

ЎЎЎЎХвЦЦДЈКҪПВЈ¬ҙжФЪТФПВјёёцОКМв
ЎЎЎЎ1 ҝЙУГРФЈәјЩЙиТ»ёцНкХыөДТөОсБчіМP·ГОКөДКэҫЭҝвұ»Ір·ЦОӘAЎўBЎўCЎўDЎўE ОеёцҝвЈ¬јЩЙиГҝёцРҙҝвҝЙУГРФОӘ99%Ј¬ДЗГҙХвёцТөОсБчіМPөДҝЙУГРФҫНОӘ99%*99%*99%*99%*99%=95%,ҝвІр·ЦөДФҪ¶аЈ¬¶ФПөНіөДХыМеҝЙУГРФМфХҪҫНФҪҙуЎЈ
ЎЎЎЎ2 РФДЬЈәУЙУЪҙ№ЦұТөОсҝвГҝёцҝвөДёәФШҝЙДЬІ»Т»СщЈ¬јЩЙиҪ»ТЧҝвёәФШәЬёЯЈ¬Т»ёцҪ»ТЧРҙҝвҝП¶ЁІ»ДЬ№»ВъЧгРиЗуЈ¬ХвёцЗйҝцПВЈ¬Ҫ»ТЧҝвіЙОӘХыёцПөНіөДЖҝҫұЎЈ
ЎЎЎЎ3 ҝЙА©Х№РФЈәөҘёцҪЪөгөДҝЙА©Х№РФГ»УРөГөҪёДЙЖЈ¬Ҫ»ТЧҝвІ»ДЬөҘ¶АҪшРРА©Х№ЎЈ
ЎЎЎЎөҘТөОсҝвЛ®ЖҪЎўҙ№ЦұІр·Ц
ЎЎЎЎФЪЙПТ»ЦЦЗйҝцЈ¬јЩЙиҪ»ТЧҝвКЗХыёцПөНіөДЖҝҫұЈ¬РиТӘ¶ФҪ»ТЧҝвҪшРРөҘ¶АөДА©Х№ЎЈҝЙТФҝјВЗҪ»ТЧөДЛ®ЖҪІр·Ц»тХЯҙ№ЦұІр·ЦЈ¬УРҝЙДЬН¬КұҪшРРБҪЦЦ·ҪКҪІр·ЦЎЈ
ЎЎЎЎЛ®ЖҪІр·ЦТ»°гёщҫЭТөОсОЮ№ШөД№ШјьЧЦҪшРРІр·ЦЈ¬әбПтА©Х№РФұИҪПәГЈ¬ө«КЗ¶ФУЪІйСҜөДМфХҪұИҪПҙу
ЎЎЎЎҙ№ЦұІр·ЦТ»°гёщҫЭТөОсАҙІр·ЦЈ¬ө«КЗҝЙДЬөјЦВКэҫЭІ»ҫщФИТФј°Ір·ЦІ»№»Бй»оЎЈ¶ФУЪІйСҜАҙЛөЈ¬Па¶ФұИҪПУСәГ
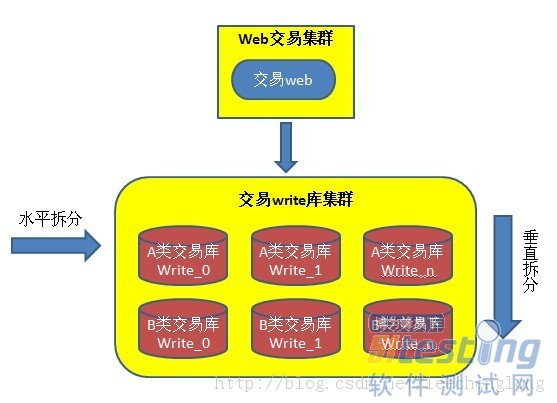
ЎЎЎЎДГҪ»ТЧҝвҫЩёцАэЧУЈ¬ҝЙТФПИҪ»ТЧөДАаРНҪшРРТөОсЙПөДҙ№Цұ·ЦҝвЈ¬ФЪ°ҙХХ¶©өҘәЕҪшРРЛ®ЖҪ·ЦҝвЎЈ
ЎЎЎЎјЩЙиҝЙТФ·ЦіЙM*NёцҝвЈ¬ДЗГҙөҘёцҝвөД№КХП»бУ°Пм1/M*N өДҪ»ТЧЈ¬ө«КЗјЩЙиГҝёцҝвҝЙУГРФОӘ99% Ј¬ДЗГҙҪ»ТЧКэҫЭҝв№КХПёЕВКОӘ (99%)өД(M+N)ҙО·ҪЈ¬Из№ыКэҫЭҝвІр·ЦөДФҪ¶аЈ¬·ўЙъөҘёцКэҫЭҝв№КХПёЕВКҫНФҪёЯЎЈ
ЎЎЎЎХвЦЦ·ҪКҪҙжФЪөДОКМвЈә
ЎЎЎЎ1 ЛдИ»өҘёцҪЪөг№КХПУ°ПмөДУГ»§әЬЙЩЈ¬ө«КЗХыМеҝЙУГ»бҪөөНЎЈ
ЎЎЎЎ2 КэҫЭҝв№ЬАнЙПҙшАҙёҙФУөДМфХҪЈ¬јЩЙиҪ»ТЧҝвұнҪб№№ұдёьЈ¬РиТӘЦҙРРMЎБNҙОҪЕұҫұдёьЎЈ
ЎЎЎЎ3 УЙУЪ·ўЙъөҘёцКэҫЭҝв№КХПөДёЕВКұИҪПёЯЈ¬dba»бәЬҝаұЖөДЈ¬№АјЖҫӯіЈРФТӘҫИ»р
ЎЎЎЎ4 ҝӘ·ўәНІвКФЖрАҙ»б·ЗіЈҝаұЖЈ¬ҝӘ·ўәНІвКФіЙұҫ»бұдёЯЈ¬ІйСҜ·ЗіЈёҙФУЎЈ
ЎЎЎЎ5 өҘёцҪЪөгИз№ы·ўЙъ№КХПЈ¬Г»УРК§°ЬјмІвІўЗТЗР»»»ъЦЖ
ЎЎЎЎ6 ·Цҝв»№І»ДЬФЪЛ®ЖҪ·ҪПтЧцөҪОЮПЮА©Х№Ј¬ОТГЗөДЛг·ЁКЗКВПИ·ЦЕдMёцҝвЈ¬Из№ыМнјУТ»ёцҝв»щұҫЙПІ»ҝЙРР
ЎЎЎЎЛж»ъ·Цҝв
ЎЎЎЎ¶ФУЪөЪБщёцОКМвЈ¬ФЪЛ®ЖҪ·ҪПтөДОЮПЯА©Х№Ј¬ҝЙТФҝјВЗТ»ЦЦ»ъЦЖЈ¬ФЪinsertКэҫЭөДКұәтЈ¬ЙкЗлТ»ёцКэҫЭҝвұаәЕЈ¬И»әу°СКэҫЭҝвөДұаәЕЧчОӘТ»ёцЧЦ¶ОұЈҙж»тХЯФЪ°СХвёцұаәЕМнјУөҪТСҫӯЧЦ¶ОЙПЎЈ
ЎЎЎЎАэИзјЩЙиОТГЗЙкЗлinsertКэҫЭҝвЈ¬өГөҪТ»ёцКэҫЭҝвұаәЕОӘ1000Ј¬ДЗГҙОТГЗҝЙТФ№№ФміцАҙТ»ёц¶©өҘәЕОӘ1000_tradenoЈ¬¶©өҘәЕЗ°ГжКЗ·ЦҝвұаәЕЈ¬¶©өҘәЕәуГжКЗКөјКtradenoЈ¬ХвСщҪвҫцБЛЛ®ЖҪОЮПЯА©Х№өДОКМвЎЈХвЦЦҫНКЗЛж»ъ·ЦҝвДЈКҪЎЈө«КЗХвТ»ЦЦ·ҪКҪөДҫЦПЮРФәЬҙуЈ¬

ЎЎЎЎЛж»ъ·ЦҝвөДИұөгЈә
ЎЎЎЎ1 ·ЦҝвЛг·ЁәНТөОссоәПФЪТ»ЖрЈ¬ұИҪПККәПМШ¶ЁөДіЎҫ°Ј¬ККУГ·¶О§ұИҪПХӯ
ЎЎЎЎ2 ¶ФУЪinsertІЩЧчЈ¬ұИҪПИЭТЧЈ¬¶ФУЪupdateІЩЧчЈ¬ұШРлУР·ЦҝвұаәЕЈ¬ТІҫНКЗЛөЈ¬Ц»ДЬёщҫЭМШ¶ЁөДЧЦ¶ОАҙҪшРРёьРВ
ЎЎЎЎ3 І»ККәПЕъБҝІйСҜөДіЎҫ°Ј¬ІйСҜ№ҰДЬПЮЦЖұИҪПҙуЈ¬ХвТІКЗ·ЦҝвҙшАҙөДОКМв
ЎЎЎЎөҘКэҫЭҝвұё·ЭТФј°К§°ЬЗР»»
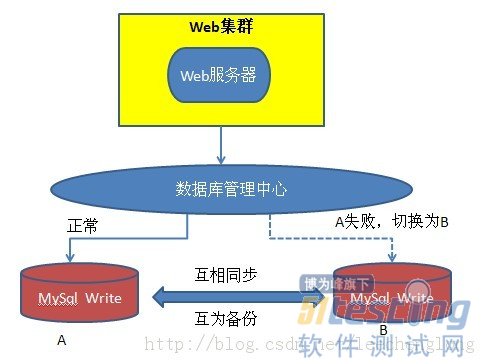
ЎЎЎЎ¶ФУЪөҘёцКэҫЭҝвЈ¬Из№ы·ўЙъ№КХПЈ¬»бУ°ПмТөОсЈ¬ө«КЗДЬ·сФЪ·ўЙъ№КХПөДКұәтҪшРРЗР»»ЎЈЛдИ»ҝЙТФКөПЦЈ¬ө«КЗ»бҙжФЪТ»¶ЁөДОКМвЈ¬РиТӘМШ¶ЁіЎҫ°ҪшРРМШ¶ЁөД·ЦОцЎЈХвТ»ҝйұИҪПёҙФУЈ¬ЛөЖрАҙҝЙТФФЪРҙТ»ЖӘОДХВЈ¬ҫНјтөҘөДҪйЙЬТ»ПВ
ЎЎЎЎТФЙПҫНКЗЧЬҪбөДКэҫЭҝвөДјЬ№№СЭұдЈ¬КэҫЭҝвөДСЭұдРиТӘәЬ¶а»щҙЎјјКхЧцЦ§іЕЈ¬ЦчТӘ°ьАЁ
ЎЎЎЎ1 ЗҝҙуөД·ЦІјКҪКэҫЭҝвөД№ЬАнЦРјдјюЈ¬ЦчТӘЖБұОөЧІгөДКэҫЭҝвВ·УЙТФј°КэҫЭ№ЬАн№ҰДЬ
ЎЎЎЎ2 ЗҝҙуөДКэҫЭФЛО¬НЕ¶УТФј°јаҝШМеПөЈ¬ДЬ№»јмІвіцГҝёцҪЪөгөДКэҫЭҝвЧҙМ¬
ЎЎЎЎ3 ЗҝҙуөДКэҫЭҝв№ЬАн№ЬАнНЕ¶УЈ¬ДЬ№»О¬»ӨХвГҙөДКэҫЭҝвјҜИә
ЎЎЎЎ4 ЗҝҙуөДТөОсјЬ№№ДЬБҰәНјјКхјЬ№№ДЬБҰЈ¬ДЬ№»ХЖҝШХвГҙёҙФУөДТөОсіЎҫ°ЎЈ












