

ЎЎЎЎҪшТ»ІҪЛјҝјјёёцОКМв
ЎЎЎЎФЪС№ЛхОДјюөДКұәтЈ¬ИЛГЗІ»Ҫы»бІъЙъТ»Р©РВПл·Ё»тХЯУцөҪТ»Р©ТЙОКЈәКЗ·сҝЙТФ¶ФС№ЛхәуөДКэҫЭФЩҙОС№ЛхЈҝөұ2 n өДnұдҙуәуЈ¬УцөҪAЈә1010Ј¬BЈә10ХвСщөДЗйҝцЈ¬ИзәОҪв¶Б10101010Јҝ
ЎЎЎЎҫНІЩЧчЙПАҙЛөЈ¬өұИ»ДЬ·ҙёҙұаВлЈ¬ө«НЁ№э¶ФұҫОДАэЧУЦРөГөҪөДРВұаВлФЩҙОІЩЧчәу»б·ўПЦЈ¬Ҫб№ыКЗІ»»бУРИОәОұд»ҜөДЎЈС№ЛхөДКөЦКЈ¬ФЪУЪПыіэМШ¶ЁЧЦ·ы·ЦІјЙПөДІ»ҫщәвЈ¬НЁ№эҪ«¶МВл·ЦЕдёшёЯЖөЧЦ·ыЈ¬¶шіӨВл¶ФУҰөНЖөЧЦ·ыКөПЦіӨ¶ИЙПөДУЕ»ҜЎЈ¶шКэҫЭҫӯ№эТ»ҙОС№ЛхәуЈ¬ЧЦ·ыөД·ЦІјТСҫӯјёәхЖҪҫщ»ҜБЛЈ¬әЬДСёьҪшТ»ІҪөДС№ЛхБЛЎЈ
ЎЎЎЎ¶шөЪ¶юёцОКМвГиКцөДЗйҝцКЗІ»»біцПЦөДөДЎЈҙУ№№Фм»ф·тВьКчІЩЧчЙПҝЙТФҝҙөҪЈ¬Т»ёцЧЦ·ыОЮ·ЁФЪБнТ»ёцЧЦ·ыөДЙПІгЎЈЦ»ТӘІЩЧчХэИ·Ј¬ҫНТ»¶ЁҝЙТФ№№ФміцОЁТ»өДҙъВлұнЈ¬І»ҙжФЪЖзТеЎЈ
ЎЎЎЎ»№УРТ»ёцУРИӨөДОКМвКЗЈәЛдИ»°С40ЧЦҪЪөДДЪИЭС№ЛхөҪБЛ34ЧЦҪЪЈ¬ө«РиТӘҪ«ПаУҰөДВлұнТ»Іў·ўЛНёшҪУКХ·ҪЈЁГ»УР¶ФУҰВлұнЈ¬ОЮ·ЁҪвС№Ј©ЎЈХвІ»·ҙ¶шК№өГС№ЛхәуөДКэҫЭұИС№ЛхЗ°өД»№ТӘіӨЈҝ
ЎЎЎЎКВКөТІИ·КөИзҙЛЎЈұҫОДАэЧУЦРЈ¬ХжХэөДЧоЦХҪб№ыМе»эКЗҙуУЪФӯОДөДЎЈө«ХвІ»ТвО¶БЛЛг·ЁҙнОуЎЈХвКЗТтОӘЎ°nЎұ№эРЎЈЁАэЧУЦРОӘ2Ј¬КөјКНЁіЈОӘ8Ј©өјЦВөДЎЈ
ЎЎЎЎЧЬіӨ¶ИөДІ»№»К№өГҪЪКЎіцАҙөДДЗІҝ·ЦИЭБҝ»№І»ЧгТФГЦІ№ВлұнұҫЙнөДҙўҙжҝХјдЎЈКөјКУҰУГЦРЈ¬Из№ыДг·ЗТӘИҘС№ЛхТ»ёцЦ»УРјёёцЧЦҪЪөДОДјюЈ¬өГөҪөДС№Лх°ьТІҫӯіЈ»бҙуУЪОДјюұҫЙнЎЈНЁіЈЈ¬С№ЛхИнјю»бФЪГҝС№Лх4kbөҪ32kbКэҫЭәуЈ¬ЦШРВЙъіЙІўұЈҙжТ»ёц»ф·тВьКчЎЈөұ·Цҝй№эҙуКұЈ¬НіјЖЙПөДХыМеЖҪҫщЈ¬»бСЪёЗРЎЗшУтДЪөДј«¶ИІ»ЖҪҫщЈ¬ЛрК§БЛС№ЛхөДҝХјдЎЈұИИзҙжФЪТ»ёцХвСщөДОДјюЈә
ЎЎЎЎAAAAAЎӯЎӯAAAAAЈЁТ»НтёцЈ©BBBBBЎӯЎӯBBBBBЈЁТ»НтёцЈ©ЎӯЎӯZZZZЈЁТ»НтёцЈ©ЎЈ
ЎЎЎЎИз№ыҙУХыМеЙПҪшРР»ф·тВьКчІЩЧчЈ¬Ҫ«І»»бІъЙъИОәОС№ЛхЈ¬ө«КЗХвКұәтОТГЗ°СЛь·ЦіЙ26ҝйЈ¬С№ЛхІўёчЧФұЈҙжПаУҰөДЦШРВұаВлөД»ф·тВьКчЈ¬С№ЛхВКҪ«·ЗіЈҫӘИЛЈ¬ФјөИУЪ12.5%ЎЈ
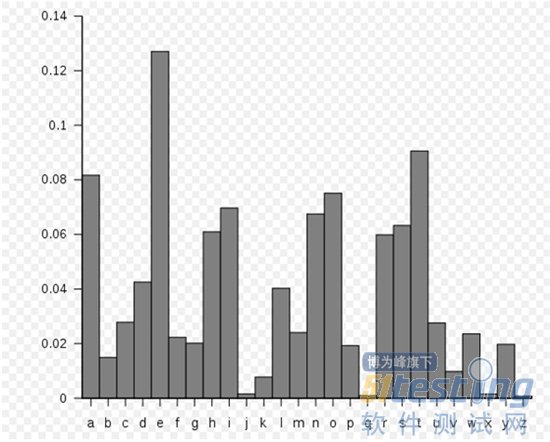
УўУпЦРёчЧЦДёіцПЦЖөВККҫТвНј
ЎЎЎЎҙУЙПГжЧЦЖөНјОТГЗЦӘөАЈ¬ФЪПЦКөөДОДұҫЦРЈ¬УўУпЧЦДёК№УГЖөВКёчІ»ПаН¬Ј¬¶шЗТІоұрәЬҙуЎЈУРЧЕәЬёЯөДІ»ЖҪҫщ¶ИЎЈЛщТФҙуІҝ·ЦС№ЛхИнјю¶ФОДұҫОДјюТАИ»УРЧЕәЬёЯөДС№ЛхВКЎЈ












