

ЁЁЁЁ2.3 ЗжВМЪНдЫааТпМ
ЁЁЁЁетРяЕФТпМжївЊЪЧСНПщЃЌвЛВПЗжЪЧБОЕиВПЗжЃЌвЛВПЗжЪЧЗжВМЪННкЕуЛњЦїВПЗжЁЃЮвУЧНЋЗжВМЪНВтЪджДааЙ§ГЬЗтзАЕНвЛИіhadoop jobРяЁЃ
ЁЁЁЁБОЕиВПЗжЃК
ЁЁЁЁ1ЁЂЛёШЁМЦЫузЪдДЁЃетРяЕФМЦЫузЪдДжИПЩгУЕФtasktrackerЕФВлЮЛЪ§ЃЌетИіВлЮЛЪЧcaseЧаЗжЕФЗжФИЁЃ
ЁЁЁЁ2ЁЂИљОнМЦЫузЪдДЩњГЩcaseСаБэЁЃгаСЫВлЮЛЪ§ЃЌзюМђЕЅЕФЧаЗжЫуЗЈОЭЪЧЃКУПНкЕуcaseЪ§=змcaseЪ§/ВлЮЛЪ§ЁЃ
ЁЁЁЁ3ЁЂвЕЮёВуздЖЈвхВйзїЁЃР§ШчвЕЮёВуВтЪджДааЪБашвЊЕФГЬађЛђепХфжУЛёШЁЃЌвРРЕЕФДѓЪ§ОнЭЦЫЭЕНhdfsЕШЁЃ
ЁЁЁЁ4ЁЂХфжУhadoopЕФjobЁЃАќРЈinputЃЌoutputЃЌжДааjobЫљашЕФЮФМўЛђепtarАќЕШЁЃетРяЕФinputОЭЪЧcaseСаБэЁЃ
ЁЁЁЁ5ЁЂжДааВтЪджДааjobЁЃетИіЪЕМЪЪЧИіhadoop jobЁЃ
ЁЁЁЁ6ЁЂЗЂЫЭБЈИцЁЃЛузмУПИіНкЕуЕФдЫааНсЙћЃЌВЂЗЂГіБЈИцЁЃ
ЁЁЁЁУПИіtasktrackerЕФmapШЮЮёЪфШыЪЧЧаЗжКѓЕФcaseСаБэЃЌЭЈЙ§етжжЗНЪННЋећИіВтЪджДааВПЗжЗжЗЂЕНУПИіtasktrackerЩЯЁЃ
ЁЁЁЁНкЕуВПЗжЃК
ЁЁЁЁ1ЁЂзМБИcaseСаБэЁЃДгmapЕФinputЛёШЁЁЃ
ЁЁЁЁ2ЁЂИљОнcaseСаБэЯТдиcaseЁЃЃЌетРяРрЫЦгкБОЕиЕЅЛњАцЕФcaseЛёШЁЃЌРДдДШдШЛЪЧSVNЛђепCASEПтЁЃ
ЁЁЁЁ3ЁЂАВзАlibПтЁЃЭЌБОЕиЕЅЛњАцЁЃ
ЁЁЁЁ4ЁЂАВзАВтЪдЛЗОГЁЃЭЌБОЕиЕЅЛњАцЁЃ
ЁЁЁЁ5ЁЂжДааcaseЁЃЭЌБОЕиЕЅЛњАцЁЃ
ЁЁЁЁ6ЁЂЭЦЫЭБЈИцЁЃ
ЁЁЁЁетРяhadoopЛЙЛсИљОнУПИіmapШЮЮёЕФЗЕЛижЕЃЌРДНјаажиЪддЫааЕФЕїЖШЁЃ
ЁЁЁЁДгвдЩЯЕФУшЪіПЩвдПДЕНЃЌдкhadoopМЏШКНкЕуЛњЦїЩЯ(tasktracker)ЃЌВтЪджДааЕФТпМКЭЕЅЛњАцЛљБОЮоВюБ№ЃЌЫљвдећИіИФдьЕФЙ§ГЬвВЪЧБШНЯМђЕЅЕФ
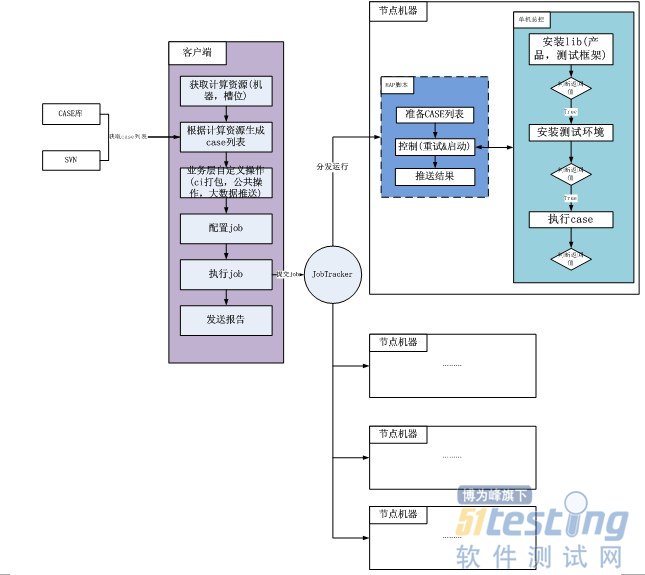
ЁЁЁЁ2.4 ЗжВМЪНВтЪдМЏШКМмЙЙЩшМЦ
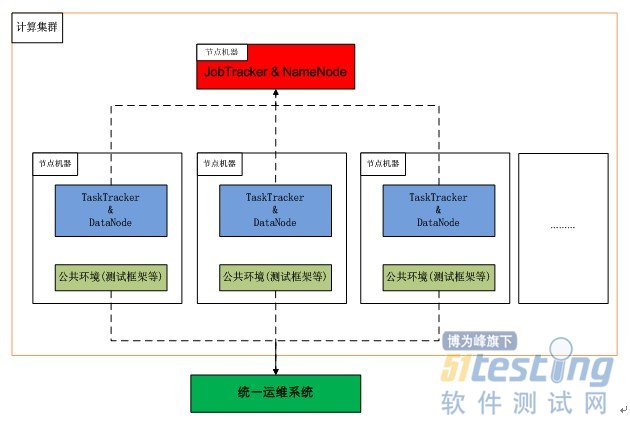
ЁЁЁЁећИіЗжВМЪНВтЪджДаавРЭагквЛИіЙЋЙВЕФМЦЫуМЏШКЃЌетИіМЦЫуМЏШКгЩСНВПЗжзщГЩЃЌвЛВПЗжЪЧhadoopЯрЙиЕФЃЌАќРЈhadoopЕФзмПиЃЌзгНкЕуЕФtasktrackerЗўЮёЁЃСэЭтвЛВПЗжОЭЪЧЙЋЙВЛЗОГЃЌАќРЈВтЪдПђМмЃЌЙЋЙВЙЄОпР§ШчvalgrindЕШЁЃЧАепЭЈЙ§jobtrackerРДЙмРэЃЌКѓепЭЈЙ§ЭГвЛдЫЮЌЯЕЭГРДЙмРэЃЌЦфЙІФмЛљБООЭЪЧЙЋЙВЛЗОГЕФАВзАКЭЮЌЛЄЁЃ
ЁЁЁЁ3 Ъевц
ЁЁЁЁОЙ§ЮвУЧЕФЪЕМЪЯюФПЪЕМљЃЌетВПЗжЕФЪевцжївЊЬхЯждкШчЯТСНЕуЃК
ЁЁЁЁ1ЁЂВтЪджДааЪБМфДѓЗљгХЛЏЁЃ15ЬЈЛњЦїЕФЧщПіЃЌЫљгадВтЪджДааЪБМфвЊ1-2аЁЪБЕФФЃПщЃЌгХЛЏЕН10ЗжжгвдФкЁЃ
ЁЁЁЁ2ЁЂЛњЦїзЪдДЕФНкЪЁЁЃЭЈЙ§ЙЋЙВМЏШКЕФЮЌЛЄЃЌБЃжЄЫљгаЛњЦїcpuТњИККЩдЫзїЃЌБмУтСЫвдЭљЕЅЛњВтЪджДааЕФcpuРЫЗбЁЃ
ЁЁЁЁ4 зМШыддђМАЗЂеЙЗНЯђ
ЁЁЁЁ4.1 ЗжВМЪНИФдьЕФзМШыддђ
ЁЁЁЁВЂВЛЪЧЫљгаЕФВтЪджДааЖМПЩвдЗжВМЪНЛЏЃЌдкЮвУЧЕФЪЕМЪВйзїЙ§ГЬжаЃЌзмНсГівдЯТМИЕузМШыддђЃЌЙЉВЮПМЃК
ЁЁЁЁ1ЁЂПеАзЛњЦїПЩдЫааЁЃЭЈЙ§вЛИізмПиНХБООЭПЩвдзіЕНвРРЕЛЗОГзМБИЃЌlibПтАВзАЃЌВтЪдcaseжДааЕШЁЃ
ЁЁЁЁ2ЁЂВтЪдПђМмдЪаэcaseВЂааЁЃ
ЁЁЁЁ3ЁЂвЕЮёВуcaseЖдЭтВПВЛДцдкЙЬЖЈвРРЕЃЌР§ШчвРРЕгкФГИіаДЫРЕФФПТМЁЃ
ЁЁЁЁ4ЁЂвЕЮёВуcaseвРРЕЕФserverЖЫПкЃЌзюКУЪЧЫцЛњЕФЁЃ
ЁЁЁЁ5ЁЂВЛдЪаэвЕЮёВуШЅВйзїЙЋЙВЛЗОГЁЃ
ЁЁЁЁ4.2 КѓајПЩФмЕФММЪѕЗНЯђ
ЁЁЁЁ1ЁЂcaseАДеежДааЪБМфЧаЗжЁЃАДееЪБМфЧаЗжРДЬцДњАДееcaseЪ§ЧаЗжЁЃ
ЁЁЁЁ2ЁЂДгЗжВМЪНВтЪджДааЙ§ЖЩЕНдЦВтЪдЗўЮёЁЃ











