以往的人脸识别主要是包括人脸图像采集、人脸识别预处理、身份确认、身份查找等
技术和系统。现在人脸识别已经慢慢延伸到了ADAS中的驾驶员检测、行人跟踪、甚至到了动态物体的跟踪。
由此可以看出,人脸识别系统已经由简单的图像处理发展到了视频实时处理。而且算法已经由以前的Adaboots、PCA等传统的统计学方法转变为CNN、RCNN等深度学习及其变形的方法。现在也有相当一部分人开始研究3维人脸识别识别,这种项目目前也受到了学术界、工业界和国家的支持。
首先看看现在的研究现状。如上的发展趋势可以知道,现在的主要研究方向是利用深度学习的方法解决视频人脸识别。
主要的研究人员:
如下:中科院计算所的山世光教授、中科院生物识别研究所的李子青教授、清华大学的苏光大教授、香港中文大学的汤晓鸥教授、Ross B. Girshick等等。
主要开源项目:
SeetaFace人脸识别引擎。该引擎由中科院计算所山世光研究员带领的人脸识别研究组研发。代码基于C++实现,且不依赖于任何第三方的库函数,开源协议为BSD-2,可供学术界和工业界免费使用。
主要软件API/SDK:
·face++。Face++.com 是一个提供免费人脸检测、人脸识别、人脸属性分析等服务的云端服务平台。Face++是北京旷视科技有限公司旗下的全新人脸技术云平台,在黑马大赛中,Face++获得年度总冠军,已获得联想之星投资。
· skybiometry.。主要包含了face detection、face recognition、face grouping。
主要的人脸识别图像库:
目前公开的比较好的人脸图像库有LFW(Labelled Faces in the Wild)和YFW(Youtube Faces in the Wild)。现在的实验数据集基本上是来源于LFW,而且目前的图像人脸识别的精度已经达到99%,基本上现有的图像
数据库已经被刷爆。下面是现有人脸图像数据库的总结:
现在在中国做人脸识别的公司已经越来越多,应用也非常的广泛。其中市场占有率最高的是汉王科技。主要公司的研究方向和现状如下:
· 汉王科技:汉王科技主要是做人脸识别的身份验证,主要用在门禁系统、考勤系统等等。
· 科大讯飞:科大讯飞在香港中文大学汤晓鸥教授团队支持下,开发出了一个基于高斯过程的人脸识别技术–Gussian face, 该技术在LFW上的识别率为98.52%,目前该公司的DEEPID2在LFW上的识别率已经达到了99.4%。
· 川大智胜:目前该公司的研究亮点是三维人脸识别,并拓展到3维全脸照相机产业化等等。
· 商汤科技:主要是一家致力于引领人工智能核心“深度学习”技术突破,构建人工智能、
大数据分析行业解决方案的公司,目前在人脸识别、文字识别、人体识别、车辆识别、物体识别、图像处理等方向有很强的竞争力。在人脸识别中有106个人脸关键点的识别。
人脸识别的过程
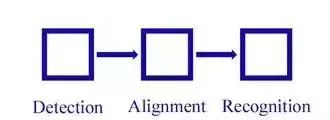
人脸识别主要分为四大块:人脸定位(face detection)、 人脸校准(face alignment)、 人脸确认(face verification)、人脸鉴别(face identification)。
人脸定位(face detection):
对图像中的人脸进行检测,并将结果用矩形框框出来。在openCV中有直接能拿出来用的Harr分类器。
人脸校准(face alignment):
对检测到的人脸进行姿态的校正,使其人脸尽可能的”正”,通过校正可以提高人脸识别的精度。校正的方法有2D校正、3D校正的方法,3D校正的方法可以使侧脸得到较好的识别。
在进行人脸校正的时候,会有检测特征点的位置这一步,这些特征点位置主要是诸如鼻子左侧,鼻孔下侧,瞳孔位置,上嘴唇下侧等等位置,知道了这些特征点的位置后,做一下位置驱动的变形,脸即可被校”正”了。如下图所示:
这里介绍一种MSRA在14年的技术:Joint Cascade Face Detection and Alignment(ECCV14)。这篇
文章直接在30ms的时间里把detection和alignment都给做了。
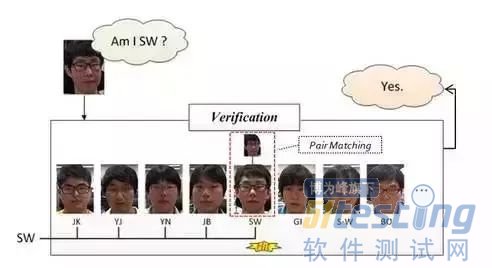
人脸确认(face verification):
Face verification,人脸校验是基于pair matching的方式,所以它得到的答案是“是”或者“不是”。在具体操作的时候,给定一张
测试图片,然后挨个进行pair matching,matching上了则说明测试图像与该张匹配上的人脸为同一个人的人脸。
一般在小型办公室人脸刷脸打卡系统中采用的(应该)是这种方法,具体操作方法大致是这样一个流程:离线逐个录入员工的人脸照片(一个员工录入的人脸一般不止一张),员工在刷脸打卡的时候相机捕获到图像后,通过前面所讲的先进行人脸检测,然后进行人脸校正,再进行人脸校验,一旦match结果为“是”,说明该名刷脸的人员是属于本办公室的,人脸校验到这一步就完成了。
在离线录入员工人脸的时候,我们可以将人脸与人名对应,这样一旦在人脸校验成功后,就可以知道这个人是谁了。
上面所说的这样一种系统优点是开发费用低廉,适合小型办公场所,缺点是在捕获时不能有遮挡,而且还要求人脸姿态比较正(这种系统我们所有,不过没体验过)。下图给出了示意说明:
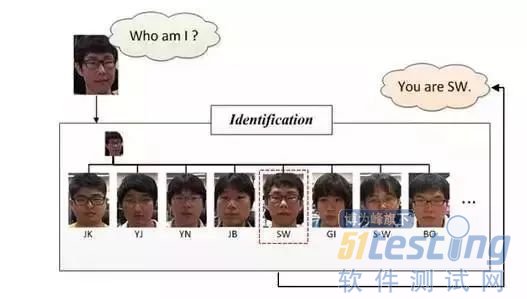
人脸识别(face identification/recognition):
Face identification或Face recognition,人脸识别正如下图所示的,它要回答的是“我是谁?”,相比于人脸校验采用的pair matching,它在识别阶段更多的是采用分类的手段。它实际上是对进行了前面两步即人脸检测、人脸校正后做的图像(人脸)分类。
根据上面四个概念的介绍,我们可以了解到人脸识别主要包括三个大的、独立性强的模块:
我们将上面的步骤进行详细的拆分,得到下面的过程图:
人脸识别分类
现在随着人脸识别技术的发展,人脸识别技术主要分为了三类:一是基于图像的识别方法、二是基于视频的识别方法、三是三维人脸识别方法。
基于图像的识别方法:
这个过程是一个静态的图像识别过程,主要利用图像处理。主要的算法有PCA、EP、kernel method、 Bayesian Framwork、SVM 、HMM、Adaboot等等算法。但在2014年,人脸识别利用Deep learning 技术取得了重大突破,为代表的有deepface的97.25%、face++的97.27%,但是deep face的训练集是400w集的,而同时香港中文大学汤晓鸥的Gussian face的训练集为2w。
基于视频的实时识别方法:
这个过程可以看出人脸识别的追踪过程,不仅仅要求在视频中找到人脸的位置和大小,还需要确定帧间不同人脸的对应关系。
DeepFace
DeepFace是FaceBook提出来的,后续有DeepID和FaceNet出现。而且在DeepID和FaceNet中都能体现DeepFace的身影,所以DeepFace可以谓之CNN在人脸识别的奠基之作,目前深度学习在人脸识别中也取得了非常好的效果。所以这里我们先从DeepFace开始学习。
在DeepFace的学习过程中,不仅将DeepFace所用的方法进行介绍,也会介绍当前该步骤的其它主要算法,对现有的图像人脸识别技术做一个简单、全面的叙述。
DeepFace的基本框架
1. 人脸识别的基本流程
face detection -> face alignment -> face verification -> face identification
2.人脸检测(face detection)
2.1 现有技术:
haar分类器:
人脸检测(detection)在opencv中早就有直接能拿来用的haar分类器,基于Viola-Jones算法。
Adaboost算法(级联分类器):
2.2 文章中所用方法
本文中采用了基于检测点的人脸检测方法(fiducial Point Detector)。
先选择6个基准点,2只眼睛中心、 1个鼻子点、3个嘴上的点。
通过LBP特征用SVR来学习得到基准点。
效果如下:
3. 人脸校准(face alignment)
2D alignment:
对Detection后的图片进行二维裁剪, scale, rotate and translate the image into six anchor locations。将人脸部分裁剪出来。
3D alignment:
找到一个3D 模型,用这个3D模型把二维人脸crop成3D人脸。67个基点,然后Delaunay三角化,在轮廓处添加三角形来避免不连续。
·将三角化后的人脸转换成3D形状
· 三角化后的人脸变为有深度的3D三角网
· 将三角网做偏转,使人脸的正面朝前
· 最后放正的人脸
效果如下:
上面的2D alignment对应(b)图,3D alignment依次对应(c) ~ (h)。
4 人脸表示(face verification)
4.1 现有技术
LBP && joint Beyesian:
通过高维LBP跟Joint Bayesian这两个方法结合。
论文:Bayesian Face Revisited: A Joint Formulation
DeepID系列:
将七个联合贝叶斯模型使用SVM进行融合,精度达到99.15%
论文:Deep Learning Face Representation by Joint Identification-Verification
4.2 文章中的方法
论文中通过一个多类人脸识别任务来训练深度神经网络(DNN)。网络结构如上图所示。
结构参数:
经过3D对齐以后,形成的图像都是152×152的图像,输入到上述网络结构中,该结构的参数如下:
·Conv:32个11×11×3的卷积核
· max-pooling: 3×3, stride=2
· Conv: 16个9×9的卷积核
· Local-Conv: 16个9×9的卷积核,Local的意思是卷积核的参数不共享
· Local-Conv: 16个7×7的卷积核,参数不共享
· Local-Conv: 16个5×5的卷积核,参数不共享
· Fully-connected: 4096维
· Softmax: 4030维