
-
大型RAILS应用(网络考试)性能测试与调优过程
2008-06-30 11:24:30
一 背景介绍
系统为上海一家IT公司rail on ruby快速开发出来的网络考试系统。核心功能:登录、考试。考试分为html的单/多选题,flash展现的操作题。在内部一次模拟考试中,系统曾经出现性能故障,导致无法正常做题。
二 系统架构分析接到性能测试任务,第一感觉:要很注意每一个细节,包括用户行为模拟、场景设计合理全面等。
咨询了解到系统架构为: ruby+rails+ apache2.x+mysql5。
登录系统:登录web与登录的DB分开
考试系统:考试web与考试DB 集中部署在一台机器上。答一道题目即插入数据库表
三 用户行为分析1 考试要求在 0~45分钟内考试完毕
2 多数考生一般先做选择题,再做操作题;少部分反之。
3 多数考生做完全部题目,少部分考生中途就提交结束答卷
4 题目可以回退或者选择任意一题目修改答案
5 同一个考生在提交答卷后,不能再答题由于系统更加细致的数据没有log分析,就简单采用80-20原则随机模拟。
四 脚本开发小技巧
1 随机模拟脚本
init.c 加入 srand(time(NULL));action.c 加入 rand() % 100;
2 cookie处理服务器端检查cookie信息。
加入web_add_auto_header 确保后续每一个http请求都自动把cookie加入header3 并发处理
由于一次性考试,故并发数没有按考试人数缩放,但考试按照一定的随机think time等待。
五 系统调优主要的线索是environment.rb定义的config.log_level 生成product.log,
以及rail bench。(一) 精简登录首页
1 登录:削减登录网页,很轻量级,仅仅包含Login 窗口(二) flash下载模式变更
原来做操作题目,该flash操作题才下载到客户端。
为了减轻并发下载flash的网络流量压力,变更为在登录成功后,客户端javascrīpt采用ajax技术(xmlhttpquest)随机1-60秒内后台主动下载flash试题到客户端。改变网络流量瞬间飙升的情况。(三) apache2.0 调整httpd.conf 关键参数以及加载mod_proxy 、mod_mem_cache
1 apache httpd work mpm模式。
增加 MaxClient。<IfModule worker.c>
StartServers 2
ServerLimit 2500
MaxClients 2500
MinSpareThreads 75
MaxSpareThreads 255
ThreadsPerChild 25
MaxRequestsPerChild 0
</IfModule>
2 上apache 负载均衡模块 mod_proxyProxyRequests off
<Proxy balancer://kaoshi>
BalancerMember http://localhost:6000
BalancerMember http://localhost:6001
BalancerMember http://localhost:6002
BalancerMember http://localhost:6003
BalancerMember http://localhost:6004
BalancerMember http://localhost:6005
</Proxy>
ProxyPass /images !
ProxyPass /stylesheets !
ProxyPass /javascrīpts !
ProxyPass /expert_photos !
ProxyPass /uploads !ProxyPass / balancer://kaoshi/
ProxyPassReverse / balancer://kaoshi/
ProxyPreserveHost on
3 LoadModule mem_cache_module modules/mod_mem_cache.so加载cache模块CacheEnable mem /
MCacheMaxStreamingBuffer 65536
MCacheRemovalAlgorithm LRU
MCacheSize 3000000
MCacheMaxObjectCount 256000
CacheIgnoreHeaders None
CacheIgnoreCacheControl On
MCacheMinObjectSize 1
MCacheMaxObjectSize 2560000
CacheDefaultExpire 10(四) rails 相关调整
1 变更默认连接器为C-based MySQL library mysql-2.7。
2 直接写SQL不用activeRecord 接口。
3 修改mogrel 服务参数mongrel_cluster.yml
cwd: /home/www/kaoshi/current
port: "6000"
environment: production
address: 0.0.0.0
servers: 7
4 rails负载均衡
[app@b2bsearch114 controllers]$ pwd
/home/app/download/match_export/app/controllersclass ExamsController < ApplicationController
IPS = %w(10.0.6.91 10.0.6.91 10.0.6.91 10.0.6.91 10.0.6.91 10.0.6.91)def host
index = (session["no"] || 1) % IPS.size
render :text => IPS[index]
end5 rails 部署Memcached缓存模块
(五) 数据库结构以及SQL 调优调整MYSQL配置文件、以及增加部分字段索引之后,iowati%从20%下降到0.4%
祥见
http://nnix.blogbus.com/logs/14824821.html
/bin/sh /usr/bin/mysqld_safe --user=mysql[root@aligame etc]# vi my.cnf
[client]
#password = your_password
port = 3306
socket = /var/lib/mysql/mysql.sock# Here follows entries for some specific programs
# The MySQL server
[mysqld]
port = 3306
socket = /var/lib/mysql/mysql.sock
skip-locking
key_buffer = 64M
max_allowed_packet = 1M
table_cache = 512
sort_buffer_size = 2M
read_buffer_size = 2M
read_rnd_buffer_size = 8M
myisam_sort_buffer_size = 64M
thread_cache_size = 8
thread_concurrency = 8
query_cache_size = 64M
event_scheduler=1
lower_case_table_names=1
max_connections=200
back_log=512
default-character-set=utf8log_slow_queries
log_long_format
long_query_time=1
server-id = 1
#innodb_data_file_path = ibdata1:1025M;ibdata2:256M:autoextend
innodb_buffer_pool_size = 1024M
innodb_max_dirty_pages_pct = 90
innodb_additional_mem_pool_size = 16M
#innodb_log_file_size = 256M
innodb_log_buffer_size = 8M
innodb_log_files_in_group = 2
innodb_flush_log_at_trx_commit = 2
innodb_lock_wait_timeout = 50
innodb_file_io_threads = 4
innodb_thread_concurrency = 8[mysqldump]
quick
max_allowed_packet = 16M[mysql]
no-auto-rehash
# Remove the next comment character if you are not familiar with SQL
#safe-updates[isamchk]
key_buffer = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M这 log_slow_queries,log_long_format,long_query_time=1 慢的查询语句将被打印
在目录下可见*slow.log文件记录可能有性能问题的SQL
七 小结
本次rails程序从应用程序调优、APACHE配置与调优、MYSQL索引与SQL优化多个细节提升性能。
调整从最显著的一个瓶颈(apache Maxclient->Mysql SQL)开始的,一次仅调整一个。
本次调优一个环节后,瓶颈从一个环节转移到另外一个环节。
-
介绍一个opensourse软件
2008-06-24 20:13:52
KnowledgebasePublisher是一个开源FAQ系统,也可做为一个用于发布文章的内容管理器。
定位:采用KBPublisher作为一个文档管理和搜索为中心的平台
主要功能有:1.无上限的目录分类
2.全文搜索
3.角色管理
4.评价/推荐:有Commenting / Rating / Send to friend / Users can ask questions等等功能
5.好用的所见即所得编辑器
6.添加附件,RSS等
缺点:交流功能略显不足
优点:搜索很强大(支持全文search),一目了然的目录结构,方便查询
总体而言:KBPublisher和conflunce比较类似,但是具备confluence没有的部门专属性
-
loadrunner的不足与jmeter用武之地
2008-06-20 22:03:54
我们购买了LoadRunner 8.1 作为性能测试主流工具,商业工具确实用的蛮好的,在部门层面推行顺利。
结合实践,发现有几点相当不错:1) LoadRunner controller运行稳定
2) 支持多个load generator 一起施加压力
3) 监控指标相对齐全
4) 性能测试结果颗粒细致
5) 预留有性能结果在monitor上的api 接口
...但LoadRunner是否足够完美了呢?答案:NO
1) 对汉语的编码支持问题:utf-8/gbk设置导致有时仅用英文作web_reg_find的check point
2) LoadRunner 8.1 Udp方式监控unix资源导致有断续, 呵呵,改天要电话咨询下HP有无补丁。
(LR 8.0有的)3) 有时应用vugen 录制/回放异常退出程序
4) 最为诟病的:昂贵
5) 支持jboss/tomcat/mysql等的应用性能数据需要自己实现,实际上监控linux也无可用内存、iowait%、网络流量等指标
...
我们把更多眼光关注开源社区,评估opensta、jmeter、webload...。 最终选取与公司主流技术平台( java+apache2+ jboss4.2 +oracle9i/10g + redhat linux)一致的jmeter做一个补充。
对于Jmeter最为关键的几步:1) 分析性能测试结果和loadrunner不同的原因
2) jmeter 产生压力的稳定性以及原理
3) 监控扩展能力。 linux+oracle9i+jboss+mod_jk 等这些需要支持,呵呵,否则很可能需要手工收集各个平台性能数据,造成效率低下
4) jmeter脚本调试能力,支持参数化、关联、检查点、http协议自主控制(超时、cookie、http头、是否下载non-html资源)等
-
阿里巴巴质量保证平台整合趋势
2008-06-20 20:59:35
当下阿里巴巴质量保证部门采用主要的平台、软件、工具有:
1) 项目管理工具: IBM rpm 。系统架构: jboss4.2 + oracle9 + redhat 3.8 。缺点:由于IBM SQL 加密以及数据库表结构未提供,经过几次系统调优,操作响应速度依然不尽如人意。
目前所需要的部分报表是不满足的,需要导入到数据仓库平台分析。初步评估Microsoft share point。接触HP ppm(能够和quanlity center 、Microsoft project很好集成)。
国内华为花费重点购买rpm以及昂贵的咨询费让IBM 一起提升软件开发规范度。
2) 需求管理工具
需求部门采用confluence。系统架构: linux。用例颗粒度尚未符合软件工程的Use case,细致程度待提升。
目前部分测试报告、测试文档也放在confluence。
confluence用 wiki风格。其版本管理能力、交流能力稍弱。comment具有类似回帖功能。
3) 测试用例与缺陷管理
采用quality center。 系统架构: jboss +IIS + sql server express+ windows 2003 server
QA 经常使用的模块:测试用例分析与设计、缺陷管理、后台备份恢复等需求管理、dashboard报表系统未充分使用,另外有些团队测试实验室利用率稍低。
由于web项目频繁变更,报表模板复用率偏低,故报表系统能力未充分发挥。
主要缺点:每个全功能缺陷连接license在3-5万。4) 测试部门文档管理
采用svn。系统架构: apache + redhat linux
缺点:全文检索能力弱。可以结合google 本地搜索功能或者MS的搜索功能
5) 内部技术论坛
自主研发的论坛opentech。 系统架构: java + webx+ linux 。
我个人认为还是相当不错的,功能齐全。有论坛、知识库,支持帖子搜索。且有高质量的文档。缺点:QA评价是有点阳春白雪:) ,我看来缺点就是外部合作伙伴由于信任证书无法登录。
6) 即时通信
采用阿里巴巴自主研发的贸易通。系统架构:c++ + linux。
平常各个测试组建立群,可以在群上迅速交流。缺点:新来的员工无法看到先行者的一些讨论、分享。
7) 数据仓库平台
MicroStrategy之上二次开发。后端Oracle。
从上面看,信息分散到不同的平台中,为了进一步提升使用效能,整合平台工具需求呼之欲出。
主线大致有几点:1) 项目管理->需求分析->测试分析与用例设计->BUG 管理->报表、统计分析,一个环状的闭环系统。
由于平台采用多家产品,整合难度提高。仅仅从数据层面流动意义不大。希望上述多个环节能穿接起来,形成一个宏观层次提供报表、微观层次给测试工程师工作的平台
2) 需求分析->测试分析与用例设计->BUG 管理->源代码,形成一个需求和源代码的映射关系,做到需求和代码的有效变更跟踪
sina 采用开源工具做。
3) 测试文档、交流、搜索功能一体化
主要针对文档放在SVN,项目计划文档放Confluence,交流在贸易通上集散。
希望能做到集文档、交流、全文检索功能于一身。这个过于个性化的需求,暂时没有找到开源工具解决。
光针对全文检索需求,可以采用自主研发的isearch3.0或者开源lucense。带附件的帖子不能简单做搜索。4) 其他
针对项目管理平台RPM,改善成性能更好 、数据纬度更丰富、数据流/接口清晰的平台...
每一个需求真正融汇贯通,实现成本相当不菲。
-
[论坛] 获取页面上所有指定属性的对象
2008-06-17 17:00:45
by jack
在QTP脚本编写的时候,我们可能会遇到这种检查点:比如获取checkbox的个数等等,这时会提出“获取页面上所有指定属性的对象”的需求。下面是用descrīption对象实现的一个函数,作用就是实现上述需求。
Function getItemList(PageObject,PropertyName,PropertyValue)
Dim oItemDesc
Dim nSet ōItemDesc=descrīption.Create
If isarray(PropertyName) and isarray(PropertyValue) Then
Dim iCountPropertyName
Dim iCountPropertyValue
iCountPropertyName = ubound(PropertyName)
iCountPropertyValue = ubound(PropertyValue)If iCountPropertyName <= iCountPropertyValue Then
For n=0 to ubound(PropertyName)
oItemDesc(PropertyName(n)).value=PropertyValue(n)
Next
Else
'lost property value
'msgbox "lost property value"
Exit Function
End If
Else If (not isarray(PropertyName)) and (not isarray(PropertyValue)) Then
oItemDesc(PropertyName).value=PropertyValue
Else
'error
'msgbox "error"
Exit Function
End If
End IfSet getItemList=PageObject.childobjects(oItemDesc)
End Function
输入参数有3个,page对象,属性名,属性值;其中属性名和属性值可以为数组,应用举例:
'取出页面所有编辑框
set ōChildList = getItemList(page("51Testing软件测试网"),"micclass","WebEdit")
'编辑框数量
iCountChildList = oChildList.count
'取出页面所有name含有“测试”的链接
set ōChildList = getItemList(page("51Testing软件测试网"),array("micclass","name"),array("Link","测试.*"))'点击第二个链接
oChildList(1).click
-
阿里巴巴测试难题
2008-06-17 16:55:27
测试技术方面
(一) 功能测试
1测试环境搭建时编译抛出错误,快速判断是否系代码问题
2测试中抛出500错误(或log文件中error),快速判断系代码or数据or外部接口问题
3自动化测试脚本是否细化验证点为所有可验证内容(页面所有内容显示区域、数据库、搜索引擎、cache、本地cookies等)? 检查细化,但维护量非常大
4(高优先级) 测试数据准备工具(数据库、搜索引擎、cache等持久化或临时数据)
5个人pc机本地测试环境差异(操作系统状态、完整性,浏览器版本、完整性),引起问题的原因是软件的添加/卸载,浏览器插件安装/删除,补丁程序,系统设置与浏览器设置等等
6 数据准备 如:不同类型账号生成,像生成10中供新单账号, 10个中供服务中账号等等,批量生成而不需要手工完成,否则效率慢了。
7 搜索引擎支持多个站点,每个站点又有不同的数据应用,se.conf存在众多的配置项、分词器,测试的矩阵非常庞大,如何保证尽少资源获取最好测试效果
8 抽样检查分词器的功能有遗漏,但分词器算法和外部已有的分词器算法不同,如何提高分词效果核对效率
10 海量数据查询结果正确性验证
(二) 性能测试
1 生产环境硬件模拟
生产环境依赖于外部昂贵的设备,在测试环境开展性能测试如何模拟?比如有专用邮件服务器,图片服务器,CACHE服务器?
2 数据模拟
生产环境的数据量巨大,如何剪裁合适的数据集作为性能测试基准数据?
3 用户行为模拟
虽时间变化日志系统分析的数据会很快过时,如何低成本跟进访问模式
4 特殊场景下性能瓶颈定位与监控等等
比如国际站凌晨2点突然LOAD 升高,原因未明
5 容量规划的效果如何衡量
(三) 质量管理平台
1 没有缺陷报告平台,需要详细或自定义报表时无法给出
如QC 的报表、需求管理2部分功能一直没有采用。
2 项目管理、需求管理、缺陷管理多个系统入口, 并没有统一关联。另外代码与需求之间映射关系随着业务变更也难以一一映射
3 现有的软件测试平台更适合传统的大型软件测试,能否、如何定制更适合快速上线的WEB系统?
(四) 测试管理
1 测试机器的使用权限(Linux、Windows)管理,做到近少互相干扰
2 如何有效度量测试工程师的绩效?
3 (高优先级) 如何更快找到合适的测试人才?
4 (高优先级)如何提高开发、测试双方的满意度?
5 (高优先级)如何提高估计测试时间的准确度?
(五) 测试新技术的应用与推广
1 如何有效开展安全与漏洞测试
如:sql注入,cookie安全机制,安全证书、加密等. 服务器与客户端的安全漏洞检测等
2 白盒测试工具引入及白盒技术等
如:单元测试工具Junit, parasoft的白盒测试工具使用与引入等。
3 自动化测试在项目中是否需要介入,何时介入?(数据准备?回归测试?)
4 如何在自动化覆盖率和验证点密度 与自动化成本间找到一个合理的平衡点
测试策略与方法方面
(一) 测试用例分析与设计
1 冗余的测试用例的精简化问题
2 (高优先级) 底层代码的修改如何测试,回归范围如何确定,测试策略如何确定?
如 ejb, jboss改造的性能与功能测试
3 如何使用冒烟测试对大型软件进行快速测试,用例的选择问题
4 如何为复杂产品/大型测试项目选取测试策略? 如
镜像站点测试
异地数据同步测试
重构项目测试
5 Apache Modul如何测试(功能测试与性能测试)如中文站最近发布的将Image server固定域名通过modul替换成动态域名?
6 (高优先级)支持多浏览器(IE6/ie7/firefox...)/多OS软件如何测试? 支持国际化语言版本的软件如何测试?如国际站网站支持英文,繁体版,马来西亚语言。
降低成本的测试方法有哪些?
正交表测试方法满足我们的需求么?
7 (高优先级)如何在时间、进度压力下,最优选取测试集合?回归测试的面积多大算合理?
8(高优先级) 跨部门、跨公司的接口测试如何开展,以提高协调效率?
如中文站和阿里软件贸易通状态接口,国际站和后台CRM 接口,
(二) 测试执行
1开发的代码中缺少足够的接口来支持自动化或者黑盒测试的问题
2 反复测试引发的测试疲劳如何应对(个人、团队)?交叉测试什么时候引入合适?如何衡量交叉测试的绩效?
(三) 测试标准
1 如何定义测试“完成”,比如如何定义搜索引擎测试完成?
2 如何提升对项目是否可以release的影响力
3 (高优先级)如何清晰度量产品的测试质量
按测试覆盖率?按BUG遗漏数?按已经发现BUG的曲线图?哪些标准度量最合适
4 测试人员是否需要了解代码,了解代码需要到达何种程度?
5 如何在没有单元测试代码情况下,度量代码测试覆盖率 -
容量规划问题列表,期待专家深入交流
2008-06-15 22:15:32
沙龙交流前自己准备的容量规划方面的问题列表,呵呵,也期待业界这方面的专家指点。
1 瓶颈资源到达75%以后,容量预测偏差难以衡量,预测准确率陡降。
现有容量规划软件包容这种情况?或者如何做能提升这个区域的预测准确度
2 SAP 的容量规划工具可容忍偏差范围多大?
3 SAP 内部有自己的监控软件么?包括应用级别的监控。
现在的软件更多针对应用服务器、web server和os层面的监控,但对应用本身的监控是缺乏的
假如没有这些细粒度的监控数据,SAP 如何更好为用户行为建模?
4 SAP 容量规划软件建模算法是什么?是否为排队网络?
可以调整客户到达分布与服务时间分布等参数?
5 BELL实验室网络测试发现,用长相关或自相似随机模型比排队网络模型更符合web 网站客户到达分布? SAP 容量规划软件针对更合适的模型做调整么?
6 SAP 容量规划软件内部有what-if 假设分析么?直接支持针对内存或者硬盘的what-if分析?
7 SAP 针对跨机型的容量规划如何做?
尤其是sun公司不参加TPCC评估后的机型 。
8 如何做容量规划效果的反馈
9 做容量规划的团队组员有几个,都是怎么样的专业背景(数学?计算机?)
10 开源容量建模工具要求手工采集非常多数据,必然引入较大的误差?对于这种状况,有何建议
经过和SAP 工程师交流。负责容量规划的工程师和负责测试的不属于同一个部门,容量规划工程师面对咨询公司,提供硬件建议。
国内的SAP工程师更多是规划软件的应用者。SAP 软件相对成熟,且部署的机型相对单一。目前容量规划结果满足需求。
SAP有商业逻辑的监控。SAP容量规划软件采集生产系统数据建模,在web页面上输入参数,降低建模门槛。目前SAP容量规划软件建模依赖经验值,而非各种复杂的数学模型。当下没有必要研究开源建模工具。
SAP软件用内部开发的语言开发的。有很好的扩展性。
由于上述背景,我自己碰到的一些问题就没有很深入交流。
目前阿里巴巴需要自己建立模型,并需要长期校准模型,另外由于需求、应用的多变,容量规划的门槛依然需要具备较高的数学建模与计算机性能分析方面的背景。
-
容量规划沙龙4原则以及个人理解
2008-06-15 01:08:29
个人觉得今天容量规划沙龙最核心内容即4原则1)经过良好调优的系统才容量规划
2)可扩展性好的系统才做容量规划
3)人人有容量规划意识。执行T-shirt sizing是一个巨大进步
4) 最关键的事情是测量其他的还有
5) 用真实的产品数据做容量规划
6) 特别区分对待的容量规划场景
7) 追求响应时间与成本间平衡欢迎其他朋友补充。
以上的点说得都很实在。
根据自己的实践做一个发散说明1)容量规划有一个难点:在系统扩容和调优之间取得平衡。
就是停止调优的标准是什么?目前我是根据经验值判断特定的硬件、配置参数支撑一定的访问模式、数据量、并发数、吞吐率且满足响应时间等SLA指标。 另外,检查系统不存在core dump或者大量连接超时,日志无异常等。
有较大的主观性。2) 系统扩展性良好。
根据了解,SAP 没有结合性能测试做系统的可扩展性判断。呵呵,也许SAP架构很多年稳定了,没有必要做这个事情。
我们实践中,会设置多个场景执行性能测试或者了解系统架构判断。
如是否采用多线程技术?集群是否采用session技术?建模采用的数学模型一般有很多的假设,就是公式成立有很多前提条件。性能测试需要判断结果是否违背了假设。同样预测时,也需要判断是否背离假设
3) 人人容量规划意识
从阿里巴巴的角度看,应该是从架构设计权衡系统扩展性、开发加入代码性能探针、性能测试判断是否该停止调优、运维部门长期跟踪反馈性能监控数据以及采购规划、数据仓库平台采集PV、运营部门预测下一年业务增长速度等多个环节。
据目前看,要走的路还很长。
对阿里巴巴而言,在网站购买的大量便宜的PC server背景下,容量规划的收益与成本不是足够一目了然,以及资源紧缺是最头大的问题。与前同事聊天,目前广东电信研究院的容量规划的驱动力不足是当下最头痛的事情。
4) 第四个观点:测量是最关键的。
这个论点放到阿里巴巴。我个人有不同的看法。
测量是很重要。个人认为借助测量到的数据,如何构造一个合理的容量模型、如何校准模型负荷实际情况更关键,否则预测的偏差过大导致没有太多的参考价值。另外,目前的商业工具或者开源工具都存一些不足,如何对工具做二次开发完善,也是一件很有挑战性的工作。
-
阿里巴巴的容量规划设计方案
2008-06-15 00:21:33
by liangjz针对今天容量规划沙龙由于时间关系没有回答的问题--阿里巴巴的容量规划设计方案,做一个简单的说明。
呵呵,我去年10月份这个问题写了很长的技术方案书。大致思路如下
容量规划方案贯穿软件开发整个流程。
针对已经上线运行的系统
1) 性能需求: 从数据仓库平台或者web 日志分析工具awstats分析access_log日志得到用户访问模型;
从监控中心(cacti 和nigos ) 获取服务器资源消耗数据,如cpu,io,内存,网络等细节,得到系统资源消耗模型。
如果要求更细致的颗粒,可以在应用层加以监控,如jmx获取JVM 的性能;oracle db 通过statspack获取性能
2) 性能测试与监控
建立性能测试场景(用户、数据量、硬件、软件系统等),执行性能测试;获取当前系统的承受负荷以及获取临界值。
经过确认,系统经过良好调优、且无伸缩性问题后。可以按照容量规划理论来看,寻求伸缩因子。其=1/(1-利用率%)。
比如找到瓶颈资源临界点,如50%资源消耗,75%资源消耗。一旦伸缩因子>2后,容量预测的估计偏差难以估计,因为已经不是线性关系
3) 建模以及预测
采用开源工具java model tool或者 pdq (2工具可以从sourceforge.net下载) ,建立客户到达时间分布与服务时间分布等众多容量规划参数,模型可以选择排队网络。流程:建模->MVA求解- 与性能测试结果对比校准模型,迭代逼近误差容忍范围。
what-if 预测可以从 增加并发数、合并/拆分应用、变更硬件等角度考虑
呵呵,当然也可以尝试找teamquest临时 license。
针对新开发系统:
1) 性能需求: 可以定义得更加苛刻一些。
参考同类系统,初步用TPCC 等参数比较。
实际上,这样可能误差较大。
另外,需要架构师评估系统是否有代码保证最大连接数限制
2) 性能测试与监控
场景细分更加细致,获取新系统承受负荷以及获取临界值。
3) 建模与预测
模型校准的工作量比较大。
需要长期与生产系统实际的用户行为、系统资源消耗、响应时间、吞吐率等SLA指标比较,修正容量规划模型。
这个过程可能很漫长。 -
容量规划工具
2008-06-14 23:57:17
1 开源
java model tool
pdq
2 借用定律A
little's law
N = X * RN = Number of requests in the system
X = Throughput
R = Response TimeB Utilization law
U = X * S
U = Utilization
X = Throughput
S = Service Timec Stretch Factor
Stretch Factor=1/ (1-U) =response time/service time
where U is the utilization of the server.
The analytic formula for estimating stretch factor assumes the following:
There are an infinite number of customers
The arrival times are exponentially distributed
The service times are exponentially distributed
3 商业工具
teamquest,国外SUN 公司、国内广东电信研究院用
bmc performance assurance,上海电信研究院用
原来Mercury工具也和一厂商有容量规划工具的合作的现在没有了 -
[论坛] 别让她蒙上你的眼——进程干扰导致的性能测试失败
2008-06-10 13:08:55
先给大家看几个由LoadRunner的场景运行产生的结果报表(Analysis输出结果)
首先是Average Transaction Response Time图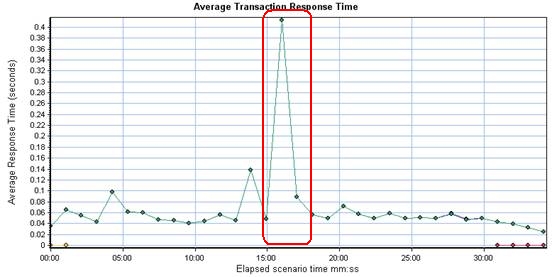
然后是Unix Resources图
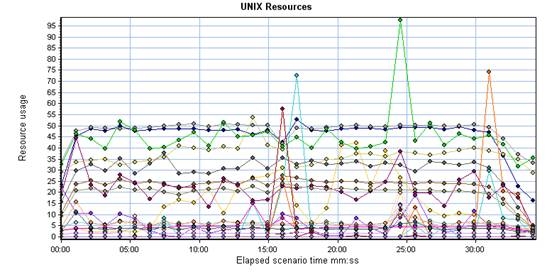
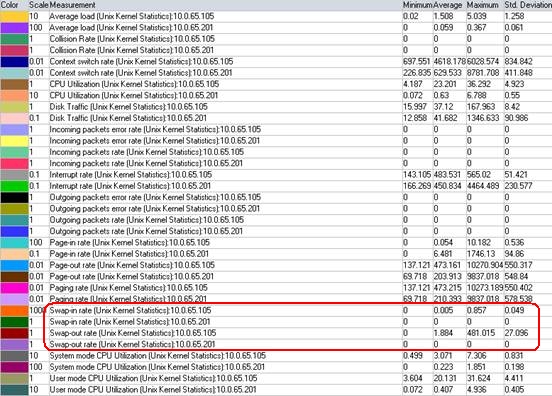
Unix Resources数据表格
这是前一段时间某个同学性能测试的报告中的图。当时看到这个图我马上问了一下:
问:这个是什么类型的应用?
答:纯java,ip:10.0.65.105是应用服务器
问:为什么中间有那么大的响应时间的陡升?
答:测了好几次都有的
问:找到原因了吗?
答:没有
问:Unix Resources里面的应用服务器的swap是怎么回事?
答:不知道……没注意其实这个同学性能测试报告总结部分写得不错,但仔细看了一下图表,发现了些问题,就马上提出给他了。
这次性能测试的结果是不可靠的。为什么呢?
要说清这个问题,还需要先简单提一下jvm调优:纯java应用(没有在java进程外的应用程序),其内存使用变化在jvm内;通常我们调优jvm都会注意的就是在满足应用运行所需要的内存前提下,还要让jvm最大内存小于剩余物理内存,这样避免了使用虚拟内存造成的磁盘io。
从上面这段介绍可以看出,纯java应用,正常调优后,其服务器表现出来的Unix Resources中的swap应该一直为0
那么swap是怎么出现的呢?很简单,物理内存不足。为什么会物理内存不足呢?对于本文提到的这次性能测试来说,不外两种可能:
1.jvm内存最大值过大,超过剩余物理内存
2.其它进程占用内存导致物理内存不足
与做这次性能测试的同学核对过后证实:是第二种原因,而响应时间的陡升,也是该时刻大量磁盘io导致io wait引起的响应变慢。
在我们做性能测试的过程中,一定要保证环境的纯净,特别是不能受到一些内存用量大、cpu占用率高的进程的干扰;最好能在运行场景前重启服务器。另外在linux系统的性能测试中,常常把着眼点总放在cpu,load上,有时会忽略内存的影响,这也告诉了我们:对待性能测试必须谨慎;对报告数据的自信来自于认真和细致的工作。
-
面对棘手问题如何向老板汇报工作
2008-06-07 00:06:26
在日常工作当中,某一个难题面临几种选择技术方案,每一种方案都没有绝对的优势胜出,这个时候如何请示老板拍板?
在这个情况下,单纯向老板诉苦或者让老板直接给答案都不是高明的作法。
汇报之前,你多问自己几句,你真的做足功课了?你准备的材料与判断依据充分到足以让老板拍板的程度了?你充分考虑部门的接口系统、远期系统整合目标了?每一个方案的优势、劣势考试的维度覆盖全了?你有借助外脑思考了?
最优方案可以转换成成本效益分析,综合权衡利弊得出的。有时候,某个场景下,该方案最优,但随实施推进,方案优劣可能颠覆。比如计划做PHP开发的系统二次开发,距离客户需求最贴近,但市场上PHP开发资源太缺乏了;再迂回确定用JAVA全新开发,近期成本高,但远期维护扩展性很好。不管多么艰难,老板肯定问你选择哪个,你给的答案应该是底气十足的。在交流时,切记思路不能被老板左右,同时不断理清自己的思路。
-
看看阿里巴巴牛P如何不断自我提升
2008-06-07 00:05:07
偶看到刊物上一些专业领域非常出类拔萃的技术人员的提升秘诀,冲动分享。版权归阿里巴巴
A 学习不分场合和时间,随时可以获取知识,比如网络、电视、书籍、同事、客户,甚至竞争对手。
学习不能靠一时热情冲动,需要长期积累。平时的学习大多零碎、不系统,还需要整理、盘活现有知识B 在成功和失败中获取经验
C 以个人兴趣为出发点,理论与实践相结合,并做到循序渐进
D 在网上尝试引导别人解决问题,解决大量别人碰到的问题,让自己掌握的知识更加全面、深刻
E 订阅大量RSS获取有价值的技术信息,写网志,认识技术圈子朋友,互通有无
F 坚持和兴趣是关键。学习与自我提升是一个漫长的过程,经常长久在黑暗中徘徊,然后突然有阳光普
照的一刻。将学习融入每天的工作与生活中,每一个项目都是很好的学习机会,都可以设法超越原先做
事的定式,去学习并运用一些新的知识与方法。当学习感觉迷茫时,找同事交流讨论,常有豁然开朗的
感觉。
G 多思考问题,在工作中碰到的问题,去想想有无更好方法解决它,来提高自己
H 多读,多观察,多思考
真的很精辟,学以致用更重要
-
对象识别怪现象
2008-06-06 09:34:52
by jiale
最近在做中文站自动化脚本时,碰到了一个奇怪的现象,是一个image对象,用qtp的object spy获取这个对象的filename属性用来识别它,但回放的时候总是提示无法识别该对象,filename属性是可以用来作为识别image对象的唯一属性的,而且这个页面也只有一个image对象,相当的奇怪呀,多次用object spy抓取时发现,抓取前与抓取后的filename是不一致的,赶紧打开源代码看看缘由,原来该对象的onmouse事件将这个对象的图片source给改变了,当鼠标移到该对象时,改变图片A为图片B,因此object spy抓取的filename属性是图片B,而回放时并没有onmouse为图片A,当然用图片B作为识别属性就无法识别该对象,只有用(filename:=图片A)才能正常识别。
-
使用ADO查询Oracle中文乱码问题
2008-06-06 09:34:20
by jiale
QTP做自动化脚本,用MS ADO对象操作数据库的时候,发现一个奇怪的问题,查询中带有中文时如:select count(*) from xxx where xxx like '中文%',查询失败,有数据也返回0,同样insert语句插入中文时乱码,初步判断是客户端字符集的问题,当前使用的客户端字符集与服务器端不匹配,select * from V$NLS_PARAMETERS WHERE parameter = 'NLS_CHARACTERSET'查询,发现服务器端为US7ASCII,查看客户端注册表HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE下NLS_LANG键值为NA,而HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\HOME0下NLS_LANG键值为AMERICAN_AMERICA.us7ascii,统一修改为AMERICAN_AMERICA.us7ascii,以为问题解决,可是查询仍然失败。
后来想到我们使用前面讲到的OraOleDb.Oracle字串链接数据库,那是不是OraOleDb.Oracle与MS的ADO配合有问题呢?我们将OraOleDb.Oracle改成MS的MSDAORA,查询一切ok。
因此这个中文乱码是两个错误的叠加,1、客户端没有使用正确的字符集——修改注册表ORACLE字符集,2、ADO的数据库连接没有使用正确的容器——MS的ADO就使用MS提供的MSDAORA数据库连接。 -
利用wshell.exec方法执行命令信息交互
2008-06-04 20:57:15
By Wiston Li
自动化通常碰到cmd执行窗口,可以用qtp的操作对象的方法控制窗口,并取到命令执行后返回的文本,
如:
Syntax : object.GetVisibleText ([Left], [Top], [Right], [Bottom])
但当命令返回多于一屏时,此命令就不行了,可以用下面的替代方法来解决:
Option Explicit
Const SystemFolder = 1
Dim wShell, exec, fso
Dim dirList
Set wShell = CreateObject( "Wscrīpt.Shell" )
Set fso = CreateObject("scrīpting.FileSystemObject")
dirList = fso.GetSpecialFolder( SystemFolder ) & "\*.exe"
Set exec = wShell.Exec( "%comspec% /C dir " & dirList & " /B /O-N /L" )
Do While True
If Not exec.StdOut.AtEndOfStream Then
dirList = exec.StdOut.ReadAll
If exec.ExitCode = 1 then
Reporter.ReportEvent micWarning, "Command failed", dirList
End If
Exit Do
End If
If Not exec.StdErr.AtEndOfStream Then
dirList = "STDERR: " & exec.StdErr.ReadAll
Reporter.ReportEvent micFail, "Command failed", dirList
Exit Do
End If
Wait 1
Loop
Print dirList
-
解压缩文件到目标目录
2008-06-04 20:51:47
by Wiston Li
解压文件
Dim sZIPFile
Dim sExtractToPath
Dim oShell
Dim oZippedFiles
sZIPFile="d:\bid.zip"
sExtractToPath="d:\temp"
Set ōShell = CreateObject("Shell.Application")
'取到zip包中的内容
Set ōZippedFiles=oShell.NameSpace(sZIPFile).items
' 释放到目标目录
oShell.NameSpace(sExtractToPath).CopyHere(oZippedFiles)
' 释放对象
Set ōZippedFiles = Nothing
Set ōShell = Nothing -
压缩文件到某个zip文件中
2008-06-04 20:49:07
by Wiston Li
通常,为了传送与保存大文件时,可以考虑打包到zip的方法,
'变量定义
Dim sSourceFolder
Dim sArchiveFile
Dim oShell
Dim oZIP
Dim oSourceFolder
'初始化sSourceFolder = "d:\bid"
sArchiveFile = "d:\bid.zip"
set ōShell = CreateObject("Shell.Application")
'建立zip对象,namespace是oshell内置对象
Set ōZIP= oShell.NameSpace(sArchiveFile)
'得到源目录
Set ōSourceFolder=oShell.NameSpace(sSourceFolder)'加文件到zip包中。
oZIP.CopyHere(oSourceFolder.Items) -
用CDO对象发邮件
2008-06-04 20:44:21
By wiston Li
今天,开始和大家分享一下,基于windows scrīpting tips,
此类小知识,可能在大家准备自动化脚本时碰到,有些windows开放的com对象,应用到自动化测试中
特别时调用com对象内置的方法与属性,能起到事半功倍的作用。
在这里整理一下:
Function sendmailbysmtp(Mailto, FilePath)
Dim objEmail
Set ōbjEmail = CreateObject("CDO.Message")
objEmail.From = "B2bTA@b2btest.com"
objEmail.To = Mailto
objEmail.Subject = "This is an email sent by TA"
objEmail.Textbody = "Pls see the enclosed for the TA execution log"objEmail.AddAttachment (FilePath)
objEmail.Configuration.Fields.Item _
("http://schemas.microsoft.com/cdo/configuration/sendusing") = 2
objEmail.Configuration.Fields.Item _
("http://schemas.microsoft.com/cdo/configuration/smtpserver") = _
"10.0.32.124"
objEmail.Configuration.Fields.Item _
("http://schemas.microsoft.com/cdo/configuration/smtpserverport") = 25
objEmail.Configuration.Fields.Update
objEmail.Send
End Function这个函数,也是我们现在自动化框架用到的发邮件,
另外,也除了发送txt文本格式的邮件,也可以发送基于html格式的,详见:
Set ōbjMessage = CreateObject("CDO.Message")
objMessage.Subject = "Example CDO Message"
objMessage.From = "wiston.lifb@alibaba-inc.com"
objMessage.To = "wiston.lifb@alibaba-inc.com" objMessage.CreateMHTMLBody "file://d|/temp/test.htm" ' 把d:/temp/test.htm作为邮件内容发送。
objMessage.Bcc = "wiston.lifb@alibaba-inc.com"
objMessage.Cc = "wiston.lifb@alibaba-inc.com"
objMessage.Send -
关于服务器信息搜集并展示__collectd+RRDtool
2008-06-03 17:31:46
by_wxc
最近看到两个好工具,来不及细细研究,先记下来,做个记号。
collectd用于搜集Linux系统的信息。以守护进程的方式在后台运行,刷新、收集系统数据,然后写入RRD格式的日志文件中。通过RRDfiles进行前端图形化展示。
collectd:http://collectd.org/
RRDfiles:http://oss.oetiker.ch/rrdtool/
图形化展示的特色有:cpu,内存使用量、swap、网络流量,进程
可以和loadrunner的监控形成有效的补充
