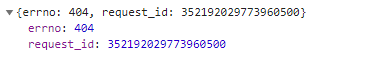有个读者在微信上问我:
百度网盘的秒传功能是如何实现的?
这个问题我其实有想过,我猜测大概是前端计算一个文件的哈希值(比如MD5)发送给后端,网盘服务器判断是否存在这个文件,如果存在就直接在后端完成文件的“转存”,直接告诉前端:上传成功。
不过这是我自己猜测的,到底对不对,一直也没有去验证过。
我把我的猜测告诉了他,结果他问了一句:如果发生哈希冲突了怎么办呢?。
我想了一下又说:那就多加几个哈希!
不过百度网盘到底是怎么做的呢?这位读者既然问到了,我就趁机花了几分钟研究了一下,算是解答了这个疑惑,增加了知识。
MD5 冲突
首先,只用一个哈希值,已经有事实证明是会发生冲突的,而不只是理论上。
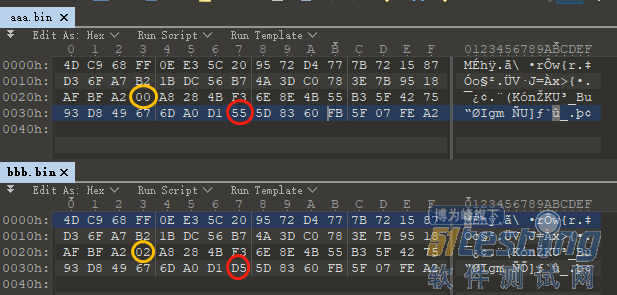
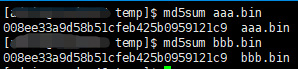
比如我在知乎上找到了一个例子,下面两段不同的数据,只相差两个字节:
分别计算md5,结果是一样的:
所以,如果只用一个哈希值就判定是同一个文件,那就比较容易会出现张冠李戴的情况。
甚至,有人还基于此提出一种哈希碰撞攻击:如果我知道一个文件的md5值,但拿不到这个文件,我通过数学计算,构造一个相同md5的文件,那岂不是就把那个文件直接给我转存过来了?如果是一个私密的文件呢?那不出事了!
百度网盘的做法
那百度网盘是咋做的呢?
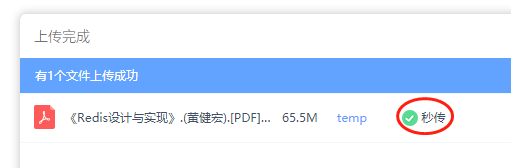
首先上传一个稍微大一点的文件(小文件有计算哈希的功夫早就传完了),使用浏览器F12大法,看一下它的网络请求:
可以看到,百度网盘对文件进行了分块传输,这也是目前业界比较流行的做法,对大文件进行分块,如果网络不好断开了,下次只需要传输剩下的分块就行了,做到了断点续传。
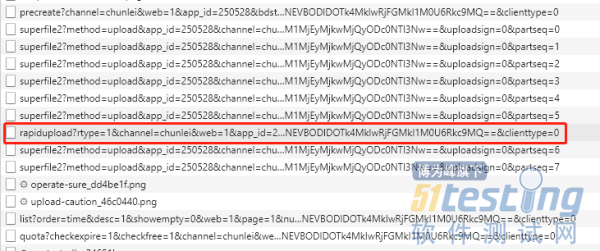
不过注意看,在上面分块的中间,插入了一个叫rapidupload接口的请求,从名字你也可以猜出来了,这个接口肯定跟它的“秒传”功能有关系
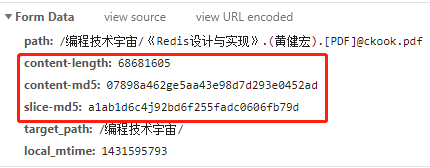
来看一下请求的参数,是一个Form表单,有这么几个字段:
content-length: 文件长度
content-md5: 文件的MD5
slice-md5: 文件切片的MD5
看到这里你估计猜到了,肯定是这三个参数联合判断,同时满足条件才算是同一个文件!
来看下服务器响应了什么:
秒传成功了!
那如果上传一个后端肯定不存在的文件会是返回什么呢?我构造了一个做
测试:
看到了吧,404!说明后端没这个文件,那就老老实实传吧!
接着,我想看一下这个切片md5,百度网盘是怎么在切的。
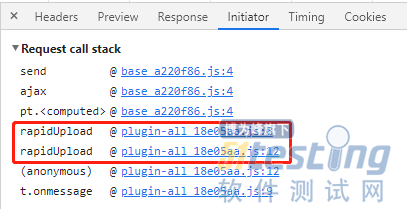
通过网络通信中的Initiator功能,可以定位到是哪里的JS代码在发生请求:
通过调用堆栈,看到了叫rapidUpload这个函数,再上下一跟进,找到了这个切片MD5计算的地方:
其实就是对文件的前262144个字节,也就是256KB进行计算。如果文件比这还小,那就用不着秒传了。
但奇怪的是,我扣取了文件的前256个字节,计算出来的md5,和它接口中上传的参数并不一致!
这让我疑惑了好几分钟,难道事情没这么简单?
我又打了断点在计算的位置,发现它计算的跟我计算的又是一样的,但通过网络发出去以后就变了,真是薛定谔的MD5,奇怪了!
不过,程序不是量子力学,它不会骗人,很快我就找到了问题所在:百度网盘可能担心自己的路数被发现,对文件的MD5和切片MD5都进行了**!
这就是**函数:
一些简单的字符串处理而已。
好了,现在可以回答前面读者的问题了:
百度网盘上传时,如果是超过256KB的文件,将计算整个文件的MD5和文件前256KB内容的MD5,并对两个MD5值**后请求后端执行秒传。后端通过两个MD5和长度信息判断是否存在该文件,如果存在则完成秒传。
这样做,虽然理论上也不能保证不会发生哈希碰撞,但通过这种方式,至少将概率降低了许多。
最后给大家留一个思考题:后端拿到MD5后,怎么判断后端是否有这个MD5呢? 这可是大厂经常爱考的一个面试题哦,来开动脑筋想一下!