实战演练
这次我们爬虫步骤是:
1. 获取景点基本信息
2. 获取评论数据
4. 保存数据
5. 创建线程池
6. 数据分析
获取景点基本信息
首先我们先获取景点的名字、id、价格、特色、地点和等级,主要代码如下所示:
def get_parse(url): response=requests.get(url,headers=headers) Xpath=parsel.Selector(response.text) data=Xpath.xpath('/html/body/div') for i in data: Scenery_data={ 'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(), 'sid':i.xpath('//div[@class="list_l"]/div/@sid').extract_first(), 'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''), 'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(), 'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(), 'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8] }
首先自定义方法get_parse()来发送网络请求后使用parsel.Selector()方法来解析响应的文本数据,然后通过xpath来获取数据。
获取评论数据
获取景点基本信息后,接下来通过景点基本信息中的sid来构造评论信息的URL链接,主要代码如下所示:
def get_data(Scenery_data): for i in range(1,3): link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832' response=requests.get(link,headers=headers) Json=response.json() commtent_detailed=Json.get('dpList') # 有评论数据 if commtent_detailed!=None: for i in commtent_detailed: Comment_information={ 'dptitle':Scenery_data['title'], 'dpContent':i.get('dpContent'), 'dpDate':i.get('dpDate')[5:7], 'lineAccess':i.get('lineAccess') } #没有评论数据 elif commtent_detailed==None: Comment_information={ 'dptitle':Scenery_data['title'], 'dpContent':'没有评论', 'dpDate':'没有评论', 'lineAccess':'没有评论' }
首先自定义方法get_data()并传入刚才获取的景点基础信息数据,然后通过景点基础信息的sid来构造评论数据的URL链接,当在构造评论数据的URL时,需要设置pageSize和page这两个变量来获取多条评论和进行翻页,构造URL链接后就发送网络请求。
这里需要注意的是:有些景点是没有评论,所以我们需要通过if语句来进行设置。
创建MySQL数据库
这次我们把数据存放在MySQL数据库中,由于数据比较多,所以我们把数据分为两种数据表,一种是景点基础信息表,一种是景点评论数据表,主要代码如下所示:
#创建数据库def create_db(): db=pymysql.connect(host=host,user=user,passwd=passwd,port=port) cursor=db.cursor() sql='create database if not exists commtent default character set utf8' cursor.execute(sql) db.close() create_table()#创建景点信息数据表def create_table(): db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent') cursor=db.cursor() sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)' cursor.execute(sql) db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接,最后调用自定义方法create_table()来创建景点信息数据表。
这里我们只给出了创建景点信息数据表的代码,因为创建数据表只是sql这条语句稍微有点不同,其他都一样,大家可以参考这代码来创建各个景点评论数据表。
保存数据
创建好数据库和数据表后,接下来就要保存数据了,主要代码如下所示:
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,使用了try-except语句,当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
#保存景点数据到景点数据表中def saving_scenery_data(srr): db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent') cursor = db.cursor() sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)' try: cursor.execute(sql, srr) db.commit() except: db.rollback() db.close()
注意:srr是传入的景点信息数据。
创建线程池
好了,单线程爬虫已经写好了,接下来将创建一个函数来创建我们的线程池,使单线程爬虫变为多线程,主要代码如下所示:
urls = [ f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0' for i in range(1, 6)]def multi_thread(): with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool: h=pool.map(get_parse,urls)if __name__ == '__main__': create_db() multi_thread()
创建线程池的代码很简单就一个with语句和调用map()方法。
运行结果如下图所示:
好了,数据已经获取到了,接下来将进行数据分析。
数据可视化
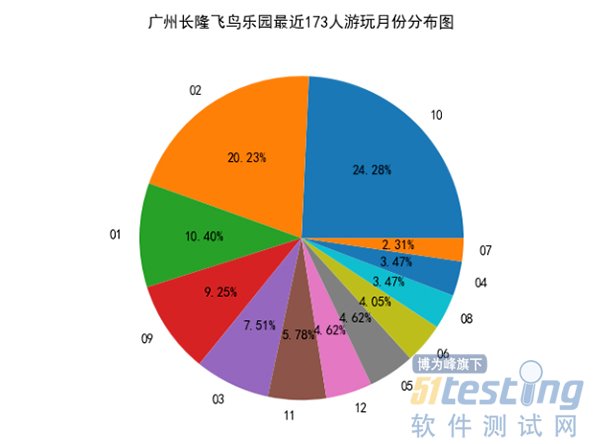
首先我们来分析一下各个景点那个月份游玩的人数最多,这样我们就不用担心去游玩的时机不对了。
我们发现10月、2月、1月去广州长隆飞鸟乐园游玩的人数占总体比例最多。分析完月份后,我们来看看评论情况如何:
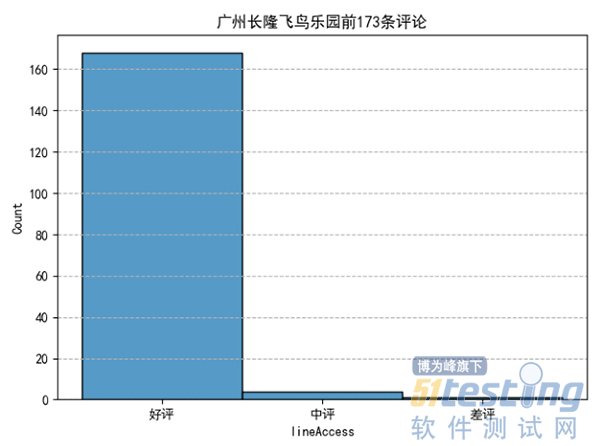
可以发现去好评占了绝大部分,可以说:去长隆飞鸟乐园玩耍,去了都说好。看了评论情况,评论内容有什么:
好了,获取旅游景点信息及评论并做词云、数据可视化就讲到这里了。