

实际应用中很多报表的数据来源于多个不同类型的数据库,报表数据源跨数据库是报表开发中的常态。目前实现这类跨库关联报表的方式有多种,但都会存在这样那样的问题。
使用报表工具自身多源关联功能
现在大多数主流报表工具都支持多数据源关联,这在某些方面确实为报表用户带来了便利。然而我们也经常会遇到通过报表自身的多源关联功能很难实现一些跨库关联的报表(由于数据结构和业务本身决定)。这当然容易理解,报表工具主要是来做数据展现的,而对数据计算本身来说并不擅长。
即使有的能实现,在报表中做跨库关联计算的效率也较低,远远不如数据库的性能,而且经常因为在实现过程中使用了大量隐藏行列进一步降低报表性能并加大内存占用。
于是一般会采用下面的两种方式。
将数据统一到一个数据库中
将不同数据库的数据统一到一个数据库中,这种做法在各类应用中很常见,目的是使用数据库(SQL)强大的计算能力。然而,这种做法会增加额外的成本开销,将多个数据库中的数据统一到一个数据库中势必会占用昂贵的数据库空间,并造成该数据库数据过多、管理困难、压力增大等问题,而且还可能负担额外的数据库购买成本以及管理成本。另外,完成ETL迁移数据也是一份不小的工作量,对实时性要求较高的报表还得用触发器方式来做ETL(一般ETL是定时的),会严重影响原数据库的性能。
使用高级语言实现跨库关联为报表准备数据
基于上面提到两种方式中存在的问题,有些用户使用高级语言(Java等)编程完成跨库运算,为报表自定义数据源。这种做法的优点是灵活,理论上任何运算通过程序都能完成;缺点是太难写。很多像Java这样的高级语言缺乏对集合运算的有效支持,没有相应的类库,导致完成个简单的group也要写很多(循环)代码,更不用说关联以后还要再进行分组汇总等其他运算了。
这种情况下,使用集算器来实现跨库关联报表就是个不错的选择。
集算器如何实现跨库关联报表?
我们通过一个例子来看集算器是如何快速实现跨库关联报表的。
业务描述
企业员工每月应发工资跟员工的基本工资、考勤以及绩效有关,考勤信息来源于人力部门的考勤系统(hsql数据库),基本工资和绩效信息则存储在财务系统(mysql数据库)中。需要将这两类信息合起来计算员工的工资。
实现步骤
编写脚本(crossDB.dfx)完成跨库关联计算,为报表准备数据
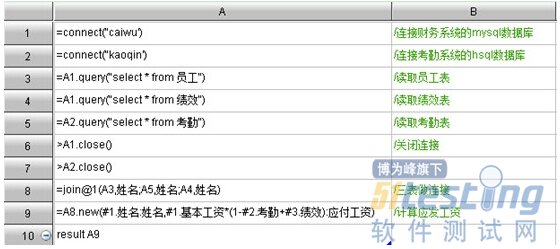
在A1、A2中通过connect分别连接hsql和mysql数据源
在A3、A4、A5中通过query语句分别从两个数据库中取出用到的数据,此时数据已全部取出,不再需要与数据库交互,在A6、A7中关闭两个数据库连接
在A8中使用join完成三表的连接
在A9中计算应发工资,算法为:基本工资*(1-考勤系数+绩效系数)
最后通过A10的result生成供报表使用的结果集
报表调用集算器脚本完成报表展现
集算器的类包封装成标准的JDBC,允许报表工具以类存储过程的调用方式调用集算器脚本,如本例中在报表工具中像配置数据库连接一样配置起好集算器的JDBC,然后建立存储过程数据集后使用 call crossDB()即可完成调用。












