环境:CentOS 6.4, hadoop-2.0.0-cdh4.2.0, JDK 1.6, spark-0.8.0-incubating-bin-cdh4.tar.gz,Scala 2.9.3
1. 安装、部署集群环境
参考前章《安装Spark 0.8集群(CentOS6.4) - 大数据之内存计算》
2. 测试描述
使用在线测试数据生工具,动态生成如下json数据(名称DATA[1-9].json):
{"id":10,"first_name":"Ralph","last_name":"Kennedy","country":"Colombia","ip_address":"12.211.41.162","email":"rkennedy@oyonder.net"},
{"id":11,"first_name":"Gary","last_name":"Cole","country":"Nepal","ip_address":"242.67.150.18","email":"gcole@browsebug.info"},
…
可以数据可以先生成100M左右,然后通过linux cp / cat工具进行数据复制、合并,产生不同大小数据,方便测试。
测试任务:
对所有*.json数据的ip地址进行简单统计,包括:ip地址总数统计,“241.*”ip地址段总数统计。将其上传到HDFS集群上
2.1启动 Spark 集群
在master上执行
$>cd ~/spark-0.8.0 $>bin/start-all.sh |
检测进程是否启动
$> jps 11055 Jps 2313 SecondaryNameNode 2409 JobTracker 2152 NameNode 4822 Master |
浏览master的web UI(默认http://localhost:8080). 这是你应该可以看到所有的word节点,以及他们的CPU个数和内存等信息。
2.2运行spark-shell从HDFS读取文件并统计IP地址
// set the master node of spark cluster and runspark-shell $> MASTER=spark://centos01:7077./spark-shell // read the json data $>val file = sc.textFile("hdfs://sdc/user/hadoop/In/DATA*.json") // filter the json data $>val ips = file.filter(line => line.contains("ip_address")) // Count all the IP $>ips.count() // Count all the“241.*”IP $>ips.filter(line => line.contains("241.")).count() $>ips.filter(line => line.contains("241.")).collect() |
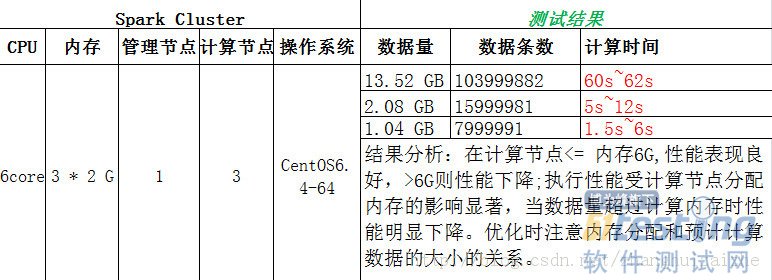
2.3 运行结果