

3.2 基准测试应该运行多长时间
基准测试应该运行足够长的时间,这一点很重要。如果需要测试系统在稳定状态时的性能,那么当然需要在稳定状态下测试并观察。而如果系统有大量的数据和内存,要达到稳定状态可能需要非常长的时间。大部分系统都会有一些应对突发情况的余量,能够吸收性能尖峰,将一些工作延迟到高峰期之后执行。但当对机器加压足够长时间之后,这些余量会被消耗尽,系统的短期尖峰也就无法维持原来的高性能。
有时候无法确认测试需要运行多长的时间才足够。如果是这样,可以让测试一直运行,持续观察直到确认系统已经稳定。下面是一个在已知系统上执行测试的例子,图2-1 显示了系统磁盘读和写吞吐量的时序图。
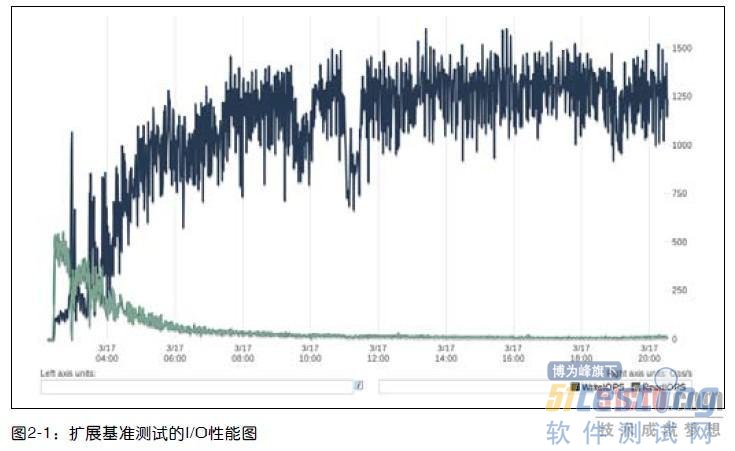
系统预热完成后,读I/O 活动在三四个小时后曲线趋向稳定,但写I/O 至少在八小时内变化还是很大,之后有一些点的波动较大,但读和写总体来说基本稳定了注4。一个简单的测试规则,就是等系统看起来稳定的时间至少等于系统预热的时间。本例中的测试持续了72 个小时才结束,以确保能够体现系统长期的行为。
一个常见的错误的测试方式是,只执行一系列短期的测试,比如每次60 秒,并在此测试的基础上去总结系统的性能。我们经常可以听到类似这样的话:“我尝试对新版本做了测试,但还不如旧版本快”,然而我们分析实际的测试结果后发现,测试的方式根本不足以得出这样的结论。有时候人们也会强调说不可能有时间去测试8 或者12 个小时,以验证10 个不同并发性在两到三个不同版本下的性能。如果没有时间去完成准确完整的基准测试,那么已经花费的所有时间都是一种浪费。有时候要相信别人的测试结果,这总比做一次半拉子的测试来得到一个错误的结论要好。
3.3 获取系统性能和状态
在执行基准测试时,需要尽可能多地收集被测试系统的信息。最好为基准测试建立一个目录,并且每执行一轮测试都创建单独的子目录,将测试结果、配置文件、测试指标、脚本和其他相关说明都保存在其中。即使有些结果不是目前需要的,也应该先保存下来。多余一些数据总比缺乏重要的数据要好,而且多余的数据以后也许会用得着。需要记录的数据包括系统状态和性能指标,诸如CPU 使用率、磁盘I/O、网络流量统计、SHOWGLOBAL STATUS 计数器等。
下面是一个收集MySQL 测试数据的shell 脚本:
|
这个shell 脚本很简单,但提供了一个有效的收集状态和性能数据的框架。看起来好像作用不大,但当需要在多个服务器上执行比较复杂的测试的时候,要回答以下关于系统行为的问题,没有这种脚本的话就会很困难了。下面是这个脚本的一些要点:
迭代是基于固定时间间隔的,每隔5 秒运行y 一次收集的动作,注意这里sleep 的时间有一个特殊的技巧。如果只是简单地在每次循环时插入一条“sleep 5”的指令,循环的执行间隔时间一般都会稍大于5 秒,那么这个脚本就没有办法通过其他脚本和图形简单地捕获时间相关的准确数据。即使有时候循环能够恰好在5 秒内完成,但如果某些系统的时间戳是15:32:18.218192,另外一个则是15:32:23.819437,这时候就比较讨厌了。当然这里的5 秒也可以改成其他的时间间隔,比如1、10、30 或者60 秒。不过还是推荐使用5 秒或者10 秒的间隔来收集数据。
每个文件名都包含了该轮测试开始的y 日期和小时。如果测试要持续好几天,那么这个文件可能会非常大,有必要的话需要手工将文件移到其他地方,但要分析全部结果的时候要注意从最早的文件开始。如果只需要分析某个时间点的数据,则可以根据文件名中的日期和小时迅速定位,这比在一个GB 以上的大文件中去搜索要快捷得多。












