

ЎЎЎЎєЬ¶аИЛ¶јМэЛµ№эЕАіжЈ¬ОТТІІ»АэНвЎЈФшїґµЅ±рИЛ±аРґµДЕАіжґъВлЈ¬ЛдИ»Г»УРЙоИлСРѕїЈ¬µ«ёРѕх·ЗіЈЗїґуЎЈТтґЛЈ¬ЅсМмОТѕц¶ЁґУБгїЄКјЈ¬»Ё·СЅц5·ЦЦУС§П°ИлГЕЕАіжјјКхЈ¬ТФєуЦ»РиЗбЗбТ»ЕАѕНДЬІйїґЛщУРёРРЛИ¤µДНшХѕДЪИЭЎЈ№гёжЈїІ»ґжФЪµДЈ¬ТтОЄОТїґІ»јыЎЈЕАіжЦ»»б»сИЎОТёРРЛИ¤µДРЕПўЈ¬І»РиТЄµДДЪИЭ¶ФОТ¶шСФЦ»КЗТ»¶СґъВлЎЈОТГЗІ»ФЪєхНшХѕµДЅзГжЈ¬ЕАИЎНкКэѕЭєуЦ»»б№ШЧўЧоєЛРДµДДЪИЭЎЈ
ЎЎЎЎФЪХвёц№эіМЦРЈ¬јјКх·ЅГжКµјКЙПГ»УРМ«¶аёґФУµДДЪИЭЈ¬КµјКЙПѕНКЗТ»ПоДНРДПёЦВµД№¤ЧчЎЈТтґЛІЕ»бУРДЗГґ¶аИЛСЎФсґУКВЕАіжјжЦ°№¤ЧчЈ¬ТтОЄЛдИ»єДК±ЅПі¤Ј¬µ«јјКхТЄЗуІўІ»КЗєЬёЯЎЈЅсМмС§НкЦ®єуЈ¬ДгѕНІ»»бПсОТТ»СщИПОЄЕАіжєЬА§ДСБЛЎЈ»тРнФЪОґАґДг»бРиТЄїјВЗИзєО±ЈіЦ»б»°ЈЁsessionЈ©»тХЯИЖ№эСйЦ¤µИОКМвЈ¬ТтОЄНшХѕФЅДСЕАИЎЈ¬ЛµГч¶Ф·ЅІўІ»ПЈНы±»ЕАИЎЎЈКµјКЙПЈ¬ХвІї·ЦДЪИЭКЗЧоѕЯМфХЅРФµДЈ¬УР»ъ»бµД»°ОТГЗїЙТФФЪТФєуµДС§П°ЦРЙоИлМЦВЫЎЈ
ЎЎЎЎЅсМмОТГЗТФСЎФсІЛЖЧОЄ°ёАэЈ¬АґЅвѕцОТГЗФЪіФ·№К±ЛщГжБЩµДЎ°іФКІГґЎ±µДЙъ»оДСМвЎЈ
ЎЎЎЎЕАіжЅвОц
ЎЎЎЎЕАіжµД№¤ЧчФАнАаЛЖУЪДЈДвУГ»§ФЪдЇААНшХѕК±µДІЩЧчЈєКЧПИ·ГОК№Щ·ЅНшХѕЈ¬јмІйКЗ·сУРРиТЄµг»чµДБґЅУЈ¬ИфУРЈ¬ФтјМРшµг»чІйїґЎЈµ±Ц±ЅУ·ўПЦЛщРиµДНјЖ¬»тОДЧЦК±Ј¬јґїЙЅшРРПВФШ»тёґЦЖЎЈХвЦЦЕАіжµД»щ±ѕјЬ№№ИзНјЛщКѕЈ¬ПЈНыХвСщµДГиКцДЬ°пЦъДгёьєГµШАнЅвЎЈ
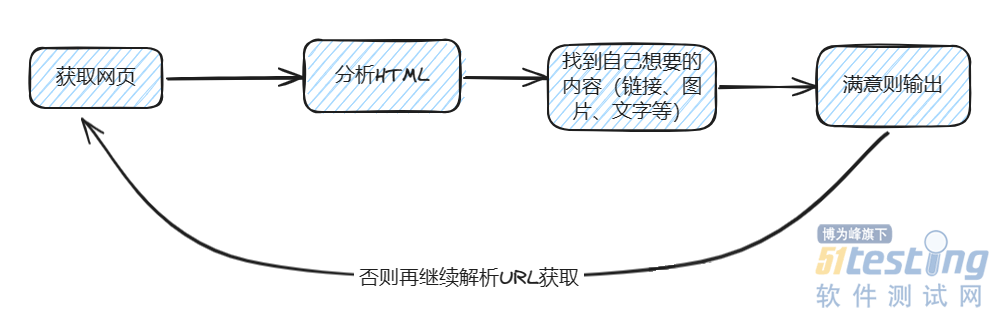
ЎЎЎЎЕАНшТіHTML
ЎЎЎЎФЪЅшРРЕАіж№¤ЧчК±Ј¬ОТГЗНЁіЈґУµЪТ»ІЅїЄКјЈ¬јґ·ўЛНТ»ёцHTTPЗлЗуТФ»сИЎ·µ»ШµДКэѕЭЎЈФЪОТГЗµД№¤ЧчЦРЈ¬НЁіЈ»бЗлЗуТ»ёцБґЅУТФ»сИЎJSONёсКЅµДРЕПўЈ¬ТФ±гЅшРРТµОсґ¦АнЎЈИ»¶шЈ¬ЕАіжµД№¤Чч·ЅКЅВФУРІ»Н¬Ј¬ТтОЄОТГЗРиТЄКЧПИ»сИЎНшТіДЪИЭЈ¬ТтґЛХвТ»ІЅНЁіЈ·µ»ШµДКЗHTMLТіГжЎЈФЪPythonЦРЈ¬УРРн¶аЗлЗуївїЙ№©СЎФсЈ¬ОТЦ»ѕЩТ»ёцАэЧУЧчОЄІОїјЈ¬µ«ДгїЙТФёщѕЭКµјКРиЗуСЎФсЖдЛыµЪИэ·ЅївЈ¬Ц»ТЄДЬ№»НкіЙИООсјґїЙЎЈ
ЎЎЎЎФЪїЄКјЕАіж№¤ЧчЦ®З°Ј¬КЧПИРиТЄ°ІЧ°ЛщРиµДµЪИэ·ЅївТААµЎЈХвІї·ЦєЬјтµҐЈ¬Ц»РиёщѕЭРиТЄ°ІЧ°ПаУ¦µДївјґїЙЈ¬Г»УРМ«¶аёґФУµДІЅЦиЎЈ
ЎЎЎЎИГОТГЗІ»¶а·П»°Ј¬Ц±ЅУїґПВГжµДґъВлКѕАэЈє
ЎЎЎЎfrom urllib.request import urlopen,Request
ЎЎЎЎheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
ЎЎЎЎreq = Request("https://www.meishij.net/?from=space_block",headers=headers)
ЎЎЎЎ# ·ўіцЗлЗ󣬻сИЎhtml
ЎЎЎЎ# »сИЎµДhtmlДЪИЭКЗЧЦЅЪЈ¬Ѕ«ЖдЧЄ»ЇОЄЧЦ·ыґ®
ЎЎЎЎhtml = urlopen(req)
ЎЎЎЎhtml_text = bytes.decode(html.read())
ЎЎЎЎprint(html_text)
ЎЎЎЎНЁіЈЗйїцПВЈ¬ОТГЗїЙТФ»сИЎХвёцІЛЖЧНшТіµДНкХыДЪИЭЈ¬ѕНПсОТГЗФЪдЇААЖчЦР°ґПВF12ІйїґµДНшТіФґґъВлТ»СщЎЈ
ЎЎЎЎЅвОцФЄЛШ
ЎЎЎЎЧо±їµД·Ѕ·ЁКЗК№УГЧЦ·ыґ®ЅвОцЈ¬µ«УЙУЪPythonУРРн¶аµЪИэ·ЅївїЙТФЅвѕцХвёцОКМвЈ¬ТтґЛОТГЗїЙТФК№УГBeautifulSoupАґЅвОцHTMLЎЈЖдЛыёь¶аµДЅвОц·Ѕ·ЁѕНІ»Т»Т»ЅйЙЬБЛЈ¬ОТГЗРиТЄУГµЅКІГґѕНИҐЛСЛчјґїЙЈ¬І»РиТЄѕіЈК№УГµДТІГ»±ШТЄЛАјЗУІ±іЎЈ
ЎЎЎЎИИЛСІЛЖЧ
ЎЎЎЎФЪХвАпЈ¬ИГОТГЗ¶ФИИГЕЛСЛчЦРµДІЛЖЧЅшРРЅвОцєН·ЦОцЎЈ
ЎЎЎЎfrom urllib.request import urlopen,Request
ЎЎЎЎfrom bs4 import BeautifulSoup as bf
ЎЎЎЎheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
ЎЎЎЎreq = Request("https://www.meishij.net/?from=space_block",headers=headers)
ЎЎЎЎ# ·ўіцЗлЗ󣬻сИЎhtml
ЎЎЎЎ# »сИЎµДhtmlДЪИЭКЗЧЦЅЪЈ¬Ѕ«ЖдЧЄ»ЇОЄЧЦ·ыґ®
ЎЎЎЎhtml = urlopen(req)
ЎЎЎЎhtml_text = bytes.decode(html.read())
ЎЎЎЎ# print(html_text)
ЎЎЎЎ # УГBeautifulSoupЅвОцhtml
ЎЎЎЎobj = bf(html_text,'html.parser')
ЎЎЎЎ# print(html_text)
ЎЎЎЎ# К№УГfind_allєЇКэ»сИЎЛщУРНјЖ¬µДРЕПў
ЎЎЎЎindex_hotlist = obj.find_all('a',class_='sancan_item')
ЎЎЎЎ# ·Ц±рґтУЎГїёцНјЖ¬µДРЕПў
ЎЎЎЎfor ul in index_hotlist:
ЎЎЎЎ for li in ul.find_all('strong',class_='title'):
ЎЎЎЎ print(li.get_text())
ЎЎЎЎЦчТЄІЅЦиКЗЈ¬КЧПИФЪЙПТ»ІЅЦРґтУЎіцHTMLТіГжЈ¬И»єуНЁ№эИвСЫ№ЫІмИ·¶ЁЛщРиДЪИЭО»УЪДДёцФЄЛШПВЈ¬ЅУЧЕАыУГBeautifulSoup¶ЁО»ёГФЄЛШІўМбИЎіцЛщРиРЕПўЎЈФЪОТµДЗйїцПВЈ¬ОТМбИЎµДКЗОДЧЦДЪИЭЈ¬ТтґЛіЙ№¦МбИЎБЛЛщУРliБР±нФЄЛШЎЈ
ЎЎЎЎЛж»ъёЙ·№
ЎЎЎЎФЪЙъ»оЦРЈ¬КµјКЙПёЙ·№ІўІ»ёґФУЈ¬ДСµгФЪУЪСЎФсіФКІГґЎЈТтґЛЈ¬ОТГЗїЙТФЅ«ЛщУРІЛЖЧЅвОцІўґжґўФЪТ»ёцБР±нЦРЈ¬И»єуИГіМРтЛж»ъСЎФсІЛЖЧЎЈХвСщЈ¬ѕНДЬёьЗбЛЙµШЅвѕцГї¶Щ·№іФКІГґµДДСМвБЛЎЈ
ЎЎЎЎЛж»ъСЎИЎТ»µАІЛК±Ј¬їЙТФК№УГТФПВКѕАэґъВлЈє
ЎЎЎЎfrom urllib.request import urlopen,Request
ЎЎЎЎfrom bs4 import BeautifulSoup as bf
ЎЎЎЎfor i in range(3):
ЎЎЎЎ url = f"https://www.meishij.net/chufang/diy/jiangchangcaipu/?&page={i}"
ЎЎЎЎ html = urlopen(url)
ЎЎЎЎ # »сИЎµДhtmlДЪИЭКЗЧЦЅЪЈ¬Ѕ«ЖдЧЄ»ЇОЄЧЦ·ыґ®
ЎЎЎЎ html_text = bytes.decode(html.read())
ЎЎЎЎ # print(html_text)
ЎЎЎЎ obj = bf(html_text,'html.parser')
ЎЎЎЎ index_hotlist = obj.find_all('img')
ЎЎЎЎ for p in index_hotlist:
ЎЎЎЎ if p.get('alt'):
ЎЎЎЎ print(p.get('alt'))
ЎЎЎЎХвАпОТГЗФЪХвёцНшХѕЙПХТµЅБЛРВµДБґЅУµШЦ·Ј¬ОТТСѕ»сИЎБЛЗ°ИэТіµДКэѕЭЈ¬ІўЅшРРБЛЛж»ъСЎФсЈ¬ДгїЙТФСЎФсИ«Ії»сИЎЎЈ
ЎЎЎЎІЛЖЧЅМіМ
ЎЎЎЎЖдКµЙПТ»ІЅТСѕНкіЙБЛЈ¬ЅУПВАґЦ»РиПВµҐНвВфБЛЎЈНвВфЦЦАа·±¶аЈ¬µ«¶ФУЪПсОТХвСщµД№ЛјТДМ°ЦАґЛµІўІ»єПККЈ¬ТтґЛОТ±ШРлЧФјє¶ЇКЦЧц·№ЎЈХвК±єтЅМіМѕНПФµГУИОЄЦШТЄБЛЎЈ
ЎЎЎЎОТГЗПЦФЪјМРшЙоИлЅвОцЅМіМДЪИЭЈє
ЎЎЎЎfrom urllib.request import urlopen,Request
ЎЎЎЎimport urllib,string
ЎЎЎЎfrom bs4 import BeautifulSoup as bf
ЎЎЎЎurl = f"https://so.meishij.net/index.php?q=ємЙХЕЕ№З"
ЎЎЎЎurl = urllib.parse.quote(url, safe=string.printable)
ЎЎЎЎhtml = urlopen(url)
ЎЎЎЎ# »сИЎµДhtmlДЪИЭКЗЧЦЅЪЈ¬Ѕ«ЖдЧЄ»ЇОЄЧЦ·ыґ®
ЎЎЎЎhtml_text = bytes.decode(html.read())
ЎЎЎЎobj = bf(html_text,'html.parser')
ЎЎЎЎindex_hotlist = obj.find_all('a',class_='img')
ЎЎЎЎ# ·Ц±рґтУЎГїёцНјЖ¬µДРЕПў
ЎЎЎЎurl = index_hotlist[0].get('href')
ЎЎЎЎhtml = urlopen(url)
ЎЎЎЎhtml_text = bytes.decode(html.read())
ЎЎЎЎobj = bf(html_text,'html.parser')
ЎЎЎЎindex_hotlist = obj.find_all('div',class_='step_content')
ЎЎЎЎfor div in index_hotlist:
ЎЎЎЎ for p in div.find_all('p'):
ЎЎЎЎ print(p.get_text())
ЎЎЎЎ°ьЧ°Т»ПВ
ЎЎЎЎЙПГжМбµЅµД·Ѕ·ЁТСѕВъЧгБЛОТГЗµДРиЗ󣬵«КЗЦШёґКЦ¶ЇЦґРРГїёцІЅЦиІўІ»КЗТ»ёцёЯР§µД·ЅКЅЎЈТтґЛЈ¬ОТЅ«ХвР©ІЅЦи·вЧ°іЙТ»ёцјтµҐµДУ¦УГіМРтЎЈХвёцУ¦УГіМРтК№УГїШЦЖМЁЧчОЄУГ»§ЅзГжЈ¬І»РиТЄТААµИОєОµЪИэ·ЅївЎЈИГОТГЗТ»ЖрАґїґТ»ПВХвёцУ¦УГіМРт°ЙЈє
ЎЎЎЎ# µјИлurllibївµДurlopenєЇКэ
ЎЎЎЎfrom urllib.request import urlopen,Request
ЎЎЎЎimport urllib,string
ЎЎЎЎ# µјИлBeautifulSoup
ЎЎЎЎfrom bs4 import BeautifulSoup as bf
ЎЎЎЎfrom random import choice,sample
ЎЎЎЎfrom colorama import init
ЎЎЎЎfrom os import system
ЎЎЎЎfrom termcolor import colored
ЎЎЎЎfrom readchar import readkey
ЎЎЎЎFGS = ['green', 'yellow', 'blue', 'cyan', 'magenta', 'red']
ЎЎЎЎprint(colored('ЛСЛчКіЖЧЦР.....',choice(FGS)))
ЎЎЎЎheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
ЎЎЎЎreq = Request("https://www.meishij.net/?from=space_block",headers=headers)
ЎЎЎЎ# ·ўіцЗлЗ󣬻сИЎhtml
ЎЎЎЎ# »сИЎµДhtmlДЪИЭКЗЧЦЅЪЈ¬Ѕ«ЖдЧЄ»ЇОЄЧЦ·ыґ®
ЎЎЎЎhtml = urlopen(req)
ЎЎЎЎhtml_text = bytes.decode(html.read())
ЎЎЎЎhot_list = []
ЎЎЎЎall_food = []
ЎЎЎЎfood_page = 3
ЎЎЎЎ# '\n'.join(pos(y, OFFSET[1]) + ' '.join(color(i) for i in l)
ЎЎЎЎdef draw_menu(menu_list):
ЎЎЎЎ clear()
ЎЎЎЎ for idx,i in enumerate(menu_list):
ЎЎЎЎ print(colored(f'{idx}:{i}',choice(FGS)))
ЎЎЎЎ print(colored('8:Лж»ъСЎФс',choice(FGS)))
ЎЎЎЎdef draw_word(word_list):
ЎЎЎЎ clear()
ЎЎЎЎ for i in word_list:
ЎЎЎЎ print(colored(i,choice(FGS)))
ЎЎЎЎdef clear():
ЎЎЎЎ system("CLS")
ЎЎЎЎdef hot_list_func() :
ЎЎЎЎ global html_text
ЎЎЎЎ # УГBeautifulSoupЅвОцhtml
ЎЎЎЎ obj = bf(html_text,'html.parser')
ЎЎЎЎ # print(html_text)
ЎЎЎЎ # К№УГfind_allєЇКэ»сИЎЛщУРНјЖ¬µДРЕПў
ЎЎЎЎ index_hotlist = obj.find_all('a',class_='sancan_item')
ЎЎЎЎ # ·Ц±рґтУЎГїёцНјЖ¬µДРЕПў
ЎЎЎЎ for ul in index_hotlist:
ЎЎЎЎ for li in ul.find_all('strong',class_='title'):
ЎЎЎЎ hot_list.append(li.get_text())
ЎЎЎЎ # print(li.get_text())
ЎЎЎЎdef search_food_detail(food) :
ЎЎЎЎ print('ХэФЪЛСЛчПкПёЅМіМЈ¬ЗлЙФµИ30ГлЧуУТЈЎ')
ЎЎЎЎ url = f"https://so.meishij.net/index.php?q={food}"
ЎЎЎЎ # print(url)
ЎЎЎЎ url = urllib.parse.quote(url, safe=string.printable)
ЎЎЎЎ html = urlopen(url)
ЎЎЎЎ # »сИЎµДhtmlДЪИЭКЗЧЦЅЪЈ¬Ѕ«ЖдЧЄ»ЇОЄЧЦ·ыґ®
ЎЎЎЎ html_text = bytes.decode(html.read())
ЎЎЎЎ obj = bf(html_text,'html.parser')
ЎЎЎЎ index_hotlist = obj.find_all('a',class_='img')
ЎЎЎЎ # ·Ц±рґтУЎГїёцНјЖ¬µДРЕПў
ЎЎЎЎ url = index_hotlist[0].get('href')
ЎЎЎЎ # print(url)
ЎЎЎЎ html = urlopen(url)
ЎЎЎЎ html_text = bytes.decode(html.read())
ЎЎЎЎ # print(html_text)
ЎЎЎЎ obj = bf(html_text,'html.parser')
ЎЎЎЎ random_color = choice(FGS)
ЎЎЎЎ print(colored(f"{food}Чц·ЁЈє",random_color))
ЎЎЎЎ index_hotlist = obj.find_all('div',class_='step_content')
ЎЎЎЎ # print(index_hotlist)
ЎЎЎЎ random_color = choice(FGS)
ЎЎЎЎ for div in index_hotlist:
ЎЎЎЎ for p in div.find_all('p'):
ЎЎЎЎ print(colored(p.get_text(),random_color))
ЎЎЎЎdef get_random_food():
ЎЎЎЎ global food_page
ЎЎЎЎ if not all_food :
ЎЎЎЎ for i in range(food_page):
ЎЎЎЎ url = f"https://www.meishij.net/chufang/diy/jiangchangcaipu/?&page={i}"
ЎЎЎЎ html = urlopen(url)
ЎЎЎЎ # »сИЎµДhtmlДЪИЭКЗЧЦЅЪЈ¬Ѕ«ЖдЧЄ»ЇОЄЧЦ·ыґ®
ЎЎЎЎ html_text = bytes.decode(html.read())
ЎЎЎЎ # print(html_text)
ЎЎЎЎ obj = bf(html_text,'html.parser')
ЎЎЎЎ index_hotlist = obj.find_all('img')
ЎЎЎЎ for p in index_hotlist:
ЎЎЎЎ if p.get('alt'):
ЎЎЎЎ all_food.append(p.get('alt'))
ЎЎЎЎ my_food = choice(all_food)
ЎЎЎЎ print(colored(f'Лж»ъСЎФсЈ¬ЅсМміФЈє{my_food}',choice(FGS)))
ЎЎЎЎ return my_food
ЎЎЎЎinit() ## ГьБоРРКдіцІКЙ«ОДЧЦ
ЎЎЎЎhot_list_func()
ЎЎЎЎprint(colored('ТСЛСЛчНк±ПЈЎ',choice(FGS)))
ЎЎЎЎmy_array = list(range(0, 9))
ЎЎЎЎmy_key = ['q','c','d','m']
ЎЎЎЎmy_key.extend(my_array)
ЎЎЎЎprint(colored('m:ґъ±нЅсИХІЛЖЧ',choice(FGS)))
ЎЎЎЎprint(colored('c:ґъ±нЗеїХїШЦЖМЁ',choice(FGS)))
ЎЎЎЎprint(colored('d:ґъ±нІЛЖЧЅМіМ',choice(FGS)))
ЎЎЎЎprint(colored('q:НЛіцІЛЖЧ',choice(FGS)))
ЎЎЎЎprint(colored('0~8:СЎФсІЛЖЧЦРµДІЛ',choice(FGS)))
ЎЎЎЎwhile True:
ЎЎЎЎ while True:
ЎЎЎЎ move = readkey()
ЎЎЎЎ if move in my_key or (move.isdigit() and int(move) <= len(random_food)):
ЎЎЎЎ break
ЎЎЎЎ if move == 'q': ## јьЕМЎ®QЎЇКЗНЛіц
ЎЎЎЎ break
ЎЎЎЎ if move == 'c': ## јьЕМЎ®CЎЇКЗЗеїХїШЦЖМЁ
ЎЎЎЎ clear()
ЎЎЎЎ if move == 'm':
ЎЎЎЎ random_food = sample(hot_list,8)
ЎЎЎЎ draw_menu(random_food)
ЎЎЎЎ if move.isdigit() and int(move) <= len(random_food):
ЎЎЎЎ if int(move) == 8:
ЎЎЎЎ my_food = get_random_food()
ЎЎЎЎ else:
ЎЎЎЎ my_food = random_food[int(move)]
ЎЎЎЎ print(my_food)
ЎЎЎЎ if move == 'd' and my_food : ## јьЕМЎ®DЎЇКЗІйїґЅМіМ
ЎЎЎЎ search_food_detail(my_food)
ЎЎЎЎ my_food = ''
ЎЎЎЎНкіЙТ»ёцјтµҐµДРЎЕАіжЖдКµІўІ»ёґФУЈ¬Из№ыІ»їјВЗ¶оНвµД·вЧ°ІЅЦиЈ¬ЅцРи5·ЦЦУјґїЙНкіЙЈ¬ХвТСѕЧг№»їмЛЩИГДгИлГЕЕАіжјјКхЎЈїЄКјЕАИЎДіёцНшХѕµДКэѕЭКµјКЙПКЗТ»ПоПёЦВµД№¤ЧчЎЈЦ»РиФЪНшЙПЛСЛчПа№ШјјКхРЕПўЈ¬ХТµЅККєПµД·Ѕ·ЁјґїЙЈ¬Из№ыУРР§ѕНјМРшК№УГЈ¬І»РРѕНКФКФЖдЛы·Ѕ·ЁЎЈ
ЎЎЎЎЧЬЅб
ЎЎЎЎ±ѕОДµДЦШµгФЪУЪТэµј¶БХЯИзєОіхІЅХЖОХЕАіжјјКхЎЈіхІЅХЖОХЕАіжјјКхІўІ»ДСЈ¬µ«КЗФЪКµјКІЩЧчЦРїЙДЬ»бУцµЅТ»Р©А§ДСЈ¬±ИИзТ»Р©НшХѕІ»ФКРнЦ±ЅУ·ГОКЈ¬РиТЄµЗВј»тХЯЅшРРёчЦЦИЛ»ъСйЦ¤µИЎЈТтґЛЈ¬ЧоєГПИґУЕАИЎТ»Р©РВОЕЧКС¶АаµДНшХѕїЄКјЈ¬ТтОЄХвСщПа¶ФИЭТЧЎЈЙжј°УГ»§Ц§ё¶µИГфёРРЕПўµДНшХѕѕНІ»ДЗГґИЭТЧ»сИЎБЛЎЈТтґЛЈ¬ФЪИлГЕЅЧ¶ОЈ¬ЅЁТйІ»ТЄѕАЅбУЪСЎФсТ»ёцёґФУµДНшХѕЈ¬ПИіўКФИлГЕјґїЙЎЈТ»µ©АнЅвБЛ»щ±ѕФАнЈ¬УцµЅОКМвК±ѕНїЙТФїјВЗМнјУЧйјю»тХЯК№УГµЪИэ·ЅївАґЅвѕцЎЈ
ЎЎЎЎ±ѕОДДЪИЭІ»УГУЪЙМТµДїµДЈ¬ИзЙжј°ЦЄК¶ІъИЁОКМвЈ¬ЗлИЁАыИЛБЄПµ51TestingРЎ±а(021-64471599-8017)Ј¬ОТГЗЅ«Бўјґґ¦Ан












