51testing本周问题是“如何量化评估被测试软件的质量?”,问题的详细描述请看
http://bbs.51testing.com/thread-107919-1-1.html
如何去量化评估软件的质量,属于发散性的问题,可从多个角度去考虑。其实国际上关于软件质量已有公认的国际标准(ISO/IEC 9126),我国在此基础之上,也形成了我国的国家标准GB/T 16260,二者在内容上非常相似。
ISO/IEC 9126标准中规定,软件的质量可以从以下6个大的特性来衡量:功能性(Functionability)、可靠性(Reliability)、可用性(Usability)、有效性(Efficiency)、可维护性(Maintainability)、可移植性(Portability),每个质量特性还可以细分为很多子特性,如下图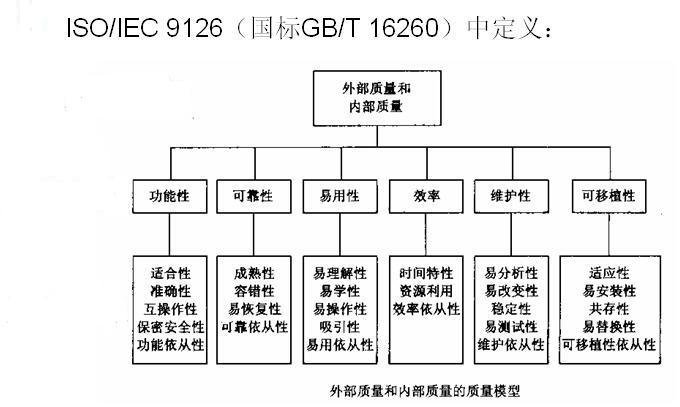
针对本文的问题,可以从各种元数据(即度量元,英文Metrics)分析,得到相应的质量标准。具体到“量化”评估,我只对我所熟悉的部分做简单说明。
1 可维护性:
借助于静态质量度量法,软件的可维护性成为目前“量化”评估最成熟的一个质量特性之一。
×针对的是程序源代码
×主要用于质量评审阶段,即每个模块在版本管理库中形成了“基线”后,各小组对代码的评审
ISO/IEC 9126标准对软件可维护性采用四个分类标准来评估:可分析性、可修改性、稳定性、可测性。
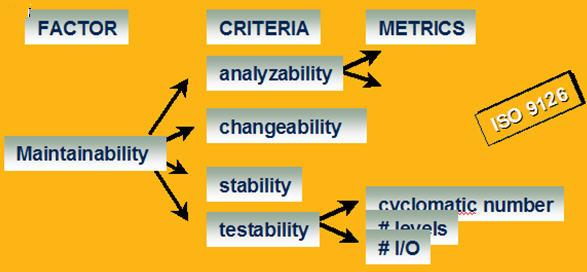
每个分类标准又由一系列度量元组成,每个度量元分配一个权重,由规则的取值与权重值,加权平均计算出每个标准的值。通过质量标准值的大小,可将程序代码的质量分成四个级别,由高到底依次是EXCELLENT(优秀)、GOOD(良好)、FAIR(合格)、POOR(不合格)。其中属于前三个等级的编码遵守或基本遵守了质量标准的要求,属于最后一个等级的编码没有遵守质量标准的要求,需要对其进行修改和完善。举例如下

这个质量标准是评价函数的稳定性的。最上面一行是这个质量标准的计算公式:
function_STABILITY = ic_varpe + ct_exit + dc_calls + ic_param该公式表明,该质量标准由四个度量元所决定,即ic_varpe 、ct_exit、dc_calls、ic_param,每个度量元的权重均为一。该质量标准的最高得分为4分,即当构成该质量标准的四个度量元的值均在我们设定的范围内时,该项质量标准得分为4分,当有三个度量元的值均在我们设定的范围内时,该项质量标准得分为3分,以此类推。最后根据具体的得分,可以判定程序代码在该项质量标准上所处的等级。 最后,综合多个质量标准,得出代码的可维护性质量标准。根据具体的得分,可以判定程序代码在可维护性上所处的等级。
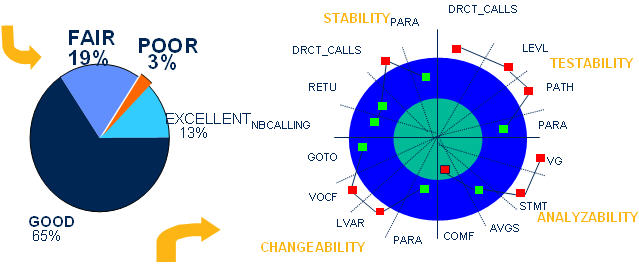
从上面的最终结果可以看出,整个项目中,成绩为“优秀”的达到13%,“良好”的达到65%,“不合格”的为3%。我们借助于ISO/IEC 9126提供的质量模型,可以得出:成绩为“不合格”的3%的函数为整个项目的薄弱点,根据实际情况,这些代码可能需要重写或者在测试活动中重点关注。
以上的方法在实施过程中,如果单靠人工的话,效率会很低。之所以说针对“可维护性”的量化比较成熟,是因为市场上已经有了专门的工具协助,例如Logiscope、Macabe等,可以大大的提高工作效率。
通过分析软件的可靠性,可以尽早发现程序在编码上的质量薄弱点,从而以比较低的成本使不足得到修改。
2 功能性
功能测试是最基本的测试类型,也是最容易被理解的。但具体到软件功能测试的“量化”,可以借助于BUG的估算。举例子说明:
两个小组独立地测试同一个程序的某一个公共模块,第一组发现25个错误,第二组发现30个错误,在两个小组发现的错误中有15个是共同的,那么根据估算的方法S = m / (p/n),估计出该模块中的错误总数是50个,第一组测试的得分为25/50 × 100% = 50%,第二组为30/50 ×100%=60%。把该得分推而广之到程序的其他部分,从而可以估算出量化的功能测试效果,预估出软件功能测试的结束时间。
在元数据量不大的情况下,该方法具有一定的随机性,不同的人参与可能会得到不同的结果,但随着元数据的逐步积累,该方法得到的结果会更加趋向于真实。
3 可靠性
关于软件的可靠性方面,据我了解,目前还不是特别成熟,大多都是借鉴硬件可靠性的做法,如,FTA(故障树分析)、FMEA(失效模式与效应分析)等,而且多处于理论研究阶段。
通过分析软件的可靠性,可以评估软件的发布风险。
以上是我的一点看法,一家之言,仅供参考!
注:参考文章
黄民德老师 的《软件质量与评价》
我的好朋友 赵秋阳 编写的《Logiscope测试机理》
关河的测试生活:错误植入法与老祖宗的智慧
对以上文章的作者表示感谢!

