

ЁЁЁЁЭМ12жаЃЌНЋЪфШыдДжаЕФУПвЛИіЬѕФПОЙ§ЩЂСаКЏЪ§ЕФМЦЫуЖМЗХЕНВЛЭЌЕФHash BucketжаЃЌЦфжаHash FunctionЕФбЁдёКЭHash BucketЕФЪ§СПЖМЪЧКкКаЃЌЮЂШэВЂУЛгаЙЋВМОпЬхЕФЫуЗЈЃЌЕЋЮвЯраХвбОЪЧЗЧГЃКУЕФЫуЗЈСЫЁЃСэЭтдкHash BucketжЎФкЕФЬѕФПЪЧЮоађЕФЁЃЭЈГЃРДНВЃЌВщбЏгХЛЏЦїЖМЛсЪЙгУСЌНгСНЖЫжаБШНЯаЁЕФФФИіЪфШыМЏРДзїЮЊЕквЛНзЖЮЕФЪфШыдДЁЃ
ЁЁЁЁНгЯТРДЪЧЬНВтНзЖЮЃЌЖдгкСэвЛИіЪфШыМЏКЯЃЌЭЌбљеыЖдУПвЛааНјааЩЂСаКЏЪ§ЃЌШЗЖЈЦфЫљгІдкЕФHash BucketЃЌдкеыЖдетааКЭЖдгІHash BucketжаЕФУПвЛааНјааЦЅХфЃЌШчЙћЦЅХфдђЗЕЛиЖдгІЕФааЁЃ
ЁЁЁЁЭЈЙ§СЫНтЙўЯЃЦЅХфЕФдРэВЛФбПДГіЃЌЙўЯЃЦЅХфЩцМАЕНЩЂСаКЏЪ§ЃЌЫљвдЖдCPUЕФЯћКФЛсЗЧГЃИпЃЌДЫЭтЃЌдкHash BucketжаЕФааЪЧЮоађЕФЃЌЫљвдЪфГіНсЙћвВЪЧЮоађЕФЁЃЭМ13ЪЧвЛИіЕфаЭЕФЙўЯЃЦЅХфЃЌЦфжаВщбЏЗжЮіЦїЪЙгУСЫБэЪ§ОнСПБШНЯаЁЕФProductБэзїЮЊЩњГЩЃЌЖјЪЙгУЪ§ОнСПДѓЕФSalesOrderDetailБэзїЮЊЬНВтЁЃ
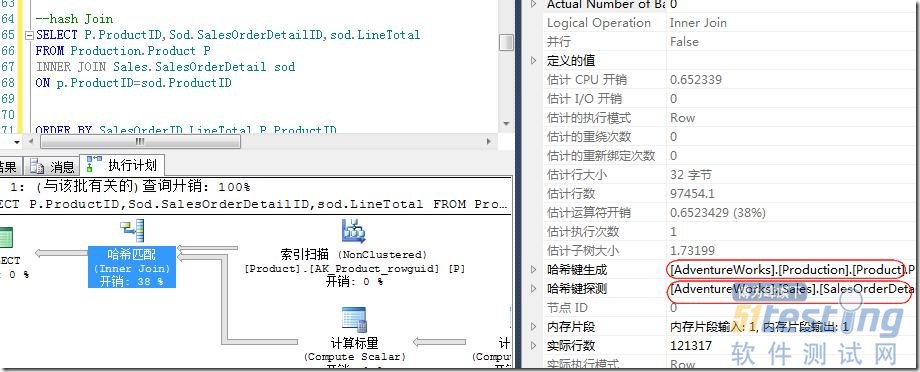
ЭМ13.вЛИіЕфаЭЕФЙўЯЃЦЅХфСЌНг
ЁЁЁЁЩЯУцЕФЧщПіЖМЪЧФкДцПЩвдШнФЩЯТЩњГЩНзЖЮЫљашЕФФкДцЃЌШчЙћФкДцГдНєЃЌдђЛЙЛсЩцМАЕНGraceЙўЯЃЦЅХфКЭЕнЙщЙўЯЃЦЅХфЃЌетОЭПЩФмЛсгУЕНTempDBДгЖјГдЕєДѓСПЕФIOЁЃетРяОЭВЛЯИЫЕСЫЁЃ
ЁЁЁЁзмНс
ЁЁЁЁЯТУцЮвУЧЭЈЙ§вЛИіБэИёМђЕЅзмНсетМИжжСЌНгЗНЪНЕФЯћКФКЭЪЙгУГЁОАЃК
| ЧЖЬзбЛЗСЌНг | КЯВЂСЌНг | ЙўЯЃСЌНг | |
| ЪЪгУГЁОА | ЭтВубЛЗаЁЃЌФкДцбЛЗЬѕМўСагаађ | ЪфШыСНЖЫЖМгаађ | Ъ§ОнСПДѓЃЌЧвУЛгаЫїв§ |
| CPU | ЕЭ | ЕЭЃЈШчЙћУЛгаЯдЪНХХађЃЉ | Ип |
| ФкДц | ЕЭ | ЕЭЃЈШчЙћУЛгаЯдЪНХХађЃЉ | Ип |
| IO | ПЩФмИпПЩФмЕЭ | ЕЭ | ПЩФмИпПЩФмЕЭ |











