
-
转-Windows下JProfiler监控本地tomcat性能之安装配置
2011-06-21 13:42:11
有的时候Tomcat跑Web应用会慢慢死掉,CPU 100%占用。一般情况下是程序哪里出了问题,慢慢的DEBUG,几乎翻遍所有的代码,是不是很累?这里介绍一下JProfiler,比较优秀的性能监控和分析工具。
JProfiler我用的是4.3.3版本,他是收费的,不过google上面很多注册码可供使用。
安装的时候会提示一些比如寻找JVM等过程,这里就不多说了。安装完JProfiler,运行,出现如下界面:
由于我们是要创建对本地tomcat的监控,选择an application server,locally or remotely.
在接下来的窗口中,选择tomcat及版本,
下一步,选择本地:

下一步,选择启动批处理文件

下一步,选择JVM类型:

接着选择JProfiler的监听端口:

接着,选择直接启动:

下面会有一个很重要的提示,可能很多人在这里都没有注意而总是配置不好JProfiler:

第一,需要把
-agentlib:jprofilerti=port=8849,nowait,id=103,config=C:\Documents and Settings\stefanie_wu\.jprofiler4\config.xml"
"-Xbootclasspath/a:D:\Program Files\jprofiler4\bin\agent.jar" -Xbootclasspath/a:D:\usr\agent.jar
两个参数加载启动项中,
第二,要把D:\Program Files\jprofiler4\bin\windows放在PATH中。我是使用.bat来启动tomcat的,所以在startup.bat中加入一段代码:
set JAVA_OPTS=%JAVA_OPTS% -agentlib:jprofilerti=port=8849,nowait,id=103,config=C:\Documents and Settings\stefanie_wu\.jprofiler4\config.xml -Xbootclasspath/a:D:\Program Files\jprofiler4\bin\agent.jar" -Xbootclasspath/a:D:\usr\agent.jar
但是这样启动会有问题,因为其中路径包含了空格,
所以拷贝comfig.xml和agent.jar到一个新的路径下面,比如:
set JAVA_OPTS=%JAVA_OPTS% -agentlib:jprofilerti=port=8849,nowait,id=102,config=D:\usr\config.xml -Xbootclasspath/a:D:\usr\agent.jar这里的jprofilerti=port=8849就是刚才设置的jprofiler监控端口。
设置完这些,通过startup.bat启动tomcat,然后
点OK

-
WEB安全测试所需的基础知识
2011-04-25 20:31:40
WEB安全测试所需的基础知识
来自:http://bbs.51testing.com/thread-121779-1-1.html
第一章:BS架构体系安全渗透测试基础
1. HTTP协议基本概念
(1)介绍HTTP标示URL
(2)HTTP响应状态码
(3)HTTP协议传输内容
2. WEB应用认证基本概念
(1)HTTP常见认证机制
(2)BASE64编码介绍
3. BS架构常见安全问题
(1)拒绝服务攻击基础
(2)Smurf攻击模型
(3)Fraggle攻击模型
(4)SynFlooding攻击模型
(5)碎片攻击
4. 嗅探理论基础
(1)网络嗅探原理
(2)密码嗅探介绍
(3)协议分析基础介绍
第二章:BS架构体系安全渗透测试攻击基础
1. BS架构结构端口扫描分析
(1)SuperScan工具
(2)Nmap端口扫描工具2. 输入验证攻击基础知识
(1)输入验证攻击基本概念
(2)Unicode漏洞介绍
(3)输入验证二次解码漏洞介绍
3. ASP脚本注入基础知识
(1)ASP脚本注入基本概念
(2)ASP脚本注入检测
(3)ASP脚本注入信息获取
(4)AASP脚本注入提权
4. PHP脚本注入基础知识
(1)PHP脚本注入基本概念
(2)PHP脚本注入检测
(3)PHP脚本注入信息获取
(4)PHP脚本注入提权
5.跨站脚本原理及防御
(1)跨站脚本基本概念
(2)跨站脚本实例
(3)跨站脚本解决方法
6、 Web权限提升分析
(1)Web权限提升基本概念
(2)WeBShell上传方法
(3)Web权限提升7大方法:密码破解、本地提权、Gina木马…
7.APR嗅探基础
(1)APR协议概念
(2)APR欺骗攻击
(3) 交换域网络嗅探
第三章:BS架构体系安全渗透测试攻击与测试工具
1、 攻击工具介绍
(1)注入攻击工具原理
(2)注入攻击工具分析
(3)攻击测试平台搭建
2.注入攻击工具使用练习(ASP+SQL Server注入攻击实战)
(1)注入攻击工具使用
(2)域名检查攻击工具使用及域名信息查询用
3.拒绝服务攻击工具使用练习
(1)SynFlooding攻击工具测试
(2)UDPflood攻击工具测试
(3)畸形DDOS攻击工具
4.嗅探攻击工具使用练习
(1)ARP欺骗攻击工具 密码嗅探练习
(2)嗅探协议分析练习
5. BS安全评估工具使用练习
(1)Web脚本评估工具安装
(2)BS架构扫描
(3)评估报告分析撰写模版 -
转-Web安全测试知多少
2011-04-25 20:30:28
1. 数据验证流程:一个好的web系统应该在IE端,server端,DB端都应该进行验证。但有不少程序偷工减料,script验证完了,就不管了;app server对数据长度和类型的验证与db server的不一样,这些都会引发问题。有兴趣的可参看一下script代码,设计一些case,这可是你作为一个高级测试人员的优秀之处哦。我曾修改了页面端的script代码,然后提交了一个form,引发了一个系统的重大漏洞后门2. 数据验证类型: 如果web server端提交sql语句时,不对提交的sql语句验证,那么一个黑客就可暗喜了。他可将提交的sql语句分割,后面加一个delete all或drop database的之类语句,能将你的数据库内容删个精光!我这一招还没实验在internet网站上,不知这样的网站有没有,有多少个。反正我负责的那个web系统曾经发现这样的问题。
3. 网络加密,数据库加密不用说了吧。
WEB软件最常碰到的BUG为:
1、SQL INJETION
2、对文件操作相关的模块的漏洞
3、COOKIES的欺骗
4、本地提交的漏洞
●SQL INJETION的测试方法
原理:
如有一新闻管理系统用文件news.asp再用参数读取数据库里的新闻譬如
http://www.xxx.com/news.asp?id=1这一类网站程序
如果直接用
rs.open "select * from news where id=" &
cstr(request("id")),conn,1,1
数据库进行查询的话即上面的URL所读取的文章是这样读取的
select * from news where id=1
懂得SQL语言的就知道这条语言的意思是在news读取id为1的文章内容。
但是在SQL SERVER里select是支持子查询和多句执行的。如果这样提交URL的话
http://www.xxx.com/news.asp?id=1and 1=(select count(*) from admin
where left(name,1)=a)
SQL语句就变成了
select * news where id=1 and 1=(select count(*)
from admin where left(name,1)=a)
意思是admin表里如果存在字段字为name里左边第一个字符是a的就查询news表里id为1的内容,news表里id为1是有内容的,从逻辑上的角度来说就是1&P。只要P为真,表达式就为真,页面会返回一个正确的页面。如果为假页面就会报错或者会提示该id的文章不存在。黑客利用这点就可以慢慢得试用后台管理员的用户和密码。
测试:
测试存不存在SQL INJETION很简单如果参数为整数型的就在URL上分别提交http://www.xxx.com/news.asp?id=1and 1=1 和http://www.xxx.com/news.asp?id=1and 1=2
如果第一次返回正确内容,第二次返回不同页面或者不同容内的话表明news.asp文件存在SQL INJETION。如何利用就不多说了,毕竟我们都不是为了入侵。
● 对文件操作相关的模块的漏洞在测试
原理:
如一上传文件功能的程序upload.asp如果程序员只注重其功能上的需求没有考虑到用户不按常规操作的问题。如上传一个网页木马程序上去,整个网站甚至整个服务器的架构和源码都暴露而且还有一定的权限。
测试:
试上传asp,php,jsp,cgi等网页的文件看是否成功。
补充:
还有像 http://www.xxx.com/download/filespath.asp?path=../abc.zip
下载功能的软件如果
http://www.xxx.com/download/filespath.asp?path=../conn.asp
很可能下载到这些asp的源码数据库位置及用户密码都可能暴露。
其它还有很多,就不一一举例了。
● COOKIES的欺骗
原理:
COOKIES是WEB程序的重要部分,COOKIES有利有弊。利在于不太占用服务器的资源,弊在于放在客户端非常容易被人修改加以利用。所以一般论坛前台登陆用COOKIES后台是用SESSION,因为前台登陆比较频繁,用SESSION效率很低。但如论坛程序管理员用户在前台也有一定的权限,如果对COOKIES验证不严的话,严重影响了WEB程序的正常工作。如前期的LEADBBS,只有后台对COOKIES验证严格,前台的位置只是从COOKIES读取用户的ID,对用户是否合法根本没有验证。
测试:
推荐使用MYBROWER浏览器,可即时显示及修改COOKIES。尝试一下修改里面的对应位置。
● 本地提交表单的漏洞
原理:
Action只接爱表单的提交,所以表单是客户WEB程序的接口。先举一个例子,一个投票系统,分A,B,C,D各项的VALUE是100,80,60,40。
但是如果先把些页面以HTML形式保存在本地硬盘里。然后修改其VALUE,再向其ACTION提交,ACTION会不会接受呢?
测试:
如一投票系统,把投票的页面保存在本地硬盘,用记事本打开,找到对应项的VALUE值,对其修改,然后提交。
强制后台浏览:绕过登陆页面,直接提交系统文件夹或文件页面。不完善的系统如果缺少index.html就可能被绕过登陆验证页面。在系统文件夹中保留一些公司机密内容也会造成不可估计的损失。
跨站脚本攻击:基本上这个我只是在论坛——各种形式的论坛里看到过,具体的一个例子,比如这段代码可以被填在任何输入框里 “<script>alert("attacking!");</script>”,如果未对一些字符,如 “<”、">"进行转换,就会自动执行这个脚本。百度快照所提供的网页都自动将代码执行了。不信大家搜一点JS的代码,看看你能不能看到。
堆栈溢出攻击:完全的不了解,只是在某个网站上看到,可以对现在的2000、XP、2003进行攻击,非常恐怖,MS应该打了补丁了吧?
-
转-软件测试方法与经验
2011-04-25 20:15:29
一、等价类法1.定义
是把所有可能的输入数据,即程序的输入域划分成若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。该方法是一种重要的,常用的黑盒测试用例设计方法。
2.划分等价类
等价类是指某个输入域的子集合。在该子集合中,各个输入数据对于揭露程序中的错误都是等效的,并合理地假定:测试某等价类的代表值就等于对这一类其它值的测试,因此,可以把全部输入数据合理划分为若干等价类,在每一个等价类中取一个数据作为测试的输入条件就可以用少量代表性的测试数据取得较好的测试结果。等价类划分可有两种不同的情况:有效等价类和无效等价类。
1)有效等价类
是指对于程序的规格说明来说是合理的、有意义的输入数据构成的集合。利用有效等价类可检验程序是否实现了规格说明中所规定的功能和性能。
2)无效等价类
与有效等价类的定义恰巧相反。无效等价类指对程序的规格说明是不合理的或无意义的输入数据所构成的集合。对于具体的问题,无效等价类至少应有一个,也可能有多个。
设计测试用例时,要同时考虑这两种等价类。因为软件不仅要能接收合理的数据,也要能经受意外的考验,这样的测试才能确保软件具有更高的可靠性。
3.划分等价类的标准
1)完备测试、避免冗余;
2)划分等价类重要的是:集合的划分,划分为互不相交的一组子集,而子集的并是整个集合;
3)并是整个集合:完备性;
4)子集互不相交:保证一种形式的无冗余性;
5)同一类中标识(选择)一个测试用例,同一等价类中,往往处理相同,相同处理映射到"相同的执行路径"。
4.划分等价类的方法
1)在输入条件规定了取值范围或值的个数的情况下,则可以确立一个有效等价类和两个无效等价类。
如:输入值是学生成绩,范围是0~100;
2)在输入条件规定了输入值的集合或者规定了"必须如何"的条件的情况下,可确立一个有效等价类和一个无效等价类;
3)在输入条件是一个布尔量的情况下,可确定一个有效等价类和一个无效等价类。
4)在规定了输入数据的一组值(假定n个),并且程序要对每一个输入值分别处理的情况下,可确立n个有效等价类和一个无效等价类。
例:输入条件说明学历可为:专科、本科、硕士、博士四种之一,则分别取这四种这四个值作为四个有效等价类,另外把四种学历之外的任何学历作为无效等价类。
5)在规定了输入数据必须遵守的规则的情况下,可确立一个有效等价类(符合规则)和若干个无效等价类(从不同角度违反规则);
6)在确知已划分的等价类中各元素在程序处理中的方式不同的情况下,则应再将该等价类进一步的划分为更小的等价类。
5.设计测试用例
在确立了等价类后,可建立等价类表,列出所有划分出的等价类输入条件:有效等价类、无效等价类,然后从划分出的等价类中按以下三个原则设计测试用例:
1)为每一个等价类规定一个唯一的编号;
2)设计一个新的测试用例,使其尽可能多地覆盖尚未被覆盖地有效等价类,重复这一步, 直到所有的有效等价类都被覆盖为止;
3)设计一个新的测试用例,使其仅覆盖一个尚未被覆盖的无效等价类,重复这一步,直到所有的无效等价类都被覆盖为止。
二、边界值法1.定义
边界值分析法就是对输入或输出的边界值进行测试的一种黑盒测试方法。通常边界值分析法是作为对等价类划分法的补充,这种情况下,其测试用例来自等价类的边界。
2.与等价划分的区别
1)边界值分析不是从某等价类中随便挑一个作为代表,而是使这个等价类的每个边界都要作为测试条件。
2)边界值分析不仅考虑输入条件,还要考虑输出空间产生的测试情况。
3.边界值分析方法的考虑
长期的测试工作经验告诉我们,大量的错误是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部。因此针对各种边界情况设计测试用例,可以查出更多的错误。
使用边界值分析方法设计测试用例,首先应确定边界情况。通常输入和输出等价类的边界,就是应着重测试的边界情况。应当选取正好等于,刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据。
4.常见的边界值
1)对16-bit 的整数而言 32767 和 -32768 是边界
2)屏幕上光标在最左上、最右下位置
3)报表的第一行和最后一行
4)数组元素的第一个和最后一个
5)循环的第 0 次、第 1 次和倒数第 2 次、最后一次
5.边界值分析
1)边界值分析使用与等价类划分法相同的划分,只是边界值分析假定错误更多地存在于划分的边界上,因此在等价类的边界上以及两侧的情况设计测试用例。
例:测试计算平方根的函数
--输入:实数
--输出:实数
--规格说明:当输入一个0或比0大的数的时候,返回其正平方根;当输入一个小于0的数时,显示错误信息"平方根非法-输入值小于0"并返回0;库函数Print-Line可以用来输出错误信息。
2)等价类划分:
I.可以考虑作出如下划分:
a、输入 (i)<0 和 (ii)>=0
b、输出 (a)>=0 和 (b) Error
II.测试用例有两个:
a、输入4,输出2。对应于 (ii) 和 (a) 。
b、输入-10,输出0和错误提示。对应于 (i) 和 (b) 。
3)边界值分析:
划分(ii)的边界为0和最大正实数;划分(i)的边界为最小负实数和0。由此得到以下测试用例:
a、输入 {最小负实数}
b、输入 {绝对值很小的负数}
c、输入 0
d、输入 {绝对值很小的正数}
e、输入 {最大正实数}
4)通常情况下,软件测试所包含的边界检验有几种类型:数字、字符、位置、重量、大小、速度、方位、尺寸、空间等。
5)相应地,以上类型的边界值应该在:最大/最小、首位/末位、上/下、最快/最慢、最高/最低、最短/最长、 空/满等情况下。
6)利用边界值作为测试数据
项
边界值
测试用例的设计思路
字符
起始-1个字符/结束+1个字符
假设一个文本输入区域允许输入1个到255个 字符,输入1个和255个字符作为有效等价类;输入0个和256个字符作为无效等价类,这几个数值都属于边界条件值。
数值
最小值-1/最大值+1
假设某软件的数据输入域要求输入5位的数据值,可以使用10000作为最小值、99999作为最大值;然后使用刚好小于5位和大于5位的 数值来作为边界条件。
空间
小于空余空间一点/大于满空间一点
例如在用U盘存储数据时,使用比剩余磁盘空间大一点(几KB)的文件作为边界条件。
7)内部边界值分析:
在多数情况下,边界值条件是基于应用程序的功能设计而需要考虑的因素,可以从软件的规格说明或常识中得到,也是最终用户可以很容易发现问题的。然而,在测试用例设计过程中,某些边界值条件是不需要呈现给用户的,或者说用户是很难注意到的,但同时确实属于检验范畴内的边界条件,称为内部边界值条件或子边界值条件。
内部边界值条件主要有下面几种:
a)数值的边界值检验:计算机是基于二进制进行工作的,因此,软件的任何数值运算都有一定的范围限制。项
范围或值
位(bit)
0 或 1
字节(byte)
0 ~ 255
字(word)
0~65535(单字)或 0~4294967295(双字)
千(K)
1024
兆(M)
1048576
吉(G)
1073741824
b)字符的边界值检验:在计算机软件中,字符也是很重要的表示元素,其中ASCII和Unicode是常见的编码方式。下表中列出了一些常用字符对应的ASCII码值。
字符
ASCII码值
字符
ASCII码值
空 (null)
0
A
65
空格 (space)
32
a
97
斜杠 ( / )
47
Z
90
0
48
z
122
冒号 ( : )
58
单引号 ( ‘ )
96
@
64
c)其它边界值检验
6.基于边界值分析方法选择测试用例的原则
1)如果输入条件规定了值的范围,则应取刚达到这个范围的边界的值,以及刚刚超越这个范围边界的值作为测试输入数据。
例如,如果程序的规格说明中规定:"重量在10公斤至50公斤范围内的邮件,其邮费计算公式为……"。作为测试用例,我们应取10及50,还应取10.01,49.99,9.99及50.01等。
2)如果输入条件规定了值的个数,则用最大个数,最小个数,比最小个数少一,比最大个数多一的数作为测试数据。
比如,一个输入文件应包括1~255个记录,则测试用例可取1和255,还应取0及256等。
3)将规则1)和2)应用于输出条件,即设计测试用例使输出值达到边界值及其左右的值。
例如,某程序的规格说明要求计算出"每月保险金扣除额为0至1165.25元",其测试用例可取0.00及1165.24、还可取一0.01及1165.26等。
再如一程序属于情报检索系统,要求每次"最少显示1条、最多显示4条情报摘要",这时我们应考虑的测试用例包括1和4,还应包括0和5等。
4)如果程序的规格说明给出的输入域或输出域是有序集合,则应选取集合的第一个元素和最后一个元素作为测试用例。
5)如果程序中使用了一个内部数据结构,则应当选择这个内部数据结构的边界上的值作为测试用例。
6)分析规格说明,找出其它可能的边界条件。
三、因果图法1.定义
是一种利用图解法分析输入的各种组合情况,从而设计测试用例的方法,它适合于检查程序输入条件的各种组合情况。
2.因果图法产生的背景
等价类划分法和边界值分析方法都是着重考虑输入条件,但没有考虑输入条件的各种组合、输入条件之间的相互制约关系。这样虽然各种输入条件可能出错的情况已经测试到了,但多个输入条件组合起来可能出错的情况却被忽视了。
如果在测试时必须考虑输入条件的各种组合,则可能的组合数目将是天文数字,因此必须考虑采用一种适合于描述多种条件的组合、相应产生多个动作的形式来进行测试用例的设计,这就需要利用因果图(逻辑模型)。
3.因果图介绍
1) 4种符号分别表示了规格说明中向4种因果关系。
2) 因果图中使用了简单的逻辑符号,以直线联接左右结点。左结点表示输入状态(或称原因),右结点表示输出状态(或称结果)。
3) Ci表示原因,通常置于图的左部;ei表示结果,通常在图的右部。Ci和ei均可取值0或1,0表示某状态不出现,1表示某状态出现。
4.因果图概念
1) 关系
①恒等:若ci是1,则ei也是1;否则
转-Web安全测试学习笔记(Cookie&Session)
2011-04-25 19:54:09
一,Session:含义:有始有终的一系列动作\消息
1, 隐含了“面向连接”和“保持状态”两种含义
2, 一种用来在客户端与服务器之间保持状态的解决方案
3, 也指这种解决方案的存储结构“把××保存在session里”二,http协议本来是无状态的,所以引进了cookie和session机制来保持连接状态
cookie与session机制之间的区别与联系:
cookie机制采用的是在客户端保持状态的方法
session机制采用的是在服务器端保持状态的方案,由于在服务器端保 持状态的同时必须要求客户端提供一个标识,三,关于cookie机制
Cookie的使用是由浏览器按照一定的原则在后台自动发送给服务器的,浏览器会检查所有存储的cookie,如果某个cookie所声明的作用范围大于等于将要请求的资源所在的位置,则把该cookie附在请求资源的http请求头上发送给服务器。
存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而保存在内存里的cookie,不同的浏览器有不同的处理方式,对于IE,在一个打开的窗口上按CTRL+N(从文件菜单)打开的窗口可以与原窗口共享cookie,而使用其他方式新开的IE进程则不能共享已经打开的窗口的内存cookie。
Cookie的内容包括:名字,值,过期时间,路径和域四,关于session的机制
当程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个请求是否含了一个session标识(session id),如果有,则说明以前为该客户创建了一个session,服务器就按照session id把这个session检索出来用,一般一个cookie的名字就是类似于session ID,如果cookie被禁止的时候(cookie可以被人为的禁止),经常使用重写URL的方式,把session ID附加在URL路径后面,为了在整个交互过程中始终保持状态,就必须在每个客户端可能请求的路径后面都包含这个session id。
人们以为:“把浏览器关闭了,session就小时了”其实不对,除非程序通知服务器删除一个session,否则服务器会一直保留,而程序一般都是在用户作log off的时候发个指令去删除session。人们之所以会产生这种错觉,是因为大部分session会采用cookie来保存session,而关闭浏览器后这个session就消失了,如果服务器设置的cookie被保存到硬盘上,或者使用某种手段改写浏览器发出的http请求头,把原来的session id发送给服务器,则再次打开浏览器,其实是可以再次找到之前的session id的。所以设置失效时间可以起到一定的保护作用。五,关于session的一些问题
1, session何时被创建:不是在客户端访问时就被创建,而是在服务器端调用httpservletRequest.getSession(true)时才被创建。
2, session何时被删除: A,程序调用httpSession.invalidate(),B距离上一次收到客户端发送的session id时间间隔超过了session的超时设置C, 服务器进程被停止(非持久session)
3, 如何做到关闭浏览器同时关闭session: 严格说做不到,可以让所有的客户端页面使用window.onclose来监视浏览器的关闭东西,然后向服务器发送一个请求来删除session,但是对于浏览器崩溃或者强行杀死进程时仍然无能为力。web安全测试的checklist 【转】
2011-04-25 19:53:09
1. 不登录系统,直接输入登录后的页面的url是否可以访问2. 不登录系统,直接输入下载文件的url是否可以下载,如输入http://url/download?name=file是否可以下载文件file
3. 退出登录后按后退按钮能否访问之前的页面
4. ID/密码验证方式中能否使用简单密码。如密码标准为6位以上,字母和数字混合,不能包含ID,连续的字母或数字不能超过n位
5. 重要信息(如密码,身份证号码,信用卡号等)在输入或查询时是否用明文显示;在浏览器地址栏里输入命令javascrīpt:alert(doucument.cookie)时是否有重要信息;在html源码中能否看到重要信息
6. 手动更改URL中的参数值能否访问没有权限访问的页面。如普通用户对应的url中的参数为l=e,高级用户对应的url中的参数为l=s,以普通用户的身份登录系统后将url中的参数e改为s来访问本没有权限访问的页面
7. url里不可修改的参数是否可以被修改
8. 上传与服务器端语言(jsp、asp、php)一样扩展名的文件或exe等可执行文件后,确认在服务器端是否可直接运行
9. 注册用户时是否可以以'--,' or 1=1 --等做为用户名
10. 传送给服务器的参数(如查询关键字、url中的参数等)中包含特殊字符(','and 1=1 --,' and 1=0 --,'or 1=0 --)时是否可以正常处理
11. 执行新增操作时,在所有的输入框中输入脚本标签(<scrīpt>alert("")</scrīpt>)后能否保存
12. 在url中输入下面的地址是否可以下载:http://url/download.jsp?file=C:\windows\system32\drivers\etc\hosts,http://url/download.jsp?file=/etc/passwd
13. 是否对session的有效期进行处理
14. 错误信息中是否含有sql语句、sql错误信息以及web服务器的绝对路径等
15. ID/密码验证方式中,同一个账号在不同的机器上不能同时登录
16. ID/密码验证方式中,连续数次输入错误密码后该账户是否被锁定
17. 新增或修改重要信息(密码、身份证号码、信用卡号等)时是否有自动完成功能(在form标签中使用autocomplete=off来关闭自动完成功能
转-Tomcat6设置虚拟目录及server.xml配置详解
2011-04-25 19:04:46
Tomcat是流行的JSP服务器,正如ASP中需要使用IIS一样,在编辑的JSp页面部署时需要一个服务器,Tomcat正是常用的首选服务器。网上 下载的程序或者从别处拷贝的jsp工程,可以直接放在TOmcat主目录中Webapps目录中就可以运行,但我们不希望能放到任意的目录下都能通过浏览 器进行访问吗?其实,很简单,打开Tomcat主目录中conf文件夹下Server.xml文件,在<host>标签中加入文件中加入如下 代码即可:<Context path="/myjsp" docBase="c:\myjsp" debug="0" reloadable="true" crossContext="true"></Context>
其中,path为我们要建立的虚拟目录,docBase为实际目录在硬盘上的位置。当然,修改server.xml后需要重新启动Tomcat服务器,才能生效。<Server>元素
它代表整个容器,是Tomcat实例的顶层元素.由org.apache.catalina.Server接口来定义.它包含一个<Service>元素.并且它不能做为任何元素的子元素. <Server port="8005" shutdown="SHUTDOWN" debug="0">
<Server port="8005" shutdown="SHUTDOWN" debug="0">
1>className指定实现org.apache.catalina.Server接口的类.默认值为org.apache.catalina.core.StandardServer
2>port指定Tomcat监听shutdown命令端口.终止服务器运行时,必须在Tomcat服务器所在的机器上发出shutdown命令.该属性是必须的.
3>shutdown指定终止Tomcat服务器运行时,发给Tomcat服务器的shutdown监听端口的字符串.该属性必须设置
<Service>元素
该元素由org.apache.catalina.Service接口定义,它包含一个<Engine>元素,以及一个或多个<Connector>,这些Connector元素共享用同一个Engine元素 <Service name="Catalina"> <Service name="Apache"> 第一个<Service>处理所有直接由Tomcat服务器接收的web客户请求. 第二个<Service>处理所有由Apahce服务器转发过来的Web客户请求
1>className 指定实现org.apahce.catalina.Service接口的类.默认为org.apahce.catalina.core.StandardService
2>name定义Service的名字
<Engine>元素
每个Service元素只能有一个Engine元素.元素处理在同一个<Service>中所有<Connector>元素接收到的客户请求.由org.apahce.catalina.Engine接口定义.<Engine name="Catalina" defaultHost="localhost" debug="0">1>className指定实现Engine接口的类,默认值为StandardEngine
2>defaultHost指定处理客户的默认主机名,在<Engine>中的<Host>子元素中必须定义这一主机
3>name定义Engine的名字
在<Engine>可以包含如下元素<Logger>, <Realm>, <Value>, <Host><Host>元素
它由Host接口定义.一个Engine元素可以包含多个<Host>元素.每个<Host>的元素定义了一个虚拟主机.它包含了一个或多个Web应用. <Host name="localhost" debug="0" appBase="webapps" unpackWARs="true" autoDeploy="true">1>className指定实现Host接口的类.默认值为StandardHost
2>appBase指定虚拟主机的目录,可以指定绝对目录,也可以指定相对于<CATALINA_HOME>的相对目录.如果没有此项,默认为<CATALINA_HOME>/webapps
3>autoDeploy如果此项设为true,表示Tomcat服务处于运行状态时,能够监测appBase下的文件,如果有新有web应用加入进来,会自运发布这个WEB应用
4>unpackWARs如果此项设置为true,表示把WEB应用的WAR文件先展开为开放目录结构后再运行.如果设为false将直接运行为WAR文件
5>alias指定主机别名,可以指定多个别名
6>deployOnStartup如果此项设为true,表示Tomcat服务器启动时会自动发布appBase目录下所有的Web应用.如果Web应用中的server.xml没有相应的<Context>元素,将采用Tomcat默认的Context
7>name定义虚拟主机的名字
在<Host>元素中可以包含如下子元素
<Logger>, <Realm>, <Value>, <Context><Context>元素
它由Context接口定义.是使用最频繁的元素.每个<Context元素代表了运行在虚拟主机上的单个Web应用.一个<Host>可以包含多个<Context>元素.每个web应用有唯一
的一个相对应的Context代表web应用自身.servlet容器为第一个web应用创建一个
ServletContext对象.<Context path="/sample" docBase="sample" debug="0" reloadbale="true">1>className指定实现Context的类,默认为StandardContext类
2>path指定访问Web应用的URL入口,注意/myweb,而不是myweb了事
3>reloadable如果这个属性设为true, Tomcat服务器在运行状态下会监视在WEB-INF/classes和Web-INF/lib目录CLASS文件的改运.如果监视到有class文件被更新,服务器自重新加载Web应用
3>cookies指定是否通过Cookies来支持Session,默认值为true
4>useNaming指定是否支持JNDI,默认值为了true在<Context>元素中可以包含如下元素
<Logger>, <Realm>, <Resource>, <ResourceParams>
<Connector>元素
由Connector接口定义.<Connector>元素代表与客户程序实际交互的给件,它负责接收客户请求,以及向客户返回响应结果.<Connector port="8080" maxThread="50" minSpareThreads="25" maxSpareThread="75" enableLookups="false" redirectPort="8443" acceptCount="100" debug="0" connectionTimeout="20000" disableUploadTimeout="true" /><Connection port="8009" enableLookups="false" redirectPort="8443" debug="0" protocol="AJP/1.3" />第一个Connector元素定义了一个HTTP Connector,它通过8080端口接收HTTP请求;第二个Connector元素定义了一个JD Connector,它通过8009端口接收由其它服务器转发过来的请求.
Connector元素共用属性
1>className指定实现Connector接口的类
2>enableLookups如果设为true,表示支持域名解析,可以把IP地址解析为主机名.WEB应用中调用request.getRemoteHost方法返回客户机主机名.默认值为true
3>redirectPort指定转发端口.如果当前端口只支持non-SSL请求,在需要安全通信的场命,将把客户请求转发至SSL的redirectPort端口
HttpConnector元素的属性
1>className实现Connector的类
2>port设定Tcp/IP端口,默认值为8080,如果把8080改成80,则只要输入http://localhost即可
因为TCP/IP的默认端口是80
3>address如果服务器有二个以上ip地址,此属性可以设定端口监听的ip地址.默认情况下,端口会监听服务器上所有的ip地址目.默认值为200
4>bufferSize设定由端口创建的输入流的缓存大小.默认值为2048byte
5>protocol设定Http协议,默认值为HTTP/1.1
6>maxThreads设定在监听端口的线程的最大数目,这个值也决定了服务器可以同时响应客户请求的最大数
7>acceptCount设定在监听端口队列的最大客户请求数量,默认值为10.如果队列已满,客户必须等待.
8>connectionTimeout定义建立客户连接超时的时间.如果为-1,表示不限制建立客户连接的时间
JkConnector的属性
1>className实现Connector的类
2>port设定AJP端口号
3>protocol必须设定为AJP/1.3loadrunner对数据库进行查询和插入的脚本
2011-03-02 14:42:41
(1)VUSER_INIT中脚本(连帹数据库)
#include "lrd.h"
static LRD_INIT_INFO InitInfo = {LRD_INIT_INFO_EYECAT};
static LRD_DEFAULT_DB_VERSION DBTypeVersion[] =
{
{LRD_DBTYPE_NONE, LRD_DBVERSION_NONE}
};
static LRD_CONNECTION * Con1;
static LRD_CURSOR * Csr1;
vuser_init()
{
lrd_init(&InitInfo, DBTypeVersion);
lrd_open_connection(&Con1, LRD_DBTYPE_ORACLE, "用户名", "密码", "服務名", "", 0, 0, 0);
}
(2)ACTION中的脚本 (进行数据库操作)
Action()
{
lr_start_transaction("Insert");
lrd_open_cursor(&Csr1, Con1, 0);
//lrd_open_cursor(&Csr1, Con1, 0);
lrd_stmt(Csr1,"SQL娪句", -1, 0, 1, 0);
lrd_exec(Csr1, 0, 0, 0, 0, 0);
/*
PrintRow2, 0);
lrd_close_cursor(&Csr1, 0);
*/
lrd_commit(0, Con1, 0);
lr_end_transaction("Insert", LR_AUTO);
}
(3)vuser_end中的脚本(释放资源,关闭数据库)
vuser_end()
{
lrd_close_connection(&Con1, 0, 0);
lrd_end(0);
return 0;
}
转-LoadRunner获取数据库中内容并参数化【已验证】
2011-03-02 13:50:21
工作上有使用LoadRunner时又需要到数据库中取相应的数据作为参数,经过一番折腾及验证代码如下
运行成功条件:需安装oracle客户端,且设置了odbc连接,否则会报错illegal character `\0241'
Action()
{#include "lrun.h"
#include "vdf.h"
#include "print.inl"
#include "lrd.h"
//code by shiwanli----------参数定义
unsigned long rownum;
char Temp[200];
char Prem_value[200];
//code by shiwanli----------以下两行为结构声明,在绑定时使用,如果不声明则会报错
//code by shiwanli----------LRD_VAR_DESC数据结构声明是很重要的,他是用来存储sql结果数据集的结构体
//code by shiwanli----------第二个参数,设置结果集中最大行数,在lrd_ora8_fetch中的第二个参数如果大于该值,则会报错。
//code by shiwanli----------第三个参数,设置结果集中每一行的最大长度,如果获得的查询结果比定义的长,运行时就会报错,提示列被截断
//code by shiwanli----------最后一个参数是查询结果的类型,可以再帮助中的索引输入data types, database,列出的表格中是各种变量类型的名称
//code by shiwanli----------常用的数据类型有DT_VARCHAR, DT_DECIMAL, DT_DATETIME, DT_SF, DT_SZ, DT_NUMERIC
static LRD_VAR_DESC NUM ={LRD_VAR_DESC_EYECAT, 10, 32, LRD_DBTYPE_ORACLE, {1, 1, 0},DT_LONG_VARCHAR};
static LRD_VAR_DESC NUM1 ={LRD_VAR_DESC_EYECAT, 10, 32, LRD_DBTYPE_ORACLE, {1, 1, 0},DT_LONG_VARCHAR};
static LRD_VAR_DESC OBJECT_NAME_D1;
static LRD_INIT_INFO InitInfo = {LRD_INIT_INFO_EYECAT};
static LRD_DEFAULT_DB_VERSION DBTypeVersion[] = {{LRD_DBTYPE_NONE,LRD_DBVERSION_NONE}};static void FAR * OraEnv1;
static void FAR * OraSvc1;
static void FAR * OraSrv1;
static void FAR * OraSes1;
static void FAR * OraStm1;
static void FAR * OraDef1;
static unsigned long uliFetchedRows;//code by shiwanli----------初始化数据库
lrd_init(&InitInfo, DBTypeVersion);
lrd_initialize_db(LRD_DBTYPE_ORACLE, 3, 0);
lrd_env_init(LRD_DBTYPE_ORACLE, &OraEnv1, 0, 0);
lrd_ora8_handle_alloc(OraEnv1, SVCCTX, &OraSvc1, 0);
lrd_ora8_handle_alloc(OraEnv1, SERVER, &OraSrv1, 0);
lrd_ora8_handle_alloc(OraEnv1, SESSION, &OraSes1, 0);
//code by shiwanli----------连接数据库,这里数据库服务名为lisx
lrd_server_attach(OraSrv1, "lisx", -1, 0, 0);
lrd_ora8_attr_set_from_handle(OraSvc1, SERVER, OraSrv1, 0, 0);
//code by shiwanli----------设定数据库用户名密码checker
lrd_ora8_attr_set(OraSes1, USERNAME, "checker", -1, 0);
lrd_ora8_attr_set(OraSes1, PASSWORD, "checker", -1, 0);
//code by shiwanli----------初始化连接session
lrd_ora8_attr_set_from_handle(OraSvc1, SESSION, OraSes1, 0, 0);
//code by shiwanli----------开始连接数据库
lrd_session_begin(OraSvc1, OraSes1, 1, 0, 0);
lrd_ora8_handle_alloc(OraEnv1, STMT, &OraStm1, 0);
//code by shiwanli----------设定查询语句
lrd_ora8_stmt(OraStm1, "select sum(prem) from lccont where prtno='120010100000470' \n", 1, 0, 0);
//code by shiwanli----------执行查询语句
//code by shiwanli----------第三个参数,执行次数
//code by shiwanli----------第四个参数,跳过记录数
//code by shiwanli----------第五个参数,返回执行影响的行数
//code by shiwanli----------第九个参数,设置执行模式,0是默认值执行(不提交),16不执行,32代表执行且自动提交
//code by shiwanli----------第十个参数,设置警告级别,0是默认值,代表错误,1代表警告
lrd_ora8_exec(OraSvc1, OraStm1, 0, 0,&rownum, 0, 0, 0, 0, 1);
//code by shiwanli----------绑定该列
lrd_ora8_bind_col(OraStm1,&OraDef1,1,&NUM,0,0);
//code by shiwanli----------绑定第二列 lrd_ora8_bind_col(OraStm1,&OraDef2,2,&NUM1,0,0);//code by shiwanli----------设定保存列中的某个数据到row中,第二个参数为第几列,第三个参数为第几行(只能保存一个值),最后一个参数就是你想要保存到的parameter名称
lrd_ora8_save_col(OraStm1, 1, 1, 0, "ResultQuery");
//code by shiwanli----------获取第二列并赋值 lrd_ora8_save_col(OraStm1, 2, 1, 0, "resultusername");
//code by shiwanli----------获取结果集
lrd_ora8_fetch(OraStm1, -2, 2, &rownum, 0, 2, 0, 0);
//code by shiwanli----------打印结果
lr_message("查询出的结果为: %s", lr_eval_string("{ResultQuery}"));
//code by shiwanli----------释放连接数据库的各种变量
lrd_handle_free(&OraStm1, 0);
lrd_session_end(OraSvc1, OraSes1, 0, 0);
lrd_server_detach(OraSrv1, 0, 0);
lrd_handle_free(&OraEnv1, 0);
strcat(Temp,lr_eval_string("{ResultQuery}"));
lr_save_string(Temp,"Prem_value");
lr_message("缴费金额为: %s", lr_eval_string("{Prem_value}"));
return 0;
}
工作过程中发现我在某台机器上执行成功,但是我重新新建一个脚本就会报这样那样的错误。为了让看到后来人能少走弯路下面我将详细解释下如何才能成功执行此脚本。
1、如果你是直接使用oracle(2-tier)协议创建的脚本的话那你需要修改
vdf.h print.inl 这两个文件【此两个文件中的内容我将在后面贴出来,这个博客不会贴附件。。。。。。】
然后你再执行一下脚本,试一下是不是可以了?可以从数据库中查出数据了?
2、如果你是使用web协议创建的脚本的话,需要修改的内容如下
修改脚本目录下的.usr文件中的如下字段
AdditionalTypes=Oracle,QTWeb
ActiveTypes=Oracle,QTWeb
GenerateTypes=Oracle,QTWeb
修改脚本目录下的globals.h添加如下内容
#include "vdf.h"
#include "print.inl"
拷贝vdf.h文件到脚本目录下
拷贝print.inl文件到脚本目录下再执行下,看看应该是ok了吧。
下面贴出vdf.h内容
/* vdf.h */
#ifndef VDF_H
#define VDF_H#define LRD_RECORDED_UNDER_WIN32
#include "lrd.h"static LRD_INIT_INFO InitInfo = {LRD_INIT_INFO_EYECAT};
static LRD_DEFAULT_DB_VERSION DBTypeVersion[] =
{
{LRD_DBTYPE_NONE, LRD_DBVERSION_NONE}
};
static unsigned long uliRowsProcessed;
static LRD_VAR_DESC USER_D1 =
{LRD_VAR_DESC_EYECAT, 1, 31, LRD_DBTYPE_ORACLE, {0, 1, 0}, DT_SZ};
static unsigned long uliFetchedRows;
static LRD_VAR_DESC ATTRIBUTE_D2 =
{LRD_VAR_DESC_EYECAT, 1, 250, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC SCOPE_D3 =
{LRD_VAR_DESC_EYECAT, 1, 250, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC NUMERIC_VALUE_D4 =
{LRD_VAR_DESC_EYECAT, 1, 250, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC CHAR_VALUE_D5 =
{LRD_VAR_DESC_EYECAT, 1, 250, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC DATE_VALUE_D6 =
{LRD_VAR_DESC_EYECAT, 1, 250, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC CHAR_VALUE_D7 =
{LRD_VAR_DESC_EYECAT, 1, 250, LRD_DBTYPE_ORACLE, {0, 1, 0}, DT_SZ};
static LRD_VAR_DESC P1D8 =
{LRD_VAR_DESC_EYECAT, 1, 8, LRD_DBTYPE_ORACLE, {1, 1, 0},
DT_SF_STRIPPED_SPACES};
static LRD_VAR_DESC DECODE_A_A_1_2_D9 =
{LRD_VAR_DESC_EYECAT, 1, 22, LRD_DBTYPE_ORACLE, {1, 1, 0},
DT_NUMERIC};
static LRD_VAR_DESC USERCODE_D10 =
{LRD_VAR_DESC_EYECAT, 15, 21, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC USERNAME_D11 =
{LRD_VAR_DESC_EYECAT, 15, 21, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC COMCODE_D12 =
{LRD_VAR_DESC_EYECAT, 15, 21, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC PASSWORD_D13 =
{LRD_VAR_DESC_EYECAT, 15, 17, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC USERDESCRIPTION_D14 =
{LRD_VAR_DESC_EYECAT, 15, 51, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC USERSTATE_D15 =
{LRD_VAR_DESC_EYECAT, 15, 2, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC UWPOPEDOM_D16 =
{LRD_VAR_DESC_EYECAT, 15, 11, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC CLAIMPOPEDOM_D17 =
{LRD_VAR_DESC_EYECAT, 15, 3, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC OTHERPOPEDOM_D18 =
{LRD_VAR_DESC_EYECAT, 15, 3, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC POPUWFLAG_D19 =
{LRD_VAR_DESC_EYECAT, 15, 2, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC SUPERPOPEDOMFLAG_D20 =
{LRD_VAR_DESC_EYECAT, 15, 2, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC OPERATOR_D21 =
{LRD_VAR_DESC_EYECAT, 15, 61, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC MAKEDATE_D22 =
{LRD_VAR_DESC_EYECAT, 15, 15, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC MAKETIME_D23 =
{LRD_VAR_DESC_EYECAT, 15, 9, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC VALIDSTARTDATE_D24 =
{LRD_VAR_DESC_EYECAT, 15, 15, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC VALIDENDDATE_D25 =
{LRD_VAR_DESC_EYECAT, 15, 15, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC CERTIFYFLAG_D26 =
{LRD_VAR_DESC_EYECAT, 15, 2, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC EDORPOPEDOM_D27 =
{LRD_VAR_DESC_EYECAT, 15, 3, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static LRD_VAR_DESC AGENTCOM_D28 =
{LRD_VAR_DESC_EYECAT, 15, 21, LRD_DBTYPE_ORACLE, {1, 1, 0}, DT_SZ};
static void FAR * OraEnv1;
static void FAR * OraSvc1;
static void FAR * OraStm1;
static void FAR * OraStm2;
static void FAR * OraStm3;
static void FAR * OraStm4;
static void FAR * OraStm5;
static void FAR * OraStm6;
static void FAR * OraStm7;
static void FAR * OraBnd1;
static void FAR * OraDef1;
static void FAR * OraDef2;
static void FAR * OraDef3;
static void FAR * OraDef4;
static void FAR * OraDef5;
static void FAR * OraDef6;
static void FAR * OraDef7;
static void FAR * OraDef8;
static void FAR * OraDef9;
static void FAR * OraDef10;
static void FAR * OraDef11;
static void FAR * OraDef12;
static void FAR * OraDef13;
static void FAR * OraDef14;
static void FAR * OraDef15;
static void FAR * OraDef16;
static void FAR * OraDef17;
static void FAR * OraDef18;
static void FAR * OraDef19;
static void FAR * OraDef20;
static void FAR * OraDef21;
static void FAR * OraDef22;
static void FAR * OraDef23;
static void FAR * OraDef24;
static void FAR * OraDef25;
static void FAR * OraDef26;
static void FAR * OraDef27;
static void FAR * OraSrv1;
static void FAR * OraSes1;
static void FAR * OraSes2;
#endif
下面贴出print.inl文件内容#ifndef INL_H
#define INL_H
LRD_ORA8_PRINT_ROW_PROTO(PrintRow2)
{
LRDRET gjLRDRet = LRDRET_I_OK;
char szUSER_D1[256];
lrd_to_printable(&USER_D1, muliRowIndex, szUSER_D1, 256, "");
lr_debug_message(LR_MSG_CLASS_RESULT_DATA, "%s", szUSER_D1);
return gjLRDRet;
}LRD_ORA8_PRINT_ROW_PROTO(PrintRow6)
{
LRDRET gjLRDRet = LRDRET_I_OK;
char szDECODE_A_A_1_2_D9[256];
lrd_to_printable(&DECODE_A_A_1_2_D9, muliRowIndex, szDECODE_A_A_1_2_D9, 256, "");
lr_debug_message(LR_MSG_CLASS_RESULT_DATA,a "%s", szDECODE_A_A_1_2_D9);
return gjLRDRet;
}LRD_ORA8_PRINT_ROW_PROTO(PrintRow8)
{
LRDRET gjLRDRet = LRDRET_I_OK;
char szUSERCODE_D10[256];
char szUSERNAME_D11[256];
char szCOMCODE_D12[256];
char szPASSWORD_D13[256];
char szUSERDESCRIPTION_D14[256];
char szUSERSTATE_D15[256];
char szUWPOPEDOM_D16[256];
char szCLAIMPOPEDOM_D17[256];
char szOTHERPOPEDOM_D18[256];
char szPOPUWFLAG_D19[256];
char szSUPERPOPEDOMFLAG_D20[256];
char szOPERATOR_D21[256];
lrd_to_printable(&USERCODE_D10, muliRowIndex, szUSERCODE_D10, 256, "");
lrd_to_printable(&USERNAME_D11, muliRowIndex, szUSERNAME_D11, 256, "");
lrd_to_printable(&COMCODE_D12, muliRowIndex, szCOMCODE_D12, 256, "");
lrd_to_printable(&PASSWORD_D13, muliRowIndex, szPASSWORD_D13, 256, "");
lrd_to_printable(&USERDESCRIPTION_D14, muliRowIndex, szUSERDESCRIPTION_D14, 256, "");
lrd_to_printable(&USERSTATE_D15, muliRowIndex, szUSERSTATE_D15, 256, "");
lrd_to_printable(&UWPOPEDOM_D16, muliRowIndex, szUWPOPEDOM_D16, 256, "");
lrd_to_printable(&CLAIMPOPEDOM_D17, muliRowIndex, szCLAIMPOPEDOM_D17, 256, "");
lrd_to_printable(&OTHERPOPEDOM_D18, muliRowIndex, szOTHERPOPEDOM_D18, 256, "");
lrd_to_printable(&POPUWFLAG_D19, muliRowIndex, szPOPUWFLAG_D19, 256, "");
lrd_to_printable(&SUPERPOPEDOMFLAG_D20, muliRowIndex, szSUPERPOPEDOMFLAG_D20, 256, "");
lrd_to_printable(&OPERATOR_D21, muliRowIndex, szOPERATOR_D21, 256, "");
lr_debug_message(LR_MSG_CLASS_RESULT_DATA, "%s, %s, %s, %s, %s, %s,"
"%s, %s, %s, %s, %s, %s, ...", szUSERCODE_D10, szUSERNAME_D11,
szCOMCODE_D12, szPASSWORD_D13, szUSERDESCRIPTION_D14,
szUSERSTATE_D15, szUWPOPEDOM_D16, szCLAIMPOPEDOM_D17,
szOTHERPOPEDOM_D18, szPOPUWFLAG_D19, szSUPERPOPEDOMFLAG_D20,
szOPERATOR_D21);
return gjLRDRet;
}#ifndef CCI
BEGIN_VUSER_DECLARATION
DECLARE_VUSER_RUN("Vuser Run", Actions)
END_VUSER_DECLARATION
#endif#endif
转-LoadRunner动态访问Oracle数据库+多协议录制解决方案
2011-03-01 10:37:05
一、LoadRunner9.0动态访问Oracle数据库
#include "lrd.h"
static LRD_INIT_INFO lnitlnfo = {LRD_INIT_INFO_EYECAT};static LRD_DEFAULT_DB_VERSION DBTypeVersion[] = {{LRD_DBTYPE_NONE,LRD_DBVERSION_NONE}};
//这里的LRD_VAR_DESC数据结构声明是很重要的,他是用来存储sql结果数据集的结构体,第一个参数头文件中就是这么写的,第二个参数是最 大行数,第三个参数是每一行的最大长度,如果获得的查询结果比定义的长,运行时就会报错,提示列被截断,最后一个参数是查询结果的类型,可以再帮助中的索 引输入data types, database,列出的表格中是各种变量类型的名称
static LRD_VAR_DESC OBJECT_NAME_D1;
static LRD_VAR_DESC NUM ={LRD_VAR_DESC_EYECAT, 10, 32, LRD_DBTYPE_ORACLE, {1, 1, 0},DT_LONG_VARCHAR};
//定义初始化数据库的各种变量
static void FAR * OraEnv1;
static void FAR * OraSvc1;
static void FAR * OraSrv1;
static void FAR * OraSes1;
static void FAR * OraStm1;
static void FAR * OraDef1;
static unsigned long uliFetchedRows;
unsigned long rownum;
//初始化数据库
lrd_init(&lnitlnfo, DBTypeVersion);
lrd_initialize_db(LRD_DBTYPE_ORACLE,3,0);
lrd_env_init(LRD_DBTYPE_ORACLE, &OraEnv1,0,0);
lrd_ora8_handle_alloc(OraEnv1,SVCCTX,&OraSvc1,0);
lrd_ora8_handle_alloc(OraEnv1,SERVER,&OraSrv1,0);
lrd_ora8_handle_alloc(OraEnv1,SESSION,&OraSes1,0);
//连接数据库,我的是oracle,odbc中连接数据库名称就是这个
lrd_server_attach(OraSrv1,"数据库名",-1,0,0);
lrd_ora8_attr_set_from_handle(OraSvc1,SERVER,OraSrv1,0,0);
//用户名和密码
lrd_ora8_attr_set(OraSes1,USERNAME,"用户名",-1,0);
lrd_ora8_attr_set(OraSes1,PASSWORD,"密码",-1,0);
//初始化连接session
lrd_ora8_attr_set_from_handle(OraSvc1,SESSION,OraSes1,0,0);
//开始连接数据库
lrd_session_begin(OraSvc1,OraSes1,1,0,0);
lrd_ora8_handle_alloc(OraEnv1,STMT,&OraStm1,0);
//设定sql语句
lrd_ora8_stmt(OraStm1, "select XXX from XXX", 1, 0, 0);
//执行sql语句,并且将结果行数返回到rownum中
lrd_ora8_exec(OraSvc1, OraStm1, 0, 0,&rownum, 0, 0, 0, 0, 1);
//绑定该列
lrd_ora8_bind_col(OraStm1,&OraDef1,1,&NUM,0,0);
//设定保存列中的某个数据到row中,第二个参数为第几列,第三个参数为第几行(只能保存一个值),最后一个参数就是你想要保存到的parameter名称lrd_ora8_save_col(OraStm1, 1, 1, 0, "resu1");
lrd_ora8_fetch(OraStm1, -2, 2, &rownum, 0, 2, 0, 0);
lr_error_message("sql result: %s", lr_eval_string("{resu1}"));
//释放连接数据库的各种变量
lrd_handle_free(&OraStm1, 0);
lrd_session_end(OraSvc1, OraSes1, 0, 0);
lrd_server_detach(OraSrv1, 0, 0);
lrd_handle_free(&OraEnv1, 0);
(1)首先要安装oracle客户端,通过客户端连接oracle数据库。如果不装数据库客户端会报错,如下:illegal character `\0241'(2)写访问oracle数据库的脚本用oracle(2-tier)+web协议新建脚本,否则执行时会报错,如下:Error -- Unresolved symbol : lrdfnc_init
然后将录制的脚本拷到写好的访问oracle数据库脚本中。(3)数据库连接不上
Action.c(47): Error: lrdo_server_attach: "OCIServerAttach" return-code=OCI_ERROR, error-code=12154:
Action.c(47): Error: ORA-12154: TNS: 无法解析指定的连接标识符
Action.c(47): server_attach: ERROR, return-code=LRDE2009. ServerHandle=OraSrv1, ServerID="XXXX"(4)sql语句错误,报如下错误
Action.c(81): Error: lrdo_ora8_fetch: "OCIStmtFetch" return-code=OCI_ERROR, error-code=24338:
Action.c(81): Error: ORA-24338: 未执行语句句柄
Action.c(81): lrd_ora8_fetch: ERROR, return-code=LRDE2009. StmtHandle=OraStm1, 0 row(s) fetched
(5) 如果用controller执行涉及好的脚本报如下错误:you do not have a license for this vuser type please contact mercury interactive to renew your license
解决方案:原因是由于目前使用的License不支持Socket场景运行,将License替换一下就可以了。
使用的License也就是目前网络上比较通用的两个:
global 100user:AEAMAUIK-YAFEKEKJJKEEA-BCJGI
10000 web clients:AEABEXFR-YTIEKEKJJMFKEKEKWBRAUNQJU-KBYGB
一开始使用的10000 web clients的,出现该问题,后来替换成global 100 user 就可以了。具体视情况而定。
二、多协议录制脚本,协议web(http/html),ie打开后没有反应了
在recording options中advanced里选择support charset utf-8三、多协议录制脚本,协议web(http/html),ld根本没反应
修改ie设置,工具-高级,把启动第三方浏览器扩展(需要重启动)四、单协议录制脚本,系统中有些东西出不来
原因:客户端安装了插件,插件会向服务器发送请求转-使用LR测试Oracle数据库经验总结
2011-02-28 21:22:34
1、我将登录SQL*Plus的操作也录制在Action中,添加迭代运行会报错,提示如下:Action.c(11): Error: lrdo_server_attach: "OCIServerAttach" return-code=OCI_ERROR, error-code=24309:
Action.c(11): Error: ORA-24309: 已连接至服务器
Action.c(11): server_attach: ERROR, return-code=LRDE2009. ServerHandle=OraSrv1, ServerID="customs"
Abort was called from an action.解决办法:1、将登陆SQL*Plus的操作录制在vuser_init中;2、同时录制退出SQL*Plus的操作
2、测试压力上来以后,会有好多Vuser出现Error,具体报错如下:
Action.c(37): Error: lrdo_ora8_exec: "OCIStmtExecute" return-code=OCI_ERROR,error-code=00054:解决方法:把lrd_ora8_exec(OraSvc1, OraStm<i>, 0, 0, &uliRowsProcessed, 0, 0, 0, 0, 0);
改为:lrd_ora8_exec(OraSvc1, OraStm<i>, 0, 0, &uliRowsProcessed, 0, 0, 0, 0, 1);3、测试压力上来以后,会有好多Vuser出现Error,具体报错如下:
Action.c(13): Error: lrdo_server_attach: "OCIServerAttach" return-code=OCI_ERROR, error-code=12514:解决办法:开启数据库服务器监听,启动数据库服务器。
4、测试压力上来以后,会有好多Vuser出现Error,具体报错如下:
Action.c(26): Error: C interpreter run time error: Action.c (26): Error -- Unresolved symbol : lrd_session_begin.解决办法:在vuser_init中添加 #include "lrd.h"
5、测试压力上来以后,会有好多Vuser出现Error,具体报错如下:
Starting iteration 1.
Starting action Action.
Action.c(13): Error: lrdo_server_attach: "OCIServerAttach" return-code=OCI_ERROR, error-code=12541:
Action.c(13): Error: ORA-12541: TNS: 没有监听器
Action.c(13): server_attach: ERROR, return-code=LRDE2009. ServerHandle=OraSrv1, ServerID="lr"解决办法:启动数据库服务器,开启listener。如果需要使用isqlplus的话,开启服务:$isqlplusctl start
6、测试压力上来以后,会有好多Vuser出现Error,具体报错如下:
Action.c(13): Error: lrdo_server_attach: "OCIServerAttach" return-code=OCI_ERROR, error-code=12514:
Action.c(13): Error: ORA-12514: TNS: 监听进程不能解析在连接描述符中给出的 SERVICE_NAME
Action.c(13): server_attach: ERROR, return-code=LRDE2009. ServerHandle=OraSrv1, ServerID="lr"解决办法:检查压力机Oracle客户端解析文件tnsnames.ora,确保正确配置了这个文件。
检查测试的数据库服务器,确保正确配置了监听,并已经开启。7、 使用Controller产生负载,最后测试数据只有以下4条性能曲线:Running Vusers、Trans Response Time、Trans/Sec(Passed)、Total Trans/Sec(Passed)、其余的Throughput、HTTP Responses per Second、Connections等等性能统计项均显示为灰色,没有统计数据
解决办法:因为sqlplus.exe是一个win32程序,那么在测试的过程中只统计上面的四项,它不会统计Throughput这些Web测试才有的性能曲线。
所以,如果想对数据库服务器测试的更全面,这个时候就要使用isqlplus来发出查询。
1)在DB server上启动isqlplus服务:isqlplusctl start
2)启动VuGen,在客户端(压力机)启动isqlplus的Web页面
3)输入用户名、密码,我这里采用scott/tiger@lr
OK!录制完成之后,产生压力执行测试。顺利结束之后,可以看到如下曲线已经抓取出来了:
Throughput、HTTP Responses per Second、Connections
剩余的工作就是如何分析性能数据了。转-Loadrunner测试MySql数据库性能,测试SQL语句性能的脚本例子
2011-02-28 20:17:12
此代码为Loadrunner 8 通过C API类型的Vuser 测试MySQL性能,或者测试sql语句性能的脚本。
view plaincopy to clipboardprint?
/*需要的表结构如下
CREATE TABLE `test_data` (
`order_id` BIGINT UNSIGNED NOT NULL COMMENT 'Order numbers. Must be unique.',
`status` BOOL NOT NULL DEFAULT '0' COMMENT 'Whether data has been used or not. A value of 0 means FALSE.',
`date_used` DATETIME NULL COMMENT 'Date/time that the data was used.',
UNIQUE (
`order_id`
)
) ENGINE = innodb COMMENT = 'LoadRunner test data';
*/
Action()
{
int rc;
int db_connection; // 数据库连接
int query_result; // 查询结果集 MYSQL_RES
char** result_row; // 查询的数据衕
char *server = "localhost";
char *user = "root";
char *password = "123456";
char *database = "test";
int port = 3306;
int unix_socket = NULL;
int flags = 0;
// 找到libmysql.dll的所在位置.
rc = lr_load_dll("C:\\Program Files\\MySQL\\MySQL Server 5.1\\bin\\libmysql.dll");
if (rc != 0) {
lr_error_message("Could not load libmysql.dll");
lr_abort();
}
// 创建MySQL对象
db_connection = mysql_init(NULL);
if (db_connection == NULL) {
lr_error_message("Insufficient memory");
lr_abort();
}
// 连接到MySQL数据库
rc = mysql_real_connect(db_connection, server, user, password, database, port, unix_socket, flags);
if (rc == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
// 向数据库插入数据
// 此处的 {ORDER_ID} 是一个参数,简单测试时可以用一个常数代替
lr_save_string (lr_eval_string("INSERT INTO test_data (order_id) VALUES ({ORDER_ID})"),"paramInsertQuery");
rc = mysql_query(db_connection, lr_eval_string("{paramInsertQuery}"));
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
// 从数据库读取一个数据并显示
rc = mysql_query(db_connection, "SELECT order_id FROM test_data WHERE status IS FALSE LIMIT 1");
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
query_result = mysql_use_result(db_connection);
if (query_result == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
// 如果结果集包含多行数据,需要多次调用 mysql_fetch_row 直到返回NULL
result_row = (char **)mysql_fetch_row(query_result);
if (result_row == NULL) {
lr_error_message("Did not expect the result set to be empty");
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
// 保存参数,用于删除这行数据
lr_save_string(result_row[0], "paramOrderID");
lr_output_message("Order ID is: %s", lr_eval_string("{paramOrderID}"));
mysql_free_result(query_result);
// 在事务里更新一行数据,需要用InnoDB引擎
rc = mysql_query(db_connection, "BEGIN"); //启动事务
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
// 使用 "FOR UPDATE" 锁住要更新的数据行
rc = mysql_query(db_connection, "SELECT order_id FROM test_data WHERE status IS FALSE LIMIT 1 FOR UPDATE");
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
query_result = mysql_use_result(db_connection);
if (query_result == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
result_row = (char **)mysql_fetch_row(query_result);
if (result_row == NULL) {
lr_error_message("没有查询到结果");
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
lr_save_string(result_row[0], "paramOrderID");
lr_output_message("Order ID is: %s", lr_eval_string("{paramOrderID}"));
mysql_free_result(query_result);
lr_save_string(lr_eval_string("UPDATE test_data SET status=TRUE, date_used=NOW() WHERE order_id='{paramOrderID}'"),"paramUpdateQuery");
rc = mysql_query(db_connection, lr_eval_string("{paramUpdateQuery}"));
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
rc = mysql_query(db_connection, "COMMIT"); // 提交事务
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
// 再次查找数据,应该为空了,因为前面的事务更新了标志
rc = mysql_query(db_connection, "SELECT order_id FROM test_data WHERE status IS FALSE LIMIT 1");
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
query_result = mysql_use_result(db_connection);
if (query_result == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
result_row = (char **)mysql_fetch_row(query_result);
if (result_row == NULL) {
lr_output_message("Result set is empty as expected");
mysql_free_result(query_result);
} else {
lr_error_message("Did not expect the result set to contain any rows");
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
// 删除数据
lr_save_string(lr_eval_string("DELETE FROM test_data WHERE order_id = '{paramOrderID}'"),"paramDeleteQuery");
rc = mysql_query(db_connection, lr_eval_string("{paramDeleteQuery}"));
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
// 释放MySQL资源
mysql_close(db_connection);
return 0;
}
/*需要的表结构如下
CREATE TABLE `test_data` (
`order_id` BIGINT UNSIGNED NOT NULL COMMENT 'Order numbers. Must be unique.',
`status` BOOL NOT NULL DEFAULT '0' COMMENT 'Whether data has been used or not. A value of 0 means FALSE.',
`date_used` DATETIME NULL COMMENT 'Date/time that the data was used.',
UNIQUE (
`order_id`
)
) ENGINE = innodb COMMENT = 'LoadRunner test data';
*/
Action()
{
int rc;
int db_connection; // 数据库连接
int query_result; // 查询结果集 MYSQL_RES
char** result_row; // 查询的数据衕char *server = "localhost";
char *user = "root";
char *password = "123456";
char *database = "test";
int port = 3306;
int unix_socket = NULL;
int flags = 0;// 找到libmysql.dll的所在位置.
rc = lr_load_dll("C:\\Program Files\\MySQL\\MySQL Server 5.1\\bin\\libmysql.dll");
if (rc != 0) {
lr_error_message("Could not load libmysql.dll");
lr_abort();
}// 创建MySQL对象
db_connection = mysql_init(NULL);
if (db_connection == NULL) {
lr_error_message("Insufficient memory");
lr_abort();
}// 连接到MySQL数据库
rc = mysql_real_connect(db_connection, server, user, password, database, port, unix_socket, flags);
if (rc == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}// 向数据库插入数据
// 此处的 {ORDER_ID} 是一个参数,简单测试时可以用一个常数代替
lr_save_string (lr_eval_string("INSERT INTO test_data (order_id) VALUES ({ORDER_ID})"),"paramInsertQuery");
rc = mysql_query(db_connection, lr_eval_string("{paramInsertQuery}"));
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}// 从数据库读取一个数据并显示
rc = mysql_query(db_connection, "SELECT order_id FROM test_data WHERE status IS FALSE LIMIT 1");
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
query_result = mysql_use_result(db_connection);
if (query_result == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
// 如果结果集包含多行数据,需要多次调用 mysql_fetch_row 直到返回NULL
result_row = (char **)mysql_fetch_row(query_result);
if (result_row == NULL) {
lr_error_message("Did not expect the result set to be empty");
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
// 保存参数,用于删除这行数据
lr_save_string(result_row[0], "paramOrderID");
lr_output_message("Order ID is: %s", lr_eval_string("{paramOrderID}"));
mysql_free_result(query_result);// 在事务里更新一行数据,需要用InnoDB引擎
rc = mysql_query(db_connection, "BEGIN"); //启动事务
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
// 使用 "FOR UPDATE" 锁住要更新的数据行
rc = mysql_query(db_connection, "SELECT order_id FROM test_data WHERE status IS FALSE LIMIT 1 FOR UPDATE");
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
query_result = mysql_use_result(db_connection);
if (query_result == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
result_row = (char **)mysql_fetch_row(query_result);
if (result_row == NULL) {
lr_error_message("没有查询到结果");
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
lr_save_string(result_row[0], "paramOrderID");
lr_output_message("Order ID is: %s", lr_eval_string("{paramOrderID}"));
mysql_free_result(query_result);
lr_save_string(lr_eval_string("UPDATE test_data SET status=TRUE, date_used=NOW() WHERE order_id='{paramOrderID}'"),"paramUpdateQuery");
rc = mysql_query(db_connection, lr_eval_string("{paramUpdateQuery}"));
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
rc = mysql_query(db_connection, "COMMIT"); // 提交事务
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}// 再次查找数据,应该为空了,因为前面的事务更新了标志
rc = mysql_query(db_connection, "SELECT order_id FROM test_data WHERE status IS FALSE LIMIT 1");
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
query_result = mysql_use_result(db_connection);
if (query_result == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
result_row = (char **)mysql_fetch_row(query_result);
if (result_row == NULL) {
lr_output_message("Result set is empty as expected");
mysql_free_result(query_result);
} else {
lr_error_message("Did not expect the result set to contain any rows");
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}// 删除数据
lr_save_string(lr_eval_string("DELETE FROM test_data WHERE order_id = '{paramOrderID}'"),"paramDeleteQuery");
rc = mysql_query(db_connection, lr_eval_string("{paramDeleteQuery}"));
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}// 释放MySQL资源
mysql_close(db_connection);
return 0;
}转-Loadrunner 测试sql语句性能(sql Server)
2011-02-28 20:06:24
本次通过loadrunner录制Sql Server介绍一下如何测试一个sql语句或存储过程的执行性能。
主要分如下几个步骤完成:
第一步、测试准备
第二步、配置ODBC数据源
第三步、录制SQL语句在Sql Server查询分析器中的运行过程
第四步、优化录制脚本,设置事务
第五步、改变查询数量级查看SQL语句的性能
第六步、在controller中运行脚本
转载请注明出处:http://www.51testing.com/?41972
下面开始具体的介绍:
测试准备阶段我们首先要确认测试数据库服务器:我们可以在本地安装SQL SERVER数据库服务端及客户端,也可以确定一台装好的SQL SERVER服务器。
接下来,准备测试数据:对数据库测试时我们要考虑的不是SQL语句是否能够正确执行,而是在某数量级的情况下SQL语句的执行效率及数据库服务的运行情况,所以我们分别准备不同数量级的测试数据,即根据实际的业务情况预估数据库中的记录数,在本次讲解中我们不考虑业务逻辑也不考虑数据表之间的关系,我们只建立一张表,并向此表中加入不同数量级的数据,如分别加入1000条、10000条、50000条、100000条数据查看某SQL语句的执行效率。
在查询分析器中运行如下脚本:
--创建测试数据库
create database loadrunner_test;
use loadrunner_test
--创建测试数据表
create table test_table
(username varchar(50),sex int,age int,address varchar(100),post int)
--通过一段程序插入不同数量级的记录,具体的语法在这里就不多说了
declare @i int
set @i=0
while @i<1000 //循环1000次,可以根据测试数据情况改变插入条数
begin
BEGIN TRAN T1
insert into test_table (username,sex,age,address,post) values ('户瑞海'+cast(@i as varchar),@i-1,@i+1,'北京市和平里'+cast(@i as varchar)+'号',123456);
IF @@ERROR <> 0
begin
rollback;
select @@error
end
else
begin
commit;
set @i = @i+1
end
end
转载请注明出处:http://www.51testing.com/?41972
好了,执行完上述语句后,建立的数据表中已经有1000条记录了,下面进行第二步的操作,配置ODBC数据源,为了能让loadrunner能够通过ODBC协议连接到我们建立的SQL SERVER数据路,我们需要在本机上建立ODBC数据源,建立方法如下:
控制面板—性能和维护—管理工具—数据源(ODBC)--添加,在列表中选择SQL SERVER点击完成,根据向导输入数据源名称,链接的服务器,下一步,输入链接数据库的用户名和密码,更改链接的数据库,完成ODBC的配置,如果配置正确的话,在最后一步点击“测试数据源”,会弹出测试成功的提示。
配置好ODBC数据源后就要录制SQL语句在查询分析器中的执行过程了:
1、 打开loadrunner,选择ODBC协议
2、 在start recording中的application type 选择win32 application;program to record中录入SQL SERVER查询分析器的路径“..\安装目录\isqlw.exe”
3、 开始录制,首先通过查询分析器登录SQL SERVER,在打开的查询分析器窗口中输入要测试的SQL语句,如“select * from test_table;”
4、 在查询分析器中执行该语句,执行完成后,结束录制
好了,现在就可以看到loadrunner生成的脚本了(由于脚本过长,在这里就不粘贴了,有需要的朋友可以加我QQ,我把脚本发给你们),通过这些语句,我们可以看出,登录数据库的过程、执行SQL语句的过程
转载请注明出处:http://www.51testing.com/?41972
接下来,我们来优化脚本,我们分别为数据库登录部分和执行SQL语句的部分加一个事物,在增加一个double的变量获取事务执行时间,简单内容如下:
Action()
{ double trans_time; //定义一个double型变量用来保存事务执行时间
lr_start_transaction("sqserver_login"); //设置登录事务的开始
lrd_init(&InitInfo, DBTypeVersion); //初始化链接(下面的都是loadrunner生成的脚本了,大家可以通过帮助查到每个函数的意思)
lrd_open_context(&Ctx1, LRD_DBTYPE_ODBC, 0, 0, 0);
lrd_db_option(Ctx1, OT_ODBC_OV_ODBC3, 0, 0);
lrd_alloc_connection(&Con1, LRD_DBTYPE_ODBC, Ctx1, 0 /*Unused*/, 0);
………………
trans_time=lr_get_transaction_duration( "sqserver_login" ); //获得登录数据库的时间
lr_output_message("sqserver_login事务耗时 %f 秒", trans_time); //输出该时间
lr_end_transaction("sqserver_login", LR_AUTO); //结束登录事务
lr_start_transaction("start_select");//开始查询事务
lrd_cancel(0, Csr2, 0 /*Unused*/, 0);
lrd_stmt(Csr2, "select * from test_table;\r\n", -1, 1, 0 /*None*/, 0);//此句为执行的SQL
lrd_bind_cols(Csr2, BCInfo_D42, 0);
lrd_fetch(Csr2, -10, 1, 0, PrintRow24, 0);
……………..
trans_time=lr_get_transaction_duration( "start_select" ); //获得该SQL的执行时间
lr_output_message("start_select事务耗时 %f 秒", trans_time); //输出该时间
lr_end_transaction("start_select", LR_AUTO); //结束查询事务
优化后,在执行上述脚本后,就可以得到登录到数据库的时间及运行select * from test_table这条语句的时间了,当然我们也可以根据实际情况对该条语句进行参数化,可以测试多条语句的执行时间,也可以将该语句改为调用存储过程的语句来测试存储过程的运行时间。
接下来把该脚本在controller中运行,设置虚拟用户数,设置集合点,这些操作我就不说了,但是值得注意的是,没有Mercury 授权的SQL SERVER用户license,在运行该脚本时回报错,提示“You do not have a license for this Vuser type.
Please contact Mercury Interactive to renew your license.”我们公司穷啊买不起loadrunner,所以我也无法继续试验,希望有license朋友们监控一下运行结果!
最起码在VUGen中运行该脚本我们可以得到任意一个SQL语句及存储过程的执行时间,如果我们测试的B/S结构的程序,我们也可以通过HTML协议录制的脚本在CONTROLLER中监控SQL SERVER服务器的性能情况,这样两方面结合起来就可以对数据库性能做一个完整的监控了。
本人对LOADRUNNER也是在摸索中,如果文章有写的不对,或理解错误的地方请指出,不甚感激
转-测试过程总结(用例,执行,沟通)
2011-02-28 20:04:25
1、测试过程中往往容易忽略最简单的测试,比如:系统的单词拼写,界面的显示与兼容性,易用性测试等。测试人员认为将单词放在最后测试,会出现测试疲劳,导致忽略这部分的测试。(建议:测试人员在针对一个需求进行验证的时候,应该明白存在哪几个方面的测试,比如:功能测试,业务需求测试,兼容性测试,安全性测试,界面测试,易用性测试等,将这几种融入到自己的意识里,每次测试过程中检查是否覆盖或遗漏了上述测试)
2、测试用例里没有区分用例的重要级别,输入数据及预置条件不是很准确。(建议:在写测试用例的时候,要注意分清楚测试用例的重要等级(H、M、L),在后期的测试执行中可以根据重要等级来划分执行的先后顺序,在时间不充足的情况下,可以安排只执行High与Medium级别的用例。说明:跟业务流程或 需求紧密相关的测试用例可以定义为High,一般的功能点及异常检查或数据内容显示的测试用例可定义为Medium,对于界面性显示的测试用例可定义为 Low。同样预置条件与输入数据对于在测试执行的时候起了很大的帮助作用,测试人员应该根据实际需要准确的定义预置条件与输入数据。
3、测试人员编写测试用例不能把握编写的粒度,到底写到哪个程度用例应该算恰到好处的。(建议:测试人员首先应根据项目组的要求,允许投入的时间及不同类型的业务系统去着手编写测试用例,其次测试人员每针对一个需求点编写测试用例的时候,尽量从以下几种测试类型去考虑测试点的覆盖:用户界面、数据的初始化、数据的同步性、数据的一致性、数据的有效性、出错处理测试、关键功能点、权限检查、业务数据流、业务状态转换、系统间接口集成、可用性、安全性、性能。因为测试用例的粗细同样决定着后续的测试执行工作以及测试用例维护工作的投入时间,不能因为测试用例而导致整个测试工作的后延。)
4、测试人员编写的测试用例没有注意到每种测试用例类型的排列先后顺序,以及测试用例执行的连贯性,同时没有与实际的测试执行结合起来。(建 议:一个需求所扩展出来的测试用例应尽量按照一定的顺序进行排列,如:界面显示检查 -> 数据内容检查 -> 功能点的出错处理检查 -> 功能点的正常处理检查 -> 业务流程的检查 -> 权限检查,这样可以让用例看起来条理清晰,可读性较强。同时测试用例更应该与测试执行时所做的操作相吻合,比如测试人员首先登录系统,进入某一个页面,先检查界面文本显示,然后查看数据内容是否正确,接着检查某个功能是否进行了出错处理,它是否达到了正常的可用性,最后提交数据,检查业务流程流转是否正确等。所以用例应该根据上面的这些检查操作来编写,通过一连串测试用例来实现这些操作.
7、问题单的严重级别定义不准确。在测试过程中,测试人员往往对于系统权限,流程错误等问题单给予提示或一般的严重级别,这样可能导致开发经理在分发问题的时候产生误导,或者导致项目质量分析报告中出现误差。(建议:测试人员应该根据缺陷给用户所带来的影响,以及与业务操作的关系等多方面去考虑,实事求是的给出准确的定义。bug严重级定义请参考缺陷填写规范V0.2.doc5、一旦测试任务较多时,测试人员不能较好的把握测试的主次及优先顺序。不知道业务集中在哪些地方,哪些场景用户操作比较多。(建议:测试人员应该了解业务人员的基本操作习惯以及业务集中区域,对于业务人员经常操作的模板及业务,或者业务人员依赖性很强的功能点,测试人员应该重点对待,认真测试,比如:创建合同,邮件通知等。同时对于的不同的业务流程,测试人员应该与需求人员进行咨询,得出测试的优先级,比如:在某系统里,合同的业务单数最多,其次为开票,站点。)
6、测试过程中提交问题单的占用的时间过多,导致测试的时间不够。 (建议:测试人员在前期提单尽量标准化,规范化。随着测试的深入以及工作量的增加,测试人员可以通过标题准确来描述问题单,让开发人员通过标题就可以知道问题所在。其次测试人员对于比较容易重现的问题单或者容易理解的,可以尽量忽略问题描述,但还是需要提供截图。对于组合操作发现的问题单,描述里面需要写明重现步骤及测试数据与条件。)
8、测试人员的沟通积极性不足。测试人员在整个软件开发生命周期里需要跟各种不同的角色进行沟通,比如需求人员,开发人员,开发经理,项目经理,架构师,运维人员及编辑人员等,与各种不同角色的人员进行沟通可以更好的支撑测试人员顺利的完成测试工作。(建 议:测试人员在熟悉需求及编写用例的时候,应该主动与需求人员进行沟通,明确需求,解答需求疑惑。主动与开发人员进行沟通,咨询系统原型,获取开发人员的 开发思路,从而完善测试用例,更全面的覆盖测试执行;应主动向项目经理或开发经理,提出风险问题或者自己的建议,如测试的面太广,测试时间不够等问题。性能测试人员更应该向系统架构师咨询系统的设计与架构,为后面的性能测试打下结实的基础,尽早的发现测试过程中的难点与问题点)[转载]测试部门绩效考评标准(供参考)
2011-02-28 20:03:24
一、 专业素质得分:绩效 60% MAX分值 1001、用例进度(15分):
A、要求:制定checklist,包括3个时间点(第一次发送用例、邮件评审后第二次发送用例、组内评审后第三次发送最终用例)。checklist和3次的输出一起发送,例如邮件内容为checklist时间点,附件为用例或会议记录。如有临时紧急工作穿插,checklist及时修订发送。(以月度版本为单位)
B、评分标准:
(1)每个时间点按照checklist提前完成,+5。
(2)终稿时间按照checklist提前完成,+3。
(3)按checklist终稿时间按时完成,为基础分10分。
(4)如果终稿时间有所delay,扣除2分。
2、用例质量(25分):
A、要求:主要按照测试用例的遗漏点进行扣分制算法。整体分包括了策划功能面用例设计、技术实现面用例设计、格式细节面用例设计和系统漏洞面发现及游戏性考虑设计。以上评审内容包括邮件评审和会议评审,重复的补充点不重复扣除分数。
B、评分标准:
(1)在评审中,功能点(包括策划和程序面)用例设计缺失,一点扣除2分。
(2)在评审中,重点漏洞的测试点考虑缺失,一点扣除1分。
(3)在评审中,细节考虑缺失,一点扣除0.2分。
3、测试流程(15分):
A、要求:根据版本计划安排制定测试计划checklist(第一轮测试完成时间、bug回归完成时间、第二轮测试完成时间)。根据每日日报的时间点来进行check,是否有delay的问题存在。
B、评分标准:
(1)每个时间点按照checklist提前完成,+5。
(2)最后一个时间点按照checklist提前完成,+3。
(3)最后完成时间点按照checklist按时完成,为10分。
(4)最后完成时间点delay,为8分。
4、测试质量(25分):
A、要求:根据测试用例和在测试中考虑的异常测试点的遗漏,以满分制按照遗漏bug等级进行扣分,遗漏bug包括第二轮测试中发现的bug和外 网玩家提交的bug。如果在第二轮测试中按照发现的新增bug根据bug的等级进行加分。Bug扣除分数按照bugtrace的提交等级划分按照测试组定 义的bug分类等级划分。进入计算的bug属于大家公投可重现的bug,无法重现或难于重现的bug不计入bug扣分记录。
B、评分标准:
(1)遗漏致命bug,一个扣除2分。
(2)遗漏严重bug,一个扣除1分。
(3)遗漏一般bug,一个扣除0.2。
(4)在运营期项目均采取此项分数,对于非运营期项目,主要为发现bug加分机制,加分分数为基础分22分+以上对应等级分数的一半。
(5)第二轮测试发现以上等级bug同等加分,无上限分值限制。
5、测试接口人(7分):
A、要求:按照版本的工作内容,进行工作日报和出档邮件的输出以及测试进度的跟进。以上责任为项目测试接口人,但是具体执行为轮流得版本当前负责人。
B、评分标准:
(1)完成每日测试日报,内容包括测试进度和计划以及版本情况和bug情况反馈等,1分。
(2)出档邮件发送和出档情况跟进督促,1分。
(3)加壳情况和预更新配置情况跟进督促,1分。
(4)对于版本测试用例完成后的GM指令需求和工具需求的一个收集整理和输出,以及对提交bug的规范检查和跟进指导,2分;
(5)对于版本结束后放到外网体验一周后的运营质量的总结和问题的总结,以及后继解决方案的输出,2分;
(6)以上各项如有疏漏和时间的delay不得分。
6、用例补充加分(10分):
A、要求:根据现有的用例补充,包括邮件补充和用例评审会议补充,进行加分的一项分数。用例补充,包括评审会上的提出点均作为加分项目进行鼓励,包括提出问题,如果有助于理解实现上的问题也作为补充项目。
B、评分标准:
(1)补充用例的点是构成用例编写人扣分的点的,给与扣除分数同等加分,即对方扣除1分,则第一个补充的人+1分,这也是鼓励大家尽快回复的一项,先补充的先得分,调动积极性。
(2)在用例邮件回复和评审会中提出关键性问题的,给与对应严重程度的加分。
(3)本项得分累计加分不超过10分。
(4)第一个后重复补充的不算分,机会给跑在最前面的人。
7、工具需求和整理使用加分(3分):
A、要求:根据现有测试中发现的问题,或者是新增系统中的提高质量和效率的,或者是对原有系统常重复使用的功能的测试,能从方法上提出工具的实际需求,并且能给对应测试开发人员提出具体的实现的一个想法和方案,共同完成工具或者流程建设上的方法。
B、评分标准:
(1)切实利用率和开发时间性价比较高,或者能总结现有工具给出新的优化方案,切实优化后大家好评一致,将直接给分。
(2)此项加分由项目接口人提出,统计大家意见后,直接加3分。
二、专业得分:绩效 60% MAX分值 100
1、考勤得分:考勤 15% MAX分值 100
2、 执行得分:执行能力 15% MAX分值 100
考核内容【补充】:
1) 个人制定根据组内计划制定合理的个人计划,积极主动的执行各类需求,根据优先级合理安排工作内容,按照计划按时完成既定目标。
2) 很好的把握工作进度和推动影响自己进度的相关步骤的前进,以期能够很好的达到自己的既定目标。
3) 发现问题能及时调整偏差。根据变动能迅速调整目标,很好的关注问题的重点和细节的改进。
4) 能够推动某一类规范/流程的执行。
3、沟通得分:沟通能力 10% MAX分值 100
考核内容【补充】:
1)工作中同组的工作沟通和流程沟通以及经验分享。
2)能很好的组内沟通很好的促进需求的理解和任务的执行。
4)跨组的沟通能比较好的提出解决方案并且反馈问题。
5)跨组沟通中达到双方可接受的方案并记录在案,并以解决问题的心态去面对出现的问题。
转-COOKIES测试
2011-02-28 20:01:50
COOKIE 是本地文件,是40大盗在阿里巴巴家做的记号,
或者是送牛奶的人在你家门口钉的箱子。
SESSION 是服务器端内存,是你洗澡时浴池发给你的钥匙。
自己专用,可以开自己的好多箱子。
APPLICATION 是公共浴池。
在这里能看见所有人,包括ppmm哦:)。那么为什么要用COOKIE而不用SESSION呢
看下区别有效时间以及存储方式 传输内容
COOKIE 可设置并在本地保留 明码信息
SESSION 在IE不关闭并服务器不超时 只有SESSIONID当如果想让用户下次登入网站不需要输入用户名或者密码的时候就只能用COOKIE,
因为他可以保留相当长的时间(在COOKIE记录被删除或者失效日期之前)
而SESSION就不可以,他不会保留太长时间,而且IE在关闭后就自动清除了SESSIONID记录
在下次登入的时候会请求新的SESSIONID
而服务器想通过用户个人变量校验用户的状态的时候,就不能用COOKIE
如果用设置用户权限是USER。而IE访问的时候就把USER的明码传输到服务器。
那么如果我通过一定手段,比如直接修改COOKIE记录,把USER修改成ADMIN呢~~
就麻烦了。
但存储用户名和密码或者网站的配色方案这样的信息,用COOKIE是最好的转-jira从HSQL迁移到MYSQL
2011-02-23 11:49:29
JIRA使用自带的嵌入式数据库还是比较快的,不过占用内存太大。所以考虑将JIRA迁移到别的数据库上,迁移到oracle10g后,发现速度比较慢,听朋友说MYSQL不错,就准备迁移到MYSQL上。
迁移过程很简单
1.将项目导出成XML文件。
2、停止JIRA服务。
3.安装MYSQL,最好将MYSQL的字符集设置为UTF-8.在服务启动所使用的my.ini中修改。
default-character-set=utf8
4.创建MYSQL数据库,create database jiradb character set utf8;,如果不是UTF8的字符集,长的文本导入时会报错,无法导入。
5.创建连接用户,密码。 如果连接的是远程的数据库,请在用户配置中HOSTNAME这一栏,标明应用服务器的IP。(我用Navicat mysql配置MYSQL数据库的)
6.修改conf/server.xml
<Context path="" docBase="${catalina.home}/atlassian-jira" reloadable="false">
<Resource name="jdbc/JiraDS" auth="Container" type="javax.sql.DataSource"
username="[enter db username]"
password="[enter db password]"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost/jiradb?autoReconnect=true&useUnicode=true&characterEncoding=UTF8"
[ 删除这儿的 minEvictableIdleTimeMillis 和 timeBetweenEvictionRunsMillis 参数配置] />7、配置 JIRA Entity Engine
<!-- DATASOURCE - You will need to update this tag for your installation.
-->
<datasource name="defaultDS" field-type-name="mysql"
[ 如果这句存在的话,请删除。schema-name="PUBLIC" ]8.MySQL driver
将MySQL JDBC 驱动 (mysql-connector-java-3.x.x-bin.jar) 放在common/lib/ 目录下,否则会报连接不到数据库的错误。注意,在CLASSPATH不要放Debug版本的驱动 (mysql-connector-java-3.x.x-bin-g.jar) 否则会引起这个错误(JRA-8674).
9.启动JIRA,看一下有没有错误。一般如果报用户名密码不对,尝试三次连接的,请检查你的用户密码。报连接不到MYSQL的,请检查你的MYSQL 驱动。启动完成后,进入JIRA安装页面,将备份的XML文件导入就OK了。LoadRunner配置方案
2010-10-09 14:57:07
1.配置方案运行时设置选择“Tools”>“Options”。在“Options”对话框有“Run-Time Settings”(运行时设置)、“Timeout”(超时)、“Run-Time File Storage”(运行时文件存储)、“Path Translation Table”(路径转换表)等选项卡。
(1)“Run-Time Settings”选项卡
“Run-Time Settings”(运行时设置)选项卡如图2-52所示。
● Vuser Quota(Vuser配额):要防止系统过载,可以设置Vuser活动的配额。Vuser配额适用于所有负载生成器上的Vuser。其中,“Number of Vusers that may be initialized at one time all load generators”(一次可以初始化的Vuser数——所有负载生成器)用来设置负载生成器一次可以初始化的最大Vuser数,默认的最大数目为999。

图2-52 运行时设置
● When stopping Vusers:此组合框中的选项用于控制在单击“停止”按钮时Vuser停止运行的方式。其选项依次为:
Ø Wait for the current iteration to end before stopping(退出前等待当前迭代结束):指示LoadRunner允许Vuser在停止前完成正在运行的迭代。Vuser将移动到“正在逐步退出”状态,然后逐渐退出方案。
Ø Wait for the current action to end before stopping(退出前等待当前操作结束):指示LoadRunner允许Vuser在停止前完成正在运行的操作。Vuser将移动到“正在逐步退出”状态,然后逐渐退出方案。
Ø Stop immediately(立即停止):指示LoadRunner立即停止运行Vuser。Vuser将移动到“正在退出”状态,然后立即退出方案。
● Use random sequence with seed:勾选此复选框,表示允许LoadRunner使用随机顺序的种子数。每个种子值代表用于测试执行的一个随机值顺序。每当使用该种子值时,会将相同顺序的值分配给方案中的Vuser。该设置适用于使用Random方法从数据文件中分配值的参数化Vuser脚本。它还将影响录制的思考时间的随机百分比,如果在测试执行中发现问题,并且要使用相同的随机值顺序重复该测试,请启用该选项。
(2)“TimeOut”选项卡
“TimeOut”(超时)选项卡如图2-53所示。“Command Timeout”(命令超时)是各种LoadRunner命令的最长时间限制。在控制台发出命令时,可以设置负载生成器或Vuser执行该命令的最长时间。如果在超时间隔内没有完成该命令,控制台将发布一条错误消息。

图2-53 超时设置
● Enable timeout checks:即启用超时检查,指示LoadRunner在控制台发出命令后监视负载生成器和Vuser的状态。如果负载生成器或Vuser在指定的超时间隔内没有完成命令,控制台将发布一条错误消息。如果禁用超时限制,LoadRunner将无限长地等待负载生成器进行连接和断开连接,并且等待执行Initialize、Run、Pause和Stop命令。
● Connect:在此数值框中输入LoadRunner等待连接到任何负载生成器的时间限制值。如果在该时间内连接不成功,负载生成器的状态将更改为“失败”,默认连接超时是120秒。
● Disconnect:在此数值框中输入LoadRunner等待从任何负载生成器断开连接的时间限制值。如果在该时间内断开连接不成功,负载生成器的状态将更改为“失败”。默认的断开连接超时是120秒。
LoadRunner承认活动Vuser的数量会影响超时值。例如,1000个Vuser尝试初始化将比10个Vuser尝试初始化花费更长的时间。LoadRunner将基于活动Vuser的数量向指定的超时值中添加内部值。
● Init:在此数值框中输入Initialize命令的超时值,默认的时间限制是180秒。
● Run:在此数值框中输入Run命令的超时值,默认的时间限制是120秒。
● Pause:在此数值框中输入Pause命令的超时值,默认的时间限制是120秒。
● Stop:在此数值框中输入Stop命令的超时值,默认的时间限制是120秒。
● Update Vuser elapsed time every(更新Vuser已用时间):指定LoadRunner更新在“Vuser”对话框中的“Elapsed Time”(已用时间)列中显示的值的频率。默认每隔4秒更新一次Vuser已用时间。
如果选择一个Vuser并单击“Init”(初始化)按钮,LoadRunner将检查该Vuser在180秒(默认的“初始化”超时时间)内是否达到了“就绪”状态;如果没有达到,控制台将发布一条消息,指出该“初始化”命令超时。
(3)“Run-Time File Storage”选项卡
“Run-Time File Storage”(运行时文件存储)选项卡页面如图2-54所示。

图2-54 运行时文件存储设置
存储的脚本和结果可以使用下列选项之一:
● On the current Vuser machine(在当前Vuser计算机上):指示控制台将运行时文件保存在运行Vuser脚本的计算机上。在基于NT的计算机上,这些结果将保存到由TEMP或TMP环境变量定义的目录中。在UNIX计算机上,这些结果将保存到由 TMPDIR环境变量定义的目录中。如果没有定义TMPDIR环境变量,这些结果将保存到/tmp目录。
● On a shared network drive(在共享网络驱动器上):指示控制台将方案结果和/或Vuser脚本保存在共享网络驱动器上。共享网络驱动器是控制台和方案中的所有负载生成器对其拥有读写权限的驱动器。如果选择将结果保存到共享网络驱动器,可能需要执行路径转换。路径转换确保远程负载生成器可以识别指定的结果目录。如果指定所有Vuser在某个共享位置上直接访问其Vuser脚本,则在运行时不会传输任何脚本文件。该替代方法在以下两种情况可能很有用:
Ø 文件传输设备无法工作。
Ø Vuser脚本文件太大,因此要花费很长时间进行传输。切记,Vuser脚本文件在方案运行期间仅传输一次。
(4)“Path Translation Table”选项卡
“Path Translation Table(路径转换表)”选项卡如图2-55所示。

图2-55 路径转换表
如果指定了运行时文件存储的共享网络驱动器,可能需要执行“路径转换”,路径转换是LoadRunner用来转换远程路径名的一种机制。在典型的性能测试设备配置方案中,根据实际情况,多台负载生成器(计算机)会以不同方式映射共享网络驱动器。
2.运行环境设置
操作后出现“Run-Time Setting”窗口,其中有不同的标签页。下面对运行时经常需要配置的标签页进行简要的配置说明。
(1)“General:Miscellaneous”标签页(如图2-56所示)
此界面为运行期间针对某些特殊功能,例如出现错误时如何处理等的一些辅助设置,一般的情况下不需要改动,其中有三项供用户设置。

图2-56 环境设置
“Error Handing”栏设置LoadRunner在遇到错误时的处理方法,一般情况下不需要改动。此选项下有三个复选框,分别为运行期间遇到错误不同的处理方法,
● Continue on error:选择此项后,如果运行时出现错误,将继续执行脚本,不会因为错误出现而停止,以此来保证脚本整个运行过程的完整性。
● Fail open transactions on lr_error message:选择此项后,如果运行时出现错误,系统会在事先脚本中插入的lr_error_message函数中显示出错误,此项需要与一些函数进行配合使用。
● Generate snapshot on error:选择此项后,如果运行时出现错误,系统会根据错误的级别将错误界面形成快照记录下来,运行结束后可以打开错误窗口进行查看。
“Multithreading”栏用于确定Vuser运行时为多线程还是多进程,默认是多线程,一般不需要修改。如果选择“Run Vuser as a process”,则场景运行时会为每个Vuser创建一个进程;如果选择“Run Vuser as a thread”,则会将每个Vuser作为一个线程来运行,在任务管理器中只看到一个mmdrv.exe,这种方式的运行效率更高,能造成更大的压力。
“Automatic Transactions”栏默认选择的是第一项“Define any actions as a transcation”,但如果需要把脚本的每一步都当作事务,可以选择第二项“Define any step as a transcation”,这样可以省去多次添加事务的烦琐操作。
(2)“General:Think Time”标签页(如图2-57所示)

图2-57 思考时间设置
● Ignore think time(忽略录制思考时间):选择该项,VuGen在脚本回放过程中将不执行Lr_think_time()函数,这样将给服务器造成更大的压力。
● Replay think time(使用录制思考时间):如选中该项,依次有以下4种选择:
Ø As record:按照录制过程中的Think Time值回放脚本,使用lr_think_time函数中显示的参数。
Ø Multiply recorded think time by:按照录制过程中的Think Time值的整数倍回放脚本,这种方法可以增加或减少在回放脚本期间应用的思考时间。
例如,如果录制思考时间为4秒,则可以指示Vuser用2乘以该值,即总共为8秒。要将思考时间减少至2秒,可以用0.5乘以录制时间。
Ø Use random percentage of recorded think time:指定一个最小值和一个最大值,可设置Think Time值的范围,通过指定Think Time的范围,取其中的一个随机数的值来回放脚本。
例如,如果Think Time参数为4,并且指定最小值为该值的50%,而最大值为该值的150%,则Think Time的最小值为2(50%),而最大值为6(150%)。
Ø Limit think time to:限制Think Time的最大值,这样VuGen在回放脚本过程中就会把脚本中大于该限制值的Think Time值用该限制值来代替。
(3)“NetWork:Speed Simulation”标签页(如图2-58所示)

图2-58 网络配置
此界面为带宽的选择:选择能够最好地模拟所测试的环境的带宽,带宽越大,给Web服务器造成的压力就越大。为了方便选择带宽的大小,提供了几种选项,自上而下依次表示:
● Use maximum bandwidth(使用最大带宽):此项为默认选项,一般情况下运行场景不会考虑带宽大小情况,Vuser就按照网络上的最大可用带宽来运行。
● Use bandwidth(使用带宽):指明Vuser要模拟的特定带宽级别。如果此软件程序运行时要考虑带宽大小情况,需要规定带宽范围或者需要特定的带宽级别,就可以选择此项进行设置,可以选择从14.4K至512K bps范围内的几个带宽级别,以便模拟调制解调器、ISDN或DSL。
● Use custom bandwidth(使用自定义带宽):指明Vuser进行模拟的带宽限制,以位为单位指定带宽,若选择此项用户可以自己手动添加想要的带宽大小,1K=1024。
(4)“Internet Protocol:Preferences”标签页(如图2-59所示)
这里仅仅对两个经常需要改动的选项进行说明。
“Checks”栏下的Enable Image and text check”:启用Image/Text检查。默认情况下此选项是没有选中的。如果在前面设置了检查点,需要先选中该项,否则运行时LoadRunner不会执行检查这个步骤。

图2-59 启用检查点设置
“Advanced”栏下的“Non-critical resource error as warnings”:默认选中该项,这样一些不是特别重要的资源问题(比如一个小图片)出现错误时,LoadRunner仅仅把它们当作警告,不会当作错误,至于到底哪些资源不是特别重要,请选择“Recording Option”>“Advanced”>“Non-Resources”进行设置。
(5)“Internet Protocol:ContentCheck”标签页(如图2-60所示)

图2-60 错误页面处理设置
这里的设置是为了让VuGen检测何种页面为错误页面。如果被测的Web应用没有使用自定义的错误页面,那么这里不用作更改;如果被测的Web应用使用了自定义的错误页面,那么这里需要定义,以便让VuGen在运行过程中检测服务器返回的页面是否包含预定义的字符串,进而判断该页面是否为错误页面。如果是,VuGen就停止运行,指示运行失败。
● “Enable ContentCheck during replay”:默认选中此项,表示VuGen在回放脚本的过程中会检查页面是否包含错误信息。
● “New Application”:新建一类应用程序,比如ASP.NET或者JSP等。
● “New Rule”:在该应用下新建规则,规则中包含字符串或者字符前缀和后缀。
● “Set as Default”:默认情况下,当前所作的更改只适用于当前的脚本,如果想让更改适用于本机所有脚本的话,单击该按钮即可。
● “Import/Export”:利用该按钮可以把定义好的规则导入和导出。
其他的标签设置采用默认值即可,这里不再详细地介绍。
黑盒测试用例设计方法实践---(判定表驱动法)
2010-10-08 11:17:26
概念理解:
判定表是分析和表达多逻辑条件下执行不同操作的情况的工具
a、可配合因果图后期使用;
b、适合于多逻辑条件下的组合分析 ;
掌握判定表的结构:
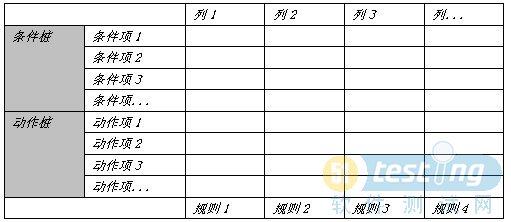
1)条件桩:列出了问题的所有条件
2)动作桩:列出了问题规定可能采取的操作
3)条件项:列出针对它左列条件的取值。如Y或N
4)动作项:列出在条件项的各种取值情况下应该采取的动作。如X表示
实践方法:
Step1:确定规则的个数(假如有n个条件。每个条件有两个取值(0,1),故有2的 n次方 种规则);
Step2:列出所有的条件桩和动作桩;
Step3:填入条件项(如Y或N);
Step4:填入动作项(X);
Step5:简化.合并相似规则(整列)
实践心得:
1、列出所有的条件桩和动作桩
2、前几步大家都很容易执行得出,但是关键在于最后的规则合并;
合并原则一般为:1、以相同动作项出发;2、相同的条件项直接合并;3、相反的条件忽略(注意:此处为一般情况,需结合业务再次明确其必要性,否则不予合并)
示例:
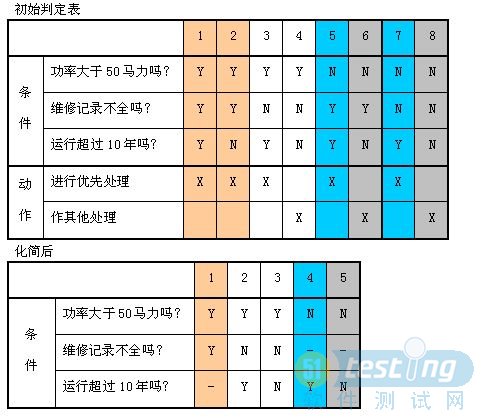
性能测试结果分析
2010-05-29 13:07:18
1. 具体问题具体分析(这是由于不同的应用系统,不同的测试目的,不同的性能关注点)
2. 查找瓶颈时按以下顺序,由易到难。
服务器硬件瓶颈-〉网络瓶颈(对局域网,可以不考虑)-〉服务器操作系统瓶颈(参数配置)-〉中间件瓶颈(参数配置,数据库,web服务器等)-〉应用瓶颈(SQL语句、数据库设计、业务逻辑、算法等)
注:以上过程并不是每个分析中都需要的,要根据测试目的和要求来确定分析的深度。对一些要求低的,我们分析到应用系统在将来大的负载压力(并发用户数、数据量)下,系统的硬件瓶颈在哪儿就够了。
3 分段排除法 很有效
分析的信息来源:
1 根据场景运行过程中的错误提示信息
2 根据测试结果收集到的监控指标数据
一.错误提示分析
分析实例:
1 Error: Failed to connect to server “10.10.10.30:8080″: [10060] Connection
Error: timed out Error: Server “10.10.10.30″ has shut down the connection prematurely
分析:
A、应用服务死掉。
(小用户时:程序上的问题。程序上处理数据库的问题)
B、应用服务没有死
(应用服务参数设置问题)
例:在许多客户端连接Weblogic应用服务器被拒绝,而在服务器端没有错误显示,则有可能是Weblogic中的server元素的AcceptBacklog属性值设得过低。如果连接时收到connection refused消息,说明应提高该值,每次增加25%
C、数据库的连接
(1、在应用服务的性能参数可能太小了 2、数据库启动的最大连接数(跟硬件的内存有关))
2 Error: Page download timeout (120 seconds) has expired
分析:可能是以下原因造成
A、应用服务参数设置太大导致服务器的瓶颈
B、页面中图片太多
C、在程序处理表的时候检查字段太大多
二.监控指标数据分析
1.最大并发用户数:
应用系统在当前环境(硬件环境、网络环境、软件环境(参数配置))下能承受的最大并发用户数。
在方案运行中,如果出现了大于3个用
户的业务操作失败,或出现了服务器shutdown的情况,则说明在当前环境下,系统承受不了当前并发用户的负载压力,那么最大并发用户数就是前一个没有出现这种现象的并发用户数。
如果测得的最大并发用户数到达了性能要求,且各服务器资源情况良好,业务操作响应时间也达到了用户要求,那么OK。否则,再根据各服务器的资源情况和业务操作响应时间进一步分析原因所在。
2.业务操作响应时间:
分析方案运行情况应从平均事务响应时间图和事务性能摘要图开始。使用“事务性能摘要”图,可以确定在方案执行期间响应时间过长的事务。
细分事务并分析每个页面组件的性能。查看过长的事务响应时间是由哪些页面组件引起的?问题是否与网络或服务器有关?
如果服务器耗时过长,请使用相应的服务器图确定有问题的服务器度量并查明服务器性能下降的原因。如果网络耗时过长,请使用“网络监视器”图确定导致性能瓶颈的网络问题3.服务器资源监控指标:
内存:
1 UNIX资源监控中指标内存页交换速率(Paging rate),如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。也可能是内存访问命中率低。
2 Windows资源监控中,如果Process\Private Bytes计数器和Process\Working Set计数器的值在长时间内持续升高,同时Memory\Available bytes计数器的值持续降低,则很可能存在内存泄漏。
内存资源成为系统性能的瓶颈的征兆:
很高的换页率(high pageout rate);
进程进入不活动状态;
交换区所有磁盘的活动次数可高;
可高的全局系统CPU利用率;
内存不够出错(out of memory errors)
处理器:
1 UNIX资源监控(Windows操作系统同理)中指标CPU占用率(CPU utilization),如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。如果服务器专用于SQL Server,可接受的最大上限是80-85%
合理使用的范围在60%至70%。
2 Windows资源监控中,如果System\Processor Queue Length大于2,而处理器利用率(Processor Time)一直很低,则存在着处理器阻塞。
CPU资源成为系统性能的瓶颈的征兆:
很慢的响应时间(slow response time)
CPU空闲时间为零(zero percent idle CPU)
过高的用户占用CPU时间(high percent user CPU)
过高的系统占用CPU时间(high percent system CPU)
长时间的有很长的运行进程队列(large run queue size sustained over time)
磁盘I/O:
1 UNIX资源监控(Windows操作系统同理)中指标磁盘交换率(Disk rate),如果该参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统。
2 Windows资源监控中,如果 Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec页面读取操作速率很低,则可能存在磁盘瓶径。
I/O资源成为系统性能的瓶颈的征兆 :
过高的磁盘利用率(high disk utilization)
太长的磁盘等待队列(large disk queue length)
等待磁盘I/O的时间所占的百分率太高(large percentage of time waiting for disk I/O)
太高的物理I/O速率:large physical I/O rate(not sufficient in itself)
过低的缓存命中率(low buffer cache hit ratio(not sufficient in itself))
太长的运行进程队列,但CPU却空闲(large run queue with idle CPU)
4.数据库服务器:
SQL Server数据库:
1 SQLServer资源监控中指标缓存点击率(Cache Hit Ratio),该值越高越好。如果持续低于80%,应考虑增加内存。
2 如果Full Scans/sec(全表扫描/秒)计数器显示的值比1或2高,则应分析你的查询以确定是否确实需要全表扫描,以及SQL查询是否可以被优化。
3 Number of Deadlocks/sec(死锁的数量/秒):死锁对应用程序的可伸缩性非常有害,并且会导致恶劣的用户体验。该计数器的值必须为0。
4 Lock Requests/sec(锁请求/秒),通过优化查询来减少读取次数,可以减少该计数器的值。
Oracle数据库:
1 如果自由内存接近于0而且库快存或数据字典快存的命中率小于0.90,那么需要增加SHARED_POOL_SIZE的大小。
快存(共享SQL区)和数据字典快存的命中率:
select(sum(pins-reloads))/sum(pins) from v$librarycache;
select(sum(gets-getmisses))/sum(gets) from v$rowcache;
自由内存: select * from v$sgastat where name=’free memory’;
2 如果数据的缓存命中率小于0.90,那么需要加大DB_BLOCK_BUFFERS参数的值(单位:块)。
缓冲区高速缓存命中率:
select name,value from v$sysstat where name in (’db block gets’,
‘consistent gets’,'physical reads’) ;
Hit Ratio = 1-(physical reads / ( db block gets + consistent gets))
3 如果日志缓冲区申请的值较大,则应加大LOG_BUFFER参数的值。
日志缓冲区的申请情况 :
select name,value from v$sysstat where name = ‘redo log space requests’ ;
4 如果内存排序命中率小于0.95,则应加大SORT_AREA_SIZE以避免磁盘排序 。
内存排序命中率 :
select round((100*b.value)/decode((a.value+b.value), 0, 1, (a.value+b.value)), 2)from v$sysstat a, v$sysstat b where a.name=’sorts (disk)’ and b.name=’sorts (memory)’
注:上述SQL Server和Oracle数据库分析,只是一些简单、基本的分析,特别是Oracle数据库的分析和优化,是一门专门的技术,进一步的分析可查相关资料。性能测试的结果分析是性能测试的重中之重。在实际工作中,由于测试的结果分析比较复
杂、需要具备很多相关的专业知识,因此常常会感觉拿到数据不知从何下手。这也是我学习性能
测试过程中感觉比较尴尬和棘手的事,为此我在研读了《WEB性能测试实战》后特作了以下笔
记,这里只是书中第4章WEB应用程序性能分析的一
部分,贴出来希望和大家共同讨论:
一:性能分析的基础知识:
1.几个重要的性能指标:相应时间、吞吐量、吞吐率、TPS(每秒钟处理的交易数)、点
击率等。
2.系统的瓶颈分为两类:网络的和服务器的。服务器瓶颈主要涉及:应用程序、WEB服务
器、数据库服务器、操作系统四个方面。
3.常规、粗略的性能分析方法:
当增大系统的压力(或增加并发用户数)时,吞吐率和TPS的变化曲线呈大体一致,则系统
基本稳定;若压力增大时,吞吐率的曲线增加到一定程度后出现变化缓慢,甚至平坦,很可能是
网络出现带宽瓶颈,同理若点击率/TPS曲线出现变化缓慢或者平坦,说明服务器开始出现颈。
4.作者提出了如下的性能分析基本原则,此原则本人十分赞同:
——由外而内、由表及里、层层深入
应用此原则,分析步骤具体可以分为以下三步:
第一步:将得到的响应时间和用户对性能的期望值比较确定是否存在瓶颈;
第二步:比较Tn(网络响应时间)和Ts(服务器响应时间)可以确定瓶颈发生在网络还是服
务器;
第三步:进一步分析,确定更细组件的响应时间,直到找出发生性能瓶颈的根本原因。
二:以WEB应用程序为例来看下具体的分析方法:
1.用户事务分析:
a.事务综述图(Transaction Summary ):以柱状图的形式表现了用户事务执行的成功与
失败。通过分析成功与失败的数据可以直接判断出系统是否运行正常。若失败的事务非常多,则
说明系统发生了瓶颈或者程序在执行过程中发生了问题。
b.事务平均响应时间分析图(Average Transaction Response Time): 该图显示在
测试场景运行期间的每一秒内事务执行所用的平均时间,还显示了测试场景运行时间内各个事务
的最大值、最小值和平均值。通过它可以分析系统的性能走向。若所有事务响应时间基本成一条
曲线,则说明系统性能基本稳定;否则如果平均事务响应时间逐渐变慢,说明性能有下降趋势,
造成性能下降的原因有可能是由于内存泄漏导致。
c.每秒通过事务数分析图(Transaction per Second即TPS):显示在场景运行的每一
秒中,每个事 务通过、失败以及停止的数量。通过它可以确定系统在任何给定时刻的实际事务
负载。若随着测试的进展,应用系统在单位时间内通过的事务数目在减少,则说明服务器出现瓶
颈。
d.每秒通过事务总数分析图(Total Transactions per Second):显示场景运行的
每一秒中,通过、失败以及停止的事务总数。若在同等压力下,曲线接近直线,则性能基本趋于
稳定;若在单位时间内通过的事务总量越来越少,即整体性能下降。原因可能是内存泄漏或者程
序中的缺陷。
e.事务性能摘要图(Transaction Performance Summary):显示方案中所有事务的
最小、最大平均执行时间,可以直接判断响应时间是否符合客户要求(重点关注事务平均、最大
执行时间)。
f.事务响应时间与负载分析图(Transaction Response Time Under load):通过
该图可以看出在任一时间点事务响应时间与用户数目的关系,从而掌握系统在用户并发方面的性
能数据。
g.事务响应时间(百分比)图(Transaction Response Time(percentile)):该
图是根据测试结果进行分析而得到的综合分析图。分析该图应从整体出发,若可能事务的最大响
应时间很长,但如果大多数事务具有可接受的响应时间,则系统的性能是符合。
h.事务响应时间分布情况图(Transaction Response Time (Distribution)):该
图显示了测试过程中不同响应时间的事务数量。若系统预先定义了相关事务可以接受的最小和最
大事务响应时间,则可以使用此图确定系统性能是否在接受范围内。
分析到这一步,只能大概判断出瓶颈可能会出在那,要具体定位瓶颈还需要更深入
的分析。没有贴图,看起来有点费劲,如果你对这些图都比较了解,应该是比较简单的.
标题搜索
我的存档
数据统计
- 访问量: 178435
- 日志数: 90
- 建立时间: 2009-01-09
- 更新时间: 2013-03-22
