看博客,说观点,聊意见,交朋友。
现在已经习惯了用微博客表达自己的观点,因此这里也会微博一下。
--------专写软件测试博客读后感

发布新日志
-
2010-03-15 13:53:06
看了架构师Jack写的“测试的价值不仅仅是找bug”一文,跟我在我的微博上写的“测试是为了加快软件的流动速度”非常一致。下面就谈谈如何才能提升测试的价值,今天先说说工作任务的分配。
作为测试经理,在测试开展之前需要考虑一下测试工作任务的分工,通常按照模块或者测试类型居多,比如功能测试2个人完成,性能测试1个人完成。这里就有一个问题,这种全面开花的并行分配方式是否是最优的工作任务分配方式。
从国内整体的测试水平来看,测试工程师存在人少、水平参差不齐的现状,不少测试工程师并不具有很好的独立做好工作的能力,那这种情况下还四处出击、各自为战是否能保证测试的进度和质量。越是个人能力不够强的时候才越应该借助于团队的力量,三个臭皮匠抵个诸葛亮。
敏捷开发强调各个击破,团队协作,这些完全可以借鉴到现在的测试中来。测试经理细分工作任务并根据优先级进行排序,然后集中力量迅速的顺序完成各个工作任务,比如一起完成一个模块的测试,针对这个模块的测试再考虑每个人的分工。还可以以某个或者某几个人为主,其他人辅助,充分的进行配合。
做测试跟玩F1一样,追求的是一种极限速度的快感,你够快吗?你的团队够快吗?
查看(1624)
评论(8)
收藏
分享
管理
-
2010-03-07 22:44:03
好久没写点东西了,看了下humh写的测试职业生涯探讨,瞎写了下面这段文字(标题貌似有点标题党)。
1、测试神功第一层:一招一式,博览网上各种教程、手册、宝典,不管是不是足够理解,照猫画虎。这个时候突出一个“博”和一个“似”。神功练成的“症状”是觉得自己用例也会设计了,LoadRunner也会用了,反正感觉啥都挺简单了。
2、测试神功第二层:活学活用,开始紧跟技术发展步伐了,嘴里的技术名词那是相当的多,不会老问这是为什么呢,不管手上的软件如何千变万化,心中总是胸有成足。这个时候突出一个“活”和一个“信”。神功练成的“症状”是觉得什么软件自己都有信心和把握测了,需要学习的技术还挺多的,开始练自己的必杀技。
3、测试神功第三层:随心所欲,不再受限于技术的条条框框,也不再纠结各种技术名词,感兴趣的是技术的本质,大炮也可以用来打蚊子。这个时候突出一个“心”和一个“新”。神功练成的“症状”是全天候作战(忽视时间,忽视环境,忽视行业),测试就是娱乐,娱乐还是娱乐。
哥们,你现在练到第几层了?
查看(1751)
评论(11)
收藏
分享
管理
-
2006-12-04 23:27:59
archonwang在回复我的“也说软件测试中的80-20定律”一文时提到了这样一个问题:
如何估算剩余的bug数量,曾尝试过用80-20法则进行估算,不过精确度似乎不高,应该怎样计算比较合理?
以前好像看过这方面的资料,但实际工作中没有尝试过,有点纸上谈兵的意思了,呵呵。下面就胡乱说点吧,希望能有点帮助。
我们通过测试发现软件中的bug实际上可以看成对软件中存在的所有bug进行采样的一个过程,不同人的人采样出来的bug可能有区别,但所针对的bug群体是相同的。
单纯从一个测试人员来看,仅根据他的采样是无法去判断到底还剩余多少bug的,要想比较好的估算bug的总数或者剩余的bug数,只能借助于多个测试人员的采样了。这里实际上就是常见的鱼塘法。
鱼塘法是用来估算鱼塘中鱼的数量的:从鱼塘中捞上来比如100条鱼,为每条鱼都作上标记,表明这些鱼是曾经被捕捉过的,然后把这些鱼放回鱼塘中去,过一段时间后(主要是想让被捕到的鱼尽量均匀的分布到鱼塘中去),再补100条上来,检查有多少条是标记的,比如是50条,那么就可以估算出鱼塘中的鱼的总数为100*100/50=200条了。
这种思路也可以借鉴到bug的估算中来:让两个测试人员A和B同时独立对同一被测对象进行测试,自己使用自己的思路和方法。测试结束后,A发现了m个bug,而B发现了n个bug,两人相同的bug有k个,那么总的bug数就可以估算成m*n/k了。
当然这种思路有其前提条件:
1、采样要足够多,也就是说发现的bug数不能太少,要和总的bug数具有可比性,否则这种基于采样的思路就行不通了;
2、测试人员的水平要比较接近,不能相差太大,不然很容易出现,一个人发现的bug是另一个人的子集,那就没意思了;
3、针对的被测对象一定要完全相同,不能有bug修复的过程,否则两个人所针对的样本空间就不一样了,那样这种思路也就失效了。
在实际工作中想对所有的测试都进行这种成对的测试是不可能的,因此很多大的公司主要还是采用收集历史数据获得经验参数的方式来进行估算的,比如经过相当长时间数据的收集和整理,可以得到bug数/KLOC,这样要估算剩余的bug就比较简单了。
而对于一些没有什么历史数据收集整理的公司,这种鱼塘法就能派上用场了。选择部分代码作为被测试对象,选择两个还算有点经验的测试人员(主要是为了保证采样不会太差),独立对这些代码进行测试,最后能估算出这些代码对应的总的bug数出来,然后除以代码行数,就得到了bug数/KLOC了,那这个参数就可以用于其它代码bug数的估算了。
PS:不知道archonwang是如何用80-20法则来进行估算的,呵呵。
查看(2631)
评论(4)
收藏
分享
管理
-
2006-12-03 16:13:52
John Lee写的一篇“Tricks of Software testing”中提到的:
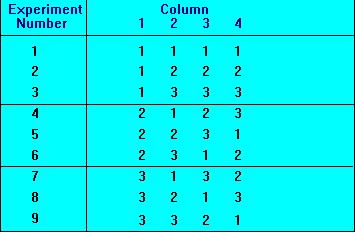
5)黑盒测试的典型方法: 正交矩阵法是减少测试用例的有效方法。等价类划分的缺点是没有考虑边界。
正交矩阵法或者正交分析法是在测试用例设计中比较常用的一种方法,不少人在其blog中都对其进行了介绍:
1、OATS正交表测试策略-Zee
2、正交表方法在创建测试套件上应用
3、正交表方法在创建测试套件上的应用(2)
这里不想再介绍正交分析法到底如何来使用,关于使用这几篇blog中都有介绍,随便找本软件测试方面的书应该都能找到具体的使用过程。这里要说的是使用正交分析法的好处在哪,其发挥效力的关键地方在哪,不搞清这些是无法把握正交分析法的实质的。
我们知道正交分析法是针对多个变量的组合的,因此不少地方就提到:正交分析法是用最少的测试用例来覆盖所有的组合。这句话本身来说就是矛盾的,要像覆盖所有的组合当然就是进行全排列组合了,那又何来用最少的测试用例呢。因此正交分析法的核心在于:
用最少的测试用例来覆盖
查看(3743)
评论(8)
收藏
分享
管理
-
2006-12-02 17:02:22
John Lee写的一篇“Tricks of Software testing”中提到的:
(2)用例: 一般考虑3个方面的,合理的,不合理的和边界的。
感觉这里提到的合理的、不合理的应该是针对输入而言的,或者也可以用合法的、不合法的以及有效的、无效的来进行替代,这样与之相对应的方法就是等价类划分。
我们经常说设计用例时要考虑合法的情况也要考虑非法的情况,但这种思路容易让我们把测试用例的设计简单化、机械化。为什么这样说呢,原因有二:
1、单纯的合理不合理容易产生遗漏。比如现在有这样一个软件,是专门用来统计我们写的.c文件中的代码行数的。如果要测试这个软件统计代码行数的功能,很容易想到的就是统计一个合法的.c文件,考虑有不同的代码行数;统计一个非法的.c文件,这里的非法有多种情况。但这样是否就意味着是比较好的测试用例设计了呢?我们是不是还应该看看这个软件会不会把注释行误判成代码行等等呢。
2、为了使用方法而使用方法,比如等价类、边界值、正交分析等等,反而忽略了我们设计这些用例到底是为了什么目的、每个测试用例的测试点到底在什么地方。
既然单纯考虑合理不合理并不是一种很好的方式,那么应该按照一个什么思路来去考虑我们的用例设计呢?其实这个思路已经有了,那就是正向(positive testing)和逆向(negative testing)。
先来看一下正向测试和逆向测试的含义:
正向测试:验证被测对象是不是做了它该做的事情。
逆向测试:验证被测对象有没有做它不该做的事情。
可以看出,正向测试并不一定就是简单的输入合法数据,而逆向测试也不一定就是简单的输入非法数据。正向和逆向不仅让我们知道如何去选择测试数据,还让每组数据的目的性也突出出来了。
还是回到前面提到的统计代码行软件的测试,测试该软件会不会把注释行误判成代码行就是一种逆向测试。
从上面的分析可以看出,选择正向逆向比合理不合理更能让我们把握测试用例设计的本质,也更有助于我们去不断提高自己的测试水平和能力,因为下面我们要做的一个工作就是搞清楚哪些是被测对象该做的事情而哪些是被测对象不该做的事情,分析的越细越清楚,测试用例设计的就越好。
PS:接下来准备针对
(5)黑盒测试的典型方法: 正交矩阵法是减少测试用例的有效方法。等价类划分的缺点是没有考虑边界。
再写一篇“正交分析法到底好在哪”。
查看(1357)
评论(3)
收藏
分享
管理
-
2006-11-30 23:48:19
写这篇文章的想法来源于John Lee写的一篇“Tricks of Software testing”中提到的:
(1)群集现象:发现问题越多的地方,隐含的缺陷也越多,需要重点处理。
佩瑞多定理:(80-20定律)许多软件现象都遵循佩瑞多分布规律:80%的贡献来自于20%的贡献者。例如20%的模块含有80%的错误。
这里提到集群现象也就是我们一般所说的bug的群居现象(我们为什么把在软件中发现的问题叫bug呢?除了众所周知的美国海军计算机继电器的故事,再就是软件中的问题也像bug一样具有群居性和抗药性)。
如果简单归纳一下软件测试中的80-20定律,大致有这些:
1、80%的bug隐藏在20%的代码中;
2、80%的bug是由20%的测试人员发现的;
3、80%的bug属于20%的错误类型;
4、80%的时间用在测试计划、测试设计、测试实现上,20%的时间用于测试执行上;
5、80%的bug通过静态测试发现,20%的bug通过动态测试发现;
6、80%的bug通过人工测试发现,20%的bug通过自动化测试发现;
7、对于一个测试人员而言,20%的时间发现80%的bug,而剩余的80%的时间只能发现20%的bug。
。。。。。。
(一下子也想不到太多了,想到了再更新,也欢迎大家补充)
这里不想对这些所谓的定律做更多的说明,主要是想关注一下80-20中的20这个小部分(比如80%的代码中包含的20%的错误),80这个大的部分大家已经重视的很多了(比如进行缺陷分析时针对的是属于20%错误类型的80%的bug)。
提到80-20定律,就不得不提下长尾定律(没见过的去google一下:)):简单一点说就是看似不起眼的20%的部分,有可能产生的影响要等于甚至大于80%的部分。这个听起来比较绕口,还是针对上面提到的80-20定律好了:
1、20%的bug隐藏在80%的代码中。那说明这些bug其实是很难去查找的,也就是说我们前面发现的80%的错误更多的是比较明显的错误,那下面就有这样一个问题了,怎样去尽量快的把这20%的bug找出来呢?
2、80%的测试人员只发现了20%的bug。这说明从整个团队而言,能力上存在比较明显的等级分化,真正的高级测试工程师很少,更多的是茫然的、无助的、民工似的普通测试工程师,而这些普通测试工程师又是公司测试的主力军,怎样去提高这80%的测试人员的水平呢?
3、一个测试人员80%的时间只能发现20%的bug。因此不少测试人员会感觉自己很多时间都在做无用功、没有什么收获,那么应该怎样去充分利用这80%的时间呢?
这里只是胡乱抛出了几个问题,希望能和大家交流。
PS:接下来准备针对
(2)用例: 一般考虑3个方面的,合理的,不合理的和边界的。
再写一篇“合理不合理还是正向逆向”。
查看(4424)
评论(14)
收藏
分享
管理
