中的 Loan Specialist。Loan Specialist 业务角色转换为系统参与者和系统用例。让我来解释一下。
Loan Specialist 是图 7 中所示的业务模型中的角色。在我们的系统用例模型中,需要有作为 Loan Specialist 角色的参与者。但是,在我们正在开发的新的软件解决方案中将 Loan Specialist 的一些业务职责自动化了。业务分析模型中的那些业务职责成为了系统用例模型中的系统用例。
其他的纯业务角色自动化候选者将不会转换为系统用例模型中的系统角色。这回答了问题,“系统用例是从哪里来的?”系统用例是根据业务分析模型中的业务角色自动化候选者的业务职责而创建的。如果您回到图 5,显示了 ISM Broker 的 VOPC 图,每个业务职责,例如 Query for Information,都可以转换为系统用例模型中的系统用例。
分析模型显示了业务实体如何映射到系统分析模型中的类上。这些类表示系统将使用的“数据”。
总结
我的目标是概括出 RUP 业务建模和系统用例建模的比较情况。我讨论了相似点和差别,以及业务用例模型和系统用例模型之间的关系。如果您对这些比较和关系有任何疑问,可以通过 arthur.english@unisys.com 联系我。
注释
1用例视图(Use-Case View)、逻辑视图(Logical View)是 UML 4+1 视图模型架构(UML 4+1 View Model Architecture)的一部分。要了解更多关于 4+1 视图模型架构的信息,您应该学习分析与设计规程中的 URUP 软件架构概念。
-
从测试用例看测试的问题及变化
2010-01-21 15:24:44
对于一个测试人员来说测试用例的设计编写是一项必须掌握的能力。但有效的设计和熟练的编写却是一个十分复杂的技术,它需要你对整个软件不管从业务还是从功能上都有一个明晰的把握。
一、问题:
许多测试类书籍中都有大幅的篇章介绍用例的设计方法,如等价类划分,边界值,错误推断,因果图等。但实际应用中这些理论却不能给我们很明确的行为指导,尤其是业务复杂,关联模块紧密,输入标准和输出结果间路径众多时,完全的遵循这些方法只能让我们在心理上得到一种满足,而无法有效的提高测试效率。有时我们只有依靠以前项目的用例编写经验(或习惯),希望能在这一个项目中更加规范,但多数情况下我们规范的只是“书写的规范”,在用例设计上以前存在的问题现在依旧。
当好不容易用例基本完成,我们却发现面对随之而来的众多地区特性和新增需求,测试用例突然处于一种十分尴尬的境地:- 从此几乎很少被执行
- 已经与程序的实现发生了冲突(界面变动,功能变动)
- 执行用例发现的bug很少
- 根本没有时间为新的功能需求增补用例
- 有时间补充,但用例结构越来越乱,
- 特性的用例与通性用例之间联系不明确(以新增需求为主线列出所有涉及到的更改,但特性与通行之间的数据或业务联系在用例中逐渐淡化)
- 知道怎样执行这个用例,但它要说明什么呢?(多数用例给我们的感觉是只见树木,不见森林,只对某一功能,无法串起)
通过上面的一系列问题可以看到,似乎测试用例给我们带来的问题远多于益处,也正是因为在实际过程中遇到的问题积累,导致我们有很充分的理由忽视或拒绝用例的应用。
但没有用例或简略用例的编写我们又会舒服很多么?不言自明,谁也不想倒退发展吧。二、原因:
事实上我们在测试用例编写和设计上遇到的一系列问题只是一种表面的呈现,究其原因我认为有如下几点:1、没有适合的规范
“适合的规范”或称“本地化的规范”。这是我们在测试过程中遇到的第一个问题,通常也是很容易习惯且淡忘的。我们拥有相当多的流程文档、书本上的定义,但它适合我们当前的项目么?
每一个测试工程师在进入这个职业的初期都会了解一些测试上的概念和术语,进入公司或项目组后也会进一步学习相应的文档,例如怎样规范编写,怎样定义bug级别,软件实现的主要业务等。但当测试经理开始给我们分配某一模块的用例编写时,又有多少人知道该怎样去写,怎样写算是好?
在测试论坛中常能看到介绍用例编写方法的帖子,而迷茫于怎样应用到实践的回复也不为少数。为何我们无法在公司和项目组内找到明确且适合的规范?于是我们只得选择从书本或之前的用例中复制,不管是结构还是方式都依赖于以往?的经验,我并不是说这样就是错误的,但不能总结成文的经验无法给予测试更多帮助。
我们有太多经验,但却没有形成适合的规范。2、功能与业务的分离
我们知道怎样列举一个输入框的用例,但却很少考虑说明这个输入框是用来做什么的,如果仔细分析不难发现,用例中这种功能与业务的分离越来越普遍也越来越明显。
边界值、等价类划分、因果图,这些用例方法是一种高度提纯的方法,本身就很偏向于功能及代码,所以怎样编写业务的用例我们就从理论上失去了参考。
复杂的业务会贯穿于整个软件,涉及众多功能点,里面组合的分支更不可胜数。测试用例务求简洁、明确,这一点也与业务“格格不入”。功能用例依赖程序界面,业务描述依赖需求文档。于是我们更偏向于根据已实现的界面编写功能用例,列举出众多的边界值、等价类。流程的操作只有凭借经验和理解,这时测试出的bug是最多的,但我们却无法使这个bug对应到一个用例中(点击一个按钮报出的错误有时原因并不在这个按钮或按钮所在的窗体)。正因为我们没有很好的积累业务上的用例,才使得我们感到执行用例时发现的bug不多。
用例结构的划分一定程度上也造成了功能和业务的分离,依照界面模块建立文件夹,并在其中新建不同用例,这使得用例从结构上就很难联通起来。3、测试未能跟上变化
变化!想象一下,当我们越来越多的听到开发人员在那里高呼“拥抱变化”“敏捷开发”的时候,测试又有什么举措呢?当地区特性,软件版本越来越多的时候,测试是否在积极响应呢?变化是我们面临的最大挑战,我认为测试未能跟上变化是造成测试过程中遇到种种问题和矛盾的主要原因。
对需求和程序的变化测试人员的感受是非常深的,测试总是跟在需求和开发后面跑,使得所有风险都压在自己身上。不断压缩的时间和资源使我们只能放弃那些“不必要”的工作:尽快投入测试,尽快发现bug,而非从整体把握软件的质量情况,统筹策略。
疲于应对的直接影响就是程序质量无法准确度量,进度无法控制,风险无法预估。用例与程序脱节,新增用例混乱和缺少。长此以往我们只得放弃修改、增补用例,甚至放弃之前积累的所有成果。用例变为程序变更的记录摘要,没有测试数据的保留,测试步骤和重点无法体现,新加功能与原来的程序逐渐“脱离”,可能还会出现相互违背的情况,但这我们却无法很快发现。
永远是变化决定我们的下一步工作,这也是混乱的开始。三、可能的解决办法:
在这里我希望以探讨的方式提出一些可能的解决办法,因为上面的问题也许在成熟的公司和项目组内很少遇到,而遇到问题的也需根据不同的情况单独考虑。不用拘泥形式,最适合的就是最好的。1、测试驱动开发,用例指导结果,数据记录变化
“测试驱动开发”(TDD)是一个比较新的概念,在网上可以看到很多介绍文章,它主要讨论如何让开发的代码更奏效(Work)更洁净(Clean),“测试驱动开发的基本思想就是在开发功能代码之前,先编写测试代码”。可以看到,TDD是建立在“代码”级别的驱动,但目前我们需要探讨的问题是怎样在黑盒测试中做到“测试驱动开发”。
首先我们需要纠正一个态度,很多人认为黑盒测试的技术含量不高,可思考可拓展的内容不多,主要的工作就是用鼠标在那里瞎点,于是很多“高级”的技术方法都试图与黑盒测试划清界限。但测试人员发现的bug有80%以上都是黑盒测试发现的,手工操作软件仍是目前检验软件质量最有效的一种方法。
如何在黑盒测试中做到测试驱动开发?我认为可以从用例级别做起,以业务用例指导过程和结果。
开发人员通常比较关注技术,对于业务上的理解容易忽视并出现偏差,而需求文档又不会很明确的指出应该实现怎样的结果,这使得从业务到功能出现一个“阅读上的障碍”,如果最后程序错误了还需返工,这样耗费的人力物力就非常大了。使用业务用例驱动开发,就是一个比较好的方法,同样这也需要运用测试中的各种方法,列举出业务流程里数据的等价类和边界值。
业务用例的构造要先于程序实现,与需求和开发人员沟通一致,并以此作为一个基准,保证程序实现不会错,还能对整个软件的进度和质量有一个很好的估计和度量。业务用例可以不关注程序的界面,但一定要有数据的支持。这就是测试主导变化的另一点“数据记录变化”。
我们不仅要应对变化,还要记录变化,使测试用例成为对程序持续性的监控,数据可以作为最基本、最简单的支持。当一个业务很复杂时可以拆分成段(业务段与程序中以窗体或页面的划分是不一样的),使用典型的用例方法列出实际输入和预期结果。我们希望数据能做到通用和共享,最理想的情况就是建立一个“数据库”,每个业务用例都从“数据库”中取得输入数据和预期结果,这个数据只是针对业务入口和出口的,当程序内部设计变更时,保留的数据不会因此而作废。举一个例子,例如我的程序要从某种文件中读取数据并计算结果,一段时间后程序内部字段增加了,如果是以保存的文件附件方式提供数据,则现在程序很可能就打不开这个文件了。使用“数据库”指导测试人员可以在变化的程序里直接针对业务输入,而不关心程序内部结构。
再进一步的话“数据库”就开始涉及到程序内部的接口了,这需要开发人员的配合。2、为用例标明时间(版本)和优先级
为测试用例标明时间或版本可以起到一种基准的作用,标明项目进度过程中的每一个阶段,使用例直接和需求基线、软件版本对应。同样这需要规范流程,也是对变更的一种确认和控制。或者可以为用例增加一个状态,指明这个用例目前是否与程序冲突,当程序变更时改变用例的状态,并更新用例版本。
为测试用例标明优先级可以指出软件的测试重点、用例编写的重点,减少用例回归的时间,增加重点用例执行的次数,帮助项目组新人尽快了解需求,在自动化测试的初期也可以参考这个优先级录制脚本。3、功能用例与业务用例分开组织
将功能用例与业务用例分开组织,按照不同关注点列举执行路径。业务用例应在开发前或同期编写,帮助测试人员和开发人员明确业务,了解正确流程和错误流程。功能用例更依赖于程序界面的描述,但功能用例并不等于使用说明。对某些模块的等价类、边界值测试会发现很多严重的bug,也许与业务无关,但用户往往很容易这样操作(例如登录名,你是否考虑到很长的名字,或者用户的键盘有问题,总是敲入n多空格在里面,这与业务无关,但程序将会怎样处理?)。4、审核用例,结对编写
测试组长或经理对用例进行审核可以做到用例的补充和校对,但一般情况下是很难做到的,我们可以采用另一种方法,就是结对编写测试用例(前提是你有两个以上的测试人员),内部审核。
测试用例不是一个人编写一个人执行,它需要其他测试人员都能读懂且明白目标所指。结对编写可以尽量减少个人的“偏好习惯”,同时也能拓展思维,加强测试重点的确认,小组内部达到统一。一定程度上结对编写也可以减少组长或经理对用例的管理,提高组员的参与积极性。四、发展
上面的这些解决方法只是一种建议,具体怎样实施到项目中还需根据情况而定。可以看到测试的发展方向是很多很广的,传统的黑盒测试并不是毫无新意,测试工作怎样适合我们而发展,将给予我们更多的思考。 -
用例及用例与业务用例的区别
2010-01-21 15:23:10
转自网络http://hi.baidu.com/xpup/blog/item/e023a5090027eecb3bc76359.html
RUP里有两个重要的概念,用例和业务用例。初识RUP人常常会问,到底什么是用例,用例和业务用例的区别是什么。以下简要说明一下用例以及用例与业务用例之间的区别。
用例又叫系统用例,是一种软件需求定义的方法或形式。基于用例的需求定义方法与其他需求定义方法相比,有如下一些特点:
一、用例更加从用户(actor)的角度定义需求、强调用户目标,因此很容易为用户所理解。
传统以特性或功能的方式定义需求常常表现为系统必须这样或系统应该那样。如在描述一个在线书店的系统时,基于特性的方法会描述为:
1.系统应该提供搜索功能;
2.系统必须具备分类浏览的功能;
3.系统必须具有按折扣计算最终价格的能力等。
系统需求以一条条孤立的特性的方式表现出来,如果系统相对复杂,用户可能就会发出如下的疑问:“系统到底能帮我做什么,怎么帮我做的?”。用例正好回答了这个问题。以用例的方式定义需求处处关心用户到底想用系统做什么,如何做。例如,上例中网上书店系统,用户到底用它做什么呢?购书!嗯,购书就是其中的一个用例。接着,在购书这个用例中就会具体描述用户怎样和系统交互并最终完成购书过程。基本事件流示意如下:
1.用户准备在网上书店购书,用例开始。
2.用户浏览图书分类,查找图书。系统显示分类、子分类以及子分类下的图书。
3.用户选择准备购买的图书,并加入购物车。系统记录已加入购物车的图书并计算价格。
4.用户准备结账,系统提示确认购物清单,并提示输入银行账号、送货地址等关键信息。
5.用户输入以上信息,并确认。系统完成交易,并显示交易信息。用例结束。
二、用例不是功能也不是特性,用例不能被逐层分解为更小的用例。
用例的价值在于展现系统最终能帮用户做什么以及如何做到的。如果我们试图分解用例,那么谁去承担这个责任呢?最终结果与以特性方式定义需求相比又能有什么优越性呢。
在FDD方法中,提倡将基于特性的需求描述方式改进为以特性集的方式来描述需求,即将任务相关性强的特性组织在一起。在XP中,需求以用户故事的方式来描述,即以相对随意的方式描述用户怎么使用系统完成任务。可见关注用户任务的整体性并不是用例特有的。只是用例方法更为形式化一些。
三、用例主要以事件流的方式定义需求,但不是唯一的方式,用例形式化程度很高。
用例的主体是事件流,事件流分为基本流和备选流。基本流是用户使用系统时,最常用路径,一般不包括异常和分支。备选流则相反,一般是分支或异常等。不论是基本流还是备选流,都是以用户与系统的交互方式定义的,即用户如何使用系统,系统如何响应,但描述中不应夹杂UI设计信息。
除了主事件流之外,参与者描述了谁会使用这个用例。前置条件描述了必须具备什么样的条件或状态才能执行该用例。后置条件描述用户成功执行后应处于什么样的状态。特殊需求则会以特性的方式描述与用例相关的其他功能或非功能性需求,一般以非功能性需求居多。与XP、FDD等敏捷方法相比,用例更加形式化,定义需求更为严谨,当然花费的时间也会相对较多。
四、用例在同一时间只能有一个主要参与者(actor)。
用例充分关注用户使用系统到底做什么,但它只关注特定参与者与特定系统的交互而不包括参与者之间如何交互。如果在同一时间有两个主参与者在执行用例,就意味着你描述的不只是系统需求还包括系统所处环境中参与者之间的协作关系。例如,如果你的用例中包括类似如下的描述:
1.学生准备申请助学金,系统提示学生输入学习成绩、家庭条件等信息。
2.学生提交以上信息等待审批。
3.助学金审批人员审查学生助学金申请,决定批准,系统提示输入核准意见。
4.助学金审批人员输入理由并确认。
那么,你的用例就包括两个参与者,你的用例就不是真正的用例。同一时间,用例之所以只能有一个参与者,是因为用例只定位在描述系统的需求上,而不是定位在描述参与者之间如何协作上。如果将让用例同时描述参与者间协作,那用例将不只是定义需求还将定义业务流程,用例的复杂性增加、针对性降低、实用性减弱。
那参与者之间协作在哪描述呢,我们也确实需要它。实际上那是业务用例实现的职责。
五、用例不是需求的唯一定义形式,用例需要和其他需求定义形式一起定义完整的需求。
用例较其他需求方法具有优越性,但只使用用例是无法有效地定义完整的需求。用例主要定义的是功能性和行为性的需求,系统还有大量的非功能性需求需要定义,如易用性、性能、可支持性等等。这些需求以用例的方式定义都是不可行的,而定义他们最好的形式还应该是特性。
另外对于一些功能性需求,可能也不适合使用用例来定义,如系统对外提供的服务接口等。而对于一些不与参与者交互的中间件产品中的大量需求尤其不适合使用用例定义。其需求定义的方式使用特性更为合适。
以上大致描述的什么是用例,用例有什么特点。实践中总是有人分不清用例和业务用例。业务用例是用例思想的延续,只是改变了使用场合。用例是从使用者的角度定义“软件系统”需求。而业务用例不研究“软件系统”需求,它更关心一个“业务组织”对外提供哪些服务。如住房公积金中心是一个业务组织,你或许就是一个业务参与者(如果你准备作住房公积金贷款)。那么办理住房公积金贷款就是一个业务用例。这个业务用例会描述什么呢?它会描述类似如下内容(由于内容复杂仅作示意):
1.职工准备相关资料去住房公积金中心办理货款。业务用例开始。
2.职工向中心提交准备贷款的相关资料,中心工作人员对资料进行初审。
3.若审核通过,职工准备办理抵押合同,中心工作人员委托担保公司与职工签订抵押合同。
4.担保办理完成后,职工与中心签订理借款合同,中心工作人员要求职工办理银行卡并提供卡号。
5.借款合同签订后,中心工作人员要求贷款合同必须办理公证,职工与中心一道办理公证。
6.职工办理完公证后,中心发放贷款。业务用例结束。
可见,此处的业务用例描述的是业务参与者(职工)如何使用业务组织(中心)提供的服务的过程。因此业务用例实际上是一种业务流程。它以业务组织外部业务参与者的角度定义业务组织提供的服务。当然业务用例还包括一些内部流程,它可能不是由业务参与者启动的,如采购流程等。因此,业务用例只是使用了用例的思想和形式而已,研究的主题是完全不同的。用例研究软件系统,借助用例定义软件系统需求。而业务用例研究一个目标组织,借助业务用例定义目标组织应该具有哪些业务流程,以及这些流程应该是什么样子的。
-
计算机技能考试网
2009-12-01 11:05:37
http://www.rkb.gov.cn/jsj/cms/s_contents/jjrk/jjrk2009112701.html -
VB 学习手册与指南
2009-10-12 11:17:45
找VB学习手册时,发现一个好贴,收集的真是全面呀,嘻嘻,转过来方便一下手册与指南
VB速查手册之技巧篇
http://download.chinaitlab.com/soft/9306.htm
VB.Net与ASP.Net代码手册
http://download.chinaitlab.com/soft/10468.htm
VB 6.0中文版语言参考手册
http://download.chinaitlab.com/soft/10467.htm
VB编程经验手册
http://download.chinaitlab.com/soft/9412.htm
VB API 函数使用手册
http://download.chinaitlab.com/soft/9308.htm
VBA高级开发手册
http://download.chinaitlab.com/soft/9307.htm
VB与VBA技术手册
http://download.chinaitlab.com/soft/9305.htm
VB.NET Remoting 技术手册
http://download.chinaitlab.com/soft/9146.htm
VB.Net调试技术手册
http://download.chinaitlab.com/soft/9145.htm
VB.Net字符串和正则表达式参考手册
http://download.chinaitlab.com/soft/9137.htm
VBScript语言参考
http://download.chinaitlab.com/soft/7915.htm
VB6程序设计参考手册
http://download.chinaitlab.com/soft/7599.htm
VB技巧问答10000例
http://download.chinaitlab.com/soft/6694.htm
VB5 开发WEB数据库指南
http://download.chinaitlab.com/soft/6181.htm
VBscript英文帮助手册
http://download.chinaitlab.com/soft/5950.htm
VB6控件参考手册
http://download.chinaitlab.com/soft/5946.htm
VB6语言参考手册
http://download.chinaitlab.com/soft/5947.htm
VB6程序员指南
http://download.chinaitlab.com/soft/5944.htm
VB 5开发WEB数据库指南
http://download.chinaitlab.com/soft/4702.htm
VBA 高级开发指南
http://download.chinaitlab.com/soft/4604.htm
VB中文版实用参考手册
http://download.chinaitlab.com/soft/3682.htm
VB编程经验手册
http://download.chinaitlab.com/soft/2161.htm
VB6组件工具指南
http://download.chinaitlab.com/soft/1752.htm
Visual Basic API函数参考手册
http://download.chinaitlab.com/soft/9843.htm
Visual Basic 6.0中文版实用参考手册
http://download.chinaitlab.com/soft/9398.htm
Vsual Basic 6.0 控件参考手册
http://download.chinaitlab.com/soft/9288.htm
Visual Basic.NET 串行化参考手册
http://download.chinaitlab.com/soft/9241.htm
Visual Basic.net 反射参考手册
http://download.chinaitlab.com/soft/9240.htm
Visual Basic.NET类设计手册
http://download.chinaitlab.com/soft/9235.htm
Visual Basic.net线程参考手册
http://download.chinaitlab.com/soft/9126.htm
Visual Basic编程经验手册
http://download.chinaitlab.com/soft/7975.htm
Visual Basic.Net专家指南
http://download.chinaitlab.com/soft/10311.htm
Visual Basic.NET编程指南
http://download.chinaitlab.com/soft/9841.htm
Visual Basic 6.0 组件工具指南
http://download.chinaitlab.com/soft/7602.htm其它相关资源
VBSCRIPT函数方法速查
http://download.chinaitlab.com/soft/6158.htm
VBScript学习
http://download.chinaitlab.com/soft/5949.htm
VB学习一点通 V1.0
http://download.chinaitlab.com/soft/5762.htm
Access 2003 VBA 程序员参考书
http://download.chinaitlab.com/soft/5293.htm
VB、C快速进阶 V3.0
http://download.chinaitlab.com/soft/4735.htm
VB系统资源
http://download.chinaitlab.com/soft/4701.htm
VB Script语言参考
http://download.chinaitlab.com/soft/4451.htm
VB编程技巧集
http://download.chinaitlab.com/soft/3882.htm
VBScript. 教程及语言参考
http://download.chinaitlab.com/soft/3881.htm
VBScript与JScript实例教程
http://download.chinaitlab.com/soft/2639.htm
VB Script基础
http://download.chinaitlab.com/soft/2160.htm
VBScript. 帮助手册
http://download.chinaitlab.com/soft/2135.htm
VB常用函数
http://download.chinaitlab.com/soft/1753.htm
VB精华文摘
http://download.chinaitlab.com/soft/1269.htm
Visual Basic 术语解释
http://download.chinaitlab.com/soft/10677.htm
Visual Basic 常用数值算法集
http://download.chinaitlab.com/soft/9301.htm
Visual Basic 第三方控件大全
http://download.chinaitlab.com/soft/9300.htm
Visual Basic 语言参考-函数速查
http://download.chinaitlab.com/soft/6244.htm
视频相关:
VB.net多媒体教学
http://download.chinaitlab.com/soft/1567.htm
洪恩编程之道VB.NET
http://download.chinaitlab.com/soft/9559.htm
编程高手教程-VB
http://download.chinaitlab.com/soft/9180.htm
边用边学Visual Basic 6视频教学
http://download.chinaitlab.com/search.asp?keywords=边用边学Visual%20Basic%206视频教学&tt=3
程序设计基础视频教学
http://download.chinaitlab.com/search.asp?keywords=VB程序设计基础视频教学&tt=3
VB编程与应用视频
http://download.chinaitlab.com/search.asp?keywords=VB编程与应用视频&tt=3
VB.net 英文视频教程
http://download.chinaitlab.com/search.asp?keywords=VB.net%20英文视频教程&tt=3 -
VB入门
2009-10-09 17:11:57
VB里的Select语句的格式是这样的:
Select Case <变量名>
Case <情况1>
……
Case <情况2>
……
Case <情况3>
……
……
……
Case Else
……End Select
例如:
Select Case a%
Case 1
Print “a=1”
Case 2
Print “a=2”
Case Else
Print “a does not equal to 1 or 2.”End Select
五、循环语句
For <循环变量>=<初赋值> To <终值> [Step <步长>]
……
……Next <循环变量>
在默认情况下,Step被设为“1”,可以省略,Step也可以设为负值,例如:
Dim a=0
For I=1 To 10
a=a+I
Next I
这是一个最简单的累加器的例子,把1到10累加在一起,然后赋值给“a”这样的效果和上面是一样的,只不过是倒着加罢了,请看:
Dim a=0
For I=10 To 1 Step –1
a=a+I
Next I
-
[论坛] 测试方法大全
2009-08-27 17:06:15
今天去找一个叫Bate测试的概念。
于是在上面泡了一下午。顺便把上面提到的测试方法也做了个总结。为了自己以后学习查看方便,也为了和朋友们分享。所以拿过来啦。大家一块学习学习
β测试_Beta测试
β测试,英文是Beta testing。又称Beta测试,用户验收测试(UAT)。
β测试是软件的多个用户在一个或多个用户的实际使用环境下进行的测试。开发者通常不在测试现场,Beta测试不能由程序员或测试员完成。
当开发和测试根本完成时所做的测试,而最终的错误和问题需要在最终发行前找到。这种测试一般由最终用户或其他人员员完成,不能由程序员或测试员完成。
α测试_Alpha测试
α测试,英文是Alpha testing。又称Alpha测试.
Alpha测试是由一个用户在开发环境下进行的测试,也可以是公司内部的用户在模拟实际操作环境下进行的受控测试,Alpha测试不能由该系统的程序员或测试员完成。
在系统开发接近完成时对应用系统的测试;测试后,仍然会有少量的设计变更。这种测试一般由最终用户或其他人员来完成,不能由程序员或测试员完成。
可移植性测试
可移植性测试,英文是Portability testing。又称兼容性测试。
可移植性测试是指测试软件是否可以被成功移植到指定的硬件或软件平台上。
用户界面测试-UI测试
用户界面测试,英文是User interface testing。又称UI测试。
用户界面,英文是User interface。是指软件中的可见外观及其底层与用户交互的部分(菜单、对话框、窗口和其它控件)。
用户界面测试是指测试用户界面的风格是否满足客户要求,文字是否正确,页面是否美观,文字,图片组合是否完美,操作是否友好等等。UI 测试的目标是确保用户界面会通过测试对象的功能来为用户提供相应的访问或浏览功能。确保用户界面符合公司或行业的标准。包括用户友好性、人性化、易操作性测试。
用户界面测试用户分析软件用户界面的设计是否合乎用户期望或要求。它常常包括菜单,对话框及对话框上所有按钮,文字,出错提示,帮助信息 (Menu 和Help content)等方面的测试。比如,测试Microsoft Excel中插入符号功能所用的对话框的大小,所有按钮是否对齐,字符串字体大小,出错信息内容和字体大小,工具栏位置/图标等等。
冒烟测试
冒烟测试,英文是Smoke testing。
冒烟测试的名称可以理解为该种测试耗时短,仅用一袋烟功夫足够了。也有人认为是形象地类比新电路板功基本功能检查。任何新电路板焊好后,先通电检查,如果存在设计缺陷,电路板可能会短路,板子冒烟了。
冒烟测试的对象是每一个新编译的需要正式测试的软件版本,目的是确认软件基本功能正常,可以进行后续的正式测试工作。冒烟测试的执行者是版本编译人员。
随机测试
随机测试,英文是Ad hoc testing。
随机测试没有书面测试用例、记录期望结果、检查列表、脚本或指令的测试。主要是根据测试者的经验对软件进行功能和性能抽查。随机测试是根据测试说明书执行用例测试的重要补充手段,是保证测试覆盖完整性的有效方式和过程。
随机测试主要是对被测软件的一些重要功能进行复测,也包括测试那些当前的测试样例(TestCase)没有覆盖到的部分。另外,对于软件更新和新增加的功能要重点测试。重点对一些特殊点情况点、特殊的使用环境、并发性、进行检查。尤其对以前测试发现的重大Bug,进行再次测试,可以结合回归测试(Regressive testing)一起进行。
本地化测试
本地化测试,英文是Localization testing。
本地化就是将软件版本语言进行更改,比如将英文的windows改成中文的windows就是本地化。本地化测试的对象是软件的本地化版本。本地化测试的目的是测试特定目标区域设置的软件本地化质量。本地化测试的环境是在本地化的操作系统上安装本地化的软件。从测试方法上可以分为基本功能测试,安装/卸载测试,当地区域的软硬件兼容性测试。测试的内容主要包括软件本地化后的界面布局和软件翻译的语言质量,包含软件、文档和联机帮助等部分。
本地化能力测试
本地化能力测试,英文是Localizability testing。
本地化能力测试是指不需要重新设计或修改代码,将程序的用户界面翻译成任何目标语言的能力。为了降低本地化能力测试的成本,提高测试效率,本地化能力侧是通常在软件的伪本地化版本上进行。
本地化能力测试中发现的典型错误包括:字符的硬编码(即软件中需要本地化的字符写在了代码内部),对需要本地化的字符长度设置了国定值,在软件运行时以控件位置定位,图标和位图中包含了需要本地化的文本,软件的用户界面与文档术语不一致等。
国际化测试
国际化测试,英文是International testing。又称国际化支持测试。
国际化测试的目的是测试软件的国际化支持能力,发现软件的国际化的潜在问题,保证软件在世界不同区域都能正常运行。国际化测试使用每种可能的国际输入类型,针对任何区域性或区域设置检查产品的功能是否正常,软件国际化测试的重点在于执行国际字符串的输入/输出功能。国际化测试数据必须包含东亚语言、德语、复杂脚本字符和英语(可选)的混合字符。
国际化支持测试是指验证软件程序在不同国家或区域的平台上也能够如预期的那样运行,而且还可以按照原设计尊重和支持使用当地常用的日期,字体,文字表示,特殊格式等等。比如,用英文版的 Windows XP 和 Microsoft Word 能否展示阿拉伯字符串?用阿拉伯版的 Windows XP 和 阿拉伯版的Microsoft Word 能否展示阿拉伯字符串?又比如,日文版的Microsoft Excel对话框是否显示正确翻译的日语?一旦来说执行国际化支持测试的测试人员往往需要基本上了解这些国家或地区的语言要求和期望行为是什么。
安装测试
安装测试,英文是Installing testing。
安装测试是确保软件在正常情况和异常情况下,例如,进行首次安装、升级、完整的或自定义的安装都能进行安装的测试。异常情况包括磁盘空间不足、缺少目录创建权限等场景。核实软件在安装后可立即正常运行。安装测试包括测试安装代码以及安装手册。安装手册提供如何进行安装,安装代码提供安装一些程序能够运行的基础数据。
白盒测试-结构测试-逻辑驱动测试
白盒测试,英文是White Box Testing。又称结构测试或者逻辑驱动测试。
白盒测试是把测试对象看作一个打开的盒子。利用白盒测试法进行动态测试时,需要测试软件产品的内部结构和处理过程,不需测试软件产品的功能。
白盒测试法的覆盖标准有逻辑覆盖、循环覆盖和基本路径测试。其中逻辑覆盖包括语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖和路径覆盖。
白盒测试是知道产品内部工作过程,可通过测试来检测产品内部动作是否按照规格说明书的规定正常进行,按照程序内部的结构测试程序,检验程序中的每条通路是否都有能按预定要求正确工作,而不顾它的功能,白盒测试的主要方法有逻辑驱动、基路测试等,主要用于软件验证。
白盒测试常用工具有:Jtest、VcSmith、Jcontract、C++ Test、CodeWizard、logiscope。
黑盒测试-功能测试-数据驱动测试
黑盒测试,英文是Black Box Testing。又称功能测试或者数据驱动测试。
黑盒测试是根据软件的规格对软件进行的测试,这类测试不考虑软件内部的运作原理,因此软件对用户来说就像一个黑盒子。
软件测试人员以用户的角度,通过各种输入和观察软件的各种输出结果来发现软件存在的缺陷,而不关心程序具体如何实现的一种软件测试方法。
黑盒测试常用工具有:AutoRunner、winrunner、loadrunner。
本文讲述的是:黑盒测试的概念,什么是黑盒测试。什么是功能测试,什么是数据驱动测试,功能测试的意思,数据驱动测试的意思。
自动化测试
自动化测试,英文是Automated Testing。
使用自动化测试工具来进行测试,这类测试一般不需要人干预,通常在GUI、性能等测试和功能测试中用得较多。通过录制测试脚本,然后执行这个测试脚本来实现测试过程的自动化。国内领先的自动化测试服务提供商是泽众软件。自动化测试工具有AutoRunner和TAR等。
回归测试
回归测试,英文是Regression testing。
回归测试是指在发生修改之后重新测试先前的测试以保证修改的正确性。理论上,软件产生新版本,都需要进行回归测试,验证以前发现和修复的错误是否在新软件版本上再次出现。
根据修复好了的缺陷再重新进行测试。回归测试的目的在于验证以前出现过但已经修复好的缺陷不再重新出现。一般指对某已知修正的缺陷再次围绕它原来出现时的步骤重新测试。通常确定所需的再测试的范围时是比较困难的,特别当临近产品发布日期时。因为为了修正某缺陷时必需更改源代码,因而就有可能影响这部分源代码所控制的功能。所以在验证修好的缺陷时不仅要服从缺陷原来出现时的步骤重新测试,而且还要测试有可能受影响的所有功能。因此应当鼓励对所有回归测试用例进行自动化测试。
验收测试
验收测试,英文是Acceptance testing。
验收测试是指系统开发生命周期方法论的一个阶段,这时相关的用户或独立测试人员根据测试计划和结果对系统进行测试和接收。它让系统用户决定是否接收系统。它是一项确定产品是否能够满足合同或用户所规定需求的测试。
验收测试一般有三种策略:正式验收、非正式验收活Alpha 测试、Beta 测试。
动态测试
动态测试,英文是Moment Testing。
动态测试是指通过运行软件来检验软件的动态行为和运行结果的正确性。
根据动态测试在软件开发过程中所处的阶段和作用,动态测试可分为如下几个步骤:
1、单元测试
2、集成测试
3、系统测试
4、验收测试
5、回归测试
探索测试
探索测试,英文是Exploratory Testing。
探索测试是指通常用于没有产品说明书的测试,这需要把软件当作产品说明书来看待,分步骤逐项探索软件特性,记录软件执行情况,详细描述功能,综合利用静态和动态技术来进行测试。探索测试人员只靠智能、洞察力和经验来对bug的位置进行判断,所以探索测试又被称为自由形式测试。
单元测试
单元测试,英文是Unit Testing。
单元测试是最微小规模的测试;以测试某个功能或代码块。典型地由程序员而非测试员来做,因为它需要知道内部程序设计和编码的细节知识。这个工作不容易做好,除非应用系统有一个设计很好的体系结构; 还可能需要开发测试驱动器模块或测试套具。
集成测试
集成测试,英文是Integration Testing。
集成测试是指一个应用系统的各个部件的联合测试,以决定他们能否在一起共同工作并没有冲突。部件可以是代码块、独立的应用、网络上的客户端或服务器端程序。这种类型的测试尤其与客户服务器和分布式系统有关。一般集成测试以前,单元测试需要完成。
集成测试是单元测试的逻辑扩展。它的最简单的形式是:两个已经测试过的单元组合成一个组件,并且测试它们之间的接口。从这一层意义上讲,组件是指多个单元的集成聚合。在现实方案中,许多单元组合成组件,而这些组件又聚合成程序的更大部分。方法是测试片段的组合,并最终扩展进程,将您的模块与其他组的模块一起测试。最后,将构成进程的所有模块一起测试。此外,如果程序由多个进程组成,应该成对测试它们,而不是同时测试所有进程。
集成测试识别组合单元时出现的问题。通过使用要求在组合单元前测试每个单元,并确保每个单元的生存能力的测试计划,可以知道在组合单元时所发现的任何错误很可能与单元之间的接口有关。这种方法将可能发生的情况数量减少到更简单的分析级别
系统测试
系统测试,英文是System Testing。
系统测试是基于系统整体需求说明书的黑盒类测试,应覆盖系统所有联合的部件。系统测试是针对整个产品系统进行的测试,目的是验证系统是否满足了需求规格的定义,找出与需求规格不相符合或与之矛盾的地方。
系统测试的对象不仅仅包括需要测试的产品系统的软件,还要包含软件所依赖的硬件、外设甚至包括某些数据、某些支持软件及其接口等。因此,必须将系统中的软件与各种依赖的资源结合起来,在系统实际运行环境下来进行测试。
端到端测试
端到端测试,英文是End to End Testing。
端到端测试类似于系统测试,测试级的“宏大”的端点,涉及整个应用系统环境在一个现实世界使用时的模拟情形的所有测试。例如与数据库对话,用网络通讯,或与外部硬件、应用系统或适当的系统对话。端到端架构测试包含所有访问点的功能测试及性能测试。端到端架构测试实质上是一种"灰盒"测试,一种集合了白盒测试和黑盒测试的优点的测试方法。
健全测试
健全测试,英文是Sanity testing。
健全测试是指一个初始化的测试工作,以决定一个新的软件版本测试是否足以执行下一步大的测试努力。例如,如果一个新版软件每5分钟与系统冲突,使系统陷于泥潭,说明该软件不够“健全”,目前不具备进一步测试的条件。
衰竭测试
衰竭测试,英文是Failure Testing。
衰竭测试是指软件或环境的修复或更正后的“再测试”。可能很难确定需要多少遍再次测试。尤其在接近开发周期结束时。自动测试工具对这类测试尤其有用。
接受测试
接受测试,英文是Accept Testing。
接受测试是基于客户或最终用户的规格书的最终测试,或基于用户一段时间的使用后,看软件是否满足客户要求。一般从功能、用户界面、性能、业务关联性进行测试。
负载测试
负载测试,英文是Load testing。
负载测试是测试一个应用在重负荷下的表现。例如测试一个 Web 站点在大量的负荷下,何时系统的响应会退化或失败,以发现设计上的错误或验证系统的负载能力。在这种测试中,将使测试对象承担不同的工作量,以评测和评估测试对象在不同工作量条件下的性能行为,以及持续正常运行的能力。
负载测试的目标是确定并确保系统在超出最大预期工作量的情况下仍能正常运行。此外,负载测试还要评估性能特征,例如,响应时间、事务处理速率和其他与时间相关的方面。
强迫测试
强迫测试,英文是Force Testing。
强迫测试是在交替进行负荷和性能测试时常用的术语。也用于描述象在异乎寻常的重载下的系统功能测试之类的测试,如某个动作或输入大量的重复,大量数据的输入,对一个数据库系统大量的复杂查询等。
压力测试
压力测试,英文是Stress Testing。和负载测试差不多。
压力测试是一种基本的质量保证行为,它是每个重要软件测试工作的一部分。压力测试的基本思路很简单:不是在常规条件下运行手动或自动测试,而是在计算机数量较少或系统资源匮乏的条件下运行测试。通常要进行压力测试的资源包括内部内存、CPU 可用性、磁盘空间和网络带宽等。一般用并发来做压力测试。
性能测试
性能测试,英文是Performance Testing。
性能测试是在交替进行负荷和强迫测试时常用的术语。理想的“性能测试”(和其他类型的测试)应在需求文档或质量保证、测试计划中定义。性能测试一般包括负载测试和压力测试。
通常验证软件的性能在正常环境和系统条件下重复使用是否还能满足性能指标。或者执行同样任务时新版本不比旧版本慢。一般还检查系统记忆容量在运行程序时会不会流失(memory leak)。比如,验证程序保存一个巨大的文件新版本不比旧版本慢。
可用性测试
可用性测试,英文是Practical Usability Testing。
可用性测试是对“用户友好性”的测试。显然这是主观的,且将取决于目标最终用户或客户。用户面谈、调查、用户对话的录象和其他一些技术都可使用。程序员和测试员通常都不宜作可用性测试员。
卸载测试
卸载测试,英文是Uninstall Testing。
卸载测试是对软件的全部、部分或升级卸载处理过程的测试。主要是测试软件能否卸载,卸载是否干净,对系统有无更改,在系统中的残留与后来的生成文件如何处理等。还有原来更改的系统值是否修改回去
恢复测试
恢复测试,英文是Recovery testing。
恢复测试是测试一个系统从如下灾难中能否很好地恢复,如遇到系统崩溃、硬件损坏或其他灾难性问题。恢复测试指通过人为的让软件(或者硬件)出现故障来检测系统是否能正确的恢复,通常关注恢复所需的时间以及恢复的程度。
恢复测试主要检查系统的容错能力。当系统出错时,能否在指定时间间隔内修正错误并重新启动系统。恢复测试首先要采用各种办法强迫系统失败,然后验证系统是否能尽快恢复。对于自动恢复需验证重新初始化(reinitialization)、检查点(checkpointing mechanisms)、数据恢复(data recovery)和重新启动 (restart)等机制的正确性;对于人工干预的恢复系统,还需估测平均修复时间,确定其是否在可接受的范围内。
安全测试
安全测试,英文是Security Testing。
安全测试是测试系统在防止非授权的内部或外部用户的访问或故意破坏等情况时怎么样。这可能需要复杂的测试技术。安全测试检查系统对非法侵入的防范能力。安全测试期间,测试人员假扮非法入侵者,采用各种办法试图突破防线。例如:
①想方设法截取或破译口令;
②专门定做软件破坏系统的保护机制;
③故意导致系统失败,企图趁恢复之机非法进入;
④试图通过浏览非保密数据,推导所需信息,等等。理论上讲,只要有足够的时间和资源,没有不可进入的系统。因此系统安全设计的准则是,使非法侵入的代价超过被保护信息的价值。此时非法侵入者已无利可图。
兼容性测试
兼容测试,英文是Compatibility Testing。
兼容测试是测试软件在一个特定的硬件/软件/操作系统/网络等环境下的性能如何。向上兼容向下兼容,软件兼容硬件兼容。软件的兼容性有很多需要考虑的地方。
比较测试
比较测试,英文是Compare Testing。
比较测试是指与竞争伙伴的产品的比较测试,如软件的弱点、优点或实力。来取长补短,以增强产品的竞争力。
可接受性测试
可接受性测试,英文是Acceptability Testing。
可接受性测试是在把测试的版本交付测试部门大范围测试以前进行的对最基本功能的简单测试。因为在把测试的版本交付测试部门大范围测试以前应该先验证该版本对于所测试的功能基本上比较稳定。必须满足一些最低要求。比如不会很容易程序就挂起或崩溃。如果一个新版本没通过可测试性的验证,就应该阻拦测试部门花时间在该测试版本上测试。同时还要找到造成该版本不稳定的主要缺陷并督促尽快加以修正
边界条件测试
边界条件测试,英文是Boudary Testing。又称边界值测试。
一种黑盒测试方法,适度等价类分析方法的一种补充,由长期的测试工作经验得知,大量的错误是发生在输入或输出的边界上。因此针对各种边界情况设计测试用例,可以查出更多的错误。
边界条件测试是环绕边界值的测试。通常意味着测试软件各功能是否能正确处理最大值,最小值或者所设计软件能够处理的最长的字符串等等。
强力测试
强力测试,英文是Mightiness Testing。
强力测试通常验证软件的性能在各种极端的环境和系统条件下是否还能正常工作。或者说是验证软件的性能在各种极端环境和系统条件下的承受能力。比如,在最低的硬盘驱动器空间或系统记忆容量条件下,验证程序重复执行打开和保存一个巨大的文件1000次后也不会崩溃或死机。
装配/安装/配置测试
装配/安装/配置测试是验证软件程序在不同厂家的硬件上,所支持的不同语言的新旧版本平台上,和不同方式安装的软件都能够如预期的那样正确运行。比如,把英文版的 Microsoft Office 2003安装在韩文版 的Windows Me 上,再验证所有功能都正常运行。
静态测试
静态测试,英文是Static Testing。
静态测试指测试不运行的部分,例如测试产品说明书,对此进行检查和审阅.。静态方法是指不运行被测程序本身,仅通过分析或检查源程序的文法、结构、过程、接口等来检查程序的正确性。静态方法通过程序静态特性的分析,找出欠缺和可疑之处,例如不匹配的参数、不适当的循环嵌套和分支嵌套、不允许的递归、未使用过的变量、空指针的引用和可疑的计算等。静态测试结果可用于进一步的查错,并为测试用例选取提供指导。
静态测试常用工具有:Logiscope、PRQA;
隐藏数据测试
隐藏数据测试在软件验收和确认阶段是十分必要和重要的一部分。程序的质量不仅仅通过用户界面的可视化数据来验证,而且必须包括遍历系统的所有数据。
假设一个应用程序要求用户两条信息-----用户名和密码来创建帐户。这个用户输入这两条数据后保存。最后,一个确认窗口将通过数据库中找到这条数据来显示用户名和密码给用户。为了验证所有的数据保存是否正确,一个QA测试人员会在这个确认窗口简单的查看下用户名和密码。如果他们成功了?假设数据库记录了第三条信息----创建日期,它可能不会出现在确认窗口,而只在存档中才出现。如果创建日期保留的不正确,而QA测试人员只验证屏幕上的数据,那么这个问题就不可能被发现。创建日期可能就是一个bug,由于一个用户帐户保存了一个错误的日期到数据库中,这个问题也不可能会被引起注意,因为它被用户界面所隐藏。这只是一个简单的例子,但是它却演化出了一点:隐藏数据测试的重要性。 -
编写Bug,Report Bug注意事项
2009-08-24 12:07:15
【IT168 技术文档】1.Bug的Description的描述 Report Bug时,描述有效的Description的关键点:
Condense-精简,清晰而简短;
Accurate-准确,确定是Bug;
Neutralize-用中性的语言描述事实,不带偏见,不用幽默或者情绪化的语言;
Precise-精确;
Isolate-定位,尽量缩小这个问题的范围;
Generalize-还有没有其他的某些地方存在这样的问题;
Re-Create-如何引发和重现这个Bug?(环境,步骤,前提条件)
Impact-影响,这个缺陷对客户的影响以及对测试的影响;
DeBug-怎么做才可以让开发更容易来修改这个Bug?(跟踪,截图,日志,直接访问等等)
Evidence-证据。
Condense-精简,清晰而简短
首先,去掉不必要的词;
其次,不要添加无关的信息。
包含相应的信息是最重要的,但是确保这些信息都是有用的。对于那些没有描述清楚如何重现或者难以理解的问题,都应该提供更多的信息。但也要避免写过多的不必要的信息。
Accurate-准确,确定是Bug
确信是一个Bug,避免因为其他原因,导致错误的Report Bug,需要考虑:
是否会因为安装的某个原因导致这个问题?例如,是否安装了正确的版本而且各种先决条件也已经满足?是否登陆,安全设定,命令或者操作的顺序有错误?
是否存在清除不干净,或者结果不完整,或者因为上次测试的某些更改导致?
是否是网络或者环境的问题?
是否理解了期望的结果?
中性的语言
客观的描述Bug,不要使用幽默的或者其他带有感情色彩的语句。在提交Bug之前,仔细阅读Bug的描述,删除或者修改可能让人产生歧义的句子。
Precise-精确
当Bug的描述很长时,例如:“我按了回车键,然后现象A出现,接着按了后退键,现象B出现,接着输入命令‘XYZ’,现象C出现”,看到这样的说明,很难明白到底想说明什么问题,三个现象中哪一个是错误的。清晰准确并且客观的描述Bug,而不是简单说明发生了什么。
Isolate-定位,尽量缩小这个问题的范围
定位发现的问题。在试图隔离一个问题的时候,需要考虑下面的几点:
尝试找到最短,最简单的步骤来重现这个问题。
查看是否是外部的什么特殊的原因引起的这个问题?例如,系统挂起或延时,会不会是因为网络的问题?
对于一个存在多种输入条件的项目,尝试不断的改变输入值,并查看结果,直到确定哪个值导致的错误。
在问题描述中,在尽可能的范围内,精确描述所使用的测试输入值。例如,如果在测试中发现打印一份脚本的时候会出错,首先判断是不是打印所有的这种类型的脚本都会出错。
归纳
Report Bug时,采用合理的步骤来确定这个问题是通常会发生还是偶然一次出现或者是在特殊条件才出现。
重现
如果测试时,可以重现Bug,那么,应该准确的解释重现Bug所必需的条件。列出所有的步骤,包括精确的组合,文件名以及碰到或者重现这个问题的操作顺序。如果确认这个问题在任何文件,任何的操作顺序等条件下都会发生,那也最好能够给出一个明确的示例用来帮助开发来重现。
如果测试时,不能重现Bug,那就提供尽可能多的有效的信息。在开发没有重现或者开发没有解决之前,不要清除相应的测试数据,或者至少要备份这些数据。
影响
发布产品时,需要判断未解决的影响问题。例如,在某一个窗口发现一个排版错误或者拼写错误,这类Bug对测试人员来说可能是微不足道的,但对于客户来说,这是接触产品的第一件事,所以必须在给客户实施前修改好。
调试
如果需要,在Report时,提供跟踪、截图、日志等对捕获这个Bug有帮助的信息。
证据提供Report的是一个Bug的证据信息,这些信息可能包括操作指导,文档,必备条件等等,还有可能是客户以前反馈过来的零碎的信息,或者是竞争对手的软件中的一些标准,又或者来源于以往版本中的结果。
2.Bug的标题
Bug的标题在很多情况下是一个有力的和项目组成员之间的沟通工具,在很多情形下,PM,Team Leader等只是查看Bug的标题。
简单,明确的说明问题(不能只是说出现问题)
建议(如果长度允许的话):
使用有意义的单词;
描述环境和影响;
回答5W1H的问题(why,when,who,where,what,how);
使用简写,例如挂起,异常中止,拼写错误等
相对于描述清楚而言,语法不是很重要
例如:下面的标题就没有提供足够多的信息。
例一:Summary:在保存和恢复数据成员时出错。
例二:Summary:一个比较好的标题可能是这样:在WINNT环境下,XYZ的保存和恢复数据失败,数据丢失。
3. 其它注意事项
使用Bugzilla,报Bug时,需要注意以下事项:
第一,应先确认Bugzilla上已经建立了相应当前的版本;
第二,在报Bug时,需要选择,Show Advanced Fields,这样才会罗列出详细的信息,如要CC的人,QA Contact等等;
第三,Attachment,保存和发送的图片格式一般为JPG格式,OS操作系统也要选择好。
Bugzilla上,有7个严重程度等级。
具体定义如下,This field describes the impact of a Bug.
blocker Blocks development and/or Testing work
critical crashes, loss of data, severe memory leak
major major loss of function
normal regular issue, some loss of functionality under specific circumstances
minor minor loss of function, or other problem where easy workaround is present
trivial cosmetic problem like misspelled words or misaligned text
enhancement Request for enhancement
第四,在报告Bug时,除了在描述中说明Bug的复现步骤外,还要在Description中,添加该Bug的测试发生率。测试发生率为按照特定步骤执行多次的Bug重现率。测试发生率=ug重现次数/按照特定步骤执行的总次数。其中:对于概率性问题,执行的总次数应根据Bug的复杂程度执行(20-50次)。这样对于再现Bug,定位问题等都有帮助。
-
Bug关键字
2009-08-14 11:44:29
Bug的生命周期开始(Start):找到一个问题
新建(New):确认这个问题是一个缺陷
分配(Assigned):分配给某个开发人员
打开(Open):开发人员修改中
验证(Verified):修改完成等待测试人员验证
关闭(Closed):测试人员验证通过
其他流转关键字
重新分配(Reassigned):开发人员无法完成,需要重新分配
帮助(NeedInfo):开发人员需要一些其他信息;
重新打开(Reopen):测试验证未通过
重复出现(Reopend):重复出现的bug
Bug的严重等级
危急的(Critical):导致操作系统出现问题
重大的(Grave):导致软件无法使用
严重的(Serous):违反软件规则,影响软件正常使用
锁定的(Blocker):这个bug阻碍了后续操作
重要的(Important):影响部分软件使用
常规的(Normal):对软件使用造成影响,但是软件依然可以使用
轻微的(Minor):错误不影响软件使用,且错误很容易被修复
微不足道(Trivial):错误基本上没有影响
Bug的解决关键字
已经修复(Fixed):被修复的bug(得到测试人员确认)
无法修复(Wontfix):无法修复的或者需要专家团队确认是否需要修复的bug
下版本解决(Later):发现的bug在当前版本不解决,下个版本再解决
无法确定(Remind):bug可能在当前版本解决,也可能在下个版本解决
重复的(Duplicate):发现的bug已经有提交了
无法证实(Incomplete):没有办法重现的bug
测试错误(NotaBug):提交的bug报告有问题
无效的(Invalid):测试人员提交的不是bug
归档(Worksforme):暂时无法重现的bug,但是在信息丰富的情况下还是需要重现的
-
Bug状态流程
2009-08-07 15:25:16
Bug状态流程图________________________________________
对Bug的处理
开发组长/经理
每天对Bug进行分配,标注处理意见,给定优先级(发版前必须三方:需求、开发、产品共同确定)。问题分配时,应尽可能将咨询类、理解错误类等问题处理掉,而不是留给开发人员。有可能是需求的问题,分配给需求人员。定期对Bug库分析,找出常出错的模块,进行代码审查
开发人员
分析Bug,写出问题原因,修改Bug;实行Bug优先原则,严重程度B-Major类或紧急程度3-High类以上(包含)bug5个或5个以上,停止新功能的开发。
需求人员
解释需求,给出处理意见,将Bug库中的建议整理成需求文档。评审确定后列入开发计划
测试人员
不参与问题的优先级的定位,只用Bug级别反映Bug的严重程度。验证Bug是否已被解决
测试组长/经理
审核测试人员提交的Bug。定期对Bug库进行分析,描绘出曲线图等,报告现状、预测趋势。在测试总结报告中给出意见
产品人员
可以对优先级和处理意见等进行审核,如果有意见,和项目组商量定夺
Bug状态(Status):指缺陷通过一个跟踪修复过程的进展情况。包括New、Open、Reopen、Fixed、Closed及Rejected等
New 为测试人员新问题提交所标志的状态。
Open 为任务分配人(开发组长/经理)对该问题准备进行修改并对该问题分配修改人员所标志的状态。Bug解决中的状态,由任务分配人改变。对没有进入此状态的Bug,程序员不用管。
Reopen 为测试人员对修改问题进行验证后没有通过所标志的状态;或者已经修改正确的问题,又重新出现错误。由测试人员改变。
Fixed 为开发人员修改问题后所标志的状态,修改后还未测试。
Closed 为测试人员对修改问题进行验证后通过所标志的状态。由测试人员改变。
Rejected 开发人员认为不是Bug、描述不清、重复、不能复现、不采纳所提意见建议、或虽然是个错误但还没到非改不可的地步故可忽略不计、或者测试人员提错,从而拒绝的问题。由Bug分配人或者开发人员来设置。
Bug严重级别(Severity,Bug级别):是指因缺陷引起的故障对软件产品的影响程度。由测试人员指定。
A-Crash 错误导致了死机、产品失败(“崩溃”)、系统悬挂无法操作;
B-Major 功能未实现或导致一个特性不能运行并且不可能有替代方案;
C-Minor 错误导致了一个特性不能运行但可有一个替代方案;
D-Trivial 错误是表面化或微小的(提示信息不太准确友好、错别字、UI布局或罕见故障等),对功能几乎没有影响,产品及属性仍可使用;
E-Nice to Have(建议) 建设性的意见或建议。
Bug优先级(Priority):指缺陷必须被修复的紧急程度。由Bug分配者(开发组长/经理)指定。
5-Urgent 阻止相关开发人员的进一步开发活动,立即进行修复工作;阻止与此密切相关功能的进一步测试
4-Very High 必须修改,发版前必须修正
3-High 必须修改,不一定马上修改,但需确定在某个特定里程碑结束前须修正
2-Medium 如果时间允许应该修改
1-Low 允许不修改
功能模块(Subject):TD中需在Test Plan页中定义好Subject,才能在Defects页中使用。
问题描述、附件附图 请参见后面第四部分‘Bug描述要求’的有关内容。
处理意见:开发组长/经理(或具体Bug分配人员) 在审核新Bug时、将Bug分配给开发人员解决前,需要给出该Bug的处理意见。
Fixable 可修改。表示Bug可以被修复或更正
Duplicated 重复。表示该Bug已经被其它测试人员找出来了(‘纯粹’重复),或者开发认为原因是相同的(但从测试来看,认为出现的地方有所不同、表现有所不同等)
Postponed 延后。由于时间、进度、重要程度或者技术/需求等方面的原因,认为不能解决、须延期解决、或者本版不做留待到后续版本解决的Bug。
(注:因‘Bug状态’字段中也有该值,根据各组各自使用情况,可以只保留一个,或者开发/测试各有侧重地使用这两个Postponed)
By Design 因设计结构问题无法修改。测试人员认为是Bug,不符合逻辑,也不符合用户的要求,但开发人员则认为是按照设计做的、只能如此处理,否则修改代价太大
Can’t Reproduce 不可复现。不能重现(如因Bug出现的环境重现不了了),或以前出现的某个Bug自动消失了(可能是在处理其他Bug的时候把这个Bug 一并修复掉了)。
(注:因TD本身亦带有‘是否复现(Reproducible)’字段,根据各组各自使用情况,可以用它来标识,或者不用它而在‘处理意见’字段中用该值标识出)
Disagree With Suggestion 不同意所提意见或建议,不采纳
Not Error 不是问题。测试人员提错了
Won’t Fix 这个Bug是一个错误,但还没有重要到非要更正不可的地步,可以忽略不计
说明:
1. 定为Duplicated的Bug,必须注明和XXXbug重复
2. 测试人员对标明为Duplicated的Bug复测,需要XXXBug修改后方可进行
3. 定期回顾Can't Reproduce,Postponed
4. 定期整理By Design
其它一些字段(及所定义的枚举值)的定义解释,供有需要用到的组参考:
测试状态(TestState):新提交的Bug定位标准。由测试人员指定。一般有8个(提交Bug时给出)
1-New Defects(或写成Defect) 新Bug
2-Second Defects(或写成SB) 复测时新出现的Bug
3-Faculative 偶发性
4-Reappear 原来修改过的问题又重新出现
5-By Requirement 需求要求但没有做的功能
6-Suggestion 需求需要完善
7-Differ With Requirement 与需求不一致
8-By Design 设计要求但没有做的功能
复测状态(ReTestState):复测时给出的状态,测试人员对于经过验证的Bug应按以下几种标准进行定位。由测试人员指定。一般有1-OK、2-PD、3-DV、4-NB、5-NR、6-AR。
OK 正确
PD 此问题悬而不决
DV 有错误可以暂时不考虑
NB 不是错误
NR 不能复现的错误
AR 需求不明确
问题定位:
Calculate_error 计算错误,指计算过程中、计算结果错误。
Data_error 数据错误,指非计算结果类的数据错误。
Graphics_error 图形错误,指绘图、图形显示、图形编辑时发生的错误。
Interface_error 界面错误
Requirement_error 需求错误
Function_error 功能错误
Unknown_error 未知错误
缺陷来源(Source):指引起缺陷的起因。
Requirement 由于需求的问题引起的缺陷
Architecture 由于构架的问题引起的缺陷
Design 由于设计的问题引起的缺陷
Code 由于编码的问题引起的缺陷
Test 由于测试的问题引起的缺陷
Integration 由于集成的问题引起的缺陷
类型(Type):是根据缺陷的自然属性划分的缺陷种类。
F- Function 影响了重要的特性、用户界面、产品接口、硬件结构接口和全局数据结构。并且设计文档需要正式的变更。如逻辑,指针,循环,递归,功能等缺陷
A- Assignment 需要修改少量代码,如初始化或控制块。如声明、重复命名,范围、限定等缺陷
I- Interface 与其他组件、模块或设备驱动程序、调用参数、控制块或参数列表相互影响的缺陷。
C- Checking 提示的错误信息,不适当的数据验证等缺陷。
B- Build/package/merge 由于配置库、变更管理或版本控制引起的错误
D- Documentation 影响发布和维护,包括注释。
G- Algorithm 算法错误。
U- User Interface 人机交互特性:屏幕格式,确认用户输入,功能有效性,页面排版等方面的缺陷
P- Performance 不满足系统可测量的属性值,如:执行时间,事务处理速率等。
N- Norms 不符合各种标准的要求,如编码标准、设计符号等。
(以上依各组实际情况可以作适当调整)
项目组各角色在Bug库中的权限
管理员:全部权限
测试组长/经理:全部权限
测试人员:可添加Bug、不能删除Bug、可添加注释评论(R&D Comments)、不可修改他人所提Bug、可调整:Bug概要(题目,Summary)、问题描述、附件附图(Attachments)、Bug状态、Bug级别、测试版本、测试产品、功能模块、测试状态、问题定位、复测状态、注释评论(R&D Comments)、复测人、复测日期、修改人
开发人员/需求人员:不能删除Bug、可添加注释评论(R&D Comments)、可调整:注释评论(R&D Comments)、是否复现、Bug状态(不过无法直接标为closed)、问题描述、处理意见、待测版本、修改人、修改日期。可添加Bug。
开发组长/经理/需求经理:除了开发人员的权限,还可调整:优先级别、责任人、Bug概要(题目,Summary) 、附件附图(Attachments)
项目经理:可添加Bug、可添加注释评论(R&D Comments)、可修改字段:Bug概要(题目,Summary) 、问题描述、附件附图(Attachments) 、Bug状态(不过无法直接标为closed)、修改人、优先级别、问题定位、处理意见、注释评论(R&D Comments) 、是否复现、责任人、待测版本。也可删除Bug,但要与测试组长/经理协商。
不属于项目组成员的其他人如研发中心经理组成员等,有必要查看TD库的话,可分配给其帐号及查看的权限。
Bug描述要求
Bug描述的要求为分类准确、叙述简洁、步骤清楚、有实例、易再现、复杂问题有据可查(截图或其它形式的附件)。测试组长/经理把关,以开发人员的角度来审查Bug描述,看其是否描述清楚了Bug,不好描述的把工程文件或截图作为附件提交。具体要求为:
• 问题描述一般格式:问题描述时,建议分几步描述:模块或功能点=>测试步骤=>期望结果=>实际结果=>其它信息,可依实际情况调整;
• 单一:尽量一个报告只针对一个软件缺陷,报告形式应方便阅读。在主报告之后应注明不同的条件;
• 简洁:每个步骤的描述应尽可能简洁明了。只解释事实、演示和描述软件缺陷必要的细节,不要写无关信息;
• 再现:问题必须在自己机器上能复现方可入库(个别严重问题复现不了也可入库,但需标明);
• 复杂的问题应附截图补充说明或直接通知指定的修改人;考虑到网络数据传输效率,截图的文件格式建议用JPG或GIF,不建议用BMP;抓图可用TestDirector自带的功能,亦可用HyperSnap之类的专用抓图工具。
• 报告中不允许使用抽象词句:比如“有错误”之类;
• 有关操作系统特征问题:应在不同操作系统上进行操作,看是否能重现,并在Bug报告中标识;
• Bug描述示例:
例一
河北98土建标准换算
操作:
1.输入9-24
2.F8
3.在F8输入10
期望结果:进行换算
实际结果:提示“输入的厚度应大于20” 例二(模块或功能点也可在‘功能模块’字段中规定,则Bug描述中就不必写了)
操作:
1.打开新建向导;
2.在“新建”中的“项目名称”中输入>80个字符;
3.点击“下一步”
期望结果:“项目名称”应<=80个字符,输入大于80个字符,点击“下一步”应有错误提示
实际结果:进入“比重调整”界面 例三(程序员知道期望结果的情况下)
云南98土建
操作:
1.输入13-170
2.F5
3.在F5中修改3240008的名称, 处于编辑状态
4.到人材机,再回来
实际结果: F5中变白板
注:若3不处于编辑态切换则正常 例四(建议、需求类)
功能:预算页,子目排序后可恢复原顺序
用途:用户误操作后可复原
注:所有项目采用TestDirector进行Bug管理,该工具能从测试步骤自动生成Bug报告,因此对于Bug描述要求在测试方案用例设计(在Test Plan页中)阶段就可以进行控制。
附:好的Bug报告应满足以下几方面的要求:
• 结构清晰
• 复现故障再写报告
• 隔离Bug:更改条件复测
• 归纳:是否其他模块也有相同的Bug
• 比较:其他测试用例是否使用到此Bug
• 总结:报告的开头有Bug的总结
• 精简:不要有多余的步骤和语言
• 无歧义:语言明确
• 中立:无批评性语言
• 讨论:将要发出的报告送其他测试人员讨论
小结
• 通过专业的技术测试出精确的Bug;
• 通过准确的文档报告Bug;
• 通过良好的沟通使Bug尽快解决。
-
软件质量与测试效果评估标准
2009-08-06 12:00:27
又在一个贴子里找到一个好东西,嘻嘻,方便学习,先收了,发现51上好东西是真多,热心人也多,继续混下去
1编写目的
本文档是对独立测试效果及软件质量从缺陷方面进行考核的依据,该标准仅作为整体考核标准中的一个组成部分即:缺陷考核部分。
2适用范围
本标准适用于软件质量与软件测试质量的考核。
3 评价基准
软件质量考核基准: 以最后测试组递交的测试总结报告中所提交的有效缺陷为考核指标。
测试质量考核基准: 以软件试运行阶段用户发现的有效缺陷和非测试人员发现的有效缺陷为考核指标。
有效缺陷: 经过评审确定为影响软件质量或发布的缺陷(包括:确定修改、暂缓修改的)建议性的E类缺陷不算有效缺陷。
4 验收测试进入准则
1) 软件产品通过单元测试、集成测试和系统测试。
2) 测试组提交以下测试工件:测试计划、测试任务书、测试用例、测试报告、测试分析总结。
5软件验收测试工作程序
测试完成后按项目管理规定,成立测试(项目)验收小组,启动测试验收总结会
5.1根据测试任务书进行测试质量前期评审。
5.2根据测试总结报告进行软件质量评审。(测试角度)
6 软件验收测试合格通过准则
1 软件需求分析说明书中定义的所有功能已全部实现,性能指标全部达到要求
2 所有测试项没有残余一级、二级错误
3 立项审批表、需求分析文档、设计文档和编码实现一致
4 验收测试工件齐全(见验收测试进入准则)
5软件测试合格须符合以下标准。
A类错误 B类错误 C类错误 D类错误 E类建议
无 无 ≤2% ≤4% 暂不作要求
1)以上比例为错误占总测试模块(不包括E类)的比例。
2)软件产品未经测试合格,不允许投运。
6 测试质量合格须符合以下标准
A类错误 B类错误 C类错误 D类错误 E类建议
≤2 ≤4 ≤5 ≤5 暂不作要求
1)以上为用户或非测试人员发现的有效缺陷,且改缺陷不是由需求、功能的变更引起的且在测试任务书规定的测试内容范围内的缺陷。
2) A类错误、B类错误为独立条件,C类错误、D类错误为组合条件
3)用户或非测试人员发现的有效缺陷的总数不得大于一定的比例:(10%)
用户或非测试人员发现的有效缺陷的总数/测试总结报告提交有效缺陷总数×100%
举例:满足以下任何一条即视为测试质量不合格
用户或非测试人员发现的有效A类错误>2
用户或非测试人员发现的有效A类错误>4
用户或非测试人员发现的有效缺陷的总数与测试发现的有效缺陷总数的比例>10%
用户或非测试人员发现的有效C类错误、D类错误均>5
Bug级别定义
Bug按照严重程度分类为五级:
A. Critical(致命),
B. Serious(严重),
C. Average(一般),
D. Minor(改进).
E. Enhancement(建议与新增)
A)Critical(致命)
定义为数据丢失,数据计算错误,系统崩溃和非常死机。具体表现:
1. 死机,非法退出
2. 死循环
3. 数据库发生死锁
4. memory leak
5. 程序崩溃
6. Data loss
7. 造成网络堵塞或者瘫痪
8. 对操作系统造成破坏
B)Serious(严重)
定义为规定的功能没有实现或实现不完整,设计不合理造成性能低下,影响系统的运营。具体表现:
1. 基本功能缺失
2. 基本功能错误
3. 程序错误
4. 因错误操作迫使程序中断
5. 程序接口错误
6. 数据库的表、业务规则、缺省值未加完整性等约束条件
7. 边界限制错误
8. 安装引起的数据丢失
9. 数据库设计未达到要求或需求规格
10. 业务逻辑错误
C)Average(一般)
定义为不影响业务运营的功能问题, 具体表现:
1. 格式错误
2. 删除操作未给出提示
3. 安装异常
4. 界面设计不符合规范或者界面不整齐
5. 变量命名不符合规范
6. 归档文档格式模版不符合规范
7. 界面校验错误或者提示信息与异常处理不符合
8. 对异常没有本地处理,提示的异常是机器码
9. 设计文档出现错误或者说明出现错误
D)4、Minor(改进)
定义为:软件设计和功能实现等不合理需要改进, 具体表现:
1. 辅助说明描述不清楚
2. 输入输出不规范
3. 长操作未给用户提示
4. 提示窗口文字未采用行业术语
5. 可输入区域和只读区域没有明显的区分标志
6. 简单的输入限制未放在前台进行控制
7. 拼写错误
8. 界面字段定义不准确
9. 设计文档出现书写错误
10. 界面设计优化意见
11. 设计文档中优化意见
E)Enhancement(新增)
定义:为完善系统需要增加的功能
B: 优先级别
优先级(Priority)的定义取决于解决时间的长度。分为四级:
1-Resolve Immediately
2-Give High Attention
3-Normal Queue
4-Low Priority
通常情况下,优先级为1的BUG要求在一天内解决;优先级为2的BUG要求在三天内解决;优先级为3的BUG要求在五天内解决;优先级为3的BUG要求在七天内解决。当然,具体的天数定义还会根据测试时间的不同而略做调整。
-
访问量统计代码
2009-04-17 11:34:25
<script. language=JavaScript> <!--
var caution = false
function setCookie(name, value, expires, path, domain, secure) {
var curCookie = name + "=" + escape(value) +
((expires) ? "; expires=" + expires.toGMTString() : "") +
((path) ? "; path=" + path : "") +
((domain) ? "; domain=" + domain : "") +
((secure) ? "; secure" : "")
if (!caution || (name + "=" + escape(value)).length <= 4000)
document.cookie = curCookie
else
if (confirm("Cookie exceeds 4KB and will be cut!"))
document.cookie = curCookie
}
function getCookie(name) {
var prefix = name + "="
var cookieStartIndex = document.cookie.indexOf(prefix)
if (cookieStartIndex == -1)
return null
var cookieEndIndex = document.cookie.indexOf(";", cookieStartIndex + prefix.length)
if (cookieEndIndex == -1)
cookieEndIndex = document.cookie.length
return unescape(document.cookie.substring(cookieStartIndex + prefix.length, cookieEndIndex))
}
function deleteCookie(name, path, domain) {
if (getCookie(name)) {
document.cookie = name + "=" +
((path) ? "; path=" + path : "") +
((domain) ? "; domain=" + domain : "") +
"; expires=Thu, 01-Jan-70 00:00:01 GMT"
}
}
function fixDate(date) {
var base = new Date(0)
var skew = base.getTime()
if (skew > 0)
date.setTime(date.getTime() - skew)
}
var now = new Date()
fixDate(now)
now.setTime(now.getTime() + 365 * 24 * 60 * 60 * 1000)
var visits = getCookie("counter")
if (!visits)
visits = 1
else
visits = parseInt(visits) + 1
setCookie("counter", visits, now)
document.write("当前访问量为" + visits + "")
// -->
</script>
-
HTTP服务器状态代码定义(Status Code Definitions)
2009-03-16 12:08:30
1.1 消息1xx(Informational 1xx) 该类状态代码用于表示临时回应。临时回应由状态行(Status-Line)及可选标题组成, 由空行终止。HTTP/1.0中没有定义任何1xx的状态代码,所以它们不是对HTTP/1.0请求的 合法回应。实际上,它们主要用于实验用途,这已经超出本文档的范围。
1.2 成功2xx(Successful 2xx)
表示客户端请求被成功接收、理解、接受。
200 OK
请求成功。回应的信息依赖于请求所使用的方法,如下:
GET 要请求的资源已经放在回应的实体中了。
HEAD 没有实体主体,回应中只包括标题信息。�
POST 实体(描述或包含操作的结果)。
201 Created
请求完成,结果是创建了新资源。新创建资源的URI可在回应的实体中得到。原始服务器应在发出该状态代码前创建该资源。如果该操作不能立即完成,服务器必须在该资源可用时在回应主体中给出提示,否则,服务器端应回应202(可被接受)。
在本文定义的方法,只有POST可以创建资源。
202 Accepted
请求被接受,但处理尚未完成。请求可能不一定会最终完成,有可能被处理过程随时中断,在这种情况下,没有办法在异步操作中重新发送状态代码。
202回应是没有义务的,这样做的目的是允许服务器不必等到用户代理和服务器间的连接结束,就可以响应其它过程的请求(象每天运行一次的,基于批处理的过程)。
在某些回应中返回的实体中包括当前请求的状态指示、状态监视器指针或用户对请求能否实现的评估信息。
204 No Content
服务器端已经实现了请求,但是没有返回新的信息。如果客户是用户代理,则勿需为此更新自身的文档视图。该回应主要是为了在不影响用户代理激活文档视图的前提下,进行scrīpt语句的输入及其它操作。该回应还可能包括新的、以实体标题形式表示的元信息,它可被当前用户代理激活视图中的文档所使用。
1.3 重定向(Redirection 3xx)
该类状态码表示用户代理要想完成请求,还需要发出进一步的操作。这些操作只有当后跟的请求是GET或HEAD时,才可由用户代理来实现,而不用与用户进行交互。用户代理永远也不要对请求进行5次以上的重定向操作,这样可能导致无限循环。
300 Multiple Choices
该状态码不被HTTP/1.0的应用程序直接使用,只是做为3xx类型回应的缺省解释。存在多个可用的被请求资源。
除非是HEAD请求,否则回应的实体中必须包括这些资源的字符列表及位置信息,由用户或用户代理来决定哪个是最适合的。
如果服务器有首选,它应将对应的URL信息存放在位置域(Location field)处,用户代理会根据此域的值来实现自动的重定向。
301 Moved Permanently
请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源。有编辑链接功能的客户端会尽可能地根据服务器端传回的新链接而自动更新请求URI。 新的URL必须由回应中的位置域指定。除非是HEAD请求,否则回应的实体主体 (Entity-Body)必须包括对新URL超链接的简要描述。
如果用POST方法发出请求,而接收到301回应状态码。在这种情况下,除非用户确认,否则用户代理不必自动重定向请求,因为这将导致改变已发出请求的环境。
注意:当在接收到301状态码后而自动重定向POST请求时,一些现存的用户代理会错误地将其改为GET请求。
302 Moved Temporarily
请求到的资源在一个不同的URL处临时保存。因为重定向有时会被更改,客户端应继续用请求URI来发出以后的请求。新的URL必须由回应中的位置域指定。除非是HEAD请求,否则回应的实体主体 (Entity-Body)必须包括对新URL超链接的简要描述。
如果用POST方法发出请求,而接收到302回应状态码。在这种情况下,除非用户确认,否则用户代理不必自动重定向请求,因为这将导致改变已发出请求的环境。
注意:当在接收到302状态码后而自动重定向POST请求时,一些现存的用户代理会错误地将其改为GET请求。
304 Not Modified
如果客户端成功执行了条件GET请求,而对应文件自If-Modified-Since域所指定的日期以来就没有更新过,服务器应当回应此状态码,而不是将实体主体发送给客户端。回应标题域中只应包括一些相关信息,比如缓存管理器、与实体最近更新(entity's Last-Modified)日期无关的修改。相关标题域的例子有:日期、服务器、过期时间。每当304回应中给出的域值发生变化,缓存都应当对缓存的实体进行更新。
1.4 客户端错误(Client Error )4xx
4xx类的状态码表示客户端发生错误。如果客户端在收到4xx代码时请求还没有完成,它应当立即终止向服务器发送数据。除了回应HEAD请求外,不论错误是临时的还是永久的,服务器端都必须在回应的实体中包含错误状态的解释。这些状态码适用于任何请求方法。
注意:如果客户端正在发送数据,服务器端的TCP实现应当小心,以确保客户端在关闭输入连接之前收到回应包。如果客户端在关闭后仍旧向服务器发送数据,服务器会给客户 端发送一个复位包,清空客户端尚未处理的输入缓冲区,以终止HTTP应用程序的读取、解释活动。
400 非法请求(Bad Request)
如果请求的语法不对,服务器将无法理解。客户端在对该请求做出更改之前,不应再次向服务器重复发送该请求。
401 未授权(Unauthorized)
请求需要用户授权。回应中的WWW-Authenticate标题域(10.16节)应提示用户以授权方式请求资源。客户端应使用合适的授权标题域(10.2节)来重复该请求。如果请求中已经包括了授权信任信息,那回应的401表示此授权被拒绝。如果用户代理在多次尝试之后,回应一样还是返回401状态代码,用户应当察看一下回应的实体,因为在实体中会包括一些相关的动态信息。HTTP访问授权会在11节中解释。
403 禁止(Forbidden)
服务器理解请求,但是拒绝实现该请求。授权对此没有帮助,客户端应当停止重复发送此请求。如果不是用HEAD请求方法,而且服务器端愿意公布请求未被实现原因的前提下,服务器会将拒绝原因写在回应实体中。该状态码一般用于服务器端不想公布请求被拒绝的细节或没有其它的回应可用。
404 没有找到(Not Found)
服务器没有找到与请求URI相符的资源。404状态码并不指明状况是临时性的还是永久性的。如果服务器不希望为客户端提供这方面的信息,还回应403(禁止)状态码。
1.5 服务器错误(Server Error )5xx
回应代码以‘5’开头的状态码表示服务器端发现自己出现错误,不能继续执行请求。如果客户端在收到5xx状态码时,请求尚未完成,它应当立即停止向服务器发送数据。除了回应HEAD请求外,服务器应当在其回应实体中包括对错误情况的解释、并指明是临时性的还永久性的。
这类回应代码没有标题域,可适用于任何请求方法。
500 服务器内部错误(Internal Server Error)
服务器碰到了意外情况,使其无法继续回应请求。
501 未实现(Not Implemented)
服务器无法提供对请求中所要求功能的支持。如果服务器无法识别请求方法就会回应此状态代码,这意味着不能回应请求所要求的任何资源。
502 非法网关(Bad Gateway)
充当网关或代理的服务器从要发送请求的上游(upstream)服务器收到非法的回应。
503 服务不可用(Service Unavailable)
服务器当前无法处理请求。这一般是由于服务器临时性超载或维护引起的。该状态码暗示情况是暂时性的,要产生一些延迟。
注意:503状态码并没有暗示服务器在超载时一定要返回此状态码。一些服务器可能希望在超载时采用简单处理,即断掉连接。
IIS 错误代码大汇总
400 无法解析此请求。 401.1 未经授权:访问由于凭据无效被拒绝。
401.2 未经授权: 访问由于服务器配置倾向使用替代身份验证方法而被拒绝。
401.3 未经授权:访问由于 ACL 对所请求资源的设置被拒绝。
401.4 未经授权:Web 服务器上安装的筛选器授权失败。
401.5 未经授权:ISAPI/CGI 应用程序授权失败。
401.7 未经授权:由于 Web 服务器上的 URL 授权策略而拒绝访问。
403 禁止访问:访问被拒绝。
403.1 禁止访问:执行访问被拒绝。
403.2 禁止访问:读取访问被拒绝。
403.3 禁止访问:写入访问被拒绝。
403.4 禁止访问:需要使用 SSL 查看该资源。
403.5 禁止访问:需要使用 SSL 128 查看该资源。
403.6 禁止访问:客户端的 IP 地址被拒绝。
403.7 禁止访问:需要 SSL 客户端证书。
403.8 禁止访问:客户端的 DNS 名称被拒绝。
403.9 禁止访问:太多客户端试图连接到 Web 服务器。
403.10 禁止访问:Web 服务器配置为拒绝执行访问。
403.11 禁止访问:密码已更改。
403.12 禁止访问:服务器证书映射器拒绝了客户端证书访问。
403.13 禁止访问:客户端证书已在 Web 服务器上吊销。
403.14 禁止访问:在 Web 服务器上已拒绝目录列表。
403.15 禁止访问:Web 服务器已超过客户端访问许可证限制。
403.16 禁止访问:客户端证书格式错误或未被 Web 服务器信任。
403.17 禁止访问:客户端证书已经到期或者尚未生效。
403.18 禁止访问:无法在当前应用程序池中执行请求的 URL。
403.19 禁止访问:无法在该应用程序池中为客户端执行 CGI。
403.20 禁止访问:Passport 登录失败。
404 找不到文件或目录。
404.1 文件或目录未找到:网站无法在所请求的端口访问。
注意 404.1 错误只会出现在具有多个 IP 地址的计算机上。如果在特定 IP 地址/端口组合上收到客户端请求,而且没有将 IP 地址配置为在该特定的端口上侦听,则 IIS 返回 404.1 HTTP 错误。例如,如果一台计算机有两个 IP 地址,而只将其中一个 IP 地址配置为在端口 80 上侦听,则另一个 IP 地址从端口 80 收到的任何请求都将导致 IIS 返回 404.1 错误。只应在此服务级别设置该错误,因为只有当服务器上使用多个 IP 地址时才会将它返回给客户端。
404.2 文件或目录无法找到:锁定策略禁止该请求。
404.3 文件或目录无法找到:MIME 映射策略禁止该请求。
405 用于访问该页的 HTTP 动作未被许可。
406 客户端浏览器不接受所请求页面的 MIME 类型。
407 Web 服务器需要初始的代理验证。
410 文件已删除。
412 客户端设置的前提条件在 Web 服务器上评估时失败。
414 请求 URL 太大,因此在 Web 服务器上不接受该 URL。
500 服务器内部错误。
500.11 服务器错误:Web 服务器上的应用程序正在关闭。
500.12 服务器错误:Web 服务器上的应用程序正在重新启动。
500.13 服务器错误:Web 服务器太忙。
500.14 服务器错误:服务器上的无效应用程序配置。
500.15 服务器错误:不允许直接请求 GLOBAL.ASA。
500.16 服务器错误:UNC 授权凭据不正确。
500.17 服务器错误:URL 授权存储无法找到。
500.18 服务器错误:URL 授权存储无法打开。
500.19 服务器错误:该文件的数据在配置数据库中配置不正确。
500.20 服务器错误:URL 授权域无法找到。
500 100 内部服务器错误:ASP 错误。
501 标题值指定的配置没有执行。
502 Web 服务器作为网关或代理服务器时收到无效的响应。
WIN2003 SERVER IIS6.0 ASP 错误解析
事件 ID 描述
0100 内存不足。无法分配所需的内存。
0101 意外错误。函数返回 |。
0102 要求字符串输入。函数需要字符串输入。
0103 要求数字输入。函数需要数字输入。
0104 不允许操作。
0105 索引超出范围。数组索引超出范围。
0106 类型不匹配。遇到未处理的数据类型。
0107 数据大小太大。请求中发送的数据大小超出允许的限制。
0108 创建对象失败。创建对象 '%s' 时出错。
0109 成员未找到。
0110 未知的名称。
0111 未知的界面。
0112 参数丢失。
0113 脚本超时。超过了脚本运行的最长时间。可以通过为 Server.scrīptTimeout 属性指定一个新值或在 IIS 管理工具中修改值来更改此限制。
0114 对象不可用于自由线程。应用程序对象仅接受自由线程对象;而对象 '%s' 不可用于自由线程。
0115 意外错误。外部对象中发生一个可捕捉的错误 (%X)。脚本无法继续运行。
0116 脚本分隔符结束标记丢失。脚本块缺少脚本结束标记 (%>)。
0117 脚本结束标记丢失。脚本块缺少脚本结束标记 (</scrīpt>) 或标记结束符号 (>)。
0118 对象的结束标记丢失。对象块缺少对象结束标记 (</OBJECT>) 或标记结束符号 (>)。
0119 Classid 或 Progid 属性丢失。对象实例 '|' 在对象标记中需要有效的 Classid 或 Progid。
0120 Runat 属性无效。脚本标记或对象标记的 Runat 属性只能有 'Server' 值。
0121 对象标记中的范围无效。对象实例 '|' 的作用范围不能是 Application 或 Session。要创建有 Session 或 Application 作用范围的对象实例,请将在 Global.asa 文件中加入 Object 标记。
0122 对象标记中的范围无效。对象实例 '|' 必须有 Application 或 Session 作用范围。这将应用于所有在 Global.asa 文件内创建的对象。
0123 缺少 Id 属性。缺少 Object 标记所需的 Id 属性。
0124 Language 属性丢失。缺少 Object 标记所需的 Language 属性。
0125 属性结束标记丢失。'|' 属性的值没有结束分隔符。
0126 未找到 Include 文件。未找到 Include 文件 '|'。
0127 HTML 注释的结束标记丢失。HTML 注释或在服务器端的包含文件缺少结束标记 (-->)。
0128 File 或 Virtual 属性丢失。Include 文件名必须用 File 或 Virtual 属性指定。
0129 未知的脚本语言。服务器上找不到脚本语言 '|'。
0130 File 属性无效。File 属性 '|' 不能以斜杠或反斜杠开始。
0131 不允许的父路径。Include 文件 '|' 不能包含 '..' 来表示父目录。
0132 编译错误。无法处理 Active Server Page '|'。
0133 ClassID 属性无效。对象标记有一个无效的 ClassID '|'。
0134 ProgID 属性无效。对象有一个无效的 ProgID '|'。
0135 循环包含。文件 '|' 包含它本身(可能是非直接地包含)。请检查包含文件中的其他 Include 语句。
0136 对象实例名无效。对象实例 '|' 试图使用一个保留名称。这个名称被 Active Server Pages 的内部对象使用。
0137 全局脚本无效。脚本块必须是允许的 Global.asa 过程之一。Global.asa 文件中不允许在 <% ... %> 内使用脚本指令。允许的过程名称是 Application_OnStart、Application_OnEnd、Session_OnStart 或 Session_OnEnd。
0138 脚本块嵌套。脚本块不可放在另一个脚本块内。
0139 嵌套对象。对象标记不能放在另一个对象标记内。
0140 页命令次序有误。@ 命令必须是 Active Server Page 中的第一个命令。
0141 页命令重复。@ 命令只可以在 Active Server Page 中使用一次。
0142 线程令牌错误。无法打开线程令牌。
0143 应用程序名无效。未找到有效的应用程序名称。
0144 初始化错误。初始化时页级别的对象列表失败。
0145 新应用程序失败。无法添加新的应用程序。
0146 新会话失败。无法添加新的会话。
0147 500 服务器错误。
0148 服务器太忙。
0149 正在重新启动应用程序。重启动应用程序期间无法处理请求。
0150 应用程序目录错误。无法打开应用程序目录。
0151 更改通知错误。无法创建更改通知事件。
0152 安全错误。处理用户安全凭据时发生错误。
0153 线程错误。新线程请求已失败。
0154 HTTP 头写入错误。HTTP 头无法写入客户端浏览器。
0155 页内容写入错误。页内容无法写入客户端浏览器。
0156 头错误。HTTP 头已经写入到客户端浏览器。任何 HTTP 头必须在写入页内容之前修改。
0157 启用缓冲。缓冲启用后不能关闭。
0158 URL 丢失。URL 是必需的。
0159 缓冲已关闭。缓冲必须启用。
0160 日志记录错误。将条目写入日志失败。
0161 数据类型错误。将 Variant 转换为 String 变量失败。
0162 不能修改 Cookie。不能修改 Cookie 'ASPSessionID'。它是一个保留的 Cookie 名。
0163 逗号用法无效。日志条目内不可使用逗号。请选择另一个分隔符。
0164 TimeOut 值无效。指定的 TimeOut 值无效。
0165 SessionID 错误。无法创建 SessionID 字符串。
0166 对象未初始化。试图访问未初始化的对象。
0167 会话初始化错误。初始化 Session 对象时发生错误。
0168 禁止的对象使用。Session 对象中不能保存内部对象。
0169 缺少对象信息。Session 对象中不能保存信息不全的对象。需要对象的线程模型信息。
0170 删除会话错误。无法正确删除 Session。
0171 路径丢失。必须为 MapPath 方法指定 Path 参数。
0172 路径无效。MapPath 方法的路径必须是虚拟路径。使用了一个实际的路径。
-
软件测试面试常用英语(转)
2009-03-16 11:21:00
With my qualifications and experience, I feel I am hardworking, responsible and diligent in any project I undertake. Your organization could benefit from my analytical andinterpersonal skills.依我的资格和经验,我觉得我对所从事的每一个项目都很努力、负责、勤勉。我的分析能力和与人相处的技巧,对贵单位必有价值。
Q:Why did you leave your lastjob?你为什么离职呢?
A:Well, I am hoping to get an offer of a better position. If opportunity knocks, I will take it.
我希望能获得一份更好的工作,如果机会来临,我会抓住。
With my strong academic background, I am capable and competent.
凭借我良好的学术背景,我可以胜任自己的工作,而且我认为自己很有竞争力。
Q:What do you think you are worth to us?你怎么认为你对我们有价值呢?
A:I feel I can make some positive contributions to your company in the future.
我觉得我对贵公司能做些积极性的贡献。
Q:What make you think you would be a success in this position?
你如何知道你能胜任这份工作?
A:My graduate school training combined with my internship should qualify me for this particular job. I am sure I will be successful.
我在研究所的训练,加上实习工作,使我适合这份工作。我相信我能成功。
Q:What is your strongest trait(s)?你个性上最大的特点是什么?
A:Helpfulness and caring.乐于助人和关心他人。
A:Adaptability and sense of humor.适应能力和幽默感。
A:Cheerfulness and friendliness.乐观和友爱。
Q:How do you normally handle criticism?你通常如何处理別人的批评?
A:Silence is golden. Just don't say anything; otherwise the situation could become worse. I do, however, accept constructive criticism.
沈默是金。不必说什么,否则情况更糟,不过我会接受建设性的批评。
A:When we cool off, we will discuss it later. 我会等大家冷靜下来再讨论。)
Q:How do you handle your conflict with your colleagues in your work?
你如何处理与同事在工作中的意见不和?
A:I will try to present my ideas in a more clear and civilized manner in order to get my points across. 我要以更清楚文明的方式,提出我的看法,使对方了解我的观点。
Q:How do you handle your failure?你怎样对待自己的失敗?
A:None of us was born "perfect". I am sure I will be given a second chance to correct my mistake.我们大家生来都不是十全十美的,我相信我有第二个机会改正我的错误。
Q:What provide you with a sense of accomplishment.什么会让你有成就感?
A:Do my best job for your company. 为贵公司竭力效劳。)
A:Finish a project to the best of my ability. 尽我所能,完成一个项目。
Q:How long would you like to stay with this company?你会在本公司服务多久呢?
A:I will stay as long as I can continue to learn and to grow in my field.
只要我能在我的行业力继续学习和长进,我就会留在这里。
Q:Could you project what you would like to be doing five years from now?
你能预料五年后你会做什么吗?
A:As I have some administrative experience in my last job, I may use my organizational and planning skills in the future.
我在上一个工作中积累了一些行政经验,我将来也许要运用我组织和计划上的经验和技巧。
A:I hope to demonstrate my ability and talents in my field adequately.
我希望能充分展示我在这个行业的能力和智慧。
Don't appear to be pushy or overly anxious to get a job. 不必过分表现急着要工作。
Be honest but not too modest. 要诚实,但不必太谦虚。
Don't put yourself down or cut yourself up. 不可妄自菲薄或自贬。
-
SQL常用命令使用方法
2009-03-13 10:13:15
(1) 数据记录筛选:
sql="select * from 数据表 where 字段名=字段值 order by 字段名 [desc]"
sql="select * from 数据表 where 字段名 like '%字段值%' order by 字段名 [desc]"
sql="select top 10 * from 数据表 where 字段名 order by 字段名 [desc]"
sql="select * from 数据表 where 字段名 in ('值1','值2','值3')"
sql="select * from 数据表 where 字段名 between 值1 and 值2"
(2) 更新数据记录:
sql="update 数据表 set 字段名=字段值 where 条件表达式"
sql="update 数据表 set 字段1=值1,字段2=值2 …… 字段n=值n where 条件表达式"
(3) 删除数据记录:
sql="delete from 数据表 where 条件表达式"
sql="delete from 数据表" (将数据表所有记录删除)
(4) 添加数据记录:
2种insert语句:1)带字段名2)不带字段名(即针对所有的字段,并进行赋值,值不确定为null)
sql="insert into 数据表 (字段1,字段2,字段3 …) values (值1,值2,值3 …)"
也可以不写上字段名:
如果加入表的所有列的数据,不用写字段名了(ID是自动排列的不用写!字符型的数据不要加引号!除非是浮点型的数据)
sql=”insert into 包装 values('009','恐龙',2.3,null,null)”//前提:列名或所提供值的数目与表定义必须匹配
sql="insert into 目标数据表 select * from 源数据表" (把源数据表的记录添加到目标数据表) //前提:列名或所提供值的数目与表定义必须匹配
(5) 数据记录统计函数:
AVG(字段名) 得出一个表格栏平均值
COUNT(*¦字段名) 对数据行数的统计或对某一栏有值的数据行数统计
MAX(字段名) 取得一个表格栏最大的值
MIN(字段名) 取得一个表格栏最小的值
SUM(字段名) 把数据栏的值相加
引用以上函数的方法:
sql="select sum(字段名) as 别名 from 数据表 where 条件表达式"
set rs=conn.excute(sql)
用 rs("别名") 获取统的计值,其它函数运用同上。
(5) 数据表的建立和删除:
CREATE TABLE 数据表名称(字段1 类型1(长度),字段2 类型2(长度) …… )
例:CREATE TABLE tab01(name varchar(50),datetime default now())
DROP TABLE 数据表名称 (永久性删除一个数据表)
//字段类型 char:数字,用于ID号,比较短的名称如州,邮编,电话等char(3)
Varchar:字符,用于文字等,varchar(20)||varchar(20) null
Money:价格,money|money null可允许为空||money not null不允许为空
Image:照片,image null
Int:年份,销售数量,int
Smallint:月份,samllint
Datetime:日期,datetime||datetime null
-
Google的一份面试题集,
2009-03-12 15:58:33
>> Google的一份面试题集,看看你是否能够回答出来。其中很多问题都是开放式
>> 的,正确的解答有许多种,所以在这里就不提供答案了。
>> 1) 一辆学校班车里面能装多少个高尔夫球?
>> 2) 你被缩小到只有硬币厚度那么点高(不是压扁,是按比例缩小),然后被扔到一
>> 个空的玻璃搅拌器中,搅拌刀片一分钟后就开始转动。你怎么办?
>> 3) 要是让你清洗整个西雅图的所有窗子,你会收取多少费用?
>> 4) 怎么才能识别出电脑的内存堆栈顶是向上溢出还是向下溢出?
>> 5) 你要向你8岁的侄子解释什么是数据库,请用三句话完成。
>> 6) 时钟的指针一天内会重合几次?
>> 7) 你需要从A地去B地,但你不知道能不能到,这时该怎么办?
>> 8) 好比你有一个衣橱,里面塞满了各种衬衫,你会怎么整理这些衬衫,好让你以后
>> 找衬衫的时候容易些?
>> 9) 有个小镇有100对夫妇,每个丈夫都在欺骗他的妻子。妻子们都无法识破自己丈
>> 夫的谎言,但是她们却能知道其他任何一个男人是否在撒谎。镇上的法律规定不准
>> 通奸,妻子一旦证明丈夫不忠就应该立刻杀死他,镇上所有妇女都必须严格遵守这
>> 项法律。有一天,镇上的女王宣布,至少有一个丈夫是不忠的。这是怎么发生的
>> 呢?
>> 10) 在一个重男轻女的国家里,每个家庭都想生男孩,如果他们生的孩子是女
>> 孩,就再生一个,直到生下的是男孩为止。这样的国家,男女比例会是多少?
>> 11) 如果在高速公路上30分钟内到一辆车开过的几率是0.95,那么在10分钟内看到
>> 一辆车开过的几率是多少(假设为常概率条件下)
>> 12) 如果你看到钟的时间是3:15,那一刻时针和分针的夹角是多少?(肯定不是0
>> 度!)
>> 13) 4个人晚上要穿过一座索桥回到他们的营地。可惜他们手上只有一支只能再坚持
>> 17分钟的手电筒。通过索桥必须要拿着手电,而且索桥每次只能撑得起两个人的份
>> 量。这四个人过索桥的速度都不一样,第一个走过索桥需要1分钟,第二个2分
>> 钟,第三个5分钟,最慢的那个要10分钟。他们怎样才能在17分钟内全部走过索桥?
>> 14) 你和朋友参加聚会,包括你们两人在内一共有10个人在场。你朋友想跟你打
>> 赌,说这里每有一个人生日和你相同,你就给他1元,每有一个人生日和你不同,他
>> 给你2元。你会接受么?
>> 15) 全世界有多少个钢琴调音师?
>> 16) 你有8个一样大小的球,其中7个的重量是一样的,另一个比较重。怎样能够用
>> 天平仅称两次将那个重一些的球找出来。
>> 17) 有5个海盗,按照等级从5到1排列。最大的海盗有权提议他们如何分享100枚金
>> 币。但其他人要对此表决,如果多数反对,那他就会被杀死。他应该提出怎样的方
>> 案,既让自己拿到尽可能多的金币又不会被杀死?(提示:有一个海盗能拿到98%的
>> 金币)
>> 你觉得自己有把握去Google工作了么
标题搜索
我的存档
数据统计
- 访问量: 415576
- 日志数: 186
- 文件数: 1
- 建立时间: 2008-08-26
- 更新时间: 2018-08-07
