

目前正在做XX系统的冗余代码清理,系统瘦身,过程中整理的一些方法见下:
代码清理流程图:

其中几个关键的步骤:
1、TCC采集线上代码覆盖数据作为样本
先用TCC 对线上的xx应用的war包代码进行插装,然后部署插装后的代码到线上;运行一段时间(1-2周),采集到线上应用的真实的代码覆盖数据。
2、用埋点中心对样本数据进行二次确认
然后对TCC采集的代码覆盖数据作为样本数据,进行分析:可以先确定class覆盖数据为0的文件。对这些文件应用埋点中心进行埋点统计。
关于埋点中心的详细用法及介绍见淘宝百科:埋点中心。
关于为什么要用埋点中心对TCC的统计的样本数据进行二次确认?相信通过对比两个工具,就会知道答案了。
两个工具的对比:
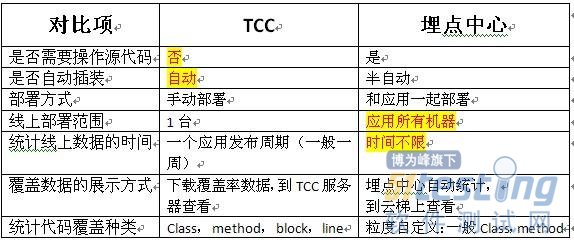
所以,结合两个工具:TCC进行初步的样本筛选,然后用埋点中心进行精确的线上所有机器、不限时间的埋点统计确认,就会得到非常准确的class或method覆盖数据了。
本次xx系统的数据统计,其中TCC 统计的未被调用的类文件是:202个,通过埋点中心再次确认:未被调用的的java文件有170个 ,反复确认后,进一步精确缩小了代码覆盖数据的范围。
经过线上代码覆盖率的数据采集,并进行了分析,开始进行refund的代码清理。
3、埋点中心用法示例
代码中加入埋点中心的功能非常的简单:引入jar包,编写配置文件,用日志的方式记录统计数据。
引入埋点中心的client. jar包:
编写埋点配置文件:













