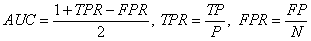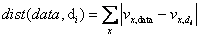引言
软件缺陷预测是软件工程中的一个非常重要的研究课题,它基于数据中的模块缺陷
记录,如软件模块的静态代码数量、耦合度和复杂度等,对新的软件模块进行缺陷预测,还能用以指导软件项目的规划与过程管理。
为了更好构建软件缺陷数据集中各属性与模块缺陷之间的关系模型,基于统计概率理论、优化理论、决策理论等多学科理论的机器学习方法,近年来已被用于预测软件缺陷,由于机器学习方法能够建立多属性到软件缺陷值之间的更为复杂的函数关系,因此基于机器学习的分类算法能够有效地预测软件缺陷。
常用软件缺陷预测模型,包括基于实例学习的k最近邻预测模型,基于决策树的预测模型,基于朴素贝叶斯的预测模型,基于支持向量机的预测模型及集成的预测模型等等。经实验比较分析,发现并不存在单一的分类算法在所有的软件缺陷预测问题上均获得最优的分类性能。正如“NoFreeLunch”(NFL)理论所述:没有一种算法适用于解决所有问题,数据集不同,所适用的方法也不相同。
对于给定的软件缺陷预测数据集,如何找出该数据集上最适用的分类算法是一个亟待解决的难题。针对该问题,本文提出了一种基于元学习的软件缺陷预测算法推荐方法,依据待预测的软件缺陷数据集本身的特征,利用基于实例学习的k-最近邻分类方法,即可为其推荐出最适用的分类算法。
1.推荐方法原理
推荐方法主要由元知识
数据库的构建与缺陷预测算法推荐两部分构成,具体过程如图1所示:
1)元知识数据库构建
首先,抽取各软件缺陷数据集中描述数据集本身特征的度量,生成相应的特征向量,同时评估各数据集上所有候选软件缺陷预测算法的性能,选出最优的预测算法作为目标概念;然后,将各数据集的特征向量与最优的软件缺陷预测算法一一对应,建立“数据集特征-最优软件缺陷预测算法”元知识数据库。
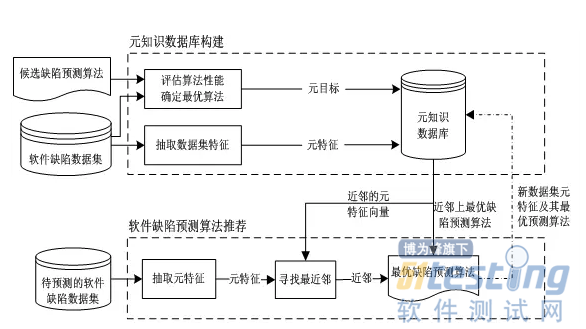
图1基于元学习的缺陷预测算法推荐框架
2)软件缺陷预测算法推荐
若软件缺陷数据集相似,那么其上最适用的缺陷预测算法的性能也相似。利用基于实例学习的k-最近邻分类方法给出待预测的软件缺陷数据集上最适用的预测算法。
当待预测软件缺陷数据集到来时,首先,抽取该数据集的特征向量;然后,从元知识数据库中找到距离该特征向量最近的k个近邻,对k最近邻上的最优预测算法进行投票,可获得该数据集上最优的软件缺陷预测算法。
3)元知识库更新
每次推荐结果都揭示了新数据集上软件缺陷预测算法与数据集特征之间的内在联系。该信息被添加到元知识数据库中,元知识数据库中信息越多,则越有利于提高软件缺陷预测算法推荐方法的准确率。因此,每次推荐后,新数据集上的<数据集特征,最优软件缺陷预测算法>二元关系,均被添加到元知识数据库,进而实现元知识数据库的更新。
2.元特征抽取
学者们从不同的角度提出了许多数据集特征度量用以描述数据集特征与分类算法之间的关系,如传统特征量、问题复杂度、Landmarking度量、基于模型度量以及结构信息度量等。
1)传统特征度量
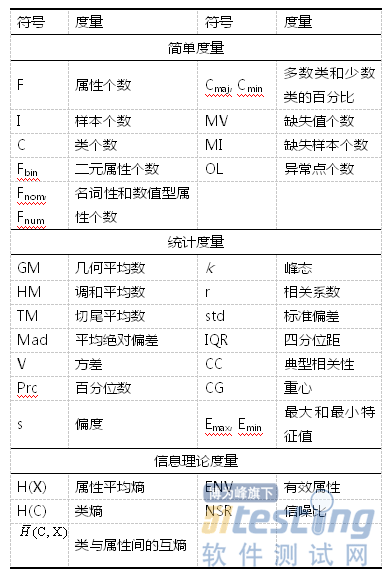
Brazdil等人在实验研究中采用了一些与分类性能有关的传统特征度量,包括简单度量、统计度量和信息理论度量。其中,简单度量主要用于描述数据集的基本信息,如样本数量、属性个数、类别个数及缺失样本数量等;统计度量主要包括中心趋势、方差分析和相关分析,描述了数据集中数据分布、数值特征及随机变量之间的相关性;信息理论度量则常用于描述数据集中属性特征及属性间的关系,熵是信息理论度量中的一个关键度量,用于量化随机变量的不确定性。传统特征度量的表示符号和具体含义详见表1。
表1传统特征度量
2)问题复杂度
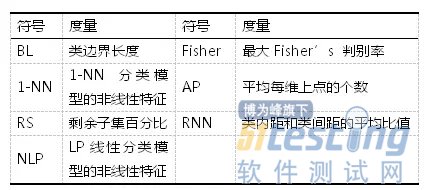
Ho和Basu实验证明问题复杂度度量与分类算法性能紧密相关。问题复杂度则关注于类边界的复杂度,突出刻画不同类别之间的关系,如分离或交叉重叠度等特征。问题复杂度的含义及其表示符号详见表2
表2问题复杂度度量
3)Landmarking度量
Duin等人利用简单有效的学习算法分类性能上的差异性,间接地描述待分类问题的特征,即Landmarking度量。该度量不仅能够判别不同类型的分类问题,还能突出分类算法的适用范围。本文利用一组简单有效的分类算法(Na?veBayes,IB1和C4.5)在各数据集上的分类性能作为Landmarking度量,用以描述不均衡数据集的特征。
4)基于模型的度量
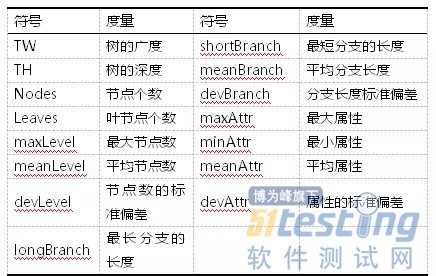
Peng等人提出了基于决策树的数据特征度量,将原始数据集归纳成决策树的形式,而后抽取决策树的模型信息来描述数据集本身特征。本章采用了C4.5算法为每个数据集构建决策树,用以描述不均衡数据集的特征。基于模型的数据集特征度量的详细信息见表3。
表3基于模型的度量
5)结构信息度量
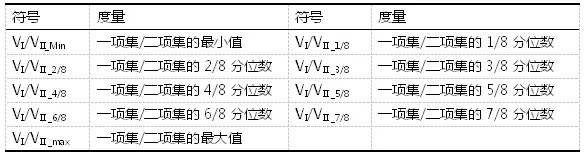
Song等人提出了一种结构信息度量,用以描述数据集特征与分类算法之间的关系,实现分类算法的自动推荐。表4给出了结构信息度量。与传统的数据集特征度量不同,结构信息度量并不是从原始的数据集上直接获取,而须将原始数据集转换为二元数据集,获得二元数据集的一项集VI和二项集VII。其中,VI是由二元数据集中每一项出现的频率组成的项集,而二项集则是由二元数据集中每两项同时出现的频率组成的项集。为了实现不同数据集的同一比较,将两个项集VI和VII升序排列,并抽取VI和VI中的最小值、八分位数和最大值描述数据集特征。
表4基于结构信息的度量
3.最优算法识别
软件缺陷预测算法的性能主要通过软件缺陷数据集上的分类算法的性能来体现。为了评估候选软件缺陷预测算法的性能,本文采用了接收者操作特征曲线(ReceiveOperatingCharacteristics,ROC)曲线下面积(AreaoftheCurve,AUC)来评价软件缺陷预测算法的分类性能。依据AUC对软件缺陷预测算法进行排序,选取最高AUC对应的分类算法作为最优预测算法。
ROC曲线是一种用于比较分类模型有效性的可视化工具,它显示了分类模型的真正例率(TPR)与假正例率(FPR)的权衡。其中,TPR和FPR是两个进行比较的操作特征。软件缺陷预测数据集大多类不均衡分布数据集,对于这一类数据集,ROC曲线可用于直观地描述分类模型正确地识别少数类样本的比例与误分多数类样本的比例之间的权衡。ROC曲线下方的面积AUC是分类精度,AUC越大,分类精度越高。计算公式如下:
4.缺陷预测算法推荐
推荐方法旨在不需对所有候选缺陷预测算法进行反复试验评估,即可给出待预测软件缺陷数据集上最优的预测算法,图2给出了详细的推荐过程。
首先,由于各指标度量单位不同,为了能够使各指标能够参与评价计算,需要对元知识数据库中的特征向量进行规范化,本章采用了极值法将特征度量统一地映射到[0,1]区间。然后,从规范化的元知识数据库MetaDB中,找出与待分类数据集最相似的k个最近邻。其中,利用无权重的L1范数[168]度量数据集间的相似性,不仅易于计算且便于理解,计算公式如下:
式中,data表示待分类数据集,di代表元知识数据库MetaDB中第i个数据集,vx,data和vx,di分别代表数据集data和di中第x个元特征值。最后,对k最近邻上的最优预测算法进行投票,即可获得待分类数据集上最适用的软件缺陷预测算法。

图2软件缺陷预测算法推荐过程
推荐算法的计算开销主要在于构建“数据集特征-最优缺陷预测算法”元知识数据库。假设有n个历史数据集,抽取数据特征的时间复杂度为;评估所有候选软件预测算法性能的时间复杂度为,其中,Ci为第i种软件缺陷预测算法;构建元知识数据库的时间复杂度为。
当待分类软件缺陷数据集到来时,利用基于实例学习的k-最近邻方法,为其推荐最适用的软件缺陷预测算法。k-最近邻方法的优点在于它不预先构建分类模型,而只是从元知识数据库中,找出离该数据集最近的k个近邻,并对k最近邻上最优的软件缺陷预测算法进行投票,即可获得待分类软件缺陷数据集上最优的软件缺陷预测算法,预测过程的时间度为。
5.实验结果与分析
为了保证实验的客观性和可再现性,本章在公开的软件缺陷预测数据集上对基于实例学习的软件缺陷预测算法推荐方法进行了实验评估与验证。
5.1实验数据
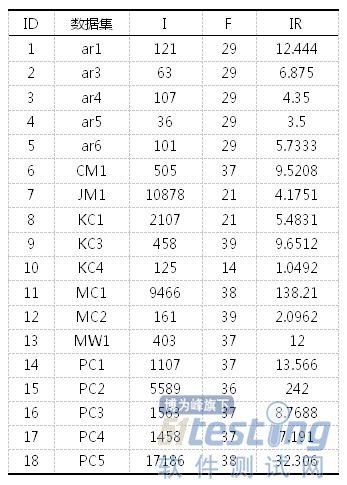
本实验在18个来自Promise数据库的软件缺陷数据集,其中5个源自PROMISE软件工程数据库,13个源自美国宇航局(NASA)MDP项目的数据集。MDP是由美国宇航局提供一个软件度量库,并通过网站提供给普通用户。MDP的数据存储了系统在模块(函数/方法)级的软件产品的度量数据和相关的缺陷数据;实验数据集的样本数量分布在115~5472之间,属性数量分布于5~63之间,不均衡率分布在1.06~41.1之间。表5给出了18个软件缺陷数据集的统计信息,其中F、I、IR分别代表属性数量、样本数量以及不均衡率。
表518软件缺陷数据集的统计信息
5.2实验设置
为了全面地验证推荐算法的有效性,并保证实验的可再现性,本节对实验中的各个环节进行了如下设置:
1)数据集特征
在软件预测方法推荐过程中,哪些数据集特征更能刻画出不均衡数据处理方法的适用范围是未知的。因此,实验过程中收集了所有可用的数据集特征度量,以便尽可能全面地描述软件缺陷数据集的特性,主要包括传统特征度量(TraditionalMetrics)、问题复杂度(ComplexityMetrics)、Landmarking度量、基于模型的度量(ModelBasedMetrics)以及结构信息度量(NewMetrics和NewMetricXor)。
2)软件缺陷预测算法
给定待分类不均衡数据集,为了能够推荐出最适用的软件缺陷预测算法,收集了7种最常用的软件缺陷预测算法作为候选预测算法,在各实验数据集上进行学习。
(1)基于实例学习的最近邻分类算法(k-NN),该算法并不预先构建预测模型,而是当待分类元组到来时,从训练样本中寻找距离待分类样本最近的元组,即最近邻,该最近邻的类别即为待分类元组的类别。该算法能快速地学习复杂的目标函数,同时不会丢失信息,而且对噪声有较强的鲁棒性。然而,该算法在预测时花销很大。此外,该算法的性能与样本间的相似性及最近邻个数的确定有着密切的关系。
(2)决策树分类算法(J48),该算法是一种类似于流程图的树结构,其中,每个内部节点(非树叶节点)表示在一个属性上的
测试,每个分枝代表该测试的一个输出,而每个树叶节点(或终端节点)存放一个类标号。数的最顶层节点是根节点。给定一个类标号未知的元组,在决策树上测试该元组的属性值。跟踪一条由根到叶节点的路径,叶节点就存放着该元组的类预测。决策树很容易转换成分类规则。该算法的性能取决于树节点的分裂规则以及修剪
技术。
(3)神经网络分类算法(MLP),神经网络是一组连接的输入/输出单元,其中每个连接都与一个权重相关联。在学习阶段,通过调整这些权重,使得它能够预测输入元组的正确类标号来学习。目前发展最为**、应用最为广泛,且常用语软件缺陷预测的是基于后向传播的多层前馈神经网络。该算法对噪声数据具有较高的承受能力,并能够对未经训练的数据模式进行分类,尤其适用于属性与类间的联系知识缺失时的分类任务。然而,该算法训练时间较长,且有大量的参数需预先设定,大多靠经验来确定。
(4)朴素贝叶斯分类法(NB),是一种统计学分类方法,可用以预测类隶属关系的概率。该算法假定一个属性值在给定类上的影响独立于其他属性的值(类条件独立性)。理论上,贝叶斯分类法具有最小的错误率。然而,实践中并非总是如此,因为类条件独立是理想情况。Menzies等和Rish采用了朴素贝叶斯分类算法构建了软件缺陷预测模型,获得了很好的分类性能。
(5)支持向量机SVM分类法(SVM),使用一种非线性映射,把原训练数据映射到较高的维上。在新的维上,搜索最佳分离超平面(即将一个类的元组与其他类分离的“决策边界”)。该算法对复杂的非线性边界具有较强建模能力,对噪声有较好的鲁棒性,不易过分拟合,且能够提供全局最佳的决策平面。邢飞等人利用支持向量机分类算法构建了软件缺陷预测模型,并获得了较好的分类性能。
(6)逻辑回归法(Log),将软件缺陷预测模型看作是学习一个近似函数,若是预测缺陷数量,该学习任务就是统计方法中的回归问题;若是预测软件模块是否有缺陷,则是二元分类问题。McCabe和Ostrand利用回归方法建立了软件缺陷预测模型,获得了较低的回归误差。然而,基于回归方法建立的软件缺陷预测模型缺乏可解释性,无法对预测模型给出的结果难以分析其原因。
(7)随机森林(RandomForest),是一种组合分类方法。其中每个分类器都是一棵决策树,因此分类器的集合就是一个“森林”。随着森林中数的个数增加,森林的泛化误差收敛。随机森林的准确率对错误和离群点更鲁棒,在大型数据库上非常有效,且可能比装袋和提升方法更快。
3)性能评估方法
在评估不均衡数据处理方法的分类性能时,采用10*10折交叉验证,充分利用数据信息的同时,尽可能地减少随机序列产生的偶然误差。为了无偏地评估推荐方法的预测性能,采用了Jackknife方法,每次将建模数据集分成两部分,测试集中只包含一个样本,其余样本作为训练集,用于构建推荐模型,直至每一个样本都被推荐一个软件缺陷预测算法。Jackknife方法不仅能够降低序列相关性评估量的偏差,也能够提高预测模型的泛化能力。
4)性能评价指标
利用后向传播神经网络方法预测各软件缺陷数据集上最适用的缺陷预测算法。为了更全面地评价推荐方法的性能,采用了命中率以及分类性能。
(1)命中率(HR),用以评价推荐算法的准确性。每个软件缺陷数据集都对应着一个最优的分类算法。当推荐的软件缺陷预测方法与实际最优的分类算法相同时,即命中;否则,没有命中,即推荐的不准确。
(2)分类性能(AUC),通过评估推荐的分类算法在软件缺陷数据集上的分类性能,间接地评价推荐算法的准确性。
5.3结果与分析
5.3.1命中率
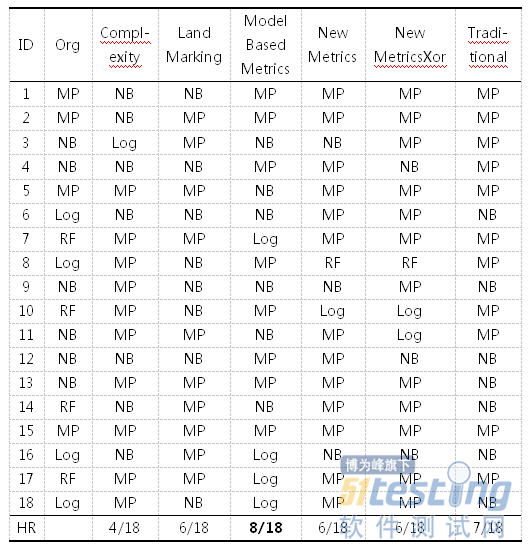
本节了软件缺陷预测算法推荐方法在18个软件缺陷数据集上的推荐结果,并针对每一种数据集特征度量,给出了推荐模型的命中率,详见表6。其中,Org代表各数据集上实际最优的软件缺陷预测算法,其他各列代表基于不同的数据集度量推荐出的软件缺陷预测算法。HR表示命中率。
表6推荐命中率比较分析
通过比较分析,基于决策树的模型度量(ModelMetrics)时,采用基于实例学习的IBk(k=3)推荐算法的命中率最高,意味着基于决策树的模型度量(ModelBasedMetrics)能够更好地用于描述软件缺陷数据集的特性。
5.3.2分类性能
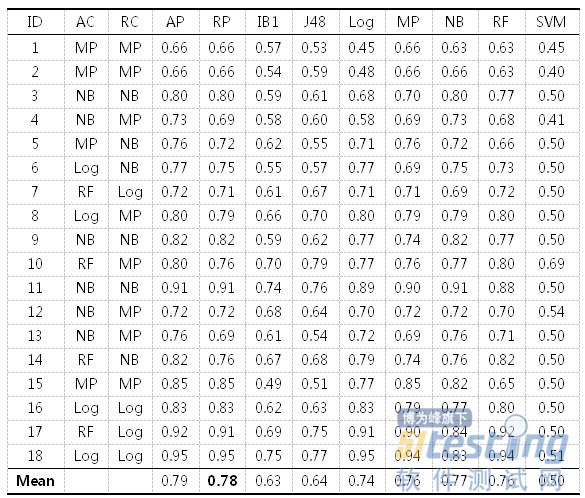
本节给出软件缺陷预测算法推荐方法在18个软件缺陷数据集上的推荐性能。表7给出了各数据集上实际最优的分类算法(AC),推荐出的最优分类算法(RC),实际最优分类性能(AP),推荐算法对应的分类性能(RP),IB1、J48、Log、MP、NB、RF及SVM分别代表采用指定单一分类算法进行软件缺陷预测时对应的分类性能。
通过比较可以发现,虽然推荐出的软件缺陷预测算法的分类性能相较于实际最优的分类性能平均低了2.17%,但相比于采用其他单一算法的分类性能,推荐算法的分类性能平均提高了1.58~55.39%。分别来看,推荐出的软件缺陷预测算法的分类性能平均比IB1提高了24.27%,比J48提高了21.68%,比Log提高了5.28%,MP提高了2.04%,NB提高了1.58%,比RF提高了2.92%,比SVM提高了55.39%。
表7推荐分类算法的性能比较
结语
针对如何为待预测的软件缺陷预测问题推荐最适用的缺陷预测算法的问题,本文提出了一种基于元学习和实例学习的软件缺陷预测算法推荐方法。实验结果表明,基于元学习和实例学习的软件缺陷预测算法推荐方法能够有效地为未知数据推荐出最适用的软件缺陷预测算法。