

hadoop 0.19版本有个自带的slive test,这套测试框架是利用mapreduce作为依托来做hdfs的性能测试,设计的很不错,代码非常漂亮,可复用性,可扩展性都做的很强。
简单的说下mapreduce,它是一个分布式计算框架,把任务分为多个map,分发到多台机器上进行并发计算,然后在reduce阶段把结果收集起来进行处理。这是一个很强大的计算框架,详情请google之。
那么slive test利用mapreduce的好处是什么?个人认为:
1、贴近用户的需求,大量用户的大量作业依赖于mapreduce,谁说直接写job的用户并不多,大部分用hive,但是hive就是hive sql的解析,下层利用mapreduce来处理。
2、mapreduce发展至今,这个框架本身已经较为成熟,如果自己开发一个分布式调度计算框架来支撑分布式测试,首先性能怎么样是个问题,本身是要来测性能的,结果框架本身成了瓶颈问题,那就成了"虾扯蛋"了,其次工作量很大,其中必然会遇到各种问题,如均衡性,数据的可信性等。
3、易用性,mapreduce的job写起来比较简单,遇到问题,资料也好找
slive test 本身已经实现了很多接口的性能测试,比如create,append,list,delete,rename等等,这些接口都是继承自operation,hdfs的其他需要测的接口就可以模仿那些slive已经实现的接口来写code,很方便。
当然,有一点,需要注意,就是slive test本身有一个PathFinder类,绝大部分hdfs的接口都有对hdfs的文件进行相应的操作,而这些操作所找的文件就是利用PathFinder里面的接口。
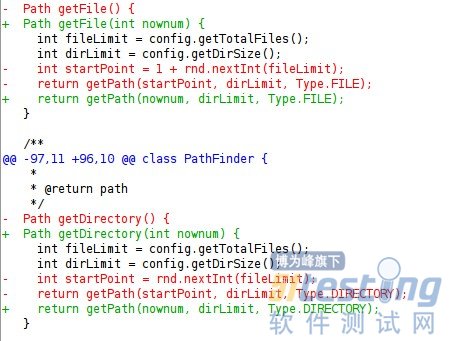

看getFile函数,其实它内部是调用getPath来获取path,getPath是一个递归函数,它的算法很简单,就是目前传进来的file值,比50,如果每个路径下限值是30个文件,那么它就在这个文件下再创建一个文件夹,继续往下走,直到走到文件是可以在当前文件夹创建并且在文件夹限制的文件个数之内。比如50的话,就要递归2次,不明白的同学纸上画下即可明白。
第一幅图中‘-’代表的是slive test本来的code,但是被我改掉了,可以理解成被删除了,‘+’可以理解成添加上去的code,可以看见原来的code,getFile和getDirectory都是random产生一个file数或者path数,然后去找相应的path,这个会对测试产生怎样的影响呢?
假如我create10万个file,那么,由于file 在代码中getFile的时候,里面是随机的产生一个file,这里的随机是有很大几率重复的,因为随机的范围是在fileLimit之内,经过测试,即使把fileLimt设的很大,比如100万,也有一部分重复的, 而且即使fileLimt设的很大,那么create好file之后,去append时就很有可能append的那个file根本就找不到,为啥?因为随机啊~~~append file随机产生的那个file, create阶段就不一定会产生,所以,就会导致其实append根本就没做,所以,会导致测试误差很大。
这个函数改完之后,是多少个file,就给我老老实实地去得到多少个file,directory也一样
其他的修改比较有用的就是对ReportWrite的修改,可以按照自己的需求,定制api 的response time, ops等等。
这样Slive Test就可以做为能够满足我们性能测试的一个工具了。












