

3、黑天鹅发生之后的“假想解释”
不管怎样,那些你认为不应该发生的“黑天鹅”经常如期而至。很多组织要求缺陷发生后开展缺陷根因分析(RCA)(我总是在尽力避免使用“缺陷回溯”这个词)。尤其对黑天鹅这样的重要的bug,更要仔细开展缺陷根因分析了。对黑天鹅开展RCA的目的是利用这个黑天鹅,挖掘它带给我们的信息,从而尽可能在以后的测试中发现更多类似的缺陷,对开发而言则是在以后尽可能避免引入此类的bug。
RCA的目的是做到基于缺陷的过程改进,而不是解释黑天鹅的发生这个动作本身。不要试图去解释所有的黑天鹅,尤其是那些在实验室很难重现的黑天鹅。我看到有些测试团队,当黑天鹅发生了很紧张,又是一个严重的bug漏测了,赶紧组织人力调查分析,尽快写出一个看起来像样的缺陷分析报告。而阅读这个RCA报告,很难从中找出真正有力的措施可以有效避免今后这类bug不再漏测。举几个现实中的“RCA现象”:RCA报告中,错误的原因有“人为错误”、“沟通不畅”、“缺乏相应的测试用例”等;避免漏测的措施有“加强代码走读”、“加强白盒测试”、“提高测试设计能力”、“加强与开发人员的沟通”等。Nassim发现,“我们的头脑是非常了不起的解释机器,能够从几乎所有事物中分析出道理,能够对各种各样的现象罗列出各种解释,并且通常不能接受某件事是不可预测的想法。”
我曾对多个团队进行T-RCA(我提出的一个缺陷根因分析的方法)引导,发现一个有趣的现象,尽管各个团队所测试的产品是不同的,但是他们RCA分析的结论却是惊人的相似,很多团队都存在我上述所列的“RCA现象”。我分析原因大致有二,一是没有找到有效开展RCA的方法,没有找到缺陷发生的根本原因;二是很多团队使用了比较“细致”的RCA模板,模板里对每一项可能的情况进行了细致的分类,比如该缺陷所处的测试级别、涉及的测试活动、所属的测试类型、可能的原因分类等等。缺陷根因分析工作仿佛变成了测试人员只要对照模板逐一打钩去筛选就可以了,但实际上RCA是个高度探索性的过程,需要与缺陷相关的各干系人去沟通,需要从纷繁复杂的种种因素中创造性地找到改进的措施。面对着电脑,填写那些RCA模板中的空白项不是最主要的工作。实际上,某种程度上讲,过细的RCA模板简化了缺陷分析过程,掩盖了缺陷根因分析过程的复杂性,也比较容易导致分析结果的雷同。《黑天鹅》里的这句话也许可以给我们更多启示:“我们对周围世界的任何简化都可能产生爆炸性后果,因为它不考虑不确定性的来源,它使我们错误地理解世界的构成。”
4、黑天鹅形成之中的“柏拉图化”
既然,测试中的黑天鹅的发生是个经常性的事件,那么测试的过程不也正处于黑天鹅形成的过程吗?想象一下,当前我们正在测试一个产品,我们了解黑天鹅理论,我们知道这个产品发布给用户后极有可能会冒出“黑天鹅”来,那么我们当前可以采取什么措施呢?
我在“认识软件测试中黑天鹅”一文中解释了什么是“测试的柏拉图化”:只注重外在的形式、尤其是针对具体明确的事情进行简单分类的时候,犯“柏拉图化”错误的人容易高估他们已经掌握的事实性信息的价值,而对大量的他们还不知晓的并且非常重要的信息视而不见。我是在2006年发现这个“我所不知道的大量信息的”,也同时发现了之前我所犯的“测试的柏拉图化”的错误,即特别重视诸如“测试用例设计个数、测试用例执行个数、发现的bug数”等这些数据,也许在这些明确的、外在的形式之外,有更多值得我们思考的东西。
那一年,我负责一个特性(大体就是在手机上通过蜂窝小区广播的形式收看电视)的测试,这个特性是个全新开发的特性,我是第一个、也是当时唯一一个测试人员,测试任务很紧张,因为这个特性已经定于一、两个月以后在香港某个运营商网络里首次商用。像大多数测试人员一样,我很辛勤地、按照既定方法和策略测试这个特性,在有限的测试时间里:我熟悉了这个特性、设计了很多测试用例、执行了大量的测试用例、发现了很多bug、对这个特性相关的每一个bug都了如指掌、通过和开发人员不断地交涉和定位bug还对该特性当前存在的缺陷非常清楚、熟悉这个特性的代码和问题定位手段。当我奔赴香港作为测试人员辅助开通这个特性的商用之前,研发团队解决了所有严重的缺陷,我很有信心应对各种可能的状况,我几乎认为我对这个特性的了解已经很完整了。
可是,当我抵达用户那里,看到我们的产品在真实网络中的运行环境、配置、使用方式,与用户和当地技术支持人员的各种交流,坐在地铁里看到身边的人员拿着手机正在开启使用我刚刚参与开通商用的特性,从真实网络环境中获取的大量错误报告和跟踪消息和后台日志。。。短短几天内,有关这个特性的、以前我所不知道的、大量的信息冲进了我的大脑,我像突然捡到宝藏一样地忙着分析日志、记录bug,生怕遗漏了哪个bug没有记录,然后回到实验室都不知道如何触发。
我发现了一个重要的事实:这一回,我只用了几天时间,没有设计任何测试用例,没有执行任何测试用例,却在一个我几乎认为没有什么严重缺陷的特性上,“不费吹灰之力”似的又发现了很多严重的缺陷。而且这些缺陷不是实验室触发的,而是就发生在用户的身上,有些遭到用户的投诉,有些用户还不知晓,换句话说,这些缺陷都是优先级很高的非常重要的缺陷。
从香港回来,我一直在思考,测试团队如何发现这些重要的缺陷?甚至如何让平常我们在实验室中的测试也能这么高效、这么有效?您可能已经猜到了,这就是后来备受重视的UBT(Usage Based Testing),或者有的行业叫做TiP(Test in Production),也有人称为Testing-in-the-wild。
再回到前面曾提到的一个关于测试评估的问题上:假如平常的测试更关注典型场景的测试,那么对于非典型场景如何测试以及如何评估呢?我想UBT是个不错的选择。既然无法做到全覆盖的测试,就不去做,不要试图在现有的测试模式下,测试设计和测试执行都投入很大精力去覆盖各种场景和交互,因为这样做收效甚微,依然达不到目的。平常的功能测试只做最普通、最典型、最重要场景下的功能验证,保证每个测试特性的基本功能OK。此外,还要开展UBT或TiP,主要考虑各种配置和场景,用模拟器模拟真实商用组网环境和业务模型,或者直接在用户使用产品的真实环境中开展测试。
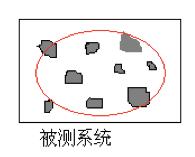
假如被测系统如下图的方框,灰色的小块就是我们平常的功能测试覆盖,可能很多测试团队的做法是试图尽最大能力增加这些灰色小块的覆盖,但依然会有很多覆盖不到的地方。而UBT就相当于红色的范围,虽然没有针对性的设计测试用例,但由于模拟了可能使用的商用场景和业务,业务之间交互的测试在这种测试环境下自动进行,潜在的一般的bug都被自动发现(比较难触发的异常bug依然发现不了),如果这样的UBT测试连续执行几天或数周都没有问题,此时测试的评估中就可以很有信心地写到:在XXX UBT环境下连续运行XX天,没有发现严重问题。 这样,也大大减少了版本发布后“黑天鹅”出现的几率。
5、结论
如果你认同“测试的黑天鹅”就在我们身边,那么:
● 在“测试的黑天鹅”发生之前,不要在信息不完整的情况下对全局做“盲目预测”,因为你只掌握了部分信息,你要做的是更准确地陈述这些“部分信息”;
● 在“测试的黑天鹅”发生之后,不要试图对所有黑天鹅都做“假想解释”,更重要的是从已经发生的黑天鹅身上挖掘更有价值的信息,以减少更多类似黑天鹅事件的发生;
● 在“测试的黑天鹅”形成过程之中,不要犯“测试的柏拉图化”错误,重视你知道的信息,更重视那些你所不知道的大量的更有价值的信息。
本文转载自:http://www.taixiaomei.com/archives/223
相关链接:











