

ЁЁЁЁseleniumЛёШЁдЊЫиаХЯЂГЃгУЗНЗЈ
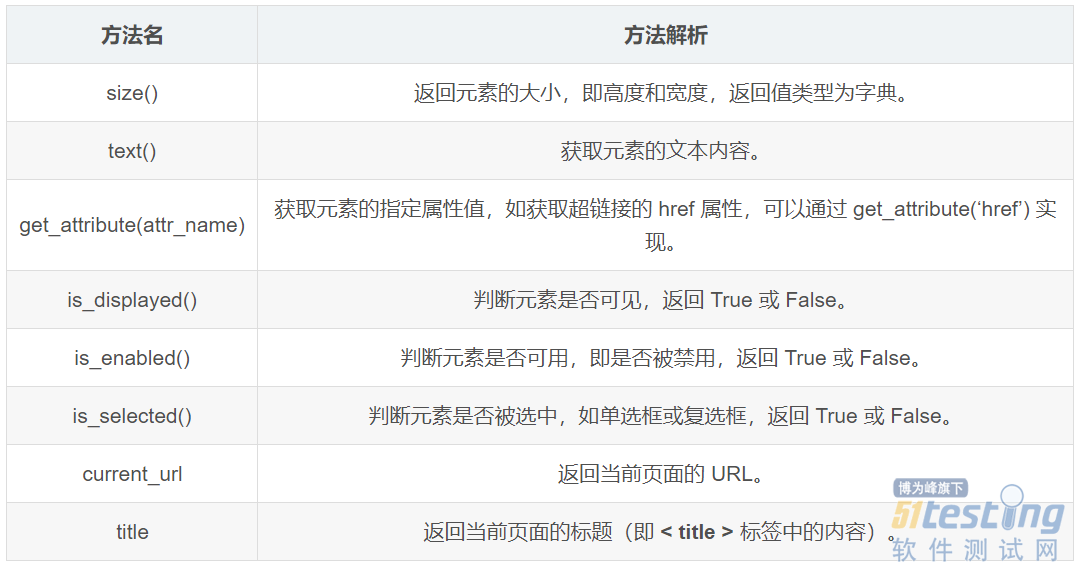
ЁЁЁЁШчКЮЪЙгУ Selenium ЛёШЁЭјвГдЊЫиЕФаХЯЂЃК
ЁЁЁЁSelenium ЪЧвЛИігУгк Web гІгУГЬађВтЪдЕФЙЄОпЃЌПЩвдЪЙгУЫќРДФЃФтгУЛЇдкфЏРРЦїжаЕФВйзїЃЌВЂНјааздЖЏЛЏВтЪдЁЃЦфжазюГЃМћЕФШЮЮёжЎвЛОЭЪЧЛёШЁЭјвГдЊЫиЕФаХЯЂЃЌЮвУЧПЩвдЪЙгУ Selenium ЬсЙЉЕФЗНЗЈРДЛёШЁдЊЫиЕФЮФБОФкШнЁЂДѓаЁЁЂЪєаджЕЕШаХЯЂЃЌНјЖјЖдвГУцНјааЗжЮіКЭДІРэЁЃ
ЁЁЁЁЪЕР§НВНт
ЁЁЁЁАИР§вЛ
ЁЁЁЁ# ЕМШыБивЊЕФПт
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁfrom selenium.webdriver.common.by import By
ЁЁЁЁ# ДДНЈвЛИіаТЕФ Chrome фЏРРЦїЪЕР§
ЁЁЁЁd = webdriver.Chrome()
ЁЁЁЁ# ДђПЊОЉЖЋЪзвГ
ЁЁЁЁd.get('https://www.jd.com')
ЁЁЁЁ# ЭЈЙ§ CSS бЁдёЦїВщевдЊЫиЃЌВЂЪЙгУ size ЗНЗЈЛёШЁСЫдЊЫиЕФДѓаЁЃЈМДИпЖШКЭПэЖШЃЉ
ЁЁЁЁjd_supermarket = d.find_element(By.CSS_SELECTOR, '[aria-lable="ОЉЖЋГЌЪа"]')
ЁЁЁЁprint(jd_supermarket.size)
ЁЁЁЁ# ЭЈЙ§ XPath ВщевдЊЫиЃЌВЂЪЙгУ text ЗНЗЈЛёШЁСЫГЌСДНгЕФЮФБОФкШн
ЁЁЁЁjd_seckill = d.find_element(By.XPATH, '//div/a[4]')
ЁЁЁЁprint(jd_seckill.text)
ЁЁЁЁ# ЭЈЙ§ XPath ВщевдЊЫиЃЌВЂЪЙгУ get_attribute ЗНЗЈЛёШЁСЫГЌСДНгЕФ href ЪєаджЕ
ЁЁЁЁjd_vipshop = d.find_element(By.XPATH, '//div/div/div[4]/ul/li/a')
ЁЁЁЁprint(jd_vipshop.get_attribute('href'))
ЁЁЁЁ# ЙиБефЏРРЦї
ЁЁЁЁd.quit()
ЁЁЁЁАИР§Жў
ЁЁЁЁХаЖЯдЊЫиЪЧЗёПЩЕуЛї
ЁЁЁЁХаЖЯдЊЫидквГУцЩЯЪЧЗёПЩвдЕуЛїЃЌWebElementЖдЯѓЕїгУ is_enabled() ЗНЗЈЁЃ
ЁЁЁЁis_enabled()ЗНЗЈЗЕЛивЛИіВМЖћжЕЃЌШєПЩЕуЛїЗЕЛиЃК True ЁЃШєВЛПЩЕуЛїдђЗЕЛиЃК False ЁЃ
ЁЁЁЁ# ЕМШыашвЊЕФФЃПщ
ЁЁЁЁfrom selenium import webdriver # ЕМШыwebdriverФЃПщ
ЁЁЁЁimport time # ЕМШыtimeФЃПщ
ЁЁЁЁfrom selenium.webdriver.common.by import By # ЕМШыByФЃПщ
ЁЁЁЁ# ДДНЈвЛИіChromeфЏРРЦїЪЕР§
ЁЁЁЁdriver = webdriver.Chrome()
ЁЁЁЁ# ДђПЊАйЖШЪзвГ
ЁЁЁЁdriver.get('https://www.baidu.com/')
ЁЁЁЁ# ЖЈЮЛАйЖШЪзвГЕФЕиЭМАДХЅ
ЁЁЁЁelm = driver.find_element(By.XPATH, '//*[@id="s-top-left"]/a[3]')
ЁЁЁЁ# ХаЖЯдЊЫиЪЧЗёПЩЕуЛї
ЁЁЁЁanswer = elm.is_enabled()
ЁЁЁЁ# ДђгЁНсЙћ
ЁЁЁЁprint(answer) # жДааНсЙћЃКTrueЃЌЙЪПЩвдЕуЛїЁЃ
ЁЁЁЁ# ЕШД§3Уы
ЁЁЁЁtime.sleep(3)
ЁЁЁЁ# ЙиБефЏРРЦї
ЁЁЁЁdriver.quit()
ЁЁЁЁАИР§Ш§
ЁЁЁЁХаЖЯдЊЫиЪЧЗёПЩМћ
ЁЁЁЁХаЖЯдЊЫидквГУцЩЯЪЧЗёПЩМћЃЌWebElementЖдЯѓЕїгУ is_displayed() ЗНЗЈЁЃ
ЁЁЁЁ# ЕМШыseleniumФЃПщжаЕФwebdriverКЭByФЃПщ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁfrom selenium.webdriver.common.by import By
ЁЁЁЁ# ДДНЈвЛИіChromeфЏРРЦїЪЕР§
ЁЁЁЁdriver = webdriver.Chrome()
ЁЁЁЁ# зюДѓЛЏфЏРРЦїДАПк
ЁЁЁЁdriver.maximize_window()
ЁЁЁЁ# ДђПЊАйЖШЪзвГ
ЁЁЁЁdriver.get('https://www.baidu.com/')
ЁЁЁЁ# ЖЈЮЛЕНАйЖШЕиЭМАДХЅ
ЁЁЁЁelm = driver.find_element(By.XPATH,'//*[@id="s-top-left"]/a[3]')
ЁЁЁЁ# ХаЖЯАйЖШЕиЭМАДХЅЪЧЗёПЩМћ
ЁЁЁЁanswer = elm.is_displayed()
ЁЁЁЁprint(answer)
ЁЁЁЁ# ЙиБефЏРРЦї
ЁЁЁЁdriver.quit()
ЁЁЁЁАИР§ЫФ
ЁЁЁЁХаЖЯдЊЫиЪЧЗёПЩБЛбЁжа
ЁЁЁЁХаЖЯдЊЫидквГУцЩЯЪЧЗёБЛбЁжаЃЌWebElementЖдЯѓЕїгУ is_selected() ЗНЗЈЁЃ
ЁЁЁЁis_selected() ЗНЗЈЗЕЛивЛИіВМЖћжЕЃЌШєБЛбЁжадђЗЕЛиЃКTrue ЁЃШєУЛБЛбЁжадђЗЕЛиЃКFalse ЁЃ
ЁЁЁЁ# ЕМШыseleniumФЃПщжаЕФwebdriverКЭByФЃПщ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁfrom selenium.webdriver.common.by import By
ЁЁЁЁ# ДДНЈвЛИіChromeфЏРРЦїЪЕР§
ЁЁЁЁdriver = webdriver.Chrome()
ЁЁЁЁ# зюДѓЛЏфЏРРЦїДАПк
ЁЁЁЁdriver.maximize_window()
ЁЁЁЁ# ДђПЊАйЖШЪзвГ
ЁЁЁЁdriver.get('https://www.baidu.com/')
ЁЁЁЁ# ЖЈЮЛЕНАйЖШЕиЭМАДХЅ
ЁЁЁЁelm = driver.find_element(By.XPATH,'//*[@id="s-top-left"]/a[3]')
ЁЁЁЁ# ХаЖЯАйЖШЕиЭМАДХЅЪЧЗёБЛбЁжа
ЁЁЁЁanswer = elm.is_selected()
ЁЁЁЁprint(answer)
ЁЁЁЁ# ЙиБефЏРРЦї
ЁЁЁЁdriver.quit()
ЁЁЁЁжДааНсЙћЃКFalseЃЌЫЕУїЮДБЛбЁжаЁЃ
ЁЁЁЁЮЪЬтЃКгавЛИібЁЯюПђЃЌБОЩэОЭЪЧбЁжазДЬЌЃЌШчЙћдйЕуЛївЛЯТЃЌЫќОЭЗДЖјБфГЩСЫЮДБЛбЁжаЕФзДЬЌЃЌЦкЭћНсЙћЪЧИУбЁЯюПђДІгкбЁжазДЬЌЃЛЕБИУбЁЯюПђЮЊЮДбЁжазДЬЌЪБЃЌХаЖЯШЅЕуЛїбЁжаИУбЁЯюПђЃЛЕБИУбЁЯюПђДІгкбЁжазДЬЌЪБЃЌВЛзіШЮКЮВйзїЁЃ
ЁЁЁЁНтОіЫМТЗЃК is_selected() МьВщЪЧЗёбЁжаИУдЊЫиЃЌвЛАуеыЖдЕЅбЁПђЃЌИДбЁПђЃЌЗЕЛиЕФНсЙћЪЧbool жЕЃЌдЊЫиДІгкЮДбЁжазДЬЌЕФЪБКђЗЕЛи FalseЃЌдЊЫиДІгкбЁжазДЬЌЪБЗЕЛи TrueЁЃ
ЁЁЁЁ# ЕМШыseleniumФЃПщжаЕФwebdriverКЭByФЃПщ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁfrom selenium.webdriver.common.by import By
ЁЁЁЁ# ДДНЈвЛИіChromeфЏРРЦїЪЕР§
ЁЁЁЁdriver = webdriver.Chrome()
ЁЁЁЁ# зюДѓЛЏфЏРРЦїДАПк
ЁЁЁЁdriver.maximize_window()
ЁЁЁЁ# ДђПЊАйЖШИпМЖЫбЫївГУц
ЁЁЁЁdriver.get("https://www.baidu.com/gaoji/preferences.html")
ЁЁЁЁ# ЖЈЮЛЕНЁАНіМђЬхжаЮФЁБетИібЁЯю
ЁЁЁЁelement = driver.find_element(By.XPATH,"//*[text()='НіМђЬхжаЮФ']")
ЁЁЁЁ# ХаЖЯЁАНіМђЬхжаЮФЁБетИібЁЯюЪЧЗёБЛбЁжа
ЁЁЁЁif element.is_selected():
ЁЁЁЁ print("дЊЫивбОБЛбЁжа")
ЁЁЁЁelse:
ЁЁЁЁ print("дЊЫиУЛгаБЛбЁжа")
ЁЁЁЁ# ЙиБефЏРРЦї
ЁЁЁЁdriver.quit()
ЁЁЁЁЛёШЁurlЕижЗ
ЁЁЁЁдк Web гІгУздЖЏЛЏВтЪджаЃЌЛёШЁЕБЧАвГУцЕФ URL ЕижЗЪЧвЛИіЗЧГЃЛљДЁЕФВйзїЁЃSelenium ЬсЙЉСЫЖрИіЛёШЁЗНЗЈРДЛёШЁЕБЧАвГУцЕФ URLЃЌЯТУцНЋЗжБ№НщЩметаЉЗНЗЈЕФЪЙгУЁЃ
ЁЁЁЁЪЙгУ current_url Ъєад
ЁЁЁЁЪЙгУ current_url ЪєадПЩЗЕЛиЕБЧАвГУцЕФ URLЁЃ
ЁЁЁЁ# ЕМШыseleniumПтжаЕФwebdriverФЃПщ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁ# ДДНЈвЛИіChromeфЏРРЦїЪЕР§
ЁЁЁЁdriver = webdriver.Chrome()
ЁЁЁЁ# ЗУЮЪАйЖШЪзвГ
ЁЁЁЁdriver.get('https://www.baidu.com')
ЁЁЁЁ# ЛёШЁЕБЧАвГУцЕФURLВЂДђгЁГіРД
ЁЁЁЁcurrent_url = driver.current_url
ЁЁЁЁprint(current_url)
ЁЁЁЁ# ЙиБефЏРРЦї
ЁЁЁЁdriver.quit()
ЁЁЁЁЪЙгУ execute_script() ЗНЗЈ
ЁЁЁЁЪЙгУ execute_script() ЗНЗЈПЩЛёШЁЕБЧАвГУцЕФURLЁЃ
ЁЁЁЁ# ЕМШыseleniumПтжаЕФwebdriverФЃПщ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁ# ДДНЈвЛИіChromeфЏРРЦїЪЕР§
ЁЁЁЁdriver = webdriver.Chrome()
ЁЁЁЁ# ЗУЮЪАйЖШЪзвГ
ЁЁЁЁdriver.get('https://www.baidu.com')
ЁЁЁЁ# ЪЙгУJavaScriptгябдЛёШЁЕБЧАвГУцЕФURLВЂДђгЁГіРД
ЁЁЁЁcurrent_url = driver.execute_script("return window.location.href")
ЁЁЁЁprint(current_url)
ЁЁЁЁ# ЙиБефЏРРЦї
ЁЁЁЁdriver.quit()
ЁЁЁЁЪЙгУ window_handles ЪєадКЭ switch_to.window() ЗНЗЈ
ЁЁЁЁШчЙћфЏРРЦїжажЛгавЛИіБъЧЉвГЃЌПЩвджБНгЭЈЙ§ current_url ЪєадЛёШЁЕБЧАURLЁЃ
ЁЁЁЁШчЙћДђПЊСЫЖрИіБъЧЉвГЃЌДЫЪБЛёШЁЕФЪЧЕБЧАЛюЖЏБъЧЉвГЕФURLЁЃШчЙћашвЊЛёШЁЦфЫћБъЧЉвГЕФURLЃЌдђПЩвдЪЙгУ window_handles ЪєадЛёШЁЫљгаЕФБъЧЉОфБњЃЌШЛКѓЭЈЙ§ switch_to.window() ЗНЗЈЧаЛЛЕНЖдгІЕФБъЧЉвГЃЌдйЛёШЁURLЁЃ
ЁЁЁЁ# ЕМШыseleniumПтжаЕФwebdriverФЃПщ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁ# ДДНЈвЛИіChromeфЏРРЦїЪЕР§
ЁЁЁЁdriver = webdriver.Chrome()
ЁЁЁЁ# ЗУЮЪАйЖШЪзвГ
ЁЁЁЁdriver.get('https://www.baidu.com')
ЁЁЁЁ# дкаТЕФБъЧЉвГжаДђПЊGoogleЪзвГ
ЁЁЁЁdriver.execute_script('''window.open("https://www.google.com")''')
ЁЁЁЁ# ЛёШЁЕБЧАБъЧЉвГЕФURLВЂДђгЁГіРД
ЁЁЁЁcurrent_url = driver.current_url
ЁЁЁЁprint(current_url)
ЁЁЁЁ# ЛёШЁЫљгаБъЧЉвГЕФОфБњ
ЁЁЁЁhandles = driver.window_handles
ЁЁЁЁ# ЧаЛЛЕНаТБъЧЉвГ
ЁЁЁЁdriver.switch_to.window(handles[1])
ЁЁЁЁ# ЛёШЁЕБЧАБъЧЉвГЕФURLВЂДђгЁГіРД
ЁЁЁЁcurrent_url = driver.current_url
ЁЁЁЁprint(current_url)
ЁЁЁЁ# ЙиБефЏРРЦї
ЁЁЁЁdriver.quit()
ЁЁЁЁЪЙгУ page_source Ъєад
ЁЁЁЁЪЙгУ page_source ЪєадПЩЛёШЁЕБЧАвГУцЕФдДДњТыЃЌШЛКѓЭЈЙ§е§дђБэДяЪНЛђЦфЫћЗНЗЈНтЮіГіURLЁЃ
ЁЁЁЁ# ЕМШыseleniumПтжаЕФwebdriverФЃПщ
ЁЁЁЁfrom selenium import webdriver
ЁЁЁЁ# ЕМШыreПтжаЕФе§дђБэДяЪНФЃПщ
ЁЁЁЁimport re
ЁЁЁЁ# ДДНЈвЛИіChromeфЏРРЦїЪЕР§
ЁЁЁЁdriver = webdriver.Chrome()
ЁЁЁЁ# зюДѓЛЏфЏРРЦїДАПк
ЁЁЁЁdriver.maximize_window()
ЁЁЁЁ# ЗУЮЪАйЖШЪзвГ
ЁЁЁЁdriver.get('https://www.baidu.com')
ЁЁЁЁ# ЛёШЁвГУцдДДњТы
ЁЁЁЁpage_source = driver.page_source
ЁЁЁЁ# ЭЈЙ§е§дђБэДяЪННтЮіГіURL
ЁЁЁЁurl_pattern = re.compile(r'https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+')
ЁЁЁЁurls = url_pattern.findall(page_source)
ЁЁЁЁ# БщРњЫљгаЕФURLЕижЗЃЌВЂДђгЁГіРД
ЁЁЁЁfor url in urls:
ЁЁЁЁ print(url)
ЁЁЁЁ# ЙиБефЏРРЦї
ЁЁЁЁdriver.quit()
ЁЁЁЁБОЮФФкШнВЛгУгкЩЬвЕФПЕФЃЌШчЩцМАжЊЪЖВњШЈЮЪЬтЃЌЧыШЈРћШЫСЊЯЕ51TestingаЁБр(021-64471599-8017)ЃЌЮвУЧНЋСЂМДДІРэ












