
-
C# 中的委托和事件(上)
2010-03-31 17:48:43
C# 中的委托和事件(上)
发布时间: 2010-3-31 10:09 作者: 未知 来源: 51Testing软件测试网采编
引言
委托和事件在 .Net Framework中的应用非常广泛,然而,较好地理解委托和事件对很多接触C#时间不长的人来说并不容易。它们就像是一道槛儿,过了这个槛的人,觉得真 是太容易了,而没有过去的人每次见到委托和事件就觉得心里别(biè)得慌,混身不自在。本文中,我将通过两个范例由浅入深地讲述什么是委托、为什么要使 用委托、事件的由来、.Net Framework中的委托和事件、委托和事件对Observer设计模式的意义,对它们的中间代码也做了讨论。
将方法作为方法的参数
我们先不管这个标题如何的绕口,也不管委托究竟是个什么东西,来看下面这两个最简单的方法,它们不过是在屏幕上输出一句问候的话语:
public void GreetPeople(string name) {
// 做某些额外的事情,比如初始化之类,此处略
EnglishGreeting(name);
}
public void EnglishGreeting(string name) {
Console.WriteLine("Morning, " + name);
}暂且不管这两个方法有没有什么实际意义。GreetPeople用于向某人问好,当我们传递代表某人姓名的name参数,比如说“Jimmy”,进去的 时候,在这个方法中,将调用EnglishGreeting方法,再次传递name参数,EnglishGreeting则用于向屏幕输出 “Morning, Jimmy”。
现在假设这个程序需要进行全球化,哎呀,不好了,我是中国人,我不明白“Morning”是什么意思,怎么办呢?好吧,我们再加个中文版的问候方法:
public void ChineseGreeting(string name){
Console.WriteLine("早上好, " + name);
}这时候,GreetPeople也需要改一改了,不然如何判断到底用哪个版本的Greeting问候方法合适呢?在进行这个之前,我们最好再定义一个枚举作为判断的依据:
public enum Language{
English, Chinese
}public void GreetPeople(string name, Language lang){
//做某些额外的事情,比如初始化之类,此处略
swith(lang){
case Language.English:
EnglishGreeting(name);
break;
case Language.Chinese:
ChineseGreeting(name);
break;
}
}OK,尽管这样解决了问题,但我不说大家也很容易想到,这个解决方案的可扩展性很差,如果日后我们需要再添加韩文版、日文版,就不得不反复修改枚举和GreetPeople()方法,以适应新的需求。
在考虑新的解决方案之前,我们先看看 GreetPeople的方法签名:
public void GreetPeople(string name, Language lang) 我们仅看 string name,在这里,string 是参数类型,name 是参数变量,当我们赋给name字符串“jimmy”时,它就代表“jimmy”这个值;当我们赋给它“张子阳”时,它又代表着“张子阳”这个值。然后, 我们可以在方法体内对这个name进行其他操作。哎,这简直是废话么,刚学程序就知道了。
如果你再仔细想想,假如GreetPeople()方法可以接受一个参数变量,这个变量可以代表另一个方法,当我们给这个变量赋值 EnglishGreeting的时候,它代表着 EnglsihGreeting() 这个方法;当我们给它赋值ChineseGreeting 的时候,它又代表着ChineseGreeting()方法。我们将这个参数变量命名为 MakeGreeting,那么不是可以如同给name赋值时一样,在调用 GreetPeople()方法的时候,给这个MakeGreeting 参数也赋上值么(ChineseGreeting或者EnglsihGreeting等)?然后,我们在方法体内,也可以像使用别的参数一样使用 MakeGreeting。但是,由于MakeGreeting代表着一个方法,它的使用方式应该和它被赋的方法(比如ChineseGreeting) 是一样的,比如:
MakeGreeting(name);
好了,有了思路了,我们现在就来改改GreetPeople()方法,那么它应该是这个样子了:
public void GreetPeople(string name, *** MakeGreeting){
MakeGreeting(name);
}注意到 *** ,这个位置通常放置的应该是参数的类型,但到目前为止,我们仅仅是想到应该有个可以代表方法的参数,并按这个思路去改写GreetPeople方法,现在就出现了一个大问题:这个代表着方法的MakeGreeting参数应该是什么类型的?
NOTE:这里已不再需要枚举了,因为在给MakeGreeting赋值的时候动态地决定使用哪个方法,是ChineseGreeting还是 EnglishGreeting,而在这个两个方法内部,已经对使用“morning”还是“早上好”作了区分。
聪明的你应该已经想到了,现在是委托该出场的时候了,但讲述委托之前,我们再看看MakeGreeting参数所能代表的 ChineseGreeting()和EnglishGreeting()方法的签名:
public void EnglishGreeting(string name)
public void ChineseGreeting(string name)如同name可以接受String类型的“true”和“1”,但不能接受bool类型的true和int类型的1一样。MakeGreeting的 参数类型定义 应该能够确定 MakeGreeting可以代表的方法种类,再进一步讲,就是MakeGreeting可以代表的方法 的 参数类型和返回类型。
于是,委托出现了:它定义了MakeGreeting参数所能代表的方法的种类,也就是MakeGreeting参数的类型。
NOTE:如果上面这句话比较绕口,我把它翻译成这样:string 定义了name参数所能代表的值的种类,也就是name参数的类型。
本例中委托的定义:
public delegate void GreetingDelegate(string name); 可以与上面EnglishGreeting()方法的签名对比一下,除了加入了delegate关键字以外,其余的是不是完全一样?
现在,让我们再次改动GreetPeople()方法,如下所示:
public void GreetPeople(string name, GreetingDelegate MakeGreeting){
MakeGreeting(name);
}如你所见,委托GreetingDelegate出现的位置与 string相同,string是一个类型,那么GreetingDelegate应该也是一个类型,或者叫类(Class)。但是委托的声明方式和类却 完全不同,这是怎么一回事?实际上,委托在编译的时候确实会编译成类。因为Delegate是一个类,所以在任何可以声明类的地方都可以声明委托。更多的 内容将在下面讲述,现在,请看看这个范例的完整代码:
using System;
using System.Collections.Generic;
using System.Text;namespace Delegate {
//定义委托,它定义了可以代表的方法的类型
public delegate void GreetingDelegate(string name);
class Program {private static void EnglishGreeting(string name) {
Console.WriteLine("Morning, " + name);
}private static void ChineseGreeting(string name) {
Console.WriteLine("早上好, " + name);
}//注意此方法,它接受一个GreetingDelegate类型的方法作为参数
private static void GreetPeople(string name, GreetingDelegate MakeGreeting) {
MakeGreeting(name);
}static void Main(string[] args) {
GreetPeople("Jimmy Zhang", EnglishGreeting);
GreetPeople("张子阳", ChineseGreeting);
Console.ReadKey();
}
}
}输出如下:
Morning, Jimmy Zhang
早上好,张子阳我们现在对委托做一个总结:
委托是一个类,它定义了方法的类型,使得可以将方法当作另一个方法的参数来进行传递,这种将方法动态地赋给参数的做法,可以避免在程序中大量使用If-Else(Switch)语句,同时使得程序具有更好的可扩展性。
将方法绑定到委托
看到这里,是不是有那么点如梦初醒的感觉?于是,你是不是在想:在上面的例子中,我不一定要直接在GreetPeople()方法中给 name参数赋值,我可以像这样使用变量:
static void Main(string[] args) {
string name1, name2;
name1 = "Jimmy Zhang";
name2 = "张子阳";GreetPeople(name1, EnglishGreeting);
GreetPeople(name2, ChineseGreeting);
Console.ReadKey();
}
而既然委托GreetingDelegate 和 类型 string 的地位一样,都是定义了一种参数类型,那么,我是不是也可以这么使用委托?static void Main(string[] args) {
GreetingDelegate delegate1, delegate2;
delegate1 = EnglishGreeting;
delegate2 = ChineseGreeting;GreetPeople("Jimmy Zhang", delegate1);
GreetPeople("张子阳", delegate2);
Console.ReadKey();
}如你所料,这样是没有问题的,程序一如预料的那样输出。这里,我想说的是委托不同于string的一个特性:可以将多个方法赋给同一个委托,或者叫将多个方法绑定到同一个委托,当调用这个委托的时候,将依次调用其所绑定的方法。在这个例子中,语法如下:
static void Main(string[] args) {
GreetingDelegate delegate1;
delegate1 = EnglishGreeting; // 先给委托类型的变量赋值
delegate1 += ChineseGreeting; // 给此委托变量再绑定一个方法// 将先后调用 EnglishGreeting 与 ChineseGreeting 方法
GreetPeople("Jimmy Zhang", delegate1);
Console.ReadKey();
}输出为:
Morning, Jimmy Zhang
早上好, Jimmy Zhang
实际上,我们可以也可以绕过GreetPeople方法,通过委托来直接调用EnglishGreeting和ChineseGreeting:static void Main(string[] args) {
GreetingDelegate delegate1;
delegate1 = EnglishGreeting; // 先给委托类型的变量赋值
delegate1 += ChineseGreeting; // 给此委托变量再绑定一个方法// 将先后调用 EnglishGreeting 与 ChineseGreeting 方法
delegate1 ("Jimmy Zhang");
Console.ReadKey();
}NOTE:这在本例中是没有问题的,但回头看下上面GreetPeople()的定义,在它之中可以做一些对于EnglshihGreeting和ChineseGreeting来说都需要进行的工作,为了简便我做了省略。
注意这里,第一次用的“=”,是赋值的语法;第二次,用的是“+=”,是绑定的语法。如果第一次就使用“+=”,将出现“使用了未赋值的局部变量”的编译错误。
我们也可以使用下面的代码来这样简化这一过程:
GreetingDelegate delegate1 = new GreetingDelegate(EnglishGreeting);
delegate1 += ChineseGreeting; // 给此委托变量再绑定一个方法看到这里,应该注意到,这段代码第一条语句与实例化一个类是何其的相似,你不禁想到:上面第一次绑定委托时不可以使用“+=”的编译错误,或许可以用这样的方法来避免:
GreetingDelegate delegate1 = new GreetingDelegate();
delegate1 += EnglishGreeting; // 这次用的是 “+=”,绑定语法。
delegate1 += ChineseGreeting; // 给此委托变量再绑定一个方法但实际上,这样会出现编译错误: “GreetingDelegate”方法没有采用“0”个参数的重载。尽管这样的结果让我们觉得有点沮丧,但是编译的提示:“没有0个参数的重载”再次 让我们联想到了类的构造函数。我知道你一定按捺不住想探个究竟,但再此之前,我们需要先把基础知识和应用介绍完。
既然给委托可以绑定一个方法,那么也应该有办法取消对方法的绑定,很容易想到,这个语法是“-=”:
static void Main(string[] args) {
GreetingDelegate delegate1 = new GreetingDelegate(EnglishGreeting);
delegate1 += ChineseGreeting; // 给此委托变量再绑定一个方法// 将先后调用 EnglishGreeting 与 ChineseGreeting 方法
GreetPeople("Jimmy Zhang", delegate1);
Console.WriteLine();delegate1 -= EnglishGreeting; //取消对EnglishGreeting方法的绑定
// 将仅调用 ChineseGreeting
GreetPeople("张子阳", delegate1);
Console.ReadKey();
}
输出为:Morning, Jimmy Zhang
早上好, Jimmy Zhang
早上好, 张子阳让我们再次对委托作个总结:
使用委托可以将多个方法绑定到同一个委托变量,当调用此变量时(这里用“调用”这个词,是因为此变量代表一个方法),可以依次调用所有绑定的方法。
-
缺陷跟踪的两个经典分析模型
2009-12-08 10:42:00
发布时间: 2009-12-07 14:38 作者: 天彤 来源: Taobao QA Team
缺陷跟踪过程是软件工程中的一个极其重要的过程。本文介绍了如何使用两个经典的分析模型,来控制缺陷跟踪的过程。这两个模型叫做《活动bug走势图》、《bug打开关闭图》。
另外,在文章中还会提到两个概念:“bug收敛”、“零bug反弹”,具体含义会在介绍中说明。
先看张图片,这就是两个模型的分析图片,集成在一个坐标里面了。活动bug走势是一条线,bug打开关闭是柱图,X轴是时间。下面我们详细说说这两个模型的含义。
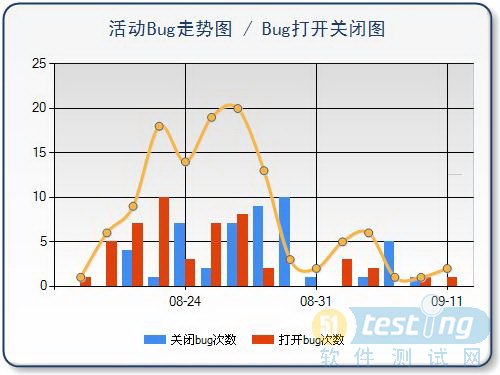
先要说几个名词解释:
1、活动bug数。状态不是closed的所有bug的总数。活动bug指在项目中还需要大家去关注的bug,有的bug管理工具还有invalid、duplicate状态,这些是不属于活动bug的,但是later的bug,属于活动bug。
2、打开bug次数和关闭bug次数。每新增1个bug或者是reopen一个bug,打开次数都会被记加一。每close一个bug,关闭次数会加一。
说明了这些概念,上面两个模型就比较好理解了。活动bug走势曲线上的每个点,表示当天软件中还存在多少个活动bug。这个数字越大,说明软件的质量越 差。而bug打开关闭图中,每天都会有红色、蓝色共两根柱子,表示当天打开、关闭bug的次数,如果当天这两个数字都很高,说明bug的处理非常活跃,软 件非常不稳定。注意,活动bug的单位是“个”,而打开关闭的单位是“次”,因此我们用线图和柱图分别表示。
下面讲一下模型的用法。一般的软件测试过程,都有3个阶段,从上面的图中能清楚的看出来。
阶段1:测试组对系统开始进行全面测试,打开bug的速度明显高于关闭bug的速度,活动bug数急速上升,当完成了全部测试用例的执行时,活动bug数达到最大;
阶段2:开发组全力修复bug,测试组一边验证bug,一边小范围的回归测试,验证bug的周边功能。这时,关闭bug的速度高于打开 bug的速度,活动bug数回落。当活动bug数刚开始回落的时候,称为“bug收敛”。最终,活动bug会降到一个很低的位置,有时,会达到“零bug ”,不过,这并不说明项目可以发布。
阶段3:测试组再次对软件系统进行一次完整的回归测试。在这个过程,还会打开一些bug,但是,数量很少,这称为“零bug反弹”。完成了这一轮回归之后,软件才真正稳定下来,进入发布候选过程。
所以,我们可以通过这两个模型,来检查项目的测试进展是否正常,软件的质量是否稳定,检查方法如下:
* 如果第二阶段已经开始,但是活动bug仍在继续上升,没有回落,说明打开bug速度仍很高,可能是第一阶段用例执行还没有完成,或者开发组修复bug速度较低;
* 如果第二阶段结束,活动bug没有回落到低水平,说明大量的bug还需要修复,软件质量低;
* 如果第三阶段,打开、关闭bug的次数很多,说明bug活动频繁,系统稳定性差。
因此,正常的项目测试应该是,活动bug先上扬,再回落,最后在低位小幅振荡,并且打开关闭次数很少。有了这两个分析模型,我们对项目进度得控制,就更有把握了。
-
【软件测试自动化-VBScript基础讲座 1】== 变量显示声明 =【转】
2009-11-27 16:20:24
VBScript是Visual Basic Script的简称,即 Visual Basic 脚本语言,有时也被缩写为VBS。由于QTP的脚本语言是基于VBS的,因此VBS对于学习自动化还是起到了相当大的作用,VBScript可以通过 Windows脚本宿主调用COM,因而可以使用Windows操作系统中可以被使用的程序库,比如它可以使用Microsoft Office的库,WSH,AOM等,当然它也可以使用其它程序和操作系统本身的库。因此学习VBScript对于测试人员来说就显得非常的重要。- 定义变量 ---- Dim
例如:
Dim helloworld '定义变量
helloworld = "zzxxbb112" '给变量进行赋值
msgbox helloworld '弹出消息框显示变量
复制以上保存为helloworld.vbs后直接运行后

由于VBScript语法不是非常的严谨,因此我们其实可以不用申明变量就可以直接使用
例如:
helloworld = "zzxxbb112" '给变量进行赋值
msgbox helloworld '弹出消息框显示变量
这样的话就可以省去很多申明变量的时间,增加代码开发的速度,但是这样却会有一个问题,我们来看一下脚本
例如:
helloworld = "zzxxbb112" '给变量进行赋值
msgbox helloword '弹出消息框显示变量
保存以上脚本后,运行之后,会发现弹出框并没有任何数据,而是一个空值

为 什么?因为我们这里输入的helloworld 被我们拼写成了helloword少了一个L,因此导致打印出来一个空值,当我们在大量声明变量的时候其实是很容易范这种错误的,因此这里就要给代码中加 上显示声明,这样才不会出现上述的这种情况,下面就来看一下具体怎么使用。
- 显示声明 ---- Option Explicit 强制所有变量必须先声明才能使用
例如:
Option Explicit '显示声明变量
Dim helloworld '定义变量
helloworld = "zzxxbb112" '给变量进行赋值
msgbox helloword '弹出消息框显示变量
运行以上代码就可以直接定位问题,出现错误提示“变量未定义”

很多朋友在VBS时,比较懒,不喜欢使用显示声明,其实显示声明能够检查你的程序,建议大家能够养成这个好习惯,否则在大量的变量面前你一定会束手无策,或者累死累活,简单总结下它的优点:
- 显示声明是对脚本编写人员的一种好习惯
- 可以防止很多不必要的错误发生,大型项目更加明显
- 减少资源的占用
- 代码提示的优势

-
自动化测试获取和删除cookies的方法(转)
2009-03-19 17:22:27
自动化测试获取和删除cookies的方法
一. document.cookie(ruby与qtp都兼容的方法)
1. 使用方法
Set document=browser(“taobao”).page(“taobao”).object
2. 获取cookies
a= document.cookie
3. 删除cookies
为了删除一个cookie,可以将其过期时间设定为一个过去的时间:
document.cookie=”userId=828; expire=”+date.toGMTString();
二. QTP中的WebUtil(最有效推荐在qtp中使用)
1. 使用方法
在QTP中输入 webutil然后打点就可以看到所有对应方法:
2. 获取cookie
A= WebUtil.GetCookies(url)
3. 删除cookie
WebUtil.DeleteCookie(domain,cookies)
webutil.DeleteCookies
三. 原始方法(解决所有不能解决问题的万能方法)
Browser(”Browser”).WinToolbar(”ToolbarWindow32″).Press “&Tools”
Browser(”Browser”).WinMenu(”ContextMenu”).Select “Tools;Internet Options…”
Browser(”Browser”).Dialog(”Internet Options”).WinButton(”Delete Cookies”).Click
Browser(”Browser”).Dialog(”Internet Options”).Dialog(”Delete Cookies”).WinButton(”OK”).Click
Browser(”Browser”).Dialog(”Internet Options”).WinButton(”OK”).Click
-
通过测试并不能保证质量(转)
2009-02-16 16:06:21
其实这句话我已经不止一次看到了,每次看到这一思想,我就想把它宣导给我们老板,让他有个正确的认识。但我没有这样做,因为我没有想到好的阐述方式并找到合适的机会,而且对于独裁的老板,他会认为他的思想境界远高于你,就像他的口头禅:“我不想听你解释,你只要按照我的意思去做就可以了”那些没有认识到“通过测试并不能保证质量”的主管们,在软件出了问题时,第一个想到的就是测试的问题,我对他们的这个条件反射表示理解,但也非常的忧虑,因为这会直接导致最终测试人员的绩效不好,而这也容易形成一个恶性循环。
而团队中也并非仅仅主管会不理解,客服人员最先埋怨的对象往往也是测试人员,因为表象显示的就是客服电话多,客户的问题没有测出来,那责任就应该是测试人员的了。当然对于他们的不满还是比较容易转移的,只要合理的解释说明,那么他们也会理解的。
而要扭转测试员的这一尴尬境地,解释或者自我检讨只能治标,就像作者所说的质量保证要来自整个项目团队,建制、建全软件开发过程,保证每一个节点、每一个阶段的质量,才是治本之道。
附注:
有一篇名为《需求与测试》的文章里有这么一段话:“其实我们有时候会抱怨需求为什么会考虑不周全,可是换个角度想想,我们认可程序会存在bug,那么需求同样也会有。这就像是一场接力赛,需求是第一棒,开发是第二棒,测试是第三棒,每一棒的交接都有上一棒的辛苦付出,也只有彼此信任和共同的努力,才能最终传递胜利。”
本文出自souchy的51Testing软件测试博客:http://www.51testing.com/?200708
-
自动化不是灵丹妙药(转)
2009-02-16 15:26:31
一天和同事聊天,他试图实现一个功能,让一个程序在系统重启后能自动启动,并且加载指定的配置。我分析了一下发现实现这个功能会比较复杂,主要是涉及多处配置文件的修改。回头再看看,发现这个系统很少会重启,可能一年就4,5次。于是我建议他放弃这个想法。因为维护配置文件会成为一个负担,考虑到系统重启的频率,这会是得不偿失。
但是看来他并不以为然。他说他的目标是这些配置工作完全不用人来参与,“最好是在家里动一个手指所有的配置工作都自动化的为我做好了”。看到他信心满怀的样子,我不愿意扫他兴。但我相信如果即使有一天他真正实现了这个目标,维护这个自动化系统也会让他寝食难安。
这样悲观的看法,我想在两三年前我肯定没有。那个时候我像他一样对“自动化”抱有无限美好的期望,好像只要测试自动化了,软件测试工作马上变得和“公务员一样轻松”,只需要动一下指头,所有的testcase都自动化得跑起来。
但随着做了更多的自动化测试项目,也看了更多的成功和失败的案例。对自动化的特点了解得来越多,对自动化的期望也在一直不断的下降。
这种看法的变化,我倒觉得是越来越贴近真实的“自动化测试”。
如果要充分利用一个工具,一定要了解其特点。现在在业界,自动化软件测试就像一个人见人爱的香馍馍。自动化测试好像已经和“高科技”,“高测试效率”,“成熟的测试team”…这些褒义词联系了起来。在这种一边倒的氛围下,自动化程序的缺点和不足和必须要付出的代价被掩盖了起来。
认识自动化的不足,我觉得首先要转变的一个想法是“自动化测试并不是用来发现bug的”。原因很简单,自动化测试基于testcase,但所有的bug中只有大约1/4是仅仅按照testcase来测试就能发现的,其它的bug,来自于聪明的“人”的经验,分析,发散思维和说不清道不明的“灵光一闪”,而这些特性对于自动化程序来说完全是无能为力。所以,幻想“动一下手指”,所以的bug都被自动化程序发现出来是完全不可能实现的。
自动化另外一个特点是自动化本身也是程序,也需要投入大量的人力来实现。一个软件买出的copy越多,它的价值越大。对于自动化测试程序来说,它运行的次数越多,它的价值越大。有下面一些原因都可能减少自动化测试程序运行的次数,甚至导致自动化项目的失败。
1)测试产品功能或界面变化频繁
2)自动化的case本身不需要频繁的测试,比如安装过程或者一些非核心的功能
3)自动化程序不稳定,容易跑“死”掉
看到了一些自动化测试程序因为这些原因而效果大打折扣,我对“自动化一切”的热度慢慢退烧了。
最后一个需要注意的自动化测试程序的特点是,自动化测试程序不是商业产品,它的用户都是专业人士,所以它不用商业产品那样高的扩展性,灵活性,可配置性,友好的交互性。因为这些特性的得来是要付出高昂的代价的,那就是人力投入和软件的复杂度大大增加。对于设计师来说,如果要在这些特性和简单中选择的话,一定要选择简单。
1)对于错误处理要简单直接,而不要灵活和聪明。打印错误并直接退出是最好的选择,不要试图猜测错误的根源并试图从错误恢复。这里包括用户输入,环境错误等。
2)对于环境设置,要求单纯一些,不要去兼容环境变化。一般来说测试环境都是有测试人员在维护。试图兼容环境可能导致代码大大增加。
3)对于自动化测试的代码来说,也不要用太炫的设计技巧和复杂的设计模式。因为自动化测试的代码最好能被使用它的测试人员读懂,甚至能做简单的修改和排错,这样能提高自动化测试的次数。
对自动化期望不能太高和自动化程序不要设计得太完美,是我对自动化测试程序设计和使用过程中获得的最深刻的体会。
本文出自lifr的51Testing软件测试博客:http://www.51testing.com/?764
-
接口测试在淘宝的应用(转)
2009-02-04 17:17:28
一、为什么做接口测试目前的BS结构的软件层级体系大致如下,对此的功能测试也主要是针对表现层的内容,下图灰色的部分是未测试的内容(占80%的比例)。

对于较小型的网站,通过表现层的测试,路径会大致渗透到下面各个层级。但是一个超大型的网站,其层级会有4层甚至更多,每一个层级又可能包含相互关联的不同业务。如同一个城市的自来水系统,如果只测试水龙头里面是否有水,水质是否优良,这显然远远不够。要想点办法对此进行改进,设想如下图。

对于底下几层,采用单元测试,持续集成;对于表现层,采用QTP和类似的工具,编写测试代码,设计测试条件,做到大部分的自动化测试。这样以来,测试的覆盖率会大大提升(灰色部分占20%左右)。如此测试,从技术上来看并没有太大的障碍,从成本上来讲,就是需要大批的能写测试代码的技术人员,这些人员的技能丝毫不逊于开发人员,他们需要完成的测试代码量要高于软件本身的代码量。而一旦自动化的功能测试体系建立起来,在软件的重构和发展的过程中,测试的效率会大大提高。一个成熟的测试体系运转起来就像下图所示了。前图是测试的几个纬度,后图是功能测试的几个组成部分。


而整个测试的流程大致如下:(其中安全测试是功能测试的一部分)

二、选用什么样的测试工具
基于Java技术的软件代码,有一些比较成熟的测试框架,Junit、Dbunit等等。Junit已经有了很长时间的应用,在JDK1.5之后,其推出了基于annotation的Junit4.4版,使单元测试的代码更加简洁,开发人员可以更加专注于对接口中业务逻辑的校验。Dbunit是一个测试数据的框架,它能够使用excel或xml文件里的数据来对数据库做插入,对比,删除等逻辑,可以完成数据的生成和校验。Junit和Dbunit结合使用就可以完成业务逻辑和数据方面的校验。
当一个项目的测试代码编写完毕的时候,我们需要对此进行持续集成,业界总是有一些慷慨无私的人来帮助可爱的开发人员,CruiseControl是一个不错的持续集成工具。每当有代码提交到版本管理工具的时候,它都不知疲倦的执行测试代码,通过邮件和IM软件告诉我们,哪些通过测试了,哪些发现问题了。这个时候你可以相当有自信的说“一切尽在掌握”,这神情会比刘德华都要帅。
但对于一个大型的网站来说,其单元测试也非测试“helloWorld”一样如此简单,最大的难题是解决代码之间的依赖性。淘宝网主演主要的架构是基于 Spring的,一般的系统分至少三层,业务层、逻辑层、持久层。spring架构下这三层通过配置文件来装载起来,持久层依赖于自己的配置文件、逻辑层依赖于自己的和持久层的、业务层依赖于三种配置文件。如果有发送邮件,调用外部接口等,还需要相应的配置文件和接口服务器。这种情况下,要做一个单元测试,需要配置很多东西,任何一个配置有误都无法启动spring容器,而且这些配置都在xml文件里面,内容是否正确无法自动检测。要做业务层的测试,不是一个容易的事情。其中持久层的东西相对固定,需要配置的文件也较少,相比较而言,这一层测试很容易完成,逻辑层和业务层的测试难度成指数性增长。
三、需要什么样的工作流程
我们不要提测试驱动开发,或者TDD之类的名词,适合我们的就是最好的,或许我们可以成为测试开发并驾齐驱。接口测试的工程师我们叫做测试开发工程师,在项目启动的时候就要参与进来,要做需求的分析,系统设计,在开发人员编写功能代码的同时,我们在编写测试代码,无所谓谁快谁慢,写好功能代码就测试,或者写好测试代码就写功能实现。当编码完毕的时候,也是接口测试完毕的时候,然后测试开发工程师写一份测试报告,送给功能测试工程师,告诉他们哪些东西我们测试过,哪些东西需要重点关注。

当系统发布运行之后,功能修改的时候我们修改测试代码,平时我们就重点关注CruiseControl,一旦它报错,那一定是有些代码出问题了,Just fix it!
四、需要什么样的规范
Java编码规范想必都比较清楚,OK,去做好它。另外请在注释里面写清楚测试的场景,输入输出,异常情况。测试代码的可读性一定要高于功能代码。
五、到底是单元测试还是接口测试
OK,看这么多想必都搞糊涂了,我们测的是接口,写的是单元测试的代码,爱叫什么是什么吧。
-
数据库设计规范化的五个要求(转)
2009-01-13 15:26:18
通常情况下,可以从两个方面来判断数据库是否设计的比较规范。一是看看是否拥有大量的窄表,二是宽表的数量是否足够的少。若符合这两个条件,则可以说明这个数据库的规范化水平还是比较高的。当然这是两个泛泛而谈的指标。为了达到数据库设计规范化的要求,一般来说,需要符合以下五个要求。要求一:表中应该避免可为空的列。
虽然表中允许空列,但是,空字段是一种比较特殊的数据类型。数据库在处理的时候,需要进行特殊的处理。如此的话,就会增加数据库处理记录的复杂性。当表中有比较多的空字段时,在同等条件下,数据库处理的性能会降低许多。
所以,虽然在数据库表设计的时候,允许表中具有空字段,但是,我们应该尽量避免。若确实需要的话,我们可以通过一些折中的方式,来处理这些空字段,让其对数据库性能的影响降低到最少。
一是通过设置默认值的形式,来避免空字段的产生。如在一个人事管理系统中,有时候身份证号码字段可能允许为空。因为不是每个人都可以记住自己的身份证号码。而在员工报到的时候,可能身份证没有带在身边。所以,身份证号码字段往往不能及时提供。为此,身份证号码字段可以允许为空,以满足这些特殊情况的需要。但是,在数据库设计的时候,则可以做一些处理。如当用户没有输入内容的时候,则把这个字段的默认值设置为0或者为N/A。以避免空字段的产生。
二是若一张表中,允许为空的列比较多,接近表全部列数的三分之一。而且,这些列在大部分情况下,都是可有可无的。若数据库管理员遇到这种情况,笔者建议另外建立一张副表,以保存这些列。然后通过关键字把主表跟这张副表关联起来。将数据存储在两个独立的表中使得主表的设计更为简单,同时也能够满足存储空值信息的需要。
要求二:表不应该有重复的值或者列。
如现在有一个进销存管理系统,这个系统中有一张产品基本信息表中。这个产品开发有时候可以是一个人完成,而有时候又需要多个人合作才能够完成。所以,在产品基本信息表产品开发者这个字段中,有时候可能需要填入多个开发者的名字。
如进销存管理中,还需要对客户的联系人进行管理。有时候,企业可能只知道客户一个采购员的姓名。但是在必要的情况下,企业需要对客户的采购代表、仓库人员、财务人员共同进行管理。因为在订单上,可能需要填入采购代表的名字;可是在出货单上,则需要填入仓库管理人员的名字等等。
为了解决这个问题,有多种实现方式。但是,若设计不合理的话在,则会导致重复的值或者列。如我们也可以这么设计,把客户信息、联系人都放入同一张表中。为了解决多个联系人的问题,可以设置第一联系人、第一联系人电话、第二联系人、第二联系人电话等等。若还有第三联系人、第四联系人等等,则往往还需要加入更多的字段。
可是这么设计的话,会产生一系列的问题。如客户的采购员流动性比较大,在一年内换了六个采购员。此时,在系统中该如何管理呢?难道就建立六个联系人字段?这不但会导致空字段的增加,还需要频繁的更改数据库表结构。明显,这么做是不合理的。也有人说,可以直接修改采购员的名字呀。可是这么处理的话,会把原先采购订单上采购员的名字也改变了。因为采购单上客户采购员信息在数据库中存储的不是采购员的名字,而只是采购员对应的一个编号。在编号不改而名字改变了的情况下,采购订单上显示的就是更改后的名字。这不利于时候的追踪。
所以,在数据库设计的时候要尽量避免这种重复的值或者列的产生。笔者建议,若数据库管理员遇到这种情况,可以改变一下策略。如把客户联系人另外设置一张表。然后通过客户ID把供应商信息表跟客户联系人信息表连接起来。也就是说,尽量将重复的值放置到一张独立的表中进行管理。然后通过视图或者其他手段把这些独立的表联系起来。
要求三:表中记录应该有一个唯一的标识符。
在数据库表设计的时候,数据库管理员应该养成一个好习惯,用一个ID号来唯一的标识行记录,而不要通过名字、编号等字段来对纪录进行区分。每个表都应该有一个ID列,任何两个记录都不可以共享同一个ID值。另外,这个ID值最好有数据库来进行自动管理,而不要把这个任务给前台应用程序。否则的话,很容易产生ID值不统一的情况。
另外,在数据库设计的时候,最好还能够加入行号。如在销售订单管理中,ID号是用户不能够维护的。但是,行号用户就可以维护。如在销售订单的行中,用户可以通过调整行号的大小来对订单行进行排序。通常情况下,ID列是以1为单位递进的。但是,行号就要以10为单位累进。如此,正常情况下,行号就以10、20、30依次扩展下去。若此时用户需要把行号为30的纪录调到第一行显示。此时,用户在不能够更改ID列的情况下,可以更改行号来实现。如可以把行号改为1,在排序时就可以按行号来进行排序。如此的话,原来行号为30的纪录现在行号变为了1,就可以在第一行中显示。这是在实际应用程序设计中对 ID列的一个有效补充。这个内容在教科书上是没有的。需要在实际应用程序设计中,才会掌握到这个技巧。
要求四:数据库对象要有统一的前缀名。
一个比较复杂的应用系统,其对应的数据库表往往以千计。若让数据库管理员看到对象名就了解这个数据库对象所起的作用,恐怕会比较困难。而且在数据库对象引用的时候,数据库管理员也会为不能迅速找到所需要的数据库对象而头疼。
为此,笔者建立,在开发数据库之前,最好能够花一定的时间,去制定一个数据库对象的前缀命名规范。如笔者在数据库设计时,喜欢跟前台应用程序协商,确定合理的命名规范。笔者最常用的是根据前台应用程序的模块来定义后台数据库对象前缀名。如跟物料管理模块相关的表可以用M为前缀;而以订单管理相关的,则可以利用C作为前缀。具体采用什么前缀可以以用户的爱好而定义。但是,需要注意的是,这个命名规范应该在数据库管理员与前台应用程序开发者之间达成共识,并且严格按照这个命名规范来定义对象名。
其次,表、视图、函数等最好也有统一的前缀。如视图可以用V为前缀,而函数则可以利用F为前缀。如此数据库管理员无论是在日常管理还是对象引用的时候,都能够在最短的时间内找到自己所需要的对象。
要求五:尽量只存储单一实体类型的数据。
这里将的实体类型跟数据类型不是一回事,要注意区分。这里讲的实体类型是指所需要描述对象的本身。笔者举一个例子,估计大家就可以明白其中的内容了。如现在有一个图书馆里系统,有图书基本信息、作者信息两个实体对象。若用户要把这两个实体对象信息放在同一张表中也是可以的。如可以把表设计成图书名字、图书作者等等。可是如此设计的话,会给后续的维护带来不少的麻烦。
如当后续有图书出版时,则需要为每次出版的图书增加作者信息,这无疑会增加额外的存储空间,也会增加记录的长度。而且若作者的情况有所改变,如住址改变了以后,则还需要去更改每本书的记录。同时,若这个作者的图书从数据库中全部删除之后,这个作者的信息也就荡然无存了。很明显,这不符合数据库设计规范化的需求。
遇到这种情况时,笔者建议可以把上面这张表分解成三种独立的表,分别为图书基本信息表、作者基本信息表、图书与作者对应表等等。如此设计以后,以上遇到的所有问题就都引刃而解了。
以上五条是在数据库设计时达到规范化水平的基本要求。除了这些另外还有很多细节方面的要求,如数据类型、存储过程等等。而且,数据库规范往往没有技术方面的严格限制,主要依靠数据库管理员日常工作经验的累积。
-
cvs基本概念与wincvs的使用(转)
2009-01-07 11:54:27
1. CVS基本概念CVS是很早的时候在Unix下发展起来的,它使用的术语比较特殊,需要先熟悉和理解,这是使用CVS的第一步。
Repository: 中文名称:仓库。它是 CVS服务器(可能在远程,也可能在本地)的根目录,我们所有的工作都保存在这个仓库中,包括源代码和这些代码的全部历史。你可以把Repository想像成一个仓库,仓库中有许多“木桶”,每个“木桶”就是我们的一个让 CVS管理起来的工程。对于CVS来说,这些“木桶”之间是没有什么关联的,删除一个“木桶”不会影响别的“木桶”。我们所想像的木桶,在CVS术语中,又叫模块(Module)。
Module:中文名称:模块。就是上面我们所想像的仓库中的“木桶”,里面放的是一个项目的所有文件(包括源代码,文档文件,资源文件等等)。在物理上,Module是CVS服务器根目录下的第一级子目录。
Import:中文名称:导入。我们本地有一个软件项目,里面有许多各种类型的文件,都需要用CVS进行版本管理,那么第一步就是把这个软件项目的整个目录结构都Import到CVS的仓库中去。经过这种导入,CVS将为你的项目创建一个新的“木桶”----Module,即模块。
Checkout:中文名称:导出。指将仓库中的一个“木桶”(Module, 模块)中的东西导出到本地的工作目录下,然后我们可以在WinCvs的管理下,进行工作,修改其中的内容。
Commit:中文名称:提交修改。我们在本地的工作目录下,对工程中的文件进行修改,这些修改,需要提交给CVS的仓库,这个过程,就叫Commit。你可以Commit一个文件,也可以Commit整个目录。
Update:中文名称:同步。它与Commit相对应,是从仓库中的“木桶”(模块)中下载你同事修改过的文件(别忘记你的项目有许多人共同参与),如果这个文件在你本地也有,就会更新本地的拷贝,如果你本地没有,就会把新文件下载到你的本地。
Revision:中文名称:文件版本。这是CVS中一个需要特别注意的概念,它指的是单个文件的版本,而不是整个项目的版本。基本上,单个文件每次的修改,经过Commit 之后,它的Revision都要改变一次,比如从1.1到1.2到1.3等等。特别要注意,单个文件的版本(Revision)与整个工程产品的版本(Version,或者Release)可以没有任何关系。例如,整个产品现在发行1.0版本(Version 1.0)了,但是产品的源代码文件中,有的文件版本(Revision)可能是1.9, 有的是2.1,等等。这很容易理解,因为为了发行产品V1.0,我们需要对源代码进行多次修改编译。
Release:中文名称:发行版本。整个产品的版本,例如VC5.0, VC6.0等。
Tag:中文名称:标签。在一个开发的特定期,对一个文件或者多个文件给的符号名,一般是有意义的字符串,如“stable”,“release_1_0”等。比如,我们对某个文件的1.5版本加上标签:“memory_bug_fixed”,借助这个有意义的标签,我们可以理解1.5版本解决了内存Bug,所以说Tag赋予了版本一些文字含义。
2. WinCvs的两种工作模式、工作流程与目录
理解上述基本概念之后,我们需要对WinCvs的工作方式有一个基本了解。
CVS工作于服务器/客户端模式(Client/Server模式)。WinCvs是CVS在Windows下的图形客户端。它有两个基本工作模式:
2.1 WinCvs作为远程CVS的客户端
WinCvs 的第一种工作模式是作为远程CVS服务器在本地的客户端使用。CVS由于是在Unix下发展起来的,在使用的时候,有很多命令行,命令行中又带很多参数,习惯于Windows的读者很难记忆这些命令行和参数。WinCvs提供了用图形界面使用远程CVS服务的直观方法。
在这种工作模式下,第一次使用WinCvs的基本流程如下:
1) 您首先要让CVS管理员给您分配一个用户名和密码,先使用WinCvs登录(Login)到CVS服务器。
2) 把本地需要CVS管理的原始目录导入(Import)到CVS服务器上去,使之成为CVS服务器上仓库(Repository)的一个Module。
3) 在本地硬盘上创建一个工作目录。
4) 从CVS服务器的仓库(Repository)导出(Checkout)一个Module到本地硬盘的工作目录
5) 从CVS服务器同步(Update)你同事的修改到你本地工作目录。在工作目录上进行工作,在这个过程中,把文件的中间版本(Revision)提交(Commit)给CVS服务器。
当您已经进行过上述流程,以后再使用时,就简化成只需要步骤1)和步骤5)就可以了。
2.2 WinCvs作为本地的服务器和客户端
如果没有远程CVS服务器,WinCvs 1.3版本能够在本地同时作为Server和Client来工作。其中,服务器端的功能是WinCvs启动CVSNT在后台实现的,CVSNT(www.cvsnt.org)也是一个开源项目,WinCvs1.3版本自带CVSNT,您不用单独安装。在这种工作模式下,你需要在本地硬盘上开设一个CVS仓库目录,它的作用和地位其实就和远程CVS仓库目录一样。
WinCvs工作在这个模式时,当您开始从头工作时,需要下面的工作流程:
1) 首先在本地硬盘上,创建CVS的仓库(Repository)目录。目录名可任意,一般是CVSRoot
2) 把本地需要CVS管理的原始目录导入(Import)到CVS服务器上去,使之成为CVS服务器上仓库(Repository)的一个Module。
3) 在本地硬盘上创建一个工作目录。
4) 从CVS服务器的仓库(Repository)导出(Checkout)一个Module到本地硬盘的工作目录
5) 从CVS服务器同步(Update)你自己从前的修改到你本地工作目录。在工作目录上进行工作,在这个过程中,把文件的中间版本(Revision)提交(Commit)给CVS服务器。
当您已经进行过上述流程,以后再使用时,就简化成只需要步骤5)就可以了。
无论WinCvs工作在上述哪种模式下,下面是它的工作流程图:

从WinCvs的工作流程图中可以知道,WinCvs的工作涉及三个目录:一是原始目录,我们从这里把文件导入到CVS进行管理,从此以后这个目录下的文件就不再参与WinCvs活动了;二是CVS仓库目录,所有的Module都存放在这里,它可能是远程Linux下由CVS服务器管理员创建的,也可能是你自己在本地硬盘创建的,这决定于你工作在哪种模式下;三是您本地硬盘的工作目录,您在这里对文件进行多次修改和提交。
-
登陆界面测试的主要内容(转)
2009-01-07 10:30:43
快捷键的使用是否正常:1. TAB 键的使用是否正确
2.上下左右键是否正确
3.界面如果支持 ESC键 看是否正常的工作
3.ENTER 键的使用是否正确切换时是否正常。
布局美感
界面的布局是否符合人的审美的标准
具体因人而依
输入框的功能:
输入合法的用户名和密码可以成功进入
输入合法的用户名和不合法密码不可以进入,并给出合理的提示
输入不合法的用户名和正确密码不可以进入,并给出合理的提示
输入不合法的用户名和不正确的密码不可以进入,并给出合理的提示
不合法的用户名有:不正确的用户名,,使用了字符大于用户名的限制
正常用户名不允许的特殊字符 空的用户名,系统(操作系统和应用系统)的保留字符
不合法的密码有:空密码(除有特殊规定的),错误的密码,字符大于密码的限制
正常密码不允许的特殊字符,系统(操作系统和应用系统)的保留字符
界面的链接:
对于界面有链接的界面,要测试界面上的所有的链接都正常或者给出合理的提示
补充
输入框是否支持 复制和黏贴 和移动
密码框显示的不要是具体的字符,要是一些密码的字符
验证用户名前有空格是否可以进入,一般情况可以。
验证用户名是否区分大小写。(有的软件是区分大小写的)
验证必填项为空,是否允许进入。
验证登录的次数是否有限制。从安全角度考虑,有些安全级别高的软件会考虑这方面的限制。
-
自动化测试的前提及过程(转)
2008-12-30 17:54:17
自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程。通常,在设计了测试用例并通过评审之后,由测试人员根据测试用例中描述的规程一步步执行测试,得到实际结果与期望结果的比较。在此过程中,为了节省人力、时间或硬件资源,提高测试效率,便引入了自动化测试的概念。1. 自动化测试的前提条件
实施自动化测试之前需要对软件开发过程进行分析,以观察其是否适合使用自动化测试。通常需要同时满足以下条件:
1) 软件需求变动不频繁。
测试脚本的稳定性决定了自动化测试的维护成本。如果软件需求变动过于频繁,测试人员需要根据变动的需求来更新测试用例以及相关的测试脚本,而脚本的维护本身就是一个代码开发的过程,需要修改、调试,必要的时候还要修改自动化测试的框架,如果所花费的成本不低于利用其节省的测试成本,那么自动化测试便是失败的。
项目中的某些模块相对稳定,而某些模块需求变动性很大。我们便可对相对稳定的模块进行自动化测试,而变动较大的仍是用手工测试。
2) 项目周期足够长。
由于自动化测试需求的确定、自动化测试框架的设计、测试脚本的编写与调试均需要相当长的时间来完成。这样的过程本身就是一个测试软件的开发过程,需要较长的时间来完成。如果项目的周期比较短,没有足够的时间去支持这样一个过程,那么自动化测试便成为笑谈。
3) 自动化测试脚本可重复使用。
如果费尽心思开发了一套近乎完美的自动化测试脚本,但是脚本的重复使用率很低,致使其间所耗费的成本大于所创造的经济价值,自动化测试便成为了测试人员的练手之作,而并非是真正可产生效益的测试手段了。
另外,在手工测试无法完成,需要投入大量时间与人力时也需要考虑引入自动化测试。比如性能测试、配置测试、大数据量输入测试等。
2. 自动化测试的过程
自动化测试与软件开发过程从本质上来讲是一样的,无非是利用自动化测试工具(相当于软件开发工具),经过对测试需求的分析(软件过程中的需求分析),设计出自动化测试用例(软件过程中的需求规格),从而搭建自动化测试的框架(软件过程中的概要设计),设计与编写自动化脚本(详细设计与编码),测试脚本的正确性,从而完成该套测试脚本(即主要功能为测试的应用软件)。
1) 自动化测试需求分析。
当测试项目满足了自动化的前提条件,并确定在该项目中需要使用自动化测试时,我们便开始进行自动化测试需求分析。此过程需要确定自动化测试的范围以及相应的测试用例、测试数据,并形成详细的文档,以便于自动化测试框架的建立。
2) 自动化测试框架的搭建。
所谓自动化测试框架便是像软件架构一般,定义了在使用该套脚本时需要调用哪些文件、结构,调用的过程,以及文件结构如何划分。
而根据自动化测试用例,我们很容易能够定位出自动化测试框架的典型要素:
a. 公用的对象。
不同的测试用例会有一些相同的对象被重复使用,比如窗口、按钮、页面等。这些公用的对象可被抽取出来,在编写脚本时随时调用。当这些对象的属性因为需求的变更而改变时,只需要修改该对象属性即可,而无需修改所有相关的测试脚本。
b. 公用的环境。
各测试用例也会用到相同的测试环境,将该测试环境独立封装,在各个测试用例中灵活调用,也能增强脚本的可维护性。
c. 公用的方法。
当测试工具没有需要的方法时,而该方法又会被经常使用,我们便需要自己编写该方法,以方便脚本的调用。
d. 测试数据。
也许一个测试用例需要执行很多个测试数据,我们便可将测试数据放在一个独立的文件中,由测试脚本执行到该用例时读取数据文件,从而达到数据覆盖的目的。
在该框架中需要将这些典型要素考虑进去,在测试用例中抽取出公用的元素放入已定义的文件,设定好调用的过程。
3) 自动化测试脚本的编写
该编写过程便是具体的测试用例的脚本转化。初学的自动化测试人员均会使用录制脚本到修改脚本的过程。但专业化的建议是以录制为参考,以编写脚本为主要行为,以避免录制脚本带来的冗余、公用元素的不可调用、脚本的调试复杂等问题。
4) 脚本的测试与试运行
事实上,当每一个测试用例所形成的脚本通过测试后,并不意味着执行多个甚至所有的测试用例就不会出错。输入数据以及测试环境的改变,都会导致测试结果受到影响甚至失败。而如果只是一个个执行测试用例,也仅能被称作是半自动化测试,这会极大的影响自动化测试的效率,甚至不能满足夜间自动执行的特殊要求。
因此,脚本的测试与试运行极为重要,它需要祥查多个脚本不能依计划执行的原因,并保证其得到修复。同时他也需要经过多轮的脚本试运行,以保证测试结果得一致性与精确性。
-
不容忽视的软件可恢复测试(转)
2008-12-18 16:01:19
随着软件系统应用环境的复杂性,软件出错的机率越来越大了,软件面临着一个非常关键的需求就是在系统出错后能进行恢复。我是公司软件开发测试组负责人,今天老板在测试会议上批评我说,目前用户最大的抱怨是我们的系统缺少自动恢复功能,出现错误后许多的恢复过程都要人工干预来完成,说明我们的可恢复测试仍然很混乱,而且可恢复测试是完全失败的。
不容忽视的软件可恢复测试
(1)什么是软件可恢复性
随着软件应用的日益普及,对软件质量的要求也不断提高。软件质量是指软件产品中能满足给定需求的各种特性的总和。ISO/IEC 9126中规定了软件的6个质量特性,即功能性(Functionality)、可靠性(Reliability)、易用性(Usability)、效率性(Efficiency)、维护性(Maintainability)和可移植性(Portability),每个特性包含若干子特性。
可靠性是指在规定的一段时间和条件下,软件产品维持规定的性能水平的能力。3个子特性分别为:成熟性(Maturity)、容错性(Fault tolerance)、可恢复性(Recoverability)。其中容错性是指与在软件错误或违反指定接口的情况下,维持指定的性能水平的能力有关的软件属性。而可恢复性是指在故障发生后,重新建立其性能水平并恢复直接受影响数据的能力,以及为达到此目的所需的时间和努力有关的软件属性。
一般来说,许多基于计算机的软件系统必须在一定的时间内从错误中恢复过来,然后继续运行。也就是说在某些情况下,一个软件系统应该是在运行过程中的出现错误时能自动或人工进行恢复,不能使整个系统的功能都停止运作,否则就会造成严重损失。因此,软件可恢复失败包括两个方面:一是软件系统没有自动的恢复到原来的性能,这意味着恢复需要人工干预;二是即使是人工干预后,也不能恢复到原来设计性能,例如软件所涉及的数据出现某种程度的失效和损坏。
(2)什么是可恢复测试
软件测试是发现软件中的大部分缺陷的一种技术。软件测试大体上划分为三大阶段:单元测试、集成测试、系统测试。系统测试是检验整个系统是否满足《需求规格说明书》所提出的所有需求。其中系统测试的非功能性测试包括可靠性测试、容错测试和恢复性测试等。
可恢复测试(Recovery testing)是测试一个系统从灾难或出错中能否很好地恢复的过程,如遇到系统崩溃、硬件损坏或其他灾难性出错。可恢复测试一般是通过人为的各种强制性手段让软件或硬件出现故障,然后检测系统是否能正确的恢复(自动恢复和人工恢复)。简单的说,可恢复测试是一种对抗性的测试过程。在测试中将把应用程序或系统置于极端的条件下或是模拟的极端条件下产生故障,然后调用恢复进程,并监测、检查和核实应用程序和数据能否得到正确的恢复。
可恢复测试通常需要关注恢复所需的时间以及恢复的程度。例如,当系统出错时能否在指定时间间隔内修正错误并重新启动系统。对于自动恢复需验证重新初始化(Reinitialization)、检查点(Checkpointing mechanisms)、数据恢复(Data recovery)和重新启动 (Restart)等机制的正确性;而对于需要人工干预的恢复系统,还需估计平均修复时间,确定其是否在可接受的范围内。
因此,随着网络应用、电子商务、电子政务越来越普及,系统可恢复性也显得越来越重要,可恢复性对系统的稳定性、可靠性影响很大。但可恢复性测试很容易被忽视,因为可恢复测试相对来说是比较难的,一般情况下是很难设想得出来让系统出错和发生灾难性的错误,这需要足够的时间和精力,也需要得到更多的设计人员、开发人员的参与。
(3)容错测试与可恢复测试的区别
容错测试一般是输入异常数据或进行异常操作,以检验系统的保护性。如果系统的容错性好的话,系统会给出提示或内部消化掉,而不会导致系统出错甚至崩溃。而可恢复测试是通过各种手段,让软件强制性地发生故障,然后验证系统已保存的用户数据是否丢失、系统和数据是否能很快恢复。因此,可恢复测试和容错测试是互补的关系,可恢复测试也是检查系统的容错能力的方法之一,但不能只重视其中之一。
(4)故障转移测试和可恢复测试的关系
故障转移测试(Failover)指当主机软硬件发生灾难时候,备份机器是否能够正常启动,使系统可以正常运行,这对于电信,银行等领域的软件是十分重要的。因此,故障转移是确保测试对象在出现故障时,能成功地将运行的系统或系统某一关键部分转移到其它设备上继续运行,即备用系统将不失时机地“顶替”发生故障的系统,以避免丢失任何数据或事务,不影响用户的使用。
故障转移测试和可恢复测试也是一种互补关系的测试,它们共同可确保测试对象能成功完成故障转移,并能从导致意外数据损失或数据完整性破坏的各种硬件、软件或网络故障中恢复。因此,他们两者的关系一个是测试备用系统能否及时工作,另一个是测试系统能否恢复到正确运行状态。
可恢复测试主要内容和步骤
(1)恢复性测试的基本内容
通过可恢复测试,一方面使系统具有异常情况的抵抗能力,另一方面使系统测试质量可控制。因此,可恢复测试包括以下几种情况:
① 硬件及有关设备故障。测试对于硬件及设备故障是否有有效的保护及恢复能力,系统是否具有诊断、故障报告及指示处理方法的能力,是否具备冗余及自动切换能力,故障诊断方法是否合理和即时。例如,设备掉电后(如客户端和服务器端断电)的可恢复程度。
② 软件系统故障。测试系统的程序及数据是否有足够可靠的备份措施,在系统遭破坏后是否具有重新恢复正常工作的能力,对系统故障是否自动检测和诊断的功能。故障发生时,是否能对操作人员发出完整的提示信息和指示处理方法能力,是否具有自动隔离局部故障,进行系统重组和降级使用使系统不中断运行。还有,若系统局部故障可否进行占线维护,而不中断系统的运行。最后,在异常情况时是否记录故障前后的状态,搜集有用信息供测试分析。
③ 数据故障。是测试数据处理周期未完成时的恢复程度,例如数据交换或同步进程被中断,异常终止或提前终止的数据库进程,最后还有操作异常等情况。
④ 通信故障和错误。测试有没有纠正通信传输错误的措施,有没有恢复到与其他系统通信发生故障前原状的措施,还有对通信故障所采取的措施是否满足运行要求等。
(2)可恢复测试的基本流程
首先需要制定可恢复测试计划,并准备好可恢复测试用例和可恢复测试规程。其次,是要对照基线化软件等级和基线化需求分配。第三,进行软件可恢复测试。在此过程中,要用文档记录好在可恢复性测试期间所出现的问题并跟踪直到结束。然后,将可恢复测试结果写成文档,说明测试所揭露的软件软件能力、缺陷和不足,以及可能给软件运行带来的影响。最后,说明能否通过测试和测试结论,并提交可恢复测试分析报告。
可恢复测试经验总结与分享
从测试技术和测试管理的角度来看,目前对高可靠性软件测试特别是可恢复测试方案,许多测试人员还缺乏真正的认识。因此,对需要高可恢复的软件如何实施可恢复测试,在技术和经验上仍是一个颇不成熟的领域,更缺少一种体系化的方法。
(1)必须从认识上有足够的重视和关注
让人非常遗憾的是在可恢复测试上,许多测试人员还缺乏足够的重视和关注。例如,许多测试人员认为只要我们有制定可恢复测试方案,有获得所需的硬件和软件,配置了系统,然后也有测试故障转移和灾难恢复响应系统,一切按照预期计划进行就OK了。但是大多数的测试人员只会在常规环境下进行可恢复测试,并没有想尽一切可能的办法在更多的不同环境下的进行可恢复测试,结果是他们并没有确保自己进行了足够的可恢复测试。
(2)必须制定明确的测试计划和测试制度
如果没有制定明确的测试计划和需要遵循的测试制度,那么测试就会马虎了事,根本无法满足可恢复测试的要求。那么完成测试目标也成了空中楼阁,软件可恢复性质量也无从谈起了。
(3)必须要用真实数据进行测试
用真实数据进行真实测试是可恢复测试中最棘手的部份。因为在没有用真实数据测试的时候,就很难评价系统进行可恢复或故障转移过程中的各种技术指标的有效性。我在可恢复测试中得到的宝贵经验是,用真实数据进行测试会得到让人难以接受的事实,但这是提高软件测试质量的关键之一。
(4)确保测试过程和文档的一致性
软件可恢复测试工作还包括:验证应用程序不同环境下的表现、书面需求分析文档、联机帮助、界面资源等。因此,当进行可恢复测试活动时,应确保测试手册、联机帮助、测试分析报告和应用程序测试需求的完整性和一致性。
-
测试用例设计白皮书--测试用例基本概念(转)
2008-12-01 10:33:08
目 录1. 概述
2.1. 测试用例的定义
2.2. 测试用例的特征
2.3. 测试用例组成元素
2.4. 测试用例设计原则
3. 测试用例设计方法
3.1. 等价类划分方法
3.2. 边界值分析方法
3.3. 错误推测方法
3.4. 因果图方法
3.5. 判定表驱动分析方法
3.6. 正交实验设计方法
3.7. 功能图分析方法
3.8. 场景设计方发
4. 测试用例设计综合策略
1.概述
Grenford J. Myers在《The Art of Software Testing》一书中提出:一个好的测试用例是指很可能找到迄今为止尚未发现的错误的测试,由此可见测试用例设计工作在整个测试过程中的地位,我们不能只凭借一些主观或直观的想法来设计测试用例,应该要以一些比较成熟的测试用例设计方法为指导,再加上设计人员个人的经验积累来设计测试用例,二者相结合应该是非常完美的组合。本文所介绍的测试用例设计方法对于测试设计人员将是一个很好的方法指导,当然看完本文也未必能设计出好的测试用例,有了好的方法作为指导后需要更多的实践经验加以巩固和提炼。只有将测试设计思想与丰富的实践经验相融合才能设计出高质量的测试用例,相信你行!
本文描述的范围:测试用例基本概念、测试用例设计方法、测试用例设计综合策略。
关键词:测试用例、等价类划分、边界值分析、错误推测、因果图、判定表驱动分析、正交实验、功能图分析、场景设计
读者对象:测试设计人员、测试人员 参考文献: 1. 《计算机软件测试技术》 郑人杰 2. 《The Art of Software Testing》 Grenford J. Myers2.测试用例基本概念
2.1.测试用例的定义
测试用例是为特定的目的而设计的一组测试输入、执行条件和预期的结果。测试用例是执行的最小实体。简单地说,测试用例就是设计一个场景,使软件程序在这种场景下,必须能够正常运行并且达到程序所设计的执行结果。
2.2.测试用例的特征1.最有可能抓住错误的;
2.不是重复的、多余的;
3.一组相似测试用例中最有效的;
4.既不是太简单,也不是太复杂。
2.3.测试用例组成元素1.用例ID;
2.用例名称;
3.测试目的;
4.测试级别;
5.参考信息;
6.测试环境;
7.前提条件;
8.测试步骤;
9.预期结果;
10.设计人员。
2.4.测试用例设计原则1.测试用例的代表性:能够代表并覆盖各种合理的和不合理的、合法的和非法的、边界的和越界的以及极限的输入数据、操作和环境设置等。
2.测试结果的可判定性:即测试执行结果的正确性是可判定的,每一个测试用例都应有相应的期望结果。
3.测试结果的可再现性:即对同样的测试用例,系统的执行结果应当是相同的。
相关文章:
-
光洁肌肤 消印去疤小秘方(转)
2008-09-29 11:26:03
脸上多多少少会留下痘印或者疤痕,怎样消除这些影响美丽的瑕疵呢?,以下小方法可以帮到你哦~
1、按摩法:用手掌根部揉按疤痕,每天三次。这个方法对于刚脱痂的伤口效果最佳,对于旧伤疤效果比较弱。2、姜片摩擦法:生姜切片后轻轻擦揉疤痕,可以抑制肉芽组织继续生长。
3、维生素E涂抹法:把维生素E胶囊用针戳破,取其内的液体涂抹在疤痕上轻轻揉按5-10分钟,每天两次,持之以恒就会有比较好的效果。
4、维生素C涂抹法:把维生素C涂抹在颜色较深的疤痕上来美白疤痕,使之与周围健康的肌肤色调一致。
5、薰衣草精油涂抹法:薰衣草精油淡化疤痕的作用也被广泛认同。另外,精油的使用总是要特别小心的,给疤痕上精油的时候可千万别福泽没有疤的肌肤了。
-
Cookie测试工具小汇(转)
2008-09-18 10:45:43
现在很多网站都用到Cookies,特别是用户的登陆以及购物网站的购物车。 Cookies 通常用来存储用户信息和用户在某应用系统的操作,当一个用户使用Cookies 访问了某一个应用系统时,Web 服务器将发送关于用户的信息,把该信息以Cookies 的形式存储在客户端计算机上,这可用来创建动态和自定义页面或者存储登陆等信息。
如果Web 应用系统使用了Cookies ,就必须检查Cookies 是否能正常工作。测试的内容包括Cookies是否起作用,存储的内容是否正确,是否按预定的时间进行保存,刷新对Cookies 有什么影响等。如果到\Local Settings\Temporary Internet Files文件夹下查看每个Cookies文件是一件很麻烦的事情,这个时候就需要有工具来帮助我们。
1、Cookie Editor
http://www.proxoft.com/CookieEditor.asp
Cookie Editor is an application that helps you manage cookies set by Internet Explorer, Netscape or Mozilla Browsers.
Cookie Editor allows you to maintain the level of your privacy by allowing you to see, edit or delete any unwanted cookies. It searches your drives for all IE cookies then displays them is easy grid-like format. You can examine content of any cookie or delete it.
For advanced users, you can also edit the contents of cookies. So, for example, if you want to change your zip code for 'movies.yahoo.com', or move up the expiration date of a given cookie, you could do so without even opening your browser!
比较大的特点是可以显示出IE,Netscape和Firefox的Cookie;因为Netscape和Firefox的Cookie不是存储在Temporary Internet Files文件夹下的,而是在Application Data文件夹下的对应文件夹里。

2、IECookiesView
http://www.nirsoft.net/utils/iecookies.html
一个可以帮你搜寻并显示出你计算机中所有的Cookies档案的数据,包括是哪一个网站写入Cookies的,内容有什么,写入的时间日期及此Cookies的有效期限..等等资料。你是否常常怀疑一些网站写入Cookies内容到你的计算机中是否会对你造成隐私的侵犯!使用软件来看看这些Cookies的内容都是些什么呢!如此你就不会再担心怀疑了。此软件只对IE浏览器的Cookies有效。

3、Cookies Manager
Cookies Manager helps you to select which cookies you want to keep and which cookies you want to delete.

4、My Cookie
My Cookie是一款可以实时查看、修改IE内 Cookied的软件。并且可以设置 Cookie值的生命周期。
-
不再傻等的wait()方法-QTP中Wait与同步点的区别[转]
2008-09-16 17:04:10
QTP中Wait与同步点的区别[转]
先说wait函数,当脚本走到wait函数时,就开始执行这个函数.如:wait(10),就等待10秒种后再继续执行下面的语句.wait函数的这个等待的时间,那相对来说是比较固定的.如上例子,一定要等待完10秒后再执行.所以写脚本的时候要自己估算一下时间.不然可能造成时间的浪费,或者等待时间的不足.
那同步点呢.等待时间就比较灵活了,它的等待时间是不固定的.设置同步点后,当脚本执行到这句话后,脚本就开始执行等待.脚本会在规定时间内不断的去检查,所同步的对象有没有出现,一但出现,脚本就继续往下执行.不需要等完所有规定时间.如果在规定的时间内,所要同步对象还没有出现,那就提示超时的错误信息.51testing软件测试
例如:
Window("Flight Reservation").ActiveX("Threed Panel Control").WaitProperty "text", "Insert Done...", 10000
当脚本执行到这句话时,就开始执行同步等待时间.这里设置超时时间为10000.在这个时间内,脚本会不断去查看该对象的text属性的属性值Insert Done...,有没有出现.一但同步到这个属性值,就开始执行下面的脚本了.而不需要再继续等待,直到1000秒结束为止.那这样的话,这个等待时间不用自己去控制,设置好后由程序自己去判断,就比较灵活,也不会出现浪费时间的情况.能提高脚本的执行率.傻妞评语:这个方法很好,解决了"傻等" 问题。不过,我们依然现选择"傻等",是因为这样会比较common,一但做成,处处受用.使用这种WaitProperty的方法,会遇到的问题就是,不同的页面要等待的属性不一。可能就造成每个business component都需要量身定做一个这样的function,比较耗时.嘻嘻,对于工作量小的business component还是很可行的。




标题搜索
我的存档
数据统计
- 访问量: 7473
- 日志数: 16
- 建立时间: 2008-09-10
- 更新时间: 2010-03-31
