
如何做LoadRunner结果分析
上一篇 /
下一篇 2009-03-10 14:13:23
/ 个人分类:LOAD RUNNER
1.前言:
LoadRunner最重要也是最难理解的地方--测试结果的分析.其余的录制和加压测试等设置对于我们来讲通过几次操作就可以轻松掌握了.
针对 Results Analysis我用图片加文字做了一个例子,希望通过例子能给大家更多的帮助.
这个例子主要讲述的是多个用户同时接管任务,测试系统的响应能力,确定系统瓶颈所在.客户要求响应时间是1个人接管的时间在5S内.
2.系统资源:
2.1 硬件环境:
CPU:奔四2.8E
硬盘:100G
网络环境:100Mbps
2.2 软件环境:
操作系统:英文windowsXP
服务器:tomcat服务
浏览器:IE6.0
系统结构:B/S结构
3.添加监视资源
下面要讲述的例子添加了我们平常测试中最常用到的一些资源参数.另外有些特殊的资源暂时在这里不做讲解了.我会在以后相继补充进来。
Mercury Loadrunner Analysis中最常用的5种资源.
1. Vuser
2. Transactions
3. Web Resources
4. Web Page Breakdown
5. System Resources
在Analysis中选择“Add graph”或“New graph”就可以看到这几个资源了.还有其他没有数据的资源,我们没有让它显示.
如果想查看更多的资源,可以将左下角的display only graphs containing data置为不选.然后选中相应的点“open graph”即可.
打开Analysis首先可以看的是Summary Report.这里显示了测试的分析摘要.应有尽有.但是我们并不需要每个都要仔细去看.下面介绍一下部分的含义:
Duration(持续时间):了解该测试过程持续时间.测试人员本身要对这个时期内系统一共做了多少的事有大致的熟悉了解.以确定下次增加更多的任务条件下测试的持续时间。
Statistics Summary(统计摘要):只是大概了解一下测试数据,对我们具体分析没有太大的作用.
Transaction Summary(事务摘要):了解平均响应时间Average单位为秒.
其余的看不看都可以.都不是很重要.
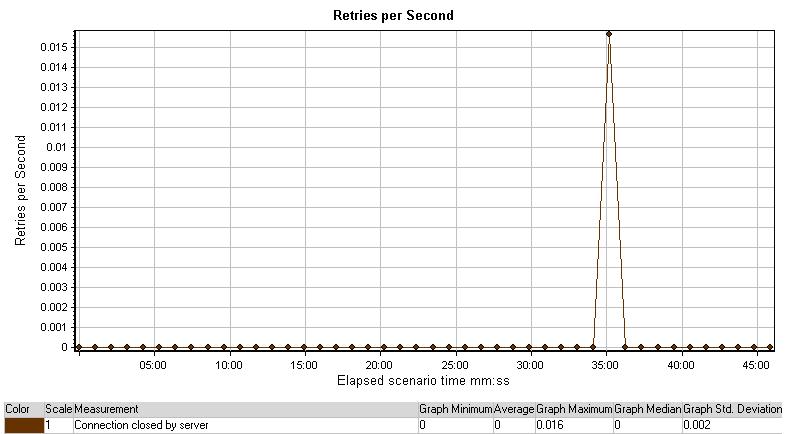
每秒重试图表显示了测试中某一时刻服务器联接重试的数量。图中重试数数大多时刻为0,除了运行到35分钟时,每秒重试数达到0.016每秒.从上图中很难做出结论,因为这个重试的峰值很像一个与其它结果不相关的独立的事件
Connections
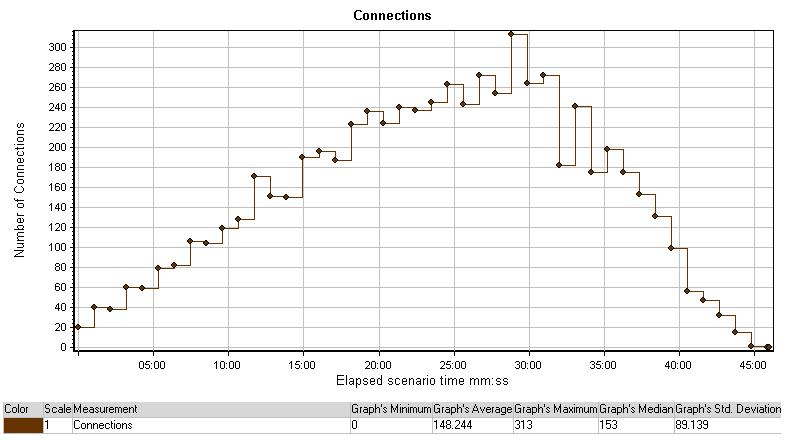
连接图表展示了场景中超时开放TCP/IP联接的数量。一个有超链接的HTML页面可能促使浏览器开放多个连接以打开不同的网页地址。每个网站服务器都会开放2个连接。理论上,打开连接的数量可以反映虚拟用户的运行数。
这张图有助于发现何时需要额外的连接。例如,如果连接的数量攀升到了一个稳定期,而且事务响应时间急剧增长,增加连接可能在执行过程中导致一个戏剧性的增长(事务响应时间的减小)
图中开放连接的数量在到达时间表中的ramp-down之前是不断地增长的。这表明连接的数量即使到达250个用户的压力承受度是足够的。所以,在运行25分钟左右时出现的问题一定是有其它原因。

每秒连接图表显示每秒新建连接的开放与连接的关闭。通常,新建的连接会反应关闭的连接数,如图中所示。注意图中的峰值,出现在20-35分钟,与此对应的是测试中虚拟用户到达峰值的数量也持续在这段期间。而且,连接的数量在这些结果中看起来没有什么问题

错误统计表显示了测试期间错误发生的数量,以错误代码分类。连接服务器和本地页面出错是最常出现的。这里的错误代码出现次数最高的是26366和26609.在下面的图表中我们会得到这些错误的详细说明。
Error Statistics (by Descrīption)

错误统计(按类型分类)图表显示了场景或按步执行期间错误增长的数量,这里的错误按类型分类。图中有错误的描述。错误与失败的事务是不同的概念,后者不在此图中统计,因为通常情况下一个独立的错误是不会导致事务失败的。有时由于一个独立事务的失败会出现复合错误.例如,LR运行中会在每一页查找特定字符来核实这些页面是正确的显示,但如果页面没有正确显示,则找不到这个字符,这时会记录一个错误。导致页面显示失败的原因并是文本的检查出现的,而是一些其它也会被LR记录的错误
图中绿色占了大部分,它是与“search”这个文字检查的失败相对应的。第2大的米色部分与HTTP503的状态或是“service temporarily unavailale”(服务暂时不可用)相对应。想要确定错误的原因,需要检查脚本“search”检查字的出现并分析此时虚拟用户需要哪些资源。在每个网站服务器的日志文件中查找服务器响应的503类型,如果是可用的,对确定响应的原因是可能助的。
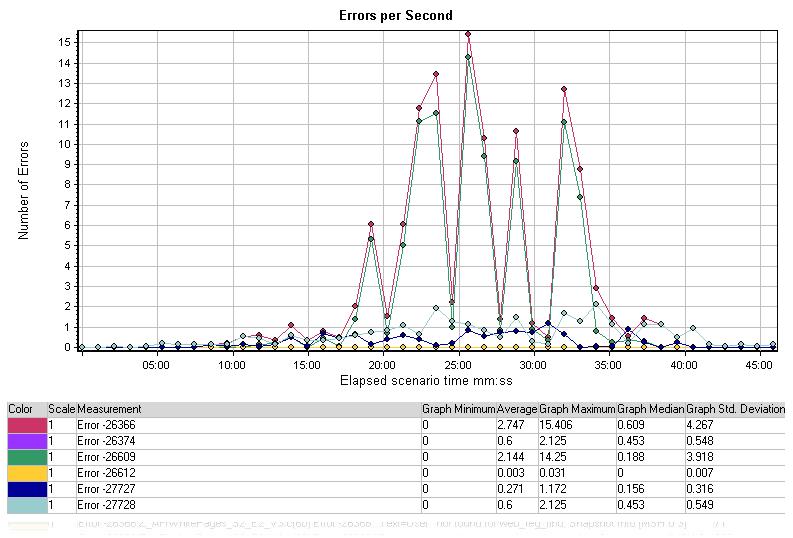
每秒错误图表显示了测试场景中每秒出现错误的平均值,按错误类型分类。在测试结果的分析中,这张表在确定应用程序施压时的具体情况有很大帮助。
图中有20-35分时出现了预期中的峰值,这与其它图相对应。尽管这里没有给出错误的详细描述,但错误出现的主体是在一个确定的时段,使我们可以诊断出异常的行为。下一步可以检查应用程序及数据库组在20-30这一时段产生的各种日志文件。
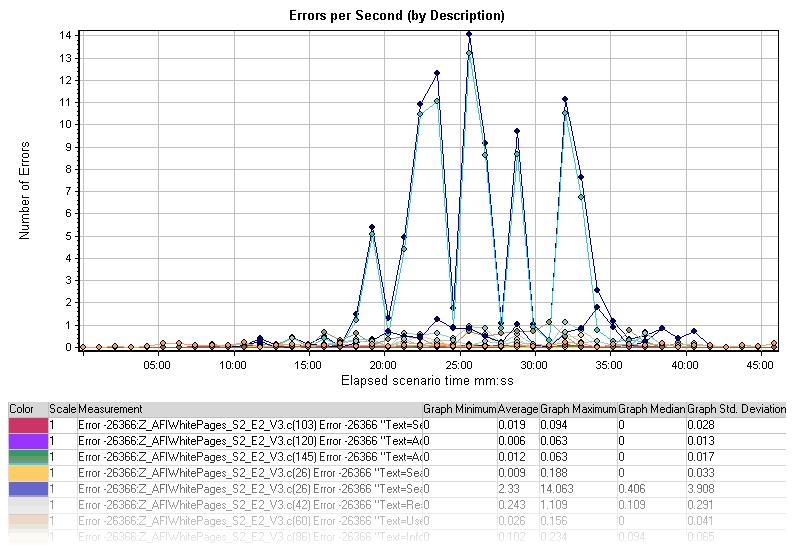
每秒错误(按性质分类)图展示了场景或会话按步运行中,每秒错误的平均数,以错误的性质分类。错误的性质在词汇汇总中有描述。
深蓝色的错误与相同的“Search”这个词的文本检查相对应,而浅蓝色的错误与同样的HTTP状态代码503相对应。相同的查询可以用在诊断这些错误出现的原因上。
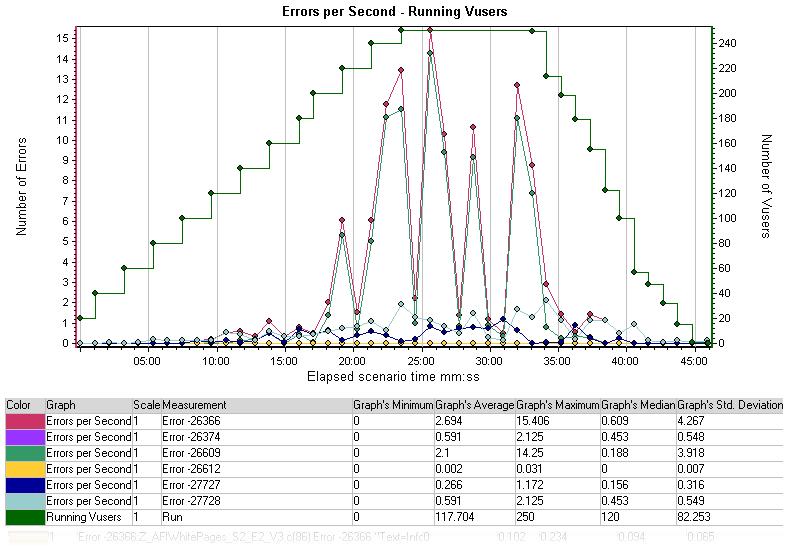
每秒错误数—运行的虚拟用户图表显示的是每秒的覆盖和错误以及在图表Y轴对面显示运行的虚拟用户。
你可以用这张图看到在虚拟用户和每秒错误的数量中是否存在某种关系。
明显在,在运行到20-35分钟时是存在一些关系的。大概从200个虚拟用户开始,错误的峰值达到最大每秒出现15个,并持续到该压力期间的结束,直到35分钟运行到ramp-down为止。
从这些结果中判断问题的下一步就是要在检查在发生错误的时间段内所有有用的日志文件,并且,如果需要的话,可以改变或更新硬件的物理配置以改善性能,并需要返测以证实这些变化是否与期望一样。
收藏
举报
TAG:

