

下面来看批量处理系统整体上是如何配合工作的。假设写一个网站分析程序来跟踪页面访问量,你需要能够查询到任意时间段的页面访问量,数据是以小时方式提供的。如图2所示。
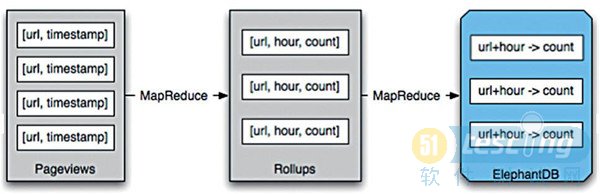
图2 批处理工程流程示例(timestamp代表时间戳,count代表个数)
实现这个很简单,每一个数据记录包括一个单一页面的访问量。这些数据通过文件形式存储到HDFS中,一个函数通过实现MapReduce计算任务,来计算一个URL下页面每小时的访问量。这个函数产生的是key/value对,其中[URL, hour]是key,value是页面的访问量。这些key/value对被导出到ElephantDB中去,使得应用程序可以快速得到任意[URL, hour]对对应的值。如果应用程序想要知道某个时间范围内某个页面的访问量,它可以查询ElephantDB中那段时间内的数据,然后把这些数据相加就可以得到这个访问量数据了。
在数据滞后几小时这个缺陷下,批量处理可以计算任意数据集上的任意函数。系统中的“任意性”是指这个系统可以处理任何问题。更重要的是,它很简单,容易理解和完全可扩展,你需要考虑的只是数据和查询函数,Hadoop会帮你处理并行的事情。
批处理系统、CAP定理和容忍人为错误
截至目前,我们的系统都很不错,这个批处理系统是不是可以达到容忍人为错误的目标呢?
让我们从CAP定理开始。这个批处理系统总是最终一致的:写入的数据总可以在几小时后被查询到。这个系统是一个很容易掌控的最终一致性系统,使得你可以只用关注你的数据和针对数据的查询函数。这里没有涉及读取修复、并发和其他一些需要考虑的复杂问题。
接下来看看这个系统对人为错误的容忍性。在这个系统中人们可能会犯两个错误:部署了一个有Bug的查询函数或者写入了错误的数据。
如果部署了一个有Bug的查询函数,需要做的所有事情就是修正那个Bug,重新部署这个查询函数,然后在主数据集上重新计算它。这之所以能起作用是因为查询只是一个函数而已。
另外,错误的数据有明确的办法可以恢复:删除错误数据,然后重新计算查询。由于数据是不可变的,而且数据集只是往后添加新数据,写入错误的数据不会覆盖或者删除正确的数据,这与传统数据库更新一个数据就丢掉旧的数据形成了鲜明的对比。
注意到MVCC和HBase类似的行版本管理并不能达到上面人为错误容忍级别。MVCC和HBase行版本管理不能永久保存数据,一旦数据库合并了这些版本,旧的数据就会丢失。只有不可变数据系统能够保证你在写入错误数据时可以找到一个恢复数据的方法。
实时层
上面的批量处理系统几乎完全解决了在任意数据集上运行任意函数的实时性需求。任何超过几个小时的数据已经被计算进入了批处理视图中,所以剩下来要做的就是处理最近几个小时的数据。我们知道在最近几小时数据上进行查询比在整个数据集上查询要容易,这是关键点。
为了处理最近几个小时的数据,需要一个实时系统和批处理系统同时运行。这个实时系统在最近几个小时数据上预计算查询函数。要计算一个查询函数,需要查询批处理视图和实时视图,并把它们合并起来以得到最终的数据。

图3 计算一个查询












