
-
[论坛] 并发用户数与think time
2008-11-30 23:10:32
by jack
有位同学问道:1用户每秒发一次请求,一分钟计60次请求;4用户每4秒发一次请求,一分钟计也是60次请求,从请求的处理量上来看是完全一样的,那么还有什么区别呢?
问题所举的例子中,不同的请求方式模拟出不同的效果:1用户的情况是第一秒1个请求,第二秒1个请求,第三秒还是1个请求……4用户的情况是第一秒4个请求,第二秒0个请求,第三秒是0个请求,第四秒是0个请求,第五秒又是4个请求……
上面这样描述可能不太好理解,打个不是很恰当的比方来说明吧:
比如我有10袋净重25kg的水泥,甲每次能背1袋,分10次全部从仓库背到工地,每次5分钟,总共50分钟搞定;乙每次能背2袋,分5次全部从仓库背到工地,每次10分钟,总共也是50分钟搞定。从结果上看,都是50分钟搞定10袋水泥;但是如果让我们说谁的力气大呢?毫无疑问大家都会说是乙。
同样的评估并发性能也是如此,如果要评估的系统是支持多用户请求并行处理的(如web系统),就必须要注意这个问题。
-
web系统单用户与多用户请求的区别
2008-11-30 22:58:22
by jack
前几天在某个技术分享会上,有人问起:单用户请求与多用户请求到底有什么区别?
这是一个比较泛的问题,涉及面其实是比较多的,也是很多人都感到比较模糊的问题。
从请求处理的各个环节来分析,涉及到的有网络连接、应用程序线程处理、操作系统线程处理。
从网络连接上来说,当单个用户连接被复用时,其实tcp连接只建立了一次,之后通过连接保持一致使用当前连接;而4个用户发出请求时若连接未被复用,则出现建立多个连接的情况。主要是受web server的连接设置keep alive影响。
应用程序线程处理就比较复杂:主要是多线程处理的机制,对于新用户的请求如果是创建新线程来处理,则每增加一个用户就会增加一个线程。
还有一个层面就是操作系统的线程处理,也是主要取决于多线程处理的机制。
具体各种情况的处理将会在今后的博文中逐一介绍。
-
[论坛] 并发用户数与单位时间事务数
2008-11-30 22:10:53
by jack
近日听到有人提及性能测试的并发用户数,言及之时总以“每秒多少多少并发用户”云云,而提到“每秒事务数”时又无法弄清楚其与所谓“每秒并发用户数”的关系。
其实“并发用户数”与“每秒事务数”是性能数据中不同性质的名词,没有直接关系。“并发用户数”针对的是时刻,比如我查看上午8时31分32秒这个时刻的在线人数是23,这个23就是这一时刻的“并发用户数”;而我提取31分到35分这5分钟的访问量是600,那么每秒平均事务数就是2了。
但是“并发用户数”与“每秒事务数”也不是完全割裂的。
比如有20个并发用户,每个用户4秒钟做一次访问,那么1分钟里每个用户访问15次,20个并发用户就做了300次,每秒平均事务数就是5。
一般来说,当用户操作的样本数量足够多的时候,用户表现的操作会体现出规律与一致性,假设用户表现因子为α,可以近似的认为每秒事务数tps与并发用户数nu之间为一元关系
tps=α×nu
正确认识并发用户数和每秒事务数,是做好性能测试的充要条件。
-
性能测试的问题分析和总结
2008-11-28 23:52:29
by qjy
转载请保留:本文出自qaarchitech的51Testing软件测试博客:http://www.51testing.com/?170805
今天给部门做了性能测试分享,内容讲的比较泛泛,人还有点小紧张,还需要多学习怎么分享才能取到好的效果,现在仅摘其中的一部分,分享出来,内容不一定全面~~仅作交流常见的性能问题
1.最重要的性能问题是应用程序设计及与数据库的交互
应用程序设计:好的应用程序设计可能会获得优秀的响应时间(但不能确保),但差的应用程序设计很难获得好的性能。差的性能设计比如:不管怎么操作,让用户检索出大量结果集(比如
2.数据库设计
物理和逻辑设计,涉及非常多的方面,俺也不懂,举一个简单的例子:一个测试问题,大数据量下列表展现(多表联合查询)问题不能满足性能需求。DBA修改了数据库设计采用汇总表去展现列表(单表查询),汇总表也方便创建索引。
3.参数调整
4.硬件环境(包括网络对性能的影响会比较大)
5.其他,因素很多。就几个常见的性能问题,举例展开,性能问题非常多,也总结不全面,但可以经常回顾,分类汇总,逐步完善性能问题总结这部分工作。
转载请保留:本文出自qaarchitech的51Testing软件测试博客:http://www.51testing.com/?170805
一、数据库交互过多
Ø 现象:单个操作发送给数据库sql的数据量过多,数据库延迟。
Ø 发现方法:采用监控工具分析程序与数据库的交互(sql数量和响应时间),比如P6spy及类似工具。
Ø 数据库交互与程序设计方式息息相关
建议使用P6spy帮助去做数据库交互分析,截获页面操作的sql。P6spy使用具体请参考
http://dodomail.javaeye.com/blog/117934
http://blog.csdn.net/hennylee/archive/2007/03/07/1523410.aspx
http://www.blogjava.net/itstarting/articles/48969.aspx二、列表效率低
Ø 列表查询未使用索引。
Ø 查询全部字段,而不是所需字段,带来额外的I/O和网络负担。
Ø 分页算法效率低,甚至未使用分页。
1.查询未使用索引
此问题比较常见,通过查看sql的执行时间和I/O。查看查询计划可以清楚看出sql是否索引查询,或者全表扫描
select ID 。。 from B where xxx
2. 比如 Select xxx from where UPPER(name)=‘A’
在字段上使用函数,导致不使用索引,虽然Oracle是有基于函数的索引。更好的方式 a.update现有数据 b.改程序,直接改存储模式为大写的数据。
3.冗余字段的优化
select 。。。 from A where 。。。。比如 where 条件查询的字段的长度较大,创建索引效果后不明显,考虑增加了冗余的字段,进行标识,结合在冗余字段上创建索引会比较快。
4.分页算法,遇到的状况也比较混乱。。。。。好的分页算法要推广,公用。三、查询结果集过大
Ø 返回全部的数据(建议从业务角度出发,分析返回全部的数据是否必要)
Ø 空查询(默认条件查询)
Ø 不规范的查询(where 1=1)
1.查询结果集(建议从业务角度优化系统)
建议参考淘宝的一篇帖子
http://rdc.taobao.com/blog/dba/html/187_optimize_from_business.html
2.空查询(默认查询造成压力比较大,其实空查询可能是没有必要的)
建议页面增加默认过滤条件
3.Where 1=1
a、性能上的影响(可能会影响orale的查询计划)
b、安全性的影响
create table A tablespace tbs_temp as select * from B where 1<>1
create table A as select * from B where 1<>1
Sybase不支持这样的语法,但是有:
select * into A from B where 1 <> 1
where 1 <> 1 ,复制表的结构,但注意这样没有主键
4.不规范的查询sql很多,建议多参考部门的相关规范,从规范的角度出发去发现问题。四、复杂查询sql (大数据量测试)
Ø 复杂查询sql一定在大数据量下进行测试
Ø 结合操作和sql本身效率进行测试。
Ø 建议多与DBA配合
如果你只使用小表进行测试(比如小于100条数据),那么在真实数据下会异常缓慢直至停滞。Sql的例子就不列出了,比较多,通常对于多表联合查询,复杂的sql都要在大数据量下测试。其实越复杂的东西越难维护和优化,建议对系统中复杂的sql都记录下来,可能是性能隐患。
转载请保留:本文出自qaarchitech的51Testing软件测试博客:http://www.51testing.com/?170805
五、数据库连接池
Ø 未使用连接池,应用程序在建立数据库连接上消耗的时间较长,影响性能效率。
Ø 连接池配置参数不当(通过测试确定合适的值)
六、并发事务处理和死锁问题
Ø 程序对事务并发处理上的错误。
Ø 资源争用引起锁阻塞和死锁。
Ø SYBASE的锁模式为行锁,可以减小死锁发生的可能性。
死锁或者锁阻塞,如何检查锁阻塞的大致步骤
比如mysql 为例子
1.Show processlist,查看有locked的进程
2.查看阻塞进程执行的sql
3.关掉程序,或者杀死进程,解掉死锁,不建议杀死进程,可能导致不完整的数据。
4.查看sql问题,单独确认问题
5.优化sql或者查程序问题
还以一个实际问题中,sybase锁阻塞的例子
环境维护发现锁阻塞,发现很慢,检查到有问题的sql
1. sp_lock 看到死锁
2.查看阻塞进程信息
select * from master..sysprocesses where ipaddr =‘XXXX‘
3.造成锁阻塞的进程是spid为 1 和 2 的
使用dbcc traceon(3604)
dbcc sqltext(1)
dbcc sqltext(2)
查看到进程执行的sql
select * from View(视图) where ID = null (未列出原sql,仅举个例子)
4.关掉程序,杀死进程,解掉死锁
单独使用sql adv连接数据库,执行该sql,很慢。
查看创建View的语法,sybase可以使用sp_helptext View,可以看到建视图的大致的sql是
create view as select xxxx from A ,B where A.ID*=B.ID and A.C=10
查看sql的I/O和执行时间 set statistics time,io on,查看到sql具体的执行时间和I/O
5.简单看了一下,试着在C字段上增加了索引
再查询响应时间变小了和查询计划变了,有问题的就是这个查看视图的sql了,可能是资源争用造成了死锁。七、页面过大,网络延迟
Ø 页面中图形多且大
Ø 使用比较大的控件等等
Ø 建议参数WEB前端性能优化,推荐Yslow工具
中国雅虎有相关使用Yslow的一个很好的ppt。建议参考,帖子可以看看,推荐《高性能网站建设指南》http://www.cnblogs.com/JustinYoung/archive/2007/11/20/speeding-up-web-site-14rule.html
http://www.cnblogs.com/JustinYoung/archive/2007/11/28/speeding-up-web-site-yslow.html八、内存溢出、应用终止、服务器宕机等严重问题
Ø 批量对数据进行操作,会返回大量数据给应用服务器占用了较多的应用服务器的内存,可能会导致应用服务器内存溢出。
Ø 消耗服务器某种资源过多的操作可能会使服务器出现宕机和应用终止的情况。
Ø 检查应用程序日志和操作系统的日志或者core文件
九、参数调整和日志级别设置
服务器的参数调整不合理。完善性能环境检查的各种checklist。
生产环境中日志级别应当设置的较高,不打印出sql语句和调试信息,额外的I/O会降低性能效率。 -
[论坛] jmeter应用指南(脚本设计、场景设置、查看监控)
2008-08-19 11:13:42
by jack
一直以来都希望能有一套能够基本满足常规性能测试需求,并有效产生报表的工具,用以部分替代LoadRunner的依赖。所以专门针对jmeter进行了评估和研究,在评估过程中完成了一份使用说明;经过代码研究,对jmeter进行了改进,主要是增加了linux资源监控功能和报表功能。由于时间仓促,对增加的代码只进行了单元测试。
可用于面向B/S WEB应用测试的工程师使熟悉jmeter使用,章节安排按照脚本设计、场景设置、查看监控三部分顺序组织。十四、十五两章内容是关于增进的监控和报表功能的,不适用于apache网站提供的原jmeter。
内容主要是使用上的,不涉及性能测试分析的内容。
 Jmeter应用指南.pdf
Jmeter应用指南.pdf
(2008-08-19 11:13:16, Size: 1.45 MB, Downloads: 0) -
测试工具loadrunner扩展开发的一点感想
2008-08-13 22:39:46
by liangjz
最近在应用VC6,大量采用win32 api扩展Loadrunner8.0/8.2的一些外围功能,做到自动调节面向资源消耗目标的合适(临界)并发数,碰到了几个相当棘手问题。
如
(1) 在loadrunner controller design 界面上编程实现更改并发用户数
(2) 确保安全停止在运行的loadrunner但不破坏已存在结果文件,如res.lrr等等
由于没有loadrunner源代码以及很detail的介绍Loadrunner内部结构的资料,为了突破这些点,耗费了相当的力气。
如果我们换成对JMeter的外围扩展内,在一堆结构清晰的代码面前,突破这些功能难度可能陡降
经过这些天的尝试,对扩展黑盒工具的难度有一个更加清晰的认知,实践才知道水有多深
下面简单介绍下如何做到编程更改loadrunner并发数的几个思路
1)EnumWindows/GetWindowText 结合spy++,硬编码检索到窗口层次关系,获取classname=GridControl、windows caption=GridClass的控件,然后利用grid控件的行、列改写数据。
可是classname=GridControl仅仅是注册窗口时的一个友好名字,并非真正实现类。这个实现这个控件的类是什么呢? 这下卡壳了。
从安全工程师哪边拿到LookingGlass.exe、FABERTOYS(进程管理).EXE等工具,企图嗅探出ocx但未果。
其他难度、实现成本比较高、非常笨拙操控grid的方式还有: 利用IDAPro动态调试或者进程注入修改对应内存内容,这个有时间再琢磨下。
2)修改loadrunner 场景设计文件.lrs的GroupChief内容
由于loadrunner controller designed 界面大量选项,每一个选项可能都对loadrunner结果产生敏感影响。为了弄清楚每一个选项对应文件内容,很土也很管用的方法
一次只更改一个,然后对比变化,最后跟踪发现groupchief 段才是loadrunner 并发数关键所在。
lrs文件格式不是Ini 格式,是mercury自有格式,我们要做的事情就是fgets逐行读取,然后填充入自定义的数据结构(偶采用了链表)。
增加、删除修改并发数就是减少ChiefSettings所在的段,最后用fwrite将数据结构回填。
最后第二个方法成功实现需求。
不过综合权衡下,如果loadrunner升级lrs数据结构,第二种方法是相当脆弱的。
哈,要是偶遇一个mercury工具研发工程师问到grid控件实现类并把头文件和lib给我,然后彻底解决这个问题该多好啊 -
MSXML6 SDK解析中文XML文件
2008-08-10 01:54:08
1.1 下载msxml6_SDK.msi安装
默认安装在C:\Program Files\MSXML 6.0\
1.2 在vc6上建立编译环境
Preprocessor 编译加入 Additional include directorie加入C:\Program Files\MSXML 6.0\inc
LINK module加入: msxml6.lib
Link Additional library path加入:C:\Program Files\MSXML 6.0\lib
1.3 解决vc6 link错误问题
msxml6.lib(msxml6_i.obj) : fatal error LNK1103: debugging information corrupt; recompile module
参见 :
All I get from Google is that VS6 doesn't work with platform SDK's later than february 2003.
必须采用release版本编译、链接才成功。(build->set active project configuration->win32 release)
1.4 汉语问题
//解决汉语问题
setlocale(LC_ALL,"chinese-simplified");
1.5 源代码
#include <objbase.h>
#include <msxml6.h>
#include <stdio.h>
#include <windows.h>
#include <stdarg.h>
#include <locale.h>
#include <AtlBase.h>
#import <msxml6.dll> raw_interfaces_only
// Macro that calls a COM method returning HRESULT value:
#define HRCALL(a, errmsg) \
do { \
hr = (a); \
if (FAILED(hr)) { \
dprintf( "%s:%d HRCALL Failed: %s\n 0x%.8x = %s\n", \
__FILE__, __LINE__, errmsg, hr, #a ); \
goto clean; \
} \
} while (0)
// Helper function that put output in stdout and debug window
// in Visual Studio:
void dprintf( char * format, ...)
{
static char buf[1024];
va_list args;
va_start( args, format );
sprintf(buf, format, args);
vsprintf(buf, format, args );
va_end( args);
OutputDebugStringA( buf);
printf("%s", buf);
}
// Helper function to create a DOM instance:
IXMLDOMDocument3 * DomFromCOM()
{
HRESULT hr;
IXMLDOMDocument3 *pxmldoc = NULL;
HRCALL( CoCreateInstance(CLSID_DOMDocument60,
NULL,
CLSCTX_INPROC_SERVER,
//__uuidof(IXMLDOMDocument),
IID_IXMLDOMDocument3,
(void**)&pxmldoc),
"Create a new DOMDocument");
HRCALL( pxmldoc->put_async(VARIANT_FALSE),
"should never fail");
HRCALL( pxmldoc->put_validateOnParse(VARIANT_FALSE),
"should never fail");
HRCALL( pxmldoc->put_resolveExternals(VARIANT_FALSE),
"should never fail");
return pxmldoc;
clean:
if (pxmldoc)
{
pxmldoc->Release();
}
return NULL;
}
int Get_nodeValue(IXMLDOMElement * pRoot , char * tagName,char *ret_text)
{
USES_CONVERSION;
IXMLDOMNodeList * pNodeList = NULL;
IXMLDOMNode * pNode = NULL;
HRESULT hr;
BSTR bstr = NULL;
hr=pRoot->getElementsByTagName(_bstr_t(tagName),&pNodeList) ;
if (FAILED(hr))
return -1;
//取第一个满足条件的
hr= pNodeList->get_item(0,&pNode);
if (FAILED(hr))
return -1;
hr=pNode->get_text(&bstr);
if (FAILED(hr))
return -1;
//dprintf("v=%s\n",W2A(bstr));
sprintf(ret_text,W2A(bstr));
return 0;
}
int main(int argc, char* argv[])
{
/*
HRESULT hr;
IXMLDOMDocument3 *pXMLDoc = NULL;
CoInitialize(NULL);
hr = CoCreateInstance(CLSID_DOMDocument60,
NULL,
CLSCTX_INPROC_SERVER,
IID_IXMLDOMDocument3,
(void**)&pXMLDoc);
if (FAILED(hr))
{
printf("Error code: %x\n", hr);
}
*/
USES_CONVERSION;
IXMLDOMDocument3 *pXMLDom=NULL;
IXMLDOMParseError *pXMLErr=NULL;
BSTR bstr = NULL;
VARIANT_BOOL status;
VARIANT var;
HRESULT hr;
IXMLDOMElement * pRoot = NULL;
VARIANT_BOOL isHasChild=VARIANT_FALSE;
long listLen=0;
long i=0;
char ret_scrīpttext[48]={0};
char ret_steptime[48]={0};
char sz_xmlFile[]="lr.xml";
CoInitialize(NULL);
//解决汉语编码问题
setlocale(LC_ALL,"chinese-simplified");
pXMLDom = DomFromCOM();
if (!pXMLDom)
goto clean;
VariantInit(&var);
V_BSTR(&var) = SysAllocString(_bstr_t(sz_xmlFile));
V_VT(&var) = VT_BSTR;
HRCALL(pXMLDom->load(var, &status), "");
if (status!=VARIANT_TRUE) {
HRCALL(pXMLDom->get_parseError(&pXMLErr),"");
HRCALL(pXMLErr->get_reason(&bstr),"");
dprintf("Failed to load DOM from stocks.xml. %S\n",
bstr);
goto clean;
}
HRCALL(pXMLDom->get_xml(&bstr), "");
dprintf("XML DOM loaded from stocks.xml:\n%S\n",bstr);
HRCALL( pXMLDom->get_documentElement(&pRoot) ,"get_documentElement");
Get_nodeValue(pRoot,"scrīpt",ret_scrīpttext);
Get_nodeValue(pRoot,"steptime",ret_steptime);
printf("%s %d",ret_scrīpttext,atoi(ret_steptime));
/*
HRCALL(pNode->get_nodeValue(&value),"get_nodeValue");
USES_CONVERSION;
dprintf("v=%s\n",OLE2A(value.bstrVal));
SysFreeString(bstr);
*/
clean:
if (bstr) SysFreeString(bstr);
if (&var) VariantClear(&var);
if (pXMLErr) pXMLErr->Release();
if (pXMLDom) pXMLDom->Release();
CoUninitialize();
return 0;
}
Lr.Xml文件如下(notepad保存为ascii格式):
<?xml version="1.0" encoding="GB2312"?>
<root>
<scrīpt type="string">d:\工程\1.lrr</scrīpt>
<steptime>30</steptime>
</root>
-
jmeter利用http代理服务器组件录制脚本
2008-08-07 19:14:35
by jack
在“工作台”添加“HTTP代理服务器”
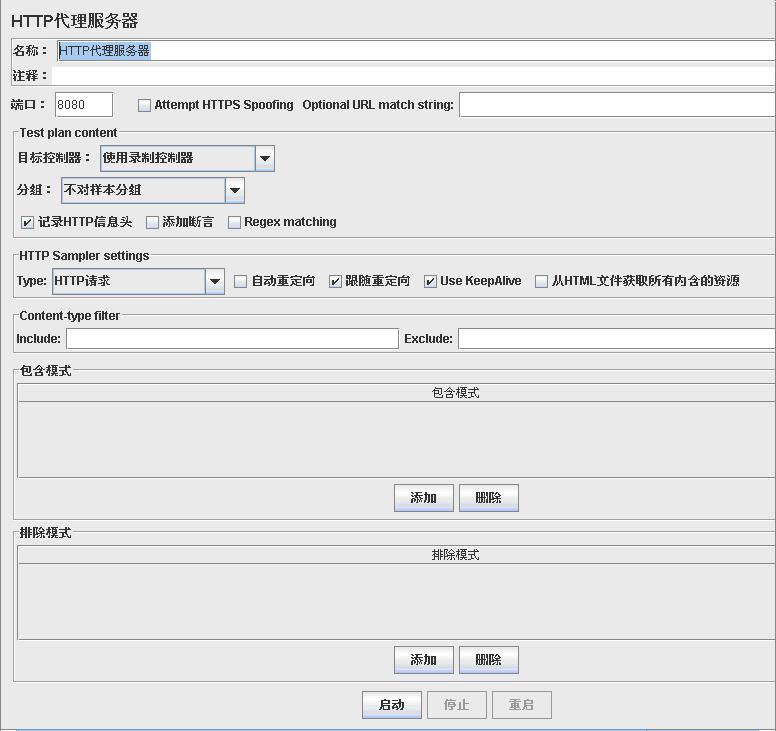
端口:
代理服务器的端口,默认8080,可自行修改,但不要与其它应用端口冲突
目标控制器:录制的脚本存放的位置,可选择项为测试计划中的线程组
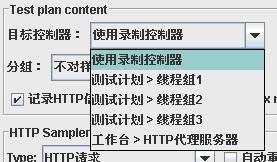
分组:
对请求进行分组。“分组”的概念是将一批请求汇总分组,可以把url请求理解为组。

“不对样本分组”:所有请求全部罗列
“在组间添加分隔”:加入一个虚拟的以分割线命名的动作,运行同“不对样本分组”,无实际意义
“每个组放入一个新的控制器”:执行时按控制器给输出结果
“只存储每个组的第一个样本”:对于一次url请求,实际很多次http请求的情况,这个选项很好用,因为我们常常是不关心后面的那些请求的。
记录HTTP信息头:
录制request的head信息
添加断言:
录制时加入空的检查点(需自行填写内容)
Regex matching:
录制时加入空的正则匹配(需自行填写内容)
在浏览器中录制
启动HTTP代理服务器后,打开浏览器(IE,Firefox,Opera等),添加代理,地址填写本机ip或host name,端口填写刚刚设置的代理端口(本例中8080),在浏览器中进行正常网页浏览,即可录制下对应的http请求。IE上的设置:

-
自动化友好、干净停止loadrunner运行场景的源代码
2008-08-01 23:28:10
最近针对loadrunner做功能扩展,其中一个环节是:尽力正常点击stop停止,如经过处理无法停止,则干净停止loadrunner进程。
loadrunner手册有命令行方式启动wlrun.exe进程的方式,但没有停止wlrun.exe的方式。本方法用win32实现友好停止Loadrunner场景。
窗口层次关系可以用spy++察看 .
测试程序的方法,启动一个loadrunner运行场景。
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
#include <errno.h>
#include <locale.h>
#include <windows.h>
#include <vdmdbg.h>
typedef struct
{
DWORD dwID ;
DWORD dwThread ;
} TERMINFO ;BOOL CALLBACK TerminateAppEnum( HWND hwnd, LPARAM lParam ) ;
DWORD WINAPI TerminateApp( DWORD dwPID, DWORD dwTimeout )
{
HANDLE hProc ;
DWORD dwRet ;// If we can't open the process with PROCESS_TERMINATE rights,
// then we give up immediately.
hProc = OpenProcess(SYNCHRONIZE|PROCESS_TERMINATE, FALSE,
dwPID);if(hProc == NULL)
{
return FALSE ;
}// TerminateAppEnum() posts WM_CLOSE to all windows whose PID
// matches your process's.
EnumWindows((WNDENUMPROC)TerminateAppEnum, (LPARAM) dwPID) ;// Wait on the handle. If it signals, great. If it times out,
// then you kill it.
if(WaitForSingleObject(hProc, dwTimeout)!=WAIT_OBJECT_0)
dwRet=(TerminateProcess(hProc,0)?TRUE:FALSE);
else
dwRet = TRUE ;CloseHandle(hProc) ;
return dwRet ;
}
BOOL CALLBACK TerminateAppEnum( HWND hwnd, LPARAM lParam )
{
DWORD dwID ;GetWindowThreadProcessId(hwnd, &dwID) ;
if(dwID == (DWORD)lParam)
{
PostMessage(hwnd, WM_CLOSE, 0, 0) ;
}return TRUE ;
}//MyEnumWindow 函数本身只能枚举最top-level的窗口。
//嵌套的窗口自己枚举//这里用spy++观察层次结构
//模拟用户鼠标操作停止loadrunner的过程
BOOL CALLBACK MyEnumWindow(HWND hWnd, LPARAM lParam)
{
char sz_text[MAX_PATH]={0};
int len =0;
char * p_title = NULL;
int ret;
HWND child_hWnd=NULL,dialog_hWnd=NULL,next_hWnd=NULL;
int i=0;
BOOL isFound = FALSE;
int try_time=10;
WINDOWINFO winInfo;
DWORD dwID ;
p_title=(char*)lParam;len= GetWindowText(hWnd, sz_text, sizeof(sz_text)/sizeof(sz_text[0]));
if (strstr(sz_text,"LoadRunner"))
printf("%s\r\n",sz_text);
child_hWnd = hWnd;
if(strstr(sz_text,p_title))
{
while(1)
{
//获取子窗口
child_hWnd=GetWindow(child_hWnd, GW_CHILD);
//恶意关闭loadrunner时,窗口是否为存在?防止死循环。
if(child_hWnd!=NULL)
{
len= GetWindowText(child_hWnd, sz_text, sizeof(sz_text)/sizeof(sz_text[0]));
if (!strcmp(sz_text,"&Start Scenario"))
{
//获取兄弟窗口
next_hWnd=GetWindow(child_hWnd, GW_HWNDNEXT);
len= GetWindowText(next_hWnd,sz_text, sizeof(sz_text)/sizeof(sz_text[0]));
if (!strcmp(sz_text,"S&top") )
{
//找到停止的窗口
isFound =TRUE;
break;
}
}
}
else //child_hWnd!=NULL
{
break;
}
} //while
if (FALSE ==isFound )
{
//失败退出
printf("not found S&top!\r\n");
return TRUE;
}//尝试投递try_time次。
//for(i=0;i < try_time; i++)
while(1)
{//SendMessage(next_hWnd, BM_CLICK,0, 0);
PostMessage(next_hWnd, BM_CLICK,0, 0); // 这里不能用SendMessage,否则阻塞进程
dialog_hWnd = FindWindow("#32770", "LoadRunner Controller");
if (!dialog_hWnd)
{
printf("Find dialog error. ret=%d\r\n",GetLastError());
}
else
{
//if (IsWindowVisible(dialog_hWnd))
//{
len= GetWindowText(dialog_hWnd, sz_text, sizeof(sz_text)/sizeof(sz_text[0]));
printf("GetWindowText return %s\r\n",sz_text);
//查找对话框上按纽
child_hWnd = FindWindowEx(dialog_hWnd,0,"Button","确定");
if (!child_hWnd)
{
printf("确定 button ret=%d\r\n",GetLastError());
continue;
}SendMessage(child_hWnd, BM_CLICK,0, 0);
ret = GetLastError();
if (ret)
{
printf("button error. ret=%d\r\n",ret);
}
else
{
printf("正常停止loadrunner!\r\n");
}
//经过如上处理后
printf("destroywindows\r\n");
Sleep(10);
//强行关闭loadrunner相关进程
GetWindowThreadProcessId(hWnd, &dwID) ;
TerminateApp(dwID,10);
return FALSE;
//}
} //(!prev_hWnd)
}//for
}return TRUE;
}
int stop_loadrunner()
{char sz_title[]="Mercury LoadRunner Controller ";
// char sz_title[]="S&top";
if (EnumWindows(MyEnumWindow,(long) sz_title) )
printf("failed,errno=%d",GetLastError());
}
void main(){
stop_loadrunner();
}
-
[论坛] Jmeter Linux资源监控器
2008-08-01 21:00:22
by jack
最近完成了jmeter linux资源监控器的开发,方法并不怎么高明,但相信可以帮助很多用jmeter来做性能测试的同仁解决jmeter缺少linux资源监控的问题
附件中是编译好的包以及linux上所用的脚本。基本的原理是利用shell脚本生成资源xml,让jmeter利用http请求获取该xml,解析展现数据。
欢迎各位同仁测试使用,有问题也可以与我交流。
监控器实现的是linux系统上的资源监控,要求:服务器上至少有一个web server(因需要通过http请求获取资源xml),用于生成服务器资源xml的脚本中使用了sysstat包中的指令,所以需要安装sysstat包。
使用方法:
下载:
LinuxResourcesMonitor.rar
(2008-08-01 20:56:32, Size: 756 kB, Downloads: 0)
首先解开压缩包,取出status脚本,登录到被监控的服务器上,将status脚本放上去。该脚本执行时会在所在路径生成status.xml文件,可以直接将status脚本放在web server的目录下,也可以用软链接来链到status.xml文件。下面介绍在基于apache的web server上的配置方法:
在apache的配置文件httpd.conf中找到DocumentRoot,一般默认是apache目录下的htdocs,将status脚本放到该目录下;
更改执行权限:
chmod 744 status
启动该脚本:
./status start
启动起来之后就会在当前目录下产生status.xml文件
不需要监控时,停止该脚本:
./status stop
然后到运行jmeter的机器上,解开压缩包里的ext.rar包,将解压得到的两个jar包:ApacheJMeter_core.jar和ApacheJMeter_monitors.jar,复制到jmeter的lib/ext目录下,覆盖原来的jar包。
之后就可以到jmeter上来监控了:打开jmeter,建立一个线程组,添加一个http请求,ip就是要监控的服务器地址,端口号就是apache侦听的http端口,协议是“http”,路径是“/status.xml”,勾选“用作监视器”;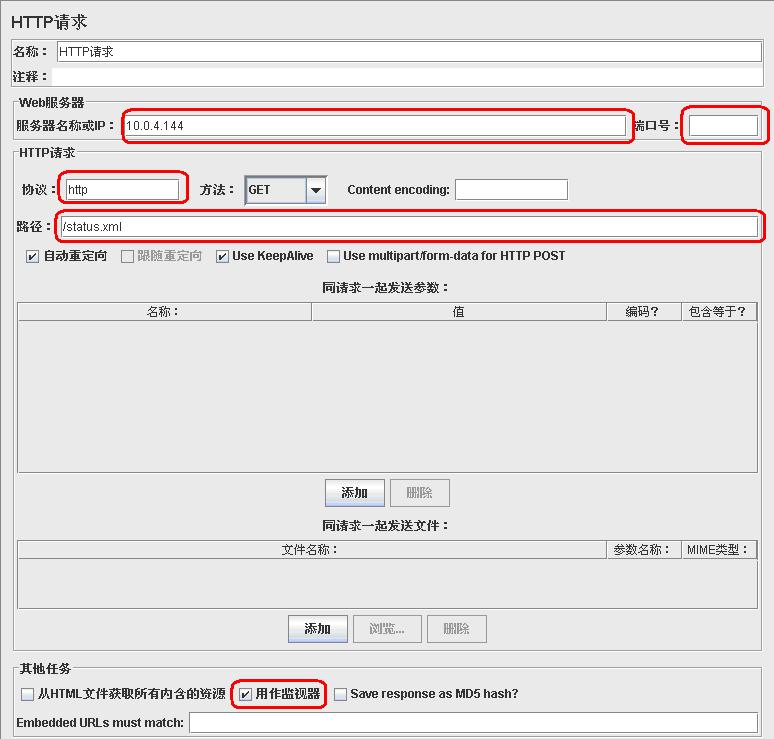
http request.JPG
再为该http请求添加一个“固定定时器”组件和一个“监视器结果”组件,“固定定时器”的延时要设置为大于1秒的时间,即数据的采样时间。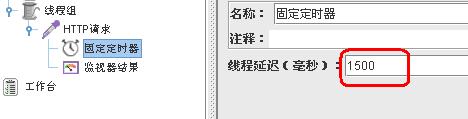
timer.JPG
在线程组中循环次数设置勾选“永远”;
thread group.JPG
Run一下,就可以在监视器结果上看到刚刚添加的监控服务器了,目前已经监控了6个参数:cpu%user,cpu%iowait,load,mem%(used/total),swap in,swap out。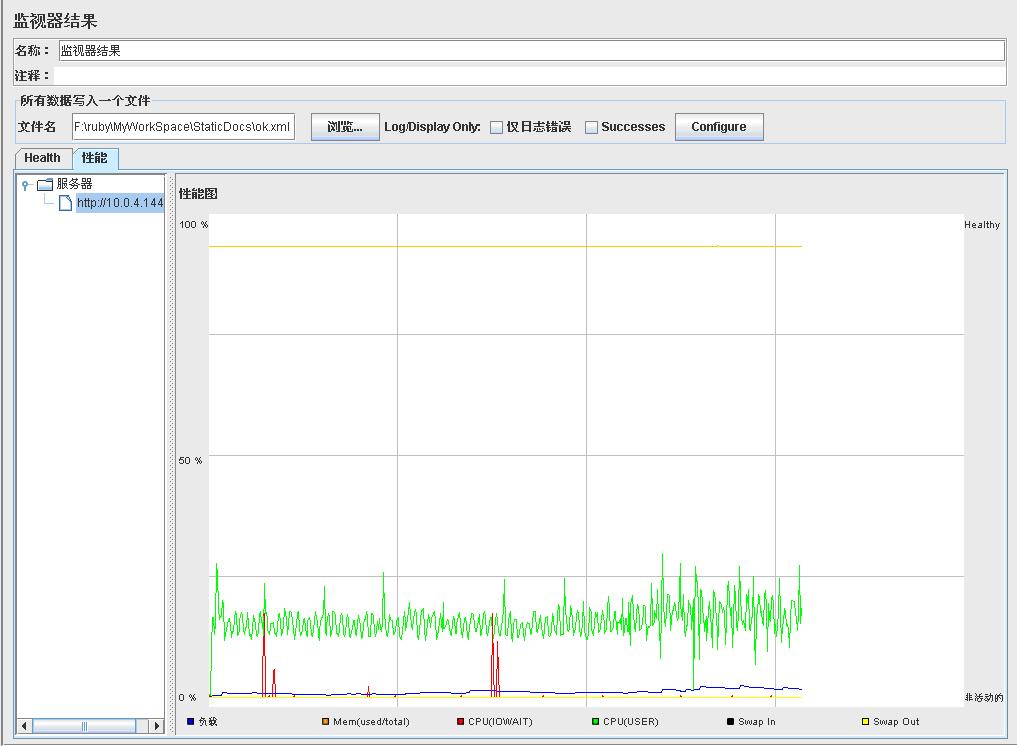
monitor.JPG
如果被监控的linux上没有安装sysstat包,是无法正常生成监控数据的,这里附上sysstat包的安装方法:
首先到 http://perso.wanadoo.fr/sebastien.godard/ 下载最新的版本,最好是源码包,比如sysstat-5.1.1.tar.gz
1.解包:
tar zxvf sysstat-5.1.1.tar.gz
2.安装:
cd sysstat-5.1.1
make config
这步可以省略,有些发行版中会出错;如果不用这个命令,可以直接安装到其默认的/usr/local/lib目录中
make
编译
make install
安装
这样就安装好了。
[ 本帖最后由 qaarchitech 于 2008-8-1 20:58 编辑 ] -
[论坛] jmeter资源监控器开发——my sharing
2008-07-31 22:54:31
by jack
You'll get it because of your sharing.
我修改的源码,解压缩后覆盖原有源码中的src目录,重新编译就可以用了;对编译有疑问的可参见我的帖子http://bbs.51testing.com/thread-121772-1-1.html
src.rar
(2008-07-31 22:33:51, Size: 1.59 MB, Downloads: 0)
监控的xml
status.rar
(2008-07-31 22:33:51, Size: 342 B , Downloads: 1)
编译好的包,象征性收取一点点数 ,希望大家还是自己尝试改一下编译一下,这样今后可以比较容易的扩展出自己想要的监控
,希望大家还是自己尝试改一下编译一下,这样今后可以比较容易的扩展出自己想要的监控
下载编译好的包,把包里的两个jar包拷贝到jmeter的lib\ext目录下,覆盖原来的jar,重启启动jmeter,就可以使用我写的监控器了
ext.rar
(2008-07-31 22:33:51, Size: 755 kB, Downloads: 0)
目前还在写一个shell,用于生成linux下性能数据的符合上面格式的xml,写好后也会分享出来
[ 本帖最后由 qaarchitech 于 2008-7-31 22:38 编辑 ] -
大型RAILS应用(网络考试)性能测试与调优过程
2008-06-30 11:24:30
一 背景介绍
系统为上海一家IT公司rail on ruby快速开发出来的网络考试系统。核心功能:登录、考试。考试分为html的单/多选题,flash展现的操作题。在内部一次模拟考试中,系统曾经出现性能故障,导致无法正常做题。
二 系统架构分析接到性能测试任务,第一感觉:要很注意每一个细节,包括用户行为模拟、场景设计合理全面等。
咨询了解到系统架构为: ruby+rails+ apache2.x+mysql5。
登录系统:登录web与登录的DB分开
考试系统:考试web与考试DB 集中部署在一台机器上。答一道题目即插入数据库表
三 用户行为分析1 考试要求在 0~45分钟内考试完毕
2 多数考生一般先做选择题,再做操作题;少部分反之。
3 多数考生做完全部题目,少部分考生中途就提交结束答卷
4 题目可以回退或者选择任意一题目修改答案
5 同一个考生在提交答卷后,不能再答题由于系统更加细致的数据没有log分析,就简单采用80-20原则随机模拟。
四 脚本开发小技巧
1 随机模拟脚本
init.c 加入 srand(time(NULL));action.c 加入 rand() % 100;
2 cookie处理服务器端检查cookie信息。
加入web_add_auto_header 确保后续每一个http请求都自动把cookie加入header3 并发处理
由于一次性考试,故并发数没有按考试人数缩放,但考试按照一定的随机think time等待。
五 系统调优主要的线索是environment.rb定义的config.log_level 生成product.log,
以及rail bench。(一) 精简登录首页
1 登录:削减登录网页,很轻量级,仅仅包含Login 窗口(二) flash下载模式变更
原来做操作题目,该flash操作题才下载到客户端。
为了减轻并发下载flash的网络流量压力,变更为在登录成功后,客户端javascrīpt采用ajax技术(xmlhttpquest)随机1-60秒内后台主动下载flash试题到客户端。改变网络流量瞬间飙升的情况。(三) apache2.0 调整httpd.conf 关键参数以及加载mod_proxy 、mod_mem_cache
1 apache httpd work mpm模式。
增加 MaxClient。<IfModule worker.c>
StartServers 2
ServerLimit 2500
MaxClients 2500
MinSpareThreads 75
MaxSpareThreads 255
ThreadsPerChild 25
MaxRequestsPerChild 0
</IfModule>
2 上apache 负载均衡模块 mod_proxyProxyRequests off
<Proxy balancer://kaoshi>
BalancerMember http://localhost:6000
BalancerMember http://localhost:6001
BalancerMember http://localhost:6002
BalancerMember http://localhost:6003
BalancerMember http://localhost:6004
BalancerMember http://localhost:6005
</Proxy>
ProxyPass /images !
ProxyPass /stylesheets !
ProxyPass /javascrīpts !
ProxyPass /expert_photos !
ProxyPass /uploads !ProxyPass / balancer://kaoshi/
ProxyPassReverse / balancer://kaoshi/
ProxyPreserveHost on
3 LoadModule mem_cache_module modules/mod_mem_cache.so加载cache模块CacheEnable mem /
MCacheMaxStreamingBuffer 65536
MCacheRemovalAlgorithm LRU
MCacheSize 3000000
MCacheMaxObjectCount 256000
CacheIgnoreHeaders None
CacheIgnoreCacheControl On
MCacheMinObjectSize 1
MCacheMaxObjectSize 2560000
CacheDefaultExpire 10(四) rails 相关调整
1 变更默认连接器为C-based MySQL library mysql-2.7。
2 直接写SQL不用activeRecord 接口。
3 修改mogrel 服务参数mongrel_cluster.yml
cwd: /home/www/kaoshi/current
port: "6000"
environment: production
address: 0.0.0.0
servers: 7
4 rails负载均衡
[app@b2bsearch114 controllers]$ pwd
/home/app/download/match_export/app/controllersclass ExamsController < ApplicationController
IPS = %w(10.0.6.91 10.0.6.91 10.0.6.91 10.0.6.91 10.0.6.91 10.0.6.91)def host
index = (session["no"] || 1) % IPS.size
render :text => IPS[index]
end5 rails 部署Memcached缓存模块
(五) 数据库结构以及SQL 调优调整MYSQL配置文件、以及增加部分字段索引之后,iowati%从20%下降到0.4%
祥见
http://nnix.blogbus.com/logs/14824821.html
/bin/sh /usr/bin/mysqld_safe --user=mysql[root@aligame etc]# vi my.cnf
[client]
#password = your_password
port = 3306
socket = /var/lib/mysql/mysql.sock# Here follows entries for some specific programs
# The MySQL server
[mysqld]
port = 3306
socket = /var/lib/mysql/mysql.sock
skip-locking
key_buffer = 64M
max_allowed_packet = 1M
table_cache = 512
sort_buffer_size = 2M
read_buffer_size = 2M
read_rnd_buffer_size = 8M
myisam_sort_buffer_size = 64M
thread_cache_size = 8
thread_concurrency = 8
query_cache_size = 64M
event_scheduler=1
lower_case_table_names=1
max_connections=200
back_log=512
default-character-set=utf8log_slow_queries
log_long_format
long_query_time=1
server-id = 1
#innodb_data_file_path = ibdata1:1025M;ibdata2:256M:autoextend
innodb_buffer_pool_size = 1024M
innodb_max_dirty_pages_pct = 90
innodb_additional_mem_pool_size = 16M
#innodb_log_file_size = 256M
innodb_log_buffer_size = 8M
innodb_log_files_in_group = 2
innodb_flush_log_at_trx_commit = 2
innodb_lock_wait_timeout = 50
innodb_file_io_threads = 4
innodb_thread_concurrency = 8[mysqldump]
quick
max_allowed_packet = 16M[mysql]
no-auto-rehash
# Remove the next comment character if you are not familiar with SQL
#safe-updates[isamchk]
key_buffer = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M这 log_slow_queries,log_long_format,long_query_time=1 慢的查询语句将被打印
在目录下可见*slow.log文件记录可能有性能问题的SQL
七 小结
本次rails程序从应用程序调优、APACHE配置与调优、MYSQL索引与SQL优化多个细节提升性能。
调整从最显著的一个瓶颈(apache Maxclient->Mysql SQL)开始的,一次仅调整一个。
本次调优一个环节后,瓶颈从一个环节转移到另外一个环节。
-
loadrunner的不足与jmeter用武之地
2008-06-20 22:03:54
我们购买了LoadRunner 8.1 作为性能测试主流工具,商业工具确实用的蛮好的,在部门层面推行顺利。
结合实践,发现有几点相当不错:1) LoadRunner controller运行稳定
2) 支持多个load generator 一起施加压力
3) 监控指标相对齐全
4) 性能测试结果颗粒细致
5) 预留有性能结果在monitor上的api 接口
...但LoadRunner是否足够完美了呢?答案:NO
1) 对汉语的编码支持问题:utf-8/gbk设置导致有时仅用英文作web_reg_find的check point
2) LoadRunner 8.1 Udp方式监控unix资源导致有断续, 呵呵,改天要电话咨询下HP有无补丁。
(LR 8.0有的)3) 有时应用vugen 录制/回放异常退出程序
4) 最为诟病的:昂贵
5) 支持jboss/tomcat/mysql等的应用性能数据需要自己实现,实际上监控linux也无可用内存、iowait%、网络流量等指标
...
我们把更多眼光关注开源社区,评估opensta、jmeter、webload...。 最终选取与公司主流技术平台( java+apache2+ jboss4.2 +oracle9i/10g + redhat linux)一致的jmeter做一个补充。
对于Jmeter最为关键的几步:1) 分析性能测试结果和loadrunner不同的原因
2) jmeter 产生压力的稳定性以及原理
3) 监控扩展能力。 linux+oracle9i+jboss+mod_jk 等这些需要支持,呵呵,否则很可能需要手工收集各个平台性能数据,造成效率低下
4) jmeter脚本调试能力,支持参数化、关联、检查点、http协议自主控制(超时、cookie、http头、是否下载non-html资源)等
-
容量规划问题列表,期待专家深入交流
2008-06-15 22:15:32
沙龙交流前自己准备的容量规划方面的问题列表,呵呵,也期待业界这方面的专家指点。
1 瓶颈资源到达75%以后,容量预测偏差难以衡量,预测准确率陡降。
现有容量规划软件包容这种情况?或者如何做能提升这个区域的预测准确度
2 SAP 的容量规划工具可容忍偏差范围多大?
3 SAP 内部有自己的监控软件么?包括应用级别的监控。
现在的软件更多针对应用服务器、web server和os层面的监控,但对应用本身的监控是缺乏的
假如没有这些细粒度的监控数据,SAP 如何更好为用户行为建模?
4 SAP 容量规划软件建模算法是什么?是否为排队网络?
可以调整客户到达分布与服务时间分布等参数?
5 BELL实验室网络测试发现,用长相关或自相似随机模型比排队网络模型更符合web 网站客户到达分布? SAP 容量规划软件针对更合适的模型做调整么?
6 SAP 容量规划软件内部有what-if 假设分析么?直接支持针对内存或者硬盘的what-if分析?
7 SAP 针对跨机型的容量规划如何做?
尤其是sun公司不参加TPCC评估后的机型 。
8 如何做容量规划效果的反馈
9 做容量规划的团队组员有几个,都是怎么样的专业背景(数学?计算机?)
10 开源容量建模工具要求手工采集非常多数据,必然引入较大的误差?对于这种状况,有何建议
经过和SAP 工程师交流。负责容量规划的工程师和负责测试的不属于同一个部门,容量规划工程师面对咨询公司,提供硬件建议。
国内的SAP工程师更多是规划软件的应用者。SAP 软件相对成熟,且部署的机型相对单一。目前容量规划结果满足需求。
SAP有商业逻辑的监控。SAP容量规划软件采集生产系统数据建模,在web页面上输入参数,降低建模门槛。目前SAP容量规划软件建模依赖经验值,而非各种复杂的数学模型。当下没有必要研究开源建模工具。
SAP软件用内部开发的语言开发的。有很好的扩展性。
由于上述背景,我自己碰到的一些问题就没有很深入交流。
目前阿里巴巴需要自己建立模型,并需要长期校准模型,另外由于需求、应用的多变,容量规划的门槛依然需要具备较高的数学建模与计算机性能分析方面的背景。
-
容量规划沙龙4原则以及个人理解
2008-06-15 01:08:29
个人觉得今天容量规划沙龙最核心内容即4原则1)经过良好调优的系统才容量规划
2)可扩展性好的系统才做容量规划
3)人人有容量规划意识。执行T-shirt sizing是一个巨大进步
4) 最关键的事情是测量其他的还有
5) 用真实的产品数据做容量规划
6) 特别区分对待的容量规划场景
7) 追求响应时间与成本间平衡欢迎其他朋友补充。
以上的点说得都很实在。
根据自己的实践做一个发散说明1)容量规划有一个难点:在系统扩容和调优之间取得平衡。
就是停止调优的标准是什么?目前我是根据经验值判断特定的硬件、配置参数支撑一定的访问模式、数据量、并发数、吞吐率且满足响应时间等SLA指标。 另外,检查系统不存在core dump或者大量连接超时,日志无异常等。
有较大的主观性。2) 系统扩展性良好。
根据了解,SAP 没有结合性能测试做系统的可扩展性判断。呵呵,也许SAP架构很多年稳定了,没有必要做这个事情。
我们实践中,会设置多个场景执行性能测试或者了解系统架构判断。
如是否采用多线程技术?集群是否采用session技术?建模采用的数学模型一般有很多的假设,就是公式成立有很多前提条件。性能测试需要判断结果是否违背了假设。同样预测时,也需要判断是否背离假设
3) 人人容量规划意识
从阿里巴巴的角度看,应该是从架构设计权衡系统扩展性、开发加入代码性能探针、性能测试判断是否该停止调优、运维部门长期跟踪反馈性能监控数据以及采购规划、数据仓库平台采集PV、运营部门预测下一年业务增长速度等多个环节。
据目前看,要走的路还很长。
对阿里巴巴而言,在网站购买的大量便宜的PC server背景下,容量规划的收益与成本不是足够一目了然,以及资源紧缺是最头大的问题。与前同事聊天,目前广东电信研究院的容量规划的驱动力不足是当下最头痛的事情。
4) 第四个观点:测量是最关键的。
这个论点放到阿里巴巴。我个人有不同的看法。
测量是很重要。个人认为借助测量到的数据,如何构造一个合理的容量模型、如何校准模型负荷实际情况更关键,否则预测的偏差过大导致没有太多的参考价值。另外,目前的商业工具或者开源工具都存一些不足,如何对工具做二次开发完善,也是一件很有挑战性的工作。
-
阿里巴巴的容量规划设计方案
2008-06-15 00:21:33
by liangjz针对今天容量规划沙龙由于时间关系没有回答的问题--阿里巴巴的容量规划设计方案,做一个简单的说明。
呵呵,我去年10月份这个问题写了很长的技术方案书。大致思路如下
容量规划方案贯穿软件开发整个流程。
针对已经上线运行的系统
1) 性能需求: 从数据仓库平台或者web 日志分析工具awstats分析access_log日志得到用户访问模型;
从监控中心(cacti 和nigos ) 获取服务器资源消耗数据,如cpu,io,内存,网络等细节,得到系统资源消耗模型。
如果要求更细致的颗粒,可以在应用层加以监控,如jmx获取JVM 的性能;oracle db 通过statspack获取性能
2) 性能测试与监控
建立性能测试场景(用户、数据量、硬件、软件系统等),执行性能测试;获取当前系统的承受负荷以及获取临界值。
经过确认,系统经过良好调优、且无伸缩性问题后。可以按照容量规划理论来看,寻求伸缩因子。其=1/(1-利用率%)。
比如找到瓶颈资源临界点,如50%资源消耗,75%资源消耗。一旦伸缩因子>2后,容量预测的估计偏差难以估计,因为已经不是线性关系
3) 建模以及预测
采用开源工具java model tool或者 pdq (2工具可以从sourceforge.net下载) ,建立客户到达时间分布与服务时间分布等众多容量规划参数,模型可以选择排队网络。流程:建模->MVA求解- 与性能测试结果对比校准模型,迭代逼近误差容忍范围。
what-if 预测可以从 增加并发数、合并/拆分应用、变更硬件等角度考虑
呵呵,当然也可以尝试找teamquest临时 license。
针对新开发系统:
1) 性能需求: 可以定义得更加苛刻一些。
参考同类系统,初步用TPCC 等参数比较。
实际上,这样可能误差较大。
另外,需要架构师评估系统是否有代码保证最大连接数限制
2) 性能测试与监控
场景细分更加细致,获取新系统承受负荷以及获取临界值。
3) 建模与预测
模型校准的工作量比较大。
需要长期与生产系统实际的用户行为、系统资源消耗、响应时间、吞吐率等SLA指标比较,修正容量规划模型。
这个过程可能很漫长。 -
容量规划工具
2008-06-14 23:57:17
1 开源
java model tool
pdq
2 借用定律A
little's law
N = X * RN = Number of requests in the system
X = Throughput
R = Response TimeB Utilization law
U = X * S
U = Utilization
X = Throughput
S = Service Timec Stretch Factor
Stretch Factor=1/ (1-U) =response time/service time
where U is the utilization of the server.
The analytic formula for estimating stretch factor assumes the following:
There are an infinite number of customers
The arrival times are exponentially distributed
The service times are exponentially distributed
3 商业工具
teamquest,国外SUN 公司、国内广东电信研究院用
bmc performance assurance,上海电信研究院用
原来Mercury工具也和一厂商有容量规划工具的合作的现在没有了 -
[论坛] 别让她蒙上你的眼——进程干扰导致的性能测试失败
2008-06-10 13:08:55
先给大家看几个由LoadRunner的场景运行产生的结果报表(Analysis输出结果)
首先是Average Transaction Response Time图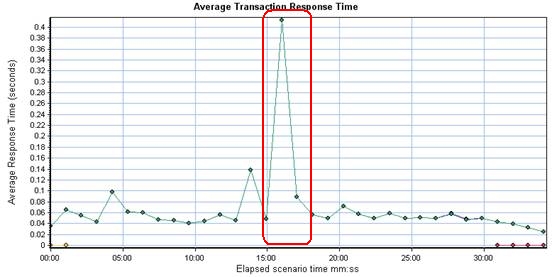
然后是Unix Resources图
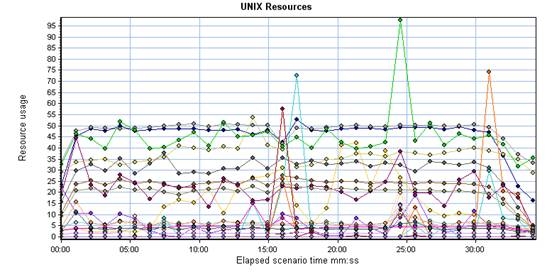
Unix Resources数据表格
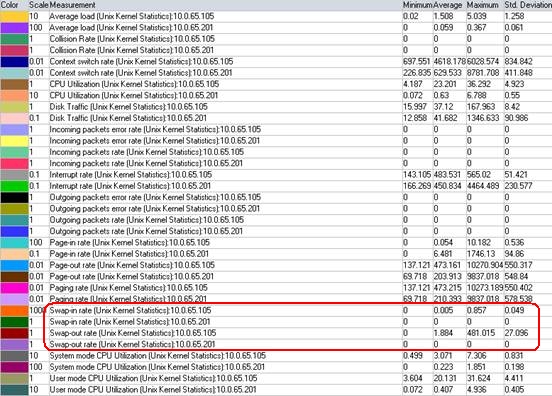
这是前一段时间某个同学性能测试的报告中的图。当时看到这个图我马上问了一下:
问:这个是什么类型的应用?
答:纯java,ip:10.0.65.105是应用服务器
问:为什么中间有那么大的响应时间的陡升?
答:测了好几次都有的
问:找到原因了吗?
答:没有
问:Unix Resources里面的应用服务器的swap是怎么回事?
答:不知道……没注意其实这个同学性能测试报告总结部分写得不错,但仔细看了一下图表,发现了些问题,就马上提出给他了。
这次性能测试的结果是不可靠的。为什么呢?
要说清这个问题,还需要先简单提一下jvm调优:纯java应用(没有在java进程外的应用程序),其内存使用变化在jvm内;通常我们调优jvm都会注意的就是在满足应用运行所需要的内存前提下,还要让jvm最大内存小于剩余物理内存,这样避免了使用虚拟内存造成的磁盘io。
从上面这段介绍可以看出,纯java应用,正常调优后,其服务器表现出来的Unix Resources中的swap应该一直为0
那么swap是怎么出现的呢?很简单,物理内存不足。为什么会物理内存不足呢?对于本文提到的这次性能测试来说,不外两种可能:
1.jvm内存最大值过大,超过剩余物理内存
2.其它进程占用内存导致物理内存不足
与做这次性能测试的同学核对过后证实:是第二种原因,而响应时间的陡升,也是该时刻大量磁盘io导致io wait引起的响应变慢。
在我们做性能测试的过程中,一定要保证环境的纯净,特别是不能受到一些内存用量大、cpu占用率高的进程的干扰;最好能在运行场景前重启服务器。另外在linux系统的性能测试中,常常把着眼点总放在cpu,load上,有时会忽略内存的影响,这也告诉了我们:对待性能测试必须谨慎;对报告数据的自信来自于认真和细致的工作。
-
连接池对性能测试施压的影响
2008-05-14 22:03:56
by jack
前几天有人来问我一个关于性能测试施压时的问题:他在设计场景时,并发用户数低于50个的时候场景运行没有什么问题,但设置为60个或更高的时候出现一些502,503错误。
我去帮他看了一下,在脚本里加入了一些变量的日志输出,看了一下出现错误时访问到什么页面,以及所用的一些参数化数据;排除了数据引起问题(用日志打出来的数据手工操作是没有错误的)。多次调整了并发用户数,重现了他说的问题。
登录到服务器上看了一下上面的连接量(netstat),发现有150个之多,猜想是不是超过了apache的连接数限制;检查服务器上的httpd.conf,果然找到MaxClients 150
这条设置。马上将参数改为1024,重启apache之后再施压,问题不再出现。
他又问,为什么60个并发用户却产生了这么多连接。检查他的脚本发现脚本中action确实是单一的访问,按说不该有这么多连接(会有少量的TIME_WAIT);再次登录服务器查看,发现了很多Foreign Address也是本机的连接,相信是应用程序本身访问造成的了。
这次的问题其实并不复杂,只是并发导致的访问超出了应用服务器设置的限制;但从中可以发现,施压的访问量并不需要达到设置的限制,连接量也有可能达到限制。这跟应用本身也有很大关系。增加压力时逐渐出现错误不要急着下结果;当然根本上的做法应该是事先将连接设置配好。 -
性能测试小小经验
2008-05-13 09:04:23
by jiale
给apathe加载将url某个固定域名替换为变化域名的modul的功能做加载前加载后的对比性能测试,测试的结果发现,加载后的相应时间、tps都比加载前的性能要差,唯独cpu占用率却比加载前要低,但这个modul是非常占cpu的,不可能出现比加载前cpu占用率低的情况,肯定是哪个环节上有问题了。
原来是由于加载后的tps比加载前的要低,因此cpu占用率也就相应的降低了,为了能够获得可靠的对比数据,我们可以在loadrunner给两个场景设置相同的tps。
设置方法:打开Controller,选择Goal-Oriented Scenario模式打开Scenario,在Edit Scenario就可以对加载前后两个场景设置相同TPS。
如此设置后测试,加载后的相应时间、cpu占用率均比加载前的要高,得到了预想的对比测试结果
