
-
linux-shell 脚本转换 十六进制 十进制 八进制 二进制-zt
2014-10-15 17:47:55
其它进制转为10进制八进制转十进制:[chengmo@centos5 ~]$ ((num=0123));[chengmo@centos5 ~]$ echo $num;83[chengmo@centos5 ~]$ ((num=8#123));[chengmo@centos5 ~]$ echo $num;83((表达式)),(())里面可以是任意数据表达式。如果前面加入:”$”可以读取计算结果。十六进制转十进制:[chengmo@centos5 ~]$ ((num=0xff));[chengmo@centos5 ~]$ echo $num;255[chengmo@centos5 ~]$ ((num=16#ff));[chengmo@centos5 ~]$ echo $num;255base-32转十进制:[chengmo@centos5 ~]$ ((num=32#ffff));[chengmo@centos5 ~]$ echo $num;507375base64转十进制:[chengmo@centos5 ~]$ ((num=64#abc_));[chengmo@centos5 ~]$ echo $num;2667327二进制转十进制[chengmo@centos5 ~]$ ((num=2#11111111));[chengmo@centos5 ~]$ echo $num;255十进制转为其它进制十进制转八进制这里使用到:bc外部命令完成。bc命令格式转换为:echo "obase=进制;值"|bc[chengmo@centos5 ~]$ echo "obase=8;01234567"|bc4553207二进制,十六进制,base64转换为 十进制也相同方法。[chengmo@centos5 ~]$ echo "obase=64;123456"|bc30 09 00shell,内置各种进制表示方法非常简单。记得base#number 即可。这里记得赋值时候用(())符号。不能直接用=号了。=号没有值类型。默认将后面变成字符串了。如:[chengmo@centos5 ~]$ num=0123;[chengmo@centos5 ~]$ echo $num;01230开头已经失去了意义了。可以通过定义符:let达到(()) 运算效果。[chengmo@centos5 ~]$ let num=0123;[chengmo@centos5 ~]$ echo $num;83 -
linux下iptables配置详解-zt
2014-10-14 09:12:15
转自:http://www.cnblogs.com/JemBai/archive/2009/03/19/1416364.html如果你的IPTABLES基础知识还不了解,建议先去看看.开始配置我们来配置一个filter表的防火墙.(1)查看本机关于IPTABLES的设置情况[root@tp ~]# iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destinationChain FORWARD (policy ACCEPT)
target prot opt source destinationChain OUTPUT (policy ACCEPT)
target prot opt source destinationChain RH-Firewall-1-INPUT (0 references)
target prot opt source destination
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmp type 255
ACCEPT esp -- 0.0.0.0/0 0.0.0.0/0
ACCEPT ah -- 0.0.0.0/0 0.0.0.0/0
ACCEPT udp -- 0.0.0.0/0 224.0.0.251 udp dpt:5353
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:631
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:80
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:25
REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited
可以看出我在安装linux时,选择了有防火墙,并且开放了22,80,25端口.如果你在安装linux时没有选择启动防火墙,是这样的[root@tp ~]# iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destinationChain FORWARD (policy ACCEPT)
target prot opt source destinationChain OUTPUT (policy ACCEPT)
target prot opt source destination什么规则都没有.(2)清除原有规则.不管你在安装linux时是否启动了防火墙,如果你想配置属于自己的防火墙,那就清除现在filter的所有规则.[root@tp ~]# iptables -F 清除预设表filter中的所有规则链的规则
[root@tp ~]# iptables -X 清除预设表filter中使用者自定链中的规则我们在来看一下[root@tp ~]# iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destinationChain FORWARD (policy ACCEPT)
target prot opt source destinationChain OUTPUT (policy ACCEPT)
target prot opt source destination什么都没有了吧,和我们在安装linux时没有启动防火墙是一样的.(提前说一句,这些配置就像用命令配置IP一样,重起就会失去作用),怎么保存.[root@tp ~]# /etc/rc.d/init.d/iptables save这样就可以写到/etc/sysconfig/iptables文件里了.写入后记得把防火墙重起一下,才能起作用.[root@tp ~]# service iptables restart现在IPTABLES配置表里什么配置都没有了,那我们开始我们的配置吧(3)设定预设规则[root@tp ~]# iptables -p INPUT DROP[root@tp ~]# iptables -p OUTPUT ACCEPT[root@tp ~]# iptables -p FORWARD DROP
上面的意思是,当超出了IPTABLES里filter表里的两个链规则(INPUT,FORWARD)时,不在这两个规则里的数据包怎么处理呢,那就是DROP(放弃).应该说这样配置是很安全的.我们要控制流入数据包而对于OUTPUT链,也就是流出的包我们不用做太多限制,而是采取ACCEPT,也就是说,不在着个规则里的包怎么办呢,那就是通过.可以看出INPUT,FORWARD两个链采用的是允许什么包通过,而OUTPUT链采用的是不允许什么包通过.这样设置还是挺合理的,当然你也可以三个链都DROP,但这样做我认为是没有必要的,而且要写的规则就会增加.但如果你只想要有限的几个规则是,如只做WEB服务器.还是推荐三个链都是DROP.注:如果你是远程SSH登陆的话,当你输入第一个命令回车的时候就应该掉了.因为你没有设置任何规则.怎么办,去本机操作呗!(4)添加规则.首先添加INPUT链,INPUT链的默认规则是DROP,所以我们就写需要ACCETP(通过)的链为了能采用远程SSH登陆,我们要开启22端口.[root@tp ~]# iptables -A INPUT -p tcp --dport 22 -j ACCEPT[root@tp ~]# iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT (注:这个规则,如果你把OUTPUT 设置成DROP的就要写上这一部,好多人都是望了写这一部规则导致,始终无法SSH.在远程一下,是不是好了.其他的端口也一样,如果开启了web服务器,OUTPUT设置成DROP的话,同样也要添加一条链:[root@tp ~]# iptables -A OUTPUT -p tcp --sport 80 -j ACCEPT ,其他同理.)如果做了WEB服务器,开启80端口.[root@tp ~]# iptables -A INPUT -p tcp --dport 80 -j ACCEPT
如果做了邮件服务器,开启25,110端口.[root@tp ~]# iptables -A INPUT -p tcp --dport 110 -j ACCEPT
[root@tp ~]# iptables -A INPUT -p tcp --dport 25 -j ACCEPT
如果做了FTP服务器,开启21端口[root@tp ~]# iptables -A INPUT -p tcp --dport 21 -j ACCEPT[root@tp ~]# iptables -A INPUT -p tcp --dport 20 -j ACCEPT如果做了DNS服务器,开启53端口[root@tp ~]# iptables -A INPUT -p tcp --dport 53 -j ACCEPT如果你还做了其他的服务器,需要开启哪个端口,照写就行了.上面主要写的都是INPUT链,凡是不在上面的规则里的,都DROP允许icmp包通过,也就是允许ping,[root@tp ~]# iptables -A OUTPUT -p icmp -j ACCEPT (OUTPUT设置成DROP的话)[root@tp ~]# iptables -A INPUT -p icmp -j ACCEPT (INPUT设置成DROP的话)
允许loopback!(不然会导致DNS无法正常关闭等问题)IPTABLES -A INPUT -i lo -p all -j ACCEPT (如果是INPUT DROP)
IPTABLES -A OUTPUT -o lo -p all -j ACCEPT(如果是OUTPUT DROP)
下面写OUTPUT链,OUTPUT链默认规则是ACCEPT,所以我们就写需要DROP(放弃)的链.减少不安全的端口连接[root@tp ~]# iptables -A OUTPUT -p tcp --sport 31337 -j DROP[root@tp ~]# iptables -A OUTPUT -p tcp --dport 31337 -j DROP有些些特洛伊木马会扫描端口31337到31340(即黑客语言中的 elite 端口)上的服务。既然合法服务都不使用这些非标准端口来通信,阻塞这些端口能够有效地减少你的网络上可能被感染的机器和它们的远程主服务器进行独立通信的机会还有其他端口也一样,像:31335、27444、27665、20034 NetBus、9704、137-139(smb),2049(NFS)端口也应被禁止,我在这写的也不全,有兴趣的朋友应该去查一下相关资料.当然出入更安全的考虑你也可以包OUTPUT链设置成DROP,那你添加的规则就多一些,就像上边添加允许SSH登陆一样.照着写就行了.下面写一下更加细致的规则,就是限制到某台机器如:我们只允许192.168.0.3的机器进行SSH连接[root@tp ~]# iptables -A INPUT -s 192.168.0.3 -p tcp --dport 22 -j ACCEPT如果要允许,或限制一段IP地址可用 192.168.0.0/24 表示192.168.0.1-255端的所有IP.24表示子网掩码数.但要记得把 /etc/sysconfig/iptables 里的这一行删了.-A INPUT -p tcp -m tcp --dport 22 -j ACCEPT 因为它表示所有地址都可以登陆.或采用命令方式:[root@tp ~]# iptables -D INPUT -p tcp --dport 22 -j ACCEPT然后保存,我再说一边,反是采用命令的方式,只在当时生效,如果想要重起后也起作用,那就要保存.写入到/etc/sysconfig/iptables文件里.[root@tp ~]# /etc/rc.d/init.d/iptables save这样写 !192.168.0.3 表示除了192.168.0.3的ip地址其他的规则连接也一样这么设置.在下面就是FORWARD链,FORWARD链的默认规则是DROP,所以我们就写需要ACCETP(通过)的链,对正在转发链的监控.开启转发功能,(在做NAT时,FORWARD默认规则是DROP时,必须做)[root@tp ~]# iptables -A FORWARD -i eth0 -o eth1 -m state --state RELATED,ESTABLISHED -j ACCEPT[root@tp ~]# iptables -A FORWARD -i eth1 -o eh0 -j ACCEPT丢弃坏的TCP包[root@tp ~]#iptables -A FORWARD -p TCP ! --syn -m state --state NEW -j DROP处理IP碎片数量,防止攻击,允许每秒100个[root@tp ~]#iptables -A FORWARD -f -m limit --limit 100/s --limit-burst 100 -j ACCEPT设置ICMP包过滤,允许每秒1个包,限制触发条件是10个包.[root@tp ~]#iptables -A FORWARD -p icmp -m limit --limit 1/s --limit-burst 10 -j ACCEPT我在前面只所以允许ICMP包通过,就是因为我在这里有限制.
二,配置一个NAT表放火墙1,查看本机关于NAT的设置情况[root@tp rc.d]# iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destinationChain POSTROUTING (policy ACCEPT)
target prot opt source destination
SNAT all -- 192.168.0.0/24 anywhere to:211.101.46.235Chain OUTPUT (policy ACCEPT)
target prot opt source destination我的NAT已经配置好了的(只是提供最简单的代理上网功能,还没有添加防火墙规则).关于怎么配置NAT,参考我的另一篇文章当然你如果还没有配置NAT的话,你也不用清除规则,因为NAT在默认情况下是什么都没有的如果你想清除,命令是[root@tp ~]# iptables -F -t nat[root@tp ~]# iptables -X -t nat[root@tp ~]# iptables -Z -t nat2,添加规则添加基本的NAT地址转换,(关于如何配置NAT可以看我的另一篇文章),添加规则,我们只添加DROP链.因为默认链全是ACCEPT.防止外网用内网IP欺骗[root@tp sysconfig]# iptables -t nat -A PREROUTING -i eth0 -s 10.0.0.0/8 -j DROP
[root@tp sysconfig]# iptables -t nat -A PREROUTING -i eth0 -s 172.16.0.0/12 -j DROP
[root@tp sysconfig]# iptables -t nat -A PREROUTING -i eth0 -s 192.168.0.0/16 -j DROP
如果我们想,比如阻止MSN,QQ,BT等的话,需要找到它们所用的端口或者IP,(个人认为没有太大必要)例:禁止与211.101.46.253的所有连接[root@tp ~]# iptables -t nat -A PREROUTING -d 211.101.46.253 -j DROP禁用FTP(21)端口[root@tp ~]# iptables -t nat -A PREROUTING -p tcp --dport 21 -j DROP这样写范围太大了,我们可以更精确的定义.[root@tp ~]# iptables -t nat -A PREROUTING -p tcp --dport 21 -d 211.101.46.253 -j DROP这样只禁用211.101.46.253地址的FTP连接,其他连接还可以.如web(80端口)连接.按照我写的,你只要找到QQ,MSN等其他软件的IP地址,和端口,以及基于什么协议,只要照着写就行了.最后:drop非法连接
[root@tp ~]# iptables -A INPUT -m state --state INVALID -j DROP
[root@tp ~]# iptables -A OUTPUT -m state --state INVALID -j DROP
[root@tp ~]# iptables-A FORWARD -m state --state INVALID -j DROP
允许所有已经建立的和相关的连接
[root@tp ~]# iptables-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
[root@tp ~]# iptables-A OUTPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
[root@tp ~]# /etc/rc.d/init.d/iptables save
这样就可以写到/etc/sysconfig/iptables文件里了.写入后记得把防火墙重起一下,才能起作用.
[root@tp ~]# service iptables restart
别忘了保存,不行就写一部保存一次.你可以一边保存,一边做实验,看看是否达到你的要求,上面的所有规则我都试过,没有问题.写这篇文章,用了我将近1个月的时间.查找资料,自己做实验,希望对大家有所帮助.如有不全及不完善的地方还请提出.因为本篇文章以配置为主.关于IPTABLES的基础知识及指令命令说明等我会尽快传上,当然你可以去网上搜索一下,还是很多的. -
linux命令 — lsof 查看进程打开哪些文件 或者 查看文件给哪个进程使用-zt
2014-10-08 10:47:44
转自:http://blog.csdn.net/kozazyh/article/details/5495532lsof命令是什么?
可以列出被进程所打开的文件的信息。被打开的文件可以是
1.普通的文件,2.目录 3.网络文件系统的文件,4.字符设备文件 5.(函数)共享库 6.管道,命名管道 7.符号链接
8.底层的socket字流,网络socket,unix域名socket
9.在linux里面,大部分的东西都是被当做文件的…..还有其他很多
怎样使用lsof
这里主要用案例的形式来介绍lsof 命令的使用
1.列出所有打开的文件:
lsof
备注: 如果不加任何参数,就会打开所有被打开的文件,建议加上一下参数来具体定位
2. 查看谁正在使用某个文件
lsof /filepath/file
3.递归查看某个目录的文件信息
lsof +D /filepath/filepath2/
备注: 使用了+D,对应目录下的所有子目录和文件都会被列出
4. 比使用+D选项,遍历查看某个目录的所有文件信息 的方法
lsof | grep ‘/filepath/filepath2/’
5. 列出某个用户打开的文件信息
lsof -u username
备注: -u 选项,u其实是user的缩写
6. 列出某个程序所打开的文件信息
lsof -c mysql
备注: -c 选项将会列出所有以mysql开头的程序的文件,其实你也可以写成 lsof | grep mysql, 但是第一种方法明显比第二种方法要少打几个字符了
7. 列出多个程序多打开的文件信息
lsof -c mysql -c apache
8. 列出某个用户以及某个程序所打开的文件信息
lsof -u test -c mysql
9. 列出除了某个用户外的被打开的文件信息
lsof -u ^root
备注:^这个符号在用户名之前,将会把是root用户打开的进程不让显示
10. 通过某个进程号显示该进行打开的文件
lsof -p 1
11. 列出多个进程号对应的文件信息
lsof -p 123,456,789
12. 列出除了某个进程号,其他进程号所打开的文件信息
lsof -p ^1
13 . 列出所有的网络连接
lsof -i
14. 列出所有tcp 网络连接信息
lsof -i tcp
15. 列出所有udp网络连接信息
lsof -i udp
16. 列出谁在使用某个端口
lsof -i :3306
17. 列出谁在使用某个特定的udp端口
lsof -i udp:55
特定的tcp端口
lsof -i tcp:80
18. 列出某个用户的所有活跃的网络端口
lsof -a -u test -i
19. 列出所有网络文件系统
lsof -N
20.域名socket文件
lsof -u
21.某个用户组所打开的文件信息
lsof -g 5555
22. 根据文件描述列出对应的文件信息
lsof -d description(like 2)
23. 根据文件描述范围列出文件信息
lsof -d 2-3
-
Linux base shell重定向详解-zt
2014-09-23 10:56:32
这篇文章主要介绍了Linux base shell重定向的相关资料,并用一个简明例子总结了常见用法(在第三节),需要的朋友可以参考下一、标准输入,标准输出与标准错误输出在linux shell执行命令时,每个进程都和三个打开的文件相联系,并使用文件描述符来引用这些文件。由于文件描述符不容易记忆,shell同时也给出了相应的文件名:文件 文件描述符输入文件—标准输入 0(缺省是键盘,为0时是文件或者其他命令的输出)输出文件—标准输出 1(缺省是屏幕,为1时是文件)错误输出文件—标准错误 2(缺省是屏幕,为2时是文件)系统中实际上有12个文件描述符,我们可以任意使用文件描述符3到9.标准输入:从键盘输入数据,即从键盘读入数据。标准输出:把数据输出到终端上。标准错误输出:把标准错误输出到终端上。默认的标准输入指的是键盘,默认的标准输出与标准错误输出指的是屏幕或者是终端。系统为这三个文件分配了文件标识符fd(file descripter).在Linux系统下,一切皆是文件,对文件的操作,一般要用到文件标识符。它们的文件标识符,分别为0,1,2。他们的关系如下表:文件描述符 名称 通用缩写 默认值0 标准输入 stdin 键盘1 标准输出 stdout 屏幕2 标准错误 stderr 屏幕二.文件重定向:改变程序运行的输入来源和输出地点1.输出重定向:Command > filename 把标准输出重定向到一个新文件中Command >> filename 把标准输出重定向到一个文件中(追加)Command > filename 把标准输出重定向到一个文件中Command > filename 2>&1 把标准输出和错误一起重定向到一个文件中Command 2 > filename 把标准错误重定向到一个文件中Command 2 >> filename 把标准输出重定向到一个文件中(追加)Command >> filename2>&1 把标准输出和错误一起重定向到一个文件(追加)2.输入重定向:Command < filename > filename2 Command命令以filename文件作为标准输入,以filename2文件作为标准输出Command < filename Command命令以filename文件作为标准输入Command << delimiter 从标准输入中读入,知道遇到delimiter分界符3.绑定重定向Command >&m 把标准输出重定向到文件描述符m中Command < &- 关闭标准输入Command 0>&- 同上三、使用实例代码如下:cmd > file#说明: 将 cmd 的输出发送到 file 文件(覆盖模式)cmd >> file#说明: 将 cmd 的输出发送到 file 文件(追加模式)cmd < file#说明: 以 file 文件的内容作为 cmd 的输入cmd << text#说明: 嵌入文件(here document, 类似于PHP语法)形式的输入#shell 可在行内输入中做变量、命令和算术替换cmd <<- text#说明: 作用同上, 不过会自动删除here document中每行开头的制表符Tabcmd <<< word#说明: here string 格式的输入#参见: http://bash.cyberciti.biz/guide/Here_strings#参见: http://linux.die.net/abs-guide/x15683.htmlcmd <> file#说明: 以读写方式打开文件 filecmd >| file#说明: 强制以覆盖方式将 cmd 的输出发送到 file 文件#即便 shell 设置了 noclobber 选项也是如此cmd >&n#说明: 将 cmd 的输出发送到文件描述符 ncmd m>&n#说明: 作用同上。将本该输出到文件描述符 m 的内容, 发送到文件描述符 ncmd >&-#说明: 关闭标准输出cmd <&n#说明: 从文件描述符 n 处获取内容作为 cmd 命令的输入cmd m<&n#说明: 作用同上。除了本该从文件描述符 m 处获取输入,改为从文件描述符 n 处获取cmd <&-#说明: 关闭标准输入cmd <&n-#说明: 通过复制移动文件操作符 n 为标准输入并且关闭原始输入cmd >&n-#说明: 通过复制移动文件操作符 n 为标准输出并且关闭原始输出cmd 2>file#说明: 将标准错误输出发送到文件 filecmd > file 2>&1#说明: 将标准输出发送到文件 file, 将标准错误发送到文件描述符 1, 也即 file 文件cmd >& file#说明: 将标准输出和标准错误都发送到文件 file (作用同上)cmd &> file#说明: 作用同上, 更好的格式cmd &>> file#说明: 将标准错误和标准输出发送到文件 file (追加模式)cmd > f1 2> f2#说明: 将标准输出发送到文件 f1, 将标准错误发送到文件 f2cmd | tee files#说明: 发送 cmd 的输出到标准输出 (通常为终端) 和 文件 filescmd 2>&1 | tee files#说明: 发送 cmd 的输出和错误到标准输出 (通常为终端) 和 文件 filescmd |& tee files#说明: 作用同上四、shell重定向的一些高级用法1.重定向标准错误例子1:代码如下:command 2> /dev/null如果command执行出错,将错误的信息重定向到空设备例子2:代码如下:command > out.put 2>&1将command执行的标准输出和标准错误重定向到out.put(也就是说不管command执行正确还是错误,输出都打印到out.put)。2.exec用法exec命令可以用来替代当前shell;换句话说,并没有启动子shell,使用这一条命令时任何现有环境变量将会被清除,并重新启动一个shell(重新输入用户名和密码进入)。代码如下:exec command其中,command通常是一个shell脚本。对文件描述符操作的时候用(也只有再这时候),它不会覆盖你当前的shell例子1:代码如下:#!/bin/bash#file_descexec 3<&0 0<name.txtread line1read line2exec 0<&3echo $line1echo $line2其中:首先,exec 3<&0 0<name.txt的意思是把标准输入重定向到文件描述符3(0表示标准输入),然后把文件name.txt内容重定向到文件描述符0,实际上就是把文件name.txt中的内容重定向到文件描述符3。然后通过exec打开文件描述符3;然后,通过read命令读取name.txt的第一行内容line1,第二行内容line2,通过Exec 0<&3关闭文件描述符3;最后,用echo命令输出line1和line2。最好在终端运行一下这个脚本,亲自尝试一下。例子2:代码如下:exec 3<>test.sh;#打开test.sh可读写操作,与文件描述符3绑定while read line<&3doecho $line;done#循环读取文件描述符3(读取的是test.sh内容)代码如下:exec 3>&-exec 3<&-#关闭文件的,输入,输出绑定五、bash shell 重定向的几个特殊文件文件 说明/dev/stdin 文件描述符 0 的复制品/dev/stdout 文件描述符 1 的复制品/dev/stderr 文件描述符 2 的复制品/dev/fd/n 文件描述符 n 的复制品/dev/tcp/host/port Bash 在 port 打开到 host 的 TCP 连接/dev/udp/host/port Bash 在 port 打开到 host 的 UDP 连接 -
Linux Shell实现模拟多进程并发执行-zt
2014-09-23 10:27:40
转自:http://www.51testing.com/html/28/116228-238978.html
在bash中,使用后台任务来实现任务的“多进程化”。在不加控制的模式下,不管有多少任务,全部都后台执行。也就是说,在这种情况下,有多少任务就有多少“进程”在同时执行。我们就先实现第一种情况:
实例一:正常情况脚本
———————————————————————————–
#!/bin/bash
 for ((i=0;i<5;i++));do { sleep 1;echo 1>>aa && echo ”done!” }donecat aa|wc -lrm aa
for ((i=0;i<5;i++));do { sleep 1;echo 1>>aa && echo ”done!” }donecat aa|wc -lrm aa———————————————————————————–
这种情况下,程序顺序执行,每个循环3s,共需15s左右。
$ time bash test.sh
done!done!done!done!done!5real 0m15.030suser 0m0.002ssys 0m0.003s实例二:“多进程”实现
———————————————————————————–
#!/bin/bash
for ((i=0;i<5;i++));do { sleep 3;echo 1>>aa && echo ”done!” } &donewaitcat aa|wc -lrm aa———————————————————————————–
这个实例实际上就在上面基础上多加了一个后台执行&符号,此时应该是5个循环任务并发执行,最后需要3s左右时间。
$ time bash test.sh
done!done!done!done!done!5real 0m3.011suser 0m0.002ssys 0m0.004s效果非常明显。
这里需要说明一下wait的左右。wait是等待前面的后台任务全部完成才往下执行,否则程序本身是不会等待的,这样对后面依赖前面任务结果的命令来说就可能出错。例如上面wc -l的命令就报错:不存在aa这个文件。
以上所讲的实例都是进程数目不可控制的情况,下面描述如何准确控制并发的进程数目。
——————————————————————————————————————
#!/bin/bash
# 2006-7-12, by wwy#———————————————————————————–# 此例子说明了一种用wait、read命令模拟多线程的一种技巧# 此技巧往往用于多主机检查,比如ssh登录、ping等等这种单进程比较慢而不耗费cpu的情况# 还说明了多线程的控制#———————————————————————————–function a_sub { # 此处定义一个函数,作为一个线程(子进程)sleep 3 # 线程的作用是sleep 3s}tmp_fifofile=”/tmp/$.fifo”mkfifo $tmp_fifofile # 新建一个fifo类型的文件exec 6<>$tmp_fifofile # 将fd6指向fifo类型rm $tmp_fifofilethread=15 # 此处定义线程数for ((i=0;i<$thread;i++));doechodone >&6 # 事实上就是在fd6中放置了$thread个回车符for ((i=0;i<50;i++));do # 50次循环,可以理解为50个主机,或其他read -u6# 一个read -u6命令执行一次,就从fd6中减去一个回车符,然后向下执行,# fd6中没有回车符的时候,就停在这了,从而实现了线程数量控制{ # 此处子进程开始执行,被放到后台 a_sub && { # 此处可以用来判断子进程的逻辑 echo ”a_sub is finished” } || { echo ”sub error” } echo >&6 # 当进程结束以后,再向fd6中加上一个回车符,即补上了read -u6减去的那个} &donewait # 等待所有的后台子进程结束exec 6>&- # 关闭df6exit 0
——————————————————————————————————————sleep 3s,线程数为15,一共循环50次,所以,此脚本一共的执行时间大约为12秒
即:
15×3=45, 所以 3 x 3s = 9s
(50-45=5)<15, 所以 1 x 3s = 3s
所以 9s + 3s = 12s$ time ./multithread.sh >/dev/null
real 0m12.025s
user 0m0.020s
sys 0m0.064s而当不使用多线程技巧的时候,执行时间为:50 x 3s = 150s。
此程序中的命令 mkfifo tmpfile和linux中的命令 mknod tmpfile p效果相同。
区别是mkfifo为POSIX标准,因此推荐使用它。该命令创建了一个先入先出的管道文件,并为其分配文件标志符6。管道文件是进程之间通信的一种方式,注意这一句很重要
exec 6<>$tmp_fifofile # 将fd6指向fifo类型
如果没有这句,在向文件$tmp_fifofile或者&6写入数据时,程序会被阻塞,直到有read读出了管道文件中的数据为止。而执行了上面这一句后就可以在程序运行期间不断向fifo类型的文件写入数据而不会阻塞,并且数据会被保存下来以供read程序读出
-
linux-PROC系列之---/proc/loadavg-zt
2014-09-09 16:13:13
转自:http://blog.csdn.net/zjl_1026_2001/article/details/2294061
该文件中的所有值都是从系统启动开始累计到当前时刻。该文件只给出了所有CPU的集合信息,不能该出每个CPU的信息。
[root@localhost ~]# cat /proc/loadavg
4.61 4.36 4.15 9/84 5662
每个值的含义为:
参数 解释
lavg_1 (4.61) 1-分钟平均负载
lavg_5 (4.36) 5-分钟平均负载
lavg_15(4.15) 15-分钟平均负载
nr_running (9) 在采样时刻,运行队列的任务的数目,与/proc/stat的procs_running表示相同意思
nr_threads (84) 在采样时刻,系统中活跃的任务的个数(不包括运行已经结束的任务)
last_pid(5662) 最大的pid值,包括轻量级进程,即线程。
假设当前有两个CPU,则每个CPU的当前任务数为4.61/2=2.31
-
linux-UTC与CST时间转换
2014-08-11 11:08:24
安装服务器时,可以设置是否使用UTC时间
System clock uses UTC
世界协调时间(Universal Time Coordinated,UTC)
GPS 系统中有两种时间区分,一为UTC,另一为LT(地方时)两者的区别为时区不同,UTC就是0时区的时间,地方时为本地时间,如北京为早上八点(东八区),UTC时间就为零点,时间比北京时晚八小时,以此计算即可
在linux中,用data查看时间的时候显示:
2008年 12月 17日 星期三 09:04:14 CST
这个CST是什么意思呢?CST China Standard Time UTC+8:00 中国沿海时间(北京时间)
从CST转换为UTC:
1、cp -af /usr/share/zoneinfo/UTC /etc/localtime
2、vi /etc/sysconfig/clock
如果有:UTC=false,修改为:UTC=true
如果没有,增加:UTC=true
同样的,如果想从UTC转为CST,则进行如下操作
1、cp -af /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
2、vi /etc/sysconfig/clock
如果有:UTC=true,修改为:UTC=false
-
linux-使用shell脚本来批量操作telnet
2014-06-20 17:44:17
经常会用到telnet来做一些测试,有时是一直重复的做,所以写了个telnet的脚本,这里做下记录
脚本说明:
1、echo_sleep(),这个函数比较简单,只是做个echo及sleep,sleep的作用是为了发送命令后,等待服务器应答,然后再继续发送后续命令
2、while [ TRUE ];这里是做了一个死循环,因为测试场景需要一直发送邮件,所以直接做了个死循环,也可以修改为for计数等等
# cat testTel.sh
#!/bin/bash
function echo_sleep()
{
echo $1
sleep 1
}
#for((i=1;i<=1000;i++))
while [ TRUE ];
do
(
#sleep 1
echo_sleep "ehlo aa"
echo_sleep "auth login"
echo_sleep "bHVseUBsdWx5MTgyLmNvbQo="
echo_sleep "YWJjMTIzM1EK"
echo_sleep "mail from:<11@luly182.com>"
echo_sleep "rcpt to:<luly@luly182.test.net>"
echo_sleep "data"
echo_sleep "abctest"
echo_sleep ""
echo_sleep "."
echo_sleep "quit"
) | telnet 192.168.146.182 25 >> /tmp/tel.log
echo "telnet finish!" >> /tmp/tel.log
done -
linux-去除vim时文件末尾自动换行的处理方法
2014-04-30 12:36:14
根据fileformat的不同,vim会自动在文件的最未尾添加一个换行符,如下:
# cat /tmp/a
a
#
想去除最末尾的换行符,可进行如下处理:
1、进入vim前,增加-b参数
vim -b xxx
2、进入命令行模式,开启 set noeol
3、再进行编辑
如下:
# cat /tmp/a
a#
-
linux-/proc/pid下的相应信息说明-zt
2013-11-13 17:36:07
转自:http://www.cnblogs.com/GoodGoodWorkDayDayUp/archive/2011/05/27/2059685.html一、/proc/pid/statm
pid/statm包含了在此进程中所有CPU活跃的信息,该文件中的所有值都是从系统启动开始累计到当前时刻。
/proc/1 # cat statm
550 70 62 451 0 97 0
输出解释
CPU 以及CPU0。。。的每行的每个参数意思(以第一行为例)为:
参数 解释 /proc/1/status
Size (pages)= 550 任务虚拟地址空间的大小 VmSize/4
Resident(pages)= 70 应用程序正在使用的物理内存的大小 VmRSS/4
Shared(pages)= 62 共享页数
Trs(pages)= 451 程序所拥有的可执行虚拟内存的大小 VmExe/4
Lrs(pages)= 0 被映像到任务的虚拟内存空间的库的大小 VmLib/4
Drs(pages)= 97 程序数据段和用户态的栈的大小 (VmData+ VmStk )4
dt(pages) 0
二、/proc/pid/stat
pid/stat包含了进程所有CPU活跃的信息,该文件中的所有值都是从系统启动开始累计到当前时刻。
/proc/1 # cat stat
1 (linuxrc) S 0 0 0 0 -1 8388864 50 633 20 4 2 357 72 342 16 0 1 0 22 2252800 70 4294967295 32768 1879936 3199270704 3199269552 1113432 0 0 0 674311 3221479524 0 0 0 0 0 0
每个参数意思为:
参数 解释
pid=1 进程(包括轻量级进程,即线程)号
comm= linuxrc 应用程序或命令的名字
task_state=S 任务的状态,R:runnign, S:sleeping (TASK_INTERRUPTIBLE), D:disk sleep (TASK_UNINTERRUPTIBLE), T: stopped, T:tracing stop,Z:zombie, X:dead
ppid=0 父进程ID
pgid=0 线程组号
sid=0 c该任务所在的会话组ID
tty_nr=0(pts/3) 该任务的tty终端的设备号,INT(0/256)=主设备号,(0-主设备号)=次设备号
tty_pgrp=-1 终端的进程组号,当前运行在该任务所在终端的前台任务(包括shell 应用程序)的PID。
task->flags=8388864进程标志位,查看该任务的特性
min_flt=50该任务不需要从硬盘拷数据而发生的缺页(次缺页)的次数
cmin_flt=633 累计的该任务的所有的waited-for进程曾经发生的次缺页的次数目
maj_flt=20该任务需要从硬盘拷数据而发生的缺页(主缺页)的次数
cmaj_flt=4 累计的该任务的所有的waited-for进程曾经发生的主缺页的次数目
utime=2 该任务在用户态运行的时间,单位为jiffies
stime=357 该任务在核心态运行的时间,单位为jiffies
cutime=72 累计的该任务的所有的waited-for进程曾经在用户态运行的时间,单位为jiffies
cstime=342 累计的该任务的所有的waited-for进程曾经在核心态运行的时间,单位为jiffies
priority=16 任务的动态优先级
nice=0 任务的静态优先级
num_threads=1 该任务所在的线程组里线程的个数
it_real_value=0 由于计时间隔导致的下一个 SIGALRM 发送进程的时延,以 jiffy 为单位.
start_time=22 该任务启动的时间,单位为jiffies
vsize=2252800(bytes) 该任务的虚拟地址空间大小
rss=70(page) 该任务当前驻留物理地址空间的大小
Number of pages the process has in real memory,minu 3 for administrative purpose.
这些页可能用于代码,数据和栈。
rlim=4294967295=0xFFFFFFFF(bytes) 该任务能驻留物理地址空间的最大值
start_code=32768=0x8000 该任务在虚拟地址空间的代码段的起始地址(由连接器决定)
end_code=1879936该任务在虚拟地址空间的代码段的结束地址
start_stack=3199270704=0Xbeb0ff30该任务在虚拟地址空间的栈的开始地址
kstkesp=3199269552 sp(32 位堆栈指针) 的当前值, 与在进程的内核堆栈页得到的一致.
kstkeip=1113432 =0X10FD58 指向将要执行的指令的指针, PC(32 位指令指针)的当前值.
pendingsig=0 待处理信号的位图,记录发送给进程的普通信号
block_sig=0 阻塞信号的位图
sigign=0 忽略的信号的位图
sigcatch=674311被俘获的信号的位图
wchan=3221479524 如果该进程是睡眠状态,该值给出调度的调用点
nswap=0 被swapped的页数
cnswap=0 所有子进程被swapped的页数的和
exit_signal=0 该进程结束时,向父进程所发送的信号
task_cpu(task)=0 运行在哪个CPU上
task_rt_priority=0 实时进程的相对优先级别
task_policy=0 进程的调度策略,0=非实时进程,1=FIFO实时进程;2=RR实时进程
三、/proc/pid/status
包含了所有CPU活跃的信息,该文件中的所有值都是从系统启动开始累计到当前时刻。
/proc/286 # cat status
Name: mmtest
State: R (running)
SleepAVG: 0%
Tgid: 286
Pid: 286
PPid: 243
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 32
Groups:
VmPeak: 1464 kB
VmSize: 1464 kB
VmLck: 0 kB
VmHWM: 344 kB
VmRSS: 344 kB
VmData: 20 kB
VmStk: 84 kB
VmExe: 4 kB
VmLib: 1300 kB
VmPTE: 6 kB
Threads: 1
SigQ: 0/256
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000000000
SigCgt: 0000000000000000
CapInh: 0000000000000000
CapPrm: 00000000fffffeff
CapEff: 00000000fffffeff
输出解释
参数 解释
Name 应用程序或命令的名字
State 任务的状态,运行/睡眠/僵死/
SleepAVG 任务的平均等待时间(以nanosecond为单位),交互式任务因为休眠次数多、时间长,它们的 sleep_avg 也会相应地更大一些,所以计算出来的优先级也会相应高一些。
Tgid=286 线程组号
Pid=286 任务ID
Ppid=243 父进程ID
TracerPid=0 接收跟踪该进程信息的进程的ID号
Uid Uid euid suid fsuid
Gid Gid egid sgid fsgid
FDSize=32 文件描述符的最大个数,最多能打开的文件句柄的个数file->fds
Groups:
VmPeak: 60184 kB /*进程地址空间的大小*/
VmHWM: 18020 kB /*文件内存映射和匿名内存映射的大小*/VmSize(KB)=1499136 任务虚拟地址空间的大小 (total_vm-reserved_vm),其中total_vm为进程的地址空间的大小,reserved_vm:进程在预留或特殊的内存间的物理页
VmLck(KB)=0 任务已经锁住的物理内存的大小。锁住的物理内存不能交换到硬盘 (locked_vm)
VmRSS(KB)= 344 kB 应用程序正在使用的物理内存的大小,就是用ps命令的参数rss的值 (rss)
VmData(KB)=20KB 程序数据段的大小(所占虚拟内存的大小),存放初始化了的数据; (total_vm-shared_vm-stack_vm)
VmStk(KB)=84KB 任务在用户态的栈的大小 (stack_vm)
VmExe(KB)=4KB 程序所拥有的可执行虚拟内存的大小,代码段,不包括任务使用的库 (end_code-start_code)
VmLib(KB)=1300KB 被映像到任务的虚拟内存空间的库的大小 (exec_lib)
VmPTE=6KB 该进程的所有页表的大小,单位:kb
Threads=1 共享使用该信号描述符的任务的个数,在POSIX多线程序应用程序中,线程组中的所有线程使用同一个信号描述符。
SigQ 待处理信号的个数
SigPnd 屏蔽位,存储了该线程的待处理信号
ShdPnd 屏蔽位,存储了该线程组的待处理信号
SigBlk 存放被阻塞的信号
SigIgn 存放被忽略的信号
SigCgt 存放被俘获到的信号
CapInh Inheritable,能被当前进程执行的程序的继承的能力
CapPrm Permitted,进程能够使用的能力,可以包含CapEff中没有的能力,这些能力是被进程自己临时放弃的,CapEff是CapPrm的一个子集,进程放弃没有必要的能力有利于提高安全性
CapEff Effective,进程的有效能力
四、/proc/loadavg
该文件中的所有值都是从系统启动开始累计到当前时刻。该文件只给出了所有CPU的集合信息,不能该出每个CPU的信息。
/proc # cat loadavg
1.0 1.00 0.93 2/19 301
每个值的含义为:
参数 解释
lavg_1 (1.0) 1-分钟平均负载
lavg_5 (1.00) 5-分钟平均负载
lavg_15(0.93) 15-分钟平均负载
nr_running (2) 在采样时刻,运行队列的任务的数目,与/proc/stat的procs_running表示相同意思
nr_threads (19) 在采样时刻,系统中活跃的任务的个数(不包括运行已经结束的任务)
last_pid(301) 最大的pid值,包括轻量级进程,即线程。
假设当前有两个CPU,则每个CPU的当前任务数为4.61/2=2.31
五、/proc/286/smaps
该文件反映了该进程的相应线性区域的大小
/proc/286 # cat smaps
00008000-00009000 r-xp 00000000 00:0c 1695459 /memtest/mmtest
Size: 4 kB
Rss: 4 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 4 kB
Private_Dirty: 0 kB
00010000-00011000 rw-p 00000000 00:0c 1695459 /memtest/mmtest
Size: 4 kB
Rss: 4 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 4 kB
00011000-00012000 rwxp 00011000 00:00 0 [heap]
Size: 4 kB
Rss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
40000000-40019000 r-xp 00000000 00:0c 2413396 /lib/ld-2.3.2.so
Size: 100 kB
Rss: 96 kB
linux-查询rpm包相关安装、卸载脚本
2013-11-04 17:40:38
测试过程中,有时要测试开发自己打的rpm包,为了确认打包正确,需要查询rpm包相关安装、卸载脚本,可以使用命令:[root@6 /]# rpm -q --scripts mysqlpostinstall scriptlet (using /bin/sh):/sbin/install-info /usr/share/info/mysql.info.gz /usr/share/info/dir/sbin/ldconfigpreuninstall scriptlet (using /bin/sh):if [ $1 = 0 ]; then/sbin/install-info --delete /usr/share/info/mysql.info.gz /usr/share/info/dir || :fipostuninstall scriptlet (using /bin/sh):if [ $1 = 0 ] ; then/sbin/ldconfigfi会有一些下面这些标识声明的脚本段preinstall scriptlet (using /bin/sh)::安装前执行脚本postinstall scriptlet (using /bin/sh)::安装后执行脚本preuninstall scriptlet (using /bin/sh)::卸载前执行脚本postuninstall scriptlet (using /bin/sh)::卸载后执行脚本如果安装过程中,不想执行其中一个脚本,可以指定:-nopre:不执行安装前脚本--nopost:不执行安装后脚本--nopreun :不执行卸载前脚本--nopostun:不执行卸载后脚本全部不执行,使用:--noscripts 即相当于前面四个的总合sed-文本增加内容常用方法记录
2013-10-30 16:21:04
范例文本:[root@nagios test]# cat quote.txtThe honeysuckle band polayed al ngint long for only $90.It was an evening of splendid music and company.Too bad the disco floor fell through at 23:10.The local nurse Misss P.Neave was in attendance.1、第n行前面增加内容(ni)例子:第一行前面增加内容[root@nagios test]# sed '1i --->APPEDED TEXT<---' quote.txt--->APPEDED TEXT<---The honeysuckle band polayed al ngint long for only $90.It was an evening of splendid music and company.Too bad the disco floor fell through at 23:10.The local nurse Misss P.Neave was in attendance.2、第n行后面增加内容(na)例子:第三行后面增加内容[root@nagios test]# sed '3a --->APPEDED TEXT<---' quote.txtThe honeysuckle band polayed al ngint long for only $90.It was an evening of splendid music and company.Too bad the disco floor fell through at 23:10.--->APPEDED TEXT<---The local nurse Misss P.Neave was in attendance.例子:最后一行后面增加内容[root@nagios test]# sed '$a --->APPEDED TEXT<---' quote.txtThe honeysuckle band polayed al ngint long for only $90.It was an evening of splendid music and company.Too bad the disco floor fell through at 23:10.The local nurse Misss P.Neave was in attendance.--->APPEDED TEXT<---3、附加文本(a)[root@nagios test]# sed '/^Too/a\ --->APPEDED TEXT<---' quote.txtThe honeysuckle band polayed al ngint long for only $90.It was an evening of splendid music and company.Too bad the disco floor fell through at 23:10.--->APPEDED TEXT<---The local nurse Misss P.Neave was in attendance.4、插入文本(i)[root@nagios test]# sed '/^Too/i\ ---> INSERTED TEXT<---' quote.txtThe honeysuckle band polayed al ngint long for only $90.It was an evening of splendid music and company.--->INSERTED TEXT<---Too bad the disco floor fell through at 23:10.The local nurse Misss P.Neave was in attendance.5、修改文本(c)[root@nagios test]# sed '/^Too/c\ --->CHANGED TEXT<---' quote.txtThe honeysuckle band polayed al ngint long for only $90.It was an evening of splendid music and company.--->CHANGED TEXT<---The local nurse Misss P.Neave was in attendance.6、删除文本(d)[root@nagios test]# sed -e '1,3d' quote.txtThe local nurse Misss P.Neave was in attendance.说明:删除1-3行文本sed -n '$!N;/pattern/!P;D' file删除匹配行前一行linux-shell字符串操作(长度,查找,替换)详解-zt
2013-02-19 09:13:51
转自:http://www.cnblogs.com/chengmo/archive/2010/10/02/1841355.html在做shell批处理程序时候,经常会涉及到字符串相关操作。有很多命令语句,如:awk,sed都可以做字符串各种操作。 其实shell内置一系列操作符号,可以达到类似效果,大家知道,使用内部操作符会省略启动外部程序等时间,因此速度会非常的快。
一、判断读取字符串值
表达式 含义 ${var} 变量var的值, 与$var相同 ${var-DEFAULT} 如果var没有被声明, 那么就以$DEFAULT作为其值 * ${var:-DEFAULT} 如果var没有被声明, 或者其值为空, 那么就以$DEFAULT作为其值 * ${var=DEFAULT} 如果var没有被声明, 那么就以$DEFAULT作为其值 * ${var:=DEFAULT} 如果var没有被声明, 或者其值为空, 那么就以$DEFAULT作为其值 * ${var+OTHER} 如果var声明了, 那么其值就是$OTHER, 否则就为null字符串 ${var:+OTHER} 如果var被设置了, 那么其值就是$OTHER, 否则就为null字符串 ${var?ERR_MSG} 如果var没被声明, 那么就打印$ERR_MSG * ${var:?ERR_MSG} 如果var没被设置, 那么就打印$ERR_MSG * ${!varprefix*} 匹配之前所有以varprefix开头进行声明的变量 ${!varprefix@} 匹配之前所有以varprefix开头进行声明的变量 加入了“*” 不是意思是: 当然, 如果变量var已经被设置的话, 那么其值就是$var.
[chengmo@localhost ~]$ echo ${abc-'ok'}
ok
[chengmo@localhost ~]$ echo $abc[chengmo@localhost ~]$ echo ${abc='ok'}
ok
[chengmo@localhost ~]$ echo $abc
ok如果abc 没有声明“=" 还会给abc赋值。
[chengmo@localhost ~]$ var1=11;var2=12;var3=
[chengmo@localhost ~]$ echo ${!v@}
var1 var2 var3
[chengmo@localhost ~]$ echo ${!v*}
var1 var2 var3${!varprefix*}与${!varprefix@}相似,可以通过变量名前缀字符,搜索已经定义的变量,无论是否为空值。
二、字符串操作(长度,读取,替换)
表达式 含义 ${#string} $string的长度 ${string:position} 在$string中, 从位置$position开始提取子串 ${string:position:length} 在$string中, 从位置$position开始提取长度为$length的子串 ${string#substring} 从变量$string的开头, 删除最短匹配$substring的子串 ${string##substring} 从变量$string的开头, 删除最长匹配$substring的子串 ${string%substring} 从变量$string的结尾, 删除最短匹配$substring的子串 ${string%%substring} 从变量$string的结尾, 删除最长匹配$substring的子串 ${string/substring/replacement} 使用$replacement, 来代替第一个匹配的$substring ${string//substring/replacement} 使用$replacement, 代替所有匹配的$substring ${string/#substring/replacement} 如果$string的前缀匹配$substring, 那么就用$replacement来代替匹配到的$substring ${string/%substring/replacement} 如果$string的后缀匹配$substring, 那么就用$replacement来代替匹配到的$substring 说明:"* $substring”可以是一个正则表达式.
1.长度
[web97@salewell97 ~]$ test='I love china'
[web97@salewell97 ~]$ echo ${#test}
12${#变量名}得到字符串长度
2.截取字串
[chengmo@localhost ~]$ test='I love china'
[chengmo@localhost ~]$ echo ${test:5}
e china
[chengmo@localhost ~]$ echo ${test:5:10}
e china${变量名:起始:长度}得到子字符串
3.字符串删除
[chengmo@localhost ~]$ test='c:/windows/boot.ini'
[chengmo@localhost ~]$ echo ${test#/}
c:/windows/boot.ini
[chengmo@localhost ~]$ echo ${test#*/}
windows/boot.ini
[chengmo@localhost ~]$ echo ${test##*/}
boot.ini[chengmo@localhost ~]$ echo ${test%/*}
c:/windows
[chengmo@localhost ~]$ echo ${test%%/*}${变量名#substring正则表达式}从字符串开头开始配备substring,删除匹配上的表达式。
${变量名%substring正则表达式}从字符串结尾开始配备substring,删除匹配上的表达式。
注意:${test##*/},${test%/*} 分别是得到文件名,或者目录地址最简单方法。
4.字符串替换
[chengmo@localhost ~]$ test='c:/windows/boot.ini'
[chengmo@localhost ~]$ echo ${test/\//\\}
c:\windows/boot.ini
[chengmo@localhost ~]$ echo ${test//\//\\}
c:\windows\boot.ini${变量/查找/替换值} 一个“/”表示替换第一个,”//”表示替换所有,当查找中出现了:”/”请加转义符”\/”表示。
三、性能比较
在shell中,通过awk,sed,expr 等都可以实现,字符串上述操作。下面我们进行性能比较。
[chengmo@localhost ~]$ test='c:/windows/boot.ini'
[chengmo@localhost ~]$ time for i in $(seq 10000);do a=${#test};done;real 0m0.173s
user 0m0.139s
sys 0m0.004s[chengmo@localhost ~]$ time for i in $(seq 10000);do a=$(expr length $test);done;
real 0m9.734s
user 0m1.628s速度相差上百倍,调用外部命令处理,与内置操作符性能相差非常大。在shell编程中,尽量用内置操作符或者函数完成。使用awk,sed类似会出现这样结果。
linux 下nc 命令的使用-zt
2013-02-16 10:52:28
转自:http://samyubw.blog.51cto.com/978243/555247
netcat被誉为网络安全界的‘瑞士军刀’,一个简单而有用的工具,透过使用TCP或UDP协议的网络连接去读写数据。它被设计成一个稳定的后门 工具,能够直接由其它程序和脚本轻松驱动。同时,它也是一个功能强大的网络调试和探测工具,能够建立你需要的几乎所有类型的网络连接。
一、基本使用
想要连接到某处: nc [-options] hostname port[s] [ports] …
绑定端口等待连接: nc -l port [-options] [hostname] [port]
参数:
-h 帮助信息
-l 监听模式,用于入站连接
-n 指定数字的IP地址,不能用hostname
-u UDP模式-t TCP模式(默认模式)
-v 详细输出——用两个-v可得到更详细的内容
-w secs timeout的时间
-z 将输入输出关掉——用于扫描时
其中端口号可以指定一个或者用lo-hi式的指定范围。
1)扫描端口
tcp扫描
shell>nc -v -z -w2 192.168.1.131 1-30
udp扫描
shell>nc -u -v -z -w2 192.168.1.131 1-30
2)连接到REMOTE主机,例子:
格式:nc -nvv 192.168.x.x 80
讲解:连到192.168.x.x的TCP80端口
3)监听LOCAL主机,例子:
格式:nc -l 80
讲解:监听本机的TCP80端口
4)扫描远程主机,例子:
格式:nc -nvv -w2 -z 192.168.x.x 80-445
讲解:扫描192.168.x.x的TCP80到TCP445的所有端口5)两台linux主机间传送数据
Linux A:192.168.1.131
Linux B:192.168.1.132
现在需要从B主机上传输一个文件file_b到B主机上,那么操作方法如下所示:
在A主机上:nc -d -l 1000 > /data/file_out &(启动端口监听)
在B主机上:nc 192.168.1.131 1000 < file_in(从A主机上启动的监听端口传送数据)
文件传输完毕后,系统会自动断开连接。从上面来看,它其实是一个很简单的Server/Client模式,服务器端开启侦听端口,并用输入输出重定向到一 个文件file.out当中,等待客户端的连接。客户端主动连接主机,并和它建立一个Socket连接,然后把传输的文件重定向到数据流当中。
需要注意的一点是,主机侦听的端口必须是已经开放的端口,可以通过查看iptables进行配置。====================================================
早期想要确认udp端口是否正常使用,一直没有什么好方法,使用nc就可以方便确认
例:(扫描192.168.134.55的udp协议8000端口,是否正常开放)
[root@a a]# nc -u -z -v -w2 192.168.134.55 8000
Connection to 192.168.134.55 8000 port [udp/irdmi] succeeded!linux-blkid查询文件系统类型、LABEL、UUID等信息
2013-01-18 14:13:24
blkid主要用来对系统的块设备(包括交换分区)所使用的文件系统类型、LABEL、UUID等信息进行查询。
[root@CentOS6-x64 ~]# blkid
/dev/sda1: UUID="3b8d3145-f851-475b-811a-ad84ef0aae67" TYPE="ext4"
/dev/sda2: UUID="b3bbf9ee-d1ff-42bd-bb06-430fcb2e1d65" TYPE="ext4"
/dev/sda3: UUID="ba13625e-b2c6-4275-82dc-5f52cd948fcf" TYPE="swap"
/dev/sda5: UUID="604528ec-dfdd-4207-bcfd-6223836ca8ee" TYPE="ext4"
/dev/sdb1: UUID="9eaeb45b-ac0d-4c4b-8d2a-ea3b400ff3ab" TYPE="ext4"
CentOS 6.3 64位操作系统,/etc/fstab配置中,需要使用uuid
新加分区进行自动挂载设置时,通过blkid命令得到UUID后,在对应位置增加即可;(注意增加后使用mount -a进行检验,如果出错重新进行修改,以免开启后,无法正常启动)
[root@CentOS6-x64 ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Fri Jan 18 11:16:46 2013
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
UUID=604528ec-dfdd-4207-bcfd-6223836ca8ee / ext4 defaults 1 1
UUID=3b8d3145-f851-475b-811a-ad84ef0aae67 /boot ext4 defaults 1 2
UUID=b3bbf9ee-d1ff-42bd-bb06-430fcb2e1d65 /var ext4 defaults 1 2
UUID=ba13625e-b2c6-4275-82dc-5f52cd948fcf swap swap defaults 0 0
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
[root@CentOS6-x64 ~]#
linux-逻辑卷与分区对应关系
2012-07-05 17:21:30
服务器使用逻辑卷,进行IO监控时,不确认分区对应的是哪个设备;
可通过下述方法来确认:
[root@localhost luly]# df -lh
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root
50G 14G 33G 30% /
tmpfs 3.9G 0 3.9G 0% /dev/shm
/dev/sda1 485M 36M 424M 8% /boot
/dev/mapper/VolGroup-lv_home
209G 190M 198G 1% /mail
[root@localhost luly]# iostat -x
Linux 2.6.32-220.el6.x86_64 (localhost.localdomain) 07/06/2012 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.18 0.00 0.27 0.68 0.00 98.86
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 3.84 1842.64 13.92 15.30 3239.47 14863.94 619.43 4.88 167.12 1.58 4.61
dm-0 0.00 0.00 0.72 15.38 144.69 123.07 16.63 4.18 259.80 0.26 0.41
dm-1 0.00 0.00 4.82 5.43 38.59 43.48 8.00 3.10 302.48 0.09 0.09
dm-2 0.00 0.00 12.22 1837.17 3056.14 14697.40 9.60 6.70 3.62 0.02 4.41
[root@localhost luly]# lvdisplay
--- Logical volume ---
LV Name /dev/VolGroup/lv_root
VG Name VolGroup
LV UUID RDbdK7-WPUJ-OzjM-1z5T-TEHj-Cj68-mKKnU7
LV Write Access read/write
LV Status available
# open 1
LV Size 50.00 GiB
Current LE 12800
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
--- Logical volume ---
LV Name /dev/VolGroup/lv_home
VG Name VolGroup
LV UUID 4xuokn-NhML-iv3t-hCI2-T8nd-oAT9-cwgOzo
LV Write Access read/write
LV Status available
# open 1
LV Size 211.95 GiB
Current LE 54258
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:2
--- Logical volume ---
LV Name /dev/VolGroup/lv_swap
VG Name VolGroup
LV UUID W0RDNe-GL2v-yN6N-p8gp-VfHu-x8wS-BCNCO1
LV Write Access read/write
LV Status available
# open 1
LV Size 9.81 GiB
Current LE 2512
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:1
[root@localhost luly]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Sat Jun 30 01:26:25 2012
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/VolGroup-lv_root / ext4 defaults 1 1
UUID=69becaa0-60c9-426f-8729-8439fd0f5ba1 /boot ext4 defaults 1 2
/dev/mapper/VolGroup-lv_home /mail ext4 defaults,noatime,noexec,nodiratime,nodev 1 2
/dev/mapper/VolGroup-lv_swap swap swap defaults 0 0
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
通过三述四个命令,可以确认:
/对应dm-0
swap对应dm-1
/mail对应dm-2
linux-cacti使用snmp自定义OID进行制图-yc
2012-06-27 10:00:34
样例:使用cacti进行邮件队列监控:
在被监控服务器上,增加脚本:
/usr/local/luly/MonitorMailq.sh
#!/bin/bash
# check postfix mail for snmpdmailq=$(mailq | grep 'Request')
if [ $? -eq 1 ]; then
echo '0'
exit 0
fi
mail_sum=$(echo $mailq | awk '{print $5}')
echo $mail_sum授权:chmod +x /usr/local/luly/MonitorMailq.sh
在/usr/local/etc/snmp/snmpd.conf最后增加一行:
extend .1.3.6.1.4.1.2021.53 mailq /usr/local/luly/MonitorMailq.sh其中mailq是命令的名称,后面是命令以及参数。命令的名称可以随便起。
重启snmpd;
[root@localhost ~]# snmpwalk -v 2c localhost -c public .1.3.6.1.4.1.2021.53
UCD-SNMP-MIB::ucdavis.53.1.0 = INTEGER: 1
UCD-SNMP-MIB::ucdavis.53.2.1.2.12.77.111.110.105.116.111.114.77.97.105.108.113 = STRING: "/usr/local/luly/MonitorMailq.sh"
UCD-SNMP-MIB::ucdavis.53.2.1.3.12.77.111.110.105.116.111.114.77.97.105.108.113 = ""
UCD-SNMP-MIB::ucdavis.53.2.1.4.12.77.111.110.105.116.111.114.77.97.105.108.113 = ""
UCD-SNMP-MIB::ucdavis.53.2.1.5.12.77.111.110.105.116.111.114.77.97.105.108.113 = INTEGER: 5
UCD-SNMP-MIB::ucdavis.53.2.1.6.12.77.111.110.105.116.111.114.77.97.105.108.113 = INTEGER: 1
UCD-SNMP-MIB::ucdavis.53.2.1.7.12.77.111.110.105.116.111.114.77.97.105.108.113 = INTEGER: 1
UCD-SNMP-MIB::ucdavis.53.2.1.20.12.77.111.110.105.116.111.114.77.97.105.108.113 = INTEGER: 4
UCD-SNMP-MIB::ucdavis.53.2.1.21.12.77.111.110.105.116.111.114.77.97.105.108.113 = INTEGER: 1
UCD-SNMP-MIB::ucdavis.53.3.1.1.12.77.111.110.105.116.111.114.77.97.105.108.113 = STRING: "4"
UCD-SNMP-MIB::ucdavis.53.3.1.2.12.77.111.110.105.116.111.114.77.97.105.108.113 = STRING: "4"
UCD-SNMP-MIB::ucdavis.53.3.1.3.12.77.111.110.105.116.111.114.77.97.105.108.113 = INTEGER: 1
UCD-SNMP-MIB::ucdavis.53.3.1.4.12.77.111.110.105.116.111.114.77.97.105.108.113 = INTEGER: 0
UCD-SNMP-MIB::ucdavis.53.4.1.2.12.77.111.110.105.116.111.114.77.97.105.108.113.1 = STRING: "4"
确认mailq中的个数可知,
UCD-SNMP-MIB::ucdavis.53.4.1.2.12.77.111.110.105.116.111.114.77.97.105.108.113.1 = STRING: "4"这个即为我们想要的值;
[root@localhost ~]# snmpwalk -v 2c localhost -c public .1.3.6.1.4.1.2021.53.4.1.2.12.77.111.110.105.116.111.114.77.97.105.108.113.1
UCD-SNMP-MIB::ucdavis.53.4.1.2.12.77.111.110.105.116.111.114.77.97.105.108.113.1 = STRING: "4"
生成数据源
在cacti界面中console->Templates->Data Templates,然后点击右上角的Add,如下图:
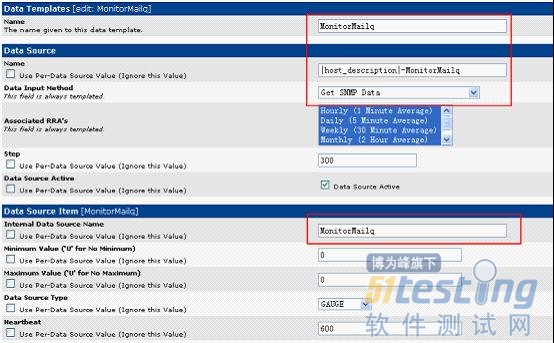
Templates 中的name是给这个数据模板的命名,Data Source中的name将来显示在Data Sources中,我这里添加“|host_description|-MonitorMailq”,选get snmp data,Internal Data Source Name也可以随便添,这个用来给rrd文件命名,设置完之后点击create,然后下面会多出一些选项,我们只需填写一项就可以,就是OID那一项,把 我们上面记下来的OID填写进去:

添加模板制图
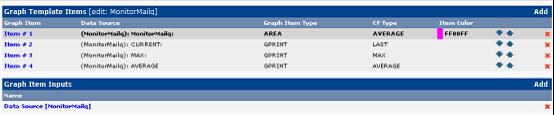
在cacti界面中console->Templates->Graph Templates,然后点击右上角的Add,如下图:

Graph Template中的name是将来显示在图片上面中间的内容,我这里添加"|host_description|-MonitorMailq",然后create,上面会多出一些选项,Graph Template Items 这里就是让我们添加数据源;
这里增加Graph Item Type为AVEA区域显示类型;

然后分别增加:average/last/max这几个类型的数据源;



添加完后如下图:
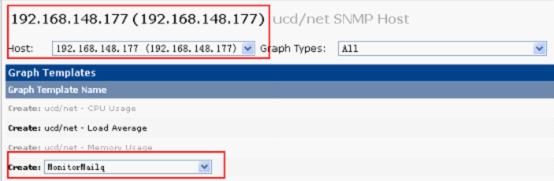
把模板添加进去被监控机里
在New Graphs中选择主机然后在Graph Templates中的下拉表拉选我们添加的模板,点击create
Console->Management->Graph Tress->Default Tree->Tree Items->对应IP旁边的Add
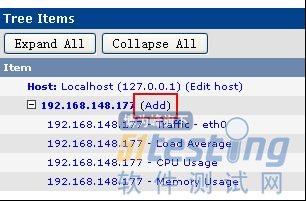
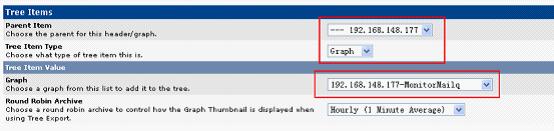
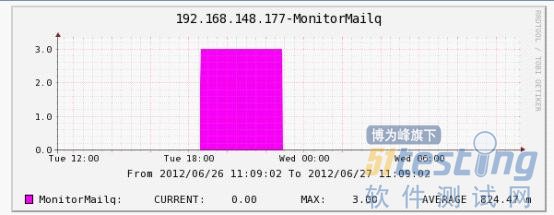
这时在Graphs->Tree Mode->IP中,应该可以看到监控的数据了;
linux-cacti使用-yc
2012-06-27 09:54:49
新建设备:
进入主界面,显示如下,点击“Devices”
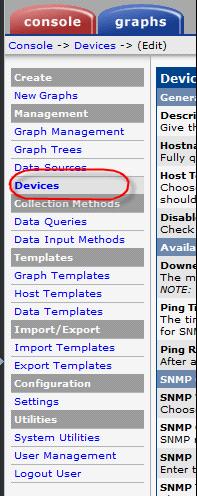
在显示的页面右上角点击“Add”

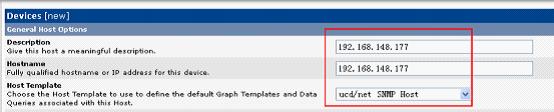
填写要监控的IP,Host Template选择:ucd/net SNMP Host,完成后,点击Create
增加图像:
Console->Create->New Graphs
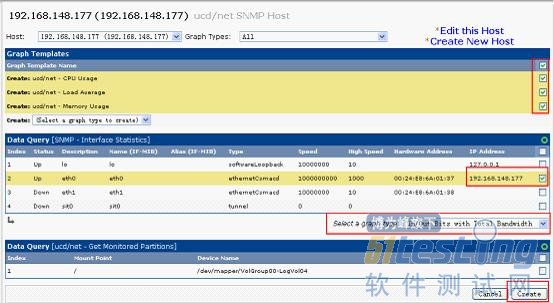
图像树管理:
Console->Management->Graph Trees->Default Tree->Add

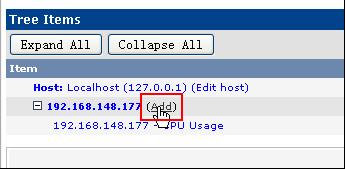


linux-安装配置cacti-yc
2012-06-27 08:47:01
安装配置cacti前,需要安装:httpd、php、mysqld、php-mysql、net-snmp、rrdtool
httpd、php、mysqld、php-mysql,可以直接rpm或yum安装,其它使用的软件包为:net-snmp-5.4.2.1.tar.gz
rrdtool-1.4.7.tar.gz
cacti-0.8.8a.tar.gz相关软件包全部上传至:/usr/local目录下;
net-snmp安装:
cd /usr/local
tar xzvf net-snmp-5.4.2.1.tar.gz
cd net-snmp-5.4.2.1
./configure(小括号中为configure时的信息:
************** Configuration Section **************
You are about to be prompted with a series of questions. Answer
them carefully, as they determine how the SNMP agent and related
applications are to function.
After the configure script finishes, you can browse the newly
created net-snmp-config.h file for further - less important - parameters to
modify. Be careful if you re-run configure though, since net-snmp-config.h
will be overwritten.
-Press return to continue-
//这里按回车
……
*** Default SNMP Version:
Starting with Net-SNMP 5.0, you can choose the default version of
the SNMP protocol to use when no version is given explicitly on the
command line, or via an 'snmp.conf' file. In the past this was set to
SNMPv1, but you can use this to switch to SNMPv3 if desired. SNMPv3
will provide a more secure management environment (and thus you're
encouraged to switch to SNMPv3), but may break existing scripts that
rely on the old behaviour. (Though such scripts will probably need to
be changed to use the '-c' community flag anyway, as the SNMPv1
command line usage has changed as well.).
At this prompt you can select "1", "2" (for SNMPv2c), or "3" as
the default version for the command tools (snmpget, ...) to use. This
can always be overridden at runtime using the -v flag to the tools, or
by using the "defVersion" token in your snmp.conf file.
Providing the --with-default-snmp-version="x" parameter to ./configure
will avoid this prompt.
Default version of SNMP to use (3):
//这里输入2,默认为3,我们使用的是2版本
//后面几处都输入回车即可)
make
make install
安装成功后,会生成可执行文件:/usr/local/sbin/snmpd
[root@luly net-snmp-5.4.2.1]# which snmpd
/usr/local/sbin/snmpd
直接执行/usr/local/sbin/snmpd,就可启动snmp
使用net-snmp-5.4.2.1.tar.gz安装成功后,会发现找不到snmpd.conf文件
cd /usr/local/net-snmp-5.4.2.1
mkdir /usr/local/etc/snmp
cp EXAMPLE.conf /usr/local/etc/snmp/snmpd.conf
修改配置文件:
原文件内容:
# sec.name source community
com2sec local localhost COMMUNITY
com2sec mynetwork NETWORK/24 COMMUNITY
修改后内容:
# sec.name source community
com2sec local 192.168.146.228 public //被监控服务器的IP
com2sec mynetwork 192.168.146.0/24 public //监控客户端所在的网段
com2sec mynetwork 192.168.133.0/24 public //如果需要,可以增加多个监控网段
原文件内容:
# context sec.model sec.level match read write notif
access MyROGroup "" any noauth exact all none none
access MyRWGroup "" any noauth exact all all none
修改后内容:
# context sec.model sec.level match read write notif
access MyROGroup "" any noauth exact all all none
access MyRWGroup "" any noauth exact all all none
保存修改,退出,重启snmpd:
[root@luly net-snmp-5.4.2.1]# ps -e | grep snmpd //查看进程
6126 ? 00:00:00 snmpd
[root@luly net-snmp-5.4.2.1]# kill 6126 //杀死PID为6126的进程
[root@luly net-snmp-5.4.2.1]# /usr/local/sbin/snmpd //启动snmpd
[root@luly net-snmp-5.4.2.1]# ps -e | grep snmpd //确认是否启动成功
6143 ? 00:00:00 snmpd //(PID有变,说明有重启过)
rrdtool安装:
安装rrdtool之前,需要先安装一些相关依赖包(这里使用光盘镜像安装,也可以直接使用yum安装):
mount -t nfs 192.168.146.75:/centos54_i386 /mnt
cd /mnt/CentOS
rpm -ivh libXau-devel-1.0.1-3.1.i386.rpm libX11-devel-1.0.3-11.el5.i386.rpm xorg-x11-proto-devel-7.1-13.el5.i386.rpm libXdmcp-devel-1.0.1-2.1.i386.rpm mesa-libGL-devel-6.5.1-7.7.el5.i386.rpm cairo-devel-1.2.4-5.el5.i386.rpm pango-devel-1.14.9-6.el5.centos.i386.rpm libXrender-devel-0.9.1-3.1.i386.rpm fontconfig-devel-2.4.1-7.el5.i386.rpm libXext-devel-1.0.1-2.1.i386.rpm libXft-devel-2.1.10-1.1.i386.rpm libart_lgpl-2.3.17-4.i386.rpm libart_lgpl-devel-2.3.17-4.i386.rpm
yum install -y libxml2-devel
cd /usr/local/
tar xzvf rrdtool-1.4.7.tar.gz
cd rrdtool-1.4.7
./configure -prefix=/usr/local/rrdtool
make
make install
whereis rrdtool
/usr/local/rrdtool/bin/rrdtool -v
cacti安装:
tar xzvf cacti-0.8.8a.tar.gz
mv cacti-0.8.8a /var/www/html/cacti
cd /var/www/html/cacti/
创建cactidb库,并导入相关表:
mysql> create database cactidb;
mysql -u root -p cactidb<cacti.sql
vi /var/www/html/cacti/include/config.php
修改数据库配置:
$database_type = "mysql";
$database_default = "cactidb";
$database_hostname = "localhost";
$database_username = "postfix";
$database_password = "postfix";
$database_port = "3306";
$database_ssl = false;
访问:http://IP/cacti进行首次安装配置:
配置:RRDTool Binary Path为:/usr/local/rrdtool/bin/rrdtool
第一次默认登陆账号:admin 密码 admin
登陆后它就会让你立即修改新密码登录cacti后,也可以在Configuration-Settings-Paths中进行配置;
另修改:
Configuration-Settings-General-RRDTool Utility Version为:RRDTool 1.4.x
SNMP Version为:Version 2
手动执行:php -f /var/www/html/cacti/poller.php
执行如果成功,把*/5 * * * * root php -f /var/www/html/cacti/poller.php >/dev/null 2>&1增加到/etc/crontab中,每5分钟进行一次数据采样;
被监控端安装配置
安装net-snmp即可;
具体步骤见“监控端安装配置”;
linux-统计库表记录数的脚本-yc
2012-06-26 18:16:32
测试的时候,常常要统计库表的记录数,当库表比较多时,就比较麻烦了
所以写了一个脚本来统计
这里做下备忘
#!/bin/bash
for db in db1 db2 db3
do
t_s=`mysql -e "use $db;show tables;"`;
for t in $t_s
do
if [[ $t != "Tables_in_$db" ]]
then
a=`mysql -e "select count(*) from $db.$t";`
echo $db"."$t":"$a
fi
done
done
for db in db1 db2 db3
这里有指定数据库为db1/db2/db3
同样也可以使用show databases来获取;
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 1096980
- 日志数: 260
- 文件数: 1
- 书签数: 1
- 建立时间: 2009-01-05
- 更新时间: 2017-08-22
RSS订阅

清空Cookie - 联系我们 - 51Testing软件测试网 - 交流论坛 - 空间列表 - 站点存档 - 升级自己的空间
Powered by 51Testing
© 2003-2021
沪ICP备05003035号