
-
linezing量子统计
2010-04-27 23:17:25
Bash Framework的统计可真是一波三折啊。
本来使用google document的表单功能统计所有的访问记录。但是google document功能很快就被墙了。
后来改用zoho,发现一直有限制,非常不爽。浪费了这么多的精力去研究如何使用shell提交代码了。
采用了半个月,就达上限了。
听说百度统计不错,一上网站,才发现只给收费用户免费使用。汗。。。
最后辗转到了yahoo的量子统计上了。
看来是免费的,貌似也没有什么限制。就写了一行代码开始使用linezing。
linezing ()
{
curl 'http://img.tongji.linezing.com/你的ip/tongji.gif' -e "http://www.bash_framework.com/$*" &>/dev/null
}
通过附加特殊的refer头信息,让提交自己的个性化请求。
在量子统计中,正巧也有页面的访问记录。使用起来,还是不错的。
使用过程中发现,数据的更新比较慢,发请求上去需要等2分钟才可以出现。
估计要么就是机器,数据库反应迟缓,要么就是采用了搜索引擎的设计,采用了增量更新方式解决的。所以才造成时间差。
另外,深夜更新的数据,会发生丢失现象。唉。
测试不到位。
先凑活着用用吧。一直想找个稳定的地方,可以好好的记录下Bash Framework的成长史。
可惜,一直未能如愿。
参考网址
http://tongji.linezing.com/report.html?unit_id=1654429
分析图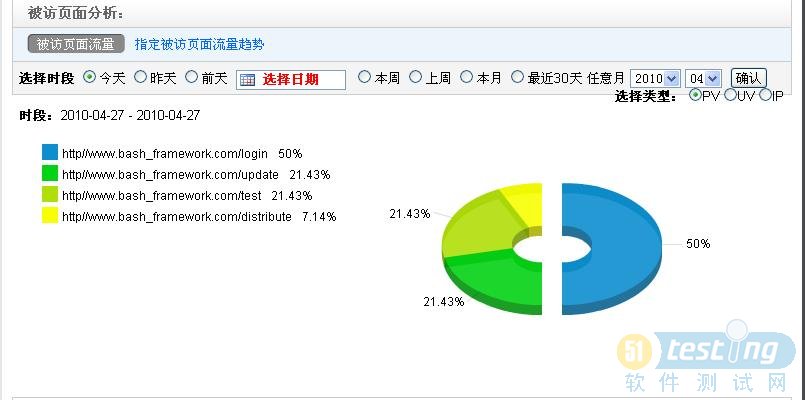
关于Bash Framework想说的。
Bash Framework的目标是作为一门新语言,就像Rails on ruby, Groovy on java那样的语言。
同时,它也是一套测试工具集,可以极大的提升个人的工作效率。
同时,它也是一套团队协作的管理体制,就像svn那样,可以实现一定的协作。
同时,它也可以体现一种标准,介入到工作相关的各个领域。
目前一直在忙项目,也不急于推广应用。短期内,先计划在小组内进行推广。
实现一定的应用。有价值是最重要的。
-
系统级mock脚本
2010-04-17 17:38:38
图片空间上传满了。只上传一个图片。
背景
小组内存在测试数据构造困难的问题。前段的web测试,需要依赖后端平台进行测试。
为了配合mock方法的推进,专门开发了mock工具。
采用python+Bash技术。
Mock工具已经开发完成。欢迎大家测试。
用法介绍
使用方法:
执行mock命令
会在当前目录中生成2个目录,bin与data。Bin存放mock文件,用于解析。
Dta存放查询的结果数据。还有一个mock.conf文件,保存mock的信息。
mock -url http://10.20.146.4:6146/bin/search?sample_en?q= -port 8000
url参数为你要mock的请求地址。去掉参数。
此时,mock程序会进入一种学习状态。
你可以在前段查询MP3,手机,之类的关键词。如果mock发现之前没有查询过这次关键词,没有这些query的保存结果,就自动去被mock的真正服务上去取数据。然后保存。
如果发现之前查询过,就会取之前的查询结果。你可以在之前的查询结果中修改原来的输出。
首先搭建好前段的web环境,然后修改sq,或者isearch的环境为mock的ip与端口。
第一次查询mp3,mp4,mp5
系统会自动保存对应的数据文件
查询mp3的结果
真实服务器的查询结果与mock程序的结果比对。是一样的。
出于测试的需要,我去修改mp3的结果输出。直接去mock的data目录下修改q=mp3文件的内容
然后再次查询MP3
其他高级功能
如果是下次想重新使用之前的数据进行mock。直接执行mock就可以了。它会读取默认的配置,启动先前的mock。不需要做初始化工作。
Mock –url ‘http://10.20.146.4:6146/bin/search?sample_en?q=mp3’ #启动mock
Mock –url ‘http://10.20.146.4:6146/bin/search?sample_en?q=mp3’ –port 8000 #设定端口
Mock –url ‘http://10.20.146.4:6146/bin/search?sample_en?q=mp3’ -data key.data #一次性读取key.data里面的所有关键词,然后自动去被mock服务上去查询,用于预先的学习。
Mock百度搜索
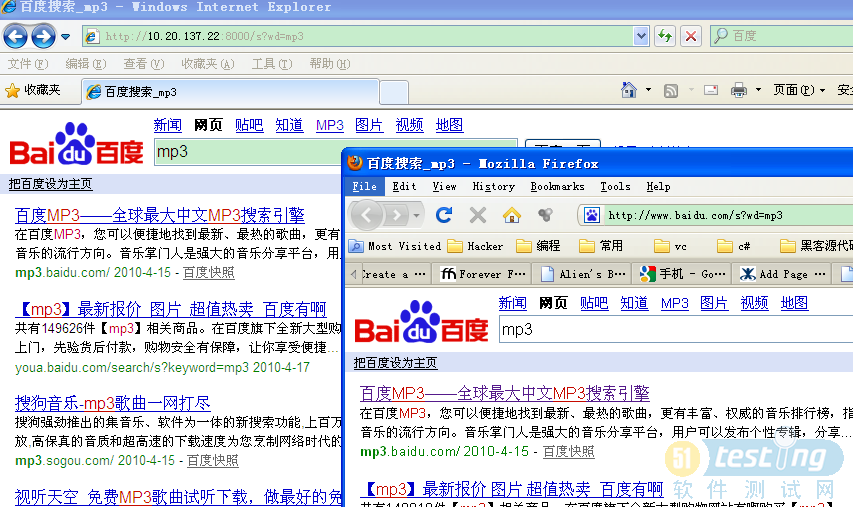
Mock google搜索,被google查出来了。看来google的确小心了很多。不过相信通过设置一定的header可以绕过这个限制。
应用场景
可以用于基于http协议的服务mock。Mock后台服务以及其他的接口。实现数据的干预与输出结果自定义。
理论上经过扩展可以支持tcp协议级别的mock。
目前可应用于后端的接口测试中。
:<<mock_help
Mock -url 'http://10.20.146.4:6146/bin/search?sample_en?q=mp3'
Mock -url 'http://10.20.146.4:6146/bin/search?sample_en?q=mp3' -port 8000
Mock -url 'http://10.20.146.4:6146/bin/search?sample_en?q=mp3' -data key.data
mock -url http://www.baidu.com/s?wd= -port 8000
mock
mock_help
mock()
{
local port url mock_ip mock_port data # service=SimpleHTTPServer
seven_getopt "$@"
[[ -n $url ]] &&
{
#service=CGIHTTPServer
mkdir bin data
echo '#!/bin/bash
echo "Content-type: text/html"
echo
if [ "$REQUEST_METHOD" = "POST" ]; then
if [ "$CONTENT_LENGTH" -gt 0 ]; then
read -n $CONTENT_LENGTH POST_DATA <&0
fi
fi
request_data="$QUERY_STRING$POST_DATA"
' > bin/http.sh
chmod +x bin/http.sh
mock_ip=`echo "$url" |awk -F'//' '{print $2}' |awk -F ':|/' '{print $1}'`
mock_port=`echo "$url" |awk -F'/' '{print $3}' |awk -F ':|/' '{if(NF==2) print $NF; else print "80";}'`
[[ -z $port ]] && port=$mock_port
bin_dir=`echo "$url" | awk -F '?' '{print $1}' |awk -F/ '{for(i=4;i<NF;i++) printf $i"/"}'`
bin_file=`echo "$url" | awk -F '?' '{print $1}' |awk -F/ '{print $NF}'`
mkdir -p $bin_dir &>/dev/null
echo -e '#!/bin/bash\n. bin/http.sh;data_file=data/${request_data}_data
[[ -f $data_file ]] && cat $data_file && exit;
. mock.conf;
curl "http://$mock_ip:$mock_port$SCRIPT_NAME?$request_data" 2>/dev/null |tee data/${request_data}_data
' > $bin_dir$bin_file
chmod +x $bin_dir$bin_file
echo -e "port=$port\nmock_port=$mock_port\nmock_ip=$mock_ip\nbin_dir=$bin_dir\nbin_file=$bin_file" |tee mock.conf
}
[[ -n $data ]] &&
{
while read line
do
curl "$url$line" 2>/dev/null | tee data/${line}_data
echo -e "$line===data/${line}_data" >> data/data.conf
done < $data
}
#python -m $service $port
[[ -f mock.conf ]] && . mock.conf
print "Start Listenning , Try visit http://`ip`:$port/$bin_dir$bin_file"
echo -e "
\rfrom CGIHTTPServer import CGIHTTPRequestHandler
\rfrom BaseHTTPServer import HTTPServer
\rclass Handler(CGIHTTPRequestHandler):
\r\tcgi_directories = ['/cgi-bin','/bin','$bin_dir','$bin_dir$bin_file']
\rserver_address=('',$port)
\rhttpd = HTTPServer(server_address, Handler)
\rhttpd.serve_forever()
" |python
} -
Bash Framework更新计划2010
2010-03-21 17:18:56
看到了google release了几个安全类的工具了。
这几个工具,用来做安全测试是很有用的。而且部门里已经有了安全测试的领域,这个方向可以加入到函数库中。
最近很忙,所以把计划列一下。
1、bash framework帮助文档整理。很多人对这个有误解,都以为只是一个bash的函数库,其实它所代表的工作模式,其他人理解的都很长。
2、之前写的函数,功能太炫了。导致了移植不方便。所以在逐步的梳理。
3、性能测试函数库,配置管理函数库,c++代码测试函数库,搜索引擎函数库,安全测试函数库的整理与数理。
上述工作,可能要一个月之后才能完成了。最近争取从繁忙的工作中脱离出来。
如果上述工作完成,并且达到了我的满意程度,我会用邮件在公司里面推广。
目前感觉还不太完善,工作又忙,所以一直delay着。
-
bash下使用百汇zohoAPI
2010-03-13 15:49:39
ZohoReport API:
https://zohoreportsapi.wiki.zoho.com/Request-Format.html
获取API Key与ticket:
http://writer.zoho.com/public/help/zohoapi/fullpage#AccessingAPI
1、zoho上申请一个自己的账户。
2、在上面创建自己的数据库。
3、创建自己的表,设计字段
4、读zoho report的api。看看示例。
5、在linux shell下,使用curl,构造请求,发送请求。我的请求格式。
curl 'http://reports.zoho.com/api/username/seven/use?ZOHO_ACTION=ADDROW&ZOHO_OUTPUT_FORMAT=XML&ZOHO_ERROR_FORMAT=XML&ZOHO_API_KEY=yourkey&ticket=yourticket&ZOHO_API_VERSION=1.0' -d "&user=$USER@$HOSTNAME&svn=$QA_svn&version=$QA_version&action=$1"
6、封装为函数
zoho_report()
{
.....
}
7、以后就可以使用zoho_report在linux下发送数据了。
8、效果
9、后续可以使用zoho进行绘图分析。比如自动生成曲线图。
bash framework每天的使用情况统计图
https://reports.zoho.com/ZDBDataSheetView.cc?OBJID=141061000000008035&STANDALONE=true&privatelink=9430aba12f31e13efda74764bc511590&LP=RIGHT&ZDB_THEME_NAME=blue&REMTOOLBAR=true
Bash Framework一直使用google的表单工具去统计数据,最近发现google document被墙了。
只好换用zoho。说实话,zoho非常好用。有些方面,比google还好。
以后还是要善加利用。zoho也提供了一些客户端的api,比如java,python封装的库去调用。
非常不错。可以试试。
-
Bash Framework加入了新成员BashUnit
2010-01-27 02:03:54
试用了一把bashunit。发现很不错。
把它加入到了bash Framework中。
用法
编写你的脚本,每个TC为一个函数。
每个函数使用test_开头,风格和xunit一样。同样支持setup与teardown函数。
test_xxx1()
{
echo "xxx"
assert_pass_message "ffffffff"
}
test_xxx2()
{
echo 'ffffffffffffffff'
ls ddd
assert_fail_message "testxxxxxx"
}
test_xxx3()
{
[[ 2 == 3 ]] && assert_pass_message "xx33333333333333" || assert_fail_message "xx333333333333333 faul"
}
建议你按照test_xxx3的使用方法去使用,这样更明确些。
保存为test.sh
然后使用bashunit去执行。我已经别名了一下,使用bu即可。
执行
bu test.sh
[huangysh@qa17 bashunit]$ bu test.sh
xxx
.ffffffffffffffff
ls: ddd: No such file or directory
FF
FAILURES!!!
Runs = 3 Success = 1 Failures = 2
test.sh:10: test::test_xxx2 (testxxxxxx)
test.sh:15: test::test_xxx3 (xx333333333333333 faul
蛮不错的一个小框架。里面还有不少值得改进的地方。
春节后好好的用用,然后改进下。
已经更新至shell函数库中。
-
Bash Framework中加入了公司Logo
2010-01-03 23:24:39
-
Bash $*与$@的微妙区别
2009-09-19 12:48:09
经过这个实验,我把自己的脚本全部改为"$@"了。
[huangysh@qa16 bin]$ ff()
> {
> for f in $@
> do
> echo $f
> done
> for f in "$@"
> do
> echo $f
> done
> for f in "$*"
> do
> echo $f
> done
> }
[huangysh@qa16 bin]$ ff 2 3 "4 5"
2
3
4
5
2
3
4 5
2 3 4 5
[huangysh@qa16 bin]$ ff 2 3 '"4 5" 6 7'
2
3
"4
5"
6
7
2
3
"4 5" 6 7
2 3 "4 5" 6 7
-
bash 获得get与post请求数据的cgi脚本
2009-09-12 04:47:00
为了测试http_load ,就临时写了cgi脚本。用bash+apache去跑。
挺方便的。分别获得get请求与post请求。
#!/bin/bash
echo "Content-type: text/html"
echo
if [ "$REQUEST_METHOD" = "POST" ]; then
if [ "$CONTENT_LENGTH" -gt 0 ]; then
read -n $CONTENT_LENGTH POST_DATA <&0
fi
fi
{
echo "$QUERY_STRING"
echo dddd $POST_DATA $CONTENT_LENGTH ddddend
}|tee -a /tmp/post.tmp
~
-
Bash函数库终于完成稳定版开发了
2009-09-05 18:09:57
把自己的脚本整理了一下,修改了很多的设计。
完善了部分函数,加上了自动升级与统计功能,终于可以像模像样了。
这次改善,也摆脱了公司的限制,其他公司的朋友也可以使用了。
先和邮件组的朋友们共享下。呵呵。小规模使用一下。
show一下部分函数库的内容。
rsa 机器名列表 #自动打通所有的服务器
gexec 机器列表 命令 #机器批量操作。可以自动填写密码
sevenexpect -p 提示 -a 动作 #自动化脚本自动生成
screen_share #使用screen异地共享shell窗口
google_top #使用google spreadsheet收集服务器监控数据,并绘图
。
QA_valgrind #使用valgrind分析内存泄漏。这个没有技术含量。但是代表了一种封装的思想。
httpload #封装了http_load ,可以模拟loadrunner的加压方式,不断的增加并发数,然后自动统计多个结果为excel,发到邮箱。
其他的函数,需要和朋友们与同事再慢慢完善。
解决了ssh ip cmd与ssh ip,然后输入cmd的不同。提高了部分性能。
终于形成了一个拿出手的稳定版了,庆祝下。
下一步,就是慢慢把它变得更加易用,实用。切实产生效益。
-
进程级性能测试监控函数更新simon_common
2009-09-02 01:50:22
发帖纪念一下,加班到了现在凌晨1点半。
为了改善一个性能测试监控的函数。
之前通过单纯的客户端直接发送数据到服务器进行绘图。
实际中遇到了一些问题。
1、客户端存在兼容性的问题。需要使用公司形形色色的服务器。
2、监控的数据越多,会影响服务器的自身资源。
后来进行了几种方法的尝试。
1、通过google form把数据发送到google,让google去绘图。
2、通过svn更新,传递到直接的绘图服务器上,然后通过绘图服务器上自己的客户端去分析数据,这样被监控的服务器只需要定期发送数据即可。节省了很多的资源。
第一种方法也不错,但是google api需要啃下,短期内还不能形成好的可行的方案。
第二种也有困难,公司的权限设置太严格,svn服务器在不同的机器上,有无法访问的风险。
只好采用了第三种,直接通过nc发送数据到绘图的服务器,或者scp,rsync等。
采用scp可能会影响到一点io,不过限于公司特殊的条件,也只有这个可以搞了。
经过屡次的修改与完善,终于搞定了。
实现了如下的功能
[huangysh@qa16 ~]$ man simon_common
=========================
:<<simon_common_help
simon_top_common methods_monitor process_name_or_pids [CPU MEM]
simon_top_common top simond #通过top收集特定关键词的进程信息,会进行求和统计。监控指标包括cpu,mem,rss,virt,shr
simon_top_common ps sql #通过ps去获得进程信息,可监控的指标包括cpu,mem,res,vsz,chtcount(进程的线程数)
simon_top_common pid "3681,3787" #通过pid去监控,这种比较节省资源。
simon_top_common sql_pid "3681,3787" #可以更改标示,用于区别不同的监控。但是标示的结尾一定要是ps,top,pid三种方式。
simon_common_help[huangysh@qa16 ~]$ man simon_common
=========================
:<<simon_common_help
simon_top_common methods_monitor process_name_or_pids [CPU MEM]
simon_top_common top simond
simon_top_common ps sql
simon_top_common pid "3681,3787"
simon_top_common sql_pid "3681,3787"
simon_common_help
=========================
========source code=========
simon_common is a function
simon_common ()
{
[[ $# -eq 0 ]] && echo "${function_name} java" && return;
function_name="$1";
process=$2;
metrics=${*:3};
if [[ ${*:$#} = "stop" ]]; then
>~/QA/tmp/${function_name}_${process%%,*}_$USER.tmp.stop;
echo ${function_name} would stop in 10s;
gexec se1.asc.cnz.alimama.com "simon_file /home/$USER/QA/tmp/${function_name}_${process%%,*}_$USER.tmp $metrics stop";
return;
fi;
case $function_name in
*top)
pids_get="top -b -n1 -p \`ps -o uname,pid,ppid,command -e|grep $process|grep -v 'grep $process'|awk '{print \$2}'|xargs|tr ' ' ',' \`|grep $process|awk '{print \$9,\$10,\$6,\$5,\$7}'|awk '{c+=\$1;m+=\$2;r+=\$3;v+=\$4;t+=\$5}END{print c,m,r,v,t}'";
set ${metrics:="CPU MEM RES VIRT SHR"};
print "the process is";
pf $process
;;
*pid)
pids_get="top -b -n1 -p$process|sed 1,7d|awk '{print \$9,\$10,\$6,\$5,\$7}'|awk '{c+=\$1;m+=\$2;r+=\$3;v+=\$4;t+=\$5}END{print c,m,r,v,t}'";
set ${metrics:="CPU MEM RES VIRT SHR"};
print "the process is";
top -b -n1 -p$process
;;
*ps)
pids_get="ps -eo uname,pid,ppid,thcount,pcpu,pmem,rss,vsz,sz,command|grep $process|grep -Ev '(grep $process|simon_file)'|awk '{print \$5,\$6,\$7,\$8,\$4}'|awk '{c+=\$1;m+=\$2;r+=\$3;v+=\$4;t+=\$5}END{print c,m,r,v,t}'";
set ${metrics:="CPU MEM RSS VSZ THCOUNT"};
print "the process is";
pf $process
;;
esac;
echo $pids_get;
[[ -f ~/QA/tmp/${function_name}_${process%%,*}_$USER.tmp.stop ]] && rm -rf ~/QA/tmp/${function_name}_${process%%,*}_$USER.tmp.stop ~/QA/tmp/${function_name}_${process%%,*}_$USER.tmp;
while [[ ! -f ~/QA/tmp/${function_name}_${process%%,*}_$USER.tmp.stop ]]; do
eval $pids_get;
gsyn se1.asc.cnz.xxxx.com ~/QA/tmp/${function_name}_${process%%,*}_$USER.tmp >&/dev/null;
sleep ${simon_ps_interval:=10};
done >>~/QA/tmp/${function_name}_${process%%,*}_$USER.tmp & echo sleep 10s for init;
sleep 10;
gexecbg se1.asc.cnz.xxxx.com "simon_file /home/$USER/QA/tmp/${function_name}_${process%%,*}_$USER.tmp $metrics";
print OK
}
============================
-
linux下使用bash进行url编码的两种方法
2009-07-24 19:59:31
看到网上广为流传的一篇文章,使用awk与od对汉字进行url编码。本来想拿来用的,结果发现通用性也太不好了,如果哦不是汉字什么的,就编码出错。
原文地址 http://linux.ccidnet.com/art/302/20061009/916847_1.html
后来感觉这个urlquote编码很常用,很多地方都用到了。使用我原来的的方法有些限制,就重新使用od再实现了一个。
分享下。
我原来的解决方式是在shell中调用python去编码,代码如下。
urlquote()
{
[[ $# = 0 ]]&&echo urlquote string&&return
echo "#coding=utf-8;
import urllib,sys;print urllib.quote('$1');" |python
}
小技巧,这是shell语句,其实却是调用的python。大家以后使用shell不爽的话,可以在shell中调用python,ruby之类的,都是可以的。要想歪点子。呵呵。
需要注意的是,格式要拍好,因为python是靠缩进来判断语句的。vi的默认缩进,容易把格式搞乱。
但是这种方式依赖python,如果机器上没有的话,就很麻烦。另外效率也是个问题。的确用python慢一些。
看到了网上有人使用od来获得16进制数据来拼装,我也就使用od去拼装吧。
网上的那位仁兄使用awk处理的那么麻烦,其实是忽略了od的-x1 参数。使用单个字节就可以了。
默认的两个字节显示的话,顺序上是颠倒的。
:<<url_help
used for replace urlquote
url 123xxxxxx
url_help
urlquote()
{
local msg=`echo "$*"|od -t x1 -A n|xargs|tr -d '*'|tr " " %` #使用od转换为16进制,同时把空格换成%,正好实现了url编码。
msg=${msg/$msg/%$msg} #加上头部缺少的%
echo ${msg%\%0a} #去掉最后多余的%oa。od生成的。
}
不过在编码大数据量的时候,od会进行一些特殊的处理,比如加星号之类的,所以我重新修改了下。
要是想干脆点的话,直接使用如下代码即可。
echo 你要编码的文字|od -t x1 -A n -v -w10000000000 | tr " " %
下面我是写的一个比较完备的方式。可以支持多种调用方式,也可以与以前的方式兼容。使用的时候,使用如下三种方式调用就可以。
urlquote 你要编码的文字
echo 你要编码的文字|urlquote
urlquote < 你的文件
详细代码。[huangysh@qa16 ~]$ qahelp urlquote
=========================
:<<urlquote_help
used for replace urlquote
urlquote 123xxxxxx
urlquote mesage"fsef
fsefsf" #support for multiline
urlquote_help
=========================
========source code=========
urlquote is a function
urlquote ()
{
[[ -n $* ]] && {
echo "$*" | od -t x1 -A n -v -w10000000000 | tr " " %;
return
};
while read line; do
echo -n $(echo "$line"|od -t x1 -A n -v|tr " " %) | tr -d " ";
done;
echo
}
============================
==========================
最近从网上搜索资料,发现这个blog排名满靠前的。
上面介绍的方法之适合处理少量的文本,如果你的文本有上百万行,性能与时间就是问题了。解决方法很简单。直接使用python或者ruby去处理即可。echo,read line之类的命令就可以丢掉了。
ruby的推荐如下。
使用urlquote_ruby 文件名 即可。
速度绝对没的说。
urlquote_ruby()
{
local f=$1
ruby -e "require 'cgi';IO.foreach('"$f"') { |line| puts CGI.escape(line.chomp) }"
}
标题搜索
我的存档
数据统计
- 访问量: 164047
- 日志数: 227
- 建立时间: 2008-04-09
- 更新时间: 2012-02-10
